

Multigres v0.1 α版リリース、Postgres向け水平スケーリングOSの概要
2026年6月4日、SupabaseのチームがオープンソースプロジェクトMultigresの初のパブリックマイルストーンとなるv0.1 Alphaを公開した。このプロジェクトはPostgresにVitess級の水平スケーリング、高可用性、運用のシンプルさをもたらす「オペレーティングシステム」を目指している。
v0.1 Alphaでは高度なコネクションプーリング、自動フェイルオーバー、Kubernetesオペレーターが提供される。シャーディング機能は今後のリリースで追加予定だ。以下の記事ではその設計思想と仕組みを掘り下げる。
Multigresとは
・フェイルオーバーは運用者が判断
・コネクション制限への個別対処
・バックアップは別ツールで管理
・自動フェイルオーバーでダウンタイム最小
・コンテキスト認識型コネクションプーリング
・バックアップとリストアを統合管理
MultigresはPostgresインスタンスを包括的に管理する「スケーラブルなオペレーティングシステム」だ。シャーディング、コネクションプーリング、自動フェイルオーバー、バックアップオーケストレーションを単一のシステムで提供する。
Postgresスケーリングの課題
Postgresを大規模に運用する際、読み取りレプリカの管理、フェイルオーバーの対応、コネクション上限対策、バックアップのスケジューリングなど、運用負荷が高い。これらをバラバラのツールで解決しようとすると、複雑さが増していく。
Multigresが解決すること
Multigresはこれらを一貫したシステムとして自動化する。データベースのスケールが必要になったタイミングでシャーディングも処理し、水平スケーリングを実現する。v0.1 Alphaではまだ単一シャードだが、基盤は整っている。
Kubernetesオペレーター
Kubernetesオペレーターによって、Multigresクラスタのデプロイと管理が抽象化される。必要なのはKubernetesクラスタとバックアップ用のストレージ(共有ファイルシステムやAWS S3バケット)だけだ。ローカルのKindクラスタでも動作検証が可能で、必要なコンテナイメージはすべて公開されている。
高可用性(HA)の仕組み
データの不整合やコミット消失のリスク
耐久性ポリシーをユーザーが自由に定義可能
MultigresはHAを合意形成の問題として扱い、スプリットブレインが起きてもコミット済みデータを失わない。これを一般化合意(generalized consensus)モデルで実現している。これは従来のコンセンサスベースシステムにはない柔軟性をもたらす。
一般化合意モデル
Multigresは無修正のPostgresレプリケーションの上に実装されており、厳密な一貫性要件を満たす。さらに、過半数のクォーラムのような制約に縛られず、ユーザーが任意の耐久性ポリシーを定義できる。例えば「単一のアベイラビリティゾーン(AZ)障害に耐える」を設定すれば、それ以上のゾーンにスタンバイを配置することも可能だ。
レプリカの動的追加と削除
クラスタ稼働中にレプリカを安全に増減できる。パフォーマンスに影響を与えず、設定された耐久性ポリシーと整合性を保ったままスケーリングが可能だ。
コネクションプーリングの革新
Multigresは独自の2サービスアーキテクチャによるコネクションプーリングを採用している。クライアント接続を受け付ける「multigateway」と、バックエンド接続を管理する「multipooler」で構成され、単一プロセスのプーラーにはない利点がある。
