

.ALドメインのDNSSEC障害、CloudflareがEDE 33で透明性を向上
2026年7月3日、アルバニアの国別コードトップレベルドメイン「.AL」でDNSSECの鍵ロールオーバーに失敗する障害が発生した。この影響で、.ALドメインを使用する政府機関や銀行、メディアサイトが一時的にアクセス不能となった。
Cloudflareが運用するパブリックDNSリゾルバ「1.1.1.1」は、この障害に対してネガティブトラストアンカー(NTA)を適用して暫定対応を実施。同時に、新しい拡張DNSエラー(EDE)コード「EDE 33」を初めて導入し、NTAが適用されていることをクライアントに明示した。
この記事では、.AL障害の経緯と、DNS運用におけるNTAの透明性を高めるEDE 33の技術的意義を解説する。TLDレベルのDNSSEC障害がもたらす影響と、再発防止に向けた課題を考察する。
.ALドメインで何が起きたのか
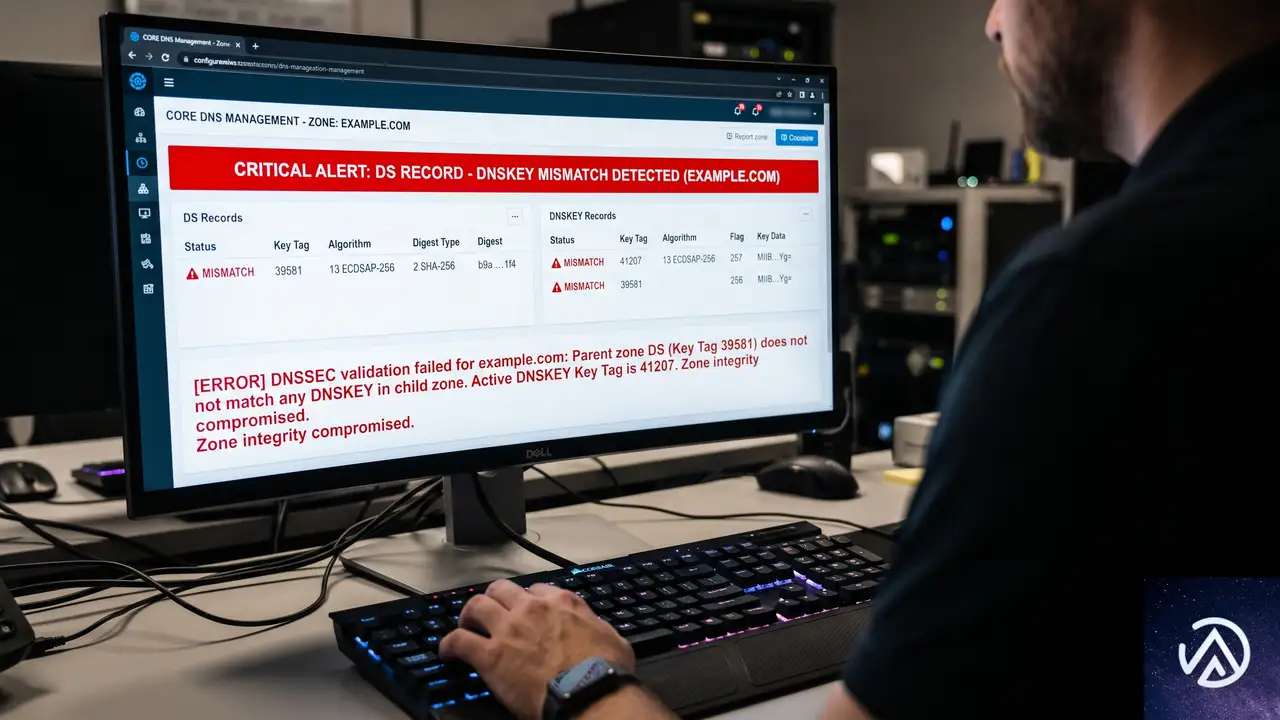 .DEに続くTLD障害の連鎖
.DEに続くTLD障害の連鎖この障害は、わずか2ヶ月前にドイツの.DE TLDで発生した同様のDNSSEC障害を想起させる。.DEの事例でも、1.1.1.1はNTAを適用して暫定対処を行い、事業者の対応を待つ形となった。
TLDレベルのDNSSEC障害は頻発するものではないが、一度発生すると配下の全ドメインに影響が波及する。.ALはCloudflare RadarのTLDランキングで191位に位置し、アルバニアの政府サービスや金融機関、報道機関などが集まる重要なドメイン空間だ。
この比較からわかるように、DNSSECの信頼チェーンはルートゾーンのDSレコードとTLDゾーンのDNSKEYが一致して初めて成立する。ロールオーバーの手順を誤ると、連鎖的に全下位ドメインの検証が失敗する仕組みだ。
NTA適用の判断基準
CloudflareはNTAを適用する前に、AKEPへの直接連絡とDNS-OARC Mattermostへの投稿を通じてコミュニティに注意喚起を行った。しかし、AKEPの連絡先アドレス自体が.ALドメインだったため、障害発生中は連絡が取れないという悪循環に陥った。
NTAの適用は、DNSSEC検証を停止するという強い措置だ。Cloudflareの著者によれば、.DEの事例と同様に「障害が公共に確認されており、すべての検証リゾルバに等しく影響する」という点を重視して判断したという。検証を停止しても名前解決を維持する方を優先した格好だ。
NTAの抱える透明性の課題

NTAはDNSSECの緊急回避手段として有効だが、一つ大きな欠点がある。それは、クライアント側からNTAの適用を検知できないことだ。NTA配下で返されたDNS応答は、通常の検証済み応答と見分けがつかない。
RFC 7646でもこの問題は認識されており、NTAの適用状況を運用者が公開することが推奨されている。Cloudflareは.DEや.ALの際にステータスページで情報を公開したが、それでも利用者が自発的に確認しなければ気づけない。監視ツールやアプリケーションがDNS応答だけで状況を把握する手段がなかった。
ANSWER: google.al → 142.251.142.196
EDE: 9 (DNSKEY Missing)
EDE: 33 (Negative Trust Anchor)
ANSWER: google.al → 142.251.142.196
● EDE 9で根本的なDNSSECエラーも同時に通知
この「見えないNTA」は、なりすましDNS応答と正当な応答を区別するDNSSECの根幹を揺るがす。NTAが適用されている間、利用者は保護されていない状態で通信していることになるが、それを知る術がなかったのだ。
EDE 33がもたらす透明性

拡張DNSエラー(EDE)コードはRFC 8914で定義されており、DNSリゾルバがエラー時だけでなく成功応答にも追加のコンテキスト情報を付加できる仕組みだ。Quad9のBabak Farrokhi氏が提案し、Cloudflareも共同執筆者として参加したインターネットドラフトで、NTAの適用を示す新しいEDEコード「EDE 33」が定義された。
1.1.1.1は.AL障害において、このEDE 33を初めて実運用に投入した。NTAが適用されている間、.ALドメインへのすべてのDNSクエリに対して、EDE 33が付加された応答が返されている。これにより、クライアントや監視ツールはDNS応答だけで「この応答はDNSSEC未検証である」と判断できるようになった。
EDE 33の実装と応答例
以下は、1.1.1.1にgoogle.alの名前解決を問い合わせた際の応答だ。ステータスはNOERRORで正しい回答が返されているが、2つのEDEコードが付加されている。
$ kdig @1.1.1.1 google.al
;; ->>HEADER<<- opcode: QUERY; status: NOERROR; id: 32848
;; Flags: qr rd ra; QUERY: 1; ANSWER: 1; AUTHORITY: 0; ADDITIONAL: 1
;; EDNS PSEUDOSECTION:
;; Version: 0; flags: ; UDP size: 1232 B; ext-rcode: NOERROR
;; EDE: 9 (DNSKEY Missing): 'no SEP matching the DS found for al.'
;; EDE: 33 (Negative Trust Anchor): 'a Negative Trust Anchor has been applied for this query (see RFC 7646)'
;; ANSWER SECTION:
google.al. 300 IN A 142.251.142.196EDE 9(DNSKEY Missing)は、DNSSECの信頼チェーンが切断された根本原因を示している。EDE 33(Negative Trust Anchor)は、1.1.1.1がNTAを適用して応答を返したことを示す。この2つの情報が揃うことで、運用者は「本来は検証エラーになる状況だが、NTAによって暫定的に解決された」という全体像を把握できる。
このフローは、1.1.1.1内部でNTAがどのように処理されるかを示している。EDE 33は、NTAが有効な間、DNSSECを使っていないドメインへのクエリにも付加される。NTAはゾーン全体に適用されるため、透明性もゾーン全体に対して一律に提供される設計だ。
.DE障害で生じた問題も解決
.DE障害の際、1.1.1.1はDNSSECの根本エラーではなく「EDE 22(No Reachable Authority)」を誤って返していた。これは、NTA配下で権威サーバーに到達できない場合に発生するエラーであり、真の原因を隠蔽してしまう問題があった。
.AL障害ではこの点が改善され、EDE 9(DNSKEY Missing)が正しく返されている。EDE 33と組み合わせることで、「なぜ検証に失敗したのか」と「なぜ応答が返されたのか」の両方をクライアントが把握できるようになった。
今後の標準化と運用への影響

EDE 33はIANA(Internet Assigned Numbers Authority)によって正式に割り当てられており、Knot DNSプロジェクトのkdigツールはすでにEDE 33を名前で認識するようになっている。また、Unbound向けのプルリクエストもレビュー段階にある。他のDNSリゾルバ実装も追随することが期待される。
このインターネットドラフトはIETFのDNSOPワーキンググループに提出済みで、2026年7月18日から24日にウィーンで開催されるIETF会合で議論される予定だ。標準化が進めば、EDE 33はすべての主要DNSリゾルバで実装される可能性が高い。
国内DNS運用者への示唆
国内のISPや企業が運用するDNSリゾルバでも、DNSSEC検証を有効にしているケースが増えている。.ALのようなTLDレベルの障害は稀だが、.JPや他のccTLDで発生しないとは限らない。EDE 33に対応したリゾルバ実装を採用することで、障害時の透明性を確保できる。
また、NTAの運用には慎重さが求められる。Cloudflareは.DEと.ALの両方で、コミュニティへの通知後にNTAを適用し、問題解決後に速やかに解除している。このバランス感覚は、他のDNS運用者にとっても参考になる対応だ。
残された課題
記事公開現在、.ALはDNSSEC未署名のままだ。DSレコードがルートゾーンに再登録されない限り、.AL配下のすべてのドメインはDNSSECの保護を受けられない。AKEPがいつ復旧作業を完了させるかは不透明である。
より根本的な問題として、TLD事業者のDNSSEC運用スキル不足が浮き彫りになった。鍵ロールオーバーは手順を誤ると広範囲に影響を及ぼす重要なオペレーションだ。ICANNやレジストリコミュニティによるガイドラインの整備や訓練の機会提供が求められる。
この記事のポイント
- .AL TLDのDNSSEC鍵ロールオーバー失敗により、2026年7月3日に全.ALドメインが一時的に解決不能となった
- Cloudflareの1.1.1.1はNTAを適用して暫定対処を行い、同時に新しいEDEコード「EDE 33」を初めて実運用に投入した
- EDE 33はNTAの適用をDNS応答内で明示し、従来の「見えないNTA」問題を解決する
- .DEに続くTLDレベルのDNSSEC障害は、TLD事業者の運用スキル向上とNTAの標準化の必要性を浮き彫りにした

・ 複数業界における17年間のデジタルビジネス開発経験
・ ウェブサイト開発のためのHTML、PHP、CSS、JavaScript等の実用的知識
・ 15ヶ国語対応の多言語SaaSの開発経験
・ 17年間にも及ぶ、Eコマース長期運営経験
・ 幅広い業界でのSEO最適化の豊富な経験

Cloudflare Workers Cache登場、Worker専用キャッシュでコスト削減
Workers Cache の登場でCloudflare Workersが「オリジン」から「静的配信」へ進化

