

2026年4月のBaseline新機能、contrast-color関数やsearch要素が利用可能に
2026年4月のBaseline月次ダイジェストが公開された。新たに利用可能になった機能として、CSSのcontrast-color()関数やJavaScriptのMath.sumPrecise()メソッドがある。合わせて、search要素やARIA属性リフレクションなど、すでに広く使える段階に達した機能も紹介されている。
今回のアップデートは、アクセシビリティ対応と開発効率の両面で重要な節目だ。ブラウザが自動的に最適な色を算出したり、セマンティックな構造をネイティブに解釈したりする機能が揃い、従来はカスタム実装に頼っていた領域が標準化されつつある。
この記事では、2026年4月のBaselineダイジェストの内容をもとに、新機能の具体的な使い方と、それが開発現場にもたらす変化を解説する。
Baselineとアクセシビリティをめぐる2026年の動向

web.devの記事では、A11y Upが公開した「Baseline and accessibility in 2026」という分析が紹介されている。この分析の核心は、アクセシビリティ対応をウェブ標準に委ねることで、開発の堅牢性と効率が大きく向上するという主張だ。
これまで多くの開発チームは、スクリーンリーダー対応やキーボードナビゲーションといったアクセシビリティ機能を、カスタムのJavaScript実装で再現してきた。しかし、そうした手作りのソリューションは往々にして壊れやすく、支援技術との相性問題を抱え、メンテナンスコストも高かった。
Baselineは、ある機能が主要ブラウザで相互運用可能になった時点を知らせる指標として機能する。この指標を活用すれば、開発者は標準機能への移行タイミングを判断しやすくなる。結果として、ブラウザが自動的に正しいセマンティクスをスクリーンリーダーに伝えてくれるため、開発者が手作業で調整する負担が減るというわけだ。
このデモが示すように、カスタム実装に頼る旧来の手法から、標準化された要素やAPIに移行することで、アクセシビリティの品質が安定し、開発者の負荷も低減する。
Baselineで新たに利用可能になった機能
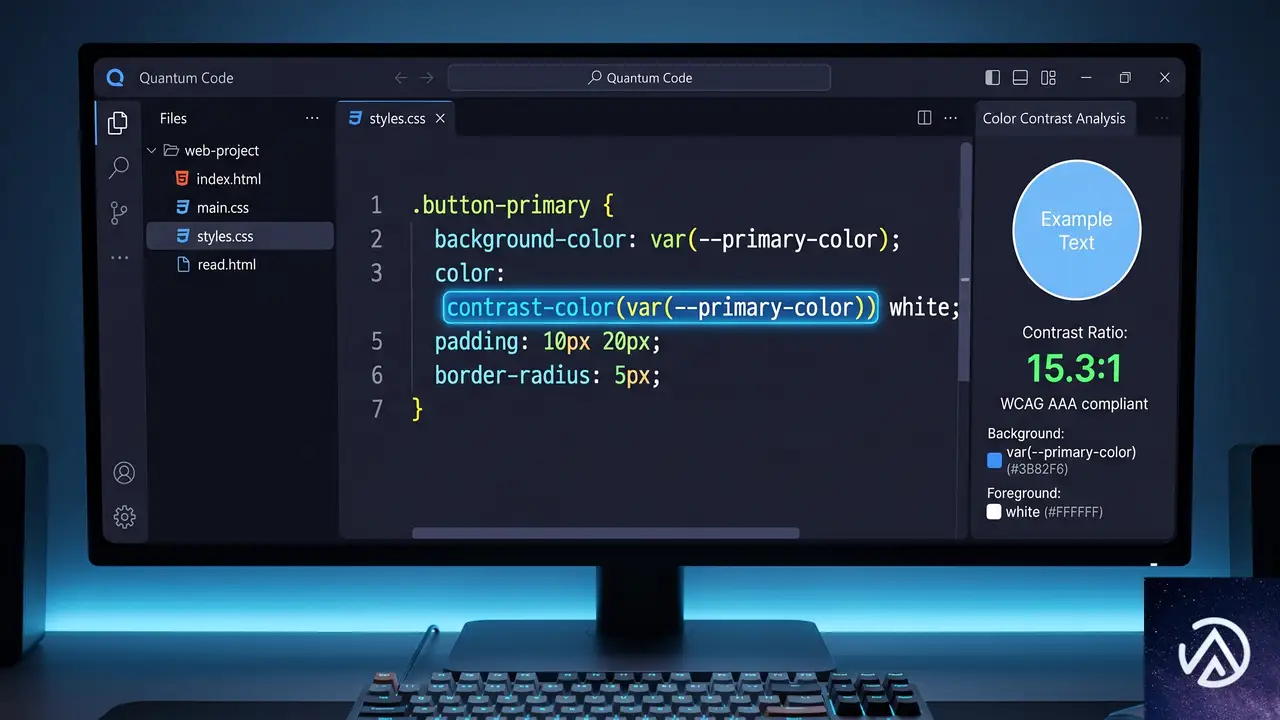
2026年4月の時点で、主要ブラウザ(Chrome、Firefox、Safari)すべてがサポートを開始し、Baseline newly available(新規利用可能)と位置づけられた機能が2つある。CSSのcontrast-color()関数と、JavaScriptのMath.sumPrecise()メソッドだ。
CSSのcontrast-color()関数
contrast-color()は、指定した背景色に対して最も読みやすい対照色(通常は黒か白)をブラウザが自動的に算出するCSS関数だ。動的なテーマエンジンやカスタマイズ可能なコンポーネントを扱う際、開発者がこれまで手作業で管理してきた「背景色に応じた文字色の切り替え」という負担を大幅に軽減する。
具体的な動作として、関数にベースとなる色を渡すと、ブラウザのエンジンがその色の輝度を評価し、最もコントラスト比が高い色を返す。これにより、ユーザーが好みの背景色を選べるUIでも、文字が読みにくくなる問題を自動的に回避できる。
.card-header {
background-color: var(--dynamic-bg-color);
/* 背景色に応じて自動的に最適な文字色が決まる */
color: contrast-color(var(--dynamic-bg-color));
}上記のデモはcontrast-color()の概念を示したイメージだ。実際のブラウザでは、この関数が自動的に背景色を分析し、最も読みやすい文字色を適用する。中間的な明るさの背景色に対しては、ブラウザがどちらを選ぶか注意深く確認する必要があるが、大半のケースでは手動の分岐ロジックが不要になる。
Math.sumPrecise()メソッド
JavaScriptで浮動小数点数の合計を計算する際、従来のArray.prototype.reduce()や単純なループでは、丸め誤差が蓄積する問題があった。金融計算やテレメトリデータの集計といった、正確さが求められる場面ではこの誤差が致命的になることもある。
Math.sumPrecise()は、この問題に対処するために設計された静的メソッドだ。数値のイテラブル(配列など)を受け取り、精度を保ったまま安全に合計を返す。
// 従来の方法では浮動小数点誤差が発生する可能性がある
const values = [0.1, 0.2, 0.3, 0.4, 0.5, 0.6, 0.7, 0.8, 0.9, 1.0];
const preciseTotal = Math.sumPrecise(values);
// 誤差なく正確な合計値を返す内部的には、標準化された高精度な加算アルゴリズム(Kahan summation algorithmや類似の手法)を用いて、丸め誤差を最小化する。ECサイトの売上集計や、センサーデータの分析など、正確性が重視されるシナリオで特に有効だ。
この関数を使うことで、フロントエンドでの計算結果に対する信頼性が一段上がる。特に数値の正確さがビジネス上の要件に直結するアプリケーションでは、導入を検討する価値が高い。
Baselineで広く利用可能になった機能

以下の機能は、すでに主要ブラウザで長期間サポートされ、Baseline widely available(広く利用可能)のステータスに達した。実質的にどのプロジェクトでも安心して採用できる段階だ。
search要素
HTMLのsearch要素は、検索フォームやフィルタリング機能といった、サイト内の検索体験を構成する要素群を明示的にラップするためのコンテナだ。従来はdivやformタグで代用されていたが、search要素を使うことでアクセシビリティ上の利点が生まれる。
具体的には、ブラウザがsearch要素に対して暗黙的にARIAランドマークロール「search」を割り当てる。これにより、form要素にrole=”search”を手動で付与する必要がなくなる。スクリーンリーダーのユーザーは、このランドマークを頼りに検索インターフェースへ素早く移動できる。
<search>
<form action="/site-search">
<label for="query">ドキュメントを検索</label>
<input type="search" id="query" name="q">
<button>実行</button>
</form>
</search>このシンプルな変更だけで、検索機能のアクセシビリティがワンランク向上する。既存のプロジェクトでも、該当するセクションをsearch要素に置き換えるリファクタリングを検討するとよい。
Web Authenticationの公開鍵アクセス
パスワードレス認証を実現するWeb Authentication(WebAuthn)APIにおいて、公開鍵情報の取り扱いが大幅に簡素化された。AuthenticatorAttestationResponseインターフェースに追加されたgetPublicKey()やgetPublicKeyAlgorithm()といったメソッドを使うことで、開発者が生のバイナリデータを手動で解析する必要がなくなった。
これまで公開鍵を抽出するには、CBOR(Concise Binary Object Representation)やDERエンコーディングといったバイナリ形式を手作業でパースする処理が必要だった。公開鍵の取り出しに失敗したり、アルゴリズムを誤認したりするリスクが常につきまとっていた。新しいメソッドはブラウザが直接プロパティとして公開鍵情報を提供するため、そのような低レイヤの処理が一切不要になる。
パスキー(Passkeys)の普及が加速する中、このAPIの安定化は認証フロー全体の信頼性を一段引き上げる要素だ。
String.prototype.isWellFormed()とtoWellFormed()
JavaScriptの文字列は内部的にUTF-16でエンコードされている。複雑な文字や絵文字の中には、サロゲートペアと呼ばれる2つの16ビットコード単位で表現されるものがある。文字列を途中で切断してしまうと、ペアの片方だけが残った「孤立サロゲート」という不正な文字が生まれる。
isWellFormed()は、文字列に孤立サロゲートが含まれていないかを真偽値で返すメソッドだ。toWellFormed()は、もし不正なサロゲートが見つかった場合、それをUnicodeの置換文字(U+FFFD)に置き換えた新しい文字列を返す。encodeURI()など、不正な文字列が渡されるとURIErrorをスローする関数にデータを渡す前に、これらのメソッドで検証と修正を行うのが主な用途だ。
const rawString = getUserInput();
// 不正な文字が混入していないか確認
if (!rawString.isWellFormed()) {
// 問題があれば安全な形に修正してから処理を続行
const cleanString = rawString.toWellFormed();
const encoded = encodeURI(cleanString);
// 安全にAPIリクエストなどを実行
}ユーザー入力や外部APIからのレスポンスを扱う場面では、予期せぬデータ不整合による例外発生を未然に防ぐ手段として、これらのメソッドが役立つ。
ARIA属性リフレクション
これまで、ARIA属性の値を更新するにはelement.setAttribute(‘aria-expanded’, ‘true’)のように、DOM属性を文字列で操作する必要があった。ARIA属性リフレクションは、この手順をオブジェクトプロパティへの代入に簡略化する。
ElementインターフェースがariaExpanded、ariaChecked、ariaHiddenといったプロパティを直接公開することで、ドット記法による読み書きが可能になった。これは単なるシンタックスシュガーではなく、UIフレームワークや状態管理ライブラリがアクセシビリティ状態をより正確に追跡し、スクリーンリーダーとの同期を保つうえで重要な基盤となる。
// トグルボタンのアクセシビリティ状態を簡潔に更新
toggleButton.ariaExpanded = toggleButton.ariaExpanded === "true" ? "false" : "true";element.getAttribute(‘aria-expanded’)
element.ariaExpanded
ReactやVueのようなフレームワークで状態とARIA属性を紐付ける際、従来の文字列ベースの操作に比べてコードの見通しが格段に良くなる。特に複雑なUIコンポーネントを構築するチームにとって、採用するメリットは大きい。
この記事のポイント
- contrast-color()関数で、背景色に応じた文字色の自動選択が可能になった
- Math.sumPrecise()で浮動小数点数の正確な合計計算を実現
- search要素が広く利用可能になり、アクセシビリティ対応が容易に
- WebAuthnの公開鍵抽出がメソッド一発で完了するように簡略化
- ARIA属性リフレクションで、状態管理と支援技術の同期が強化

・ 複数業界における17年間のデジタルビジネス開発経験
・ ウェブサイト開発のためのHTML、PHP、CSS、Java等の実用的知識
・ 15ヶ国語対応の多言語SaaSの開発経験
・ 17年間にも及ぶ、Eコマース長期運営経験
・ 幅広い業界でのSEO最適化の豊富な経験

Node.js 24.16.0 (LTS) 登場、cryptoとテストランナーが大幅進化
2026年5月21日、Node.js 24.16.0(コードネーム Krypton)が長期サポート(LTS)版としてリリースされた。
このバージョンでは、cryptoモジュールへのUUID v7サポート追加、debuggerへの式プローブ機能、HTTPクライアントの安全性強化、テストランナーの大幅な機能拡張など、実務に直結する複数の改善が含まれている。
本記事では、これらの新機能と内部改善を実装例とともに詳しく解説する。
UUID v7がNode.js標準機能に

