

Amazon Bedrock AgentCoreにWeb Search機能が一般提供開始、AIエージェントの回答を最新Web情報で根拠づけ
AWSは2026年6月17日、Amazon Bedrock AgentCoreにWeb Search機能の一般提供を開始した。AIエージェントがユーザーからの質問に対し、最新のWeb情報を参照しながら根拠のある回答を提示できるようにする。トレーニングデータだけではカバーしきれない直近の出来事や新事実を、AWS環境内で安全に取得できる点が最大の特徴だ。
この機能は、Amazonが長年培ってきた検索インフラ上に構築されている。Alexa+やAmazon Quick、Kiroといった製品で実績のある基盤を活用し、WebインデックスとAmazon Knowledge Graphを組み合わせたマルチソースな根拠付けを実現する。検索クエリは外部APIプロバイダに送信されず、AWS環境内で完結するため、企業のガバナンス要件にも適合する。
本記事では、Bedrock AgentCore Web Searchの仕組み、料金体系、導入事例を詳しく解説する。
Web Search機能の概要と背景

Bedrock AgentCoreの位置づけ
Amazon Bedrock AgentCoreは、AIエージェントの構築と運用を管理するフレームワークである。エージェントに必要なツールやデータソースとの接続をGatewayという仕組みで一元管理し、モデルの推論と外部機能の呼び出しを連携させる。今回発表されたWeb Searchは、AgentCore Gateway上で利用できる組み込みコネクタターゲットのひとつだ。
Web Searchが解決する課題
LLM(大規模言語モデル)は、学習時点のデータに基づいて回答を生成するため、つねに最新の情報を反映できるとは限らない。たとえば、企業の決算発表や法改正、製品アップデートなど、学習後に発生した出来事には対応できない。Web Searchを用いれば、エージェントがリアルタイムにWeb検索を実行し、得られたスニペットやURLを参照して回答を生成できる。回答には引用元が明示されるため、情報の信頼性をユーザーが確認しやすくなる。
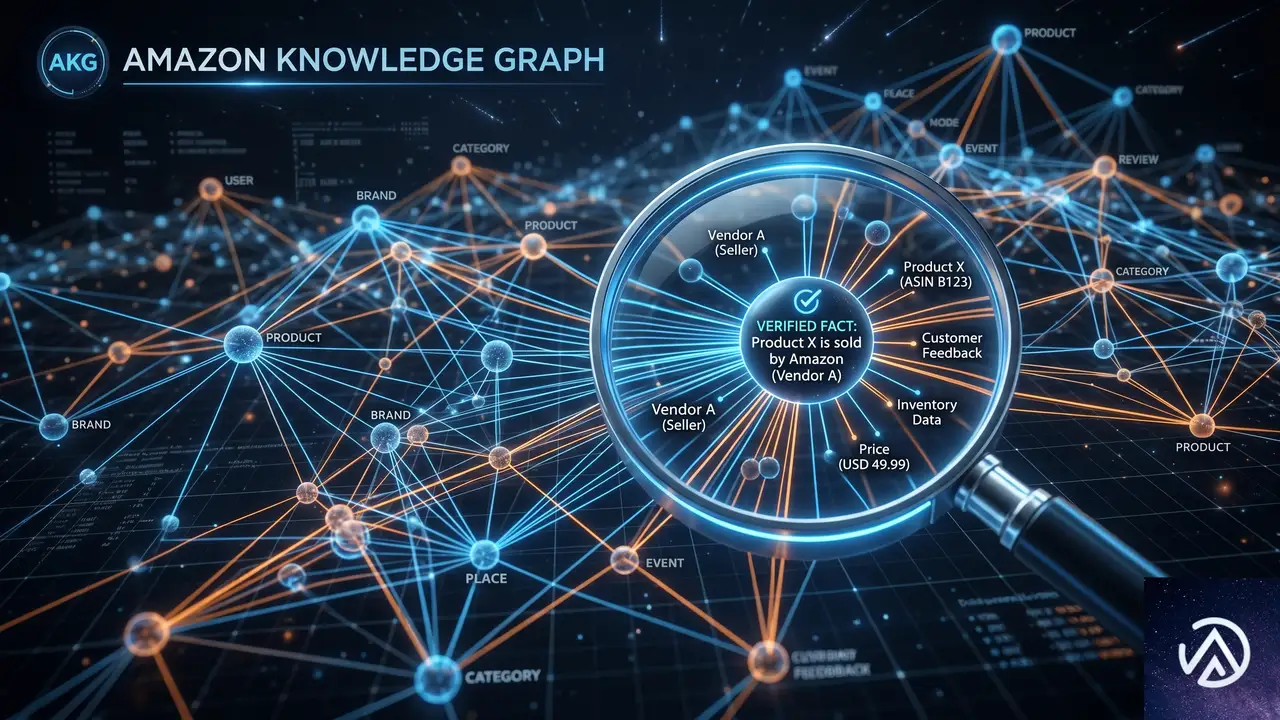
仕組み:MCP接続とAmazon知識グラフによる根拠付け
MCP(Model Context Protocol)の役割
Web Searchは、MCP(Model Context Protocol)と呼ばれる標準プロトコルを介してAgentCore Gatewayに接続される。MCPを使うことで、エージェントは自然言語のクエリを送信し、関連性の高い検索結果(スニペット、URL、タイトル、公開日)を取得できる。GatewayがMCPターゲットとしてWeb Searchツールを仲介するため、開発者が個別に検索APIを実装する必要はない。
Amazon知識グラフとの統合
一般的なWeb検索に加え、Amazon Knowledge Graphの構造化データが検索結果に組み込まれる。これにより、単なるWebスニペットではカバーしきれない検証済みの事実情報をエージェントが参照できるようになる。AWSのブログ記事によれば、このマルチソースアプローチが従来のWeb検索だけに頼る場合と比較して、より的確な回答につながるとされている。
エージェントが回答を生成するまでの流れ
以下のデモは、ユーザーが質問してからエージェントが根拠付き回答を返すまでの一連のステップを図示したものだ。
STEP 3の段階でAmazon Knowledge Graphが活用される点が、単なるWeb検索を超えた信頼性につながる。エージェントは受け取った情報をそのまま返すのではなく、モデルが内容を推論した上で回答を構成するため、質問の文脈に合った自然な応答になる。
AWS環境内で閉じるセキュアなWeb検索の価値
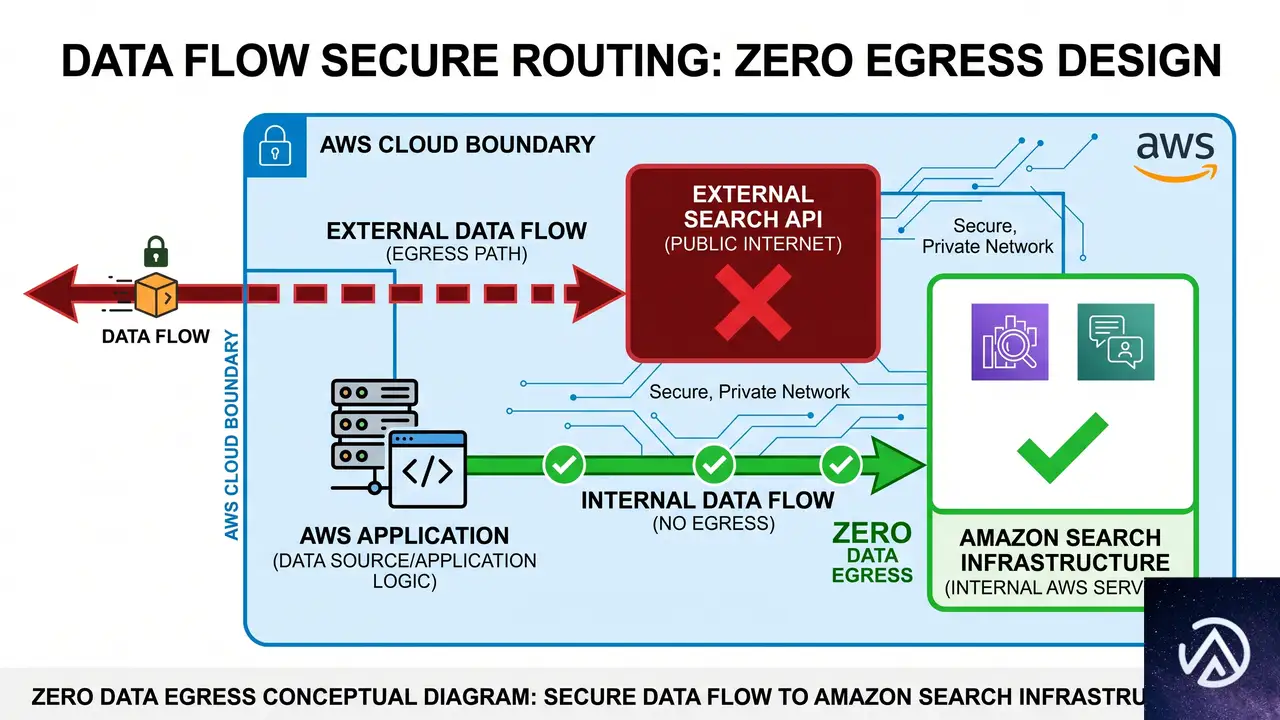
多くのAIエージェント向けWeb検索ソリューションでは、ユーザーのクエリやプロンプトが外部の検索APIプロバイダに送信される。これに対しBedrock AgentCoreのWeb Searchは、Amazon自身の検索インフラを使用するため、データがAWS環境の外に流出しない。これにより、機密性の高い業務データを扱う企業でも、ガバナンスやコンプライアンスの要件を満たしながらエージェントにWeb検索機能を組み込める。
AWSの説明によれば、この仕組みはAlexa+やKiroなどのプロダクトで培われた検索技術を基盤にしており、信頼性とスケーラビリティの両面で実績がある。ユーザーは外部の検索サービス契約やAPIキー管理を気にすることなく、AgentCoreの設定画面上でWeb Searchを有効化するだけで利用を開始できる。
料金体系と利用開始手順
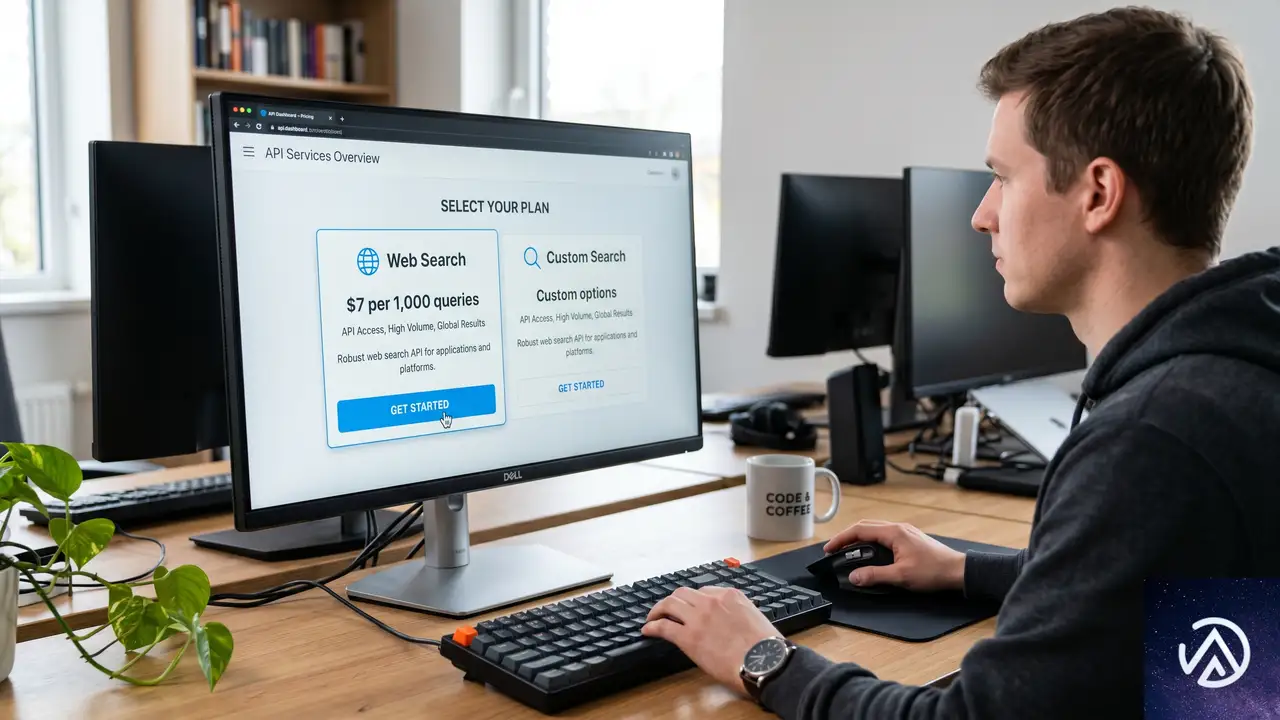
料金詳細
Web Searchの料金は従量課金制で、エージェントが実行した検索クエリの数に応じて計算される。具体的には、1,000クエリあたり7ドルである。新規のAWS顧客には最大200ドル相当の無料利用枠も提供される。利用料はすべてAWSの請求に統合されるため、別途外部サービスへの支払い管理は不要だ。
セットアップ手順
Bedrock AgentCoreコンソール(us-east-1リージョン)にアクセスし、Gatewayを作成する。ターゲットの追加時に「MCP target」プロトコルと「Connectors」タイプを選択し、プリコンフィギュアされた「Web Search tool」を指定する。Gatewayの詳細ページに遷移すると、PythonやMCP Inspectorを用いた呼び出しコードのサンプルが表示されるため、これをコピーして自環境に組み込むだけで統合が完了する。
テスト用途であれば、MCP InspectorをGatewayのリソースURLに接続し、Web Searchツールにクエリを直接入力して動作を確認できる。実運用では、エージェントのプロンプト設計にWeb検索の呼び出しトリガーを組み込み、回答生成時に適宜検索が走るように構成することになる。
企業での活用事例

Benchling:科学研究の加速
ライフサイエンス分野のR&Dプラットフォームを提供するBenchlingは、早期アクセスを通じてWeb Searchを試験導入した。同社AIエージェント責任者Nicholas Larus-Stone氏によると、科学者が研究対象について質問すると、Benchling内の組織データと公開文献の両方に基づく回答が得られるようになったという。これにより、仮説生成の質が向上し、顧客のデータ管理ポリシーにも適合する安全な環境を維持できている。
Gen Digital:オンライン評判管理の強化
消費者向けセキュリティ製品を展開するGen Digital(Nortonブランド)は、Norton RevampというサービスにWeb Searchを組み込んだ。プロフェッショナルが自身のオンライン評判を構築する際、最新のトレンドや事実に基づいたコンテンツアイデアをエージェントが提案できるようになる。同社AI・イノベーション部門シニアディレクターIskander Sanchez-Rola氏は、すべてのクエリが信頼できるAWS環境内で処理される点を高く評価しているとコメントした。
いずれの事例でも、外部サービスを利用せずにAWS内で完結するセキュリティと、Amazon独自の検索インデックスによる高精度な情報取得が決め手となっている。
この記事のポイント
- Amazon Bedrock AgentCoreでWeb Search機能が一般提供開始。MCP経由でWeb検索と知識グラフを統合し、エージェントの回答を最新情報で根拠づける
- 検索クエリはAWS環境外に出ず、Amazonの検索インフラで処理されるため、データガバナンスとコンプライアンスに対応
- 料金は1,000クエリあたり7ドルの従量課金。新規顧客向けに200ドル分の無料枠あり
- BenchlingやGen Digitalなどの企業がすでに導入し、研究支援や評判管理の精度向上に活用している
- us-east-1リージョンで利用可能。AgentCoreコンソールから数ステップで設定できる

