

Google-Agent登場、AIがユーザー代理でWebを閲覧する時代へ
Webサイトを訪れるのは人間だけではなくなった。2026年3月20日、Googleは公式のフェッチャーリストに「Google-Agent」という新たな項目を追加した。これはクローラーでもなければ、学習用のボットでもない。ユーザーの指示で動くAIエージェントだ。
AIアシスタントに「この商品をリサーチして」「最安値のサイトを比較して」と頼む場面を想像してほしい。そのとき実際にサイトを訪問し、情報を読み取り、フォームを操作するのがGoogle-Agentである。Googleの実験的ブラウジングツール「Project Mariner」が最初の採用例となる。
これまでのSEOは「クローラーにどう読まれるか」が主眼だった。しかし今回の発表で、Web運営者は「ユーザーの代わりに行動するAI」という第三の訪問者像を明確に意識せざるを得なくなった。
Google-Agentが従来のクローラーと根本的に異なる点

GooglebotはWeb全体を巡回し、検索インデックスを構築する自動プログラムだ。一方、Google-Agentが発動する条件はただ一つ、人間がAIに「調べて」と依頼したときである。この「ユーザートリガー」という性質が、あらゆるルールを塗り替える。
robots.txtは通用しない
GoogleはGoogle-Agentを「ユーザートリガーフェッチャー」に分類している。Google Read Aloud(テキスト読み上げ)やNotebookLM(文書分析)、Feedfetcher(RSS)と同じカテゴリだ。いずれも「人間がリクエストを起こした」という共通点がある。Googleの公式見解は明快で、ユーザートリガーフェッチャーは「原則としてrobots.txtを無視する」としている。
考え方はシンプルだ。ChromeのアドレスバーにURLを入力して開くとき、ブラウザはrobots.txtの内容に関係なくページを取得する。Google-Agentはユーザーの代理であり、自律型クローラーではない。したがって同じ理屈が適用される。
この判断はOpenAIやAnthropicのアプローチと明確に異なる。ChatGPT-UserやClaude-Userはいずれもユーザートリガーフェッチャーでありながら、robots.txtの指示に従う仕様だ。robots.txtでブロックすれば、ユーザーに頼まれてもページを取得しない。Googleはそこに別の線を引いた形になる。
robots.txtを万能のアクセス制御手段と考えていたサイト運営者にとって、これは大きな認識転換になる。Google-Agentを拒否したい場合は、サーバーサイドの認証やIP制限など、人間の訪問者をブロックするのと同じ手段を採る必要がある。
暗号認証「Web Bot Auth」がもたらす信頼性

Google-Agentの発表でより重要なのは、付随する技術的布石だ。公式ドキュメントの一行に、Google-Agentが「web-bot-auth」プロトコルの実験に参加していることが記されている。識別子は「https://agent.bot.goog」である。
デジタルパスポートの仕組み
Web Bot AuthはIETF(インターネット技術標準化委員会)で策定が進む標準規格である。簡単に言えば、ボットのためのデジタルパスポートだ。各エージェントは秘密鍵を持ち、公開鍵をディレクトリに登録する。そして全てのHTTPリクエストに暗号署名を付与する。
Webサイト側はその署名を検証することで、訪問者が名乗る通りの存在であることを暗号学的に確認できる。ユーザーエージェント文字列は誰でも偽装できるが、Web Bot Authの署名は偽装できない。この差は決定的だ。
すでにAkamai、Cloudflare、AmazonのAgentCore Browserがこのプロトコルをサポートしている。Googleの参入は、標準化に向けたクリティカルマス(臨界量)の獲得を意味する。
