

OpenAIがTanStack npm攻撃に対応、Macユーザーは6月12日までにアプリ更新を
広く利用されるオープンソースライブラリ「TanStack」のnpmパッケージが悪意ある第三者によって改ざんされた「Mini Shai-Hulud」と呼ばれるサプライチェーン攻撃。この影響はOpenAIにも及び、同社は2026年5月13日に公式な対応報告を公開した。
OpenAIの調査によると、ユーザーデータや本番システム、知的財産への不正アクセスは確認されていない。しかし、同社のコード署名証明書が一時的に影響下にあったことから、予防的な措置としてMacユーザーを対象に全アプリケーションの更新を2026年6月12日までに完了するよう呼びかけている。
今回の記事では、攻撃の具体的な影響範囲、OpenAIが講じたセキュリティ対策、なぜMacだけが更新対象なのか、そして実務者が理解すべきサプライチェーンリスクの本質を解説する。
TanStackを狙ったサプライチェーン攻撃とは
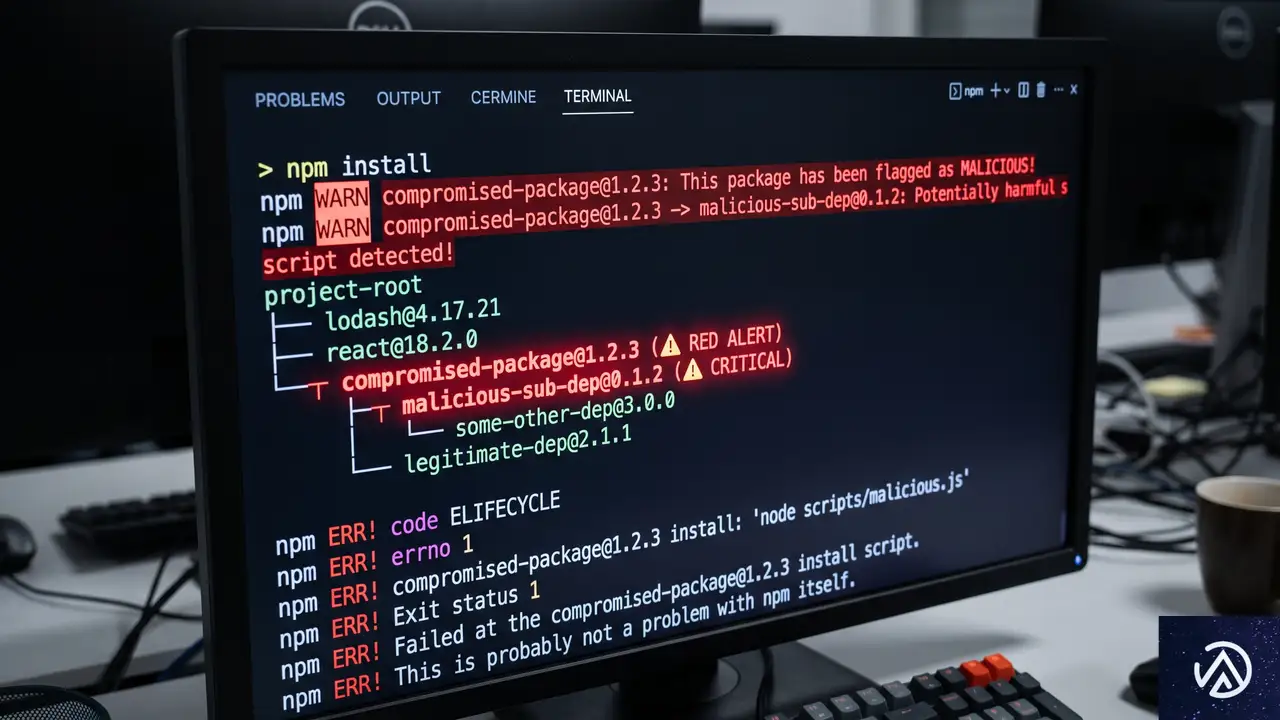
2026年5月11日(UTC)、フロントエンド開発で広く使われるJavaScriptライブラリ群「TanStack」のnpmパッケージが、攻撃グループによって改ざんされた。この攻撃は「Mini Shai-Hulud」と名付けられ、ソフトウェアサプライチェーンの弱点を突く大規模なキャンペーンの一環だ。
サプライチェーン攻撃とは、正規のソフトウェアやライブラリを踏み台にし、その利用者にマルウェアを拡散する手法を指す。開発者が信頼して導入するパッケージマネージャー(npm、PyPI、RubyGemsなど)を通じて感染が広がるため、一企業だけでなく、エコシステム全体に被害が連鎖する点が最大の脅威だ。
今回の攻撃では、改ざんされたパッケージをインストールした開発者の端末から認証情報が引き出される挙動が確認されている。OpenAIの事例でも、このメカニズムにより2台の社内端末が侵害を受けた。
攻撃の構造とマルウェアの挙動
Socket.devの分析によれば、Mini Shai-Huludは主に認証情報(トークン、APIキー、セッション情報など)の窃取を目的としている。感染後の典型的な挙動は、開発者端末に保存されたGit認証情報や環境変数への不正アクセス、そして一部の内部コードリポジトリへの侵入だ。
OpenAIが委託した第三者デジタルフォレンジック企業の調査では、影響を受けた2名の社員がアクセス可能だった一部の内部ソースコードリポジトリで、認証情報の引き出しが成功した形跡が確認された。ただし、コードそのものや他の情報が流出した証拠はない。
OpenAIの初動対応と封じ込め
OpenAIは悪意ある活動を検知した直後、以下の封じ込め措置を即座に実行した。
- 影響を受けた端末とIDの隔離
- 全ユーザーセッションの強制無効化
- 影響リポジトリに関連する全認証情報のローテーション(再発行)
- コードデプロイワークフローの一時的制限
- ユーザーおよび認証情報の挙動調査の徹底
これらの対応により、攻撃者による追跡アクセスや窃取された認証情報の悪用は確認されていない。また、顧客データやOpenAIの知的財産への影響は一切なかったと報告されている。
Macユーザーに更新が必要な理由
一見すると「社内端末2台の侵害だけなら、なぜエンドユーザーが対応するのか」と疑問に思うかもしれない。この背景には、コードサイニング証明書(コード署名証明書)の重要性がある。
コードサイニング証明書とは、ソフトウェアの開発元を電子的に証明する仕組みだ。macOSやWindows、iOSといったプラットフォームは、この証明書を確認することで「正規の開発者がリリースしたアプリかどうか」を判定している。
OpenAIの内部リポジトリには、iOS、macOS、Windows、Android向けのコードサイニング証明書が保管されていた。この証明書自体が直接流出したわけではないが、アクセス可能な状態にあったことから、OpenAIは予防的措置としてすべての証明書を新しいものに置き換える判断を下した。
証明書失効のタイムラインと影響
2026年6月12日をもって、旧証明書は完全に失効する。これ以降、旧証明書で署名されたmacOSアプリは、Appleのセキュリティ保護機能(Gatekeeper)によって新規ダウンロードや初回起動がブロックされる。
WindowsやiOS、Androidのアプリについても新しい証明書で再署名されるため、将来的なアップデートは必要になる。ただ、これらのプラットフォームでは即時のユーザー操作は不要とされている。
Macだけが個別アクションを求められる理由は、Appleのセキュリティモデルが証明書の有効性を厳格に検証する設計になっているためだ。更新を怠ると、以下のアプリが正常に動作しなくなる可能性がある。
- ChatGPT Desktop(バージョン 1.2026.125 以前)
- Codex App(バージョン 26.506.31421 以前)
- Codex CLI(バージョン 0.130.0 以前)
- Atlas(バージョン 1.2026.119.1 以前)
なぜ即時の証明書失効ではないのか
OpenAIはすでにプラットフォーム事業者と連携し、旧証明書を用いた新規の公証(ノータリゼーション)を全面的にブロックしている。公証とは、Appleがアプリをスキャンして悪意あるコードが含まれていないことを確認するプロセスだ。
仮に攻撃者が旧証明書を使って偽のOpenAIアプリを作成したとしても、公証を受けられないため、デフォルトのmacOSセキュリティ設定では実行が阻止される。この防御策が機能している間に、ユーザーがスムーズに公式アプリへ移行できるよう約1か月の猶予期間が設けられた。
この猶予期間中に、アプリ内アップデートまたは公式サイトからの再インストールを通じて、最新バージョンへの切り替えを済ませておくことが推奨される。
攻撃が浮き彫りにした開発エコシステムの脆弱性
今回の事案は、特定企業を標的とした攻撃というよりも、オープンソースエコシステム全体の構造的な弱点を突いたものと言える。攻撃者は個別の企業ではなく、広く使われる共有ライブラリを侵害することで、一度に多数の組織へ侵入できる。
現代のソフトウェア開発は、npm、PyPI、Maven Centralといったパッケージレジストリに大きく依存している。1つのパッケージが侵害されれば、依存関係の連鎖によって数百、数千のプロジェクトが影響を受ける。実際、TanStackのパッケージを依存関係に持つプロジェクトは膨大だ。
OpenAIが進めるサプライチェーン防御
OpenAIは2025年末に発生したAxios開発者ツールの侵害を受け、すでにサプライチェーン攻撃への防御を段階的に強化していた。具体的には以下の対策が進められていた。
- CI/CDパイプラインで扱う機密度の高い認証情報の追加保護
minimumReleaseAgeなどの設定を用いたパッケージマネージャーの制御導入- 新規パッケージの信頼性を検証する追加セキュリティソフトウェアの展開
minimumReleaseAge とは、パッケージがレジストリに公開されてから一定時間(例:3日間)経過しないとインストールを許可しない設定だ。これにより、公開直後の悪意あるパッケージを誤って取り込むリスクを低減できる。
しかし、これらの対策が全社的に展開される途中の段階で、今回のインシデントは発生した。侵害を受けた2台の端末には、新たな制御設定がまだ適用されていなかったのである。
実務者が今すぐ取るべき対策
OpenAIの事例から学べる教訓は、単一の企業だけに留まらない。自社の開発環境においても、以下の対策を早急に検討すべきだ。
- パッケージマネージャーのロックファイル(package-lock.jsonなど)を定期的に監査する。 意図しないバージョン変更や新規依存関係が混入していないか、CI環境で自動チェックする仕組みを作る。
- サプライチェーンセキュリティツールの導入。 Socket.dev、Snyk、GitHub Dependabotなどを使い、脆弱性や悪意あるパッケージを早期に検出する。
- コードサイニング証明書の厳格な管理。 CI/CD環境とは完全に切り離し、必要最小限の担当者のみがアクセスできる保管場所を確保する。
- 依存パッケージの更新を自動化しすぎない。 パッチバージョンであっても、公開直後の即時適用は避け、一定の猶予を設ける。
このような防御策は、自社の開発文化や速度とバランスを取りながら段階的に導入していくのが現実的だ。しかし、攻撃の連鎖速度は日に日に速まっている。放置するリスクの方がはるかに大きいことは、今回の事例が明確に示している。
ユーザーが取るべき具体的なアクション

OpenAIのアプリをMacで利用している個人および企業は、以下の手順を確実に実施してほしい。
- 公式の更新経路のみを使用する。 アプリ内のアップデート通知、またはOpenAI公式ウェブサイト(openai.com)からダウンロードする。メール、メッセージ、広告、ファイル共有リンク経由の「ChatGPT」「Codex」インストーラーには絶対に手を出さない。
- 6月12日までに更新を完了する。 期限を過ぎると、旧証明書で署名されたアプリはmacOSによってブロックされる。業務で利用している企業は、社内のIT管理者が一括アップデートを計画すべきだ。
- パスワード変更は不要。 OpenAIは公式に、顧客のパスワードやAPIキーが影響を受けていないと明言している。無用なパスワード変更はフィッシングのリスクを高めるだけだ。
企業のIT管理者向け追加ガイダンス
組織内でOpenAIアプリを管理している場合、6月12日の証明書失効までにMDM(モバイルデバイス管理)やソフトウェア配布ツールを通じて、全Mac端末のアプリを最新バージョンに更新する計画を立てる必要がある。
更新対象となるアプリと、失効する旧バージョンの一覧は以下の通りだ。
- ChatGPT Desktop(旧バージョン 1.2026.125)
- Codex App(旧バージョン 26.506.31421)
- Codex CLI(旧バージョン 0.130.0)
- Atlas(旧バージョン 1.2026.119.1)
これらのバージョンが社内で稼働している場合、速やかに更新手続きを進めることが求められる。
この記事のポイント
- OpenAIはTanStack npmパッケージへのサプライチェーン攻撃により社内端末2台が侵害されたが、ユーザーデータや本番システムへの影響はなかった。
- 予防措置としてコードサイニング証明書を全面的にローテーション。Macユーザーは6月12日までにアプリを更新する必要がある。
- 旧証明書を用いた新規の公証はすでにブロック済みのため、偽アプリがmacOSで実行されるリスクは低い。
- 攻撃の本質はオープンソースエコシステムの脆弱性を突いたものであり、全開発組織がパッケージ管理の防御策強化を求められている。
- パッケージの即時自動更新を避け、minimumReleaseAgeの設定や監査プロセスの導入が有効な対策となる。

・ 複数業界における17年間のデジタルビジネス開発経験
・ ウェブサイト開発のためのHTML、PHP、CSS、JavaScript等の実用的知識
・ 15ヶ国語対応の多言語SaaSの開発経験
・ 17年間にも及ぶ、Eコマース長期運営経験
・ 幅広い業界でのSEO最適化の豊富な経験

