

Microsoft Discovery GAとDiscoveryアプリプレビュー
マイクロソフトはMicrosoft Buildにおいて、研究開発向けエージェントAIプラットフォーム「Microsoft Discovery」を一般提供開始した。同時に、研究者がローカル環境で利用できる「Microsoft Discoveryアプリ」のプレビュー版も公開された。
このリリースは、科学研究におけるAIの役割を単なるアシスタントから、反復的な実験計画や仮説検証を統括する「研究の中核」へと引き上げるものだ。製薬業界の新薬探索や材料工学の最適化問題など、複雑な条件が絡み合う領域での利用が見込まれている。
従来のチャット型AIとは異なり、このプラットフォームは専門的なモデリングツールや実験データと連携し、人間の専門家による判断プロセスを補強する設計がなされている。大規模な組織の研究開発(R&D)ワークフローに、再現性と透明性をもたらす点が最大の特徴だ。
エージェントAIによる研究開発ワークフローの再現性確保
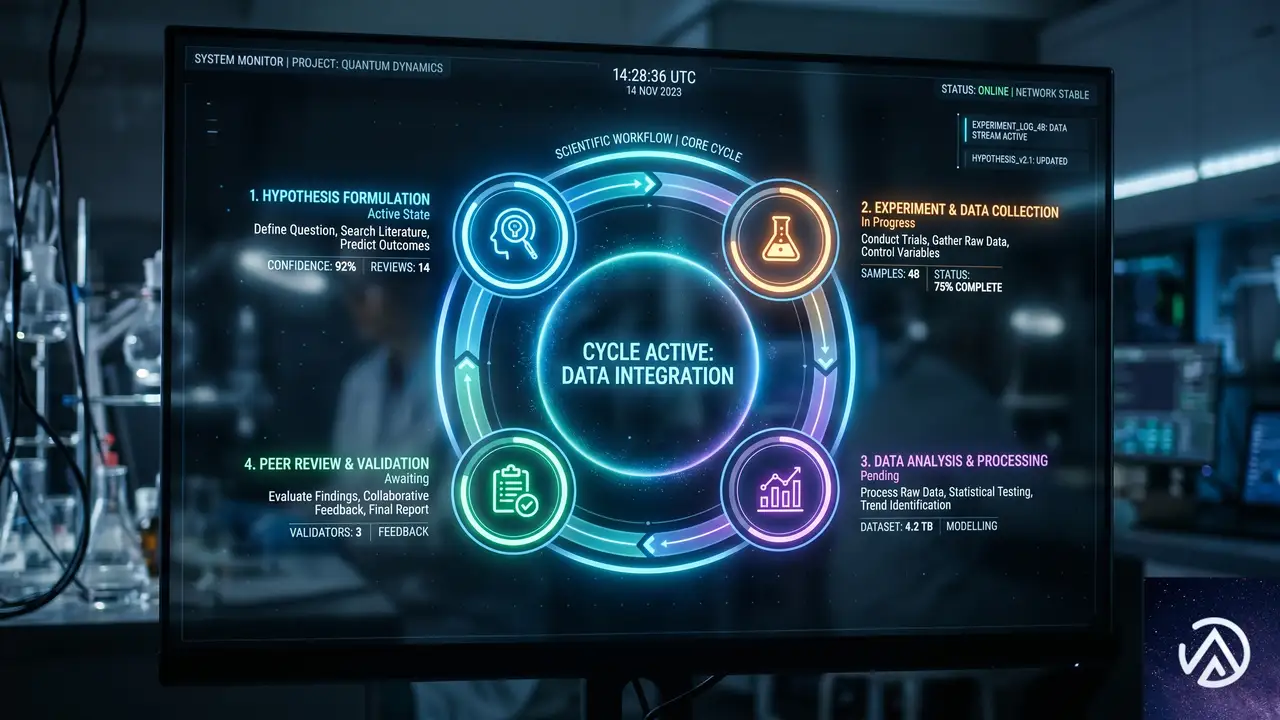
科学研究の突破口は、一度のひらめきで生まれるものではない。仮説、実験、改良、レビューという繰り返しのサイクルの中からしか姿を現さない。Microsoft Discoveryは、この本質的なループ構造を組織的に管理し、加速させるために作られた。
✓ 再現可能なワークフロー
✓ 組織固有の知識との統合
このプラットフォームの中心にあるのが「Microsoft Discovery Engine」だ。これはエビデンス(証拠)から仮説を導き出し、AIエージェントが各種のシミュレーションや分析ツールを呼び出して検証し、次のイテレーションへ進むという一連の流れを支える。Azure Blogの記事によれば、このエンジンは「単発の分析を超えて、比較検討や前提の疑問視を繰り返し可能な形で行える」よう設計されている。
プロダクション環境で求められる信頼性
研究開発の現場にAIを持ち込む際、最も難しいのは「信頼」の確立だ。Microsoft Discoveryの一般提供版では、以下の要件が重視されている。
- ワークフローの再現性
- 出力結果のレビュー可能性
- 企業固有の知的財産の適切な統治
- 既存のR&D組織の運営モデルへの適合
つまり、AIが出した「答え」だけを信じるのではなく、その推論の道筋を後からなぞり、専門家が納得できる形で提示することが求められている。これは、ブラックボックス化しがちな大規模言語モデルの弱点を補うアプローチであり、規制の厳しい製薬業界や材料産業での採用を後押しする要素だ。
ローカル環境を拓く「Discoveryアプリ」のプレビュー公開
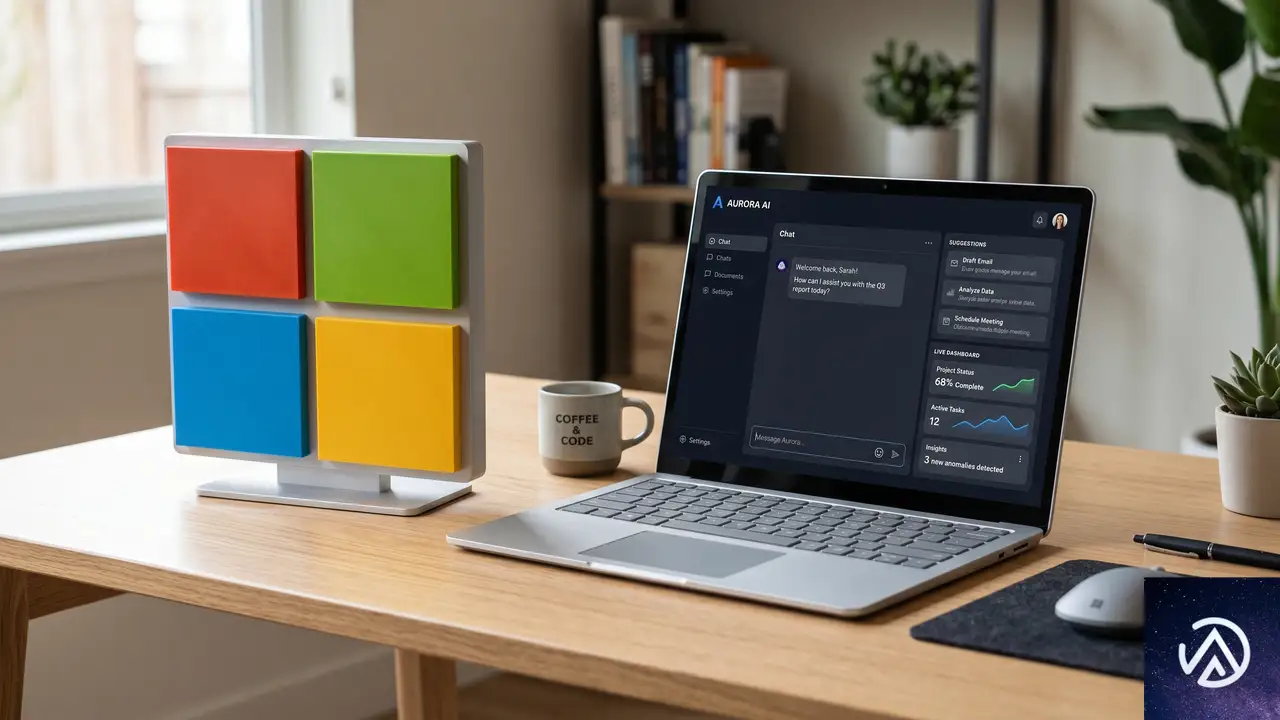
組織全体での大規模な導入と並行して、マイクロソフトは個人や小規模チームがすぐに利用を開始できる「Microsoft Discoveryアプリ」のプレビュー版もリリースした。これは、企業のIT部門による本格的なデプロイを待たずに、研究者が自身のマシン上でエージェントAIの能力を試せるようにするための入り口だ。
このアプリは、学術研究室や学生が「まず触ってみる」ことを最重要視している。研究のアイデアが小規模なプロジェクトや個人の探求から始まることは珍しくない。そこから成果が成熟し、より高度な制御や大規模な計算リソースが必要になった段階で、クラウド上のMicrosoft Discoveryへシームレスに移行できる点が特徴だ。
最先端の現場における応用事例

