

AI引用シェア率をBingが公開、llms.txtの効果に疑問符
AI検索の可視性をどう測るか、そして構造化データファイルにどこまで期待すべきか。この一週間でその答えに直結する動きが複数出てきた。
MicrosoftがAI引用のシェア率を計測する新機能を公開し、GoogleとAhrefsのデータはllms.txtの効果に冷や水を浴びせた。さらにAIエージェント向けの新仕様が2つ登場するなど、情報が一気に動いている。英国CMAによる公正ランキング命令も含め、今週のトップ4ニュースを実務視点で整理する。
BingがAI引用シェア率を公開。競合との差が初めて数値化された

MicrosoftはBing Webmaster ToolsのAIパフォーマンスダッシュボードに、新たな4機能をプレビュー公開した。追加されたのは「Citation Share(引用シェア率)」「Intents(検索意図別グループ)」「Topics(トピック別グループ)」「Compare(期間比較)」だ。いずれも現在はプレビュー段階でグローバルに順次ロールアウトされている。
このCitation Shareによって、AI検索結果における自サイトの存在感が、競合との比較で初めて把握できるようになる。ただしこのデータはBing独自であり、CopilotやBingの回答を対象とする。Google検索側では検索コンソールにこれに相当する引用カウント機能は提供されていない。
SEO担当者の受け止めと実務への示唆
ILoveSEO.netの創業者Gianluca Fiorelli氏はLinkedInで「Bing Webmaster Toolsこそ、我々がGoogleサーチコンソールに望んでいた姿だ」と評価した。AI可視性を測る新しい物差しが登場したことは、今後の施策優先度をデータドリブンに決める上で大きい。
現時点ではBingに限られた指標だが、AI検索のトラフィックが今後さらに一般化すれば、Googleも類似の指標を導入せざるを得なくなる可能性がある。先行してBing側でのデータ取得と分析のノウハウを積んでおくことは、将来のAI検索対策で優位に立つ一手になる。
llms.txtへの期待に新データが疑問符。97%がアクセスゼロ
llms.txtは、大規模言語モデル(LLM)向けにサイト情報を構造化して提供するテキストファイルだ。AIがサイト内容を理解しやすくする目的で提唱され、導入が進んでいる。しかし今週、その効果に疑念を投げかける材料が二つ重なった。
Mueller氏は「Search Off the Record」ポッドキャストで、llms.txtが自己申告型のファイルである以上、LLMがサイトを発見したり他サイトと比較して評価したりする用途には使えないと明言した。本質的に重要なのは従来のHTMLと内部リンク構造だという立場だ。
Ahrefsのデータも同じ方向を指している。13万7000ドメインのうち、97%のllms.txtファイルには一度もボットからのアクセスがなかった。さらにアクセスが確認されたケースでも、ChatGPTやPerplexityといった引用生成ボットからのリクエストは全体の1%に過ぎない。この結果は、数ヶ月前にSE Rankingが30万ドメインを調査して導いた「llms.txtはAI引用に明確な効果を示さない」という結論とも整合する。
SEO専門家の見解と実務上の落とし所
Clio Websitesの創業者Nat Miletic氏はLinkedInで「llms.txtは公開コストが低いので置いておくのは構わない。ただしそれでAI可視性が上がるとは今は期待しないほうがいい」と総括した。コーディングエージェントや学習用クローラー向けに一部で参照されているため維持コストに見合う面はあるが、AI検索結果への表示を目的とした投資としては優先度を下げる判断が妥当だ。
AIエージェント向け新仕様が2つ登場。OKFとARDの注目点

Google Cloudは「OKF(Open Knowledge Format)」を公開した。組織内の知識(データセット、メトリクス、運用手順書など)をAIエージェントが読めるマークダウン形式でパッケージングする仕様だ。ほぼ同時期に、GoogleやMicrosoft、GitHub、Hugging Faceを含む連合が「ARD(Agentic Resource Discovery)」の草案を発表した。こちらはAIエージェントがツールやスキル、他のエージェントを発見・検証するためのプロトコルを定義する。
両仕様とも現時点で即時の対応を求めるものではない。OKFはバージョン0.1、ARDは0.9と初期段階だ。Harton Worksの創業者Martin Jeffrey氏はARDを「ページではなく機能のためのサイトマップが再来したようなものだ」と表現した。Snippet Digitalの共同創業者Suganthan Mohanadasan氏は「魔法のキノコではない。これで一夜にしてAI可視性が上がるわけではない」と期待値を引き締めている。
実務的には、どのフォーマットが実際に普及するかを見極める観察期間に入る。llms.txtの事例が示すように、仕様の存在と実際の効果は別問題だ。導入判断は普及の兆候を確認してからでも遅くない。
英国CMAがGoogleに公正ランキングを命令。事前通知義務が実務に波及

英国の競争市場庁(CMA)がGoogle検索に対し、新たなルールを設定した。オーガニック検索結果のランキングに客観的かつ非差別的な基準を使うこと、そして大規模な変更の際には事前通知を行うことを義務づける内容だ。
このルールの適用範囲は英国のオーガニック検索結果で、AI Overviewsも対象に含まれる(広告は除く)。Googleは「現行のランキングはすでに公正かつ透明だ」と反論しているが、CMAは6月初旬にもAI検索機能からのオプトアウトを認めるよう命令しており、規制圧力は強まっている。
SEO専門家の反応から読む今後の展開
Searchpediaの創業者Laura Iancu氏はLinkedInで「もうこれで『コアアップデートを突然リリースしました』なんてことはできなくなる」と単刀直入に表現した。Blue Arrayの戦略SEO責任者Chloe Smith氏は「Googleは何らかの回避策を探るだろう」と予測しつつも、事前通知と異議申し立ての枠組みができたこと自体に意味があると見ている。
現状では英国限定の措置だが、EUや他の地域にも波及する可能性は否定できない。特に、大規模アップデートの事前通知が実務化すれば、SEO施策の計画立案や緊急対応のあり方そのものが変わる。今後のGoogleの実装方法を注視する必要がある。
構造化ファイルを置くだけでは済まない。AI可視性の本質に立ち返る
今週のニュースを横断して浮かび上がるテーマは、「構造化ファイルを自ドメインに置いておけばAIに見つけてもらえる」という発想への再考だ。llms.txtはその教訓をすでに示している。ファイルを公開しても、Googleはサイト差別化に寄与しないと断言し、データは大半のファイルが読まれていない事実を突きつけた。
OKFやARDが登場したことで、構造化ファイルへの要求はこれからも繰り返されるだろう。しかし破綻しているのは「ファイルを置けば報われる」という期待のほうだ。BingのCitation Shareは、そうした取り組みが実際に引用に結びついているかを数値で示してくれる、貴重なフィードバックループになり得る。
AI検索時代の可視性は、小手先のファイル配置ではなく、コンテンツそのものの強さと、信頼される情報源としてサイト全体を設計し続ける積み重ねで決まる。今週のデータと専門家の声は、その原則を改めて強調する結果になった。
この記事のポイント
- Bing Webmaster Toolsの新機能「AI Citation Share」で、AI検索での競合とのシェア比較が初めて可能になった。Googleにはまだ同等機能はない
- llms.txtは97%がアクセスゼロ。AI検索可視性への効果はデータで否定され、自己申告ファイルの限界が明確になった
- OKFとARDという新たなAIエージェント向け仕様が登場したが、普及は未知数。llms.txtの教訓を踏まえ導入判断は慎重に行うべきだ
- 英国CMAがGoogleに対し、検索順位の公正化と大規模変更前の事前通知を義務づけた。SEO施策の計画立案に影響する可能性がある
- 結局、AI可視性の本質は構造化ファイルではなく、通常のHTMLコンテンツの品質と情報設計にある

・ 複数業界における17年間のデジタルビジネス開発経験
・ ウェブサイト開発のためのHTML、PHP、CSS、JavaScript等の実用的知識
・ 15ヶ国語対応の多言語SaaSの開発経験
・ 17年間にも及ぶ、Eコマース長期運営経験
・ 幅広い業界でのSEO最適化の豊富な経験

AI可視性ツール9選、AI検索でブランドを追跡する方法
少し前まで、商品を探す人の行動は数段階に分かれていた。Googleで検索し、いくつかのサイトを開き、情報を比較してようやく購入を決める。だが今、そのプロセスが大きく変わりつつある。
ChatGPTや Gemini、Perplexity に質問を投げかければ、AIが直接「ベストな選択」を推奨してくる。複数サイトを見比べる中間段階が省略され、ブランドが検討対象にすら入らなくなっているのだ。
AI検索が変えたブランド発見の流れ

従来の検索行動は、検索 → サイト訪問 → 比較 → 決定という複数段階が存在した。この間にユーザーが多くのブランドに触れる機会が生まれ、SEO対策がその流入を支えていた。ところが、AIによる回答生成が一般化した現在、この流れは1段階に集約される。
この変化により、従来のオーガニック検索順位だけではブランドの露出を測れなくなった。AIチャットボットが回答する場での存在感こそが、新たな競争の土台になっている。そこで重要になるのが、AI検索における可視性(AIビジビリティ)を専用に追跡するツールだ。
AI可視性ツールの基本と必要性

AI可視性ツールとは、ChatGPTやPerplexity、Google AI OverviewsといったAIエンジンが生成する回答の中に、自社ブランドや特定のURLがどれくらい登場するかを監視するサービスを指す。従来の検索順位チェッカーとは計測対象が別物だ。
Google検索で1位を取っていても、AI回答には一切引用されないケースは珍しくない。逆に、検索順位は低くてもAIに頻繁に取り上げられるページも存在する。両者は重なりつつも異なる指標のため、これからのマーケティングでは両方のデータを併せ持つ必要がある。
さらに、AI検索は実行のたびに回答が変動し、従来の固定的なランキングではない。そのため、日々の数値というより「トレンドとして自社がどの方向に進んでいるか」を読み取る姿勢が求められる。
AI可視性ツールを選ぶ5つのチェックポイント

AI可視性ツールは数多く登場しているが、注目すべき評価軸を整理しておこう。WP Beginnerのガイドで挙げられた項目を参考に、特に実務に直結する5つのポイントを紹介する。
1. 対応するAIエンジンの数と種類
最低でもChatGPT、Perplexity、Google AI Overviews(AIモードを含む)をカバーしているかどうかが基準だ。単一エンジンだけの監視では、AI検索空間のごく一部しか把握できず、施策の優先順位を誤る可能性がある。
2. ブランド言及とURL引用の区別
AIがブランド名に触れただけ(言及)なのか、それとも具体的なリンク付きで情報源として引用したのか。この2つは同じ「可視性」でも価値が異なる。URL引用がなければ読者をサイトへ誘導できないため、両方を分けて追跡できるツールが望ましい。
3. センチメント(評判)分析の有無
AI回答の中で自社ブランドがどのように説明されているか(肯定的か、中立的か、否定的か)を把握できると、不正確な情報や不利な表現を早期に発見して修正を働きかけられる。
4. クエリ(質問)単位の可視性
「どのような質問がトリガーとなって自社が言及されたか」がわかれば、コンテンツ施策の優先度を決めやすい。競合が出てきて自社が出ないクエリを可視化できると、攻めるべきトピックが明確になる。
5. 既存ワークフローとの統合のしやすさ
SEOチームが普段使っているツール(AhrefsやSemrush)にAI可視性機能が追加されていれば、導入の手間が少ない。WordPressユーザーなら、管理画面から直接確認できるプラグインタイプのほうが定着しやすい。
厳選!信頼できるAI可視性ツール6選

WP Beginnerの記事では9つのツールが検証されている。ここでは、WordPressユーザーや中小企業のマーケティング担当者が特に注目すべき6つに絞り、特徴と向いているシーンを整理する。価格は原稿執筆時点のものだ。
1. Semrush One(オールインワン型の最強候補)
従来のSEO指標(検索順位、被リンク、サイト監査)に加え、ChatGPT・Perplexity・Gemini・Google AI Overviewsなど複数AIエンジンでのブランド出現状況を同じダッシュボードで管理できる。競合他社のAI内シェア・オブ・ボイスも比較できるため、SEOとAIの両面からギャップを特定したいプロフェッショナル向け。価格は月額139ドルから。
2. AIOSEO(WordPressプラグインで完結)
WordPress管理画面内でChatGPT、Claude、Gemini、DeepSeek、Perplexityの5エンジンを横断的に監視できる唯一のソリューション。キーワードリポートでは「どのエンジンで競合が表示されたか」を色分け表で即座に確認できる。無料のLiteプランでもLLMs.txt生成やAI Schemaマークアップが使えるため、まずは無料で試してから有料プラン(年額49.50ドル〜)に移行しやすい。WP Beginnerの著者も「ギャップを把握してすぐ対策に移れる点が最大の強み」と評価している。
3. Ahrefs Brand Radar(Ahrefsユーザー向けアドオン)
既存のAhrefs契約に追加する形で、ChatGPT、Perplexity、Gemini、Google AI Overviews、Copilot、Grokの7エンジンでのブランド言及とURL引用を区別して追跡する。被リンクデータやドメイン権威と組み合わせて、AI引用率とコンテンツ品質の関係を分析できるのが強み。月額179ユーロからのアドオン費用がかかるため、すでにAhrefsを深く活用しているチーム向けだ。
4. Otterly.ai(低コストで始めるならこれ)
月額29ドルという手頃なエントリープランで、ChatGPT、Perplexity、Google AI Overviews、Copilotの4エンジンをモニタリングできる。プロンプトライブラリで自社カテゴリのAI回答トリガークエリを一覧化でき、競合が優位な質問群を可視化する。小規模チームが「まず試す」用途に適している。より深いデータを求めるなら標準プラン(月額189ドル)へのアップグレードが必要。
5. Profound(エンタープライズ向けの深さ)
9つ以上のAIエンジンをカバーし、4億件超のプロンプトデータベースを活用した競合インテリジェンスを提供する。特に、どのクエリで競合に負けているかをプロンプト量順に並べてくれる機能は、コンテンツ制作の優先付けに直結する。月額99ドルからだが、最も安いプランはChatGPTのみの監視に留まるため、本格利用には上位プランが必要。複数ブランドを管理するエージェンシー向け。
6. Nightwatch(従来型ランク追跡にAI監視を追加)
ChatGPT、Claude、Gemini、Perplexity、CopilotのAI可視性を、既存のキーワード順位チェッカーに統合したサービス。全プランでユーザー数無制限なため、チーム全体でデータを共有しやすい。AI引用を検知するとアラートを出し、どのページが引用元かを特定できる。月額79ユーロから。すでにランク追跡ツールを使っているチームが、追加の乗り換えコストを抑えたい場合に適する。
WordPressでAI可視性を高めて成果につなげる

