

GA4にAI Assistantチャネル追加、ChatGPT流入を可視化
Google Analytics 4(GA4)に2026年5月、生成AIプラットフォームからの流入を可視化する「AI Assistant」チャネルが追加された。ECサイト運営者にとって、ChatGPTやClaudeが商品情報を紹介した結果のトラフィックを正確に把握できる初めての標準機能だ。
この記事ではAI Assistantチャネルの基本的な仕組みと、ECサイトでの具体的な活用法を解説する。設定不要でデータが自動収集される一方、AI Overviewsは含まれないといった注意点もあるため、正しい読み方を押さえておく必要がある。
WooCommerceサイトを運営する中小企業の担当者や、ECのアクセス解析を担当するWeb担にとって、これまで「参照元不明」だったAI経由の流入を可視化できる意味は大きい。
AI Assistantチャネルとは何か
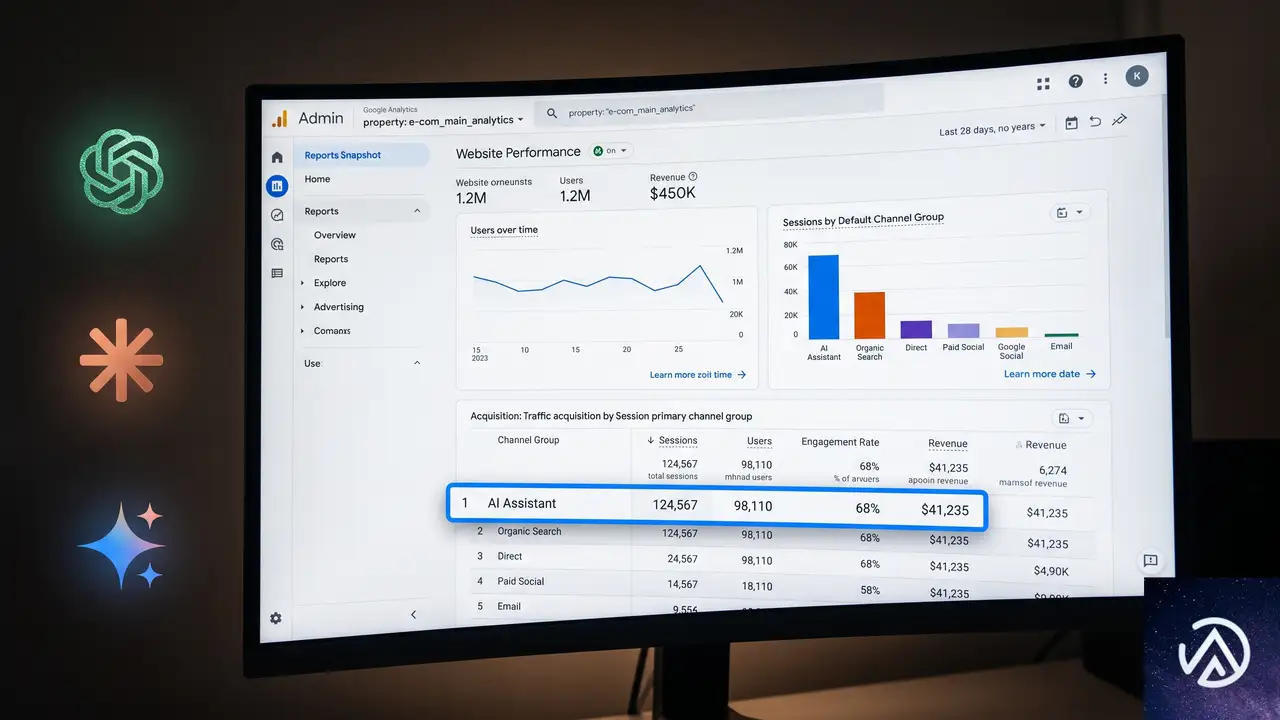
AI Assistantチャネルは、GA4のデフォルトチャネルグループに追加された新しい分類項目だ。ChatGPTやGemini、Claudeといった主要な生成AIプラットフォームからのトラフィックを自動的に判別し、ひとつのチャネルとして集計する。
計測対象となるプラットフォーム
Googleの公式ヘルプドキュメントによると、AI Assistantチャネルに含まれるのは「ChatGPT、Gemini、Claudeといったチャットボット」からのトラフィックだ。具体的な全リストは公開されていないが、主要な生成AIサービスはおおむねカバーされていると見てよい。
ここで重要な注意点がある。Google検索のAI Overviews(旧SGE)やAI Modeは、このチャネルには含まれない。これらは引き続き「Organic Search(オーガニック検索)」チャネルとして報告される。同じAI由来の流入でも、検索エンジン経由かチャットボット経由かで扱いが異なるわけだ。
ECサイトにとっての意味
ECサイト運営者にとって、AIチャットボット経由の流入は従来のSEOとは異なる文脈で発生する。たとえば「予算3万円で買えるおすすめのワイヤレスイヤホン」といった自然言語の質問に対し、ChatGPTが具体的な製品名とURLを提示するケースだ。この流入経路を正確に把握できれば、AIに自社商品がどのような文脈で言及されているかを分析できる。
AIトラフィックの確認手順
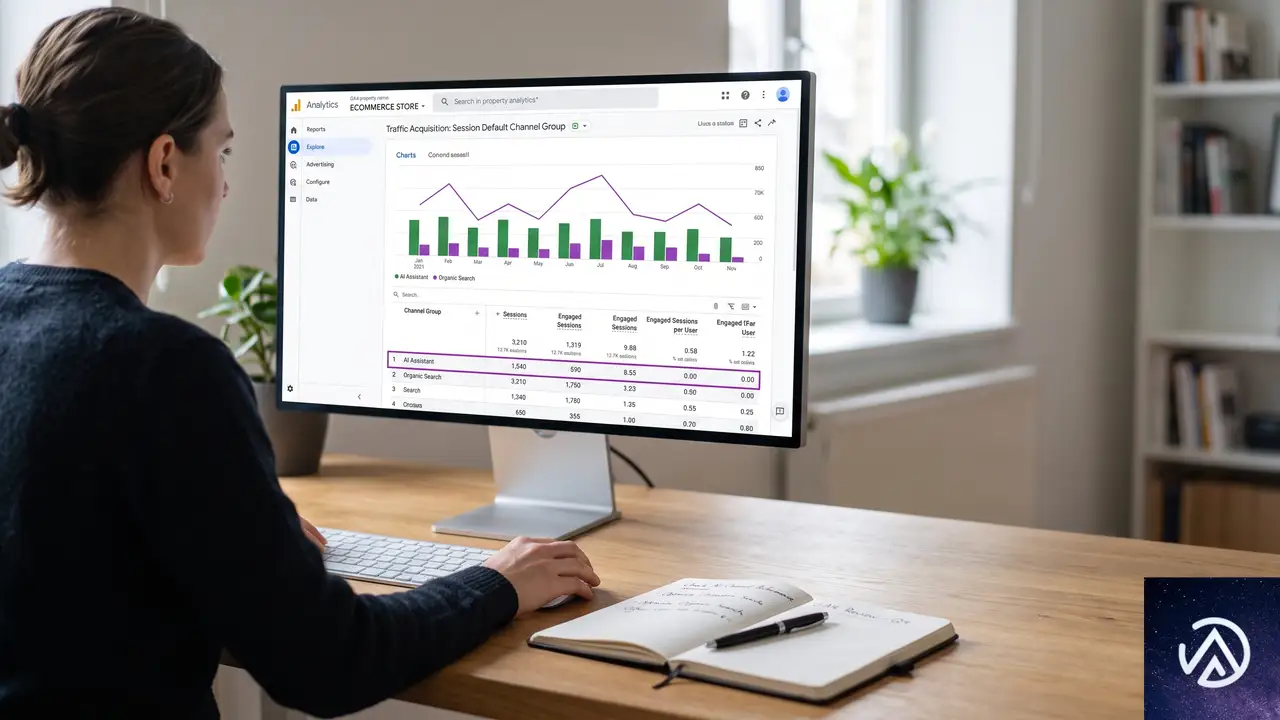
GA4でAI Assistantチャネルのデータを見るための手順を解説する。初期設定は不要で、GA4が自動的に分類を開始しているため、すぐに確認できる。WooCommerceサイトでGA4を導入済みであれば、追加のコード実装も必要ない。
トラフィック全体像の把握
まずはECサイト全体で、AI経由の流入がどの程度あるのかを確認する。GA4管理画面で「レポート」→「集客」→「トラフィック獲得」の順に開き、「セッションのデフォルトチャネルグループ」ディメンションを選択する。ここで「AI Assistant」という行が表示されていれば、すでにAI経由のトラフィックが発生している。
表示される指標はエンゲージメント率、セッションあたりのイベント数、平均セッション時間などだ。これらの数字をOrganic Searchチャネルと比較することで、AI経由ユーザーの行動特性が見えてくる。
ランディングページの特定
AIがどの商品ページを参照しているのかを特定するには、「レポート」→「エンゲージメント」→「ページとスクリーン」を開く。画面上部の「フィルタを追加」から、以下の条件で絞り込む。
- ディメンション:セッションのデフォルトチャネルグループ
- マッチタイプ:完全一致
- 値:AI Assistant
このフィルタを適用すると、AIプラットフォームからのクリックが多いページが上位に表示される。WooCommerceの商品ページやカテゴリページのうち、どのURLがAIに評価されているかを把握できるはずだ。
AIトラフィックと他チャネルの比較
同じ「ページとスクリーン」レポートで「比較を追加」ボタンを使うと、AI経由とオーガニック検索経由のトラフィックを横並びで比較できる。Practical Ecommerceの記事著者Carlo Daniele氏の検証によれば、オーガニック検索で上位のページとAI Assistant経由で上位のページは重複しなかったという。
これはEC担当者にとって示唆が大きい。Google検索で上位表示されている商品と、AIがユーザーに推薦する商品が異なる可能性があるためだ。AI経由の流入を伸ばすには、従来のSEO対策とは別のアプローチが必要になるかもしれない。
正規表現を使った詳細なソース分析

AI Assistantチャネルは便利だが、どのAIプラットフォームからの流入なのかまでは分解できない。ChatGPT経由なのかClaude経由なのかを個別に知りたい場合は、正規表現(regex)を使ったフィルタリングが有効だ。
設定手順
「レポート」→「集客」→「トラフィック獲得」で、グラフ上部の「フィルタを追加」をクリックする。ディメンションに「セッションの参照元/メディア」、マッチタイプに「matches regex」を選択し、以下の正規表現を値欄に貼り付ける。
.*chatgpt.com.*|.*perplexity.*|.*edgepilot.*|.*copilot.microsoft.com.*|.*openai.com.*|.*gemini.google.com.*|.*claude.ai.*|.*grok.x.ai.*このフィルタを適用すると、AIプラットフォームごとのセッション数やエンゲージメント指標を一覧できる。ただしPractical Ecommerceの記事でも指摘されているように、AI Assistantチャネルとの間にわずかなデータの不一致が生じる場合がある。これは「Organic」や「(not set)」と分類される一部のAIトラフィックが正規表現では拾えていないためだ。
WooCommerceサイトでの活用ポイント
正規表現フィルタを使えば、たとえば「ChatGPT経由では商品Aへの流入が多いが、Claude経由では商品Bが多い」といったプラットフォーム別の傾向を把握できる。AIによって得意とする商品カテゴリや、参照する情報ソースが異なる可能性があるためだ。
このデータをもとに、特定のAIプラットフォームで自社商品が言及されやすいコンテンツを強化するといった戦略が考えられる。Semrushなどの外部ツールで、どのようなプロンプトがAIの引用を生んでいるのかを調査するのも有効だ。
EC担当者が今すぐやるべき3つのアクション