なぜこの仕組みが今必要なのか
Webは深刻なアイデンティティ問題に直面しつつある。AIエージェントのトラフィックが増えるほど、正規のエージェントと、エージェントを装うスクレイパーを区別する必要が高まる。IPアドレスによる検証は有効だが、暗号署名のほうが大規模にスケールしやすく、なりすましも極めて難しい。
Google-AgentへのWeb Bot Auth導入は実験段階だが、エージェント認証の方向性を強く示す一手とみられている。Search Engine Journalの記事でも、この暗号認証こそがGoogle-Agent発表の最も重要な要素だと指摘されている。
Webサイト運営者が今すべき具体的対応

Google-Agentの登場で、Webの訪問者モデルは3層構造として明確化された。人間が直接ブラウジングする層、GooglebotやGPTBotのようにコンテンツをインデックスするクローラー層、そして特定の人間の指示でリアルタイムにタスクを実行するエージェント層である。それぞれに異なるアクセスルールと目的がある。
この3層構造を前提に、運営者が取るべき現実的な対策は以下の通りだ。
サーバーログの監視を始める
Google-Agentはユーザーエージェント文字列に「compatible; Google-Agent」を含む。Googleは検証用のIPレンジも公開している。まずは自社サイトにどの程度の頻度でエージェントが訪れているか、どのページを標的にしているか、何を試みているかを把握することが出発点になる。
CDNとファイアウォールの設定を確認する
非ブラウザトラフィックを積極的にブロックするセキュリティ設定を導入している場合、Google-Agentがサーバーに到達する前に拒否されている可能性がある。公開されているIPレンジが許可リストに含まれているか、確認しておくべきだ。
フォームや予約フローの検証
Google-Agentはフォームの送信や複数ステップのフロー操作も行う。チェックアウト、予約、問い合わせといった機能がJavaScriptに過度に依存していると、エージェントが正常に処理できず、裏側で静かに失敗しているケースが生じる。セマンティックなHTMLと明確なラベル設計が、これまで以上に重要になる。
robots.txtは完全なアクセス制御手段ではないと認識する
robots.txtはクローラー向けに設計された仕組みであり、エージェントの時代には通用しない場面が増える。どうしてもアクセスを制限すべきコンテンツには、認証を導入する必要がある。境界線の引き直しが求められている。
ハイブリッドWebはすでに始まっている

1年前まで、AIエージェントが人間と並んでWebサイトを閲覧する未来はカンファレンスの予測トークに過ぎなかった。しかし今、その存在にはユーザーエージェント文字列があり、公開されたIPレンジがあり、暗号認証プロトコルがあり、Googleの公式ドキュメントへの記載がある。
Webは人間用と機械用に分岐しなかった。融合したのだ。公開する全てのページは、人間とエージェントの両方に同時にサービスを提供している。Googleが可視化したのは、その非人間のオーディエンスがいつ現れたかを正確に把握できる手段である。
Search Engine Journalの記事は、この動きを「SEO史上最大の意識改革」と位置づけている。誇張ではない。検索エンジンにどう読まれるかだけでなく、「ユーザーの代理としてやってくるAI」にどう対応するかが、これからのWeb運営の新たな基軸になる。
この記事のポイント
- Googleがユーザー代理でWebを閲覧する新フェッチャー「Google-Agent」を公開、Project Marinerが最初の採用例
- ユーザートリガーフェッチャーに分類されるためrobots.txtは原則無効、アクセス制御にはサーバー認証が必要
