

PostgreSQLで大規模削除をスケールさせるならDROP TABLE一択
PostgreSQLでテーブルから大量の行を削除する必要に迫られたとき、DELETE文をそのまま使うのは最悪の選択肢のひとつだ。一見直感的ではないが、大規模なDELETEはデータベースに余計な仕事を追加するだけに終わる。
一方で、DROP TABLEやTRUNCATEはテーブルごと削除することで、デッドタプルやバキュームといった負債を生まず、即座にディスク領域を開放する。この記事では、なぜDELETEがスケールしないのか、そしてDROP TABLEがなぜ高速なのかをMVCCや物理ストレージの観点から解説する。
さらに、大量の不要データが混入したテーブルを安全にクリーンアップする実践的な手法や、日常的な削除処理をパーティショニングでDROPに変える設計術も紹介する。
なぜDELETEはスケールしないのか

このデモはDELETEとDROP TABLEのデータ処理フローの違いを示している。DELETEはデッドタプルとバキュームという負債を生み、領域をOSに返さない。DROP TABLEはファイル削除だけで完了する。
MVCCとデッドタプルの正体
PostgreSQLは行が更新されるたびに、元の行を「古いバージョン」として内部に保持する。これはMVCC(Multi-Version Concurrency Control / マルチバージョン同時実行制御)と呼ばれ、異なるトランザクションがそれぞれの時点のデータを正しく読み取れるようにする仕組みだ。
この設計では、DELETE文を実行しても行が物理的に即座に消えるわけではない。削除された行は「デッドタプル」としてテーブルやインデックスに残り続ける。後にバキューム処理がそれらを回収して領域を再利用可能にするが、その間も読み取りクエリはデッドタプルをスキップするためのオーバーヘッドを負う。
さらに、通常のバキュームや自動バキューム(autovacuum)は、デッドタプルが占めていたページを「書き込み可能」とマークするだけで、OSにディスク領域を返還しない。PostgreSQLはINSERTとDELETEが混在するワークロードで領域を再利用しやすいようにこの挙動を選んでいる。OSへの領域返還にはVACUUM FULLが必要だが、長時間の強力なロックを伴う。
レプリケーションとバキュームの重み
DELETEは書き込み操作としてWAL(Write Ahead Log)に記録され、レプリカにも転送される。同期レプリケーション環境では、大量のDELETEがコミットされるまで他の書き込みトランザクションが待たされる可能性がある。つまり、DELETEは「それ自体が負荷を増やす」のであり、後片付けもバキュームに丸投げする形になる。
インデックスに関しても、DELETE実行時にインデックスのエントリは即座に消されない。読み取り時に「このタプルは無効か」を逐一判定する必要があり、インデックススキャンがデッドタプルを見つけた場合、ベストエフォートでそのエントリを無効化する最適化はあるものの、根本的なオーバーヘッドは残る。
DROP TABLE/TRUNCATEが高速な理由

DROP TABLEとTRUNCATEはテーブルに対してAccessExclusiveLock(アクセス排他ロック)を取得するため、他のトランザクションがそのテーブルを読み書きできなくなる。しかし、処理そのものはデータ量にほぼ依存しない。内部的にはテーブルに関連する物理ファイルをOSから直接削除し、共有バッファキャッシュからも該当ページのメタデータを一掃する。
PostgreSQLの共有バッファは8KBのページ単位で管理され、各ページに64バイトの固定サイズのヘッダが付与される。テーブル削除時にスキャンするのはページ本体ではなく、このヘッダ情報のみだ。例えば128GBの共有バッファがあっても、スキャンするメタデータは全体の1/128の約1GBに過ぎず、シーケンシャルアクセスで高速に処理できる。これがデータサイズに依存しない真の理由である。
一時的な大量削除への実践アプローチ

