

GPT-5.5の応答を改善、VS Codeのプロンプトチューニング手法
GPT-5.5の応答が改善された技術的背景

VS Codeが提供するAIエージェント機能は、コード生成の裏側で「コーディングハーネス」と呼ばれる仕組みが動いている。これはモデルとツール、コンテキスト、指示、エージェントのループを繋ぐ層だ。モデルがコードを書くための土台となる部分といえる。
2026年7月、VS CodeチームはOpenAIと協力し、GPT-5.5向けのシステムプロンプトを改善する実験を実施した。焦点は「エージェントの探索を減らし、検証を早める」ことにある。この変更で応答速度とコストの両方を改善できるかどうかが検証された。
プロンプトチューニングの目的と仮説
GPT-5.5のリリース後、VS Codeチームはエージェントがトークンをどのように消費しているかを分析した。分析の結果、モデルが実際の編集に入る前に過剰な探索を行っているパターンが浮かび上がった。具体的には、ファイルの再読込や周辺コードの比較に多くのトークンが費やされていた。
この観察から1つの仮説が導かれた。それは「エージェントはさまよう努力を減らし、証拠、行動、検証という意図的なループに注力すべきである」というものだ。この仮説を検証するため、2種類のプロンプトが用意された。
エージェントが編集前に「考えすぎる」状態を減らし、必要最小限の探索で行動に移すよう誘導する。この考え方は、トークン消費と応答時間の両方に直接影響を与える。
実験の中身と2つのアプローチ
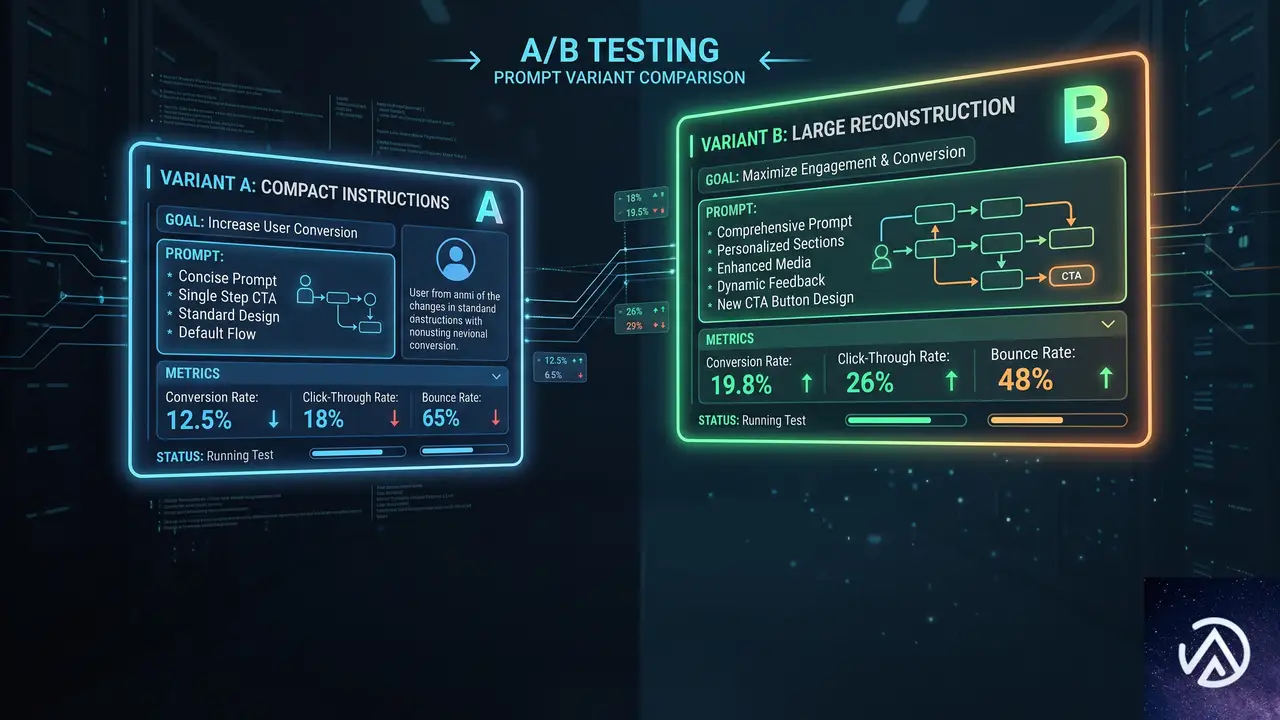
実験は2週間にわたって実施された。GPT-5.5のエージェントトラフィックを、対照群と2つの処置群に25%ずつ分割し、残りの25%はスコアカード外でデフォルトプロンプトが使用された。この設計により、同じ種類のユーザートラフィックで公平な比較が可能になる。
処置A「PRPT_SRCH」簡潔な探索と編集
処置Aは小規模で焦点を絞った変更だ。プロンプトに1つのコンパクトな指示を追加し、不必要な探索を減らすようモデルに促す。この指示は「economical_search_and_edit」セクションと呼ばれる。
具体的には、次の5つの行動指針が与えられた。最も具体的なアンカー(ファイル、シンボル、失敗している動作など)から開始すること。1つの仮説とそれを否定できる安価なチェックを選ぶために十分な周辺コンテキストだけを集めること。広範なリポジトリ探索より1回の対象検索を優先すること。最も安価な判別チェックがわかったら即座に行動すること。そして、新しい結果が関連性を示さない限り、変更されていないコンテキストを再読しないことだ。
economical_search_and_edit:
- 最も具体的なアンカーから開始する
- 1つの仮説とその反証チェックに十分なコンテキストだけを集める
- 広範な探索より1回の対象検索を優先する
- 最も安価な判別チェックがわかったら即行動する
- 変更されていないコンテキストは再読しない処置B「PRPT_LRG」大規模プロンプト再構成
処置Bは同じ仮説をより広範に展開したものだ。エージェントのワークフローを「Before_the_first_edit(最初の編集前)」と「After_the_first_edit(最初の編集後)」の2つの明示的なセクションに再編成する。
このアプローチの狙いは、検索ステップだけでなくループ全体を解決することにある。最初の編集前に局所的な仮説を形成し、広範な探索を避け、根拠のある最初の編集を行い、最初の実質的な編集後に即座に検証する。処置Aと異なり、プロンプト自体のサイズは大きくなるため、構造の追加が効率を改善できるかどうかが重要な論点だった。
両処置の設計思想の違いは明確だ。処置Aは最小限の介入で探索を抑えるのに対し、処置Bはエージェントの行動全体を構造化して制御しようとする。この差が実際のパフォーマンスにどう現れるかが実験の焦点になった。
2週間のスコアカードが示した結果
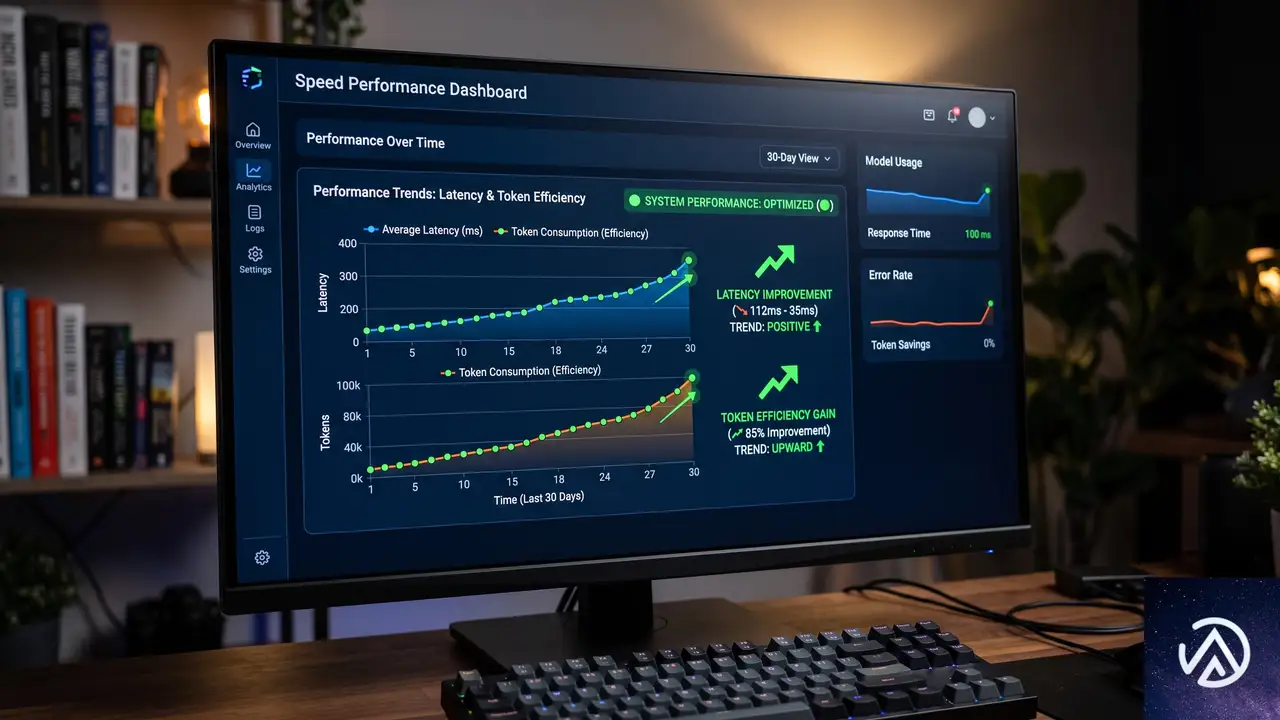
実験では品質、レイテンシ、効率の3つの次元で評価が行われた。品質は「コードが定着するか」、レイテンシは「最初の編集がどれだけ早く行われるか」、効率は「トークンとツール呼び出しの数」で測定される。
品質指標 10分生存率とコミット生存率