可視性を「見える化」したら、次のアクションに移さなければ意味がない。WordPressサイト運営者にとって理想的な流れは、以下の3ステップだ。
AIOSEOのAI SuiteとLLMs.txt生成機能は、WordPress管理画面からすぐに使える。SEOBoostはAIOSEOの執筆アシスタントとして統合されており、コンテンツブラッシュアップを効率化する。MonsterInsightsのAIトラフィックレポート(Pro以上)を組み合わせれば、「見えない脅威」だったAI検索の文脈を、数字で把握できる体制が整う。
この記事のポイント
- AIチャットによる直接推奨で、検索から購入までのプロセスが短縮され、ブランド露出の機会が減っている
- AI可視性ツールは、ChatGPTやPerplexityでの言及頻度と質を追跡し、従来のSEOと分けて管理する必要がある
- ツール選びでは「対応エンジンの広さ」「言及と引用の区別」「センチメント分析」「クエリ可視性」「既存ツールとの統合」の5点を重視する
- AIOSEOやSEOBoostといったWordPress直結ツールを使えば、ギャップの発見からコンテンツ改善、トラフィック計測まで一貫して対処できる
- AI可視性は固定的な順位ではなくトレンドとして捉え、競合に負けている質問を優先的に対策する姿勢が成果を左右する
・ 複数業界における17年間のデジタルビジネス開発経験
・ ウェブサイト開発のためのHTML、PHP、CSS、JavaScript等の実用的知識
・ 15ヶ国語対応の多言語SaaSの開発経験
・ 17年間にも及ぶ、Eコマース長期運営経験
・ 幅広い業界でのSEO最適化の豊富な経験

Googleのノンコモディティ方針、ECサイトが取るべきコンテンツ戦略
Googleが2026年5月、AI検索時代を見据えた新しい可視性ガイドラインを公開した。その中核にあるのが「ノンコモディティ・コンテンツ(Non-Commodity Content)」という概念だ。誰にでも書ける凡庸な情報ではなく、書き手自身の経験や独自の視点がにじむコンテンツを評価するという方針である。
Practical Ecommerceの記事によると、この考え方自体は目新しいものではない。Googleは長年にわたりEEAT(経験・専門性・権威性・信頼性)を重視してきた。しかしAIによるゼロクリック検索が急速に台頭する中で、改めて「人間にしか書けないコンテンツ」の重要性が言語化された形だ。
この記事では、Googleの「ノンコモディティ」方針の具体的な内容を整理する。あわせて、ECサイトを運営する事業者やWooCommerceユーザーがこの変化をどう受け止め、どんなコンテンツ戦略を取るべきかを実務目線で解説する。
Googleが定義する「コモディティコンテンツ」とは何か

GoogleのAI可視性ガイドラインは、検索上位を目指すコンテンツを2つに大別している。「コモディティコンテンツ」と「ノンコモディティコンテンツ」だ。まず前者の定義から確認しよう。
誰が書いても同じになる情報
コモディティコンテンツとは、いわゆる「一般的な知識」に基づいて書かれた情報のことだ。具体例としてGoogleが挙げているのが「初めて住宅を購入する人への7つのヒント」といった記事である。この手の内容は、どの書き手が担当しても似たような仕上がりになる。
実務的にいえば、競合他社の記事を参考に構成し、公開データだけを元にまとめた商品比較記事や、製品スペックを並べただけの紹介ページが該当する。生成AIを使えば数分で量産できるタイプのコンテンツだ。
検索におけるコモディティコンテンツの限界
Google検索のインハウスリエゾンであるダニー・サリバン氏は、2026年4月のSearch Central Live Torontoでこのテーマを取り上げている。同氏が示した業界別の対比表を見ると、コモディティコンテンツの問題点がより明確になる。
- ランニングシューズ販売店の場合「ランニングシューズ購入時に考慮すべき10のポイント」
- インテリアデザイナーの場合「2024年に見逃せないキッチントレンド」
これらは情報として誤りではない。しかし、検索エンジンから見れば「どのサイトを上位表示してもユーザー体験に大差がない」と判断されるリスクをはらむ。AIによる回答生成が進むほど、この傾向は強まるだろう。
ノンコモディティコンテンツが評価される理由

一方のノンコモディティコンテンツは、書き手固有の経験や専門知識に裏打ちされた情報を指す。生成AIが簡単に要約したり、出典なしで再利用したりしにくい性質を持つ。
Googleが示した具体例
先のダニー・サリバン氏による業界別の対比表では、ノンコモディティに該当する例として以下が挙げられている。
- ランニングシューズ販売店「なぜこの顧客のシューズは400マイルで壊れたのか、摩耗パターンの分析」
- インテリアデザイナー「大理石 vs ブドウジュース、5人家族に石材を勧めなかった理由」
どちらも実際の顧客対応や施工現場で起きた具体的なエピソードだ。競合が簡単に真似できる内容ではなく、読み手に「この店で買いたい」「このデザイナーに依頼したい」と思わせる力がある。
EEATとの関係性
ノンコモディティという用語は新しいが、背景にある考え方はGoogleが長年重視してきたEEATと重なる。EEATとは「Experience(経験)」「Expertise(専門性)」「Authoritativeness(権威性)」「Trustworthiness(信頼性)」の頭文字を取った評価基準だ。
Practical Ecommerceの記事では、Googleが以前から人間の評価者に対してEEATに基づくサイト評価を指示しており、ランキングアルゴリズムにもヘルプフルコンテンツシステムの一部としてEEATに似た要素が組み込まれている可能性が高いと指摘している。要するに、新しい概念が登場したというより、AI時代に合わせて既存の評価軸を再定義したと見るのが自然だ。
上図の対比からわかるように、ノンコモディティコンテンツは「そのサイトでなければ読めない情報」を提供する。この一点がAI時代の検索評価において決定的な差となる。
ECサイトが取り組むべきコンテンツ戦略

では、WooCommerceをはじめとするECサイト運営者は、この方針転換にどう対応すればよいのか。具体的な打ち手を3つの軸で整理する。
独自データに基づく分析記事
顧客の購買データや問い合わせ履歴を分析し、傾向を記事化する手法はノンコモディティコンテンツの典型例だ。「昨年と比べて20代女性の購入単価が15%上昇した理由」「雨の日に売れる商品トップ5とその背景」といった内容である。
WooCommerceのレポート機能やGoogleアナリティクスのデータを活用すれば、小規模店舗でも十分に独自性のある分析が可能だ。数字と具体的な事例をセットにすることで、読み手の信頼を得やすくなる。
実際の使用例や顧客ストーリー
商品紹介ページに顧客の使用シーンを詳細に盛り込むことも効果的だ。「30代男性がキャンプで3日間使用した感想」「子育て中の女性が選んだ理由と1カ月後の変化」といった具体的なエピソードは、スペック表では伝わらない価値を読者に届ける。
重要なのは、単なるレビュー評価の転載ではなく、店舗スタッフが直接ヒアリングした内容や観察した気づきを文章化することだ。この一手間が、生成AIでは代替できない独自性を生む。
専門家としての見解や実験結果
自社で取り扱う商材について、スタッフが実際に検証した結果を公開する方法もある。「3種類の防水スプレーを実際に試して効果を比較した」「同価格帯の Bluetooth イヤホン5製品を音質測定器でテストした」といった記事だ。
これらは手間とコストがかかるが、検索エンジンからの評価だけでなく、ブランドの信頼構築やリピーター獲得にも直結する。YouTube動画と組み合わせれば、さらに効果は高まるだろう。
コモディティコンテンツが無価値というわけではない

ここまでノンコモディティの重要性を強調してきたが、誤解してはいけない点がある。商品リリース情報や価格改定のお知らせ、採用情報といった「コモディティ的」なコンテンツにも確かな価値は存在する。
読者が求めるなら迷わず発信する
Practical Ecommerceの記事はこの点を明確に指摘している。読者が知りたい情報であれば、それがコモディティコンテンツであっても積極的に発信すべきだ。自社ブランドのファンは新製品の発表を待っているし、既存顧客はメンテナンス情報を必要としている。
直接流入の強化は、結局のところ最も確実なSEO対策である。コモディティかノンコモディティかという区分に過度に縛られるより、まずは目の前の顧客が何を求めているかに集中する姿勢が大切だ。
バランスの取れたコンテンツ設計を
理想的なのは、両方のタイプをバランスよく配置することだ。商品ページはコモディティ的な基本情報をしっかり押さえつつ、ブログ記事ではノンコモディティ的な独自コンテンツで差別化する。この二層構造が、AI検索時代のECサイトに求められるコンテンツ戦略の基本線となる。
WooCommerceサイト運営者が今すぐ始めるべき3つの施策

ここまでの内容を踏まえ、WooCommerceでECサイトを運営する事業者が今日から取り組める具体的なアクションを3つに絞って提案する。
1. 商品説明文に実体験を注入する
メーカー提供のスペック情報をそのまま転載している商品説明ページがあるなら、すぐに手を入れるべきだ。スタッフが実際に商品を使った感想や、想定外の使い方の発見、競合品との微妙な違いなどを追記するだけで、コンテンツの独自性は格段に高まる。
2. 社内ブログに顧客事例カテゴリを新設する
WooCommerceサイトにブログ機能を追加するのは難しくない。そこに「お客様事例」というカテゴリを作り、月1本のペースで実際の顧客ストーリーを掲載していく。許可を得た上で、購入のきっかけや使用後の変化を具体的に聞き取って記事化する。
3. アクセス解析から問いの種を探す
Googleサーチコンソールで自社サイトに流入している検索クエリを確認し、まだ十分に回答できていない質問を特定する。「〇〇 比較」「〇〇 口コミ」「〇〇 使い方」といったクエリに対して、自社の実体験やデータに基づいた回答記事を用意すれば、それがそのままノンコモディティコンテンツになる。
この記事のポイント
- GoogleはAI検索時代に対応するため「ノンコモディティコンテンツ」の重要性を正式に打ち出した
- ノンコモディティとは、書き手固有の経験や専門知識に裏打ちされた、生成AIでは簡単に再現できない情報を指す
- ECサイトでは顧客データ分析、使用事例の詳細な紹介、自社検証記事の公開が有効な差別化策となる
- 読者が求める情報であれば、コモディティ的なコンテンツにも価値はある、バランスが肝心
・ 複数業界における17年間のデジタルビジネス開発経験
・ ウェブサイト開発のためのHTML、PHP、CSS、JavaScript等の実用的知識
・ 15ヶ国語対応の多言語SaaSの開発経験
・ 17年間にも及ぶ、Eコマース長期運営経験
・ 幅広い業界でのSEO最適化の豊富な経験

会員制サイトSEOの7つの戦略、ティーザーで制限コンテンツを検索上位に
会員制サイトを運営していると、せっかく質の高いコンテンツを制作しても、Google検索にまったく表示されないという問題に直面しやすい。原因の多くは、価値のある記事やコースがログインページやペイウォールの奥に隠れていることにある。検索エンジンは会員専用エリアをクロールできず、サイト全体のテーマを正しく把握できないのだ。
しかし、コンテンツ保護とSEOはトレードオフではない。適切な設計を施せば、プレビュー部分を検索エンジンに読み取らせつつ、中核の有料コンテンツはしっかり守れる。WPBeginnerがまとめた「会員制サイトSEOの7つの戦略」をもとに、具体的な実装方法を解説する。
会員制サイトのSEO課題と「ティーザーコンテンツ」の考え方