SupabaseがChatGPT公式アプリに。データベースとEdge Functionsを自然言語で操作可能に
SupabaseがChatGPTの公式アプリとして提供を開始した。これにより、ChatGPTの対話画面から直接Supabaseプロジェクトのデータベース管理やEdge Functionsのデプロイが可能になる。コードを書かずに自然言語でインフラを操作できる時代が一歩進んだ形だ。
今回の連携では、全部で29種類のツールが提供される。SQLクエリの実行、テーブルスキーマの設計変更、セキュリティアドバイザーの確認と修正、開発用ブランチの作成とマージなど、データベース運用に必要なほぼすべての操作をカバーしている。対象は全Supabaseプランと、ChatGPTの有料プラン(Plus / Pro / Team / Enterprise)だ。
この記事では、Supabase ChatGPTアプリで実現できること、導入方法、技術的な仕組み、そして国産の類似サービスと比較した実務的な評価を解説する。データベース管理の自動化に興味がある開発者や、Supabaseを使ったプロダクト開発の効率化を目指すチームにとって役立つ情報をまとめた。
ChatGPT側からSupabaseを直接操作できるようになった背景
これまでSupabaseの管理は、公式ダッシュボードやCLI(コマンドラインインターフェース)から手動で行うのが一般的だった。開発者であればSQLクライアントを起動し、APIキーを確認し、適切なエンドポイントを叩く。これらの手順に慣れている人にとっては日常的な作業だが、チームに非エンジニアが加わったり、素早いプロトタイピングが求められる場面では操作のハードルが高かった。
一方でChatGPTは、2025年以降、外部アプリとの連携機能を急速に拡充してきた。単なるテキスト生成AIから、実際のサービスを操作する「AIエージェント」としての側面を強めている。この流れの中で、SupabaseがChatGPTの公式アプリとして認定されたのは、両者の方向性が一致した自然な結果といえる。
この連携を支える技術が、MCP(Model Context Protocol / モデルコンテキストプロトコル)だ。MCPは、AIモデルが外部のツールやサービスと安全にやり取りするための標準プロトコルである。ChatGPTはこのMCPを通じてSupabaseのAPIを呼び出し、ユーザーの自然言語による指示を実際のデータベース操作に変換している。
従来のデータベース管理とChatGPT連携の比較
従来のSupabase管理(Before)
※非エンジニアが操作できない。ツールの切り替えが発生
ChatGPTアプリ連携後(After)
※対話の中でデータベース操作が完結。非エンジニアも参加可能
この仕組みは、単に検索して情報を得るだけの従来のAIアシスタントとは一線を画す。ChatGPTはSupabaseのAPIを通じて実際にテーブルを作成し、SQLを実行し、Edge Functionsをデプロイする。つまり「調べるAI」から「実行するAI」への進化を象徴する連携だ。
実務におけるインパクト
開発現場では、ちょっとしたデータ確認のためにSQLクライアントを起動する手間が意外に大きい。ChatGPT上で「先週登録したユーザーの数を教えて」と入力するだけで結果が返ってくれば、コンテキストスイッチ(作業の切り替えにかかる認知的負荷)が大幅に減る。また、セキュリティアドバイザーの指摘に対して「修正して」と指示するだけで実際の設定変更が行われる点は、運用負荷の軽減に直結する。
Supabaseの記事によれば、ChatGPTの「プロジェクト」機能と組み合わせることで、特定のSupabaseプロジェクトに会話のスコープを固定することもできる。プロジェクトの参照IDを一度設定しておけば、その後の会話では自動的に正しいデータベースに接続される仕組みだ。
ChatGPTアプリが提供する29種類の操作ツール

Supabase ChatGPTアプリには、以下の5カテゴリにわたる29種類のツールが実装されている。いずれも自然言語での指示をChatGPTが解釈し、適切なAPI呼び出しに変換して実行する形式だ。
データベース管理(Database Management)
Postgresデータベースに対するSQLクエリの実行、テーブルスキーマの設計と変更、テーブルや拡張機能の一覧表示、セキュリティに関する推奨事項の取得が含まれる。たとえば「usersテーブルに最終ログイン日時のカラムを追加して」と依頼すれば、ChatGPTが適切なALTER TABLE文を生成し、実行する。
セキュリティアドバイザーの確認機能はとくに実用的だ。RLS(Row Level Security / 行レベルセキュリティ)の設定漏れや、公開すべきでないAPIエンドポイントの検出など、見落としがちな設定項目を自動でチェックし、必要に応じて修正まで行える。
プロジェクト運用(Project Operations)
プロジェクトの作成と一覧表示、コスト見積もりの取得、プロジェクトの一時停止と再開、リアルタイムログへのアクセスといった運用系の操作をカバーする。開発用に一時的なプロジェクトを作成して使い終わったら停止する、といったライフサイクル管理をChatGPT上で完結できる。
ブランチとマイグレーション(Branching and Migrations)
データベースの開発用ブランチ作成、変更のマージ、リベースやリセット、マイグレーションの一覧表示と適用が可能だ。Supabaseのブランチ機能は、Gitを使ったコード管理と同様の考え方をデータベースに適用したもので、スキーマ変更を安全にテストしてから本番環境に反映できる。ChatGPT経由で「開発ブランチを作って、そこに新しいインデックスを追加して」と指示するだけで、一連の作業が実行される。
Edge Functions(エッジファンクション)
サーバーレス関数の一覧表示、デプロイ、管理を行う。Edge Functionsとは、ユーザーに近い地理的に分散したサーバー上で実行される軽量なサーバーレス関数のことで、低レイテンシでの処理が求められるAPIエンドポイントやWebhook処理に適している。ChatGPTに「新規ユーザー登録時にウェルカムメールを送信するEdge Functionを作ってデプロイして」と指示すれば、コードの生成からデプロイまでを自動で処理する。
ドキュメント検索(Documentation)
ChatGPTから直接Supabaseの公式ドキュメントを検索できる。コーディング中に詰まったとき、別タブでドキュメントを開かずに会話の流れの中で解決策を見つけられるのは、開発スピードの向上に寄与する。
29ツールのカテゴリ構成
データベース管理
■ SQL実行 ■ スキーマ設計 ■ テーブル一覧 ■ セキュリティ推奨
プロジェクト運用
■ プロジェクト作成・一覧 ■ コスト見積もり ■ 一時停止・再開 ■ リアルタイムログ
ブランチとマイグレーション
■ 開発ブランチ作成 ■ マージ ■ リベース ■ マイグレーション適用
Edge Functions
■ 一覧表示 ■ デプロイ ■ 関数管理
ドキュメント検索
■ Supabase Docsの直接検索
※各カテゴリのツール数はSupabase公式ブログの発表に基づく(2026年5月8日時点)
これらのツールは単独でも有用だが、組み合わせることで真価を発揮する。たとえば「セキュリティアドバイザーを実行して、問題があれば修正用のブランチを作成し、修正後に本番へマージして」という一連の指示を自然言語で伝えられる。従来であれば複数の画面とCLI操作を往復する必要があったフローが、1つの会話で完結する。
利用開始手順と対応プラン
利用開始はシンプルだ。ChatGPTのアプリディレクトリで「Supabase」を検索するか、直接Supabaseのアプリページにアクセスして認証を行う。ChatGPTにSupabase組織へのアクセスを許可すれば、すぐに使い始められる。
対応しているのは全Supabaseプラン(無料プランを含む)と、ChatGPTの有料プランだ。ChatGPT側はPlus、Pro、Team、Enterpriseのいずれかの契約が必要になる。無料のChatGPTアカウントではこのアプリを利用できない点に注意したい。Supabase側に有料プランの制限はなく、無料枠のプロジェクトでも問題なく連携できる。
Supabaseアカウントをまだ持っていない場合は、supabase.comから無料でプロジェクトを開始できる。作成後、ChatGPTに接続して自然言語での管理を始める流れになる。認証にはSupabaseのアクセストークンが使用され、ChatGPTがユーザーに代わってAPIを呼び出す際の権限管理はこのトークンを通じて行われる。
ChatGPTプロジェクトとの連携で効率をさらに上げる
OpenAIが提供する「ChatGPT Projects」機能を使えば、会話のスコープを特定のSupabaseプロジェクトに固定できる。プロジェクトの参照IDをプロジェクト指示に一度設定しておくと、そのプロジェクト内のすべての会話が自動的に正しいデータベースを参照する。複数のSupabaseプロジェクトを抱えるチームでは、この設定で誤操作を防ぎつつ作業効率を高められる。
技術的な仕組みとMCPプロトコル
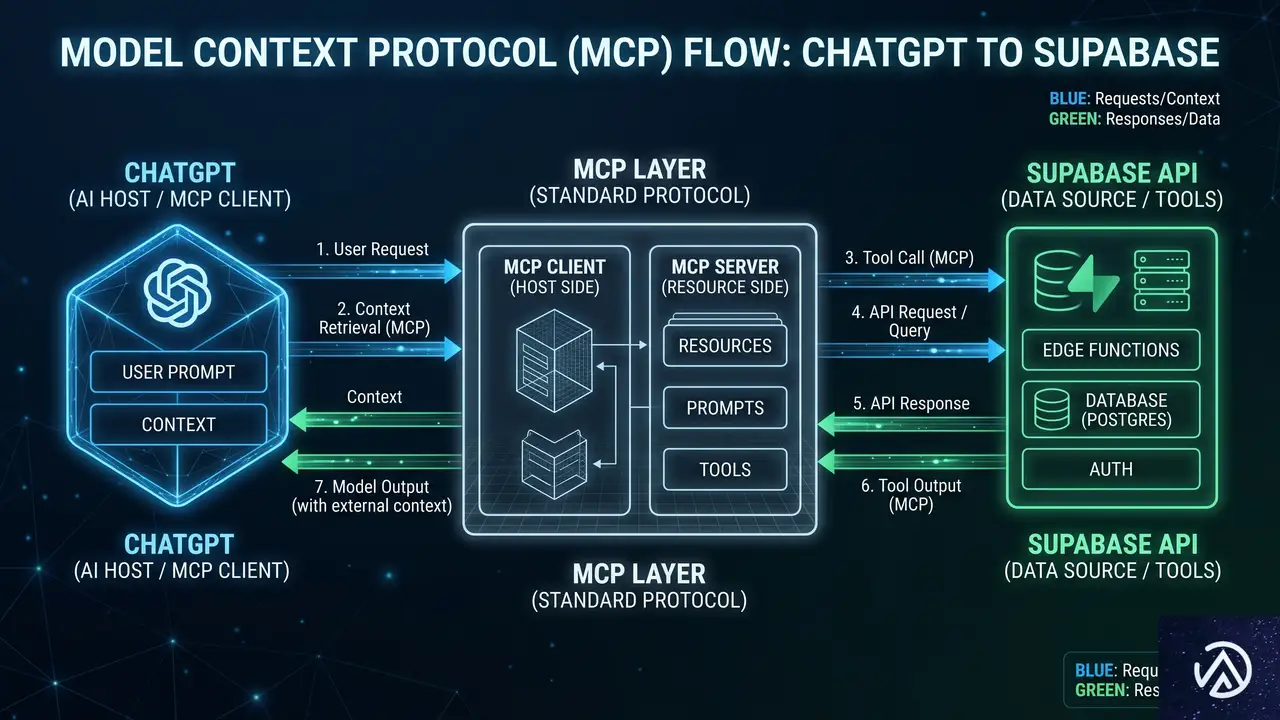
この連携の技術基盤となっているのが、MCP(Model Context Protocol)だ。MCPは2024年にAnthropicが提唱し、現在ではOpenAIを含む複数のAIプラットフォームで採用が進んでいるオープンプロトコルである。AIモデルが外部ツールやデータソースとやり取りするための共通言語のような役割を果たす。
MCPの仕組みを簡単に説明すると、AIモデルに対して「このツールはこういう機能を持っていて、こういう引数を受け取る」という定義(ツールディスクリプション)を提供する。ユーザーが自然言語で指示を出すと、AIはその定義を参照して適切なツールを選択し、必要なパラメータを推論して実行する。Supabaseの29ツールも、このMCPの枠組みに沿ってChatGPTに公開されている。
認証にはOAuth 2.0が使われており、ChatGPTがユーザーのSupabaseアカウントに代わってAPIを呼び出す際の権限は、ユーザーが許可した範囲に制限される。すべての操作はユーザーの認可の下で実行され、ChatGPTが勝手にデータベースを変更することはない。また、実行前にはChatGPTが「これからこういう操作をしますがよろしいですか」と確認を求める設計になっており、安全性にも配慮されている。
MCPによるSupabase操作の流れ
例「先月の売上を商品カテゴリ別に集計して」
「execute_sql_query」ツールを呼び出し、適切なSQLを生成
OAuth認証を通じてユーザーの権限でPostgresにクエリを発行
クエリ結果を要約してチャットで表示。必要に応じてグラフ化も提案
※実際の処理では、破壊的操作の前にChatGPTが確認を求める安全機構が働く
特筆すべきは、この仕組みが単なる「自然言語からSQLへの変換」にとどまらない点だ。ChatGPTはSupabaseから返ってきたデータを解釈し、必要に応じて追加の質問をしたり、結果をわかりやすく要約したりする。エラーが発生した場合も、ログを解析して原因を特定し、修正案を提示できる。
セキュリティと権限管理
AIにデータベースの操作権限を与えることに対する懸念は当然ある。SupabaseのChatGPTアプリでは、以下の3層の安全機構が実装されている。1つ目はOAuth 2.0によるスコープ制限で、ChatGPTがアクセスできる操作はユーザーが明示的に許可した範囲に限定される。2つ目は破壊的操作(DROP、DELETE、スキーマ変更など)の実行前確認だ。3つ目は、すべての操作がSupabaseの監査ログに記録される点で、事後的な追跡と検証が可能になっている。
国産データベースサービスとの比較と実務評価
SupabaseとChatGPTの連携は、BaaS(Backend as a Service / バックエンドをサービスとして提供する形態)市場全体に波及効果をもたらす可能性がある。現時点で国内の類似サービスには、このレベルのAI連携を実装しているものは見当たらない。国産BaaSの多くは管理画面のUI/UX改善に注力しており、自然言語による操作という発想自体がまだ新しい。
ただし、実務に導入する際にはいくつかの注意点がある。第一に、ChatGPTが生成するSQLが常に最適とは限らない点だ。複雑なJOINやサブクエリを含むクエリでは、パフォーマンスの観点から人手によるレビューが推奨される。第二に、ChatGPTの有料プランが必要なため、チーム全体で利用する場合はコストの試算が欠かせない。第三に、プロダクション環境での破壊的操作をAIに委ねることのリスクは依然として存在する。スキーマ変更やデータ削除を伴う操作は、ステージング環境でのテストを挟む運用ルールを設けるのが現実的だ。
一方で、この連携が真価を発揮するのはプロトタイピングとトラブルシューティングの場面だ。アイデアを素早く形にしたいとき、あるいは深夜の障害対応で素早く原因を特定したいときに、ChatGPT上でSupabaseを直接操作できる利便性は大きい。とくにスタートアップや少人数チームでは、開発リソースの制約を補う手段として有効に機能するだろう。
今後の展望
SupabaseがChatGPT公式アプリとなったことで、他のBaaSやクラウドサービスにもAI連携の波が広がるのはほぼ確実だ。すでにVercelやCloudflareもAIエージェントとの統合を進めており、2026年後半には「ChatGPTから操作できるクラウドサービス」が標準的な提供形態になっていく可能性がある。
開発者にとっては、コーディングの効率化だけでなく、インフラ管理や運用監視といった領域までAIがカバーする時代が目前に迫っている。Supabaseの今回の発表は、その転換点を象徴する出来事といえる。
この記事のポイント
- SupabaseがChatGPT公式アプリとして提供開始。チャットからデータベース管理が可能になった
- SQL実行、スキーマ変更、Edge Functionsのデプロイなど29種類のツールを搭載
- 全SupabaseプランとChatGPT有料プランで利用可能。無料枠のプロジェクトでも連携できる
- 技術基盤はMCP(Model Context Protocol)。OAuth 2.0による権限制御で安全性を確保
- 実務導入ではSQLの最適性確認や本番操作の運用ルール整備が推奨される
・ 複数業界における17年間のデジタルビジネス開発経験
・ ウェブサイト開発のためのHTML、PHP、CSS、JavaScript等の実用的知識
・ 15ヶ国語対応の多言語SaaSの開発経験
・ 17年間にも及ぶ、Eコマース長期運営経験
・ 幅広い業界でのSEO最適化の豊富な経験

