

Google 3月コアアップデートで何が変わったか、集約サイトに逆風で自社サイトに追い風
2026年3月に実施されたGoogleのコアアップデートで、検索結果の可視性に大きな地殻変動が起きた。特に影響を受けたのは、YouTubeやRedditに代表される「集約サイト」や「ユーザー投稿型プラットフォーム」だ。これらが軒並み可視性を落とす一方で、ブランドの公式サイトや政府機関ドメインが上昇した。
デジタルマーケティング企業Amsiveの分析によれば、YouTubeは可視性スコアを567ポイントも失い、全ドメイン中最大の下落を記録した。TripAdvisorも45ポイント減、Redditも64ポイント減と、多くの有名サービスが影響を受けている。こうした動きは「情報の一次発信者をより重視する」というGoogleの姿勢を反映したものだと受け止められている。
この記事では、Amsiveの調査データの詳細に加え、業界別の勝ち組・負け組、そして復活パターンまでを解説する。3月のアップデートで自社サイトがどう評価されたかを振り返り、今後のSEO戦略を練るための材料としてほしい。
3月コアアップデートで何が起きたのか
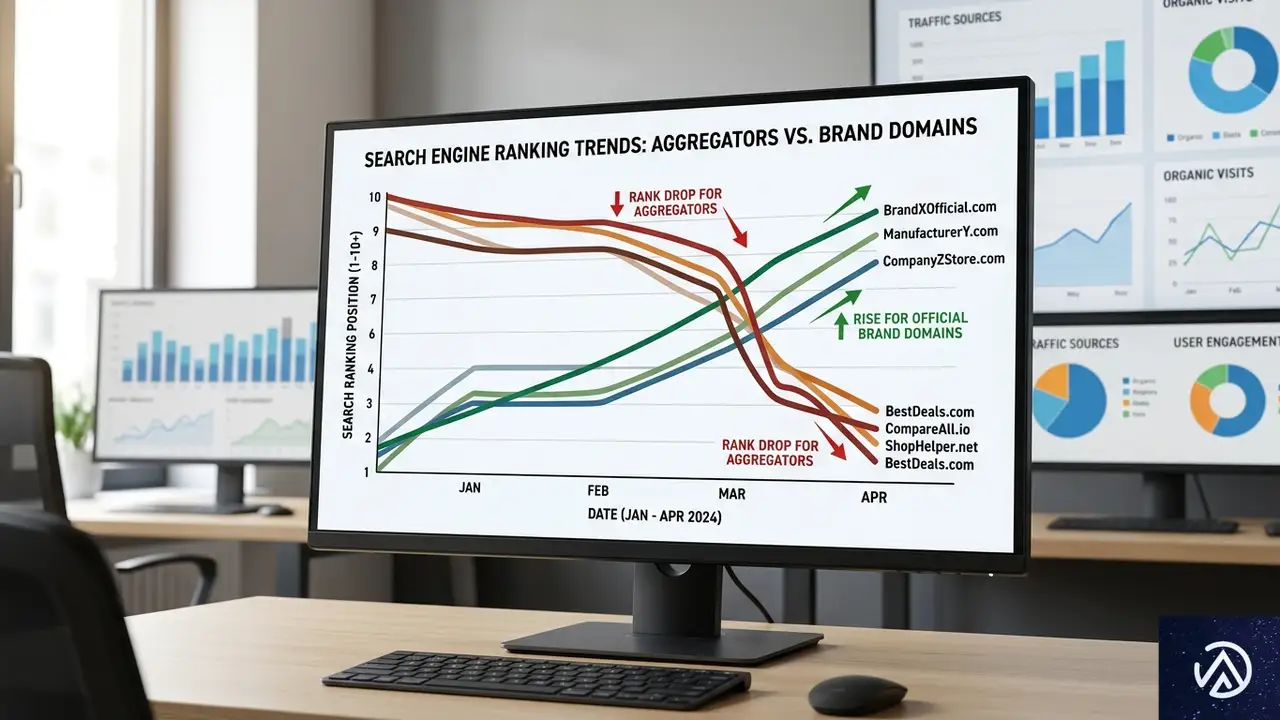
AmsiveはSISTRIX Visibility Indexを用いて、2,000以上のドメインを分析した。分析対象期間は2026年3月27日(ロールアウト開始日)から4月8日(完了日)までである。さらにDataForSEO APIを使い、各ドメインにGoogleの商品分類タグを付与して、業界別の傾向を浮き彫りにした。
ここで言う「可視性スコア」とは、SISTRIXが算出するキーワード単位の表示機会の指標であり、実際のオーガニックトラフィックそのものとは異なる。ただ、大規模なランキング変動を捉えるには十分なデータセットだ。
「情報の一次発信者」を優遇する流れ
Amsiveは今回の変化を「過度にインデックスされていたUGCやアグリゲーターコンテンツに対する是正」と位置づけている。つまり、「ある物事について人々が話し合うプラットフォーム」よりも、「その物事を実際に提供・所有する企業や組織」のサイトを上位に表示しようという補正だ。
この傾向は、旅行、求人、健康など複数の業界で一貫して見られた。たとえば旅行分野では、OTA(オンライン旅行代理店)が集客力を落とし、ホテルチェーンや空港の公式サイトが上昇した。これは、単なるアルゴリズムの一時的な揺らぎではなく、意図的な方向修正である可能性が高い。
このデモで示したように、単なる口コミや他者コンテンツの再掲載ではなく、自社サービスや公式情報そのものを発信するサイトが検索上で優位に立つ構図が鮮明になった。
ドメイン別の勝者と敗者
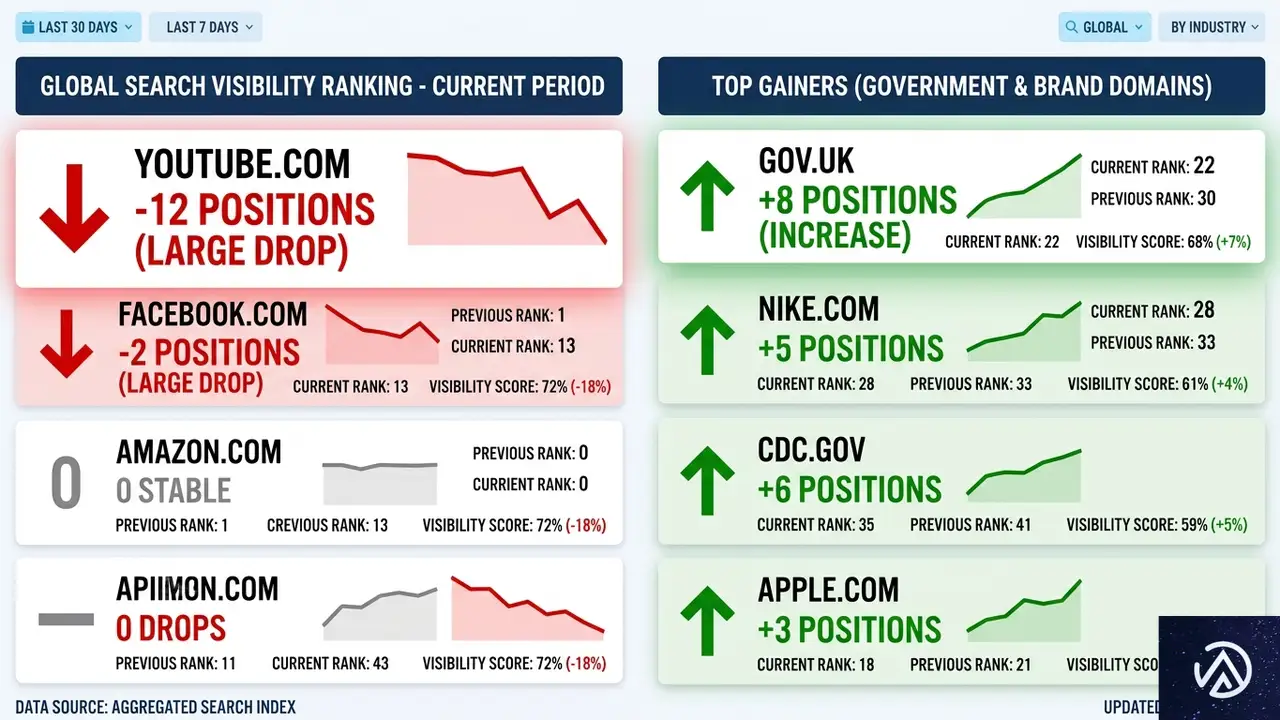
Amsiveのデータセットで最も激しい動きを見せたのはYouTubeだった。可視性スコアを567ポイントも下げており、これは全ドメイン中最大の下落幅である。比較対象として、2025年12月のコアアップデートでWikipediaが経験した435ポイント減よりも約30%大きい。
主要ドメインのスコア変動
以下のリストは、AmsiveがSISTRIXデータから抽出した可視性変動の一部である。
- YouTube 567ポイント減(最大の下げ幅)
- Reddit 64ポイント減
- Instagram 48ポイント減
- X(旧Twitter) 46ポイント減
- TripAdvisor 45ポイント減
- Yelp 33ポイント減
- Expedia 33ポイント減
注目すべきは、YouTubeの下落が「過去の一時的な急騰の反動」である可能性だ。AmsiveのLily Ray氏は、YouTubeの可視性は3月初旬の急上昇前の水準に戻ったに過ぎず、過去最低を更新したわけではないと補足している。つまり、異常値の補正と見ることもできる。
一方で、RedditやXといったテキスト系UGCプラットフォームの低下は構造的だ。これらは2024年から2025年にかけて大幅に検索可視性を伸ばしてきた経緯があり、今回のアップデートはその反動という見方が強い。
この視覚化からもわかるとおり、減少幅ではYouTubeが突出している。それでも、複数のUGC系プラットフォームがまとまってスコアを落とした点が、今回のアップデートの特徴と言える。
業界別の影響 旅行、求人、健康
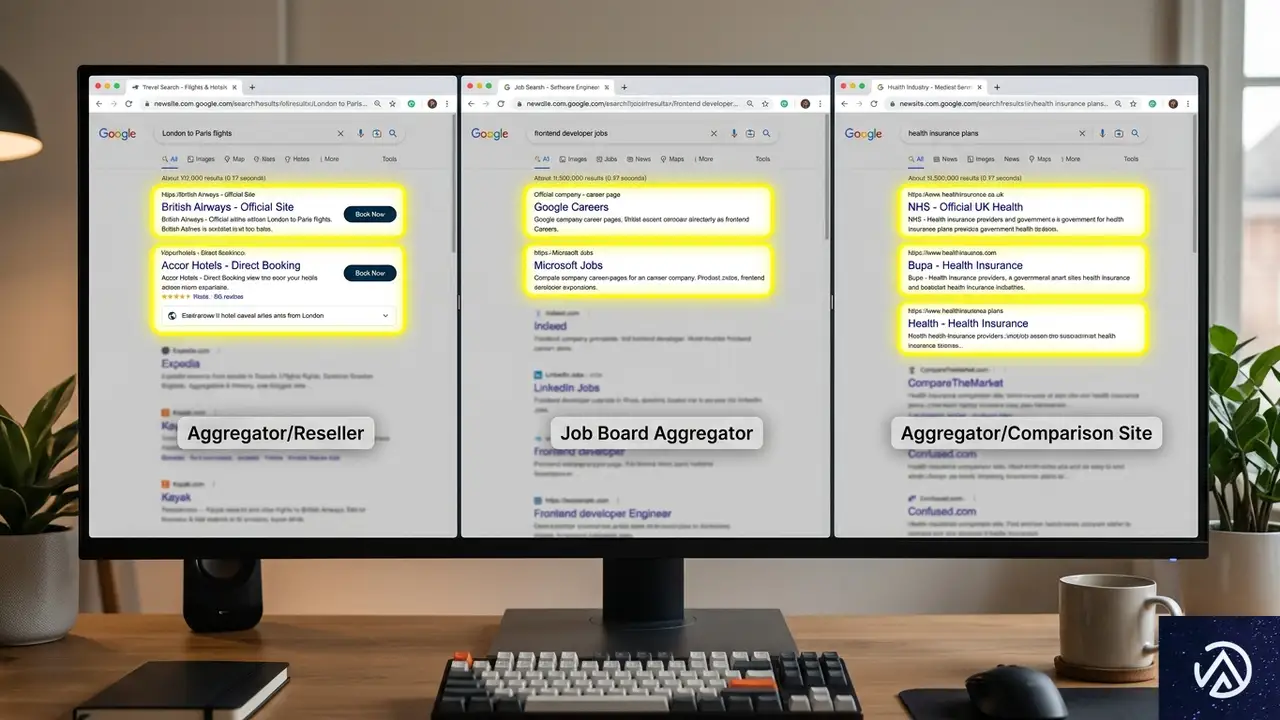
ドメイン単位の分析に加えて、業界カテゴリ別のパターンも明確になった。AmsiveはDataForSEOのAPI経由でGoogle商品分類タグを各ドメインに割り当て、旅行、求人、健康の3分野を重点的に分析している。
旅行分野 OTAが後退しホテル公式が台頭
旅行業界では、TripAdvisor(45ポイント減)、Yelp(33ポイント減)、Expedia(33ポイント減)がそろって下げた。代わりに上昇したのは、ヒルトンの公式サイト(4ポイント増)、Hotels.com(3.6ポイント増)、Trivago(3.2ポイント増)だった。さらに、米国国立公園局のNPS.govが9.9ポイント増、複数の空港公式サイトも大幅に上げている。
これは「旅行先を探す」という行動において、Googleが「個人のレビューを集めたサイト」よりも「宿泊施設や交通機関の公式情報」を優先するようになったことを示唆する。OTAのマーケティング担当者にとっては、SEOの前提を見直す転換点になるかもしれない。
求人分野 雇用主のキャリアページが評価上昇
求人・教育カテゴリでも、Indeed(18ポイント減)、ZipRecruiter(13ポイント減)といった求人アグリゲーターが下げた一方で、米国労働統計局のBLS.gov(5.4ポイント増)、米国政府求人サイトのUSAJobs.gov(16%増)、Disney Careers(59%増)、CVS Health Careers(45%増)といった雇用主直轄のキャリアページや政府系ドメインが目立って上昇した。
求職者が「特定の企業で働きたい」と考えたとき、検索結果の上位に企業の公式採用ページが表示されやすくなった形だ。これにより、求人専門サイト経由での応募導線に依存していた企業は、自社キャリアページのSEO強化が急務となっている。
健康分野 信頼できる公的機関が選ばれる傾向
健康分野では、処方薬割引サービスのGoodRxが55%増(9.5ポイント増)と大幅に伸び、米国国立衛生研究所(NIH.gov)も9.3ポイント増えた。その一方で、クリーブランドクリニックは12ポイント減、WebMDは9ポイント減、メイヨークリニックは6ポイント減と、有名な消費者向け健康情報サイトが軒並み下げた。
ここでの解釈は慎重を要するが、「権威性の高い公的機関の情報」をより重視する動きの一環と見ることができる。医学情報のように正確性が求められるジャンルでは、この傾向が今後も強まる可能性がある。
回復パターンと注意点
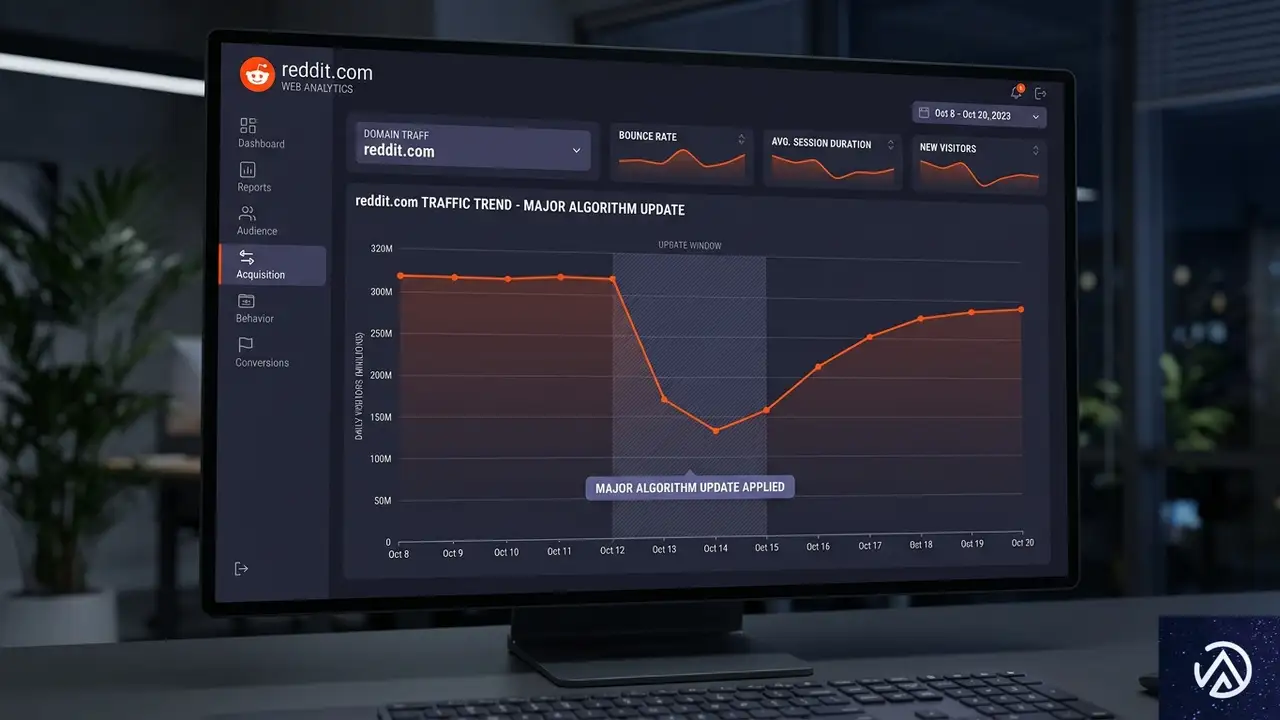
今回の分析で興味深いのは、一部の「敗者」ドメインがアップデート直後に可視性を急回復させた点だ。RedditとIndeedは、ロールアウト完了からほどなくしてスコアを取り戻した。このことから、アップデート期間中のスナップショットだけを見て「負けた」と判断するのは早計であることがわかる。
AmsiveのLily Ray氏も、今回の敗者リストはあくまで「アップデート期間中」の変動を捉えたものであり、その後に各ドメインがどこに落ち着いたかまでは示していないと強調している。SEO担当者は、ランキング変動を確認する際に、少なくともロールアウト完了後1〜2週間のデータを見て判断することが重要だ。
Zyppyの先行分析とも整合
今回のAmsiveによる発見は、同月に公開された別の分析結果とも整合している。ZyppyのCyrus Shepard氏が400以上のサイトを調査したレポートでは、「タスクを完了させる製品・サービスを提供するサイト」がオーガニックトラフィックを伸ばす傾向が示されていた。
手法は異なる。Shepard氏はサードパーティのトラフィック推計データとの相関を測定したのに対し、AmsiveはSISTRIXの可視性スコアをアップデート期間で追跡した。それでも、到達した結論はほぼ同じで、「情報の受け売りではなく、本物の価値を提供するサイト」が評価されるという方向性は確からしい。
さらに、ドイツのデータを用いたSISTRIX独自の分析でも同様の結果が得られている。オンラインショップや便利系サイトが可視性を下げ、公式サイトやブランドドメインが相対的に強かった。この世界的な共通傾向は、Googleがグローバルに同様の評価軸を適用している可能性を示す。
自社サイトへの示唆と対策