プライベートプレビュー期間中、各分野のリーディングカンパニーとの協業を通じて、このプラットフォームの実践的な価値が検証された。単なる概念実証ではなく、実際の製品開発や学術研究のスピードを変えつつある。
バッテリー科学での分子設計ループ
イェール大学工学部とマイクロソフトリサーチの共同研究では、大規模蓄電向け「有機レドックスフロー電池」の電解質分子設計にDiscovery Engineが利用された。この問題は、酸化還元電位や水溶性、合成のしやすさなど、相反する複数の物性を同時に最適化する必要がある極めて複雑なものだ。
エージェントAIは、実験から得られたデータを解釈して次の候補分子を提案し、さらに診断的な実験計画を立案する役割を担った。実際の実験検証と結果の評価は、人間の専門家が主導している。イェール大学のDavid Kwabi准教授は、この枠組みが「人間主導の実験の強みと、AIの広大な化学空間探索能力を組み合わせたもの」と評価している。
半導体から生命起源まで
Syensqo社は、次世代半導体製造用の熱伝達流体の開発にこの技術を適用し、研究から営業、マーケティングまで含めたビジネス全体の意思決定速度を向上させている。ジョージア工科大学では、生命の起源に関わるアミノ酸「ヒスチジン」の生成経路を、複数のAIエージェントが質量分析データや文献情報を統合して再評価するユニークな試みが進められている。
これらの事例に共通するのは、AIが「単独で答えを出す」のではなく、人間の研究者とツールの間に立って「探索と検証のサイクル」を加速させている点だ。BHPのJessica Farrell氏は、銅の浸出技術開発において「無限に近い可能性の領域を、実用可能な少数の選択肢に絞り込めた」と述べ、数か月単位での成果創出に貢献したことを示唆している。
いずれも「探索 → 検証 → 絞り込み」のループをAIが加速する構造が共通している。
自律ラボとの融合が示す次のフェーズ

パシフィック・ノースウェスト国立研究所(PNNL)との協業は、AIエージェントが物理世界と直接つながる未来を明確に示している。ここでは、Discoveryが仮説を生成するだけでなく、ロボット実験設備を直接駆動し、得られた実験結果をリアルタイムで学習して次の指示を出す「自己駆動型の科学ワークフロー」が実証されている。
PNNLのRobert Runkle氏は、これを「ロボティクスと自律ラボがAIとクラウドインフラと融合した、一つのインテリジェントなクローズドループ発見エンジン」と表現する。アイデアから実際のブレイクスルーまでのタイムラインを劇的に短縮し、材料合成や生物学における新時代の扉を開くものだという。
この動きは、ケンブリッジ・コンサルタンツが「数か月の実験作業を数日から数時間に変える」と表現したインパクトと完全に一致する。AIが提案し、ロボットが試し、その結果をAIが解釈する、このサイクルが自動で回り始めたとき、研究開発の定義そのものが変わるだろう。
この記事のポイント
- Microsoft DiscoveryはR&Dワークフローの再現性と透明性を確保するエージェントAI基盤
- クラウド上の本格運用と、個人が即日試せるローカルアプリの二軸で提供開始
- 研究における「仮説→実験→検証」の反復ループを、専門家の判断を中心に据えつつ加速する設計
- バッテリー開発、創薬、鉱業など、実際の産業応用で開発スピードを劇的に向上させた事例が複数報告されている

・ 複数業界における17年間のデジタルビジネス開発経験
・ ウェブサイト開発のためのHTML、PHP、CSS、Java等の実用的知識
・ 15ヶ国語対応の多言語SaaSの開発経験
・ 17年間にも及ぶ、Eコマース長期運営経験
・ 幅広い業界でのSEO最適化の豊富な経験

AIだけでは企業変革できない、カギは実行基盤(Azureブログ発表)
AIが企業のあらゆるワークフローに浸透し始めている。だが、本当の変革をもたらすのは最先端のAIモデルそのものではなく、それを動かすシステムの設計だという指摘が、マイクロソフトの公式ブログで発表された。同社はエージェントを中心とした統合プラットフォームを打ち出し、開発から運用、ガバナンスまでを一貫して支える環境を構築している。
発表の背景には、個別のAIチャットボットや単発のツール導入に終始する企業では、大規模な業務変革が進まないという現実がある。Azure Blogの記事では、複数のAIエージェントが部門を横断して長期間にわたり作業を実行し、しかも統制の取れた形で運用できる仕組みこそが次世代の競争力を決めると述べられている。
なぜAI単体では不十分なのか