ChatGPTに広告が登場。OpenAIがテスト運用を発表、日本への展開も明らかに
OpenAIは2026年2月、ChatGPTの無料プランとGoプランにおいて広告のテストを開始した。回答の内容に広告が影響することはなく、会話データは広告主に対して非公開に保たれる。すでに米国でのテストを経て、カナダや豪州への拡大が始まっている。
5月7日のアップデートでは、日本、英国、メキシコ、ブラジル、韓国の5カ国にもパイロットを拡大する計画が発表された。このテストはAIモデルの開発コストを一部カバーし、無料での利用を継続可能にする目的がある。実際に広告がどう表示されるのか、具体的な仕組みを見ていく。
ChatGPTで始まった広告テストの実態

今回のテストは、ChatGPTのログイン済み成人ユーザーのうち、無料プランとGoプランを対象とする。月額20ドルのPlusや200ドルのPro、契約型のBusinessやEnterprise、Educationの各プランには広告が表示されない。OpenAIの公式ブログでの発表によれば、目的は「より多くの人が強力なChatGPTの機能にアクセスできるようにする」ことだ。
無料層を支えるインフラと広告の役割
ChatGPTは数億人のユーザーが学習や日常の判断に使うサービスである。無料プランとGoプランを高速かつ安定して提供し続けるには、大規模な計算基盤と継続的な投資が欠かせない。広告収入はその運用費を補填し、無料層や低価格帯の品質を落とさずにAIの能力を向上させるための資金源と位置づけられている。
実際にどの程度のリクエスト数がさばかれているかというと、SimilarWebの推計では2026年3月時点でChatGPTの月間訪問数は約50億回に達している。これだけのアクセスをリアルタイムで処理するためのGPUクラスタの電気代だけでも、月あたり数十億円規模と試算するエンジニアもいる。
広告の表示要件
テスト段階では、会話の話題とユーザーの過去のチャット履歴、過去の広告とのインタラクションに基づいて表示する広告が選ばれる。たとえば料理のレシピを検索しているときには、食材キットや食料品の宅配サービスといった関連性の高い広告が出る仕組みだ。
自然検索結果はスクロールが必要
食材キットの広告が1件だけ表示
このデモでは、従来の検索エンジン型の広告表示と、ChatGPTの会話型広告表示の違いを示している。検索エンジンでは広告が検索結果の上位を占めることが多いが、ChatGPTでは回答と明確に分離され、会話の流れを妨げない形で1件の関連広告が表示される。
広告が回答内容に与えない影響とプライバシー設計
OpenAIは今回のテストに際して、「広告はChatGPTの回答に一切影響を与えない」という基本方針を明示している。回答はユーザーにとって最も役立つ内容に最適化され、広告は常に「スポンサー」ラベル付きで回答とは視覚的に分離される。
会話データは広告主に渡らない
プライバシー面では、広告主がユーザーのチャット内容やチャット履歴、メモリ機能に保存された情報、個人の詳細にアクセスすることはできない。広告主に提供されるのは、自社の広告が何回表示され何回クリックされたかといった集計データのみである。
これは、Cookieやデバイスフィンガープリントで個人を追跡する従来の行動ターゲティング広告とは根本的に異なるアプローチだ。OpenAIは「狭いターゲティングを防ぐためのガードレール」を設け、詐欺広告や有害・誤解を招く広告のリスクを減らす保護策も組み込んでいる。
18歳未満とセンシティブな話題では表示しない
テスト期間中、18歳未満と判明しているまたは予測されるアカウントには広告が表示されない。また、健康やメンタルヘルス、政治といったセンシティブまたは規制対象の話題の近くにも広告は表示されない設計である。これは、広告がユーザーの信頼を損なわないようにするための重要な仕組みだ。
ユーザーに提供される広告管理の選択肢
ChatGPTでは、広告に対してユーザーが細かく制御できる仕組みが用意されている。広告を見たくない場合は、PlusまたはProプランにアップグレードする方法と、無料プランのまま1日の無料メッセージ数を減らす代わりに広告を非表示にする方法の2つが提供される。
広告コントロールパネルの機能
設定画面からは次の操作が可能である。広告を閉じる、フィードバックを送信する、なぜその広告が表示されたのか理由を確認する、ワンタップで広告データを削除する、広告のパーソナライズ設定を管理する。
● インタレスト(推定される興味関心の確認)
● 広告データの削除(ワンタップで全消去)
● パーソナライズ設定(オン / オフ切替)
● 過去のチャットとメモリの使用(許可 / 不許可)
このパネルはChatGPTの設定内に組み込まれており、数タップで広告の表示有無やパーソナライズのオンオフを切り替えられる。一般的なSNS広告の設定画面よりも項目が整理されており、非エンジニアでも迷わず操作できる設計だ。
地域拡大のロードマップと日本市場への示唆

OpenAIは段階的にテスト地域を拡大している。2026年2月の米国を皮切りに、3月にはカナダ、豪州、ニュージーランドでのパイロットが開始された。そして5月の発表で、英国、メキシコ、ブラジル、日本、韓国の5カ国に拡大する計画が明らかになった。
地域ごとに異なる広告体験を学習する狙い
OpenAIの発表によれば、このパイロットの目的は「地域ごとに何が効果的かを理解し、拡大にあわせて体験を継続的に改善すること」にある。つまり単なる広告枠の販売ではなく、文化や商習慣の違いが広告の受け入れられ方にどう影響するかを検証する意図がある。
日本市場においては、LINEやYahoo! JAPANなどが提供するAIアシスタントとの競合が意識される局面でもある。ChatGPT上での広告が日本のユーザーにどのように受け止められるかは、国内でのサービス定着を左右する要素のひとつになるだろう。
広告主にとっての意味
OpenAIは企業向けに広告プログラムへの参加登録ページを公開している。現在は限定的だが、将来的には広告フォーマットの拡張や、目的別の広告購入モデルの追加が検討されている。とくにChatGPTの会話型インターフェースでは、ユーザーが「探している」タイミングで広告が表示されるため、検索広告とは異なる高いコンバージョン率が期待できると見られている。
対話型AIにおける広告の可能性と課題

OpenAIは今回のテストを「学習」の機会と位置づけている。広告が「役に立つ」と感じられ、ChatGPTの体験に自然に溶け込むかどうかを注意深く観察するとしている。初期の結果では、消費者の信頼指標に悪影響は見られず、広告の非表示率は低く、関連性は改善を続けているという。
会話型インターフェースならではの広告価値
ChatGPTのユーザーは、何かを積極的に調べたりアイデアを比較したり、意思決定に向けて動いている最中であることが多い。そうしたタイミングで表示される広告は、ユーザーが求める商品やサービスとの出会いを支援する可能性を持つ。OpenAIは「会話型インターフェースでは、広告がより関連性が高く有用になり、人々を新しい商品やサービスに自然な形でつなげられる」と述べている。
広告の独立性与信頼性の維持
ただし、AIアシスタントに広告を組み込むことへの懸念も根強い。ユーザーが「AIは中立的であるべき」と考える傾向があるためだ。OpenAIは「ChatGPTの回答は独立しており偏りがなく、会話は非公開に保たれ、人々は自分の体験を意味のある形で制御し続ける」という基本原則を、広告プログラムが拡大しても変えないと明言している。
この原則が実際に守られるかどうかは、今後の第三者監査やユーザーからのフィードバックの蓄積によって検証されていくことになるだろう。少なくともテスト段階では、広告が回答内容に干渉しないという設計は一貫している。
この記事のポイント
- ChatGPTの無料層で広告テストが始まり、日本を含む6カ国に拡大予定である
- 広告は回答内容に影響せず、会話データは広告主に非公開。プライバシー設計が明確だ
- ユーザーは広告の非表示やパーソナライズ設定の管理が可能である
- 対話型AIならではの広告価値が期待される一方、信頼性維持が最大の課題となる
・ 複数業界における17年間のデジタルビジネス開発経験
・ ウェブサイト開発のためのHTML、PHP、CSS、JavaScript等の実用的知識
・ 15ヶ国語対応の多言語SaaSの開発経験
・ 17年間にも及ぶ、Eコマース長期運営経験
・ 幅広い業界でのSEO最適化の豊富な経験

GPT-5.5 Instant 登場。回答精度とパーソナライズ性能が大幅に向上
OpenAIがChatGPTのデフォルトモデルを「GPT-5.5 Instant」に更新した。これまで標準搭載されていたGPT-5.3 Instantを置き換える形で、全ユーザーに順次提供が開始されている。
今回のアップデートの核心は3つだ。事実誤認の大幅な減少、回答の簡潔さの向上、そして過去のチャット履歴や接続アプリを活用した高度なパーソナライズ機能の追加である。内部評価では、医療や法律、金融といった高精度が求められる分野でのハルシネーション(もっともらしい嘘)が52.5%も削減された。
何億人ものユーザーが日常的に利用するデフォルトモデルだからこそ、小さな改善の積み重ねが実用面では大きな差を生む。本記事ではGPT-5.5 Instantの具体的な進化点と、それが実際の利用体験にどう影響するのかを掘り下げていく。
事実誤認を半減させた精度向上の仕組み