会員制サイトには特有のSEOの壁がある。Googleは公開されている情報だけをインデックスするため、ログイン必須のレッスンやダウンロード資料、会員ダッシュボードの中身は一切読み取れない。一方で、完全に閉ざしてしまうと検索流入を失い、新規会員の獲得機会が減ってしまう。
検索エンジンはゲート付きコンテンツをどう扱うか
Googleは、ログイン前の訪問者にも表示される「公開プレビュー」部分をインデックス可能だ。一方、認証画面の奥にある会員専用ページはクローラーのアクセス対象外となる。この仕組みを逆手に取り、ティーザーコンテンツ(Teaser Content)と呼ばれる一部公開方式を採用するサイトが多い。WPBeginnerの著者も、これが会員制サイトのSEOにおいて最も効果的で安全な手法だと述べている。
ティーザーコンテンツが有効な理由
ティーザーとは、記事の導入部やレッスンの要約、キーポイントなどを会員以外にも公開し、続きはログイン後に読めるようにする仕組みだ。Googleはこの公開部分をもとにページの主題を理解し、検索結果に表示できるようになる。訪問者にとっては内容の魅力を事前に感じられるため、会員登録へのコンバージョン率も向上しやすい。WPBeginnerの実践では、無料の動画コース一覧を誰でも閲覧可能にし、レッスン本体は会員登録後に開放する形で、SEOと会員獲得を両立している。
このデモのように、Googleは公開部分のテキストからページの内容を把握し、ランキング評価に活用する。訪問者にとっては「続きも見たい」というモチベーションが生まれ、会員獲得の導線としても機能する。
ティーザーとコンテンツドリッピングを安全に運用する
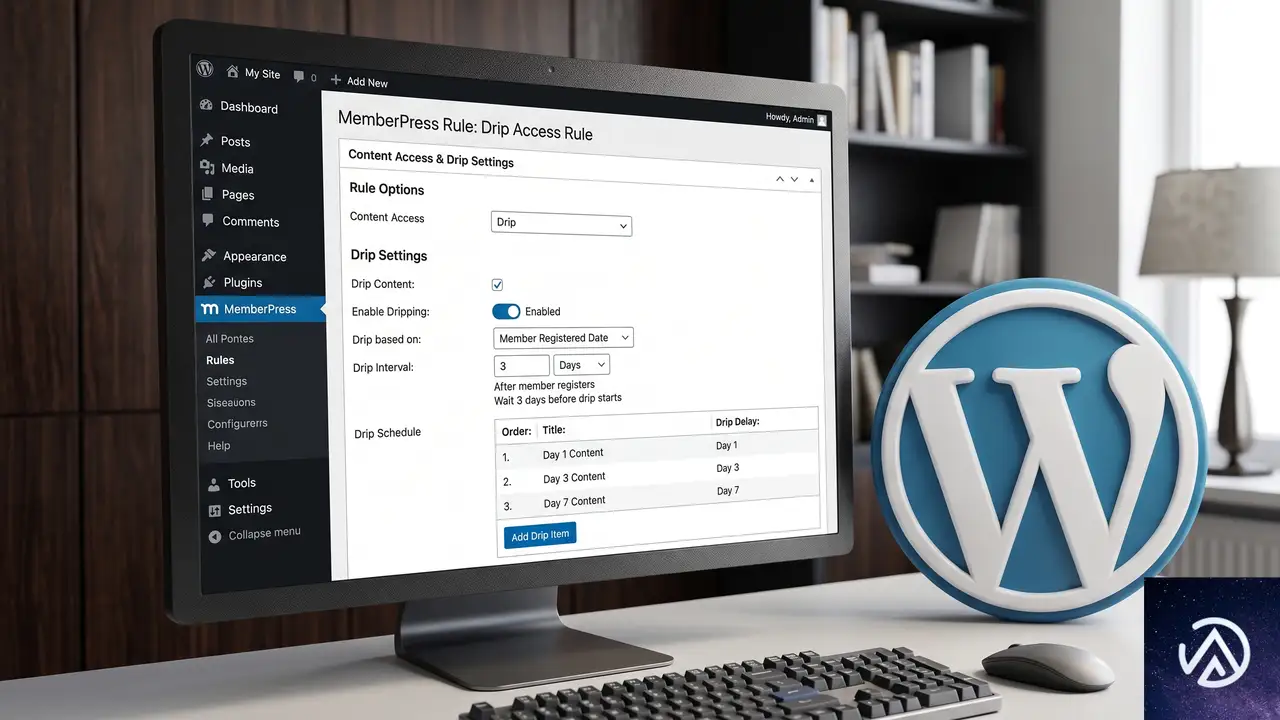
ティーザー表示の設定ができたら、次は会員にコンテンツを段階的に提供する「コンテンツドリッピング」について理解しておきたい。これはオンラインコースなどでよく使われる手法で、SEOに悪影響を及ぼさないためにはいくつかの注意点がある。
MemberPressを使ったティーザー公開の設定手順
WordPressで会員制サイトを構築する場合、高い機能を持つプラグインとしてMemberPressが広く使われている。管理画面の「MemberPress」→「ルール」から新規ルールを追加し、保護したい投稿やカテゴリを選択する。その後「アクセス条件」で特定の会員レベルを指定し、「未認証時のアクション」で抜粋の表示を有効にすれば、公開ティーザーが実装できる。
抜粋の長さは200〜300語程度を目安に設定すると、検索エンジンがページ主題を理解するのに十分な情報量を提供できる。WPBeginnerのガイドでは、未認証時に表示されるメッセージに料金ページや登録ページへのリンクを埋め込むことで、コンバージョン向上を図る方法も推奨されている。
コンテンツドリッピングがSEOに与える影響と事前対策
ドリッピングとは、会員登録後の日数経過や特定の日付に合わせて、レッスンを少しずつ開放していく仕組みだ。未解放のコンテンツは検索エンジンからも見えないため、その期間はインデックスされない。しかし、事前にティーザーページやレッスン概要を用意しておけば、後日開放されたときにスムーズにクロールされる。
動画コースの場合は、各レッスンに短いプレビュー動画や書き起こしテキスト、キーポイントをまとめた公開ランディングページを設ける方法が有効だ。WPBeginnerの著者は、これによって開放前から検索エンジンに内容を認識させられると指摘している。
無料コンテンツを拡充して検索トラフィックを底上げする
会員制サイトの運営者の中には、コンテンツの大半をペイウォールの内側に置いてしまうケースがある。だが、それではGoogleがサイト全体の専門性を評価する材料が不足し、オーガニック流入が伸び悩む。実際に成果を上げているサイトは、無料コンテンツを充実させ、そこから有料会員プログラムへと誘導する設計をとっている。
無料と有料の境界線の引き方
無料コンテンツは、幅広い検索キーワードでアクセスを集める役割を担う。一方、有料コンテンツにはテンプレートやワークシート、詳細な実装ガイドなど、より深い価値を置く。WPBeginnerが提示する枠組みでは、初心者向けチュートリアルや統計レポート、業界の基礎知識は無料とし、高度なノウハウや会員限定のツールキットは有料会員向けに保護する。
- 無料コンテンツ:検索ボリュームの大きいキーワードを狙うブログ記事、初心者向け解説、バックリンクを獲得しやすいリソース
- 有料コンテンツ:テンプレート、ワークシート、オンラインコース、会員限定の実装ガイド
このように切り分けると、無料記事で集めた訪問者に「より深い学びを得たければ会員登録を」と自然に促せる。
E-E-A-Tシグナルとキーワード戦略で信頼を構築する
会員制サイトは、専門知識やトレーニングを販売する性質上、訪問者からの信頼獲得が欠かせない。Googleが評価するE-E-A-T(経験、専門性、権威性、信頼性)の観点からも、無料コンテンツを使って実績や実例を示すことが有効だ。WPBeginnerの著者は、実際に自分たちでツールを使い、結果やケーススタディを共有することで、サイトの専門性を高めている。
具体的には、著者プロフィールの充実、会員の声や成功事例の掲載、実際の運用画面の紹介などが信頼構築に役立つ。無料記事にこうしたシグナルを埋め込んでおくと、検索エンジンだけでなく、人間の読者にも「このサイトは信用できる」と感じてもらいやすい。
テクニカルSEOとnoindex設定でクローラーの集中力を高める

どれだけ優れたコンテンツ戦略を立てても、サイトの技術的な土台が整っていなければ、検索順位は伸びにくい。会員制サイトでは特に、ログインページやアカウントページといった「低価値ページ」が検索結果に紛れ込むのを防ぐことも重要になる。
サイトスピードやHTTPSなど基盤のチェックリスト
- HTTPSによるセキュリティ保護とランキングシグナルの確保
- キャッシュプラグインの導入と画像最適化によるサイトスピード改善
- モバイルフレンドリーなデザインの採用
- XMLサイトマップを生成し、検索エンジンにサイト構造を伝える
- リンク切れや404エラーを定期的に検出し修正する
これらの対策は会員制サイトに限らず重要だが、ペイウォールがあるぶん、クローラビリティの健全性を保つ意識がより求められる。
ログインページやアカウントページをnoindexに
会員ログインページやアカウント管理画面、決済完了後のサンキューページなどは、検索結果に表示されてもユーザーにとってほとんど価値がない。むしろ、これらのページがインデックスされると、サイトの評価につながる重要なコンテンツの存在が薄れてしまう可能性がある。
そのため、All in One SEO(AIOSEO)などのSEOプラグインを使って、該当ページの編集画面から「Robots Meta」設定で「No Index」を有効にすることを推奨する。WPBeginnerの著者も、会員向け機能ページはnoindexに設定し、ブログ記事やコースランディングページなどの集客に集中させる方針をとっている。
内部リンクとコンバージョン最適化で会員化を加速する

無料コンテンツで訪れたユーザーを会員登録へと導くためには、サイト内の動線設計が欠かせない。内部リンクを活用して無料記事から有料プランへつなぎ、さらにポップアップやスライドインなどの施策で後押しすれば、SEOで獲得したトラフィックを収益に結びつけられる。
無料記事から有料コンテンツへの自然な導線
ブログ記事で「会員制サイトの始め方」を解説しているなら、記事の途中や末尾に「さらに詳しいテンプレートは会員プログラムでダウンロード可能」といったリンクを設置する。リンクのアンカーテキストは「こちらをクリック」ではなく「会員限定テンプレートを入手する」のように具体的に書くと、クリック率とSEO評価の両面で効果が高い。
- ブログ記事 → 関連する有料コースのランディングページ
- 無料のチュートリアル → 会員限定の上級編トレーニング
- リソースガイド → プレミアムテンプレートのダウンロードページ
内部リンクを張り巡らせると、Googleがサイト構造を理解しやすくなるのに加え、訪問者を収益化ページへ自然に誘導できる。
OptinMonsterによるExit-Intentやスライドインの活用
WPBeginnerの著者が特に効果的だと評価しているのが、OptinMonsterを使った出口検知ポップアップやスクロール連動スライドインだ。MemberPressとの連携機能により、未会員の訪問者だけを対象にキャンペーンを表示できるため、無料トライアルや割引オファーを最適なタイミングで提示できる。
たとえば、記事を最後まで読んだユーザーに対して「続きは会員限定です。今なら初月無料」と表示するスライドインは、押しつけがましくなく自然に感じられる。実際に、WPBeginnerの運営する複数のサイトでも、こうした導線によってメールリストの拡大や会員登録数の増加を実現している。
効果測定の指標とMonsterInsightsでの追跡
会員制サイトのSEO施策が成果を上げているかは、アクセス数だけでなく会員登録数やコンバージョン率で判断する必要がある。MonsterInsightsを使えば、GoogleアナリティクスのデータをWordPress管理画面に取り込み、どの記事が最も会員登録につながっているかを直感的に把握できる。
- オーガニックトラフィックの推移
- ティーザーページへの流入と直帰率
- 会員登録完了ページへの到達数
- バックリンク獲得状況
定期的にこれらの指標を確認し、特に会員登録につながっているコンテンツを強化していくと、施策の費用対効果を最大化しやすい。
この記事のポイント
- 会員制サイトのSEOには、公開ティーザーで検索エンジンに内容を伝える手法が欠かせない
- MemberPressで抜粋表示を設定し、一部のコンテンツを誰でも見られるようにする
- コンテンツドリッピングは事前にティーザーページを用意すればSEO上のデメリットは最小限
- 無料コンテンツで集客し、内部リンクとコンバージョン施策で有料会員へ誘導する
- 会員向け機能ページはnoindexにして、クロールのリソースを重要なページに集中させる
・ 複数業界における17年間のデジタルビジネス開発経験
・ ウェブサイト開発のためのHTML、PHP、CSS、JavaScript等の実用的知識
・ 15ヶ国語対応の多言語SaaSの開発経験
・ 17年間にも及ぶ、Eコマース長期運営経験
・ 幅広い業界でのSEO最適化の豊富な経験

AnthropicのFable 5が米政府命令で強制停止、SEO業界に衝撃
Fable 5とMythos 5、米国政府の輸出管理命令で突然の利用停止

米国政府は2026年6月13日、国家セキュリティを理由にAnthropicへ輸出管理命令を出し、同社の最新AIモデル「Fable 5」および「Mythos 5」の全利用停止を強制した。命令は外国籍の個人によるアクセスを禁じており、実質的に全顧客の接続を遮断せざるを得ない内容だ。
Anthropicは同日に声明を発表し、政府の見解に反論した。両モデルには強固なセーフガードが重層的に組み込まれており、既存のAIモデルと同等のリスク水準に留まっていると主張している。しかし、命令受領からわずか数時間でFable 5とMythos 5のアクセスは世界中で停止された。
この措置は、SEOやデジタルマーケティングで最先端AIを活用してきた企業・個人に直接的な影響を及ぼす。高性能モデルの急な遮断は、コンテンツ制作フローや競合分析の自動化パイプラインを根底から揺るがすためだ。
このデモでは、Fable 5が突然使えなくなり、SEOワークフローに穴が空く状況を図示している。高性能なモデルに依存していた自動化プロセスは、一気に精度と速度が落ちる。
輸出管理命令の具体的な中身
命令は輸出管理指令と呼ばれる法的措置で、技術やデータの国外移転を制限する。Anthropicはこの命令を「外国籍の者へのアクセスを一切禁じる」と解釈せざるを得ず、結果的に全世界のユーザーが利用不能になった。同社が受けたのは東部夏時間17時21分。ほぼその日のうちに、サービス停止が現実となった。
政府はFable 5のセーフガードを突破する手法があると指摘しているが、Anthropicは提示された事例を「軽微な脆弱性」と一蹴。同社は既に多層防御と厳重なモニタリングでリスクを抑え込んでいる立場だ。
SEO業界が受ける打撃、AI駆動型ワークフローの寸断

Fable 5の急停止は、SEO担当者やアフィリエイトマーケターに具体的な痛みをもたらした。特に月額200ドルの「Claude Max」プランに切り替えたばかりのユーザーからは、返金を求める声がXで相次いだ。新しいモデルを前提にした記事生成や分析タスクが突然止まったためだ。
この流れは、AIモデルをコンテンツ制作パイプラインに組み込んできたSEOチームにとって、サプライチェーン途絶に近い。短納期の記事更新や、多言語でのローカライズ、高度なエンティティ抽出にFable 5を使っていたケースでは、代替モデルへの切り替えに伴う品質低下と工数増加が避けられない。
上のフローは、AIモデルを活用したSEOコンテンツ制作の典型的な手順だ。Fable 5が消失すれば、STEP 1の時点で生産性が大幅に落ちる。
返金要求とMaxプランの混乱
Xの投稿では、多くのユーザーが「Fable 5を使うためにMaxプランに切り替えたのに、当日に遮断された」と訴えている。あるユーザーは「生物学の基本的な質問さえできなかった」と、セーフガードの過剰さを指摘。多額の課金が一瞬で無駄になった苛立ちが広がった。
これはBtoBのSEO支援会社にとっても同様で、クライアント向けのコンテンツをFable 5に依存していた場合、納期の遅延と追加コストが発生する。急速なAI導入が裏目に出る典型例と言える。
国家セキュリティとAI規制、SEOに迫る論点