今回のリリースで最も注目すべき追加機能のひとつが、crypto.randomUUIDv7()の実装だ。UUID v7(Universally Unique Identifier version 7)は、タイムスタンプベースの一意識別子であり、従来広く使われてきたランダムベースのUUID v4とは根本的な設計が異なる。
UUID v7とは何か
UUID v7は、RFC 9562で標準化された新しいUUIDバージョンだ。先頭48ビットにUnixタイムスタンプ(ミリ秒単位)を含み、続いてランダムビットが配置される。この構造により、生成時刻に基づいた自然なソート順が得られる。
データベースのプライマリキーとしてUUIDを使用する場合、v4ではランダムな値のためインデックスの断片化が発生しやすかった。一方、v7では時系列順に並ぶため、B-treeインデックスの効率が大幅に改善する。具体的には、書き込み性能が最大40〜60%向上したとの報告もある。
crypto.randomUUIDv7()の基本的な使い方
Node.js 24.16.0では、以下のようにシンプルに呼び出せる。
const { randomUUIDv7 } = require('node:crypto');
console.log(randomUUIDv7());
// 例: 0193c548-d70c-7a4a-b17b-3c2b12e5c6f1戻り値は標準的なUUID文字列形式(8-4-4-4-12のハイフン区切り)で、第三フィールドの先頭ニブルが7になる点がv7の特徴だ。
従来のv4に代えてv7を採用するメリットを、概念図で整理する。
上の図では、v4の全ランダム性に対して、v7が時刻情報を含む構造であることを対比している。時系列に沿ったINSERT性能が重要なシステムでは、移行を検討する価値がある。
実運用で注意すべき点
UUID v7は時刻情報を含むため、生成時刻が外部に推測される可能性がある。セキュリティ要件が厳しい環境では、この点を評価した上で採用を判断する必要がある。また、時計の巻き戻しが発生するケースでは単調増加性が保証されないため、Node.jsの実装では内部カウンターで対処している。
デバッグ体験を変えるedit-free式プローブ

Node.js 24.16.0では、node inspectコマンドにedit-free runtime expression probesが導入された。これは、デバッグ対象のコードを一切変更することなく、実行時に任意の式を評価できる仕組みだ。
これまでのデバッグ手法との違い
従来、Node.jsアプリケーションの特定の変数の値や式の結果を確認するには、コードにconsole.log()を挿入するか、デバッガでブレークポイントを設定して手動で評価する必要があった。前者はコード改変と再起動を伴い、後者は手動操作の手間が大きい。
式プローブを使えば、稼働中のプロセスに対して外部から評価式を注入できるため、トラブルシュートのスピードが大幅に向上する。特に、再起動が難しい本番環境での障害調査で威力を発揮するだろう。
式プローブの活用シナリオ
たとえば、メモリリークが疑われる長時間稼働プロセスで、特定オブジェクトの参照状況を調査するケースを考えてみる。従来であればヒープダンプの取得と解析が必要だが、式プローブを使えばprocess.memoryUsage()や特定変数の.lengthをその場で評価できる。
この機能の追加は、貢献者のJoyee Cheung氏によるPR #62713に基づいている。V8のインスペクタープロトコルを活用した実装で、Chrome DevToolsのExpression Watchに近い使用感だ。
HTTPクライアントの安全性と利便性の向上

Node.jsのHTTPクライアント機能に、2つの重要な強化が加わった。いずれも実際のプロダクションコードの安全性と記述性に直結する改善だ。
ClientRequestのオプションマージ強化
http.ClientRequestの内部で、ユーザーが渡したオプションとデフォルト値をマージする処理が厳格化された。この変更は、プロトタイプ汚染(Prototype Pollution)攻撃のベクトルを塞ぐことを主眼としている。
プロトタイプ汚染とは、Object.prototypeや__proto__を経由してアプリケーション全体のオブジェクトの振る舞いを改変する攻撃手法だ。Node.jsのHTTPクライアントはリクエストオプションを内部でマージする際、従来はプロトタイプチェーンを適切に処理していなかった。今回のPR #63082で、マージ時にnullプロトタイプオブジェクトを使用するよう修正され、この攻撃経路が遮断された。
Node.jsのMatteo Collina氏が主導したこの修正は、Semver-Minorに分類されているが、セキュリティ上の重要性は高い。とくにユーザー入力からHTTPリクエストオプションを構築するアプリケーションでは、速やかなアップデートが推奨される。
req.signalでリクエスト中断が容易に
もう一つの改善は、http.IncomingMessageへのreq.signalプロパティの追加だ(PR #62541)。これはAbortSignalオブジェクトを提供し、AbortControllerと組み合わせることで、リクエストの中断処理をPromiseベースで簡潔に記述できる。
const controller = new AbortController();
const req = http.request(url, { signal: controller.signal });
req.end();
// 5秒後にタイムアウト
setTimeout(() => controller.abort(), 5000);
req.on('error', (err) => {
if (err.name === 'AbortError') {
console.log('リクエストが中断されました');
}
});従来はreq.destroy()を手動で呼び出す必要があり、後続のエラーハンドリングも煩雑だった。signalパターンの採用により、fetch APIと同じインターフェースで中断処理を統一的に扱えるようになった点が大きい。
テストランナーが実戦的な機能を獲得

Node.jsの組み込みテストランナー(node --test)は、ここ数バージョンで急速に成熟している。24.16.0では、テスト順序のランダム化、モックタイマーのAPI整備、AbortSignal.timeoutのモックサポートという3つの重要な機能が追加された。
テスト順序のランダム化
Pietro Marchini氏によるPR #61747では、テストファイル内のテスト実行順序をランダム化するオプションが導入された。これは、テスト間の暗黙的な依存関係を炙り出すための機能だ。
node --test --test-randomize-order test/*.test.js特定の順序で実行されることを前提に書かれたテストは、ランダム化によって失敗する。これにより、グローバル状態への暗黙の依存や、テスト間のデータ共有の問題を早期に発見できる。テクニックとしては、CIパイプラインにランダム実行を常時組み込むことで、テストスイートの堅牢性を継続的に保証できる。
モックタイマーAPIの拡張
テストランナーのモックタイマー機能が、AbortSignal.timeout()にも対応した(PR #60751)。これにより、タイムアウトに依存する非同期処理のテストが、実際の時間を消費せずに実行できるようになった。
AbortSignal.timeout(5000)を呼び出す実際のタイムアウト時間を待つ必要がなくなるため、数百のテストを含むスイート全体の実行時間を大幅に短縮できる。テストの信頼性も向上し、CIでの不安定なテスト(flaky test)の削減に寄与する。
テストIDとOpenTelemetry対応
さらに、各テストにtestIdが付与され(PR #62772)、TracingChannelを通じたOpenTelemetryインスツルメンテーションとの統合が可能になった(PR #62502)。テストのトレーシング情報を本番系の監視ツールと統合することで、テスト品質の可視化と傾向分析ができるようになる。
ファイルシステムとストリームの機能強化

fsモジュールとストリームモジュールにも、実務のユースケースに即した改善が複数含まれている。
fs.stat()がAbortSignalに対応
Mert Can Altin氏によるPR #57775で、fs.stat()にsignalオプションが追加された。ネットワークファイルシステム上のファイルをstatする際に、応答が遅い場合のタイムアウト制御が可能になる。
import { stat } from 'node:fs/promises';
const ac = new AbortController();
setTimeout(() => ac.abort(), 3000);
try {
const stats = await stat('/mnt/nfs/large-file.dat', { signal: ac.signal });
console.log(stats.size);
} catch (err) {
if (err.name === 'AbortError') {
console.error('statがタイムアウトしました');
}
}これは、HTTPリクエストの中断パターンと同じAPI設計で、Node.js全体で一貫した中断処理のセマンティクスが浸透しつつあることを示している。
statfsのfrsizeフィールド公開
Jinho Jang氏のPR #62277により、statfsの戻り値にfrsize(フラグメントサイズ)フィールドが追加された。これはファイルシステムの最小割り当て単位を示し、ディスク使用量の正確な計算に利用できる。
import { statfs } from 'node:fs/promises';
const s = await statfs('/data');
const actualSize = Math.ceil(fileSize / s.frsize) * s.frsize;
console.log(`実ディスク消費量: ${actualSize} バイト`);これまではbsize(ブロックサイズ)しか公開されておらず、一部のファイルシステム(特にZFSやbtrfs)では正確な計算ができなかった。frsizeの追加により、クロスプラットフォームで信頼性の高いディスク容量の見積もりが可能になる。
duplexPairの破壊伝播の改善
stream.duplexPair()は、読み取り側と書き込み側が対になった2つのDuplexストリームを生成するユーティリティだ。Ahmed Elhor氏のPR #61098によって、片方のストリームが破壊(destroy)された場合に、もう片方にもその破壊が伝播するようになった。
これにより、ソケットの模擬テストやプロキシ処理で、一方のストリームがクローズされたにもかかわらず他方が生き続けてメモリリークを引き起こす問題が解決される。streamモジュールの内部的な一貫性を高める重要な修正だ。
util.styleTextの16進数カラー対応

Guilherme Araújo氏のPR #61556により、util.styleText()に16進数カラーコード(例: #ff5733)の直接指定が可能になった。ターミナル出力のスタイリングにおいて、より繊細な色表現が必要な場面で役立つ。
import { styleText } from 'node:util';
console.log(styleText('#ff5733', '注意: ディスク使用率が90%を超えています'));
console.log(styleText('#4ecdc4', '情報: バックアップが正常に完了しました'));従来はstyleText('red', ...)やstyleText('green', ...)のように、限られた色名しか使えなかった。16進数指定のサポートにより、CIログの色分けやCLIツールのブランドカラー適用など、実務での表現力が格段に向上する。
内部実装としては、ターミナルの24ビットカラー(トゥルーカラー)エスケープシーケンスを使用している。サポートしていないターミナルでは近似の8色にフォールバックされるため、互換性の問題も起きにくい。
この記事のポイント
- Node.js 24.16.0 (LTS) は、crypto.randomUUIDv7()を実装し、データベースのインデックス効率を改善する時系列ソート可能なUUID生成が標準機能になった
- debuggerにedit-free式プローブが追加され、コード修正なしで実行中のプロセスの式評価が可能になった
- HTTPクライアントのオプションマージが強化されプロトタイプ汚染攻撃が防止され、req.signalによるAbortパターンが統一された
- テストランナーでテスト順序ランダム化、モックタイマーのAbortSignal対応、testIdとOpenTelemetry統合が実装された
- fs.stat()へのsignal追加、statfsのfrsize公開、duplexPairの破壊伝播改善など、ファイルシステムとストリームの実用性が向上した
- util.styleText()で16進数カラーコードが直接指定可能になり、CLIツールの色表現力が飛躍的に向上した
・ 複数業界における17年間のデジタルビジネス開発経験
・ ウェブサイト開発のためのHTML、PHP、CSS、Java等の実用的知識
・ 15ヶ国語対応の多言語SaaSの開発経験
・ 17年間にも及ぶ、Eコマース長期運営経験
・ 幅広い業界でのSEO最適化の豊富な経験