・ 複数業界における17年間のデジタルビジネス開発経験
・ ウェブサイト開発のためのHTML、PHP、CSS、JavaScript等の実用的知識
・ 15ヶ国語対応の多言語SaaSの開発経験
・ 17年間にも及ぶ、Eコマース長期運営経験
・ 幅広い業界でのSEO最適化の豊富な経験

AWS WAFがAIボット収益化機能を追加、コンテンツ所有者が課金可能に
AWSは2026年6月15日、AWS WAFにAIトラフィック収益化機能を追加した。コンテンツ所有者やパブリッシャーが、自社のWebコンテンツにアクセスするAIボットやAIエージェントに対して、ネットワークエッジで直接課金できるようになる。
AIボットによるWebトラフィックは、多くのコンテンツプロバイダーで全体の50%を超え、AI専用クローラーは前年比300%以上増加している。従来の検索エンジンクローラーはリンクを返すことで参照トラフィックをもたらすが、AIボットはコンテンツを要約してAIインターフェイス上で表示するため、元のサイトにはほとんどトラフィックが還元されない。その結果、コンテンツ提供者はインフラコストだけを負担し、広告収入や購読コンバージョンといった従来の収益源が得られない状況が続いていた。
今回の新機能は、このギャップを埋めるものだ。AWS WAF Bot Controlの仕組みを拡張し、コンテンツパスごと、ボットカテゴリごと、検証ティアごとにリクエスト単価を設定できる。また、ステーブルコインによる支払いをウォレットで受け取り、単一のダッシュボードで収益とボットアクティビティを追跡可能にする。
AIボット収益化の新機能がAWS WAFに追加された背景

AIトラフィックの爆発的な増加
GPTBotやClaude-Web、Perplexity-BotといったAIクローラーは、学習用データやリアルタイム情報の収集のためにWebサイトを大量にクロールする。こうしたトラフィックは増加の一途をたどり、一部のコンテンツプロバイダーではAIボットが全リクエストの50%を超えるまでになっている。検索エンジンのクローラーとは異なり、AIボットはインデックスを生成する代わりにテキストを直接消費し、要約をAIチャット画面に表示する。そのため、元記事を読むための流入はほとんど発生しない。
従来のBot Controlでは限界があった理由
AWS WAF Bot Controlはこれまで、650種類以上のAIボットを検出し、ブロックまたはレート制限をかけることができた。しかし、ボットのトラフィックを完全に遮断するのではなく、課金して収益化したいというニーズは強く存在していた。コンテンツを無料で提供し続ければインフラコストがかさむ一方、単純にブロックすればAIサービスへの露出が途絶えてしまう。そこで、ボットにコンテンツ利用の対価を支払わせる仕組みが求められていた。
AIトラフィック収益化の仕組み

x402プロトコルとHTTP 402 Payment Required
今回の収益化機能の核は、x402というマシンツーマシン決済のオープンプロトコルだ。ルールに合致したAIボットからのリクエストに対し、AWS WAFはHTTP 402 Payment Requiredレスポンスを返す。このレスポンスボディには、コンテンツの価格(USDC建て)、受け入れ可能なブロックチェーンネットワーク(BaseやSolanaなど)、送金先ウォレットアドレス、支払いタイムアウトを含むJSON形式のプライスマニフェストが含まれる。これを受け取ったx402対応のエージェントランタイムは、自律的に署名付き支払い承認を提出し、AWS WAFがそれを検証したうえでコンテンツを提供するという流れだ。
ステーブルコイン決済の流れ
決済はステーブルコイン(USDC)で行われ、サードパーティのファシリテーターサービス(現在はCoinbaseのx402 Facilitator)がオンチェーン上の決済処理を支援する。Stripeによる直接アカウント決済やMachine Payments Protocol(MPP)への対応も近日中に予定されている。コンテンツ所有者は、AWS WAFの設定パネルでウォレットアドレスを指定するだけでよく、独自の決済インフラを構築する必要はない。また、AWS自体は決済手数料を徴収しない。
上記のように、収益化を有効にするとAIボットのアクセスが自動的に402レスポンスに切り替わり、支払いが完了したリクエストだけがコンテンツに到達する。コンテンツ所有者はアクセスを遮断する代わりに料金を設定し、ボットトラフィックを収益源に変えることができる。
収益化の設定手順
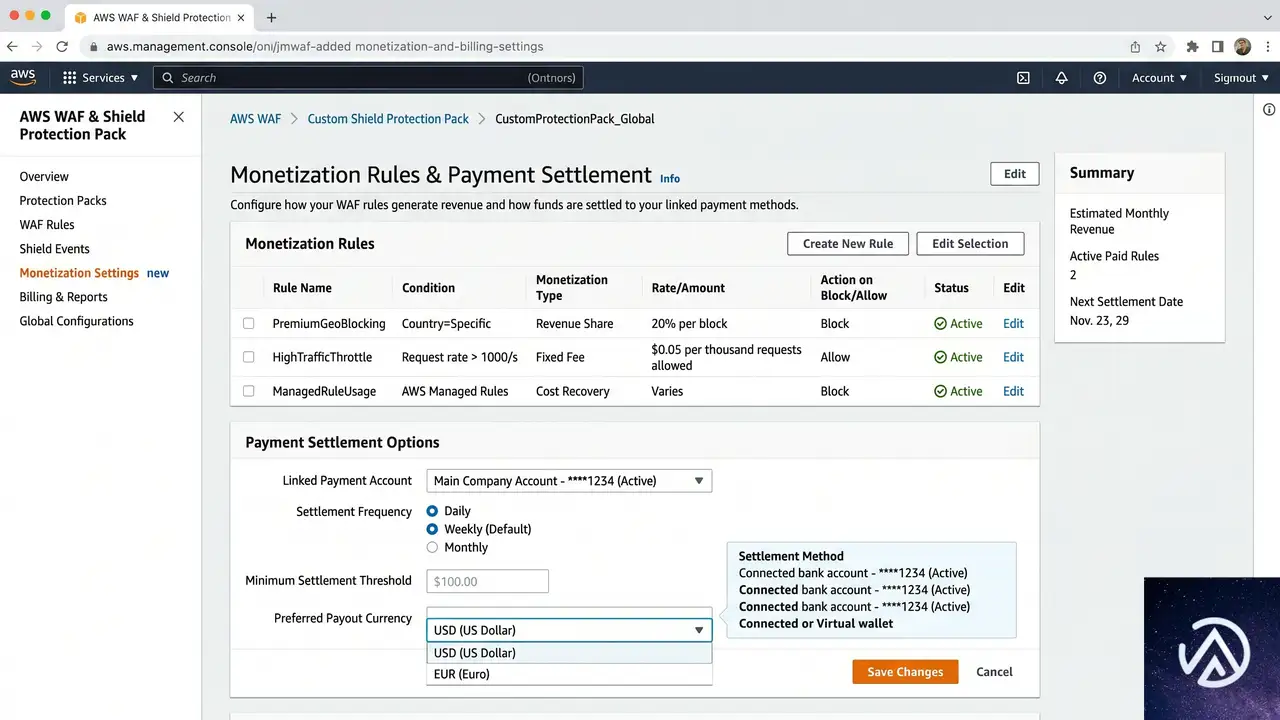
プロテクションパックの作成
AIトラフィック収益化を使うには、まずAWS WAF Bot ControlをCommonまたはTargetedレベルで有効にしたうえで、プロテクションパック(Protection Pack)を作成する。プロテクションパックとは、どのコンテンツパスを収益化するか、各検証ティアにいくら課金するか、どの支払い方法を受け入れるかといったポリシーをまとめた設定単位だ。AWSマネジメントコンソールで「WAF & Shield」を開き、「Protection packs (web ACLs)」から作成を開始する。
作成時にアプリカテゴリ(コンテンツ・パブリッシングシステム、Eコマースなど)を選択し、保護対象のリソース(CloudFrontディストリビューション)をひも付ける。推奨ルールパッケージが提示されるが、個別のルールを選ぶことも可能だ。プロテクションパックを作成したら、必要に応じて価格帯や支払い方法、コンテンツ範囲、ライセンス条項をカスタマイズする。
収益化ルールの設定
プロテクションパックを選び、「Configure AI monetization」から検証ティアごとにアクションを割り当てる。アクションは6種類ある。Monetize(402を返し課金)、Allow(無料アクセス許可)、Block(完全遮断)、Count(課金せずログだけ記録)、CAPTCHA(人間の確認)、Challenge(ブラウザかどうかのサイレントチェック)だ。Monetizeを選択すると、支払い決済用のブロックチェーンネットワーク(BaseやSolanaなど)を指定し、ウォレットアドレスとUSDC建てのページ単価を設定する。
Monetizeアクションは、Amazon CloudFrontディストリビューションに関連付けられたWeb ACLでのみサポートされる。リージョナルWeb ACLでは使えない点に注意が必要だ。また、本番投入前にテストモード(Currency modeをTestに切り替え)で、テストネット(Base SepoliaやSolana Devnet)を使った検証が可能となっている。テストモードでも実際の402レスポンスと支払いフローが再現され、すべてのイベントにCurrencyMode: TESTのログが付与される。
この一連の流れは、サイトのオリジンサーバーに一切手を加えることなく、AWS WAFのエッジで完結する。コンテンツ提供者はアプリケーションコードを修正する必要がないため、既存のWebサイトに迅速に収益化機能を追加できる。
AIトラフィック分析ダッシュボードと収益トラッキング
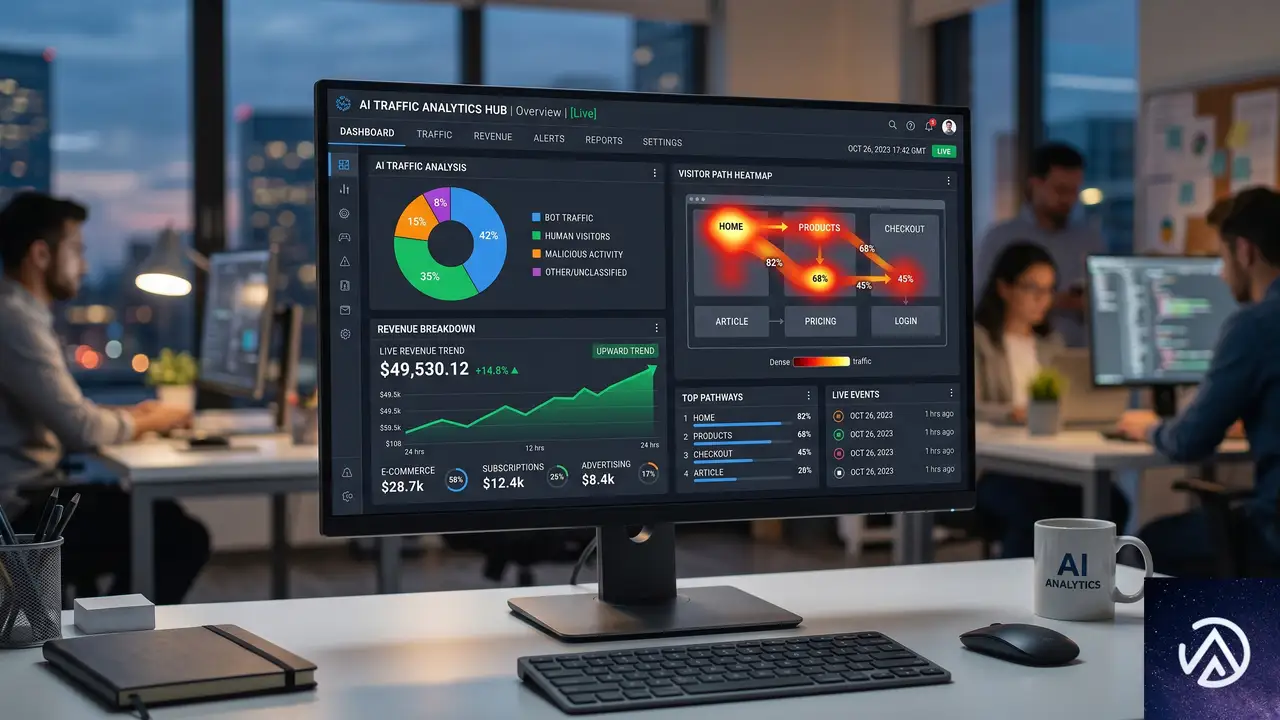
価格設定を最適化するためのAIトラフィック分析ダッシュボードも提供される。プロテクションパックを選択すると、ボットリクエスト全体、AIボットリクエスト、検証済みAIトラフィック、未検証AIトラフィックの4カテゴリに分けてトラフィックを可視化する。帯域幅の消費量、推定月間コスト、ピークリクエストレートといったインフラ影響指標も表示され、パスごとのヒートマップで時間帯別のAIボット集中度がわかる。
Currency modeをRealに切り替えると、「AI access monetization」ダッシュボードで実際の収益をリアルタイムに追跡可能だ。総収益、検証済みボットと未検証ボットの内訳、リクエストあたりの平均単価が表示され、上位の収益ソースやコンテンツパス別の収益ランキングも確認できる。Settlementsタブでは決済プロバイダーごとの精算状況や支払い失敗の分析も行える。
導入のポイントと今後の展望
この機能は、CloudFrontを利用するすべてのAWS WAFユーザーに対して追加料金なしで提供される。ただし、Monetizeを適用できるのはCloudFrontディストリビューションに関連付けたWeb ACLのみである点は押さえておきたい。また、テストモードを活用して本番適用前に価格設定やウォレット設定、x402フローを十分に検証することが推奨される。
今後、Stripeの直接アカウント決済やMPPに対応することで、より多様な支払い手段が利用可能になる見通しだ。AIボットのトラフィックが増え続ける中、コンテンツの価値を適切に回収する仕組みとして、この収益化機能は重要な選択肢となる。自社サイトへのAIクローラーの影響を分析している企業は、まずBot Controlのダッシュボードでトラフィックの可視化から始め、段階的に収益化を検討するのが良いだろう。
この記事のポイント
- AWS WAFにAIボット向け課金機能が追加され、HTTP 402とx402プロトコルでマシンツーマシン決済を実現
- コンテンツパスや検証ティアごとにリクエスト単価を設定でき、ステーブルコインで収益を受け取れる
- 設定はプロテクションパック単位で行い、CloudFront環境のエッジで自律的に課金とコンテンツ配信が完結
- AIトラフィック分析ダッシュボードでコストと収益を可視化し、価格設定を最適化できる
- テストネットを使った検証モードがあり、本番適用前にリスクを評価可能
・ 複数業界における17年間のデジタルビジネス開発経験
・ ウェブサイト開発のためのHTML、PHP、CSS、JavaScript等の実用的知識
・ 15ヶ国語対応の多言語SaaSの開発経験
・ 17年間にも及ぶ、Eコマース長期運営経験
・ 幅広い業界でのSEO最適化の豊富な経験

