

Claude Fable 5がAWSで利用可能に。長時間実行と安全策を両立する新モデル
AWSがClaude Fable 5のAmazon Bedrock対応を発表した。Anthropicの新モデルはMythosクラスの最高性能を備えつつ、有害利用リスクへの安全策を組み込んだ点が最大の特徴だ。ソフトウェア開発や文書解析など長時間の自律作業を任せられる設計になっている。
Fable 5はほぼすべてのベンチマークで最先端のスコアを記録する。注目すべきは、人間の介入なしで複雑なコーディングやナレッジワークを長時間継続できる実行能力だ。単発の応答を超えた「作業の持続」が可能になったことで、開発現場やビジネスプロセスへの組み込みが現実味を帯びてきた。
Claude Fable 5の3つの技術的特徴
従来のLLM(大規模言語モデル)が得意としてきた「質問への即答」とは異なり、Fable 5は「長時間タスクの遂行」にフォーカスしている。AWS公式ブログとAnthropicの技術発表から、その差別化要素を整理した。
長時間の非同期実行
従来のモデルは数分を超えるタスクで精度が低下したり、文脈を見失ったりする課題があった。Fable 5は複雑なコーディングや調査作業を長時間・自律的に続行できる。具体的には、複数ファイルにまたがる大規模なリファクタリングや、長大なドキュメントの横断的分析といった作業を途中で止めずに完了させる。
これは単にトークン数が増えただけではない。モデル内部のアーキテクチャが「途中経過の自己管理」を強化しており、タスクのゴールを見失わずに作業を継続する仕組みだ。AWSの発表では「長時間のコーディングや知識労働を継続的に実行する」と表現されている。
この変化により、ソフトウェア開発における「任せっぱなし運用」の幅が広がる。たとえばコードベース全体のリファクタリングを夜間に任せ、朝には完了しているというワークフローが視野に入る。
高度なビジョン機能
Fable 5はテキストだけでなく、図表、グラフ、PDF内に埋め込まれた表などを高精度で理解する。金融や法務、建築、ゲーム開発など、文書や設計図を扱う業種での活用が期待される領域だ。
コーディングの文脈でも大きな意味を持つ。デザインファイルを読み取ってUIを実装したり、出力結果のスクリーンショットを自己チェックして「要件と合っているか」を検証したりできる。従来のモデルはテキスト情報だけを頼りにしていたが、Fable 5は「見て判断する」能力を作業フローに組み込める。
プロアクティブな自己検証
Fable 5はタスク実行中に得た学習をもとにスキルを自己更新し、自ら評価用のハーネス(テストフレームワーク)を作成する。AWSの発表では「自身の出力を目標と照らし合わせて批判的に評価する」と説明されている。
これはソフトウェアテストの自動化と深く関わる。たとえば「単体テストのコードを生成する」という指示ではなく「この機能を実装し、テストを作成し、通るまで修正を繰り返せ」という指示が現実的になる。モデルが自律的にPDCAを回すため、人間は成果物の最終確認に集中できる。
安全策の仕組みとMythos 5との棲み分け

Fable 5の最大の独自性は「性能と安全策の両立」にある。同じモデルから安全性を引き上げたFable 5と、制限を外したMythos 5という2つのバリエーションが用意されている。
有害プロンプトは自動でOpus 4.8にルーティング
Fable 5はサイバーセキュリティ、生物学、化学、健康に関連する有害プロンプトを受け取ると、内部で自動的にOpus 4.8へルーティングする。AWSの公式発表では「安全策によって、ほぼすべての最先端機能へのアクセスを提供しつつ、誤用リスクの高い領域では応答を制限する」と説明されている。
重要なのは、ユーザー側で切り替えを意識する必要がない点だ。通常のAPIコールでFable 5を指定しておけば、安全と判断されたプロンプトにはFable 5が、リスクありと判断されたプロンプトにはOpus 4.8が自動で応答する。
Mythos 5は限定的なプレビュー提供
Fable 5の制限を取り払ったMythos 5も、Amazon Bedrockで限定的に利用可能だ。ただしMythos 5はサイバーセキュリティやライフサイエンス(創薬、バイオディフェンススクリーニング等)といった専門領域向けであり、審査を受けた一部の顧客のみアクセスできる。一般提供は行われない。
この「制限付きスーパーモデル」と「制限なし最強モデル」の二層構造は、AIの社会実装における新たなパラダイムとなり得る。AWSの発表でも、Mythos 5はデュアルユース(軍民両用)の性質を持つため厳格な管理下に置かれていると明記されている。
Amazon Bedrockでの利用環境とセットアップ

Fable 5はAmazon BedrockとClaude Platform on AWSの両方で利用できる。ここではBedrock経由のセットアップ手順を中心に解説する。
データ共有へのオプトインが必須
Fable 5を利用するには、データ保持ポリシーでプロバイダーデータ共有(provider_data_share)にオプトインする必要がある。AnthropicはMythosクラスの全モデルで、入力と出力の30日間保持および人間によるレビューを必須としている。これは単一のやり取りでは検出できない誤用パターンを長期的に監視するためだ。
オプトインするとデータはAWSのセキュリティ境界を離れる。機密性の高いデータを扱う場合は、この点を事前に評価しておく必要がある。設定はAWS CLIで以下のように実行する(bedrock-mantleエンジン向け)。
curl -X PUT https://bedrock-mantle.us-east-1.api.aws/v1/data_retention \
-H "x-api-key: <your-bedrock-api-key>" \
-H "Content-Type: application/json" \
-d '{ "mode": "provider_data_share" }'bedrock-runtimeエンジンを使う場合は、エンドポイントと認証方式が異なる点に注意が必要だ。詳細はAWSの公式ドキュメントを参照してほしい。
Python SDKからの呼び出し例
Anthropic SDKをインストールした後、Messages API経由でFable 5を呼び出すコードは以下の通りになる。リージョンは現時点で米国東部(バージニア北部)と欧州(ストックホルム)に対応している。
import anthropic
client = anthropic.Anthropic(
base_url="https://bedrock-mantle.us-east-1.api.aws/anthropic",
api_key=<your-bedrock-api-key>
)
message = client.messages.create(
model="anthropic.claude-fable-5",
max_tokens=4096,
messages=[
{
"role": "user",
"content": "秒間10万リクエストを複数リージョンで処理するAWS分散アーキテクチャを設計してほしい"
}
]
)
print(message.content[0].text)BedrockのConverse APIを使う場合はBoto3経由となる。マルチモデル対応の統一インターフェースが使えるため、既存のBedrockワークロードとの統合が容易だ。
課金体系の注意点
有害プロンプトがOpus 4.8にルーティングされた場合、そのリクエストの課金はOpusの価格で計算される。また途中でブロックされた会話では、Fable 5が処理した初期トークンはFable 5の料金、それ以降はOpusの料金が適用される。大規模なワークロードを計画する際は、見積もりにこの変動要素を含めておく必要がある。
ソフトウェア開発の現場に与える影響