エージェントがもたらす真の変革
Azure Blogによれば、現在の企業AI活用で話題になるのはチャットボットのような対話型インターフェースだ。だが、そうしたエクスペリエンスは便利ではあるものの、組織全体のオペレーションを根本から変えるものではない。真に価値があるのは、ソフトウェア開発、サポート、財務、人事、運用といった複数の業務領域で、複数のAIエージェントが連携し、長期にわたって作業を自律的に遂行することである。
エージェントが本格稼働するには、単に強力なAIモデルやスケーラブルな計算資源が手に入れば良いわけではない。エージェントを「誰が」「どのデータを使って」「どう安全に」動かすかという企業コンテキスト、ポリシー、人的監視の枠組みが不可欠だ。Azure Blogの記事では、これらを欠いた状態では、AIの導入は断片的で脆弱、大規模に信頼するのが難しいと指摘している。
個別ツールの寄せ集めではリスクが高まる
多くの企業は、コード生成ツール、データ連携基盤、実行環境、監視システムをそれぞれ別々に導入し、後付けで連携させる方法を取りがちだ。だがAzure Blogの記事は、こうしたばらばらのツールを寄せ集めただけの環境では、開発速度が落ち、不必要なリスクを招くと警告している。たとえば、エージェントに意図しないアクセス権が渡ったり、部門間でガバナンスが効かなくなったりする問題が起こり得る。
このデモで示したように、断片化したツール群ではエージェントの挙動を一貫して管理できない。マイクロソフトの新たなアプローチは、これらの要素を統合した単一のプラットフォームでエージェントを動かす点にある。
Microsoftの統合エージェントプラットフォームとは
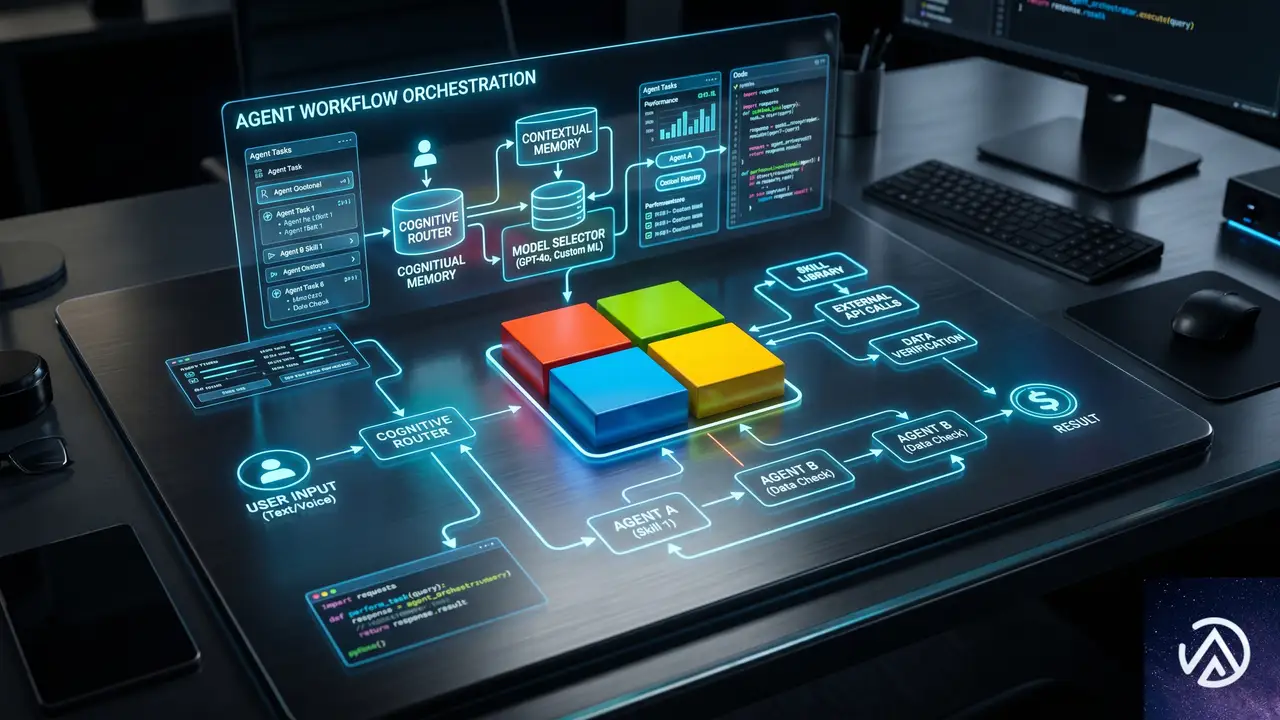
Azure Blogの発表では、同社が「包括的エージェントプラットフォーム」を構築していると説明されている。このプラットフォームは、多様なAIモデルをサポートしながら、開発者を中心に据えた柔軟な設計になっている。そして何より、実際の本番ワークロードを動かし、組織の複雑さとビジネス責任を扱える水準を目指している。
3つの設計原則
このプラットフォームは、以下の3つの基本原則に基づいて設計されている。
- 単一の統合システムで多様なモデルをサポートする:Azure、GitHub、Microsoft IQ、Fabric、Foundry、Windows、Microsoft 365、Microsoft Securityを一つのシステムとして連携させる。これにより、構築から改善までをバラバラのツールなしで行える。さらに、マイクロソフト自社モデルだけでなくパートナーモデルやオープンモデルも自由に選べる。
- セキュリティとガバナンスが設計に組み込まれている:Entra、Purview、Defender、Agent 365といったセキュリティスタックを開発段階から本番まで一貫して適用する。後付けではなく、システムにネイティブに統合されたガバナンスを実現する。
- 継続的に改善する:エージェントの動作結果や人間からのフィードバックをシステムに還元し、時間とともに安全に改善させる。モデルやワークフローが企業固有の業務プロセスに適合し、使い続けるほど価値が複利的に高まる仕組みを目指す。
これらの原則は今や「あると良い」ものではなく、競争力を左右する必須条件になるとAzure Blogの記事は強調している。四半期単位で差がつくという見立てだ。
エージェントライフサイクルの全体像
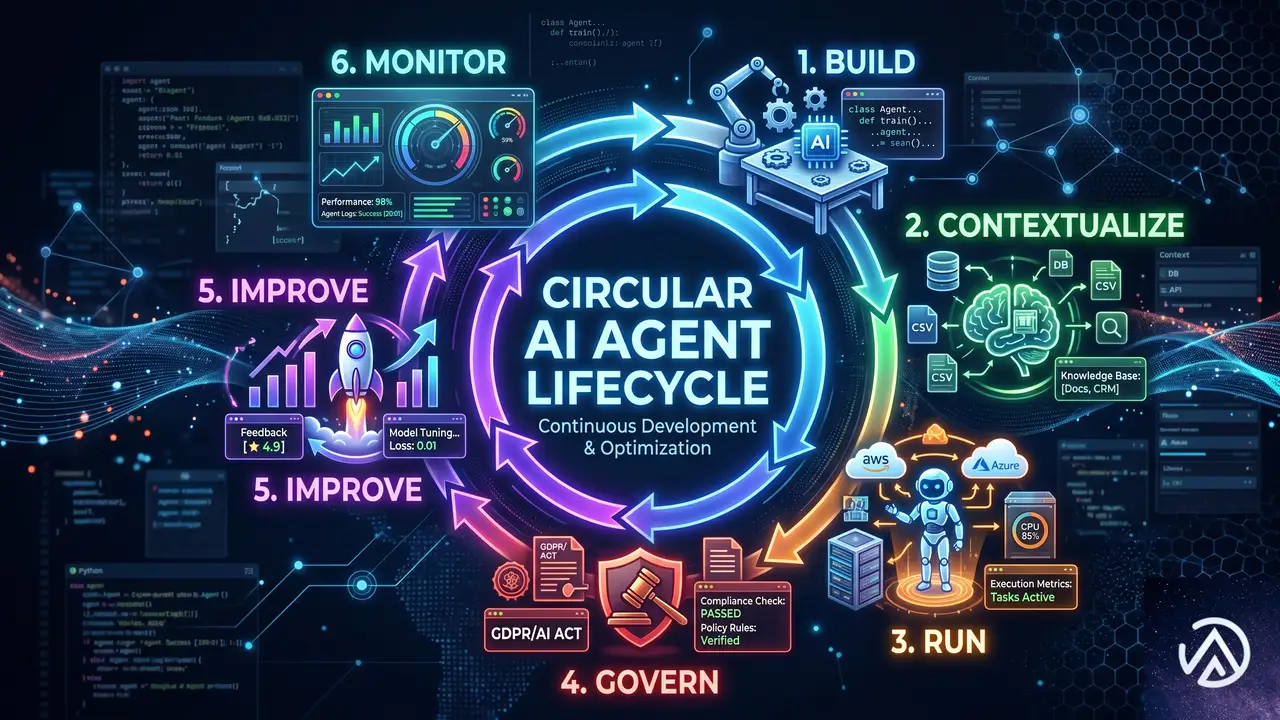
では、このプラットフォーム上でエージェントはどのように構築され、動いていくのか。Azure Blogの発表に沿って、主要な段階を順を追って見ていく。
構築〜GitHubで開発する
エージェントの開発は、すでに多くの開発者が日常的に使うGitHubを起点とする。コードベース、ワークアイテム、スキル、ツールなど重要なアセットを同じ場所に集約し、本番ソフトウェアと同じライフサイクル(ソース管理、テスト、デプロイ、監視、改善)をエージェントにも適用する。
GitHub Copilotを活用してコード作成を加速し、評価(eval)や可観測性(observability)のアセットもバージョン管理下に置く。これにより、最初から適切なガードレールを備えたエージェント開発が可能になる。発表では、このために新しいGitHubアプリが提供されることも述べられている。
企業データの文脈化〜Microsoft IQ
コードだけでは、エージェントは汎用的なAIにとどまる。真に役立つには、顧客情報、製品データ、契約書、業務プロセスといった企業特有の文脈を理解しなければならない。Azure Blogの記事では、いくら高性能なモデルを使っても、企業文脈なしでは推測に過ぎないと指摘している。
Microsoft IQは、Microsoft 365や基幹業務システム、ナレッジベース、自社ウェブサイトなど、社内外のデータソースにエージェントを接続する。さらに、Web IQによってウェブ上の情報も適切に取り込める。単にデータにアクセスさせるのではなく、情報を整理し、エージェントが扱いやすい形で安全に提供する点が重要だ。
さらに、Frontier Tuningと呼ばれる仕組みによって、実際の業務データとワークフローからモデルを改善できる。今回発表された音声、画像、コーディング、推論向けの7つの新しいMAIモデルを含め、モデルが企業のプロセスを学習し、その企業に特化した知能として機能するようになる。学習結果は企業の環境内に保持されるため、知的財産は外部に出ない。
実行環境〜Foundry
構築し文脈化したエージェントは、本番環境で実行されなければならない。Foundryは、エージェント特有の要求(推論、ツール呼び出し、他のエージェントとの連携、時間経過による適応)に応えるランタイムだ。
Foundryでは、タスクやコストに応じて最適なモデルを選択できるルーター機能を備え、Fireworks AIによる高速な推論も統合している。Microsoft Agent Frameworkはもちろん、LangGraph、GitHub Copilot SDK、Claude Agent SDKなど多様なエージェントフレームワークもサポートする。ツールやアクションはMCP、コネクター、API、ワークフロー経由で安全に実行され、評価とトレースによってエージェントの振る舞いを計測可能にしている。
ガバナンス〜Agent 365
ひとたび企業全体で何百、何千ものエージェントが稼働し始めると、全体を把握し制御するガバナンスが不可欠になる。Agent 365は、組織内の全エージェントを単一のカタログに表示し、誰がデプロイしたか、どのデータやツールにアクセスできるか、どのように動作しているか、コストはいくらかをIT管理者が一元的に確認できる仕組みだ。
Entra、Purview、Defenderと連携し、必要に応じてポリシーを強制したりアクションを取ったりできる。これにより、設計の良いエージェントもそうでないエージェントも、組織として統制下に置かれる。Azure Blogでは、ガバナンスの基盤が最初から組み込まれている点が後付けとの大きな違いだと強調されている。
継続的改善ループ
エージェントシステムは静的なままではない。すべての動作結果やフィードバックがシグナルとして蓄積され、評価、改善、安全なロールアウトが繰り返される。この学習ループは本番環境で連続的に動作し、プロンプトの調整からモデルルーティング、ファインチューニング、強化学習まで、段階的に高度化していく。
Azure Blogの記事は、このプロセスを「hill-climbingモデル」と表現し、システムを稼働させながら価値を複利で高める考え方を示している。重要なのは、改善ループが完全な自動化ではなく、人間の監査と修正のもとで制御されることだ。
業務現場への提供〜TeamsとAzure
エージェントの価値は、実際に業務を行う人々の手元に届いて初めて発揮される。このプラットフォームでは、TeamsやMicrosoft 365、自社アプリケーションの中にエージェントが自然に表面化する。アイデンティティ、セキュリティ、コンプライアンスは最初から組み込まれており、日常業務で使うツールと同じ信頼モデルを継承する。
また、Windows環境での最適化されたエージェント実行、クラウドとローカルの両方でのモデル稼働、サンドボックス技術による常駐型エージェントの安全な動作もサポートされる。大規模なAIワークロードやグローバルな展開が必要な場合は、Azureが基盤として全体をスケールさせる。
システムが価値を複利で増幅させる仕組み

