

Claude Fable 5がGoogle Cloudで一般提供開始。エージェント構築の新たな基盤を考察
Anthropicの最新モデル「Claude Fable 5」が、Google Cloud上で一般提供を開始した。このモデルは複雑な多段階推論や高度なコード生成を得意とし、長期間にわたって自律的に動作するエージェントの構築に適している。クラウドAIの基盤に何が起きているのかを読み解く。
Claude Fable 5の登場とその戦略的な位置付け
Anthropicのモデル群には、Haiku(軽量高速)、Sonnet(バランス)、Opus(超高性能)がある。今回登場したFableシリーズは、これらのニックネームとは明らかに異なる文脈を持つ。筆者の見解では、Fableは「物語(ストーリー)の生成」、つまり長文脈の一貫性維持や、複雑なオーケストレーションを必要とするエージェントタスクに特化した系統と位置付けられる。
このモデルは単に速度や知識量を競うだけでなく、「どれだけ複雑な仕事を最後までやり遂げられるか」を重視している。特に、長期稼働エージェントとしての使用が強く想定されている点が、他のモデルとの差別化要因だ。
Fable 5は、単発のレスポンスを返すだけではない。途中で文脈を見失ったり、指示を忘れたりする問題を大幅に低減し、ソフトウェア開発や分析業務といった長時間の集中を要するタスクで真価を発揮する。
Fable 5の主要な能力と想定されるユースケース

Google Cloudの公式発表とAnthropicのリリースノートから、Fable 5の中核的な機能強化点を読み解くと、以下の3つに集約される。
複雑な多段階推論と高度なコード生成
Fable 5は、数学的推論やコード生成ベンチマークで大幅な性能向上を達成している。これは単にコードを出力するだけでなく、既存のリポジトリ全体を理解し、アーキテクチャレベルの提案ができることを示す。典型的な「次のトークン予測」を超え、人間のソフトウェアアーキテクトのように数手先を読む能力が強化された。
長期稼働エージェントの実現
多くのLLMは文脈が長くなると応答精度が落ちる。Fable 5は「長時間にわたって自律的にツールを使い、タスクを完了させる」というエージェント動作に最適化されている。カスタマーサポートの自動化、継続的なデータ収集、IT運用の自動化など、数時間から数日単位で動くAIエージェント基盤として機能する。
深いマルチモーダル文書分析
テキストだけでなく、PDF内のグラフ、パワーポイントの図表、画像内のテキストまでを横断的に理解する能力が向上した。これにより、企業内に散在する非構造化データの分析ハードルが大幅に下がる。数百ページの契約書や仕様書を読み込ませ、瞬時に要約や矛盾点の洗い出しを行うといった使い方が視野に入る。
これらの能力は、もはや「優秀なアシスタント」ではなく「自立したチームメンバー」という表現が近い。開発現場ではコードレビューを完全自動化し、法務部門では契約書の精査を任せられる。人間が最終判断する仕事の質とスピードが、根本から変わる可能性をはらんでいる。
Google CloudのAgent Platformがもたらす実用性

モデル単体の性能もさることながら、今回の発表で注目すべきはGoogle Cloudの「Agent Platform」上で提供される点だ。これは単なるAPIゲートウェイではない。エージェントの構築、テスト、デプロイ、監視までを垂直統合した基盤である。
具体的には、Googleが持つエンタープライズグレードのセキュリティ(IAM、VPC Service Controls)、Vertex AIのMLOps機能(モデル評価、メタデータ管理)、そしてCloud RunやBigQueryといった周辺サービスとの統合がシームレスに行える。Fable 5のような高度なモデルを「安全に」「堅牢に」本番環境で動かすために必要なピースがあらかじめ揃っている。
ここで重要なのは、強力なモデルを手に入れることと、それをビジネスで使いこなすことの間にあるギャップが、Agent Platformによって埋められる点だ。認証基盤や監査ログが整っていない状態でAIエージェントに重要な業務を任せることは難しい。Google Cloudのプレゼンスは、企業のAI導入における「最後の1マイル」を解決する。
開発者が今日から試すべき3つのアプローチ
Fable 5とAgent Platformが利用可能になったことで、Web制作やシステム開発の現場で即座に試せる実験領域が広がった。筆者の視点から、特に費用対効果が高いと想定される3つのシナリオを提示する。
コードレビューの完全自動化プロトタイプ
GitHub連携をトリガーに、Fable 5がPull Request全体を解析する。コーディング規約のチェックだけでなく、コードの脆弱性、パフォーマンス劣化リスク、過去の類似実装との矛盾点までを自然言語でレビューコメントする。人間のレビューアは、Fable 5が出した指摘が正しいかどうかの最終判断だけに集中できる。
非構造化ドキュメントのデータベース化
クライアントから提供された古い仕様書のPDF、競合分析のスライド、展示会で撮影したホワイトボードの写真などをまとめてFable 5に投入する。モデルはこれらを横断的に解析し、共通する要求定義や矛盾する記述を抽出して構造化データとして出力する。データベースに格納することで、後続の検索やレポート作成が自動化される。
社内向け「なんでも調査エージェント」の起案
定型的なリサーチ業務をエージェント化する。例えば「3ヶ月以内に更新された特定分野の法改正情報を、週次で一覧化してSlackに投げる」といったタスクをFable 5に任せる。モデルが自律的にGoogle検索や社内Wikiを巡回し、複数ステップの推論を経て最終的なサマリーを生成するPoCは、数日あれば構築可能だ。
このアプローチによって、人間の工数は「クリエイティブな問題解決」と「AIの提案に対する最終的な意思決定」に集中できるようになる。
この記事のポイント
- Anthropicの最新モデルClaude Fable 5は、複雑な推論と長期稼働エージェントに特化してGoogle Cloud上で一般提供が開始された
- 高いコード生成能力と深いマルチモーダル分析を持ち、単なるテキスト生成を超えたタスクの自動化が可能になった
- Google CloudのAgent Platformとの統合により、エンタープライズレベルのセキュリティと運用基盤が整備されている
- 人間はAIの最終判断に集中する働き方へシフトするため、コードレビューや文書分析のプロトタイプを早期に試す価値がある

・ 複数業界における17年間のデジタルビジネス開発経験
・ ウェブサイト開発のためのHTML、PHP、CSS、Java等の実用的知識
・ 15ヶ国語対応の多言語SaaSの開発経験
・ 17年間にも及ぶ、Eコマース長期運営経験
・ 幅広い業界でのSEO最適化の豊富な経験

