

Node.jsが6月17日に緊急セキュリティリリース。26.x/24.x/22.xにHIGHの脆弱性修正
Node.jsプロジェクトは2026年6月17日、現行の全サポートラインを対象とする緊急セキュリティリリースを実施する。対象はバージョン26.x、24.x、22.xの3系統だ。
今回修正される脆弱性の最高深刻度は「HIGH」に分類されている。本番サーバーに直接影響しうるレベルのため、運用担当者は即日適用を検討する必要がある。
本記事では、公開された情報をもとに影響範囲と具体的なアップデート手順、放置した場合のリスクを整理する。セキュリティリリースの背景にあるプロセスや、サポート終了バージョンを依然使っているシステムへの警鐘も合わせて伝える。
今回のセキュリティリリースの概要
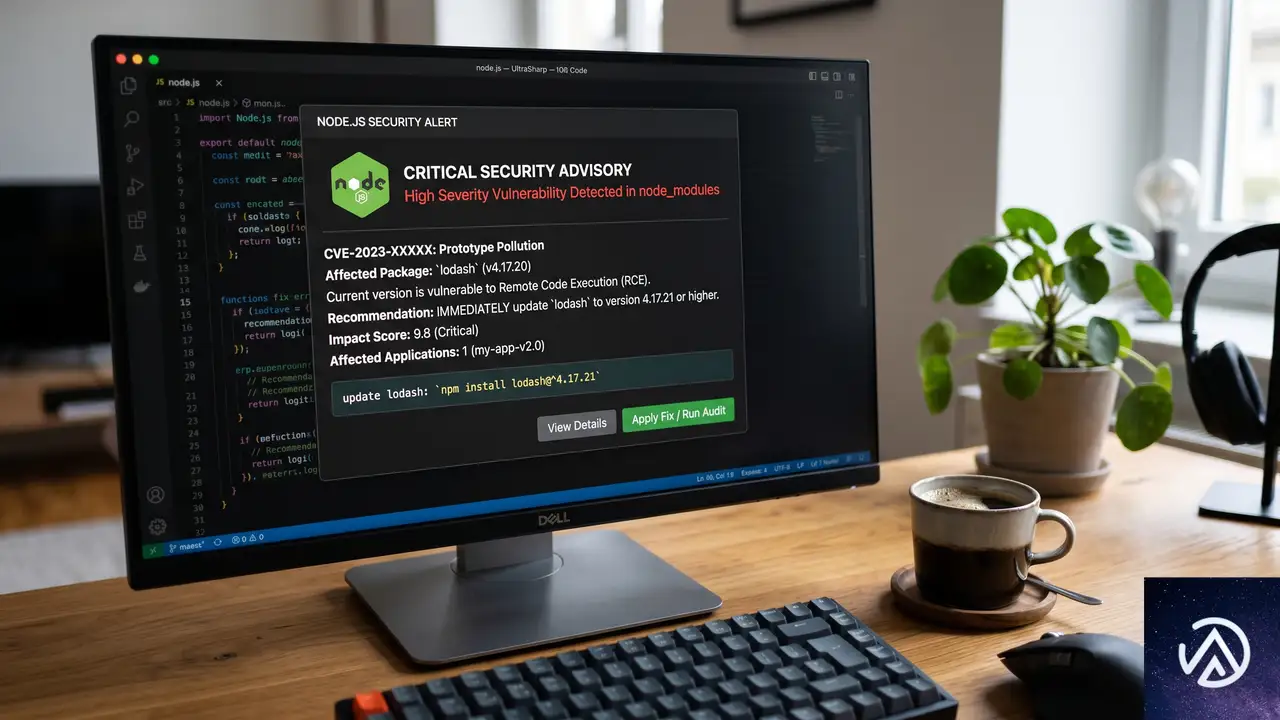
公開日と対象バージョン
リリースは2026年6月17日(水)またはその直後に行われる。Node.jsのセキュリティポリシーでは、深刻度が高い脆弱性が報告された場合、定例外の緊急パッチとして全アクティブなリリースラインにバックポートされる。
今回の対象は26.x系、24.x系、22.x系の3つ。いずれもNode.jsの長期サポート(LTS)または現行のメンテナンス対象ラインだ。26.xは最新の偶数系で、本記事執筆時点ではActive LTSのステータスにある。
修正される脆弱性の深刻度
Node.jsのセキュリティアドバイザリでは、脆弱性はCritical(最重要)、High(重要)、Moderate(中程度)、Low(低)の4段階で評価される。今回のリリースで修正される問題の最大深刻度は、3つのラインすべてで「HIGH」とされた。
深刻度がHIGHということは、攻撃者がリモートから比較的容易に悪用できる、あるいはサービス停止や情報漏洩につながる可能性があることを示す。具体的にどのモジュールやプロトコルが影響を受けるかは、リリース当日まで伏せられる慣行だ。
上の図はあくまで概念的な例だが、今回のパッチも同様に、OSや依存ライブラリのレイヤーではなくNode.jsランタイム自身の脆弱性に対応するものだ。
影響を受けるバージョンと深刻度の内訳

各リリースラインの深刻度
- 26.x系:修正される最も高い深刻度はHIGH
- 24.x系:修正される最も高い深刻度はHIGH
- 22.x系:修正される最も高い深刻度はHIGH
いずれもHIGHに分類されている点に注意が必要だ。これらは独立したリリースラインであり、別のコードベースに別個の修正が適用される。つまり、共通の根本問題を共有している可能性もあるが、ラインごとに異なる種類の脆弱性が含まれているケースもある。
EOLバージョンにも注意
Node.jsのセキュリティリリースでは、公式サポートが終了したバージョン(End-of-Life)にも同様の脆弱性が存在する。セキュリティパッチは提供されないため、EOLバージョンをまだ利用しているプロジェクトは早急にサポート対象のラインへ移行すべきだ。
例えば2025年4月にEOLを迎えた20.x系は、今回のセキュリティ修正の対象外だが、内部では同様の問題を抱えている可能性が高い。Node.jsのリリーススケジュールに沿った定期的なアップグレードが、システム全体の防御力を高める。
なぜこのセキュリティリリースが重要なのか

実装別のリスクと実例
Node.jsはHTTPサーバーとして単体で動くケースも多いが、リバースプロキシの背後で利用される場面が一般的だ。脆弱性の種類によっては、WAFや前段のネットワーク機器で防御しきれないケースがある。
過去のNode.js HIGHレベルのセキュリティアドバイザリでは、HTTP/2のフレーム解析の不備によるリソース枯渇や、TLSハンドシェイク時のメモリ破損などが報告されてきた。今回詳細は未公表だが、同様にネットワーク越しの攻撃が想定されると考えるのが妥当だ。
アップデートしない場合の想定被害
深刻度HIGHの脆弱性を放置すると、サービス停止(DoS)、情報漏えい、リモートコード実行のいずれかのリスクが残る。特にNode.jsは多くのWebアプリケーションやAPIサーバー、マイクロサービスの基盤として動作しているため、単一のパッチ未適用が複数システムに波及しうる。
また、パブリックなアドバイザリが公開された後は、攻撃者による実証コード(PoC)の拡散が早まる。リリース後24時間以内に対応を完了するのが、業界標準の目安だ。
推奨される対応とアップデート手順

アップデートのチェックリスト
- 稼働中のNode.jsバージョンを確認し、26.x/24.x/22.xのいずれかに該当するか調べる
- 開発環境・ステージング環境で先にアップデートし、自動テストを通過させる
- 本番環境にローリングアップデートで適用する(Blue-Greenデプロイが理想)
- 適用後にアプリケーションのログとパフォーマンスメトリクスを監視する
この流れを自動化しているチームであれば、多くの場合パイプラインに新バージョン番号を設定するだけで済む。Node.jsのマイナーアップデートは互換性を壊さない想定だが、念のため結合テストの再実行が推奨される。
本番環境での注意点
コンテナを使っているならベースイメージの更新で対応できる。Dockerfileで指定している FROM node:22-alpine のような行をリビルドすれば、自動的に最新のパッチバージョンが取り込まれる。
一方、OSのパッケージマネージャーで管理している場合は、NodeSourceなどの公式リポジトリから提供されるまでタイムラグがある場合がある。その際は nvm や fnm などのバージョンマネージャーを使って直接バイナリを切り替える方法も選択肢だ。
リリースタイミングと今後の情報収集