- 「Web Bot Auth」暗号認証プロトコルを実験導入中、エージェントのなりすまし防止を狙う
- Web訪問者は「人間」「クローラー」「エージェント」の3層構造へ移行、各層で対応が異なる
- サーバーログ監視、CDN設定確認、フォームのセマンティックHTML対応が即時の実務対策となる

・ 複数業界における17年間のデジタルビジネス開発経験
・ ウェブサイト開発のためのHTML、PHP、CSS、Java等の実用的知識
・ 15ヶ国語対応の多言語SaaSの開発経験
・ 17年間にも及ぶ、Eコマース長期運営経験
・ 幅広い業界でのSEO最適化の豊富な経験

Google検索結果の「続きを読む」リンク表示を増やす3つの法則!robots.txtドキュメント拡充と最新SEO動向
Googleが検索結果の表示をより詳細にする「続きを読む(Read more)」ディープリンクのベストプラクティスを公開した。これは検索結果のスニペット内に、ページ内の特定セクションへ直接ジャンプできるリンクを表示させるための指針だ。これまで経験則で語られてきた部分が、公式ドキュメントによって明確化された形となる。
あわせて、robots.txtのドキュメント拡充や、EUでのAIチャットボットに対するデータ共有規制、さらには検索画面上でタスクを完結させる新機能についても動きがある。2026年4月の最新情報を踏まえ、Webサイト運営者が今取り組むべき構造改革について解説する。
これらのアップデートは単なる表示の変化ではなく、Googleが「AIエージェントにとって読みやすい構造」をWebサイトに求めていることの表れだ。サイトの構造が古いままでは、検索結果での露出機会を大きく損なう可能性がある。技術的な背景とともに、具体的な対策を確認していこう。
Google検索のディープリンク表示を増やす3つの鉄則
Googleは検索結果のスニペット(説明文)の下に表示される「続きを読む」リンクについて、その出現率を高めるための具体的な方法を明らかにした。ディープリンクとは、ページ全体ではなくページ内の特定の章や節に直接ユーザーを誘導するリンクのことだ。これが表示されると、検索結果の占有面積が増え、クリック率の向上が期待できる。
コンテンツはページ読み込み時に即座に表示させる
最も重要なポイントは、ユーザーがページを開いた瞬間にコンテンツが人間にとって可視化されていることだ。クリックしないと中身が見えない「折りたたみ式(アコーディオン)」や「タブ切り替え」の中に重要な情報を隠している場合、ディープリンクとして採用される確率は下がる。Googleは、ユーザーの操作なしにレンダリングされる情報を優先して評価している。
これは「隠れたテキスト」がインデックスされないという意味ではないが、検索結果の拡張機能(リッチスニペットやディープリンク)においては、露出の優先度が低くなることを示唆している。特にモバイルユーザー向けに情報をコンパクトにまとめようとして、重要な見出しや本文をアコーディオン内に閉じ込める設計には注意が必要だ。
H2やH3の見出しタグを適切に活用する
ディープリンクのリンク先となるセクションには、必ず <h2> や <h3> といった見出しタグを使用する必要がある。Googleのシステムは、これらの見出しをページの構造的な区切りとして認識し、リンクのアンカー(目的地)として利用するからだ。
また、検索結果に表示されるスニペットのテキストと、実際のページ内の見出しや本文の内容が一致していることも条件となる。見出しが画像だけで構成されていたり、装飾目的で <div> タグにスタイルを当てただけの「見出し風」のデザインになっていたりすると、Googleはそこをセクションの開始点として正しく認識できない。
UIデザインのBeforeとAfter比較