10分生存率は、AIが書いたコードのうち10分後もファイルに残っている割合を示す。コミット生存率は、さらに厳格にgitコミットまで生き残ったコードの割合だ。この2つが品質のガードレール指標となる。
結果として、コミット生存率は処置Bで+0.68%とわずかに上昇し、処置Aでは-0.48%とわずかに低下したが、いずれも統計的に有意ではなかった。10分生存率は両処置ともわずかに低下し、処置Bの-0.44%だけが統計的有意の閾値をわずかに超えた(p=0.0493)。VS Codeチームはこれを「実際のトレードオフとして考慮すべきだが、動きは小さく、他の品質ガードレールは後退しなかった」と評価している。
レイテンシ指標 初回編集までの時間
編集レイテンシでは処置Bが最も強い改善を示した。p50(中央値)の初回編集時間は-5.68%(3.9秒高速化、p=2e-5)、p95(下位5%の遅いケース)では-9.30%(38.8秒高速化、p=1e-10)といずれも高い統計的有意性を示した。
処置Aもp50で-2.88%(2.0秒高速化、p=0.0271)と改善したが、p95の改善は統計的に有意ではなかった。遅いケースでの差が特に顕著で、「なぜこれが遅いのか」というストレスを感じる場面での改善が大きかったことになる。
トークン効率とツール呼び出し回数
1ユーザーあたりの日次トークン消費量(p50)は両処置とも減少したが、統計的有意ではなかった。しかし、トークン消費の裾野(p95、特に重いリクエスト)では、処置Bが-7.64%(p=0.0003)、処置Aが-5.19%(p=0.0157)と明確な改善を示した。
平均ツール呼び出し回数も両処置で減少した。処置Bは-8.54%(1ターンあたり2.04回の呼び出し削減、p=1e-12)、処置Aは-3.19%(0.77回削減、p=0.0091)だ。処置Bの優位性は極めて高い統計的有意性で裏付けられた。
処置Bは総合的に最も強いプロファイルを示した。レイテンシの明確な勝利、裾野トークンの有意な削減、ツール呼び出しの減少、そして品質ガードレールのほぼ安定。10分生存率のわずかな低下は軽微な有意性(p=0.0493)にとどまり、レイテンシやトークン、ツール呼び出しの改善ははるかに大きく堅牢だった。
プロンプトチューニングが示す開発体験の進化
この実験の成果は数字の変化だけではない。重要なのは、プロバイダからのフィードバックに基づく検証可能な仮説を、オフライン評価で事前検証し、2週間の本番環境で確認するという一連のループが機能したことだ。
モデルのリリースはチューニングループの終点ではない。VS Code上の実際の動作を観察し、焦点を絞った改善をテストし、より速く、信頼性が高く、効率的な体験を実現する新たな方法を見つける機会となる。このプロンプトチューニングは、その1つの具体的な実例だ。
使用量ベース課金におけるトークン効率の重要性
この改善が特に重要なのは、使用量ベースの課金モデルが前提にあるからだ。トークン効率は単なるインフラ指標ではない。エージェントが探索に費やすすべてのトークンは、ユーザーが支払い、待たされる対象だ。根拠のある編集に早く到達するエージェントは、より良い体験とより小さい請求額の両方をもたらす。
VS Codeチームはこの取り組みを継続する方針を示している。モデル、プロンプト、ツール、コーディングハーネス全体にわたって改善点を探し続け、エージェントの予算が必要な作業に集中できるよう最適化していくという。
このループが示すのは、AI開発支援ツールの進化がモデルの性能向上だけに依存する段階から、プロンプト設計やツール連携の最適化を含む総合的な取り組みへと移行していることだ。モデルが高性能でも、使い方が適切でなければ本来の力を発揮できない。その橋渡しをするのがプロンプトチューニングの役割といえる。
この記事のポイント
- GPT-5.5向けのプロンプトチューニングで、エージェントの探索を抑制し検証を早める改善が実施された
- 処置B(大規模プロンプト再構成)が最も優れた結果を示し、p95の初回編集時間を9.30%短縮した
- ツール呼び出し回数は8.54%削減され、トークン消費の裾野(重いリクエスト)でも7.64%の改善が確認された
- 品質指標(コード定着率)はほぼ維持され、速度と効率の改善が品質を犠牲にしないことが実証された
- 使用量ベース課金の文脈では、トークン効率の改善がユーザーのコスト削減に直結する重要性を持つ