Fable 5の登場は、とりわけソフトウェアエンジニアリングのワークフローを変える可能性が高い。AWSの発表でも「長時間のコーディングタスク」と「自己検証」が前面に押し出されている。
「コードを書く」から「コードを任せる」へ
従来のLLMは「関数を1つ書いて」という短い指示には強かったが、プロジェクト全体を見渡すようなタスクには限界があった。Fable 5は「このリポジトリの全テストを補充し、カバレッジが90%を超えるまで繰り返せ」といった高レベルな指示を理解し、自律的に遂行できる。
これは開発者の役割を「実装者」から「設計者・監督者」へとシフトさせる。コードを書く時間が減り、アーキテクチャの意思決定やビジネスロジックの検討に集中できるようになる。ただし出力の品質チェックは依然として人間の責任だ。
CI/CDパイプラインとの統合可能性
Fable 5の自己検証機能は、CI/CD(継続的インテグレーション/継続的デリバリー)の自動化範囲を拡大する。プルリクエストの自動レビュー、テスト自動生成、失敗時の自律的な修正までを一気通貫で行える可能性がある。
ただし現時点でFable 5は非同期実行向けに設計されており、リアルタイムのチャット応答を前提とした従来のCI/CDトリガーとはワークフローが異なる。ジョブキューと組み合わせたバッチ処理型の統合が現実的なアプローチになるだろう。
日本市場での受け入れと課題
国内のソフトウェア開発現場では、セキュリティ要件の厳しさから「データを外部に出せない」という制約が根強い。Fable 5の必須条件である30日間のデータ保持と人間によるレビューは、金融や医療分野での採用ハードルになる。AWSの東京リージョンでの利用可能時期も現時点では未発表だ。
一方で、スタートアップやゲーム開発のようにスピードを重視する領域では、Fable 5の長時間自律実行能力は強力な武器になる。日本でも段階的に導入が進むと見られる。
この記事のポイント
- Claude Fable 5はMythosクラスの性能を持ちつつ、有害利用を自動遮断する安全策を内蔵している
- 長時間の非同期実行により、コードの大規模リファクタリングや文書横断分析を自律的に完了できる
- 図表やPDFを読み取るビジョン機能が加わり、金融・法務・建築など文書集約型の業種で活用が広がる
- 有害プロンプトは自動でOpus 4.8にルーティングされ、ユーザーはモデルを意識せず使える
- Amazon Bedrockでの利用には30日間のデータ保持オプトインが必須。機密データの扱いには注意が必要だ

・ 複数業界における17年間のデジタルビジネス開発経験
・ ウェブサイト開発のためのHTML、PHP、CSS、Java等の実用的知識
・ 15ヶ国語対応の多言語SaaSの開発経験
・ 17年間にも及ぶ、Eコマース長期運営経験
・ 幅広い業界でのSEO最適化の豊富な経験

AWS Bedrock刷新、OpenAIとAnthropic API互換コンソールが登場
AWSが2026年6月5日、Amazon Bedrockの管理コンソールを刷新した。この新体験は「bedrock-mantle」エンジン向けに設計されており、Anthropic Messages APIとOpenAI Responses APIに最適化されている。
従来のBedrockコンソールはマネージド機能(AgentsやKnowledge Basesなど)を中心に据えていたが、今回の刷新はAPI直接呼び出しを前提とする開発者向けに設計し直されている。モデル選定からプロダクション実装までの時間を大幅に短縮する狙いだ。
この記事では、新コンソールの主要機能と開発ワークフローへの影響を詳しく見ていく。API互換性を活かしたコードの簡略化や、複数モデルの並列評価がどのように実現されるのかを解説する。
Bedrockの新コンソールが生まれた背景
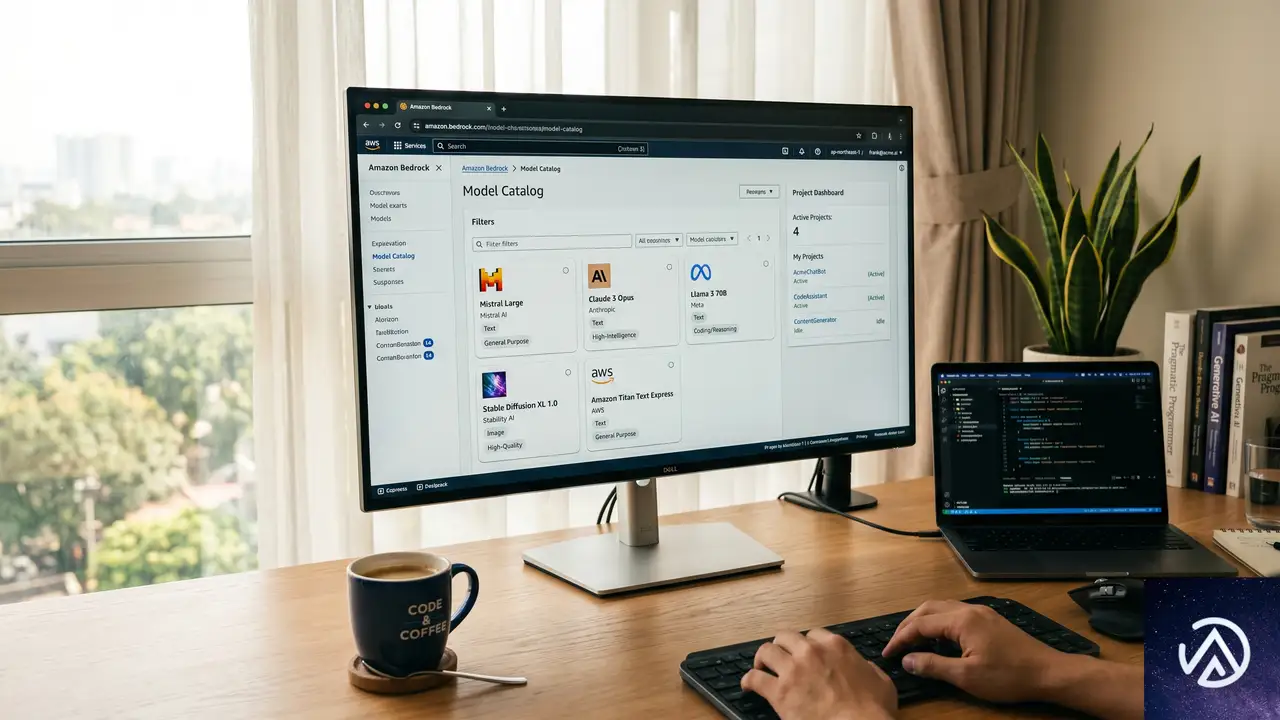
この図が示すように、新コンソールは「プロジェクト」を軸にした作りになっている。モデルの評価から実装、モニタリングまでをひとつの画面で完結させる狙いだ。
bedrock-mantleエンジンとは何か
bedrock-mantleは、Bedrockの第2世代推論エンジンとして位置づけられる。高速な処理性能と高い信頼性、そしてエンタープライズレベルのセキュリティを兼ね備えている。
最大の特徴はAnthropicとOpenAIのAPIプロトコルに互換性を提供することだ。ClaudeモデルにはAnthropic Messages API(メッセージAPI)を、GPTモデルにはOpenAI Responses API(レスポンスAPI)とOpenAI Chat Completions API(チャット補完API)を使える。これにより、既存のSDKコードをほぼ変更せずにBedrockへ移行できる。
従来のbedrock-runtimeエンドポイントを使う既存機能(InvokeModelやConverse API、Agentsなど)は、引き続き従来のBedrockコンソールから利用できる。両者は併存する設計で、急な移行は求められない。
新モデルカタログが提供する高速な比較体験

