

AdobeのAIトラフィックレポート コンバージョン率が逆転 中小サイトに必要な対策
AIアシスタント経由で小売サイトを訪れるユーザーのコンバージョン率が、2025年春から2026年春の1年間で劇的に変わった。前年は他のチャネルの約半分だったが、2026年3月には逆に42%高くなった。同じチャネル、同じ店舗群だ。
Adobe Analyticsが2026年4月16日に公開した「2026年第2四半期AIトラフィックレポート」によると、米国小売サイトへのAI経由トラフィックは前年同期比393%増、ピークの2025年12月には前年比1,151%に達した。エンゲージメントは12%増、ページ滞在時間は48%増、訪問あたりのページ数は13%増、収益は37%増という数字も並ぶ。
しかし本命は率の逆転だ。1年前は「AIレファラル」が他の流入元よりもはるかに低かった。そのチャネルが今、小売において最も収益性の高い流入経路になっている。
AIトラフィックが小売の最優良チャネルに 2025年春からの大逆転
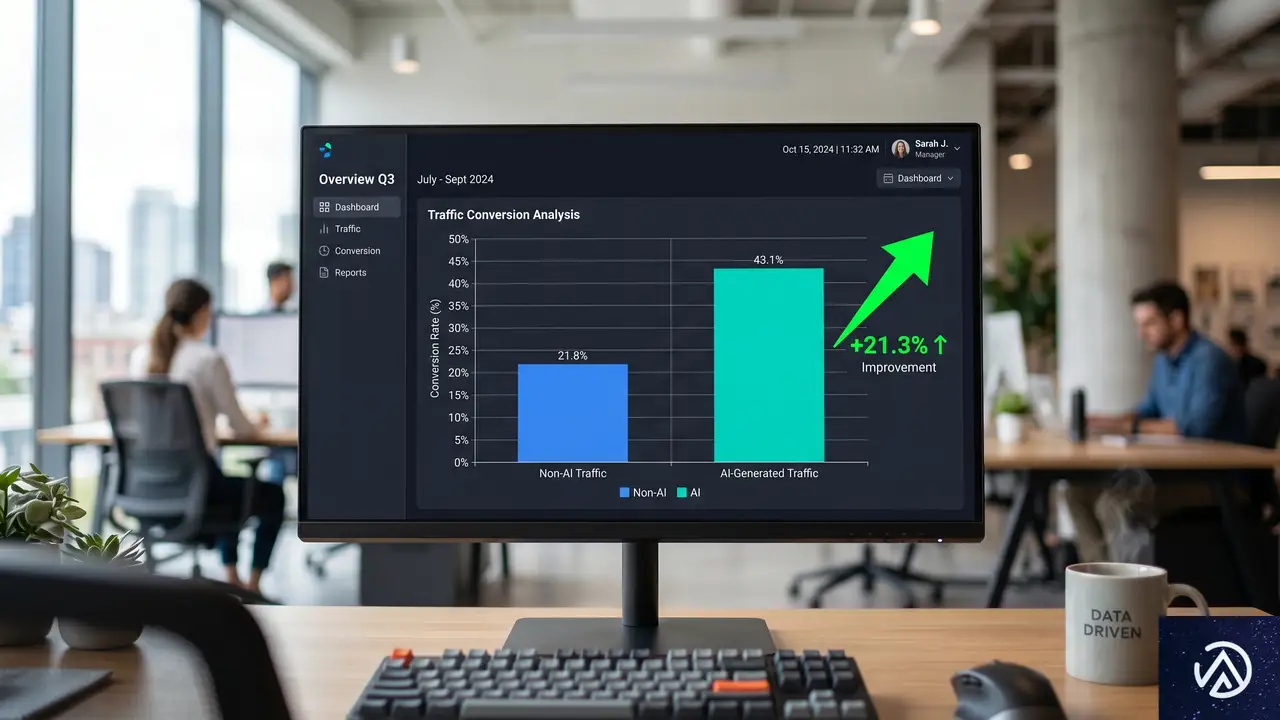
2025年は非AIの半分、2026年3月は42%上回る
Adobeのデータを具体的に見る。2025年3月の時点で、AIアシスタントから米国小売サイトに到達した訪問者のコンバージョン率は、他のチャネル全体の約半分だった。これが2026年3月になると、非AI流入を42%上回るまでに改善している。同じ店舗、同じシステムで、たった12か月の間にチャネルとしての評価が反転したことになる。
成長率393%の内訳 エンゲージメントと収益も向上
量だけではない。AI経由の訪問者は、サイト内での行動もよい。エンゲージメント率は12%増、ページ滞在時間は48%長くなり、訪問あたりのページビューも13%増。さらに重要なのは、訪問あたりの収益が37%増えている点だ。単に流入数が増えただけでなく、質の高い見込み客がAIから直接サイトに送られていることを示している。
「AIトラフィックは未成熟」という見立てが過去のものに

ペイドサーチやSNSが辿った緩やかな成熟カーブとの違い
新しいチャネルが成熟するとき、普通はゆっくりと改善していく。ペイドサーチも、モバイルも、ソーシャルもそうだった。初年度は非AIの半分のコンバージョン率だったものが、25%劣り、10%劣り、やがて均衡し、わずかに上回る。3〜4年をかけてようやく逆転するのが一般的なパターンだ。しかしAdobeのレポートが示すAIレファラルは、この曲線をまったく描いていない。たった2回の測定ポイント、12か月の間に優劣が完全に逆転した。
古い前提で動くエージェンシーへの警告