CloudflareがWorkers Cacheを正式にリリースした。これは単なるキャッシュ機能の追加ではない。Workersのアーキテクチャを根本から覆し、コストとパフォーマンスのトレードオフを解消する大きな転換点だ。一言で表せば「あなたのWorkerの前に、そのWorker専用のキャッシュを置ける機能」である。
1行の設定を追加するだけで、Workerが生成したレスポンスはCloudflareのエッジネットワークにキャッシュされる。キャッシュが有効な間はWorkerそのものが実行されず、CPU時間の課金もゼロになる。これは特に、サーバーサイドレンダリング(SSR)を行うアプリケーションにとって、待望のソリューションだ。
本記事では、なぜこの機能が必要とされていたのか、具体的に何が変わるのか、そして開発者がどのように活用できるのかを詳しく解説する。
問題: Workerがオリジンの場合、処理のたびにコードが実行され、キャッシュの恩恵を受けにくい。
効果: レスポンスが高速化し、WorkerのCPU実行コストが削減される。
この図が示すように、Workers Cacheはリクエストの最前線に立つ。これにより、Workerが事実上のオリジンサーバーとして振る舞う現代的なアプリケーションのパフォーマンスとコスト構造が劇的に改善される。
なぜサーバーサイドアプリに「Workerの前のキャッシュ」が必要だったのか
Workerが「経由点」から「オリジン」へ変わった世界
2017年のリリース当初、Cloudflare Workersはオリジンサーバーの手前でリクエストを書き換える「中間処理層」として設計された。A/Bテストの振り分けやヘッダーの追加といった、軽量な処理をエッジで実行するユースケースが中心だったのだ。当時、Workerはキャッシュよりもさらにオリジンに近い位置にあった。
しかし状況は一変した。AstroやNext.js、SvelteKitといった主要フレームワークが、ビルド成果物をCloudflare Workersで直接動かすアダプターを提供し始めたのである。これにより、Workerはもはや単なる中継点ではない。アプリケーションそのものがWorker上で動作する「サーバー」になった。裏側に別のオリジンサーバーは存在しなくなり、Worker自体がリクエストを処理するようになったのだ。
この変化は大きな問題を生んだ。従来のアーキテクチャでは、Workerがオリジンになると、すべてのリクエストがコードの実行を必要とするようになる。たとえ1秒前と全く同じHTMLを返す場合でも、だ。これはパフォーマンス上のレイテンシと、無視できないCPU実行コストを常に発生させることを意味していた。
静的生成と動的レンダリングのジレンマを解決する第三の道
この問題に対し、開発者はこれまで2つの選択肢から選ぶしかなかった。
- 静的サイト生成(SSG):すべてのページをビルド時に事前生成する。表示は高速だが、コンテンツを更新するたびに全ページを再ビルドする必要がある。数千ページのサイトでは、このビルド時間が大きなボトルネックになる。
- サーバーサイドレンダリング(SSR):リクエストのたびにページを動的に生成する。コンテンツは常に最新だが、全てのアクセスでレンダリングコストとレイテンシが発生する。
Workers Cacheはここに第三の選択肢、つまり「オンデマンドでサーバーレンダリングし、結果をキャッシュし、指定したTTL(生存期間)で更新する」という新しい手法を提供する。最初のリクエストだけがレンダリングコストを支払い、後続のリクエストはキャッシュから静的ファイルのように配信されるのだ。これはフレームワーク独自の複雑な仕組み(ISRなど)に依存しない、HTTP標準に則った解決策である。
パフォーマンスを極める主要機能「SWR」と「Vary」の内部動作
stale-while-revalidate が「待ち時間ゼロ」を実現する仕組み
Workers Cacheの真価を引き出すのが、stale-while-revalidate(SWR)ディレクティブだ。これはキャッシュされたレスポンスがTTLを超過した「古い(Stale)」状態でも、とりあえずその古いデータをユーザーに返しつつ、バックグラウンドで最新のデータを取得し直すHTTPの仕組みである。
SWRがない場合、キャッシュの有効期限が切れた後の最初のリクエストは、必ずWorkerが一からページをレンダリングするまで待たされる。しかしSWRがあれば、この最初のリクエストに対しても古いキャッシュが即座に返され、ユーザーは待ち時間を感じない。Workers CacheはこのSWRを完全にサポートしており、これによって「動的なサイトなのに、まるで静的サイトのように感じる」という体験を実現している。
この図の通り、SWRはTTLが切れた後の「最初の一人」が被る待ち時間を帳消しにする。Cloudflare Blogの記事によれば、Cloudflareは今年の早期にこのSWR機能をフルサポートしており、Workers Cacheはその上に構築されていることがわかる。
Vary ヘッダーが複数の表現をキャッシュする
現実のアプリケーションは、同じURLでもクライアントに応じて異なるレスポンスを返す必要がある。例えばブラウザにはHTMLを、APIクライアントにはJSONを返す場合や、対応状況に応じてWebPとJPEGを出し分ける場合だ。Workers Cacheは、このコンテンツネゴシエーションをHTTP標準のVaryヘッダーで解決する。
WorkerがVary: Acceptというヘッダーを付けてレスポンスを返すと、Cloudflareは「Acceptリクエストヘッダーの値」ごとに別々のキャッシュエントリを自動で作成・管理する。これにより、WebPに対応したブラウザにはWebP画像のキャッシュが、そうでない環境にはJPEG画像のキャッシュが返るようになる。開発者は複雑なキャッシュキーの設定を意識する必要はなく、標準的なHTTPのルールに従うだけで、安全かつ効率的に複数表現をキャッシュできるのだ。
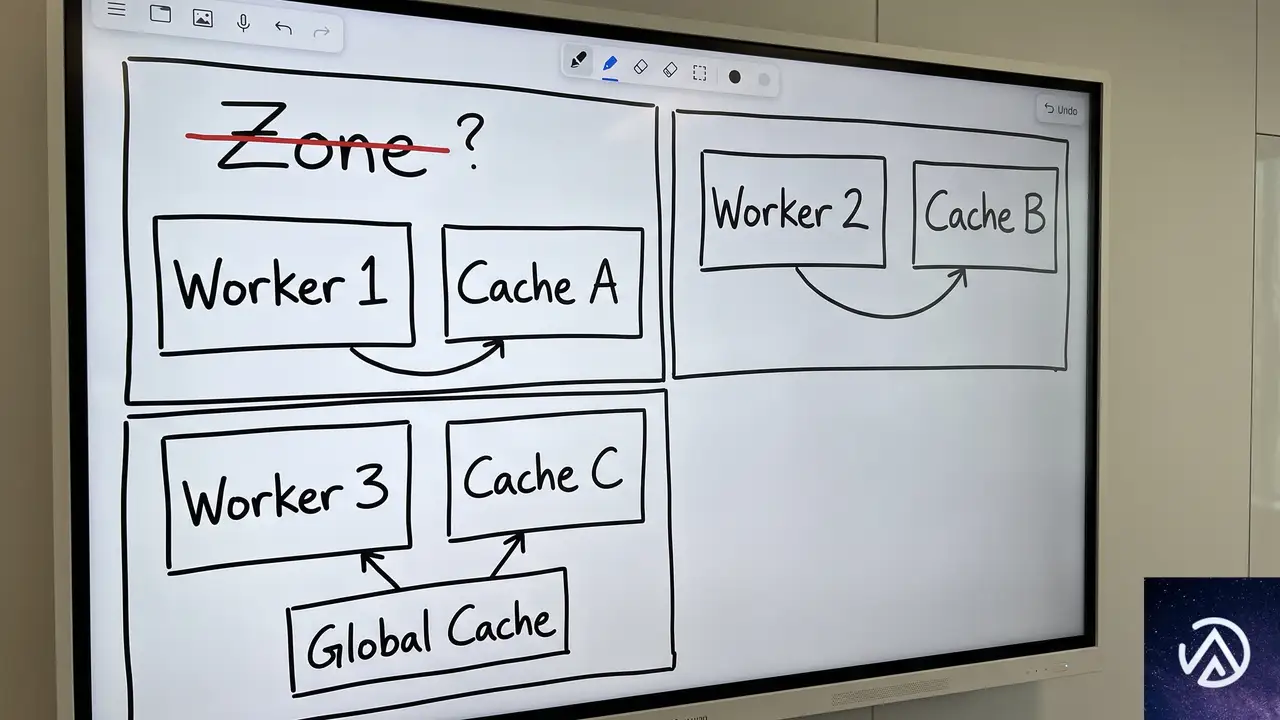
開発者が知っておくべき設計思想「ゾーンではなくWorkerのキャッシュ」
エントリーポイント単位の柔軟なキャッシュ制御
Workers Cacheの最も革新的な部分は、それが「ゾーン(ドメイン)」ではなく「Worker」に紐づくという設計思想にある。この思想が、従来のCDNでは実現できなかったいくつもの高度なユースケースを可能にしている。
特に重要なのが、Workerのエントリーポイントごとにキャッシュの有効・無効を設定できる点だ。設定ファイルでエクスポート名("default"や"CachedBackend")を指定するだけで、認証処理を行うゲートウェイWorkerはキャッシュを無効化し(常にコードを実行するため)、その背後で重い処理を行うバックエンドWorkerだけにキャッシュを有効化する、といった構成が可能になる。
このエントリーポイント単位の制御により、キャッシュはアプリケーションアーキテクチャの一部として自然に組み込めるようになる。単一のWorkerの中に、キャッシュするレイヤーとしないレイヤーを共存させ、それらをコードで自在に結合できるのだ。これは、CDNキャッシュを単一のオリジンの前に置くという従来の考え方とは一線を画す。
マルチテナントを安全にする ctx.props の仕組み
ユーザーごとに異なる情報を返すAPIのキャッシュは、セキュリティ上の大きな課題を伴う。ユーザーAのキャッシュがユーザーBに見えてしまうような事故は、絶対に避けなければならない。Workers Cacheはこの問題を、ctx.propsの一部を自動的にキャッシュキーに含めることで根本的に解決している。
例えば、ゲートウェイWorkerで認証したユーザーIDをctx.propsにセットし、キャッシュが有効なバックエンドWorkerを呼び出すとする。Workers Cacheはこの「ユーザーID」の違いを認識し、ユーザーごとに完全に独立したキャッシュ空間を作り出す。これにより、「認証済みAPIはキャッシュできない」という固定観念を覆し、ユーザー単位で安全にレスポンスをキャッシュできるようになる。Cloudflare Blogによれば、これは他の主要CDNでは提供されていない、Workers Cache独自の強力な利点だという。
Workers Cacheがもたらすプラットフォームとしての進化
パフォーマンスとデータの近接性を両立するアーキテクチャ
Webパフォーマンスにおいては、コードを「ユーザーの近く」で実行するのと「データの近く」で実行するのは、しばしばトレードオフの関係になる。Workers Cacheはこのジレンマに対して、キャッシュを「糊(にかわ)」として利用する解決策を提示する。
具体的には、次のような構成が現実的になる。ユーザーの近くで動き、認証やルーティングといった軽量な処理を担当するWorker Aを配置する。一方、データベースへの重いクエリやレンダリングを実行するWorker Bを、Smart Placement機能でデータの近くに配置する。Workers Cacheは、このWorker Bの手前にのみ配置する。
リクエストが来ると、Worker Aが処理した後、サービスバインディングを通じてWorker Bを呼び出す。この時、Worker Bのキャッシュがヒットすれば、データの近くにあるWorker Bは実行されることなく、ユーザーの近くにあるキャッシュからレスポンスが返る。キャッシュミス時のみ、実際のデータへのアクセスが発生する。これにより、「ユーザー近接性」と「データ近接性」の良いとこ取りが可能になるのだ。
フレームワークとの統合とコストの透明性
Workers CacheはすでにAstroフレームワークのアダプターでネイティブサポートされている。設定ファイルに数行追加するだけで、ページ単位のTTLやタグベースのキャッシュパージが利用できる。TanStack StartやNext.js(Vinext経由)など他のフレームワークへの統合も現在進行中だ。
コスト面も明快だ。Workers Cacheのキャッシュヒット時は、通常のリクエスト課金は発生するが、WorkerのCPU実行時間に対する課金はゼロになる。キャッシュストレージに対する追加のGB単位の課金もないため、コスト削減効果を予測しやすい。ダッシュボードでは、キャッシュヒット率やヒット/ミス/バイパスの内訳が確認でき、パフォーマンスチューニングに必要なデータが一元管理されている。
この記事のポイント
- Workers Cacheは、Workerの手前に専用の階層型キャッシュを配置する新機能である。
- これにより、サーバーサイドアプリが静的サイトのような速度を実現しつつ、CPU実行コストを削減できる。
stale-while-revalidateの完全サポートにより、キャッシュ更新中もユーザーを待たせない。- ゾーンではなくWorkerに紐づく設計により、エントリーポイント単位で柔軟なキャッシュ戦略をコードで記述できる。
ctx.propsをキャッシュキーに含めることで、マルチテナント環境でも安全なキャッシュが実現する。
・ 複数業界における17年間のデジタルビジネス開発経験
・ ウェブサイト開発のためのHTML、PHP、CSS、JavaScript等の実用的知識
・ 15ヶ国語対応の多言語SaaSの開発経験
・ 17年間にも及ぶ、Eコマース長期運営経験
・ 幅広い業界でのSEO最適化の豊富な経験