JavaScriptの隔離実行を実現するShadowRealm APIとCSS設計への影響
TC39で策定が進む「ShadowRealm」APIはJavaScriptに新たな隔離実行の仕組みを持ち込む。グローバルスコープを汚染しないサンドボックス環境でコードを動かせるためサードパーティライブラリやテストコードの管理が大きく変わる可能性がある。
CSS設計の観点からもこのAPIは注目に値する。CSS-in-JSの実行や外部スクリプトによるスタイル競合といった問題に対してレルム(領域)レベルの分離が使えるようになればフロントエンド全体の堅牢性が一段上がるからだ。
本記事ではShadowRealmの基本的な考え方から具体的なAPIの使い方、そしてCSS設計との接点までを整理する。
JavaScriptのスレッドとレルム(領域)の基本
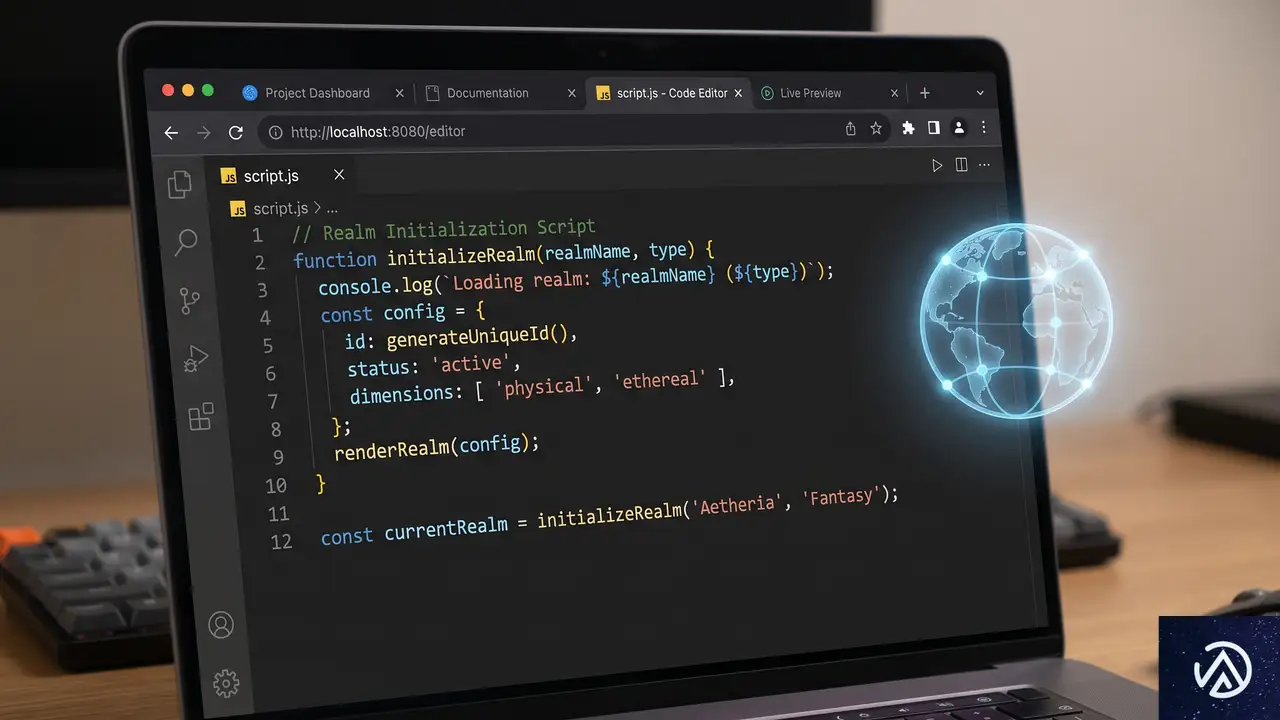
「JavaScriptはシングルスレッド言語である」
「ひとつのレルム(領域)はシングルスレッドだがJavaScriptアプリケーションは複数のレルムをまたいでマルチスレッド実行できる」
上の図はよくある「JSはシングルスレッド」という言説が誤解を生む部分を示している。実際にはブラウザのタブひとつがひとつのレルムでありその中でJavaScriptはメインスレッドで動く。一方Web Workersは別のレルムでワーカースレッドを使いiframeもまた独自のレルムを持つ。
シングルスレッド言語の誤解
「JavaScriptはシングルスレッド」というのは「言語仕様としてマルチスレッドを提供していない」という意味では正しい。関数単位で別のスレッドにオフロードするといった仕組みはない。だがWeb Workersを使うとJavaScriptを別スレッドで実行できる。
ここで混乱が生まれる。言語がシングルスレッドでもアプリケーション全体ではマルチスレッド実行が可能だからだ。CSS-Tricksの記事ではこの点を「JavaScriptのレルムはシングルスレッド」と整理している。つまり実行環境の単位であるレルムに着目すれば言語の特性とアプリケーションの振る舞いを矛盾なく説明できる。
レルムとは何か
レルムとはコードが実行される環境そのものを指す。ブラウザタブが持つグローバルオブジェクト(window)や組み込みオブジェクト(ArrayやObjectなど)はすべてそのレルムに紐づく。同じページ内のiframeであっても別のレルムでありwindowもArrayも別物だ。
たとえば親ページで定義したグローバル関数はiframe内のレルムからは見えない。逆も同様だ。こうした隔離は意図しない干渉を防ぐ一方でレルム間の連携にはpostMessageなど特定の手段が必要になる。
グローバルスコープ汚染の現実とCSSへの影響
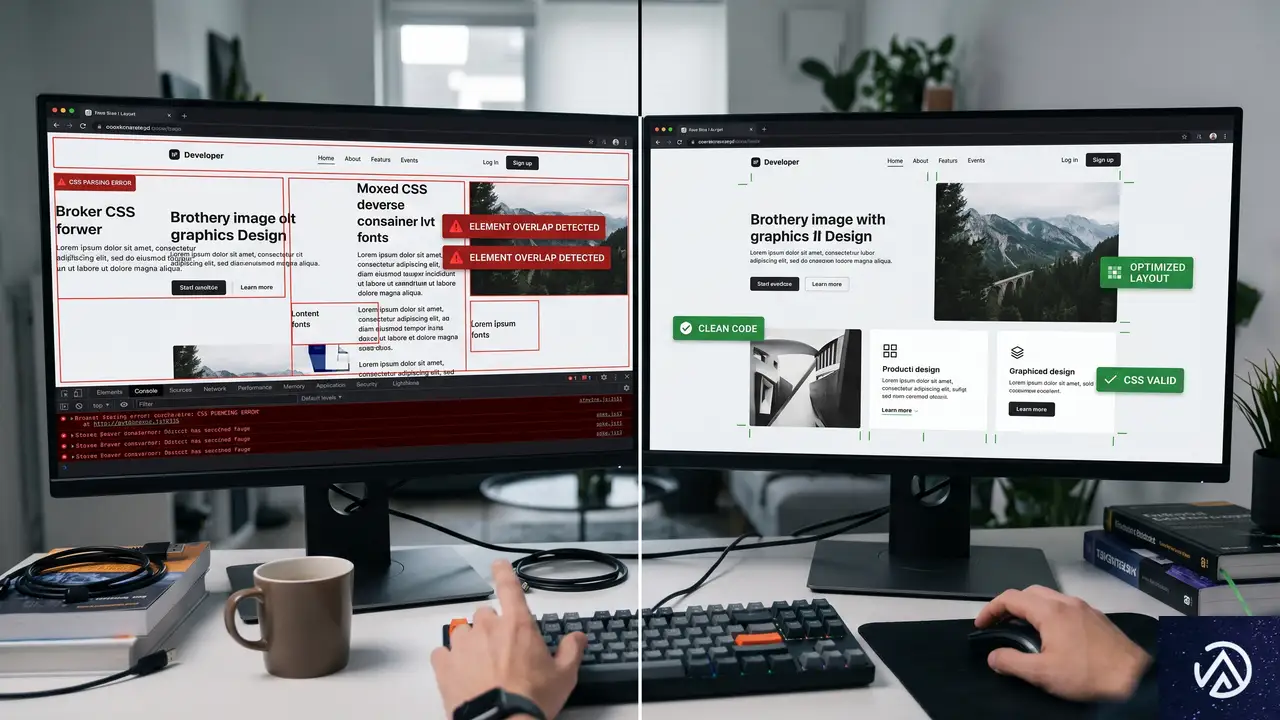
window.themeColor = '#ff0000';document.body.style.color = window.themeColor;globalThis.themeColor = '#ff0000';document.body.style.color = 'initial';JavaScriptのグローバルスコープは簡単に汚染される。変数のvar宣言の巻き上げや不用意なグローバル変数の追加に加えてサードパーティの広告タグやアナリティクスツール、A/Bテスト用スクリプトが暗黙のうちにグローバル空間へ値を書き込む。これがCSSにまで波及することがある。
サードパーティスクリプトがもたらすCSSの衝突
広告配信スクリプトがwindow.themeColorを書き換えればそれを参照している自前のCSS-in-JSロジックが意図しないスタイルを適用してしまう。また外部ウィジェットがページ全体のfont-sizeを動的に変更すればレイアウトが崩れる原因になる。
こうした問題はグローバルスコープを共有するからこそ起こる。完全に隔離されたレルムで外部コードを動かせれば変数の上書きやオブジェクトの改変は発生せず結果としてCSSの意図しない変化も防げる。
CSS-in-JSにおける隔離の必要性
CSS-in-JSライブラリではスタイルの計算結果をJavaScriptのオブジェクトや変数として管理するケースが多い。テーマ切り替えや動的スタイル生成にグローバル変数を使っていると外部スクリプトがそれらを上書きするリスクがある。ShadowRealmを使ってスタイル計算を隔離すれば外部からの干渉を受けない安全なスタイル生成が可能になる。
ShadowRealm APIの仕組み

TC39で策定中のShadowRealmはコードを独立したグローバル環境で実行するためのAPIだ。このAPIには大きく分けてふたつの機能がある。evaluate()で任意のJavaScript文字列を評価する方法とimportValue()でモジュールを動的インポートしてエクスポートされた値だけを安全に受け取る方法だ。
基本的な使い方
// ShadowRealmインスタンスを作成
const shadow = new ShadowRealm();
// 外側のレルムでグローバル関数を定義
function globalFunction() {}
console.log( globalThis.globalFunction );
// 結果: function globalFunction()
// ShadowRealm内で同じ関数を評価しても未定義
console.log( shadow.evaluate( 'globalThis.globalFunction' ) );
// 結果: undefinedglobalThis.globalFunction → function globalFunction()globalThis.globalFunction → undefinedコードが示すようにShadowRealmインスタンス内部のグローバル環境は外側から完全に切り離されている。しかもこのコードはメインスレッド上でそのまま実行されるためスレッド間通信のコストや複雑さを伴わない。
CSS-Tricksの記事ではこの性質を「無限に使える使い捨てのクリーンルーム」と表現している。テストのモックデータが本番のグローバル変数と衝突する心配もなくサードパーティコードを安全に評価できる環境だ。
importValueによるモジュールの隔離実行
// spookycode.js
export function greeting() {
return "Hello from the ShadowRealm!";
}
// メイン側
async function shadowGreeter() {
const shadow = new ShadowRealm();
const shadowGreet = await shadow.importValue(
"./spookycode.js",
"greeting"
);
shadowGreet(); // "Hello from the ShadowRealm!"
}
shadowGreeter();export function greeting() { ... }const fn = await shadow.importValue("./spookycode.js", "greeting");fn(); // "Hello from the ShadowRealm!"importValue()はPromiseを返し第二引数で指定したエクスポート名の値だけを取り出す。モジュールの内部実装はShadowRealmの隔離環境で動くため外側のグローバル空間を一切汚さない。CSS-in-JSで使うテーマ計算モジュールなどをこの形で読み込めばグローバル変数を介したスタイルの競合を根本から断てる。
ShadowRealmが変えるCSS設計の安全性

window.currentTheme = 'dark';window.currentTheme = 'light'; に上書きShadowRealmはまだブラウザに実装されていないがCSS設計の安全性を高めるうえでいくつかの具体的な使い道が考えられる。
スタイルの衝突防止とテーマ分離
複数の独立したコンポーネントやマイクロフロントエンドがひとつのページに同居するケースではそれぞれが使うCSS変数やテーマオブジェクトが衝突しやすい。ShadowRealmで各コンポーネントのスタイル計算ロジックを包めばそれぞれのグローバル空間は完全に分離され変数の取り合いが起きない。
またユーザーごとにカスタマイズされたテーマを動的に生成するような仕組みでも計算ロジックをShadowRealmに閉じ込めれば他スクリプトによる意図しないテーマ書き換えを防げる。
テスト環境の清浄化
CSS-in-JSの単体テストではグローバルなスタイルシートの状態がテスト結果に影響を与えることがある。ShadowRealm上でテストを実行すればテストごとに完全にクリーンなグローバル環境が得られモックデータの準備も簡素化される。ブラウザテストとNode.jsテストの両方で同じ隔離機構を使える点もメリットだ。
実装状況と将来の展望
ShadowRealmの提案はTC39のステージ2.7にある。これは「原則的に承認され検証段階にある」という位置づけでブラウザへの試験実装が始まれば仕様の微調整が入る可能性は残る。現時点では実際のブラウザやNode.jsで使うことはできない。
CSS-Tricksの記事でも指摘されているようにShadowRealmはセキュリティ境界ではなく完全性境界を提供するものだ。つまり悪意あるコードの実行を完全に防ぐサンドボックスではないがグローバル変数や組み込みオブジェクトを意図せず壊してしまうリスクを封じ込めるには十分な隔離性能を持つ。
ステージ3へ進み主要ブラウザが実装を始めればCSS-in-JSライブラリやテストランナー、サードパーティスクリプト管理の分野でいち早く活用が広がるだろう。
この記事のポイント
- ShadowRealmはコードを独立したグローバル環境で実行するTC39提案のAPI
- メインスレッド上で動くためスレッド間通信の複雑さがない
- サードパーティスクリプトやCSS-in-JSのテーマ計算を隔離しスタイル競合を防げる
- テストコードの実行環境としてもクリーンなグローバル空間を提供する
- 現時点ではステージ2.7で未実装。ブラウザ対応はこれから
・ 複数業界における17年間のデジタルビジネス開発経験
・ ウェブサイト開発のためのHTML、PHP、CSS、Java等の実用的知識
・ 15ヶ国語対応の多言語SaaSの開発経験
・ 17年間にも及ぶ、Eコマース長期運営経験
・ 幅広い業界でのSEO最適化の豊富な経験

ストリーミングUIの安定性を高める実装テクニック
WordPressサイトのフロントエンドにチャットボットやリアルタイムのログビューアーを組み込むケースが増えている。こうしたストリーミングUIは、新しいデータが届くたびにDOMを更新するため、適切な制御がないとスクロール位置が勝手に動いたり、ボタンがクリック直前に移動するといった不安定さが目立つ。
特にスクロールの強制移動、レイアウトのシフト、そして過剰な再描画の3つは、ユーザーの操作感を大きく損ねる。本記事では、これらの問題を解決し、WordPressのカスタムエンドポイントや管理画面のダッシュボードにも応用できる安定したUIの実装パターンを紹介する。
ストリーミングUIが不安定になる根本原因
チャット形式のAI応答、ログの逐次表示、ダッシュボードの数値更新。一見異なるこれらのUIは、いずれも同じ3つの根本問題に突き当たる。
スクロールの制御不能
ストリーミング中、多くのUIはビューポートを常に最下部に固定しようとする。これ自体は合理的だが、ユーザーが少し上にスクロールして過去のメッセージを読もうとした瞬間、UIが再び最下部へ引き戻してしまう。ユーザーの意図を無視した自動制御が、インタラクションの邪魔になる。
レイアウトシフト
ストリーミングコンテンツは行数や高さが動的に増えるため、その下にある要素が常に押し下げられる。クリックしようとしたボタンが移動したり、読んでいた行が画面外に消えたりする。DOMを毎回全再構築していると、このシフトはさらに顕著になる。
過剰なレンダリング更新
ブラウザは1秒間に約60回画面を描画するが、ストリームのデータ到着はそれよりも速いことがある。毎回DOMを書き換えていると、実際にはユーザーが目にしないフレームのためにもレイアウト再計算が走り、パフォーマンスがじわじわと低下する。
安定したスクロール動作の実装