Cloudflareが企業のAIコスト爆発を制御、AI Gatewayに利用上限を搭載
企業におけるAI導入の最大の壁はもはや技術力ではない。管理不能なコストの爆発だ。2026年6月5日、Cloudflareは自社のAI Gatewayに新たな「利用上限」機能を搭載し、この課題への直接的な解決策を提示した。
多くの企業では全エンジニアに最先端モデルのAPIキーを共有している。月末に届く高額な請求書を見て、経理とCTOが頭を抱える。誰が何に使ったのか全く分からないのだ。Cloudflareの今回の発表は、まさにこの無法地帯に統制をもたらすものだ。
併せて発表されたアイデンティティベースの予算管理は、Cloudflare Accessと既存のIdP(Identity Provider / アイデンティティプロバイダー)を組み合わせ、個人やチーム単位での正確なコスト帰属を実現する。
なぜAIコストは制御不能に陥るのか
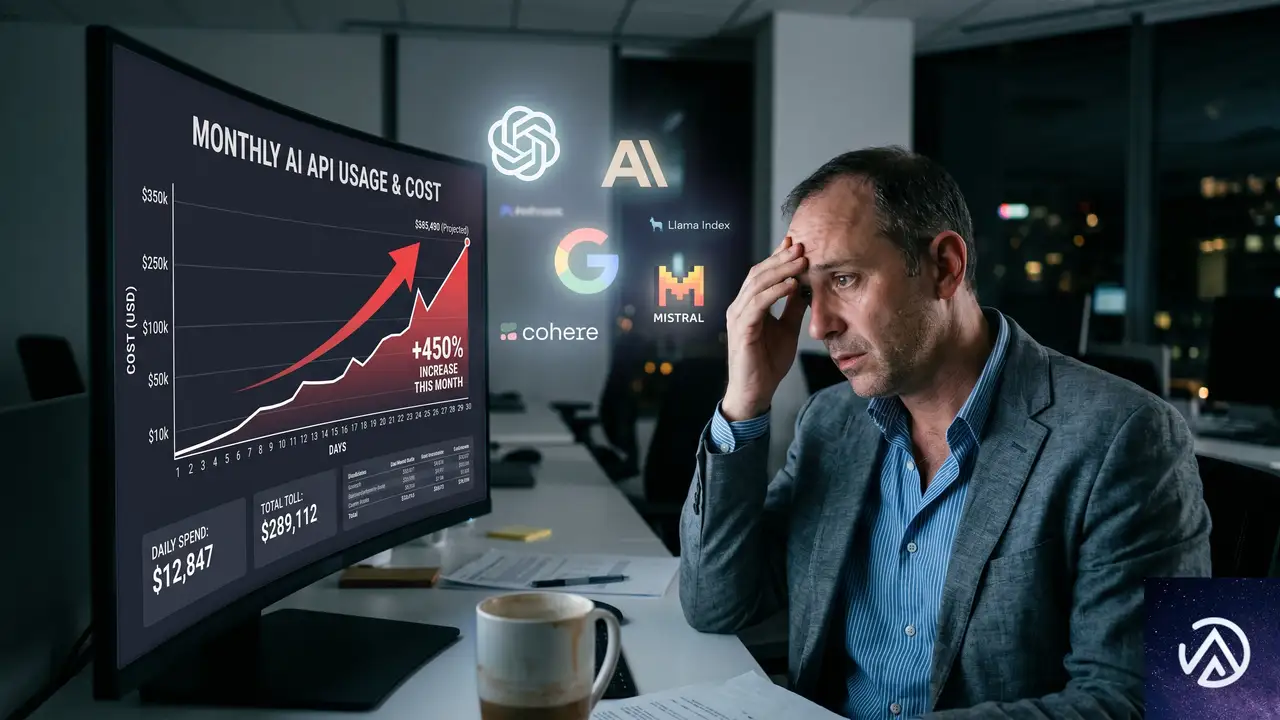
AI導入を進める企業で、まったく同じストーリーが繰り返されている。現場には「まずは最速でAIを使え。勘定は後でなんとかする」という号令が飛ぶ。これは大抵の場合うまくいく。実際、AIを積極的に取り入れたチームの生産性は飛躍的に向上している。しかし、その代償は安くない。月末に経理がAPI利用料の請求書を開くと、にわかには信じがたい桁の数字が目に飛び込んでくるのだ。
Cloudflareのブログ記事でも、この構図は明確に描写されている。社内で共有されているAPIキーでは、コストの発生源を追跡できない。機械学習チームの新規パイプライン構築が原因なのか、インターンがメールの仕分けに高額なClaude Opusを使い倒したのか、あるいはCI/CDジョブが週末のうちに何千万トークンも消費したのか、誰にも分からない。
問題の本質は、指標と制御の欠如により、合理的な判断が歪められてしまうことにある。予算も可視化もなければ、常に最も強力で高価なモデルを選ぶのが個々のエンジニアにとっては合理的な行動となる。コードレビューの要約に、大規模なアーキテクチャ再設計と同じモデルは必要ない。ログパーサーに、顧客向けコンテンツ生成と同じモデルは不要だ。しかし、現場には適切な道具を選ぶ動機も手段も存在しなかったのである。
利用上限機能を深掘りする
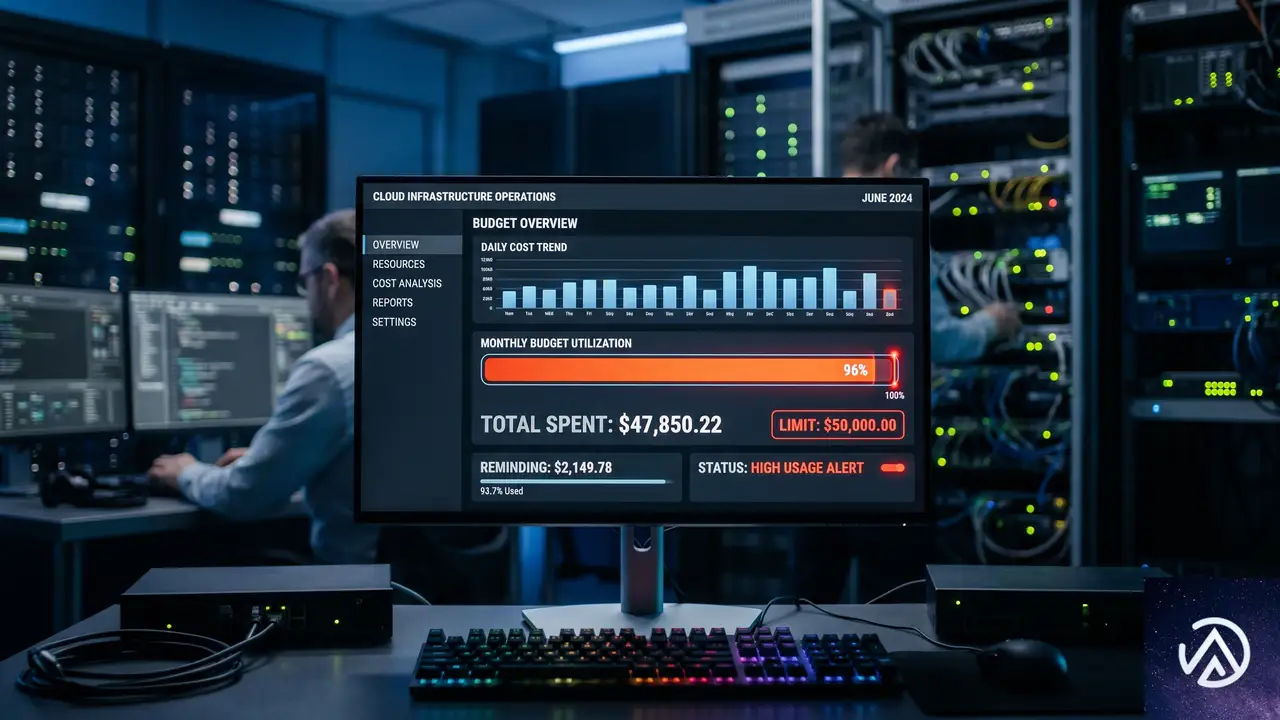
中核となる仕組み
AI GatewayはアプリケーションとAIプロバイダーの中継点として機能する。OpenAIやAnthropicへの直接APIコールを、まずこのゲートウェイを経由させる仕組みだ。これにより、リクエストの永続化ログ、キャッシュ、レート制限、リトライ、分析といった恩恵が得られていた。しかし、従来は「誰がいくら使ったか」の正確なトラッキングに限界があった。
ここに新たに導入された利用上限機能は、真のコスト統制を実現する。トークンベースではなく、ドルベースの予算で累積支出を追跡する点が実務的だ。制限のスコープは、モデル、プロバイダー、ユーザーやチームといった管理者定義のカスタム属性の任意の組み合わせで設定できる。期間も固定(月初リセットや月曜リセット)かローリング(直近N日間)かを選べ、日次、週次、月次での運用が可能だ。
予算超過時の現実的な選択肢
最も重要なポイントは、上限到達時の処理だろう。デフォルトではリクエストをブロックする。だが、ワークフローを完全に止めないための工夫として、ダイナミックルートと連携したフォールバックモデルへの切り替えが可能だ。これなら、最大予算額に達してもエンジニアの作業が完全に停止することはない。
この機能群は本日から全プランの全ユーザーにオープンベータとして提供されており、ダッシュボードかAPI経由で即座に設定できる。
アイデンティティ駆動の予算管理がもたらす透明性