今回の措置は、AIによるサイバーセキュリティリスクを巡る政府とAnthropicの長年の対立の延長線上にある。Anthropicは大量監視や自律型兵器への技術提供を拒否してきた経緯があり、それが政府の不信感を強めたと見られる。
SEO業界への教訓は単純だ。極めて高性能なAIモデルは、常に地政学的リスクの影響を受ける。特定のベンダーに過度に依存したコンテンツ戦略は、突如として停止する可能性がある。複数のAIプロバイダーを使い分けるマルチベンダー戦略が、今後の安定運用の鍵を握る。
上の図は、リスク分散のためのマルチベンダー構成の一例だ。1つのモデルが遮断されても、他のプロバイダーや自社ホストのモデルでカバーできる。
「強力すぎるAI」を喧伝したツケ
批判の矛先はAnthropic自身にも向いた。同社が長年「極めて強力で危険なAI」と自社モデルを位置付けてきたことが、政府の深刻な受け止めを招いたという指摘だ。Xでは「恐怖をブランドにして政府に輸出管理をかけられ、今更『誤解』と言うのか」と皮肉る投稿が散見された。
SEO担当者にとっては、AIの性能を過大にアピールするマーケティングが規制を早める可能性を認識する契機になる。クライアントや社内で「最強のAIを使っている」と謳う前に、その文言が持つ政治的な重みを考慮すべき局面だ。
SEO戦略に組み込むAIレジリエンス、今後の備え
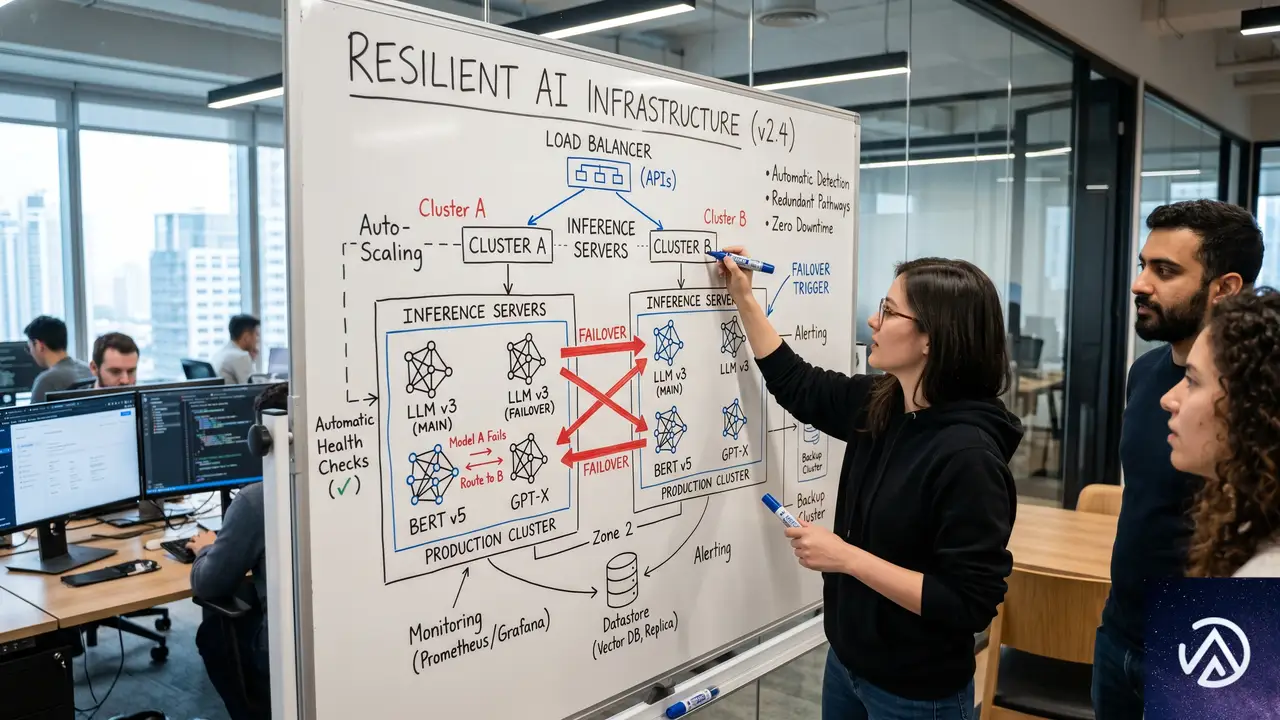
Fable 5停止のような事態に備え、SEO担当者は次の3つの柱を早急に固める必要がある。第一に、複数AIモデルへのアクセス経路の確保。第二に、AI非依存の編集プロセスとの併用。第三に、オープンソースLLMの社内導入検討だ。
Anthropicは「サービスの早期復旧を目指す」と表明しているが、法的な結末は不透明だ。最悪の場合、最先端モデルへのパブリックアクセスが恒久的に制限される可能性もゼロではない。そのとき、手元に自前の代替手段を持たないチームは、検索順位を維持するための初速で致命的な遅れを取る。
この比較が示す通り、AIに依存するほど、その供給停止がもたらすダメージは大きくなる。今のうちにバックアップのAIパイプラインをテストし、実際に切り替え可能な状態にしておくことが重要だ。
この記事のポイント
- 米国政府の輸出管理命令によりAnthropicのFable 5とMythos 5が全ユーザーに対して突然停止された
- SEO業界では高精度AIを前提としたコンテンツ制作フローが寸断され、返金要求や納期遅延が発生
- 高性能AIのブランディングが規制を呼び込むリスクが現実化した
- マルチベンダー戦略やオープンソースLLMの導入で、AIサービス遮断に強いSEO体制を構築すべき
・ 複数業界における17年間のデジタルビジネス開発経験
・ ウェブサイト開発のためのHTML、PHP、CSS、JavaScript等の実用的知識
・ 15ヶ国語対応の多言語SaaSの開発経験
・ 17年間にも及ぶ、Eコマース長期運営経験
・ 幅広い業界でのSEO最適化の豊富な経験

WordPressドメイン移転後のSEOを完全検証する7ステップ
ドメイン名の変更は、WordPressサイト運営者にとって最も神経を使うSEO判断のひとつだ。適切に実行すれば検索順位のほとんどは維持される。しかし手順を間違えると、数カ月かけて積み上げた成果が一夜で消え去る。WP Beginnerの記事では、表面上は問題なさそうに見えて、実際にはリダイレクト漏れや古い正規URLが数週間にわたって順位を押し下げた事例が報告されている。
本記事では移転前のSEOベースライン取得から始め、リダイレクトの検証、正規URLとデータベース内リンクの修正、そして復旧状況の追跡までを体系的に解説する。大半のサイトは301リダイレクトを正しく設定することで、4〜8週間以内に検索順位の80〜100%を回復できるというデータがある。
このデモでは、ドメイン移転前後でのSEO評価の流れを概念的に示している。301リダイレクトがあれば左から右へ評価が転送されるが、リダイレクトがないと旧ドメインに評価が取り残されたままになる。
ドメイン移転がSEOにリスクをもたらす理由

ドメインを変更すると、Googleは新しいURLを発見し、301リダイレクトを処理し、既存のランキング評価を転送する前にコンテンツを再評価する。このプロセスには時間がかかり、いずれかの段階でエラーが発生すると、SEOの回復が遅れたり恒久的に低下したりする。
ほとんどの順位低下は、以下の3つの具体的な障害点から発生する。
- 301リダイレクトの破損または欠落。301がない場合、Googleは新ドメインを評価シグナルのないまったく新しいサイトとして扱う
- 古い正規URL(カノニカルURL)が残ったままの状態。正規タグが旧ドメインを指していると、Googleは新しいURLではなく古い方をランク付けしようとする
- サイトマップが旧ドメインを参照しているパターン。Googleはサイトマップを使ってページを発見するため、古いURLのままだと新ドメインのコンテンツ発見が遅れる
この3つはすべて修正可能だ。以降の手順では、移転前の準備から順に対処法を説明する。
ステップ1 移転前のSEOベースラインを構築する
サイトを移転する前に、現在のSEOパフォーマンスのスナップショットを取得しておく必要がある。ベースラインがなければ、移転後に順位が正常に回復しているのか、特定のページが密かに順位を落としているのかを判断できない。
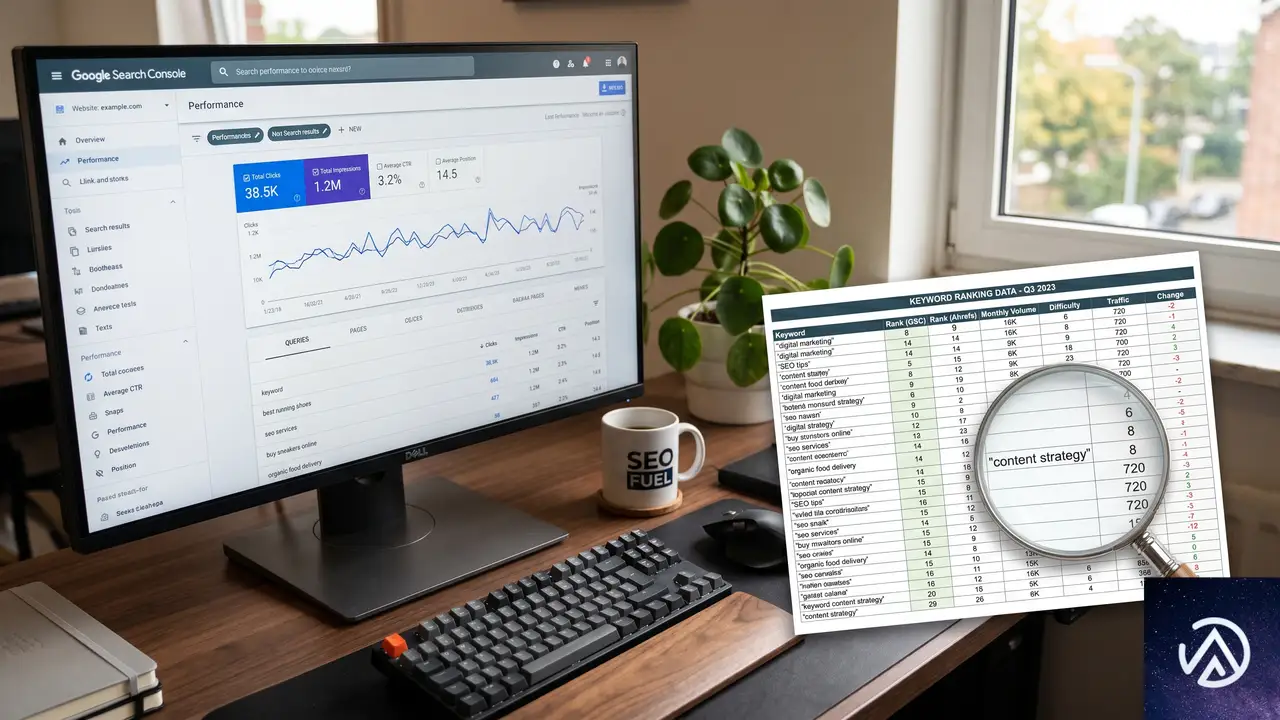
キーワードランキングをエクスポートする
キーワードのベースラインは、移転後1週間、2週間、4週間の時点で比較する「変化前の記録」になる。サイトに手を加える前に、現在のキーワード順位、クリック数、表示回数をエクスポートする。
Googleサーチコンソールから無料でエクスポートできる。対象のサイトプロパティを選択し、左サイドバーの「パフォーマンス」から「検索結果」をクリックする。期間を過去3カ月に設定し、右上の「エクスポート」からCSVをダウンロードする。エクスポート前に「表示回数」または「クリック数」の多い順に並べ替えておくと、上位1,000キーワードが最も価値の高いものになる。
All in One SEO(AIOSEO)のEliteプランを利用していれば、WordPress管理画面から直接同じデータを取得できる。AIOSEOの検索統計機能はサーチコンソールのデータを自動的に取り込んでおり、キーワード順位、クリック数、表示回数をダッシュボード上で確認できる。
現在のURL一覧をクロールして文書化する
サイト上の全ページの完全なリストは、後でリダイレクトを設定する際のロードマップになる。このリストから漏れたページはリダイレクトが設定されず、古いアドレスが機能しなくなった瞬間に、そのページが築いた検索順位は永久に失われる。
現在のサイトをクロールするには、Screaming Frog SEO Spiderが使える。500URLまでは無料で、有料プランでは無制限にクロールできる。クロールが完了したら、ファイルメニューから全URLリストをCSVとしてエクスポートし、キーワードエクスポートと同じ移転専用フォルダに保存する。
ステップ2 サイトを安全に移転する

サイト移行に使う手法は、最初の大きなSEO判断になる。WP Beginnerの記事では、移行中のデータベース処理の安全性からDuplicatorの使用が推奨されている。Duplicatorのインストーラーは、展開時にWordPressデータベース内の全URLを新しいドメインに自動更新する。内部リンクや画像パスも自動修正されるため、後述する古い正規URLや混在コンテンツの問題を防げる。
移転が完了したら、新しいWordPress管理画面の「設定」→「一般」で、WordPressアドレスとサイトアドレスの両方が新しいドメインになっていることを確認する。
robots.txtが新サイトをブロックしていないか確認する
検索エンジンのクロールをブロックできるのは、WordPressの「検索エンジンがサイトをインデックスしないようにする」チェックボックスだけではない。robots.txtファイルも同様の影響を与える。ステージング環境から引き継がれた古いルールが残っていると、重要なコンテンツがブロックされる可能性がある。
新しいドメインのrobots.txtをブラウザで開き、DisallowルールやSitemap行が新しいドメインを指しているか確認する。AIOSEOを使っている場合は、ツールメニューから「カスタムrobots.txtを有効化」トグルをオンにし、古いルールを直接修正できる。
ステップ3 旧ドメインからの301リダイレクトを設定する