今回の一連のデータは、あくまでGoogleが内部で何を変更したかを確定するものではない。しかし、旅行、求人、健康、金融、エンターテインメントという異なる業界で同じパターンが繰り返された事実は重い。これは単発の異常値ではなく、検索エンジンの評価基準に構造的なシフトがあったことを示唆している。
つまり、「他人のコンテンツを集めて並べるだけのサイト」や「ユーザーが自発的に投稿したレビューに依存するサイト」よりも、「その分野の専門知識や実サービスを持つサイト」が優遇される方向へとかじが切られたのだ。
上記の診断フローは、今回のアップデートで評価されたサイトの特徴を整理したものだ。たとえば、自社商品の技術仕様を詳述したページを持っているか、実際の導入事例データを公開しているか。そうした「自社ならではの資産」をコンテンツ化できているかどうかが、これまで以上にSEOの成否を分ける。
また、Cyrius Shepard氏の分析が示す「タスク完了型サイトの優位性」も見逃せない。ユーザーが情報を得たあとに、そのまま資料請求、購入、予約へと進める流れをサイト内で完結させることが、オーガニック検索からの流入増加につながっている。
この記事のポイント
- 2026年3月のGoogleコアアップデートでは、YouTubeやRedditなどの集約サイトが可視性を大幅に下げた
- 旅行、求人、健康の各分野でブランド公式サイトや政府ドメインが評価を上げた
- 一部ドメインはアップデート後に急回復しており、短期的なスコアだけで判断するのは危険
- 自社の一次情報を強化し、タスクをその場で完了できる体験を提供することが今後のSEOの軸になる

・ 複数業界における17年間のデジタルビジネス開発経験
・ ウェブサイト開発のためのHTML、PHP、CSS、Java等の実用的知識
・ 15ヶ国語対応の多言語SaaSの開発経験
・ 17年間にも及ぶ、Eコマース長期運営経験
・ 幅広い業界でのSEO最適化の豊富な経験

AI OverviewのCTRが61%減少 クリック数は横ばいという新データ
AI Overview(旧SGE)に自社ページが引用されるとCTR(クリックスルーレート/表示回数に対するクリック率)が大きく下がる。Search Engine Journalが紹介したSeer Interactiveの分析によれば、2025年第4四半期にブランド引用ページのCTRが前期比61%減少した。ところがクリック数そのものはほとんど動いていない。
一見すると深刻な数字だが、ダッシュボードの数字をどう読み解くかで評価は変わる。CTRが下がったからといって、すぐに「検索パフォーマンスが落ちた」と判断するのは早計だ。547万クエリを対象にしたSeerの分析をもとに、数字の裏側にある構造を整理する。
Q4に起きた数字の動き

10月のインプレッション急増がCTRを押し下げた
2025年9月時点で、AI Overview内にブランド引用されたページのインプレッション数は1,580万回、クリック数は398,798回、CTRは2.52%だった。これが10月になるとインプレッションが3,310万回へと倍増する。一方でクリック数は400,271回と微増にとどまり、CTRは1.21%に半減した。
CTRが急落した原因は、クリック自体が減ったわけではない。インプレッションの伸びがクリックの伸びを大きく上回ったことで、計算上のCTRが割り算の結果として下がったにすぎない。Search Engine Journalの記事でも「これはパフォーマンスの崩壊ではなく、クリックより速くインプレッションが成長したことによる数学的な問題だ」と指摘されている。
11月は別のパターン
11月になると傾向が変わる。インプレッションは3,950万回へさらに増えたが、クリック数は301,783回に減少し、CTRは0.76%まで落ち込んだ。インプレッションが増えているのにクリックが減る。10月とは異なる動きだ。
Seerのデータではこの原因を特定できていない。Search Consoleのデータを月ごとに分けて分析することの重要性がここにある。四半期でまとめて「CTR61%減」とだけ見ると、10月の数学的要因と11月の実質的なクリック減が混ざってしまう。
CTR低下に隠れた2つの解釈

Seerの分析が明確に切り分けられなかった点がある。10月のインプレッション急増が「GoogleがAI Overviewを表示するクエリを増やしたから」なのか、「各ブランドがSEO施策で引用を獲得したから」なのかは、集計データだけでは判断できない。
前者なら、検索結果の表示形式が変わっただけで、自社の実力とは関係ないノイズだ。後者なら、SEOの成果として素直に評価できる。多くのサイト運営者はこのどちらかに直面しているはずだ。ダッシュボードのインプレッション増加をどう読むかは、アカウント単位でクエリを掘り下げないとわからない。
CTRが下がったときに確認すべきは、同じ期間のインプレッション数だ。インプレッションが増えているなら、表示機会自体は拡大している。クリック数が横ばいか微増であれば、問題の本質はCTRの低下ではなく、表示回数あたりのクリック効率が薄まったという話になる。
これまでのAI Overview CTR研究との整合性

AI Overview表示時のクリック率は軒並み低い
AI Overviewが表示されるとオーガニック検索結果のCTRが下がることは、複数の調査で報告されている。Ahrefsが1億4,600万件の検索結果を分析した調査では、AI Overviewの表示トリガー率が20.5%に達し、特に情報検索や質問形式のクエリで高いとされた。
ドイツで実施されたSISTRIXの分析では、AI Overview表示時に検索順位1位のCTRが59%低下した。Pew Researchの調査でも、米国ユーザーのクリック率はAI Overview表示時に8%、非表示時は15%だった。AI Overviewが上位を占有することで、その下にある従来の検索結果へのクリックが奪われる構造は、国やクエリタイプを問わず共通している。
引用の有無がクリック効率を左右する
Seerのデータでは、AI Overview内でブランド引用されたページは、引用されていないページよりインプレッションあたりのクリック数が約120%多い。AI Overviewに自社ページが表示されること自体には、一定のクリック獲得効果がある。
ただし、AI Overviewが表示されない通常の検索結果と比べると、引用ページのクリック効率は38%低い。引用は「ないよりはマシ」だが、かつての1位表示の代替にはなっていない。Search Engine Journalはこの点を「引用は助けになるが、以前の順位を取り戻すものではない」と総括している。
実務にどう活かすか

AI Overview関連のCTR低下に直面したとき、まず確認すべきはクリック数の絶対値だ。CTRが下がっていても、クリック数が維持または微増しているなら、それは表示機会の拡大に伴う希釈であり、検索パフォーマンスの低下ではない。
Seerが指摘しているように、ベンチマークはあくまで傾向を示す参考値であり、自社データの実数を見るのが基本になる。インプレッションとクリックの増減を月単位で分解し、CTRだけを追わない分析習慣が求められる。
また、2025年12月から2026年2月にかけてAI Overview表示時のオーガニックCTRが1.3%から2.4%へ上昇したというデータもある。ただしSeerはこれを「回復というより横ばいへの落ち着き」と評価しており、2か月分のデータで先行きを予測するのは避けるべきだとしている。
この記事のポイント
- AI Overviewのブランド引用ページCTRはQ4で61%減少したが、クリック数はほぼ横ばい
- 10月はインプレッション急増による数学的CTR低下、11月は実質的なクリック減と原因が異なる
- インプレッション増がGoogleの仕様変更か自社SEOの成果かは、アカウント単位の分析が必要
- CTRだけを見ず、インプレッションとクリックの絶対数を月別に追うことが実務では重要
・ 複数業界における17年間のデジタルビジネス開発経験
・ ウェブサイト開発のためのHTML、PHP、CSS、Java等の実用的知識
・ 15ヶ国語対応の多言語SaaSの開発経験
・ 17年間にも及ぶ、Eコマース長期運営経験
・ 幅広い業界でのSEO最適化の豊富な経験