トラフィックルーティングとフェイルオーバー
HAシステムとの統合により、multigatewayは常に現在のプライマリに透過的に接続を転送する。フェイルオーバー発生時は新しいプライマリが昇格するまでリクエストを保留し、エラーを最小化する。読み取り負荷は複数レプリカに分散可能で、将来的にはシャード間のルーティングにも対応予定だ。
コンテキストアウェアプーリング
Multigresはトランザクションやセッションといったプーリングモードを明示的に選択する必要がない。組み込みのパーサーが各リクエストの効果を理解し、接続状態を追跡する。ステートフルなトランザクションが必要な場合だけ接続をそのクライアントに固定し、それ以外は再利用する。
ユーザー別プールとプリペアドステートメント
ユーザーごとに独立したコネクションプールを保持し、SET ROLEによるなりすましを使わない。固定の接続予算をフェアシェアアルゴリズムで分配する。さらに、プリペアドステートメントはゲートウェイ間で重複排除され、Postgres側で文の解析、計画、キャッシュが1回だけ行われる。
バックアップ戦略
MultigresはバックアップにpgBackRestを使用し、プライマリに負荷をかけないようレプリカから取得する。バックアップの種類は完全、増分、差分の3つで、通常は定期的な完全バックアップと短い間隔の増分・差分を組み合わせる。
オンデマンドとスケジュール
CLIでバックアップの一覧表示や手動バックアップ、リストアが可能だ。スケジュール機能は今後のクラスタスペックを通じて追加予定となっている。
クラスターブートストラップ
クラスタ起動時にMultigresが自動的にプライマリを特定し、バックアップを取得して他のレプリカを初期化する。これにより人手を介さずに即座に利用可能なクラスタが立ち上がる。
アルファ版の制限と今後の展望
・既知の課題がGitHubイシューにあり
・将来バージョンとの後方互換性は保証されない
・CR APIが安定していない
・パフォーマンスベンチマーク未公開
・スケジュールバックアップのサポート
・APIの安定化とベンチマークの公開
・コミュニティからのフィードバック集約
v0.1 Alphaは実験とフィードバックに十分な安定性を持つが、本番運用にはまだ適さない。シャーディングは今後のリリースで追加予定の主力機能であり、現在はHAとプーリングを備えた単一シャードクラスタの形で提供されている。ベータやv1.0に向けてAPIの安定化とベンチマークの公開が進められる見通しだ。
この記事のポイント
- MultigresはPostgresのスケーリングと運用を自動化するオープンソースOS
- v0.1 AlphaでKubernetesオペレーター、HA、高度なコネクションプーリングを提供
- 一般化合意モデルによりスプリットブレインを安全に解決
- コンテキストアウェアプーリングでモード選択不要、ユーザー別プールも実装
- シャーディングは将来リリース予定、現在はフィードバック収集段階

・ 複数業界における17年間のデジタルビジネス開発経験
・ ウェブサイト開発のためのHTML、PHP、CSS、Java等の実用的知識
・ 15ヶ国語対応の多言語SaaSの開発経験
・ 17年間にも及ぶ、Eコマース長期運営経験
・ 幅広い業界でのSEO最適化の豊富な経験

GKE Agent Sandboxが一般提供開始。エージェント向け基盤Agent Substrateも発表
Google Cloudが2026年5月20日、エージェント実行環境「GKE Agent Sandbox」の一般提供(GA)を開始した。合わせて、超大量エージェントの高密度実行を目指す新たなOSSプロジェクト「Agent Substrate」を発表している。