Azure Blogの発表は、結局のところ、AI活用で先行する企業は「中央のAIプラットフォーム」を中心に業務を再編し、データ、モデル、エージェント、人間の判断を一つの継続的に改善する安全なシステムへと収斂させていくと述べている。システムが稼働し続けるほどその価値は複利的に増大し、ボトルネックは作業量から人間の創造性と調整へと移行する。
このビジョンでは、個々の担当者が共有された文脈のもとで自律的に仕事を進められるようになり、引き継ぎや摩擦は減り、ビジネス全体のスピードが上がる。マイクロソフトのエージェントプラットフォームは、まさにその「統合されたオペレーティングシステム」として機能することを目指している。
この記事のポイント
- Azure Blogの最新発表では、企業AIの成否はモデル単体ではなく、エージェントを動かすシステム設計にかかっていると指摘されている。
- 個別ツールの寄せ集めはリスクを高めるため、GitHub、Microsoft IQ、Foundry、Agent 365などによる統合アプローチが提唱されている。
- エージェントライフサイクル全体(構築、文脈化、実行、ガバナンス、継続改善)を単一システムで回すことで、信頼性とビジネス価値が複利的に高まる。
- セキュリティとガバナンスは設計段階から組み込まれ、人的監視のもとでAIが安全に改善し続ける仕組みが特徴。
・ 複数業界における17年間のデジタルビジネス開発経験
・ ウェブサイト開発のためのHTML、PHP、CSS、Java等の実用的知識
・ 15ヶ国語対応の多言語SaaSの開発経験
・ 17年間にも及ぶ、Eコマース長期運営経験
・ 幅広い業界でのSEO最適化の豊富な経験