利用上限機能と同時に、Cloudflareはアイデンティティベースの予算とポリシーを限定ベータとして発表した。利用上限がモデルやカスタム属性による制御であるのに対し、こちらは実在の個人とチームに紐づく。アプリケーション側でメタデータを渡す必要はなく、信頼性の低いヘッダー情報に頼る必要もない。
Cloudflare Accessとの統合が生む確実な帰属
AI GatewayをCloudflare Accessと連携させると、リクエストの送信者が誰かを確実に特定できる。単なるアカウント単位ではなく、個々の従業員、IdPグループ、サービス単位だ。Cloudflare社内では既にこの仕組みを実践しており、全従業員がAIツールを利用する中で月間数十億トークンが流れるトラフィックを可視化している。
仕組みはシンプルだ。従業員がCloudflare Access経由で認証されると、そのアイデンティティがJWT(JSON Web Token)から抽出され、AI Gatewayのリクエストにメタデータとして添付される。これにより、ユーザー単位のトークン消費、チーム単位の使用量内訳、組織全体のコスト帰属が一元管理できるようになる。
CI/CDパイプラインへの適用とボット予算
この機能は人間だけのものではない。Accessサービスアカウントを利用すれば、自律的なエージェントやCI/CDパイプラインにも名前付きのIDを付与できる。コードレビューボットが今週500万トークンを消費し、ドキュメント生成器が50万トークンだった、といった詳細が手に取るように分かる。あるエージェントが制御不能に陥ったとしても、他のエージェントに影響を与えることなく個別に予算ポリシーを適用できるのだ。
Cloudflare自身、全社でこのスタックを運用した経験に基づいて本機能を公開した。自社で構築したものを他社もゼロから作る必要はない、という明快なスタンスである。
次の段階はコスト最適化の自動化
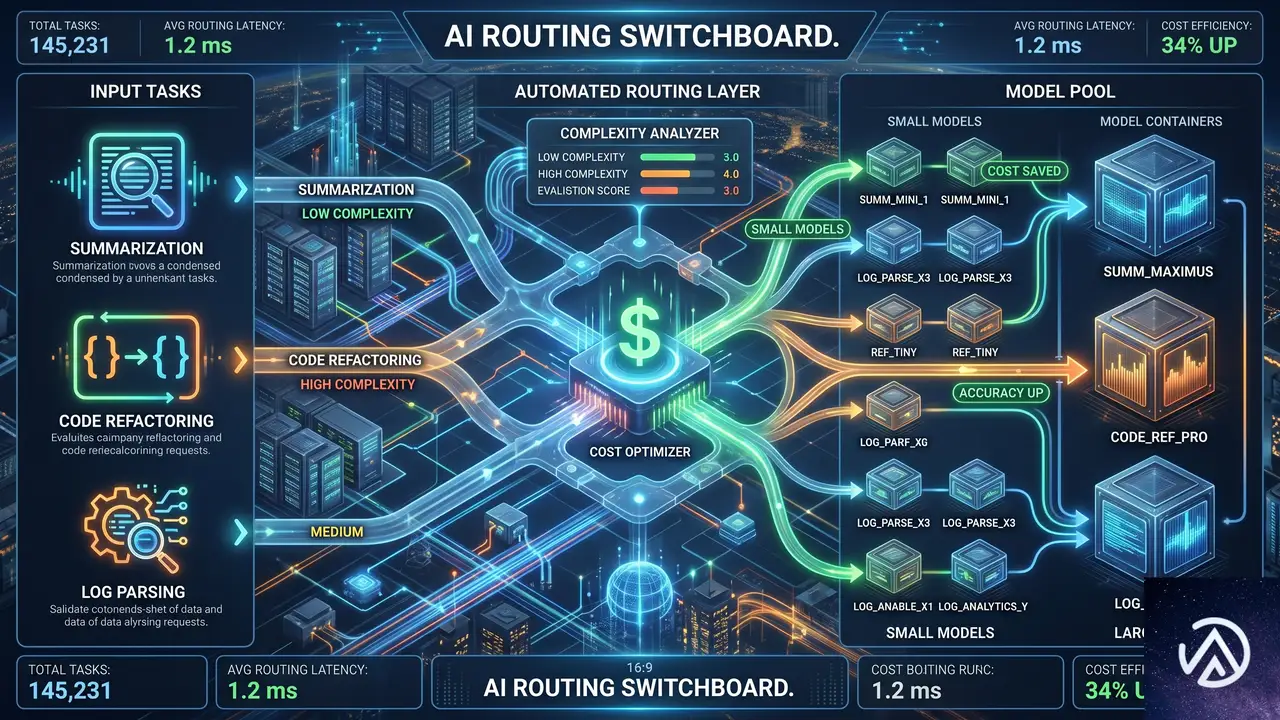
予算を設定し可視化することは、第一段階に過ぎない。次の課題は、限られた予算で最大の成果をどう引き出すかだ。現実には、すべてのリクエストに最先端モデルは不要である。要約タスクはより小さな安価なモデルでも品質を損なわずに実行できる。一方、大規模なコードリファクタリングには最新鋭のモデルが必要だ。しかし、制御がなければ人は常に最も高機能なモデルへ流れてしまう。
この問題に対し、Cloudflareはタスクベースのインテリジェントルーティングを鋭意開発中であると明かした。リクエストを分析し、最もコスト効率の良い結果を導くモデルへ自動的にルーティングする機能だ。詳細はデベロッパードキュメントとチェンジログで追って発表される。
この記事のポイント
- Cloudflare AI Gatewayにドル建ての利用上限機能が全プラン向けに登場した
- 上限到達時はリクエストをブロックするか、より安価なフォールバックモデルに自動で切り替えられる
- 限定ベータのアイデンティティベース予算は、個人やチーム単位で正確なコスト管理を実現する
- これらの機能はCloudflareが自社の大規模AI運用で実証した手法を外部化したものである
- 今後はタスクの複雑さに応じて最適なモデルへ自動ルーティングする機能の開発が予定されている
・ 複数業界における17年間のデジタルビジネス開発経験
・ ウェブサイト開発のためのHTML、PHP、CSS、Java等の実用的知識
・ 15ヶ国語対応の多言語SaaSの開発経験
・ 17年間にも及ぶ、Eコマース長期運営経験
・ 幅広い業界でのSEO最適化の豊富な経験

AIが変えるブランド競争の場。EC事業者が知るべきAIシェルフ戦略
生成AIが、消費財ブランドにとっての新しい「棚スペース」になりつつある。従来の小売店頭やECサイトの検索結果に加え、AIアシスタントやLLM(大規模言語モデル)に自社商品を推薦させる競争が始まっているのだ。
Practical Ecommerceの2026年5月の記事によれば、アメリカの消費者の42%が直近1カ月で少なくとも1つのAIツールを購買に利用していたという。この数字が示すのは、AIがもはや「未来の技術」ではなく、購買プロセスの一部として当たり前に存在する現実だ。
WooCommerceをはじめとするECプラットフォームを運営する事業者にとって、この変化は単なるトレンドではない。商品の認知から比較、選択に至る購買ジャーニー全体が、AIを経由するようになったとき、自社の立ち位置はどう変わるのかを今から考えておく必要がある。
AIが消費者の購買行動を根本から変えている

2026年現在、AIを活用した購買ツールは、商品の発見と評価のプロセスにおいて無視できない存在になっている。具体的には、ChatGPTやClaudeといった対話型AIに商品の比較を依頼したり、AIがレビューを要約して要点を伝えたりするケースが急増している。
AIショッピングの浸透度を数字で見る
CapitalOne Researchが5月に発表したファクトシートでは、消費者の約60%がAIを使って買い物をした経験があると報告されている。またNielsenIQの調査では、アメリカの消費者の42%が直近1カ月以内に少なくとも1つのAIツールを購買に活用していた。これらの数値は、AIがすでに市場の主流に組み込まれつつあることを示している。
なぜ「AI経由の購買」が重要なのか
AIが購買の意思決定に介入するということは、消費者が「Google検索」や「Amazonの検索バー」だけでなく、AIとの会話を通じて商品を絞り込む場面が増えることを意味する。AIは過去の検索エンジンと異なり、商品のスペック比較やレビュー要約を動的に生成し、あたかも「店員」のように振る舞う。そこでの推薦順位が、売上に直結する時代が来ているのだ。
この比較図が示すように、消費者の目に触れる情報量は減り、代わりにAIが厳選した「少数の選択肢」が購買の勝敗を左右するようになる。
「棚」の獲得競争はAIへと拡張された

ブランドにとっての棚スペースとは、物理的な店舗の陳列棚だけではない。長年にわたり、小売店のバイヤーに商品を採用させ、目立つ位置を確保することが重要だった。その構図はインターネットの登場で検索結果の上位表示(SEO)や、Amazon内のカテゴリランキングへと拡大した。そして2026年の今、その競争はAIの「会話」の中にまで及んでいる。
フィジカルシェルフからAIシェルフへ
eコマース技術企業WayviaのCEO、Anthony Ferry氏はPractical Ecommerceの記事の中で、ブランドの役割は本質的に変わっていないと指摘する。つまり、自社商品を競合よりも優位に見せるために宣伝し、プロモーションをかけることだ。しかし今はそれに加えて、「LLMに自社商品を推薦させるための教育」が求められているという。
これはEC事業者にとっても同じ構図だ。商品ページのメタデータ、構造化データ、レビュー、Q&Aの質が、AIに正確に解釈され、推薦されるための「栄養源」になる。AIに自社商品を「理解」させる取り組みは、もはやオプションではない。
上の図が示すように、競争の場は3層構造になった。AIシェルフはまだ黎明期だが、ここでのポジションを早期に築いたブランドが、次の購買体験で優位に立つ可能性が高い。
AIは「静かなるゲートキーパー」である
AIが購買意思決定のゲートキーパー(門番)として機能し始めている。AIが提示する情報や推薦リストは、しばしば客観的で中立的に見える。しかし現実には、LLMの学習データや参照元、プロンプトの設計によって、結果は大きく左右される。ブランドはこのゲートを通過するために、AIが「理解できるデータ」を整備しなければならない。
具体的には、商品の属性情報をJSON-LDなどの構造化データで正確にマークアップすること、FAQやナレッジベースを整備してAIが商品知識を取得しやすくすること、そしていわゆる「レビューの評価軸」を明確にすることが有効だ。これらはすべてWooCommerceのプラグインやカスタマイズで実装可能な領域である。
AIシェルフを「積み上げる」戦略と予算の再配分