SEJのSlobodan Manic氏は、「AIトラフィックはまだ初期段階だから、段階的に最適化しよう」という発想そのものが、すでに賞味期限切れだと指摘する。「今年の数字を読んでいなければ、いまだに『未成熟』とか『準備不足』という言葉を使うエージェンシーやコンサルタントがいるが、それは1年前の情報で動いているに等しい」という。同氏は、もし提案が「これから1年かけて何が効くか学びましょう」というものなら、その提案は完全に機会を逃していると分析する。
AIがサイトを読めない根本原因 Citation Readabilityが明かす格差
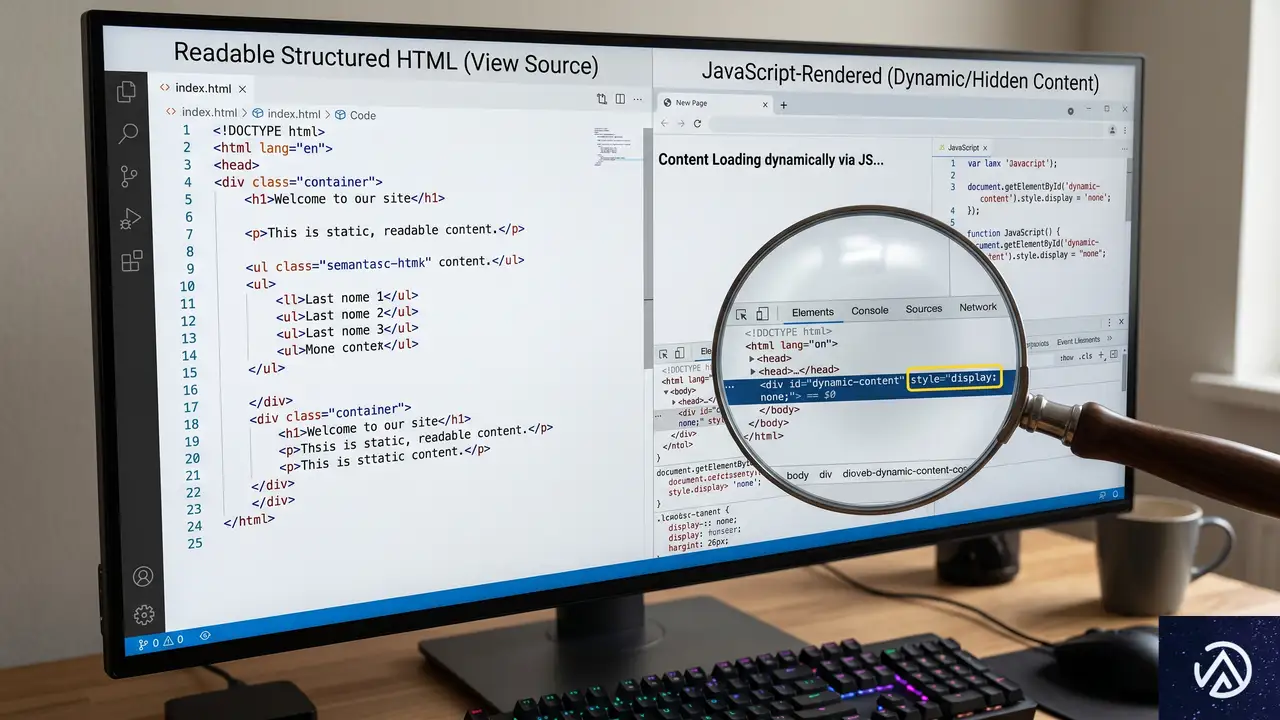
トップとボトムで可読性スコアが60%以上違う
Adobeのレポートには「Citation Readability(引用可読性)」という指標が紹介されている。これは、ページがAIシステムによってどれだけ正確に解析され、引用されやすいかを示すものだ。トップの小売サイト(AI訪問シェアが高いサイト)のホームページは、下位のサイトと比べて62%も高いスコアを記録した。検索結果ページでは32%高、ブログや記事コンテンツでも30%高い。この差が、AI経由の流入が一部のサイトに偏る理由を明確にしている。
自社サイトの「機械可読性」を把握している経営者はほぼいない
多くのサイト運営者は、毎朝アクセス解析を見て、週次でコンバージョン率を確認し、四半期ごとにCRO(コンバージョン率最適化)戦略を議論している。しかし、GPTBotやClaudeBot、PerplexityBotが自社の商品ページをクロールしたときに、何が見えているのかを把握している企業はほとんどない。ダッシュボードには表示されず、セッション記録にも残らず、正確に「AI経由」とアトリビューションを取れているケースも稀だ。
実際のところ、機械可読性が高いサイトが達成しているコンバージョン率の向上幅は、全体平均の数字よりもさらに大きいと推測される。平均値は、読めないサイトによって押し下げられているからだ。
Dellの「成果なし」とAdobeの「チャネル逆転」 両立する理由
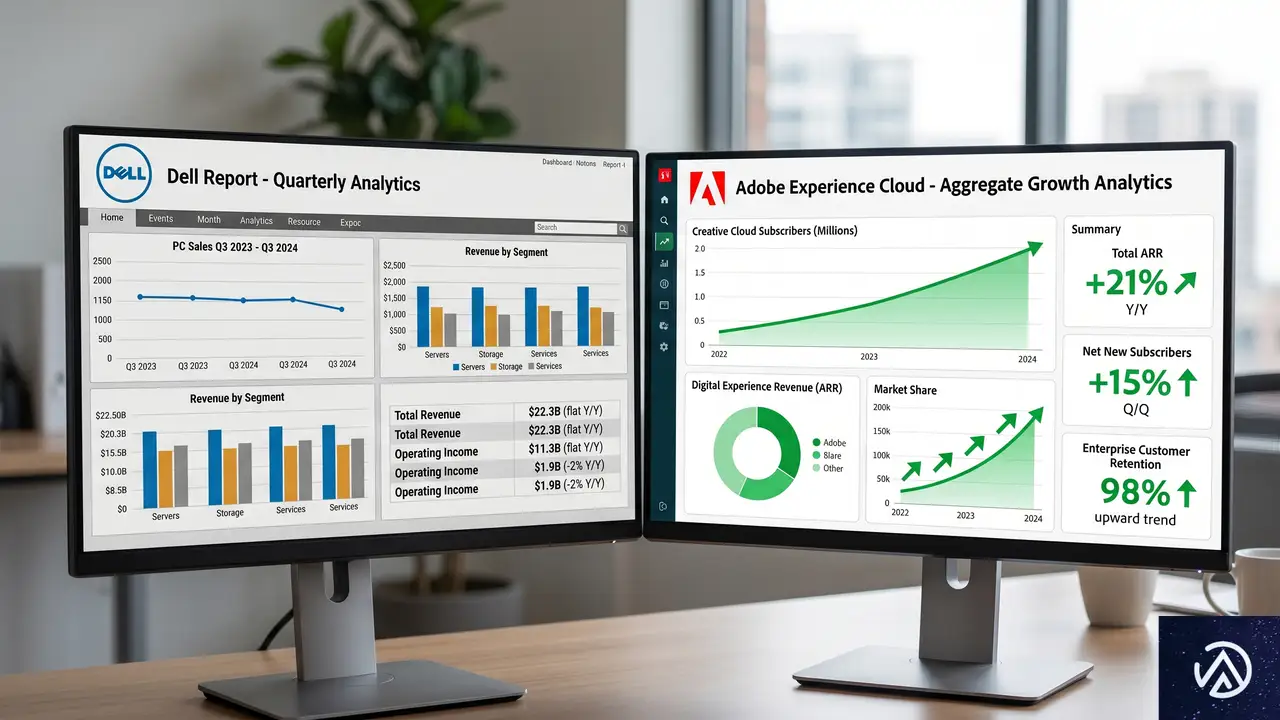
Dell社内データが示した平坦な結果
Adobeのレポートが公開される8日前、Dellのグローバルコンシューマー収益責任者がDigital Commerce 360の取材に対し、「エージェンティックショッピングは、まだ特に大きな成果をもたらしていない」と語った。同社の内部データでは、コンバージョンに目立った変化は見られなかったという。
サイト単位の監査こそが正しいアクション