テンポラリテーブルを使った外科手術
バグによってテーブルに大量の不要データが混入したケースを考えよう。保持すべきデータは数十万行程度で、残りはすべて削除対象だ。ダウンタイムが数分許容できるなら、以下の手順で一気にクリーンアップできる。
-- 1. 対象テーブルを排他ロック
LOCK TABLE big_table IN ACCESS EXCLUSIVE MODE;
-- 2. テンポラリテーブルに保持したいデータだけコピー
CREATE TEMP TABLE temp_keep_big_table AS
SELECT * FROM big_table
WHERE updated_at >= '2026-04-01';
-- 3. 元テーブルをTRUNCATE
TRUNCATE big_table;
-- 4. テンポラリテーブルからデータを再挿入
INSERT INTO big_table SELECT * FROM temp_keep_big_table;この手順ではテーブルを完全にロックするため、オンラインサービスではダウンタイムが発生する。しかし、ロック時間が分単位で許容できるメンテナンスウィンドウがあるなら、数十万行のテーブルでも数分で処理できる。実際にPlanetScale社内のオブザーバビリティツールで同様のケースが発生し、この手法で問題を解決している。WALに書き込まれるのは、4の再挿入で戻された行だけであり、DELETEによる膨大なログは一切発生しない。
トリガーを使ったゼロダウンタイムの切り替え
より高度な手法として、テーブルへの書き込みを新しいテーブルにミラーリングし、タイミングを見計らってアトミックなリネームで切り替える方法がある。具体的には、元のテーブルにトリガーを設定して、INSERTやUPDATE、DELETEを新テーブルにも反映させる。十分にデータが同期された段階で、短時間の排他ロックを取得し、テーブルをリネームして差し替える。
このアプローチはPostgreSQLの拡張であるpg_squeeze(pg_repackの後継)が行っていることと本質的に同じだ。ただし、pg_squeezeは既に肥大化したテーブルを最適化するためのツールであり、この記事で伝えたいのは「設計段階で大規模DELETEを避けておく」ことである。初めからスキーマをコントロールできれば、こうした事後対応は不要になる。
パーティショニングで日常的な削除をDROPに置き換える
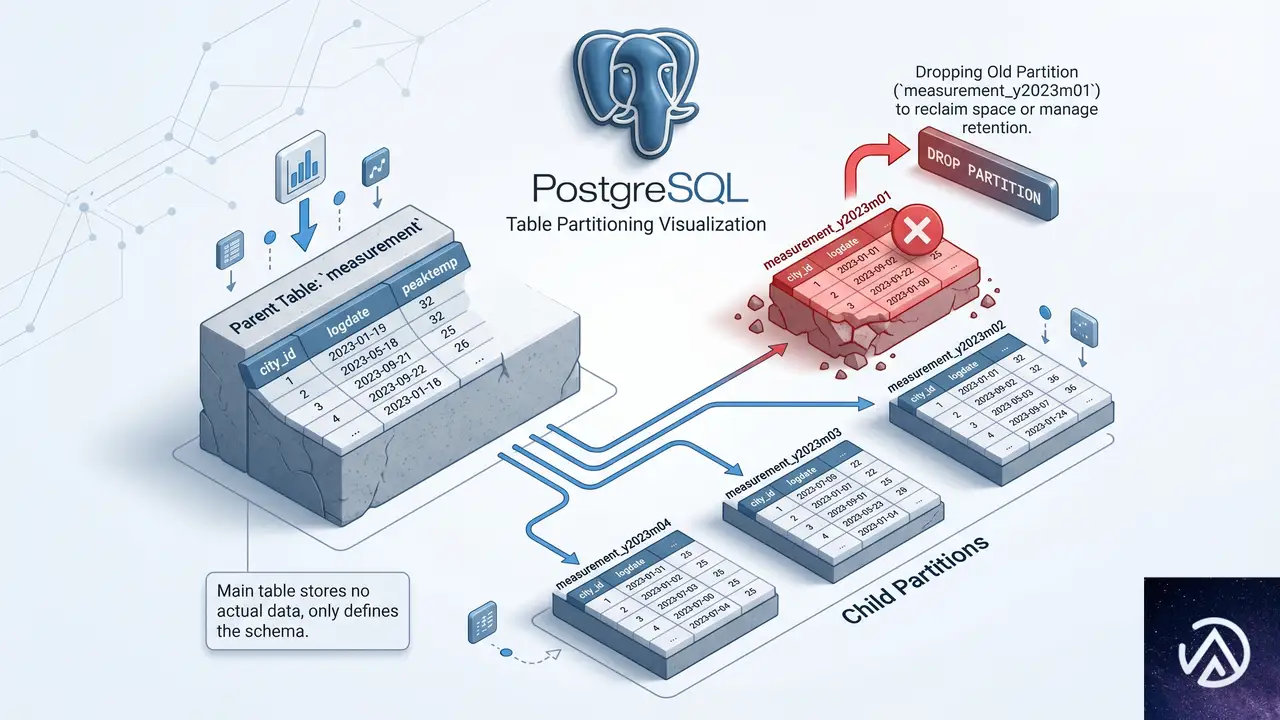