AWS Graviton5搭載EC2 M9g/M9gdがGA。汎用インスタンス性能限界突破の全容
AWSが2026年6月10日、Graviton5プロセッサを搭載したEC2 M9gおよびM9gdインスタンスの一般提供を開始した。Armアーキテクチャベースの第5世代カスタムシリコンであり、前世代比で最大25%の計算性能向上を実現したとされている。
2025年末のプレビュー公開から半年、ClickHouseやHoneycombといった企業が実運用環境で検証を重ね、コード変更ゼロで36%の性能向上を確認している。HubSpotではMySQLデータベースのクエリ処理時間が最大60%短縮されたとの報告もある。
Arm系インスタンスはこれまでも存在したが、192コア、5倍のL3キャッシュ、DDR5-8800対応メモリを搭載したGraviton5は次元が異なる。本記事ではM9g/M9gdの技術的進化と、それがビジネスにどう影響するかを具体的に解説する。
Graviton5とは何か。5世代の進化がもたらしたもの
AWSのGravitonプロセッサは、Armアーキテクチャを採用したAWS独自設計のカスタムシリコンだ。第1世代が登場したのは2018年。以来8年にわたり継続的に投資が続けられ、現在では350以上のインスタンスタイプがGravitonで稼働している。
Arm系クラウドインスタンスの現在地
Armアーキテクチャとは、スマートフォンやタブレットで広く使われている省電力設計のCPU命令セットだ。これに対し、従来のサーバCPUの多くはx86アーキテクチャ(IntelやAMDが採用)で動作していた。Armは消費電力あたりの処理効率に優れており、クラウドの大規模データセンターで電気代を抑えつつ高性能を発揮できる点が評価されている。
AWS広報情報によれば、現在12万以上の顧客がGravitonを採用。スタートアップから大企業まで幅広く、Webアプリケーション、マイクロサービス、データベース、機械学習推論、ゲームサーバ、動画エンコーディングなど多様な用途で使われている。x86依存の強い従来のクラウド常識を、Armが着実に塗り替えつつある。
クラウドインスタンスの選択肢は、この5年で一変した。Armはもはや「実験的な選択肢」ではなく、x86と並ぶ本流の一つとして位置づけられる。特にGraviton5では、その傾向がさらに加速するだろう。
Graviton5が前世代から飛躍した3つの要素
Graviton5の改良点を、AWS公式発表から整理する。最も注目すべきは次の3つだ。
- 計算性能の大幅向上:Graviton4比で最大25%の計算性能向上。Webアプリケーションで最大35%、機械学習推論で最大35%、データベースで最大30%の高速化が実測されている
- 5倍のL3キャッシュ:CPUが頻繁にアクセスするデータを一時保存する高速メモリ領域が前世代比5倍に拡大。コア間のデータ待ち時間が最大33%削減された
- DDR5-8800メモリとPCIe Gen6対応:クラウド上のプロセッサインスタンスとして最速水準のメモリ帯域幅を実現。PCIe Gen6はGen5比でデータ転送速度が2倍となり、NVMeストレージや高速ネットワークとの連携性能が飛躍的に伸びる
L3キャッシュの増量は、単なる数値スペックの向上ではない。CPUは計算のたびにメインメモリまでデータを取りに行くと時間がかかる。L3キャッシュが大きければ近くにデータを置けるため、処理待ちが減り、結果として体感性能が大きく向上する仕組みだ。
実際にAWSの広報記事で紹介された顧客事例では、ClickHouseがコード変更なしでM8g比36%の性能向上を達成。Honeycombは6カ月にわたるA/Bテストで、コアあたりのスループットが36%向上したと報告している。これらの数字は、CPUそのものの改良がアプリケーションレベルで直接的な効果を生むことを示している。
M9g/M9gdのラインアップと性能スペック
インスタンスサイズと性能の詳細
M9gは汎用用途向けで、1vCPUあたり4GiBのメモリ比率を採用している。M9gdはこれに加え、高速ローカルNVMe SSDストレージを搭載したバリエーションだ。ラインアップは1vCPUの小規模構成から、192vCPU・768GiBメモリの大規模構成まで幅広く用意されている。
最大サイズの48xlarge(192vCPU)では、ネットワーク帯域が100Gbpsに達する。前世代比で最大2倍の帯域幅になっており、大量のデータを扱うデータベースやログ処理基盤での効果が特に大きい。
IBC(Instance Bandwidth Configuration)の実用性
M9g/M9gdでは、IBC(インスタンス帯域幅設定)と呼ばれる新機能が利用可能になった。これはEBS(永続ストレージ)とVPCネットワーク間で、帯域幅の配分を最大25%調整できる仕組みだ。
たとえばデータベースサーバではEBSへの書き込み性能がボトルネックになりやすい。IBCを使えばEBS側に帯域を多めに割り当て、クエリ処理やログ書き込みを高速化できる。ネットワーク通信が少ないバッチ処理やキャッシュサーバでも有効だ。
Nitro Isolation Engineが実現する「数学的に証明されたセキュリティ」
Graviton5と同時に発表された技術の中で、最も静かでありながら最も革新的なものがNitro Isolation Engineだ。聞き慣れない用語だが、クラウドセキュリティの考え方を根本から変える可能性がある。
形式検証(Formal Verification)とは何か
通常、ソフトウェアのセキュリティは「テスト」で検証する。攻撃パターンを想定し、実際に動かして問題がないかを確認する手法だ。しかしこの方法では、想定外の攻撃や未知の脆弱性を見逃すリスクが常に残る。
形式検証(Formal Verification)はこれとは根本的に異なる。数学の定理証明と同じアプローチで、「このシステムは絶対に想定外の動作をしない」ことを数理的に証明する技術だ。特定のテストケースだけでなく、あらゆる入力パターンで期待通りに動作することを保証する。
AWSによれば、Nitro Isolation Engineはこの形式検証を適用したクラウドハイパーバイザーとして業界初の事例となる。ハイパーバイザーとは、1台の物理サーバ上で複数の仮想マシンを安全に隔離する基盤ソフトウェアだ。この隔離機能が破られると、他の顧客のデータにアクセスされる重大なセキュリティ事故につながる。Nitro Isolation Engineは、その隔離が破られる可能性を数学的にゼロにする設計となっている。
この技術は金融機関や医療機関など、厳格なデータ保護が求められる業界にとって特に重要な意味を持つ。セキュリティ監査のレベルが一段引き上げられることになるからだ。なおNitro Isolation EngineはM9g/M9gd専用の機能であり、既存のインスタンスタイプには搭載されない。
エージェントAI時代のCPU需要とGraviton5の位置づけ
AIが「考える」から「行動する」へのシフト
ここ数年、AIの進化は大規模言語モデル(LLM)のテキスト生成能力に注目が集まってきた。しかし現在、AIの主戦場は「質問に答える」から「行動を実行する」へと急速に移行している。いわゆるエージェントAIと呼ばれる分野だ。
エージェントAIとは、ユーザーの指示に対して、コードを実行し、ツールを使い、結果を評価し、複数ステップのタスクを自律的に組み立てるAIシステムを指す。たとえば「今月の売上データを分析してグラフ化し、経営陣向けのサマリをSlackに投稿して」という指示に対し、AIがデータベースに接続し、集計処理を実行し、グラフを生成し、メッセージを送信する一連の流れを自律的に処理する。
このような処理は、GPUなどのアクセラレータだけで完結しない。指示の解釈、コードのコンパイル、データベースクエリの実行、APIの呼び出しなど、CPUに依存する処理が大量に発生する。AWSの広報記事で、MetaがエージェントAI基盤として数千万コア規模のGravitonを導入していると報告されているのは、このトレンドを象徴している。
エージェントAIが実用段階に入るにつれ、クラウド上のCPU需要はむしろ増大する。Graviton5が192コアという高密度設計を採用したのは、こうした並列処理ニーズを先取りしたものといえる。
Web開発者にとっての実務的意味
中小企業のWeb担当者や個人事業主にとって、「エージェントAI」や「192コア」という言葉は遠い世界に感じられるかもしれない。しかし実際には、以下のような形でM9gの恩恵は身近な領域に及ぶ。
- MySQL/PostgreSQLの応答速度向上:HubSpotの事例ではクエリ時間が最大60%短縮。WordPressサイトやECサイトのデータベース応答が高速化する可能性がある
- コスト効率の改善:Graviton5はGraviton4比でエネルギー効率も向上。同じ処理をより少ない電力で実行できるため、ランニングコストの削減につながる
- セキュリティの底上げ:Nitro Isolation Engineによる隔離保証は、顧客データを扱うあらゆるサービスに恩恵がある
重要なのは、これらの恩恵がコード変更ゼロで得られるケースが多い点だ。ClickHouseやHoneycombの報告にあるように、Armネイティブ対応が済んでいるアプリケーションであれば、インスタンスタイプをM8gからM9gに変更するだけで性能向上が見込める。
M9g/M9gdへの移行を検討する際の実践ステップ
Graviton5インスタンスの利用を始めるには、いくつかの準備と確認が必要だ。AWS公式が提供する移行ガイドやツールを活用すれば、想定よりスムーズに移行できる。
Arm対応状況の確認と移行パス
最初に行うべきは、現在稼働中のアプリケーションがArmアーキテクチャに対応しているかの確認だ。Java、Python、Node.js、Go、PHPなど主要な言語ランタイムはすでにArm対応が完了している。ただし、x86固有のアセンブリコードを含むC/C++プログラムや、特定のx86向けバイナリに依存しているアプリケーションでは注意が必要になる。
Javaアプリケーションの場合、AWSが提供する「AWS Transform」というAI支援サービスが利用できる。x86用にコンパイルされたJavaアプリケーションをArm向けに自動変換し、互換性分析や依存関係の更新まで処理するツールだ。コードの書き換えが必要なケースでも、変換作業の多くを自動化できる。
コスト面の評価ポイント
M9g/M9gdは、Savings Plans、オンデマンド、スポットインスタンス、Dedicated Hostsのいずれでも購入可能だ。一般にGraviton系インスタンスはx86系より低価格に設定されており、さらにSavings Plansを組み合わせることで長期利用時のコストを大幅に抑えられる。
AWS公式が提供する「Graviton Savings Dashboard」を使えば、Graviton移行によるコスト削減効果を可視化できる。費用対効果を数字で把握しながら、段階的に移行を進めるのが実務的なアプローチだ。
この記事のポイント
- AWS Graviton5搭載M9g/M9gdが一般提供開始。前世代Graviton4比で最大25%の計算性能向上
- ClickHouseで36%、HubSpotのMySQLクエリで最大60%の高速化を実測。コード変更不要のケースが多い
- Nitro Isolation Engineにより、形式検証を用いた数学的に証明されたVM隔離をクラウドで初めて実現
- エージェントAIの普及でCPU需要が急増する中、192コアの高密度設計が新たな計算基盤として台頭
- 移行にはArm対応状況の確認から段階的に進めるのが安全。AWS TransformやSavings Dashboardが支援ツールとして利用可能
・ 複数業界における17年間のデジタルビジネス開発経験
・ ウェブサイト開発のためのHTML、PHP、CSS、JavaScript等の実用的知識
・ 15ヶ国語対応の多言語SaaSの開発経験
・ 17年間にも及ぶ、Eコマース長期運営経験
・ 幅広い業界でのSEO最適化の豊富な経験

Claude Fable 5がAWSで利用可能に。長時間実行と安全策を両立する新モデル
AWSがClaude Fable 5のAmazon Bedrock対応を発表した。Anthropicの新モデルはMythosクラスの最高性能を備えつつ、有害利用リスクへの安全策を組み込んだ点が最大の特徴だ。ソフトウェア開発や文書解析など長時間の自律作業を任せられる設計になっている。
Fable 5はほぼすべてのベンチマークで最先端のスコアを記録する。注目すべきは、人間の介入なしで複雑なコーディングやナレッジワークを長時間継続できる実行能力だ。単発の応答を超えた「作業の持続」が可能になったことで、開発現場やビジネスプロセスへの組み込みが現実味を帯びてきた。
Claude Fable 5の3つの技術的特徴
従来のLLM(大規模言語モデル)が得意としてきた「質問への即答」とは異なり、Fable 5は「長時間タスクの遂行」にフォーカスしている。AWS公式ブログとAnthropicの技術発表から、その差別化要素を整理した。
長時間の非同期実行
従来のモデルは数分を超えるタスクで精度が低下したり、文脈を見失ったりする課題があった。Fable 5は複雑なコーディングや調査作業を長時間・自律的に続行できる。具体的には、複数ファイルにまたがる大規模なリファクタリングや、長大なドキュメントの横断的分析といった作業を途中で止めずに完了させる。
これは単にトークン数が増えただけではない。モデル内部のアーキテクチャが「途中経過の自己管理」を強化しており、タスクのゴールを見失わずに作業を継続する仕組みだ。AWSの発表では「長時間のコーディングや知識労働を継続的に実行する」と表現されている。
この変化により、ソフトウェア開発における「任せっぱなし運用」の幅が広がる。たとえばコードベース全体のリファクタリングを夜間に任せ、朝には完了しているというワークフローが視野に入る。
高度なビジョン機能
Fable 5はテキストだけでなく、図表、グラフ、PDF内に埋め込まれた表などを高精度で理解する。金融や法務、建築、ゲーム開発など、文書や設計図を扱う業種での活用が期待される領域だ。
コーディングの文脈でも大きな意味を持つ。デザインファイルを読み取ってUIを実装したり、出力結果のスクリーンショットを自己チェックして「要件と合っているか」を検証したりできる。従来のモデルはテキスト情報だけを頼りにしていたが、Fable 5は「見て判断する」能力を作業フローに組み込める。
プロアクティブな自己検証
Fable 5はタスク実行中に得た学習をもとにスキルを自己更新し、自ら評価用のハーネス(テストフレームワーク)を作成する。AWSの発表では「自身の出力を目標と照らし合わせて批判的に評価する」と説明されている。
これはソフトウェアテストの自動化と深く関わる。たとえば「単体テストのコードを生成する」という指示ではなく「この機能を実装し、テストを作成し、通るまで修正を繰り返せ」という指示が現実的になる。モデルが自律的にPDCAを回すため、人間は成果物の最終確認に集中できる。
安全策の仕組みとMythos 5との棲み分け

Fable 5の最大の独自性は「性能と安全策の両立」にある。同じモデルから安全性を引き上げたFable 5と、制限を外したMythos 5という2つのバリエーションが用意されている。
有害プロンプトは自動でOpus 4.8にルーティング
Fable 5はサイバーセキュリティ、生物学、化学、健康に関連する有害プロンプトを受け取ると、内部で自動的にOpus 4.8へルーティングする。AWSの公式発表では「安全策によって、ほぼすべての最先端機能へのアクセスを提供しつつ、誤用リスクの高い領域では応答を制限する」と説明されている。
重要なのは、ユーザー側で切り替えを意識する必要がない点だ。通常のAPIコールでFable 5を指定しておけば、安全と判断されたプロンプトにはFable 5が、リスクありと判断されたプロンプトにはOpus 4.8が自動で応答する。
Mythos 5は限定的なプレビュー提供
Fable 5の制限を取り払ったMythos 5も、Amazon Bedrockで限定的に利用可能だ。ただしMythos 5はサイバーセキュリティやライフサイエンス(創薬、バイオディフェンススクリーニング等)といった専門領域向けであり、審査を受けた一部の顧客のみアクセスできる。一般提供は行われない。
この「制限付きスーパーモデル」と「制限なし最強モデル」の二層構造は、AIの社会実装における新たなパラダイムとなり得る。AWSの発表でも、Mythos 5はデュアルユース(軍民両用)の性質を持つため厳格な管理下に置かれていると明記されている。
Amazon Bedrockでの利用環境とセットアップ

Fable 5はAmazon BedrockとClaude Platform on AWSの両方で利用できる。ここではBedrock経由のセットアップ手順を中心に解説する。
データ共有へのオプトインが必須
Fable 5を利用するには、データ保持ポリシーでプロバイダーデータ共有(provider_data_share)にオプトインする必要がある。AnthropicはMythosクラスの全モデルで、入力と出力の30日間保持および人間によるレビューを必須としている。これは単一のやり取りでは検出できない誤用パターンを長期的に監視するためだ。
オプトインするとデータはAWSのセキュリティ境界を離れる。機密性の高いデータを扱う場合は、この点を事前に評価しておく必要がある。設定はAWS CLIで以下のように実行する(bedrock-mantleエンジン向け)。
curl -X PUT https://bedrock-mantle.us-east-1.api.aws/v1/data_retention \
-H "x-api-key: <your-bedrock-api-key>" \
-H "Content-Type: application/json" \
-d '{ "mode": "provider_data_share" }'bedrock-runtimeエンジンを使う場合は、エンドポイントと認証方式が異なる点に注意が必要だ。詳細はAWSの公式ドキュメントを参照してほしい。
Python SDKからの呼び出し例
Anthropic SDKをインストールした後、Messages API経由でFable 5を呼び出すコードは以下の通りになる。リージョンは現時点で米国東部(バージニア北部)と欧州(ストックホルム)に対応している。
import anthropic
client = anthropic.Anthropic(
base_url="https://bedrock-mantle.us-east-1.api.aws/anthropic",
api_key=<your-bedrock-api-key>
)
message = client.messages.create(
model="anthropic.claude-fable-5",
max_tokens=4096,
messages=[
{
"role": "user",
"content": "秒間10万リクエストを複数リージョンで処理するAWS分散アーキテクチャを設計してほしい"
}
]
)
print(message.content[0].text)BedrockのConverse APIを使う場合はBoto3経由となる。マルチモデル対応の統一インターフェースが使えるため、既存のBedrockワークロードとの統合が容易だ。
課金体系の注意点
有害プロンプトがOpus 4.8にルーティングされた場合、そのリクエストの課金はOpusの価格で計算される。また途中でブロックされた会話では、Fable 5が処理した初期トークンはFable 5の料金、それ以降はOpusの料金が適用される。大規模なワークロードを計画する際は、見積もりにこの変動要素を含めておく必要がある。
ソフトウェア開発の現場に与える影響