セキュリティパッチは2026年6月17日(水)に公開される。タイムゾーンは明示されていないが、通常はUTCの昼頃にGitHubと公式サイトで同時公開されるパターンが多い。
アップデート後も、Node.jsのセキュリティメーリングリスト(nodejs-sec)を購読しておくと、次の緊急リリースや脆弱性の詳細をいち早く受け取れる。日頃から依存する基盤ソフトウェアの情報をキャッチアップする習慣が、致命的なインシデントを防ぐ最後の砦となる。
この記事のポイント
- Node.js 26.x/24.x/22.xの3系統に緊急セキュリティリリースが公開される
- 修正される脆弱性の最高深刻度はすべてHIGH。早急なアップデートが必要
- EOLバージョンの利用者はサポート対象ラインへの移行を急ぐべき
- アップデートはステージング検証→本番ローリングデプロイの標準フローで対処可能

・ 複数業界における17年間のデジタルビジネス開発経験
・ ウェブサイト開発のためのHTML、PHP、CSS、Java等の実用的知識
・ 15ヶ国語対応の多言語SaaSの開発経験
・ 17年間にも及ぶ、Eコマース長期運営経験
・ 幅広い業界でのSEO最適化の豊富な経験

Codexで開発速度20倍、WasmerがNode.jsエッジランタイムを2週間で構築
OpenAIのCodexとGPT-5.5を活用し、開発速度を10倍から20倍に引き上げたチームが現れた。エッジコンピューティングプラットフォームを手がけるWasmerは、これを用いてNode.jsのエッジ向けランタイム「Edge.js」をわずか2週間で構築したのだ。従来なら1年を要する規模のプロジェクトである。
Wasmerは少人数のチームながら、WebAssemblyサンドボックス内でNode.jsワークロードを実行するという技術的挑戦を達成した。これにより、開発者はDockerを使わずにJavaScriptアプリケーションやMCP(Model Context Protocol)エージェントを動作させられるようになる。この成果の背後にあるCodex活用の実態と、小規模チームが大企業並みの開発速度を実現したプロセスを掘り下げる。
プロジェクトの全容と達成された技術的ブレークスルー