Googleへのスパム報告に新ルール。個人情報を含むと処理されない理由
Googleがスパム報告に関する公式ドキュメントを更新し、報告プロセスにおける重要な変更を明らかにした。今後、報告内容に個人を特定できる情報が含まれている場合、Googleはその報告に基づいた調査や対処を行わない方針だ。
この変更は、スパムサイトに対して「手動対策(マニュアルアクション)」が実施される際、報告内容の一部がサイト所有者に共有される仕組みに起因している。Googleはプライバシー保護と法規制への対応を優先し、不適切な情報を含む報告をあらかじめ排除する決断を下した。
SEO担当者やサイト運営者にとって、この変更は単なる手続きの修正ではない。悪質なサイトを排除するための正当な報告が無効化されるリスクを避けるため、報告の作法を再確認する必要がある。
Googleスパム報告の仕様変更。個人情報の記載が「無効」に
Googleは検索結果の品質を維持するため、ユーザーからのスパム報告を受け付けている。しかし、2026年4月に更新されたドキュメントによれば、報告フォームの自由記述欄に個人情報が含まれている場合、その報告は処理されなくなった。これは、報告者が意図せず自身の身元を相手に明かしてしまうリスクを防ぐための措置だ。
なぜ個人情報が含まれると処理されないのか
最大の理由は、Googleがスパムサイトの所有者に送る通知の仕組みにある。Googleが報告に基づいて手動対策を下した場合、その根拠となった情報をサイト所有者に伝えることがある。この際、報告者が記述したテキストがそのまま引用される可能性があるためだ。
もし報告文の中に、報告者の名前や会社名、あるいは特定のサイト運営者であることを示唆する情報が含まれていれば、スパムサイト側に報告者の正体が筒抜けになってしまう。Googleはこのような事態を避けるため、個人情報が含まれる報告自体を「破棄」するというルールを明文化した。
ドキュメントから削除された「匿名性」の記述
以前のドキュメントでは、自由記述欄に個人情報を書かない限り、報告は匿名に保たれるという主旨の記述があった。しかし、今回の更新でこの文言は削除された。代わりに「法規制を遵守するため、手動対策の文脈を理解させる目的で、提出されたテキストをサイト所有者に送信しなければならない」という強い表現が追加されている。
これは、Googleが報告者の匿名性を保証する努力をするのではなく、報告者自身に「特定される情報を一切書かないこと」を義務付けたことを意味する。ルールを守らない報告は、どれほど証拠が揃っていても無視されることになるため、注意が必要だ。
手動対策通知の仕組みと報告者が負うべきリスク

手動対策(マニュアルアクション)とは、Googleの担当者が目視でサイトを確認し、ガイドライン違反と判断した場合に検索順位を下げたり、インデックスから削除したりする処置を指す。このプロセスにおいて、ユーザーからの報告は重要な判断材料の一つとなる。
報告内容がそのまま相手に届くという事実
Googleが違反サイトの運営者に送る通知には、どのような違反があったのかを説明するテキストが含まれる。このテキストに、報告者がフォームに記入した内容が「原文のまま」転載されるケースがある。これは、違反者が自サイトのどこに問題があるのかを正確に把握させ、修正を促すための透明性を確保する目的で行われる。
しかし、この透明性が報告者にとってはリスクとなる。例えば「私のサイトの画像を盗用している」といった文言で報告すれば、相手は即座に報告者が誰であるかを特定できる。このような情報の流出は、報告者への逆恨みやさらなる攻撃を招く恐れがある。
情報の流れを視覚化する
スパム報告がどのように処理され、どの段階で情報が共有されるのかを整理しておくことは重要だ。以下のデモは、不適切な報告と適切な報告で情報の伝わり方がどう変わるかを示している。
このデモのように、自分を特定する情報を削ぎ落とし、客観的な事実のみを伝えることが、報告を有効にするための鉄則だ。
プライバシー保護と透明性のジレンマ。Googleの狙い

Googleがなぜこのような厳しいルールを設けたのか。その背景には、欧州のGDPR(一般データ保護規則)をはじめとする、世界的なプライバシー保護規制の強化がある。個人データの取り扱いには極めて慎重な対応が求められており、検索エンジンも例外ではない。
法規制への対応とユーザー保護の両立
GDPRなどの法規制下では、データの主体(この場合はサイト所有者)は、自分に関するどのような情報が収集され、誰から提供されたのかを知る権利を持つ場合がある。Googleが「報告文を相手に送る」としているのは、こうした法的要求に応えるための苦肉の策とも言える。
一方で、報告者の身の安全を守る必要もある。そこでGoogleが導き出した答えが、「個人情報が含まれる報告は最初から受け取らない(処理しない)」というフィルタリングだ。これにより、法的義務を果たしつつ、報告者が不用意に特定される事態を未然に防いでいる。
「質の高い報告」を求めるGoogleの姿勢
今回の変更は、スパム報告の「質」を向上させる狙いもあると考えられる。感情的な訴えや個人的な利害関係を排除し、アルゴリズムやガイドラインに照らして何が違反なのかを論理的に説明する報告を、Googleは求めている。
報告が無効化される条件を明確にすることで、Google側の処理コストも削減される。明らかにガイドラインを理解していない報告や、嫌がらせ目的の報告を、情報の形式だけで自動的に弾くことができるからだ。
効果的なスパム報告を行うための実践的なアドバイス

スパムサイトによって検索順位を下げられたり、コンテンツを盗用されたりした場合、冷静に報告を行うのは難しい。しかし、確実にGoogleに対処してもらうためには、以下のポイントを意識してフォームを記入する必要がある。
匿名性を保ちつつ証拠を提示するコツ
まず、一人称(私、弊社など)や固有名詞を避けることだ。例えば「私のサイトのこの記事がコピーされた」と書くのではなく、「該当URLのコンテンツは、別のドメイン(URLを提示)のオリジナルコンテンツを無断で複製している」といった書き方にする。
次に、違反の種類を具体的に指摘することだ。単に「スパムだ」と主張するのではなく、「隠しテキストが使用されている」「リンクプログラムに参加している」「クローキングが行われている」など、Googleのスパムポリシーに基づいた用語を使うと、担当者の理解が早まる。
報告文のチェックリスト
送信ボタンを押す前に、以下の項目が含まれていないか確認しよう。一つでも当てはまる場合は、処理されない可能性が高い。
- 自分の氏名や会社名、部署名
- 自分のメールアドレスや電話番号
- 自分が管理しているサイトのドメイン名(証拠として必要な場合を除く)
- 相手を非難する感情的な言葉
- 過去のやり取りや個人的なトラブルの経緯
独自の分析。SEO担当者が今後意識すべき報告の作法
今回のGoogleの対応は、SEO業界における「スパム報告」の立ち位置を大きく変える可能性がある。これまでは「困った時の神頼み」のような側面もあったが、今後はより専門的で客観的な「証拠提出」の場へと変わっていくだろう。
競合への嫌がらせ対策としての側面
この新ルールは、競合サイトを陥れるための「虚偽の報告」に対する牽制にもなる。報告内容が相手に公開される可能性がある以上、安易な嘘や根拠のない誹謗中傷は、報告者自身の首を絞めることになるからだ。Googleは情報の透明性を高めることで、報告システム自体の健全性を保とうとしている。
AI時代におけるスパム報告の価値
AIによって生成された低品質なコンテンツが急増する中、Googleのアルゴリズムだけですべてを検知するのは難しくなっている。人間の目による「これはスパムだ」というフィードバックの価値はむしろ高まっていると言えるだろう。
だからこそ、私たちは「正しい報告の作法」を身につけるべきだ。適切な形式で、個人情報を排除し、事実に基づいた報告を行うことは、検索エンジンのエコシステムを守るための貢献にもなる。今回の仕様変更を機に、社内での報告フローやテンプレートを見直してみるのも良いだろう。
この記事のポイント
- Googleへのスパム報告に個人情報が含まれている場合、調査は行われず破棄される。
- 手動対策が実施される際、報告文がそのままサイト所有者に共有されるリスクがあるためだ。
- 報告文には自分の名前や会社名を入れず、客観的な事実と違反箇所のみを記述する。
- この変更は、プライバシー保護規制への対応と報告システムの健全化を目的としている。
- 正当な報告を有効にするため、送信前のセルフチェックがこれまで以上に重要となる。
・ 複数業界における17年間のデジタルビジネス開発経験
・ ウェブサイト開発のためのHTML、PHP、CSS、Java等の実用的知識
・ 15ヶ国語対応の多言語SaaSの開発経験
・ 17年間にも及ぶ、Eコマース長期運営経験
・ 幅広い業界でのSEO最適化の豊富な経験

生成AIの普及率は3年で53%に到達。PCやネットを超える速度がSEOに与える衝撃
スタンフォード大学の人間中心人工知能研究所(HAI)が、最新の調査報告書「2026 AI Index Report」を公開した。このレポートは400ページを超え、技術的パフォーマンスから投資状況、労働市場への影響まで多岐にわたるデータを網羅している。
報告書の中で最も大きな反響を呼んでいるのが、生成AIの普及スピードだ。ChatGPTのリリースからわずか3年で、世界人口の53%が生成AIを採用するに至った。これは、かつてのパーソナルコンピュータ(PC)やインターネットが辿った普及速度を大きく上回る数字である。
検索エンジン最適化(SEO)に携わる実務者にとって、この急速な変化は無視できない。ユーザーの検索行動が根本から塗り替えられつつある現状において、データの背後にある真実を理解することが、これからの戦略を左右するだろう。
生成AIの普及速度はPC・インターネットを凌駕
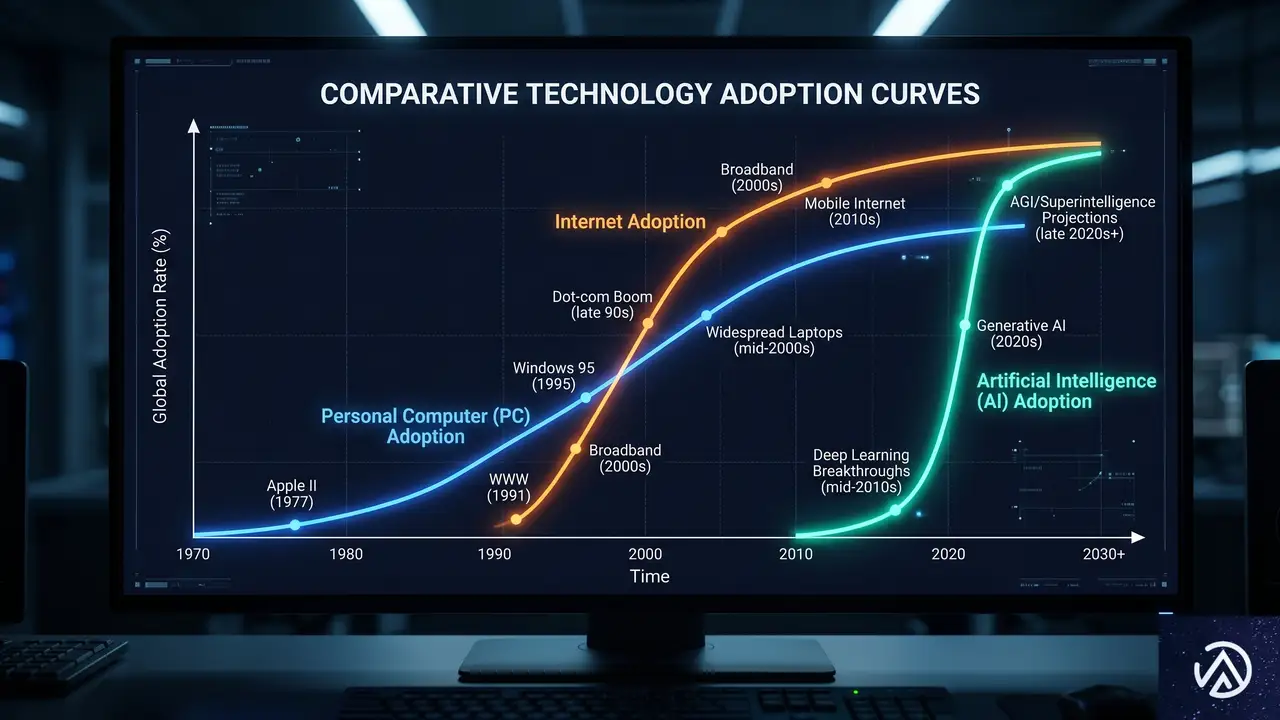
生成AIの普及は、過去のどの技術革新よりも速い。レポートによれば、主要なテクノロジーが一般に浸透するまでの期間を比較した際、生成AIの立ち上がりは際立っている。1981年のIBM PC登場や1995年のインターネット商用化と比較しても、普及曲線は急峻だ。
なぜこれほどまでに速いのか
この爆発的な普及には、先行したインフラの存在が大きく寄与している。ハーバード大学のデビッド・デミング氏は、AIが既存のPCやインターネットの上に構築されたツールであることを理由に挙げている。ユーザーは新しいハードウェアを購入する必要がなく、すでに手元にあるスマートフォンやPCから即座にアクセスできたためだ。
水道や電気が通っている家に、新しい蛇口を取り付けるような手軽さが、53%という驚異的な数字を支えている。インフラ整備の時間を飛び越えて、アプリケーションとしての利便性だけが先行して広がった結果といえる。
「普及」の定義と実態の差
ただし、この53%という数字を鵜呑みにするのは注意が必要だ。レポートでは、一度でもChatGPTなどのツールを試したユーザーも「採用者」としてカウントされている可能性がある。毎日8時間フル活用している専門家と、一度だけ挨拶を入力してみただけのユーザーが同列に扱われている側面がある。
また、国によっても普及率には大きな開きがある。スタンフォードのデータでは米国の普及率を28%としているが、セントルイス連邦準備銀行の調査では54%と、倍近い開きが出ている。これは調査の質問順序や定義の微妙な違いによるものだ。SEO担当者は、数字の大きさに圧倒されるのではなく、ユーザーが「どれほど深く、どのような文脈で」AIを使っているのかを注視すべきである。
能力の「ギザギザのフロンティア」と検索の不安定さ
AIの能力向上は目覚ましいが、その進化は均一ではない。レポートでは「ギザギザのフロンティア(Jagged Frontier)」という概念を用いて、AIの得意不得意が極端に分かれている現状を説明している。
高度な知性と単純なミスが同居する現状
最新のAIモデルは、博士レベルの科学問題や数学の難問で人間を凌駕するスコアを叩き出す。しかしその一方で、アナログ時計の針を正しく読み取るという単純なタスクにおいて、正解率が10%を切るようなケースも報告されている。複雑な推論は得意だが、直感的な視覚理解や多段階の計画立案には依然として課題が残っているのだ。
この「能力のムラ」は、検索体験にも直結している。特定の専門的な質問には驚くほど正確な回答を返す一方で、日常的な事実関係の確認で突拍子もない間違い(ハルシネーション)を犯す。AI Index運営委員会のレイ・ペロー氏は、ベンチマークテストの結果が必ずしも実世界の業務での信頼性を保証するものではないと警鐘を鳴らしている。
AI検索結果の不確実性をどう捉えるか
SEOの現場では、Googleの「AI Overviews(AIによる概要)」や「AI Mode」の挙動がクエリによって大きく変動することが確認されている。Ahrefsの調査によれば、同じクエリであってもAI OverviewsとAI Modeが参照するURLの重複率はわずか13%に過ぎない。システムごとに異なる情報源を選択しており、その基準は依然として不透明だ。
Googleのロビー・スタイン氏は、ユーザーが反応を示さない場合、AIによる回答を意図的に抑制していることを認めている。つまり、AI検索の表示は固定されたものではなく、ユーザーのエンゲージメントに応じて動的に変化する不安定なものだ。私たちは、特定のキーワードで「AIに選ばれる」ことの難しさと、その持続性の低さを認識しなければならない。
※既存の情報を要約しただけで、具体的な戦略や独自性がない。
※実体験と具体的な数字に基づき、AIには真似できない価値を提供している。
このデモは、AIによる一般的な要約と、人間が提供すべき独自情報の違いを視覚化したものだ。
低下する透明性とブラックボックス化するSEO