GPT-5.5 Instantにおける最大の改善点は、事実誤認(ハルシネーション)の劇的な減少だ。特に医療、法律、金融といった「間違いが許されない領域」で顕著な成果が出ている。
なぜここまでの改善が実現できたのか
OpenAIの公式ブログによると、GPT-5.5 Instantは高精度が求められるプロンプトにおいて、GPT-5.3 Instantと比較してハルシネーション(幻覚)を52.5%削減した。さらに、ユーザーが事実誤認を指摘したチャレンジングな会話においても、不正確な回答を37.3%減らしている。
この改善は単なる「よくわからないときは正直にわからないと言う」といった表面的な振る舞いの調整ではない。モデル自身が回答の妥当性を検証する能力が底上げされており、途中で誤りに気づいた際には自律的に修正できるようになった点が本質的な進化だ。
具体的な改善例から見えるもの
OpenAIが公開した比較例では、GPT-5.5 Instantは数学の問題に対して最初に不正確な解法を提示してしまった場合でも、代入チェックによって誤りを検出し、二次方程式の正しい解へと自力で修正している。一方でGPT-5.3 Instantは誤りに気づいてはいるものの、「解がない」と早々に結論づけてしまい、問題の本質に迫れなかった。
日常生活で使うAIアシスタントにとって、この「自己修正能力」は極めて重要だ。最初の回答が100%正しい必要はないが、誤りに気づいて軌道修正できるかどうかが実用性を大きく左右する。GPT-5.5 Instantのこの特性は、ビジネス文書の作成やデータ分析など、正確性が求められるシーンで特に頼りになるだろう。
冗長な表現を30.2%削減、それでも情報量は落とさない
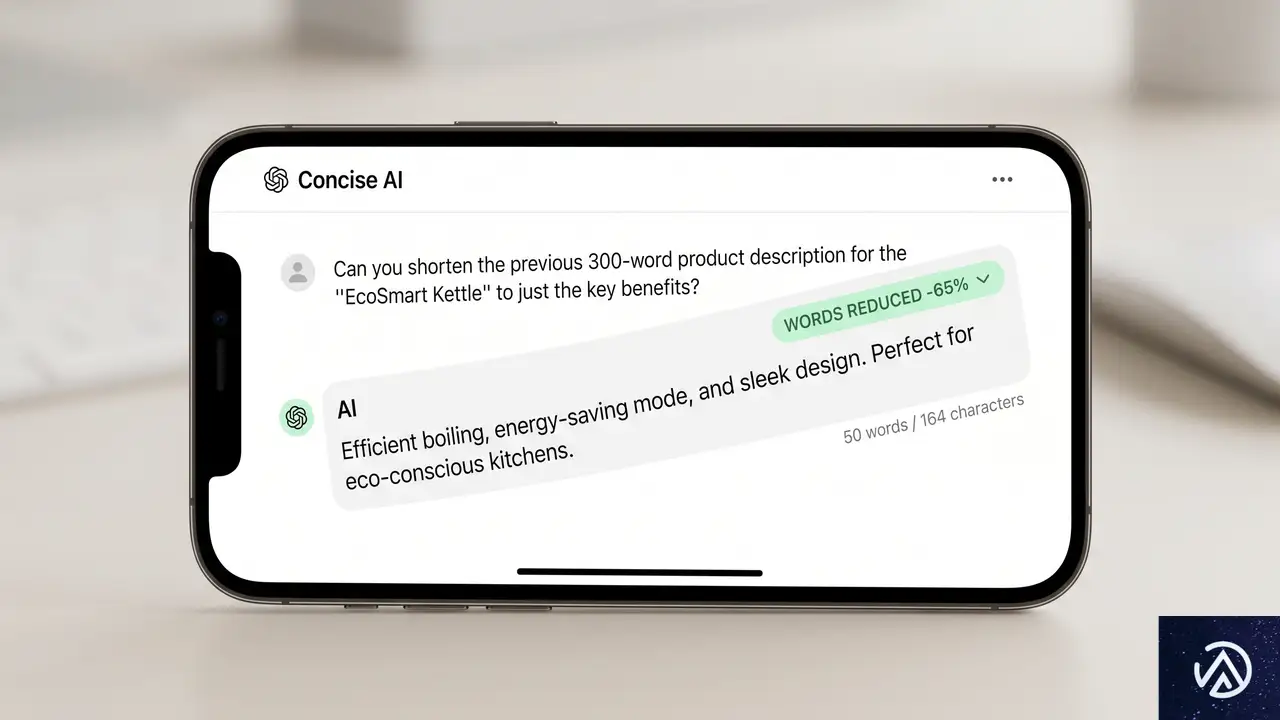
行数:基準値
過剰な絵文字:あり
行数:29.2%削減
不要な装飾:ほぼなし
GPT-5.5 Instantの回答は、前世代モデルと比較して単語数が30.2%、行数が29.2%も削減されている。この数字だけ見ると「情報量が減ったのでは」と心配になるが、実際は逆だ。余計な説明や過剰なフォーマットを省くことで、本当に必要な情報が見つけやすくなっている。
減ったのは「無駄」であって「中身」ではない
OpenAIの説明によると、新モデルは同じ情報をより少ない言葉で届けつつ、むしろ実用性は向上しているという。たとえば職場の人間関係に関するアドバイスを求めるプロンプトでは、GPT-5.3 Instantが「してはいけないこと」を含めた完全なフォーマットで回答するのに対し、GPT-5.5 Instantは状況に応じた実践的な言い回し例を提示し、問題を相手の人格ではなく「境界線」の問題として捉え直す視点を提供している。
ビジネスシーンで重要なのは、この「トーンの適切さ」だ。カジュアルな質問に過剰にフォーマルな回答が返ってくると、むしろ使う側のストレスになる。GPT-5.5 Instantは、状況に応じてフォーマル度を調整できるようになった点で、より人間らしい対話が可能になっている。
チャット履歴や接続アプリを活用した高度なパーソナライズ
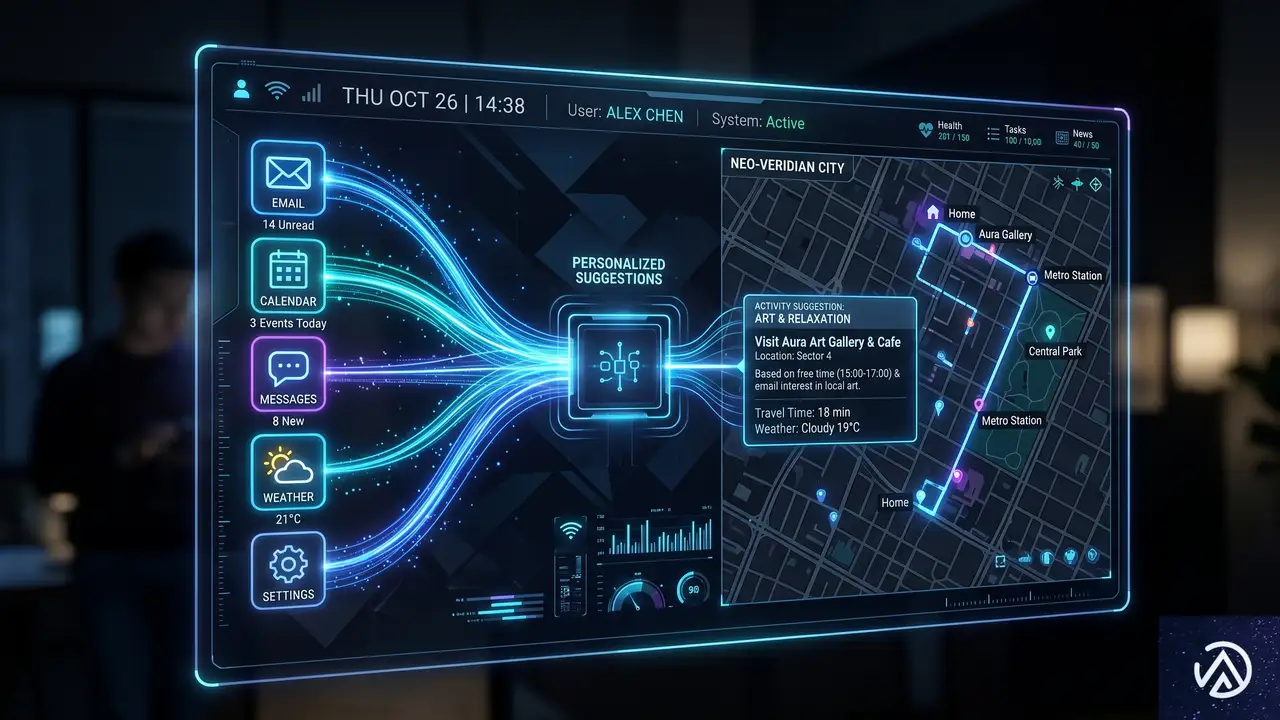
会話の開始 → 過去履歴を検索 → 関連コンテキストを取得 → カスタマイズされた回答を生成
GPT-5.5 Instantのもう一つの大きな進化が、パーソナライズ機能だ。過去のチャット履歴やアップロードしたファイル、さらに接続を許可したGmailの情報などを横断的に参照し、より個人に最適化された回答を提供できるようになった。
「メモリーソース」で見える化されたパーソナライズ
今回のアップデートで特筆すべきは「メモリーソース(Memory Sources)」という新機能の導入だ。これは、AIがどの情報を根拠にパーソナライズされた回答を生成したのかを明示する仕組みである。保存されたメモリーや過去のチャットのうち、回答に使用されたものをユーザーが直接確認でき、不要になった情報は削除や修正ができる。
OpenAIのブログ記事では、サンフランシスコ在住のユーザーに対するレストラン提案の比較例が紹介されている。GPT-5.3 Instantが居住地を考慮した一般的な提案にとどまるのに対し、GPT-5.5 Instantは過去の好みや予定をふまえた、より洗練された個別提案を行っている。この差は日常的な使い勝手に直結するだろう。
プライバシーはユーザーが制御できる設計
パーソナライズが強化されると、当然「どこまで自分の情報が使われるのか」という懸念が出てくる。この点についてOpenAIは、メモリーソースはチャットを共有しても他の人には表示されないこと、不要なチャットは削除できること、一時的なチャット(Temporary Chat)を使えばメモリーが使用も更新もされないことを明記している。
また個人情報の扱いについては、企業や教育機関向けプラン(Business、Enterprise、Edu)では、ユーザーデータがモデル学習に使用されない設定がデフォルトで適用される。個人利用でも、設定からデータ提供の可否を切り替えられる。
APIとロールアウトのスケジュール
GPT-5.5 InstantはChatGPTの全ユーザー向けに5月5日から順次提供が開始されている。APIではchat-latestとして利用可能だ。有料ユーザー向けには、旧モデルのGPT-5.3 Instantも3ヶ月間はモデル設定から選択できる形で残される。
パーソナライズ機能の強化は、まずPlusおよびProユーザー向けにWeb版で展開され、モバイル版にもまもなく対応する予定だ。その後、数週間以内にFree、Go、Business、Enterpriseプランにも拡大される。メモリーソース機能はすべてのコンシューマープランでWeb版から提供開始され、モバイル版も順次対応する。
この記事のポイント
- GPT-5.5 Instantは医療や法律など高精度が求められる分野でハルシネーションを52.5%削減した
- 回答の単語数が30.2%削減され、より簡潔で実践的なアドバイスが得られるようになった
- 過去のチャット履歴やGmailなどの接続アプリを活用したパーソナライズ機能が大幅に強化された
- メモリーソースにより、AIが参照した情報をユーザー自身が確認・管理できるようになった
- 全ユーザー向けに順次提供開始、旧モデルは有料プランで3ヶ月間利用可能
・ 複数業界における17年間のデジタルビジネス開発経験
・ ウェブサイト開発のためのHTML、PHP、CSS、JavaScript等の実用的知識
・ 15ヶ国語対応の多言語SaaSの開発経験
・ 17年間にも及ぶ、Eコマース長期運営経験
・ 幅広い業界でのSEO最適化の豊富な経験

OpenAIが高度なアカウント保護機能を発表、パスワードレス認証を標準化
OpenAIは2026年4月30日、ChatGPTアカウントのための新たな保護オプション「Advanced Account Security(高度なアカウントセキュリティ)」の提供を開始した。ChatGPTとCodexの両方に適用される、フィッシング耐性を備えた認証手段を標準化する設定だ。特にジャーナリストや研究者、政治家など、高度な標的型攻撃のリスクに晒されるユーザーを主な対象としている。
この設定を有効にすると、パスワードによるログインが無効化され、パスキーまたは物理セキュリティキーが必須になる。同時に、メールやSMSによるアカウント復旧も停止される。OpenAIのサポートチームでさえ、この設定を有効にしたアカウントの復旧支援はできない仕様だ。セキュリティと引き換えに自己責任の範囲が拡大する点が特徴といえる。
Advanced Account Securityとは何か、そしてなぜ今必要なのか

ChatGPTは個人の相談事から業務の自動化まで利用範囲が急拡大している。アカウントには長期間にわたる会話履歴、個人情報、接続された外部ツールの認証情報などが蓄積される。OpenAIのブログ記事では「時間の経過とともに、ChatGPTアカウントは機密性の高い個人情報や業務コンテキストを保持し、接続されたツールやワークフローの中心に位置するようになる」と指摘されている。
フィッシング攻撃やセッション乗っ取りによってAIアカウントが侵害された場合、単なるパスワード漏洩以上の被害が想定される。過去の会話から企業秘密が推測されたり、APIキーや連携ツール経由で二次被害が広がるリスクがある。この新機能は、そうしたアカウント乗っ取り(Account Takeover)の脅威に対抗するための総合的な防御策だ。
上記の比較で示したように、認証手段と復旧フローの両面で防御が強化される。重要なのは、この設定がOpenAIの「Cybersecurity Action Plan(サイバーセキュリティ行動計画)」の一環であることだ。同社は国家安全保障や重要システムの保護に貢献する技術へのアクセス拡大を掲げており、本機能の提供はその具体的な施策にあたる。
標的になりやすいユーザー層とは
OpenAIのブログ記事では、ジャーナリスト、選挙で選ばれた公職者、政治的反体制活動家、研究者、そして「特にセキュリティ意識の高い人々」が具体的な対象として挙げられている。こうした層は国家支援のハッキンググループや高度なソーシャルエンジニアリング攻撃の標的になりやすく、標準的なパスワード認証やSMS認証では防御が不十分だ。
フィッシング攻撃では、精巧な偽ログインページでパスワードやワンタイムコードを入力させ、その情報を攻撃者がリアルタイムで転送する手法(中間者攻撃)が多用される。こうした攻撃に対し、FIDO(Fast IDentity Online)規格に準拠したパスキーや物理セキュリティキーは、ドメイン名と秘密鍵が数学的に結びつく仕組みで偽サイトへの認証情報入力を根本的に阻止する。
4つの柱で構成される保護メカニズム

Advanced Account Securityは単一の機能ではなく、認証から復旧、セッション管理、プライバシー設定に至るまで、4つの独立したセキュリティ強化策を一括で適用するパッケージだ。ここでは各要素を詳しく解説する。
1. パスワードレス認証の強制
この設定を有効にすると、パスワードによるログインが完全に無効化される。以降はパスキー(生体認証やデバイスPINを利用したFIDO認証情報)か、YubiKeyのような物理セキュリティキーのいずれかでしかログインできなくなる。これにより、フィッシングに強い認証がデフォルトになるわけだ。
パスキーとは、公開鍵暗号方式を応用した新しい認証技術である。簡単に説明すると、ユーザーのデバイス内に秘密鍵が安全に保管され、サービス側に公開鍵が登録される仕組みだ。ログイン時には生体認証やデバイスロック解除で本人確認が行われ、偽サイトでは秘密鍵が応答しないためフィッシングが成立しない。パスワード管理の手間もなくなる点が実務上の利点として大きい。
2. アカウント復旧手段の厳格化
通常のChatGPTアカウントでは、メールアドレスや電話番号を使ってパスワードをリセットし、アカウントへのアクセスを復旧できる。しかし攻撃者がメールアカウントを侵害したり、SIMスワップ(携帯電話番号の乗っ取り)を行った場合、この復旧経路自体が弱点になりうる。
Advanced Account Securityを有効にすると、メールとSMSによる復旧が無効化される。代わりにバックアップ用のパスキー、セキュリティキー、またはリカバリーキー(事前に発行される使い切りの文字列)のいずれかでしか復旧できなくなる。OpenAIのブログ記事では「復旧がこれらのより安全な手段に制限されるため、OpenAIサポートは本機能を有効化したユーザーのアカウント復旧を支援できない」と明記されている。利便性と引き換えに、復旧は完全に自己責任になる点を理解しておく必要がある。
3. セッション管理と通知
サインイン後のセッション有効期間が短縮される。これはデバイスの紛失や盗難、あるいは社内システム上でセッションが残ったままになるリスクを低減する狙いがある。仮にアクティブなセッションが侵害されたとしても、攻撃者が悪用できる時間枠が狭まる。
加えて、アカウントに新しいログインが発生するたびに警告通知が届くようになる。ユーザーは自身のアカウントにサインインしている全デバイスのアクティブセッションを一覧表示し、不要なセッションを手動で終了させることも可能だ。これにより、異常なログインを早期に検知し対処できる。
4. モデル学習データからの自動除外
機密性の高い情報を扱うユーザーの中には、自身の会話がAIモデルの学習に使われることを望まないケースがある。Advanced Account Securityを有効にすると、この設定が自動的に適用され、該当アカウントの会話データはOpenAIのモデル訓練に使用されなくなる。通常は手動でオプトアウト設定を行う必要があるが、セキュリティ強化機能を有効にすることで同時にプライバシー保護も担保される設計だ。
Yubicoとの提携と物理セキュリティキーの提供