Ferry氏は同記事の中で、マーケティング予算の分散について重要な指摘をしている。かつてテレビやラジオ、紙媒体に集中していた広告費は、まずオンラインチャネルの登場によって分配され、いまやSNSやマーケットプレイス、さらには生成AIチャネルへと細分化されている。チャネルは実に30種類にものぼり、それぞれに予算を投じるか否かの判断が経営課題になっているのだ。
最も費用対効果が高いチャネルはどれか
実務者にとって重要なのは、AIシェルフへの投資対効果をどう測るかという点だ。現時点では、AI経由のトラフィックやコンバージョンを追跡する確立された手法はまだ整っていない。しかし少なくとも、商品情報の充実度を測る独自指標を設け、AIからの参照確率を高める取り組みを始めることはできる。
たとえば、商品説明文を「AIに比較されやすい表現」に書き換えるだけでも効果は見込める。箇条書きでスペックを明示する、類似商品との違いを数値で示す、といった対策は今日からでも着手可能だ。高額な広告予算を投じる前に、まずはコンテンツの質をAIに最適化する段階にあると言える。
この比較例のように、AIは感覚的な売り文句よりも、数値化された具体的なスペック情報を評価する傾向がある。EC事業者は、商品情報の粒度を「機械が処理しやすい形」に再構築することが求められる。
AIシェルフでの優位性をどう築くか
Ferry氏の説明を要約すると、ブランドがとるべきアプローチは以下の3段階に整理できる。第一に、AIが自社商品を正しく認識し、比較対象に含めるためのデータを整えること。第二に、競合商品との差別化ポイントをAIが学習しやすい形式で発信すること。第三に、いわゆる「AIフレンドリーなコンテンツ」を継続的に更新し、LLMの再学習サイクルに対応することだ。
これはWooCommerceの運用に置き換えれば、「商品データのクレンジングと構造化データの導入 → 比較記事やFAQの拡充 → 定期的なデータ更新の自動化」という具体的なタスクに落とし込める。特にYoast SEOやRank Mathといったプラグインの構造化データ機能は、AIシェルフ最適化の第一歩として見直す価値がある。
EC事業者が今すぐ始めるべき4つのアクション
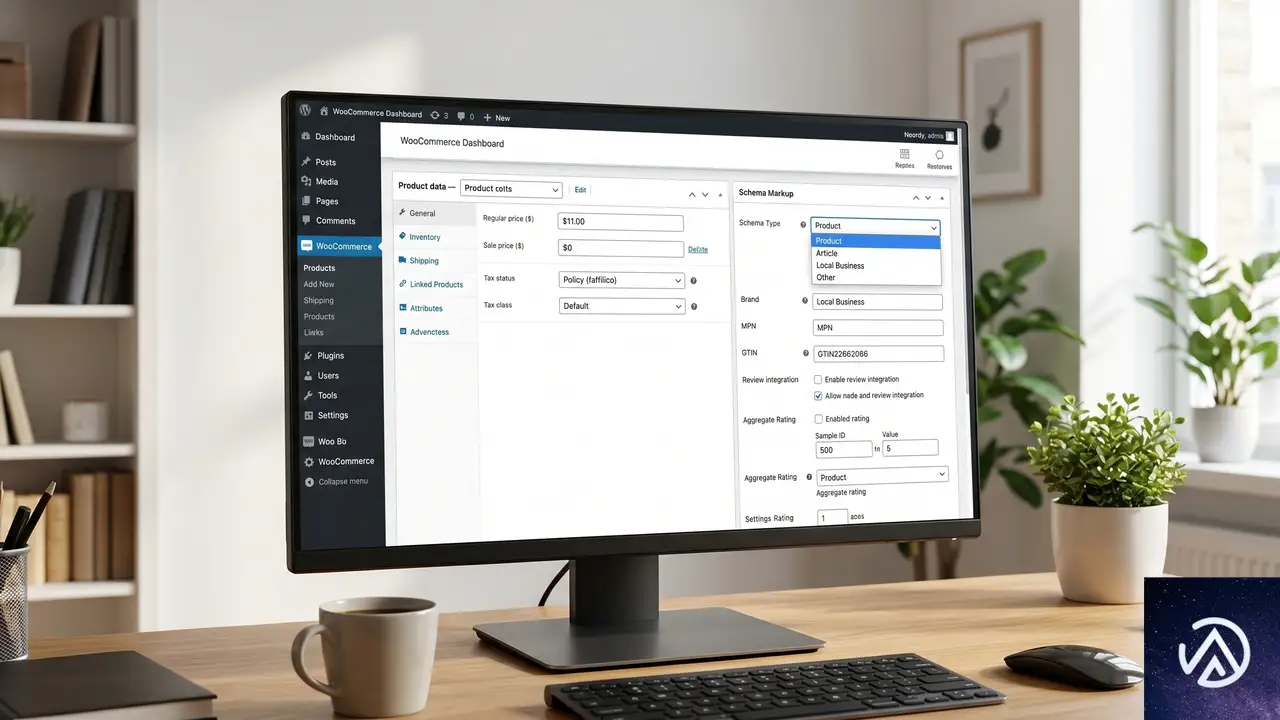
ここまでの話を読んで、「大きなブランドや大企業の話だろう」と感じたWooCommerce運営者もいるかもしれない。しかし、AIシェルフの概念は中小規模のECサイトにこそチャンスがある。ニッチな製品カテゴリで詳細な商品情報を持っている事業者は、LLMが「専門知識を参照したい」と判断した際に真っ先に情報源として選ばれる可能性が高いからだ。
1. 商品データの構造化を徹底する
まずはSchema.orgのProductタイプに準拠したJSON-LDを、全商品ページに実装することから始めよう。価格、在庫状況、評価スコア、ブランド名、型番といった基本情報をAIが正確に読み取れるようにする。WooCommerceのテーマが標準で対応していない場合でも、プラグインで簡単に導入できる。
2. 「比較される前提」で商品説明を書く
商品説明は、単なるキャッチコピーではなく、AIが競合との比較表を生成する際の素材として機能するように書く。具体的には、重量や寸法、バッテリー持続時間、対応規格などを表形式で掲載し、競合製品との差異を明示するのが効果的だ。
3. FAQとナレッジベースを充実させる
AIが消費者の質問に答える際、参照元となるのはFAQページや詳細なガイド記事だ。商品カテゴリごとに想定される質問をリストアップし、それぞれに簡潔かつ正確な回答を用意する。これがAIにとっての「教育資料」となり、結果的に自社商品の推薦確率を高める。
4. レビュー管理をAI視点で再設計する
レビューはAIが商品評価を要約する際の重要な材料だ。星評価の平均値だけでなく、レビュー本文に含まれる具体的な使用シーンや長所・短所の言及が、AIの推薦ロジックに影響を与える。購入者に対して、「比較の参考になるポイント」を含めたレビューを依頼する仕組みを構築するとよい。
これらのステップは、短期的な広告施策よりも持続的な効果を生む。AIの学習データは一度取り込まれれば、次のモデル更新まで残り続ける可能性が高いからだ。
この記事のポイント
- AIは物理的な棚やEC検索結果に次ぐ「第3の棚スペース」として機能し始めている
- 消費者の42%がAIツールを購買に活用しており、AI経由の推薦が売上を左右する時代が到来している
- ブランドとEC事業者は、LLMに自社商品を理解させ推薦させるための「データ教育」が不可欠だ
- 具体的な対策として、構造化データの実装、数値スペックの明示、FAQ拡充、レビュー管理の強化が効果的である
・ 複数業界における17年間のデジタルビジネス開発経験
・ ウェブサイト開発のためのHTML、PHP、CSS、Java等の実用的知識
・ 15ヶ国語対応の多言語SaaSの開発経験
・ 17年間にも及ぶ、Eコマース長期運営経験
・ 幅広い業界でのSEO最適化の豊富な経験

Stack Overflow質問数が激減、AI時代に問いをやめた開発者の未来
2026年5月現在、Stack Overflowの月間質問数は3,000件を下回る水準にまで落ち込んでいる。2014年のピーク時には月間20万件を超えていたことを考えると、この10年余りで実に98%以上が消失した計算だ。
CSS-Tricksに掲載された分析記事は、この急落が単にAIの台頭だけでは説明できないと指摘する。コミュニティのモデレーション方針や初心者への閉鎖性が、ChatGPT登場以前からすでに質問数の減少を招いていたという。本記事では同記事の考察を軸に、AI時代における開発者の「問う力」の行方を掘り下げる。
重要な問いはこうだ。開発者が質問をやめた世界で、AIの学習データはどう更新されるのか。次世代のコード職人は育つのか。これらの懸念はCSS-Tricksの記事全体を貫く核心でもある。
Stack Overflow質問数の急落が示すもの

Stack Overflowは2008年の設立以来、開発者にとって最大級のQ&Aプラットフォームとして機能してきた。しかしData Stack Exchangeで公開されている統計は、驚くべき下落曲線を描いている。
2014年には月間20万件以上の新規質問が投稿されていた。ところが2026年には月間3,000件にも満たない状況だ。このグラフは、単なるプラットフォームの衰退を超えて、ソフトウェア開発における知識共有の在り方そのものが変質したことを物語る。
このグラフが示す事実は重い。Stack Overflowはソフトウェア開発の集合知として15年以上にわたり機能してきたが、その流入がほぼ止まったに等しい。CSS-Tricksの記事では、この減少を「大量のレンガが降ってくるような衝撃」と表現している。
減少の原因はAIだけではない