AI Assistantチャネルの登場を受けて、ECサイトのアクセス解析にすぐに組み込むべき施策を整理する。いずれも追加コストなしで今すぐ始められるものばかりだ。
特にアクション2は重要だ。AIは商品スペックや口コミ、価格情報を総合的に評価して回答を生成する。商品ページの情報が不十分だとAIに引用されにくくなるため、商品説明の充実や構造化データの実装はAI時代のECに不可欠な施策といえる。
AIトラフィックとECの未来
GA4のAI Assistantチャネルは、ECにとって「AI経由の流入」という新たな指標を提供し始めた。現時点ではまだAIトラフィックの絶対量は小さいかもしれないが、ChatGPTやClaudeがデフォルトでWeb検索を行うようになり、AIを経由した商品発見は確実に増えていく。
AI OverviewsがOrganic Searchに含まれるという設計からもわかるように、GoogleはAIを「検索の拡張」と位置づけている。EC担当者はSEOとAI最適化を別物ではなく、同じ「検索体験」の両輪として捉えるべきフェーズに入ったといえる。
WooCommerceサイトであれば、GA4の標準機能だけでAIトラフィックの可視化は十分に可能だ。まずはデータを取得し、AIが自社商品をどう評価しているのかを把握することから始めてほしい。
この記事のポイント
- GA4に2026年5月追加のAI Assistantチャネルで、ChatGPTやClaudeなど生成AIからの流入が自動分類される
- AI OverviewsやAI Modeは含まれず、これらはOrganic Searchとして報告される点に注意が必要
- ページとスクリーンレポートでAI経由ランディングページを特定し、商品情報の最適化に活かせる
- 正規表現フィルタでAIプラットフォーム別の傾向を把握し、より細かな流入分析が可能
- AIトラフィックはSEOと地続きの指標であり、商品ページの情報充実がAIからの引用を増やす鍵になる

・ 複数業界における17年間のデジタルビジネス開発経験
・ ウェブサイト開発のためのHTML、PHP、CSS、JavaScript等の実用的知識
・ 15ヶ国語対応の多言語SaaSの開発経験
・ 17年間にも及ぶ、Eコマース長期運営経験
・ 幅広い業界でのSEO最適化の豊富な経験

OpenAI、フルデュプレックス音声モデルGPT‑Liveを発表、会話の自然さを大幅向上
OpenAIは2026年7月8日、新しい音声対話モデル「GPT‑Live」を発表した。人が話しかけるのと同時に聞き取り、相槌を打ったり沈黙を尊重したりできるフルデュプレックスアーキテクチャが最大の特徴だ。
モデル自体は単体の音声モデルでありながら、高度な質問に対してはバックエンドのGPT‑5.5に自動で推論を委譲する。これにより、速さと知性を両立させた自然な会話体験を実現している。
フルデュプレックスアーキテクチャが会話の自然さを変える

従来の音声AIが抱えていた限界
これまでのChatGPT音声機能は、大きく分けて2つの方式を経て進化してきた。最初のカスケード型は、音声認識→テキスト生成→音声合成という3つのモデルを直列に繋いでいた。各段階で情報が欠落し、応答までに長い沈黙が生まれる欠点があった。
次世代のターンベース型(Advanced Voice Mode)は単一モデルで音声を処理し、レイテンシを削減した。しかし「ユーザーが話し終えるまで待つ」というターン制のため、割り込みや考え込む間といった自然なやり取りができず、わずかな無音で誤って応答を開始する問題も残っていた。
このデモはGPT‑Liveがもつ同時双方向処理の概念を簡略化したものだ。実際の会話では秒単位で割り込みやツール呼び出しの判断が行われている。
連続的な相互作用が生むリアルタイム性
GPT‑Liveのフルデュプレックス構造では、入力と出力が同時に連続的に処理される。モデルは1秒間に何度も発話や傾聴、一時停止、割り込み、ツール起動といった行動を判断できる。この仕組みが、相槌や「ええ」といった自然なフィードバック、沈黙の尊重、さらには会話中のリアルタイム翻訳まで可能にしている。
バックエンド委譲で高度な推論をリアルタイム対話に統合

対話と思考の分離がもたらすメリット
GPT‑Liveはフロントエンドの自然な対話と、バックエンドの深い処理を分離した。Web検索や複雑な推論が必要な質問が来ると、自身は会話を続けながらGPT‑5.5にタスクを委譲する。回答が用意でき次第、会話に自然に織り込まれる。
この分離により、常に最新のフロンティアモデルが活用され、モデル更新のたびにGPT‑Liveの知性も自動的に向上する。発表時点ではGPT‑5.5がバックエンドとして使われる。
この委譲の仕組みにより、GPT‑Liveは会話のテンポを保ちつつ、最新のフロンティアモデルの知性を引き出せる。
評価指標が示す会話品質の飛躍的向上
人間による比較評価でAdvanced Voice Modeを圧倒
OpenAIの発表によれば、5〜10分の会話を対象にした人間評価では、GPT‑Live‑1とGPT‑Live‑1 miniの両方がAdvanced Voice Modeより強く選好された。話者交替のスムーズさ、割り込みの自然さ、会話全体の心地よさで高い評価を得ている。
専門的な推論力を測るGPQA(物理学・化学・生物学の高度な質問)ではGPT‑Live‑1が大幅に上回り、Web検索能力を問うBrowseCompでも強い改善を見せた。音声エージェントとしての電話サポートタスクでも、内部指標でAdvanced Voice Modeを凌駕した。
ChatGPT Voiceに搭載される新機能と使い勝手

相槌や割り込み、視覚的応答の追加
GPT‑Liveの導入により、ChatGPTの音声ボタンを押すとすぐに自然な会話が始まる。ユーザーは質問を遮ったり、考え込む間を作ったり、「ゆっくり話して」と頼んだりできる。モデルは「うん」「なるほど」といった相槌で話を聞いていることを伝え、背景ノイズがあっても話者の声に集中する。
さらに、天気や株価、スポーツの試合予定などの情報は、音声会話中にビジュアルカードとして画面に表示される。従来通り画像やファイルのアップロードにも対応し、Web検索やメモリー機能とも連携する。
回答の思考深度も選択可能で、「Instant」なら即答、「Medium」や「High」にするとモデルが時間をかけて深く推論する。全9種類の声もGPT‑Live向けにリマスターされた。
音声特化の安全性設計と継続的な監視

リアルタイムの有害出力検出と介入
GPT‑Liveは音声会話の即時性に対応するため、発話中でも安全性チェックが動作する。不適切な内容が検出されると、より安全な応答へ誘導したり、追加の安全メッセージを表示したり、深刻なケースでは会話を終了させたりする。
自傷行為に関する会話では、専門家が確認したクライシスヘルプライン情報を音声で案内する仕組みも組み込まれた。10代のユーザー向けには年齢に適した振る舞いを直接モデルに学習させ、保護者がChatGPT Voiceの利用を制限できる機能も用意されている。
実利用データに基づく安全対策の進化
OpenAIは感情的な依存に関する長期モニタリングを展開し、実際の利用パターンから新たなリスクを特定して対策を強化する方針だ。音声のなりすましを防ぐため、GPT‑LiveはChatGPTに用意された定義済みの声のみを使用し、実在の人物の声を模倣しないように設計されている。
この記事のポイント
- GPT‑Liveはフルデュプレックス構造で同時に聞きながら話し、相槌や沈黙を自然に扱える音声モデル
- 高度な質問はバックエンドのGPT‑5.5に自動委譲し、会話のテンポを保ったまま深い推論結果を返す
- 人間評価やGPQAなどのベンチマークでAdvanced Voice Modeを大きく上回る会話品質と知性を達成
- ChatGPT Voiceに即日導入され、ビジュアル応答や思考深度の選択が可能に
- リアルタイムの安全性介入や利用後監視により、音声ならではのリスクに対処している
・ 複数業界における17年間のデジタルビジネス開発経験
・ ウェブサイト開発のためのHTML、PHP、CSS、JavaScript等の実用的知識
・ 15ヶ国語対応の多言語SaaSの開発経験
・ 17年間にも及ぶ、Eコマース長期運営経験
・ 幅広い業界でのSEO最適化の豊富な経験

OpenAI GPT-Live登場、ChatGPT Voiceに検索機能を統合
OpenAIが音声会話と検索を融合させた新モデル「GPT-Live」の展開を開始した。2026年7月8日に発表されたこのアップデートにより、ChatGPT Voiceは会話の途中で最新の推論モデルやウェブ検索に質問を引き継げるようになる。
有料ユーザー(Go・Plus・Pro)には「GPT-Live-1」、無料ユーザーには「GPT-Live-1 mini」がデフォルトで提供される。Search Engine JournalのMatt G. Southern氏が報じたところによれば、週に1億5千万人以上がChatGPTと音声や音声入力で会話しており、今回の変更はその巨大なユーザー基盤に直接影響を及ぼす。
SEOの観点から特に注目すべきは、音声経由の検索結果が「どのように引用元を扱うか」の詳細がまだ明らかにされていない点だ。テキストベースのChatGPTでは回答の横にソースリンクが表示されるが、音声会話の中でどの程度サイトへの導線が確保されるかは、今後のトラフィック戦略を左右する。
GPT-Liveの仕組みと変更点

GPT-Liveの最大の特徴は、会話の自然さを追求した「全二重(Full-Duplex)」通信への移行だ。これは音声入力と応答生成を同時に行う技術で、ユーザーが話し終える前に割り込まれにくくなり、より人間らしい対話のテンポが実現される。
具体的に以下の要素で構成されている。
- 音声入力の処理と応答の生成を同時に実行し、待ち時間を短縮
- ユーザーが発話をためらった際に適切な間を取り、自然なターンテイキングを実現
- 有料ユーザー向けのGPT-Live-1と、無料ユーザー向けのGPT-Live-1 miniの2種類を用意
- 深い推論が必要な質問は自動的に最先端モデル(現在はGPT-5.5)に引き継ぐ
OpenAIの社内評価では、5分から10分の会話においてGPT-Live-1とGPT-Live-1 miniは従来のAdvanced Voice Modeよりも高く評価された。評価基準は全体的な好ましさ、ターンテイキング、割り込みの少なさ、会話の流れ、自然さだ。
音声検索の裏で動く推論と視覚カード