Wasmerが今回リリースしたEdge.jsは、Node.jsのワークロードをWebAssembly(Wasm)サンドボックス内で安全に実行するJavaScriptランタイムだ。WebAssemblyはブラウザやサーバーで高速に動作するバイナリ命令形式で、いわば「アプリケーションを隔離された環境で動かすための軽量な箱」のような役割を果たす。サンドボックス化により、ホストシステムへの不正アクセスやリソースの浪費を防ぎつつ、高いパフォーマンスを維持できる。
この技術の最大の意義は、Dockerコンテナを使わずにNode.jsアプリをデプロイできる点にある。コンテナ技術は強力だが、イメージのビルドやレジストリ管理、起動時間などのオーバーヘッドを伴う。Wasmerのアプローチなら、より軽量かつ瞬時にエッジ環境へ展開可能だ。同社の創業者兼CEOであるSyrus Akbary Nieto氏はOpenAIのブログ記事で「AIやエッジコンピューティング向けのNode.jsワークロードを動かせる初のクラウドホストになった」と述べている。
Wasmサンドボックスは「アプリを小さな防護壁で囲む」ような仕組みで、Node.jsの全機能を安全にエッジ層で提供できるようにする。これにより、レイテンシに敏感なAI推論やリアルタイムAPI、MCPエージェントといった用途で威力を発揮する。
Codexによる開発速度の飛躍的向上
WasmerがEdge.jsを構築するのにかかった期間は、わずか2週間だ。Nieto氏によれば、AIを使わなければ「容易に1年はかかっていた」プロジェクトである。CodexとGPT-5.5の導入により、開発速度は10倍から20倍に跳ね上がったという。この数字は単なる体感ではなく、実際のプロジェクト完了までの期間短縮に基づく。
Wasmerのエンジニアはプロジェクトの最初から最後までCodexを活用した。初期のアーキテクチャ設計から、最終製品の仕上げに至るまで、あらゆる段階でAIが開発を支援した形だ。特に効果を発揮したのは、バグの発見と原因特定のプロセスである。
上記のフローは、従来の開発サイクルに比べて圧倒的に短い時間で完了する。特にステップ3のデバッグ工程で、Codexは人間のエンジニアが気づきにくい低レイヤーの問題を素早く見つけ出した。
Codexがもたらしたデバッグの質的変化
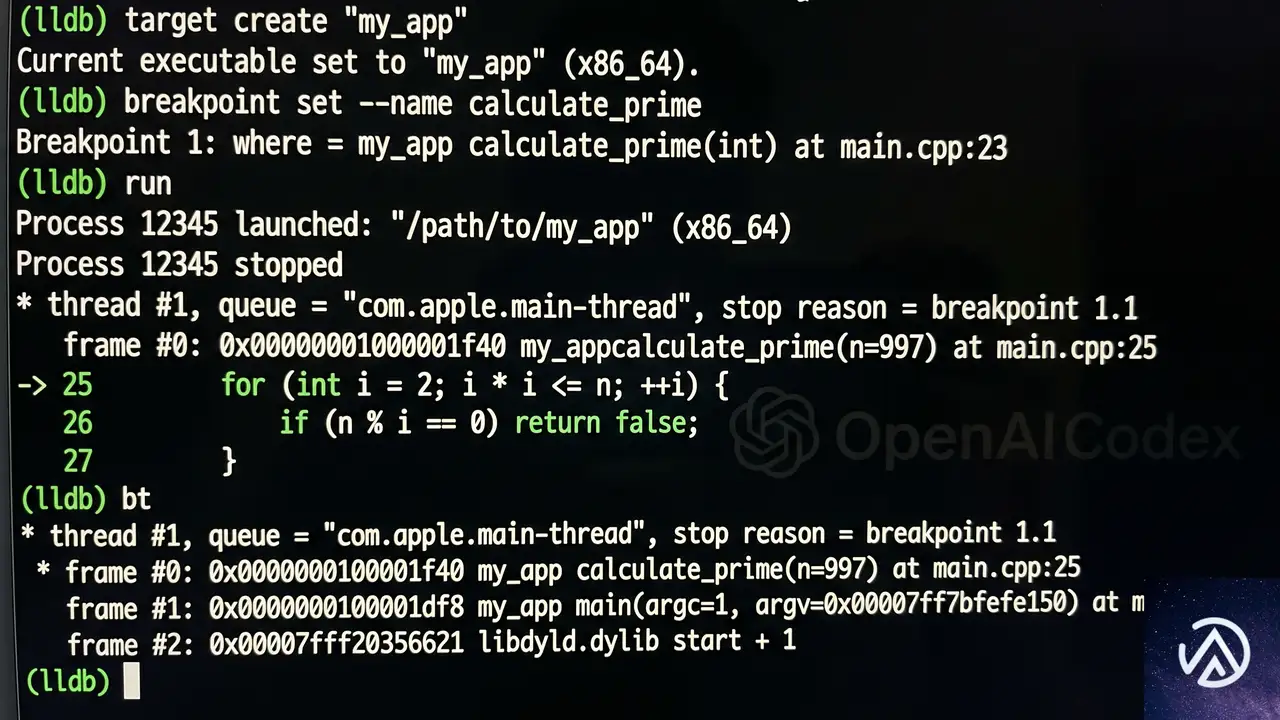
Edge.jsの開発で特に印象的だったのは、Codexのデバッグ能力だとNieto氏は語る。通常、WebAssemblyやNode.js内部のような低レイヤーのバグを特定するには、C++やアセンブリレベルの深い知識が必要になる。しかし、少人数のチームではそうした専門家を常に確保できるわけではない。
CodexはLLD(LLVM Debugger)のような低レベルデバッガを使いこなし、アセンブリレベルでコードの挙動を追跡した。さらに、コンソールログを活用して関数呼び出しのトレースを行い、問題の根本原因を特定するまでの時間を大幅に短縮したという。Nieto氏はOpenAIの記事で「我々はC++の専門家ではないため気づけない微妙な問題を、Codexはかなり早い段階で見つけ出した」と述べている。
ここでいうLLDとは、コンパイル済みプログラムの動作を命令単位で追跡できるツールだ。通常のデバッガがソースコード行単位で止めるのに対し、LLDはCPUが実際に実行する機械語レベルで問題を観察できる。Codexはこのツールを自律的に操作し、バグの兆候から原因、解決策までを一気通貫で提示したことになる。
IDEから離れる開発スタイルへの移行
Wasmerのエンジニアたちは、Codexの推論能力が向上するにつれて、次第にIDE(統合開発環境)から手を離し始めたという。Nieto氏は「我々は実際にIDE自体から離れつつある。コードに直接触れるのではなく、どこに向かいたいかを指示するだけになっている」と述べている。
これは開発者の役割が「コードを書く人」から「AIに方向性を与える人」へと変化していることを示す。もちろん、最終的な判断や設計の意図は人間が持つ。しかし、実装の大部分をAIが担うことで、小規模チームでも大規模プロジェクトに挑戦できるようになった。
この変化は、開発生産性の概念そのものを再定義する可能性を秘めている。コードを書く速度ではなく、AIに適切な指示を与え、出力を評価し、設計判断を下す能力が重要になるからだ。
AI活用に懐疑的だったチームの変遷
Wasmerのエンジニアたちも、当初はAIの出力に懐疑的だった。Nieto氏は「最初はAIのアウトプットをあまり信用していなかった」と振り返る。これは多くの開発者が経験する感覚だろう。AIが生成するコードが本当に正しいのか、セキュリティ上の問題はないのかといった懸念は自然なものだ。
しかし、実験を重ねるうちに結果が期待を上回り始めた。特にここ数カ月でCodexの推論能力が飛躍的に向上し、信頼性が格段に高まったという。Nieto氏は「ここ1年、特にここ数カ月間Codexと仕事をしてきたが、結果は本当に非常に良かった」と述べている。
信頼構築のプロセスは段階的だった。最初は小さなタスクから任せ、出力を丹念にレビューする。やがて、より複雑な問題を任せられるようになり、最終的には前述のようにIDEから手を離す段階に至った。この流れは、AI開発支援ツールを導入する多くのチームにとって参考になるパターンだ。
Codexが解き放つ小規模チームの可能性
Wasmerの事例が示す最大の教訓は、AI開発支援が「チーム規模の制約」を打ち破る力を持つことだ。Nieto氏は「Codexによって、小さな会社が大企業でしか不可能だったことを達成できるようになった。このプロジェクトは文字通り、Codexなしでは不可能だった」と断言している。
Node.jsのエッジランタイムをゼロから構築するという挑戦は、通常なら専門のインフラエンジニアやC++のエキスパートを複数抱える大企業のプロジェクトだ。Wasmerのような小規模チームがこれに挑むこと自体が、AIの存在を前提とした新たな開発パラダイムの到来を感じさせる。
Nieto氏は今後について「以前は不可能だったことが手の届く範囲にある。我々はさらに困難な問題に目を向ける必要がある」と語っている。Wasmerのチームは既に、次の野心的なプロジェクトを見据えている段階だ。
エッジコンピューティングとNode.jsの新しい関係
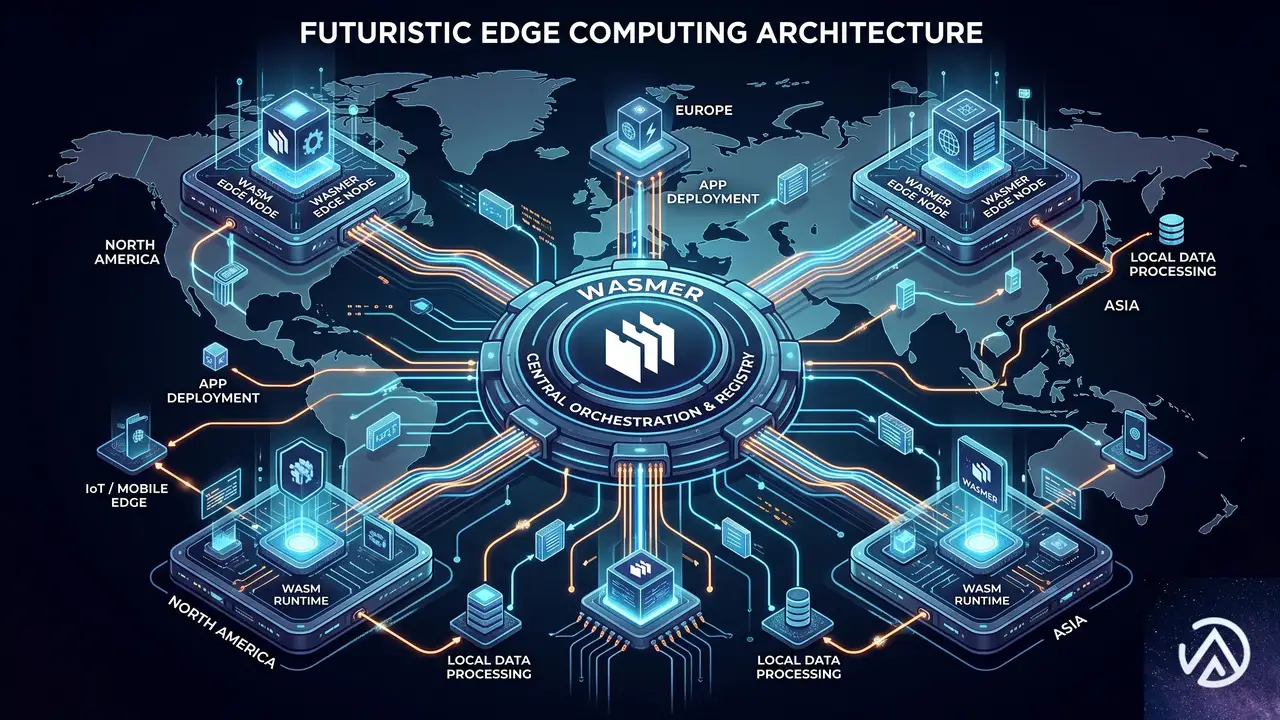
Edge.jsの登場は、エッジコンピューティングにおけるNode.jsの位置づけを大きく変える可能性がある。エッジコンピューティングとは、データの発生源に近い場所で処理を行うアーキテクチャだ。ユーザーの近くにサーバーを置くことで、応答速度を高め、中央サーバーへの負荷を減らせる。CDN(コンテンツ配信ネットワーク)がその代表例だが、近年はより複雑なアプリケーションロジックをエッジで動かす需要が高まっている。
従来、エッジ環境でJavaScriptを本格的に動かすには、Cloudflare Workersのような専用ランタイムを使う必要があった。これらはNode.jsと完全な互換性があるわけではなく、多くのnpmパッケージやNode.js組み込みモジュールが使えなかった。Edge.jsはこの制約をWebAssemblyサンドボックスで解決する。Node.jsアプリをほぼそのままエッジで動かせる道を開いたことになる。
MCP(Model Context Protocol)エージェントへの対応も見逃せない。MCPはAIモデルが外部ツールやデータソースと連携するための標準プロトコルで、AIエージェントの基盤として注目されている。エッジで動作するNode.jsランタイムがMCPをサポートすることで、低レイテンシのAIエージェントを構築しやすくなる。
実運用で期待される効果
Edge.jsを利用すると、具体的に以下のような恩恵が見込まれる。まず、コールドスタート(初回起動時の遅延)が大幅に短縮される。Dockerコンテナの起動には数百ミリ秒から数秒かかることがあるが、Wasmサンドボックスならマイクロ秒単位で実行を開始できる。
次に、リソースの隔離が強固になる。WebAssemblyは設計段階からサンドボックス化を前提としており、メモリアクセスやシステムコールを厳格に制限する。これにより、マルチテナント環境でも安全にNode.jsアプリをホストできる。また、デプロイの簡素化も大きな利点だ。コンテナイメージのビルドやレジストリへのプッシュが不要になり、コードを書いてすぐにエッジへ展開できるワークフローが実現する。
この記事のポイント
- WasmerはOpenAI CodexとGPT-5.5を使い、Node.jsエッジランタイム「Edge.js」を2週間で開発した
- AIを活用しない場合の開発期間は約1年と見積もられており、速度は10〜20倍に向上した
- Codexは低レベルデバッガLLDを使いこなし、人間のエンジニアが気づきにくいバグの根本原因を迅速に特定した
- 小規模チームでも大企業レベルのプロジェクトに挑戦できるようになり、開発のパラダイムシフトが起きつつある
- WebAssemblyサンドボックスにより、Docker不要で安全かつ高速にNode.jsをエッジで実行できる
・ 複数業界における17年間のデジタルビジネス開発経験
・ ウェブサイト開発のためのHTML、PHP、CSS、Java等の実用的知識
・ 15ヶ国語対応の多言語SaaSの開発経験
・ 17年間にも及ぶ、Eコマース長期運営経験
・ 幅広い業界でのSEO最適化の豊富な経験