Azure Cobalt 200 VMが50%性能向上、エージェンティックAIに最適化
Cobalt 200 VMの概要とプレビュー提供開始
Microsoft Build 2026にあわせ、Azure Cobalt 200 Armベース仮想マシンの早期アクセスプレビューが発表された。Azure Blogの記事によれば、第2世代の自社設計Armプロセッサを搭載するこのVMは、前世代Cobalt 100と比べて最大50%のCPU性能向上を達成し、とくにエージェンティックAIやクラウドネイティブなスケールアウト型ワークロードでの利用を見据えている。
Cobalt 200はシリコンからサーバー、サービスまでを一貫してMicrosoftが設計し、セキュリティ、ネットワーク、ストレージ、オフロード処理の最新技術を統合した。これにより、AI推論、データパイプライン、Web API層といった多様な負荷で、パフォーマンスとコスト効率の両立を狙う。Azure Blogの記事では「エージェントは従来のワークロードとは異なり、推論や逐次的意思決定を連続的に大規模実行するため、根本的に異なる計算プロファイルが求められる」と指摘している。Cobalt 200はまさにその要件に応える設計だ。
Cobalt 100からの性能向上と新アーキテクチャ

Cobalt 100はすでに世界32のAzureリージョンで稼働し、DatabricksやSnowflakeといったクラウド分析の大手が導入している。Microsoft自身のサービスでも、以前の基盤と比べて最大45%の性能向上を達成しつつ、使用コア数を35%削減できた実績がある。Azure Blogの記事によると、Microsoft Defender for Endpointのサイバーデータキュレーターでは40%の性能改善が確認され、大規模な脅威対応の高速化に貢献した。
Cobalt 200 VMは、この知見を土台にさらに一段上の性能を提供する。SoC(System-on-Chip)には、Arm Neoverse V3 Compute Subsystems(Armの高性能Vシリーズコア)を採用し、TSMCの3nm(N3P)プロセスで製造される。チップレットアーキテクチャ、カスタムアクセラレータ、そして専用設計のメモリコントローラを備え、L2キャッシュはコアあたり3MB、システムレベルのL3キャッシュは192MBに拡張された。これにより、データベースやインメモリキャッシュ、分析エンジンなど、データ集約型サービスのレイテンシ低減と応答性向上が期待できる。
この図は主要なクラウドワークロードにおけるCobalt 100からCobalt 200への相対性能の向上を示している。CPU性能は50%、Webサービングは40%、そしてデータベース処理では最大135%の改善を達成している(Azure Blogの記事に基づく)。
ネットワーク帯域幅は15%向上し、NVMeリモートストレージのIOPSは20%、スループットは10%改善する。さらに最大128vCPUまでのスケールアップが可能になった。メモリ暗号化がデフォルトで有効化されている点も、セキュリティ要件の厳しいエンタープライズ環境にとっては大きな前進だ。
エージェンティックAIに最適化された設計
Azure Blogの説明では、Cobalt 200の各コアは完全な物理コアであり、3MBの専用L2キャッシュとコアあたりの高いメモリ帯域を備える。この設計により、負荷時のアイソレーション性能が高く、エージェントのサンドボックスをVMあたりにより多く詰め込める。エージェンティックAIでは、複数のAIエージェントが並行して推論やツール呼び出しを行うため、スループットとレイテンシの両面で安定した性能が求められる。Cobalt 200はその期待に応える基盤となる。
データ集約型のキャッシュワークロードでは最大80%の性能向上が報告されており、通信暗号化処理では45%、クラウドデータベースでは135%という数字がAzure Blogの記事に示されている。こうした値は、大規模な本番サービスで確認された実測値であり、単なる理論上のピーク性能にとどまらない。
パートナー企業とMicrosoft内部サービスでの導入