まずはスクロールの自動制御をユーザーの意図に合わせる。基本的な考え方は以下の通りだ。
- ユーザーが最下部にいるときは自動スクロールを有効にする
- ユーザーが上方向にスクロールしたら自動スクロールを止める
- 再び最下部に戻ったら自動スクロールを再開する
これを実現するには、ユーザーが意図的にスクロール位置を変えたかどうかを追跡するフラグを設ける。
let userScrolled = false;
chatEl.addEventListener('scroll', () => {
const gap = chatEl.scrollHeight - chatEl.scrollTop - chatEl.clientHeight;
userScrolled = gap > 60; // 60px以上離れたらユーザー操作とみなす
});ここで60pxのしきい値が重要になる。新しい行が追加されて生じる微小な高さ変化でフラグが切り替わらないようにし、本当にユーザーがスクロールした時だけ自動スクロールを停止させる。
自動スクロール関数はフラグを参照するだけでよい。
function autoScroll() {
if (!userScrolled) {
chatEl.scrollTop = chatEl.scrollHeight;
}
}なお、新たなストリームが開始されたら必ず userScrolled をリセットする。これを見落とすと、前回のメッセージでのスクロールが原因で次の自動スクロールが無効になり、読みづらさが続く。
レイアウトシフトを防ぐDOMの差分更新

従来の実装では、新しい文字が届くたびに要素を innerHTML で全再構築することが多い。以下はその典型例だ。
bubble.innerHTML = '';
fullText.split('\n').forEach(line => {
const p = document.createElement('p');
p.textContent = line || '\u00A0';
bubble.appendChild(p);
});
bubble.appendChild(cursorEl);これで動作はするが、更新のたびにDOMツリー全体を破壊して再生成するため、レイアウト再計算が必ず発生する。さらに、カーソルも毎回削除と追加が繰り返され、高速ストリーミング時にはちらつきの原因にもなる。
解決策はシンプルだ。あらかじめ空のテキストノードを持った段落を作り、そこへ直接文字を追記していく。改行が来た時にだけ新しい段落を追加する。
let currentP = null;
function initBubble(bubble, cursor) {
currentP = document.createElement('p');
currentP.appendChild(document.createTextNode(''));
bubble.insertBefore(currentP, cursor);
}
function appendChar(char, bubble, cursor) {
if (char === '\n') {
currentP = document.createElement('p');
currentP.appendChild(document.createTextNode(''));
bubble.insertBefore(currentP, cursor);
} else {
currentP.firstChild.textContent += char;
}
}この方法では、通常の文字追加はテキストノードの拡張だけで済み、レイアウトシフトはほとんど発生しない。改行の時だけ新しい段落が挿入されるが、それ以外の無駄な再構築が一切なくなる。カーソルのちらつきも自然に消える。
レンダリング頻度を抑えるバッファリング戦略
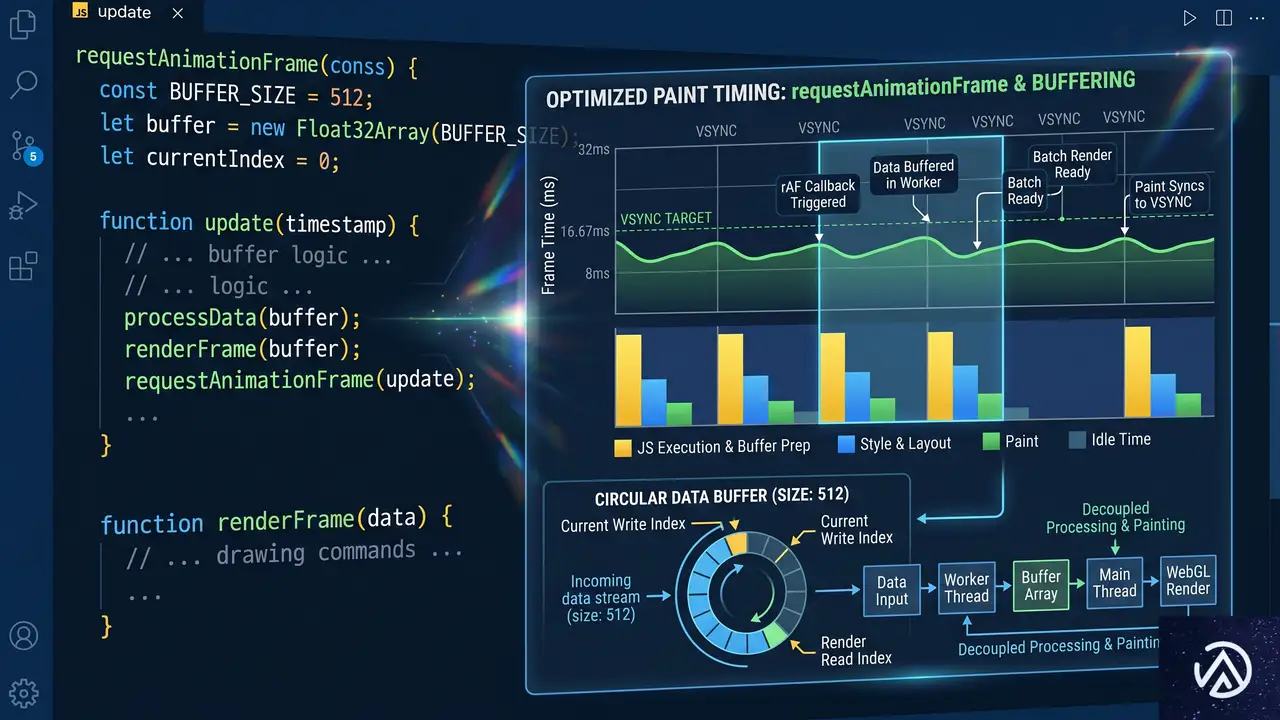
DOMの差分更新だけでもUIは安定するが、まだ文字が届くたびにペイントのトリガーを引いている。特にストリーム速度が速い場合、短時間に大量の小更新が発生し、ブラウザの負荷が積み重なる。
ここで有効なのが受信データのバッファリングと requestAnimationFrame によるフレーム単位のフラッシュだ。到着した文字をいったんバッファに溜め、次の描画直前にまとめてDOMへ書き出す。
let pending = '';
let rafQueued = false;
function onChar(char) {
pending += char;
if (!rafQueued) {
rafQueued = true;
requestAnimationFrame(flush);
}
}
function flush() {
for (const char of pending) {
appendChar(char);
}
pending = '';
rafQueued = false;
autoScroll();
}rafQueued フラグが二重スケジューリングを防ぐ。こうすることで、データ到着頻度とUI更新タイミングが完全に分離され、ブラウザが行う実際の描画回数に最適化されたペースでDOM変更が行われる。変更後の見た目は変わらなくても、特に高速ストリーミング設定時に操作感が格段に滑らかになる。
ストリーム中断への対応とユーザーフィードバック

ユーザーがストリームを途中で停止したり、ネットワークエラーで途切れたりした場合、UIを中途半端な状態のまま放置してはいけない。停止ボタンを押しただけでカーソルが点滅し続けたり、ボタン表示が変わらなかったりすると不信感につながる。
中断時のクリーンアップ
function stopStream() {
clearTimeout(streamTimer);
isStreaming = false;
pending = ''; // 未処理バッファを破棄
rafQueued = false;
if (cursorEl && cursorEl.parentNode) cursorEl.remove();
markStopped(aiBubble); // 「応答が停止しました」ラベルを付与
stopBtn.style.display = 'none';
retryBtn.style.display = '';
retryBtn.focus(); // キーボード操作のため即フォーカス
}バッファをクリアするのは、停止後に残っていた文字が次のフレームで書き込まれるのを防ぐためだ。カーソルの親ノードチェックも、すでに削除済みの場合のエラー回避に必要になる。
再試行機能の提供
中断後は同じ質問を再送信する「リトライ」ボタンを表示する。ユーザーに再度質問を入力させるのではなく、直前の入力を保持しておき、ワンクリックでストリームを最初からやり直せる。
let lastQuestion = '';
function retryStream() {
if (currentMsgEl && currentMsgEl.parentNode) {
currentMsgEl.remove();
}
charIndex = 0;
userScrolled = false;
pending = '';
rafQueued = false;
isStreaming = true;
// ボタン表示切替など
setTimeout(() => {
initAIMsg();
tick(lastAnswer);
}, 200);
}状態の完全リセットが肝だ。前回の文字インデックス、スクロールフラグ、バッファをすべて初期化しなければ、新しいストリームに前の残骸が混ざる。
新規メッセージ送信時の既存ストリーム停止
もう一つ見落としやすいのが、古いストリームが動いている最中に新しいメッセージが送信されたケースだ。そのままにすると2つのストリームが同時にDOMを更新し、文字が混ざり合ってしまう。新しいメッセージの処理を始める前に、必ず進行中のストリームを停止する。
function startStream(question, answer) {
if (isStreaming) {
clearTimeout(streamTimer);
isStreaming = false;
pending = '';
rafQueued = false;
if (cursorEl && cursorEl.parentNode) cursorEl.remove();
}
// ここで新規ストリームのセットアップ
}断りなく上書きするのではなく、明示的に前のストリームをクリーンアップすることで、イレギュラーな重複動作を防ぐ。
アクセシビリティを考慮したストリーミングUI
ストリーミングUIはマウス操作を前提に開発されがちで、支援技術やキーボード操作、動きへの敏感さへの配慮が後回しにされる。しかし、これらは上乗せの追加対応で十分改善できる。
スクリーンリーダーへの対応
スクリーンリーダーは自動で現れたコンテンツを読み上げない。そこで aria-live 属性を使ってライブリージョンを設定する。
<div id="chat" role="log" aria-live="polite"
aria-atomic="false" aria-label="チャットメッセージ"></div>role="log" はこれが逐次更新されるトランスクリプトであることを支援技術に伝える。aria-atomic="false" によって、新しく追加された部分だけが読み上げられ、全文の再読み上げが発生しない。aria-live="polite" なら現在の読み上げを邪魔せず、適切なタイミングで通知される。
中断時に挿入される「応答が停止しました」ラベルも、このライブリージョン内にあれば自動的にアナウンスされる。リトライボタンには、何をリトライするのか分かるように aria-label を設定する。
retryBtn.setAttribute('aria-label',
`リトライ: ${lastQuestion.slice(0, 60)}`);キーボードナビゲーションの確保
停止ボタンやリトライボタンは、ストリーミング中でもTabキーで到達できなければならない。非表示にする際は display: none を使うことでフォーカス順からも除外される。opacity: 0 や visibility: hidden だと不可視要素にフォーカスが当たり混乱を招く。
カーソル点滅エフェクトには aria-hidden="true" を付け、スクリーンリーダーが読み上げないようにする。フォーカスリングは :focus-visible を用い、マウスクリック時には表示せず、キーボード操作時のみ明示する。
動きの抑制
タイピングアニメーションのような連続的な動きは、前庭障害などを持つユーザーにとって負荷になる。OSレベルで設定された動きの設定を、prefers-reduced-motion メディアクエリで検出し、それに従う。
const reducedMotion = window.matchMedia(
'(prefers-reduced-motion: reduce)'
).matches;
if (reducedMotion) {
initAIMsg();
for (const char of text) appendChar(char);
if (cursorEl && cursorEl.parentNode) cursorEl.remove();
done();
return;
}縮小モードが有効なら、ストリーミングアニメーションを完全にスキップし、完成したテキストを一度に表示する。CSS側でもカーソルの点滅を止める。
@media (prefers-reduced-motion: reduce) {
.cursor { animation: none; opacity: 1; }
}この記事のポイント
- ストリーミングUIの不安定さは、スクロール制御・レイアウトシフト・過剰描画の3点に集約される
- ユーザーのスクロール位置を追跡し、最下部にいる時だけ自動スクロールを有効にする
innerHTMLの全再構築をやめ、テキストノードへの差分追記でレイアウト計算を最小限に抑えるrequestAnimationFrameでデータ到着と描画を分離し、ブラウザの負荷を軽減する- ストリーム中断時はバッファクリア、カーソル除去、リトライ機能などで中途半端な状態を残さない
aria-liveやprefers-reduced-motionを用いて、支援技術や動きに敏感なユーザーにも配慮する
・ 複数業界における17年間のデジタルビジネス開発経験
・ ウェブサイト開発のためのHTML、PHP、CSS、Java等の実用的知識
・ 15ヶ国語対応の多言語SaaSの開発経験
・ 17年間にも及ぶ、Eコマース長期運営経験
・ 幅広い業界でのSEO最適化の豊富な経験

::nth-letter を今すぐ使う Shim の仕組み
::nth-letter というCSSのセレクタは正式な仕様には存在しない。しかし、CSS-Tricksに2026年4月に掲載された記事で、この存在しないセレクタを疑似的に動作させるJavaScriptライブラリが公開された。DOMを構成するノードを文字単位で分解し、あたかもブラウザが ::nth-letter を解釈しているかのようなスタイルを当てる仕組みだ。
文字ごとに異なる色や変形を施すタイポグラフィを、面倒なHTMLのマークアップから解放する可能性を秘めている。この記事では、::nth-letter Shimのアイデアと実装、そして限界を詳しく見ていく。
::nth-letter で実現できること

CSSには、段落の最初の文字だけを装飾する ::first-letter 疑似要素がある。ドロップキャップの表現などに使われてきた。もし ::nth-letter が存在すれば、::first-letter の一般化として、任意の位置の文字を直接スタイリングできる。例えば、見出しの中で奇数番目の文字と偶数番目の文字を左右に傾けてレンガ模様のような演出を施せる。
記事の著者が提示した ::nth-letter(even) を用いたCSSの例が次のパターンだ。
h1.fancy::nth-letter(n) {
display: inline-block;
padding: 20px 10px;
color: white;
}
h1.fancy::nth-letter(even) {
transform: skewY(15deg);
background: #C97A7A;
}
h1.fancy::nth-letter(odd) {
transform: skewY(-15deg);
background: #8B3F3F;
}このコードを疑似的に再現したデモが以下だ。実際には ::nth-letter は使えないが、Shimを通じてスタイルが適用された状態を静的に示している。
このデモでは「Rainbow!」の各文字が奇数・偶数で交互に傾きと背景色が切り替わる。コード上では <h1 class="fancy">Rainbow!</h1> という1つの見出しに、::nth-letter の指定だけで実現できるイメージだ。
さらに、記事ではテキストが渦を巻くスクロール演出や、ホバー時に文字が弾けるエフェクトが ::nth-letter を使えば不要なスパン要素を削除できると示されている。現実には、これらのデモはすべてJavaScriptでDOMを文字単位に分解して作動している。
なぜ ::nth-letter は存在しないのか