Cloudflare Monetization Gateway発表、x402でAIエージェントに従量課金
広告型モデルの限界とAIエージェント向け従量課金

2026年7月1日、CloudflareはMonetization Gatewayを発表した。HTTPの402ステータスコードを拡張したオープンプロトコル「x402」を基盤に、ウェブ上のあらゆるリソースに対して従量課金を適用できる仕組みである。保護対象はウェブページ、データセット、API、MCPツールにおよび、代理店や大規模言語モデルが自律的に支払う時代を見据えている。
背景にはウェブビジネスモデルの構造変化がある。30年にわたり、コンテンツは広告や月額課金で収益化されてきた。しかしAIエージェントが人間に代わって情報を消費するようになると、バナー広告をクリックすることも、毎月のサブスクリプションを維持することもない。エージェントは必要なデータを一度取得すれば、数十回、数千回と繰り返しアクセスし始める。Cloudflareの発表資料によると、AIクローラーのリクエスト数は、そこからサイトへ誘導される訪問者1人あたり数百~数万回に達しているという。
従来のAPI従量課金は既存ユーザー向けに限定され、サブセント単位の少額決済には向かなかった。クレジットカードの手数料が取引額を上回るためだ。ここでCloudflareが着目したのが、ステーブルコインによる一瞬の決済である。Monetization Gatewayは、支払い検証と流量制御をエッジで完結させ、オリジンサーバーに過剰な負荷をかけずに課金を実現する。
CloudflareはすでにContent Independence DayでAIクローラーの制御機能を提供し、Pay Per Crawlでクローラーに課金する仕組みを導入していた。Monetization Gatewayはその延長線上にあり、クローラー以外の任意の呼び出し元に対して課金できる点が新しい。
エージェントが変える支払いの単位
AIエージェントが自律的に行動するようになれば、サービスの課金単位も座席数や月額から「リクエスト数」「トークン数」「成果物」へと移行する。Cloudflareが例示したのは、1回のウェブ検索あたり数セント、アップロードエンドポイントで0.001ドルの基本料金+1MBあたり0.01ドル、サポートエスカレーション解決時に0.99ドルといった単位である。
これまで実現が難しかったサブセントの決済を、x402プロトコルとステーブルコインが可能にする。ステーブルコイン(Open USDやUSDC)は1秒未満で決済が完了し、手数料が無視できるほど小さい。従来の決済手段では、手数料が支払い額を上回る逆転現象が起きていたが、それが解消される。
Cloudflareが提供する課金インフラ
Cloudflareの強みは、すでに自社の課金システムや顧客向けアナリティクスで従量課金の会計基盤を構築してきたことにある。Monetization Gatewayでは、売り手と買い手の間に入り、支払い証跡をHTTPリクエストに埋め込む形で検証パスを統合する。メータリング、支払い交換、決済はすべてオリジンサーバーの外で完結し、サイト運営者は課金ルールと価格だけを定義すればよい。買い手のオンボーディングや請求システムの構築は不要だ。
x402プロトコルとは

x402はHTTPのステータスコード「402 Payment Required」を実際に活用するオープンプロトコルである。この規格はCloudflareがx402 Foundationのもとで25以上の業界リーダーと共同開発を進めている。従来の402は予約状態にあり、実際の決済フローには使われていなかった。
x402のやりとりは単純だ。クライアントが支払い必須のリソースをリクエストすると、サーバーは402 Payment Requiredとともに価格、受け入れ可能な通貨、支払い先を含む小さなペイロードを返す。クライアントは支払いを実行し、支払い証明を添えてリクエストを再送する。ファシリテーター(検証者)が証明を確認し、オリジンサーバーが最終的にリソースを返す。すべてが通常のHTTPリクエスト/レスポンスの中で完了し、決済ページへのリダイレクトも個別の決済API呼び出しも発生しない。
x402の利点は2つある。1つは最小単位がセント未満まで刻めること。プロトコルのオーバーヘッドが極めて低く、取引額が支払いコストを下回る逆転を防げる。もう1つは、買い手が売り手のアカウントを事前に取得する必要がないことだ。支払い自体が資格情報として機能するため、サインアップやAPIキー発行なしに取引が成立する。
サブセント決済と一瞬の決済
ステーブルコインを使う決済は、現在の主要な決済レールでは実現できなかったスピードと低コストを両立する。Cloudflareはサブセカンド(1秒未満)の決済を目標に掲げている。エージェントが数セントのデータを購入するために数ドルの手数料と数日の決済期間を待つ必要はなくなる。この速度と低コストが、AI時代の大量のマイクロペイメントを支える。
Monetization Gatewayの機能

Monetization GatewayはCloudflareのエッジネットワーク上で動作し、330以上の都市でリクエストを処理する。x402ハンドシェイクが買い手の近くで実行されるため、レイテンシが小さくなり、オリジンサーバーへの負荷も軽減される。
具体的な課金ルールの適用方法として、以下のような機能が計画されている。
- 特定のRESTメソッドへの課金。/api/premium/* へのGETやPOSTに0.01ドルを設定できる
- タスクの複雑さに応じた変動価格。画像生成などの処理負荷に応じて最大2ドルまでの課金が可能
- 認証されていない発信者への402 Payment Requiredの返却。オリジンが401を返した際に、自動で402と価格情報に置き換える
ルールはCloudflareのダッシュボードから設定するほか、Cloudflare APIやTerraformを通じてコードとして管理できる。課金エンドポイントの追加が、単なる別のインフラ設定として扱えるようになる設計だ。
Cloudflareはまた、Web Bot Authとの連携も予定している。エージェントに認証を求め、既存のアカウントに対して従量課金を適用する柔軟性を提供する方針だ。これにより、完全な匿名取引だけでなく、信頼関係に基づく課金も選択できるようになる。
売り手にとっての変化
Monetization Gatewayを利用する売り手は、蓄積したステーブルコインをそのまま別の取引に使うことも、銀行口座で法定通貨に換金することもできる。Cloudflareが発表した構想では、支払い検証はすべてエッジで完結し、オリジンには課金ルールと実際の収益だけが残る。
これはAPIプロバイダーにとって、販売可能市場を拡大する直接的な手段になる。AIエージェントはリソースを要求し、価格を提示され、支払い、結果を得る。サインアップもAPIキーも事前の関係も必要ない。Cloudflareは、いつでも買い手の認証や既存アカウントとの紐付けを追加できる柔軟性を残している。
この記事のポイント
- CloudflareがHTTP 402を利用した従量課金プロトコルx402を実用化。Monetization Gatewayによりあらゆるウェブリソースへの課金が可能に
- AIエージェントが大量にコンテンツを消費する時代、広告に依存しない収益モデルとしてマイクロペイメントが鍵を握る
- ステーブルコインによるサブセカンド決済で、サブセント単位の取引でも手数料が収益を上回らない
- 課金ルールはコードで管理でき、売り手は買い手のオンボーディングや請求システムを構築する必要がない
- Web Bot Authとの連携や変動価格設定など、エージェント経済向けの拡張機能が計画されている
・ 複数業界における17年間のデジタルビジネス開発経験
・ ウェブサイト開発のためのHTML、PHP、CSS、JavaScript等の実用的知識
・ 15ヶ国語対応の多言語SaaSの開発経験
・ 17年間にも及ぶ、Eコマース長期運営経験
・ 幅広い業界でのSEO最適化の豊富な経験

CloudflareのAIクローラールールがGooglebotをブロックする危険性
CloudflareがAIクローラー対策の仕組みを抜本的に見直し、2026年9月15日から新たなデフォルト設定を適用する。この変更は単なるAIボット対策の強化にとどまらず、Googlebotのような検索クローラーまで巻き込む可能性がある。AIにコンテンツを学習されたくないという意図で設定したブロックが、結果的に検索エンジンからの流入を断つリスクをはらんでいるのだ。
特に影響が大きいのは、Cloudflareの無料プランを利用するWordPressサイトや中小企業のオウンドメディアだ。AI学習ブロックの意図がなくても、9月15日以降にデフォルト設定が自動適用され、知らぬ間にGooglebotのクロールが制限される可能性がある。本記事では3つの振る舞い分類、デフォルト変更の詳細、そして今すぐ取るべき対応策を解説する。
CloudflareがAIクローラー対策の方針を転換した背景

Cloudflareは2026年7月2日、第2回「Content Independence Day」の一環として、AIクローラー管理の新方式を発表した。従来の単一の「AIボットをブロック」スイッチを廃止し、クローラーの振る舞いに基づいた3つのカテゴリで制御する仕組みへ移行する。この変更は全顧客(無料プランを含む)に即時適用され、9月15日にはデフォルト設定も自動変更される。
背景にあるのは、AIクローラーによるコンテンツ収集の爆発的な増加だ。Cloudflareのネットワーク上では、AI訓練目的のクローラーリクエストが全体の過半数を占めるまでに成長した。2025年春時点では約20%だったが、1年で状況は一変した。AIエージェントのリクエスト数も前年比1700%増と、指数関数的な伸びを示している。
この急増に対し、多くのパブリッシャーやサイト運営者はAIクローラーを一律ブロックする方向に動いてきた。しかし、その「一律ブロック」が検索クローラーまで巻き込む副作用を生みつつあった。Cloudflareの今回の方針転換は、この問題に正面から取り組むものだが、同時に新たなリスクも生じさせている。
3つの振る舞い分類がクローラー制御を変える

Cloudflareの新方式は、クローラーを「AIかどうか」ではなく「サイト上で何をするか」で分類する。この考え方は、サイト運営者にとってクローラー制御の解像度を格段に上げるものだ。3つのカテゴリは以下のとおり。
Cloudflareは、ボット運営者に対して「振る舞いごとに別々のクローラーを用意すべき」と要求している。サイト側が「なぜそのボットが来ているのか」を判断し、許可・ブロックを適切に選択できるようにするためだ。この考え方自体は合理的だが、現実にはGooglebotのように検索とAI訓練の両方を行う「マルチパーパスクローラー」が存在する。この点が後述する問題の核心となる。
検索クロールとAI訓練クロールの同居がリスクを生む
Googlebot、Applebot、Bingbotは、いずれも検索インデックス作成とAIモデル訓練の両方に使用される。Cloudflareの新ルールでは、こうした「混合用途のクローラー」に対して最も厳しい制限が適用される。つまり、AI訓練目的のクロールをブロックしているサイトでは、同じクローラーによる検索目的のアクセスも自動的にブロックされるのだ。
これはrobots.txtとは根本的に異なる。robots.txtはクローラーへの「お願い」に過ぎず、無視されることもある。しかしCloudflareのブロックはネットワークレベルで動作するため、robots.txtよりはるかに強力だ。グーグルでさえバイパスできない。AI訓練を止めたい一心で設定したブロックが、検索流入というサイトの生命線を断ち切ってしまう皮肉な構造が生まれている。
9月15日のデフォルト変更が生む3つのリスク
2026年9月15日に自動適用されるデフォルト設定の変更は、Cloudflareを利用するあらゆるサイトに影響を及ぼす。特に注意すべきは以下の3点だ。
とりわけ危険なのはリスク3だ。従来の「AIボットをブロック」設定を有効にしたまま放置しているサイトは、9月15日以降にGooglebotのアクセスがネットワークレベルで遮断される可能性がある。検索クロールが停止すれば、新規コンテンツのインデックス登録が滞り、既存ページの再クロール頻度も低下する。検索順位への影響は数週間から数カ月かけて徐々に表面化するため、原因特定が遅れやすい。
robots.txtとの違いを理解しておくべき理由
多くのサイト運営者は「robots.txtでブロックしているから大丈夫」と考えがちだ。しかし、robots.txtはクローラーに対する紳士協定に過ぎず、グーグルも状況によって無視することがある。一方、Cloudflareのブロックはリクエストがオリジンサーバーに到達する前にネットワークエッジで遮断する。この違いは決定的だ。
robots.txtでのブロックは「できれば来ないでほしい」というお願いであり、Cloudflareのネットワークブロックは物理的な門番が門を閉ざすようなものだ。後者のほうが確実だが、その分だけ設定ミスの代償も大きい。AI訓練ブロックのつもりが検索クローラーまで締め出してしまうと、サイトの検索パフォーマンスは確実に悪化する。
実務者が今すぐ取るべき対応チェックリスト