このデモは日付パーティションを使ったエージングアウトと、DROP TABLEによる高速な領域解放の流れを示している。
PostgreSQL 10以降、パーティショニング機能が大幅に強化された。親テーブルの背後に子テーブルを複数持ち、クエリは自動的に該当の子テーブルに振り分けられる。日付ベースのRANGEパーティションを使えば、過去のデータを保持する子テーブルを定期的にDROP TABLEするだけで、古いデータを一瞬で削除できる。これは、数百万行単位のDELETEを定常的に実行していたワークロードを、数秒のDROP TABLEに置き換える強力なテクニックだ。
pg_partman拡張を利用すれば、子テーブルの自動作成や古いパーティションの削除をスケジュール実行できる。また、パーティショニングは再帰的に構成できるため、より高度な設計も可能だ。たとえば、最上位をLISTパーティションで「可視行」と「不可視行」に分け、「不可視行」の子テーブルをさらにRANGEパーティションで日付ごとにエージアウトさせる、といった多次元の構成が組める。
スキーマ設計でDELETEをDROPに置き換える視点
大量データを削除する必要が生じるアプリケーションでは、テーブル設計の段階からDELETEをDROPやTRUNCATEで代替できるか検討することが重要だ。DELETEを多用しない設計にすることで、読み取りクエリのレイテンシ低減、レプリケーションラグの抑制、バキューム負荷の軽減といった効果が期待できる。
パーティショニングしかり、トリガーベースのテーブル差し替えしかり、選択肢は多様だ。PostgreSQLのMVCCが持つ根本的な制約を理解し、大規模な行削除は「テーブルごと破棄して必要なデータだけを再構築する」という発想でスキーマを組み立てる。その結果、データベースの健全性は飛躍的に向上する。
この記事のポイント
- DELETEはデッドタプルを生成し、バキュームやレプリケーションに余計な負荷をかける。大規模削除には向かない
- DROP TABLEやTRUNCATEはデータ量に依存せず、物理ファイルの削除とバッファキャッシュのメタデータスイープで瞬時に領域を解放する
- 一度きりの大量削除はテンポラリテーブルとTRUNCATEの組み合わせが有効。ダウンタイムを許容できるなら強力な手法
- 定常的な古いデータの削除には、パーティショニングでDROP TABLEに置き換える設計が有効。日付パーティションとpg_partman拡張で自動化できる
- アプリケーション設計時に「大量削除が必要なテーブル」をDROPできるようスキーマを工夫することで、データベースの健全性を大幅に向上できる