SEJのManic氏は、この2つのデータは矛盾しないと解説する。Dellは1つのWebサイトを測定し、その結果が横ばいだった。一方、AdobeはAIモデルがきちんと読み取れる多数の小売サイトの集計を見て、チャネル全体が逆転したと結論づけた。自社のコンバージョン率がDellのように停滞しているなら、チャネルの成熟を待つのではなく、まず自社サイトの監査から始めるべきだ。Dellの数字はdell.comの問題を示しており、Adobeのデータはチャネル全体の方向性を示している、と同氏は分析している。
AIアシスタントが購買ファネルを短縮 求められるのは「可読性」

セッション数やインプレッションはもはや重要指標ではない
ここ30年、SEOとCROの世界では「インプレッション」「セッション」「ユニークユーザー」「ページビュー」を増やすことが正義だった。ファネルの入口を広げれば、検討するユーザーが増え、コンバージョンにつながるという計算である。しかしAIレファラルはこの前提を覆す。ChatGPTやPerplexity、Geminiからサイトに訪れるユーザーは、すでにアシスタント内で調査を終え、比較検討し、候補を絞った状態でクリックしている。サイトへの訪問は、意思決定プロセスの最終段階なのである。
上図のように、AI経由ではファネルが大幅に短縮されている。コンバージョンの瞬間だけが可視化されるため、従来型の「流入数を追う」指標は意味を失う。Adobeのデータにあるエンゲージメント48%増や収益37%増は、この短縮された購買行動の結果だ。
AIに引用されリンクされる可読性が勝敗を分ける
393%の成長全体を引き上げているのは、AIアシスタントが実際に引用し、リンクし、購入意欲の高い見込み客を送り込めているサイトだ。これは従来の「検索エンジン向け最適化」ではなく、マシンリーダビリティ(可読性)の問題である。AIに読まれる状態になっているかどうかが、アクセスの有無を決めてしまう。SEJのManic氏は、これを「可読性こそが新しいSEO」と表現し、可読性の低いサイトはチャネル全体の成長から完全に取り残されると警告する。
今週末にできるAIクローラー向けサイト監査の2ステップ
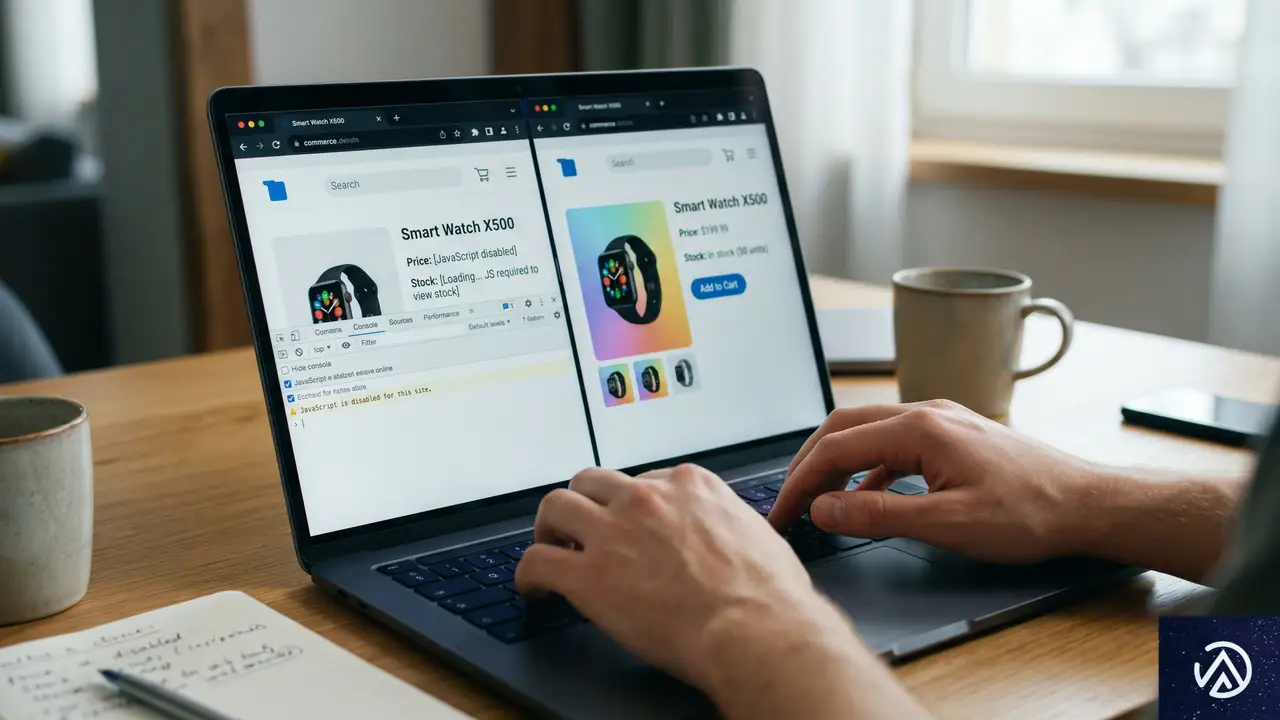
JavaScriptをオフにして価格と在庫を確認する
専門ツールやチームがなくても、すぐに着手できる監査がある。1つ目はJavaScriptを無効化したブラウザで商品ページを再読み込みする方法だ。商品名、価格、在庫状況、購入ボタンがHTMLソース内に静的に存在しているかを確認する。多くのAIクローラーはJavaScriptを実行しない、あるいは実行が不安定なため、重要な情報がすべてJSでレンダリングされていると、AIはその情報を引用できない。引用されなければ、アシスタントの回答にサイトが登場することはない。