Fable 5の登場は、とりわけソフトウェアエンジニアリングのワークフローを変える可能性が高い。AWSの発表でも「長時間のコーディングタスク」と「自己検証」が前面に押し出されている。
「コードを書く」から「コードを任せる」へ
従来のLLMは「関数を1つ書いて」という短い指示には強かったが、プロジェクト全体を見渡すようなタスクには限界があった。Fable 5は「このリポジトリの全テストを補充し、カバレッジが90%を超えるまで繰り返せ」といった高レベルな指示を理解し、自律的に遂行できる。
これは開発者の役割を「実装者」から「設計者・監督者」へとシフトさせる。コードを書く時間が減り、アーキテクチャの意思決定やビジネスロジックの検討に集中できるようになる。ただし出力の品質チェックは依然として人間の責任だ。
CI/CDパイプラインとの統合可能性
Fable 5の自己検証機能は、CI/CD(継続的インテグレーション/継続的デリバリー)の自動化範囲を拡大する。プルリクエストの自動レビュー、テスト自動生成、失敗時の自律的な修正までを一気通貫で行える可能性がある。
ただし現時点でFable 5は非同期実行向けに設計されており、リアルタイムのチャット応答を前提とした従来のCI/CDトリガーとはワークフローが異なる。ジョブキューと組み合わせたバッチ処理型の統合が現実的なアプローチになるだろう。
日本市場での受け入れと課題
国内のソフトウェア開発現場では、セキュリティ要件の厳しさから「データを外部に出せない」という制約が根強い。Fable 5の必須条件である30日間のデータ保持と人間によるレビューは、金融や医療分野での採用ハードルになる。AWSの東京リージョンでの利用可能時期も現時点では未発表だ。
一方で、スタートアップやゲーム開発のようにスピードを重視する領域では、Fable 5の長時間自律実行能力は強力な武器になる。日本でも段階的に導入が進むと見られる。
この記事のポイント
- Claude Fable 5はMythosクラスの性能を持ちつつ、有害利用を自動遮断する安全策を内蔵している
- 長時間の非同期実行により、コードの大規模リファクタリングや文書横断分析を自律的に完了できる
- 図表やPDFを読み取るビジョン機能が加わり、金融・法務・建築など文書集約型の業種で活用が広がる
- 有害プロンプトは自動でOpus 4.8にルーティングされ、ユーザーはモデルを意識せず使える
- Amazon Bedrockでの利用には30日間のデータ保持オプトインが必須。機密データの扱いには注意が必要だ
・ 複数業界における17年間のデジタルビジネス開発経験
・ ウェブサイト開発のためのHTML、PHP、CSS、JavaScript等の実用的知識
・ 15ヶ国語対応の多言語SaaSの開発経験
・ 17年間にも及ぶ、Eコマース長期運営経験
・ 幅広い業界でのSEO最適化の豊富な経験

AWS Bedrock刷新、OpenAIとAnthropic API互換コンソールが登場
AWSが2026年6月5日、Amazon Bedrockの管理コンソールを刷新した。この新体験は「bedrock-mantle」エンジン向けに設計されており、Anthropic Messages APIとOpenAI Responses APIに最適化されている。
従来のBedrockコンソールはマネージド機能(AgentsやKnowledge Basesなど)を中心に据えていたが、今回の刷新はAPI直接呼び出しを前提とする開発者向けに設計し直されている。モデル選定からプロダクション実装までの時間を大幅に短縮する狙いだ。
この記事では、新コンソールの主要機能と開発ワークフローへの影響を詳しく見ていく。API互換性を活かしたコードの簡略化や、複数モデルの並列評価がどのように実現されるのかを解説する。
Bedrockの新コンソールが生まれた背景
この図が示すように、新コンソールは「プロジェクト」を軸にした作りになっている。モデルの評価から実装、モニタリングまでをひとつの画面で完結させる狙いだ。
bedrock-mantleエンジンとは何か
bedrock-mantleは、Bedrockの第2世代推論エンジンとして位置づけられる。高速な処理性能と高い信頼性、そしてエンタープライズレベルのセキュリティを兼ね備えている。
最大の特徴はAnthropicとOpenAIのAPIプロトコルに互換性を提供することだ。ClaudeモデルにはAnthropic Messages API(メッセージAPI)を、GPTモデルにはOpenAI Responses API(レスポンスAPI)とOpenAI Chat Completions API(チャット補完API)を使える。これにより、既存のSDKコードをほぼ変更せずにBedrockへ移行できる。
従来のbedrock-runtimeエンドポイントを使う既存機能(InvokeModelやConverse API、Agentsなど)は、引き続き従来のBedrockコンソールから利用できる。両者は併存する設計で、急な移行は求められない。
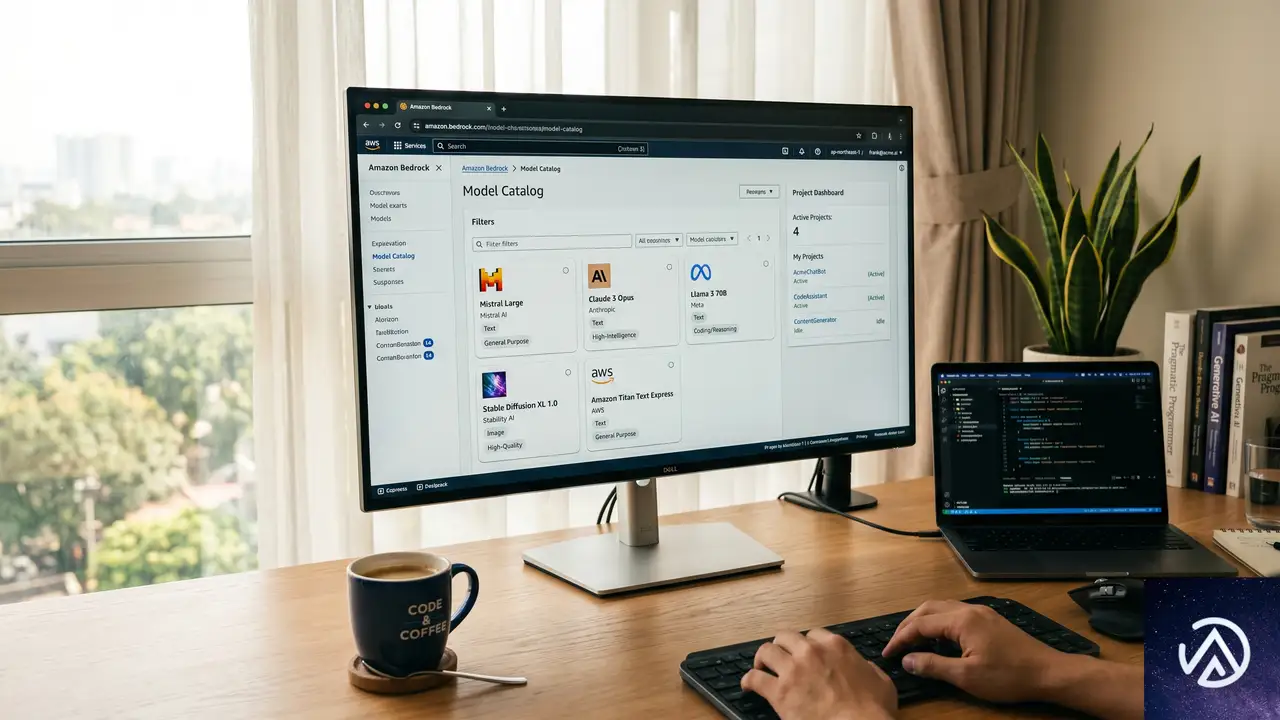
新モデルカタログが提供する高速な比較体験

新コンソールの目玉のひとつが、刷新されたモデルカタログだ。従来は各モデルの仕様を調べるためにドキュメントや料金計算ツールを行き来する必要があったが、それが1画面で完結するようになった。
最大3モデルを並べて比較
カタログ上で最大3つのモデルを選択し、機能、モダリティの対応状況、コンテキストウィンドウの大きさ、利用可能なリージョン、料金体系を横並びで比較できる。
この比較機能は、チーム内でのモデル選定会議や、PoC(概念検証)フェーズでの迅速な意思決定に力を発揮する。料金と性能のトレードオフを視覚的に把握できるのが強みだ。
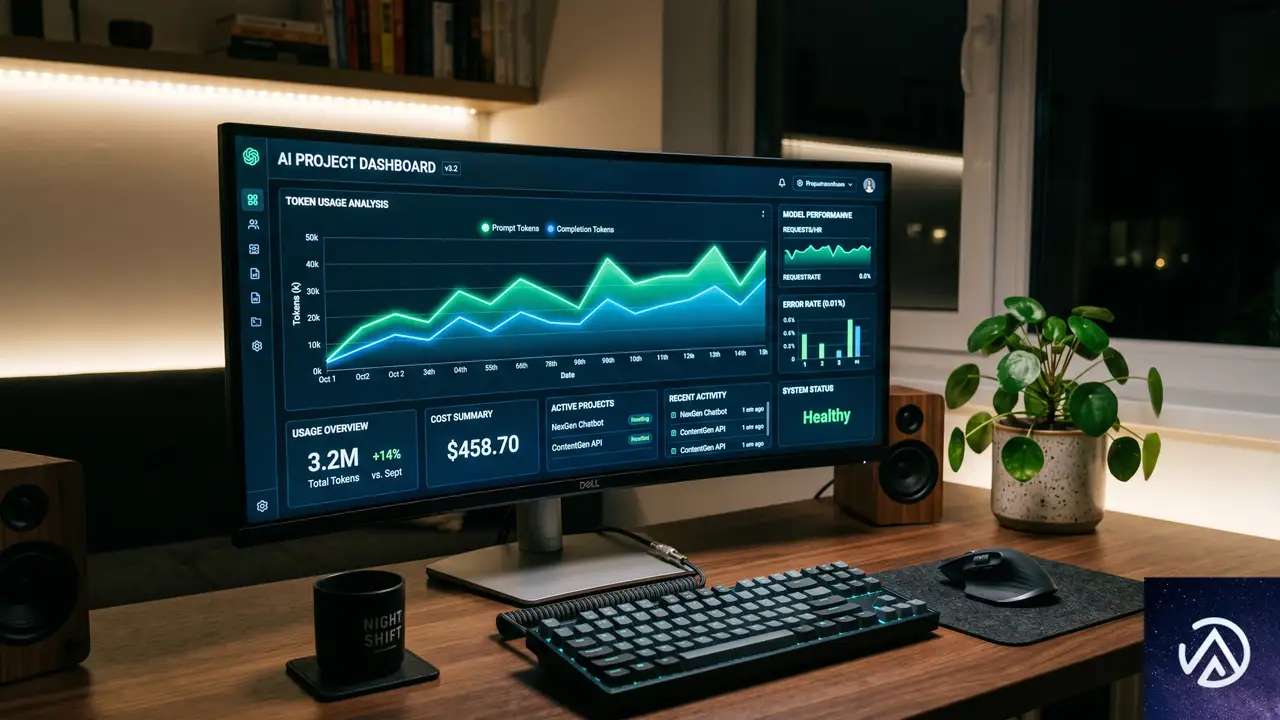
プロジェクト単位で完結する開発ワークフロー
新コンソールの中核は「プロジェクト」という概念だ。生成AIアプリケーションの開発ライフサイクルをプロジェクトとして管理し、モデルの割り当てからAPIキーの発行、推論リクエストの送信までを一気通貫で行える。
ダッシュボードでトークン消費を可視化
プロジェクトダッシュボードでは、直近の推論リクエスト数やエラー発生率を日付範囲でフィルタリングできる。さらに、総トークン消費量、1分あたりのトークン使用量、推論リクエストの回数、1リクエストあたりの平均トークン数がグラフ表示される。
このデータは、モデルの選択ミスや過剰なトークン消費を早期に発見する手がかりになる。チームの予算管理にも直結するため、プロダクション環境では特に価値が高い。
サイドバイサイド評価でプロンプトを最適化
プロジェクト内で最大3つのモデルを選択し、同じプロンプトに対する応答を横に並べて比較できる評価モードが用意されている。これにより、どのモデルが自社のユースケースに最適かを実データで判断できる。
評価結果はそのままプロダクション環境へ移行する際の根拠資料としても使える。カスタマーサポート用チャットボットであれば、回答の質と応答速度のバランスを定量的に比較できる。
コード生成とAIアシスタント連携の新機能
最も実務インパクトが大きいのが、プロジェクトに紐づいた「ライブドキュメント」機能だ。コードサンプルやSDKスニペット、APIリファレンスにプロジェクトの変数(モデルID、リージョン、エンドポイントURL、APIキー)が自動で埋め込まれる。
コピーするだけで動くコードスニペット
開発者はコンソール上で表示されたコードをそのままコピーし、ローカル環境のアプリケーションに貼り付けるだけで動作確認できる。環境変数の手動設定やエンドポイントURLの確認といった手間が省ける。
AWS_REGION=us-east-1
ENDPOINT=bedrock-mantle
API_KEY=sk-xxxxxx
client = boto3.client()
response = client.invoke(modelId=MODEL_ID)
この仕組みにより、環境構築のミスが大幅に減る。特に複数プロジェクトを抱えるチームでは、設定の食い違いによるトラブルシューティング時間を削減できる。
AIコーディングエージェントとの統合
新コンソールはAIコーディングエージェントとの連携もサポートする。Claude Code、Cline、Codex、Cursor、OpenCodeといった主要なAIアシスタントをBedrockのmantleエンジンにルーティングする手順がガイドされる。
具体的には、AWS IAM認証情報かBedrock APIキーを使い、環境変数を設定したうえで各エージェントからのリクエストをBedrock経由にする設定が案内される。これにより、AIアシスタントのバックエンドをOpenAIやAnthropicのクラウドからAWS環境に切り替えられる。企業ポリシーでデータの外部送信を制限しているケースで有効だ。
利用可能リージョンと今後の展開

新コンソール体験は、bedrock-mantleエンドポイントが提供されている全リージョンで利用可能だ。2026年6月時点での対象は以下の通り。
AWSのドキュメントにはリージョン互換性の一覧ページが用意されており、将来的な拡大があれば随時更新される見込みだ。フィードバックはAWS re:Post for Amazon Bedrock、または通常のAWSサポート窓口を通じて送ることができる。
新コンソールは既存のBedrockコンソールと並行して運用される。急な切り替えを迫られることはなく、チームの準備が整った段階で徐々に移行できる設計だ。
この記事のポイント
- Amazon BedrockにAPI互換性を重視した新コンソールが登場し、モデル評価から実装までの時間が大幅に短縮される
- bedrock-mantleエンジンはAnthropic Messages APIとOpenAI Responses APIに対応し、既存SDKコードの流用が容易
- 最大3モデルのサイドバイサイド比較と、プロジェクト単位のトークン消費可視化が組み込まれている
- コンソール上のコードスニペットはプロジェクト変数が自動プレフィルされ、コピー後即実行できる
- 東京リージョンを含む複数リージョンで利用可能、既存コンソールとの併存もサポートされる
・ 複数業界における17年間のデジタルビジネス開発経験
・ ウェブサイト開発のためのHTML、PHP、CSS、JavaScript等の実用的知識
・ 15ヶ国語対応の多言語SaaSの開発経験
・ 17年間にも及ぶ、Eコマース長期運営経験
・ 幅広い業界でのSEO最適化の豊富な経験