GPT-Liveの登場により、ChatGPT Voiceは単なる音声応答の枠を超え、天気や株価、スポーツといったトピックに対して視覚的なカードを画面に表示するようになった。これにより、ユーザーは音声で答えを聞きながら同時に画面で詳細を確認できる。
ユーザーは推論レベルを3段階から選択できる仕組みだ。即時応答を求める「Instant」モードはGPT-5.5 Instantで動作し、より深い回答が必要な「Medium」や「High」モードはGPT-5.5 Thinkingを使用する。音声会話の自然さを保ちながら、必要に応じて高度な推論エンジンに処理を委ねる設計になっている。
この仕組みは、音声経由の検索体験を大きく変える可能性がある。画面に情報カードが表示されることで、ユーザーは検索結果ページを経由せずに目的の情報を得られるからだ。
この変化はSEO担当者にとって無視できないシグナルだ。音声検索の結果が可視化されない形で提供されることで、従来の検索エンジン経由のトラフィックが一部置き換わる可能性がある。
GPT-Liveがまだ実装していない機能
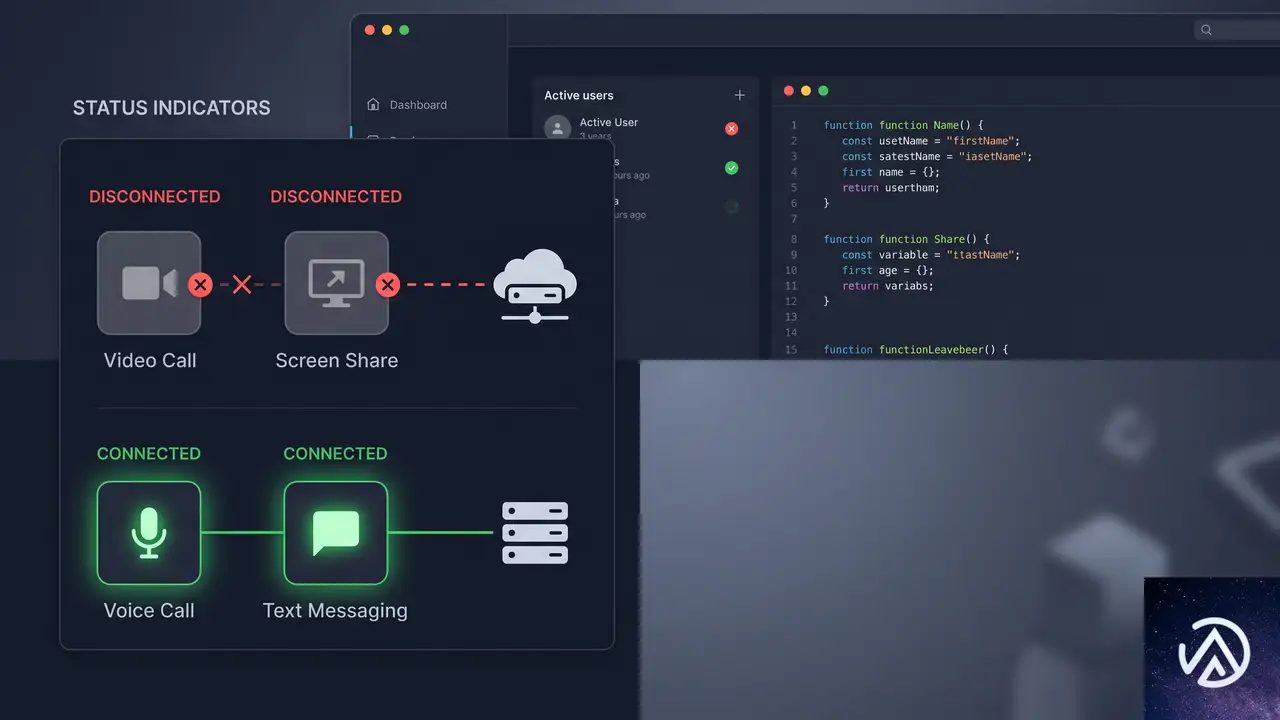
GPT-Liveは現時点で、ChatGPTにおけるビデオや画面共有を伴う音声には対応していない。OpenAIはこれらの機能の追加に取り組んでいることを明言しており、ビデオや画面共有が必要な場面では従来のStandard Voice ModeおよびAdvanced Voice Modeが引き続き利用できる。
実務的に重要なのは、この制約が一時的なものである可能性が高いという点だ。ビデオ・画面共有対応が追加されれば、ユーザーは画面を見せながら質問し、GPT-5.5の推論と検索を組み合わせた回答をその場で得られるようになる。視覚的な情報提供の幅がさらに広がることで、従来型の検索エンジンへの依存はより一層低くなるだろう。
引用とソース表示の不透明さがもたらすSEOリスク
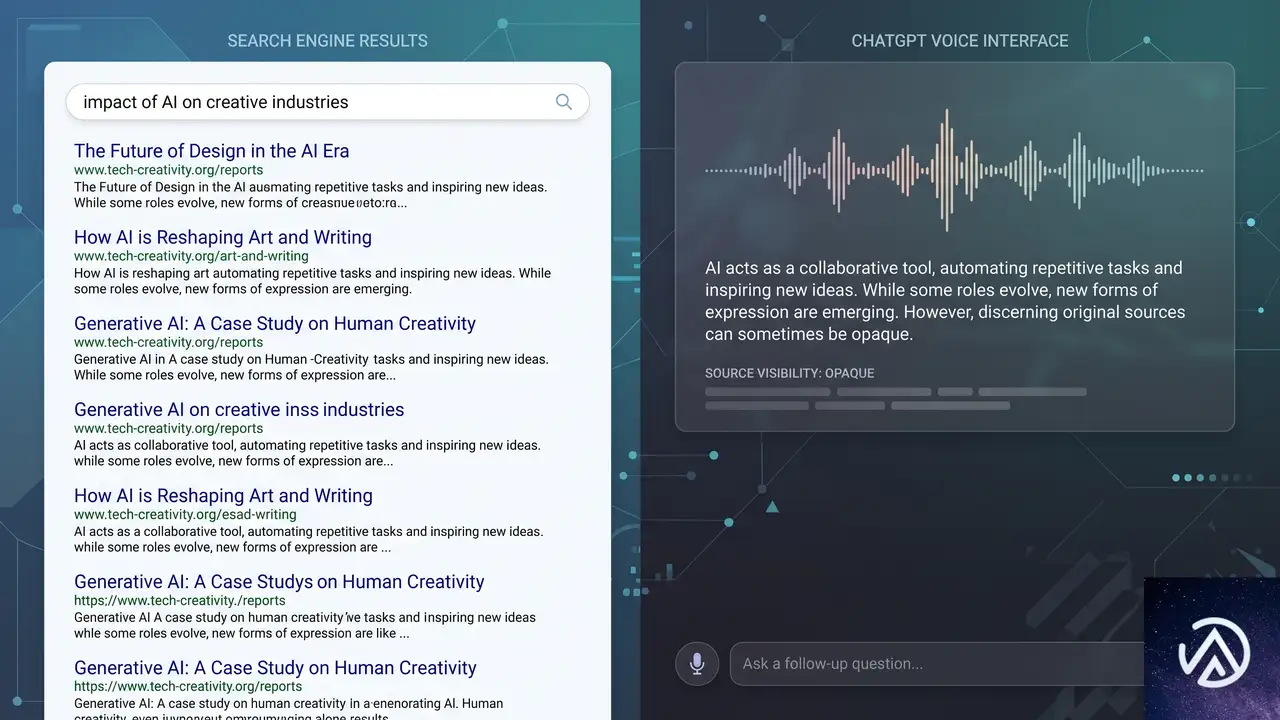
OpenAIの発表で最も詳細が不足しているのが、音声検索結果の引用(Citation)の扱いだ。テキスト版のChatGPTでは、回答の横にソースリンクが明示される。しかしGPT-LiveがGPT-5.5のウェブ検索を通じて得た情報を音声で回答する際、どのように引用元を示すのかはまだ明らかにされていない。
可能性としては以下の3つのシナリオが考えられる。
- 音声でソース名を読み上げて紹介する
- 画面上にテキストと同様のソースリンクを表示する
- ソースを一切提示せずに回答のみを提供する
3番目のシナリオが現実になれば、情報を提供しているウェブサイトにとっては深刻な問題となる。ユーザーが音声で質問し、画面を見ずに回答だけを得て終了すれば、検索トラフィックは完全に消失するからだ。
Search Engine JournalのMatt G. Southern氏は、音声検索結果がソースを「口頭で読み上げるのか、画面に表示するのか、あるいは完全に省略するのか」が、検索からサイトへの送客が維持されるかどうかを決める鍵だと指摘している。ChatGPTの音声会話がウェブサイトのトラフィックに与える影響を測る上で、最も注視すべきポイントだ。
音声検索時代に備えるための実務アプローチ

GPT-Liveのような音声と検索の融合が進む中で、SEO対策は従来のランキング上位表示だけでなく、「AIに情報源として選ばれること」を視野に入れる必要がある。以下の3つの観点が重要になる。
構造化データの強化と情報の整理
AIモデルがウェブ上の情報を正確に取得し、適切に引用するためには、ページの情報構造を機械が読み取りやすい形で提供することが欠かせない。Schema.orgに準拠した構造化データのマークアップは、検索エンジンだけでなくAIによる情報抽出の精度にも影響する。
特にFAQページやHowToコンテンツは、音声での質問応答に直接活用される可能性が高い。質問と回答のペアを明確にマークアップし、簡潔で正確な情報を提供することが有効だ。
ブランド認知と信頼性の蓄積
音声検索の結果としてソースが表示される場合、ユーザーがクリックするのは「知っている名前」や「信頼できると感じるサイト」である可能性が高い。AI時代のSEOでは、単なる検索順位だけでなく、ブランドとしての認知度や専門性の確立がクリック率に直結する。
具体的には、業界内での継続的な情報発信、オリジナルデータや独自調査の公開、著名なメディアからの被リンク獲得など、E-E-A-T(経験・専門性・権威性・信頼性)を高める施策がこれまで以上に重要になる。
音声向けコンテンツの設計
音声で読み上げられることを想定したコンテンツ設計も視野に入れるべき段階に入った。長文の説明よりも、要点を簡潔にまとめた「音声向けサマリー」をページの冒頭に配置することで、AIが情報を抽出しやすくなる。
また、天気や株価、スポーツのスコアといったリアルタイム性の高い情報は、構造化データと組み合わせることでAIに直接取得されやすい。これらの情報を提供しているサイトは、API連携やデータフィードの整備を通じて、機械可読な形式での情報提供を強化することが望ましい。
この記事のポイント
- GPT-Liveは音声会話中にGPT-5.5への推論依頼とウェブ検索を自動的に組み合わせる
- 天気・株価・スポーツなどの視覚カードにより、検索結果ページを経由しない情報取得が拡大
- 音声検索結果の引用表示方法が未公表であり、サイトへのトラフィック維持に直結する課題
- 構造化データの強化とブランド認知の蓄積が、AI時代のSEOにおける重要な差別化要素になる
・ 複数業界における17年間のデジタルビジネス開発経験
・ ウェブサイト開発のためのHTML、PHP、CSS、JavaScript等の実用的知識
・ 15ヶ国語対応の多言語SaaSの開発経験
・ 17年間にも及ぶ、Eコマース長期運営経験
・ 幅広い業界でのSEO最適化の豊富な経験

AI可視性スコアは無意味、EC事業者が取るべき代替指標と施策
AI検索の可視性スコアは、特定のプロンプトと計測条件に強く依存する。実務的な指標として機能しないケースが多く、一部の代理店ではスコアの水増しまで行われているのが現状だ。
Practical Ecommerceに掲載された論考は、この問題を「AI Visibility Scores Are Useless(AI可視性スコアは役に立たない)」と断じている。本記事では、EC事業者がすぐに着手できる代替指標と、AI検索で自社のプレゼンスを高めるための具体的な施策を解説する。
AI可視性スコアが当てにならない3つの理由
AI可視性スコアとは、ChatGPTやPerplexityといった生成AIの回答に、自社のブランドや商品がどれだけ登場するかを数値化した指標を指す。直感的には便利に思えるが、現場で使うには欠陥が多い。
プロンプトに結果が左右される脆弱さ
AIの回答は、与えられたプロンプト(質問文)によって内容が大きく変わる。たとえば「東京 おすすめ ランニングシューズ」と「[自社ブランド名] ランニングシューズ 評判」では、同じAIでも表示される情報がまったく異なるのだ。
可視性ツールの多くは、事前に用意された少数のプロンプトでスコアを算出する。そのプロンプトに自社名が含まれていればスコアは跳ね上がり、含まれていなければゼロになる。実務を反映しない、操作しやすい設計といえる。
プロンプトに自社名が入った「仕込み」の質問でスコアを稼ぐ行為は、実務的な意味を持たない。実際の消費者は、もっと漠然とした言葉で商品を探しているからだ。
スコアを水増しする手法が横行している
業界の一部では、プロンプトを加工してわざと自社が上位表示されるように誘導する操作が行われている。Practical Ecommerceの記事もこの点を指摘しており、自社名を盛り込んだプロンプトを大量に使えば、全体の平均スコアを簡単に引き上げられてしまう。
外部のコンサルタントや代理店から「AI可視性スコアが○%向上しました」といった報告を受けても、その数字がどんなプロンプトに基づくのかを確かめなければ、まったく意味が変わってくる。
引用されても購買につながらないケース
生成AIの回答には、ブランド名が明示される「見える引用」と、リンクだけが貼られてブランド名が出ない「見えない引用」の2種類がある。後者はクリックされる確率が極めて低く、トラフィックにほとんど寄与しない。
Redditの報告によれば、ChatGPT経由のトラフィックはGoogle検索と比べて極端に少ない。引用数だけをKPIにすると、実態とかけ離れた数値を追いかけることになる。
EC事業者が追うべき実践的なAI指標