上の比較のように、JSオフ時に商品情報が欠落している場合、AIクローラーからは中身のないページに見えている可能性が高い。修正の優先度は非常に高い。
回答先頭テスト ブランド演出よりも事実を最初に置く
2つ目は「回答先頭テスト」と呼ぶチェックだ。商品ページを開いて、最初に目に入るのがブランドナビゲーションやヒーローイメージ、キャッチコピーではなく、「その商品が何か、いくらか、在庫があるか」という事実情報かどうかを確かめる。AIモデルがページを要約するとき、先頭にある構造化された事実を優先的に拾う。人間はブランドの演出を許容するが、AIインデクサーはそれをスクロールで飛ばして価格を探したりはしない。
どちらかが達成できていなければ、それはトラフィックの問題ではなく、サイトアーキテクチャの問題だ。393%という成長の波は、可読性を満たしたサイトにしか届いていない。
この記事のポイント
AI経由の小売トラフィックは、わずか1年でコンバージョン率が非AIを42%上回る優良チャネルに変わった。流入数だけでなく、滞在時間や収益も大幅に伸びている。
「AIは未成熟」という前提はもはや通用しない。緩やかな成熟ではなく、急激な質的逆転が起きているため、段階的最適化という考え方では機会損失になる。
勝敗を分けるのは、AIに正しく読まれ、引用される「可読性」である。自社サイトが機械可読かどうかの監査が、セッション数やインプレッションよりも優先すべき指標になった。
今すぐJavaScriptをオフにした表示確認と、回答先頭テストを実施すれば、AIトラフィックの恩恵を受けられない根本原因を見つけられる。

・ 複数業界における17年間のデジタルビジネス開発経験
・ ウェブサイト開発のためのHTML、PHP、CSS、Java等の実用的知識
・ 15ヶ国語対応の多言語SaaSの開発経験
・ 17年間にも及ぶ、Eコマース長期運営経験
・ 幅広い業界でのSEO最適化の豊富な経験

AI時代のキャッシュ設計を再考する——AIクローラーがCDNに与える影響と対策
CDN(コンテンツデリバリネットワーク)のキャッシュ設計が、AIクローラーの台頭によって根本的な見直しを迫られている。Cloudflareのデータによると、同社ネットワーク上のトラフィックの32%は自動化されたトラフィックが占める。検索エンジンクローラーや監視ツールに加え、近年はAIアシスタントが回答生成のためにWebから情報を取得するケースが増加している。
AIエージェントは人間とは異なるアクセスパターンを示す。高頻度の並列リクエスト、人気ページではなく長尾コンテンツへの集中的なアクセス、サイト全体の網羅的なスキャンなどが特徴だ。このような振る舞いは、従来の人間向けに最適化されたキャッシュアルゴリズムを無効化し、キャッシュミス率の上昇とオリジンサーバー負荷の増大を引き起こす。