プレビュー期間中から複数のテクノロジーパートナーがCobalt 200 VMを評価し、すでに有望な結果を得ている。Azure Blogに掲載されたTeradataのEngineering FellowであるBrandon Mincey氏のコメントでは、早期テストが有望だったとし、両社の共同顧客のニーズに合わせた設計へのフィードバックを続けているという。Elasticのプロダクト管理ディレクターYuvraj Gupta氏も、検索AIプラットフォームの性能とコスト効率のさらなる改善に期待を示した。
ArmのCloud AIビジネスユニット担当VP Eddie Ramirez氏は、エージェンティックAIがクラウドを再構築していると述べ、Arm Neoverse CSS V3をベースにしたCobalt 200が、次世代のAI駆動型サービスを可能にするとコメントしている。CanonicalのPublic Cloud AllianceディレクターJehudi Castro-Sierra氏は、メモリ暗号化のデフォルト有効化や圧縮・暗号化のアクセラレーションといった進歩が本番Linuxワークロードにとって重要だとし、Ubuntu ProのLivepatchによるArm環境での再起動不要なカーネル更新にも言及した。
Microsoft自身のサービスでも導入が進む。Power Platformの中核を担うDataverseでは、Cobalt 100での良好な実績を踏まえ、Cobalt 200の検証でベースワークロードが最大60%高速化したとAzure Blogの記事は紹介している。Azure SQL Databaseにおいても、圧縮・暗号化アクセラレータを活用することで、重要なクエリ処理リソースを解放できると期待されている。
VMファミリーと仕様
Cobalt 200 VMでは、従来の汎用(Dp, Dpl)やメモリ最適化(Ep)に加え、新たに高メモリ最適化Mpsv4シリーズと高密度ローカルストレージのLpsv5シリーズが追加された。これにより、大規模インメモリデータベースやビッグデータ分析、検索エンジンといった多様なニーズに対応できる。以下が主なシリーズの概要だ。
リモートディスクはStandard SSD、Standard HDD、Premium SSD、Ultra Diskに対応し、Azureポータル、SDK、API、CLIなど既存の手法でデプロイできる。プレビューは米国西部3、東部2、中央、スウェーデン中部などから開始され、今後リージョンが拡大される予定だ。
開発者エコシステムとArm互換性

Cobalt 200 VMは、現行のCobalt 100ワークロードとの完全な互換性を維持する。C++、.NET、Java、Python、Rustといった主要言語のArmネイティブ版がすでに最適化されており、GitHub ActionsもセルフホストランナーやGitHub-hostedランナーを通じてArmをサポートする。Azure Kubernetes Service(AKS)ではArmエージェントノードとx86/Arm混在クラスタの両方に対応し、コンテナ化されたワークロードの移行も容易だ。
クラウドインフラにおけるArm採用の流れはとどまるところを知らない。Cobalt 200の登場は、単なる性能向上にとどまらず、エンタープライズ向けのセキュリティと管理性をArmエコシステム全体に持ち込む転換点になるだろう。Azure Blogの記事は「Cobalt 200はAzureのカスタムシリコン戦略の新章」と位置づけており、今後のさらなる展開が注目される。
この記事のポイント
- Cobalt 200 VMがMicrosoft Build 2026で早期アクセスプレビュー公開。Cobalt 100比で最大50%のCPU性能向上
- 128vCPUまでのスケールアップ、NVMeストレージのIOPS/スループット改善、デフォルトのメモリ暗号化を実装
- エージェンティックAIに求められる高い並列性と低レイテンシに最適化された専用設計
- Teradata、Elastic、Arm、Canonicalなど主要パートナーが早期評価で有望な結果を示し、Microsoftの内部サービスでも性能改善を確認
- 新たなVMファミリーでより多様なワークロードに対応し、Armエコシステムの成熟がさらに加速する見通し
・ 複数業界における17年間のデジタルビジネス開発経験
・ ウェブサイト開発のためのHTML、PHP、CSS、Java等の実用的知識
・ 15ヶ国語対応の多言語SaaSの開発経験
・ 17年間にも及ぶ、Eコマース長期運営経験
・ 幅広い業界でのSEO最適化の豊富な経験

Microsoft Web IQでAIエージェントがBing検索を利用可能に。SEOへの影響を考察
Microsoftが2026年6月2日、AIエージェント向けの検索基盤「Web IQ」を発表した。Bingの検索インデックスに蓄積された情報を、AIシステムが推論やタスク実行に直接利用できるようにするAPI群である。
従来のBingが人間にウェブページを提供するのに対し、Web IQはAIに「パッセージ」と呼ばれる情報の断片を返す。この違いがAI時代のコンテンツ最適化とSEO戦略に大きな影響を与える可能性がある。
この記事では、Web IQの技術的な仕組み、従来の検索エンジンとの違い、パフォーマンス、そしてパブリッシャーにとっての意味を詳しく解説する。
Web IQの基本構造 〜AIエージェントが必要とする情報だけを届ける〜

Web IQの中核にあるのは、Bingのインデックスを土台に再構築された検索スタックだ。コンテンツのインデックス化、ランキング、選択の仕組みがAIエージェントの利用を前提に設計し直されている。AIエージェントはタスクの複数ステップにわたって厳しい時間制約の中で繰り返し検索を行うため、その動作特性に合わせた設計が求められた。
パッセージ単位の情報提供
Web IQが返すのは、ウェブページ全体ではない。「パッセージ」と「構造化されたエビデンスオブジェクト」だ。ページ中からAIにとって有用な部分だけを切り出して渡す。
AIモデルが処理するトークン(テキストの最小単位)にはコストがかかり、レイテンシ(応答遅延)にも直結する。Microsoftによれば、「少ないトークンでより良い回答を、1回の呼び出しあたりのコストを抑える」という三拍子を実現するのがWeb IQの設計思想だ。
このアプローチは、SEOの世界で徐々に広がっている「パッセージベースの検索」という概念とも整合する。Googleが2020年に導入したPassage Ranking(パッセージランキング)は、ページ全体ではなくその一部を検索クエリに最も関連する情報として抽出する技術だ。Web IQはこの考え方をAIエージェント向けに特化させたものと見ることができる。
従来の検索エンジンとは何が違うのか 〜ランキングと評価基準の再設計〜

MicrosoftがWeb IQの品質評価に使う指標は「GDSAT(Grounding Satisfaction / グラウンディング満足度)」と呼ばれる。情報の新鮮さと信頼性を測定するために設計された指標で、3,000件のサンプルクエリを用いたテストでは競合他社より高いスコアを記録したと発表している。
応答速度についても具体的な数字が示された。5つのデータセンターにまたがるテストで、P95(リクエストの95%がこの時間内に完了する値)で165ミリ秒未満を達成。競合と比較して約2.5倍高速だとしている。
ここで重要なのは、Web IQが従来の検索エンジンとまったく異なる評価軸で動いている点だ。人間向けの検索では、ページ全体の権威性や被リンクプロファイル、滞在時間など多面的なシグナルが使われる。一方、Web IQでは「AIエージェントがその情報を使ってどれだけ正確にタスクを遂行できるか」という一点が重視される。
全文からパッセージへの転換が意味すること
Search Engine Journalの記事で、Microsoftの発表を引用する形で指摘されているのは「従来の検索で上位表示されるページの特徴と、AIのグラウンディングに有用なパッセージの特徴は必ずしも重ならない」という点だ。同社が2026年前半に公開したグラウンディングフレームワークの記事でも、検索インデックスとグラウンディングの違いが詳述されている。
たとえば、あるページが検索キーワードに対して高い順位を得ていても、そのページ内のどの部分がAIにとって最も価値があるかは別問題だ。見出し構造、段落のまとまり、事実と意見の明確な区別など、AIが情報を抽出しやすい構造になっているかどうかが新たな評価ポイントになる可能性が高い。
検索体験からAI体験へ 〜パブリッシャーが知っておくべき変化〜