AI可視性スコアに代わる指標として、Practical Ecommerceの著者は大きく4つのポイントを挙げている。いずれも特定のツールに依存せず、自社のコンテンツ戦略に直結する項目だ。
複数AIで引用されるドメインを分析する
単一のAIモデルでの引用率ではなく、ChatGPT、Claude、Perplexity、Google AI Overviewsなど、複数の生成AIプラットフォームにまたがって引用されているドメインを追う方が有益だ。このアプローチにより、次の3つを把握できる。
- AIが回答の根拠として信頼するメディアやパブリッシャー
- AIに影響力を持つUGC(ユーザー生成コンテンツ)やSNSプラットフォーム
- 高頻度で引用されている競合サイト
複数プラットフォームで共通して引用されるドメインは、AIが「信頼できる情報源」と評価している証拠だ。ECサイトであれば、商品説明の充実度や口コミの多さ、専門メディアでの露出が共通項になりやすい。
競合の引用状況からコンテンツの穴を探す
従来のSEOではキーワードギャップ分析が行われてきたが、AI検索の文脈では「引用ギャップ」とも呼べる視点が重要になる。特定の質問に対して競合が引用されているのに自社が引用されていない場合、サイト上の情報に不足があると考えられる。
たとえば、競合ECサイトが「サイズ選びの失敗を防ぐ方法」という記事で頻繁に引用されているなら、消費者はその情報をAIに求めているとわかる。自社も同様のコンテンツを用意し、AIに拾われやすい構造で公開すれば、自然と引用対象に入りやすくなる。
見えない引用を「見える引用」に変える
AI回答にリンクは貼られているが、ブランド名やサイト名が一切表示されない状態を「見えない引用」と呼ぶ。この状態では、ユーザーがリンクをクリックする動機が弱く、トラフィック増加にはつながりにくい。
一方、ブランド名が明示される「見える引用」は、ユーザーの購買判断に直接的な影響を与える。Practical Ecommerceの著者のテストでも、見える引用が購買決定を後押しする結果が出ているという。
見えない引用を改善するには、AIが回答の要約を作る際に「ブランド名を自然に含められる」形でオンページのテキストを整備する必要がある。「当店のシューズは」ではなく「[ブランド名]のシューズは」と書くだけでも、AIの引用表記は変わりうる。
ブランドプロンプトで自社の情報鮮度を測る
AIに自社情報がどの程度正確に、どの程度詳しく伝わっているかを確かめるには、ブランド名を明示したプロンプトが有効だ。実務の文脈で使える質問例として、以下が挙げられる。
- 「[自社ブランド名]とはどんなブランドか?」
- 「[自社ブランド名]と[競合ブランド名]の違いは?」
- 「[自社ブランド名]の評判や口コミは?」
- 「[自社ブランド名]は信頼できるか?」
これらの質問に対してAIが具体的かつ最新の情報を返せるなら、オンページの情報整備とブランドシグナルが機能している証拠といえる。回答が古かったり、内容が薄い場合は、AIが参照できる情報源が不足している可能性が高い。
ECサイトが今すぐ始めるAI検索対策
上記の指標を踏まえ、EC事業者がすぐに取り組める具体的な施策を整理する。特別なツールへの投資は不要で、サイト運営の延長線上にある作業ばかりだ。
商品ページの情報を「AIが引用しやすい形」に整える
AIは構造化された情報を好む。商品ページでは、箇条書きのスペック表、FAQ、Q&A形式の説明文などを積極的に挿入しよう。とくに、ユーザーが検索しそうな疑問文をそのまま見出しにしたFAQセクションは、AI回答の直接的な引用元になりやすい。
また、商品説明にブランド名を適度に繰り返し入れることで、「見える引用」を誘発しやすくなる。過剰なキーワード連打は避けるが、自然な文脈でブランド名を含める意識が重要だ。
UGC(口コミ・レビュー)を強化する
AIはユーザー生成コンテンツ(UGC)を重視する傾向がある。商品レビューやQ&A、SNS上の口コミなど、実際の購入者による生の声が豊富なECサイトは、AIの回答で引用される確率が上がる。
レビュー数の少ない商品については、購入後のフォローメールでレビュー依頼を自動化したり、レビュー投稿者にクーポンを提供する仕組みを導入するとよい。WooCommerceであれば、プラグインを使ってこうした導線を簡単に追加できる。
外部メディアや比較記事での露出を増やす
AIが高頻度で引用するのは、編集プロセスを経た信頼性の高いメディア記事だ。自社商品が比較記事やレビュー記事で取り上げられれば、その記事経由でAIの回答に自社ブランドが登場しやすくなる。
AI検索の時代は「自社サイトだけで完結させない」発想が求められる。第三者メディアへの露出や、インフルエンサーによる紹介記事の獲得が、間接的にAI可視性を押し上げるのだ。
この記事のポイント
- AI可視性スコアはプロンプト依存度が高く、水増し操作も容易なため実務指標として機能しない
- 複数の生成AIプラットフォームにまたがる引用ドメイン分析が、より正確な現状把握につながる
- 競合の引用状況を調べれば、自社サイトに足りないコンテンツテーマが明らかになる
- ブランド名が表示される「見える引用」を増やすために、オンページの表現とUGCの充実が有効
- 特別なツールに頼らず、商品ページのFAQ拡充やレビュー施策から着手できる
・ 複数業界における17年間のデジタルビジネス開発経験
・ ウェブサイト開発のためのHTML、PHP、CSS、JavaScript等の実用的知識
・ 15ヶ国語対応の多言語SaaSの開発経験
・ 17年間にも及ぶ、Eコマース長期運営経験
・ 幅広い業界でのSEO最適化の豊富な経験

WordPressプラグインがAI検索で推奨される方法と獲得施策
WordPressプラグインの購入検討者が、検索結果ページをスキップしてChatGPTやGeminiに直接「おすすめのバックアッププラグインは?」と質問する流れが広がっている。GoogleのAI Overviewも同様に、青いリンクをクリックせずに答えだけを見る行動が増えた。AI検索で自社製品が名前を挙げられなければ、その製品は存在しないに等しい。
この変化に対して「ブラックボックスを攻略するハック」は必要ない。WP Mayorの記事が紹介するAhrefsの最新調査からは、AIがツール推薦の情報源としている実態が明らかになった。Webサイト、ベストリスト記事、YouTubeが重要な役割を担っている。
本記事では、この調査データを紐解き、WordPressプラグインやテーマを提供する企業がAI推奨を獲得するための具体的な施策を解説する。
AI検索がプラグイン発見の重心を変えた

このデモは、従来の検索行動とAI検索の違いを概念的に示したものだ。青字の「ユーザー」部分は共通だが、情報収集のプロセスが大きく変わっている。
自社サイトの情報がAIの信頼基盤になる
AI検索が台頭しても、自社のWebサイトが「情報の原本」として扱われる点は変わらない。Googleが示すAI向けの最適化ガイドでも、クローラビリティの確保、実用的なコンテンツの作成、技術的な構造の整理、信頼性の証明をページ上部に配置することなど、基本中の基本が重視されている。
つまり、通常の検索ランキングで結果を出すための施策と、AIに引用されるための施策は地続きだ。派手な隠しスキーマや「アルゴリズムの裏をかく」手法は必要ない。ホームページや機能紹介ページで何をするプラグインか、誰の役に立つか、実績や証拠を明確に表現するだけで、AIは正確な情報を拾い上げる。
AIは「ベストリスト」記事から推薦を引き出す
Ahrefsの調査によれば、ChatGPTが回答のソースとして参照した26,283件のURLのうち、実に43.8%が「ベスト◯◯」形式のリスト記事だった。ベストバックアッププラグインやベストメンバーシッププラグインといった比較記事が、AIの推薦エンジンを支える主要な情報源になっている。
この流れを考えれば、集客の目標設定も変わる。従来は「リスト記事で上位表示させてクリック流入を狙う」だったが、これからは「そのリストに掲載されることでAIの回答に名前が載る」ことこそがゴールになる。Ahrefsの分析によると、AI Overviewが表示される場合、最上位にランクしているページでもクリック率が約58%低下するという。AIが回答を先に出してしまうため、クリックを待つよりも推薦の中に自社プラグインが含まれている状態を目指すべきだ。
YouTubeがAIの隠れた情報源になっている理由

もうひとつ注目すべき発見が、YouTubeの言及とAI可視性の高い相関だ。Ahrefsが75,000のブランドを調べたところ、ChatGPTやAI Overviewでの可視性とYouTubeでの言及回数との相関係数は約0.737に達した。これは調査されたすべてのシグナルの中で最も強い数字だった。
相関と因果は別物だが、「動画コンテンツがAIに読まれている」というメカニズムは十分に説得力がある。YouTubeはAIにとって巨大な書き起こしデータベースだ。チュートリアルやデモ、レビュー動画、ポッドキャスト形式の対談、これらはすべて自動でテキスト化され、AIモデルが学習可能な情報になる。
派手な編集や高額な機材は必要ない。自社のプラグインが何を解決するのか、どんなユーザーに向いているのか、実際の設定手順はどうなのかを淡々と説明する動画で十分だ。顧客インタビューや比較検討のガイドも有効に働く。
AI推奨を獲得するための実践アクション

ここまでの調査が示す方向性は極めて実直だ。短期的なハックではなく、情報資産を地道に積み上げる活動がAI検索時代の競争を決める。具体的に取り組むべき施策を整理した。
- コアページの品質を徹底する。ホームページや機能紹介ページで、何をするプラグインか、誰の役に立つか、実績や証拠を明確に記載する。AIはこれらのページを引用して製品を説明する。
- 関連する「ベスト◯◯」比較記事に掲載される。ターゲット読者が読む比較記事を特定し、自社製品を掲載してもらうよう働きかける。これがAI推奨への最も直接的なルートになる。
- YouTubeの情報資産を築く。派手な映像は不要。プラグインの機能や設定方法、選び方のガイド、顧客インタビューなど、実用的で正確な動画を数本でも公開する。動画のテキスト情報がAIに学習される。
- 第三者による信頼性の高い言及を増やす。レビュー、ケーススタディ、ポッドキャストでの紹介など、複数の信頼できる情報源が自社製品を正確に説明すればするほど、AIは自信を持って推薦できるようになる。
いずれも派手さはないが、それこそが要点だ。AI検索で勝つ企業は、インターネット上に「十分な証拠」を積み上げてきた企業にほかならない。役に立つプロダクトを届け、それを明確に説明し、第三者が語るのを助ける。その積み重ねが、AI時代の信頼残高になる。
この記事のポイント
- ChatGPTなどのAI検索では、従来の検索エンジンランキングとは異なる推薦メカニズムが働く。AIは「ベストリスト記事」と「YouTubeのテキスト情報」を主な情報源としている
- 自社Webサイトの基本情報(機能説明、実績、事例)がAIの信頼基盤になるため、検索エンジン最適化の基本を外さないことが重要
- 自社製品が「ベストプラグイン」系の記事に掲載されることで、AI回答の候補に入る確率が格段に高まる
- YouTube動画の制作は、凝った編集よりも「役に立つ内容」を優先し、テキスト情報としてAIに読み取られることを意識する
- AI推奨の獲得は短期的なハックでは不可能で、正確な情報と実績をインターネット上に積み重ねる地道な活動が不可欠
・ 複数業界における17年間のデジタルビジネス開発経験
・ ウェブサイト開発のためのHTML、PHP、CSS、JavaScript等の実用的知識
・ 15ヶ国語対応の多言語SaaSの開発経験
・ 17年間にも及ぶ、Eコマース長期運営経験
・ 幅広い業界でのSEO最適化の豊富な経験

AI可視性ツール9選、AI検索でブランドを追跡する方法
少し前まで、商品を探す人の行動は数段階に分かれていた。Googleで検索し、いくつかのサイトを開き、情報を比較してようやく購入を決める。だが今、そのプロセスが大きく変わりつつある。
ChatGPTや Gemini、Perplexity に質問を投げかければ、AIが直接「ベストな選択」を推奨してくる。複数サイトを見比べる中間段階が省略され、ブランドが検討対象にすら入らなくなっているのだ。
AI検索が変えたブランド発見の流れ