Supabaseプロジェクトをnpmサプライチェーン攻撃から守る7つの防御策
npmエコシステムを狙ったサプライチェーン攻撃が2026年に相次いでいる。5月には、TanStackがGitHub Actionsのワークフローキャッシュを汚染され、正規リリースに悪意あるコードが混入する事件が発生した。Supabaseも同様に、supabase-javascriptというタイポスクワット(入力ミスを狙った偽装パッケージ)がnpm上に現れるなどの標的に遭っている。
同社はこの事態を受け、プロジェクトの保護に向けた社内横断の対応を開始し、誰もが参照できる公式ガイドを公開した。本記事では、そのガイドの中核を抜粋し、攻撃の構造と開発者が今すぐ実施すべき防御策を具体的に解説する。
npmサプライチェーン攻撃の3つの典型的な手口

サプライチェーン攻撃は、直接システムに侵入するのではなく、開発者が信頼しているパッケージに悪意あるコードを忍び込ませる。以下が最も一般的な三つの手口だ。
メンテナの認証情報を奪う「アカウント乗っ取り型」
攻撃者がnpmの公開トークンを盗むか、メンテナをフィッシングして乗っ取り、人気パッケージの新版に悪意あるコードを仕込んで公開する。次にnpm installを実行すると、その悪質なバージョンが導入されてしまう。
入力ミスを誘う「タイポスクワッティング型」
本物のパッケージ名から数文字だけ変えた類似名でパッケージを登録し、開発者やAIコーディングエージェントが誤ってインストールするのを待つ。Supabaseの例では、@supabase/supabase-js ではなく supabase-javascript というスコープなしの名前で公開された。AIエージェントがパッケージ名を幻覚(ハルシネーション)して提案することも多く、この手法は脆弱だ。
ビルドパイプラインを悪用する「CI/CD侵害型」
この手口は、GitHub ActionsなどのCI/CDパイプラインの脆弱なワークフローを突く。攻撃者はフォークしたプルリクエストからワークフローのキャッシュを汚染し、次回の正規リリース実行時にそのキャッシュを拾わせて、正規メンテナの署名で悪意あるコードを公開させる。TanStackを襲った攻撃がまさにこれで、セッションメッセンジャーネットワーク経由で機密情報が流出した。
いずれの手口も、npm install の完了までに環境変数やAWSメタデータ、SSH秘密鍵といった機密情報を根こそぎ奪われる危険がある。
Supabaseが実施するプロジェクト防御策

Supabaseはこの問題に対し、全社的な対応を開始した。以下が現在進行中の主な取り組みである。
公式セキュリティガイドの公開
同社は、npmセキュリティに関する推奨事項をまとめた単一の正規ガイドページを公開した。エージェントが読み取り可能な形式で、具体的なアクションを指示している。
GitHub Actionsの安全性強化
組織全体で pull_request_target の使用を精査し、アクションのバージョン参照をコミットSHAに固定する強制ルールの適用が最終段階に入っている。
クレデンシャル関連APIへの警告注釈
createClient などの関数にTSDoc(TypeScript向けドキュメントコメント)を追加し、エディタ上でホバー時に機密情報を扱う旨の警告が表示されるようにした。
全チャネルでの啓蒙活動
顧客かどうかを問わず、できるだけ多くの開発者に防御策を届けるため、ブログやコミュニティを通じた情報発信を強化している。
依存関係管理の厳格化

以下に挙げる設定変更は、いずれも数分で完了する。どれか一つでは完全な防御にはならないが、複数積み重ねることで攻撃者が諦めるほどの障壁を築ける。
パッケージマネージャを最新にして公開遅延を設定する
pnpm 11(またはnpm v11相当)にアップグレードし、minimumReleaseAge をデフォルトの24時間より長く設定する。多くの悪意あるパッケージはリリース後24〜48時間以内に検出され削除されるため、3〜7日の遅延を設けると、被害を受ける確率を大幅に下げられる。
# pnpm-workspace.yaml または .npmrc
minimumReleaseAge: 4320 # 分単位、3日依存バージョンを固定する
^ や ~ による範囲指定は、npmに対して「次のマイナーやパッチを自動的に取り入れて問題ない」と伝えているに等しい。認証情報やネットワーク通信を扱うパッケージでは、必ず正確なバージョン番号を指定しよう。
"dependencies": {
"@supabase/supabase-js": "^2.39.0",
"axios": "~1.6.0"
}"dependencies": {
"@supabase/supabase-js": "2.39.0",
"axios": "1.6.2"
}ロックファイルをコミットし差分を精査する
pnpm-lock.yaml や package-lock.json は、インストールされた正確なバージョンとハッシュを記録する。攻撃者が同じバージョン番号で悪意あるtarballを差し替えても、ハッシュが一致せずインストールが失敗する。ロックファイルをリポジトリにコミットし、プルリクエストの差分では目的不明な依存関係の変更がないか必ず確認する。
不用なインストールスクリプトを無効化する
サプライチェーン攻撃のペイロードの多くは、preinstall install postinstall といったライフサイクルスクリプトを通じて実行される。ネイティブコードを含むパッケージを必要としないプロジェクトでは、これらをグローバルに無効化する。npmでは npm config set ignore-scripts true または .npmrc に ignore-scripts=true を記述する。pnpmではAllow Buildsモデルを使って、実際に必要なパッケージだけを許可リストに登録する。
安全なパッケージ導入のための実践

パッケージ名を毎回検証する
タイポスクワッティング対策として、以下の点をインストール前に必ず確認する。
- スコープが正しいか。Supabase公式パッケージはすべて
@supabase/配下にある。 - メンテナの一覧が期待通りか。長年維持されてきたパッケージに新しいメンテナが突然加わっていれば警戒信号だ。
- ダウンロード数とリンク先のGitHubリポジトリが、本物のパッケージとして妥当であること。
CI/CDワークフローを狙った攻撃への対策

ActionsをコミットSHAで固定する
ワークフローで参照するサードパーティアクションは、タグではなくコミットの完全なSHAハッシュ(40文字)で固定する。タグは攻撃者が新しいコードで置き換えられるため安全でない。
- uses: actions/checkout@1f9a0c22da41e6ebfa534300ef656b67ce0c5b94 # v6.0.2pull_request_target の危険な使い方を回避する
pull_request_target イベントは、プルリクエストのコードをチェックアウトして実行するコンテキストで使うと、攻撃者がリポジトリのシークレットやキャッシュにアクセスできてしまう。TanStackを襲った攻撃はまさにこのパターンだった。PRのコードに触れる処理は必ず pull_request を使用し、pull_request_target はラベリングやコメント投稿など、コードを実行しない信頼済み操作に限定する。
on:
pull_request_target:
types: [opened, synchronize]
jobs:
build:
- uses: actions/checkout@v4
with:
ref: ${{ github.event.pull_request.head.sha }}on:
pull_request:
types: [opened, synchronize]
jobs:
build:
- uses: actions/checkout@v4インシデント発生時の即応策