2025年11月のKubeCon NAでプレビューが公開されて以降、Agent Sandbox上のサンドボックス数は5か月足らずで16倍以上に成長した。LangchainやLovableといった顧客がすでに数百万単位のエージェントを本番環境で動作させている。
自律的にコードを実行するAIエージェントにとって、インフラの安全性と起動速度は実用化の鍵となる。今回のGAで安定版APIが提供され、エージェント実行基盤としての成熟度が一段と上がった。
GKE Agent Sandbox GAの主要な機能強化点

GKE Agent SandboxはKubernetes上に構築されたOSSの実行環境だ。AIエージェントが信頼できないコードを安全かつ高速に実行するための基盤として設計されている。今回のGAでは、実運用で課題となるアイドル状態の効率化と、起動レイテンシの低減に焦点が当てられた。
Pod Snapshotによるアイドルリソースの削減
エージェントのワークロードは、短いバースト的な処理の後に長いアイドル時間が続くという特徴を持つ。従来のようにアイドル中もPodを起動したままにしておくと、コンピュートリソースを無駄に消費してしまう。
GKE Agent SandboxはPod Snapshot機能と統合されている。アイドル状態のエージェントワークロードを一時停止(サスペンド)し、リクエストが来たときに数秒で再開できる。Google Cloudの発表によれば、この仕組みで不要なコンピュートコストを大幅に削減できるという。
Pod Snapshotの最大の利点は、エージェントワークロード特有の「使うときだけ高速に起動したい」という要求に応えられる点だ。サスペンド状態からの復帰は数秒で完了するため、ユーザーの待ち時間を最小限に抑えられる。
ウォームプールによる低レイテンシプロビジョニング
エージェントのリクエストが来るたびに新しいサンドボックスを作成すると、コールドスタートによる数秒の遅延が発生する。この遅延はエージェントの応答性を損ない、ユーザー体験を悪化させる要因となる。
GKE Agent Sandboxは、サンドボックスAPIにウォームプールを統合した。あらかじめ準備されたサンドボックスレプリカをプールしておき、リクエスト発生時に即座に割り当てる仕組みだ。これにより、1クラスタあたり毎秒300のサンドボックスを割り当て可能で、割り当ての90パーセントが200ミリ秒以内に完了する。
ウォームプールのコスト最適化も考慮されている。プール内のレプリカは常時稼働しているが、スタンバイキャパシティバッファと統合することで、一部のサンドボックスをサスペンド状態で待機させられる。ウォームプールが枯渇した際には、この「コールドプール」から素早く補充され、大幅なコスト削減につながる。
gVisorとネットワークポリシーによる強固な隔離
セキュリティ面では、gVisorをネイティブサポートし、デフォルト拒否のKubernetesネットワークポリシーを採用している。gVisorはユーザースペースで動作するカーネルであり、ホストOSから隔離された環境を提供する。コンテナ内のプロセスがホストカーネルに直接アクセスできないため、悪意あるコード実行のリスクを大幅に低減できる。
さらにKata ContainersのようなOSSサンドボックスにも対応するプラグイン可能なインターフェースを備えている。利用者は自社のセキュリティ要件に合わせてカーネル隔離レベルを選択できる。
コンピュートの選択肢も広がった。Google Cloud独自のAxionプロセッサ上でAgent Sandboxを実行すると、同等のハイパースケーラークラウドプロバイダと比較して最大30パーセント優れた価格性能比を達成すると発表されている。