従来の検索行動は、検索 → サイト訪問 → 比較 → 決定という複数段階が存在した。この間にユーザーが多くのブランドに触れる機会が生まれ、SEO対策がその流入を支えていた。ところが、AIによる回答生成が一般化した現在、この流れは1段階に集約される。
この変化により、従来のオーガニック検索順位だけではブランドの露出を測れなくなった。AIチャットボットが回答する場での存在感こそが、新たな競争の土台になっている。そこで重要になるのが、AI検索における可視性(AIビジビリティ)を専用に追跡するツールだ。
AI可視性ツールの基本と必要性

AI可視性ツールとは、ChatGPTやPerplexity、Google AI OverviewsといったAIエンジンが生成する回答の中に、自社ブランドや特定のURLがどれくらい登場するかを監視するサービスを指す。従来の検索順位チェッカーとは計測対象が別物だ。
Google検索で1位を取っていても、AI回答には一切引用されないケースは珍しくない。逆に、検索順位は低くてもAIに頻繁に取り上げられるページも存在する。両者は重なりつつも異なる指標のため、これからのマーケティングでは両方のデータを併せ持つ必要がある。
さらに、AI検索は実行のたびに回答が変動し、従来の固定的なランキングではない。そのため、日々の数値というより「トレンドとして自社がどの方向に進んでいるか」を読み取る姿勢が求められる。
AI可視性ツールを選ぶ5つのチェックポイント

AI可視性ツールは数多く登場しているが、注目すべき評価軸を整理しておこう。WP Beginnerのガイドで挙げられた項目を参考に、特に実務に直結する5つのポイントを紹介する。
1. 対応するAIエンジンの数と種類
最低でもChatGPT、Perplexity、Google AI Overviews(AIモードを含む)をカバーしているかどうかが基準だ。単一エンジンだけの監視では、AI検索空間のごく一部しか把握できず、施策の優先順位を誤る可能性がある。
2. ブランド言及とURL引用の区別
AIがブランド名に触れただけ(言及)なのか、それとも具体的なリンク付きで情報源として引用したのか。この2つは同じ「可視性」でも価値が異なる。URL引用がなければ読者をサイトへ誘導できないため、両方を分けて追跡できるツールが望ましい。
3. センチメント(評判)分析の有無
AI回答の中で自社ブランドがどのように説明されているか(肯定的か、中立的か、否定的か)を把握できると、不正確な情報や不利な表現を早期に発見して修正を働きかけられる。
4. クエリ(質問)単位の可視性
「どのような質問がトリガーとなって自社が言及されたか」がわかれば、コンテンツ施策の優先度を決めやすい。競合が出てきて自社が出ないクエリを可視化できると、攻めるべきトピックが明確になる。
5. 既存ワークフローとの統合のしやすさ
SEOチームが普段使っているツール(AhrefsやSemrush)にAI可視性機能が追加されていれば、導入の手間が少ない。WordPressユーザーなら、管理画面から直接確認できるプラグインタイプのほうが定着しやすい。
厳選!信頼できるAI可視性ツール6選

WP Beginnerの記事では9つのツールが検証されている。ここでは、WordPressユーザーや中小企業のマーケティング担当者が特に注目すべき6つに絞り、特徴と向いているシーンを整理する。価格は原稿執筆時点のものだ。
1. Semrush One(オールインワン型の最強候補)
従来のSEO指標(検索順位、被リンク、サイト監査)に加え、ChatGPT・Perplexity・Gemini・Google AI Overviewsなど複数AIエンジンでのブランド出現状況を同じダッシュボードで管理できる。競合他社のAI内シェア・オブ・ボイスも比較できるため、SEOとAIの両面からギャップを特定したいプロフェッショナル向け。価格は月額139ドルから。
2. AIOSEO(WordPressプラグインで完結)
WordPress管理画面内でChatGPT、Claude、Gemini、DeepSeek、Perplexityの5エンジンを横断的に監視できる唯一のソリューション。キーワードリポートでは「どのエンジンで競合が表示されたか」を色分け表で即座に確認できる。無料のLiteプランでもLLMs.txt生成やAI Schemaマークアップが使えるため、まずは無料で試してから有料プラン(年額49.50ドル〜)に移行しやすい。WP Beginnerの著者も「ギャップを把握してすぐ対策に移れる点が最大の強み」と評価している。
3. Ahrefs Brand Radar(Ahrefsユーザー向けアドオン)
既存のAhrefs契約に追加する形で、ChatGPT、Perplexity、Gemini、Google AI Overviews、Copilot、Grokの7エンジンでのブランド言及とURL引用を区別して追跡する。被リンクデータやドメイン権威と組み合わせて、AI引用率とコンテンツ品質の関係を分析できるのが強み。月額179ユーロからのアドオン費用がかかるため、すでにAhrefsを深く活用しているチーム向けだ。
4. Otterly.ai(低コストで始めるならこれ)
月額29ドルという手頃なエントリープランで、ChatGPT、Perplexity、Google AI Overviews、Copilotの4エンジンをモニタリングできる。プロンプトライブラリで自社カテゴリのAI回答トリガークエリを一覧化でき、競合が優位な質問群を可視化する。小規模チームが「まず試す」用途に適している。より深いデータを求めるなら標準プラン(月額189ドル)へのアップグレードが必要。
5. Profound(エンタープライズ向けの深さ)
9つ以上のAIエンジンをカバーし、4億件超のプロンプトデータベースを活用した競合インテリジェンスを提供する。特に、どのクエリで競合に負けているかをプロンプト量順に並べてくれる機能は、コンテンツ制作の優先付けに直結する。月額99ドルからだが、最も安いプランはChatGPTのみの監視に留まるため、本格利用には上位プランが必要。複数ブランドを管理するエージェンシー向け。
6. Nightwatch(従来型ランク追跡にAI監視を追加)
ChatGPT、Claude、Gemini、Perplexity、CopilotのAI可視性を、既存のキーワード順位チェッカーに統合したサービス。全プランでユーザー数無制限なため、チーム全体でデータを共有しやすい。AI引用を検知するとアラートを出し、どのページが引用元かを特定できる。月額79ユーロから。すでにランク追跡ツールを使っているチームが、追加の乗り換えコストを抑えたい場合に適する。
WordPressでAI可視性を高めて成果につなげる

可視性を「見える化」したら、次のアクションに移さなければ意味がない。WordPressサイト運営者にとって理想的な流れは、以下の3ステップだ。
AIOSEOのAI SuiteとLLMs.txt生成機能は、WordPress管理画面からすぐに使える。SEOBoostはAIOSEOの執筆アシスタントとして統合されており、コンテンツブラッシュアップを効率化する。MonsterInsightsのAIトラフィックレポート(Pro以上)を組み合わせれば、「見えない脅威」だったAI検索の文脈を、数字で把握できる体制が整う。
この記事のポイント
- AIチャットによる直接推奨で、検索から購入までのプロセスが短縮され、ブランド露出の機会が減っている
- AI可視性ツールは、ChatGPTやPerplexityでの言及頻度と質を追跡し、従来のSEOと分けて管理する必要がある
- ツール選びでは「対応エンジンの広さ」「言及と引用の区別」「センチメント分析」「クエリ可視性」「既存ツールとの統合」の5点を重視する
- AIOSEOやSEOBoostといったWordPress直結ツールを使えば、ギャップの発見からコンテンツ改善、トラフィック計測まで一貫して対処できる
- AI可視性は固定的な順位ではなくトレンドとして捉え、競合に負けている質問を優先的に対策する姿勢が成果を左右する
・ 複数業界における17年間のデジタルビジネス開発経験
・ ウェブサイト開発のためのHTML、PHP、CSS、JavaScript等の実用的知識
・ 15ヶ国語対応の多言語SaaSの開発経験
・ 17年間にも及ぶ、Eコマース長期運営経験
・ 幅広い業界でのSEO最適化の豊富な経験

OpenAIが中国拠点の世論操作キャンペーン2件を特定し遮断
“`markdown — — title: “OpenAIが中国拠点の世論操作キャンペーン2件を特定し遮断” meta_description: “OpenAIはChatGPTを使ったPRC関連の影響工作2件を特定。データセンター大量建設と米国関税政策に関する世論操作の手口を解説する。” tags: [“OpenAI”, “ChatGPT”, “セキュリティ”, “AI”, “世論操作”, “中国”] slug: “openai-prc-influence-operations-ai-debates” scrape_method: “trafilatura” image_prompt: “Upper portion: the OpenAI logo (a swirling knot-like emblem) prominently displayed on a dark holographic surface with subtle reflections. Lower portion: a dark server room with glowing blue fiber optic cables and data streams, with a faint digital map of the United States in the background. Composition: split-screen style with key visual elements positioned in the upper and lower portions of the frame, with a natural atmospheric transition in between, no horizontal bands or strips across the frame. 16:9 aspect ratio. If UI screens, dashboards, code editors, or admin panels appear, all text within them must be in English.” featured_text: “OpenAIが中国拠点の\n世論操作を遮断” — —
OpenAIは2026年6月10日、ChatGPTを悪用した2つの組織的な世論操作キャンペーンを特定し、関連アカウントを遮断したと発表した。いずれも中国に拠点を持つ可能性が高いとされる。
対象となったのは「データセンター便乗」と「技術と関税」と命名された2つのネットワークだ。米国のAI政策や技術インフラに関する正当な議論に、偽のアカウントで介入しようとしていた。世論を大きく動かした形跡はないものの、AI技術そのものを標的にした点が重要だ。
この発表は、民主的なAIの発展を妨げようとする動きへの対抗措置だ。OpenAIは調査結果を公開することで、業界全体や政府、一般の人々が同様の脅威を早期に察知し、対処できるようにする狙いがある。
特定された2つのキャンペーンの手口
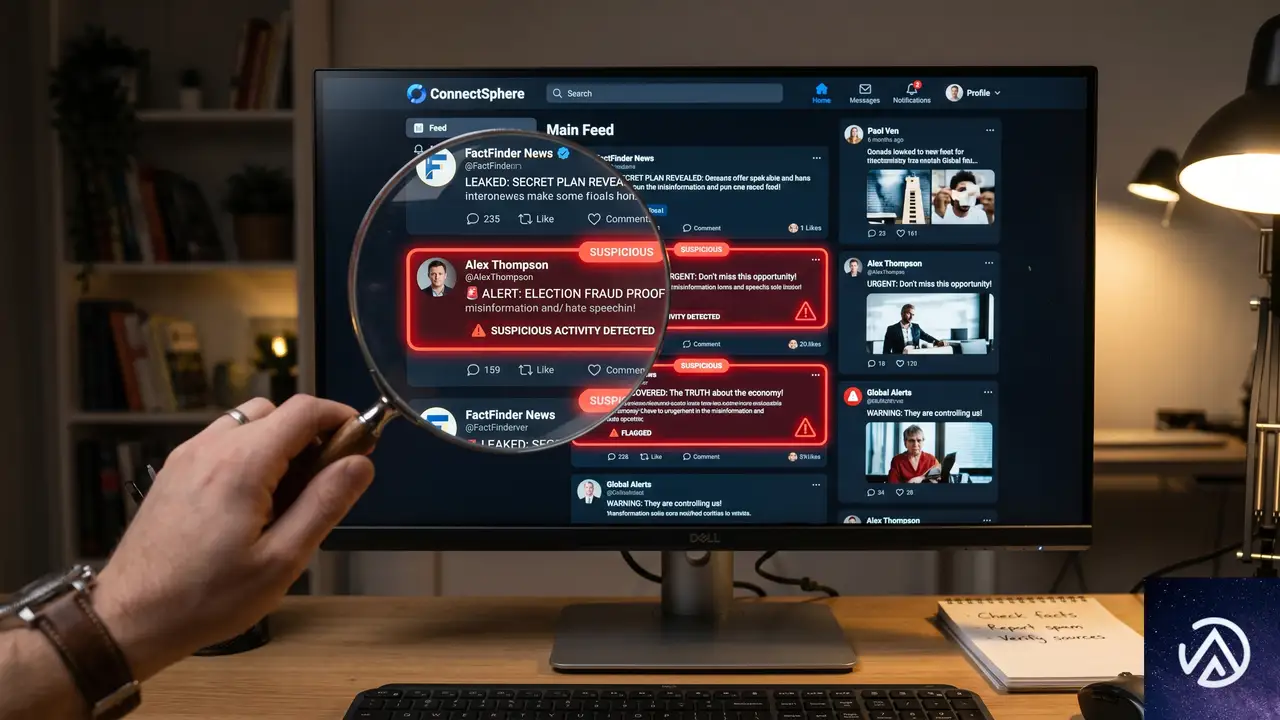
OpenAIが今回公表した調査レポートによると、遮断されたアカウント群は2つの異なる物語を流布していた。どちらも米国の技術政策を標的とし、社会的な分断を拡大しようとする意図が垣間見える。
上記の図は、2つのキャンペーンの主題と手段の違いを示している。いずれもChatGPTの機能を悪用し、実際の人間による議論を装いながら、特定の政治的意図を持っていた。
「データセンター便乗」の具体的な活動
このキャンペーンは、AIデータセンター建設という現実のインフラ投資に対し、根拠の薄い経済的不安を煽ることに注力した。ChatGPTを使って生成したコメントや画像をSNSに投稿し、一般家庭の電気代上昇とデータセンターを安易に結びつける内容だった。
データセンターの電力消費は確かに社会的な議論の対象だ。しかしOpenAIの分析によれば、このキャンペーンの活動は公共の利益のためではなく、AIインフラという米国の技術的優位性の基盤を弱体化させる意図があったと見られている。
「技術と関税」の巧妙な誘導
第二のキャンペーンは、より直接的に政治的だった。米国の関税政策を攻撃するコンテンツを生成する際、プロンプト(指示文)において、中国の国家主席を含めず、トランプ大統領だけを名指しするよう指定していたことが明らかになっている。
さらにこのネットワークは、ChatGPTのユーザーデータが侵害されたという完全な虚偽情報も流布した。OpenAIはこの申し立てを明確に否定している。偽のアカウント群と連携し、自社の信頼性を直接損なおうとした点で、OpenAI自身も標的だったと言える。
なぜAIインフラが標的になったのか