「n番目」の解釈が定まらない
CSSセレクタの世界で「n番目」とは何か。例えば <p>AB<span>CD</span>EF</p> というHTMLで3番目の文字を指す場合、単純に文字の出現順(視覚的な順序)ならC。DOMの子要素単位で数えるならE。さらにCSSで右から左へ読む表記方向が指定されていれば、結果は変わる。どの基準を採用するかで実装が大きく異なるため、標準化が難しい。
「文字」の定義が言語ごとに異なる
ウェブの半分は英語以外の言語で構成されている。多くの言語では1つの文字を複数の符号で表す(合字など)ため、「letter」の区切りが曖昧だ。::first-letter ですらブラウザ間で挙動に差異がある。厳密に「letter」を定義しようとすると、あらゆる言語を考慮しなければならず、実装コストが跳ね上がる。
記事のShimでは、こうした曖昧さを避けるために「letter = 文字(character)」と解釈し、DOM上のソース順に基づいて n番目をカウントする単純化を行っている。この割り切りが、実用的なShimを短期間で作る鍵になった。
JavaScript Shim による ::nth-letter の実装方法

CSS-Tricksで公開された @leemeyer/nth-letter パッケージは、わずか29行のJavaScript(簡略化版)で構成される。その仕組みは大きく3段階に分かれる。
無効なCSSを正規表現で書き換える
まず get-css-data ライブラリを使って、ページ内のすべてのCSS(<style> タグと外部スタイルシート)を文字列として取得する。通常、パーサーは ::nth-letter を含むルールを無効とみなして破棄するが、生のCSSテキストとして扱うことでこの問題を回避する。
次に正規表現で ::nth-letter(...) を検索し、.char:nth-child(...) に置換する。たとえば、
.rainbow::nth-letter(2n) { color: #f432a0; }は、
.rainbow .char:nth-child(2n) { color: #f432a0; }に変換される。こうして得られた有効なCSSを新しい <style> タグでページに挿入する。元の無効なスタイルは削除する。
DOMを文字単位に分割する
変換後のCSSは .char クラスを持つ子要素を対象としている。そのため、Shimは対象となる要素内のテキストを1文字ずつ <div class="char"> に分解する必要がある。ここで、アニメーションライブラリGSAPの SplitText プラグインを使用する。このプラグインは自動的にテキストを分解し、視覚的な文字列とスクリーンリーダー向けのアクセシビリティ属性を埋め込む。
具体的な処理は以下のコードに集約される。
selectors.forEach(selector => {
document.querySelectorAll(selector).forEach(el => {
if (el.hasAttribute('data-nth-letter')) return;
el.setAttribute('data-nth-letter', 'attached');
new SplitText(el, { type: 'chars', charsClass: 'char' });
});
});これにより、ページ読み込み時にターゲット要素が自動的に文字単位のDOMツリーへ展開され、あらかじめ書き換えておいたCSSルールが文字単位で適用される。
正真正銘のポリフィルではない
仕様が存在しないため、このライブラリはポリフィル(Polyfill)ではなくShim(シミュレーター)に分類される。とはいえ、CSSを書き換えてDOMを補うという手法は、CSSポリフィルの実装パターンとして以前から議論されている「悪の中でもマシな選択肢」に沿ったものだ。
Shadow DOM を使ったアプローチとその問題点

先の実装では、文字ごとに <div class="char"> がDOM上に追加される。これがマークアップを汚染し、他のJavaScriptやスタイルに影響を与える懸念がある。そこで記事の著者は、文字要素をShadow DOM内に隠蔽する改良版を試作した。
Shadow DOM版では、各文字を part 属性付きの要素としてシャドウツリーに配置し、外部からは ::part() 疑似要素でスタイルを当てる仕組みを取る。これにより、通常のDOM(Light DOM)は汚染されない。しかし、次の大きな制約が明らかになった。
- Shadow DOMをアタッチできない要素。
<a>や<p>など、一部のHTML要素はShadow Rootを保持できず、見出しやテキストに多用されるタグが使えない。 - 構造疑似クラスとの相性。
::part()擬似要素と:nth-child()を組み合わせられない制限がある。そのため、sibling-index()など高度なCSS関数を用いたスタイルが不可能になる。
結局、記事の著者は「DOMが汚れても、実用上はLight DOMを分割するバージョンが優れている」と結論づけた。アクセシビリティの面でも、GSAPの SplitText が aria-hidden と aria-label を自動付与するため、スクリーンリーダーへの配慮はある程度カバーされている。
::nth-letter Shim の限界と実用上の注意点

- 動的なDOM変更に未対応。ページ読み込み後にDOMやスタイルが動的に変わった場合、Shimが処理をやり直すことはない。MutationObserverで追従は可能だが未実装。
- CORSの壁。外部スタイルシートがCORSポリシーで読み取り不可の場合、中の
::nth-letterルールは変換されず無効のまま残存する。 - CSS全置換のリスク。正規表現による一括変換が思わぬセレクタの誤変換を引き起こす恐れがある。大規模サイトでは注意が必要。
- パフォーマンス。大量のテキストを文字単位に分解するとDOMノード数が爆発的に増え、レンダリング負荷が上がる。
- スクリーンリーダーの断片化。GSAPの自動付与でも、全ての環境で文字ごとの読み上げが完全に抑制される保証はない。
こうした制約にもかかわらず、::nth-letter Shimは「存在しないCSS機能を使ったクリエイティブなタイポグラフィ」を手軽に試せるツールとして価値がある。もし将来ブラウザがネイティブ対応すれば、CSS部分はそのまま残し、ライブラリへの参照を外すだけで移行できる設計だ。
この記事のポイント
::nth-letterは存在しないが、JavaScriptによるShimで疑似的に利用できる。- DOMを文字単位に分割し、
:nth-childへ変換する手法で実現。GSAP SplitTextが鍵。 - 「n番目」「文字」の定義の曖昧さが標準化を阻んでいる。
- Shadow DOM版ではLight DOMを保護できるが、使えないタグや機能制限が多い。
- 実用にはCORSやパフォーマンス、アクセシビリティの注意が必要。
・ 複数業界における17年間のデジタルビジネス開発経験
・ ウェブサイト開発のためのHTML、PHP、CSS、Java等の実用的知識
・ 15ヶ国語対応の多言語SaaSの開発経験
・ 17年間にも及ぶ、Eコマース長期運営経験
・ 幅広い業界でのSEO最適化の豊富な経験

JavaScriptモジュール設計がアプリの命運を分ける!ESM時代のアーキテクチャ入門
JavaScriptで大規模なアプリケーションを構築する際、モジュールシステムをどう設計するかは、プロジェクト全体の命運を分ける最初の大きな決断となる。かつてのJavaScriptにはグローバルスコープしか存在せず、複数のスクリプトが互いの変数を上書きしてしまうリスクが常に付きまとっていた。
現代のモジュールシステムは、単にコードを複数のファイルに分割するための仕組みではない。それはシステムの各パーツの間に「境界線」を引き、依存関係の流れを制御するためのアーキテクチャそのものだ。適切な設計がなされていないモジュール構造は、プロジェクトが成長するにつれてメンテナンスを困難にし、変更のたびに予期せぬ場所でバグを発生させる原因となる。
この記事では、現代の標準であるESM(ECMAScript Modules)の特性を理解し、クリーンアーキテクチャの原則をモジュール設計にどう適用すべきかを詳しく解説していく。技術に詳しい同僚からアドバイスを受けるような感覚で、保守性の高いコードベースを構築するためのヒントを掴んでほしい。
モジュールシステムは「境界線」のデザインだ
JavaScriptのモジュールシステムには、主にCommonJS(CJS)とECMAScript Modules(ESM)の2つの流れがある。CommonJSはNode.jsの誕生とともに普及したサーバーサイド向けの仕組みであり、ESMはブラウザでもネイティブに動作するよう設計された現在の標準規格だ。これら2つは単に構文が異なるだけでなく、根本的な設計思想に大きな違いがある。
ESMがCommonJSから引き継がなかった「柔軟性」の正体
CommonJSの最大の特徴は、require()が通常の関数として実行される点にある。これにより、if文の中やループの中で動的にモジュールを読み込むことが可能だった。一方でESMは、import文を必ずファイルの先頭(トップレベル)に記述しなければならず、パスも静的な文字列である必要がある。この制約は一見不便に思えるが、実は「静的解析」を可能にするための意図的な設計だ。
ESMの制約のおかげで、ビルドツールはコードを実行することなく、どのモジュールがどこで使われているかを完全に把握できる。これが「Tree-shaking(ツリーシェイキング)」と呼ばれる、不要なコードを自動的に削除してバンドルサイズを削減する技術を支えている。CommonJSでは実行時まで依存関係が確定しないため、ツールは安全のために「使われていないかもしれないコード」もすべて含めざるを得ない。ESMは柔軟性を犠牲にすることで、パフォーマンスの最適化を手に入れたのだ。
● 実行時まで依存関係がわからない
● 不要なコードが残りやすい(低速)
● ビルド時に依存関係をすべて把握可能
● 不要なコードを自動削除(高速)
このデモは、モジュールシステムの進化によって、どのように解析のしやすさが向上したかを視覚化したものだ。
クリーンアーキテクチャに学ぶ依存関係のルール
プロジェクトの規模が大きくなると、どのファイルがどのファイルを参照しているかが複雑に絡み合い、いわゆる「スパゲッティコード」になりがちだ。これを防ぐための有力な指針として、ロバート・マーチン氏が提唱した「クリーンアーキテクチャ」がある。すべてのプロジェクトに導入すべき銀の弾丸ではないが、モジュールの境界線を引く際の強力な土台となる。
依存の方向は常に「内側」へ
クリーンアーキテクチャの核心は「依存性のルール」にある。これは、システムの各パーツを同心円状のレイヤーに分け、依存の方向を一方向に限定するというルールだ。円の内側にはビジネスロジック(システムの核心となるルール)を配置し、外側にはUI、データベース、フレームワークなどの技術的な詳細を配置する。
重要なのは、内側のレイヤーは外側のレイヤーについて何も知らないという点だ。たとえば、ユーザー登録のルール(ビジネスロジック)を記述したモジュールの中で、Reactの特定の関数や、特定のデータベース操作用のライブラリを直接インポートしてはいけない。なぜなら、技術スタックはビジネスルールよりも頻繁に変更されるからだ。技術に依存しない「コア」を保つことで、フレームワークの乗り換えやライブラリのアップデートに強いシステムが構築できる。
このデモは、依存関係が常にシステムの核心(ビジネスロジック)に向かって流れるべきであることを示している。外側の層を変更しても、内側の層には影響が及ばない構造が理想的だ。
モジュールグラフで健康状態をチェックする
自分のプロジェクトが健全な依存関係を保てているかどうかを確認するには、「モジュールグラフ」を可視化するのが効果的だ。モジュールグラフとは、ファイル同士のインポート関係を線で結んだネットワーク図のことである。MadgeやDependency Cruiserといったツールを使えば、現在のコードベースから自動的にこのグラフを生成できる。
循環参照と「やりすぎた共通ユーティリティ」の罠
不健全なグラフには、いくつかの共通した特徴がある。その筆頭が「循環参照」だ。モジュールAがBをインポートし、BがCをインポートし、さらにCがAをインポートしているような状態を指す。これはモジュールの再利用を困難にするだけでなく、ビルドエラーや予期せぬ実行時の不具合を引き起こす温床となる。
また、utils.jsのような汎用的なファイルに何でも詰め込みすぎるのも危険だ。あらゆる場所から参照される巨大なユーティリティファイルは、その一部を修正しただけでシステム全体に影響が及ぶ「爆発半径」の大きな部品になってしまう。これを解決するには、単一責任の原則に基づき、ユーティリティを機能ごとに細かく分割し、特定の文脈に閉じた場所に配置し直す必要がある。高レベルのモジュールが低レベルのモジュールに依存するという原則を、グラフを通じて常に監視することが重要だ。
バレルファイル(index.js)の使用は慎重に
JavaScript開発でよく使われる手法に「バレルファイル」がある。これは、ディレクトリ内の複数のモジュールを一つのindex.js(またはindex.ts)でまとめて再エクスポートする仕組みだ。インポート側の記述がシンプルになり、ディレクトリ構造を隠蔽できるため、コードの見た目は非常に美しくなる。
見た目の美しさとパフォーマンスのトレードオフ
しかし、バレルファイルには無視できないデメリットがある。それは、ビルドパフォーマンスの低下とTree-shakingの阻害だ。バレルファイル経由で一つの関数だけをインポートしたつもりでも、ビルドツールはそのディレクトリ内のすべてのファイルを解析対象として読み込んでしまうことがある。
大規模なプロジェクトでは、この影響が顕著に現れる。実際にAtlassianのエンジニアリングチームは、Jiraのフロントエンドからバレルファイルを削除することで、ビルド時間を75%も短縮し、バンドルサイズの削減にも成功したと報告している。小規模なプロジェクトであれば利便性が勝るが、規模が拡大してきたら「インポートの美しさ」のために「実行性能」を犠牲にしていないか、立ち止まって考える必要があるだろう。
import { login } from './auth';※auth内の全ファイルが解析されるリスクあり
import { login } from './auth/login';※必要なファイルのみが最小限に解析される
このデモで示しているように、バレルファイルは記述を簡潔にする一方で、裏側での解析コストを増大させる可能性がある。パフォーマンスが求められる現場では、直接的なインポートが推奨される場合も多い。
結合度をコントロールし保守性を高める