・ 複数業界における17年間のデジタルビジネス開発経験
・ ウェブサイト開発のためのHTML、PHP、CSS、JavaScript等の実用的知識
・ 15ヶ国語対応の多言語SaaSの開発経験
・ 17年間にも及ぶ、Eコマース長期運営経験
・ 幅広い業界でのSEO最適化の豊富な経験

Codexで開発速度20倍、WasmerがNode.jsエッジランタイムを2週間で構築
OpenAIのCodexとGPT-5.5を活用し、開発速度を10倍から20倍に引き上げたチームが現れた。エッジコンピューティングプラットフォームを手がけるWasmerは、これを用いてNode.jsのエッジ向けランタイム「Edge.js」をわずか2週間で構築したのだ。従来なら1年を要する規模のプロジェクトである。
Wasmerは少人数のチームながら、WebAssemblyサンドボックス内でNode.jsワークロードを実行するという技術的挑戦を達成した。これにより、開発者はDockerを使わずにJavaScriptアプリケーションやMCP(Model Context Protocol)エージェントを動作させられるようになる。この成果の背後にあるCodex活用の実態と、小規模チームが大企業並みの開発速度を実現したプロセスを掘り下げる。
プロジェクトの全容と達成された技術的ブレークスルー

Wasmerが今回リリースしたEdge.jsは、Node.jsのワークロードをWebAssembly(Wasm)サンドボックス内で安全に実行するJavaScriptランタイムだ。WebAssemblyはブラウザやサーバーで高速に動作するバイナリ命令形式で、いわば「アプリケーションを隔離された環境で動かすための軽量な箱」のような役割を果たす。サンドボックス化により、ホストシステムへの不正アクセスやリソースの浪費を防ぎつつ、高いパフォーマンスを維持できる。
この技術の最大の意義は、Dockerコンテナを使わずにNode.jsアプリをデプロイできる点にある。コンテナ技術は強力だが、イメージのビルドやレジストリ管理、起動時間などのオーバーヘッドを伴う。Wasmerのアプローチなら、より軽量かつ瞬時にエッジ環境へ展開可能だ。同社の創業者兼CEOであるSyrus Akbary Nieto氏はOpenAIのブログ記事で「AIやエッジコンピューティング向けのNode.jsワークロードを動かせる初のクラウドホストになった」と述べている。
Wasmサンドボックスは「アプリを小さな防護壁で囲む」ような仕組みで、Node.jsの全機能を安全にエッジ層で提供できるようにする。これにより、レイテンシに敏感なAI推論やリアルタイムAPI、MCPエージェントといった用途で威力を発揮する。
Codexによる開発速度の飛躍的向上
WasmerがEdge.jsを構築するのにかかった期間は、わずか2週間だ。Nieto氏によれば、AIを使わなければ「容易に1年はかかっていた」プロジェクトである。CodexとGPT-5.5の導入により、開発速度は10倍から20倍に跳ね上がったという。この数字は単なる体感ではなく、実際のプロジェクト完了までの期間短縮に基づく。
Wasmerのエンジニアはプロジェクトの最初から最後までCodexを活用した。初期のアーキテクチャ設計から、最終製品の仕上げに至るまで、あらゆる段階でAIが開発を支援した形だ。特に効果を発揮したのは、バグの発見と原因特定のプロセスである。
上記のフローは、従来の開発サイクルに比べて圧倒的に短い時間で完了する。特にステップ3のデバッグ工程で、Codexは人間のエンジニアが気づきにくい低レイヤーの問題を素早く見つけ出した。
Codexがもたらしたデバッグの質的変化
Edge.jsの開発で特に印象的だったのは、Codexのデバッグ能力だとNieto氏は語る。通常、WebAssemblyやNode.js内部のような低レイヤーのバグを特定するには、C++やアセンブリレベルの深い知識が必要になる。しかし、少人数のチームではそうした専門家を常に確保できるわけではない。
CodexはLLD(LLVM Debugger)のような低レベルデバッガを使いこなし、アセンブリレベルでコードの挙動を追跡した。さらに、コンソールログを活用して関数呼び出しのトレースを行い、問題の根本原因を特定するまでの時間を大幅に短縮したという。Nieto氏はOpenAIの記事で「我々はC++の専門家ではないため気づけない微妙な問題を、Codexはかなり早い段階で見つけ出した」と述べている。
ここでいうLLDとは、コンパイル済みプログラムの動作を命令単位で追跡できるツールだ。通常のデバッガがソースコード行単位で止めるのに対し、LLDはCPUが実際に実行する機械語レベルで問題を観察できる。Codexはこのツールを自律的に操作し、バグの兆候から原因、解決策までを一気通貫で提示したことになる。
IDEから離れる開発スタイルへの移行
Wasmerのエンジニアたちは、Codexの推論能力が向上するにつれて、次第にIDE(統合開発環境)から手を離し始めたという。Nieto氏は「我々は実際にIDE自体から離れつつある。コードに直接触れるのではなく、どこに向かいたいかを指示するだけになっている」と述べている。
これは開発者の役割が「コードを書く人」から「AIに方向性を与える人」へと変化していることを示す。もちろん、最終的な判断や設計の意図は人間が持つ。しかし、実装の大部分をAIが担うことで、小規模チームでも大規模プロジェクトに挑戦できるようになった。
この変化は、開発生産性の概念そのものを再定義する可能性を秘めている。コードを書く速度ではなく、AIに適切な指示を与え、出力を評価し、設計判断を下す能力が重要になるからだ。
AI活用に懐疑的だったチームの変遷
Wasmerのエンジニアたちも、当初はAIの出力に懐疑的だった。Nieto氏は「最初はAIのアウトプットをあまり信用していなかった」と振り返る。これは多くの開発者が経験する感覚だろう。AIが生成するコードが本当に正しいのか、セキュリティ上の問題はないのかといった懸念は自然なものだ。
しかし、実験を重ねるうちに結果が期待を上回り始めた。特にここ数カ月でCodexの推論能力が飛躍的に向上し、信頼性が格段に高まったという。Nieto氏は「ここ1年、特にここ数カ月間Codexと仕事をしてきたが、結果は本当に非常に良かった」と述べている。
信頼構築のプロセスは段階的だった。最初は小さなタスクから任せ、出力を丹念にレビューする。やがて、より複雑な問題を任せられるようになり、最終的には前述のようにIDEから手を離す段階に至った。この流れは、AI開発支援ツールを導入する多くのチームにとって参考になるパターンだ。
Codexが解き放つ小規模チームの可能性
Wasmerの事例が示す最大の教訓は、AI開発支援が「チーム規模の制約」を打ち破る力を持つことだ。Nieto氏は「Codexによって、小さな会社が大企業でしか不可能だったことを達成できるようになった。このプロジェクトは文字通り、Codexなしでは不可能だった」と断言している。
Node.jsのエッジランタイムをゼロから構築するという挑戦は、通常なら専門のインフラエンジニアやC++のエキスパートを複数抱える大企業のプロジェクトだ。Wasmerのような小規模チームがこれに挑むこと自体が、AIの存在を前提とした新たな開発パラダイムの到来を感じさせる。
Nieto氏は今後について「以前は不可能だったことが手の届く範囲にある。我々はさらに困難な問題に目を向ける必要がある」と語っている。Wasmerのチームは既に、次の野心的なプロジェクトを見据えている段階だ。
エッジコンピューティングとNode.jsの新しい関係
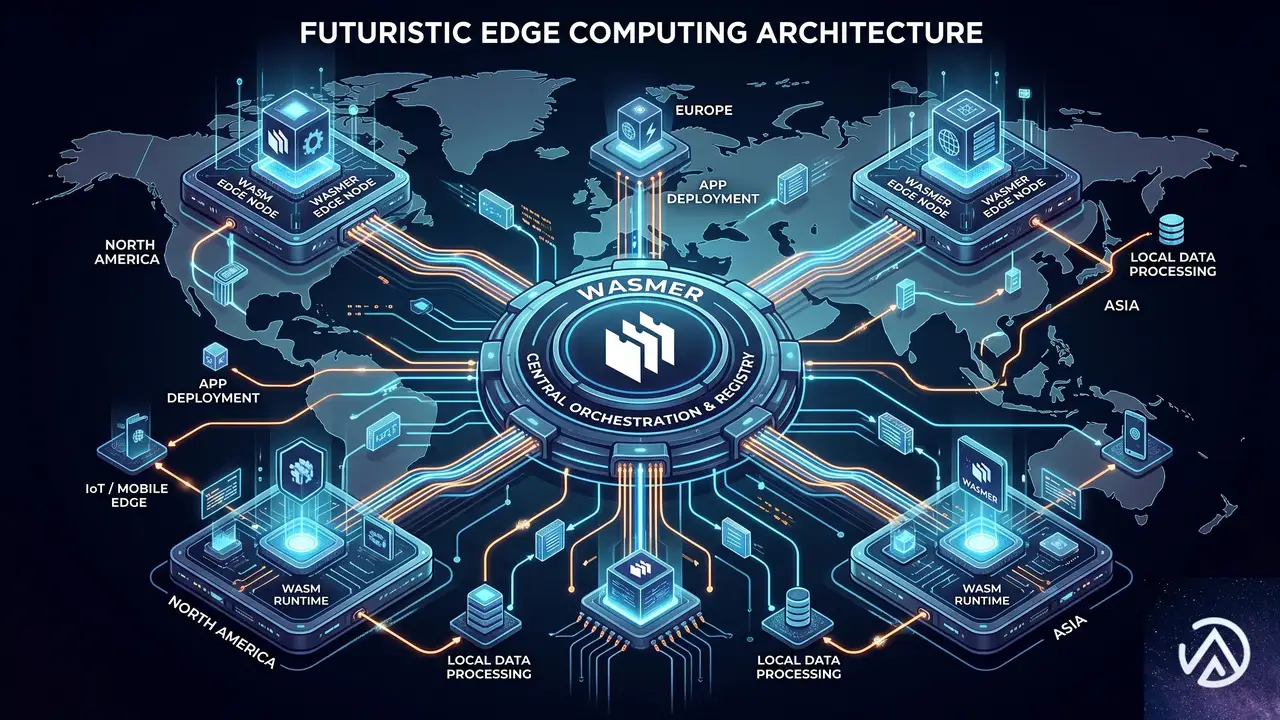
Edge.jsの登場は、エッジコンピューティングにおけるNode.jsの位置づけを大きく変える可能性がある。エッジコンピューティングとは、データの発生源に近い場所で処理を行うアーキテクチャだ。ユーザーの近くにサーバーを置くことで、応答速度を高め、中央サーバーへの負荷を減らせる。CDN(コンテンツ配信ネットワーク)がその代表例だが、近年はより複雑なアプリケーションロジックをエッジで動かす需要が高まっている。
従来、エッジ環境でJavaScriptを本格的に動かすには、Cloudflare Workersのような専用ランタイムを使う必要があった。これらはNode.jsと完全な互換性があるわけではなく、多くのnpmパッケージやNode.js組み込みモジュールが使えなかった。Edge.jsはこの制約をWebAssemblyサンドボックスで解決する。Node.jsアプリをほぼそのままエッジで動かせる道を開いたことになる。
MCP(Model Context Protocol)エージェントへの対応も見逃せない。MCPはAIモデルが外部ツールやデータソースと連携するための標準プロトコルで、AIエージェントの基盤として注目されている。エッジで動作するNode.jsランタイムがMCPをサポートすることで、低レイテンシのAIエージェントを構築しやすくなる。
実運用で期待される効果
Edge.jsを利用すると、具体的に以下のような恩恵が見込まれる。まず、コールドスタート(初回起動時の遅延)が大幅に短縮される。Dockerコンテナの起動には数百ミリ秒から数秒かかることがあるが、Wasmサンドボックスならマイクロ秒単位で実行を開始できる。
次に、リソースの隔離が強固になる。WebAssemblyは設計段階からサンドボックス化を前提としており、メモリアクセスやシステムコールを厳格に制限する。これにより、マルチテナント環境でも安全にNode.jsアプリをホストできる。また、デプロイの簡素化も大きな利点だ。コンテナイメージのビルドやレジストリへのプッシュが不要になり、コードを書いてすぐにエッジへ展開できるワークフローが実現する。
この記事のポイント
- WasmerはOpenAI CodexとGPT-5.5を使い、Node.jsエッジランタイム「Edge.js」を2週間で開発した
- AIを活用しない場合の開発期間は約1年と見積もられており、速度は10〜20倍に向上した
- Codexは低レベルデバッガLLDを使いこなし、人間のエンジニアが気づきにくいバグの根本原因を迅速に特定した
- 小規模チームでも大企業レベルのプロジェクトに挑戦できるようになり、開発のパラダイムシフトが起きつつある
- WebAssemblyサンドボックスにより、Docker不要で安全かつ高速にNode.jsをエッジで実行できる
・ 複数業界における17年間のデジタルビジネス開発経験
・ ウェブサイト開発のためのHTML、PHP、CSS、JavaScript等の実用的知識
・ 15ヶ国語対応の多言語SaaSの開発経験
・ 17年間にも及ぶ、Eコマース長期運営経験
・ 幅広い業界でのSEO最適化の豊富な経験