新コンソールの目玉のひとつが、刷新されたモデルカタログだ。従来は各モデルの仕様を調べるためにドキュメントや料金計算ツールを行き来する必要があったが、それが1画面で完結するようになった。
最大3モデルを並べて比較
カタログ上で最大3つのモデルを選択し、機能、モダリティの対応状況、コンテキストウィンドウの大きさ、利用可能なリージョン、料金体系を横並びで比較できる。
この比較機能は、チーム内でのモデル選定会議や、PoC(概念検証)フェーズでの迅速な意思決定に力を発揮する。料金と性能のトレードオフを視覚的に把握できるのが強みだ。
プロジェクト単位で完結する開発ワークフロー
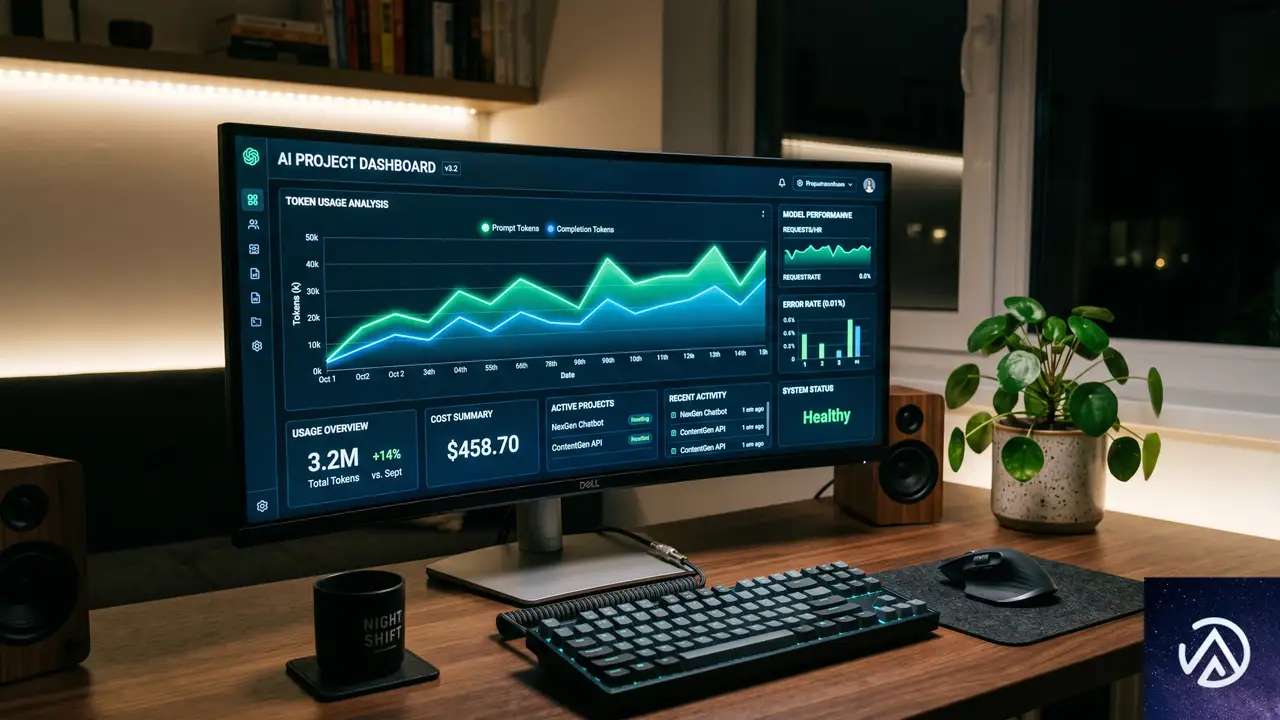
新コンソールの中核は「プロジェクト」という概念だ。生成AIアプリケーションの開発ライフサイクルをプロジェクトとして管理し、モデルの割り当てからAPIキーの発行、推論リクエストの送信までを一気通貫で行える。
ダッシュボードでトークン消費を可視化
プロジェクトダッシュボードでは、直近の推論リクエスト数やエラー発生率を日付範囲でフィルタリングできる。さらに、総トークン消費量、1分あたりのトークン使用量、推論リクエストの回数、1リクエストあたりの平均トークン数がグラフ表示される。
このデータは、モデルの選択ミスや過剰なトークン消費を早期に発見する手がかりになる。チームの予算管理にも直結するため、プロダクション環境では特に価値が高い。
サイドバイサイド評価でプロンプトを最適化
プロジェクト内で最大3つのモデルを選択し、同じプロンプトに対する応答を横に並べて比較できる評価モードが用意されている。これにより、どのモデルが自社のユースケースに最適かを実データで判断できる。
評価結果はそのままプロダクション環境へ移行する際の根拠資料としても使える。カスタマーサポート用チャットボットであれば、回答の質と応答速度のバランスを定量的に比較できる。
コード生成とAIアシスタント連携の新機能
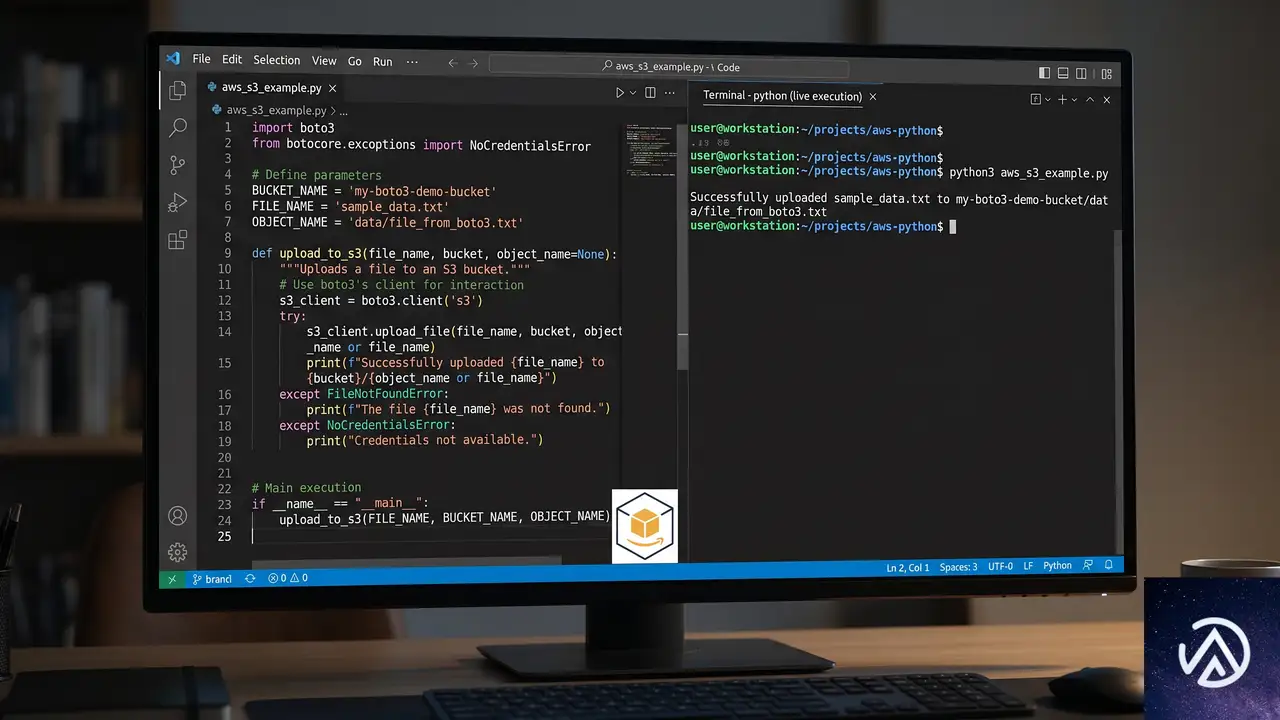
最も実務インパクトが大きいのが、プロジェクトに紐づいた「ライブドキュメント」機能だ。コードサンプルやSDKスニペット、APIリファレンスにプロジェクトの変数(モデルID、リージョン、エンドポイントURL、APIキー)が自動で埋め込まれる。
コピーするだけで動くコードスニペット
開発者はコンソール上で表示されたコードをそのままコピーし、ローカル環境のアプリケーションに貼り付けるだけで動作確認できる。環境変数の手動設定やエンドポイントURLの確認といった手間が省ける。
AWS_REGION=us-east-1
ENDPOINT=bedrock-mantle
API_KEY=sk-xxxxxx
client = boto3.client()
response = client.invoke(modelId=MODEL_ID)
この仕組みにより、環境構築のミスが大幅に減る。特に複数プロジェクトを抱えるチームでは、設定の食い違いによるトラブルシューティング時間を削減できる。
AIコーディングエージェントとの統合
新コンソールはAIコーディングエージェントとの連携もサポートする。Claude Code、Cline、Codex、Cursor、OpenCodeといった主要なAIアシスタントをBedrockのmantleエンジンにルーティングする手順がガイドされる。
具体的には、AWS IAM認証情報かBedrock APIキーを使い、環境変数を設定したうえで各エージェントからのリクエストをBedrock経由にする設定が案内される。これにより、AIアシスタントのバックエンドをOpenAIやAnthropicのクラウドからAWS環境に切り替えられる。企業ポリシーでデータの外部送信を制限しているケースで有効だ。
利用可能リージョンと今後の展開