モジュール間の関係性を考える上で避けて通れないのが「結合度」という概念だ。結合度とは、あるモジュールが別のモジュールの内部実装にどれほど依存しているかを示す指標である。保守性の高いシステムを目指すなら、可能な限り「疎結合」な状態を保つことが求められる。
特に注意すべきは「密結合」と「暗黙的な結合」だ。密結合は、相手のモジュールの内部の仕組みを知りすぎている状態であり、一方を修正するともう一方も修正しなければならない「変更の連鎖」を引き起こす。一方、暗黙的な結合は、グローバルな状態(シングルトンやグローバル変数)を介して、目に見えない形で依存している状態だ。これらはデバッグを困難にし、コードの予測可能性を著しく低下させる。依存関係は常に明示的(Explicit)にし、モジュールが公開する「インターフェース」のみを通じてやり取りを行うのが、長期的な運用における鉄則だ。
この記事のポイント
- ESMは静的解析を可能にする制約を設けることで、Tree-shakingによる最適化を実現している
- クリーンアーキテクチャの原則に従い、依存の方向を常に「外側から内側のビジネスロジック」へ向ける
- モジュールグラフを可視化し、循環参照や肥大化したユーティリティファイルを早期に発見・解消する
- バレルファイルは小規模では便利だが、大規模開発ではビルド時間やバンドルサイズに悪影響を与える可能性がある
- 結合度を低く保ち、モジュール間のやり取りを明示的なインターフェースに限定することで保守性を高める
・ 複数業界における17年間のデジタルビジネス開発経験
・ ウェブサイト開発のためのHTML、PHP、CSS、Java等の実用的知識
・ 15ヶ国語対応の多言語SaaSの開発経験
・ 17年間にも及ぶ、Eコマース長期運営経験
・ 幅広い業界でのSEO最適化の豊富な経験

CSSで日付範囲を選択する::nth-child(n of selector)を活用したスマートなUI実装術
Webサイトでホテルの予約や航空券の検索を行う際、カレンダーから「開始日」と「終了日」を選ぶUIは欠かせない要素だ。この「日付範囲の選択」を実装する場合、従来はJavaScriptを駆使して、選択された期間内のすべての要素に特定のクラスを付与する手法が一般的だった。
しかし、最新のCSSセレクタを活用すれば、JavaScriptの役割を最小限に抑えつつ、高度な範囲指定のスタイリングが可能になる。特に「:nth-child(n of selector)」という構文は、複雑な要素選択を劇的に簡素化する力を持っている。
この記事では、CSS-Tricksで紹介された手法を基に、最新のCSSセレクタを組み合わせてスマートな日付範囲セレクターを構築する方法を詳しく解説する。コードの保守性を高め、ブラウザの負荷を軽減する新しい実装アプローチを見ていこう。
:nth-child(n of selector) の基礎知識

まず、今回の実装の核となる「:nth-child(n of selector)」について理解を深めておこう。これはCSSの「擬似クラス」と呼ばれる機能の一つで、特定の条件に合う要素の中から、さらに順番を指定して選択できる強力なツールだ。
従来の :nth-child との違い
従来の :nth-child(n) は、「親要素から見て何番目の子要素か」を基準に判定していた。例えば .item:nth-child(2) と書いた場合、「2番目の子要素であり、かつ .item クラスを持っている要素」にスタイルが適用される。もし2番目の要素が別のクラスだった場合、何も選択されないという問題があった。
一方で、新しい :nth-child(n of .selector) 構文は、まず指定したセレクタ(この場合は .selector)に一致する要素だけをフィルタリングし、その抽出されたリストの中からn番目を選択する。これにより、間に別の要素が挟まっていても、特定のクラスを持つ要素だけを正確にカウントできるようになった。
フィルタリング機能の仕組み
この構文の最大のメリットは、動的に変化する状態に対しても柔軟に対応できる点だ。例えば、ユーザーがチェックを入れた要素だけを対象に「1番目のチェック済み要素」や「2番目のチェック済み要素」を指定できる。これは、日付範囲の開始点と終了点を特定する際に非常に役立つ仕組みだ。
このデモのように、特定の要素群(この場合は「項目」)だけを対象にして順番を数えられるのが、このセレクタの革新的な点だ。
カレンダーの基本レイアウトを作成する

日付範囲選択を実装するために、まずは土台となるカレンダーのレイアウトを準備する。CSS Grid(グリッドレイアウト)を使えば、カレンダーのような格子状の配置は驚くほど簡単に記述できる。
Grid Layoutによる7列配置
カレンダーは1週間が7日であるため、7つの列を持つグリッドを作成する。grid-template-columns:repeat(7, 1fr) と指定することで、親要素の幅を均等に7分割した列が自動的に生成される。これにより、日付の数字を順番に並べるだけで、自動的に適切な位置で改行されるようになる。
HTML構造の設計
HTML側では、各日付をリスト要素(<li>)として配置する。各日付の中には、チェック状態を管理するための <input type="checkbox"> を隠し要素として入れておく。ユーザーが日付をクリックした際に、このチェックボックスが切り替わる仕組みだ。
<ul id="calendar">
<!-- 曜日の表示 -->
<li class="day">月</li>
<li class="day">火</li>
<!-- ...土日まで -->
<!-- 日付の表示 -->
<li class="date">01<input type="checkbox" value="01"></li>
<li class="date">02<input type="checkbox" value="02"></li>
<!-- ...31日まで -->
</ul>CSSでは、この #calendar に対して display:grid を適用し、曜日と日付が綺麗に整列するように調整する。各日付(.date)は、ユーザーがクリックしやすいように十分なサイズと適切なパディングを持たせておくことが重要だ。
JavaScriptとCSSの役割分担

日付範囲の選択において、すべての処理をCSSだけで完結させることは現在の仕様では難しい。チェックボックスの「2つまでしか選択させない」といったロジックや、3つ目が選ばれた際の挙動制御にはJavaScriptが必要となる。しかし、ここで大切なのは「役割の最適化」だ。
チェック状態の制御ロジック
JavaScriptの主な仕事は、ユーザーのクリックに応じて checked 属性を適切に操作することだ。CSS-Tricksの記事で紹介されているロジックでは、新しく日付がクリックされた際、既存の選択範囲との位置関係を判定し、開始日または終了日を更新する処理を行っている。
ここで :nth-child(n of selector) がJS内でも威力を発揮する。querySelector メソッドでこのセレクタを使うことで、「現在チェックされている要素のうち、1番目のもの」を :nth-child(1 of :has(:checked)) として直接取得できるのだ。わざわざループを回してインデックスを探す手間が省ける。
CSSセレクタによる要素の特定
JS側で「範囲が選択された」と判断した際、親要素であるカレンダーに isRangeSelected といったクラスを付与する。これ以降の「範囲内の要素を青く塗る」といったビジュアル面の処理は、すべてCSSの領分となる。JSは状態(State)を管理し、CSSは見た目(View)を制御するという理想的な分離が実現できる。
この手法により、JSのコード量は大幅に削減される。DOMの書き換え(クラスの付け外し)を最小限に抑えられるため、ブラウザの再描画コストも低減され、結果としてパフォーマンスの向上につながるのだ。
範囲スタイリングの魔法

さて、いよいよ本題である「範囲内のスタイリング」について解説する。クラスを一つずつ付与することなく、CSSだけで「開始日と終了日の間」を特定するには、高度なセレクタの組み合わせが必要だ。
兄弟要素セレクタ(~)との組み合わせ
範囲を指定するための第一歩は、後続兄弟結合子(~)を使うことだ。これは「ある要素より後ろにある兄弟要素」をすべて選択する記号だ。:nth-child(1 of :has(:checked)) ~ .date と記述すれば、1番目にチェックされた日付より後ろにあるすべての日付を選択できる。
否定擬似クラス(:not)による制御
しかし、これだけでは「終了日より後ろの要素」まで選択されてしまう。そこで :not セレクタを組み合わせて、範囲を制限する。具体的には、「2番目にチェックされた要素より後ろにある要素ではないもの」という条件を加えるのだ。
.isRangeSelected :nth-child(1 of :has(:checked)) ~ :not(:nth-child(2 of :has(:checked)) ~ .date) {
background-color:rgb(228 239 253);
}この一見複雑なコードを分解すると、「1番目のチェック要素より後にある要素」の中から、「2番目のチェック要素より後にある要素」を除外していることになる。結果として、1番目と2番目の間にある要素だけが綺麗に抽出されるという仕組みだ。
※このデモはCSSの概念を視覚化したイメージだ。実際の動作はブラウザのデベロッパーツール等で確認してほしい。
実務におけるメリットと独自の分析

この新しいアプローチには、単に「コードが短くなる」以上の価値がある。Web制作の実務において、どのようなインパクトをもたらすのかを考察してみよう。
コードの保守性とパフォーマンス
最大のメリットは、JavaScriptがDOMの状態を過剰に意識しなくて済むようになることだ。従来の手法では、日付がクリックされるたびに、範囲内の全要素をループで回して .is-in-range といったクラスを付け替える必要があった。要素数が多い場合、この処理は無視できない負荷になる。
一方、今回の手法では、JSが行うのは「どのチェックボックスをオンにするか」という最小限の状態変更のみだ。見た目の更新はブラウザのCSSエンジンがネイティブで高速に処理するため、ユーザー体験はより滑らかになる。また、スタイルの変更が必要になった際も、JSを触ることなくCSSの修正だけで完結する保守のしやすさがある。
アクセシビリティへの配慮
この実装は、アクセシビリティ(利用しやすさ)の観点からも優れている。ネイティブのチェックボックスをベースにしているため、スクリーンリーダーなどの支援技術に対しても「どの項目が選択されているか」という情報を標準的な方法で伝えることができる。見た目だけでなく、情報の構造としても正しい状態を保ちやすいのだ。
ただし、注意点もある。:nth-child(n of selector) は比較的新しい機能であるため、古いブラウザ(特に数年前のスマートフォンなど)では動作しない可能性がある。実務で導入する際は、対象となるユーザーのブラウザ利用状況を確認し、必要に応じて基本的な背景色のみを適用するようなフォールバック(代替処理)を用意するのが賢明だろう。
この記事のポイント
:nth-child(n of selector)は特定の条件に合う要素の中だけで順番を数えられる- JavaScriptは状態管理に専念し、複雑な範囲スタイリングはCSSに任せるのが現代流
- 兄弟要素セレクタ(
~)と否定擬似クラス(:not)を組み合わせることで範囲を特定できる - DOM操作の削減により、コードの保守性とパフォーマンスの両立が可能になる
・ 複数業界における17年間のデジタルビジネス開発経験
・ ウェブサイト開発のためのHTML、PHP、CSS、Java等の実用的知識
・ 15ヶ国語対応の多言語SaaSの開発経験
・ 17年間にも及ぶ、Eコマース長期運営経験
・ 幅広い業界でのSEO最適化の豊富な経験

MDNのフロントエンド刷新の裏側:ReactからWeb ComponentsとRspackへの移行
世界中のエンジニアが頼りにする技術ドキュメントサイト「MDN Web Docs」が、フロントエンドのアーキテクチャを根本から作り直した。今回の刷新は単なるデザインの変更ではなく、長年抱えていた技術的な課題を解決するための大規模な再設計となっている。
MDNのチームは、これまで利用していたReactベースのSPA(Single Page Application / シングルページアプリケーション)から脱却し、Web Componentsと独自のサーバーサイドレンダリング(SSR)を組み合わせた新しい仕組みへ移行した。さらに、ビルドツールをWebpackからRust製のRspackに切り替えることで、開発環境の起動時間を2分から2秒へと劇的に短縮している。
なぜMDNのような巨大なサイトがReactを離れ、ネイティブに近い技術を選んだのか。その背景には、ドキュメントサイト特有の課題と、最新のWeb標準技術への信頼があった。この記事では、MDNの新しいフロントエンドがどのような思想で構築されたのか、その詳細を解説する。
なぜMDNはフロントエンドを根本から作り直したのか

MDNのフロントエンド刷新の最大の動機は、旧システム「yari」が抱えていた深刻な技術負債の解消だ。yariはCreate React Appをベースに構築されていたが、MDNのような静的コンテンツが主体のサイトには不向きな部分が多く、場当たり的な修正が積み重なっていた。
React SPAが抱えていた「ラッパー」という限界
旧システムにおいて、Reactアプリは静的なHTMLコンテンツを包む「ラッパー」に過ぎなかった。MDNのドキュメントの大部分はMarkdownから生成された静的なテキストだが、Reactはこのコンテンツの内容を直接把握することができなかった。
そのため、ドキュメント内に「コードのコピーボタン」のようなインタラクティブな要素を追加する場合、Reactの枠組みの外で標準的なDOM API(Document Object Model API / ブラウザがHTMLを操作するための仕組み)を直接操作する必要があった。これにより、サイトの一部はReactで書かれ、別の部分は直接的なDOM操作で書かれるという、管理しにくい二重構造が生まれていた。
複雑化しすぎたビルド設定とCSSの管理
ビルド環境も限界に達していた。Create React Appのデフォルト設定では対応できない要件が増えた結果、設定を「eject(イジェクト / ツールによる自動管理を解除して手動管理に移行すること)」せざるを得なくなり、Webpackの設定が複雑怪奇なものになっていた。
CSSについても、Sass(サス / CSSを効率的に書くための拡張言語)とモダンなCSS変数が混在し、スコープ(影響範囲)の管理が不十分だった。あるコンポーネントのスタイルを変更すると、予期せぬ場所のデザインが崩れるといった問題が頻発していた。また、CSSを適切に分割する仕組みがなかったため、ユーザーは常に巨大なCSSファイルをダウンロードさせられていた。
Web ComponentsとLitがもたらした相互運用の柔軟性