AWS BedrockでOpenAI GPT-5.5とCodexが利用可能に。開発効率が飛躍
AWSが2026年6月、Amazon Bedrock上でOpenAI GPT-5.5モデル、GPT-5.4モデル、そしてコーディングエージェントCodexの一般提供を開始した。これにより、Bedrockのセキュアなインフラ上で最先端の大規模言語モデルを利用できる。
GPT-5.5は最も難しいタスク向け、GPT-5.4はコストパフォーマンス重視のシナリオに適する。いずれも、新しい推論エンジン上で高速かつ信頼性の高い応答が得られる。Codexは週あたり400万人以上の開発者が使用するAIコーディングツールで、複数のIDEと連携しつつ、推論エンジン経由でBedrockからモデルを呼び出す。
データ主権要件に対応するため、すべての処理は選択したBedrockリージョン内に留まる。トークン単位の課金で、シートライセンスや開発者あたりの固定費は発生しない。本記事では利用開始手順と技術的な注意点を解説する。
AWS BedrockでOpenAI GPT-5.5とCodexが一般提供
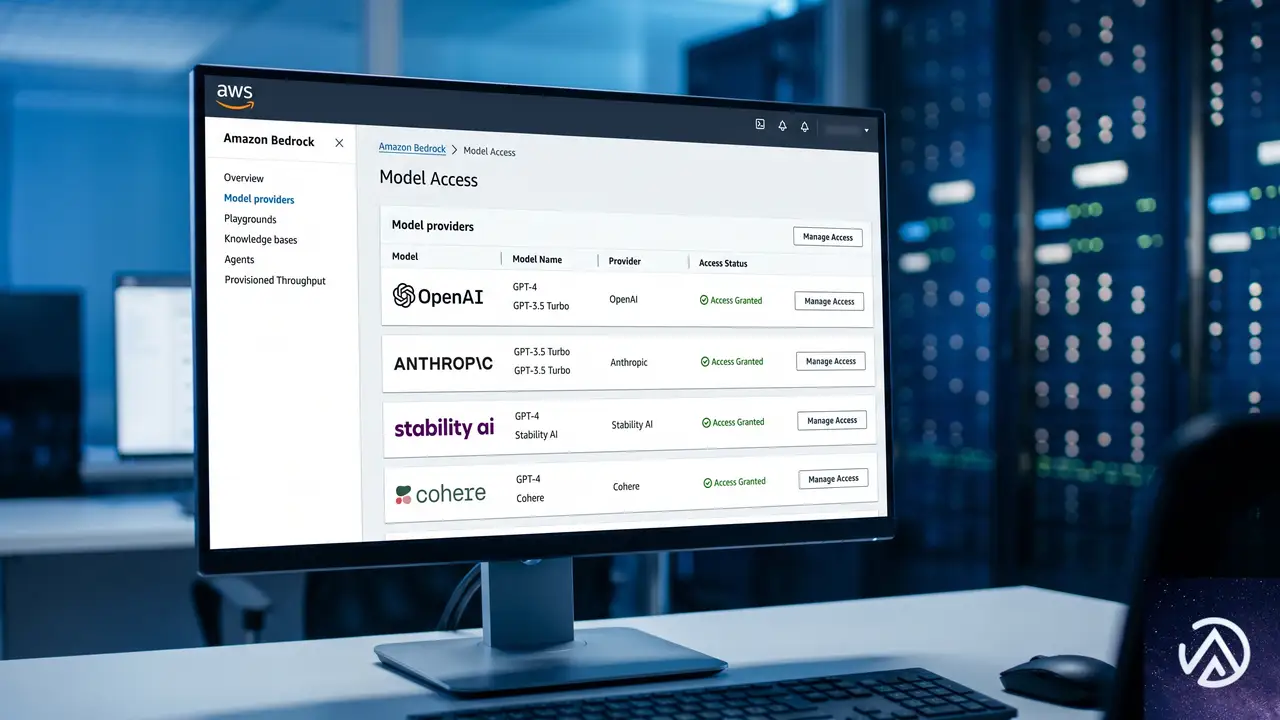
AWSの年次カンファレンスでプレビューされていたOpenAIモデルの対応が、正式に利用可能になった。GPT-5.5とGPT-5.4は、コーディング、推論、エージェントワークフロー、複雑な専門業務に優れる。AWS News BlogのChanny Yun氏は、GPT-5.5を「最も難しい顧客のワークロード」向け、GPT-5.4を「最良の価格性能比」と位置づける。
モデルへのアクセスは、新しいBedrock推論エンジンが提供するResponses APIを介して行う。このAPIは、マルチターン状態管理、ホストツール、ファンクションツール、バックグラウンド実行をサポートする。
この構成により、機密データを外部に送信することなく、AWSの管理下で最先端AIを活用できる。リージョンごとのデータ主権も担保される。
GPT-5.5モデルの利用方法

モデルへは、OpenAIのResponses APIを用いてアクセスする。Bedrock専用のエンドポイントbedrock-mantleを経由し、OpenAI SDKやcurlから呼び出す形だ。以下にセットアップ手順を示す。
Python SDKを使った呼び出し
まずOpenAI SDKを最新版にアップデートする。
pip install -U openai認証用の環境変数を設定する。BedrockのAPIキーはAWSマネジメントコンソールから取得できる。
export OPENAI_BASE_URL="https://bedrock-mantle.us-east-2.api.aws/openai/v1"
export OPENAI_API_KEY="<BEDROCK_API_KEY>"
export BEDROCK_OPENAI_MODEL_ID="openai.gpt-5.5"以下のサンプルコードで、GPT-5.5に分散アーキテクチャの設計を依頼できる。
import os
from openai import OpenAI
client = OpenAI(
base_url=os.environ["OPENAI_BASE_URL"],
api_key=os.environ["OPENAI_API_KEY"],
)
response = client.responses.create(
model=os.environ["BEDROCK_OPENAI_MODEL_ID"],
input=[
{
"role": "developer",
"content": "You are a software engineer with excellent AWS cloud knowledge. Be concise and practical.",
},
{
"role": "user",
"content": "Design a distributed architecture on AWS in Python that should support 100k requests per second across multiple geographic regions.",
},
],
reasoning={"effort": "medium"},
text={"verbosity": "low"},
)
print(response.output_text)curlによる直接アクセス
curlを使う場合も同様に環境変数を設定した上で、エンドポイントへPOSTリクエストを送る。
curl "$OPENAI_BASE_URL/responses" \
-H "Content-Type: application/json" \
-H "Authorization: Bearer $OPENAI_API_KEY" \
-d '{
"model": "openai.gpt-5.5",
"input": [
{
"role": "developer",
"content": "You are a software engineer with excellent AWS cloud knowledge."
},
{
"role": "user",
"content": "Design a distributed architecture on AWS in Python that should support 100k requests per second across multiple geographic regions."
}
],
"reasoning": {"effort": "medium"},
"text": {"verbosity": "low"}
}'コード内のreasoning.effortは推論の深さを制御する。GPT-5.5ではmediumから始め、必要に応じてhighに変更すると良い。GPT-5.4の場合は明示的にeffortを指定すべきだ(デフォルトがnoneのため)。
CodexでAI駆動開発を体験する
Codexは、GPT-5.5を推論エンジンとしてバックグラウンドで利用するコーディングエージェントだ。CLI、デスクトップアプリ、VS CodeやJetBrains、Xcodeの拡張機能が提供され、大規模コードベースの作成、リファクタリング、デバッグ、テスト、検証をAIが支援する。
Codex CLIの設定手順
Codex CLIをインストール後、Bedrock認証を有効にする。APIキー認証とAWS SDKの認証情報チェーンの2方式があり、APIキーが優先される。
export AWS_BEARER_TOKEN_BEDROCK=<your-bedrock-api-key>次に、~/.codex/config.tomlにモデル情報とリージョンを記述する。
model = "openai.gpt-5.5"
model_provider = "amazon-bedrock"
[model_providers.amazon-bedrock.aws]
region = "us-east-2"デスクトップアプリやVS Code拡張では、必要な環境変数を~/.codex/.envに記述しておく。設定変更後はアプリケーションを再起動すれば反映される。
CLIで/statusタブを表示すると、モデルがBedrock経由で接続されていることを確認できる。Channy Yun氏の記事では、実際のステータス画面が示されており、モデルとしてopenai.gpt-5.5と表示される。
レイテンシやスケーリングの注意点