9月15日までに対応を完了する必要がある。以下に具体的なアクションを時系列で整理した。
STEP 5のクロール統計監視は特に重要だ。9月15日以降にGooglebotのクロール頻度が急落した場合、Cloudflare設定に原因がある可能性が高い。Search Consoleの「クロール統計レポート」で1日あたりのクロールリクエスト数を確認し、急激な減少があれば即座にCloudflareダッシュボードを再確認する習慣をつけておきたい。
無料プランユーザーが特に注意すべきポイント
Cloudflareの無料プランを利用しているサイトは、9月15日までに一度もAIクローラー設定を変更していない場合、自動的に新デフォルトへ移行される。つまり「設定を触っていないから大丈夫」という認識が最も危険だ。何もしないことが、意図せずGooglebotブロックを招く可能性がある。
無料プランであっても、ダッシュボードから3カテゴリの設定を手動で確認・変更することは可能だ。Searchカテゴリだけは明示的に「許可」に設定し、TrainingやAgentはサイトのポリシーに応じて判断する。この一手間をかけるかどうかで、9月15日以降の検索パフォーマンスが大きく変わる。
今後の展望とサイト運営者が持つべき視点

Cloudflareは、マルチパーパスクローラーの運営者に対して「振る舞いごとにクローラーを分離する」ことを求めている。グーグルやアップル、マイクロソフトがこの要求に応じてGooglebotを用途別に分割するかどうかが、今後の分岐点となる。仮に分割が実現すれば、サイト運営者はAI訓練だけをブロックし、検索インデックスは許可するという選択が可能になる。
しかし、現時点ではその保証はない。9月15日以降もGooglebotは単一のクローラーとして動作し続ける可能性が高い。つまり、AI訓練をブロックするという選択は、当面の間「検索流入とのトレードオフ」であり続ける。この現実を直視した上で、サイト運営者は自社のコンテンツ戦略とAIポリシーを再定義する必要がある。
Cloudflareは新しいコンテンツ利用シグナルもテスト中だ。robots.txtに記述するContent Signalsの拡張で、immediate(保存しない)、reference(インデックスしてリンクバック、新デフォルト)、full(要約・複製を許可)の3段階を指定できるようにする。ただしこれは設定上の「希望表明」であり、単体ではブロック機能を持たない点に注意が必要だ。
サイト運営者が今から準備すべき3つのこと
AIにコンテンツを学習されることを完全に拒否するのか、それとも検索流入を優先するのか。この問いに明確な答えを持たないまま9月15日を迎えると、Cloudflareの新デフォルトによって想定外のブロックが発生し、検索パフォーマンスが毀損するリスクがある。サイトの規模や収益構造に応じて、今のうちに方針を固めておくことが重要だ。
この記事のポイント
- CloudflareのAIクローラー管理が3つの振る舞い分類(Search、Agent、Training)に再編された
- 9月15日から広告表示ページでTrainingとAgentがデフォルトブロックされ、無料プランユーザーも自動移行の対象
- Googlebotのような混合用途クローラーは、AI訓練をブロックすると検索クロールも停止する
- robots.txtと異なり、Cloudflareのブロックはネットワークレベルで動作しバイパスが困難
- Searchカテゴリの許可確認とSearch Consoleでのクロール統計監視が当面の最優先対応
・ 複数業界における17年間のデジタルビジネス開発経験
・ ウェブサイト開発のためのHTML、PHP、CSS、JavaScript等の実用的知識
・ 15ヶ国語対応の多言語SaaSの開発経験
・ 17年間にも及ぶ、Eコマース長期運営経験
・ 幅広い業界でのSEO最適化の豊富な経験

WPMU DEVがEmDash Hostingを発表、WordPressと同じ管理画面でTypeScript CMSを運用可能に
WordPress制作者の多くにとって、その手間こそが「EmDashを一度見てみたい」という思いを机の隅のTo-Doリストに留まらせる最大の壁だった。
WPMU DEVが発表したEmDash Hostingは、まさにその手間を取り除くために設計されたサービスだ。2026年6月の公式アナウンスにより、WordPressサイトと同じ管理画面からワンクリックでEmDashサイトを立ち上げられる環境が提供されている。
EmDash HostingがWordPress制作者にもたらすもの
EmDashそのものは、CloudflareがオープンソースのMITライセンスで公開したTypeScript製CMSだ。サーバーレスかつセキュリティ重視の設計思想を持ち、従来のCMSとは一線を画すアーキテクチャで注目を集めている。
WPMU DEVが提供するのは、そのEmDashを動かすためのホスティングと管理のレイヤーである。具体的には、同社のUnlimited Hostingプラットフォーム上でEmDashサイトを稼働させる仕組みだ。Unlimited Hostingは、多数のサイトを運用するエージェンシーやフリーランサー向けに構築されたマネージド環境で、3GHz以上のIntel XeonプロセッサとNVMe SSDを搭載した高性能サーバー上で50以上のサイトを月額15ドルから運用できる。
WordPressとEmDashの混在運用が現実に
今回の発表で重要なのは、EmDashサイトがこのUnlimited Hostingの枠組みに含まれるようになった点だ。サーバーのリソースが許す限り、WordPressのインストールと並行してEmDashサイトをいくつでも立ち上げられる。
このアプローチが最初に訴求するのは、EmDashに興味を持ちながらも、テスト用に別のインフラを用意することに二の足を踏んでいたエージェンシーやフリーランサーだろう。TypeScriptベースでAstroフレームワークを採用したCMSを、ローカル環境のセットアップなしで触れる点は、開発者にとっても低リスクな検証手段となる。
従来のCLIベースのセットアップでは、環境構築だけで数時間を要していた。EmDash Hostingではワンクリックでサイトが立ち上がり、即座に動作確認に移れる。
WordPressスタックにおけるEmDash Hostingの立ち位置
現状、EmDashを評価する人の多くは、それを独立したプロジェクトとして扱っている。専用のリポジトリ、デプロイ先、認証情報、そして運用の考え方も別々だ。サイトを維持すると決めた場合、WordPressの運用管理とEmDashの運用管理という2つの業務を並行して回すことになる。
WPMU DEVのEmDash Hostingは、この2つを1つに統合する。EmDashサイトはWordPressサイトと同じサーバー上に存在し、Hubと呼ばれる単一のダッシュボードから同じツールで管理される。
エージェンシーにとっての利点は明快だ。EmDashのクライアントサイトもWordPressのクライアントサイトも、同じ一覧に表示され、同じ方法でバックアップされ、同じログイン経路でアクセスできる。つまり、EmDashはワークフローの中で「特別扱い」する必要がなく、既存の運用に自然に溶け込む。
実験コストがゼロに近づく
WP Mayorの記事が指摘する通り、このサービスの本質的な価値は「EmDashがWordPressを置き換える」ことではなく、「EmDashが既存のワークフローで自動的に扱えるもう1つのサイト種別になる」点にある。実験にかかるコストは時間以外ほぼゼロになり、導入の敷居は極めて低くなる。
管理画面が統合されることで、EmDashサイトの追加が運用負荷の増大に直結しない。これは新技術の評価フェーズにおいて決定的な差となる。
EmDash Hostingの実際の動作
WPMU DEVの発表から、実運用面で注目すべきポイントを5つに整理する。
インストールは文字通りワンクリック
標準的なEmDashのセットアップはCLIツールを経由するが、EmDash HostingではHubの管理画面からボタン1つでサイトが作成される。構築の仕組みを知る前に、まず動く状態を確認したいというニーズに応える設計だ。
WPMU DEVは初期状態で使えるコンタクトフォームプラグインも同梱しており、今後さらにプラグインを追加する予定としている。プラグインはローカルで動作するため、Cloudflareのアカウントを別途取得する必要はない。
WordPressサイトとまったく同じ管理体験
サイトが公開されると、WPMU DEV HubからのSSOログイン、日次バックアップ、カスタムドメイン設定、無料SSL証明書、サーバーレベルのSSH/SFTPアクセス、ストレージ使用量を可視化するサーバー分析が利用できる。新興プラットフォームでは後回しにされがちな基盤機能が、WPMU DEVの既存ホスティングレイヤーからそのまま提供される点が特徴だ。
セキュリティとサポートがそのまま適用
EmDashサイトにはサーバーレベルでのWAF(Webアプリケーションファイアウォール)とAntiBot保護が適用され、Proメールおよび24時間365日のライブチャットサポートも付帯する。WP Mayorの記事が評価するのは、サポートに対するWPMU DEVの正直な姿勢だ。同社は「我々もまだ学習中である」と明言し、EmDashに関する問い合わせには最善を尽くすとしつつ、この新しいCMSに対する深い専門知識を誇示しない。初期段階のCMSを試す際、障害が発生しても自力で解決するしかない状況が多い中、少なくともホスティング環境を熟知したサポートチームが背後にいることは安心材料となる。
公開直後からページが正しく表示される
これは実際に遭遇するまで気づきにくい問題だ。デフォルトのEmDashテンプレートでは、新規ページやプロジェクトを作成して公開しても、公開URLにアクセスすると404エラーになるケースがあった。理由は、EmDashが内部でAstroフレームワークを使用しており、ルーティングがテンプレート側で処理されるためだ。WordPressのように公開コンテンツが自動的にルーティングされるわけではない。
WPMU DEVはホスティング用のテンプレートに修正を加え、公開したページやプロジェクトが即座に表示されるようにしている。書類上は小さな変更だが、新プラットフォームを触り始めて10分で「操作ミスなのかバグなのか」と困惑する事態を防ぐ効果は大きい。
メール設定が自動化されている
EmDashのメール処理はWordPressと異なる仕組みを持ち、この違いが様々な機能の動作不良を引き起こす原因になりやすい。WPMU DEVはUnlimited Hosting上のEmDashサイトにメール設定を自動構成するプラグインをバンドルしており、パスキーログインリンクやフォーム通知などのトランザクションメールが、手動の配信設定なしですぐに機能する。
新興CMSの導入時に障壁となる運用面の課題が、ホスティング側のレイヤーで吸収されている。
ユーザータイプ別に見るメリット

エージェンシー
現時点でEmDashをテストする可能性が最も高いのはエージェンシーだろう。クライアントからEmDashについて質問されたときに、運用体制を再構築することなく「対応できる」と答えられる点が最大の魅力だ。チームが日常的に使っているHubダッシュボードの中で、サイトの立ち上げ、評価、管理が完結する。
フリーランサーと開発者
現在注目を集めるTypeScript CMSを、環境構築に午後を費やすことなく実際に触れる手段となる。EmDashはAIエージェントを第一級のユーザーとして扱う設計思想を持ち、WordPress開発向けAIツールと同じ文脈で語られることが増えている。このホスティングを利用すれば、半日かけて環境を整える代わりに、すぐに自分の意見を形成できる。
ブロガーとコンテンツ制作担当者
より新しいパブリッシングスタックを試しつつ、WPMU DEVのマネージドバックアップやセキュリティ、サポートという安全網を維持できる点が訴求ポイントとなる。
WooCommerceストア運営者と大規模サイト管理者
WP Mayorの記事も指摘する通り、現時点では現実的かつ慎重な姿勢が求められる。EmDashそのものがまだ初期段階であり、本格的な移行対象として検討する段階ではない。このホスティングは「CloudflareのCMSがどこへ向かうのか、自分の手で感触を掴むための最も摩擦の少ない方法」と捉えるのが妥当だ。
制限事項とトレードオフ

最大の留保条件はホスティングそのものではなく、CMSとしてのEmDashの成熟度にある。プラグインマーケットプレイスも、サードパーティ製テーマのライブラリも、まだ充実しているとは言えない。現時点でEmDash上に構築できるものは、20年にわたるWordPressの開発が生み出した世界と比較すれば、明らかに限定的だ。
EmDash HostingはEmDashの運用を容易にするが、EmDashのエコシステムそのものを成熟させることはできない。本番サイトの大部分にとって、WordPressが依然として現実的な選択肢であることに変わりはない。
WooCommerceはさらに明確な例だ。ストアを運営している場合、ビジネスはWordPressとWooCommerceホスティングのエコシステムの中に存在しており、EmDashはその代替にはならない。ストア運営者にとっての正直な用途は、現段階では好奇心と実験に留まるだろう。
プラットフォームに関する制約もある。EmDash HostingはWPMU DEVのPremiumメンバーシップ限定で提供される。まだWPMU DEVのエコシステムに入っていない場合、EmDashを評価するということはWPMU DEVも同時に評価することを意味する。
機能面の現状
すべてのHubツールがEmDashに対応しているわけではない。現在EmDashで利用できる機能は以下の通りだ。
- ワンクリックインストール
- SSOログイン
- リセット
- リビルド/再起動
- ドメイン管理
- Proメール
- バックアップと復元
- WAF(Webアプリケーションファイアウォール)
- AntiBot保護
- サーバー分析
- SSH/SFTPアクセス
- 無料SSL証明書
- クライアント管理と請求
- サポートチケット
一方で、WordPress側では定番となっているステージング機能やクローン機能は、EmDash向けにはまだ提供されていない。SSH/SFTPはサーバーレベルでのアクセスとなり、1つのサーバーユーザーが同一サーバー上の全サイトにアクセスする形となる点にも注意が必要だ。
料金とライセンス