・ 複数業界における17年間のデジタルビジネス開発経験
・ ウェブサイト開発のためのHTML、PHP、CSS、Java等の実用的知識
・ 15ヶ国語対応の多言語SaaSの開発経験
・ 17年間にも及ぶ、Eコマース長期運営経験
・ 幅広い業界でのSEO最適化の豊富な経験

Google Cloud、AlloyDB向けリモートMCPサーバーがGA。AIエージェントとDBの安全な統合を実現
Google CloudがAlloyDB向けのリモートMCP(Model Context Protocol)サーバーの一般提供を発表した。これまでローカル開発が中心だったMCPだが、本番環境での運用に耐えるフルマネージドな仕組みとして登場した。AIエージェントが企業のオペレーショナルデータベースに直接アクセスし、安全にクエリを実行できるようになる。
この記事では、リモートMCPサーバーが解決する技術的課題と、AlloyDBを基盤にしたエージェントアプリケーションの構築方法を解説する。データの鮮度、セキュリティ、運用負荷のバランスを取るアーキテクチャを具体的に示す。
リモートMCPとは何か(ローカルMCPとの違い)

MCP(Model Context Protocol)とは、大規模言語モデル(LLM)が外部のデータソースやツールと安全に通信するためのオープン標準プロトコルだ。Anthropicが提唱し、現在では多くのAIエージェントフレームワークで採用されている。従来は開発者のローカルマシン上で動作する「ローカルMCPサーバー」が主流だった。
ローカルMCPサーバーは標準入出力(stdio)を使ってプロセス間通信を行う。これは開発段階では手軽だが、本番環境に持ち込むと途端に問題が顕在化する。複数のエージェントインスタンスが同時にデータベースへアクセスする場合、プロセス管理が複雑化し、ネットワーク越しのセキュリティ確保も難しくなる。
リモートMCPサーバーは、これらの課題をHTTPエンドポイント経由で解決する。Google Cloudのマネージドインフラ上で動作し、OAuth 2.0ベアラートークンによる認証とIAM(Identity and Access Management)によるきめ細かな権限制御を提供する。エージェント開発者はインフラ管理から解放され、クエリ実行に集中できる。
なぜAlloyDBと組み合わせるのか
AlloyDBはGoogle CloudのフルマネージドPostgreSQL互換データベースだ。標準PostgreSQLと比較して、ベクトル検索では最大6倍高速、フィルタ付きクエリでは最大10倍高速というパフォーマンスを備える。ScaNNインデックスを使えば100億ベクトル規模まで拡張でき、AIエージェントのRAG(検索拡張生成)ワークロードに最適化されている。
さらにAlloyDBには、データベース内で直接埋め込みベクトルを生成するAI Functionsや、Gemini Enterprise Platformモデルを使った検索結果のリランキング機能が組み込まれている。エージェントがデータベースにクエリを投げるだけで、最新のオペレーショナルデータに基づいた回答を得られる。データの鮮度を保つためのETLパイプラインが不要になるケースも多い。
リモートMCPサーバーが解決する5つの本番課題

Google Cloudブログの発表によると、リモートMCPサーバーは単なる通信方式の変更にとどまらない。本番環境でAIエージェントを運用するチームが直面する、以下の5つの課題を包括的に解決する設計になっている。
特に注目すべきはIAMによる権限制御だ。従来のデータベース接続では、共有パスワードやAPIキーを使うことが多かった。しかしリモートMCPでは、エージェントごとに特定のテーブルやビューへのアクセス権をIAMで付与できる。読み取り専用のSQL実行ツールを選択すれば、エージェントが誤ってデータを削除するリスクを根本から排除できる。
Model Armorによるプロンプトセキュリティ
リモートMCPサーバーは、Google CloudのModel Armorと統合されている。Model Armorはプロンプトとレスポンスの両方をスクリーニングし、プロンプトインジェクション攻撃や機密データの意図しない流出を防ぐ。エージェントのサービスアカウントが広範なデータベース権限を持っていても、Model Armorがデータの出し方をフィルタリングする仕組みだ。
たとえば、エージェントが顧客のクレジットカード番号を含むカラムにアクセスできる権限を持っていたとしても、Model Armorがレスポンスからその情報を除去できる。これは「権限はあるが出力は制限する」という新しいセキュリティモデルであり、ゼロトラストの考え方をAIエージェントに適用した形だ。
エージェントから見たAlloyDBの強み