301リダイレクトは、Googleに対して「このURLは恒久的に新しいURLに移動した」と伝える仕組みだ。郵便局に転居届を出すようなもので、SEO評価を正しく転送するための必須手続きになる。301がないと、Googleは新旧ドメインをまったく別のサイトとして扱い、ランキングシグナルは古いドメインに残ったままになる。
AIOSEOのProプラン以上に含まれる「フルサイトリダイレクト」機能を使うと、旧ドメイン全体を一度の設定で新ドメインに転送できる。旧サイトのWordPress管理画面で「All in One SEO」→「リダイレクト」→「フルサイトリダイレクト」タブを開き、「サイトを移転する」トグルを有効化して新しいドメインURLを入力する。
重要な注意点として、この手法は旧サイトのWordPressが稼働し続けていることが前提になる。旧ドメインの登録を維持し、ホスティングも停止せず、AIOSEOプラグインも有効化したままにする必要がある。旧サイトを削除したりホスティングを解約すると、リダイレクトは即座に機能しなくなる。
Googleに通知する前にリダイレクトをテストする
壊れたリダイレクトを抱えたまま変更通知を送信すると、移行全体の回復が遅れる。外部ツールのhttpstatus.ioなどを使い、旧ドメインのトップページURLが301ステータスを返し、正しい新ドメインのURLに解決されることを確認する。このテストはアクセスの多い上位5記事と主要カテゴリページでも繰り返す。
302リダイレクトや複数ホップのチェーンが発生している場合は、AIOSEOのリダイレクト設定で競合する個別ルールがないか確認する。リダイレクトチェーンが発生すると、SEO評価の受け渡しが目減りし、訪問者の待ち時間も増える。すべての旧URLが新URLに直接1ホップで転送される状態を目指す。
この比較図はリダイレクトチェーンの問題を視覚化したものだ。中間ホップを除去して直接転送にすることで、Googleが処理すべき経路が単純になり、評価の受け渡し効率が上がる。
ステップ4 新ドメインをGoogleサーチコンソールに登録する
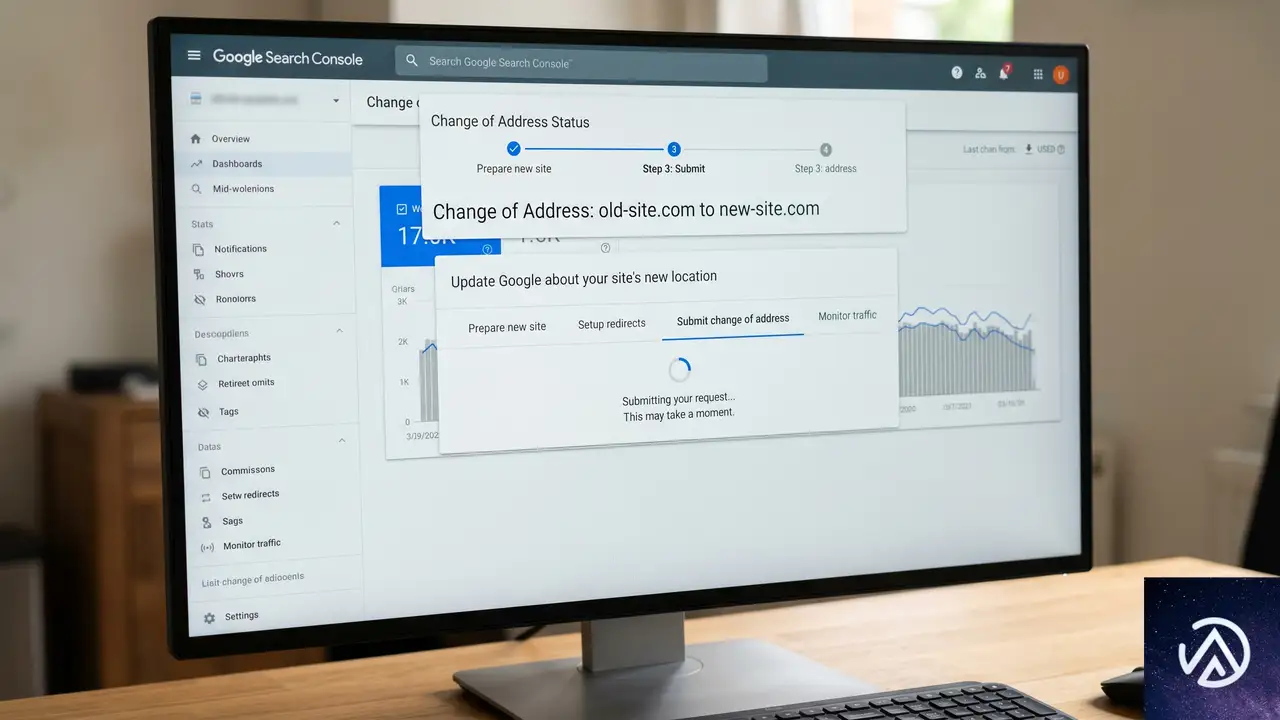
Googleは旧ドメインと新ドメインを完全に別のプロパティとして扱う。ランキングシグナルを転送するには、新ドメインをサーチコンソールで確認し、住所変更通知を送信し、サイトマップを再送信する必要がある。
新しいドメインを追加するには、サーチコンソールのプロパティドロップダウンから「プロパティを追加」を選び、確認手続きを進める。次に旧ドメインのプロパティに切り替え、「設定」→「住所変更」から新ドメインを選択して「検証して更新」をクリックする。このときGoogleが301リダイレクトを検証するため、事前にステップ3の設定が完了している必要がある。
サイトマップについては、AIOSEOがドメイン変更時に内部リンクを自動更新するが、新しいURLのサイトマップを手動で再送信することで、次の自動クロールを待たずに新URLのインデックス登録を開始させられる。
ステップ5 正規URLが正しいか検証する
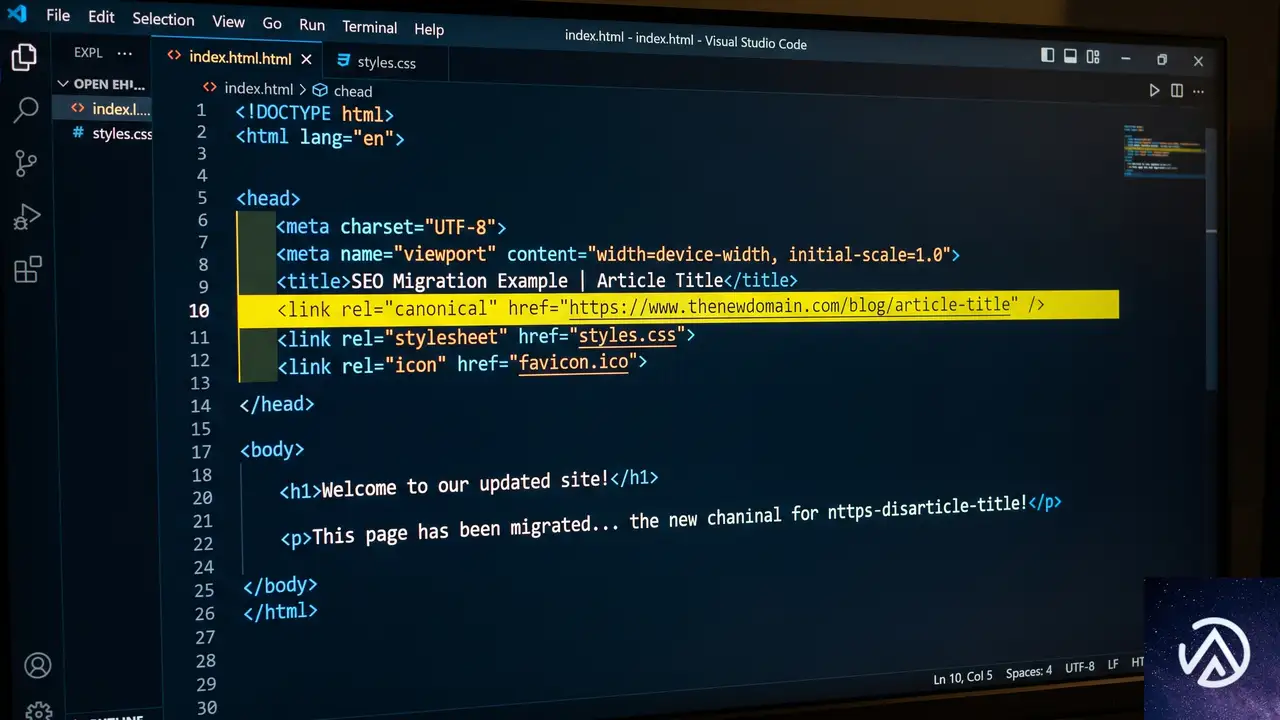
正規URL(カノニカルURL)は、検索エンジンがインデックスしてランク付けすべき「正式版」のページを指す。ドメイン移転後に正規タグが旧ドメインを指したままだと、新しいページがGoogleに対して「古いURLをランク付けしてほしい」と伝えているのと同じ状態になる。これは順位回復が遅れる最も一般的な原因のひとつだ。
Duplicatorで移転した場合、データベース内の正規URLは展開時に自動更新される。ただし、個別の投稿レベルで手動設定された正規URLオーバーライドはDuplicatorが更新しない場合があるため、以下のスポットチェックは必ず実施する。
AIOSEOのグローバル正規設定を確認する
AIOSEOはサイトURLに基づいてサイト全体の正規タグを自動生成する。移転後に確認すべきは、重複コンテンツを防ぐ2つのリダイレクト設定だ。「検索の外観」→「詳細」タブにある「ページ送りフォーマット」が空白になっていないことを確認する。また「画像SEO」タブで「添付ファイルURLのリダイレクト」が無効になっていないかをチェックする。この設定は、コンテンツの薄いメディア添付ページを親投稿にリダイレクトし、Googleのインデックスから除外する役割を持つ。
重要ページを目視チェックする
アクセスの多い上位ページをブラウザで開き、ページのソースを表示して<link rel="canonical"を検索する。URLが新ドメインを指していることを確認する。もし旧ドメインのままになっているページがあれば、その投稿の編集画面でAIOSEO設定パネルの「詳細」タブを開き、正規URLフィールドを手動で更新する。
ステップ6 データベースURLと混在コンテンツを修正する
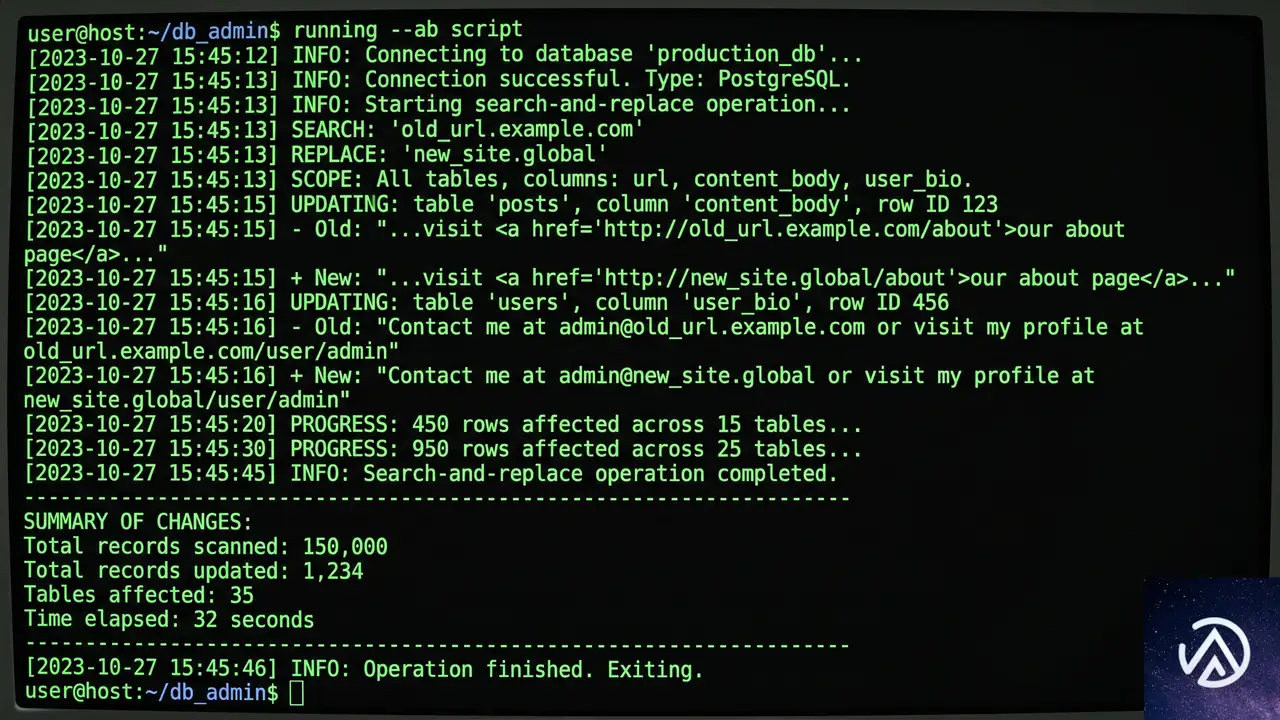
移転後、一部の画像やスクリプト、スタイルシートが旧ドメインを指したままだったり、安全でないHTTP接続で読み込まれていたりすることがある。これらの古いアセットは、旧ドメインがオフラインになった瞬間に画像の破損やセキュリティ警告を引き起こす。
データベース内のハードコードURLを置換する
Duplicatorは標準的なURL更新を処理するが、ページビルダーのレイアウトやテキストウィジェット、カスタムテーマオプションに埋め込まれたハードコードリンクは取り残されることがある。Search & Replace Everything by WPCodeプラグインを使うと、シリアル化データを破損させずにデータベース全体のURLを安全に置換できる。
WordPress管理画面の「ツール」→「WP Search & Replace」で、検索フィールドに旧ドメインURL、置換フィールドに新ドメインURLを入力し、すべてのデータベーステーブルを選択する。「検索と置換をプレビュー」で影響範囲を確認した後、「すべて置換」を実行する。
ElementorやDiviなどのページビルダーを使っている場合、Search & Replace実行後も背景画像が破損することがある。これはビルダーが静的CSSファイルにURLを保存しているためだ。この場合、Elementorなら「Elementor」→「ツール」→「ファイルとデータを再生成」を実行してキャッシュをクリアする。
SSL混在コンテンツエラーを修正する
旧ドメインが標準HTTPで新ドメインがHTTPSの場合、ブラウザのアドレスバーに壊れた鍵アイコンやセキュリティ警告が表示されることがある。これはサイト設定は安全でも、埋め込まれたスクリプトや画像が安全でない接続で読み込まれようとしている混在コンテンツエラーだ。まずは新ドメインに有効なSSL証明書がインストールされていることを確認し、その後WordPressの混在コンテンツ修正手順を実行する。
残存するリンク切れをスキャンする
データベースURLの置換が完了したら、AIOSEOのBroken Link Checkerを使って内部リンクが404エラーになっていないかスキャンする。このプラグインはバックグラウンドで自動スキャンを実行し、リンク切れを検出すると一覧表示する。各リンクに対してインラインの「URLを編集」で修正するか、「リンク解除」で削除できる。
ハード404エラーを特定して修正する
リンク切れスキャンがコンテンツ内のデッドリンクを見つけるのに対し、ハード404は「ページが移行されなかった」「URLが変更された」「リダイレクトが機能していない」などの理由で新サイト上で「見つかりません」と表示されるページだ。Screaming Frogで新ドメインをクロールし、レスポンスコードタブで4xxエラーを探す。Googleサーチコンソールの「インデックス作成」→「ページ」でも404として検出されたページを確認できる。各404について、ページを復元するか、新しいURLへの301リダイレクトを追加する。
価値の高い外部バックリンクを更新する
自サイト内のリンク修正だけでは不十分だ。他のウェブサイトが旧ドメインにリンクしている外部バックリンクは、最も強力なランキングシグナルのひとつである。301リダイレクトはその評価を新ドメインに転送するが、その受け渡しは永続的ではなく、時間経過とともに弱まる可能性がある。また旧ドメインを手放した時点で完全に停止する。
Googleサーチコンソールの「リンク」→「上位のリンク元サイト」で、最も多くリンクを送っているサイトを特定し、ゲスト投稿の著者プロフィールやプレス掲載、リソースページ掲載など、実際に更新を依頼できる高オーソリティのサイトから優先的に連絡する。すべてのリンクを変更できるわけではないが、上位の数十件を直接リンクに更新するだけでも、最も重要なランキングパワーを保護できる。
ステップ7 AIOSEOとMonsterInsightsで復旧を監視する
ドメイン移転後の順位回復には時間がかかる。この期間中に重要なのは、検索アルゴリズムによる通常の短期的な変動と、実際に対処が必要な技術的問題を区別することだ。
AIOSEO検索統計でキーワード順位を追跡する
AIOSEOの検索統計ダッシュボードは、GoogleサーチコンソールのデータをWordPress管理画面に直接取り込む。「勝ち負け」タブでは、移転後に最も可視性を失ったページを素早く特定できる。移転前のステップ1で保存したCSVと見比べることで、回復の進捗を定量的に評価できる。
MonsterInsightsでトラフィック傾向を比較する
キーワード監視が検索エンジン上の位置を示すのに対し、実際のトラフィック量はユーザーが新ドメインにどう反応しているかを確認する指標になる。MonsterInsightsはGoogle AnalyticsのデータをWordPressに取り込み、週次でのトラフィック比較を簡単にする。重要なのは、新しいGoogle Analyticsプロパティを作成せず、既存のプロパティを使い続けることだ。データストリームだけを新しいサイトURLに更新すれば、移転前のベースラインとの比較が途切れない。
MonsterInsightsのSite Notes機能(Proプラン以上)を使えば、移転日をアナリティクスのタイムラインに直接ピン留めできる。これにより、トラフィックがいつから回復し始めたかを折れ線グラフ上で視覚的に把握できる。
週次での回復タイムライン
ドメイン移転後に順位が大きく変動すると不安になるのは当然だ。しかし、正常な回復のパターンを知っておけば、パニックによるコンテンツ変更(回復を遅らせる原因になる)を避けられる。
- 第1週 発見と変動。Googleのクローラーがリダイレクトを発見し、ドメイン変更の処理を開始する。順位は大きく変動し、トラフィックはベースラインから30〜70%減少することが多い。これは想定内であり、移行の失敗を意味しない
- 第2週 シグナルの転送開始。ほとんどの301リダイレクトが処理され、ランキングシグナルが新ドメインに渡り始める。サーチコンソールでリダイレクトエラーやソフト404の通知がないか確認する
- 第4週以降 回復の評価。クリーンな301リダイレクトがあるサイトでは、4〜8週間以内に80〜100%の回復が見られることが多い。回復が遅れているページがあれば、リダイレクト、正規URL、インデックス状態の3点を再確認する
この記事のポイント
- ドメイン移転のSEOリスクは301リダイレクトの欠落、古い正規URL、旧ドメインを指すサイトマップの3つに集中する
- 移転前にキーワード順位とURL一覧のベースラインを取得し、回復度合いを測定できる状態にする
- リダイレクトは直接1ホップで完了させ、チェーンを発生させない
- 正規URLとデータベース内リンクは自動更新を過信せず、必ず手動でスポットチェックする
- 復旧状況はAIOSEOの検索統計とMonsterInsightsのトラフィック比較で定量的に追跡する
・ 複数業界における17年間のデジタルビジネス開発経験
・ ウェブサイト開発のためのHTML、PHP、CSS、JavaScript等の実用的知識
・ 15ヶ国語対応の多言語SaaSの開発経験
・ 17年間にも及ぶ、Eコマース長期運営経験
・ 幅広い業界でのSEO最適化の豊富な経験
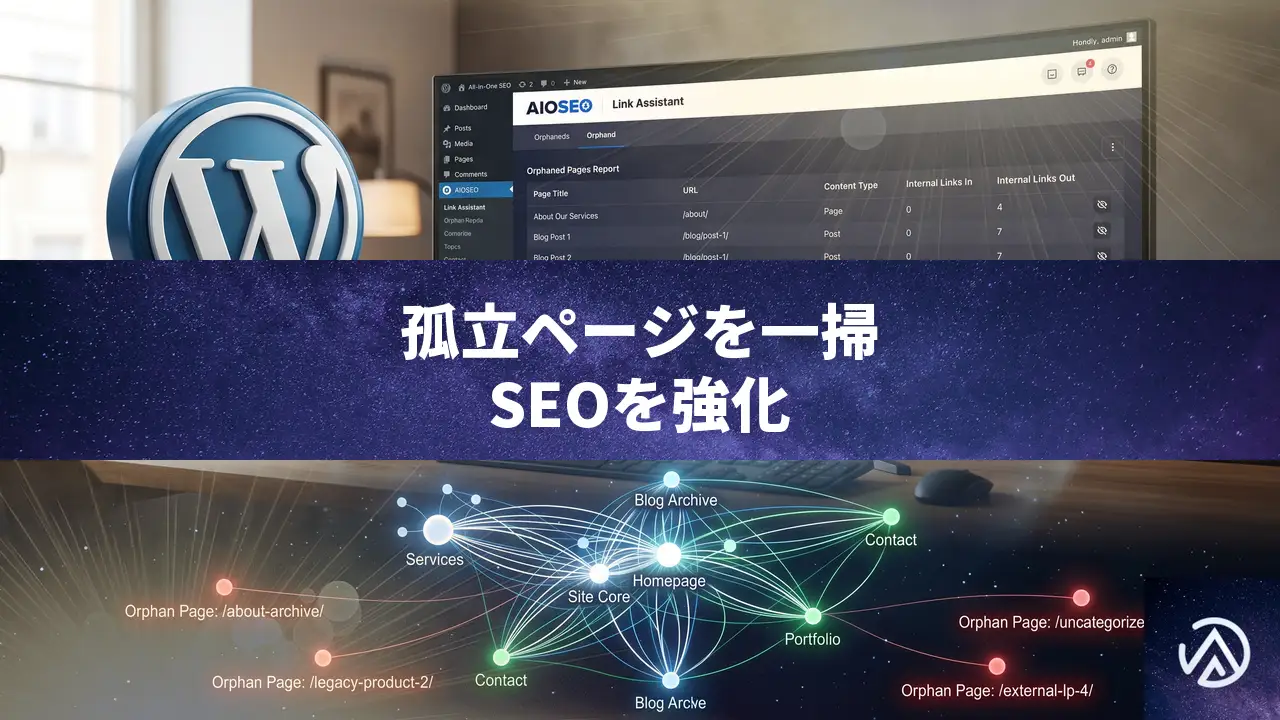
WordPressの孤立ページをAIOSEOで見つけ内部リンクを修正する完全ガイド
WordPressサイトを運営していると、検索流入が伸び悩むページに遭遇することがある。タイトルを最適化し、被リンクも獲得しているのに、なぜか成果が出ない。そんなときは、サイトの内部構造に問題が潜んでいるかもしれない。具体的には、孤立ページ(オーファンページ)の存在がSEOパフォーマンスを大きく損ねているケースがある。
孤立ページとは、サイト内のどのページからも内部リンクが貼られていないページのことだ。訪問者はもちろん、検索エンジンのクローラーもたどり着けず、インデックスされないまま埋もれてしまう。WP Beginnerの記事によれば、これは見落とされがちなSEO課題だが、修正は想像以上にシンプルだという。
ここでは、All in One SEO(AIOSEO)プラグインのリンクアシスタント機能を使い、孤立ページを一掃する具体的な手順を解説する。サイトの内部リンク構造を可視化し、検索エンジンにとっても人にとっても価値ある導線を再設計しよう。
孤立ページとは何か
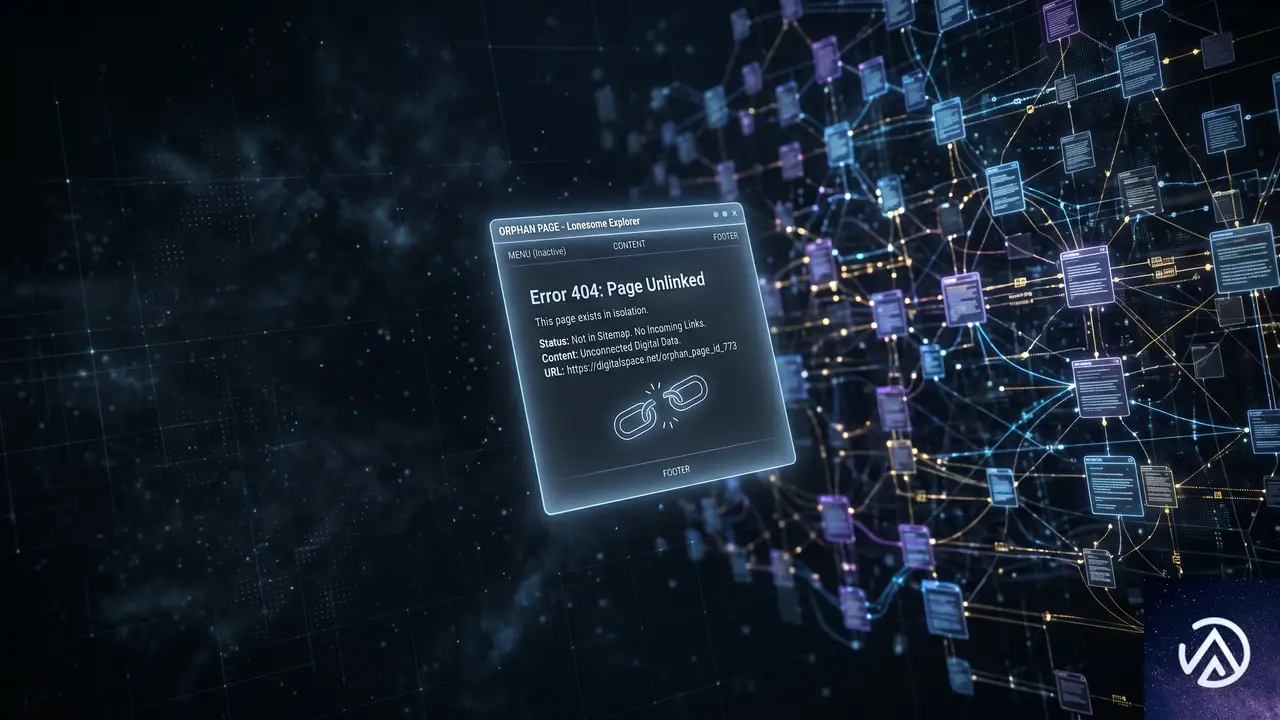
孤立ページは、サイト内に存在するにもかかわらず、他のどのページからも内部リンクで参照されていないページを指す。まるで廊下のない部屋のようなものだ。部屋自体は存在するが、そこに至る道が一切ないため、誰にも見つけられない。
WordPressでは、意図せずして孤立ページが生まれることが多い。たとえば、公開した記事をナビゲーションメニューやカテゴリーページに追加し忘れた場合だ。ほかにも、サイトの移行やリニューアル時に内部リンクが切れて発生することもある。また、キャンペーン用のランディングページのように意図的に孤立させるケースもあるが、それらも適切に管理しなければ検索エンジンに悪影響を及ぼす。
上のデモは、孤立ページがサイト内でどのように隔離されているか、そして適切な内部リンクがどれほどアクセス性を変えるかを視覚化したイメージだ。リンク一本で、不可視だったページがサイト全体の情報ネットワークに組み込まれる。
孤立ページがSEOに与える悪影響