サイト運営者はAIクローラーへの対応に迫られる。ブロックするか、サービスを提供するかの選択を迫られるが、両者のトラフィックパターンは大きく異なるため、既存のキャッシュアーキテクチャでは一方に最適化するしかない。本記事では、AIトラフィックがCDNキャッシュに与える影響を分析し、新しいキャッシュ設計の方向性を探る。
AIクローラーと人間のトラフィックの根本的な違い

AIクローラーのトラフィックは、人間のブラウジング行動と比較して3つの主要な特徴を持つ。高ユニークURL比率、コンテンツの多様性、クロールの非効率性だ。
高ユニークURL比率と長尾コンテンツへのアクセス
Common Crawlの公開データによると、大規模Webクロールでは90%以上のページがコンテンツ的にユニークだ。AIクローラーは特定のコンテンツタイプに特化する傾向があり、技術文書、ソースコード、メディアファイル、ブログ記事など、目的に応じて異なるコンテンツを対象とする。
人間のユーザーがトップページや人気記事に集中するのに対し、AIクローラーはサイトの奥深くまで探索する。Wikipediaの利用データは、かつて「長尾」とされていたほとんどアクセスされないページが、現在では頻繁にリクエストされるようになったことを示している。これはCDNキャッシュ内のコンテンツ人気度分布そのものを変化させている。
クロールの非効率性と反復ループ
AIクローラーは必ずしも最適なクロールパスをたどらない。人気のあるAIクローラーからのフェッチのかなりの割合が404エラーやリダイレクトで終わる。これはURL処理の不備によることが多い。また、ブラウザ側のキャッシュやセッション管理を人間のユーザーと同じように利用しない。
AIエージェントは検索結果を改良するために反復ループを行うことがある。これはRAG(Retrieval-Augmented Generation)における一般的なパターンだ。この反復ループは、エージェントの精度を高める一方で、一貫して高いユニークアクセス比率(70%から100%)を維持する。つまり、各ループで以前に見たページを再訪するのではなく、常に新しいユニークなコンテンツを取得し続ける。
キャッシュへの直接的な影響
長尾アセットへのこのような反復アクセスは、人間のトラフィックが依存するキャッシュをかき回す。既存のプリフェッチや従来のキャッシュ無効化戦略は、クローラートラフィックの量が増加するにつれて効果が低下する。Cloudflareの単一ノードにおけるキャッシュヒット率は、AIクローラーを含む場合と含まない場合で明確な差が見られる。ヒット率の低下は、LRU(Least Recently Used)アルゴリズムがAIクローラーの反復スキャン行動に対処できていないことを示唆している。