本番利用を始めるにあたり、いくつかの技術的なポイントを把握しておく必要がある。
モデルレイテンシの特性
GPT-5.5は高速、GPT-5.4は中速と位置づけられるが、実際の遅延は推論の深さ、出力長、ツール呼び出しの有無、バックグラウンドモード、リージョン、クォータ、スロットリング、プロンプトサイズ、キャッシュヒットに依存する。GPT-5.5ではreasoning.effortをmediumで開始し、GPT-5.4では明示的にeffortを設定することを推奨する(デフォルトがnoneで十分な推論が得られない可能性があるため)。
スケーリングとキャパシティ管理
Bedrockの新しい推論エンジンは、多数のモデルにわたって迅速にキャパシティをプロビジョニングし、需要変動に応じてスケールする設計だ。定常的なワークロードの実行を優先し、需要急増時にはリクエストをキューイングする(拒否はしない)。そのため、予期せぬトラフィック増加時にも安定した動作が期待できる。ただし、クォータ上限を事前に確認し、必要に応じて引き上げ申請を行うことが望ましい。
この記事のポイント
- Amazon Bedrock上でOpenAI GPT-5.5・GPT-5.4モデルとCodexが一般提供開始
- Responses APIを通じてモデルを呼び出し、複雑なワークロードに対応
- CodexはGPT-5.5をバックエンドに、CLI・デスクトップアプリ・IDE拡張で利用可能
- データは選択したBedrockリージョン内で処理され、データ主権を確保
- レイテンシは複数要因に依存し、effort設定やキャッシュが影響するため、初期はmediumから
- スケーリングは自動だが、クォータ管理を怠らないこと
・ 複数業界における17年間のデジタルビジネス開発経験
・ ウェブサイト開発のためのHTML、PHP、CSS、JavaScript等の実用的知識
・ 15ヶ国語対応の多言語SaaSの開発経験
・ 17年間にも及ぶ、Eコマース長期運営経験
・ 幅広い業界でのSEO最適化の豊富な経験

GPT-5.5が企業向けエージェントにもたらす変革、Databricks導入事例
大規模言語モデルの進化が、企業の実務ワークフローに直接的な成果をもたらし始めている。データ分析基盤を提供するDatabricksが、OpenAIの最新モデルGPT-5.5を社内向けAIエージェントに組み込んだ結果、複雑な文書処理タスクを評価するベンチマーク「OfficeQA Pro」でエラーが46%も減少した。GPT-5.5はこのベンチマークで初めて正解率50%を超えたモデルとなった。
この結果は「モデルの性能向上が、実際のビジネス指標にどう結びつくか」を示す重要な事例だ。単なる会話能力の評価ではなく、スキャンされたPDFや古い社内フォーマットの文書を解析し、複数ステップのタスクを自律的に遂行する能力が問われている。本記事ではGPT-5.5がどのような技術的進歩を遂げ、企業のAI活用にどんな可能性を開くのかを解説する。
企業向けAIエージェントの現在地、なぜ文書処理が壁になるのか

企業がAIエージェントを導入する際、最初にぶつかる壁が「社内文書の解析」だ。契約書や見積書、古いシステムから出力されたレポートなど、形式がバラバラな文書をAIに理解させるのは想像以上に難しい。特にスキャンされたPDF(画像として取り込まれた文書)や、数十年前のレガシーフォーマットで保存されたファイルは、最新のAIでも正確なテキスト抽出に失敗することが多い。
この問題の深刻さは、小さな認識ミスが後続の処理全体を狂わせる点にある。たとえば請求書の金額を一桁間違えて抽出すれば、その後の経理処理やレポート作成がすべて誤った情報で進んでしまう。人間なら「明らかにおかしい」と気づくようなエラーでも、AIエージェントは抽出した数値をそのまま信じて処理を続ける。これが企業現場でのAI導入を妨げる最大の障壁となっていた。
OfficeQA Proベンチマークの評価観点とは
Databricksが開発したOfficeQA Proは、こうした実務課題を忠実に再現する評価指標だ。このベンチマークでは、モデルに対して以下の3つの能力が求められる。
- 文書解析(Parsing):スキャンPDFやレガシーファイルから正確に情報を抽出する能力
- 情報検索(Retrieval):長大な文書群の中から必要な情報を見つけ出す能力
- 根拠に基づく推論(Grounded Reasoning):抽出した情報をもとに、論理的な判断や回答を生成する能力
単なる知識クイズではない。バラバラなフォーマットの文書を理解し、複数のステップを経て最終的なアウトプットを出す「エージェントとしての実務能力」が試される設計になっている。
上図のように、GPT-5.5への切り替えによって文書解析のエラーが大幅に減り、後続のワークフロー全体の信頼性が向上した。この改善の背景には、モデルの視覚認識能力と言語理解の統合が進んだことがあると見られている。
GPT-5.5が達成した二つの飛躍的改善

Databricksが報告したGPT-5.5の改善点は、大きく二つの領域に分かれる。一つは文書解析精度の劇的な向上、もう一つは複数ステップのタスクを効率的に管理するオーケストレーション能力の進化だ。
スキャン文書解析の「ステップ関数的」な進歩
Databricksの記事で同社のSinghvi氏が指摘するように、GPT-5.4まではスキャンされた古い文書から数字を正確に読み取れないケースが頻発していた。これに対しGPT-5.5は、古い文書やスキャンPDFの解析において「ステップ関数的な性能向上」を見せたという。「ステップ関数的」とは、なだらかな改善ではなく、階段を一段上がるように非連続的な飛躍があったことを意味する。
この進歩が特に重要なのは、企業が保有する文書の多くが過去の資産だからだ。10年前の契約書、5年前の監査レポート、紙をスキャンしてPDF化した資料。こうした「過去の遺産」を正確に解析できるかどうかが、AIエージェントの実用性を左右する。GPT-5.5はこの壁を一つ越えたと言える。
ムダな遠回りをしないタスク実行能力
もう一つの重要な改善が、複数ステップのタスクを実行する際の軌道(Trajectory)の最適化だ。GPT-5.4では、目的に対して不必要な検索を繰り返す「遠回り」が発生し、非効率な処理経路をたどることがあった。これはエージェントが過剰に「慎重」になりすぎる、あるいは文脈を適切に把握できずに余計な確認作業を挟んでしまう問題だ。
GPT-5.5では、必要な情報を必要なタイミングで的確に取得し、最短のステップでタスクを完了する能力が高まった。追加の監視や人間による修正なしに、複雑なワークフローを完遂できる信頼性が向上している。
この改善は、企業がAIエージェントに求める「人間の監視なしで動く自律性」に直結する。タスクが長引けばそれだけコストも増え、途中で人間が介入する必要性も高まる。GPT-5.5はこの課題に対して明確な前進を示した。
企業ワークフローへの実装、AgentBricksとAI Unity Gateway