OpenAIはハードウェア認証のリーディングカンパニーであるYubicoと提携し、Advanced Account Securityの利用者向けに割引価格のセキュリティキーバンドルを提供する。具体的には、ノートPCに挿しっぱなしで日常的な認証に使う「YubiKey C Nano」と、バックアップおよびスマートフォン認証用の「YubiKey C NFC」の2本セットだ。
物理セキュリティキーは、フィッシング攻撃に対する最も強力な防御手段のひとつとされる。偽のログインページでは正しい認証応答を生成できず、仮にユーザーが騙されて違うサイトでキーをタッチしても、認証情報が盗まれることはない。OpenAIのブログ記事では、この割引バンドルを「Advanced Account Securityの利用者向け」としながらも、すべての対象ユーザーがウェブ版ChatGPTのセキュリティ設定から購入できるとも述べている。FIDO準拠の他社製セキュリティキーや、ソフトウェアベースのパスキーも併用可能だ。
Codexおよびエンタープライズ利用への影響

今回の機能はChatGPTだけでなく、Codexアカウントにも保護を適用する。Codexは自然言語からコードを生成する開発者向けツールで、APIキーや本番環境の設定情報など、侵害された場合の影響が極めて大きい情報を扱う。OpenAIはCodexについて「開発者がアイデアを動作するソフトウェアに変える方法を変革している」と位置づけており、そのアカウント保護は開発者コミュニティ全体のセキュリティに直結する。
さらにOpenAIは、サイバーセキュリティ分野の検証済み防御者に対して最も高度なモデルへのアクセスを提供する「Trusted Access for Cyber」プログラムを展開している。2026年6月1日以降、このプログラムに参加する個人メンバーはAdvanced Account Securityの有効化が必須になる。組織向けには、シングルサインオンのワークフローにフィッシング耐性のある認証が組み込まれていることを証明する代替手段も用意される。
OpenAIのブログ記事では「ChatGPTの広範な消費者リーチは、職場への強力な流通チャネルを生み出している。需要は基本的なモデルアクセスから、ビジネス運営を再構築するインテリジェントシステムへと急速に移行している」と述べられており、個人利用から業務利用への広がりを背景に、エンタープライズ環境へのセキュリティ対策拡大も示唆されている。
任意でのオプトイン。セキュリティ設定画面から有効化。
同一ログインで保護が適用される。APIキーやコード資産も防御対象。
2026年6月1日から有効化が必須。個人は強制、組織は代替証明も可。
この記事のポイント
- OpenAIがChatGPTとCodex向けに「Advanced Account Security」を提供開始。アカウント乗っ取り対策を強化するオプトイン設定だ
- パスワードログインを無効化し、パスキーまたは物理セキュリティキーを必須にする。フィッシング耐性が飛躍的に向上する
- SMSやメールによるアカウント復旧を停止。復旧はバックアップキーでのみ可能で、サポートによる復旧支援も受けられなくなる
- Yubicoと提携し、2本組のセキュリティキーバンドルを割引価格で提供。FIDO準拠の他社製品も利用可能だ
- Trusted Access for Cyber参加者は2026年6月1日以降、本機能の有効化が必須となる
・ 複数業界における17年間のデジタルビジネス開発経験
・ ウェブサイト開発のためのHTML、PHP、CSS、JavaScript等の実用的知識
・ 15ヶ国語対応の多言語SaaSの開発経験
・ 17年間にも及ぶ、Eコマース長期運営経験
・ 幅広い業界でのSEO最適化の豊富な経験

AI検索エンジンの引用傾向比較、ブランド戦略に示唆
主要なAI検索エンジン5つを比較した調査で、引用されるウェブサイトの種類に大きな差があることがわかった。一方で、特定の製品やサービスと結びついたブランド名は、どのAIでも共通して引用されやすい傾向にある。
この記事では、BrightEdge社の調査データを基に、ChatGPTやGoogle AI Overviews、Gemini、PerplexityといったAIが「何を情報源として選ぶのか」を分析する。AI時代のSEO対策として、自社サイトの情報設計やブランディングにどう活かすべきか、具体的な論点を提示する。
5つのAIサーチエンジンが示す、引用ソースの「分散」と「集中」
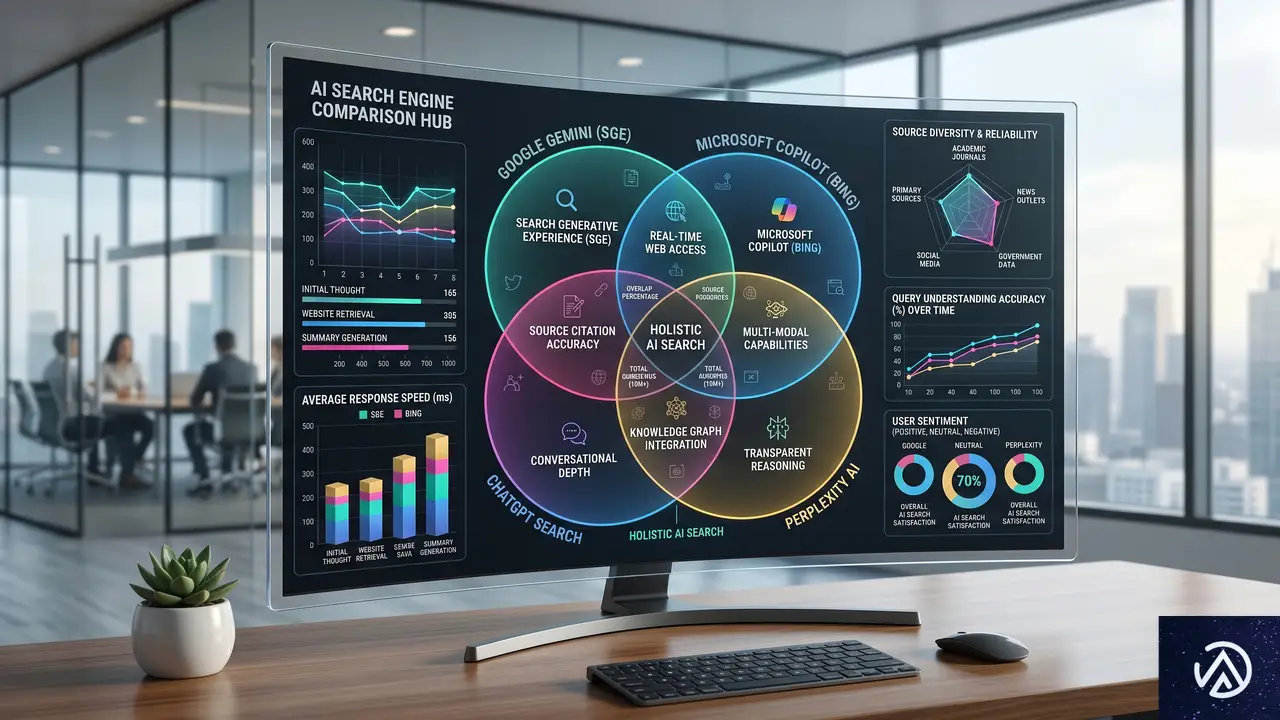
今回の調査は、2026年4月にBrightEdge社が実施したものだ。ChatGPT、Google AI Overviews、Google AI Mode、Google Gemini、Perplexityの5つについて、生成された回答の中でどのようなサイトが引用されているかを分析している。
まず注目されたのは、各AIエンジンが引用する上位サイトの重なり具合、つまり「ソース重複率」だ。最も重複が少なかった組み合わせでは、わずか16%の一致率にとどまった。対照的に、最も高い組み合わせでは59%のサイトが重複していた。
この数字が意味するのは、AIによって情報源の選び方が全く異なり得るという事実だ。あるAIで引用されるからといって、別のAIでも同様に扱われる保証はない。複数のAI検索エンジンでの露出を狙うなら、それぞれの特性を踏まえた対策が必要になる。
ブランド名の一致率は相対的に高い
ソース重複率とは対照的に、回答内で言及される「ブランド名」に関しては、AI間でより高い一致が見られた。最も低い組み合わせでも36%、高い組み合わせでは最大55%のブランド名重複率が記録されている。
つまり、各AIは異なるウェブサイトを参照しているにもかかわらず、結果として同じブランド名にたどり着く傾向がある。これは、製品やサービスと強く結びついたブランドが、業界全体で広く認知されていることの反映だ。信頼できるウェブサイトから繰り返し言及されるブランドは、AIの学習や検索プロセスでも再現性が高まる。
Search Engine Journalの著者Roger Montti氏は、この点について「消費者の頭の中でブランドと製品・サービスを結びつけることが、ブランド検索の増加につながる」と指摘している。Googleが2004年頃からNavboostと呼ばれる仕組みでユーザー行動シグナルをランキングに活用してきたことや、ブランドナビゲーションに関する特許を取得している事実も、この考えを裏付けている。
信頼されるサイトの種類はAIごとに大きく異なる

BrightEdgeは引用されたサイトを3つのカテゴリに分類した。政府や教育機関、大企業のサイトを含む「機関系サイト」、メディアやレビューサイト、リスティングを含む「商業・編集系サイト」、そしてフォーラムや動画プラットフォームなどの「UGC(User Generated Content / ユーザー生成コンテンツ)」だ。
分析の結果、すべてのAIエンジンがこれら3つを情報源として使っているが、そのバランスには大きな差があることが判明した。機関系サイトの引用率は低いエンジンで10%、高いエンジンで26%。UGCの引用率に至っては、わずか0.2%から18%まで開いている。
最も引用率が高いのは商業・編集系サイトで、AI Overviewsが51%、Geminiでも37%と、どのエンジンでも大きな割合を占める。BrightEdgeはこの結果を受け、「レビューサイト、比較コンテンツ、業界メディア、小売のリスティング、財務データがAIに最もよく参照される」とまとめている。企業はパブリックリレーションズ(PR)活動、業界メディアへの露出、カテゴリ比較コンテンツへの投資が、単独のエンジンだけでなく全てのAI検索エンジンでの可視性向上につながると考えるべきだ。
GeminiとAI Overviewsで異なる「信頼のベクトル」
同じGoogleが提供するAIサービスでも、GeminiとAI Overviewsの間には明確な傾向の違いがある。Geminiは機関系サイトの引用率が26%と突出して高く、UGCは0.2%と極端に低い。つまり、権威ある公式情報を優先する「保守的なAI」といえる。.govドメインの引用率は13%、.orgは23%にのぼる。
一方、AI OverviewsはUGCの引用率が18%と5つのAIの中で最も高い。機関系サイトは10%と相対的に低く、コミュニティの声を積極的に拾う姿勢が見える。この違いは、AI Overviewsの基盤に「FastSearch」と呼ばれる速度優先の仕組みが使われている可能性を示唆するが、Googleから公式な説明はない。
実際の使用感を調べるため、Roger Montti氏が非公式な実験として、特定の電子部品(オペアンプ)の使用感を両方のAIに質問したところ、Geminiはメーカー公式サイトのみを引用したのに対し、AI Overviewsは公式情報に加えて複数のUGCを引用した。UGCには実際のユーザーによる測定データや比較情報が含まれており、質問の文脈によっては非常に有益だ。このことから、質問の種類やユーザーの目的によって、最適な情報源の組み合わせが変わるといえる。
ChatGPTとPerplexity、それぞれの選び方
ChatGPTは他のAIと比較して、引用ソースの多様性が最も高いというデータが出ている。上位10サイトが総引用に占める割合はわずか18.5%で、特定のサイトへの依存度が低い。対照的にPerplexityは26.7%、Geminiは26.3%と、ChatGPTの約1.5倍の集中度だ。
Perplexityは機関系サイトの引用率が22%と高く、.eduドメインも3.2%と他のAIより多く引用している。BrightEdgeのレポートによれば、Perplexityの引用の約30%は医療機関、政府、百科事典、医学出版社のサイトで占められている。つまり、Perplexityは「権威性」を重視するエンジンと位置づけられる。
興味深いのは、.eduドメイン(教育機関のサイト)の扱いだ。SEOコミュニティでは長らく「.eduサイトは権威性が高い」という信念があったが、今回の調査では、いずれのAIも.eduサイトをさほど引用していない。最も高いPerplexityですら3.2%に過ぎず、ユーザーがAIに尋ねる多くの質問において、.eduサイトは権威ある情報源として選ばれにくい現実が明らかになった。
同じGoogleでも異なるAI、3系統の使い分け
GoogleにはGemini、AI Overviews、AI Modeという3つのAI検索サービスが存在するが、これらは同じ会社のプロダクトでありながら、引用傾向は一様ではない。最もサイト重複率が高いAI OverviewsとAI Modeですら一致率は59%で、GeminiとなるとAI Overviewsとの重複率は34%、AI Modeとは27%まで下がる。
このデータから、「Google AIは単一のシステムではない」という現実が浮かび上がる。各サービスは異なるアルゴリズムやデータセットに基づいて情報を選択しており、同じ質問でも表示される情報源が大きく変わる可能性がある。ウェブサイト運営者にとっては、「Google対策」という単一の施策ではなく、どのAI検索面をターゲットにするかを明確にした戦略立案が求められる。
AIエンジンに選ばれるサイトになるための実践論点