Agent Substrateがもたらす次の変革

エージェントワークロードは今後、数千万から数億インスタンス規模へとスケールアップしていく。同時に、人間の操作やイベントを待つアイドル時間もますます長くなる。カーネルとネットワークの隔離を維持しながら高密度にスケジュールするのは、既存のKubernetesコントロールプレーンでは限界が近づいている。
この課題に対してGoogle Cloudが発表したのが、新たなOSSプロジェクト「Agent Substrate」だ。
Kubernetesの限界を超える最小限のコントロールプレーン
Agent Substrateは、Agent Sandboxの安全なランタイムとSnapshot機能を中核に据えつつ、Kubernetesの制約を部分的に回避する最小限のコントロールプレーンを組み合わせる。標準のKubernetesが数千の長時間稼働サービスを扱うのに最適化されているのに対し、Agent Substrateは数百万単位のサブ秒ツール呼び出しの「チャタリング」に耐えられるよう設計されている。
新たな抽象化レイヤーを導入し、Kubernetes上で稼働するコンピュートキャパシティに対して、エージェントをリアルタイムに乗せたり外したりする。Google Cloudの発表では、従来のコントロールプレーンでは処理しきれない高頻度の短命ワークロードに対して、レイテンシを低減しつつスケールと効率を最適化できるとしている。
Agent Substrateの目標は、現在のコンピュートインフラの限界を押し広げることにある。一例として、エージェントの状態とスケジューリングが協調して動作するようデータの局所性をスケジューラの中核に組み込む構想も示された。オーバーヘッドを1ミリ秒単位で削り取るため、あらゆる可能性を探求する姿勢が打ち出されている。
Agent HarnessやAgent Executorとの関係
Agent Substrateは、単独で動作するものではなく、エージェントエコシステム全体の基盤レイヤーとして位置づけられている。Agent HarnessやAgent Runtime、さらにはGoogle Cloudが別途発表している分散エージェントランタイム「Agent Executor」プロジェクトを支える役割を担う。
Google Cloudのブログ記事では、Agent Substrateを「エージェントネイティブなインフラストラクチャの次の章」と表現している。Kubernetesが登場初期に多様なコントリビューターの知見を集めて成功したように、エージェントインフラも同じ転換点にあるという認識が示された。
この記事のポイント
- GKE Agent Sandboxが一般提供開始。安定版APIでエージェント実行の本番運用に対応
- Pod Snapshotでアイドル時のリソース消費を抑え、リクエスト時に数秒で復元可能
- ウォームプールにより毎秒300サンドボックスをサブ秒で割り当て。コスト最適化も統合
- 新OSSプロジェクトAgent Substrateは数百万規模の短命ワークロードに特化した設計
- Axionプロセッサ利用時に最大30パーセントの価格性能比向上を達成
・ 複数業界における17年間のデジタルビジネス開発経験
・ ウェブサイト開発のためのHTML、PHP、CSS、Java等の実用的知識
・ 15ヶ国語対応の多言語SaaSの開発経験
・ 17年間にも及ぶ、Eコマース長期運営経験
・ 幅広い業界でのSEO最適化の豊富な経験