SEO業界にとって最も懸念すべきデータの一つが、AIモデルの「透明性の低下」だ。レポートによれば、主要なAIモデルの透明性指数は、1年間で58から40へと急落した。モデルが高度になればなるほど、その中身が隠される傾向にある。
公開されないトレーニングデータ
Google、Anthropic、OpenAIといった主要プレイヤーは、最新モデルのトレーニングデータセットのサイズや、トレーニングに要した期間の開示を停止している。2025年にリリースされた著名なAIモデル95個のうち、トレーニングコードを公開したのはわずか15個にとどまる。
これは、検索エンジンのアルゴリズムがかつてないほど「ブラックボックス化」していることを意味する。どのようなコンテンツが評価され、なぜそのURLが引用されたのかという根拠を、プラットフォーム側が説明しなくなっているのだ。最適化のヒントが減り、推測に頼らざるを得ない領域が増えている。
「説明できない」アルゴリズムへの対策
透明性が失われる中で、SEO担当者が取るべき道は「アルゴリズムのハック」から「ユーザー価値の構築」へのシフトだ。レポート内では、AIに対する一般市民の信頼が低下していることも示されている。特に米国の公的機関によるAI規制能力への信頼度は31%と低い。
プラットフォームが詳細を明かさない以上、私たちは「AIが何を好むか」ではなく、「ユーザーが何を信頼するか」に立ち返る必要がある。AIによる回答が不透明で説明責任を果たせないからこそ、発信者の顔が見え、根拠が明示されたコンテンツの価値が相対的に高まっていく。透明性の欠如を、自サイトの透明性向上で補う戦略が求められる。
労働市場の変化と「独自の価値」の再定義

AIの普及は、コンテンツ制作の現場にも直接的な影響を及ぼしている。レポートが指摘する労働市場の変化は、Web制作やSEOに携わるチームの構成にも示唆を与えている。
若手エンジニアの雇用減少が示唆するもの
22歳から25歳のソフトウェアデベロッパーの雇用が、2024年以降で約20%減少したというデータがある。一方で、経験豊富なシニア層の雇用数は維持、あるいは増加傾向にある。これは、AIが「ジュニアレベルの定型業務」を代替し始めている可能性を示唆している。
SEOやライティングの分野でも同様のことがいえる。既存の情報を整理し、無難な構成で記事を書くといったエントリーレベルの仕事は、AIによって急速に置き換えられている。20%の雇用減少という数字は、単なる不況の影響だけでなく、業務プロセスの構造的な変化を反映していると見るべきだ。
AIに代替されない「ゴールデン・ナレッジ」
こうした状況下で提唱されているのが、シェリー・ウォルシュ氏らが言及する「ゴールデン・ナレッジ(黄金の知識)」という概念だ。これは、AIのトレーニングデータには含まれていない、独自の調査データや実体験、深い洞察に基づくコンテンツを指す。
スタンフォードのレポートが示す「AIの普及」と「能力のムラ」は、この戦略の正しさを裏付けている。AIは広く普及したが、その回答は依然として不安定で、深みに欠ける。AIがどれほど速く情報を要約しても、その元となる「新しい事実」を作り出すことはできない。一次情報の発信者としての地位を確立することが、AI時代を生き抜くための構造的なアドバンテージとなる。
2026年以降のSEO戦略(独自の分析)

スタンフォードのレポートから読み解ける未来は、AIと共存しつつ、その「隙間」を埋める戦略の重要性だ。AI Overviewsが月間15億人のユーザーにリーチし、AI Modeが日常化する中で、従来の「検索順位」という指標だけでは不十分になっている。
まず、モニタリングの単位を細分化する必要がある。AIの能力が「ギザギザ」である以上、カテゴリー単位の分析では実態を見誤る。特定のクエリでは正確な回答が出るが、少し表現を変えるだけでハルシネーションが起きる。この不安定さを逆手に取り、AIが正しく答えられない「複雑で多面的な問い」に対して、人間が最高の回答を用意しておくべきだ。
次に、検索コンソールなどのツールに頼りすぎない姿勢も重要だ。現在のツールでは、AI Overviews経由のトラフィックと通常の検索トラフィックを明確に分離して把握することが難しい。不透明なプラットフォームに依存するリスクを分散するためにも、SNSやメールマガジンといった、ユーザーと直接つながる「脱検索エンジン」のチャネル強化を並行して進めるべきだろう。
最後に、AIの普及速度を脅威ではなく「機会」として捉え直したい。53%の人がAIを使うということは、それだけ多くの人が「迅速な回答」を求めている証拠だ。しかし、迅速さと正確さは必ずしも両立しない。人々がAIの回答に物足りなさを感じたとき、真っ先に参照される「信頼の拠点」になれるかどうかが、2026年以降の勝負を分けることになる。
この記事のポイント
- 生成AIはChatGPT登場から3年で53%の普及率に達し、PCやネットを凌駕する速度で浸透している。
- AIの能力は「ギザギザのフロンティア」と呼ばれ、高度な推論と初歩的なミスの同居が検索結果の不安定さを招いている。
- AIモデルの透明性は低下しており、トレーニングデータやアルゴリズムのブラックボックス化が加速している。
- 労働市場では若手の定型業務がAIに代替され始めており、SEOでも「独自の一次情報」の価値が相対的に高まっている。
- 今後のSEOは、AIが苦手とする領域を特定し、ユーザーとの直接的な信頼関係を構築する戦略への転換が不可欠だ。
・ 複数業界における17年間のデジタルビジネス開発経験
・ ウェブサイト開発のためのHTML、PHP、CSS、Java等の実用的知識
・ 15ヶ国語対応の多言語SaaSの開発経験
・ 17年間にも及ぶ、Eコマース長期運営経験
・ 幅広い業界でのSEO最適化の豊富な経験

MetaがGoogleの広告収益を逆転へ!2026年に起きる歴史的転換の背景とSEO・広告戦略への影響
デジタル広告の世界で、長らくトップに君臨してきたGoogleの牙城がついに崩れようとしている。2026年、Metaの広告収益がGoogleを追い抜き、世界シェア1位に躍り出る見通しが明らかになった。これは単なる収益の逆転ではなく、広告の仕組みそのものが「検索」から「AIによる自動最適化」へとシフトしている現実を物語っている。
米調査会社のEmarketerが発表した予測によれば、2026年のMetaの広告収益は2,434億6,000万ドル(約37兆円)に達する見込みだ。対するGoogleは2,395億4,000万ドルにとどまり、僅差ながらも首位が入れ替わることになる。Googleがデジタル広告のトップから陥落するのは、同社が市場を支配して以来、初めての出来事だ。
この変化は、Webサイトを運営する企業や個人にとって無視できない兆候といえる。ユーザーの行動がGoogle検索から、InstagramやFacebook、WhatsAppといったSNS上の「発見」へと移り変わっているからだ。本記事では、この歴史的な逆転劇の背景と、今後のWebマーケティングに与える影響を深掘りしていく。
数字で見る広告市場の勢力図塗り替え

広告収益のシェアで見ると、その変化はより鮮明になる。2026年、Metaは世界のデジタル広告支出の26.8%を占めると予測されている。一方で、Googleのシェアは26.4%まで低下する見込みだ。かつてはGoogleが圧倒的な差をつけていたが、この数年でMetaが猛烈な勢いで差を詰めてきた結果である。
Googleの成長鈍化とMetaの加速
Googleの広告ビジネスが停滞しているわけではない。検索広告やYouTube広告は依然として巨大な収益源だが、その成長スピードが以前に比べて緩やかになっている。背景には、検索市場の成熟と、後述するAI検索の台頭による不確実性がある。既存の検索広告モデルが、かつてのような爆発的な伸びを維持できなくなっているのだ。
対照的に、MetaはAIを活用した広告運用の自動化に成功し、収益を飛躍的に伸ばしている。特に「Advantage+」などのAIツールが、広告主にとっての投資対効果(ROI)を劇的に改善させた。人間が細かくターゲットを設定しなくても、AIが最適なユーザーに広告を届ける仕組みが、企業の予算を引き寄せている。
マクロ経済が後押しするパフォーマンス広告
世界的な経済の先行き不透明感も、この逆転を後押ししている。景気が厳しくなると、企業は「認知」を目的としたブランディング広告よりも、直接的な「売上」につながるパフォーマンス広告を優先する傾向がある。Metaの広告プラットフォームは、ユーザーの興味関心に基づいた高精度なターゲティングが可能であり、より短いスパンで成果を証明しやすい。この「測れる成果」こそが、現在の市場で最も求められている価値だといえる。
なぜMetaがGoogleに競り勝つのか

Metaが勝利を収めつつある最大の要因は、広告運用の「手軽さ」と「精度の高さ」の両立にある。Google検索広告は、適切なキーワードを選定し、競合の入札状況を監視するなど、運用に一定のスキルと工数が必要とされる。しかし、Metaの最新の広告システムは、クリエイティブ(画像や動画)を用意するだけで、あとはAIがすべてを最適化してくれるレベルに達している。
AIによる「運用の民主化」
Metaは広告主に対し、AIを使ってターゲット設定やクリエイティブの生成を自動化する機能を次々と提供している。これにより、専門の広告運用担当者がいない中小企業でも、大企業に引けを取らない成果を出せるようになった。この「運用の民主化」が、Metaの広告主の裾野を大きく広げている。
● ターゲット層の細かな手動設定
● 入札単価の頻繁な調整
★ 画像・動画の自動バリエーション生成
★ リアルタイムでの予算最適化
この図は、広告運用の手間がAIによっていかに削減され、成果へと直結するようになったかを示している。
「検索」を必要としない発見のプロセス
Googleの強みは「ユーザーが何かを探している瞬間」を捉えることにある。しかし、Metaは「ユーザーが気づいていなかった欲しいもの」を提示することに長けている。SNSのタイムラインを流れるパーソナライズされた広告は、ユーザーにとって受動的な発見をもたらす。検索という能動的なアクションを必要としないこのプロセスは、スマホ時代の消費行動に極めて適合している。
Googleが直面する三重苦