今回の調査データを踏まえると、AI検索エンジンでの可視性を高めるための方針が見えてくる。すべてのエンジンに共通して効くのは、製品やサービスとブランドの結びつきを強化することだ。具体的には、業界メディアやレビューサイトでの記事露出、比較コンテンツへの掲載、プレスリリースの配信などが有効な手段になる。
一方で、AIごとの特性に合わせた対策も検討すべきだ。GeminiやPerplexityでの露出を狙うなら、公的機関や業界団体との協業、公式データの公開、学術的な裏付けの提示といった「権威性」の構築が重要になる。AI Overviewsを意識するなら、フォーラムやコミュニティでの自然な言及、ユーザーレビューの充実といったUGCの活性化も効果が見込める。
また、AI検索は信頼できるウェブサイトに掲載されたスポンサード記事(広告であることが明示された記事)も情報源として引用する。FTC(米国連邦取引委員会)のネイティブ広告ガイドラインや、Googleのスポンサード投稿ポリシーに準拠した形でブランドを訴求する手法も、引き続き検討に値する。
重要なのは、どのAIに最適化するかではなく、自社のブランドがどのカテゴリの情報として認識されるかを設計することだ。AIに「選ばれる」サイトになるには、単なるSEOテクニックではなく、実体のあるブランド価値の醸成と、それを多様なメディアに拡散させる情報戦略が欠かせない。
この記事のポイント
- AI検索エンジン5つのソース重複率は最低16%から最高59%で、引用傾向に大きな差がある
- ブランド名の重複率は最低36%と、製品・サービスに結びついたブランドは横断的に強い
- 商業・編集系サイトが最も多く引用され、PRや比較コンテンツの重要性が高まっている
- Geminiは権威性重視、AI OverviewsはUGC重視と、同じGoogle内でも戦略が異なる
- AI時代のSEOでは、個別のエンジン対策よりブランド価値の醸成と多面的な情報発信が鍵を握る
・ 複数業界における17年間のデジタルビジネス開発経験
・ ウェブサイト開発のためのHTML、PHP、CSS、JavaScript等の実用的知識
・ 15ヶ国語対応の多言語SaaSの開発経験
・ 17年間にも及ぶ、Eコマース長期運営経験
・ 幅広い業界でのSEO最適化の豊富な経験

ChatGPTでWooCommerce商品を販売する方法!最新のショッピング機能を導入する全手順
ChatGPTのチャット画面の中で、ユーザーが直接商品を探して購入できる機能が注目を集めている。ユーザーが「4,000円以下の青いヨガマットが欲しい」と入力すると、ChatGPTが登録された店舗から実際の商品を提案し、価格や在庫状況まで表示する仕組みだ。
これは「Agentic Commerce(エージェンティック・コマース)」と呼ばれる新しい販売チャネルだが、多くのWooCommerce運営者は自分の商品をどうやって掲載すればよいか分からずにいる。OpenAIは2025年後半にマーチャントプログラムを開始しており、先行して対応することで競合に差をつけることが可能だ。
この記事では、WooCommerceの商品をChatGPTの検索結果に表示させるための具体的な手順を解説する。OpenAIへのマーチャント登録から、AIが読み取りやすい商品フィードの作成、そして承認を得るためのポイントまでを詳しく見ていこう。
ChatGPT Agentic Commerceとは何か

ChatGPT Agentic Commerce(またはChatGPT Shopping)は、ユーザーがChatGPTとの会話を通じて商品を発見し、そのまま販売元のショップへ移動して購入できる機能だ。従来の検索エンジンとは異なり、AIがユーザーの意図を深く理解した上で、最適な商品を「推薦」してくれるのが特徴である。
この仕組みを支えているのが、ACP(Agentic Commerce Protocol)というプロトコルだ。これはWooCommerceなどのECサイトとChatGPTのショッピング層を接続するための規格である。ChatGPTはこのプロトコルを通じてショップの商品フィードを読み取り、内容を理解して会話の中に反映させる。
上記のように、AIがコンシェルジュのように振る舞うことで、購入意欲の高いユーザーを直接ショップへ誘導できる。ユーザーはショップの決済画面で最終的な購入手続きを行うため、顧客データやブランドのつながりはショップ側が保持し続けられる点も大きなメリットだ。
なぜChatGPTで販売すべきなのか
最大の理由は、購買意欲が非常に高いタイミングでユーザーに接触できることだ。特定の悩みや要望をAIに相談しているユーザーに対し、解決策として自社商品を提示できるため、成約率が高まりやすい。また、AI向けに整理されたデータ(構造化データ)を提供することは、将来的なAI検索最適化(AEO)にもつながる。
さらに、ChatGPTから直接自社サイトへ送客されるため、メールマガジンの登録を促したり、関連商品をアップセルしたりといった従来のマーケティング施策もそのまま活用できる。プラットフォームに完全に依存するのではなく、集客の入り口としてAIを活用する形になるからだ。
準備すべきものと商品識別コードの重要性

ChatGPTに商品を掲載するためには、正確な商品データが必要不可欠だ。特に多くのWooCommerce運営者がつまずきやすいのが、GTIN(国際取引商品番号)やMPN(製造者パーツ番号)といった識別コードの設定である。OpenAIは、フィード内の各商品にこれらの一意の識別子が含まれていることを求めている。
GTINには、バーコードでおなじみのJANコード(日本)やEANコード、書籍に使われるISBNなどが含まれる。他社ブランドの商品を転売している場合は、パッケージやメーカーサイトでこれらの番号を確認できる。自社製品の場合は、独自に管理番号(MPN)を割り当てる必要がある。
世界共通のバーコード番号。転売品や一般流通品に必須。
製造者が独自に付ける型番。自社製品やハンドメイド品で使用。
書籍専用の国際標準図書番号。
WooCommerceの標準機能では、SKU(在庫管理単位)を入力する欄はあるが、GTIN専用の入力欄が不足している場合がある。その場合は、プラグインを使用して項目を追加するか、SKU欄をMPNとして代用することになる。商品数が多い場合は、CSVファイルで一括エクスポートし、表計算ソフトで番号を入力してから再インポートする方法が効率的だ。
ハンドメイドや一点物の扱いはどうなるか
独自の商品を作っている場合、GTINを持っていないことも多いだろう。その場合は、自分たちで一貫したフォーマットのMPNを作成すればよい。例えば「SHOPNAME-ITEM-001」のような形式で、重複しない番号を各商品に割り当てる。これにより、AIはそれぞれのアイテムを個別の商品として認識できるようになる。
ChatGPT向け商品フィードの作成手順

OpenAIの仕様に適合した商品フィードを作成するには、専用のプラグインを活用するのが最も確実だ。WP Beginnerの著者によれば、この用途で特に実績があるのは「Product Feed Pro by AdTribes」だという。このプラグインはOpenAI専用の出力フォーマットをサポートしており、設定が容易だ。
まず、プラグインをインストールして有効化したら、ライセンスキーを入力する。その後、管理画面の「Create Feed」から新しいフィードの作成を開始する。ここで、チャンネルの選択肢から「OpenAI Product Feed」を選ぶのがポイントだ。
出力形式とフィールドマッピングの設定
ファイル形式については、OpenAIが推奨している「JSONL(JSON Lines)」を選択しよう。これは各行が独立したJSONオブジェクトになっている形式で、大量のデータを効率的に処理できる特徴がある。次に、フィールドマッピングの画面で、WooCommerceの各項目がOpenAIの属性と正しく結びついているか確認する。
通常、商品名や説明文、価格などは自動で紐付けられるが、先ほど準備したGTINやMPNが正しくマッピングされているかは入念にチェックすべきだ。もし独自のカスタムフィールドを使っている場合は、手動でマッピングを追加することも可能である。設定が完了したら「Generate Product Feed」をクリックしてフィードを生成する。
トラッキング設定で効果を測定する
フィードを生成する際、GoogleアナリティクスのUTMパラメータを有効にしておくことをおすすめする。これにより、ChatGPT経由でどれくらいのユーザーが流入し、実際に購入に至ったかを正確に把握できるようになる。AIチャネルがどれだけ利益に貢献しているかを可視化することは、今後の戦略立案において非常に重要だ。
OpenAIへの申請とフィードの送信

フィードの準備ができたら、OpenAIのマーチャントポータルから登録申請を行う。ビジネスの詳細や販売している商品のカテゴリー、対象地域などを入力して送信する。申請後、OpenAIによる審査が行われるが、この期間は数日から数週間かかる場合があると言われている。現在は米国から順次拡大中だが、早めに列に並んでおくことが得策だ。
審査を通過すると、商品フィードのURLを提出するための案内が届く。WooCommerceの管理画面からコピーしたフィードのURLを送信すると、自動検証プロセスが開始される。通常、24時間から48時間以内に検証結果が判明し、問題がなければChatGPTの検索結果に商品が表示され始める仕組みだ。
よくあるエラーと解決策
フィードの検証でエラーが出る場合、その原因の多くはデータの不備にある。WP Beginnerの記事では、よくある問題として「GTINの欠落」「価格フォーマットの誤り(通貨コードが含まれていないなど)」「商品画像が小さすぎる、またはサポートされていない形式である」といった点が挙げられている。
検証ツールが指摘した箇所を修正し、プラグインでフィードを再生成してから再提出しよう。特に画像については、AIが視覚的に商品を理解するためにも、高解像度でクリアなものを用意することが推奨される。一度承認されれば、あとは商品の在庫状況や価格変更が自動的にフィードに反映され、ChatGPT側の情報も更新されるようになる。
独自の分析:AI検索時代のEC戦略

今回のChatGPT連携は、単なる「新しい広告枠」以上の意味を持っている。これまでのSEO(検索エンジン最適化)が「キーワード」を重視していたのに対し、Agentic Commerceでは「データの構造化」と「文脈の理解」が鍵となる。AIが商品を正しく理解できるように情報を提供することは、もはやオプションではなく必須のスキルになりつつある。
また、この変化は中小規模のショップにとって大きなチャンスだ。巨大なモールの中で価格競争に巻き込まれるのではなく、AIが「このユーザーの悩みを解決するには、このショップのこの商品がベストだ」と判断してくれれば、ブランドの知名度が低くても選ばれる可能性があるからだ。そのためには、商品タイトルや説明文を、人間だけでなくAIにとっても分かりやすく、詳細に記述する努力が求められる。
今後はChatGPTだけでなく、Googleの「AI Overviews」や他のAIエージェントも同様の仕組みを取り入れていくだろう。今のうちにWooCommerceで商品データを整理し、外部プラットフォームへ高品質なフィードを提供できる体制を整えておくことは、数年後のショップの生存を左右する重要な投資になるはずだ。
この記事のポイント
- ChatGPT Agentic Commerceにより、チャット内での商品検索と提案が可能になった
- 掲載にはOpenAIのマーチャント登録と、GTIN/MPNを含む正確な商品データが必要である
- 専用プラグインを使用して、OpenAI推奨のJSONL形式で商品フィードを作成する
- フィードURLを提出し、自動検証をパスすることでChatGPTに商品が表示されるようになる
- AI向けにデータを最適化することは、将来的なAI検索(AEO)対策としても非常に有効である
・ 複数業界における17年間のデジタルビジネス開発経験
・ ウェブサイト開発のためのHTML、PHP、CSS、JavaScript等の実用的知識
・ 15ヶ国語対応の多言語SaaSの開発経験
・ 17年間にも及ぶ、Eコマース長期運営経験
・ 幅広い業界でのSEO最適化の豊富な経験
検索エンジンシェア2026:Google一強の変容とAI検索が変えるSEOの未来
検索エンジンの世界で、10年以上にわたり不動の地位を築いてきたGoogleのシェアに変化の兆しが見えている。2026年3月時点のデータによれば、Googleの世界シェアは90.01%となり、一時期は90%の大台を割り込む場面もあった。長らく「SEO=Google対策」という図式が続いてきたが、その前提が揺らぎ始めている。
この変化の背景には、ChatGPTやPerplexityといったAI検索ツールの急成長がある。さらに、商品の検索はAmazon、若年層のトレンド検索はTikTokといったように、特定の目的を持った検索行動が専門プラットフォームへ分散している点も見逃せない。従来の検索エンジンという枠組みを超えた、新しい集客戦略が求められている。
本記事では、2026年最新の検索エンジンシェアを紐解き、AI検索の台頭がSEOの実務にどのような影響を与えるのかを解説する。ウェブ担当者や制作エンジニアが、今後どのプラットフォームにリソースを割くべきかの判断材料として役立ててほしい。
Googleの現状:AI Overview(SGE)による検索体験の変容
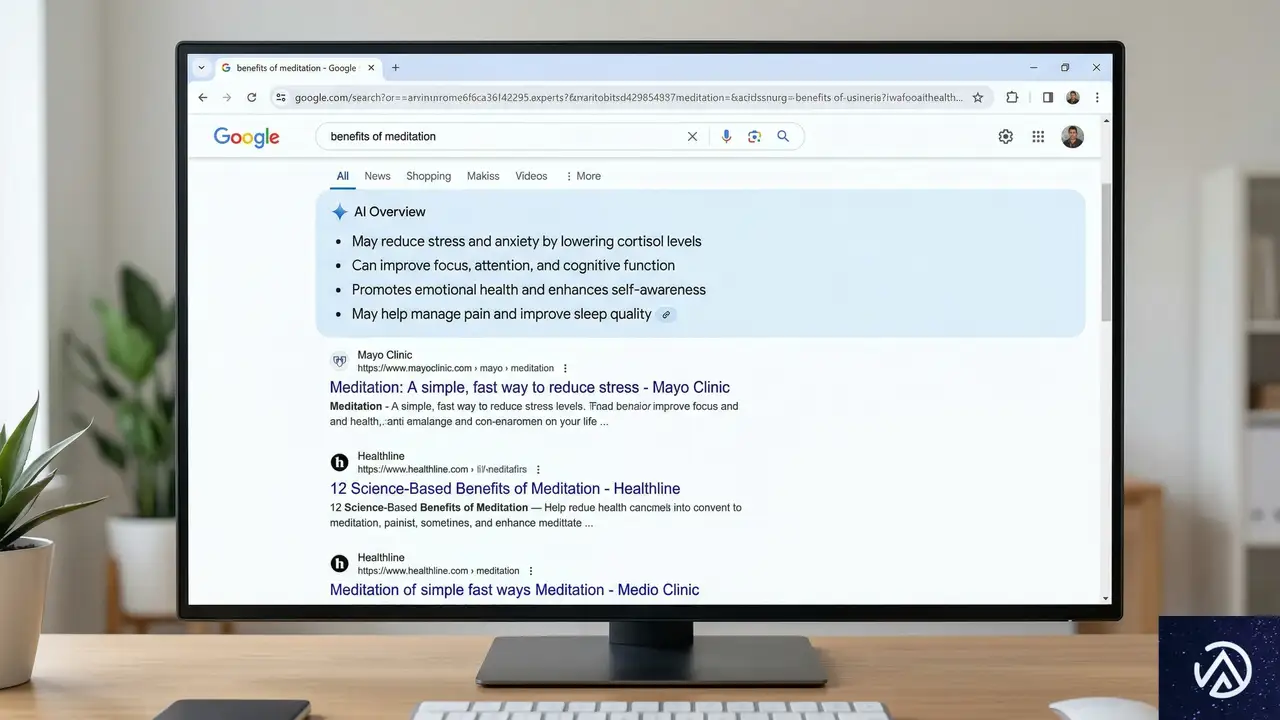
Googleは依然として検索市場の9割を支配するリーダーだ。StatCounterのデータによると、全世界の検索の10回に9回はGoogleで行われている。しかし、その内部構造はここ1年で劇的に変化した。最も大きな要因は、AI Overviews(AIによる概要回答)の全面的な展開である。
シェアの推移とデバイス別の特徴
Googleのシェアは2015年以降、約89%から93%の間で推移してきた。2024年末には3ヶ月連続で90%を下回り、2026年2月にも再び90%を切るなど、わずかながら低下傾向にある。特にデスクトップ市場ではGoogleのシェアは約82%まで下がり、代わりにMicrosoftのBingが10%を超えるシェアを獲得している。一方で、モバイル市場では94%以上という圧倒的な強さを維持しているのが特徴だ。
「ゼロクリック検索」への対策
AI Overviewsの普及により、ユーザーが検索結果画面(SERP)だけで疑問を解決し、外部サイトをクリックしない「ゼロクリック検索」が増加している。SERP(Search Engine Results Page)とは、検索ボタンを押した後に表示される結果一覧ページのことだ。従来の検索では1位のサイトをクリックするのが一般的だったが、現在はAIの回答や強調スニペット、ローカルパックなどが画面上部を占拠している。これにより、検索順位が上位であっても、必ずしもトラフィック(流入数)に結びつかないケースが増えている。
Bingと第2グループ:AI連携で存在感を増す競合たち