DatabricksはGPT-5.5を単独のチャットボットとして使っているわけではない。同社の「AI Unity Gateway」を通じて、AgentBricksやAgent Supervisor APIといったエージェント構築基盤と統合し、実際のビジネスワークフローに組み込んでいる。
AgentBricksとは、Databricksが提供するエージェント構築フレームワークだ。専門特化した複数のエージェントを組み合わせ、複雑な業務プロセスを自動化できる。ここでGPT-5.5は「監督者(Supervisor)」として機能する。各専門エージェントが文書解析やデータ検索、レポート生成といった個別タスクを担当し、GPT-5.5が全体の流れを管理して適切なタイミングで適切なエージェントに指示を出す。このアーキテクチャによって、単一モデルでは扱いきれない複雑な業務フローが実現できる。
この「監督者モデル」のアプローチは、今後の企業向けAI活用の主流になると考えられる。一つの巨大モデルがすべてを処理するのではなく、専門エージェントを束ねる統括役としてLLMを配置する設計だ。GPT-5.5のオーケストレーション能力の向上は、この設計思想と見事にマッチしている。
ナレッジワークにおけるGPT-5.5のインパクト

DatabricksのSinghvi氏は「GPT-5.5は知識作業においてステップ関数的な変化をもたらした」と評している。単に質問に答えるだけでなく、複数の文書を横断して情報を統合し、文脈を理解した上で判断を下す「知識労働の代替」としての性能が大きく向上したという評価だ。
この評価が特に重要なのは、AIが「単なる道具」から「業務のパートナー」へと役割を変えつつあることを示唆しているからだ。従来のAIアシスタントは、人間が明確に指示したタスクを実行するのが限界だった。GPT-5.5を中核に据えたエージェントは、曖昧な指示や複雑な文脈でも自律的に判断し、複数ステップの業務を完遂できる水準に近づきつつある。
日本企業への示唆、データ資産の再活用という視点
この事例から日本企業が学ぶべきポイントは明確だ。多くの企業が「過去の文書資産」を抱えている。紙で保管された契約書、古い基幹システムから出力された帳票、スキャンされたPDFの山。これらをAIで解析し、活用可能なデータに変換する技術が現実のものになりつつある。
ただし注意点もある。GPT-5.5の性能向上が顕著だったのは「スキャン文書の解析」と「複数ステップのオーケストレーション」であり、これはモデル自体の進化に加えて、Databricksのエージェント基盤との統合設計が効いている。単に高性能なLLMを導入するだけでは同様の成果は得られない。データ基盤とエージェント設計の両面からアプローチする必要がある。
この記事のポイント
- GPT-5.5は企業の実務ベンチマークOfficeQA Proでエラーを46%削減し、初めて正解率50%を突破した
- 特にスキャンPDFやレガシー文書の解析精度が飛躍的に向上し、古い文書資産の活用が現実的に
- 複数ステップのタスクを効率的に管理するオーケストレーション能力も改善し、自律的な業務遂行が可能に
- DatabricksではGPT-5.5を監督エージェントとして配置し、専門エージェント群を統括する設計を採用
- 日本企業にとっては、過去の文書資産をAIで再活用できる可能性が開けた事例として注目すべき
・ 複数業界における17年間のデジタルビジネス開発経験
・ ウェブサイト開発のためのHTML、PHP、CSS、JavaScript等の実用的知識
・ 15ヶ国語対応の多言語SaaSの開発経験
・ 17年間にも及ぶ、Eコマース長期運営経験
・ 幅広い業界でのSEO最適化の豊富な経験

OpenAIがGPT-5.5-Cyberを発表、サイバー防御の最前線に信頼済みアクセス基盤を導入
OpenAIは2026年5月7日、サイバーセキュリティの防御側を支援するための新たな取り組み「Trusted Access for Cyber(TAC / サイバー向け信頼済みアクセス)」を発表した。この枠組みに基づき、研究者やセキュリティチーム向けに最適化されたモデル「GPT-5.5-Cyber」の限定プレビューを公開している。
発表の中核にあるのは、AIの強力なサイバー攻撃支援能力を防御者にだけ安全に開放するという思想だ。すべてのユーザーに同じ性能を提供するのではなく、本人確認と用途の認証を経た防御者のみが、より深い支援を受けられる仕組みを設けている。
この記事では、GPT-5.5-CyberとTACの技術的な仕組み、セキュリティ業界全体への波及効果、そして防御者が実際にどのようなワークフローを加速できるのかを解説する。
信頼済みアクセスでAIの性能を防御側だけに開放する

TACは、AIモデルの振る舞いそのものを利用者の属性に応じて段階的に緩和していく枠組みだ。すべてのユーザーに対して一律に機能制限をかけるのではない。防御タスクを担う検証済みの主体に対してのみ、より踏み込んだ支援をモデルが行うように設計されている。
重要なのは、この仕組みが単なるアカウント管理ではないという点だ。モデル内部の分類器による拒否判断をチューニングし、認可された防御ワークフローでは拒否が起こりにくくなる。OpenAIの記事によれば、この変更によって脆弱性のトリアージ、マルウェア解析、バイナリリバースエンジニアリング、検出エンジニアリング、パッチ検証といった領域で、防御者の作業が大きく加速される見込みだ。
一方で、資格情報の窃取やマルウェア配備といった実害を伴う悪用行為に対する防御壁は、そのまま維持される。このバランス設計こそがTACの根幹をなす。
3段階のアクセスレベル
OpenAIは現在、モデルのアクセス権を3つの層に分けて提供している。一般利用向けの標準的なGPT-5.5、防御ワークフロー向けに拒否判断を最適化した「GPT-5.5 with TAC」、そして最も許容度が高く専門用途向けの「GPT-5.5-Cyber」だ。この3層構造により、用途のリスクに応じた比例的な安全策が実現されている。
GPT-5.5 with TACは、全防御ワークフローの大部分をカバーする設計だ。OpenAIの見解では、ほとんどのセキュリティチームはこの層から始めるのが適切であり、許可済みの作業でなおも拒否に遭遇する場合にのみ、より専門的なアクセスレベルを検討すべきだとされている。
認証とアカウントセキュリティの要件
TACの枠組みでは、防御側に対する本人確認と認証の厳格化が同時に進められている。OpenAIの発表によれば、最もサイバー性能が高く許容度の大きいモデルにアクセスする個人ユーザーは、2026年6月1日以降、フィッシング耐性のある高度なアカウントセキュリティの有効化が必須となる。
組織単位での信頼済みアクセスを利用する場合は、シングルサインオンワークフローの一環としてフィッシング耐性認証を導入していることを表明する代替手段も用意されている。この設計により、利便性を損なわずに信頼性を担保するバランスを取っている。
GPT-5.5-Cyberがもたらす防御ワークフローの加速

GPT-5.5-Cyberの公開にあたり、OpenAIは具体的なユースケースを挙げている。公開済みの脆弱性から概念実証コードを生成し、認可された環境下で修正の有効性を検証するといった作業が、モデルによって大幅に効率化されるという。
OpenAIの公式ブログに掲載された比較例では、標準的なGPT-5.5がセキュリティ関連のコード生成を拒否するのに対し、GPT-5.5 with TACは同じプロンプトに対して詳細な概念実証と分析を提供している。この違いは、分類器のチューニングによってもたらされるものだ。
標準モデルとの違いは「ケイパビリティ」より「許容度」
GPT-5.5-Cyberは、一般的な知識作業やセキュリティタスクにおいて最も賢く直感的なモデルであるGPT-5.5を基盤としている。OpenAIは、この初期プレビューがGPT-5.5を超えるサイバー能力を発揮することを主眼とはしていないと明言している。
性能評価の結果でも、すべてのサイバーセキュリティ評価項目でGPT-5.5を上回るわけではない。このモデルの主な価値は、多段階推論やツール利用を含む現実的な防御ワークフローにおいて、より「許可的」に振る舞う点にある。防御者が分析から検証までを止まらずに進められる環境を提供することが目的だ。
このアプローチは、単純にモデルの性能を引き上げるよりも現実的な安全策といえる。より強力な検証と監視の枠組みと組み合わせることで、専門的な作業が必要な場面にだけ踏み込んだ支援を提供できるからだ。
セキュリティエコシステム全体を回す「フライホイール」