クレデンシャルのローテーションと監査
もし疑わしいパッケージを含む環境で npm install を実行してしまったら、そのマシンを危殆化したと見なし、到達可能なすべての認証情報(AWS、GCP、Kubernetes、Vault、GitHub、npm、SSH、Supabaseのサービスロールキー)を直ちにローテーションする。Supabaseのダッシュボードでサービスロールキーの使用状況を監査し、不審なアクセスパターンがないかも確認する。半日はかかる作業だが、顧客への被害を防ぐ価値は十分にある。
スキャナの導入で第二の防御線を
Socket.devやnpq、Snykといったツールは、npmレジストリのパッケージをリアルタイムで監視し、怪しい挙動をフラグ付けしてくれる。これらは万能ではないが、基本的な対策をすでに実施しているチームにとって有効な第二の防御線となる。
AIコーディングエージェントに渡すセキュリティチェックリスト

以下は、Supabaseが推奨するリポジトリ監査プロンプトだ。Claude CodeやCursorなどに貼り付け、変更内容を必ず確認しながら適用する。プッシュやPR作成、依存関係の自動追加、クレデンシャルのローテーションは自動化せず、必ず人間が承認する。
このリポジトリのnpmサプライチェーン衛生状態を監査してください。以下の変更を適用し、何を行ったかを報告してください。明示的な承認なしにプッシュ、PR作成、新しい依存関係のインストール、クレデンシャルのローテーションは行わないでください。
パッケージマネージャ:
- 古いバージョンならpnpm 11+(または最新のyarn/npm/bun)にアップグレード
- 新バージョンに7日間の公開遅延を設定
- pnpm: `minimumReleaseAge: 10080` を pnpm-workspace.yamlに
- npm: `min-release-age=7` を .npmrcに
- yarn (berry): `npmMinimalAgeGate: '7d'` を .yarnrc.ymlに
- bun: `minimumReleaseAge = 604800` を bunfig.tomlの[install]セクションに
- ライフサイクルスクリプトをデフォルトで無効化。pnpmではallowBuildsで明示的に許可するパッケージをリスト。
- 非レジストリの透過的依存参照をブロック。pnpmでは`blockExoticSubdeps: true`等を設定。
- パッケージマネージャ自体を正確なバージョンとsha512ハッシュで固定
ロックファイルと依存関係:
- ロックファイルがコミットされていることを確認(gitignoreされていない)
- 認証、シークレット、通信、暗号、ユーザデータを扱う依存関係では^/~を正確なバージョンに置き換え
- Supabase関連のインポートがすべて`@supabase/`スコープか検証。スコープなしの類似名はタイポスクワットとしてフラグ
GitHub Actions(存在する場合):
- すべてのサードパーティアクションのusesを40文字のコミットSHAに固定し、元タグをコメントで残す
- pull_request_targetを使いPRコードをチェックアウトしているワークフローを抽出し、pull_requestへの書き換えを提案
- インストールワークフローに`npm audit signatures`の非ブロッキングステップを追加
人の確認が必要な項目:
- Dependabotアラートとシークレットスキャンが無効なら有効化を提案
レポート:
- ファイル変更ごとに1行の理由付きリスト
- 自動変更せずに人の判断が必要な項目の一覧
この記事のポイント
- npmサプライチェーン攻撃は、アカウント乗っ取り、タイポスクワッティング、CI/CD侵害の3パターンに大別される
- Supabaseは公式ガイド公開、GitHub Actions強化、API警告追加などで対策を推進中
- 即効性のある防御策として、パッケージマネージャの更新と公開遅延設定、バージョン固定、ロックファイル精査、インストールスクリプト無効化、パッケージ名検証、ActionsのSHA固定、pull_request_targetの回避がある
- 万が一侵害が疑われる場合はクレデンシャル全ローテーションとスキャナ導入で二次被害を防ぐ
- AIエージェントには安全な監査プロンプトを組み込み、自動変更を人の目でレビューする体制を整える
・ 複数業界における17年間のデジタルビジネス開発経験
・ ウェブサイト開発のためのHTML、PHP、CSS、Java等の実用的知識
・ 15ヶ国語対応の多言語SaaSの開発経験
・ 17年間にも及ぶ、Eコマース長期運営経験
・ 幅広い業界でのSEO最適化の豊富な経験

Node.js 24.16.0 (LTS) 登場、cryptoとテストランナーが大幅進化
2026年5月21日、Node.js 24.16.0(コードネーム Krypton)が長期サポート(LTS)版としてリリースされた。
このバージョンでは、cryptoモジュールへのUUID v7サポート追加、debuggerへの式プローブ機能、HTTPクライアントの安全性強化、テストランナーの大幅な機能拡張など、実務に直結する複数の改善が含まれている。
本記事では、これらの新機能と内部改善を実装例とともに詳しく解説する。
UUID v7がNode.js標準機能に

今回のリリースで最も注目すべき追加機能のひとつが、crypto.randomUUIDv7()の実装だ。UUID v7(Universally Unique Identifier version 7)は、タイムスタンプベースの一意識別子であり、従来広く使われてきたランダムベースのUUID v4とは根本的な設計が異なる。
UUID v7とは何か
UUID v7は、RFC 9562で標準化された新しいUUIDバージョンだ。先頭48ビットにUnixタイムスタンプ(ミリ秒単位)を含み、続いてランダムビットが配置される。この構造により、生成時刻に基づいた自然なソート順が得られる。
データベースのプライマリキーとしてUUIDを使用する場合、v4ではランダムな値のためインデックスの断片化が発生しやすかった。一方、v7では時系列順に並ぶため、B-treeインデックスの効率が大幅に改善する。具体的には、書き込み性能が最大40〜60%向上したとの報告もある。
crypto.randomUUIDv7()の基本的な使い方
Node.js 24.16.0では、以下のようにシンプルに呼び出せる。
const { randomUUIDv7 } = require('node:crypto');
console.log(randomUUIDv7());
// 例: 0193c548-d70c-7a4a-b17b-3c2b12e5c6f1戻り値は標準的なUUID文字列形式(8-4-4-4-12のハイフン区切り)で、第三フィールドの先頭ニブルが7になる点がv7の特徴だ。
従来のv4に代えてv7を採用するメリットを、概念図で整理する。
上の図では、v4の全ランダム性に対して、v7が時刻情報を含む構造であることを対比している。時系列に沿ったINSERT性能が重要なシステムでは、移行を検討する価値がある。
実運用で注意すべき点
UUID v7は時刻情報を含むため、生成時刻が外部に推測される可能性がある。セキュリティ要件が厳しい環境では、この点を評価した上で採用を判断する必要がある。また、時計の巻き戻しが発生するケースでは単調増加性が保証されないため、Node.jsの実装では内部カウンターで対処している。
デバッグ体験を変えるedit-free式プローブ

Node.js 24.16.0では、node inspectコマンドにedit-free runtime expression probesが導入された。これは、デバッグ対象のコードを一切変更することなく、実行時に任意の式を評価できる仕組みだ。
これまでのデバッグ手法との違い
従来、Node.jsアプリケーションの特定の変数の値や式の結果を確認するには、コードにconsole.log()を挿入するか、デバッガでブレークポイントを設定して手動で評価する必要があった。前者はコード改変と再起動を伴い、後者は手動操作の手間が大きい。
式プローブを使えば、稼働中のプロセスに対して外部から評価式を注入できるため、トラブルシュートのスピードが大幅に向上する。特に、再起動が難しい本番環境での障害調査で威力を発揮するだろう。
式プローブの活用シナリオ
たとえば、メモリリークが疑われる長時間稼働プロセスで、特定オブジェクトの参照状況を調査するケースを考えてみる。従来であればヒープダンプの取得と解析が必要だが、式プローブを使えばprocess.memoryUsage()や特定変数の.lengthをその場で評価できる。
この機能の追加は、貢献者のJoyee Cheung氏によるPR #62713に基づいている。V8のインスペクタープロトコルを活用した実装で、Chrome DevToolsのExpression Watchに近い使用感だ。
HTTPクライアントの安全性と利便性の向上