EmDash HostingはWPMU DEVのUnlimited Hostingに含まれるため、サーバー料金を支払えば、容量が許す限りWordPressサイトと並行してEmDashサイトを無制限に稼働させられる。サイト単位の追加料金は発生しない。
プランは以下の通り構成されている。
- Alpha MU(月額15ドル): 1GB RAM、23GBストレージ
- Beta MU(月額23ドル): エージェンシー向けの最も人気のあるプラン
- Eta MU(月額300ドル): 32GB RAM、455GBストレージ
全プランで帯域幅は無制限、30日間の返金保証が付く。EmDash本体はMITライセンスのオープンソースであり、CMS自体にライセンス費用はかからないが、マネージドホスティングを利用するにはWPMU DEV Premiumメンバーシップへの加入が必要となる。
このサービスは、あくまでも「CloudflareのCMSがどの方向へ進むのか、最小の摩擦で自分の手で感触を掴む手段」として読むのが賢明だ。本業のサイトは今ある場所に置いたまま、未来の選択肢を検証できる点に価値がある。
この記事のポイント
- WPMU DEVのEmDash Hostingは、WordPressと同じHub管理画面からワンクリックでEmDashサイトを立ち上げられるマネージドホスティングである
- Unlimited Hostingプランに含まれ、追加料金なしでEmDashサイトをサーバー容量の許す限り稼働させられる
- 日次バックアップ、WAF、AntiBot、SSL、SSH/SFTPなど、新興CMSに不足しがちな運用基盤が最初から整備されている
- EmDashのエコシステムはまだ初期段階であり、本番サイトの移行先としては時期尚早だが、技術検証の手段としての価値は高い
- エージェンシーやフリーランサーにとって、運用フローを変えずに次世代CMSを評価できる点が最大の利点である
・ 複数業界における17年間のデジタルビジネス開発経験
・ ウェブサイト開発のためのHTML、PHP、CSS、JavaScript等の実用的知識
・ 15ヶ国語対応の多言語SaaSの開発経験
・ 17年間にも及ぶ、Eコマース長期運営経験
・ 幅広い業界でのSEO最適化の豊富な経験

Cloudflareが企業のAIコスト爆発を制御、AI Gatewayに利用上限を搭載
企業におけるAI導入の最大の壁はもはや技術力ではない。管理不能なコストの爆発だ。2026年6月5日、Cloudflareは自社のAI Gatewayに新たな「利用上限」機能を搭載し、この課題への直接的な解決策を提示した。
多くの企業では全エンジニアに最先端モデルのAPIキーを共有している。月末に届く高額な請求書を見て、経理とCTOが頭を抱える。誰が何に使ったのか全く分からないのだ。Cloudflareの今回の発表は、まさにこの無法地帯に統制をもたらすものだ。
併せて発表されたアイデンティティベースの予算管理は、Cloudflare Accessと既存のIdP(Identity Provider / アイデンティティプロバイダー)を組み合わせ、個人やチーム単位での正確なコスト帰属を実現する。
なぜAIコストは制御不能に陥るのか
AI導入を進める企業で、まったく同じストーリーが繰り返されている。現場には「まずは最速でAIを使え。勘定は後でなんとかする」という号令が飛ぶ。これは大抵の場合うまくいく。実際、AIを積極的に取り入れたチームの生産性は飛躍的に向上している。しかし、その代償は安くない。月末に経理がAPI利用料の請求書を開くと、にわかには信じがたい桁の数字が目に飛び込んでくるのだ。
Cloudflareのブログ記事でも、この構図は明確に描写されている。社内で共有されているAPIキーでは、コストの発生源を追跡できない。機械学習チームの新規パイプライン構築が原因なのか、インターンがメールの仕分けに高額なClaude Opusを使い倒したのか、あるいはCI/CDジョブが週末のうちに何千万トークンも消費したのか、誰にも分からない。
問題の本質は、指標と制御の欠如により、合理的な判断が歪められてしまうことにある。予算も可視化もなければ、常に最も強力で高価なモデルを選ぶのが個々のエンジニアにとっては合理的な行動となる。コードレビューの要約に、大規模なアーキテクチャ再設計と同じモデルは必要ない。ログパーサーに、顧客向けコンテンツ生成と同じモデルは不要だ。しかし、現場には適切な道具を選ぶ動機も手段も存在しなかったのである。
利用上限機能を深掘りする
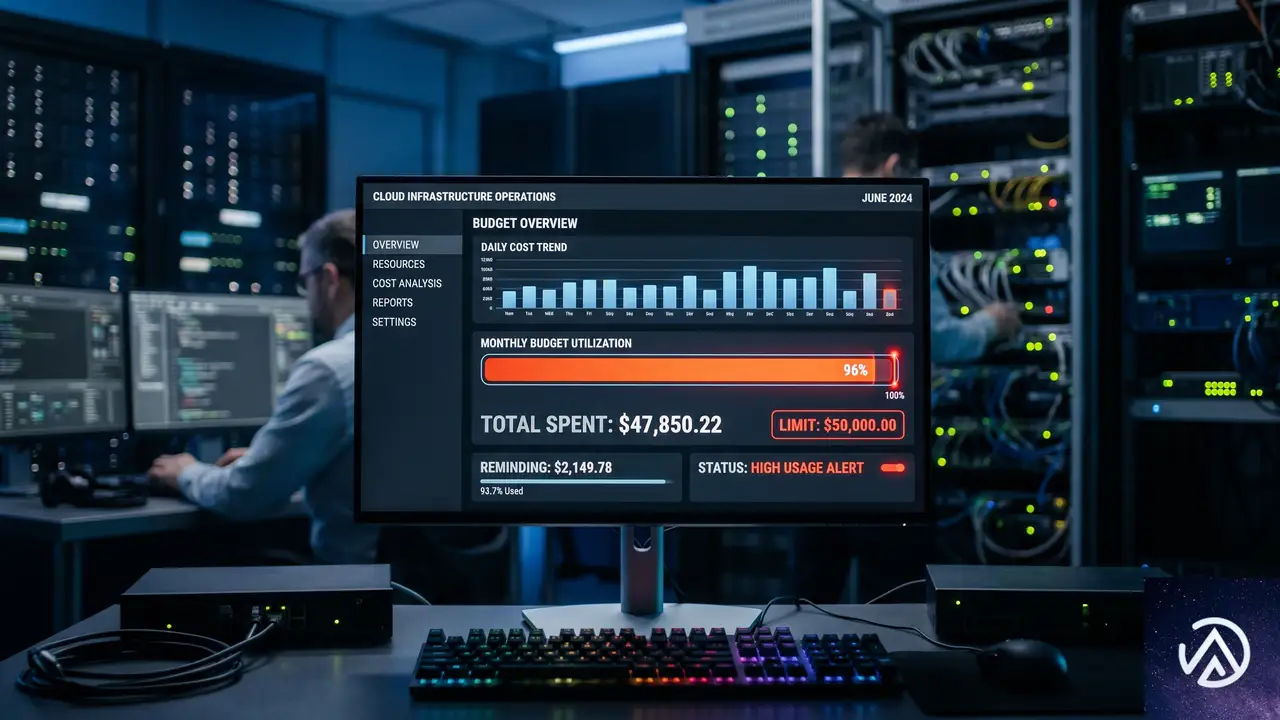
中核となる仕組み
AI GatewayはアプリケーションとAIプロバイダーの中継点として機能する。OpenAIやAnthropicへの直接APIコールを、まずこのゲートウェイを経由させる仕組みだ。これにより、リクエストの永続化ログ、キャッシュ、レート制限、リトライ、分析といった恩恵が得られていた。しかし、従来は「誰がいくら使ったか」の正確なトラッキングに限界があった。
ここに新たに導入された利用上限機能は、真のコスト統制を実現する。トークンベースではなく、ドルベースの予算で累積支出を追跡する点が実務的だ。制限のスコープは、モデル、プロバイダー、ユーザーやチームといった管理者定義のカスタム属性の任意の組み合わせで設定できる。期間も固定(月初リセットや月曜リセット)かローリング(直近N日間)かを選べ、日次、週次、月次での運用が可能だ。
予算超過時の現実的な選択肢
最も重要なポイントは、上限到達時の処理だろう。デフォルトではリクエストをブロックする。だが、ワークフローを完全に止めないための工夫として、ダイナミックルートと連携したフォールバックモデルへの切り替えが可能だ。これなら、最大予算額に達してもエンジニアの作業が完全に停止することはない。
この機能群は本日から全プランの全ユーザーにオープンベータとして提供されており、ダッシュボードかAPI経由で即座に設定できる。
アイデンティティ駆動の予算管理がもたらす透明性

利用上限機能と同時に、Cloudflareはアイデンティティベースの予算とポリシーを限定ベータとして発表した。利用上限がモデルやカスタム属性による制御であるのに対し、こちらは実在の個人とチームに紐づく。アプリケーション側でメタデータを渡す必要はなく、信頼性の低いヘッダー情報に頼る必要もない。
Cloudflare Accessとの統合が生む確実な帰属
AI GatewayをCloudflare Accessと連携させると、リクエストの送信者が誰かを確実に特定できる。単なるアカウント単位ではなく、個々の従業員、IdPグループ、サービス単位だ。Cloudflare社内では既にこの仕組みを実践しており、全従業員がAIツールを利用する中で月間数十億トークンが流れるトラフィックを可視化している。
仕組みはシンプルだ。従業員がCloudflare Access経由で認証されると、そのアイデンティティがJWT(JSON Web Token)から抽出され、AI Gatewayのリクエストにメタデータとして添付される。これにより、ユーザー単位のトークン消費、チーム単位の使用量内訳、組織全体のコスト帰属が一元管理できるようになる。
CI/CDパイプラインへの適用とボット予算
この機能は人間だけのものではない。Accessサービスアカウントを利用すれば、自律的なエージェントやCI/CDパイプラインにも名前付きのIDを付与できる。コードレビューボットが今週500万トークンを消費し、ドキュメント生成器が50万トークンだった、といった詳細が手に取るように分かる。あるエージェントが制御不能に陥ったとしても、他のエージェントに影響を与えることなく個別に予算ポリシーを適用できるのだ。
Cloudflare自身、全社でこのスタックを運用した経験に基づいて本機能を公開した。自社で構築したものを他社もゼロから作る必要はない、という明快なスタンスである。
次の段階はコスト最適化の自動化
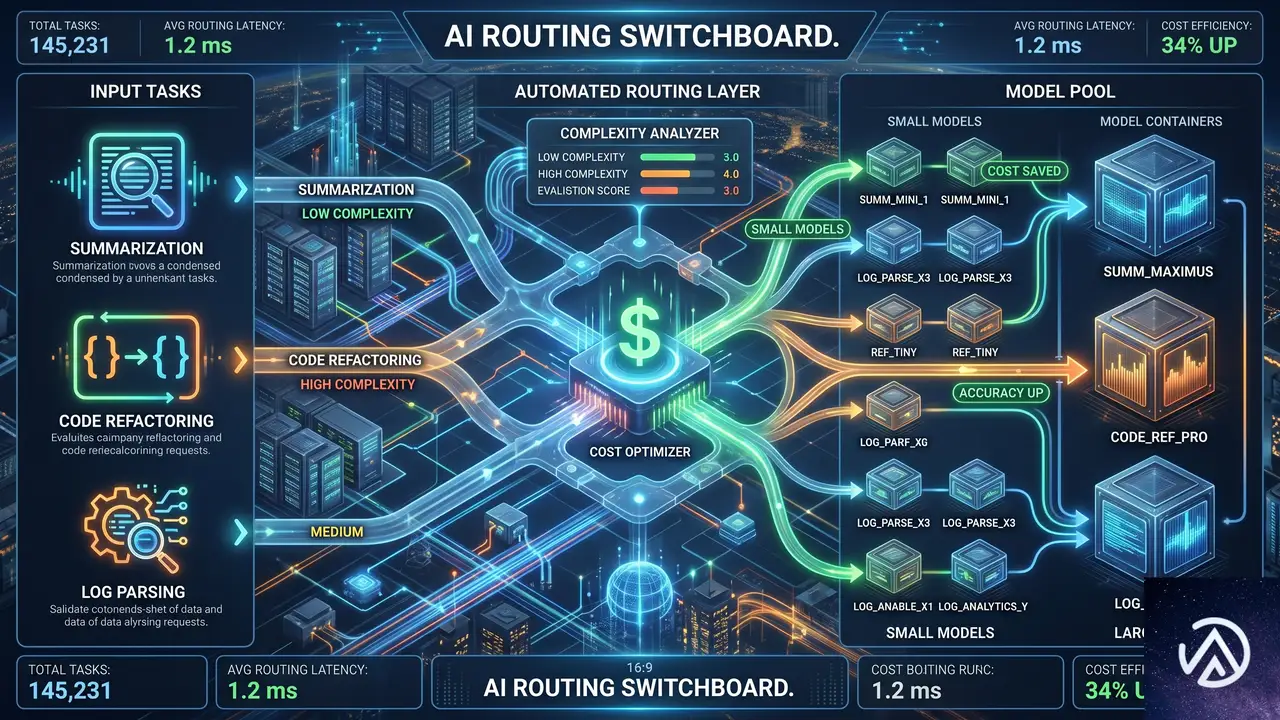
予算を設定し可視化することは、第一段階に過ぎない。次の課題は、限られた予算で最大の成果をどう引き出すかだ。現実には、すべてのリクエストに最先端モデルは不要である。要約タスクはより小さな安価なモデルでも品質を損なわずに実行できる。一方、大規模なコードリファクタリングには最新鋭のモデルが必要だ。しかし、制御がなければ人は常に最も高機能なモデルへ流れてしまう。
この問題に対し、Cloudflareはタスクベースのインテリジェントルーティングを鋭意開発中であると明かした。リクエストを分析し、最もコスト効率の良い結果を導くモデルへ自動的にルーティングする機能だ。詳細はデベロッパードキュメントとチェンジログで追って発表される。
この記事のポイント
- Cloudflare AI Gatewayにドル建ての利用上限機能が全プラン向けに登場した
- 上限到達時はリクエストをブロックするか、より安価なフォールバックモデルに自動で切り替えられる
- 限定ベータのアイデンティティベース予算は、個人やチーム単位で正確なコスト管理を実現する
- これらの機能はCloudflareが自社の大規模AI運用で実証した手法を外部化したものである
- 今後はタスクの複雑さに応じて最適なモデルへ自動ルーティングする機能の開発が予定されている
・ 複数業界における17年間のデジタルビジネス開発経験
・ ウェブサイト開発のためのHTML、PHP、CSS、JavaScript等の実用的知識
・ 15ヶ国語対応の多言語SaaSの開発経験
・ 17年間にも及ぶ、Eコマース長期運営経験
・ 幅広い業界でのSEO最適化の豊富な経験