王座を明け渡す形となるGoogleだが、同社は現在、非常に困難な舵取りを迫られている。主な要因は、AIによる検索体験の変化、法的な規制、そして主力事業の成熟という3つの課題だ。
AI検索(SGEなど)による広告モデルの破壊
PerplexityやChatGPTのようなAI回答エンジン、そしてGoogle自身が導入を進める「AI Overviews(旧SGE)」は、従来の検索広告のあり方を根底から変えようとしている。AIが直接回答を提示することで、ユーザーは検索結果のリンクをクリックする必要がなくなる。これは、クリック課金で収益を上げてきたGoogleにとって、自らのビジネスモデルを破壊しかねないリスクを孕んでいる。
独占禁止法を巡る法廷闘争
Googleは米国や欧州で、広告技術における市場独占を巡る厳しい監視下に置かれている。複数の訴訟が進行中であり、最悪の場合、広告事業の分割を命じられる可能性もゼロではない。こうした法的なリスクは、同社の積極的な事業拡大の足かせとなっており、投資家や広告主の心理に影を落としている。
YouTubeの競争激化
Googleのもう一つの柱であるYouTubeも、TikTokという強力なライバルの出現により、若年層の視聴時間と広告予算を奪われている。ショート動画市場での競争は激しさを増しており、かつてのような独走状態ではない。MetaもInstagramのリール(Reels)を通じてこの分野で強く対抗しており、動画広告の予算もMetaへと流れる要因となっている。
Web担当者が取るべき今後の戦略

広告収益のシェアが逆転するということは、ユーザーの関心がどこに集まっているかを示す指標でもある。これからのWebマーケティングでは、Google検索だけに頼るのではなく、プラットフォームの変化に合わせた柔軟な予算配分と戦略の構築が求められる。
マルチチャネルでの予算配分の再考
もし現在の集客をGoogle検索広告に依存しているなら、Meta広告への予算分散を検討する時期だ。特に、AIによる自動運用ツール(Advantage+など)を積極的に活用し、自社のデータとAIを組み合わせた最適化を試すべきである。Googleが弱体化するわけではないが、Metaの方が「安く、広く、正確に」リーチできるケースが増えている事実は無視できない。
「検索される」から「見つけられる」コンテンツ作り
SEO(検索エンジン最適化)の重要性は変わらないが、その定義は広がりつつある。これからはGoogleの検索窓に入力される言葉を狙うだけでなく、SNSのアルゴリズムに「おすすめ」として選ばれるためのコンテンツ作りが必要だ。視覚的に訴求力のある画像や、数秒で価値が伝わる縦型動画の制作は、もはやSNS担当者だけの仕事ではなく、Webマーケター全体の必須スキルとなっている。
独自の分析:広告は「意図」から「予測」へ

今回の逆転劇を分析すると、広告の本質的な価値が「ユーザーの意図に応えること」から「ユーザーの行動を予測すること」へと移行したことがわかる。Googleは、ユーザーが入力したキーワードという「明確な意図」を収益化してきた。しかしMetaは、膨大な行動データから「次に何に興味を持つか」をAIで予測し、意図が生まれる前に先回りして広告を提示する。
この「予測型広告」の勝利は、現代人が「探す」という手間を極限まで嫌っていることを示唆している。Webサイトの運営においても、ユーザーに検索させて情報を探させる構造よりも、パーソナライズされたおすすめを提示するような体験の提供が、今後のコンバージョン率を左右する鍵になるだろう。
この記事のポイント
- 2026年にMetaの広告収益がGoogleを上回り、世界シェア1位になる見通しだ
- Metaの勝因はAIによる広告運用の自動化であり、高いROIが広告主を惹きつけている
- GoogleはAI検索の台頭や独占禁止法の訴訟など、構造的な課題に直面している
- Web担当者は「検索」だけでなく、SNSでの「発見」を重視した戦略への転換が必要だ
- 今後のマーケティングは、ユーザーの意図を待つのではなく、行動を予測するアプローチが主流になる
・ 複数業界における17年間のデジタルビジネス開発経験
・ ウェブサイト開発のためのHTML、PHP、CSS、Java等の実用的知識
・ 15ヶ国語対応の多言語SaaSの開発経験
・ 17年間にも及ぶ、Eコマース長期運営経験
・ 幅広い業界でのSEO最適化の豊富な経験

Google特許が示す検索の新たな層——AI生成ランディングページの衝撃
Googleが取得した特許が、検索エンジンの未来像に大きな一石を投じた。特許の内容は、ユーザーの検索クエリとコンテキストに応じて、AIがその場でランディングページを生成するシステムだ。
この技術が実用化されれば、検索結果と従来のウェブサイトの間に、新たな「層」が出現することになる。EC事業者やコンテンツ発信者は、自社サイトのデザインやメッセージングをユーザーに直接届ける機会を、さらに奪われる可能性がある。
本記事では、特許の内容を詳細に読み解き、検索の進化の歴史に照らし合わせてその意味を考察する。さらに、この変化に対応するためにEC事業者が今から取り組むべき具体的な対策を提示する。
特許が描く「AI生成ランディングページ」の仕組み

ユーザーごとに最適化されたページを動的生成
2026年1月27日に米国特許商標庁から発行された特許「US12536233B1」は、AI生成コンテンツページに関するものだ。特許が示すシステムの核は、検索クエリとユーザー情報を基に、そのユーザー専用のランディングページを動的に生成する点にある。
システムはまず、検索クエリとユーザーのコンテキスト、そして従来のランキングアルゴリズムが選び出した候補となるランディングページ群を評価する。評価基準は多岐にわたり、商品情報の不足、コンテンツの薄さ、ナビゲーションの弱さ、ユーザーエンゲージメントの低さなどが低評価の要因となる。
評価の結果、既存ページが不十分と判断されると、システムはそれらのページを「素材」として使い、個々のユーザー向けに最適化された新たなバージョンのページを生成する。例えば、全く同じ「ランニングシューズ」というクエリを検索した二人のユーザーが、異なるランディングページに誘導される可能性がある。一人には商品比較表を中心にしたページが、もう一人には直接購入に導くページが表示されるかもしれない。
フィードバックループによる継続的改善
特許が示すもう一つの重要な要素は、フィードバックループだ。生成されたページは静的なものではない。ユーザーのクリック、ページ滞在時間、コンバージョンなどの行動データがシステムにフィードバックされ、将来生成されるページの精度を高めるために利用される。
この仕組みにより、Googleは膨大な数のユニークなページを生成し、それぞれの検索者をカスタマイズされたバージョンに誘導する動的な体験を提供できる。特に商品検索に関連するクエリでは、購入オプションを前面に押し出したページが生成される可能性が高い。
Practical Ecommerceの記事によれば、この動的ページ実現への現実的な経路は、既に導入されている「AIオーバービュー」を通じたものだと考えられる。AIオーバービューは情報を要約して提示するが、次のステップとして、その要約をインタラクティブな体験に拡張し、最終的には独立したウェブページとして展開する流れが想定される。
検索進化の歴史から見る「新たな層」の位置付け

検索とコンテンツの関係性の変遷
ECコンサルタントのGreg Zakowicz氏は、この特許の概念を「検索の経済学における新たな層」と表現した。この「層」という考え方は、検索エンジンとウェブサイト所有者の間の力関係の変化を理解する上で有効だ。
かつては、検索プラットフォームとコンテンツ所有者は相互依存の関係にあった。プラットフォームは質の高いコンテンツを必要とし、コンテンツ所有者はプラットフォームからのトラフィックを必要とした。しかし、検索産業の進化は、顧客と事業者を次第に引き離す方向に進んでいる。
この図が示すように、モノetization(広告)、Answers(ナレッジグラフ)、Evaluation(リッチリザルト)、Extraction(特集スニペット)、Interaction(垂直検索)、Synthesis(AIオーバービュー)と、各層が追加されるごとに、ユーザーが元のウェブサイトに直接アクセスする必要性は薄れてきた。AI生成ランディングページは、この流れの延長線上にある「最終的な層」と言えるかもしれない。
「検索の経済学」の変化が事業者に与える影響
Zakowicz氏が指摘する「検索の経済学」の変化とは、トラフィックと収益の流れの再分配を意味する。新しい層が出現するたびに、ウェブサイト所有者がレイアウト、メッセージング、商品提示をコントロールする影響力は弱まる。ユーザー体験は、ますますアルゴリズムによって組み立てられるものになる。
Practical Ecommerceの記事は、この状況を「サイトはGoogleの検索結果ページにおいてほとんどコントロールを失っている」と表現する。検索結果ページ自体が、外部サイトへの単なる入り口ではなく、完結した体験の場へと変貌しつつある。
EC事業者が取るべき具体的な対策

オウンドメディアと直接的な顧客関係の構築
アルゴリズムが仲介する体験の影響力が強まる中で、事業者が取るべき第一の対策は、自分自身でコントロールできるチャネルを強化することだ。具体的には、メールマーケティングやSMSなどのオウンドメディアが該当する。
ニュースレターやマーケティングメッセージを通じてサイトに訪れるユーザーは、アルゴリズムが組み立てたページではなく、ブランドそのものを選択して訪問している。検索プラットフォーム内で行われる発見が増えるほど、このような直接的な接点は「絶縁材」としての価値を高める。顧客との関係性を自ら所有することは、検索エンジンの変化に対する最も強力な防御策となる。
構造化データと高品質な入力情報の提供
第二の対策は、アルゴリズムが「読みやすい」データを提供することに注力する姿勢への転換だ。仮に特許のようなシステムが実装されれば、その生成体験は構造化された入力情報に大きく依存するだろう。
この場合、事業者の役割は、美しいランディングページをデザインすることから、正確で豊富な商品属性データ、Schema.orgマークアップ、整った商品フィードといった「高品質な入力情報」を提供することへとシフトする。ボットやプログラム、アルゴリズムが容易に理解し、利用できる形式で情報を提供することが、生成された体験の中に商品が表示され、クリックを獲得するための前提条件となる。
説得力のあるコピー、視覚的な階層、直感的なCTAボタンの配置など、人間のユーザーを説得するためのページ作りが中心だった。
正確な商品仕様、構造化されたレビュー、機械が解釈しやすい属性データなど、AIが「素材」として活用できる高品質な情報の提供が重要になる。
この変化は、SEOの本質的な作業が「検索エンジン向け」から「AI生成システム向け」に移行することを意味する。クリックを獲得する機会は残るが、その入り口の形と、そこに至るための最適化方法が根本から変わる可能性がある。
この記事のポイント
- Googleの特許は、検索クエリとユーザーごとにAIがランディングページを動的に生成するシステムを明らかにした。これは検索結果とウェブサイトの間に現れる「新たな層」となり得る。
- 検索は「発見」から「回答抽出」「統合」へと進化し、ユーザーが元サイトに到達する前の段階で体験が完結する方向にある。AI生成ページはこの流れの延長線上にある。
- この変化により、EC事業者はサイトのデザインやメッセージングを直接ユーザーに届けるコントロールをさらに失う可能性がある。
- 対策の二本柱は「オウンドメディアによる直接的な顧客関係の構築」と「構造化データなどアルゴリズム向けの高品質な入力情報の提供」である。人間向けのデザインから、機械が利用しやすいデータ提供への重心移動が求められる。
- 特許は必ずしも実用化を保証するものではないが、検索プラットフォームの長期的な方向性を示す重要なシグナルとして捉えるべきだ。
・ 複数業界における17年間のデジタルビジネス開発経験
・ ウェブサイト開発のためのHTML、PHP、CSS、Java等の実用的知識
・ 15ヶ国語対応の多言語SaaSの開発経験
・ 17年間にも及ぶ、Eコマース長期運営経験
・ 幅広い業界でのSEO最適化の豊富な経験