Googleをはじめとする検索エンジンは、内部リンクをたどってサイトをクロールし、各ページの価値を評価する。孤立ページにはその入り口がなく、クローラーが存在を認識できない。結果として、インデックスされず検索結果に一切表示されないリスクがある。
また、内部リンクはページ間でリンクエクイティ(SEO評価の伝達)を分配する役割も担う。リンクを受け取れない孤立ページは、たとえ質の高いコンテンツであっても検索順位で不利になる。大規模サイトではクロールバジェットの浪費にもつながり、限られたクロール回数が無駄に消費される。
さらに、ChatGPTやPerplexityといったAI検索ツールは、インデックスされた信頼性の高いページを優先的に参照する。孤立ページはそもそもインデックスされにくいため、AIが回答を生成する際の情報源として選ばれる可能性が極めて低くなる。
この図のように、わずかな内部リンクの有無で検索エンジンからの可視性は大きく変わる。サイト全体の評価にも影響するため、孤立ページの放置は避けたい。
AIOSEOリンクアシスタントを使った孤立ページの検出手順
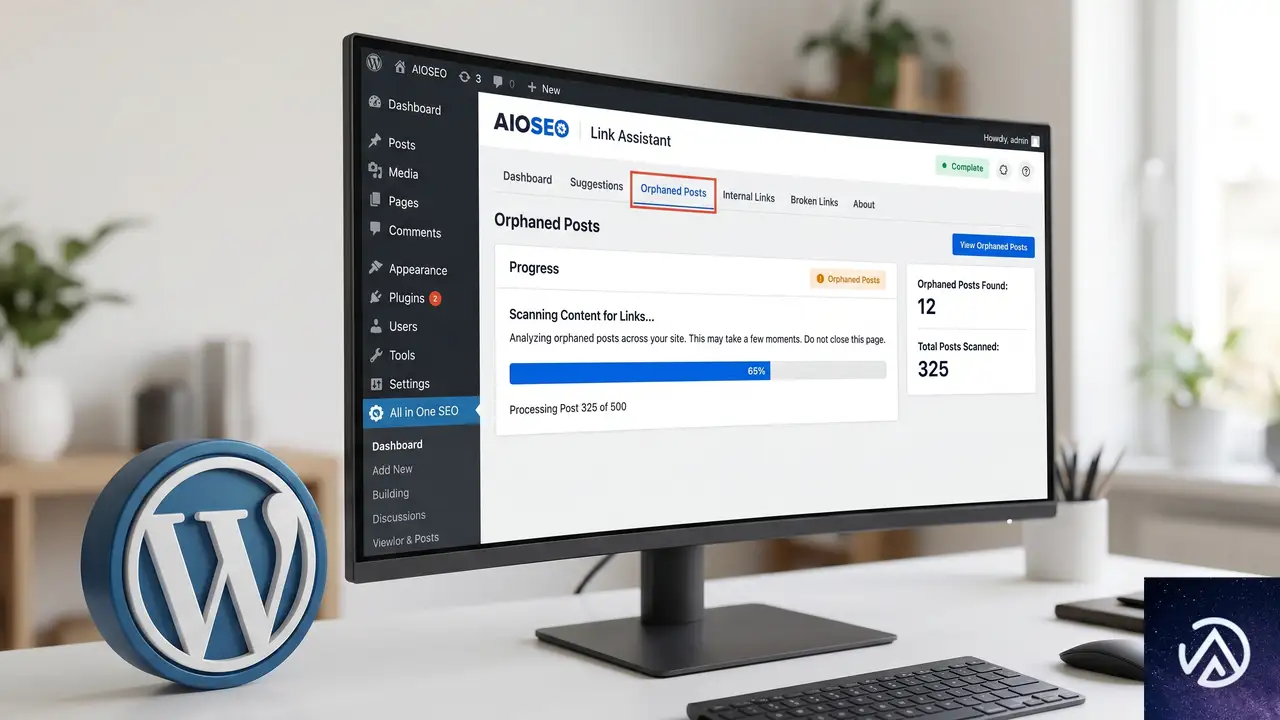
ここからは、WP Beginnerの記事でも推奨されているAll in One SEO(AIOSEO)プラグインのリンクアシスタント機能を用いた具体的な検出プロセスを見ていく。Pro版以上で利用できるが、まずは無料版でインターフェースを試すことも可能だ。
プラグインのインストールとリンクアシスタントの有効化
AIOSEOを公式サイトから入手し、WordPress管理画面の「プラグイン」→「新規追加」→「プラグインのアップロード」からzipファイルをインストールする。有効化後、AIOSEOの一般設定でライセンスキーを認証すれば準備完了だ。
次に、管理メニュー「AIOSEO」→「リンクアシスタント」へ移動し、「リンクアシスタントを有効化」ボタンをクリック。その後、表示されるポップアップで「今すぐスキャン」を実行する。これにより、サイト全体の内部リンク構造が分析され、各ページの被リンク状況がマッピングされる。初回スキャンはサイト規模によって数分かかることがあるため、完了まで待とう。
孤立ページ一覧の確認と分析
スキャンが完了したら、リンクアシスタント画面の「孤立した投稿」タブを開く。ここに、内部リンクが一切ないページが一覧表示される。各ページの公開日、内部リンク数(当然0)、アフィリエイトリンクや外部リンクの有無、そしてAIOSEOが提案する簡単な対処アドバイスも確認できる。
まずはこの一覧を眺め、量に圧倒されないことが大切だ。全てを修正する必要はなく、優先順位をつけて対応する。次のセクションでその判断基準を説明する。
孤立ページの優先順位付けと修正方法