Googleの背後で、MicrosoftのBingが着実に存在感を高めている。グローバルシェアは5.01%と数字上は小さく見えるが、米国市場では10%を超え、デスクトップ環境では無視できない勢力となっている。
Bing:ChatGPTとの連携がもたらすメリット
Bingの成長を支えているのは、AIチャット機能「Copilot」の統合だ。戦略的に重要なのは、ChatGPTの検索機能がウェブ情報の取得にBingのインデックス(索引データ)を利用している点である。つまり、Bingでの評価を高めることは、ChatGPT経由での露出を増やすことにも直結する。競合がGoogle対策に集中している今、Bingへの最適化は比較的少ないコストで成果を出せる「穴場」の戦略と言える。
YahooとDuckDuckGo:特定の層に刺さるプラットフォーム
Yahooのグローバルシェアは1.39%だが、米国では2.86%を保持している。Yahooの検索エンジンはBingの技術を採用しているため、Bing向けの対策を行えば自動的にYahooユーザーにもリーチできる。一方、DuckDuckGoはシェア0.76%ながら、プライバシーを重視する層から根強い支持を得ている。ユーザーの行動を追跡しないという独自性が、GDPR(欧州一般データ保護規則)などのプライバシー規制が厳しい地域で評価されている。
AI検索エンジンの急成長:ChatGPTとPerplexityの影響

従来の検索エンジンシェアの数字には現れないが、ユーザーの検索行動を最も大きく変えているのがAI検索エンジンだ。OpenAIの報告によれば、ChatGPTの週間アクティブユーザー数は2026年2月時点で9億人に達した。これは2025年10月の8億人から数ヶ月で1億人増加した計算になる。
従来の検索と何が違うのか
AI検索の最大の特徴は、複数のリンクを提示するのではなく、情報を統合して「回答」を生成する点にある。ユーザーは対話を通じて情報を深掘りしたり、要約を求めたりできる。Perplexity(パープレキシティ)などのサービスも急成長しており、2025年5月には月間7億8,000万件のクエリ(検索要求)を処理している。これは前年同期の2億3,000万件から3倍以上の成長だ。
新たな手法「GEO(生成エンジン最適化)」の考え方
AI検索の台頭に伴い、SEO業界では「GEO(Generative Engine Optimization:生成エンジン最適化)」という新しい概念が登場している。これは、AIが回答を生成する際の「引用元」として選ばれるための施策だ。Conductorの調査によれば、ウェブ全体のトラフィックのうちAI経由の流入はまだ1.08%程度だが、その伸び率は極めて高い。正確なデータ構造、権威性のあるコンテンツ、そしてAIが理解しやすい論理的な文章構成が、今後の評価を左右することになる。
特定領域でGoogleを凌駕する「垂直検索」の勢力
「何かを探す」という行為は、もはや汎用的な検索エンジンだけで完結しない。特定の目的に特化した「垂直検索」のプラットフォームが、Googleのシェアを実質的に削っている。
Amazon:EC検索の入り口としての地位
Jungle Scoutの調査によると、オンラインでの商品検索の56%は、GoogleではなくAmazonから直接始まっている。Amazonの検索アルゴリズム(A10と呼ばれることもある)は、購入意向の強さを重視する。商品の販売実績やレビュー、在庫状況がランキングに大きく影響するため、物販を行う企業にとってAmazon内でのSEOは、Google対策と同等かそれ以上に重要だ。
TikTok:若年層の「発見」を支えるアルゴリズム
若年層にとって、TikTokは検索ツールとしての役割を強めている。飲食店や旅行先、コスメのレビューなどを探す際、テキストではなく動画での「リアルな体験」を求める傾向がある。TikTokの検索はキーワードの一致よりも、ユーザーのエンゲージメント(反応)を重視する。従来のSEOが「答え」を提示するものだったのに対し、TikTokでの最適化は「発見」されるためのフック(引き)を作ることが中心となる。
2026年以降のSEO戦略:分散投資とAI対応の最適解
Search Engine Journalの記事が指摘するように、単一の検索エンジンだけに依存する時代は終わった。これからのSEO戦略には、以下の3つの視点が必要だ。
第一に、Google内での「AI露出」を狙うことだ。AI Overviewsに引用されるためには、単なるキーワード対策ではなく、トピックに対する網羅的で信頼性の高い回答を提示しなければならない。第二に、BingやChatGPTといったAIプラットフォームへの最適化だ。Bing Webmaster Toolsを活用し、サイトが正しくインデックスされているかを確認するだけでも、競合との差別化になる。
第三に、プラットフォームの使い分けだ。商品ならAmazon、ブランド認知ならTikTok、信頼性の構築なら自社ブログ(Google)というように、目的に応じてリソースを配分する必要がある。検索市場の変化は、ユーザーがより「自分に合った回答」を求めている証拠でもある。技術的なハックに頼るのではなく、ユーザーの検索意図に最も誠実に答えるコンテンツ作りが、結局はどのエンジンでも評価される近道だ。
この記事のポイント
- Googleのシェアは90.01%と依然として高いが、デスクトップでは低下傾向にある
- AI Overviewsの普及により、クリックを伴わない「ゼロクリック検索」への対策が急務となっている
- BingはChatGPTとの連携により、AI検索時代における重要なプラットフォームに浮上した
- ChatGPTやPerplexityなどのAI検索に対応する「GEO」という新しい最適化手法が注目されている
- AmazonやTikTokなど、検索エンジン以外のプラットフォームへの検索分散が進んでいる
・ 複数業界における17年間のデジタルビジネス開発経験
・ ウェブサイト開発のためのHTML、PHP、CSS、JavaScript等の実用的知識
・ 15ヶ国語対応の多言語SaaSの開発経験
・ 17年間にも及ぶ、Eコマース長期運営経験
・ 幅広い業界でのSEO最適化の豊富な経験
ChatGPT広告が4月に一般開放へ:新たな獲得チャネルか、それともブランド税か
OpenAIがChatGPT内に広告を自社で運用できる「セルフサーブ型プラットフォーム」を2026年4月に公開する。これまでの限定的なテスト運用から、中小企業を含む幅広い広告主が直接出稿できる段階へと移行する。この動きは、GoogleやMetaが支配してきたデジタル広告市場に新たな選択肢を提示するものだ。
先行して実施された米国でのパイロット運用では、開始からわずか6週間で年換算収益が1億ドル(約150億円)を突破した。現在、600社以上の広告主が参加しており、その約80%が中小企業であるという。PPC(Pay Per Click / クリック課金型広告)の担当者にとって、この新しいチャネルをどう評価すべきかが急務となっている。
ChatGPT広告は単なる「検索結果への表示」にとどまらず、ユーザーの対話プロセスに介入する新しい体験を提供する。しかし、初期のデータではクリック率がGoogle検索広告を大きく下回るなど、課題も浮き彫りになっている。本記事では、OpenAIの最新発表に基づき、この新チャネルの可能性とリスクを専門的な視点から分析する。
OpenAIがChatGPT広告をセルフサーブ化へ:4月の一般開放で何が変わるか
OpenAIは2026年4月に、広告主が自ら予算やターゲットを設定して広告を配信できる「セルフサーブ(自社運用型)」のプラットフォームを立ち上げる予定だ。これまでは特定の企業に限定された招待制のテストだったが、今後は誰でもアカウントを作成して広告を出稿できるようになる。
パイロット版から一般開放への転換点
2026年1月から開始された初期のテスト運用では、米国の無料プランおよび「Go」プランの成人ユーザーを対象に広告が表示されていた。この段階では、最低出稿金額が5万ドルから10万ドル(約750万〜1,500万円)と非常に高額に設定されており、実質的には大手ブランド向けのプレミアムな媒体という位置づけだった。
セルフサーブ機能の導入により、この参入障壁が取り払われる。中小企業の担当者が、Google広告やMeta広告と同じように、少額の予算からテストを開始できる環境が整うのだ。これは、ChatGPTが「特別な実験場」から「日常的な広告運用チャネル」へと進化することを意味している。
米国以外への対象地域拡大
Search Engine Journalの記事によれば、OpenAIは4月のセルフサーブ公開に合わせて、広告の配信対象地域をカナダ、オーストラリア、ニュージーランドにも拡大する計画だ。日本市場への展開時期については明示されていないが、英語圏での成功を足がかりに、多言語展開が加速するのは確実と見られている。
広告は引き続き、有料プラン(Plus、Pro、Business、Enterprise、Education)のユーザーには表示されない。あくまで無料ユーザーを対象としたマネタイズ手段として維持される方針だ。OpenAIは、広告が回答の内容を歪めることはなく、回答とは明確に区別された形式で表示されることを強調している。
パイロット運用の実績から見える「期待」と「現実」のギャップ
先行テストの結果として報じられた「年換算収益1億ドル」という数字は、一見すると驚異的な成功に見える。しかし、その内実を詳しく見ると、広告主が手放しで喜べる状況ばかりではないことが分かる。
年換算収益1億ドルの数字をどう読み解くか
「年換算収益(Annualized Revenue)」とは、ある特定の期間の収益を1年間に引き延ばして計算した予測値だ。6週間という短期間での数値をベースにしているため、初期の話題性による「お試し出稿」が含まれている可能性が高い。また、限定された在庫に対して高単価なCPM(Cost Per Mille / 1,000回表示あたりの単価)が設定されていたことも、数字を押し上げる要因となった。
Reutersの報告によると、対象ユーザーの約85%が広告を表示できる設定になっているものの、実際に毎日広告を目にしているユーザーは20%未満に抑えられている。OpenAIはユーザー体験を損なわないよう、慎重に配信量をコントロールしている。裏を返せば、まだ「収益化の余地」を残しているとも言えるが、配信密度を高めた際にユーザーがどう反応するかは未知数だ。
クリック率(CTR)に現れた検索広告との違い
マーケターにとって最も注視すべき数字は、広告の反応率だ。eMarketerの調査によれば、ChatGPT広告のCTR(Click Through Rate / クリック率)は平均で0.91%程度に留まっている。これに対し、Google検索広告の平均CTRは約6.4%とされており、大きな開きがある。
この差は、ユーザーの「インテント(検索意図)」の違いに起因すると考えられる。Google検索のユーザーは特定のウェブサイトや解決策を探しているが、ChatGPTのユーザーは「対話」や「情報の整理」を目的としている。対話の途中に差し込まれる広告は、従来の検索広告よりも「ノイズ」として捉えられやすい可能性があるのだ。
ChatGPT広告は「新しい獲得チャネル」か、それとも「ブランド税」か
ChatGPT広告の登場により、広告業界では「ブランド税(Brand Tax)」という言葉が囁かれ始めている。これは、効果が不透明であっても、競合他社に場所を取られないために出稿し続けなければならない「防衛的なコスト」を指す。
ユーザーの検索行動の変化と対話型AIの親和性
ChatGPT広告が単なるブランド税に終わらず、有効な獲得チャネルになる可能性も十分にある。ユーザーは単にキーワードを検索するのではなく、状況を説明し、選択肢を比較し、意思決定のサポートをAIに求めているからだ。この「相談プロセス」の中に、文脈に沿った解決策(広告)を提示できれば、従来の検索広告よりも深いエンゲージメントを生む可能性がある。
例えば「家族5人で北海道旅行に行く計画を立てて」という対話に対し、レンタカー会社やホテルの広告が表示されるのは、ユーザーにとって有益な情報になり得る。このように、検索(Search)とソーシャル(Social)の中間に位置する「対話型コマース」という新しいカテゴリーが確立されるかどうかが鍵となる。
広告表示のイメージ比較(静的デモ)
従来の検索広告とChatGPT広告の表示イメージの違いを、以下のデモで視覚化する。ChatGPT広告は、回答テキストの下部や横に、より文脈に馴染む形で配置される傾向がある。
/* 検索広告と対話型広告の配置イメージ */
.ad-demo-container {
display: flex;
gap: 24px;
align-items: flex-start;
flex-wrap: nowrap;
}
.ad-box {
min-width: 120px;
flex: 1;
border: 1px solid #ddd;
border-radius: 8px;
padding: 12px;
background: #fff;
box-sizing: border-box;
}※このデモは、従来の検索広告とChatGPTにおける広告の馴染み方の違いを視覚化したイメージだ。実際の広告フォーマットはOpenAIの仕様により変更される可能性がある。
どのような企業がChatGPT広告を試すべきか:適正な商材とタイミング