Amazon Cognitoがマルチリージョンレプリケーションに対応、耐障害性向上とCMKサポートの詳細
AWSがAmazon Cognitoにマルチリージョンレプリケーション機能を追加した。ユーザーデータとM2M(Machine-to-Machine)シークレットを別のAWSリージョンに自動同期し、認証基盤の耐障害性を高める。あわせてカスタマーマネージドキー(CMK)による暗号化制御もサポートされた。
これまでマルチリージョンでの整合性維持には、エンジニアリングチームが手動で複製ソリューションを構築・運用する必要があった。今回のアップデートで、Cognitoが自動的にセカンダリリージョンへデータを複製し、リージョン障害時でも認証を継続できるようになる。
レプリケーションは一方向(プライマリ→セカンダリ)で動作し、プライマリリージョンの障害発生時にはセカンダリで認証処理を受け持つ。セッション継続性も担保され、既存ユーザーは資格情報の再設定なしでサインインを続けられる。
従来は手動レプリケーションに依存し、データ不整合やセキュリティリスクがつきまとっていた。新機能により、複製にかかる運用負荷を大幅に削減しつつ、認証の継続性を確保できる。
Cognitoマルチリージョンレプリケーションとは何か
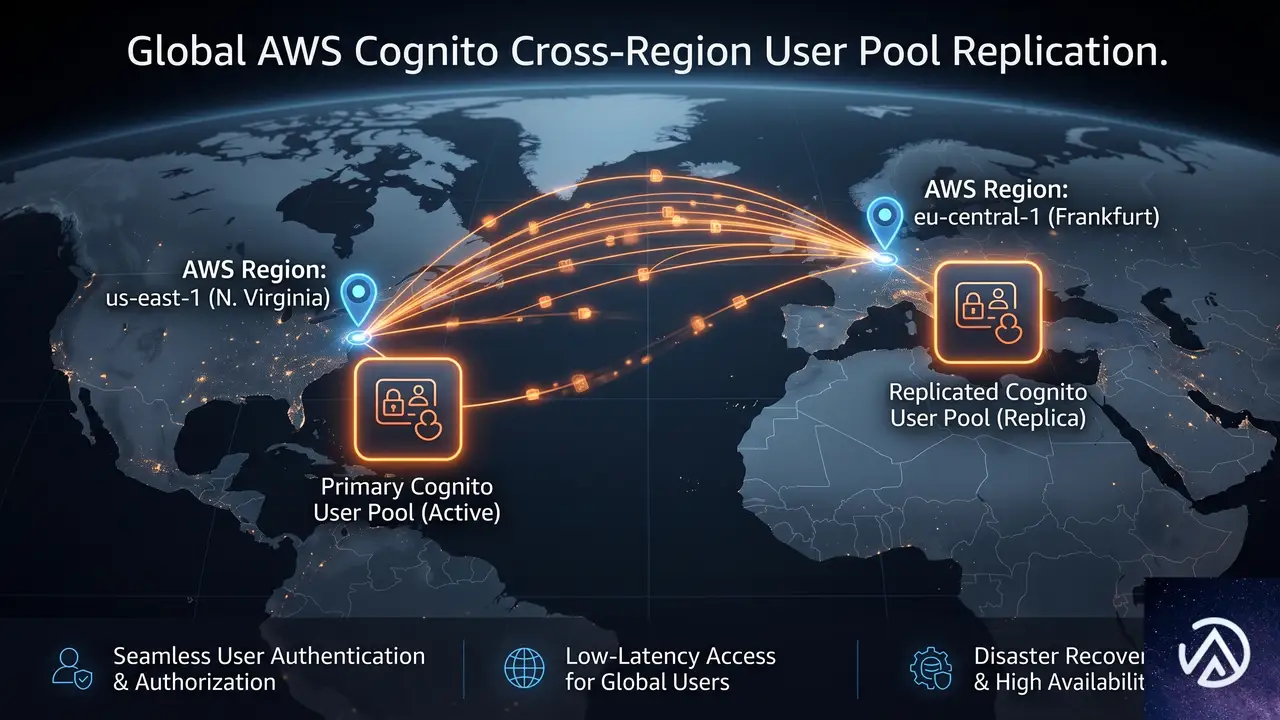
マルチリージョンレプリケーションは、Amazon CognitoがユーザーデータとM2Mシークレットの複製を自動管理する機能だ。プライマリリージョンからユーザーが選択したセカンダリリージョンへ、一方向でデータを同期する。
カバーされるデータの範囲と動作モード
複製の対象はユーザープロファイル、資格情報、ユーザープールの設定全体に及ぶ。セカンダリリージョンは読み取り専用モードで動作し、認証機能の維持に特化する。つまり、新規ユーザー登録やプロファイル更新といった書き込み操作はフェイルオーバー中には行えない。
この設計により、すべての認証方式(ソーシャルプロバイダ経由のフェデレーテッドサインイン、SAML、OIDC連携、API認可フロー)がサポートされる。対人認証だけでなく、バックエンドサービス間のM2M通信もレプリケーションの恩恵を受けられる点がポイントだ。
セッション継続性とトークンの相互認識
レプリケーション済みのユーザープールでは、プライマリ・セカンダリの双方が、どちらのリージョンで発行されたアクセストークンも有効とみなす。そのため、アクティブなセッションはリージョン切り替え前後を通じて中断されない。
この仕組みは、エンドユーザーにとって「裏側でリージョンが切り替わった」ことをまったく意識させずに済むという、実運用上の大きな利点になる。パスワードリセットの強制や再認証といった、ユーザー体験を損なう事態を回避できるわけだ。
CMKサポートで変わる暗号化の主導権

マルチリージョンレプリケーションの利用には、AWS KMS(Key Management Service)上のマルチリージョンカスタマーマネージドキー(CMK)が必須となる。CMKはユーザーデータの保存時暗号化に一貫性をもたらし、利用者側に暗号化戦略の主導権を与える。
CMKの利用は、レプリケーション機能とは独立して提供される。つまり、単一リージョンのユーザープールでもCMKによる暗号化制御は利用可能だ。医療や金融サービスなど、規制の厳しい業界ではとくに重要な選択肢となる。
3ステップで始めるレプリケーション設定
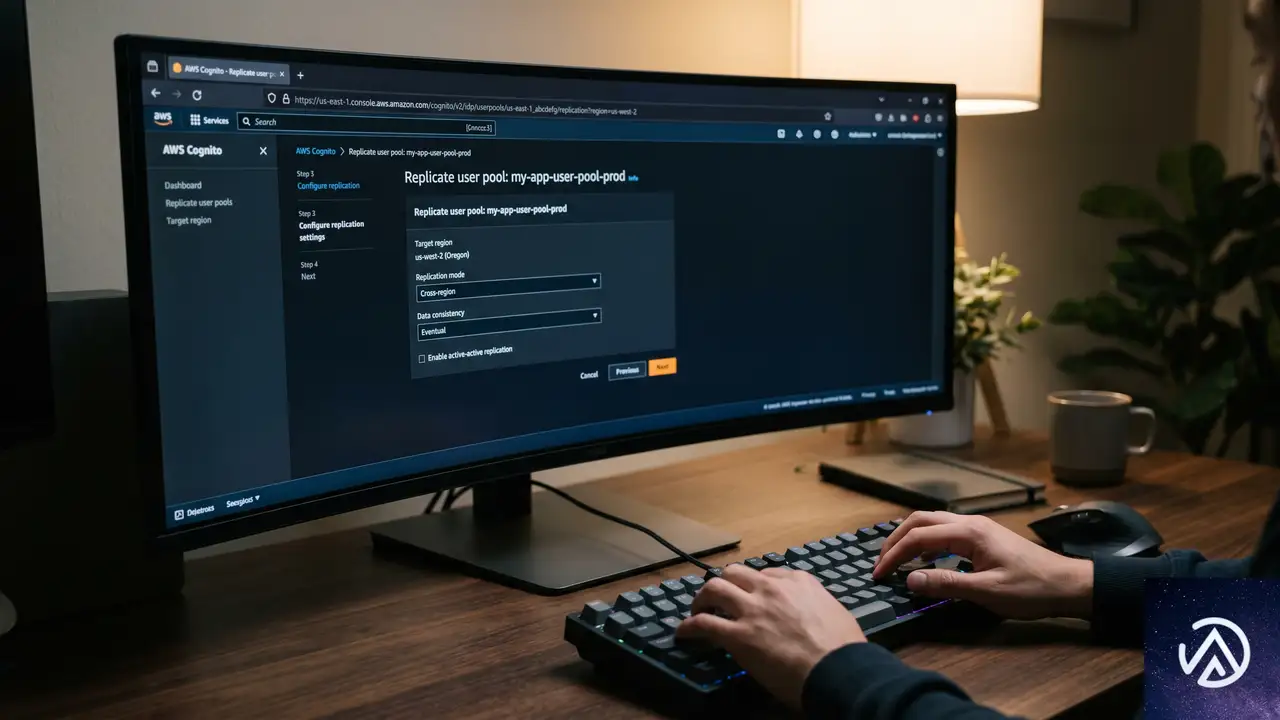
AWS News Blogの記事では、us-west-2(オレゴン)の既存ユーザープールをus-east-1(バージニア北部)に複製するデモが紹介されている。設定は管理コンソールから3つのステップで完了する。
STEP 2のOIDCエンドポイント更新は、クライアントアプリケーション側の必須対応となる。サーバーサイドアプリは再デプロイ、モバイルアプリはストアへの更新申請が必要だ。この変更を怠ると、旧エンドポイントへのリクエストが正しくルーティングされず、認証障害を引き起こす。
追加で必要な設定と注意点
レプリケーション設定の完了後も、いくつかの付随リソースは手動でセカンダリリージョンに展開する必要がある。具体的には、カスタム認証フローに使うLambda関数、SMSやメール通知の設定、ログストリーミング、AWS WAFの構成が該当する。
AWS News Blogの記事では、これらの追加設定を計画的に実施するようコンソール上でトラッキングできる点も紹介されている。フェイルオーバー前に抜け漏れを防ぐ仕掛けとして有効だ。
フェイルオーバー運用とヘルスチェックの設計
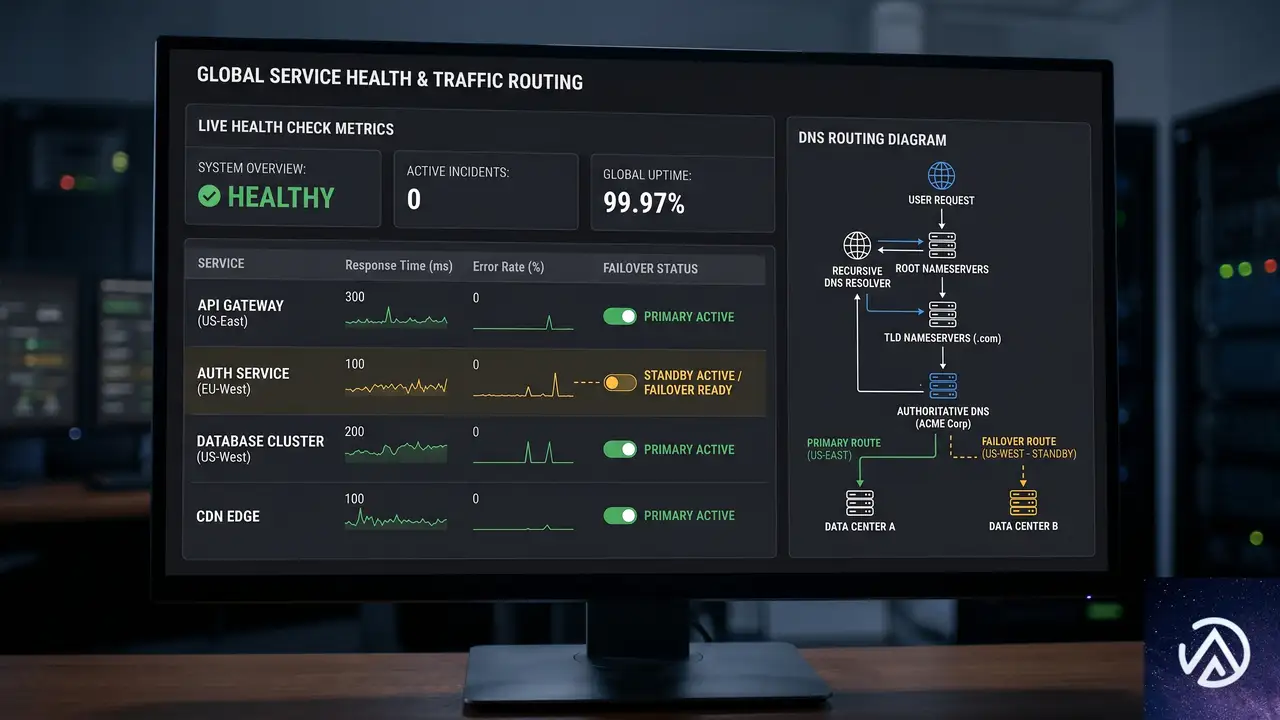
プライマリとセカンダリの両エンドポイントは常時アクティブで、いつでもトラフィックを受け入れ可能な状態にある。フェイルオーバーの判断と実行は、アプリケーションの要件に合わせて利用者側が設計する形だ。
ヘルスチェックでは、エラーレートやレイテンシのパターン、サービスアラートを監視し、事前定義した基準を満たした場合にDNSの切り替えでセカンダリへトラフィックを誘導する。オフピーク時間帯に少量のトラフィックをセカンダリに流し、認証が期待通り動作するか検証しておくことが推奨されている。
カスタムドメインでのマネージドログインやフェデレーションを利用している場合、Amazon Route 53のヘルスチェックIDをCognitoに提供することで、トラフィックルーティング機能を組み込むこともできる。これによりDNSレベルでの自動切り替えが容易になる。
料金体系と利用可能リージョン

マルチリージョンレプリケーションは、EssentialsティアおよびPlusティアのアドオン機能として提供される。料金は認証の種類によって異なる。
利用可能リージョンは、米国東部(オハイオ、バージニア北部)、米国西部(北カリフォルニア、オレゴン)、アジアパシフィック(ムンバイ、ソウル、シンガポール、シドニー、東京)、カナダ(中部)、欧州(フランクフルト、アイルランド、ロンドン、パリ、ストックホルム)、南米(サンパウロ)となっている。これらのリージョンはソース・デスティネーションのどちらとしても使用可能だ。
CMKサポートの提供リージョンはさらに広く、アフリカ(ケープタウン)、アジアパシフィック(香港、ハイデラバード、ジャカルタ、マレーシア、メルボルン、ニュージーランド、大阪など)や、イスラエル(テルアビブ)、メキシコ(中部)、AWS GovCloudもカバーされている。
この記事のポイント
- Amazon Cognitoにマルチリージョンレプリケーション機能が追加され、ユーザーデータとM2Mシークレットの自動同期が可能になった
- レプリケーションにはAWS KMSのマルチリージョンCMKが必須で、暗号化制御の主導権を利用者側に与える
- 設定は3ステップで完了するが、OIDCエンドポイント変更に伴うアプリ側の対応が必須となる
- フェイルオーバー時のセッション継続性が担保され、エンドユーザーはパスワード再設定なしで認証を継続できる
- 料金はアドオン形式で、ユーザー認証はMAUあたりの課金、M2M認証はトークンボリュームに対する30%追加となる
・ 複数業界における17年間のデジタルビジネス開発経験
・ ウェブサイト開発のためのHTML、PHP、CSS、JavaScript等の実用的知識
・ 15ヶ国語対応の多言語SaaSの開発経験
・ 17年間にも及ぶ、Eコマース長期運営経験
・ 幅広い業界でのSEO最適化の豊富な経験