見つかった孤立ページのすべてに内部リンクを追加すれば良いわけではない。薄いコンテンツや重複ページはむしろ削除やリダイレクト対象になる。ここでは、WP Beginnerの記事で紹介されている優先度の考え方を整理する。
どのページを救うべきか
まず、外部サイトから被リンクを獲得しているページは最優先だ。Google Search Consoleの「トップリンクサイト」レポートなどで確認し、既にリンクエクイティが流れ込んでいるページを内部リンクで再接続すれば、サイト全体にその価値を循環させられる。
次に、検索クエリでの表示回数やクリック数がわずかでもあるページも有望だ。Google Search Consoleの「検索パフォーマンス」レポートで、孤立ページがいくつかのインプレッションを得ているなら、内部リンクで後押しすれば順位が上昇する可能性が高い。
さらに、MonsterInsightsのような解析プラグインを使い、実際にサイト上でのページビューがあるかも確認しよう。ゼロに近いページはリダイレクトか削除を検討する。商品ページやサービスページなど、ビジネスに直結するページも積極的に救済したい。
リンクの追加とサイト構造への組み込み
修正対象を決めたら、AIOSEOのリンクアシスタントが自動提案する内部リンクを活用する。各孤立ページの詳細を開くと、「アウトバウンド提案」(このページから貼るべきリンク)と「インバウンド提案」(他のページからこのページへ貼るべきリンク)が表示される。アンカーテキストは自然な文脈で編集し、「リンクを追加」ボタンで即座に適用される。いちいち投稿編集画面を開く手間が省けるのが大きな利点だ。
特に重要なページは、ナビゲーションメニューやカテゴリーページにも追加すると、サイト全域からアクセス可能になる。一回の設定で、全ページからの強力な導線を確保できる。
このように、AIOSEOの提案を数クリックで反映するだけで、孤立ページがサイトのネットワークに組み込まれる。ただし、一つのページに内部リンクを詰め込みすぎると、かえってリンクエクイティが希薄になり不自然に見えるため、読者にとって本当に役立つリンクだけを選ぶことが肝心だ。
孤立ページ管理のベストプラクティスと監査チェックリスト
孤立ページ対策は一度きりの作業ではない。サイトの更新やリニューアルのたびに新たな孤立ページが生まれる可能性がある。定期的な監査を習慣化することで、SEOの土台を強固に保てる。
定期的な監査の流れ
WP Beginnerの記事が推奨するチェックリストは以下の通りだ。1〜2ヶ月に一度、あるいはサイト構造を大きく変えた直後に実行するとよい。
- AIOSEOリンクアシスタントで「孤立した投稿」タブを確認し、内部リンクがゼロのページを洗い出す。
- Google Search Consoleで被リンクと検索パフォーマンスをクロスチェックし、優先度を決める。
- MonsterInsightsやGoogle Analyticsで実際のページビューを確認し、トラフィックがあるページを救済対象とする。
- 各ページを「内部リンク追加」「リダイレクト」「noindex」「削除」のいずれかに分類する。
- 救済するページにはAIOSEOの提案リンクを追加し、重要なページはナビゲーションにも組み込む。
- 被リンクがある削除済みページは、関連ページへ301リダイレクトを設定してリンクエクイティを保全する(AIOSEO Proのリダイレクションマネージャーが使える)。
- 意図的な孤立ページ(広告用LPなど)にはnoindexタグを付与し、検索結果に出さないようにする。
このサイクルを回せば、孤立ページがサイトの評価を下げるリスクを大幅に減らせる。とくに大規模サイトではクロールバジェットの最適化にもつながり、重要なページが確実にインデックスされる環境を維持できる。
この記事のポイント
- 孤立ページは内部リンクがなく、検索エンジンにもユーザーにも発見されない。サイトのSEOにおいて深刻なマイナス要因となる。
- AIOSEOのリンクアシスタントを使えば、サイト全体をスキャンして孤立ページを簡単に特定できる。
- すべての孤立ページを修正する必要はなく、被リンクやトラフィック、ビジネス価値に応じて優先順位を付ける。
- 内部リンクの追加は、AIOSEOの自動提案を活用すれば編集画面を開かずに素早く実行可能。ナビゲーションへの追加も有効だ。
- 定期的な監査と適切なリダイレクト・noindex処理を含めた管理体制が、持続的なSEO改善の鍵となる。
・ 複数業界における17年間のデジタルビジネス開発経験
・ ウェブサイト開発のためのHTML、PHP、CSS、JavaScript等の実用的知識
・ 15ヶ国語対応の多言語SaaSの開発経験
・ 17年間にも及ぶ、Eコマース長期運営経験
・ 幅広い業界でのSEO最適化の豊富な経験

Redditが生成AIの表示順位を左右する。実データが示す影響力と企業が取るべき対策
生成AIが回答の情報源として最も参照するプラットフォームがRedditだ。SEO対策から「AI最適化」へと重心が移りつつある今、Redditでの立ち振る舞いを無視することはビジネス上のリスクになりつつある。
AI最適化プラットフォームProfoundが2026年5月に公開した分析によれば、ChatGPTがユーザーの質問に回答する際、訓練データとリアルタイム検索の双方でRedditの情報を最大の情報源として利用しているという。Redditはもはや単なる掲示板ではない。大規模言語モデル(LLM)があなたのブランドについて「知っていること」そのものを形成する場になっている。
この記事では、Redditの投稿がどのように生成AIの回答を左右するのか、その具体的なデータを示すとともに、企業が取るべき具体的な対策を解説する。
ChatGPTがRedditを最重要視する理由
実務者の間では「Redditの影響力が増している」という肌感覚が広がっていた。だが、AIリサーチ企業Profoundの分析は、それを単なるトレンドではなく確固たるデータとして裏付けた。同社が2026年1月から5月にかけてChatGPTの引用と「ファンアウト」データを解析した結果、Redditは引用回数でトップに立った。
ファンアウトとは、AIが1つの質問に対してどれだけ多角的に情報源を展開したかを示す指標だ。Redditはこのファンアウト数においても他を圧倒していた。つまり、ChatGPTは単にRedditを引用するだけでなく、1つのスレッドから複数の関連情報を芋づる式に収集し、回答の骨格を作っている。
検索クエリへの「reddit」自動付与
この解析で興味深いのは、ChatGPTがリアルタイム検索を実行する際、クエリの末尾に「reddit」というキーワードを自発的に追加する挙動が確認された点だ。人間が「商品名 レビュー Reddit」と検索するのと同じ行動を、AIが自律的に行っている。生成AIが「実体験に基づく生の声」を求めている証左といえる。
従来の検索エンジン最適化が「アルゴリズムに評価される公式情報」を重視していたのに対し、AI最適化では「訓練データとライブ検索の両方で参照される草の根の評判」が問われる。Redditがその中心にある。
安易な口コミ操作が通用しない構造的理由
ここで多くの企業が「ならばRedditに肯定的な投稿を大量にすればいい」と短絡的に考える。だが、生成AI時代のReddit戦略は、そうした「やらせレビュー」的な手法とは根本的に相性が悪い。構造的な理由が2つある。
訓練データに刻まれたネガティブ情報は消せない
1つ目は、LLMの訓練データの問題だ。仮にReddit上の自社に不都合なスレッドをModeratorに削除してもらえたとしても、その情報はすでにGPT-4やClaudeといったモデルの訓練データに組み込まれている。モデルの重みの中にネガティブな文脈が残り続けるため、単純な「投稿削除」ではAIの感情分析(センチメント)を覆せない。
Redditのコミュニティは作為を見抜く
2つ目は、サブレディット(コミュニティ単位の掲示板)の自主管理能力の高さだ。各サブレディットには人間のModeratorが存在し、不自然なプロモーション投稿や作為的なポジティブレビューは極めて高い精度で検知される。露骨なステマが削除されるだけでなく、アカウントがスパム判定を受ければドメイン単位でブランドの信用が失墜するリスクもある。
重要なのは、AIは情報の「出所」よりも「文脈」と「一貫性」を評価する傾向がある点だ。作為的なポジティブキャンペーンは、むしろAIによる評価を歪ませ、長期的にはブランド毀損につながりかねない。
RedditでAI表示を味方につける3段階のプロセス
では、企業は具体的に何をすればいいのか。短期的なハックではなく、AIとアルゴリズムの両方に評価される正攻法のプロセスを3段階に分けて解説する。
STEP 1. 観察に徹してコミュニティの文法を学ぶ
Redditビジネスアカウントを作成したら、すぐに投稿やコメントを始めてはいけない。少なくとも数週間は「ROM(Read Only Member)」として、ターゲットとするサブレディットの文化を観察する期間を設ける。
各サブレディットには明文化されたルールに加え、暗黙の行動規範がある。企業アカウントがそれを無視して宣伝めいた投稿をすれば、即座にアカウント停止(BAN)の対象となる。Redditのアカウント停止は異議申し立てが極めて困難なことで知られており、一度BANされるとブランド名で再登録すること自体が難しくなる。
STEP 2. Reddit Proで自社の立ち位置を可視化する
観察期間と並行して、Reddit Pro(無料のビジネス向け分析ツール)の導入をお勧めする。このツールを使うと、以下の情報がダッシュボードで把握できる。
- ユーザーが自社ブランドについてどのような文脈で言及しているか
- 競合ブランドと比較した際のセンチメント(肯定的・否定的感情)の差異
- 自社の製品カテゴリに関連して今活発に議論されているスレッド
闇雲に投稿する前に、データに基づいて「どのサブレディットで、どんなトピックなら、企業として価値を提供できるか」を特定することが先決だ。
STEP 3. ブランド認知より「権威構築」を優先する
初期の投稿やコメントでは、自社製品の宣伝を一切排除し、純粋に専門知識を提供することに集中する。たとえば、ECプラットフォームを提供する企業なら「物流のボトルネックを解消するパッキングの工夫」、マーケティングツール企業なら「GA4で離脱率を下げるレポートの読み方」といった具合だ。
この段階でブランド名を出すことは、コミュニティから「売り込み」と見なされるリスクが高い。まずは個人としての信頼を積み上げ、その後に「そういえば、この分野のプロダクトを開発している」と自然に言及できる流れを作る。
ブランド専用サブレディットという選択肢

自社ブランドへの言及が一定数を超えてきた段階で、ブランド専用のサブレディットを開設することも有効な一手だ。すでに多くのテック企業がこの手法を取り入れている。
専用サブレディットの利点は、分散していた自社関連の会話を一箇所に集約できる点にある。ユーザー同士のQAやトラブルシューティングが活発になれば、それはそのままLLMが参照する「構造化されたナレッジベース」として機能する。サポートコストの削減とAI表示の最適化を同時に実現できるわけだ。
ただし、ここでも運営姿勢が問われる。企業が一方的に情報を発信する場ではなく、ユーザーが自由に意見を交わせる「公共広場」としての設計が不可欠だ。Moderatorが批判的な投稿を削除するような運営は、Reddit全体からの強い反発を招く。
この記事のポイント
- RedditはChatGPTが回答を生成する際の最重要情報源であり、訓練データとリアルタイム検索の双方で参照される
- ネガティブスレッドの削除や偽のポジティブ投稿は、LLMの訓練データに残る情報を覆せず、コミュニティからも排除されるリスクが高い
- アカウント作成後はまず観察に徹し、Reddit Proでデータを分析した上で、ブランド宣伝ではなく専門知識の提供による権威構築を優先する
- 長期的な視点でコミュニティに貢献し、AIに「信頼できる情報源」として学習させることが、生成AI時代のブランド防衛につながる
・ 複数業界における17年間のデジタルビジネス開発経験
・ ウェブサイト開発のためのHTML、PHP、CSS、JavaScript等の実用的知識
・ 15ヶ国語対応の多言語SaaSの開発経験
・ 17年間にも及ぶ、Eコマース長期運営経験
・ 幅広い業界でのSEO最適化の豊富な経験

Shopify障害で店舗停止、広告費消失のリスクと対策
2026年6月3日、Shopifyで大規模なサービス障害が発生した。店舗フロントの表示不具合やチェックアウト機能の停止により、世界中のEC事業者が売上機会を失った。とりわけGoogleやMetaに広告予算を投下していた事業者は、クリックを集めながら購入完了に結びつけられないという致命的な状況に陥っている。
本記事では、この障害がECサイトの広告パフォーマンスとSEOに及ぼす実務的な影響、および同様の事態を想定したリスク分散策を整理する。Shopifyに限らず、SaaS型ECプラットフォームに依存する事業者共通の課題として捉えてほしい。
障害の概要と影響範囲