Bing Webmaster Toolsとの連携
Web IQは突然現れたわけではない。Microsoftは2026年に入って、段階的にAI向け検索の基盤整備を進めてきた。
- 2月、Bing Webmaster ToolsにAI引用データ(AI Citation Data)機能を追加
- 3月、グラウンディングクエリと引用ページを関連付けるAIダッシュボードを公開
- SEO Week期間中、Citation Share(AI向け引用シェア)のプレビューを発表
これらはいずれも、パブリッシャーが自分のコンテンツがAIにどのように使われているかを把握するためのツールだ。Web IQは、その裏側でAIがコンテンツを取得する仕組みに当たる。表と裏の関係にある。
つまり、Web IQの登場は「AI検索時代のSEO指標」が具体的な形を取り始めたことを意味する。従来の検索順位チェックに加えて、AIによる引用回数やパッセージ採用率といった新しいKPIが重要になる展開が予想される。
パッセージ最適化という新しい考え方
Web IQがパッセージ単位で情報を返す以上、パブリッシャー側もパッセージ単位でコンテンツを最適化する必要性が出てくる。具体的には以下のような施策が考えられる。
- 見出しと本文の関係を明確にし、各セクションが独立して意味を持つように書く
- 箇条書きや表組みを使って、AIが情報を構造的に読み取りやすくする
- 事実情報と意見・解釈を明確に分け、どちらを参照しているかAIが判断しやすくする
- 更新日を明示し、情報の鮮度をAIが評価できるようにする
これらの手法は、従来のSEOで言われてきた「E-E-A-T(経験・専門性・権威性・信頼性)」の強化とも多くの部分で重なる。違いは、AIが評価する点まで意識するかどうかだ。たとえば、ページの末尾にある免責事項や、サイドバーの関連記事リンクは従来の検索評価には影響しても、AIのパッセージ抽出ではノイズとして無視される可能性が高い。
技術面の詳細 〜オープンソース埋め込みモデルと高速検索〜

Web IQの検索パイプラインは3つの主要コンポーネントで構成される。埋め込みモデル、高速検索エンジン、そしてパッセージ選定モデルだ。
埋め込みモデルとDiskANN
Microsoftは2026年4月に、業界トップクラスの埋め込みモデル(Embedding Model)をオープンソース化した。テキストをベクトル(数値列)に変換し、意味の近さを計算できるようにする技術だ。Web IQはこのモデルを使って関連コンテンツを特定する。
大規模なインデックスを高速に検索するために使われるのが「DiskANN」という技術だ。これは全データをメモリに読み込まずに、ディスク上で効率的に類似検索を行うための仕組みだ。膨大なBingインデックスを対象に、165ミリ秒未満の応答を実現する鍵がここにある。
特筆すべきは、これらのモデルが単体のベンチマークスコアではなく、AI推論の中で実際に使われる状況を想定して訓練されている点だ。実用性を重視した設計と言える。
パブリッシャーコントロールと業界標準化
Web IQは、Bingがすでに準拠しているrobots.txtやメタタグによるクロール制御ルールを継承する。パブリッシャーが「AIにコンテンツを使われたくない」と設定していれば、Web IQもその指示に従う。
MicrosoftはIETF(インターネット技術標準化委員会)や他の業界団体とも協力し、AIシステムがウェブコンテンツにアクセスする際の標準ルール策定にも参加している。この動きは、Googleが進める「AIモード」や、その他のAI検索プロダクトとの間で、コンテンツ利用に関する共通ルールが形成されつつある兆候だ。
今後の展望と未解決の課題

現時点でWeb IQは「関心表明」を受け付けている段階であり、一般提供開始時期や価格、どのAIプラットフォームが採用するかは発表されていない。Microsoftの既存製品であるCopilotやBing Chatのグラウンディング機能がWeb IQを使っているのか、それとも別系統なのかも明らかにされていない。
とはいえ、Web IQの登場はAI検索時代の本格的な到来を示すマイルストーンだ。パブリッシャーは従来の検索エンジン最適化に加えて、「AIエージェントにどう使われるか」という視点でのコンテンツ設計を求められる局面に入ったと言える。
Bing Webmaster Toolsが提供を始めたAI引用データやCitation Shareは、そのための具体的な指標になる。まだ試験段階の数値ではあるが、早期にこれらのデータを確認し、自社コンテンツがAIにどう評価されているかを把握しておくことが競争優位につながるだろう。
この記事のポイント
- Web IQはAIエージェント向けのBing検索基盤APIであり、全文ではなくパッセージ単位で情報を返す
- 従来の検索評価とAI向け評価は異なる基準で動くため、SEO戦略の再考が必要になる
- Bing Webmaster ToolsのAI引用データやCitation Shareを使えば、AIからの評価を可視化できる
- パッセージ単位の情報設計が、今後のコンテンツ最適化の鍵になる
- 一般提供の時期や価格、対応AIプラットフォームは未発表だが、早期の動向把握が競争力を左右する
・ 複数業界における17年間のデジタルビジネス開発経験
・ ウェブサイト開発のためのHTML、PHP、CSS、Java等の実用的知識
・ 15ヶ国語対応の多言語SaaSの開発経験
・ 17年間にも及ぶ、Eコマース長期運営経験
・ 幅広い業界でのSEO最適化の豊富な経験

MicrosoftがAI Maxを発表!AIエージェントが主役の「Agentic Web」時代に備える新広告ツールとは
Microsoftが「エージェンティック・ウェブ(Agentic Web)」という新しい時代の到来を見据えた、次世代の広告ツール群を発表した。これは人間だけでなく、AIエージェントがネット上の情報を探索し、意思決定や購買を代行する世界を想定したものだ。
2026年4月、Microsoft Advertisingは「AI Max」を含む一連のアップデートを公開した。これには広告配信の最適化だけでなく、AIによるブランドの露出状況を可視化する分析ツールや、AIが直接決済まで完結させるための新しいプロトコルが含まれている。
従来の「検索してクリックする」というユーザー行動が、AIによる「最適な選択と実行」へと置き換わりつつある。企業にとって、この変化は単なる広告手法の変更ではなく、Web上での存在意義を再定義する重要な転換点となるはずだ。
エージェンティック・ウェブの到来とAIエージェントの役割