新コンソール体験は、bedrock-mantleエンドポイントが提供されている全リージョンで利用可能だ。2026年6月時点での対象は以下の通り。
AWSのドキュメントにはリージョン互換性の一覧ページが用意されており、将来的な拡大があれば随時更新される見込みだ。フィードバックはAWS re:Post for Amazon Bedrock、または通常のAWSサポート窓口を通じて送ることができる。
新コンソールは既存のBedrockコンソールと並行して運用される。急な切り替えを迫られることはなく、チームの準備が整った段階で徐々に移行できる設計だ。
この記事のポイント
- Amazon BedrockにAPI互換性を重視した新コンソールが登場し、モデル評価から実装までの時間が大幅に短縮される
- bedrock-mantleエンジンはAnthropic Messages APIとOpenAI Responses APIに対応し、既存SDKコードの流用が容易
- 最大3モデルのサイドバイサイド比較と、プロジェクト単位のトークン消費可視化が組み込まれている
- コンソール上のコードスニペットはプロジェクト変数が自動プレフィルされ、コピー後即実行できる
- 東京リージョンを含む複数リージョンで利用可能、既存コンソールとの併存もサポートされる
・ 複数業界における17年間のデジタルビジネス開発経験
・ ウェブサイト開発のためのHTML、PHP、CSS、Java等の実用的知識
・ 15ヶ国語対応の多言語SaaSの開発経験
・ 17年間にも及ぶ、Eコマース長期運営経験
・ 幅広い業界でのSEO最適化の豊富な経験