Kubernetesの1行修正で年600時間を削減——Cloudflareが直面したPVマウントの罠
Kubernetesの設定ファイルをたった1行書き換えるだけで、年間600時間ものエンジニア工数を削減した事例がある。Cloudflare(クラウドフレア)のインフラチームが直面したこの問題は、システムの規模が拡大するにつれて静かに忍び寄る「デフォルト設定の罠」を浮き彫りにした。
原因は、ストレージの権限管理を行うKubernetesの標準的な振る舞いにあった。数百万ものファイルを抱えるボリュームにおいて、再起動のたびに30分ものダウンタイムが発生していた事態を、彼らはどのように特定し、解決したのだろうか。
本記事では、CloudflareのエンジニアであるBraxton Schafer氏が公開したデバッグの過程と、大規模なKubernetes運用において見落としがちなパフォーマンスのボトルネックについて詳しく解説する。
Atlantisの再起動がなぜか「30分」もかかる謎

Cloudflareでは、Terraform(テラフォーム)によるインフラ管理の自動化ツールとして「Atlantis(アトランティス)」を利用している。Terraformはコードでインフラを定義するツールだが、Atlantisを導入することで、GitHubやGitLabのプルリクエスト上で実行計画(Plan)の確認や適用(Apply)が可能になる。
AtlantisはKubernetes上で「StatefulSet(ステートフルセット)」として動作しており、リポジトリの状態を保持するためにPV(Persistent Volume / 永続ボリューム)を使用している。StatefulSetとは、Pod(ポッド)の再起動後もデータの永続性を保証するための仕組みだ。
頻繁な再起動がエンジニアの時間を奪う
問題は、このAtlantisを再起動するたびに発生していた。新しいプロジェクトの設定を読み込ませたり、認証情報を更新したりするために、Cloudflareでは月に約100回ほどの再起動を行っていた。しかし、再起動を開始してからPodが正常に立ち上がるまで、毎回30分もの時間がかかっていたという。
この間、エンジニアはインフラの変更を行うことができず、作業が完全にブロックされてしまう。月100回の再起動で毎回30分待機が発生すれば、月間で50時間、年間では600時間もの時間が「ただの待ち時間」として消えていく計算だ。これは、一人のエンジニアが数ヶ月間フルタイムで働く時間に匹敵する大きな損失である。
「inode不足」がきっかけで表面化した問題
この遅延が決定的な問題として認識されたのは、ストレージの「inode(アイノード)」が枯渇した際だった。inodeとは、ファイルシステム上でファイルやディレクトリの情報を管理するためのデータ構造だ。ファイルが大量に作成されると、ディスク容量が残っていてもinodeが足りなくなり、新しいファイルが作成できなくなる。
Cloudflareの環境では、ファイルシステムを拡張することでしかinodeを増やせない仕様だった。拡張を反映させるにはPodの再起動が必要となり、そのたびに30分のダウンタイムが発生する。チームは当初、アラートの通知設定を調整して「見かけ上の問題」を回避することも検討したが、根本的な原因の調査に乗り出すことを決めた。
Kubernetesのログを深掘りして見えてきたボトルネック
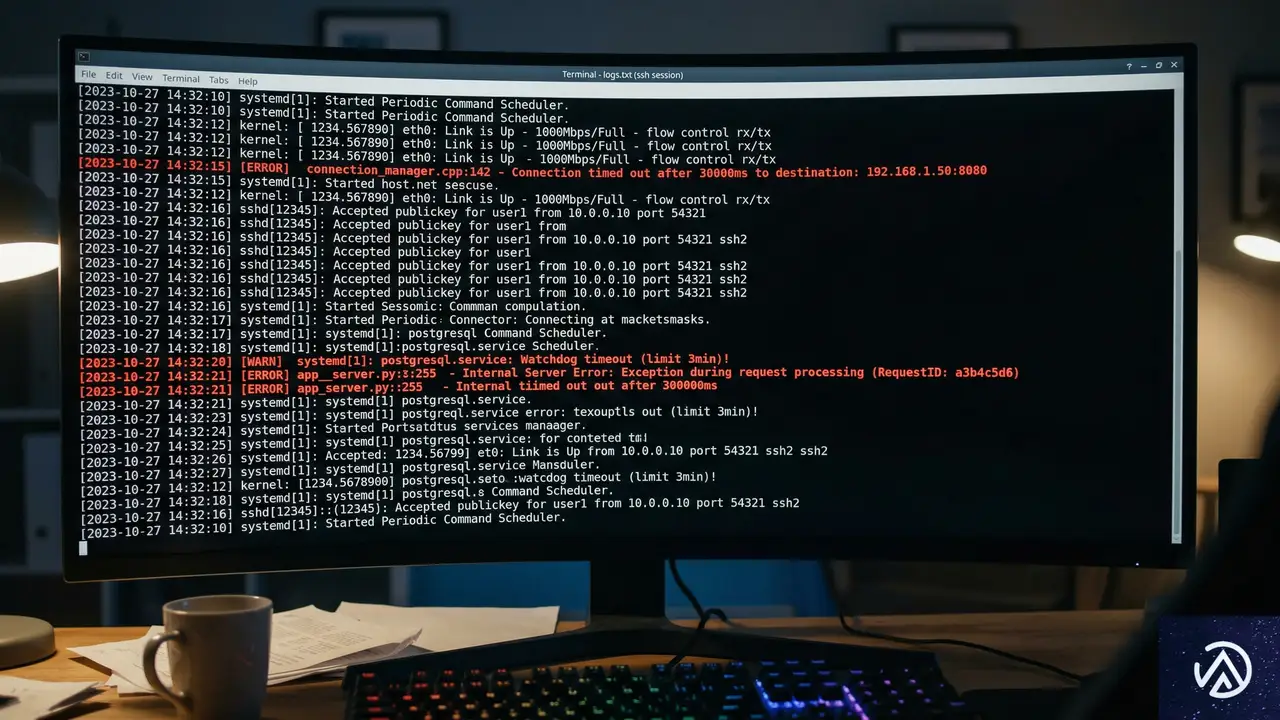
調査を開始したBraxton Schafer氏は、まずkubectl rollout restartコマンドを実行し、新しいPodが立ち上がる様子を観察した。Pod自体はすぐにスケジュールされるものの、ステータスが「Init(初期化中)」のまま30分間も停止していることが判明した。