OpenAIの戦略で特に注目すべきなのは、モデルの提供先を多層的なエコシステムとして捉えている点だ。セキュリティベンダー各社との連携を通じて、発見から開発、検出、対応、ネットワーク制御に至る防御の全レイヤーを同時に強化しようとしている。
このサイクルは「セキュリティフライホイール」と呼ばれ、各レイヤーの改善が他のレイヤーの改善を加速させる相乗効果を生み出す。研究者が概念実証とパッチガイダンス付きで脆弱性を開示し、サプライチェーンツールが本番環境への侵入を防ぎ、EDRやSIEMが攻撃の兆候を検出し、ネットワークプロバイダーがWAFレベルの緩和策を展開する。この連鎖をAIが加速する構図だ。
このエコシステム戦略が意味するのは、GPT-5.5シリーズが単独のツールとしてではなく、業界全体の防御基盤として設計されているという点だ。OpenAIは既にCisco、Intel、SentinelOne、Snykといった主要ベンダーと協業を進めており、各社の声明も公式ブログに掲載されている。
各レイヤーでの具体的な活用シナリオ
ネットワークプロバイダーは、修正パッチが完全に展開される前の段階で被害を抑え込む役割を担う。GPT-5.5はWAFルールのレビューや構成分析、インシデント調査、安全な変更管理を支援し、インターネット規模での防御展開を可能にする。
脆弱性研究の領域では、未知のコードベースの理解、影響を受ける範囲の特定、根本原因の追跡、パッチの検証、そして深刻度の優先順位付けまでを一貫して支援する。より踏み込んだ概念実証が必要な場合に、GPT-5.5-Cyberが限定的に提供される設計だ。
検出と監視の分野では、EDRやSIEMのテレメトリデータから重要なシグナルを抽出し、分析官が開示情報から調査までを迅速に進められるようにする。とくにクラウド環境では、露出の把握から修正、検出までが密接に結びついており、AIによる接続が効果を発揮する。
ソフトウェアサプライチェーンセキュリティでは、GPT-5.5 with TACが依存関係の変更点の調査や、所有コード内での悪用可能性の推論、不審なパッケージ動作の早期発見を支援する。OpenAIは、axiosの侵害事例のように、脆弱な依存関係がビルドに入り込む前に阻止することが最速の対処法だと位置づけている。
オープンソースとCodex Securityによる上流支援

OpenAIはエコシステムの上流にあたるオープンソースメンテナーへの投資も進めている。Codex Securityを活用し、コードベース固有の脅威モデルを構築した上で、現実的な攻撃経路の探索やパッチの提案を行う仕組みを研究プレビューとして提供中だ。
さらに「Codex for Open Source」プログラムを通じて、重要なプロジェクトのメンテナーにCodex Securityへの条件付きアクセスとAPIクレジットを提供している。これにより、メンテナンスやレビューの負荷を軽減しながら、上流での脆弱性対処を加速させる狙いがある。
Codex Securityのプラグインも公開されており、既存のワークフローの中で脅威モデリングから発見、検証、攻撃経路分析、修正までをシームレスに進められるよう設計されている。
TACへのアクセス方法と今後の展望

Trusted Access for Cyberへの参加は、個人ユーザーであれば専用ページから本人確認を行うだけで申請できる。企業の場合はOpenAIの担当者を通じて、チーム単位での信頼済みアクセスをリクエストする仕組みだ。承認されたユーザーは、二重用途のサイバー活動に対する分類器の拒否が緩和されたモデルを利用できるようになる。
OpenAIの発表によれば、GPT-5.5-Cyberはアルファテストの段階で既に重要システムの自動レッドチーミングや深刻度の高い脆弱性の検証に活用されている。これらの成果については、責任ある開示の一環として、今後技術的な詳細が公開される予定だ。
モデルのサイバー能力が向上するにつれて、その能力を防御側の手に届けるための信頼基盤の重要度も増していく。より強固な本人確認や組織検証、認可された用途のスコープ定義、悪用監視の仕組みが成熟するにつれて、アクセス権は徐々に拡大されていくと見られる。
この記事のポイント
- TACは利用者の属性に応じてAIの防御支援能力を段階的に開放する枠組みである
- GPT-5.5 with TACは大半の防御ワークフローを安全にカバーし、多くのチームにとって最適な出発点となる
- GPT-5.5-Cyberはレッドチーミングなど専門的な二重用途ワークフロー向けの限定プレビューである
- セキュリティベンダーとの連携により、発見から緩和までの全レイヤーを加速するフライホイール効果を狙う
- オープンソースメンテナーへのCodex Security提供など、エコシステム上流への投資も同時に進められている
・ 複数業界における17年間のデジタルビジネス開発経験
・ ウェブサイト開発のためのHTML、PHP、CSS、JavaScript等の実用的知識
・ 15ヶ国語対応の多言語SaaSの開発経験
・ 17年間にも及ぶ、Eコマース長期運営経験
・ 幅広い業界でのSEO最適化の豊富な経験

GPT-5.5 Instant 登場。回答精度とパーソナライズ性能が大幅に向上
OpenAIがChatGPTのデフォルトモデルを「GPT-5.5 Instant」に更新した。これまで標準搭載されていたGPT-5.3 Instantを置き換える形で、全ユーザーに順次提供が開始されている。
今回のアップデートの核心は3つだ。事実誤認の大幅な減少、回答の簡潔さの向上、そして過去のチャット履歴や接続アプリを活用した高度なパーソナライズ機能の追加である。内部評価では、医療や法律、金融といった高精度が求められる分野でのハルシネーション(もっともらしい嘘)が52.5%も削減された。
何億人ものユーザーが日常的に利用するデフォルトモデルだからこそ、小さな改善の積み重ねが実用面では大きな差を生む。本記事ではGPT-5.5 Instantの具体的な進化点と、それが実際の利用体験にどう影響するのかを掘り下げていく。
事実誤認を半減させた精度向上の仕組み