実例から見るAIクローラーのインパクト

AIボットトラフィックの急増は、実際のWebサービスに深刻な影響を与えている。大規模サイトにおける影響と対応策は以下の通りだ。
Wikipedia:マルチメディア帯域幅の50%急増
モデル訓練のための画像一括スクレイピングにより、マルチメディア帯域幅使用量が50%急増した。Wikimediaは最終的にクローラートラフィックをブロックする対応を取った。
SourceHutとRead the Docs:サービス不安定化
ソースコードリポジトリをスクレイピングするLLMクローラーにより、サービス不安定化と速度低下が発生。Read the Docsでは、AIクローラーが大きなファイルを1日に数百回ダウンロードし、帯域幅の大幅な増加を引き起こした。両サービスとも一時的にクローラートラフィックをブロックし、IPベースのレート制限を実施した。
FedoraとDiaspora:人間ユーザーへの影響
Fedoraはパッケージミラーを再帰的にクロールするAIスクレイパーにより、人間ユーザーに対する応答速度が低下。Diasporaソーシャルネットワークは、robots.txtを尊重しない積極的なスクレイピングにより、応答速度の低下とダウンタイムを経験した。両者とも既知のボットソースからのトラフィックを地理的にブロックするなどの対応を取った。
これらの事例が示すのは、AIクローラーを単純にブロックするだけでは根本的な解決にならないということだ。よりスマートなキャッシュアーキテクチャがあれば、サイト運営者はAIクローラーにサービスを提供しつつ、人間ユーザーの応答時間を維持できる。
AI時代に向けたキャッシュ設計の新たな方向性

AIトラフィックの特性を考慮した新しいキャッシュ設計が必要とされている。主なアプローチは2つある。AIを意識したキャッシュアルゴリズムによるトラフィックフィルタリングと、AIクローラートラフィック専用の新しいキャッシュ層の追加だ。
ワークロード対応型キャッシュアルゴリズム
現在広く使用されているLRU(Least Recently Used)アルゴリズムは、汎用状況においてシンプルさ、低オーバーヘッド、有効性のバランスが取れている。しかし、人間とAIボットの混合トラフィックに対しては、別のキャッシュ置換アルゴリズムの選択が有効かもしれない。
初期実験では、SEIVEやS3FIFOといったアルゴリズムを使用することで、AIの干渉の有無にかかわらず、人間トラフィックが同じヒット率を達成できる可能性が示されている。さらに、ワークロードを直接意識した機械学習ベースのキャッシュアルゴリズムを開発し、リアルタイムでキャッシュ応答をカスタマイズする実験も進められている。これにより、より高速でコスト効率の高いキャッシュが実現できる。