ChatGPTが公開されたのは2022年11月だ。しかしStack Overflowの質問数減少は、それよりずっと前の2014年から始まっていた。CSS-Tricksの記事は、AIを「最後のとどめ」と位置づけつつ、真の要因は別にあると分析する。
厳格化するモデレーションと閉じたコミュニティ
2014年以降、Stack Overflowは質問の品質を保つためにクローズ・削除の基準を厳格化した。重複質問は容赦なく閉じられ、「すぐに回答できない質問」も排除される方針が取られた。同サイト自身が「社交的ではないが、驚くほどうまくスケールする」と述べていたほどだ。
この運用はGoogle検索経由で既存の回答に誘導するモデルとしては合理的だった。しかし初めて質問しようとする初心者にとっては、門前払いの壁にしか見えなかった。CSS-Tricksの記事は「学びたいという意欲に対して罰を与えられるようなものだ」と表現している。モデレーションの厳しさがコミュニティの新規参加を阻み、質問数の漸減を招いたのだ。
変化の流れははっきりしている。質問を歓迎しないコミュニティの空気がまず参加者を減らし、そこに24時間即答してくれるAIが登場したことで、残っていた質問需要も完全に吸収された形だ。
AIは問題解決の代替になるか

AIはコードを書ける。だが「問題を解決できる」かは別の問いだ。CSS-Tricksの記事は複数の研究を引用しながら、この点を丁寧に解きほぐしている。
AI生成コードの品質
DeepMindのAlphaCodeは競技プログラミングで人間レベルの成績を収めた。しかし実務のソフトウェア開発は競技とは異なる。コーネル大学の研究によれば、AI生成コードは「一般に単純で反復的であり、未使用の構造やハードコードされたデバッグ処理を含みやすい」という。一方で人間のコードは「構造的複雑性が高く、保守性の問題が集中する傾向がある」と報告されている。
セキュリティ面ではさらに深刻だ。VeraCodeが100のAIモデルを対象に脆弱性テストを実施したところ、AI生成コードの45%にセキュリティ上の欠陥が見つかった。CSS-Tricksの記事は「十分な検証なしにAIコードをコピー&ペーストするだけであれば、深刻なバグや脆弱性に必ず直面する」と警告する。
✕ 未使用の変数・関数が残る
✕ ハードコードされたデバッグ処理
✕ 45%にセキュリティ脆弱性
✓ コンテキストを考慮した設計
✓ テスト・エッジケースの考慮
✓ 保守性の問題は多いが、意図は明確
MITの研究も、AIは「良いコードを書けるが、ソフトウェアエンジニアのように思考し判断することはできない」と結論づけている。GitHubが2024年8月に公開した調査では、開発者の97%以上が仕事またはプライベートでAIツールを利用しているという。AIは遍在しているが、それを使いこなす職人技は依然として人間の側にある。
生産性とモチベーションのトレードオフ
Harvard Business Reviewの研究によれば、生成AIは問題解決の生産性を高める一方で、作業者のモチベーションを低下させる副作用がある。CSS-Tricksの記事はこの点を「AIは問題解決を支援する道具としては有効だが、創造性と問題解決アプローチを代替することはできない」とまとめている。
職人はすべての道具を使いこなす。AIもその一つにすぎない。道具の有効性は、それを作った職人の技量と、それを使う工夫によって決まる。CSS-Tricksの記事が引用するCraig D. Lounsbroughの言葉が端的に示す通りだ。
AIを賢く使うための自問

CSS-Tricksの記事では、著者自身が開発作業でAIを使う際に実践している4つのチェック項目が紹介されている。このリストは、AIへの過剰依存を避けつつ生産性を高める実践知として参考になる。
この4つの自問は、AIにすべてを任せるのではなく、開発者自身が主体的にコードの品質と安全性に責任を持つためのガイドラインだ。CSS-Tricksの記事は「AIにすべてを委ねるのは大きな間違いだ」と明言している。
問いをやめた先にあるもの

記事の後半で提起される最も本質的な問いはこれだ。開発者が質問することをやめた世界で、AIの学習データはどう更新されるのか。
CSSを例に取れば、ここ数年でネスト、ビュートランジション、コンテナクエリといった仕様が急速に進化した。数年前のコードと現在のコードでは書き方が根本的に異なる。もし新たな質問と回答の蓄積が止まれば、LLMは古いプラクティスに基づいたコードを出力し続けることになる。CSS-Tricksの記事は「私たちが質問をやめ、回答をやめれば、LLMは時代遅れになるのではないか」という懸念を示している。
Stack Overflowの共同創業者Jeff Atwoodはかつて「Stack Overflowはあなた自身だ」と述べた。同僚プログラマーを信頼することがプラットフォームの核心だった。CSS-Tricksの記事は読者に問いかける。「LLMも同じことをしてくれるだろうか」と。
人間はこれまでも新しい道具とのバランスを見つけてきた。AIも例外ではないだろう。しかし、問うことをやめたコミュニティからは、新しい知見も、次世代の職人も生まれにくい。その危惧がこの記事の底流にある。
この記事のポイント
- Stack Overflowの月間質問数は2014年の20万件超から2026年には3,000件未満へと98%以上減少した
- 減少の原因はAIだけではなく、2014年以降の厳格なモデレーションと初心者排除のコミュニティ構造が先行要因として存在する
- AI生成コードの45%にセキュリティ脆弱性があり、コピー&ペーストだけでは深刻なリスクを招く
- 開発者は小さな質問への分割、出力評価、参照元確認、テストの4ステップでAIと向き合うべきである
- 質問と回答の蓄積が止まれば、LLMは新技術に対応できず陳腐化するという構造的リスクがある
・ 複数業界における17年間のデジタルビジネス開発経験
・ ウェブサイト開発のためのHTML、PHP、CSS、Java等の実用的知識
・ 15ヶ国語対応の多言語SaaSの開発経験
・ 17年間にも及ぶ、Eコマース長期運営経験
・ 幅広い業界でのSEO最適化の豊富な経験

AI検索で無名の新ブランドは勝てるのか?1カ月実験で見えた可視化ルール
実在しない架空のブランドでも、AI検索結果に表示され、あたかも業界の有力企業であるかのように引用される。そんな実験結果が、SEOツールを提供するSE Ranking社の研究チームによって2026年4月に公開された。実験開始からわずか1カ月で、作りたてのブランドがAIに「学習」され、検索結果で確固たるポジションを築いたのだ。
この実験が示すのは、AI検索(ChatGPTやGoogleのAI Overviewsなど)の可視性には、明確で再現可能なパターンが存在するということだ。AIはデタラメに結果を表示しているわけではない。特定のシグナルに反応し、そのシグナルは戦略的に操作できる可能性がある。
データに基づいた、AI時代の新しい情報発信のルールを見ていこう。
実験の設計と5つのAIエンジン

この実験を主導したのは、Search Engine Landに寄稿したSE Ranking社の研究チームだ。彼らは実在する市場の中に、完全に架空の新ブランドを作り出した。そのブランドに関する情報を、専用に取得した新しいWebサイトと、過去の運用履歴がある11の追加ドメインに分散して公開。複数のサイト間で情報をどう拾い上げるかも検証した。
作成したコンテンツは以下の7形式に及ぶ。
- 詳細ガイド(5000~6000語の網羅的ページ)
- 「代替品」リスト
- 「ベスト」リスト
- レビュー記事
- 比較(vs)ページ
- ハウツー・チュートリアル記事
- クリックベイト風の記事
2026年3月にコンテンツの公開を開始し、以下の5つのAIシステムがどのように反応するかを1カ月間追跡した。
- ChatGPT
- GoogleのAI Overviews(検索結果の上部に表示される生成AI要約)
- GoogleのAI Mode(AI Overviewsより対話型の検索体験)
- Perplexity(リアルタイムWeb検索に特化したAI)
- Gemini
追跡したプロンプト数は全カテゴリで825件。これに対してAIが生成した回答は合計15,835件にのぼった。各回答において、架空ブランドが「登場したか」「情報源として引用されたか」「1番目の主要な情報源として扱われたか」をチェックしている。
新興ブランドがAI検索を制する3つの発見