Googleのタスク型エージェント検索がSEOを今すぐ変える理由と対策
Googleの検索が「タスクを完了する」エージェントへと急速に変化している。従来の「キーワードを入力してウェブサイトのリンクを得る」モデルは、AIが直接レストランの予約を取ったり、情報を収集したりする「タスク実行型」の検索に置き換わりつつある。この変化は未来の話ではなく、すでに現在進行形で起きている。
Search Engine Journalの記事によると、GoogleのCEOサンダー・ピチャイは近い将来、検索の多くが「エージェント型」になると述べている。ユーザーは情報を探すだけでなく、AIエージェントにタスクを管理させ、複数の作業を並行して実行させるようになる。このパラダイムシフトは、SEOとコンテンツ戦略の根本的な見直しを迫るものだ。
検索が「タスク完了」へと変わる瞬間
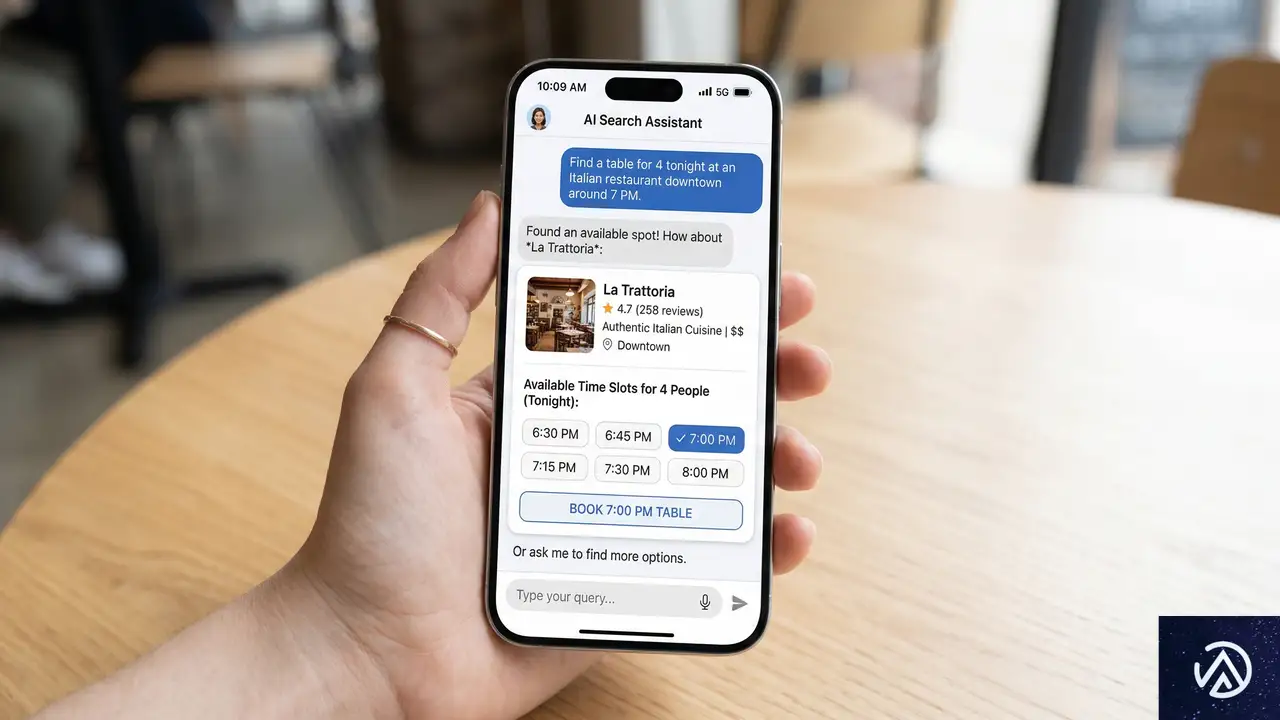
従来のインターネットと検索は、同じキーワードを入力した何百万人ものユーザーに、同じようにインデックスされたウェブページのリストを提供するモデルだった。しかしAIの登場により、ユーザーは単なる情報検索から「トピックの調査」や「タスクの実行」へと行動を移しつつある。リンクをクリックしてサイトを読むだけでは、ユーザーが求める明確な答えが得られないケースが増えている。
レストラン予約にみるエージェント検索の実例
この変化を象徴する具体例が、Googleが全世界で展開を開始した「エージェント型レストラン予約」機能だ。ユーザーは検索ボックスに「6人で土曜の夜、雰囲気の良いイタリアン」といった要望を自然言語で入力する。するとAIエージェントが複数の予約プラットフォームを同時にスキャンし、空き状況やメニューを確認した上で、実際に予約可能な店舗を提示する。
Googleの検索プロダクト責任者であるRose Yao氏は、この機能について「アプリを切り替える必要も、手間もない。ただ美味しい食事を」と説明している。これはもはや従来の「検索」ではなく、「タスクの完了」そのものだ。重要な点は、この機能が「近い将来実現するもの」ではなく、すでに利用可能であることだ。
サイト側に求められる対応
この新しい検索モデルでは、レストランなどの事業者側も対応が迫られる。AIエージェントが情報を取得できるように、空き予約枠やその日のメニュー選択肢などのデータを提供する必要がある。将来的には、AIエージェントと直接予約を完了できる仕組みがウェブサイトに求められるだろう。
これは単なる技術的なアップデートではなく、ビジネスプロセスの変革を意味する。検索マーケティングの専門家は、この変化がもたらす影響を真剣に考える時期に来ている。
「個人専用インターネット」時代の到来

タスク型エージェント検索がもたらすもっと深い変化は、インターネットそのものが「ハイパーパーソナライズ化」する点だ。クラウドフレアは最近の記事で、インターネットの進化を3つの段階に分けて説明している。
インターネット進化の3段階
クラウドフレアの比喩が分かりやすい。従来のアプリケーションは「レストラン」のようなものだ。決まったメニュー(機能)があり、それを大量に提供するために最適化された厨房(インフラ)がある。一方、AIエージェントは「個人専属シェフ」に例えられる。毎回「何が食べたい?」と聞き、その答えに応じて必要な食材や調理法が変わる。レストランの厨房では対応できない。
SEOへの具体的な影響
この変化がSEOに与える影響は計り知れない。ローカルSEO、ショッピング、情報検索のすべてが、ハイパーパーソナライズされたウェブ体験に再構築される。検索が「エージェントマネージャー」に変わるというピチャイの発言は、単なる未来予想ではなく、現在進行形の現実を指している。
デジタルマーケティング担当者が考えるべきは、数十億の人間を代表する数十億のエージェントを支えるインフラではなく、その中で自社のビジネスがどう位置づけられるかだ。エージェントがタスクを完了する過程で、どの情報源を信頼し、どのように意思決定するのか。この「意思決定レイヤー」に自社がどう登場するかが、新しいSEOの核心となる。
コンテンツ管理システムの対応:WordPress 7.0の役割
人間中心のウェブからエージェント中心のウェブへの移行に際し、コンテンツ管理システム(CMS)の対応は極めて重要だ。特に間もなくリリース予定のWordPress 7.0は、この変化に対応するための機能が多数盛り込まれている。
AIシステムとの接続機能
現在のインターネットは人間の相互作用のために構築されている。AIエージェントはその構造の中で動作しているが、これは急速に変化する見込みだ。WordPress 7.0が重視しているのは、AIシステムとシームレスに接続する機能だ。これにより、ウェブサイトが人間だけでなく、AIエージェントにも適切に情報を提供できる基盤が整う。
具体的には、構造化データの強化、APIファーストなアーキテクチャ、エージェントが理解しやすいコンテンツ形式などが挙げられる。これらの機能は、従来の人間ユーザー向け最適化に加えて、AIエージェント向けの最適化を可能にする。
エージェントが「信頼する」情報源になるために
検索マーケティングの専門家Mike Stewart氏は、この変化について重要な指摘をしている。彼はFacebookへの投稿で、「これはもはやAIが支援する段階ではなく、AIがあなたに代わって操作する段階だ」と述べた上で、以下の問いを提示している。
Stewart氏はさらに、「エージェント型検索は、それを支えるエコシステム(ウェブサイト、コンテンツ、ビジネス)なしには成立しない。その部分はなくならないが、抽象化される」と付け加えている。つまり、ウェブサイトやコンテンツの重要性は変わらないが、人間が直接アクセスする形ではなく、AIエージェントを通じて間接的に利用される形に変化するということだ。
タスク型エージェント検索への具体的な対策

理論的な理解だけでなく、実際にSEO担当者が今から取り組める対策がある。タスク型エージェント検索の時代に向けて、以下のポイントに注目すべきだ。
構造化データの徹底強化
AIエージェントが情報を正確に理解し、タスクを完了するためには、構造化データがこれまで以上に重要になる。特にSchema.orgの語彙を活用し、以下のような情報を明確にマークアップする必要がある。
APIファーストな情報提供
人間がブラウザで閲覧するHTML形式だけでなく、AIエージェントがプログラム的に情報を取得できるAPIの提供が重要になる。WordPressではREST APIが標準で搭載されているが、エージェント向けに最適化されたエンドポイントを用意する必要があるかもしれない。
情報の更新頻度も鍵となる。エージェントがレストランの空き状況を確認する場合、その情報が数時間前のものでは意味がない。可能な限りリアルタイムに近い情報提供が求められる。
コンテンツの「信頼性」シグナルの強化
Mike Stewart氏が指摘した「エージェントはどの情報源を信頼するのか」という問いは核心を突いている。エージェントが意思決定する際、信頼性の高い情報源を優先するだろう。以下の要素が信頼性シグナルとして機能すると考えられる。
具体的な信頼性シグナルとしては、正確で最新の構造化データ、他の信頼できるサイトからの言及やリンク、ユーザーレビューの質と量、企業の実在証明などが挙げられる。これらは従来のSEOでも重要だったが、エージェント検索ではさらに重要性が増す。
この記事のポイント
・ 複数業界における17年間のデジタルビジネス開発経験
・ ウェブサイト開発のためのHTML、PHP、CSS、Java等の実用的知識
・ 15ヶ国語対応の多言語SaaSの開発経験
・ 17年間にも及ぶ、Eコマース長期運営経験
・ 幅広い業界でのSEO最適化の豊富な経験

Google CEOが語る検索の未来:AIエージェントが「検索の管理人」になる日
Googleのサンダー・ピチャイCEOが、検索の未来とAI(人工知能)の進化について最新のインタビューで語った。ピチャイ氏によれば、これからの検索は単なる情報探しの道具ではなく、複数のAIエージェントを束ねてタスクを完了させる「エージェント・マネージャー」へと変貌を遂げるという。
このインタビューでは、Google社内で活用されている開発ツール「Antigravity(内部名称:Jet Ski)」の実態や、2027年に訪れるとされる技術的な大きな転換点についても触れられている。Webサイト運営者やエンジニアにとって、検索エンジンの役割が根底から変わる予兆を捉えることは、今後の戦略を立てる上で不可欠だ。
AIが自律的に行動する「エージェンティック(Agentic)」な未来が、私たちのインターネット利用体験をどう変えるのか。インタビューで明かされた5つの主要なポイントを軸に、その全容を読み解いていく。
検索の概念が変わる:キーワードから「エージェント・マネージャー」へ

ピチャイ氏は、将来的に検索の多くが「エージェンティック(Agentic)」なものになると予測している。エージェンティックとは、AIがユーザーの意図を汲み取り、自律的に判断して複雑なタスクを実行する性質を指す。これまでの検索が「答えを見つける場所」だったのに対し、これからは「目的を完遂する場所」へと進化する。
情報探索からタスク完了へのシフト
従来の検索は、ユーザーがキーワードを入力し、表示されたリンク先を自分で巡って情報を集める必要があった。しかし、ピチャイ氏が描く未来では、検索エンジンが「エージェント・マネージャー」として機能する。ユーザーは一つのスレッドで複数のタスクを同時に走らせ、AIに具体的な作業を任せることができるようになる。
たとえば「来週の出張の準備をして」と頼めば、AIが航空券の予約、ホテルの確保、現地の天気に合わせたスケジュールの調整までを一貫して行うイメージだ。ユーザーは個別のサイトを訪問することなく、検索画面という一つのインターフェース上で全ての工程を管理できるようになる。
デバイスの形状と検索体験の変化
検索のあり方が変われば、それを扱うデバイスの形状(フォームファクタ)も変わるとピチャイ氏は指摘している。スマートフォンの画面を見つめて文字を打ち込むスタイルから、より直感的で常時接続されたデバイスへの移行が想定される。AIがバックグラウンドで常に動いている状態が当たり前になり、検索という行為自体が生活に溶け込んでいく。
- ホテル予約サイトA
- おすすめホテル10選ブログ
- 旅行比較サイトB
このデモは、検索エンジンが単なるリンク集から、具体的なアクションを代行するエージェントへと進化する概念を視覚化したものだ。
Google社内で進むAIエージェントの実装:Antigravityの正体

ピチャイ氏は、Googleの社内で「Antigravity(アンチグラビティ)」というツールが活用されていることを明かした。興味深いことに、社内では「Jet Ski(ジェットスキー)」という別の名前で呼ばれているという。このツールは、エンジニアのワークフローを劇的に変えつつある。
内部名称「Jet Ski」としての活用実態
Google DeepMindやソフトウェアエンジニアのグループは、すでにこのエージェント管理ツールの世界で生活しているという。ピチャイ氏自身もこのツールを利用しており、たとえば「新機能をリリースしたが、人々の反応はどうだ? 最悪な意見を5つ教えてくれ」と入力するだけで、AIが膨大なデータから必要な情報を抽出してくる。
かつてはこうした情報を得るために、多くの時間を費やして手動で調査する必要があった。今ではAIエージェントがそのジャーニーを助けてくれるため、経営判断のスピードも向上している。社内ツールとしての「Jet Ski」は、情報の要約だけでなく、複雑なワークフローの自動化にも貢献している。
検索チームへの導入がもたらす影響
さらに、このAntigravityは最近になってGoogleの検索チームにも展開された。大規模な組織において、こうした新しいテクノロジーを浸透させる「チェンジマネジメント(組織変革)」は容易ではないが、Googleは着実にAIエージェントを業務の核心に据えようとしている。
検索チームがAIエージェントを使いこなすようになれば、検索アルゴリズムの改善や新機能の開発スピードはさらに加速するだろう。開発者自身がAIエージェントの恩恵を日常的に受けることで、ユーザーに提供する検索体験もよりエージェント的なものへと洗練されていくことが予想される。
物理世界への進出:ロボティクスとドローン配送の加速

AIの進化はデジタル空間に留まらない。ピチャイ氏は、Googleが以前はロボティクス分野において「早すぎた」ことを認めつつ、現在はAIがその欠けていたピースを埋めていると語った。10〜15年前に構想されていたアイデアが、最新のAIモデルによってようやく実現可能になっている。
AIがロボット開発の「ミッシングリンク」を埋める
Googleが開発したAIモデル「Gemini(ジェミニ)」のロボティクス版は、空間推論において世界最高水準の能力に達しているという。これにより、ロボットは周囲の状況をより正確に理解し、複雑な動作を自律的に行えるようになる。GoogleはBoston Dynamics(ボストン・ダイナミクス)などの企業と再び提携を強めており、物理的なエージェントの開発に力を入れている。
また、ドローン配送サービス「Wing(ウィング)」についても具体的な進展がある。近い将来、4,000万人以上のアメリカ人がWingの配送サービスを利用できるようになる見込みだという。これは数年先の話ではなく、現実味を帯びたタイムスケールで進んでいるプロジェクトだ。
自社ハードウェア開発への意欲
ピチャイ氏は、ロボティクスやAIの分野において、自社製(ファーストパーティ)のハードウェアを持つことが重要であるとの見解を示した。Waymo(自動運転車)やTPU(AI専用チップ)での経験から、安全性や規制、製品のフィードバックサイクルを管理するためには、ハードウェアとソフトウェアを統合して開発する必要があると考えている。
これは、将来的にGoogleがより多様な家庭用・産業用ロボットハードウェアに進出する可能性を示唆している。デジタルなAIエージェントが、物理的なロボットという体を得て、私たちの生活空間で直接タスクをこなす未来が近づいている。
2027年が大きな転換点に:人間の介在しない自律型システムの到来