VoidZeroがCloudflareに参画、ビルドツールViteはオープンソースを維持
Vite、Vitest、Rolldown、OxcといったJavaScriptエコシステムの中核ツールを開発するVoidZeroが、Cloudflareに参画した。全チームメンバーがCloudflareに合流する大規模な動きだ。
この発表で最も強調されているのは、これらのプロジェクトがこれからもオープンソースであり続けるという点だ。ViteはMITライセンスを維持し、ベンダーに依存せず、コミュニティ主導で開発が進められる。この原則が揺らぐことはないとCloudflareは明言する。
背景には、AI時代のソフトウェア開発の変化と、フルスタック化するモダンアプリケーションの複雑さがある。Viteがエコシステム全体の共有基盤となった今、この参画はツールチェーンの未来を左右する重要な転換点だ。
VoidZeroのCloudflare参画の内容

オープンソースとベンダー中立の堅持
Cloudflareは、Viteや周辺ツールの独立性を何よりも優先するとしている。具体的な約束は以下の通りだ。
- Vite、Vitest、Rolldown、Oxc、Vite+は今後もMITライセンスのオープンソースであり続ける
- 特定のクラウドベンダーに依存しない設計を維持する。Viteで構築したアプリケーションは、どこでも動作し続ける
- ロードマップはViteチームとコミュニティが引き続き主導し、公開の場で開発される
- Evan You氏をはじめとするVoidZeroチームが、プロジェクトのリーダーシップを継続する
- Cloudflareはこれらのプロジェクトにエンジニアリングリソースを投入するが、方向性を自社向けに曲げることはしない
Cloudflareのブログ記事では、このコミットメントを「言葉ではなく、日々の開発支援とプロジェクト運営で証明していく」と表現している。年初にAstroがCloudflareに参画した際と同様の、独立性を尊重するモデルだ。
100万ドルのViteエコシステム基金
この参画に伴い、CloudflareはViteエコシステム基金として100万ドルを拠出する。この基金はViteのコアチームによって管理され、メンテナーやコントリビューターへの支援に充てられる。
「ViteはVoidZeroやCloudflareよりも大きな存在だ」とCloudflareは述べており、エコシステムを支える無数の開発者を巻き込む意図が明確に示された。オープンソースの持続可能性を金銭面から支える、具体的な施策である。
この比較から分かるように、今回の参画はエコシステムの信頼を損なわないための設計が徹底されている。Viteが多くのフレームワークに採用されている共有基盤だからこそ、中立性の維持は絶対条件となる。
AIが変えたビルドツールの役割
エージェントがツールチェーンを回す時代
Cloudflareのブログ記事は、Viteの驚異的な普及の背景にAIの存在があると分析する。現在Viteの週間ダウンロード数は約1億2900万回、Cloudflare Viteプラグイン(@cloudflare/vite-plugin)は約1400万回に達している。これはVite本体のダウンロード数の10%を超える規模だ。
この急成長を牽引しているのが、AIコーディングエージェントだ。開発者だけが使っていた開発サーバーやリンター、フォーマッターを、今やAIエージェントが常時利用している。彼らはプロジェクトのスキャフォールディングから開発サーバーの起動、エラー解析、テスト実行までを自動で行う。
エージェントにとって重要なのは、高速なフィードバックループだ。ビルドが速く、テストが速く、エラーが明確で、CLIの挙動が一貫していること。VoidZeroのツールチェーン(Vitest、Rolldown、Oxc、Oxlint、Oxfmt)は、まさにこの要件に最適化されている。それぞれのカテゴリで最速クラスの性能を持ち、エージェントが何度も繰り返し実行してもストレスが少ない。
この図は、AIエージェントがコード生成からテスト、リント、修正までのサイクルを高速に回す様子を表している。各ツールの応答速度がエージェントの生産性に直結するため、VoidZeroのツールチェーンが選ばれる理由が明確になる。
フルスタック化するViteとVoidの知見

ビルドツールを超えた役割
モダンなアプリケーションは、単なる静的ファイルのバンドルでは完結しない。サーバーサイドレンダリング、API、バックグラウンドジョブ、キュー、データベース、オブジェクトストレージ、リアルタイム通信、認証、そしてAIエージェントの統合までが必要になる。
Viteはこれに対応するため、ビルドツールからフルスタックアプリケーションの基盤へと進化しつつある。Cloudflareはこの流れを加速させるために、Vite本体にプロバイダ非依存の抽象化レイヤーを追加していく方針だ。バックエンド、API、エージェント、デプロイメントのためのフックをVite側に用意し、各クラウドベンダーがそれを実装する形を目指している。
すでにVoidZeroが実験していた「Void」プラットフォームの知見が、この方向性を後押ししている。VoidはVite向けのデプロイメントプラットフォームとして設計され、モダンアプリのライフサイクル全体を一つのツールチェーンで統一する試みだった。Cloudflareは将来的にこのVoidプラットフォームをオープンソース化し、誰でも独自のプラットフォームをVite上に構築できるようにする計画も示している。
Workerd統合による開発体験の向上
CloudflareとViteの協業は2024年のVite Environment APIから始まっている。このAPIによって、Viteの開発サーバーはNode.js以外のランタイムでもサーバーコードを実行できるようになった。
Cloudflare Viteプラグインを使用すると、vite devの実行時にサーバーコードがWorkerd(Cloudflare Workersのオープンソースランタイム)上で動作する。Durable Objects、D1、KV、R2、Workers AI、エージェントなど、本番環境と同じランタイムモデルがローカルで再現される。開発環境が本番の劣化版だった時代は、このAPIによって終わりを迎えつつある。
この図が示すように、Environment APIの導入前後で開発体験は大きく変わった。ローカル環境と本番環境のランタイムが一致することで、デプロイ後の予期せぬエラーが激減する。
CloudflareがVite基盤に移行する意味

CLI統合とcfコマンドの未来
Cloudflareは自社ツールの方向性を「Viteに合わせる」と明確に宣言している。最近テクニカルプレビューが公開された新しい統合CLI「cf」は、Viteを基盤として設計される。
このCLIの目指す姿は、ViteのエルゴノミクスをそのままCloudflareプラットフォーム全体に拡張することだ。cf devはvite devのスーパーセットとして動作し、同じ速度、同じホットモジュールリプレースメント、同じプラグインモデルを持ちながら、必要に応じてCloudflareのランタイムとバインディングを利用できる。cf buildはViteプロジェクトをネイティブに理解し、cf deployはViteアプリのデプロイをシンプルにする。
すでにCloudflareのダッシュボード自体がVite上に構築されており、OxlintはCloudflareのコードベースで「数日分のエンジニアリング時間を節約している」と報告されている。Astroチームのエージェントハーネスフレームワーク「Flue」もVite基盤に移行中だ。Cloudflare自身がViteをドッグフーディングし、その価値を内部で証明している。
短期的な影響と長期的な展望
短期的には、Viteユーザーにとって何も変わらない。Vite、Vitest、Rolldown、Oxc、Vite+は引き続きリリースされ、VoidZeroチームがこれらを主導する。Cloudflare Viteプラグインも改善が続き、Environment APIもCloudflare以外のランタイムを含めて進化していく。
長期的には、CloudflareのCLIがVite上に完全に統合される。Viteにはフルスタックアプリとエージェントのためのプロバイダ非依存のプリミティブが追加され、あらゆるプラットフォームで利用可能になる。そしてVoidプラットフォームがオープンソース化され、誰でもViteとCloudflareの上に独自のプラットフォームを構築できるようになる。
この計画が実現すれば、ViteはJavaScriptエコシステムの単なるビルドツールから、アプリケーション開発全体を支える普遍的な基盤へと進化する。Cloudflareのインフラは、その基盤の上で最も統合された選択肢の一つとして位置づけられることになる。
この記事のポイント
- VoidZeroの全メンバーがCloudflareに参画。ViteやVitestなどのツールはMITライセンスのままでベンダー中立を維持する
- CloudflareはViteエコシステム基金として100万ドルを拠出し、コミュニティ主導の開発を資金面から支援する
- Viteの週間ダウンロード数1億2900万回の背景には、AIエージェントによる高速フィードバックループ需要がある
- Environment APIにより、ローカル開発環境でも本番と同じWorkerdランタイムが使用可能になった
- Cloudflareの新CLI「cf」はViteを基盤に統合され、全プラットフォームで一貫した開発体験を提供する計画だ
・ 複数業界における17年間のデジタルビジネス開発経験
・ ウェブサイト開発のためのHTML、PHP、CSS、JavaScript等の実用的知識
・ 15ヶ国語対応の多言語SaaSの開発経験
・ 17年間にも及ぶ、Eコマース長期運営経験
・ 幅広い業界でのSEO最適化の豊富な経験

イランのインターネットが部分的に復旧。Cloudflare Radarが87日ぶりの通信量増加を観測
2026年5月26日、イランで約3か月にわたって継続していた全国的なインターネット遮断が、部分的に解除された。Cloudflare Radarの観測データは、通信量とDNSクエリの急激な増加を記録しており、市民のオンラインアクセスが再開されつつあることを示している。
今回の復旧は、2月28日に始まった2度目の大規模遮断から87日目にあたる。遮断開始以来、ほぼゼロにまで落ち込んでいたイラン発の通信量が、突如として前週比の約15倍に跳ね上がった。もっとも、この回復は完全ではなく、ピーク時のトラフィックは今年の最大値と比較して40%にとどまっている。
Cloudflareのネットワークを流れるデータの詳細を読み解くことで、長期化した遮断の実態と、今回の部分復旧の意味するところが浮かび上がる。本記事では、一連のデータポイントを分析し、イランのインターネット接続状況が現在どのようなフェーズにあるのかを解説する。
2026年にイランで発生した2度の大規模インターネット遮断