OpenAIの最先端モデルとCodexがAWSで一般提供開始。Bedrock経由で本番導入が加速
2026年6月1日、OpenAIの最先端モデルとCodexがAmazon Bedrock上で一般提供を開始した。すでにAWSをインフラ基盤として使う数百万の組織が、同じ管理画面とセキュリティポリシーのままOpenAIのAI機能を本番環境へ組み込めるようになる。
Codexは毎週500万人以上の開発者が使うソフトウェアエンジニアリングエージェントだ。コードの記述、レビュー、デバッグ、レガシーコードのモダナイズまで、開発の全工程をAWS環境の中で完結できる。商用リージョンとGovCloudの両方に対応する。
企業にとって最大の意味は「AI導入の運用障壁が一段下がる」ことにある。調達、セキュリティ審査、ガバナンス、請求管理といった本番運用に必須のプロセスを、すでに信頼済みのAWSガードレールの中で処理できるからだ。
企業がAI導入でぶつかっていた3つの壁

OpenAIのAPIはここ数年で急速に高性能化した。GPT-4oをはじめとするフロンティアモデルは、自然言語の理解と生成だけでなく、構造化データの処理やマルチモーダル推論までこなす。それでも大企業の本番導入は想定より緩やかだった。理由は技術そのものではなく、運用プロセスにある。
セキュリティ審査とガバナンスの再構築
新しい外部サービスを本番環境につなぐには、情報セキュリティ部門による審査が避けられない。データの送信先、暗号化の有無、ログの保管場所、アクセス制御ポリシーとの整合性。これらを一から確認する作業は数週間から数ヶ月に及ぶ。OpenAI単体のAPIを使う場合、この審査プロセスが最初のハードルだった。
請求管理と調達フローの分断
クラウド費用をAWSで一元管理している企業にとって、別のSaaS契約を追加することは経理と調達の両面で負荷が増す。予算承認のフロー、請求書の処理、利用量の監視。それぞれが独立したサイロになり、小さなPoC(概念実証)の段階で手続きに埋もれてしまうケースも少なくなかった。
開発パイプラインとの統合コスト
AIの推論結果をアプリケーションに組み込むには、API呼び出しの認証、レート制限の管理、エラーハンドリング、モニタリングの仕組みを別途構築する必要があった。AWSのIAMやCloudWatchと統合されていないサービスを追加するたびに、運用スクリプトと監視設定を一から書く工数が発生していたのだ。
このデモ図が示すように、AWS Bedrockを経由することで調達・審査・監視のステップが一本化される。これが今回の発表でOpenAIが強調している「摩擦の低減」の正体だ。
2つの提供ルートが開いた意味
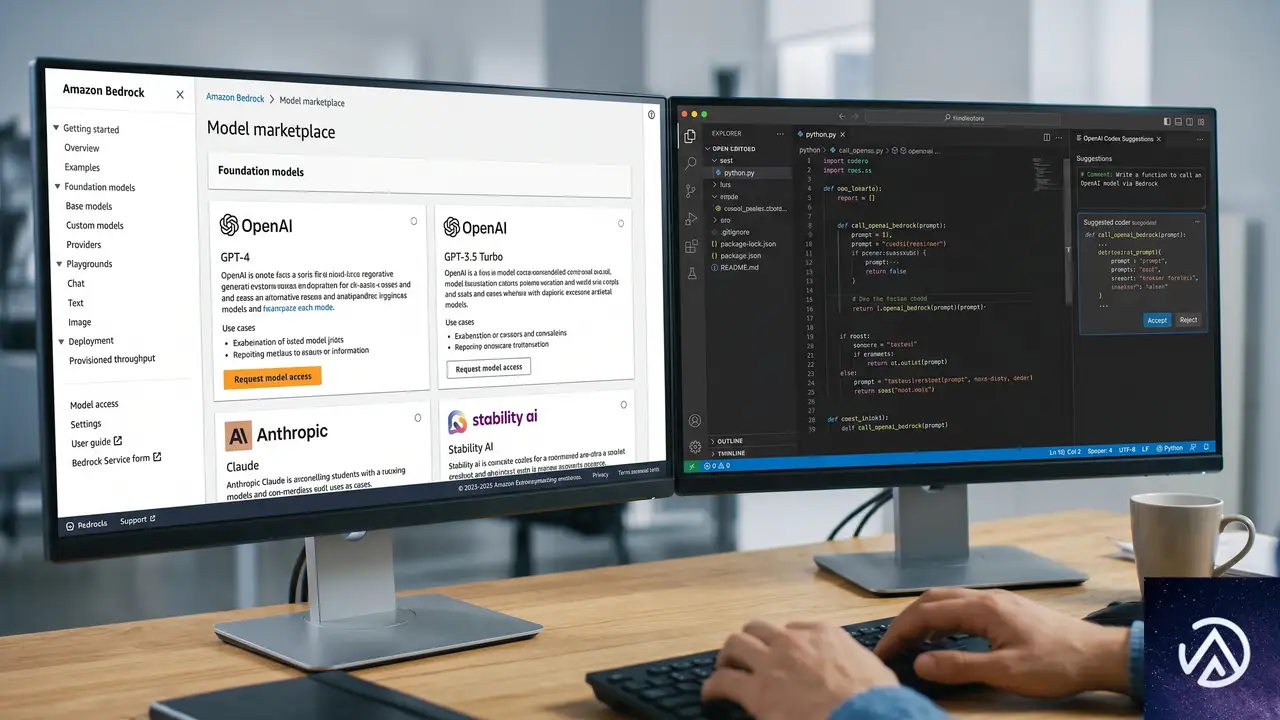
OpenAIの機能はAWS上で2つの形態で提供される。どちらもAmazon Bedrockを基盤とするが、用途と対象者が異なる。
OpenAI models on Amazon Bedrock
GPT-4oをはじめとするOpenAIのフロンティアモデルを、BedrockのAPI経由で呼び出せる。BedrockはAWSが提供するフルマネージド型の基盤モデルサービスだ。すでにBedrock上で他のモデルを使っているチームであれば、同じIAMロール、同じVPCエンドポイント、同じCloudTrailの監査ログでOpenAIのモデルを追加できる。
これにより、チャットボット、文書要約、マルチモーダル分析といったユースケースを、セキュリティチームが事前承認したネットワーク境界の中で実装可能になる。データがAWSリージョン外に送信される心配もなく、社内ポリシーとの整合性を取りやすい。
Codex on Amazon Bedrock
CodexはOpenAIが提供するソフトウェアエンジニアリングエージェントだ。コードの自動生成だけでなく、プルリクエストのレビュー、バグの特定、依存関係の分析、レガシーコードのリファクタリング提案までを対話型で実行する。GitHubやIDEと統合して使うのが一般的だったが、今回の発表でAWS環境から直接Codexを呼び出せるようになった。
週に500万人以上の開発者がすでにCodexを利用している。この数字はGitHub Copilotのユーザー数に匹敵し、AIコーディング支援が一部のアーリーアダプターの手を離れ、メインストリームの開発プラクティスになったことを示している。AWS上でCodexを使えるようになることで、CI/CDパイプラインへの組み込みや、組織全体のコードレビューポリシーとの統合が現実的になる。
Codexが開発パイプラインの中に組み込まれることで、コードレビューや依存関係チェックがプルリクエストのたびに自動で走るようになる。レビュアーの負荷が下がり、バグの早期発見にもつながる設計だ。
商用とGovCloudの両対応が示す信頼性

今回の発表で見逃せないのは、OpenAIの機能がAWSの商用リージョンとGovCloud(米国政府向けクラウド)の両方で提供される点だ。GovCloudはFedRAMPやITARなどの厳格なコンプライアンス基準を満たすために設計された隔離環境である。
政府機関や防衛産業、高い規制要件を持つ金融機関にとって、AIモデルをGovCloud内で実行できることの意味は大きい。データが閉域網から出ず、監査証跡もAWSの既存フレームワークで一貫管理される。OpenAIのモデルをパブリッククラウド越しに使うことに抵抗があった組織も、このオプションで導入検討の敷居が下がる。
OpenAIのCarlo Daniele氏は公式ブログで「企業が直面する最大の障壁は、最先端AIを既存のセキュリティとコンプライアンスの枠組みの中で本番運用することだ」と指摘している。GovCloud対応はまさにその障壁をターゲットにした一手といえる。
Daybreak構想とセキュリティ開発の未来

今回の発表と同時に、OpenAIは「Daybreak」という構想の将来提供も示唆した。Daybreakはソフトウェアの「作り方」と「守り方」の両方を変えることを狙ったビジョンだ。
Codex Securityが開発ループに入る日
Daybreakの中核には、サイバーセキュリティに特化したモデル群と「Codex Security」がある。これらは以下の機能を日常的な開発ループに組み込むことを目指している。
- セキュアコードレビューの自動化
- 脅威モデリングの支援
- パッチ検証の効率化
- 依存関係のリスク分析
- 脆弱性の検出と修復ガイダンスの提示
現状、これらの作業の多くはセキュリティ専任チームが限られた時間の中で手動で行っている。コード量が増えるほどチェックが追いつかなくなり、既知の脆弱性が修正されないまま本番環境に残るリスクが高まる。Codex Securityはこのギャップを、開発者がコードを書くタイミングで自動的に埋めようという発想だ。
AWSがセキュリティ導入の加速路になる
Daybreakのような専用機能が本格提供されたとき、AWSはその導入経路として重要な役割を果たすとOpenAIは見ている。すでにAWS上でセキュリティ運用(GuardDuty、Security Hub、Inspectorなど)を回している組織であれば、Codex Securityの出力を既存のSOC(セキュリティオペレーションセンター)ワークフローに直接流し込めるからだ。
OpenAIの記事では「セキュリティチームがすでに使っているセキュリティ、ガバナンス、調達、運用のフレームワークの中でDaybreakを導入できる」と説明されている。セキュリティ強化のための新ツール導入が、逆に運用負荷を増やすという矛盾を避ける設計思想だ。
このフローが実現すれば、セキュリティは「後付けの検査工程」から「開発と同時並行で走る自動プロセス」に変わる。Daybreakの提供時期はまだ明言されていないが、AWS基盤の上でこの構想が動き始めたこと自体が重要なシグナルだ。
開発チームが今から準備すべきこと

OpenAI on AWSはすでに一般提供が始まっている。商用リージョンとGovCloudの両方で利用可能だ。開発チームがこの変化を活かすために、今から着手できることがいくつかある。
Bedrockのアクセス権を確認する
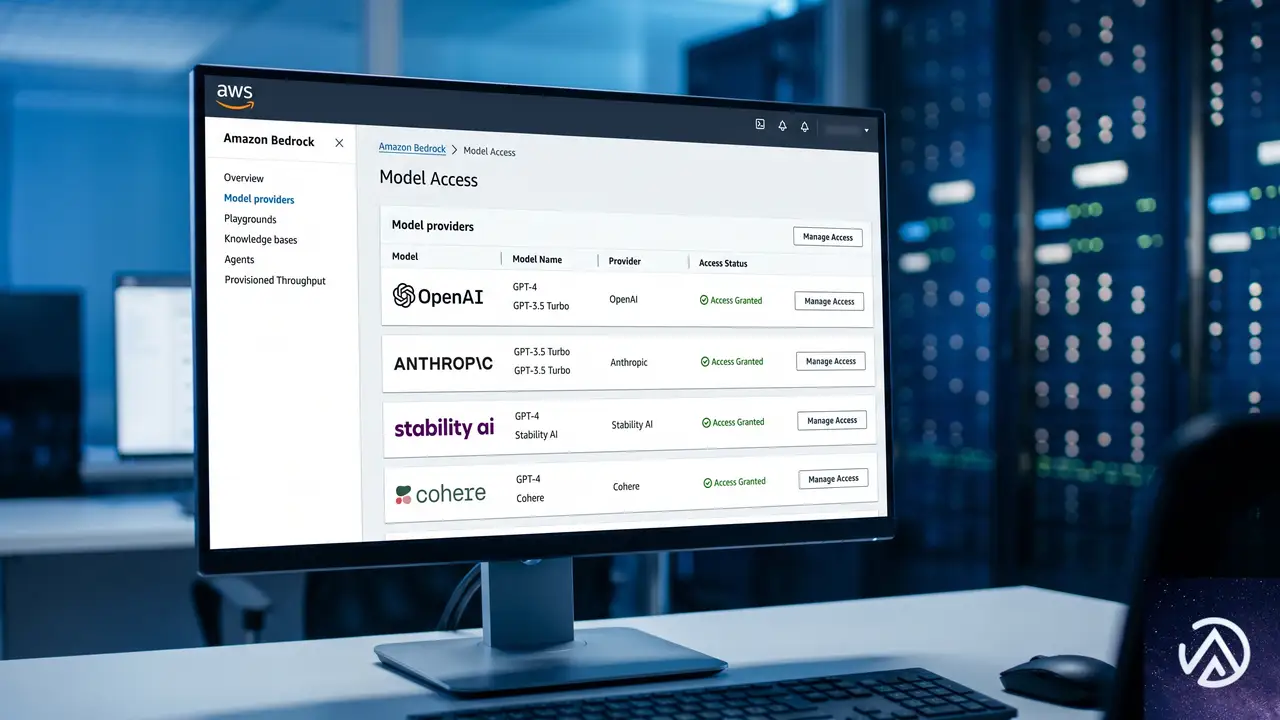
まず、自組織のAWSアカウントでBedrockが有効化されているか確認する。IAMポリシーでBedrockのモデルアクセス権限が適切に設定されているかも見直す必要がある。特にOpenAIのモデルを呼び出すには、Bedrock内でモデルアクセスを明示的にリクエストするステップが必要だ。
CodexをCI/CDパイプラインに組み込む設計を始める
Codex on BedrockはAPIとして提供されるため、GitHub ActionsやAWS CodePipelineと組み合わせて、プルリクエストの自動レビューやコード品質チェックに活用できる。すでにCodexをIDEで使っているチームは、パイプライン全体への展開を検討する段階に入ったといえる。
セキュリティチームとDaybreakのロードマップを共有する
Daybreakの具体的な提供日は未定だが、Codex Securityの方向性を事前にセキュリティチームと共有しておくことで、導入時の社内調整をスムーズにできる。脅威モデリングや依存関係分析の自動化がどのように既存のセキュリティ運用と統合されるのか、概念レベルで議論を始めておくのが有効だ。
この記事のポイント
- OpenAIのフロンティアモデルとCodexがAmazon Bedrockで一般提供を開始
- 既存のAWSセキュリティ・ガバナンス・請求管理の枠組みでAIを本番導入可能に
- Codexは週500万人以上が使うエンジニアリングエージェントで、開発パイプラインへの統合が加速
- 商用リージョンとGovCloudの両対応により、規制業界や政府機関の導入障壁が低下
- Daybreak構想(Codex Security)が将来提供されれば、セキュリティレビューが開発と同時進行する形に変わる
・ 複数業界における17年間のデジタルビジネス開発経験
・ ウェブサイト開発のためのHTML、PHP、CSS、JavaScript等の実用的知識
・ 15ヶ国語対応の多言語SaaSの開発経験
・ 17年間にも及ぶ、Eコマース長期運営経験
・ 幅広い業界でのSEO最適化の豊富な経験