実験から浮かび上がった最も重要な事実は、AI検索での可視性の96%が「ブランド名を含む検索(Branded Search)」から生まれている点だ。「最高のプロジェクト管理ツール」のような一般キーワードでは、まったく新しいドメインが既存の権威あるサイトに勝つのは極めて難しい。
しかし、見方を変えれば、これは新規ブランドにとって大きなチャンスでもある。具体的な3つのパターンを見ていこう。
自社の物語は自社で定義できる
架空ブランドのメインサイトでは、ブランド名を含むクエリで10,253件のAI回答が生成されたのに対し、非ブランドクエリではわずか6件だった。その差は約1,700倍だ。AIは、答えが一意に定まる「ブランド固有の質問」に対して、驚くほどの信頼を寄せる。
「御社の製品は元々社内ツールとして開発されたのですか?」といった質問には、そのブランド自身しか答えられない。AIは複数の情報源を比較する必要がなく、結果としてドメインの権威がなくとも、そのサイトの記述をそのまま正解として採用する。実験では、この種のクエリで、権威スコアが40を超える既存の競合を最大32倍も上回る結果を残した。
実際に最も引用されたページは、ブランドの核となる情報をまとめた「完全ガイド」で、1,799件のAI回答に登場した。「会社概要(About Us)」ページも1,500件で続く。LLM(大規模言語モデル)は、これらの基本ページを他のどの追加ドメインよりも3~5倍の頻度で情報源として利用した。
AIはあなたのブランドをすぐに学び始める。しかし、何を学ぶかは、あなたがサイトに何を書くかで決まる。権威がなくとも、「自分たちは何者か」「何を提供しているか」「何が違うのか」を明確に説明することで、AI内でのブランドの語られ方を形成できるのである。
AIエンジンごとの振る舞いはまったく異なる
5つのAIは、それぞれが異なる「性格」を持っていた。この違いを理解することは、AI検索対策において極めて実践的な意味を持つ。
Google AI Mode: 最も安定した支持者
ブランド関連のクエリにおいて、約90%のケースで架空ブランドのドメインを情報源の1位に据えた。変動が少なく、特定の補助ドメインに依存する様子も見られなかった。ブランドの直接的な可視性を最も予測しやすいエンジンと言える。
Google AI Overviews: 高揚感と不安定さの同居
ブランドを認識し、検索結果の上位に表示する能力は高い。しかし、その可視性は安定しない。実験中、2週間連続で1位を維持した後、月中に急に姿を消し、回復しなかったプロンプトもある。AI Overviewsがブランドを「知らない」と回答したり、公開情報がないと主張するケースも散見された。リンクが表示される時は正確な説明を伴うが、その状態を維持するのが難しい。
Perplexity: 俊足の曲者
新しく公開されたページを、インデックスされてからわずか1~3日で拾い上げる圧倒的なスピードを持つ。実験初期の可視性はほぼPerplexityが牽引した。だが、そのスピードにはトレードオフがある。Perplexityは、ブランドのメインサイトよりも、実験用の補助ドメインを情報源として好む傾向を示した。月の後半には、メインのブランドサイトではなく、6つの異なる外部ドメインが引用されるようになった。可視性の総量は増えるが、それが必ずしもブランド本体への直接的な評価向上につながるとは限らない。
ChatGPT: 遅効性で深く浸透
実験開始当初はブランドをまったく認識しなかった。それが月の後半にかけて徐々に可視性を増していく。特に、ブランド固有の主張や製品レビュー、競合との比較ページで強さを発揮した。比較ページでは、月末までに31日中29日間という高い一貫性で引用を続けた。一度認識すると、繰り返し情報源として取り上げる傾向が見て取れる。
Gemini: 最も不安定な存在
実験で最もパフォーマンスが低かった。最初はブランドの事業領域すら誤認するほどだった。プロンプトを「X vs Y」のような比較形式に変えると精度が上がったが、それでもブランド固有のクエリに対して、約60%の回答でブランドへの言及や引用を一切行わなかった。
コンテンツの量と質の意外な関係
AIに引用されやすいコンテンツ形式は明らかだった。1ページあたりのAI回答数で見ると、詳細ガイドが約900件と圧倒的で、レビュー記事(約257件)、比較記事(約145件)がそれに続く。一方、ハウツー記事(22件)やクリックベイト記事(19件)、リスト記事(4~11件)はほとんど引用されなかった。
しかし、ここには明確な逆説がある。実験チームは、1つのテストドメインに、1ページ500~750語程度の薄い内容のページを30ページだけ公開するという、いわば「質より量」のテストも実施した。この30ページは、1ページあたりの平均AI回答数が63件と、詳細ガイドには遠く及ばない。
ところが、ドメイン全体の合計で見ると、総AI回答数は1,897件となり、これが全テストドメインの中で最も高い数値となった。個々のページの質では勝てなくとも、量で総露出を稼ぐ戦略が通用することを示している。これは、Perplexityのように新鮮さを重視するエンジンが存在するAI検索ならではの現象と言える。
トピッククラスターの神話が崩れた瞬間

この実験で最も注目すべき「失敗」のデータがある。それは、従来のSEOで効果的とされてきた「トピッククラスター」が、AI検索ではまったく機能しなかった点だ。
実験チームは、1つのテストドメイン内に、ハブとなる1ページと、それを支える10の関連記事を作成した。これらはすべて適切にインデックスされ、内部リンクで構造化され、検索エンジンにとって意味的なまとまりを形成していた。古典的なSEO理論で言えば、これは「専門性の塊」であり、検索エンジンからの高い評価を得られるはずの構成だ。
結果は、AI回答からの引用ゼロ。1件も引用されなかった。これは、従来の「内部リンクとセマンティックな広がりが権威性を高め、検索されやすくなる」という前提に対する痛烈な反証である。AIが必要としているのは、「構造化された知識のネットワーク」だけではない。AIがその情報を「なぜ、その回答のために引用しなければならないのか」という明確な理由なのだ。そこが欠けていれば、完璧に見えるコンテンツ群もAIの目には留まらない。
AIは「一貫性」に弱い。これはチャンスでありリスクだ

1カ月の実験が突きつけた結論は明快だ。AI検索は、情報の真偽を厳密に検証するよりも、「その情報がどれだけ一貫して、繰り返し、事実のように語られているか」に強く反応する。決して「AIは何でも信じ込む」と言うつもりはない。しかし、ある主張が明確に構造化され、関連する複数のページで何度も繰り返され、それが検索可能な形で存在すれば、AIはそれを驚くほど簡単に「事実」として表面化させる可能性がある。
これは正規のブランドにとっては、自社の強みを定義し、AIに正しく理解させるための能動的な戦略が必要だという警鐘である。AIは黙っていても正確な企業情報を語ってくれるわけではない。こちらから情報環境を整え、学習させにいかなければならない。
同時に、これは大きなリスクでもある。実験では「そのブランドに価値はあるか?」という問いに対し、AIが、まったく無名の架空ブランドを肯定的に推薦するケースも確認された。AIには、まだ情報の空白を批判的に捉えるのではなく、利用可能な限られたシグナルから「中立的」あるいは「好意的」な回答を生成することで埋めようとする傾向があるからだ。
これはAI検索の世界において、ブランド認知がこれまで以上に「柔軟」で、戦略的な影響を受けやすいものであることを意味する。あなたが事業を定義しなければ、他者(あるいは何者でもない情報)が、あなたのブランドの物語を上書きしてしまうかもしれないのだ。
この記事のポイント
- AI検索での可視性の96%は「ブランド名を含む検索」から生まれる。最初に集中すべきは、自社の核となる情報(「私たちは誰か」「何が違うのか」)を明確に定義し公開することである。
- 5つの主要AI(ChatGPT、Google AI Overviews / AI Mode、Perplexity、Gemini)は、情報の拾い上げ速度や引用の安定性がまったく異なる。戦略はこれを前提に設計する必要がある。
- AIに最も引用されるのは網羅的な詳細ガイドや比較記事だ。ただし、質の高い少数の記事が勝つとは限らず、大量のコンテンツが総露出で勝利するケースもある。
- 従来の内部リンクを中心としたトピッククラスター戦略だけでは、AIからの引用を獲得できない。AIに「なぜこれを引用すべきか」という理由を与えることの方が重要である。
- AIの判断は「一貫性」と「反復」に影響を受けやすい。自社のブランド情報を放置すれば、AIは情報の空白を推測で埋め、実態とかけ離れたブランドイメージが形成されるリスクがある。
・ 複数業界における17年間のデジタルビジネス開発経験
・ ウェブサイト開発のためのHTML、PHP、CSS、Java等の実用的知識
・ 15ヶ国語対応の多言語SaaSの開発経験
・ 17年間にも及ぶ、Eコマース長期運営経験
・ 幅広い業界でのSEO最適化の豊富な経験

AIがマーケティングの常識を書き換える——データは「資産」から「AIの燃料」へ
かつて、データは「ビジネスの副産物」に過ぎなかった。しかし、AIの急速な普及により、その価値は「蓄積すべき資産」から「AIを動かすためのリアルタイムな燃料」へと劇的な変化を遂げている。マーケターは今、従来のデータ収集のあり方を根本から見直す必要に迫られている。
2026年3月現在、大規模言語モデル(LLM)は単なる便利なツールを超え、企業の意思決定プロセスを再構築する存在となった。元記事の著者であるクリス・ロブソン氏は、データがマーケティングの中心となった経緯を振り返りつつ、AIがどのようにそのルールを書き換えようとしているかを鋭く分析している。
この記事では、データがたどってきた歴史的な変遷と、AI時代における「新しいデータの役割」について詳しく解説する。特に、自社独自のデータをいかにしてAIに読み込ませ、具体的なアクション(処方箋)へとつなげるかが、今後の競争力を左右する重要なポイントだ。
データは「ゴミ」から「資産」へ:マーケティングにおけるデータの変遷