Node.jsのHTTPクライアント機能に、2つの重要な強化が加わった。いずれも実際のプロダクションコードの安全性と記述性に直結する改善だ。
ClientRequestのオプションマージ強化
http.ClientRequestの内部で、ユーザーが渡したオプションとデフォルト値をマージする処理が厳格化された。この変更は、プロトタイプ汚染(Prototype Pollution)攻撃のベクトルを塞ぐことを主眼としている。
プロトタイプ汚染とは、Object.prototypeや__proto__を経由してアプリケーション全体のオブジェクトの振る舞いを改変する攻撃手法だ。Node.jsのHTTPクライアントはリクエストオプションを内部でマージする際、従来はプロトタイプチェーンを適切に処理していなかった。今回のPR #63082で、マージ時にnullプロトタイプオブジェクトを使用するよう修正され、この攻撃経路が遮断された。
Node.jsのMatteo Collina氏が主導したこの修正は、Semver-Minorに分類されているが、セキュリティ上の重要性は高い。とくにユーザー入力からHTTPリクエストオプションを構築するアプリケーションでは、速やかなアップデートが推奨される。
req.signalでリクエスト中断が容易に
もう一つの改善は、http.IncomingMessageへのreq.signalプロパティの追加だ(PR #62541)。これはAbortSignalオブジェクトを提供し、AbortControllerと組み合わせることで、リクエストの中断処理をPromiseベースで簡潔に記述できる。
const controller = new AbortController();
const req = http.request(url, { signal: controller.signal });
req.end();
// 5秒後にタイムアウト
setTimeout(() => controller.abort(), 5000);
req.on('error', (err) => {
if (err.name === 'AbortError') {
console.log('リクエストが中断されました');
}
});従来はreq.destroy()を手動で呼び出す必要があり、後続のエラーハンドリングも煩雑だった。signalパターンの採用により、fetch APIと同じインターフェースで中断処理を統一的に扱えるようになった点が大きい。
テストランナーが実戦的な機能を獲得

Node.jsの組み込みテストランナー(node --test)は、ここ数バージョンで急速に成熟している。24.16.0では、テスト順序のランダム化、モックタイマーのAPI整備、AbortSignal.timeoutのモックサポートという3つの重要な機能が追加された。
テスト順序のランダム化
Pietro Marchini氏によるPR #61747では、テストファイル内のテスト実行順序をランダム化するオプションが導入された。これは、テスト間の暗黙的な依存関係を炙り出すための機能だ。
node --test --test-randomize-order test/*.test.js特定の順序で実行されることを前提に書かれたテストは、ランダム化によって失敗する。これにより、グローバル状態への暗黙の依存や、テスト間のデータ共有の問題を早期に発見できる。テクニックとしては、CIパイプラインにランダム実行を常時組み込むことで、テストスイートの堅牢性を継続的に保証できる。
モックタイマーAPIの拡張
テストランナーのモックタイマー機能が、AbortSignal.timeout()にも対応した(PR #60751)。これにより、タイムアウトに依存する非同期処理のテストが、実際の時間を消費せずに実行できるようになった。
AbortSignal.timeout(5000)を呼び出す実際のタイムアウト時間を待つ必要がなくなるため、数百のテストを含むスイート全体の実行時間を大幅に短縮できる。テストの信頼性も向上し、CIでの不安定なテスト(flaky test)の削減に寄与する。
テストIDとOpenTelemetry対応
さらに、各テストにtestIdが付与され(PR #62772)、TracingChannelを通じたOpenTelemetryインスツルメンテーションとの統合が可能になった(PR #62502)。テストのトレーシング情報を本番系の監視ツールと統合することで、テスト品質の可視化と傾向分析ができるようになる。
ファイルシステムとストリームの機能強化

fsモジュールとストリームモジュールにも、実務のユースケースに即した改善が複数含まれている。
fs.stat()がAbortSignalに対応
Mert Can Altin氏によるPR #57775で、fs.stat()にsignalオプションが追加された。ネットワークファイルシステム上のファイルをstatする際に、応答が遅い場合のタイムアウト制御が可能になる。
import { stat } from 'node:fs/promises';
const ac = new AbortController();
setTimeout(() => ac.abort(), 3000);
try {
const stats = await stat('/mnt/nfs/large-file.dat', { signal: ac.signal });
console.log(stats.size);
} catch (err) {
if (err.name === 'AbortError') {
console.error('statがタイムアウトしました');
}
}これは、HTTPリクエストの中断パターンと同じAPI設計で、Node.js全体で一貫した中断処理のセマンティクスが浸透しつつあることを示している。
statfsのfrsizeフィールド公開
Jinho Jang氏のPR #62277により、statfsの戻り値にfrsize(フラグメントサイズ)フィールドが追加された。これはファイルシステムの最小割り当て単位を示し、ディスク使用量の正確な計算に利用できる。
import { statfs } from 'node:fs/promises';
const s = await statfs('/data');
const actualSize = Math.ceil(fileSize / s.frsize) * s.frsize;
console.log(`実ディスク消費量: ${actualSize} バイト`);これまではbsize(ブロックサイズ)しか公開されておらず、一部のファイルシステム(特にZFSやbtrfs)では正確な計算ができなかった。frsizeの追加により、クロスプラットフォームで信頼性の高いディスク容量の見積もりが可能になる。
duplexPairの破壊伝播の改善
stream.duplexPair()は、読み取り側と書き込み側が対になった2つのDuplexストリームを生成するユーティリティだ。Ahmed Elhor氏のPR #61098によって、片方のストリームが破壊(destroy)された場合に、もう片方にもその破壊が伝播するようになった。
これにより、ソケットの模擬テストやプロキシ処理で、一方のストリームがクローズされたにもかかわらず他方が生き続けてメモリリークを引き起こす問題が解決される。streamモジュールの内部的な一貫性を高める重要な修正だ。
util.styleTextの16進数カラー対応

Guilherme Araújo氏のPR #61556により、util.styleText()に16進数カラーコード(例: #ff5733)の直接指定が可能になった。ターミナル出力のスタイリングにおいて、より繊細な色表現が必要な場面で役立つ。
import { styleText } from 'node:util';
console.log(styleText('#ff5733', '注意: ディスク使用率が90%を超えています'));
console.log(styleText('#4ecdc4', '情報: バックアップが正常に完了しました'));従来はstyleText('red', ...)やstyleText('green', ...)のように、限られた色名しか使えなかった。16進数指定のサポートにより、CIログの色分けやCLIツールのブランドカラー適用など、実務での表現力が格段に向上する。
内部実装としては、ターミナルの24ビットカラー(トゥルーカラー)エスケープシーケンスを使用している。サポートしていないターミナルでは近似の8色にフォールバックされるため、互換性の問題も起きにくい。
この記事のポイント
- Node.js 24.16.0 (LTS) は、crypto.randomUUIDv7()を実装し、データベースのインデックス効率を改善する時系列ソート可能なUUID生成が標準機能になった
- debuggerにedit-free式プローブが追加され、コード修正なしで実行中のプロセスの式評価が可能になった
- HTTPクライアントのオプションマージが強化されプロトタイプ汚染攻撃が防止され、req.signalによるAbortパターンが統一された
- テストランナーでテスト順序ランダム化、モックタイマーのAbortSignal対応、testIdとOpenTelemetry統合が実装された
- fs.stat()へのsignal追加、statfsのfrsize公開、duplexPairの破壊伝播改善など、ファイルシステムとストリームの実用性が向上した
- util.styleText()で16進数カラーコードが直接指定可能になり、CLIツールの色表現力が飛躍的に向上した
・ 複数業界における17年間のデジタルビジネス開発経験
・ ウェブサイト開発のためのHTML、PHP、CSS、Java等の実用的知識
・ 15ヶ国語対応の多言語SaaSの開発経験
・ 17年間にも及ぶ、Eコマース長期運営経験
・ 幅広い業界でのSEO最適化の豊富な経験