ディープリンクが表示されにくい構造(タブ・アコーディオン)と、表示されやすい構造(フラットな見出し構成)を比較してみよう。以下のデモは、コンテンツの露出度による構造の違いを視覚化したものだ。
このデモのように、すべての主要コンテンツがページロード時に露出している構成の方が、Googleは各セクションをディープリンクとして採用しやすくなる。ユーザーの利便性を損なわない範囲で、情報の「隠しすぎ」を避けることが重要だ。
robots.txtの公式ドキュメント拡充とスペルミスへの寛容さ
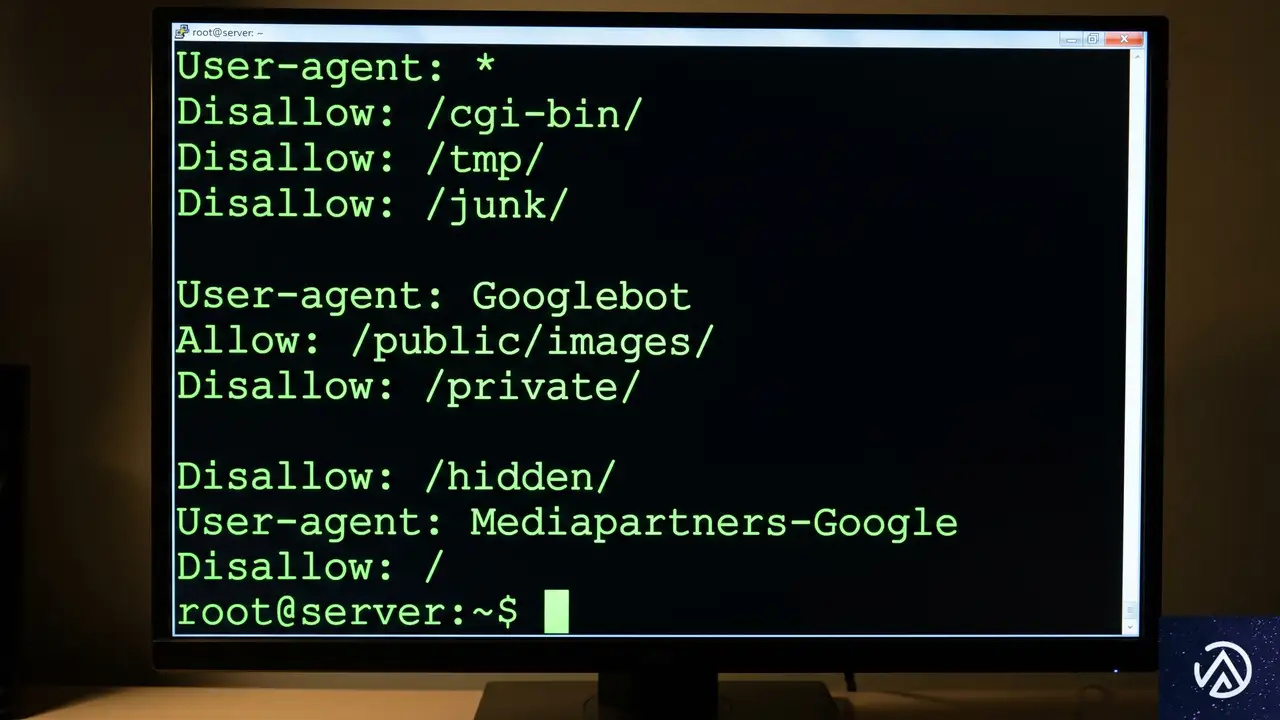
GoogleのGary Illyes(ゲイリー・イリェーシュ)氏とMartin Splitt(マーティン・スプリット)氏は、ポッドキャスト「Search Off the Record」にて、robots.txtに関する新たなプロジェクトについて語った。Googleは現在、HTTP Archiveのデータを分析し、実際に世界中のサイトで使用されているrobots.txtの記述パターンを調査している。
非サポートルールの明文化
robots.txtには、Googleが公式にサポートしていない独自の命令(ディレクティブ)が記述されているケースが多々ある。例えば、クロールの頻度を指定する Crawl-delay や、特定の条件下でのみ適用されるカスタムルールなどだ。Googleは今回の分析に基づき、よく使われているが実際にはGoogleが無視している「非サポートルール」のトップ10から15をドキュメントに追加する予定だ。
これにより、Webサイト運営者は「自分が設定しているルールがGoogleに効いているのか」を正確に判断できるようになる。もしGoogleがサポートしていないルールに頼ってクロール制御を行っている場合、それは期待通りに機能していない可能性が高い。公式ドキュメントが更新された際には、自サイトのrobots.txtを改めて監査する必要があるだろう。
記述ミスの自動補完が進む可能性
さらに興味深い点として、Googleのrobots.txtパーサー(解析機)が、記述のスペルミスをより柔軟に受け入れるようになる可能性が示唆された。例えば disallow を dissallow と書き間違えた場合でも、Googleがそれを意図通りの命令として解釈してくれるようになるかもしれない。
ただし、これはあくまで「Googleが親切に解釈してくれる」という話であり、ミスを放置してよいという意味ではない。他の検索エンジン(Bingなど)が同様の寛容さを持っているとは限らないからだ。robots.txtはサイトの立ち入り禁止区域を指定する「地図」のようなものだ。記述ミスがあれば、検索エンジンにインデックスさせたくないページが公開されてしまうリスクがある。基本的には、標準的なスペルを厳守すべきだ。
EUのデータ共有規制がAIチャットボットに波及

欧州委員会(EC)は、デジタル市場法(DMA)に基づき、Googleに対して検索データを競合他社と共有するよう求める予備的な見解を示した。この規制の対象には、従来の検索エンジンだけでなく、特定の条件を満たす「AIチャットボット」も含まれる見通しだ。
AIチャットボットが「検索エンジン」として定義される日
これまでSEO業界では、Googleのような検索エンジンと、ChatGPTやPerplexityのようなAIチャットボットを別物として扱ってきた。しかし、EUの規制当局は「オンライン検索エンジン」の定義を広げ、AIチャットボットもその範疇に含める動きを見せている。これが確定すれば、Googleが持つ膨大なランキングデータやクリックデータが、競合するAIサービスに提供されることになる。