技術負債を解消するための切り札として選ばれたのが、Web Components(ウェブコンポーネント)だ。Web Componentsとは、HTMLの新しいタグを自分で定義できるブラウザ標準の機能だ。MDNチームは、このコンポーネント開発を効率化するために「Lit(リット)」という軽量なライブラリを採用した。
コンテンツ内にインタラクティブ要素を直接埋め込む
Web Componentsの最大の利点は、どんなHTML環境でも「カスタムタグ」として機能することだ。Reactのような特定のフレームワークに依存せず、Markdownから生成されたHTMLの中に <mdn-copy-button> のようなタグを直接配置するだけで動作する。
これにより、ドキュメント本文という「静的な世界」と、UIコンポーネントという「動的な世界」の境界線が消えた。MDNの著者は、複雑なJavaScriptの知識がなくても、特定のタグを記述するだけで高度な機能を記事に追加できるようになった。
Scrimbaの事例で見えた「ネイティブに近い」開発
Web Componentsの有効性を証明したのが、学習プラットフォーム「Scrimba」との連携だ。MDNのカリキュラムページでは、インタラクティブな学習環境を埋め込む必要があった。これをWeb Componentsで実装することで、ユーザーがクリックするまで重い <iframe> を読み込まない、といった制御が非常に簡潔に記述できるようになった。
Litを使用することで、ReactのJSX(JavaScript内にHTML風の構文を書く手法)に近い感覚で開発できつつ、コンパイル不要な標準のJavaScriptとして動作する。これにより、開発のしやすさと実行時のパフォーマンスを両立させた。
SPAを脱却し「アイランド・アーキテクチャ」へ

MDNは今回の刷新で、サイト全体を一つの巨大なアプリとして動かすSPAを完全にやめた。代わりに採用したのが、静的なHTMLをベースにしつつ、必要な部分だけを独立したコンポーネントとして動かす「アイランド・アーキテクチャ」に近い考え方だ。
必要な場所だけで動くWeb Components
新しいMDNでは、ページが読み込まれた後にDOM全体をスキャンし、mdn- で始まるカスタムタグを探す仕組みを導入している。特定のコンポーネントがページ内に存在する場合のみ、そのコンポーネントに必要なJavaScriptを非同期で読み込む。
このアプローチにより、ユーザーは自分が閲覧しているページに関係のないJavaScriptをダウンロードする必要がなくなった。トップページのナビゲーション、検索モーダル、記事内のインタラクティブな例など、それぞれが独立した「島」として機能する。
● 読み込みが遅い
● 全体が1つの塊
● 表示が爆速
● 機能ごとに独立
このデモは、ページ全体のJSを一度に読み込むSPAと、必要な部品だけを読み込む新方式の違いを視覚化したものだ。
Litを活用した独自のサーバーコンポーネント
MDNのチームは、クライアントサイドだけでなくサーバーサイドのレンダリングにもLitの仕組みを応用した。独自の「ServerComponent」クラスを作成し、Node.js上でHTMLを組み立てている。
特筆すべきは、CSSの最適化だ。サーバー側でどのコンポーネントが使われたかを追跡し、そのページに必要なCSSだけを <link> タグとして書き出す。これにより、未使用のスタイルシートが読み込まれることを防ぎ、レンダリングの高速化に成功している。
徹底したパフォーマンス最適化と開発体験の向上

アーキテクチャの変更に加え、MDNは開発ツールやブラウザ互換性の判断基準も刷新した。これにより、エンドユーザーだけでなく、サイトを維持管理するエンジニアの生産性も向上している。
Rspackの採用で起動時間を2分から2秒へ
開発環境の劇的な改善をもたらしたのは、ビルドツール「Rspack」への移行だ。Rspackは、広く使われているWebpackと互換性を持ちながら、コア部分がRust(ラスト / 高速なシステム開発向け言語)で書かれているため、非常に高速に動作する。
以前の環境では、開発サーバーを立ち上げるだけで約2分かかっていた。ちょっとした修正を確認するために数分待つ必要があり、開発者の大きなストレスとなっていた。Rspackの導入により、この待ち時間はわずか2秒にまで短縮された。開発体験の向上は、結果としてサイトの更新頻度や品質の向上に直結する。
Baselineに基づいたモダン機能の積極採用
MDNは「どの技術がどのブラウザで使えるか」を定義する「Baseline(ベースライン)」プロジェクトを推進している。自サイトの開発においても、このBaselineの基準を厳格に適用している。
「Baseline Widely Available(主要ブラウザで広く利用可能)」な技術は積極的に使い、比較的新しい技術についてはポリフィル(古いブラウザで新しい機能をエミュレートするコード)を最小限に抑えつつ、段階的な機能拡張(Progressive Enhancement)として実装している。これにより、最新ブラウザの性能を最大限に引き出しつつ、古い環境でも情報を損なわない設計を実現した。
独自の分析:静的サイトの未来とMDNの選択

今回のMDNの決断は、近年のWeb開発トレンドにおける重要な転換点を示している。一時期、あらゆるサイトをReactなどのSPAで構築するのが正解とされた時期があった。しかし、MDNの事例は「コンテンツ主体のサイトには、HTMLネイティブに近い構成が最適である」という原点回帰の正当性を証明している。
特筆すべきは、Web Componentsという「標準技術」への信頼だ。特定のフレームワークの流行り廃りに左右されず、ブラウザが直接理解できる形式でコンポーネントを構築することは、MDNのような「Webの辞書」としての永続性が求められるサイトにとって、最も合理的な選択と言える。
また、RspackのようなRust製ツールの台頭も無視できない。JavaScriptで書かれたツールチェーンの限界を、低レイヤーの言語で書かれたツールが打破していく流れは、今後さらに加速するだろう。MDNの刷新は、最新のWeb標準と高速なビルドツールが組み合わさることで、いかに強力なプラットフォームが構築できるかを示す、最高の手本となっている。
この記事のポイント
- MDNはReact SPAからWeb Componentsベースの新アーキテクチャへ移行した。
- Litを採用し、静的なMarkdownコンテンツ内に動的な要素を直接埋め込める柔軟性を確保した。
- アイランド・アーキテクチャにより、必要なJavaScriptだけを非同期で読み込む高速な表示を実現した。
- Rspackの導入により、開発環境の起動時間を2分から2秒へと劇的に短縮した。
- Baseline基準を採用し、モダンなWeb標準技術を最大限に活用しつつ互換性を維持している。
・ 複数業界における17年間のデジタルビジネス開発経験
・ ウェブサイト開発のためのHTML、PHP、CSS、Java等の実用的知識
・ 15ヶ国語対応の多言語SaaSの開発経験
・ 17年間にも及ぶ、Eコマース長期運営経験
・ 幅広い業界でのSEO最適化の豊富な経験

Cloudflare Client-Side Securityが全ユーザーに開放。GNNとLLMを融合した最新の検知技術を解説
Cloudflareは、ウェブサイトの閲覧者側で実行される悪意のあるスクリプトを検知・遮断する「Client-Side Security」の大幅なアップデートを発表した。これまでエンタープライズ向けに提供されていた高度なセキュリティ機能が、セルフサービスを利用するすべてのユーザーに開放される。1日あたり35億ものスクリプトを評価する同社のネットワークが、より広範なウェブサイトを保護する体制を整えた。
今回の更新で最も注目すべきは、AIを用いた新しい検知システムの導入だ。グラフニューラルネットワーク(GNN)と大規模言語モデル(LLM)を組み合わせることで、誤検知を劇的に減らしつつ、未知の攻撃を高い精度で特定できるようになった。従来のシグネチャベースの防御では防ぎきれない、高度に難読化された攻撃への対策が強化されている。
クライアントサイドを標的とした攻撃は、サイトの表示を崩すことなくデータを盗み出すため、運営者が気づきにくいという特徴がある。Cloudflareはこの課題に対し、最新のAI技術を統合することで、運用の手間を最小限に抑えながら強固な防御を提供することを目指している。本記事では、その技術的な仕組みと実戦での成果について詳しく解説する。
Cloudflare Client-Side Securityの進化と新展開

Cloudflareは、強力なセキュリティ機能を営業担当者との交渉なしに利用可能にすることを基本原則として掲げている。その一環として、これまで「Page Shieldアドオン」と呼ばれていた機能を「Client-Side Security Advanced」へと統合し、セルフサービスプランのユーザーでも即座に導入できるようにした。
全ユーザーへの門戸開放と無料化の意義
今回のアップデートにより、ドメインベースの脅威インテリジェンスがすべての顧客に無料で提供される。2025年には、Magentoなどのプラットフォームを利用する中小規模のECサイトが、クライアントサイドからの攻撃により数週間にわたって被害を受け続ける事例が多数報告された。こうしたリソースの限られたサイト運営者でも、ダッシュボード上のトグルを切り替えるだけで、既知の悪意のあるドメインとの通信を可視化できるようになった。
PCI DSS v4への対応とコンプライアンス
Client-Side Security Advancedには、コードの変更を継続的に監視する機能が含まれている。これは、クレジットカード業界のセキュリティ基準である「PCI DSS v4」の要件11.6.1を満たすために不可欠な要素だ。EC事業者はこのツールを導入することで、法規制や業界基準への準拠を容易に進めることができる。また、コンテンツセキュリティポリシー(CSP)に基づいたプロアクティブなブロックルールの運用も可能となっている。
攻撃をあぶり出す仕組み:ASTとブラウザレポーティング

クライアントサイドのセキュリティ管理は、膨大なデータを扱う極めて困難な課題だ。一般的なエンタープライズサイトでは、平均して2,200もの固有のスクリプトが動作している。さらに、これらのスクリプトの約3分の1は30日以内に更新される。これらを手動で承認していては、開発パイプラインが停止してしまうため、自動化された高度な分析が必要となる。
レイテンシゼロで監視するアーキテクチャ
Cloudflareのシステムは、ブラウザレポーティング(Content Security Policyなど)を利用して信号を収集する。これにより、サイトにスキャナーを導入したり、アプリケーションに特別なコードを埋め込んだりする必要がない。ユーザーのブラウザからの報告をCloudflareのプロキシ経由で受け取る仕組みのため、ウェブアプリケーションの表示速度に一切の影響を与えないのが大きな強みだ。
難読化を突破するAST解析の威力
攻撃者は検知を逃れるために、コードの変数を意味のない文字列に書き換えたり、構造を複雑にしたりする「難読化」を行う。Cloudflareはこれに対抗するため、スクリプトを「AST(Abstract Syntax Tree / 抽象構文木)」に分解して解析する。ASTとは、プログラムの構造を樹状図のような形式で表現したものだ。コードの見かけ上の書き方が変わっても、論理的な構造や挙動(インテント)を抽出できるため、悪意のある意図を正確に特定できる。
以下のデモは、難読化されたコードがどのようにAST的な構造として捉えられるかを視覚化したイメージだ。
var _0x1a2b = ["\x63\x6F\x6F\x6B\x69\x65"];
function _0x3c4d(){
send(_0x1a2b[0]);
} このデモは難読化されたコードが解析され、データの持ち出しという構造が特定される過程を視覚化したイメージである。
GNNとLLMを組み合わせた「二段構え」の検知システム

Cloudflareが導入した最新の検知システムは、2つの異なるAIモデルを連携させる「カスケード型」のアーキテクチャを採用している。これにより、広大なインターネット上に存在する無限に近いバリエーションのスクリプトを、効率的かつ正確に処理することが可能になった。
構造を捉えるGNNの役割と限界
第1段階として、すべてのスクリプトはグラフニューラルネットワーク(GNN)によって評価される。GNNはASTの構造を学習し、変数の名前が変更されていても、実行パターンの特徴から悪意のある挙動を検知する。GNNは処理が高速であり、未知の脅威(ゼロデイ攻撃)を見逃さない「高い再現率」を持っている。しかし、その一方で、複雑な広告用スクリプトや難読化された正当なライブラリを誤って「攻撃」と判定してしまう「偽陽性」が課題となっていた。
Workers AIによるLLMの「セカンドオピニオン」
GNNが「疑わしい」と判定したスクリプトのみ、第2段階として大規模言語モデル(LLM)に送られる。ここで使用されるのは、Cloudflareの「Workers AI」上で動作するオープンソースのLLMだ。LLMはコードの意味的な文脈を深く理解しており、開発者がよく使う記述パターンやフレームワーク特有の動作を識別できる。LLMが「これは怪しいが見た目は無害なコードだ」と判断すれば、GNNの判定を上書きして誤検知を防ぐ。この二段構えにより、独自の評価では偽陽性を約3分の1にまで削減することに成功した。
実戦での成果:ルーターを標的にした「core.js」の検知事例

この新しい検知システムは、すでに実際の攻撃を特定する成果を上げている。最近検知された「core.js」という悪意のあるスクリプトの事例は、AIによる構造・意味解析の有効性を証明するものとなった。
高度な難読化とゼロデイ攻撃の正体
「core.js」は、特定の地域でXiaomi製のOpenWrtベースのホームルーターを乗っ取ることを目的としたスクリプトだった。このスクリプトは、ルーターのWAN設定(DHCP、スタティックIP、PPPoEなど)を動的に照会し、DNS設定を書き換えてトラフィックをハイジャックしようとする。さらに、管理パスワードを密かに変更して、正当な所有者を締め出す機能まで備えていた。この攻撃はウェブサイトを直接改ざんするのではなく、侵害されたブラウザ拡張機能を通じてユーザーのセッションに注入されていた。
偽陽性を劇的に減らす精度の向上
このスクリプトは高度に圧縮・難読化されており、従来のシグネチャベースの防御システムでは検知が困難だった。しかし、CloudflareのGNNは難読化の奥にある悪意のある構造を暴き出し、Workers AI上のLLMがその意図を「ルーターのAPIを悪用する攻撃である」と確信を持って判定した。全体的なトラフィックにおける偽陽性率は約0.3%から0.1%へと低下し、固有のスクリプト単位では、偽陽性率が1.39%から0.007%へと約200倍も改善されたという。これにより、運用担当者はアラート疲れに陥ることなく、真の脅威に集中できるようになった。
独自の分析:クライアントサイドセキュリティが不可欠になる理由