Podのイベントログを確認しても、イメージのプルが開始されるまでに不可解な空白時間があることしかわからなかった。そこで氏は、より低レイヤーのログを確認するため、各ノードで動作するコンポーネント「kubelet(クブレット)」のログを調査した。
kubeletのログに隠された「空白の時間」
kubeletは、各ノードでPodの実行を管理し、ボリュームのマウントなどを制御する重要なエージェントだ。システム管理ツールであるKibana(キバナ)を使ってログを分析したところ、PVのマウント自体は成功しているものの、その直後にタイムアウトエラーが発生し、リトライを繰り返している様子が記録されていた。
ログには「context deadline exceeded(処理時間の制限を超過した)」というメッセージが並んでいた。何らかの処理が異常に時間を要しており、Kubernetesの監視機構がそれを「失敗」とみなして処理を中断、再試行するというループに陥っていたのだ。
数百万個のファイルが引き起こす権限変更の罠
さらに詳細なログを追うと、決定的なメッセージが見つかった。そこには「Setting volume ownership(ボリュームの所有権を設定中)」という記述があった。実はこれが、30分もの時間を浪費させていた真犯人だった。
Kubernetesには、Pod内のプロセスがボリュームにアクセスできるように、マウント時に所有権を自動で調整する機能がある。具体的には、PodのsecurityContextで指定されたfsGroupのIDに合わせて、ボリューム内の全ファイルに対して再帰的にchgrp(グループ変更)を実行する。Atlantisのようなツールは運用期間が長くなるほど管理するファイル数が増大し、Cloudflareの環境では数百万個ものファイルが蓄積されていた。高速なストレージであっても、数百万個のファイルに対して一つずつ権限を確認・変更していく処理には膨大な時間がかかるのは必然だ。
わずか1行の修正でパフォーマンスが劇的に改善
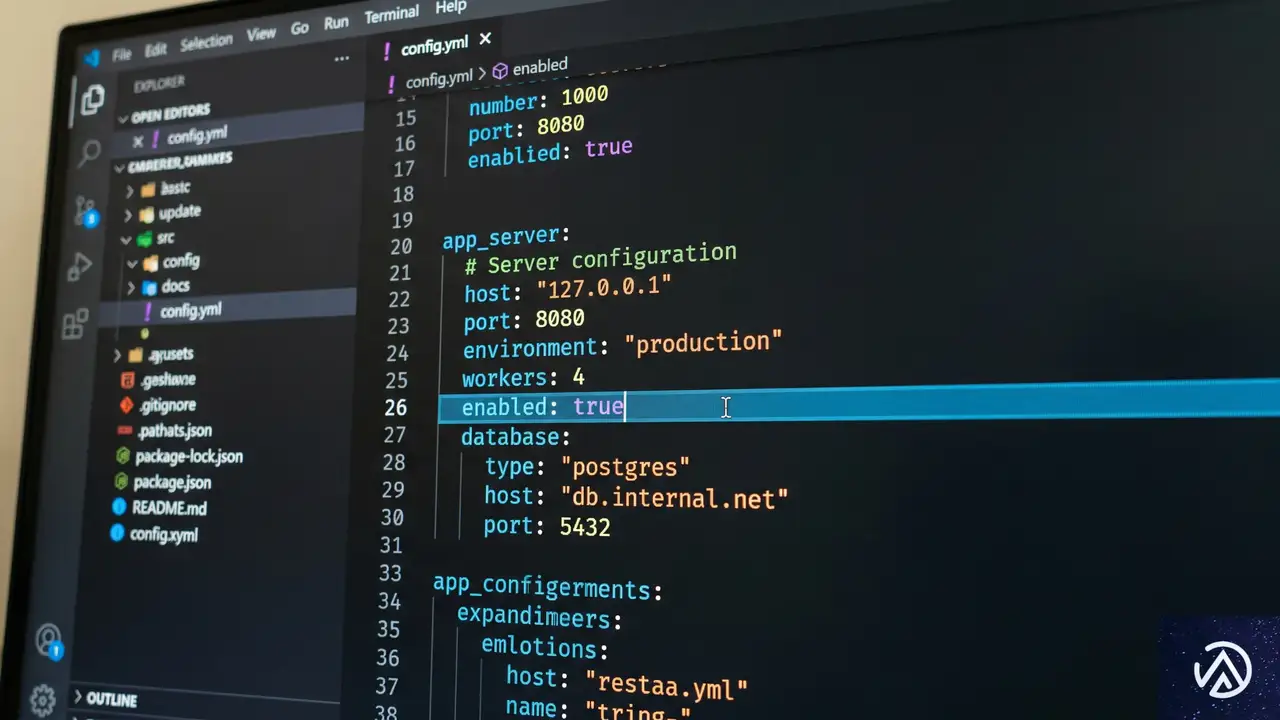
原因が「再帰的な権限変更」であると特定できれば、解決策は非常にシンプルだった。Kubernetes 1.20以降、この振る舞いを制御するための新しい設定項目が追加されている。それがfsGroupChangePolicy(エフエスグループ・チェンジ・ポリシー)だ。
デフォルトでは、このポリシーはAlways(常に実行)に設定されている。つまり、Podが起動するたびに、すでに権限が正しく設定されていようがいまいが、すべてのファイルをスキャンして権限を上書きしようとする。これが大規模なボリュームにおいて致命的な遅延を引き起こす。
fsGroupChangePolicyの設定とは
解決策は、このポリシーをOnRootMismatch(ルートディレクトリが不一致の場合のみ実行)に変更することだ。この設定にすると、Kubernetesはまずボリュームのルートディレクトリの権限を確認する。もしルートの権限がすでに正しく設定されていれば、配下のファイルに対する再帰的なスキャンをスキップする。
spec:
template:
spec:
securityContext:
fsGroupChangePolicy: OnRootMismatchこの1行をマニフェストファイルに追加するだけで、権限変更のプロセスが大幅に簡略化される。Cloudflareのケースでは、これまで30分かかっていた再起動時間が、わずか30秒にまで短縮された。実に60倍の高速化だ。