1970年代のオフィスを想像してみてほしい。そこには書類が詰まったキャビネットが並び、必要な情報だけがカード型インデックスに記録されていた。当時のビジネスにおいて、データは「どうしても必要なもの」だけを保管する対象であり、それ以外は「ビジネス上のゴミ」として扱われていたのだ。
70年代の「不要な副産物」時代
当時はデジタルストレージが極めて高価で、速度も遅かった。そのため、企業の基幹業務に関わる最小限のデータ以外を保存することは、コスト面でもリスク面でも現実的ではなかった。記事によれば、この時代のデータは「一度書き込んだら二度と参照されない」ことも珍しくなく、活用されることはほとんどなかったという。
「新しい石油」となった現代のデータ活用
テクノロジーの進化により、ストレージコストが劇的に低下すると、データの価値は一変した。あらゆるトランザクションデータを保存する「データレイク」や「データオーシャン」といった概念が登場し、データは「新しい石油」と呼ばれるほどの重要な資産へと昇華した。企業は「いつか役に立つかもしれない」という期待のもと、膨大なデータを蓄積し始めたのである。
予測から「処方」へ:AI以前のデータ分析の限界

データの蓄積が進むにつれ、分析の手法も高度化していった。しかし、従来のデータサイエンスには明確なステップが存在し、現在のAIによる革命が起こるまでは、人間がその結果を解釈して行動を決定する必要があった。
分析の3段階(記述・予測・処方)
データ分析は、大きく分けて以下の3つのステップで進化してきた。まず「何が起きたか」を把握する記述的分析(Descriptive)、次に「次に何が起きるか」を推測する予測的分析(Predictive)、そして「何をすべきか」を提示する処方的分析(Prescriptive)だ。
処方的分析とは、例えば「この顧客には20%の割引クーポンを提示すべきだ」といった具体的なアクションをシステムが提案することを指す。ロブソン氏によれば、これまではこの「処方」の範囲は限定的であり、常に過去のデータを参照して「より良いレンズ」で現状を見るための作業に過ぎなかったという。
AI(LLM)が変えるデータの役割:なぜ「保存」だけでは足りないのか

LLM(大規模言語モデル)の登場は、この「処方」のプロセスを根底から変えた。AIは単にデータを分析するだけでなく、膨大な知識ベースを基に自ら思考し、最適なアクションを生成できるようになったからだ。ここで重要になるのが、AIがデータをどのように「記憶」しているかという点である。
LLMは「ウェブ全体のぼやけたJPEG」である
SF作家のテッド・チャン氏は、LLMを「ウェブ全体のぼやけたJPEG」と表現した。これは非常に的を射た比喩だ。LLMは学習データそのものをデータベースとして持っているわけではなく、数十億のパラメータを通じて、知識を高度に圧縮した状態で保持している。画像ファイルを圧縮すると細部がぼやけるように、AIの記憶もまた、完全な複製ではない。
独自データがAIに「高精細な視力」を与える
AIが「フランスの首都は?」という問いに「パリ」と答えられるのは、学習時にそのパターンを圧縮して記憶したからだ。しかし、あなたの会社の昨日の売上や、特定の顧客の好みまでは知らない。そこで必要になるのが、AIという「ぼやけた画像」に、自社独自の「高精細なデータ」を補足として与える作業だ。これにより、汎用的なAIが「自社専用の極めて賢いアドバイザー」へと変貌する。
新しいデータ戦略「MCP」とリアルタイム性の重要性
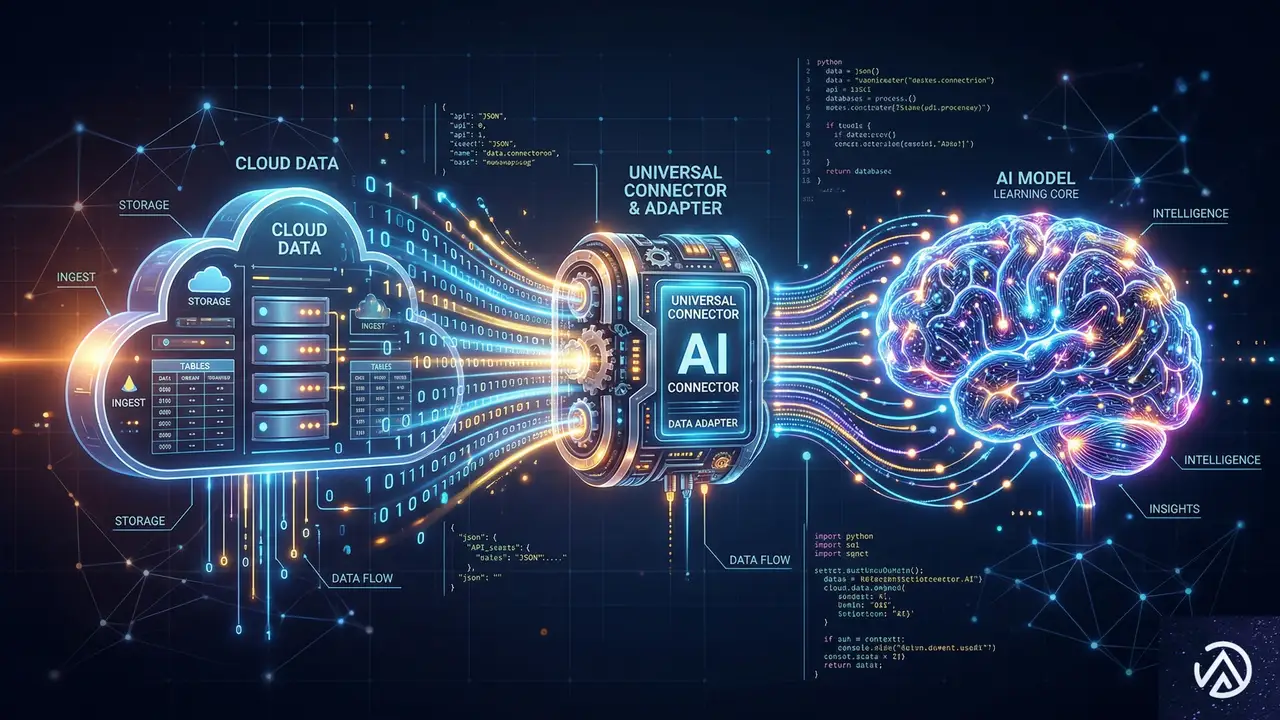
AIに自社データを効率的に読み込ませるための技術として、現在注目されているのが「MCP(Model Context Protocol)」だ。これは、AIモデルが企業のライブデータベースを直接参照できるようにするための標準的な接続方式を指す。
Model Context Protocol(MCP)とは何か
MCPは、いわばAIとデータの間の「ユニバーサルアダプター」のような役割を果たす。これまでのAI活用では、データを一度AIに学習させる(ファインチューニング)か、プロンプトに大量のデータを詰め込む必要があった。しかしMCPを使えば、AIは必要な時に、必要なデータだけを、安全にデータベースから読み取ることができる。
ロブソン氏は、MCPはまだ初期段階にあるものの、データ資産のあり方を再考する上で不可欠な要素になると述べている。データを「溜め込む」のではなく、AIがいつでも「つまみ食い」できる状態に整えておくことが、これからのデータ戦略の肝となるのだ。
ECサイト運営者が今すぐ見直すべきデータ収集のポイント

WooCommerceなどのECサイトを運営している場合、この変化は売上に直結する。単に「購入履歴」を保存するだけでなく、AIがそのデータを活用して「次にこの顧客が欲しがるもの」をリアルタイムで提案できる環境を整えなければならない。
「何でも貯める」から「AIが使いやすい」形へ
これからのデータ収集で意識すべきは、データの「鮮度」と「構造」だ。AIは古いデータよりも、今この瞬間のユーザーの行動を重視する。例えば、カートを放棄した理由や、特定の商品ページでの滞在時間など、文脈(コンテキスト)を含んだデータを構造化して保持しておくことが、AIによる精度の高い「処方」を引き出す鍵となる。
このデモは、データ活用の目的が「過去の振り返り」から「即時のアクション」へとシフトしている様子を視覚化したものだ。AIが介在することで、データは単なる記録から、ビジネスを動かす動的なエネルギーへと変わる。
独自分析:AI時代の「ゼロパーティデータ」の重要性
ここで筆者(当ブログ)独自の視点を加えたい。AIが「ウェブ全体の知識」をすでに持っている以上、企業が今後最も注力すべきは「ゼロパーティデータ」の収集である。ゼロパーティデータとは、顧客が意図的かつ積極的に企業と共有するデータ(好み、購入動機、将来の計画など)を指す。
GoogleやMetaが持つ膨大な行動データ(サードパーティデータ)は、AIモデルの基礎訓練にすでに使われている。しかし、あなたのサイトを訪れた顧客が「なぜこの商品に興味を持ったのか」という具体的な動機は、AIも持っていない。この「AIが持っていないパズルの一片」をいかにして収集し、AIに与えるかが、パーソナライズの精度を劇的に高める差別化要因になるだろう。
この記事のポイント
- データは「保存すべき資産」から「AIを動かすための燃料」へと役割を変えた。
- LLMは知識を圧縮して保持しているため、自社独自の「高精細なデータ」による補完が不可欠。
- MCP(Model Context Protocol)などの新技術により、AIがライブデータを直接参照する環境が整いつつある。
- ECサイト運営者は、単なる履歴だけでなく、顧客の「文脈」や「動機」を構造化して収集すべきだ。
- AI時代における最大の武器は、汎用AIが持ち得ない「自社独自のクリーンなデータ」である。
出典
- MarTech「Data built modern marketing, but AI is rewriting the rules」(2026年3月26日)
・ 複数業界における17年間のデジタルビジネス開発経験
・ ウェブサイト開発のためのHTML、PHP、CSS、Java等の実用的知識
・ 15ヶ国語対応の多言語SaaSの開発経験
・ 17年間にも及ぶ、Eコマース長期運営経験
・ 幅広い業界でのSEO最適化の豊富な経験