イランでは今年に入り、すでに2度の全国的なインターネット遮断が発生している。最初の遮断は1月8日に始まり、数日間でほぼすべての通信量が消失した。短期間の部分回復を挟みつつ、本格的な復旧は1月27日までずれ込んでいる。
2度目となる今回の遮断は、情勢の緊迫化を背景に2月28日から開始された。現地時間の午前10時30分ごろ、イラン国内から国外へ向かうウェブ通信量とDNSトラフィックは、遮断前の1%未満にまで急落した。それ以降、わずかなデータ漏洩を除けば、実質的に国全体がグローバルネットワークから隔絶された状態が続いていた。
この約3か月間、イランの一般市民はオンラインバンキング、地図アプリ、メッセージツール、海外のニュースメディアなど、日常生活やビジネスに不可欠なデジタルサービスから切り離されてきた。
上図の比較からわかるように、遮断期間中の通信は事実上ストップしていた。5月26日以降のデータは、国全体のネットワークが一斉に「息を吹き返した」かのような変化を示している。
トラフィック急増の詳細なデータが示すもの
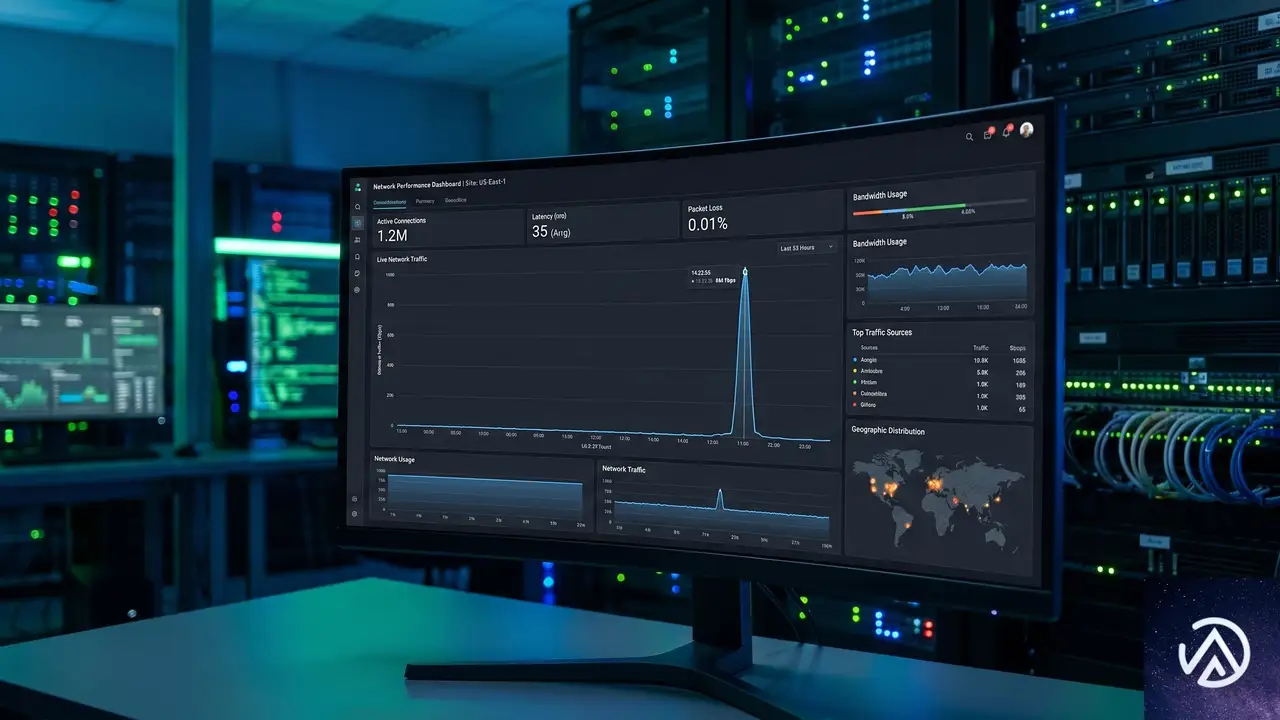
通信量は前週の約15倍に跳ね上がった
Cloudflareのネットワーク上を転送されたバイト数のデータを見ると、復旧の兆候は明瞭だ。協定世界時(UTC)の5月26日11時45分に最初のスパイクが記録され、12時00分からは持続的な増加へと転じた。この通信量の急増は、遮断期間中の前週の水準と比較して約15倍に達している。
転送バイト数の増加とは、単に「接続が戻った」というだけでなく、画像や動画、ファイルダウンロードといった実データが国境を越えて再び流れ始めたことを意味する。ウェブの閲覧だけでなく、アプリのアップデートやクラウドストレージへの同期など、より帯域を消費する活動が再開された可能性が高い。
トラフィックの推移は、人間の生活リズムと一致する日内変動にも従っている。UTCの21時ごろ(現地時間の深夜0時30分ごろ)に通信量が減少し、翌27日の3時(現地時間6時30分ごろ)から再び増加に転じた。このパターンは、実際に人々が朝を迎えて端末を操作し始めたことを如実に反映している。
この比較は、ネットワークが単に技術的に「オン」になったのではなく、エンドユーザーによる実需要が即座に反映されたことを示している。
全体の91.6%がテヘランに集中する地域別の偏り
回復したトラフィックのほとんどは、首都テヘランに集中している。Cloudflare Radarの地域別データによれば、HTTPリクエスト全体の実に91.6%がテヘラン州から発信されていた。他の地域でもわずかな増加は見られるものの、テヘランとの差は圧倒的だ。
この極端な偏りからは、いくつかのシナリオが推測できる。第一に、政府や通信規制当局が首都から優先的に復旧を進めている可能性が高い。第二に、テヘランには国内で最も多くのデータセンターや国際接続ポイントが集中しており、物理的に復旧作業が行いやすいというインフラ面の要因も考えられる。
ただし、この偏りが地方に住む大多数の市民にとって「ネットが戻った」という実感からはほど遠い状況を生んでいる点は重要だ。現在の復旧状況は、あくまで「部分的」であり、国の隅々まで接続性が戻るにはさらなる時間を要するだろう。
ネットワーク事業者別に見る復旧状況
通信量の増加は、複数の主要なインターネットサービス事業者(ISP)で同時に観測されている。11時45分の最初のバーストに続いて、TCI(イラン通信)、IranCell、RighTel、MCCIといった事業者のネットワークで一斉にトラフィックが立ち上がった。
これらの事業者は、それぞれ異なる自律システム番号(ASN)という一意の識別子で管理されている。ASNとは、インターネット上で個々のネットワークを識別するための番号で、例えるなら「インターネット世界における電話の市外局番と加入者番号を組み合わせたようなもの」だ。複数のASNで同時に復旧が確認されたことは、特定の事業者のみの一時的な不具合ではなく、国家レベルでの規制変更やゲートウェイの開放が行われたことを強く示唆している。
複数事業者での同時回復という事実は、今回の復旧が偶発的なものではなく、中央政府の明確な意図に基づいて実行された可能性が高いことを示している。
DNSクエリの急増と1.1.1.1への影響

転送バイト数だけでなく、DNS(ドメインネームシステム)クエリの数も急増している。DNSとは、人間が覚えやすい「google.com」のようなドメイン名を、コンピュータが理解できるIPアドレスに変換する、インターネットの「電話帳」にあたる仕組みだ。このDNSクエリが増えるということは、利用者が実際にウェブサイトやアプリに接続しようとしている直接的な証拠となる。
Cloudflareが提供するパブリックDNSリゾルバ「1.1.1.1」へのクエリも、5月26日を境にスパイクを記録した。このリゾルバは、インターネットサービス事業者が提供するデフォルトのDNSよりも高速で、プライバシーに配慮していることから、技術に詳しいユーザーを中心に世界中で広く利用されている。イラン国内から1.1.1.1へのクエリが増えたことは、単にネットが使えるようになっただけでなく、ユーザーが意識的に「より速く、より自由な」DNS解決手段を選択し始めた可能性を示唆する。
DNSトラフィックの回復は、ウェブページの閲覧だけに留まらない。メールの送受信、アプリのプッシュ通知、VoIP通話など、多種多様なインターネットサービスは、すべて通信の最初の段階でDNSクエリを発生させる。したがって、DNSクエリの増加傾向は、デジタル社会の活動そのものが再開されつつあることの強い指標と言える。
通信量はピーク時の40%にとどまる依然として本格復旧には遠い現実

今回の回復を楽観視するのはまだ早い。5月26日のピーク時でさえ、トラフィックは今年に入ってから遮断前に記録された最大通信量のわずか40%にとどまっている。ネットワークの「部分的」復旧という言葉が示す通り、まだ多くの障害が残っていると見るべきだ。
加えて、1月の事例が示すように、一時的な復旧はすぐに逆戻りするリスクをはらんでいる。1月にも、一度は戻ったかに見えた通信が24時間足らずで再び遮断された経緯がある。現時点でのトラフィックの増加は心強い兆候ではあるが、これが持続的な復旧の始まりなのか、それとも再び訪れる「通信のブラックアウト」の前触れなのかは、今後の数日から数週間のデータを注視しなければ判断できない。
上記の警告表示が示す通り、ネットワーク状況は依然として流動的だ。本来あるべき水準からはほど遠く、完全な「日常」のネット利用が戻ったとは到底言えない。
IPv6アドレス消失が示す遮断の技術的メカニズム

イランのインターネット遮断を語る上で、見逃せないデータポイントがある。IPv6(インターネットプロトコルバージョン6)アドレス空間の消失だ。
IPv6とは、次世代のインターネットアドレス規格である。従来のIPv4アドレスが世界的に枯渇しつつある中で、ほぼ無限に近いアドレス数を提供できるIPv6への移行が世界中で進められている。このIPv6アドレスの広報(グローバルな経路表に自ネットワークのアドレスを登録すること)が、1月の最初の遮断が始まる数時間前に、イラン国内からほぼ完全に消失した。そして、驚くべきことに、5月の部分復旧後もIPv6アドレス空間の広報量は事実上ゼロのままだ。
一方、旧来のIPv4アドレス空間の広報は、2度の大規模遮断中も一貫して安定的に維持されていた。一見すると矛盾するこの事実は、イランの遮断が物理的なケーブルの切断やルーターの停止といった単純な手法ではなく、より高度なフィルタリング技術によって達成されていたことを強く示唆している。
この対比から導き出される仮説は明快だ。イランの規制当局は、特定のアプリケーションやプロトコルを識別して遮断するDPI(ディープパケットインスペクション)や、許可リストに登録された宛先以外への通信をすべて遮断するホワイトリスト方式を用いて、通信を制御していた可能性が高い。IPv4が「抜け殻」として維持されていたのは、将来的な復旧を想定した準備であったとも考えられる。IPv6が戻らない理由は定かではないが、次世代プロトコルに対する管理・監視体制が整っていないことが一因かもしれない。
この記事のポイント
- 2月28日から87日間続いたイランのインターネット遮断が、5月26日に部分的に解除された。
- Cloudflare Radarのデータでは、前週比約15倍の通信量とDNSクエリの急増が観測された。
- 回復したトラフィックの91.6%は首都テヘランに集中しており、地方との格差が大きい。
- 通信量は遮断前の通常時と比較すると40%の水準に留まり、本格復旧には至っていない。
- IPv6アドレス空間の広報は依然として消失したままであり、遮断の技術的複雑さを示している。
・ 複数業界における17年間のデジタルビジネス開発経験
・ ウェブサイト開発のためのHTML、PHP、CSS、JavaScript等の実用的知識
・ 15ヶ国語対応の多言語SaaSの開発経験
・ 17年間にも及ぶ、Eコマース長期運営経験
・ 幅広い業界でのSEO最適化の豊富な経験

Astro 6.4リリース。プラグ可能なMarkdownパイプラインとRust製プロセッサーSätteriが登場
Astro 6.4が2026年5月28日にリリースされた。Markdown処理パイプラインを自由に差し替え可能にする新API「markdown.processor」、Rustで書かれた高速MarkdownプロセッサーSätteriの試験的導入、そしてCloudflare環境向けのルーティングヘルパーが追加された。
これまでの設定方法は非推奨となり、将来的なAstro 8.0では完全に廃止される予定だ。今回のアップデートで、静的サイト構築におけるMarkdown処理の柔軟性とパフォーマンスが大幅に向上する。
プラグ可能なMarkdownプロセッサーAPI