AWS BedrockでOpenAI GPT-5.5とCodexが利用可能に。開発効率が飛躍
AWSが2026年6月、Amazon Bedrock上でOpenAI GPT-5.5モデル、GPT-5.4モデル、そしてコーディングエージェントCodexの一般提供を開始した。これにより、Bedrockのセキュアなインフラ上で最先端の大規模言語モデルを利用できる。
GPT-5.5は最も難しいタスク向け、GPT-5.4はコストパフォーマンス重視のシナリオに適する。いずれも、新しい推論エンジン上で高速かつ信頼性の高い応答が得られる。Codexは週あたり400万人以上の開発者が使用するAIコーディングツールで、複数のIDEと連携しつつ、推論エンジン経由でBedrockからモデルを呼び出す。
データ主権要件に対応するため、すべての処理は選択したBedrockリージョン内に留まる。トークン単位の課金で、シートライセンスや開発者あたりの固定費は発生しない。本記事では利用開始手順と技術的な注意点を解説する。
AWS BedrockでOpenAI GPT-5.5とCodexが一般提供
AWSの年次カンファレンスでプレビューされていたOpenAIモデルの対応が、正式に利用可能になった。GPT-5.5とGPT-5.4は、コーディング、推論、エージェントワークフロー、複雑な専門業務に優れる。AWS News BlogのChanny Yun氏は、GPT-5.5を「最も難しい顧客のワークロード」向け、GPT-5.4を「最良の価格性能比」と位置づける。
モデルへのアクセスは、新しいBedrock推論エンジンが提供するResponses APIを介して行う。このAPIは、マルチターン状態管理、ホストツール、ファンクションツール、バックグラウンド実行をサポートする。
この構成により、機密データを外部に送信することなく、AWSの管理下で最先端AIを活用できる。リージョンごとのデータ主権も担保される。
GPT-5.5モデルの利用方法

モデルへは、OpenAIのResponses APIを用いてアクセスする。Bedrock専用のエンドポイントbedrock-mantleを経由し、OpenAI SDKやcurlから呼び出す形だ。以下にセットアップ手順を示す。
Python SDKを使った呼び出し
まずOpenAI SDKを最新版にアップデートする。
pip install -U openai認証用の環境変数を設定する。BedrockのAPIキーはAWSマネジメントコンソールから取得できる。
export OPENAI_BASE_URL="https://bedrock-mantle.us-east-2.api.aws/openai/v1"
export OPENAI_API_KEY="<BEDROCK_API_KEY>"
export BEDROCK_OPENAI_MODEL_ID="openai.gpt-5.5"以下のサンプルコードで、GPT-5.5に分散アーキテクチャの設計を依頼できる。
import os
from openai import OpenAI
client = OpenAI(
base_url=os.environ["OPENAI_BASE_URL"],
api_key=os.environ["OPENAI_API_KEY"],
)
response = client.responses.create(
model=os.environ["BEDROCK_OPENAI_MODEL_ID"],
input=[
{
"role": "developer",
"content": "You are a software engineer with excellent AWS cloud knowledge. Be concise and practical.",
},
{
"role": "user",
"content": "Design a distributed architecture on AWS in Python that should support 100k requests per second across multiple geographic regions.",
},
],
reasoning={"effort": "medium"},
text={"verbosity": "low"},
)
print(response.output_text)curlによる直接アクセス
curlを使う場合も同様に環境変数を設定した上で、エンドポイントへPOSTリクエストを送る。
curl "$OPENAI_BASE_URL/responses" \
-H "Content-Type: application/json" \
-H "Authorization: Bearer $OPENAI_API_KEY" \
-d '{
"model": "openai.gpt-5.5",
"input": [
{
"role": "developer",
"content": "You are a software engineer with excellent AWS cloud knowledge."
},
{
"role": "user",
"content": "Design a distributed architecture on AWS in Python that should support 100k requests per second across multiple geographic regions."
}
],
"reasoning": {"effort": "medium"},
"text": {"verbosity": "low"}
}'コード内のreasoning.effortは推論の深さを制御する。GPT-5.5ではmediumから始め、必要に応じてhighに変更すると良い。GPT-5.4の場合は明示的にeffortを指定すべきだ(デフォルトがnoneのため)。
CodexでAI駆動開発を体験する
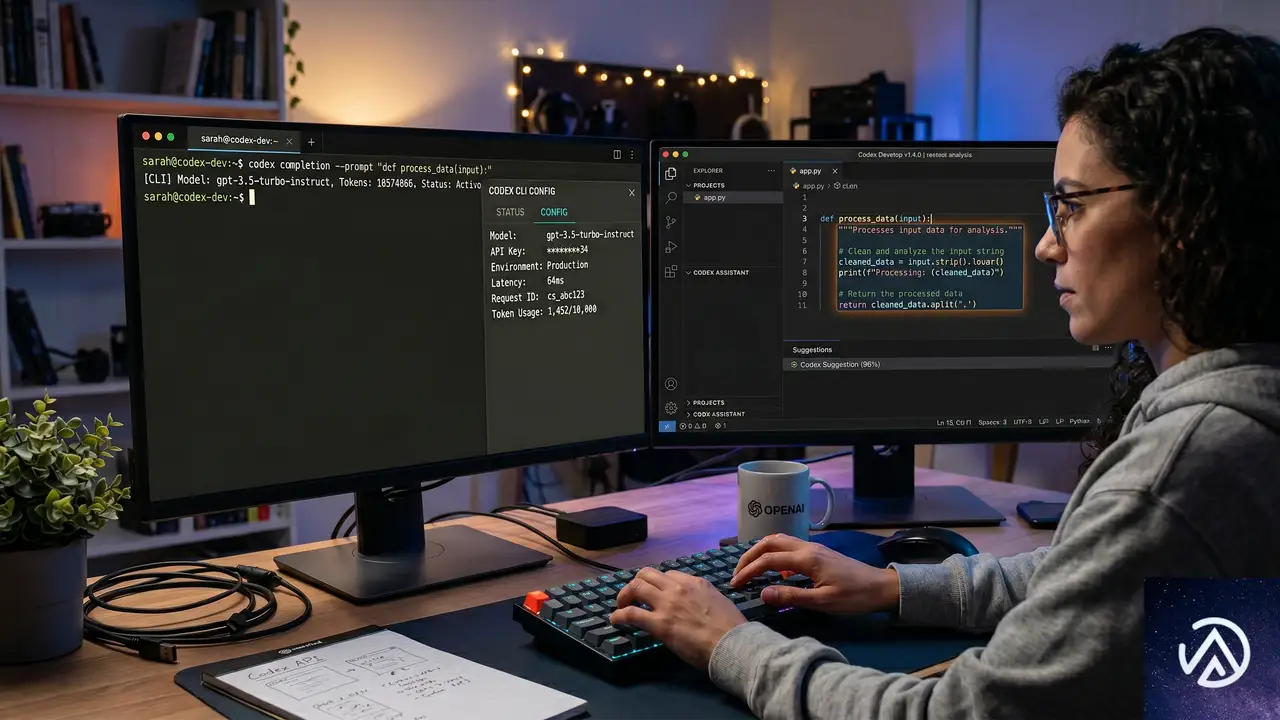
Codexは、GPT-5.5を推論エンジンとしてバックグラウンドで利用するコーディングエージェントだ。CLI、デスクトップアプリ、VS CodeやJetBrains、Xcodeの拡張機能が提供され、大規模コードベースの作成、リファクタリング、デバッグ、テスト、検証をAIが支援する。
Codex CLIの設定手順
Codex CLIをインストール後、Bedrock認証を有効にする。APIキー認証とAWS SDKの認証情報チェーンの2方式があり、APIキーが優先される。
export AWS_BEARER_TOKEN_BEDROCK=<your-bedrock-api-key>次に、~/.codex/config.tomlにモデル情報とリージョンを記述する。
model = "openai.gpt-5.5"
model_provider = "amazon-bedrock"
[model_providers.amazon-bedrock.aws]
region = "us-east-2"デスクトップアプリやVS Code拡張では、必要な環境変数を~/.codex/.envに記述しておく。設定変更後はアプリケーションを再起動すれば反映される。
CLIで/statusタブを表示すると、モデルがBedrock経由で接続されていることを確認できる。Channy Yun氏の記事では、実際のステータス画面が示されており、モデルとしてopenai.gpt-5.5と表示される。
レイテンシやスケーリングの注意点

本番利用を始めるにあたり、いくつかの技術的なポイントを把握しておく必要がある。
モデルレイテンシの特性
GPT-5.5は高速、GPT-5.4は中速と位置づけられるが、実際の遅延は推論の深さ、出力長、ツール呼び出しの有無、バックグラウンドモード、リージョン、クォータ、スロットリング、プロンプトサイズ、キャッシュヒットに依存する。GPT-5.5ではreasoning.effortをmediumで開始し、GPT-5.4では明示的にeffortを設定することを推奨する(デフォルトがnoneで十分な推論が得られない可能性があるため)。
スケーリングとキャパシティ管理
Bedrockの新しい推論エンジンは、多数のモデルにわたって迅速にキャパシティをプロビジョニングし、需要変動に応じてスケールする設計だ。定常的なワークロードの実行を優先し、需要急増時にはリクエストをキューイングする(拒否はしない)。そのため、予期せぬトラフィック増加時にも安定した動作が期待できる。ただし、クォータ上限を事前に確認し、必要に応じて引き上げ申請を行うことが望ましい。
この記事のポイント
- Amazon Bedrock上でOpenAI GPT-5.5・GPT-5.4モデルとCodexが一般提供開始
- Responses APIを通じてモデルを呼び出し、複雑なワークロードに対応
- CodexはGPT-5.5をバックエンドに、CLI・デスクトップアプリ・IDE拡張で利用可能
- データは選択したBedrockリージョン内で処理され、データ主権を確保
- レイテンシは複数要因に依存し、effort設定やキャッシュが影響するため、初期はmediumから
- スケーリングは自動だが、クォータ管理を怠らないこと
・ 複数業界における17年間のデジタルビジネス開発経験
・ ウェブサイト開発のためのHTML、PHP、CSS、JavaScript等の実用的知識
・ 15ヶ国語対応の多言語SaaSの開発経験
・ 17年間にも及ぶ、Eコマース長期運営経験
・ 幅広い業界でのSEO最適化の豊富な経験

Amazon OpenSearch Serverless次世代版、AIエージェント構築向けに発表
AWSが2026年5月28日、Amazon OpenSearch Serverlessの次世代版を一般提供開始した。AIエージェントアプリケーションの構築に特化したフルマネージド検索・ベクトルエンジンであり、スケールゼロからピーク時までシームレスに拡縮する。
従来のプロビジョニング型クラスタと比較して最大60%のコスト削減が可能とされる。リソース作成は数秒、スケーリング速度は前世代比で最大20倍に向上した。VercelやKiroといったAI開発プラットフォームとのネイティブ統合も備え、インフラ管理を意識せずに本番対応のバックエンドを数分で立ち上げられる。
この記事では、次世代OpenSearch Serverlessの主要な特徴、アーキテクチャ上の進化、AIエージェント開発への実践的な活用法を詳しく見ていく。
OpenSearch Serverless次世代版の概要

OpenSearchはElasticsearchからフォークしたオープンソースの分散型検索・分析エンジンだ。Amazon OpenSearch Serviceはそのマネージド版であり、サーバーレスオプションは2022年に導入された。今回の次世代版は、そのサーバーレスアーキテクチャを根本から刷新したものである。
AWS News Blogの記事によると、次世代版は「AIエージェントを構築する顧客向けに設計された」と位置づけられている。フルマネージドである点は変わらないが、スケーリングの速度とコスト効率が大幅に向上した。
主な改良点はスケールゼロと高速スケーリング
特筆すべきはスケールゼロへの対応だ。利用が途絶えると自動的にリソースが解放され、アイドル状態のコストがほぼゼロになる。リクエストが発生すると数秒でリソースが再作成され、前世代比で最大20倍速いスケールアップを実現する。
つまり、開発中の本番前ステージング環境や、トラフィックが断続的なAIエージェントのバックエンドで、大幅な無駄を省けるということだ。
このデモは、従来型と次世代版のリソース管理モデルの違いを概念的に示したものだ。実際の環境では、数秒単位でプロビジョニングが動的に切り替わる。
コレクションタイプは全文検索とベクトル検索に限定
今回のリリース時点では、対応するコレクションタイプは全文検索(SEARCH)とベクトル検索(VECTORSEARCH)の2種類である。既存のOpenSearch Serverlessにあった時系列データやログ分析向けのタイプは、現時点では次世代版で選択できない。
これは、まずAIエージェント向けの検索基盤として最適化された領域に集中した戦略と見られる。今後のアップデートで順次拡張される可能性は高い。
スケールゼロと高速スケーリングの仕組み

次世代版のアーキテクチャを理解するには、従来のサーバーレス版との違いを押さえておくとよい。前世代のOpenSearch Serverlessは、あらかじめ設定された最小キャパシティユニット(OCU)を常に確保するモデルだった。利用がゼロになっても、その最小ユニット分のコストは発生し続けたのである。
OCUの最小値をゼロに設定可能
次世代版では、インデックス用と検索用それぞれの最小OCUをゼロに指定できるようになった。CLIコマンドを見ると、minIndexingCapacityInOCUとminSearchCapacityInOCUに0が設定されているのがわかる。
この仕組みにより、トラフィックが完全に途絶えた時間帯はコンピューティングリソースが解放され、ストレージのみの課金になる。実質的に「寝ている間は課金されない検索エンジン」として振る舞うわけだ。
リソース作成が数秒で完了する理由
従来のサーバーレス版でコレクションを作成すると、数分かかることもあった。次世代版では、内部的なリソースプロビジョニングのパイプラインが刷新されており、数秒で利用可能になる。
これはAIエージェントの開発フローにおいて非常に重要だ。たとえばVercel上で新しいプロジェクトを作成し、そこにベクトルデータベースを接続する場合、即座にプロビジョニングが完了しなければ開発テンポが落ちてしまう。数秒で立ち上がるという体験は、プロトタイピングの高速化に直結する。
このフローはVercel統合を活用した典型的なAIエージェントのセットアップ手順を図示したものだ。実際の操作はVercelの管理画面から数クリックで完了する。
VercelやKiroとの統合でAIエージェント構築を加速

次世代OpenSearch Serverlessの重要な価値は、AIエージェント開発プラットフォームとのシームレスな連携にある。Vercelの管理画面から直接OpenSearchコレクションを作成・接続できるようになったのがその典型だ。
Vercel統合の実用性
Vercelユーザーは、フロントエンド(Next.js等)のデプロイに加え、検索やベクトルストアをバックエンドインフラとして簡単に追加できる。従来であれば、別途Elasticsearch互換のDBを用意し、VPCネットワークを設定し、認証情報を安全に管理する手間が発生した。
これが管理画面上で完結するということは、開発者がインフラの設定に費やす時間を劇的に減らせる。特にAIエージェントのように試行錯誤を重ねるプロジェクトでは、この迅速さが競争力に直結する。
OpenSearch Agent SkillsとKiro Powers
AWS News Blogの記事では、Claude CodeやCursor、Kiroといった開発ツールとの連携も紹介されている。GitHub上のOpenSearch Agent Skillsというリポジトリには、特定のワークフロー向けのドメイン知識やベストプラクティスがスキルとしてパッケージ化されている。
たとえば「あるテーマに関する最新の技術ドキュメントを検索し、その結果を要約する」といった複数ステップのタスクを、エージェントがOpenSearchのスキルを呼び出すだけで実行できる。エージェントは単に検索結果を受け取るだけでなく、その検索がどのように実行されたかのプロセスも理解できるようになる。
このインラインフローは、開発者がAIエージェントに指示を出してからOpenSearchが検索を実行し、結果が返るまでの一連の流れを色分けで示している。OpenSearch Agent Skillsによって、エージェントは適切なスキルを自動選択できる。
一方、Kiro Powersで提供されるOpenSearch Launchpadは、エンドツーエンドのアーキテクチャ計画をガイド付きで進められるツールだ。検索アプリケーションの全体設計をAIが支援することで、開発の初期段階から生産性を高められる。
導入方法、コンソールとCLI