OpenAIの最先端モデルとCodexがAWSで一般提供開始。Bedrock経由で本番導入が加速
2026年6月1日、OpenAIの最先端モデルとCodexがAmazon Bedrock上で一般提供を開始した。すでにAWSをインフラ基盤として使う数百万の組織が、同じ管理画面とセキュリティポリシーのままOpenAIのAI機能を本番環境へ組み込めるようになる。
Codexは毎週500万人以上の開発者が使うソフトウェアエンジニアリングエージェントだ。コードの記述、レビュー、デバッグ、レガシーコードのモダナイズまで、開発の全工程をAWS環境の中で完結できる。商用リージョンとGovCloudの両方に対応する。
企業にとって最大の意味は「AI導入の運用障壁が一段下がる」ことにある。調達、セキュリティ審査、ガバナンス、請求管理といった本番運用に必須のプロセスを、すでに信頼済みのAWSガードレールの中で処理できるからだ。
企業がAI導入でぶつかっていた3つの壁

OpenAIのAPIはここ数年で急速に高性能化した。GPT-4oをはじめとするフロンティアモデルは、自然言語の理解と生成だけでなく、構造化データの処理やマルチモーダル推論までこなす。それでも大企業の本番導入は想定より緩やかだった。理由は技術そのものではなく、運用プロセスにある。
セキュリティ審査とガバナンスの再構築
新しい外部サービスを本番環境につなぐには、情報セキュリティ部門による審査が避けられない。データの送信先、暗号化の有無、ログの保管場所、アクセス制御ポリシーとの整合性。これらを一から確認する作業は数週間から数ヶ月に及ぶ。OpenAI単体のAPIを使う場合、この審査プロセスが最初のハードルだった。
請求管理と調達フローの分断
クラウド費用をAWSで一元管理している企業にとって、別のSaaS契約を追加することは経理と調達の両面で負荷が増す。予算承認のフロー、請求書の処理、利用量の監視。それぞれが独立したサイロになり、小さなPoC(概念実証)の段階で手続きに埋もれてしまうケースも少なくなかった。
開発パイプラインとの統合コスト
AIの推論結果をアプリケーションに組み込むには、API呼び出しの認証、レート制限の管理、エラーハンドリング、モニタリングの仕組みを別途構築する必要があった。AWSのIAMやCloudWatchと統合されていないサービスを追加するたびに、運用スクリプトと監視設定を一から書く工数が発生していたのだ。
このデモ図が示すように、AWS Bedrockを経由することで調達・審査・監視のステップが一本化される。これが今回の発表でOpenAIが強調している「摩擦の低減」の正体だ。
2つの提供ルートが開いた意味
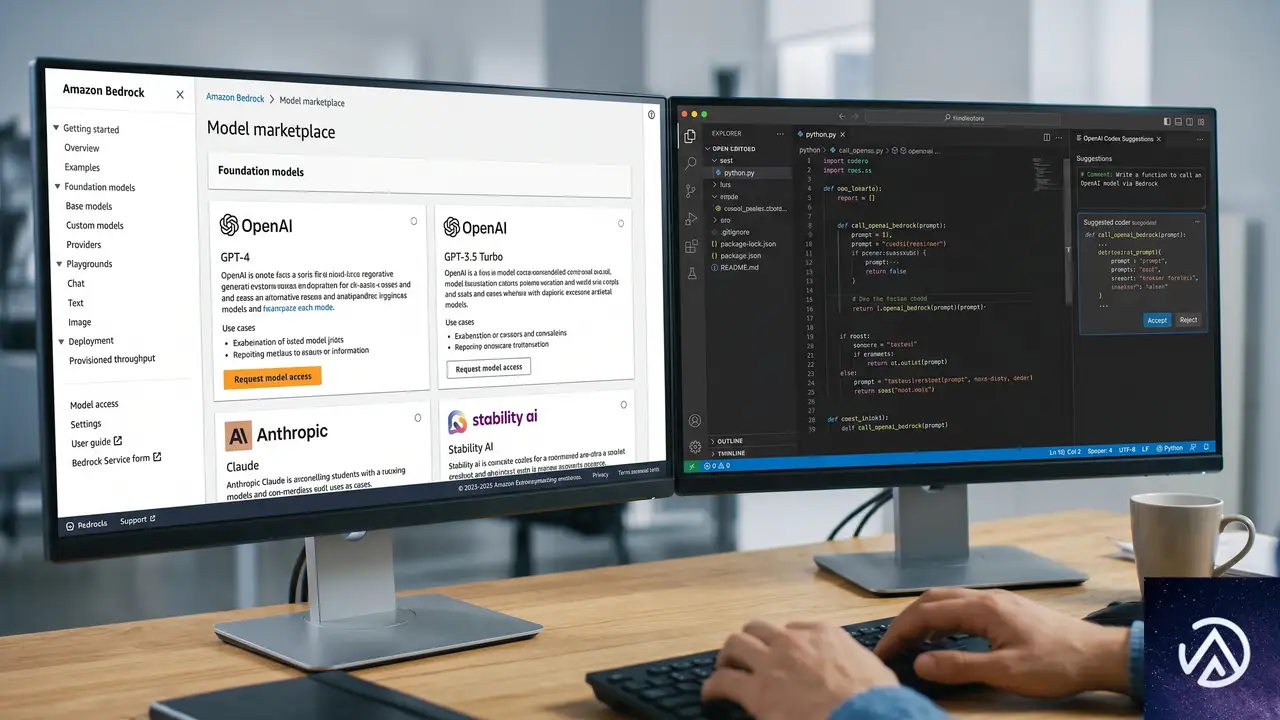
OpenAIの機能はAWS上で2つの形態で提供される。どちらもAmazon Bedrockを基盤とするが、用途と対象者が異なる。
OpenAI models on Amazon Bedrock
GPT-4oをはじめとするOpenAIのフロンティアモデルを、BedrockのAPI経由で呼び出せる。BedrockはAWSが提供するフルマネージド型の基盤モデルサービスだ。すでにBedrock上で他のモデルを使っているチームであれば、同じIAMロール、同じVPCエンドポイント、同じCloudTrailの監査ログでOpenAIのモデルを追加できる。
これにより、チャットボット、文書要約、マルチモーダル分析といったユースケースを、セキュリティチームが事前承認したネットワーク境界の中で実装可能になる。データがAWSリージョン外に送信される心配もなく、社内ポリシーとの整合性を取りやすい。
Codex on Amazon Bedrock
CodexはOpenAIが提供するソフトウェアエンジニアリングエージェントだ。コードの自動生成だけでなく、プルリクエストのレビュー、バグの特定、依存関係の分析、レガシーコードのリファクタリング提案までを対話型で実行する。GitHubやIDEと統合して使うのが一般的だったが、今回の発表でAWS環境から直接Codexを呼び出せるようになった。
週に500万人以上の開発者がすでにCodexを利用している。この数字はGitHub Copilotのユーザー数に匹敵し、AIコーディング支援が一部のアーリーアダプターの手を離れ、メインストリームの開発プラクティスになったことを示している。AWS上でCodexを使えるようになることで、CI/CDパイプラインへの組み込みや、組織全体のコードレビューポリシーとの統合が現実的になる。
Codexが開発パイプラインの中に組み込まれることで、コードレビューや依存関係チェックがプルリクエストのたびに自動で走るようになる。レビュアーの負荷が下がり、バグの早期発見にもつながる設計だ。
商用とGovCloudの両対応が示す信頼性