GPT-5.5 Instantにおける最大の改善点は、事実誤認(ハルシネーション)の劇的な減少だ。特に医療、法律、金融といった「間違いが許されない領域」で顕著な成果が出ている。
なぜここまでの改善が実現できたのか
OpenAIの公式ブログによると、GPT-5.5 Instantは高精度が求められるプロンプトにおいて、GPT-5.3 Instantと比較してハルシネーション(幻覚)を52.5%削減した。さらに、ユーザーが事実誤認を指摘したチャレンジングな会話においても、不正確な回答を37.3%減らしている。
この改善は単なる「よくわからないときは正直にわからないと言う」といった表面的な振る舞いの調整ではない。モデル自身が回答の妥当性を検証する能力が底上げされており、途中で誤りに気づいた際には自律的に修正できるようになった点が本質的な進化だ。
具体的な改善例から見えるもの
OpenAIが公開した比較例では、GPT-5.5 Instantは数学の問題に対して最初に不正確な解法を提示してしまった場合でも、代入チェックによって誤りを検出し、二次方程式の正しい解へと自力で修正している。一方でGPT-5.3 Instantは誤りに気づいてはいるものの、「解がない」と早々に結論づけてしまい、問題の本質に迫れなかった。
日常生活で使うAIアシスタントにとって、この「自己修正能力」は極めて重要だ。最初の回答が100%正しい必要はないが、誤りに気づいて軌道修正できるかどうかが実用性を大きく左右する。GPT-5.5 Instantのこの特性は、ビジネス文書の作成やデータ分析など、正確性が求められるシーンで特に頼りになるだろう。
冗長な表現を30.2%削減、それでも情報量は落とさない
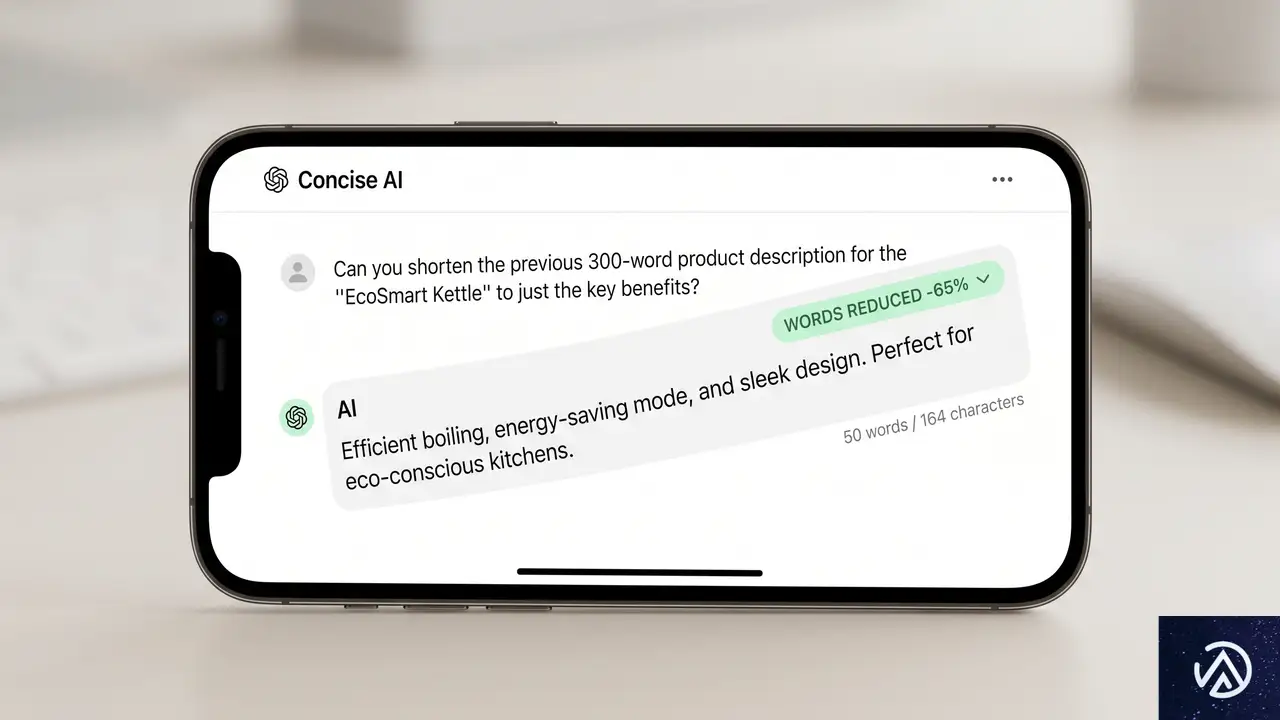
行数:基準値
過剰な絵文字:あり
行数:29.2%削減
不要な装飾:ほぼなし
GPT-5.5 Instantの回答は、前世代モデルと比較して単語数が30.2%、行数が29.2%も削減されている。この数字だけ見ると「情報量が減ったのでは」と心配になるが、実際は逆だ。余計な説明や過剰なフォーマットを省くことで、本当に必要な情報が見つけやすくなっている。
減ったのは「無駄」であって「中身」ではない
OpenAIの説明によると、新モデルは同じ情報をより少ない言葉で届けつつ、むしろ実用性は向上しているという。たとえば職場の人間関係に関するアドバイスを求めるプロンプトでは、GPT-5.3 Instantが「してはいけないこと」を含めた完全なフォーマットで回答するのに対し、GPT-5.5 Instantは状況に応じた実践的な言い回し例を提示し、問題を相手の人格ではなく「境界線」の問題として捉え直す視点を提供している。
ビジネスシーンで重要なのは、この「トーンの適切さ」だ。カジュアルな質問に過剰にフォーマルな回答が返ってくると、むしろ使う側のストレスになる。GPT-5.5 Instantは、状況に応じてフォーマル度を調整できるようになった点で、より人間らしい対話が可能になっている。
チャット履歴や接続アプリを活用した高度なパーソナライズ
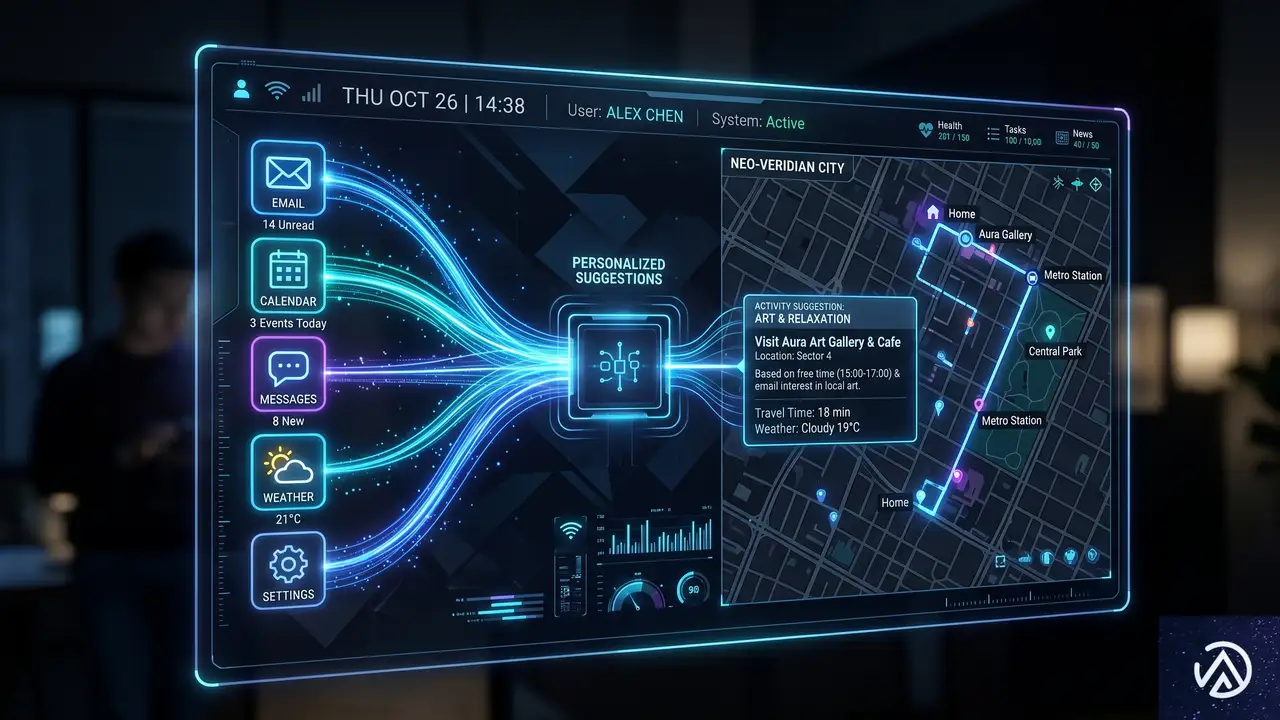
会話の開始 → 過去履歴を検索 → 関連コンテキストを取得 → カスタマイズされた回答を生成
GPT-5.5 Instantのもう一つの大きな進化が、パーソナライズ機能だ。過去のチャット履歴やアップロードしたファイル、さらに接続を許可したGmailの情報などを横断的に参照し、より個人に最適化された回答を提供できるようになった。
「メモリーソース」で見える化されたパーソナライズ
今回のアップデートで特筆すべきは「メモリーソース(Memory Sources)」という新機能の導入だ。これは、AIがどの情報を根拠にパーソナライズされた回答を生成したのかを明示する仕組みである。保存されたメモリーや過去のチャットのうち、回答に使用されたものをユーザーが直接確認でき、不要になった情報は削除や修正ができる。
OpenAIのブログ記事では、サンフランシスコ在住のユーザーに対するレストラン提案の比較例が紹介されている。GPT-5.3 Instantが居住地を考慮した一般的な提案にとどまるのに対し、GPT-5.5 Instantは過去の好みや予定をふまえた、より洗練された個別提案を行っている。この差は日常的な使い勝手に直結するだろう。
プライバシーはユーザーが制御できる設計
パーソナライズが強化されると、当然「どこまで自分の情報が使われるのか」という懸念が出てくる。この点についてOpenAIは、メモリーソースはチャットを共有しても他の人には表示されないこと、不要なチャットは削除できること、一時的なチャット(Temporary Chat)を使えばメモリーが使用も更新もされないことを明記している。
また個人情報の扱いについては、企業や教育機関向けプラン(Business、Enterprise、Edu)では、ユーザーデータがモデル学習に使用されない設定がデフォルトで適用される。個人利用でも、設定からデータ提供の可否を切り替えられる。
APIとロールアウトのスケジュール
GPT-5.5 InstantはChatGPTの全ユーザー向けに5月5日から順次提供が開始されている。APIではchat-latestとして利用可能だ。有料ユーザー向けには、旧モデルのGPT-5.3 Instantも3ヶ月間はモデル設定から選択できる形で残される。
パーソナライズ機能の強化は、まずPlusおよびProユーザー向けにWeb版で展開され、モバイル版にもまもなく対応する予定だ。その後、数週間以内にFree、Go、Business、Enterpriseプランにも拡大される。メモリーソース機能はすべてのコンシューマープランでWeb版から提供開始され、モバイル版も順次対応する。
この記事のポイント
- GPT-5.5 Instantは医療や法律など高精度が求められる分野でハルシネーションを52.5%削減した
- 回答の単語数が30.2%削減され、より簡潔で実践的なアドバイスが得られるようになった
- 過去のチャット履歴やGmailなどの接続アプリを活用したパーソナライズ機能が大幅に強化された
- メモリーソースにより、AIが参照した情報をユーザー自身が確認・管理できるようになった
- 全ユーザー向けに順次提供開始、旧モデルは有料プランで3ヶ月間利用可能
・ 複数業界における17年間のデジタルビジネス開発経験
・ ウェブサイト開発のためのHTML、PHP、CSS、JavaScript等の実用的知識
・ 15ヶ国語対応の多言語SaaSの開発経験
・ 17年間にも及ぶ、Eコマース長期運営経験
・ 幅広い業界でのSEO最適化の豊富な経験