次世代OpenSearch Serverlessの利用開始は簡単だ。マネジメントコンソールから「Serverless」メニューを選び、「Create collection」をクリックする。次の画面で「NextGen」を選択し、Express createを選べばデフォルト設定で即座にコレクションが作成される。
Express createで手間を省く
Express createは設定不要のクイック作成機能だ。セキュリティポリシーやネットワーク設定は自動で適用され、後から一部の設定を変更できる。プロトタイピングや検証用途では、まずExpress createで立ち上げ、必要に応じて細かな設定を詰めるアプローチが現実的だろう。
CLIからの作成手順
AWS CLIを使う場合は、まずコレクショングループを作成し、その中にコレクションを作る2段階の手順になる。以下はAWS公式ブログに掲載されたコマンド例を、実際の利用に即して整理したものだ。
# コレクショングループの作成(生成世代をNEXTGENに指定)
aws opensearchserverless create-collection-group \
--name my-nextgen-group \
--standby-replicas ENABLED \
--generation NEXTGEN \
--description "My NextGen collection group" \
--capacity-limits '{
"maxIndexingCapacityInOCU": 96,
"maxSearchCapacityInOCU": 96,
"minIndexingCapacityInOCU": 0,
"minSearchCapacityInOCU": 0
}' \
--region "us-east-1"
# コレクションの作成(SEARCHまたはVECTORSEARCH)
aws opensearchserverless create-collection \
--name my-nextgen-collection \
--type SEARCH \
--collection-group-name my-nextgen-group \
--standby-replicas ENABLED \
--description "My collection in NextGen group" \
--region "us-east-1"なお、ブログ公開時のCLIコマンドには最大OCUのデフォルト値に誤りがあり、後日修正された点には注意が必要だ。実際に使う場合は最新のドキュメントを参照してほしい。
AIエージェント時代のデータバックエンドの在り方

OpenSearch Serverless次世代版の登場は、単なる新バージョン発表以上の意味を持つ。AIエージェントが自律的に情報を取得し、判断し、行動する時代において、「検索とベクトル演算のバックエンドをいかに手軽に、安く、速く用意できるか」が開発の成否を分けるからだ。
スケールゼロがもたらす開発文化の変化
従来、検索バックエンドの構築には「とりあえず動かす」だけでもある程度の初期コストが発生した。そのため、プロトタイプ段階では簡易的なインメモリ検索で代用し、後から本格的な検索エンジンに切り替えるパターンが一般的だった。
スケールゼロで最小OCUゼロが可能になったことで、最初から本番同様のOpenSearchを組み込んで開発を進められる。切り替えの手戻りがなくなり、より忠実な検証が可能になる。これはAIエージェントの品質を高める上で、見過ごせない利点だ。
マルチプラットフォーム連携の拡大予測
AWSはVercelとKiroに加え、今後さらに多くのAI開発プラットフォームとの統合を進めると見られる。GitHub CodespacesやReplit、Bolt.newなど、ブラウザベースの開発環境で動作するAIエージェントが増えれば、それらと連携する検索バックエンドの需要は右肩上がりだ。
OpenSearchがこの領域で競争力を発揮するためには、統合の容易さだけでなく、GPUアクセラレーションを活用したベクトル検索のパフォーマンスも鍵を握る。今回の次世代版ではGPU対応が明記されており、大量の埋め込みベクトルを扱う大規模AIエージェントのワークロードにも耐えられる設計が示されている。
コスト構造の変革と注意点
最大60%のコスト削減というインパクトは大きいが、これは「ピークキャパシティに合わせて常時プロビジョニングしていたクラスタ」との比較である。利用が常に一定水準以上あるサービスでは、スケールゼロの恩恵は限定的だ。
OCU単位の従量課金は、予測不能なトラフィックパターンを持つAIエージェントと相性が良い。一方、安定的に高いトラフィックが続く場合は、従来のプロビジョニング型OpenSearch Serviceの方がコストパフォーマンスに優れるケースもある。慎重な見積もりが求められる。
この記事のポイント
- OpenSearch Serverless次世代版はAIエージェント構築に特化し、スケールゼロと高速スケーリングを実現
- ピークプロビジョニング対比で最大60%のコスト削減、リソース作成は数秒で完了
- VercelやKiroとのネイティブ統合で、数分で検索バックエンドをデプロイ可能
- OCUの最小値をゼロに設定できるため、アイドルコストを極小化できる
- 全商用リージョンで一般提供開始、導入はコンソールのExpress createまたはCLIで
・ 複数業界における17年間のデジタルビジネス開発経験
・ ウェブサイト開発のためのHTML、PHP、CSS、JavaScript等の実用的知識
・ 15ヶ国語対応の多言語SaaSの開発経験
・ 17年間にも及ぶ、Eコマース長期運営経験
・ 幅広い業界でのSEO最適化の豊富な経験

AWS Resilience Hubが大幅刷新、生成AIで障害モードを分析しSREの信頼性管理を効率化
AWSが「Resilience Hub」の次世代版を一般公開した。最大の変更点は生成AIを活用した障害モード評価の搭載だ。組織全体の信頼性を構造化されたポリシーで管理し、数百に及ぶアプリケーションの可用性リスクを一元的に可視化する。
今回の刷新では新たなアプリケーションモデルが導入され、依存関係の自動検出機能やモジュール式の信頼性ポリシーも追加された。SREチームと開発チームが同じ指標で対話し、エンタープライズ全体のレジリエンスを継続的に改善する基盤が整った形だ。
従来のResilience Hubが個々のアプリケーション評価に留まっていたのに対し、今回の刷新は「信頼性の管理」を組織のガバナンス領域に引き上げる。本記事ではその具体的な機能と実務への影響を詳しく解説する。
AWS Resilience Hubの全体像と考え方の変化
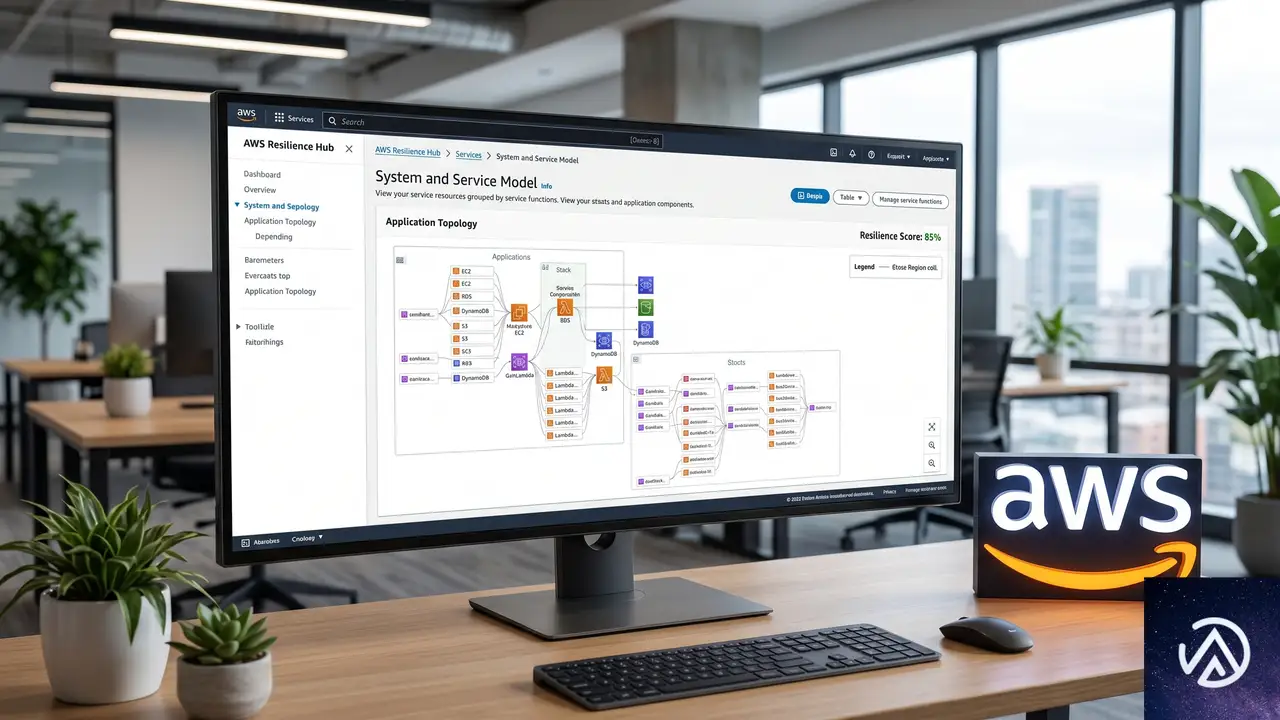
この比較が示すように、次世代版の本質は「個別最適から全体最適への転換」だ。AWS Organizationsとの統合により、委任管理者アカウントから複数アカウントを横断したレジリエンス評価が可能になった。
「ビジネス視点」で捉え直されたアプリケーションモデル
新しいモデルは3層構造になっている。最上位にビジネスアプリケーション全体を表す「システム」、その下にクリティカルな業務経路を示す「ユーザージャーニー」、さらに実際のデプロイ単位である「サービス」が配置される。サービスはAWSリソースやコード、オブザーバビリティの構成要素を束ねる役割だ。
この構造により「ログインできないと売上が止まる」という業務インパクトと、IAMロールの設定ミスという技術的リスクが地続きで評価できるようになる。AWS News Blogの記事でChanny氏は「ビジネス成果に直接結びつくクリティカルなエンドユーザー経路」という表現でこの概念を説明している。
モジュール式ポリシーでチーム間の共通言語を確立
信頼性ポリシーも大きく変わった。旧来は固定されたポリシータイプを選ぶ方式だったが、次世代版では必要な要件を組み合わせて構築できる。たとえば「可用性SLO 99.95%」「マルチリージョン災害復旧」「RTO 15分、RPO 5分」といった要素を選択し、金融系アプリケーション用のポリシーとして再利用する運用が可能だ。
SREと開発チームの間で「どの水準を目指すか」の共通理解が生まれ、属人的な判断を減らせる効果が期待できる。特に複数の開発チームを持つ組織では、この統一ポリシーがガバナンスの要になる。
生成AIが障害モードを評価する仕組み

次世代版の目玉機能が、生成AIを用いた障害モード評価である。サービスにポリシーを紐付けて評価を実行すると、AIが自動的に設定ミスや単一障害点を洗い出し、具体的な改善策を提案する。
この4ステップのフローにより、人手では発見が難しいクロスアカウントの依存関係や、リージョンをまたぐ意図しない呼び出しまで検出できる。AIは単にデータを収集するだけでなく、障害が発生した場合の影響範囲を推定し、優先度付きの修正ガイダンスを出力する。
AWS Well-Architectedと分析フレームワークの統合
AIの評価ロジックはAWS Well-Architectedフレームワークのベストプラクティスと、AWS Resilience Analysis Frameworkを参照している。これにより「なんとなく不安」ではなく、定義された基準に照らした再現性のある評価が実現する。
評価結果では「どのポリシー要件に違反しているか」が明示される。たとえば「RTO 15分を満たすには、このAuto Scalingグループのインスタンスが起動するまでの時間が長すぎる」といった具体的な指摘が得られる。対策の優先順位をビジネスインパクトに基づいて判断できる点が実務的に価値が高い。
また、ユーザーがAssertion(表明)を追加してAIの分析精度を高める仕組みも用意されている。たとえば「このサービスは特定のリージョンでのみ稼働する」といった前提条件をAIに伝えることで、無関係なマルチリージョン構成の提案を除外できる。
依存関係の自動検出がもたらす可視性の向上

多くの障害は「認識されていない依存関係」から発生する。次世代Resilience HubはDNSクエリログを解析し、VPC内のエンドポイントから呼び出されているAWSサービスや内部API、サードパーティの外部エンドポイントを自動で特定する。
この機能の価値は運用の暗黙知を形式知に変換する点にある。「ベテランSREだけが知っている」依存関係を、システムが自動でドキュメント化してくれる。異動や退職によるナレッジロスを防ぎ、障害対応の属人性を低減する効果が期待できる。
依存関係検出はサービス作成時に有効化する。VPCフローログではなくDNSクエリログを解析する仕組みのため、ネットワークトラフィックの暗号化状況に影響されず、比較的軽量に動作する設計だ。不要な場合は管理画面の設定から無効化できる。
実際の利用フローと移行パス

新規導入の基本的な流れ
導入の流れはシンプルだ。まず信頼性ポリシーを作成し、次にビジネスアプリケーションを表す「システム」を登録する。システム配下に、マイクロサービスなどのデプロイ単位である「サービス」を作成し、AWSリソースのタグやCloudFormationスタック、Terraformのステートファイル、EKSクラスタなどを指定してリソースを関連付ける。
準備が整ったら「障害モード評価の実行」をクリックする。Resilience HubがInvokerロールを引き受け、指定されたリソースの親子関係を解析し、トポロジを構築。その上でAIがポリシーに対するギャップを評価する。
評価完了後は「サービス詳細」画面の「Assessment」タブで発見事項を確認できる。各項目には障害モードの説明、アーキテクチャへの影響、修正方法、関連するポリシー要件が明記される。対応が完了した項目は「Mark as resolved」でクローズし、未対応の課題だけをトラッキングできる。
既存ユーザー向けの移行API
すでに従来版のResilience Hubを利用している組織向けには、移行用APIが提供されている。従来の評価ポリシーを新ポリシー形式に変換し、複数の関連アプリケーションを新モデルの「1システム配下の複数サービス」構造に再マッピングする機能だ。
手動での再設定が不要なため、既存の評価データを活かしつつスムーズな移行が可能になっている。大規模組織ほどこの移行APIの価値は大きい。
運用に組み込む際のポイントと今後の展望

Resilience Hubの次世代版を実運用に組み込む場合、いくつか意識すべき点がある。第1にポリシー設計の重要性だ。SLOやRTO、RPOの値はビジネス要件から逆算する必要がある。「とりあえず99.99%」といった一律設定では、過剰なコストを生むか、逆に重要なサービスを見落とすリスクがある。
第2に、依存関係検出のスコープ調整だ。DNSクエリログ解析は強力だが、ノイズとなる外部通信も拾う可能性がある。検出結果を精査し、クリティカルでない依存関係をフィルタリングする運用プロセスを組み込むことが望ましい。
第3に、AIの分析結果を鵜呑みにしないことだ。Assertion機能を活用し、自社のアーキテクチャ特性をAIに正しく伝える努力が求められる。あくまで「AIの提案をSREが判断する」という協調モデルが効果的である。
料金体系は新たなサービスベースモデルに移行した。各サービスにつき月2回の障害モード評価が含まれ、依存関係の自動評価はオプションとなる。大規模環境では評価回数がボトルネックになる可能性があるため、クリティカルなサービスに絞って評価頻度を設定するなどの工夫が必要だ。
今後はAWS Organizationsとの統合がさらに強化され、組織全体のレジリエンススコアをスコアカード化する機能や、CI/CDパイプラインへの組み込みによるシフトレフトな信頼性評価への展開が期待される。
この記事のポイント
- 生成AIによる障害モード評価で、人手では困難な依存関係や設定ミスを自動的に発見できる
- ビジネス視点のアプリケーションモデルにより、技術リスクと業務インパクトを地続きで評価可能になった
- モジュール式ポリシーがチーム間の共通言語として機能し、ガバナンスの実効性が高まる
- DNSクエリログ解析による依存関係の自動可視化で、運用の暗黙知を形式知に変換できる
- 既存ユーザー向けの移行APIが用意されており、大規模組織でもスムーズに移行可能である
・ 複数業界における17年間のデジタルビジネス開発経験
・ ウェブサイト開発のためのHTML、PHP、CSS、JavaScript等の実用的知識
・ 15ヶ国語対応の多言語SaaSの開発経験
・ 17年間にも及ぶ、Eコマース長期運営経験
・ 幅広い業界でのSEO最適化の豊富な経験