今回の発表で見逃せないのは、OpenAIの機能がAWSの商用リージョンとGovCloud(米国政府向けクラウド)の両方で提供される点だ。GovCloudはFedRAMPやITARなどの厳格なコンプライアンス基準を満たすために設計された隔離環境である。
政府機関や防衛産業、高い規制要件を持つ金融機関にとって、AIモデルをGovCloud内で実行できることの意味は大きい。データが閉域網から出ず、監査証跡もAWSの既存フレームワークで一貫管理される。OpenAIのモデルをパブリッククラウド越しに使うことに抵抗があった組織も、このオプションで導入検討の敷居が下がる。
OpenAIのCarlo Daniele氏は公式ブログで「企業が直面する最大の障壁は、最先端AIを既存のセキュリティとコンプライアンスの枠組みの中で本番運用することだ」と指摘している。GovCloud対応はまさにその障壁をターゲットにした一手といえる。
Daybreak構想とセキュリティ開発の未来

今回の発表と同時に、OpenAIは「Daybreak」という構想の将来提供も示唆した。Daybreakはソフトウェアの「作り方」と「守り方」の両方を変えることを狙ったビジョンだ。
Codex Securityが開発ループに入る日
Daybreakの中核には、サイバーセキュリティに特化したモデル群と「Codex Security」がある。これらは以下の機能を日常的な開発ループに組み込むことを目指している。
- セキュアコードレビューの自動化
- 脅威モデリングの支援
- パッチ検証の効率化
- 依存関係のリスク分析
- 脆弱性の検出と修復ガイダンスの提示
現状、これらの作業の多くはセキュリティ専任チームが限られた時間の中で手動で行っている。コード量が増えるほどチェックが追いつかなくなり、既知の脆弱性が修正されないまま本番環境に残るリスクが高まる。Codex Securityはこのギャップを、開発者がコードを書くタイミングで自動的に埋めようという発想だ。
AWSがセキュリティ導入の加速路になる
Daybreakのような専用機能が本格提供されたとき、AWSはその導入経路として重要な役割を果たすとOpenAIは見ている。すでにAWS上でセキュリティ運用(GuardDuty、Security Hub、Inspectorなど)を回している組織であれば、Codex Securityの出力を既存のSOC(セキュリティオペレーションセンター)ワークフローに直接流し込めるからだ。
OpenAIの記事では「セキュリティチームがすでに使っているセキュリティ、ガバナンス、調達、運用のフレームワークの中でDaybreakを導入できる」と説明されている。セキュリティ強化のための新ツール導入が、逆に運用負荷を増やすという矛盾を避ける設計思想だ。
このフローが実現すれば、セキュリティは「後付けの検査工程」から「開発と同時並行で走る自動プロセス」に変わる。Daybreakの提供時期はまだ明言されていないが、AWS基盤の上でこの構想が動き始めたこと自体が重要なシグナルだ。
開発チームが今から準備すべきこと

OpenAI on AWSはすでに一般提供が始まっている。商用リージョンとGovCloudの両方で利用可能だ。開発チームがこの変化を活かすために、今から着手できることがいくつかある。
Bedrockのアクセス権を確認する
まず、自組織のAWSアカウントでBedrockが有効化されているか確認する。IAMポリシーでBedrockのモデルアクセス権限が適切に設定されているかも見直す必要がある。特にOpenAIのモデルを呼び出すには、Bedrock内でモデルアクセスを明示的にリクエストするステップが必要だ。
CodexをCI/CDパイプラインに組み込む設計を始める
Codex on BedrockはAPIとして提供されるため、GitHub ActionsやAWS CodePipelineと組み合わせて、プルリクエストの自動レビューやコード品質チェックに活用できる。すでにCodexをIDEで使っているチームは、パイプライン全体への展開を検討する段階に入ったといえる。
セキュリティチームとDaybreakのロードマップを共有する
Daybreakの具体的な提供日は未定だが、Codex Securityの方向性を事前にセキュリティチームと共有しておくことで、導入時の社内調整をスムーズにできる。脅威モデリングや依存関係分析の自動化がどのように既存のセキュリティ運用と統合されるのか、概念レベルで議論を始めておくのが有効だ。
この記事のポイント
- OpenAIのフロンティアモデルとCodexがAmazon Bedrockで一般提供を開始
- 既存のAWSセキュリティ・ガバナンス・請求管理の枠組みでAIを本番導入可能に
- Codexは週500万人以上が使うエンジニアリングエージェントで、開発パイプラインへの統合が加速
- 商用リージョンとGovCloudの両対応により、規制業界や政府機関の導入障壁が低下
- Daybreak構想(Codex Security)が将来提供されれば、セキュリティレビューが開発と同時進行する形に変わる
・ 複数業界における17年間のデジタルビジネス開発経験
・ ウェブサイト開発のためのHTML、PHP、CSS、Java等の実用的知識
・ 15ヶ国語対応の多言語SaaSの開発経験
・ 17年間にも及ぶ、Eコマース長期運営経験
・ 幅広い業界でのSEO最適化の豊富な経験