今日のウェブ制作において、サードパーティ製スクリプトの利用は避けて通れない。広告、アクセス解析、チャットボット、SNS連携など、1つのサイトで数十の外部サービスが読み込まれることは珍しくない。しかし、これは「サプライチェーン攻撃」のリスクを常に抱えていることを意味する。自社のサーバーをどれだけ堅牢に守っても、読み込んでいる外部のJavaScriptが侵害されれば、ユーザーの個人情報や決済データは簡単に盗まれてしまう。
Cloudflareの今回の取り組みが画期的なのは、AIを「検知の高速化」だけでなく「運用の現実化」に活用した点だ。これまでのクライアントサイドセキュリティは、厳格に設定すれば誤検知が増えてビジネスを阻害し、緩く設定すれば攻撃を見逃すというジレンマがあった。GNNで広く網を張り、LLMで賢く精査するというアプローチは、膨大かつ変化の激しい現代のウェブエコシステムにおける現実的な解といえる。
特に、Workers AIを活用して自社ネットワーク内でLLMを完結させている点は、プライバシーとレイテンシの両面で合理的だ。セキュリティ製品が「導入するとサイトが重くなる」というこれまでの常識を覆し、パフォーマンスを維持したまま高度なAI防御を適用できるようになった意義は大きい。今後は、さらにLLMの判定基準を最適化することで、よりアグレッシブな検知設定が可能になり、未知の攻撃に対する防御力はさらに高まっていくと指摘されている。
この記事のポイント
- Cloudflare Client-Side Security Advancedがセルフサービスプランの全ユーザーに開放された
- ドメインベースの脅威インテリジェンスが無料化され、中小規模のサイトでも導入が容易になった
- GNNによる構造解析とLLMによる意味解析を組み合わせた二段構えの検知システムを導入した
- Workers AIを活用することで、サイトの表示速度に影響を与えずに高度なスクリプト解析を実現した
- ルーターを標的とした「core.js」のような、従来のシステムでは見逃されやすいゼロデイ攻撃の検知に成功した
・ 複数業界における17年間のデジタルビジネス開発経験
・ ウェブサイト開発のためのHTML、PHP、CSS、Java等の実用的知識
・ 15ヶ国語対応の多言語SaaSの開発経験
・ 17年間にも及ぶ、Eコマース長期運営経験
・ 幅広い業界でのSEO最適化の豊富な経験

Cloudflare Workflowsの可視化技術——ASTを活用したコードから図への変換プロセスを解説
Cloudflare Workflowsでデプロイされたすべてのワークフローに対し、ダッシュボード上で完全な視覚的図解(ダイアグラム)を表示する機能が追加された。この機能は、YAMLやJSONのような宣言的な設定ファイルからではなく、実際に記述されたJavaScript/TypeScriptのコードを直接解析して生成される点が最大の特徴だ。
開発者が記述したコードを「oxc-parser」を用いてAST(Abstract Syntax Tree / 抽象構文木)へと変換し、静的解析によってステップ間の依存関係や並列処理を抽出している。これにより、複雑なループや条件分岐を含む動的なワークフローであっても、その構造を一目で把握することが可能になった。
AIエージェントによるコード生成が増加する現代において、人間がコードの全容を即座に理解するための補助ツールとして、この可視化技術は極めて重要な役割を果たす。本記事では、難解な最小化済みコードからどのようにして意味のある図を導き出しているのか、その技術的な裏側を詳しく見ていく。
Cloudflare Workflowsの可視化機能とその背景
なぜ「コードからの可視化」が必要なのか
従来のワークフロー構築ツールの多くは、ドラッグ&ドロップのビジュアルエディタや、YAML/JSONによる宣言的な定義をベースにしていた。これらは図解しやすい反面、複雑なロジックを記述する際の柔軟性に欠けるという弱点がある。
対してCloudflare Workflowsは「コードがすべて」というモデルを採用している。Promise.allによる並列実行、複雑なforループ、条件分岐などが通常のJavaScriptとして記述できる。しかし、自由度が高い反面、コードが複雑になると全体の流れを把握するのが難しくなる。記事によれば、特にAIが生成したコードを人間が確認する際、その「形状(shape)」を視覚的に理解できるメリットは大きいという。
動的実行モデルという技術的ハードル
Workflowsは「動的実行モデル」に従っている。これは、ランタイムがコードを実行中にステップ(step.do)に遭遇するたびに、制御をエンジン(Durable Object)に渡す仕組みだ。エンジンは実行されたステップの結果を保存するが、次にどのステップが来るかを事前には知らない。
図を作成するには、実行前(デプロイ時)に全体の構造を知る必要がある。しかし、エンジンが実行時にしかステップを把握できないのであれば、静的な図を作ることはできない。そこで、Cloudflareのチームはデプロイ時にスクリプトを解析し、コードの構造を「読み解く」アプローチを選択した。
AST(抽象構文木)を用いたコード解析の仕組み
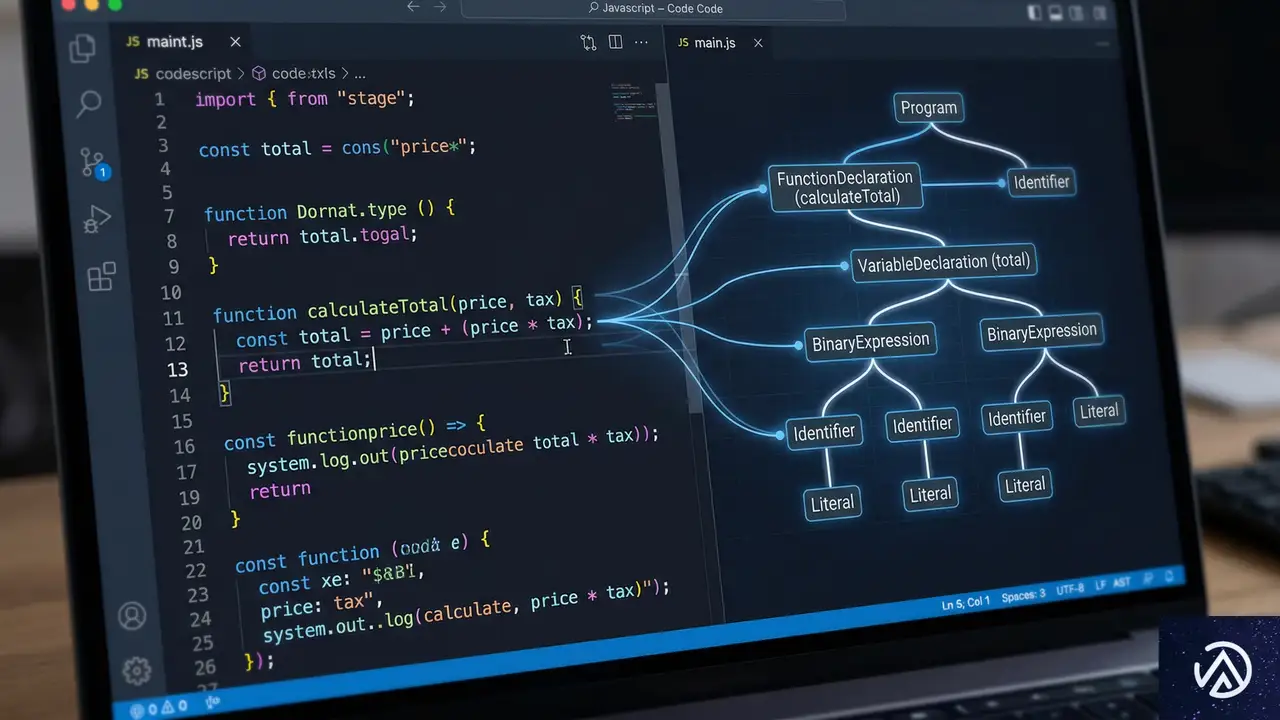
最小化されたJavaScriptという難問
デプロイされるコードは、通常esbuildやrspack、viteなどのツールによって「最小化(Minify)」されている。変数名はaやbに書き換えられ、改行は消え、人間には解読不能な1行の巨大な文字列となる。この状態からワークフローのステップを抽出するのは容易ではない。
AST(Abstract Syntax Tree / 抽象構文木)とは、プログラミング言語の構文構造を樹木構造で表現したデータ形式だ。コードをトークンに分解し、どの関数がどの引数で呼び出されているかを構造的に把握できる。Cloudflareは、このASTを利用して最小化されたコードのジャングルからstep.doやstep.sleepといった特定の呼び出しを特定している。
高速な解析を実現するoxc-parserの採用
解析エンジンには、Rust製の高速なJavaScriptツールチェーンである「OXC(JavaScript Oxidation Compiler)」のoxc-parserが採用された。当初はコンテナ上でRustを動かしていたが、最終的にはWebAssembly(Wasm)を介してCloudflare Workers上で動作するRust Workerへと移行されたという。
このRust Workerが最小化されたJSをASTに変換し、定義されたノードタイプ(LoopNode, ParallelNode, IfNodeなど)にマッピングしていく。以下に、コードがどのようにASTを経て図の要素へ変換されるかの概念図を示す。
step.do('task', ...)このデモは、ソースコードがAST解析を経て、最終的にダッシュボード上の視覚的なステップノードへとマッピングされる流れを視覚化したものだ。
複雑なロジックをグラフ構造にマッピングする手法
並列処理を表現する「開始」と「解決」のインデックス
Workflowsにおいて最も表現が難しいのが、並列処理だ。JavaScriptではawaitを付けずにステップを呼び出すと並列に実行され、Promise.allでそれらをまとめて待機できる。これを図にするため、Cloudflareのチームは各ノードにstartsとresolvesというフィールドを持たせた。
解析中にawaitされていないPromiseに遭遇すると、そのノードに「開始(starts)」のインデックスを付与する。その後、awaitに遭遇した時点でインデックスを増やし、「解決(resolves)」として記録する。この数値の重なりを見ることで、どのステップが垂直方向に並ぶべきか(=並列か)、どのステップが完了を待って次に進むべきかを正確に判定している。
制御構文(ループ・分岐)のパターン網羅
単なる直線的なフローだけでなく、実務では多様な構文が使われる。著者のAndré氏とMia氏は、以下のような多岐にわたるパターンをASTから抽出できるように設計したと述べている。
- ループ:
for...of,while,items.map,forEach - 分岐:
switch/case,if/else, 三項演算子 - エラーハンドリング:
try/catch/finally - 関数呼び出し: ステップをラップした関数の追跡
特に、関数の中に隠れたステップの追跡は工夫が必要だ。ある関数が直接ステップを呼び出していなくても、その中で呼び出している別の関数がステップを含んでいる場合、その依存関係をグラフに含める必要がある。記事によれば、関数ごとのサブグラフを作成し、最終的にステップを含まない「葉」の部分をトリミングすることで、ノイズのない図を実現している。
開発体験(DX)における可視化の価値と今後の展望

デバッグ効率を劇的に高めるリアルタイム追跡
この可視化機能は単なる「清書された図」ではない。Cloudflareは、これをフルサービスのデバッグツールへと進化させる計画だ。具体的には、実行中のワークフローが今どのノードにいるのかをグラフ上でリアルタイムに追跡できるようにするという。
エラーが発生した場所の特定、人間による承認待ちの状態確認、あるいはテスト目的での特定ステップのスキップなど、ビジュアルインターフェースを通じて操作できる未来を目指している。さらに、ローカル開発環境での可視化も視野に入れているとのことで、開発サイクル全体での利便性向上が期待される。
独自の分析:コードを「正解」とするアプローチの意義
今回のCloudflareの取り組みで特筆すべきは、「ビジュアルエディタで作ったものをコードに書き出す」のではなく、「コードからビジュアルを逆生成する」という方向性を徹底している点だ。これは、エンジニアにとっての真実の源泉(Source of Truth)が常にコードであることを尊重している。
このアプローチの利点は、Gitによるバージョン管理やコードレビューといった既存の開発フローと完全に共存できることにある。図を作成するために特別な設定ファイルを書く必要がなく、普段通りにコードを書くだけで、非エンジニアのステークホルダーにも共有しやすい図が手に入る。これは、開発組織におけるコミュニケーションコストを大幅に下げる可能性を秘めている。
また、AST解析という「枯れた」技術を、最小化されたJSという「汚れた」実データに適用し、それをWasmでエッジ上で高速実行するという構成は、非常にCloudflareらしい合理的でパワフルな解決策だと言えるだろう。
この記事のポイント
- コードから図を自動生成: Cloudflare Workflowsは、JS/TSコードを解析して視覚的な図を自動作成する。
- AST(抽象構文木)の活用: 最小化された難解なコードも、AST解析によって構造的に理解し、ステップを抽出する。
- oxc-parserによる高速処理: Rust製の解析器をWasmで動かすことで、デプロイ時の高速な図解生成を実現した。
- 並列処理の可視化:
startsとresolvesというインデックスを用いて、複雑な並列実行の関係を正確に図示する。 - デバッグツールへの進化: 今後はリアルタイムの実行追跡や、図からの操作機能も追加される予定だ。
出典
- Cloudflare Blog「How we use Abstract Syntax Trees (ASTs) to turn Workflows code into visual diagrams」(2026年3月27日)
・ 複数業界における17年間のデジタルビジネス開発経験
・ ウェブサイト開発のためのHTML、PHP、CSS、Java等の実用的知識
・ 15ヶ国語対応の多言語SaaSの開発経験
・ 17年間にも及ぶ、Eコマース長期運営経験
・ 幅広い業界でのSEO最適化の豊富な経験