リモートMCPサーバーは接続の仕組みを提供するが、その先にあるデータベース自体の性能も重要だ。AlloyDBはエージェントアプリケーションに特化したいくつかの特徴を持つ。
まず、ベクトル検索性能だ。ScaNNインデックスを使うと、標準PostgreSQLの最大6倍の速度でベクトルクエリを実行できる。100億ベクトルまでスケールするため、大規模なRAGアプリケーションでもパフォーマンスが劣化しない。フィルタ条件付きのベクトル検索では最大10倍高速化される。これは「直近30日以内のドキュメントから類似検索」のような実用的なクエリで差が出る。
次に、ハイブリッド検索とリランキングだ。RUM(RUMインデックス / Row Usage Matrix)を使った全文検索とベクトル検索の組み合わせや、Reciprocal Rank Fusionによる結果の融合が可能だ。さらにGemini Enterprise Platformモデルを使ったインテリジェントなリランキングにより、エージェントは最も関連性の高い情報を優先的に取得できる。
また、AlloyDBのAI Functionsはデータベース内部で埋め込みを生成する。外部の埋め込みAPIを呼び出す必要がなく、数百万件の埋め込みを効率的に生成できる。Lakehouse Federationを使えば、BigQueryの分析データやIcebergテーブルのアーカイブデータにも、同じPostgreSQLインターフェースから透過的にアクセスできる。
AIエージェントにとって重要なのは「データの鮮度」と「アクセスの容易さ」だ。AlloyDBのリアルタイム埋め込み生成とLakehouse Federationの組み合わせにより、エージェントは最新のオペレーショナルデータと過去の分析データを区別なく扱える。配送車両の位置情報のような刻々と変化するデータでも、クエリを発行した瞬間の状態を取得できる。
実際の導入手順とデモの流れ
Google Cloudは今回のGA発表にあわせて、Codelab(ハンズオン形式のチュートリアル)を公開した。導入手順は以下の4ステップに整理されている。
接続が確立すると、エージェントは自動的にデータベースのスキーマを把握する。テーブル名やカラム名をイントロスペクションクエリで取得し、ユーザーの質問に応じて適切なJOINや集計クエリを組み立てられる。たとえば「過去24時間で最も遅延が発生している配送ルートは?」という質問に対して、エージェントが配送テーブルと車両テーブルをJOINし、リアルタイムの位置情報と組み合わせて回答する。
AIエージェントが実行できる操作の範囲
リモートMCPサーバー経由でエージェントが実行できる操作は、単なるSELECTクエリにとどまらない。AlloyDBのツールセットを使うと、以下のような運用操作も可能になる。
- データのエクスポートとインポート
- バックアップの作成とリストア
- クラスタの設定更新
- AI Functionsを使ったテキストのランキング(AI.RANK())
もちろん、これらの操作はIAM権限の範囲内でのみ実行される。読み取り専用のSQLツールを選択していれば、データ定義や変更を伴う操作はブロックされる。本番環境での安全な運用を第一に設計されている点が重要だ。
導入時に検討すべきポイント
リモートMCPサーバーのGAは、AIエージェントとデータベースの統合を大きく前進させる。しかし導入にあたっては、いくつかの点を事前に検討する必要がある。
まず、コスト構造の把握だ。AlloyDB自体がエンタープライズ向けのプレミアムデータベースであり、さらにMCPサーバーの利用にもGoogle Cloudの料金が発生する。30日間の無料トライアルが提供されているので、まずは小規模なクラスタで検証し、ワークロードに応じたコストを見積もることを推奨する。
次に、IAMポリシーの設計だ。エージェントに必要最小限の権限を付与する「最小権限の原則」を徹底する必要がある。テーブル単位、カラム単位でのアクセス制御が可能だが、データベースの規模が大きくなるとポリシー管理が複雑化する。事前にアクセス制御のルールを整理しておくことが重要だ。
最後に、プロンプト設計の重要性も変わらない。MCPサーバーがデータへのアクセスを提供しても、エージェントが適切なクエリを生成できるかどうかはプロンプトの質に依存する。スキーマの説明やクエリの方針をプロンプトに含めることで、より正確な結果を得られる。
この記事のポイント
- AlloyDB向けリモートMCPサーバーがGAとなり、HTTPエンドポイント経由でAIエージェントが安全にデータベースへアクセス可能になった
- IAMによるテーブル単位の権限制御と、Model Armorによるプロンプトセキュリティで本番運用に耐える設計
- AlloyDBのベクトル検索性能とAI Functionsの組み合わせにより、RAGアプリケーションの構築が効率化される
- 30日間の無料トライアルとCodelabが提供されており、小規模な検証から始められる
・ 複数業界における17年間のデジタルビジネス開発経験
・ ウェブサイト開発のためのHTML、PHP、CSS、Java等の実用的知識
・ 15ヶ国語対応の多言語SaaSの開発経験
・ 17年間にも及ぶ、Eコマース長期運営経験
・ 幅広い業界でのSEO最適化の豊富な経験

Neon、有料プランのデータ転送量を5倍に増量。500GBで実質エグレスフリー
サーバーレスPostgreSQLサービスのNeonは2026年6月1日、全有料プランに含まれる月間データ転送量を従来の100GBから500GBへと5倍に引き上げた。この変更は自動的に適用され、利用者側での設定変更は不要だ。
500GBという上限は、ほとんどの一般的なワークロードにおける全データ転送(エグレス)コストを実質的にゼロにする水準だ。Neonのブログによれば、チャットボットのバックフィル処理や設定ミスによる超過リスクも、この増量によって大幅に緩和される。
本記事では、増量の具体的な内容と背景、利用者が知っておくべきポイントを整理する。
月間500GBへの増量。その具体的な内容