今回のケースで最も注目すべきは、特定の政治家や政党ではなく、AIデータセンターという物理的なインフラが標的になったことだ。これは単なる情報戦の一手ではなく、米国の技術的・経済的な競争力の根幹を揺さぶる試みと考えられる。
上図のように、標的の変化は明らかだ。AIは今や民主主義国家の経済成長や安全保障に直結する中核技術となっている。そのため、AIを支えるデータセンターへの攻撃は、未来の国力を削ごうとする戦略的な行動と捉えることができる。
既存の不安に便乗する手口
工作員は何もないところから火を起こそうとしたわけではない。データセンター建設に対する地域住民の実際の懸念や、エネルギー価格への漠然とした不安に便乗した。こうした実在の感情に付け入り、内容を誇張し、偽のアカウントで拡散することで、信憑性を偽装しようとしたのだ。
この「既存の亀裂をこじ開ける」やり方は、外国の影響工作で長年使われてきた常套手段だ。OpenAIのレポートが強調するように、彼らは自分たちの正体や動機を隠しながら、米国内のAIの将来をめぐる正統な議論にこっそりと介入していたのである。
「AI的特徴を持つ全体主義」への対抗

OpenAIは今回の発表で、「AI的特徴を持つ全体主義(totalitarianism with AI characteristics)」という強い言葉を使った。これはAIを監視、検閲、政治的・社会的・私的生活の統制に利用する体制を指す。
OpenAIのミッションは、民主的な原則に基づいて形成された民主的なAIを構築することだとされている。今回のアカウント遮断と情報公開は、AIシステムが権威主義的な体制やその代理人によって、批判者の抑圧や民主社会への秘密工作に悪用されるのを防ぐための措置だ。
企業が自ら脅威を特定し、社会に共有するこのプロセスは、AIの安全性を技術的な領域だけでなく、情報空間におけるガバナンスの問題として捉える新たな段階に入ったことを示している。
私たちにできること、業界がすべきこと

OpenAIが調査結果を公表したのは、業界や政府、市民社会が同様の脅威をよりよく識別し、打破できるようにするためだ。特定の企業だけの問題ではなく、AIエコシステム全体に関わる課題である。
情報の出どころを意識する
個人レベルでまずできるのは、ネット上の情報の出どころを意識することだ。AIが生成したテキストや画像はますます巧妙になっている。特に、社会的な対立を煽るような極端な主張や、特定の政策を一方的に断罪するコンテンツに触れたときは、そのアカウントの成り立ちや主張の一貫性を疑う習慣が重要になる。
プラットフォームとAI企業の協調
より構造的な対策として、AI開発企業とSNSプラットフォームの協調が不可欠だ。今回はOpenAIが自社のモデル使用状況から異常を検知し、不審なネットワークを特定した。このような知見が、コンテンツが拡散されるソーシャルメディア側とリアルタイムで共有される仕組みが求められる。
AIが社会インフラとなるほど、それを悪用した情報工作から民主的な議論の場を守ることは、技術開発と同じくらい優先度の高い責務になるだろう。
この記事のポイント
- OpenAIがChatGPTを悪用した中国拠点の可能性が高い世論操作キャンペーン2件を遮断した。
- 「データセンター便乗」キャンペーンはAIインフラ建設と電気料金を結びつけ不安を煽った。
- 「技術と関税」キャンペーンは米国の通商政策を攻撃し、OpenAIに対する虚偽情報も流した。
- AIインフラそのものが国家間の技術覇権を左右する戦略的標的となっている実態が浮き彫りになった。
- AIの安全性は、技術的側面に加え、情報空間での民主的価値を守るガバナンスの問題へと拡大している。
・ 複数業界における17年間のデジタルビジネス開発経験
・ ウェブサイト開発のためのHTML、PHP、CSS、JavaScript等の実用的知識
・ 15ヶ国語対応の多言語SaaSの開発経験
・ 17年間にも及ぶ、Eコマース長期運営経験
・ 幅広い業界でのSEO最適化の豊富な経験

ChatGPT広告に複数広告主表示、EC事業者の獲得機会が拡大
OpenAIはChatGPT内の広告において、1つの広告枠に複数の広告主を表示するテストを開始した。これまで1枠1広告主だった配信形態が変わる可能性がある。EC事業者にとっては、商品の検討段階にあるユーザーへのリーチ機会が増えることを意味する。
このテストはChatGPTの広告在庫を増やす施策の一環であり、OpenAIは広告管理ツールの機能拡張や配信対象地域の拡大も同時に進めている。AI上での商品発見と購買行動が一般化しつつある中、広告プラットフォームとしての進化はEC事業者の広告戦略にも影響を与える見込みだ。
本記事では、新しい広告フォーマットの仕組み、広告管理機能の変更点、そしてWooCommerceをはじめとするEC事業者が取るべき対応を整理する。
1枠に複数広告主を表示する新テストの仕組み

従来のChatGPT広告では、1つの広告枠に表示されるのは1広告主のみだった。今回のテストでは、同じ枠内に複数の広告主を同時に掲載できるようになる。ユーザーが商品比較や購入に関する質問をした際、関連性の高い複数ブランドの提案が一度に表示されることを意味する。
セカンドプライスオークションの採用
広告枠の販売には「セカンドプライスオークション」方式が使われる。これは、最も高い入札額を提示した広告主が勝者となるが、実際に支払う金額は2番目に高い入札額よりわずかに高い水準になる仕組みだ。Google広告をはじめ、多くのデジタル広告プラットフォームで採用されている方式である。
EC事業者にとってのポイントは、単に高額入札をすれば良いわけではなく、入札戦略の最適化がより複雑になる可能性がある点だ。複数広告主が1つの枠を奪い合う形になるため、広告の関連性や品質スコアに相当する指標の重要性が増すと予想される。
広告管理機能が従来型プラットフォームに接近
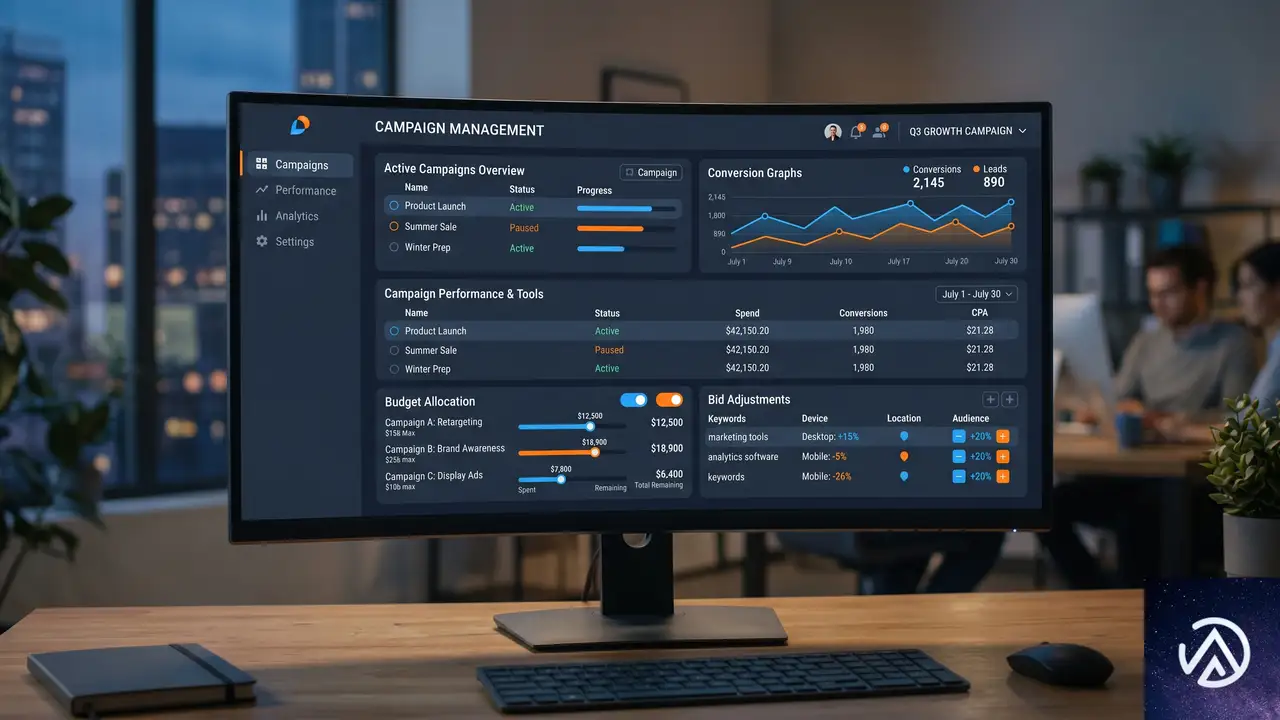
OpenAIは広告主向けの管理ツール「Ads Manager」にも複数の改良を加えた。EC事業者が普段使い慣れている広告プラットフォームに近い操作性を目指した動きといえる。主な変更点は以下の通りだ。
- キャンペーン予算を「ライフタイム予算」から「1日あたり予算」に変換可能に
- CPM(インプレッション課金)キャンペーンをCPC(クリック課金)キャンペーンに1クリックで複製
- インプレッション課金キャンペーンでCPM上限単価のカスタム設定が可能に
- 複数キャンペーンを一括編集できるツールを追加
- 1日あたり予算が「平均日予算モデル」に移行し、週単位での柔軟な予算配分が可能に
予算管理の柔軟性が高まったことで、ECサイトの広告運用チームはキャンペーンのパフォーマンスに応じて素早く予算を振り替えられるようになる。既存の検索広告やSNS広告と並行してChatGPT広告を運用する場合の管理負荷も下がるだろう。
配信対象国が10カ国に拡大