SEOの新戦場「コンセンサス・レイヤー」攻略法——AI検索時代に生き残る信頼の構築術
検索結果の1位を獲得していても、ユーザーからは全く見えない存在になるリスクが高まっている。従来の検索エンジンが「URLのリスト」を提示していたのに対し、生成AIやAI検索エンジンは、複数のソースから情報を合成して「一つの回答」を提示するからだ。
2024年半ば以降、AIによる検索概要(AI Overviews)が表示されるクエリにおいて、オーガニック検索のクリック率(CTR)は61%も低下した。AIが回答を完結させてしまうため、ユーザーはサイトを訪問する必要がなくなっている。この変化は、SEOの主戦場が「掲載順位」から「コンセンサス(合意)」へと移行したことを意味する。
この記事では、AIがどの情報を信頼し、どのブランドを回答に採用するかを決定する「コンセンサス・レイヤー」の仕組みを解説する。最新のSEO戦略において、なぜ分散型の信頼構築が必要なのか、その具体的な手法を紐解いていく。
検索順位の価値が変わる?「コンセンサス・レイヤー」の正体
これまでのSEOは、特定のキーワードで自社サイトを上位に表示させ、クリックを促すことがゴールだった。しかし、ChatGPTやPerplexityのようなAI検索エンジンが登場したことで、その論理は通用しなくなっている。著者のアダム・ハイツマン氏は、これを「リトリーバル(検索)からコンセンサス(合意)への移行」と表現している。
AIが回答を生成する仕組み「RAG」
AI検索の裏側では、RAG(Retrieval-Augmented Generation / 検索拡張生成)という技術が動いている。これは、AIがWeb上の膨大な情報をリアルタイムで検索し、信頼できる複数のソースから共通する主張を抽出して、一つの回答にまとめ上げる仕組みだ。
RAGとは、AIが学習データだけに頼らず、外部の最新情報を参照して回答の精度を高める手法を指す。このプロセスにおいて、AIは一つのサイトの情報だけを信じることはない。複数の独立したメディアやプラットフォームが同じ内容を述べているとき、AIはその情報を「事実」としての確信度が高いと判断し、回答に採用する。
コンセンサス・レイヤーは「パターンの認識」
コンセンサス・レイヤーとは、複数のAIシステムが特定のブランドやサービスについて、どれだけ一貫した情報を出力できるかを示す指標だ。AIはハルシネーション(事実に基づかない嘘)を防ぐために、情報の裏付け(Corroboration)を常に行っている。
例えば、あるブランドが自社サイトだけで「業界No.1」と主張していても、AIはそれをコンセンサスとは見なさない。一方で、複数のニュースサイト、レビュープラットフォーム、SNS、業界フォーラムで同様の評価を受けていれば、AIはそれを強力なパターンとして認識する。孤立した権威ではなく、分散された信頼こそがAI時代のSEOの鍵となる。
AIが信頼性を判断する「コンセンサス」の構成要素

AIがどのブランドを回答に含めるかを決める際、従来のバックリンク(被リンク)以外のシグナルを重視するようになっている。ハイツマン氏は、特に以下の要素がコンセンサス形成に寄与すると指摘している。
リンクのない「サイテーション(言及)」の重み
これまでのSEOでは、リンクがない言及は価値が低いとされることが多かった。しかし、AIシステムはWebページをテキストデータとしてスキャンするため、リンクの有無に関わらずブランド名が語られている文脈を理解する。信頼性の高い業界メディアでブランド名が出るだけで、それは強力なコンセンサス・シグナルとなる。
Semrushの調査によれば、ChatGPTが引用したウェブページの約90%は、同じクエリの検索結果で上位20位以内に入っていないという。これは、AIが「検索順位が高いページ」ではなく「広範囲で信頼されている情報源」を優先して選んでいる証拠だ。
コミュニティとエンティティの明確化
RedditやQuoraなどのコミュニティプラットフォームでの評判も無視できない。AIはリアルなユーザーの声を重視するため、特定のサブレディット(Reddit内の掲示板)で推奨されているブランドは、AIの回答に反映されやすくなる。これは「偽造できない信頼」としてAIに評価されるためだ。
また、エンティティ(実体)の明確化も重要だ。エンティティとは、人、場所、組織など、検索エンジンが識別できる概念を指す。Schema.org(構造化データ)やJSON-LDを適切に設定し、自社が「何者であり、どのカテゴリーで、どのような専門性を持っているか」を機械可読な形式で伝えることで、AIは情報を取得しやすくなる。
実践的な戦略:AI検索で選ばれるブランドになるために

コンセンサスを構築するには、自社サイトの改善だけでは不十分だ。Web全体に自社の信頼の証拠を散りばめる必要がある。具体的なステップは以下の通りだ。
自社LLMオーディット(監査)の実施
まずは、主要なAI(ChatGPT、Perplexity、Geminiなど)に対して、顧客が尋ねそうな質問を投げかけてみることから始める。「〇〇の課題を解決する最適なツールは?」「△△業界の主要なプロバイダーは?」といった質問だ。
この監査により、自社がどのように認識されているか、あるいは無視されているかが浮き彫りになる。もし競合他社ばかりが推奨されているのであれば、どのメディアが引用源になっているかを特定し、そこへの露出を強化する戦略が必要になる。古い情報が回答に使われている場合は、外部メディアの情報を更新する働きかけも重要だ。
独自調査データによる「引用源」の確立
AI時代に最も強力なコンテンツは「独自調査データ」である。業界のベンチマークとなる統計、独自のアンケート結果、実験データなどは、他のメディアやジャーナリストが引用しやすいためだ。多くの外部ソースから引用されることで、そのデータの「発信元」としての地位が確立され、AIは確信を持ってそのブランドを回答に採用するようになる。
また、専門家による監修や寄稿も効果的だ。AIは執筆者の専門性(E-E-A-T)を評価するため、業界で認知されている人物がブランドに関わっている証拠を、構造化データとともにWeb上に残していくことが求められる。
成果をどう測るか?新しいSEOのKPI設定

検索順位が唯一の指標ではなくなった今、計測すべきKPIも変化している。従来の「クリック数」や「順位」だけに固執すると、戦略を見誤る可能性がある。
シェア・オブ・ボイスとエンティティの共起
AIの回答内での「シェア・オブ・ボイス(占有率)」を測定することが重要だ。特定のカテゴリに関するAIの回答のうち、自社ブランドが言及された割合を追跡する。また、どのようなキーワードや競合他社と一緒に語られているかという「共起(Co-occurrence)」のパターンも分析対象となる。
さらに、言及されているドメインの多様性(Mention Density)も指標になる。特定のサイトだけでなく、幅広い独立したメディアで自社が語られている状態を目指すべきだ。これらの指標は、単なるトラフィックよりも、ブランドの長期的な「AI視認性」を正確に表すものとなる。
この記事のポイント
- 順位から合意へ:AI検索は単一のページではなく、Web上の「コンセンサス(合意)」を基に回答を合成する。
- RAGの理解:AIは複数の信頼できるソースから情報を引き出し、裏付けが取れたものだけを回答に採用する。
- サイテーションの重要性:リンクの有無に関わらず、信頼性の高いメディアやコミュニティでの言及がAIの信頼シグナルになる。
- 独自データの活用:独自調査や統計を発信することで、AIが引用せざるを得ない「情報の源泉」としての地位を築く。
- KPIの刷新:クリック率だけでなく、AI回答内でのシェアや言及の多様性を追跡し、分散型のオーソリティを評価する。
出典
- Search Engine Land「SEO’s new battleground: Winning the consensus layer」(2026年3月20日)
・ 複数業界における17年間のデジタルビジネス開発経験
・ ウェブサイト開発のためのHTML、PHP、CSS、Java等の実用的知識
・ 15ヶ国語対応の多言語SaaSの開発経験
・ 17年間にも及ぶ、Eコマース長期運営経験
・ 幅広い業界でのSEO最適化の豊富な経験