インタビューの中で最も注目すべき発言の一つが、2027年という具体的な数字だ。ピチャイ氏は、エージェントシステムが人間の介在なしに完全に動作できるようになる大きな転換点(インフレクションポイント)として、2027年を二度も挙げている。
プログラミングとワークフローの自動化
現在でも、エンジニアがAIを使ってコードを書く風景は珍しくない。しかし、現状ではAIが生成したコードを人間がコピーして実行し、エラーが出たら再びAIに尋ねるという「人間が介在するループ」が存在する。ピチャイ氏は、このプロセスにおいて人間が「コピペロボット」になっている現状を指摘している。
Antigravityのような次世代システムでは、AIが自らコードを実行し、エラーを検知して修正し、タスクを完遂する。2027年までには、こうした「ヒューマン・イン・ザ・ループ(人間による確認工程)」が不要になる領域が大幅に増え、ワークフローそのものが根本から切り替わるという予測だ。
AIによる「自己改善」がもたらす飛躍的進化
ピチャイ氏が期待を寄せているのは、AIが自ら学習し、有用性を高めていく「自己改善」のプロセスだ。ポストトレーニング(事後学習)の改善により、AIの能力が一段と跳ね上がる兆候が見えているという。人間が具体的に指示(プロンプト)を出さなくても、AIシステムが自律的に自身の機能を向上させていく段階に入れば、進化のスピードは指数関数的に加速する。
2027年は、AIが単なる「便利なツール」から、独立して価値を生み出し続ける「自律的なパートナー」へと進化を遂げる年になるかもしれない。この変化は、Web制作やソフトウェア開発のあり方を一変させる力を持っている。
Webサイト運営者とSEO担当者が備えるべき未来
検索が「エージェント・マネージャー」へと進化する未来において、Webサイトの役割はどう変わるのだろうか。Search Engine Journalの記事に基づき、ピチャイ氏の発言から読み取れる今後のSEO(検索エンジン最適化)戦略を分析する。
独自の分析:エージェント時代に求められるコンテンツ
AIエージェントがユーザーの代わりに情報を収集し、タスクを実行するようになると、従来の「クリックを稼ぐためのコンテンツ」は価値を失う可能性がある。エージェントが情報を正確に抽出できるよう、構造化データ(Schema.orgなど)の整備はこれまで以上に重要になるだろう。Webサイトは「人間が読むための雑誌」から「AIが処理するためのデータベース」としての側面を強めていく。
一方で、AIが代替できない「一次情報」や「独自の体験談」の価値は相対的に高まると考えられる。AIは既存の情報を要約することは得意だが、新しい発見や独自の視点、感情を伴うレビューを生み出すことはできない。エージェントがユーザーに提示する「最終的な判断材料」として選ばれるためには、信頼性と独自性が鍵となる。
また、ピチャイ氏が言及した「OpenClaw」のようなオープンなエージェントシステムの普及にも注目したい。特定のプラットフォームに依存せず、ユーザーが独自のAIエージェントを構築し、Web上の情報を自由に活用する時代が来る。Web制作者は、画面上の見た目だけでなく、APIやデータ連携を通じてエージェントに「使ってもらえる」サイト設計を意識する必要があるだろう。
この記事のポイント
- 検索は「答えの提示」から、AIエージェントを管理してタスクを完遂する「エージェント・マネージャー」へと進化する。
- Google社内では「Jet Ski(Antigravity)」というAIエージェントツールが日常的に使われ、意思決定や開発を加速させている。
- 2027年が技術的な転換点となり、人間の介在なしにAIが自律的にワークフローを完了させる時代が到来する見込みだ。
- ロボティクス分野でもAI(Gemini)による空間推論が進化し、ドローン配送や物理的なハードウェア開発が加速している。
- 今後のSEOでは、AIエージェントが処理しやすいデータ構造の整備と、AIには真似できない独自性の高い一次情報の発信が重要になる。
・ 複数業界における17年間のデジタルビジネス開発経験
・ ウェブサイト開発のためのHTML、PHP、CSS、Java等の実用的知識
・ 15ヶ国語対応の多言語SaaSの開発経験
・ 17年間にも及ぶ、Eコマース長期運営経験
・ 幅広い業界でのSEO最適化の豊富な経験

AI検索で勝つのは自社サイトではなくReddit?コミュニティ信号がSEOの鍵を握る理由
AIに「どの製品を買うべきか」や「どのソフトウェアが最適か」を尋ねたとき、その回答の出典がメーカーの公式サイトではないケースが増えている。多くの場合、AIが答えの根拠としているのは、1年以上前にReddit(レディット)に書き込まれた、見知らぬ誰かのコメントだ。Redditは米国最大級の掲示板サイトであり、日本でいえば「5ちゃんねる」に近い側面を持ちつつ、より専門的な議論が行われるプラットフォームだ。
この現象は偶然ではなく、AI検索の構造的な変化によって引き起こされている。2025年にかけてのデータによると、GoogleのAI Overviews(AIによる検索結果の要約)において、Redditの引用数はわずか数ヶ月で450%も増加した。自社でコントロールできる「オウンドメディア」のコンテンツが、コミュニティ内の「生の声」に敗北し始めているのだ。
なぜAIは企業の公式情報よりも、匿名の投稿を信頼するのか。この記事では、AI検索エンジンがコミュニティ信号を重視する仕組みと、企業が今後取るべき具体的な対策について解説する。従来のSEO(検索エンジン最適化)の常識が通用しなくなる中で、新しい「信頼の構築方法」を理解することが重要だ。
AI検索エンジンの主役に躍り出たRedditの影響力

RedditがAI回答の主要なソースになった背景には、巨大なテック企業同士の戦略的な提携がある。Googleは2024年初頭、Redditと年間約6,000万ドルのライセンス契約を結んだ。これにより、GoogleはReddit上の膨大な投稿やコメントにリアルタイムでアクセスし、AIモデルの学習やAI Overviewsの生成に利用できるようになった。同様の契約はOpenAIなどの他のAI企業とも結ばれており、契約総額は2億ドルを超えている。
巨額のライセンス契約と引用データの裏付け
Search Engine Journalの報告によれば、2024年8月から2025年6月にかけて、RedditはGoogle AI OverviewsとPerplexity(パープレキシティ:対話型AI検索エンジン)の両方で、最も引用されるドメインとなった。ChatGPTにおいても、Wikipediaに次いで2番目に多く引用される情報源となっている。特に製品比較やレビューに関するクエリでは、Redditが検索結果に表示される割合は97%以上に達するというデータもある。
これは、AIが「事実」だけでなく「人間の経験」を求めていることを示している。企業の公式サイトには、その製品のメリットが整然と並んでいる。しかし、Redditには「実際に使ってみたらここが不便だった」「競合他社の製品と比べてここが優れている」といった、装飾のない本音が蓄積されている。AIはこの「本音の集積」を、ユーザーにとって最も価値のある情報だと判断しているのだ。
なぜRedditはGoogle検索結果でも強いのか
Redditの強さはAIの回答レイヤーだけにとどまらない。従来のGoogle検索結果(SERP)においても、Redditのスレッドが上位を占める光景は一般的になった。2025年初頭にはRedditのオーガニック順位が一時的に下落した時期もあったが、AI回答層での存在感は依然として揺るぎない。これは、AIシステムが単なるランキングアルゴリズムとは異なる基準で、データの「信頼性」を評価しているためだ。
AIは情報の「新鮮さ」と「多角的な視点」を重視する。1つの企業が発信する情報は一方向的だが、Redditのスレッドは数百人のユーザーによる議論で構成されている。この「多対多」の対話構造が、AIにとっては情報の正確性を担保する強力なシグナルとして機能している。以下に、AIが情報を取得するフローを視覚化したデモを示す。
AIの情報取得フローのデモを見る
企業が発信した情報をそのままユーザーが受け取る構造だ。
AIが複数のコミュニティ信号を分析・統合して、一つの回答を生成する。
このデモのように、AIは単一のソースではなく、複数のコミュニティから得られる「合意」を回答の根拠としている。
AIがコミュニティの「声」を信頼する2つのメカニズム

AIがコミュニティコンテンツを重視する理由は、単なるライセンス契約の結果だけではない。AIのアーキテクチャ自体が、コミュニティの信号を「質の高いデータ」として認識するように設計されているからだ。これには「パラメトリック(Parametric)」と「リトリーバル(Retrieval)」という2つの経路が関係している。
学習データとリアルタイム検索の二段構え
第一の経路であるパラメトリック経路とは、AIモデルの事前学習(トレーニング)の段階でコミュニティの内容が組み込まれることを指す。AIが学習を終えた時点で、すでにそのブランドや製品に関する「世間の評判」がAIの知識の一部として定着している状態だ。もし学習データに含まれるRedditのスレッドで自社製品が酷評されていた場合、AIはその知識に基づいて回答を生成する。
第二の経路は、RAG(Retrieval-Augmented Generation / 検索拡張生成)と呼ばれるリトリーバル経路だ。これは、AIがユーザーの質問に対して、リアルタイムでインターネット上の情報を検索し、その結果を基に回答を補強する仕組みだ。RAGにおいて、AIは最新の議論や特定のトラブル解決策を探すためにコミュニティサイトを優先的にクロールする。つまり、過去の学習データと現在の検索結果の両方でコミュニティ信号が支配的な役割を果たしているのだ。
アップボート(高評価)が質を保証するフィルターになる
AIにとって、情報の「正しさ」を判断するのは難しい。そこでAIが活用しているのが、コミュニティ内の「評価システム」だ。Redditには、良い投稿に投票する「Upvote(アップボート)」という仕組みがある。OpenAIのトレーニングデータ階層に関する報告によると、3つ以上のアップボートを獲得したRedditコンテンツは、Wikipediaやライセンス済みの出版パートナーに次ぐ「ティア2(第2階層)」の高品質データとして扱われている。
数百、数千の人間が「この記事は役に立つ」と判断したという事実は、AIにとって強力な信頼の証となる。企業が自社サイトで「わが社の製品は最高だ」と1万回書くよりも、Redditで100人のユーザーが「この製品は最高だ」と評価する方が、AIの目には価値ある情報として映るのだ。これは、個別のリンクの強さを競っていた従来のSEOから、コミュニティ全体の「文脈上の合意」を重視するSEOへの転換を意味している。
偽装された合意の罠とアストロターフィングの代償

コミュニティの評価がAI回答を左右するのであれば、意図的に高評価を捏造しようと考える者が現れるのは当然だ。これを「アストロターフィング(偽の草の根運動)」、いわゆるステマ(ステルスマーケティング)と呼ぶ。しかし、AI時代のコミュニティ操作は、かつてのリンクスパムよりもはるかに高いリスクを伴う。
ステマ行為に対するコミュニティとAIの監視
2025年後半に起きた「Trap Plan事件」は、このリスクを象徴している。あるマーケティング会社がRedditに約100件の偽の口コミを投稿し、その手法を自慢げにブログで公開した。しかし、Redditのコミュニティと自動監視システムはすぐに不自然な投稿パターン(アカウント作成時期や投稿間隔の偏り)を検知した。結果としてその会社は激しいバッシングを受け、ブランド名は「不正を行う企業」としてRedditのスレッドに永久に刻まれることになった。Googleはこのスレッドもインデックスするため、ブランド名で検索するすべての潜在顧客に不正の事実が知れ渡ることになったのだ。
Redditのモデレーター(管理者)や熱心なユーザーコミュニティは、企業による操作に対して非常に敏感だ。一度「不誠実なブランド」というレッテルを貼られると、そのネガティブな文脈をAIが学習し、将来的に「あのブランドは避けるべきだ」という回答を生成する原因になりかねない。短期的な露出のためにコミュニティの信頼を損なうことは、AI時代のSEOにおいて致命的な戦略ミスとなる。
AI生成コンテンツによる汚染問題
もう一つの懸念は、AI自身がコミュニティを汚染し始めていることだ。Originality.aiの調査によると、2025年のReddit投稿の約15%がAIによって生成された可能性が高いという。これは、人間による純粋な合意形成のプロセスが、AIによる自動投稿によって歪められていることを示唆している。AIが「AIが書いた偽の合意」を学習するという、自己参照的なフィードバックループが発生しているのだ。
このような状況下では、AI検索エンジン側も「人間による真正なシグナル」を判別するためのアルゴリズムを強化せざるを得ない。今後は、単なるアップボートの数だけでなく、投稿者の過去の活動履歴や、議論の深さ、専門性といった「人間らしさ」の証明がより重要視されるようになるだろう。企業ができる最も戦略的な行動は、検出システムが厳格化される前に、本物のコミュニティプレゼンス(存在感)を築いておくことだ。
レビュープラットフォームの選択がAIの視認性を左右する