エージェンティック・ウェブとは、AIエージェントがユーザーの代わりにタスクを遂行するWeb環境を指す。これまでのWebは、人間がブラウザを開き、検索エンジンにキーワードを入力して、表示されたリンク先を一つずつ確認する場所だった。
しかしAIエージェントの普及により、このプロセスが劇的に変化している。ユーザーは「週末の旅行プランを立てて、予算に合うホテルを予約しておいて」とAIに頼むだけで済むようになる。AIは複数のサイトを巡回し、価格や評価を比較し、最終的な選択までを行う。
クリックから「選択」へのパラダイムシフト
これまでの広告ビジネスは「クリック」を指標にしてきた。ユーザーを自社サイトへ誘導し、そこでコンバージョンを狙うのが一般的だ。しかし、AIエージェントが情報を集約して回答する場合、ユーザーは必ずしも元のサイトを訪問する必要がなくなる。
ここで重要になるのが、AIに「選ばれる」ことだ。AIがユーザーに提示する回答の中に、自社の製品やサービスが適切に含まれているか。そして、AIがその情報を信頼できると判断しているか。この「選択の最適化」が、次世代のマーケティングの中心となる。
このデモは、Web利用の構造がどのように変化しているかを視覚化したものだ。ユーザーの行動が簡略化される一方で、AIが裏側で行う処理の重要性が増していることがわかる。
AI MaxとOffer Highlightsの仕組み

Microsoftが導入した「AI Max for Search」は、AI環境に特化した新しいキャンペーン形式だ。これは従来の検索広告を拡張し、CopilotやBingのAIチャット回答内など、AIが生成するあらゆるインターフェースに広告を最適化して配信する。
AI Maxの特徴は、クエリのマッチング精度が大幅に向上している点だ。ユーザーがAIと対話する中で、文脈を深く理解し、最も関連性の高いタイミングで広告を表示する。これにより、単なるキーワード一致を超えた、意図に基づいたリーチが可能になる。
会話の中に溶け込むOffer Highlights
もう一つの注目機能が「Offer Highlights」だ。これはAIとの会話の中で、製品の主要なセールスポイントを直接提示する広告フォーマットである。例えば「送料無料」や「期間限定の割引」といった情報が、AIの回答の一部として自然に組み込まれる。
AIチャットを利用しているユーザーは、情報を素早く得たいと考えている。別サイトに移動して詳細を確認させるのではなく、会話の流れの中でメリットを伝えることで、離脱を防ぎながら購買意欲を高めることができる。これは「AI時代のリスティング広告」とも呼べる進化だ。
AI Visibilityによる露出状況の可視化

新しい時代において、自社がAIにどのように認識されているかを知ることは極めて重要だ。そこでMicrosoftは、ウェブ分析ツール「Microsoft Clarity」に「AI Visibility」という新機能を搭載した。これはAIの回答内で自社ブランドがどのように表示されているかを分析するツールだ。
AI Visibilityでは、どのコンテンツがAIに引用されたか、どのキーワードで自社が推奨されたかを詳しく追跡できる。また、競合他社がAIの回答内でどのような位置を占めているかを比較することも可能だ。これは従来のSEOにおける検索順位チェックの、AI回答版と言えるだろう。
引用元としての信頼性を高める
AIは回答を生成する際、信頼できるソースを引用する。Clarityの新しいレポートを使えば、自社のどのページがAIにとって「引用しやすい」と判断されているかが明確になる。データ構造が整理されているか、主張が明確かといった要素が、AIによる露出度に直結するのだ。
このイメージ図は、AI Visibilityが提供するインサイトを簡略化したものだ。自社サイトのどの部分がAIに評価され、引用されているかを把握することで、次にとるべき施策が明確になる。
Universal Commerce Protocolと直接購入

AIエージェントが「買い物」を代行するためには、商品データがAIにとって読み取りやすい形式である必要がある。Microsoftは「Microsoft Merchant Center」において「Universal Commerce Protocol」のサポートを開始した。これはAIエージェントが製品を発見し、取引を円滑に行うための標準規格だ。
このプロトコルに準拠することで、AIは商品の価格、在庫、仕様だけでなく、配送条件や返品ポリシーまでを正確に把握できるようになる。AIエージェントがユーザーの代理人として「最も条件の良い商品」を選ぶ際、このデータ構造化が勝敗を分けることになる。
Copilot Checkoutで摩擦のない購買体験を
さらにMicrosoftは、Copilot内で直接決済を完結させる「Copilot Checkout」の強化も進めている。ユーザーがAIとの対話で商品を決めた後、外部サイトへ移動することなく、その場で注文を確定できる仕組みだ。
発見から購入までの摩擦(フリクション)を最小限に抑えることで、コンバージョン率は飛躍的に向上すると期待されている。企業側は自社サイトへの流入を失うことになるが、その代わりに「AIエージェント経由の売上」という新しいチャネルを確保することになる。
独自分析:SEOからAIO(AI最適化)への戦略的転換

Microsoftの今回の発表は、Webマーケティングの軸足が「人間向けのSEO」から「AI向けのAIO(AI Optimization)」へ移りつつあることを示唆している。AIエージェントに選ばれるためには、単にキーワードを散りばめるだけでは不十分だ。
AIOにおいて最も重要になるのは、情報の「正確性」と「構造化」である。AIは不確かな情報を嫌う。出典が明確で、構造化データ(Schema.orgなど)によって意味が厳密に定義された情報は、AIに採用される確率が高まる。また、自然言語によるターゲット設定ツールの登場により、広告主は「誰に」届けたいかをより直感的に指定できるようになる。
中小企業が今から準備すべきこと
この変化は、リソースの限られた中小企業にとってもチャンスだ。巨大な広告予算がなくても、特定のニッチな分野で「最もAIに信頼される情報源」になれば、AIエージェントを通じて多くのユーザーにリーチできる可能性がある。
まずは、自社サイトの情報を整理し、AIが理解しやすい形に整えることから始めよう。具体的には、製品のスペックをテーブル形式で明記する、独自の調査データを公開する、といった「AIが引用したくなるコンテンツ」の作成が有効だ。AIエージェントという新しい「顧客」とどう付き合うかが、今後の成長を左右するだろう。
この記事のポイント
- MicrosoftがAIエージェント時代を見据えた広告ツール「AI Max」を発表した
- エージェンティック・ウェブでは、AIがユーザーの代わりに情報を探し、意思決定を行う
- 「AI Visibility」により、自社ブランドがAIの回答にどう露出しているか分析可能になった
- 「Universal Commerce Protocol」により、AIエージェントが直接購入を代行する仕組みが整いつつある
- これからのマーケティングは、検索順位だけでなく「AIに選ばれるための最適化(AIO)」が重要になる
・ 複数業界における17年間のデジタルビジネス開発経験
・ ウェブサイト開発のためのHTML、PHP、CSS、Java等の実用的知識
・ 15ヶ国語対応の多言語SaaSの開発経験
・ 17年間にも及ぶ、Eコマース長期運営経験
・ 幅広い業界でのSEO最適化の豊富な経験