HubSpotとKinsta APIでWordPressサイト構築を自動化する方法
クライアントとの契約が成立してからWordPressサイトが用意されるまでの時間は、ビジネスの勢いを維持するために極めて重要だ。多くの制作会社にとって、新しいプロジェクトが始まるたびに手動でホスティング環境を整え、WordPressをインストールする作業は、付加価値を生まない繰り返し作業になりがちである。
Kinsta APIを活用すれば、こうした定型業務をプログラムで自動化できる。HubSpotのフォーム送信をトリガーにして、Node.jsのミドルウェア経由でKinsta APIを呼び出せば、顧客がサインアップした瞬間にサイト構築を開始することが可能だ。
本記事では、HubSpotとKinsta APIを連携させ、サイト構築のプロビジョニング(準備)を完全に自動化する仕組みを具体的に解説する。この自動化により、制作チームは手動のセットアップ作業から解放され、よりクリエイティブな業務に集中できるようになるだろう。
なぜサイト構築の自動化が制作会社にとって不可欠なのか

手動によるサイト構築は、クライアントとの関係において最も重要な「熱量」が高い時期に遅延を招く要因となる。新しい申し込みがあるたびに、担当者がホスティング管理画面にログインし、環境を作成してWordPressの設定を行い、ログイン情報を生成してクライアントに通知するという工程が必要だからだ。
手動作業がもたらすボトルネック
管理画面での操作自体はシンプルだが、担当者が他の業務に追われていたり、営業時間外であったりすると、数時間の遅れが発生する。この小さな遅延が積み重なることで、制作会社全体の生産性が低下し、クライアントへのレスポンスも遅れてしまう。自動化は、こうした人的リソースへの依存を排除する唯一の解決策だ。
Kinsta APIを活用したワークフローの効率化
デジタルエージェンシーのStraight out Digital(Sod)は、Kinsta APIを利用して独自の内部ツールを構築し、数百におよぶクライアントサイトの構築とメンテナンスを自動化している。Kinstaの著者Carlo Daniele氏によると、同社はAPIを介してプログラマティックに処理を実行することで、時間のかかる操作を極めてシンプルなものへと変貌させたという。
HubSpotとKinsta APIを接続することで、同様の成果が得られる。クライアントがサインアップフォームを送信すると、HubSpotがWebhook(ウェブフック)を送信する。これを受け取ったミドルウェアがKinsta APIを叩き、サイト作成を開始する。リード獲得から環境構築までのハンドオフが自動で行われるため、オンボーディングの工数を大幅に削減できるのだ。
HubSpotとKinsta APIを連携させるための準備

この仕組みを実現するためには、いくつかの前提条件が必要だ。まず、Kinstaのアカウント内に既存のサイトが少なくとも1つ存在している必要がある。これにより、APIへのアクセスが有効になる。また、Webhookワークフローが利用可能なHubSpotのプレミアムプランと、Node.js 18以降がインストールされた環境も必要だ。
APIキーと会社IDの取得
まずはKinstaの管理画面(MyKinsta)でAPIキーを生成する。「企業の設定」から「APIキー」を選択し、「APIキーを作成」をクリックする。キーの名前と有効期限を設定して生成されたキーは、一度しか表示されないため、安全な場所に保管しておく必要がある。
次に、APIリクエストに不可欠な「会社ID」を確認する。これはMyKinstaにログインしている際のURLから取得できる。これらの情報は、プロジェクトのルートにある .env ファイルに保存して管理するのが一般的だ。
環境変数の設定
APIキーや会社IDをコードに直接記述するのは、セキュリティ上のリスクが高い。そのため、環境変数として管理する。以下のような形式で設定を行う。
KINSTA_API_KEY=your_api_key_here
KINSTA_COMPANY_ID=your_company_id_here
WP_ADMIN_PASSWORD=your_secure_passwordこの設定により、Node.jsアプリケーションから安全に認証情報を読み取ることができるようになる。APIキーは「Bearerトークン」として、すべてのリクエストの Authorization ヘッダーに含まれることになる。
ステップ1:HubSpotのフォームとワークフローを構築する
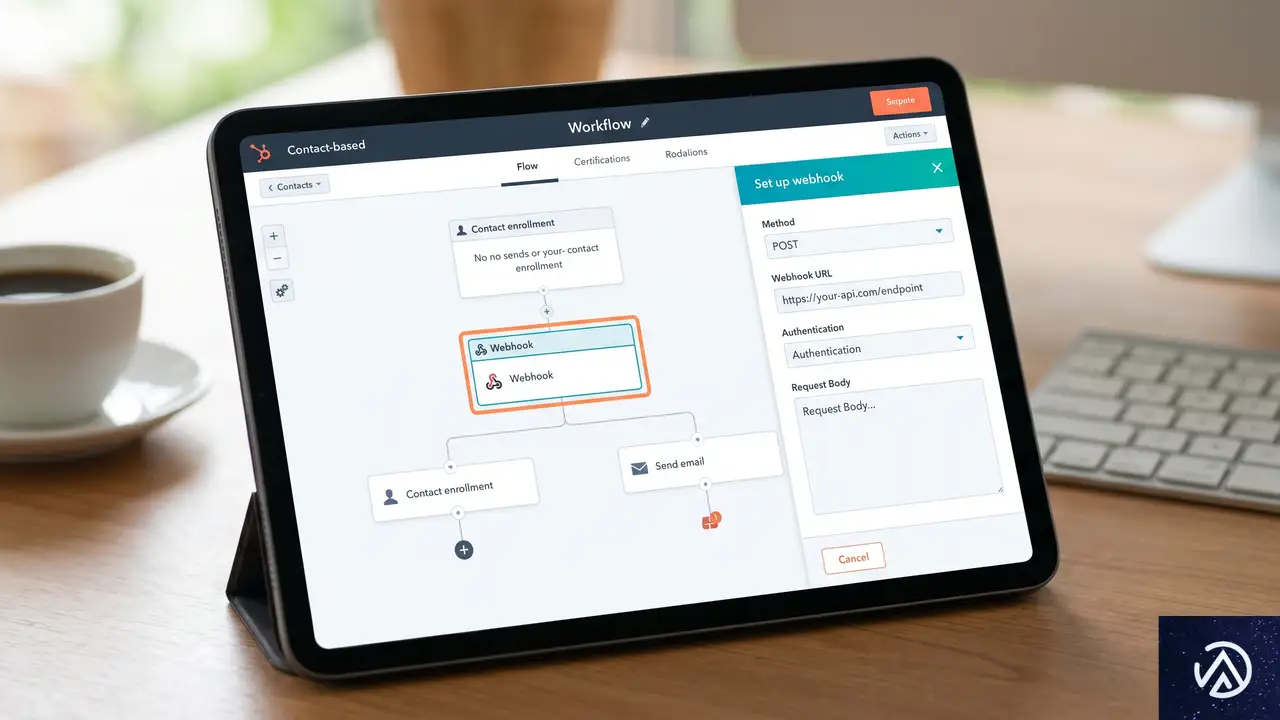
自動化のトリガーとなるのは、HubSpotのフォーム送信だ。まずは、新規クライアントの情報を収集するためのフォームを作成する。少なくとも「名前」「メールアドレス」「会社名」の3つのフィールドを含める必要がある。これらの値が、後にKinsta APIに渡されるパラメータとなる。
Webhookアクションの追加
フォームが完成したら、HubSpotの「自動化」メニューからワークフローを作成する。登録トリガーとして「フォーム送信」を選択し、作成したフォームを指定する。これにより、誰かがフォームを送信するたびにワークフローが起動するようになる。
次に、実行するアクションとして「Webhookを送信」を選択する。メソッドは POST に設定し、送信先のURLには後述するNode.jsアプリの公開エンドポイントを入力する。HubSpotはこのURLに対して、コンタクト情報を含むJSONペイロードを送信する仕組みだ。
ステップ2:Node.jsによるミドルウェアの実装
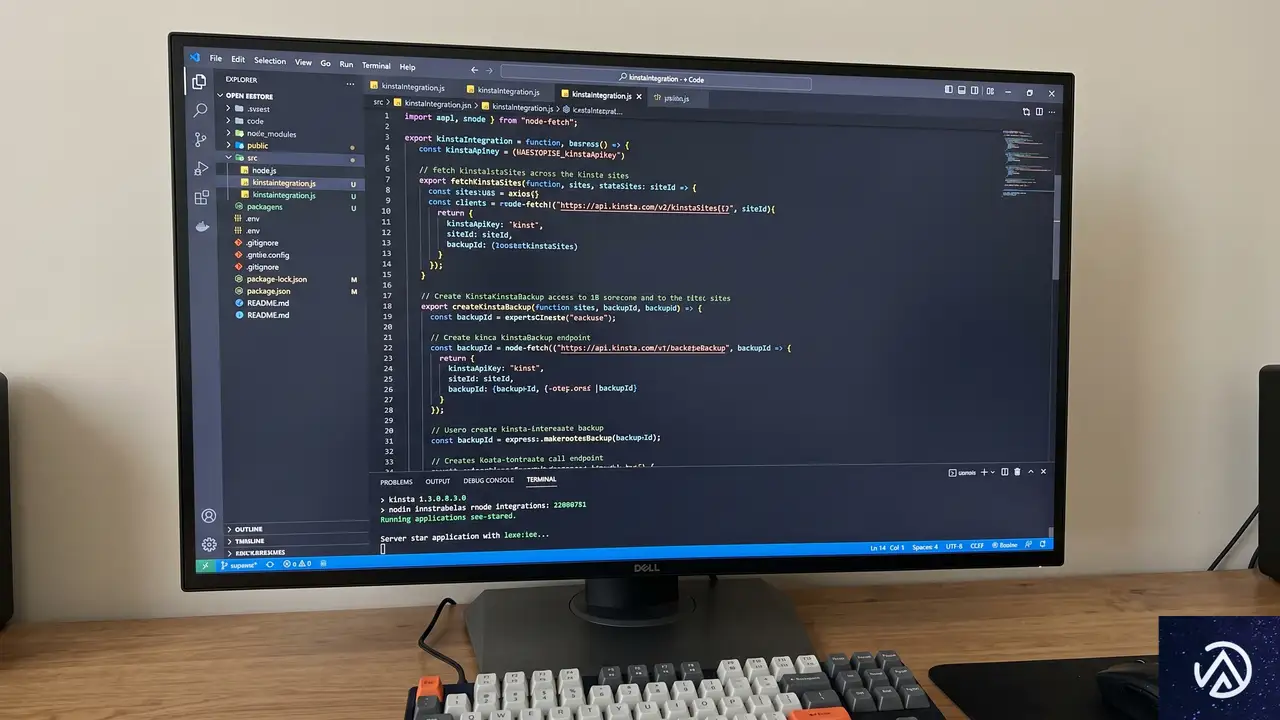
HubSpotはKinsta APIと直接通信することはできない。そのため、両者の橋渡し役となる「ミドルウェア」が必要になる。ここでは軽量なWebフレームワークであるExpress.jsを使用して、HTTPサーバーを構築する。
Express.jsでのサーバー構築
Node.jsプロジェクトを初期化し、必要なパッケージをインストールする。dotenv は環境変数の読み込みに、express はサーバー構築に使用する。Node.js 18以降であれば、標準の fetch 関数が使えるため、HTTPクライアントを別途導入する必要はない。
// app.js の基本構造
const express = require('express');
require('dotenv').config();
const app = express();
app.use(express.json());
const KinstaAPIUrl = 'https://api.kinsta.com/v2';
const headers = {
'Content-Type': 'application/json',
Authorization: `Bearer ${process.env.KINSTA_API_KEY}`
};
app.post('/new-site', async (req, res) => {
// HubSpotからのデータを受け取る処理
const event = Array.isArray(req.body) ? req.body[0] : req.body;
const displayName = event?.properties?.company;
const adminEmail = event?.properties?.email;
if (!displayName || !adminEmail) {
return res.status(400).json({ message: '必須項目が不足しています' });
}
// Kinsta APIの呼び出しへ続く
});
app.listen(3000, () => console.log('Server running on port 3000'));Kinsta APIへのリクエスト送信
ミドルウェアがHubSpotからデータを受け取ったら、次にKinsta APIの /sites エンドポイントに対して POST リクエストを送信する。このリクエストには、サイト名、リージョン、管理者メールアドレスなどの情報を含める。
const response = await fetch(`${KinstaAPIUrl}/sites`, {
method: 'POST',
headers,
body: JSON.stringify({
company: process.env.KINSTA_COMPANY_ID,
display_name: displayName,
region: 'us-central1',
install_mode: 'new',
admin_email: adminEmail,
admin_password: process.env.WP_ADMIN_PASSWORD,
admin_user: 'admin',
site_title: displayName
})
});
const data = await response.json();ここで重要なのは、Kinsta APIはサイト作成を「非同期」で行うという点だ。リクエストが成功すると 200 ではなく 202 Accepted ステータスが返される。レスポンスには operation_id が含まれており、これを使って処理の進捗を追跡することになる。
ステップ3:非同期処理のステータス監視