AWS BedrockでOpenAI GPT-5.5とCodexが利用可能に。開発効率が飛躍
AWSが2026年6月、Amazon Bedrock上でOpenAI GPT-5.5モデル、GPT-5.4モデル、そしてコーディングエージェントCodexの一般提供を開始した。これにより、Bedrockのセキュアなインフラ上で最先端の大規模言語モデルを利用できる。
GPT-5.5は最も難しいタスク向け、GPT-5.4はコストパフォーマンス重視のシナリオに適する。いずれも、新しい推論エンジン上で高速かつ信頼性の高い応答が得られる。Codexは週あたり400万人以上の開発者が使用するAIコーディングツールで、複数のIDEと連携しつつ、推論エンジン経由でBedrockからモデルを呼び出す。
データ主権要件に対応するため、すべての処理は選択したBedrockリージョン内に留まる。トークン単位の課金で、シートライセンスや開発者あたりの固定費は発生しない。本記事では利用開始手順と技術的な注意点を解説する。
AWS BedrockでOpenAI GPT-5.5とCodexが一般提供
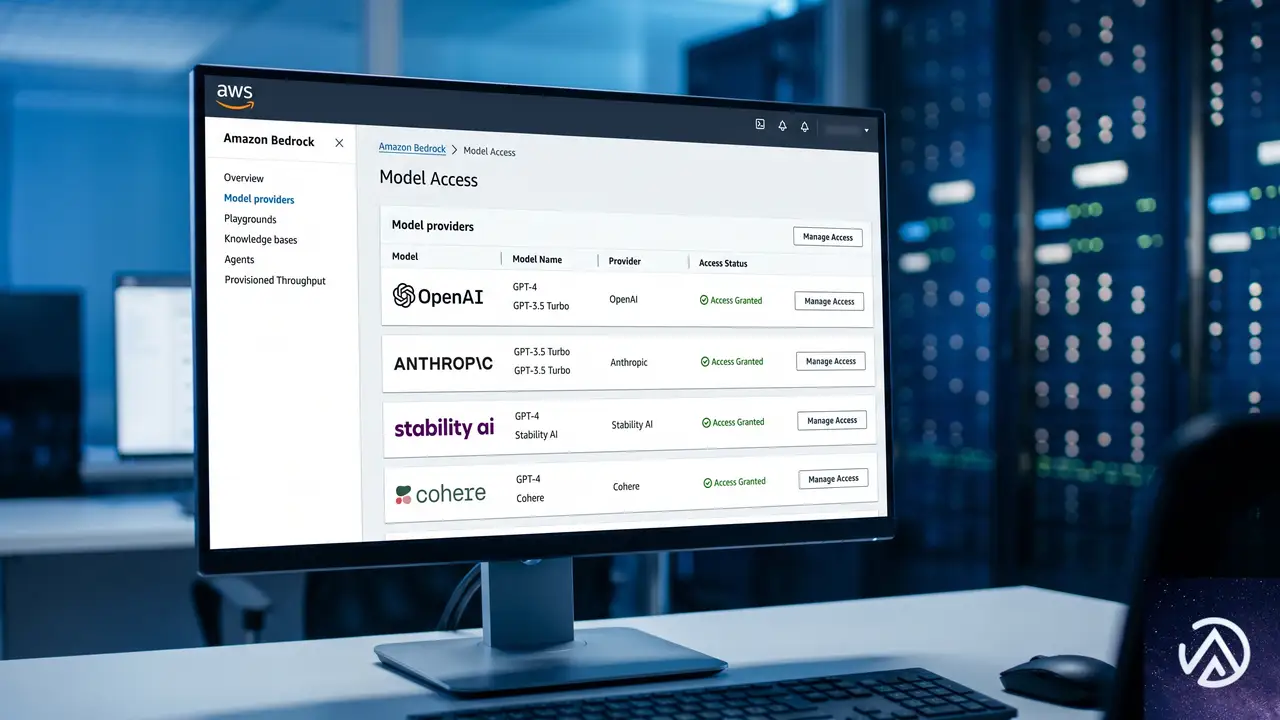
AWSの年次カンファレンスでプレビューされていたOpenAIモデルの対応が、正式に利用可能になった。GPT-5.5とGPT-5.4は、コーディング、推論、エージェントワークフロー、複雑な専門業務に優れる。AWS News BlogのChanny Yun氏は、GPT-5.5を「最も難しい顧客のワークロード」向け、GPT-5.4を「最良の価格性能比」と位置づける。
モデルへのアクセスは、新しいBedrock推論エンジンが提供するResponses APIを介して行う。このAPIは、マルチターン状態管理、ホストツール、ファンクションツール、バックグラウンド実行をサポートする。
この構成により、機密データを外部に送信することなく、AWSの管理下で最先端AIを活用できる。リージョンごとのデータ主権も担保される。
GPT-5.5モデルの利用方法