30分から30秒へ、驚異的な短縮効果
この修正により、エンジニアがデプロイの待ち時間に拘束されることがなくなった。また、再起動が長引くことによって発生していた「Podが正常に起動しない」という偽のアラートに、オンコール担当者が夜中に叩き起こされることもなくなったという。技術的には極めて単純な変更だが、組織全体の生産性に与えたインパクトは計り知れない。
大規模システムにおける「デフォルト設定」の落とし穴

今回の事例から学べる最も重要な教訓は、Kubernetesの「安全なデフォルト設定」が、規模の拡大とともに牙を向く可能性があるということだ。fsGroupによる自動的な権限変更は、初心者が権限エラーに悩まされないようにするための親切な機能として設計されている。
しかし、エンタープライズレベルの運用において、数テラバイトのデータや数百万のファイルを扱うようになると、その「親切心」がシステムの可用性を損なう要因へと変わる。これは、小規模なプロジェクトでは決して表面化しない問題だ。
小規模なら問題ないが、スケールするとボトルネックになる
多くのインフラエンジニアは、マウントが遅い場合にネットワークやストレージ装置の性能を疑う。しかし、今回のケースのように「OSレベルのファイル操作」がバックグラウンドで走っていることに気づくには、深いオブザーバビリティ(観測性)が必要だ。Braxton Schafer氏が、Kubernetesのイベントログだけでなく、kubeletのシステムログまで掘り下げたことが早期解決の鍵となった。
SRE的視点での教訓
SRE(Site Reliability Engineering / サイト信頼性エンジニアリング)の観点では、「なぜシステムはこのように振る舞うのか?」という問いを持ち続けることの重要性が再確認された。30分の待ち時間を「そういうものだ」と受け入れてしまえば、年間600時間の損失は永遠に解消されなかっただろう。
もし読者の環境でも、特定のPodの起動が異常に遅かったり、ボリュームをマウントする際にInitコンテナで止まっていたりする場合は、securityContextの設定を見直してみる価値がある。特に、大量の静的ファイルを保持するCMSや、データベースのバックアップファイルを扱うPodなどは、同様の問題を抱えている可能性が高い。
この記事のポイント
- 原因の特定: Atlantisの再起動に30分かかっていたのは、Kubernetesがマウント時に全ファイルの所有権を再帰的に変更していたため。
- 1行の修正:
fsGroupChangePolicy: OnRootMismatchを設定することで、不要な権限変更をスキップできる。 - 劇的な改善: Cloudflareはこの修正により、再起動時間を30分から30秒に短縮し、年間600時間の工数を削減した。
- 教訓: 安全のためのデフォルト設定が、大規模環境では深刻なパフォーマンス低下を招くことがある。
- 推奨アクション: 大容量PVを使用するPodでは、
securityContextの設定を監査し、不必要な再帰処理を避ける設定を検討すべきだ。
出典
- Cloudflare Blog「A one-line Kubernetes fix that saved 600 hours a year」(2026年3月26日)
・ 複数業界における17年間のデジタルビジネス開発経験
・ ウェブサイト開発のためのHTML、PHP、CSS、Java等の実用的知識
・ 15ヶ国語対応の多言語SaaSの開発経験
・ 17年間にも及ぶ、Eコマース長期運営経験
・ 幅広い業界でのSEO最適化の豊富な経験