AstroのMarkdownパイプラインはこれまで、unified(remark/rehype)エコシステムを中心に構築されてきた。強力で数千ものプラグインが利用できる一方、特定のプロジェクトの要求に合わない場合もあった。今回追加されたmarkdown.processor設定オプションでは、そのパイプライン全体を丸ごと差し替えられる。
設定の変更方法
デフォルトのプロセッサーは従来通りunified()が使われるため、既存プロジェクトは何も変更せずにそのまま動き続ける。remark/rehypeプラグインも同じ挙動を保つが、設定場所がトップレベルのmarkdownからプロセッサー内に移行した。
import { defineConfig } from 'astro/config';
import { unified } from '@astrojs/markdown-remark';
import remarkToc from 'remark-toc';
export default defineConfig({
markdown: {
processor: unified({
remarkPlugins: [remarkToc],
}),
},
});従来のトップレベルオプション(markdown.remarkPlugins, markdown.rehypePlugins, markdown.remarkRehype, markdown.gfm, markdown.smartypants)も引き続き動作するが非推奨となり、Astro 8.0で完全に削除される予定だ。
移行の注意点
既存プロジェクトの移行は比較的簡単だ。unified({...})内にプラグインをまとめて記述するだけでよい。ただし、マークダウン処理をカスタマイズした複雑な設定を行っている場合は、コードの再構成が必要になる。公式ドキュメントのMarkdownガイドが更新されているため、詳細はそちらを参照してほしい。
Rust製MarkdownプロセッサーSätteri

プラグ可能なプロセッサーAPIの追加により、Astroは標準とは異なるMarkdownプロセッサーも同梱できるようになった。今回導入された@astrojs/markdown-satteriパッケージは、Rustで書かれた高速なMarkdown/MDXパイプライン「Sätteri」をベースにしている。
パフォーマンスの劇的な向上
Sätteriはデフォルトのunifiedベースのパイプラインよりも大幅に高速で、多くのMarkdown機能をプラグインなしでネイティブ実装している。Astroの公式ブログによれば、自社のドキュメントサイトをSätteriに切り替えたところ、ビルド時間が1分以上短縮されたという。
npm install @astrojs/markdown-satteriimport { defineConfig } from 'astro/config';
import { satteri } from '@astrojs/markdown-satteri';
export default defineConfig({
markdown: {
processor: satteri({
features: { directive: true },
}),
},
});この数値はあくまで一例だが、コンテンツ量の多いサイトでは特に効果が大きい。Rustで記述されているため、CPUバウンドな処理が高速化される仕組みだ。
プラグイン互換性と今後のデフォルト化
Sätteriはremark/rehypeプラグインを実行しない。unifiedエコシステムのプラグインに依存している場合は、当面unified()を使い続けるか、SätteriのMDAST/HASTプラグインに移植する必要がある。Astroチームは、将来のメジャーバージョンでSätteriをデフォルトのMarkdownプロセッサーにすることを目指している。
Rustプロセッサーや新APIに関するフィードバックは、公式のRFCDiscussionで受け付けている。興味がある開発者はぜひ参加してほしい。
Cloudflare向け高度ルーティングヘルパー

Astro 6.3で導入された実験的な高度ルーティング機能をCloudflare環境で使いやすくするため、@astrojs/cloudflareパッケージにcf()ヘルパーが追加された。SESSION KVバインディングの注入、ASSETSバインディングによる静的アセット配信、クライアントIPアドレスやwaitUntilの処理など、Cloudflare特有の面倒な設定を一手に引き受ける。
Fetchハンドラでの利用
import { astro, FetchState } from 'astro/fetch';
import { cf } from '@astrojs/cloudflare/fetch';
export default {
async fetch(request: Request, env: Env, ctx: ExecutionContext) {
const state = new FetchState(request);
const asset = await cf(state, env, ctx);
if (asset) return asset;
return astro(state);
},
};Honoミドルウェアでの利用
import { Hono } from 'hono';
import { actions, middleware, pages, i18n } from 'astro/hono';
import { cf } from '@astrojs/cloudflare/hono';
const app = new Hono<{ Bindings: Env }>();
app.use(cf());
app.use(actions());
app.use(middleware());
app.use(pages());
app.use(i18n());
export default app;このヘルパーにより、Cloudflare上で高度なルーティングを実装する際のボイラープレートコードが大幅に削減される。実験的機能ではあるが、実用段階に入りつつあると言えるだろう。
その他の改善とアップグレード手順

細かなバグ修正と今後のロードマップ
今回のリリースには、上記の主要機能以外にも多数のバグ修正と小さな改善が含まれている。詳細は公式の変更履歴を確認してほしい。また、Astroコアチームは活発に開発を続けており、コミュニティからのコントリビュートも盛んだ。
アップグレードの手順
既存のAstroプロジェクトをアップグレードするには、自動アップグレードツールを使うのが推奨だ。
# 推奨
npx @astrojs/upgrade
# 手動の場合
npm install astro@latest
pnpm upgrade astro --latest
yarn upgrade astro --latest自動ツールは非推奨設定の移行などもサポートする。手動で行う場合は、設定ファイルの変更点を確認しながらアップデートしよう。
この記事のポイント
- Markdown処理を差し替え可能にする
markdown.processorAPIが追加された - RustベースのSätteriプロセッサーによりビルド時間を大幅に短縮できる
- Cloudflare向け
cf()ヘルパーで高度ルーティングの設定が簡略化された - 従来の設定方法は非推奨となり、Astro 8.0で廃止予定。早めの移行が望ましい
- アップグレードは
npx @astrojs/upgradeで簡単に行える
・ 複数業界における17年間のデジタルビジネス開発経験
・ ウェブサイト開発のためのHTML、PHP、CSS、JavaScript等の実用的知識
・ 15ヶ国語対応の多言語SaaSの開発経験
・ 17年間にも及ぶ、Eコマース長期運営経験
・ 幅広い業界でのSEO最適化の豊富な経験

CloudflareがClaude Managed Agentsと統合、エージェントの実行基盤を刷新
CloudflareがAnthropicと連携し、Claude Managed AgentsをCloudflareのサンドボックス環境と統合した。この新たな統合により、エージェントのコード実行からブラウザ操作、プライベートサービスへの接続までを、Cloudflareのプラットフォーム上でより柔軟に制御できる。
従来、Claude Managed AgentsはAnthropic側のインフラに完全に依存していた。今回の発表で「頭脳」であるClaudeの推論ループと「手足」であるコード実行基盤が分離され、後者をCloudflare上で運用できるようになった。
開発者は数分でテンプレートをデプロイし、セキュリティ強化やミリ秒単位のサンドボックス起動、内部サービスへの安全な接続といったメリットを得られる。この記事では、統合の仕組みと実務への影響を具体的に掘り下げる。
Claude Managed AgentsとCloudflareが目指すもの

この構成で得られるのは単なる「場所の変更」ではない。インフラをCloudflareに移すことで、エージェントの振る舞いを細かく監視し、内部サービスとの通信を暗号化し、必要なリソースだけを動的に割り当てられるようになる。
Cloudflare Blogの記事では、この仕組みを「頭脳から手足を切り離す」と表現している。開発者はClaudeの高い推論能力をそのまま活かしつつ、実行環境だけを自社ポリシーに合わせてカスタマイズできるわけだ。
Cloudflare環境の仕組み

統合をデプロイすると、Cloudflare上にWorkersベースのコントロールプレーンが立ち上がる。Claude Agentがセッションを開始するたび、このコントロールプレーンがサンドボックス環境を割り当て、コード実行やCLIツールの操作、ブラウザ操作などを代行する。
サンドボックスはセッションがスリープしても状態を自動的に保持する。コンテナイメージのカスタマイズやインスタンスサイズの調整もオプションで指定でき、既存の監視ツール(DatadogやSplunk)へのログ連携にも対応している。
特筆すべきは、Cloudflareのダッシュボードからエージェントの状態を可視化し、必要に応じてSSHでサンドボックス内部に入れる点だ。大規模なエージェント運用では、トラブルシューティングのしやすさが運用コストを大きく左右する。この設計は現場の要求をよく踏まえている。
インターネット規模のエージェント実行基盤

エージェントが本格的に普及すると、企業は1人のユーザーに対して複数のエージェントを同時に動かす必要が出てくる。従来のマイクロVM方式では、エージェントの数だけVMを起動し続けるため、リソースとコストが線形に増加してしまう。
Cloudflareはこの課題に対し、V8 Isolateを使った軽量サンドボックスを提供する。Dynamic WorkersとCodemodeを組み合わせることで、ミリ秒単位でサンドボックスを起動し、フルVMよりはるかに少ないリソースで任意のコードを実行できる。
エージェントのセットアップ時にバックエンドタイプとして「isolate」を選択するだけで、この軽量モードに切り替えられる。数万規模の同時エージェントを扱うユースケースでは、コスト効率が数十倍変わる可能性がある。
もちろん、Linuxツールをフル活用する開発エージェントには、引き続きマイクロVMベースのCloudflare Containersを使える。用途に応じて2種類の実行環境を選択できる点が、この統合の実用的な強みだ。
エージェントワークロードのセキュリティ

エージェントが組織の内部データやサービスにアクセスするとき、最大のリスクは認証情報の漏洩だ。Cloudflareの統合では、アウトバウンドプロキシを使い、サンドボックスから外部へ出る通信に対して動的に認証情報を注入する仕組みを備えている。
この設計のポイントは、エージェント自身はクレデンシャルを知らないことだ。プロキシがゼロトラストベースでリクエストに署名やトークンを付与するため、万が一サンドボックスが侵害されても、認証情報そのものが盗まれるリスクを抑えられる。
また、Cloudflare MeshとWorkers VPCを使えば、インターネットに一切公開していない内部サービスにも、ポスト量子暗号で保護されたトンネル経由で接続できる。VPNや踏み台サーバーなしでプライベートサービスと通信できる点は、インフラ担当者にとって大きな利点だろう。
プロキシはテナント単位やエージェント単位でポリシーを適用できる。特定のエンドポイントだけを許可リスト化し、それ以外の通信を遮断するといった細かな制御も、コード数行で実装可能だ。
エージェントに必要なツール群

ブラウザ操作の完全な制御
エージェントがウェブと対話する際、単純なHTTPリクエストでは不十分な場面が多い。JavaScriptを多用するモダンなウェブアプリケーションの操作や、QA用のスクリーンショット取得、フォーム入力の自動化には、実際のブラウザが必要になる。
CloudflareのBrowser Runは、エージェントにプログラム可能なブラウザを与える仕組みだ。検索、実行、スクリーンショット、ページのMarkdown変換など、複数のツールがデフォルトで利用できる。
セッションの録画機能も備わっており、エージェントがブラウザ上で何をしたかを後から完全に監査できる。許可リストや拒否リストを使ったアクセス制御も可能で、野放図なウェブアクセスを防げる。
メール送受信とプライベート接続
エージェントにメールアドレスを割り当て、送受信を自律的に行わせる機能も統合済みだ。Cloudflare Email Serviceと連携し、任意のドメインでエージェントがメールを送信できる。顧客対応の自動化や、転送されたメールへの返信といったユースケースに適している。
内部サービスへの接続にはcall_serviceツールが用意されており、Cloudflare MeshやWorkers VPC経由でプライベートAPIを安全に呼び出せる。Workers AIを使った画像生成ツールも標準で組み込まれており、Claudeのテキスト推論と組み合わせたマルチモーダルなワークフローを構築できる。
カスタムツールの追加
リポジトリをフォークし、独自のツールを追加するのも容易だ。例えばCloudflare R2にファイルをアップロードし、公開URLを返すツールを数行のコードで定義できる。以下はCloudflare Blogで示されたコード例を簡略化したものだ。
defineTool({
name: "r2_host_file",
description: "サンドボックスからR2にアップロードし公開URLを取得",
inputSchema: z.object({
key: z.string(),
content: z.string(),
contentType: z.string()
}),
run: async ({ key, content, contentType }, { env }) => {
await env.PUBLIC_BUCKET.put(key, content, { httpMetadata: { contentType }});
return `${env.PUB_R2_URL}/${encodeURI(key)}`;
}
})Workers AIを使ったエッジ推論や、Dynamic Workersによる動的なアプリケーションホスティング、Artifactsを使ったGit管理の追加など、Cloudflare Developer Platform全体をエージェントの拡張に活用できる。インフラ管理を意識せず、関数を書いてデプロイするだけで機能追加が完了する設計だ。
この記事のポイント
- Claude Managed Agentsの実行基盤をCloudflare上に構築できるようになった
- 「頭脳(Claude)」と「手足(Cloudflareサンドボックス)」の分離で、インフラ選択の自由度が向上した
- V8 Isolateを使った軽量サンドボックスで、ミリ秒起動と低コストの大規模実行が可能
- アウトバウンドプロキシによるゼロトラスト認証で、エージェントのセキュリティを強化
- ブラウザ操作、メール送受信、内部サービス接続などのツールが標準装備されている
・ 複数業界における17年間のデジタルビジネス開発経験
・ ウェブサイト開発のためのHTML、PHP、CSS、JavaScript等の実用的知識
・ 15ヶ国語対応の多言語SaaSの開発経験
・ 17年間にも及ぶ、Eコマース長期運営経験
・ 幅広い業界でのSEO最適化の豊富な経験