サイト作成のリクエストを送っただけでは、いつサイトが完成したのかがわからない。そのため、定期的にAPIに問い合わせを行う「ポーリング」という手法を用いる。Kinsta APIの /operations/{operation_id} エンドポイントを呼び出すことで、現在のステータスを確認できる。
ポーリングによる進捗確認
以下のような関数を作成し、30秒間隔でステータスを確認する。ステータスが completed になれば、サイトの構築は完了だ。Kinsta APIには「リソース作成エンドポイントは1分間に5回まで」という制限があるため、30秒間隔のポーリングは制限内で安全に動作する設定といえる。
const pollOperation = (operationId) => {
const interval = setInterval(async () => {
const resp = await fetch(
`${KinstaAPIUrl}/operations/${operationId}`,
{ method: 'GET', headers }
);
const result = await resp.json();
if (result.status === 'completed') {
clearInterval(interval);
console.log('サイトの準備が完了しました:', result);
}
}, 30000);
};この仕組みを導入することで、ミドルウェアはサイト作成の成功を見届けることができる。完了後にSlackへ通知を送ったり、クライアントに自動で「準備完了」のメールを送信したりといった、さらなる自動化の拡張も容易になる。
独自の分析:自動化がビジネスに与える付加価値

今回の自動化連携は、単なる「時短」以上の価値を制作会社にもたらす。筆者の分析によれば、最も大きなメリットは「Time to Value(価値提供までの時間)」の短縮だ。クライアントがサービスに申し込んだ直後に、すでに自分のサイトが立ち上がっているという体験は、プロフェッショナルな印象を強く植え付ける。
また、この仕組みは「人為的ミスの削減」にも寄与する。手動設定では、管理者パスワードの控え忘れや、リージョンの選択ミス、プラグインの入れ忘れなどが起こり得る。API経由であれば、WooCommerceやYoast SEOなどの必須プラグインを事前に指定してインストールすることも可能だ。これにより、すべてのプロジェクトで一定の品質が担保された環境を、瞬時に提供できる。
さらに、このミドルウェアを拡張すれば、ステージング環境の自動作成や、ドメインの自動割り当てまで一気通貫で行えるようになる。Kinsta APIを「自社のサービスの一部」として組み込むことで、競合他社にはない圧倒的なスピード感を武器にできるはずだ。
この記事のポイント
- Kinsta APIを活用すれば、WordPressサイトの作成、管理、監視をプログラムで制御できる。
- HubSpotのワークフローとWebhookを組み合わせることで、顧客の申し込みを直接サイト構築に繋げられる。
- Node.jsのミドルウェアは、HubSpotとKinsta APIの間でデータを変換し、認証を管理する重要な役割を果たす。
- サイト作成は非同期処理のため、operation_idを用いたポーリングによって完了を確認する実装が必要だ。
- 自動化により、制作会社は手動のセットアップ工数を削減し、クライアントに迅速な価値提供が可能になる。
・ 複数業界における17年間のデジタルビジネス開発経験
・ ウェブサイト開発のためのHTML、PHP、CSS、Java等の実用的知識
・ 15ヶ国語対応の多言語SaaSの開発経験
・ 17年間にも及ぶ、Eコマース長期運営経験
・ 幅広い業界でのSEO最適化の豊富な経験