モデルへは、OpenAIのResponses APIを用いてアクセスする。Bedrock専用のエンドポイントbedrock-mantleを経由し、OpenAI SDKやcurlから呼び出す形だ。以下にセットアップ手順を示す。
Python SDKを使った呼び出し
まずOpenAI SDKを最新版にアップデートする。
pip install -U openai認証用の環境変数を設定する。BedrockのAPIキーはAWSマネジメントコンソールから取得できる。
export OPENAI_BASE_URL="https://bedrock-mantle.us-east-2.api.aws/openai/v1"
export OPENAI_API_KEY="<BEDROCK_API_KEY>"
export BEDROCK_OPENAI_MODEL_ID="openai.gpt-5.5"以下のサンプルコードで、GPT-5.5に分散アーキテクチャの設計を依頼できる。
import os
from openai import OpenAI
client = OpenAI(
base_url=os.environ["OPENAI_BASE_URL"],
api_key=os.environ["OPENAI_API_KEY"],
)
response = client.responses.create(
model=os.environ["BEDROCK_OPENAI_MODEL_ID"],
input=[
{
"role": "developer",
"content": "You are a software engineer with excellent AWS cloud knowledge. Be concise and practical.",
},
{
"role": "user",
"content": "Design a distributed architecture on AWS in Python that should support 100k requests per second across multiple geographic regions.",
},
],
reasoning={"effort": "medium"},
text={"verbosity": "low"},
)
print(response.output_text)curlによる直接アクセス
curlを使う場合も同様に環境変数を設定した上で、エンドポイントへPOSTリクエストを送る。
curl "$OPENAI_BASE_URL/responses" \
-H "Content-Type: application/json" \
-H "Authorization: Bearer $OPENAI_API_KEY" \
-d '{
"model": "openai.gpt-5.5",
"input": [
{
"role": "developer",
"content": "You are a software engineer with excellent AWS cloud knowledge."
},
{
"role": "user",
"content": "Design a distributed architecture on AWS in Python that should support 100k requests per second across multiple geographic regions."
}
],
"reasoning": {"effort": "medium"},
"text": {"verbosity": "low"}
}'コード内のreasoning.effortは推論の深さを制御する。GPT-5.5ではmediumから始め、必要に応じてhighに変更すると良い。GPT-5.4の場合は明示的にeffortを指定すべきだ(デフォルトがnoneのため)。
CodexでAI駆動開発を体験する
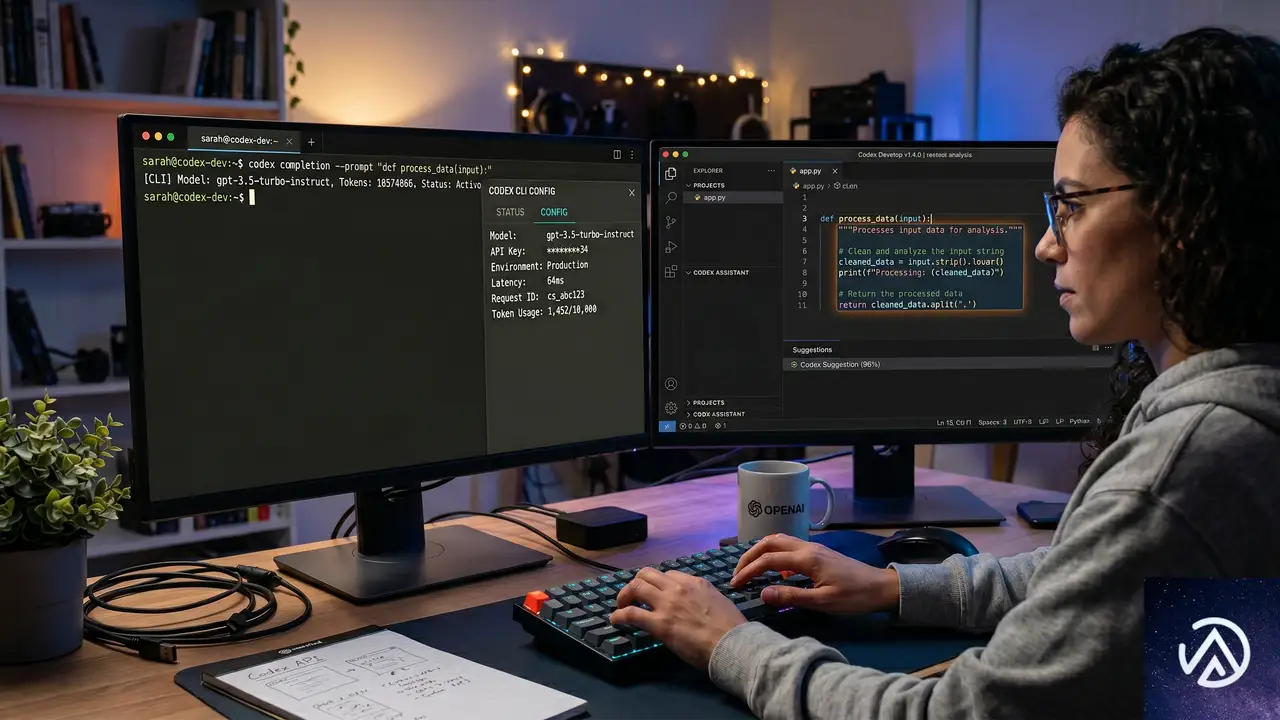
Codexは、GPT-5.5を推論エンジンとしてバックグラウンドで利用するコーディングエージェントだ。CLI、デスクトップアプリ、VS CodeやJetBrains、Xcodeの拡張機能が提供され、大規模コードベースの作成、リファクタリング、デバッグ、テスト、検証をAIが支援する。
Codex CLIの設定手順
Codex CLIをインストール後、Bedrock認証を有効にする。APIキー認証とAWS SDKの認証情報チェーンの2方式があり、APIキーが優先される。
export AWS_BEARER_TOKEN_BEDROCK=<your-bedrock-api-key>次に、~/.codex/config.tomlにモデル情報とリージョンを記述する。
model = "openai.gpt-5.5"
model_provider = "amazon-bedrock"
[model_providers.amazon-bedrock.aws]
region = "us-east-2"デスクトップアプリやVS Code拡張では、必要な環境変数を~/.codex/.envに記述しておく。設定変更後はアプリケーションを再起動すれば反映される。
CLIで/statusタブを表示すると、モデルがBedrock経由で接続されていることを確認できる。Channy Yun氏の記事では、実際のステータス画面が示されており、モデルとしてopenai.gpt-5.5と表示される。
レイテンシやスケーリングの注意点

本番利用を始めるにあたり、いくつかの技術的なポイントを把握しておく必要がある。
モデルレイテンシの特性
GPT-5.5は高速、GPT-5.4は中速と位置づけられるが、実際の遅延は推論の深さ、出力長、ツール呼び出しの有無、バックグラウンドモード、リージョン、クォータ、スロットリング、プロンプトサイズ、キャッシュヒットに依存する。GPT-5.5ではreasoning.effortをmediumで開始し、GPT-5.4では明示的にeffortを設定することを推奨する(デフォルトがnoneで十分な推論が得られない可能性があるため)。
スケーリングとキャパシティ管理
Bedrockの新しい推論エンジンは、多数のモデルにわたって迅速にキャパシティをプロビジョニングし、需要変動に応じてスケールする設計だ。定常的なワークロードの実行を優先し、需要急増時にはリクエストをキューイングする(拒否はしない)。そのため、予期せぬトラフィック増加時にも安定した動作が期待できる。ただし、クォータ上限を事前に確認し、必要に応じて引き上げ申請を行うことが望ましい。
この記事のポイント
- Amazon Bedrock上でOpenAI GPT-5.5・GPT-5.4モデルとCodexが一般提供開始
- Responses APIを通じてモデルを呼び出し、複雑なワークロードに対応
- CodexはGPT-5.5をバックエンドに、CLI・デスクトップアプリ・IDE拡張で利用可能
- データは選択したBedrockリージョン内で処理され、データ主権を確保
- レイテンシは複数要因に依存し、effort設定やキャッシュが影響するため、初期はmediumから
- スケーリングは自動だが、クォータ管理を怠らないこと
・ 複数業界における17年間のデジタルビジネス開発経験
・ ウェブサイト開発のためのHTML、PHP、CSS、Java等の実用的知識
・ 15ヶ国語対応の多言語SaaSの開発経験
・ 17年間にも及ぶ、Eコマース長期運営経験
・ 幅広い業界でのSEO最適化の豊富な経験