すべての企業が4月の一般開放と同時に飛びつく必要はない。ChatGPTの特性を考えると、初期段階で成果を出しやすい商材と、そうでない商材がはっきりと分かれるからだ。
意思決定が複雑な「高関与商材」との相性
対話型AIの最大の強みは、ユーザーが抱える複雑な課題に対して段階的に情報を整理できる点にある。そのため、以下のような「検討期間が長く、情報収集が重要な商材」は、ChatGPT広告との相性が良いと考えられる。
- B2Bソフトウェア・サービス:導入にあたって比較検討や要件の確認が必要なもの。
- 教育・スクール:自分に合ったカリキュラムを相談しながら探すユーザー。
- 住宅・リフォーム・不動産:予算や条件をAIに伝えながら選択肢を絞り込む段階。
- 高単価な耐久消費財:家具、家電、車など、スペックや口コミを精査する商品。
これらの商材では、ユーザーがAIに対して「自分の状況」を詳しく説明しているため、広告のターゲティング精度が飛躍的に高まる。単純なキーワードマッチング以上の、コンテクスト(文脈)に基づいたアプローチが可能になるのだ。
中小規模の広告主が静観すべき理由
一方で、衝動買いに近い低単価商品や、緊急性の高いサービス(鍵の紛失修理など)は、現時点ではGoogle検索広告の方が効率的だろう。また、既存の検索広告やSNS広告の運用が最適化されていない段階で、新しい未成熟なプラットフォームに予算を割くのはリスクが高い。
初期のセルフサーブプラットフォームでは、計測ツール(コンバージョン計測など)や最適化アルゴリズムがGoogle広告ほど成熟していないことが予想される。そのため、まずは余剰予算がある企業や、先行者利益を狙いたい特定のカテゴリーに絞ったテストが推奨される。
PPC担当者が今すぐ準備しておくべき3つの評価基準

4月の一般開放に向けて、広告運用担当者は「ただ試す」のではなく、効果を正しく測定するためのフレームワークを構築しておく必要がある。OpenAIが提供するデータだけでは、真の投資対効果(ROI)は見えてこないからだ。
成功を定義するKPI(重要業績評価指標)の策定
前述の通り、ChatGPT広告のCTRは低くなる傾向がある。そのため、クリック数や獲得単価(CPA)だけを指標にすると、チャネルの価値を見誤る可能性がある。以下の多角的な視点でのKPI設定を検討したい。
- アシストコンバージョン:ChatGPTでの接触が、その後の直接検索やSNS経由の成約にどれだけ貢献したか。
- ブランドリフト調査:広告表示によって、ブランド名での検索数や認知度が向上したか。
- リードの質:対話を通じて納得した上で流入したユーザーは、既存チャネルよりも成約率(CVR)が高いか。
既存チャネルとの予算配分の最適化
ChatGPT広告は、ユーザーのジャーニーにおいて「検索(需要の回収)」と「SNS(需要の創出)」の中間に位置する。そのため、予算は検索広告から削るのではなく、まずはディスプレイ広告やコンテンツマーケティングの予算の一部を試験的に充当するのが合理的だ。WP Mayorの記事でも指摘されているように、AIプラットフォームへの出稿は「コンテンツの発見」を助ける側面が強いからだ。
この記事のポイント
- OpenAIは2026年4月にChatGPT広告のセルフサーブプラットフォームを公開し、広告運用を一般開放する。
- 先行テストでは6週間で年換算1億ドルの収益を記録したが、CTRは0.91%とGoogle検索広告(6.4%)に比べ大幅に低い。
- B2Bや高単価商材など、ユーザーが「相談」を必要とする高関与商材において、文脈に沿った高い広告効果が期待される。
- 中小規模の広告主は、既存チャネルの最適化を優先しつつ、アシスト効果を測定できる体制を整えてから参入するのが賢明だ。
- 広告が「ブランド税」になるリスクを避け、対話型AI特有のユーザー体験に合わせたクリエイティブとKPI設計が求められる。
・ 複数業界における17年間のデジタルビジネス開発経験
・ ウェブサイト開発のためのHTML、PHP、CSS、JavaScript等の実用的知識
・ 15ヶ国語対応の多言語SaaSの開発経験
・ 17年間にも及ぶ、Eコマース長期運営経験
・ 幅広い業界でのSEO最適化の豊富な経験

AIに引用されるコンテンツの共通点:120万件のデータから判明したSEOの新常識
AIチャットボットが検索の代替手段となりつつある今、自社のコンテンツがAIに「引用」されるかどうかは、Webサイトのトラフィックを左右する死活問題だ。Search Engine Journalが公開した調査結果によると、AIに選ばれるコンテンツには、従来のSEO(検索エンジン最適化)とは異なる独自の評価基準が存在することが明らかになった。
この調査では、120万件を超えるChatGPTの回答と、約9万8,000件の引用データを詳細に分析している。その結果、業界を問わず引用率を14%向上させる「魔法の導入文」や、逆に引用を妨げてしまう「見出し構成のデッドゾーン」の存在が浮き彫りになった。
本記事では、この膨大なデータに基づいた「AIに好まれるコンテンツ制作」の具体策を解説する。単なる執筆テクニックにとどまらない、AI時代のコンテンツ・アーキテクチャのあり方を探っていこう。
導入文の「断定表現」が引用率を14%向上させる

AIがコンテンツを読み取る際、最も重視しているのは「情報の確実性」だ。Search Engine JournalのKevin Indig氏が分析したデータによると、記事の冒頭で「断定的な表現(Declarative Language)」を使用しているページは、そうでないページに比べて引用率が平均14%高いことが分かった。
「〜かもしれない」という曖昧さを排除する
AIは、ユーザーの質問に対して自信を持って回答を提供しようとする。そのため、「このツールは効率化に役立つ可能性がある」といった慎重な言い回し(ヘッジ表現)よりも、「このツールは業務時間を30%削減する」といった明確な主張を好む傾向がある。
特に冒頭の1,000文字以内において、修飾語や前置きを極力減らし、事実をストレートに述べる構成が有効だ。「[X] は [Y] である」あるいは「[X] を使うと [Z] ができる」という直接的な構文を意識するだけで、AIからの評価は大きく変わる。
結論から書き始める「結論先行型」の徹底
多くのWebライティングでは、読者の共感を得るために「背景の説明」や「問いかけ」から始めることが多い。しかし、AI最適化(AEO:Answer Engine Optimization)の観点では、これは逆効果になる場合がある。
AIは情報の「密度」と「即時性」を評価する。記事の最初の段落で、そのページが提供する核心的な情報を提示することが、引用対象として選ばれるための必須条件となっているのだ。
業界ごとに異なる「最適な見出し数」の正体

見出し(Hタグ)の構成は、AIが情報を構造化して理解するための地図となる。興味深いことに、見出しの数は「多ければ良い」というわけではなく、業界ごとに明確な「スイートスポット(最適値)」が存在する。
見出し3〜4個は「デッドゾーン」になるリスク
調査対象となったすべての業界において共通していたのは、「見出しが3〜4個の記事は、見出しがゼロの記事よりも引用率が低い」という衝撃的な事実だ。これは、中途半端な構造化がAIのナビゲーションを混乱させている可能性を示唆している。
構造化を徹底して情報の階層を明確にするか、あるいは一切の装飾を省いて散文として読ませるか、どちらかの極端なアプローチの方がAIには好まれる。中途半端な見出し構成は、情報の網羅性と構造の明快さの両方を損なう「デッドゾーン」となっているのだ。
業界別:SaaSは20個以上、医療は0個が有利?
最適な見出しの数は、扱うトピックによって大きく異なる。例えば、CRMやSaaS関連の分野では、20個から49個もの見出しを持つ詳細な比較ガイドが高い引用率を記録している。これは、AIが多機能なソフトウェアを比較する際、細かくセクション分けされた情報を求めているためだ。
一方で、医療(Healthcare)分野では、見出しがゼロ、あるいは極めて少ないページの方が好まれる傾向がある。医療情報においては、断片的な見出しの羅列よりも、文脈が維持された一貫性のある記述が「権威ある解説」として評価されやすいと考えられる。
AIが好むエンティティ:日付と数値、そして「価格」の罠

AIは単なる単語の羅列ではなく、意味のある情報の塊(エンティティ)を識別している。Google Natural Language APIを用いた分析によると、特定のエンティティの有無が引用の成否を分けることが判明した。
「日付」と「具体的な数値」は信頼の証
ほぼすべての業界で共通してプラスの信号となったのが、「DATE(日付)」と「NUMBER(数値)」だ。情報の鮮度を示す日付と、客観的な裏付けとなる統計数値は、AIにとって「引用する価値がある」と判断するための強力なトリガーとなる。
特に公開日や更新日を明記し、本文中で具体的なデータ(例:15%の改善、3,000人のユーザーなど)を提示することは、AIからの信頼を勝ち取るための最もシンプルな近道といえる。
価格情報の掲載が引用を妨げる理由
意外なことに、「PRICE(価格)」に関するエンティティは、金融以外のほとんどの業界でマイナスの信号として働いている。冒頭で価格について強調しすぎると、AIはそのコンテンツを「客観的な情報源」ではなく「商業的な広告ページ」と見なす傾向がある。
ただし、金融業界だけは例外で、金利や手数料などの価格情報が引用率を高める要因となっている。これは、金融系のクエリにおいては価格そのものがユーザーの求める「回答」に直結するためだ。業界の特性を理解したエンティティ配置が求められる。
UGC(ユーザー生成コンテンツ)はAIに選ばれない?

Googleの検索結果では、RedditやQuoraといったユーザー投稿型のコミュニティサイトが優遇される傾向(通称:Reddit効果)が見られる。しかし、AIの引用データはこの傾向とは全く異なる結果を示した。
Reddit効果は検索エンジン限定の現象か
調査データによると、ChatGPTが引用するソースの94.7%は企業や専門メディアによる「コーポレート/エディトリアルコンテンツ」であり、UGC(ユーザー生成コンテンツ)の割合は極めて低い。金融や医療といった専門性が求められる分野では、UGCの引用率は1%未満にとどまっている。
これは、AIが回答を生成する際、個人の主観的な意見よりも、組織が責任を持って公開している「構造化された公式情報」を優先していることを意味する。AI時代においても、公式サイトとしての権威性を磨くことの重要性は変わっていない。
暗号資産分野で見られる唯一の例外
唯一の例外は、暗号資産(Crypto)分野だ。この分野ではUGCの引用率が9.2%と比較的高い。技術の進化が速く、公式ドキュメントよりもRedditや開発者コミュニティの方が最新かつ詳細な情報を持っていることが多いため、AIも例外的にこれらのソースを頼りにしている。
この結果から、情報の「速報性」や「技術的な深さ」が公式サイトを上回る場合に限り、コミュニティサイトにもAI引用のチャンスがあることがわかる。
AI時代を生き抜くための新SEO戦略

今回の分析結果を踏まえると、これからのSEO(あるいはAEO)は「文章の質」だけでなく「情報のアーキテクチャ」の戦いになると断言できる。AIに選ばれるためには、人間にとっての読みやすさと、マシンにとっての解析しやすさを高次元で両立させる必要がある。
コンテンツ・アーキテクチャの重要性
AIは、ページ内の特定の場所を重点的にスキャンし、情報の階層を理解しようとする。単にキーワードを詰め込むのではなく、業界ごとの最適な見出し構成(SaaSなら詳細に、医療なら簡潔に)を採用し、AIが情報を抽出しやすい「器」を作ることが重要だ。
また、有名なブランド名や一般的な用語(Knowledge Graphに登録されているような既知の情報)を並べるよりも、特定のニッチな数値や独自の手法といった「具体的で詳細なエンティティ」を含める方が、AIにとっては引用する価値が高いと判断される。
業界特化型の最適化へのシフト
すべての業界に共通する「魔法の公式」は存在しない。導入文を断定的に書くという基本ルールを除けば、最適な文字数、見出しの深さ、含めるべきエンティティの種類は、すべて業界の規範(ノルマ)に依存する。
自社が属する業界において、AIがどのようなコンテンツを好んで引用しているかを分析し、そのパターンに構造を合わせていく「業界特化型の最適化」こそが、これからのWebサイト運営者に求められるスキルとなるだろう。
この記事のポイント
- 導入文は「〜かもしれない」を避け、断定的な表現で結論から書き始める
- 見出しの数は業界ごとに最適化し、中途半端な3〜4個の構成は避ける
- 日付と具体的な数値を積極的に盛り込み、情報の客観性と鮮度をアピールする
- AI引用ではReddit等のUGCよりも、企業・専門サイトの公式情報が圧倒的に有利
- 汎用的なSEOテクニックではなく、業界の特性に合わせた構造設計が必要である
・ 複数業界における17年間のデジタルビジネス開発経験
・ ウェブサイト開発のためのHTML、PHP、CSS、JavaScript等の実用的知識
・ 15ヶ国語対応の多言語SaaSの開発経験
・ 17年間にも及ぶ、Eコマース長期運営経験
・ 幅広い業界でのSEO最適化の豊富な経験