Shopifyは米国東部時間9時27分に問題を認識し、管理画面やPOSレジ、カスタマーサポートへのアクセス障害を公表した。店舗フロントやチェックアウトにも波及し、購入完了ができない状態が約1時間にわたって続いた。10時37分には根本原因を特定し、回復に向かっていると発表している。
影響を受けたのは以下の4領域だ。いずれもEC事業の中核を担う機能であり、たとえ短時間の停止でも事業者の損失は無視できない。
- 店舗フロントの表示
- チェックアウト処理
- 管理画面へのログイン
- 実店舗向けPOSレジ
Search Engine Landの記事によれば、この障害を最初に報告したのはSenior Paid Media ManagerのAyisha Yousef氏だ。同氏はLinkedIn上でエラーメッセージのスクリーンショットを共有し、広告運用担当者へ注意を呼びかけた。
Shopify障害の時系列
このタイムラインからわかるのは、障害検知から復旧まで約1時間10分というスピード感だ。しかしEC事業者にとって、ピーク時間帯の1時間は致命的な機会損失になりうる。
チェックアウト停止が広告運用に直撃する仕組み
最も深刻なのが、広告経由で流入したトラフィックが一切売上に結びつかない状況だ。Googleショッピング広告やMetaのダイナミック広告で商品を表示し、ユーザーがクリックして店舗に到達しても、チェックアウト画面でエラーが発生すれば購入は成立しない。
広告費はクリック単位で課金される。つまり「クリックは発生するがコンバージョンはゼロ」という状態が続けば、ROAS(広告費用対効果)は急落する。以下の図は、障害発生中に起こる広告費消失のメカニズムを単純化したものだ。
この構造は、広告キャンペーンのパフォーマンスデータにも深刻な歪みをもたらす。障害時間帯のコンバージョン率が異常に低くなるため、キャンペーン全体の平均値を押し下げ、自動入札戦略の学習にも悪影響を与える可能性がある。
Google広告とMeta広告への具体的な影響
Google広告では、コンバージョンデータがスマート自動入札のシグナルとして使われる。障害によるゼロコンバージョンが一定期間続くと、アルゴリズムが「このキャンペーンは効果が低い」と判断し、入札単価の引き下げや表示頻度の低下を招く。
Meta広告(Facebook・Instagram)も同様だ。コンバージョンAPIで送信される購入イベントが途絶えると、アルゴリズムが最適なオーディエンスを見失い、その後の配信精度が低下する。特に障害直後の数日間は、通常よりもCPA(顧客獲得単価)が跳ね上がる傾向があると指摘する広告運用者もいる。
Search Engine Landの記事では、Shopify障害中は広告キャンペーンの成果を通常通り評価できないため、後日パフォーマンスを検証する際には障害時間帯を除外するか、別途注釈を加えることが推奨されている。
EC事業者が直面するプラットフォーム依存リスク

今回の障害は、多くのEC事業者が単一のプラットフォームに売上インフラのすべてを依存している現実を浮き彫りにした。Shopifyは数百万のオンラインストアを支える巨大プラットフォームであり、その停止は個別店舗の努力ではどうにもならないレイヤーで発生する。
とりわけ、以下のような状況にある事業者ほど影響が大きい。
- プロモーションや新商品発売のタイミングと重なったケース
- インフルエンサー施策で集中的にトラフィックを集めていたケース
- Shopifyペイメント以外の決済手段を持たないケース
これは「SaaS型ECの構造的リスク」と言い換えられる。自社サーバーでECサイトを構築するオンプレミス型に比べ、SaaS型は運用負荷が低い半面、障害発生時のコントロール権はゼロに等しい。復旧を待つ以外に打てる手が限られるのだ。
依存度を下げるための分散戦略
完全にShopifyから離れるのは現実的ではない。しかし、致命的な売上機会損失を減らすための「保険」として、以下のような分散策を検討する価値はある。
- バックアップ用のランディングページを外部で用意しておく(NotionやGoogleサイトで簡易的な注文フォームを設置するなど)
- InstagramショップやAmazonストアなど、販売チャネルを複数持つ
- 広告のリンク先をShopifyストア以外にも切り替えられる体制を整える
- Shopifyとは別の決済リンク(Stripe Payment Linksなど)をSNSプロフィールに常設する
これらの対応は、日常的には使わなくても、緊急時に即座に切り替え可能な「避難経路」として機能する。障害発生から復旧までの1時間を耐え抜くための備えだ。
障害発生時に取るべき3つの即時対応

Shopifyに限らず、ECプラットフォームの障害を検知した際に、広告運用とSEOの両面で即座に実行すべき対応を整理した。以下の3ステップは、今回のShopify障害の事例をもとに構成している。
STEP 1の広告停止が最も重要だ。検索広告のクリック単価はリアルタイムで消費され続けるため、障害を検知してから数分以内に対応できるかどうかで、無駄になる広告費の額が大きく変わる。Google広告の自動化ルールで「コンバージョンがゼロになったらキャンペーンを停止する」条件を事前に設定しておくと、人的対応の遅れを防げる。
SEO視点で見る障害時の注意点
チェックアウトや管理画面の障害が直接的にSEOにペナルティを与えることはない。ただし、店舗フロントが完全に表示されない状態が長時間続くと、Googlebotがクロールに失敗し、インデックスの鮮度が落ちる可能性はある。
より実務的に注意すべきは、SNSや口コミで「このストア使えない」というネガティブな評判が広がることだ。ブランド検索の増加に対して、表示される検索結果がネガティブな情報に偏ると、その後のオーガニック流入にも影響が出る。障害発生時には、自社のSNSアカウントで状況を説明し、検索結果のコントロールに努めることが重要になる。
この記事のポイント
- Shopifyの大規模障害はEC事業者に広告費の無駄遣いと機会損失をもたらした
- チェックアウト停止中は広告キャンペーンを即座に停止し、復旧後にデータ補正を行う必要がある
- 単一プラットフォームへの依存度を下げるため、販売チャネルと決済手段の分散が有効
- 障害発生時に備えた広告自動化ルールの設定が、被害を最小化する鍵となる
- 復旧後はキャンペーンパフォーマンスを適切に評価し、アルゴリズムの誤学習を防ぐこと
・ 複数業界における17年間のデジタルビジネス開発経験
・ ウェブサイト開発のためのHTML、PHP、CSS、JavaScript等の実用的知識
・ 15ヶ国語対応の多言語SaaSの開発経験
・ 17年間にも及ぶ、Eコマース長期運営経験
・ 幅広い業界でのSEO最適化の豊富な経験

Microsoft Web IQでAIエージェントがBing検索を利用可能に。SEOへの影響を考察
Microsoftが2026年6月2日、AIエージェント向けの検索基盤「Web IQ」を発表した。Bingの検索インデックスに蓄積された情報を、AIシステムが推論やタスク実行に直接利用できるようにするAPI群である。
従来のBingが人間にウェブページを提供するのに対し、Web IQはAIに「パッセージ」と呼ばれる情報の断片を返す。この違いがAI時代のコンテンツ最適化とSEO戦略に大きな影響を与える可能性がある。
この記事では、Web IQの技術的な仕組み、従来の検索エンジンとの違い、パフォーマンス、そしてパブリッシャーにとっての意味を詳しく解説する。
Web IQの基本構造 〜AIエージェントが必要とする情報だけを届ける〜

Web IQの中核にあるのは、Bingのインデックスを土台に再構築された検索スタックだ。コンテンツのインデックス化、ランキング、選択の仕組みがAIエージェントの利用を前提に設計し直されている。AIエージェントはタスクの複数ステップにわたって厳しい時間制約の中で繰り返し検索を行うため、その動作特性に合わせた設計が求められた。
パッセージ単位の情報提供
Web IQが返すのは、ウェブページ全体ではない。「パッセージ」と「構造化されたエビデンスオブジェクト」だ。ページ中からAIにとって有用な部分だけを切り出して渡す。
AIモデルが処理するトークン(テキストの最小単位)にはコストがかかり、レイテンシ(応答遅延)にも直結する。Microsoftによれば、「少ないトークンでより良い回答を、1回の呼び出しあたりのコストを抑える」という三拍子を実現するのがWeb IQの設計思想だ。
このアプローチは、SEOの世界で徐々に広がっている「パッセージベースの検索」という概念とも整合する。Googleが2020年に導入したPassage Ranking(パッセージランキング)は、ページ全体ではなくその一部を検索クエリに最も関連する情報として抽出する技術だ。Web IQはこの考え方をAIエージェント向けに特化させたものと見ることができる。
従来の検索エンジンとは何が違うのか 〜ランキングと評価基準の再設計〜

MicrosoftがWeb IQの品質評価に使う指標は「GDSAT(Grounding Satisfaction / グラウンディング満足度)」と呼ばれる。情報の新鮮さと信頼性を測定するために設計された指標で、3,000件のサンプルクエリを用いたテストでは競合他社より高いスコアを記録したと発表している。
応答速度についても具体的な数字が示された。5つのデータセンターにまたがるテストで、P95(リクエストの95%がこの時間内に完了する値)で165ミリ秒未満を達成。競合と比較して約2.5倍高速だとしている。
ここで重要なのは、Web IQが従来の検索エンジンとまったく異なる評価軸で動いている点だ。人間向けの検索では、ページ全体の権威性や被リンクプロファイル、滞在時間など多面的なシグナルが使われる。一方、Web IQでは「AIエージェントがその情報を使ってどれだけ正確にタスクを遂行できるか」という一点が重視される。
全文からパッセージへの転換が意味すること
Search Engine Journalの記事で、Microsoftの発表を引用する形で指摘されているのは「従来の検索で上位表示されるページの特徴と、AIのグラウンディングに有用なパッセージの特徴は必ずしも重ならない」という点だ。同社が2026年前半に公開したグラウンディングフレームワークの記事でも、検索インデックスとグラウンディングの違いが詳述されている。
たとえば、あるページが検索キーワードに対して高い順位を得ていても、そのページ内のどの部分がAIにとって最も価値があるかは別問題だ。見出し構造、段落のまとまり、事実と意見の明確な区別など、AIが情報を抽出しやすい構造になっているかどうかが新たな評価ポイントになる可能性が高い。
検索体験からAI体験へ 〜パブリッシャーが知っておくべき変化〜

Bing Webmaster Toolsとの連携
Web IQは突然現れたわけではない。Microsoftは2026年に入って、段階的にAI向け検索の基盤整備を進めてきた。
- 2月、Bing Webmaster ToolsにAI引用データ(AI Citation Data)機能を追加
- 3月、グラウンディングクエリと引用ページを関連付けるAIダッシュボードを公開
- SEO Week期間中、Citation Share(AI向け引用シェア)のプレビューを発表
これらはいずれも、パブリッシャーが自分のコンテンツがAIにどのように使われているかを把握するためのツールだ。Web IQは、その裏側でAIがコンテンツを取得する仕組みに当たる。表と裏の関係にある。
つまり、Web IQの登場は「AI検索時代のSEO指標」が具体的な形を取り始めたことを意味する。従来の検索順位チェックに加えて、AIによる引用回数やパッセージ採用率といった新しいKPIが重要になる展開が予想される。
パッセージ最適化という新しい考え方
Web IQがパッセージ単位で情報を返す以上、パブリッシャー側もパッセージ単位でコンテンツを最適化する必要性が出てくる。具体的には以下のような施策が考えられる。
- 見出しと本文の関係を明確にし、各セクションが独立して意味を持つように書く
- 箇条書きや表組みを使って、AIが情報を構造的に読み取りやすくする
- 事実情報と意見・解釈を明確に分け、どちらを参照しているかAIが判断しやすくする
- 更新日を明示し、情報の鮮度をAIが評価できるようにする
これらの手法は、従来のSEOで言われてきた「E-E-A-T(経験・専門性・権威性・信頼性)」の強化とも多くの部分で重なる。違いは、AIが評価する点まで意識するかどうかだ。たとえば、ページの末尾にある免責事項や、サイドバーの関連記事リンクは従来の検索評価には影響しても、AIのパッセージ抽出ではノイズとして無視される可能性が高い。
技術面の詳細 〜オープンソース埋め込みモデルと高速検索〜

Web IQの検索パイプラインは3つの主要コンポーネントで構成される。埋め込みモデル、高速検索エンジン、そしてパッセージ選定モデルだ。
埋め込みモデルとDiskANN
Microsoftは2026年4月に、業界トップクラスの埋め込みモデル(Embedding Model)をオープンソース化した。テキストをベクトル(数値列)に変換し、意味の近さを計算できるようにする技術だ。Web IQはこのモデルを使って関連コンテンツを特定する。
大規模なインデックスを高速に検索するために使われるのが「DiskANN」という技術だ。これは全データをメモリに読み込まずに、ディスク上で効率的に類似検索を行うための仕組みだ。膨大なBingインデックスを対象に、165ミリ秒未満の応答を実現する鍵がここにある。
特筆すべきは、これらのモデルが単体のベンチマークスコアではなく、AI推論の中で実際に使われる状況を想定して訓練されている点だ。実用性を重視した設計と言える。
パブリッシャーコントロールと業界標準化
Web IQは、Bingがすでに準拠しているrobots.txtやメタタグによるクロール制御ルールを継承する。パブリッシャーが「AIにコンテンツを使われたくない」と設定していれば、Web IQもその指示に従う。
MicrosoftはIETF(インターネット技術標準化委員会)や他の業界団体とも協力し、AIシステムがウェブコンテンツにアクセスする際の標準ルール策定にも参加している。この動きは、Googleが進める「AIモード」や、その他のAI検索プロダクトとの間で、コンテンツ利用に関する共通ルールが形成されつつある兆候だ。
今後の展望と未解決の課題

現時点でWeb IQは「関心表明」を受け付けている段階であり、一般提供開始時期や価格、どのAIプラットフォームが採用するかは発表されていない。Microsoftの既存製品であるCopilotやBing Chatのグラウンディング機能がWeb IQを使っているのか、それとも別系統なのかも明らかにされていない。
とはいえ、Web IQの登場はAI検索時代の本格的な到来を示すマイルストーンだ。パブリッシャーは従来の検索エンジン最適化に加えて、「AIエージェントにどう使われるか」という視点でのコンテンツ設計を求められる局面に入ったと言える。
Bing Webmaster Toolsが提供を始めたAI引用データやCitation Shareは、そのための具体的な指標になる。まだ試験段階の数値ではあるが、早期にこれらのデータを確認し、自社コンテンツがAIにどう評価されているかを把握しておくことが競争優位につながるだろう。
この記事のポイント
- Web IQはAIエージェント向けのBing検索基盤APIであり、全文ではなくパッセージ単位で情報を返す
- 従来の検索評価とAI向け評価は異なる基準で動くため、SEO戦略の再考が必要になる
- Bing Webmaster ToolsのAI引用データやCitation Shareを使えば、AIからの評価を可視化できる
- パッセージ単位の情報設計が、今後のコンテンツ最適化の鍵になる
- 一般提供の時期や価格、対応AIプラットフォームは未発表だが、早期の動向把握が競争力を左右する
・ 複数業界における17年間のデジタルビジネス開発経験
・ ウェブサイト開発のためのHTML、PHP、CSS、JavaScript等の実用的知識
・ 15ヶ国語対応の多言語SaaSの開発経験
・ 17年間にも及ぶ、Eコマース長期運営経験
・ 幅広い業界でのSEO最適化の豊富な経験