コミュニティ信号のもう一つの柱は、レビューサイトだ。B2B(企業間取引)のソフトウェア選定において、かつてはGoogle検索が起点だったが、2025年の調査では50%の買い手がAIチャットボットから購買の旅を始めている。AIがどの製品を推奨するかを決定する際、その判断材料の多くはG2やCapterra、Clutchといったレビュープラットフォームから得られている。
クローラーへのアクセス制限がもたらす格差
ここで重要なのが、すべてのレビューサイトがAIに対してオープンではないという点だ。2025年6月の分析によると、レビュープラットフォームはAIクローラー(情報を収集するプログラム)への対応方針によって3つに分類される。ClutchやSourceForgeのように全アクセスを許可しているサイト、G2のように選択的に許可しているサイト、そしてYelpのようにrobots.txt(クローラーへの指示書)でAIを完全に拒絶しているサイトだ。
AIクローラーをブロックしているサイトにどれだけ多くの好意的なレビューがあっても、AIはその情報を回答に反映させることができない。例えば、Perplexityのソフトウェアカテゴリにおける引用の75%はG2から来ている。企業がレビュー獲得施策(レビューマネジメント)を行う際は、そのプラットフォームがAI検索のソースとして機能しているかどうかを確認する必要がある。
B2B比較サイトがAI回答のソースになる理由
AIは「A社とB社の違いは何か?」という比較質問に答える際、構造化されたデータを好む。G2のような比較サイトは、機能ごとのスコアやユーザーの職種、企業規模といったデータが整理されているため、AIにとって非常に解釈しやすい。また、これらのサイトは強力なドメイン権威(サイトの信頼性)を持っており、AIが「信頼できる参照先」として優先的に選択する傾向がある。
以下のデモは、レビューサイトの公開設定(robots.txt)がAIの回答にどう影響するかを簡略化したものだ。
「User-agent: * Allow: /」の設定。AIはすべてのレビューを読み取れる。 「User-agent: GPTBot Disallow: /」の設定。AIはこのサイトの情報を無視する。robots.txtによるAI視認性の違いをデモで見る
このように、レビューを集める場所の選択ミスが、AI検索における「存在の消滅」につながるリスクがある。
ブランドが構築すべき「文脈の堀」と実践的な参加戦略

AI時代における真のSEOとは、自社サイトを最適化することだけではない。インターネット上のあらゆる場所に、自社に関する「好意的な文脈(コンテキスト)」を散りばめることだ。これは、競合他社が簡単には真似できない「文脈の堀(Context Moat)」を築く作業に近い。一朝一夕には完成しないが、一度構築されれば長期的な資産となる。
専門家による実名でのコミュニティ貢献
企業がコミュニティに参加する際、最も効果的なのは「ブランド」としてではなく「個人」として貢献することだ。社内の技術者や専門家が、RedditやStack Overflow、Quoraなどのプラットフォームで、自身の知識を惜しみなく共有する。質問に対して誠実に答え、役立つ情報を提供することで得られるアップボートやカルマ(貢献度スコア)は、AIにとって非常に強力な品質シグナルとなる。
実名での参加は、情報の信頼性を高めるだけでなく、AIに対して「このブランドには信頼できる専門家がいる」という関連付けを強化する。一見、遠回りに見えるこの活動が、実は10本のオウンドメディア記事を書くよりも、AI検索の視認性を高める上で効果的である場合が多い。
8対2の法則で価値を届ける
コミュニティでの活動には黄金律がある。それは「80%の貢献と20%の言及」だ。参加時間の80%は、自社製品とは無関係であっても、コミュニティの課題を解決するために費やすべきだ。残りの20%で、自社製品が本当にその質問の最適な答えである場合にのみ、控えめに紹介する。このバランスを崩して宣伝色を強めた瞬間、コミュニティからの反発を招き、AIにネガティブなシグナルを送ることになる。
また、コミュニティメンバーが「引用したくなるコンテンツ」を作成することも重要だ。独自の調査データ、具体的なベンチマーク数値、失敗談を含む詳細なケーススタディなどは、Redditなどでリンクが共有されやすい。これらの「第三者による言及」こそが、AIが合意を形成するための原材料となる。自社サイトをゴール(終着点)とするのではなく、コミュニティの議論を加速させるための「燃料」としてコンテンツを位置づける発想が必要だ。
この記事のポイント
- AI検索エンジン(Google, ChatGPT等)は、企業の公式サイトよりもRedditなどのコミュニティの声を優先的に引用している。
- AIは学習時とリアルタイム検索の両方でコミュニティ信号を利用しており、特にアップボート(高評価)を信頼の指標としている。
- ステマ行為などの操作は、コミュニティの反発を招くだけでなく、AIに「不誠実なブランド」として学習されるリスクがある。
- レビューサイトを選ぶ際は、AIクローラーへのアクセスを許可しているプラットフォーム(G2, Clutch等)を優先すべきだ。
- 企業は専門家による実名での貢献を通じて、長期的に「文脈の堀」を築くことが、AI時代の新しいSEO戦略となる。
・ 複数業界における17年間のデジタルビジネス開発経験
・ ウェブサイト開発のためのHTML、PHP、CSS、Java等の実用的知識
・ 15ヶ国語対応の多言語SaaSの開発経験
・ 17年間にも及ぶ、Eコマース長期運営経験
・ 幅広い業界でのSEO最適化の豊富な経験

Google CEOが語る検索の未来:AIエージェントの「管理者」への進化とWebサイトの行方
Googleの検索エンジンが、かつてない大きな転換期を迎えている。サンダー・ピチャイCEOは最近のインタビューで、検索の未来は単なる情報の入り口ではなく、複数のAIエージェントを束ねる「マネージャー(管理者)」のような役割になると語った。この変化は、情報の探し方だけでなく、Webサイトの存在意義そのものを塗り替える可能性がある。
検索エンジンがユーザーの意図を汲み取り、自ら実行・完結させる「エージェント型検索」への移行は、Web制作やマーケティングに携わる者にとって避けては通れないテーマだ。ピチャイCEOの発言からは、従来の「検索結果からリンクをクリックする」という体験が、AIによる「タスク実行」へと置き換わっていく未来が鮮明に浮かび上がっている。
検索は「リンクの羅列」から「AIエージェントの指揮者」へ
Googleのサンダー・ピチャイCEOは、検索の未来について「AIエージェントのマネージャーになる」という極めて具体的なビジョンを示した。これは、検索窓が単にWebページを探すための道具ではなく、複数のAIプログラムを指揮して、ユーザーの複雑な要求を完結させるための司令塔になることを意味している。
情報検索から「エージェント型検索」への転換
従来の検索は、ユーザーが入力したキーワードに対して、関連性の高いWebサイトをランク付けして表示する「情報のマッチング」が主眼であった。しかし、ピチャイCEOが提唱する「エージェント型検索(Agentic Search)」では、検索システム自体がユーザーの代わりにタスクを計画し、実行する能力を持つようになる。
AIエージェントとは、特定の目的を達成するために自律的に動作するプログラムのことだ。たとえば「次の週末、ニューヨークで3人分のディナーを予約し、その後の移動手段を確保してほしい」という要求に対し、検索エンジンがレストランの空き状況を確認し、予約を入れ、配車アプリの手配までを並行して行うような世界である。ピチャイCEOは、検索がこうした「多くのスレッドを同時に走らせ、タスクを完了させる場」になると指摘している。
AIエージェントがタスクを代行する未来
この変化において重要なのは、ユーザーがWebページを一つひとつ閲覧して情報を集める手間が省かれるという点だ。ピチャイCEOは「地下鉄の駅から出てきた人が特定の場所を探す」という例を挙げ、状況に応じて期待される検索の形が進化し続けてきたことを強調した。モバイルシフトの時と同様に、AIエージェントの台頭もまた、ユーザーの期待値の変化に応じた必然的な進化であるとの立場だ。
検索がエージェント化することで、Webサイトは「ユーザーが訪れる目的地」から「AIが処理するためのデータソース」へと役割が変化する可能性がある。このシナリオでは、検索エンジンとユーザーの間にAIエージェントが介在し、Webページの内容を要約したり、必要なデータだけを抽出してタスクに利用したりする形が一般的になると推測される。
10年後の検索は存在するか?ピチャイCEOのビジョン

インタビューの中で「10年後も検索は存在し続けるか」という問いに対し、ピチャイCEOは「進化し続ける」と答え、その存続を肯定した。ただし、その形態は現在の「検索ボックス」とは大きく異なるものになる可能性が高い。
検索窓は「オーケストレーション層」になる
ピチャイCEOが描く未来の検索は、「オーケストレーション層」として機能する。オーケストレーションとは、複雑なシステムや多数のAIエージェントを調和させ、効率的に管理・実行することを指す音楽の指揮者のような役割だ。
ユーザーは検索エンジンを通じて複数のエージェントを動かし、非同期的に(バックグラウンドで)長い時間を要するタスクを実行させるようになる。現在の検索が「即座に答えを返す」ことに特化しているのに対し、未来の検索は「複雑なプロジェクトを管理し、完了させる」という、より深い関与へとシフトしていく見込みだ。ピチャイCEOは、これを「ディープな調査クエリ(Deep Research Queries)」への適応と表現している。
10年後ではなく「1年後」の急カーブに注目すべき理由
興味深いのは、ピチャイCEOが「10年先を予測して思考停止に陥るよりも、目の前の1年間に集中すべきだ」と述べている点だ。AIモデルの進化速度はあまりに速く、1年後のカーブが非常に急であるため、長期的な予測よりも現在の変化に柔軟に適応し続けることが重要であると説いた。
デバイスの形状(フォームファクター)や入出力の方法(I/O)も劇的に変わる中で、検索というプロダクトの境界線は常に拡張され続ける。ピチャイCEOは、この状況を「ゼロサムゲーム(誰かが得をすれば誰かが損をする状態)」として捉えるのではなく、AIによってユーザーができることの価値が爆発的に高まる「拡張の瞬間」であると前向きに評価している。
SearchとGeminiの共存と分岐
Googleは現在、従来の「Google検索」と、生成AIである「Gemini」の両方を展開している。これら2つのプロダクトが今後どのように関わっていくのかも、Web運営者にとっては大きな関心事だ。
競合ではなく補完し合う関係性
ピチャイCEOによれば、検索とGeminiは「特定の面で重なり合い、特定の面で深く分岐していく」という。双方は競合するものではなく、異なるユーザーニーズを満たすための両輪として機能する。検索は情報の信頼性や最新の事実確認に強みを持ち、Geminiは創造的なタスクや複雑な推論を得意とする。
この二つの融合が進むことで、検索結果にAIによる要約(AI Overviews)が表示される現在の形は、さらに進化していく。ユーザーは情報の質や用途に応じて、従来型の検索結果とAIによる生成コンテンツを使い分けるようになり、その橋渡しをAIエージェントが担うことになる。
ユーザーの適応能力が検索の形を変える
ピチャイCEOは、ユーザーが新しいAIの機能に驚くほど早く適応している点にも言及した。検索結果にAIの回答が表示されるようになっても、ユーザーはそれを自然に受け入れ、より深い調査に活用しているという。この「ユーザー側の適応」こそが、プロダクトの進化を加速させる要因となっている。
Webサイト運営者は、ユーザーがAIと対話しながら情報を探すことが「当たり前」になる前提で、自社のコンテンツをどう届けるかを再考する必要がある。AIエージェントが情報を収集しやすい構造(構造化データなど)の重要性は、今後さらに高まるだろう。
独自分析:Webサイトの存在意義はどう変わるのか

ピチャイCEOの1時間に及ぶインタビューの中で、驚くべき事実がある。それは「Webサイト(Websites)」という言葉が一度も登場しなかったことだ。「Webページ(Web pages)」という言葉は2回使われたが、いずれも技術的な理解や過去の例え話としての文脈であった。
「データソース」としてのコンテンツと「目的地」としてのWeb
Googleのトップが「検索の未来」を語る際にWebサイトに言及しなかったことは、今後のWebエコシステムの変容を象徴している。Search Engine JournalのRoger Montti氏は、GoogleがWebページを「訪問すべき場所」ではなく「AIエージェントが処理するためのデータ」として扱おうとしているのではないかと分析している。
もし検索がタスク完結型のエージェントになれば、ユーザーが個別のWebサイトを訪れて広告を見たり、サービスに申し込んだりする機会は減少するかもしれない。Webサイト側は、単なる情報の提供だけでなく、AIエージェントには代替できない「独自の体験」や「信頼の源泉」としての価値を研ぎ澄まさなければならないだろう。
SEOコミュニティが抱く「ゼロサムゲーム」への懸念
ピチャイCEOは「ゼロサムゲームではない」と主張するが、パブリッシャーやSEOコミュニティの視点は異なる。GoogleがWeb上のコンテンツをAIの学習や回答生成に利用し、その結果としてWebサイトへのトラフィックが減少すれば、それはコンテンツ制作者にとって死活問題だ。
しかし、ピチャイCEOの言葉を借りれば、この変化を「拒絶」するのではなく「活用」する側に回るしかない。AIエージェントに「引用されるべき信頼できる情報源」として認識されること、そしてエージェント経由でもユーザーに価値を届けられるビジネスモデルを構築することが、これからのWeb戦略の核となるはずだ。Webサイトは「見られるもの」から、AIという知能を介して「利用されるもの」へと脱皮を求められている。
この記事のポイント
- Google検索は、AIエージェントを指揮・管理する「オーケストレーション層」へと進化する。
- 未来の検索は、情報の提示にとどまらず、予約や手配などの複雑なタスクを自律的に実行する。
- ピチャイCEOは、10年後の予測よりも「1年単位の激しい進化」に適応することの重要性を強調した。
- WebサイトはAIエージェントのための「データソース」として扱われる傾向が強まっていく。
- パブリッシャーは、AI時代においても代替不可能な独自の価値と信頼性を構築する必要がある。
・ 複数業界における17年間のデジタルビジネス開発経験
・ ウェブサイト開発のためのHTML、PHP、CSS、Java等の実用的知識
・ 15ヶ国語対応の多言語SaaSの開発経験
・ 17年間にも及ぶ、Eコマース長期運営経験
・ 幅広い業界でのSEO最適化の豊富な経験