この変化は、EU圏内での検索市場の流動性を高める可能性がある。Googleのデータを活用して精度を高めたAIチャットボットが普及すれば、ユーザーの検索行動はさらに分散するだろう。Webサイト運営者にとっては、Googleだけでなく「AIチャットボットからどう参照されるか」という視点が、法規制の面からも裏付けられた重要な課題となる。
匿名化された検索シグナルの行方
共有されるデータは匿名化されるものの、ランキング、クエリ、クリック、閲覧データといった核心的な情報が含まれる。これにより、新興のAI検索サービスが「どのコンテンツがユーザーに支持されているか」をより正確に把握できるようになる。日本国内のサイトであっても、EUからのアクセスがある場合は、これらのデータ共有の影響を間接的に受けることになるだろう。
検索結果でタスクを完結させる新機能の追加
Googleは検索結果画面(SERP)上で直接ユーザーの目的を達成させる「タスクベース」の機能を強化している。その一環として、特定のホテルの価格下落を追跡できるトグルスイッチが導入された。これは、ユーザーがホテル予約サイトへ移動することなく、Google内で価格監視を開始できる機能だ。
Webサイトへの流入機会が「Google内」に吸収される
これまで、価格下落通知は旅行予約サイトや比較サイトが提供する主要なサービスの一つだった。Googleがこの機能を検索結果に直接組み込むことで、ユーザーが各サイトを再訪する動機が減少する可能性がある。GoogleのSundar Pichai(サンダー・ピチャイ)CEOが語っていた「エージェントとしての検索」が、着実に具現化していると言える。
この変化への対策として、ホテルなどのサービス事業者はGoogleビジネスプロフィールの情報を最新に保ち、Googleのフィードに対して正確なデータを提供し続ける必要がある。検索結果が単なる「リンク集」から「実行プラットフォーム」へと進化する中で、プラットフォームとのデータ連携の重要性はかつてないほど高まっている。
AIエージェントの起動ボタン
また、Googleの「AIモード」から直接AIエージェントを起動し、複雑なタスクを委任できる機能もテストされている。例えば「旅行の計画を立てて予約まで進める」といった一連の動作を、AIが代行する仕組みだ。この際、AIがどのWebサイトの情報をソース(情報源)として採用するかは、前述した「ディープリンクのベストプラクティス」のような構造化された情報の有無に左右される。
AIエージェントは、人間と同じようにWebページを「読み」に行く。その際、Javascriptの実行や複雑なクリック操作を必要とするページよりも、シンプルで見出し構造が明確なページを好む。検索がタスク完結型になればなるほど、Webサイトは「人間が見る場所」であると同時に「AIがデータを取得するAPI」のような役割を求められるようになるのだ。
この記事のポイント
- 「続きを読む」リンクを表示させるには、コンテンツをアコーディオンやタブに隠さず、ページロード時に露出させることが重要だ。
- 適切な見出しタグ(H2、H3)を使用し、検索スニペットとページ内容の整合性を保つことで、ディープリンクの採用率が高まる。
- robots.txtの公式ドキュメントが拡充され、Googleがサポートしていないルールの実態が明確になるため、定期的な記述の監査が推奨される。
- EUの規制によりAIチャットボットが「検索エンジン」として扱われ始め、Googleの検索データが競合AIに共有される道が開かれつつある。
- Google検索は「情報を探す場所」から「タスクを完結させる場所」へ進化しており、WebサイトにはAIエージェントが読み取りやすい構造が求められている。
・ 複数業界における17年間のデジタルビジネス開発経験
・ ウェブサイト開発のためのHTML、PHP、CSS、Java等の実用的知識
・ 15ヶ国語対応の多言語SaaSの開発経験
・ 17年間にも及ぶ、Eコマース長期運営経験
・ 幅広い業界でのSEO最適化の豊富な経験