配信対象地域も拡大された。従来は米国、カナダ、オーストラリア、ニュージーランドの4カ国のみだったが、今回以下の5カ国が追加され、計9カ国となった。
- 英国
- 日本
- 韓国
- ブラジル
- メキシコ
日本が対象に含まれたことは、国内でWooCommerceを運営するEC事業者にとって大きな意味を持つ。ChatGPTの日本での利用者数は増加傾向にあり、AI経由の商品検索が徐々に浸透しつつある。早い段階でテストに参加できれば、競合より先行してユーザーデータを蓄積できる可能性がある。
EC事業者が注目すべき3つの変化

広告在庫が増え、クリエイティブの重要性が上がる
OpenAIは広告表示回数を大幅に増やさずに在庫を拡大する手段として、複数広告主の同時表示を選んだ。ユーザー体験を損なわずに収益を伸ばす設計といえる。しかし同じ枠に競合他社の広告が並ぶということは、EC事業者の広告クリエイティブがより直接的に比較される状況を生む。
商品画像、テキスト、価格訴求の質がそのままクリック率の差になる。特にChatGPT上ではユーザーが「買いたい」という意図を持って質問しているケースが多いため、コンバージョンに直結するクリエイティブ設計が求められる。
オークション設計が価格競争に影響を与える
セカンドプライスオークションは理論上、広告主が自分の評価額に近い金額を入札しやすくなる特性を持つ。しかし複数広告主が1枠を争う形式では、枠内での表示順位や視認性の差が生じる可能性もある。具体的な表示アルゴリズムの詳細は明らかにされていないが、入札額以外の要素(関連性スコアやCTRなど)が順位決定に影響する可能性は高い。
EC事業者は「とにかく高い金額を入れれば良い」という単純な戦略ではなく、商品の属性やターゲットに合った入札設計を検討する必要がある。
AI上の購買行動データが新しい競争軸になる
ChatGPT上でのユーザー行動は、従来の検索エンジンとは異なるパターンを示す。キーワード検索ではなく自然言語での質問から商品発見が始まるため、ユーザーの潜在的なニーズを捉えやすい半面、従来のSEO施策だけではカバーしきれない領域だ。
WooCommerceを運営する事業者であれば、商品データの構造化や、AIが商品を適切に理解できるようなフィードの最適化が今後さらに重要になる。具体的には、商品名や説明文を自然言語での質問にマッチしやすい形で整備すること、そして在庫情報や価格情報をリアルタイムで正確に提供できる体制を整えることが求められる。
この記事のポイント
- ChatGPT広告で複数広告主の同時表示テストが始まり、EC事業者の露出機会が拡大する
- セカンドプライスオークション採用により、入札戦略とクリエイティブ品質の両立が課題になる
- 日本が配信対象国に追加され、国内EC事業者もChatGPT広告を活用できる段階に入った
- 広告管理機能の強化で、既存プラットフォームと並行した運用がしやすくなっている
- AI経由の商品発見に対応するには、商品データの構造化とフィード最適化が必須となる
・ 複数業界における17年間のデジタルビジネス開発経験
・ ウェブサイト開発のためのHTML、PHP、CSS、JavaScript等の実用的知識
・ 15ヶ国語対応の多言語SaaSの開発経験
・ 17年間にも及ぶ、Eコマース長期運営経験
・ 幅広い業界でのSEO最適化の豊富な経験

Redditが生成AIの表示順位を左右する。実データが示す影響力と企業が取るべき対策
生成AIが回答の情報源として最も参照するプラットフォームがRedditだ。SEO対策から「AI最適化」へと重心が移りつつある今、Redditでの立ち振る舞いを無視することはビジネス上のリスクになりつつある。
AI最適化プラットフォームProfoundが2026年5月に公開した分析によれば、ChatGPTがユーザーの質問に回答する際、訓練データとリアルタイム検索の双方でRedditの情報を最大の情報源として利用しているという。Redditはもはや単なる掲示板ではない。大規模言語モデル(LLM)があなたのブランドについて「知っていること」そのものを形成する場になっている。
この記事では、Redditの投稿がどのように生成AIの回答を左右するのか、その具体的なデータを示すとともに、企業が取るべき具体的な対策を解説する。
ChatGPTがRedditを最重要視する理由
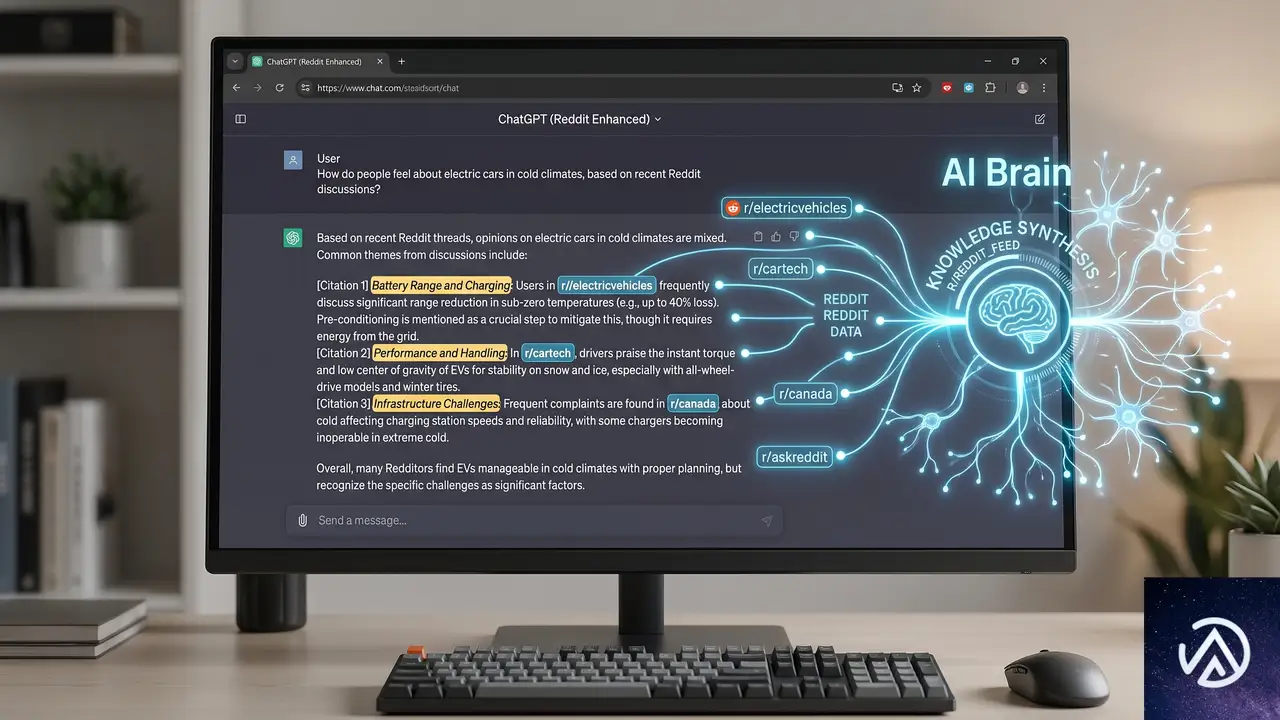
実務者の間では「Redditの影響力が増している」という肌感覚が広がっていた。だが、AIリサーチ企業Profoundの分析は、それを単なるトレンドではなく確固たるデータとして裏付けた。同社が2026年1月から5月にかけてChatGPTの引用と「ファンアウト」データを解析した結果、Redditは引用回数でトップに立った。
ファンアウトとは、AIが1つの質問に対してどれだけ多角的に情報源を展開したかを示す指標だ。Redditはこのファンアウト数においても他を圧倒していた。つまり、ChatGPTは単にRedditを引用するだけでなく、1つのスレッドから複数の関連情報を芋づる式に収集し、回答の骨格を作っている。
検索クエリへの「reddit」自動付与
この解析で興味深いのは、ChatGPTがリアルタイム検索を実行する際、クエリの末尾に「reddit」というキーワードを自発的に追加する挙動が確認された点だ。人間が「商品名 レビュー Reddit」と検索するのと同じ行動を、AIが自律的に行っている。生成AIが「実体験に基づく生の声」を求めている証左といえる。
従来の検索エンジン最適化が「アルゴリズムに評価される公式情報」を重視していたのに対し、AI最適化では「訓練データとライブ検索の両方で参照される草の根の評判」が問われる。Redditがその中心にある。
安易な口コミ操作が通用しない構造的理由
ここで多くの企業が「ならばRedditに肯定的な投稿を大量にすればいい」と短絡的に考える。だが、生成AI時代のReddit戦略は、そうした「やらせレビュー」的な手法とは根本的に相性が悪い。構造的な理由が2つある。
訓練データに刻まれたネガティブ情報は消せない
1つ目は、LLMの訓練データの問題だ。仮にReddit上の自社に不都合なスレッドをModeratorに削除してもらえたとしても、その情報はすでにGPT-4やClaudeといったモデルの訓練データに組み込まれている。モデルの重みの中にネガティブな文脈が残り続けるため、単純な「投稿削除」ではAIの感情分析(センチメント)を覆せない。
Redditのコミュニティは作為を見抜く
2つ目は、サブレディット(コミュニティ単位の掲示板)の自主管理能力の高さだ。各サブレディットには人間のModeratorが存在し、不自然なプロモーション投稿や作為的なポジティブレビューは極めて高い精度で検知される。露骨なステマが削除されるだけでなく、アカウントがスパム判定を受ければドメイン単位でブランドの信用が失墜するリスクもある。
重要なのは、AIは情報の「出所」よりも「文脈」と「一貫性」を評価する傾向がある点だ。作為的なポジティブキャンペーンは、むしろAIによる評価を歪ませ、長期的にはブランド毀損につながりかねない。
RedditでAI表示を味方につける3段階のプロセス
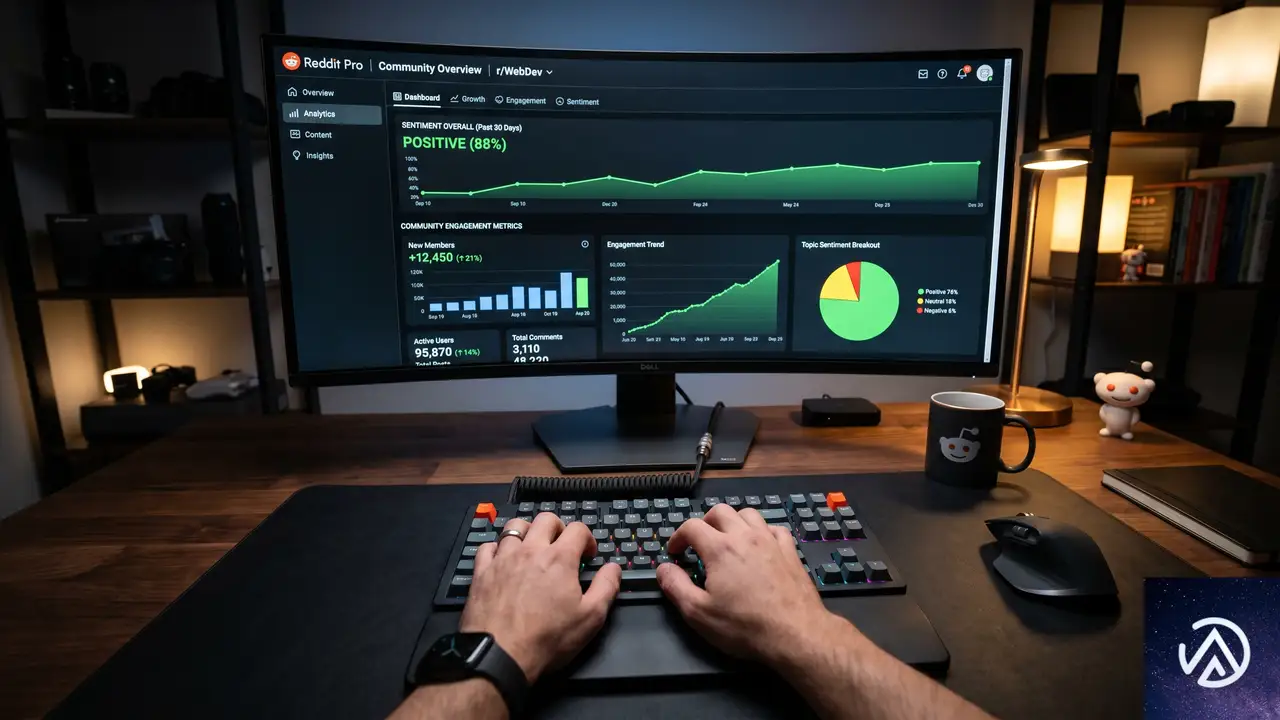
では、企業は具体的に何をすればいいのか。短期的なハックではなく、AIとアルゴリズムの両方に評価される正攻法のプロセスを3段階に分けて解説する。
STEP 1. 観察に徹してコミュニティの文法を学ぶ
Redditビジネスアカウントを作成したら、すぐに投稿やコメントを始めてはいけない。少なくとも数週間は「ROM(Read Only Member)」として、ターゲットとするサブレディットの文化を観察する期間を設ける。
各サブレディットには明文化されたルールに加え、暗黙の行動規範がある。企業アカウントがそれを無視して宣伝めいた投稿をすれば、即座にアカウント停止(BAN)の対象となる。Redditのアカウント停止は異議申し立てが極めて困難なことで知られており、一度BANされるとブランド名で再登録すること自体が難しくなる。
STEP 2. Reddit Proで自社の立ち位置を可視化する
観察期間と並行して、Reddit Pro(無料のビジネス向け分析ツール)の導入をお勧めする。このツールを使うと、以下の情報がダッシュボードで把握できる。
- ユーザーが自社ブランドについてどのような文脈で言及しているか
- 競合ブランドと比較した際のセンチメント(肯定的・否定的感情)の差異
- 自社の製品カテゴリに関連して今活発に議論されているスレッド
闇雲に投稿する前に、データに基づいて「どのサブレディットで、どんなトピックなら、企業として価値を提供できるか」を特定することが先決だ。
STEP 3. ブランド認知より「権威構築」を優先する
初期の投稿やコメントでは、自社製品の宣伝を一切排除し、純粋に専門知識を提供することに集中する。たとえば、ECプラットフォームを提供する企業なら「物流のボトルネックを解消するパッキングの工夫」、マーケティングツール企業なら「GA4で離脱率を下げるレポートの読み方」といった具合だ。
この段階でブランド名を出すことは、コミュニティから「売り込み」と見なされるリスクが高い。まずは個人としての信頼を積み上げ、その後に「そういえば、この分野のプロダクトを開発している」と自然に言及できる流れを作る。
ブランド専用サブレディットという選択肢