今回の変更の核心はシンプルだ。Neonの全有料プラン(Launch、Scale、Enterprise)において、月間のパブリックデータ転送(エグレス)の無料枠が100GBから500GBに拡大された。
500GBを超過した場合の追加課金体系に変更はない。超過分はこれまでと同一の従量課金レートで計算される。Neonの記事では「データ転送の計測方法や料金体系に変更は一切ない」と明言されている。
変更は自動適用。請求書にも即時反映
この増量は2026年6月1日からユーザー側の操作なしで自動適用される。Neonのコンソール(管理画面)で利用状況を確認可能で、6月分の請求書には新たな500GBの枠が反映される。
なぜNeonは5倍への増量を決断したのか

Neonのブログ記事は、意思決定の背景を率直に説明している。最大の動機は「予期せぬエグレス課金の排除」だ。
エグレス課金のストレスを根本から減らす
クラウドデータベースにおけるデータ転送料金は、しばしば利用者にとっての「見えないコスト」となる。チャットボットが想定以上にデータを取得したケース、分析ジョブが大量の履歴データを読み込んだケース、設定ミスでループ接続が発生したケースなど、原因は多岐にわたる。
これらの超過は後になってから請求書で気づくことが多く、事後対応が難しい。Neonの著者Carlo Daniele氏は「請求書に届いてからでは遅すぎる」と指摘している。500GBへの増量は、この「事後ショック」をほとんどのユーザーから無くす狙いがある。
競合との差別化とサーバーレスの信頼性向上
サーバーレスデータベース市場では、Vercel PostgresやSupabaseなどもデータ転送枠を設けている。500GBという閾値は、これらのサービスと比較しても実質的な「エグレスフリー」を実現する水準だ。
Neonにとって、この変更はプラットフォームの信頼性向上と、サーバーレスアーキテクチャへの移行障壁を下げる施策といえる。特にスタートアップや個人開発者にとって、突発的なコスト増はサービス継続のリスクになりうる。その不安を軽減する効果は大きい。
利用者に求められる対応と確認方法

必要な対応は一切なし
繰り返しになるが、利用者が実施すべき設定変更や申し込みは存在しない。Neonの全有料プラン契約者に対し、2026年6月1日以降の月間データ転送量が自動的に500GBへと引き上げられている。
利用状況の確認方法
自身のデータ転送量を把握したい場合は、Neon Consoleにログインし、請求および利用状況のダッシュボードでエグレス使用量を追跡できる。不明点はNeon公式Discordコミュニティで質問することも可能だ。
今後のデータ転送戦略とユーザーへの影響

今回の増量は、Neonが「データ転送をコスト障壁にしない」という姿勢を明確に打ち出したものと捉えられる。サーバーレスデータベースの利点である「従量課金の柔軟性」は、往々にして「予測不能なコスト」と紙一重だ。
500GBの無料枠は、その両面を切り離す試みだ。実際の利用データにもとづきNeonが「ほとんどのワークロードでエグレス課金が発生しなくなる」と明言している点は、単なるマーケティングではなくユーザー利用統計に裏付けられた判断といえる。
将来的にNeonがさらなるデータ転送枠の拡大や、完全なエグレスフリー化に踏み切る可能性もあるが、現時点ではこの変更が最大のハードルを解消したと評価できる。
この記事のポイント
- Neonは2026年6月1日より、全有料プランの月間データ転送量を100GBから500GBに増量
- 変更は完全自動適用。利用者による操作や設定変更は不要
- 500GB超過分の従量課金体系に変更はなく、データ転送の計測方法も据え置き
- 大半の一般的なワークロードがエグレス課金の対象外に。実質的なコスト障壁が大幅に低下
- 予期せぬエグレス課金への不安を解消し、サーバーレスデータベースの信頼性を強化
・ 複数業界における17年間のデジタルビジネス開発経験
・ ウェブサイト開発のためのHTML、PHP、CSS、Java等の実用的知識
・ 15ヶ国語対応の多言語SaaSの開発経験
・ 17年間にも及ぶ、Eコマース長期運営経験
・ 幅広い業界でのSEO最適化の豊富な経験