トラフィック種別に応じた階層化キャッシュアーキテクチャ
長期的には、AIトラフィック専用の別個のキャッシュ層が最善の道となる。人間とAIのトラフィックをネットワークの異なる層に配置された別個の階層にルーティングするキャッシュアーキテクチャが考えられる。
人間トラフィックは、応答性とキャッシュヒット率を優先するCDN PoP(Point of Presence)のエッジキャッシュから引き続きサービスされる。一方、AIトラフィックのキャッシュ処理はタスクタイプによって変えることができる。
RAGやリアルタイム要約のようなライブアプリケーションを支えるAIクローラーでは、レイテンシが重要だ。これらのリクエストは、より大きな容量と適度な応答時間のバランスが取れたキャッシュにルーティングされるべきである。これらのキャッシュは鮮度を保ちつつも、人間向けキャッシュよりもわずかに高いアクセスレイテンシを許容できる。
訓練セットの構築や大規模コンテンツ収集ジョブに使用されるAIクローラーは、かなり高いレイテンシを許容し、時間的制約がない。これらのワークロードは、到達までに時間がかかる深いキャッシュ階層(オリジン側のSSDキャッシュなど)からサービスできる。あるいは、キューベースのアドミッションやレートリミッターを使用して遅延させ、バックエンドの過負荷を防ぐことも可能だ。これにより、インフラに負荷がかかっている場合にバルクスクレイピングを延期する機会も生まれる。
この記事のポイント
- AIクローラーは全ネットワークトラフィックの約3分の1を占め、そのアクセスパターンは人間のブラウジング行動と根本的に異なる。
- 高ユニークURL比率、長尾コンテンツへの集中アクセス、反復ループによるキャッシュチャーンが、従来のLRUキャッシュアルゴリズムの効果を低下させている。
- WikipediaやFedoraなどの大規模サイトでは、AIクローラーによる帯域幅急増やサービス不安定化が実際に発生し、多くのサイトがクローラーブロックに頼らざるを得なくなっている。
- 根本的な解決策として、SEIVEやS3FIFOなどの新しいキャッシュアルゴリズムの採用と、AIトラフィック専用の階層化キャッシュアーキテクチャの構築が検討されている。
- 今後のCDN設計では、人間トラフィックとAIトラフィックを分離し、それぞれの特性に最適化したキャッシュ戦略を適用することが重要になる。
・ 複数業界における17年間のデジタルビジネス開発経験
・ ウェブサイト開発のためのHTML、PHP、CSS、Java等の実用的知識
・ 15ヶ国語対応の多言語SaaSの開発経験
・ 17年間にも及ぶ、Eコマース長期運営経験
・ 幅広い業界でのSEO最適化の豊富な経験