自社ブランドへの言及が一定数を超えてきた段階で、ブランド専用のサブレディットを開設することも有効な一手だ。すでに多くのテック企業がこの手法を取り入れている。
専用サブレディットの利点は、分散していた自社関連の会話を一箇所に集約できる点にある。ユーザー同士のQAやトラブルシューティングが活発になれば、それはそのままLLMが参照する「構造化されたナレッジベース」として機能する。サポートコストの削減とAI表示の最適化を同時に実現できるわけだ。
ただし、ここでも運営姿勢が問われる。企業が一方的に情報を発信する場ではなく、ユーザーが自由に意見を交わせる「公共広場」としての設計が不可欠だ。Moderatorが批判的な投稿を削除するような運営は、Reddit全体からの強い反発を招く。
この記事のポイント
- RedditはChatGPTが回答を生成する際の最重要情報源であり、訓練データとリアルタイム検索の双方で参照される
- ネガティブスレッドの削除や偽のポジティブ投稿は、LLMの訓練データに残る情報を覆せず、コミュニティからも排除されるリスクが高い
- アカウント作成後はまず観察に徹し、Reddit Proでデータを分析した上で、ブランド宣伝ではなく専門知識の提供による権威構築を優先する
- 長期的な視点でコミュニティに貢献し、AIに「信頼できる情報源」として学習させることが、生成AI時代のブランド防衛につながる
・ 複数業界における17年間のデジタルビジネス開発経験
・ ウェブサイト開発のためのHTML、PHP、CSS、JavaScript等の実用的知識
・ 15ヶ国語対応の多言語SaaSの開発経験
・ 17年間にも及ぶ、Eコマース長期運営経験
・ 幅広い業界でのSEO最適化の豊富な経験

ChatGPTメモリがDreamingで進化、長期記憶と時間経過を自動反映
OpenAIが2026年6月4日、ChatGPTのメモリ機能を抜本的に改良したと発表した。新たに「Dreaming V3」というシステムを導入し、大規模なユーザー数と長期間の利用を想定したメモリ管理を実現する。
従来の「保存メモリ」は、明示的な指示がなければ情報を覚えられず、時間とともに内容が陳腐化する課題を抱えていた。今回のアップデートで、ChatGPTはバックグラウンドで会話履歴を分析し、自動的にメモリを最新化する。Plus・Proユーザーは同日より利用可能で、FreeユーザーとGoユーザーへの展開も数週間以内に開始される。
メモリ機能「Dreaming」の仕組み

Dreamingは、ChatGPTがあなたとのあらゆる会話から学習し、メモリを合成するバックグラウンド処理だ。従来の「ノートを取ってくれるが、書かなかったことは忘れる同僚」のような挙動から、「会話の文脈全体を理解し、常に最新情報を反映するパートナー」への変化と言える。
なぜDreamingが必要になったのか
ChatGPTのメモリ機能は2024年4月に初登場した。これは「保存メモリ」と呼ばれ、ユーザーが「覚えておいて」と指示した情報だけを保存する仕組みだった。しかし実際の会話では、明示的に指示されない暗黙の好みや状況が大量に存在する。保存メモリだけでは、数カ月前の旅行計画が終了しても「まだ旅行中」と誤認識するなど、情報の鮮度が落ちる問題が避けられなかった。
2025年4月にDreamingの初期バージョンが導入され、保存メモリを補完する形で改善が図られた。しかし当時はまだ、単独のメモリシステムとして十分に機能する段階にはなかった。今回のDreaming V3は、この補助的な役割を超え、完全なメモリ管理システムとして再設計されている。
Dreaming V3が実現する3つの目標

OpenAIは「優れたメモリ」を定義する3つの柱を提示している。過去の会話から有用な文脈を引き継ぐこと、ユーザーの好みや制約に従うこと、そして時間経過を考慮して情報を最新に保つことだ。Dreaming V3の評価結果は、この3軸すべてで大幅な改善を示している。
文脈の引き継ぎ:過去の自分を忘れない
新しいチャットを始めるたびに自己紹介からやり直す必要がなくなる。たとえば、過去にカメラ機材について相談していれば、ChatGPTは「私の撮影構成に合うもの」という曖昧な質問にも、過去の会話を踏まえた的確な製品を提案できる。これは、長期間にわたる複雑なプロジェクトで特に威力を発揮する。
好みと制約の反映:暗黙のルールを理解する
ユーザーの好みには、明示的な指示(「スタンの話はもう出さないで」)から、個人の制約(「私はベジタリアンです」)、そして地理情報のような暗黙の好み(「サンフランシスコ近郊に住んでいる」から現地情報を優先する)まで様々な形がある。Dreaming V3は、これらの情報を会話の流れから自然に拾い上げ、矛盾のない応答を継続的に生成する。
OpenAIの評価では、「ベジタリアン」と伝えたユーザーが後日食事の提案を求めた際、Dreamingが自動的に菜食対応の選択肢を提示するかがテストされた。結果は、従来の保存メモリ単体に比べて大幅な正答率の向上を示したという。
時間経過への対応:記憶を自動で更新する
従来の最大の弱点は、時間の経過によるメモリの陳腐化だった。Dreamingはここで真価を発揮する。たとえば「7月にシンガポール旅行」という記憶は、旅行が終われば自動的に「2026年7月にシンガポールに行った」という過去の出来事に書き換えられる。ChatGPTはその後、自宅近辺の情報を優先して提供するようになる。
OpenAIの評価では、時間経過が正しい回答に影響を与えるシナリオで、Dreamingが顕著な改善を達成したと報告されている。これは、単なる事実記憶ではなく、時間的文脈を理解した応答が可能になったことを意味する。
計算効率の改善と無料ユーザーへの展開

Dreaming V3のもう一つの重要な進化は、計算効率だ。OpenAIによれば、今回の改良によりDreamingを無料ユーザーに提供するために必要な計算リソースが約5分の1に削減された。これは、大規模なユーザーベースに対して実用的なメモリシステムを展開する上で決定的なブレイクスルーである。
以前は、Dreamingの処理負荷が高く、Freeユーザーに品質基準を満たしたメモリ機能を提供することが難しかった。今回の効率化により、数週間以内にFreeユーザーとGoユーザーへの段階的なロールアウトが開始される。同時に、Plus・Proユーザーのメモリ容量も拡張される予定だ。
この効率化は、単にユーザー数を増やすためだけではない。OpenAIの長期的なビジョンである「全ユーザーに共有メモリ基盤を提供する」という目標に向けた、アーキテクチャ上の重要なマイルストーンでもある。
メモリの透明性とユーザーコントロール

Dreamingが自動で合成したメモリは、すべてメモリサマリーページで確認できる。このページでは、ChatGPTがあなたについて把握しているハイライトを一目で把握し、必要に応じて情報の追加や更新、特定の話題に関する指示を与えることが可能だ。さらに詳細を知りたい場合は、チャットを通じて深掘りすることもできる。
これは、AIのパーソナライズ機能において重要なバランスだ。高い利便性を提供しつつ、ユーザーが自分のデータの全体像を把握し、コントロールできる状態を維持している。自動化と透明性の両立が、Dreamingの設計思想に組み込まれている。
Dreamingがもたらす実務への影響と今後の展望

Dreaming V3の登場は、ChatGPTを単発の質問応答ツールから、長期的なパートナーへと進化させる転換点だ。特に、プロジェクト管理や継続的な学習相談、ビジネス上の意思決定支援など、時間をかけて関係性を構築するユースケースで真価を発揮する。
OpenAIはこのアップデートを「これまでで最も高性能なメモリシステム」と位置づけており、今後も改良を続けるとしている。Dreamingは、将来的により高度なエージェント機能や、複数のChatGPTセッションを横断したタスク実行の基盤となる可能性が高い。
一方で、バックグラウンドで常に会話履歴を分析することへのプライバシー感度は、ユーザーによって異なるだろう。OpenAIはメモリの確認・削除を容易にするインターフェースを提供しているが、AIの記憶が深まるにつれて、データ管理の重要性も比例して高まる。このバランスが、今後の普及速度を左右する要素の一つになる。
このデモは、DreamingがChatGPTの役割を根本から変えることを示している。もはや「賢い検索エンジン」ではなく、あなたの文脈を理解し続ける存在になる。
この記事のポイント
- Dreaming V3は、バックグラウンドで全チャット履歴から自動的にメモリを合成する
- 「文脈引き継ぎ」「好みの反映」「時間経過対応」の3軸で大幅な改善を達成
- 計算効率が約5倍向上し、Free・Goユーザーへの展開が開始される
- メモリサマリーページで、ChatGPTの把握内容を常に確認・編集可能
- 長期的なプロジェクト支援やパーソナライズの質が飛躍的に向上する
・ 複数業界における17年間のデジタルビジネス開発経験
・ ウェブサイト開発のためのHTML、PHP、CSS、JavaScript等の実用的知識
・ 15ヶ国語対応の多言語SaaSの開発経験
・ 17年間にも及ぶ、Eコマース長期運営経験
・ 幅広い業界でのSEO最適化の豊富な経験