

2026年WooCommerce向けクッキー同意プラグイン10選 選び方とSEOへの影響
WooCommerceストアの運営において、クッキー同意バナーの適切な実装は2026年現在、法的リスクとサイトパフォーマンスの両面で最重要課題だ。GDPR(一般データ保護規則)違反による累計罰金は450億ユーロを超え、Google Consent Mode v2の対応は欧州圏での広告計測に必須となっている。間違ったプラグイン選択は、サイト速度の低下とコンバージョンロスを同時に招く。
この記事では、WooCommerceストアに特化したクッキー同意プラグインを10種類比較する。各プラグインの特徴、価格、SEOとユーザー体験への影響を解説し、自社ストアに最適な選択肢を選ぶための判断材料を提供する。
2026年、プライバシー重視のEコマースへの転換
WooCommerceは2026年現在、世界のオンラインストアの約39%を支えるプラットフォームだ。この巨大なシェアは、国際的な規制当局の監視対象となることを意味する。GDPR発足以降の累計罰金は450億ユーロを突破しており、Eコマースサイトは非対応のトラッキングに対して厳しい制裁を受けている。
規制は緩和されるどころか、より厳格化している。Googleは2024年3月までに、EEA(欧州経済領域)および英国でGoogle Adsを利用するすべてのウェブサイトに対し、Google Consent Mode v2の対応を義務付けた。これに準拠しないストアでは、広告効果の計測が即座に機能しなくなる。
2026年における欧州向けストアの技術要件は厳しい。カリフォルニア州消費者プライバシー法(CPRA)も、10万人以上の消費者データを扱う事業、または総収入が2500万ドルを超える事業に適用される。国際的に販売するということは、複数の地域のルールを同時に遵守しなければならないことを意味する。手動での対応は現実的ではない。
適切なプラグイン選択がSEOとUXに与える影響
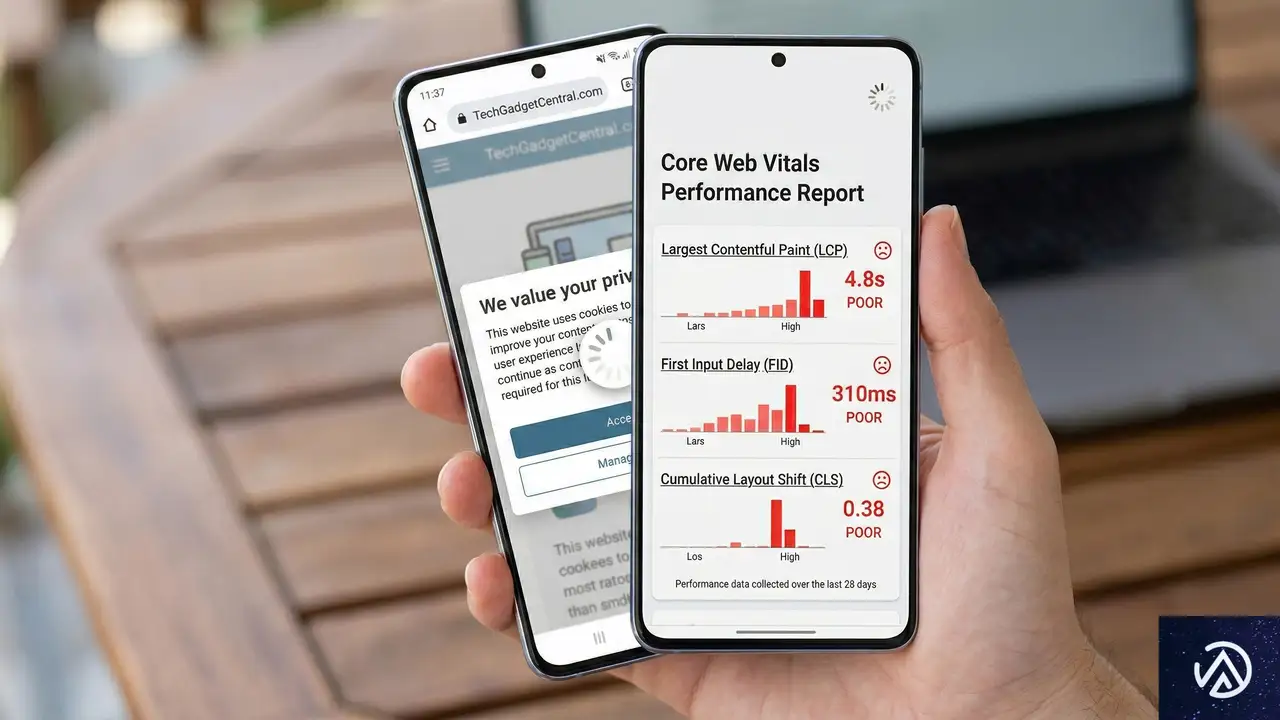
同意バナーはサイト速度に直接的な悪影響を与える。最適化されていないクッキースクリプトは、Largest Contentful Paint(LCP)を200msから500ms遅延させる。これはCore Web Vitals(コアウェブバイタル)のスコアを直接低下させる要因だ。
モバイル販売とバウンス率の関係
2026年までに、モバイルコマースは小売Eコマース売上の62%を占めると予測されている。モバイル画面で表示が遅く、見た目の悪いバナーは、確実に販売機会の損失につながる。一方、適切に設計されたバナーは、40%から60%のオプトイン率を達成できる。
ElementorのSEOチームリードを務めるイタマー・ハイム氏は、法的安全性とユーザー体験のバランスを見つけることが重要だと指摘する。不適切に設定されたバナーは、バウンス率を25%増加させる。
同意管理がコンバージョン計測に与える影響
同意管理はもはや法的なチェックボックスではない。コンバージョントラッキングの精度とページ速度の両方を大きく左右する。重いバナースクリプトは、ユーザーが商品を見る前にCore Web Vitalsを低下させる。
WooCommerce向け主要クッキー同意プラグイン10選
1. Cookiez by Elementor: Elementorユーザー向け最適解
CookiezはElementor Editor Proの体験を直接拡張するプラグインだ。すべての必須トラッキング保護機能をネイティブに処理する。Elementorは500万以上のアクティブインストールを抱え、サードパーティスクリプトの追加は通常、サイトを遅くする。Cookiezは既存のデザイントークンを利用するため、CSSを一行も触る必要がない。
主な機能は、ドラッグアンドドロップ配置のためのネイティブElementorウィジェット統合、Google Consent Mode v2(アドバンスド及びベーシック)のサポート、IPに基づく特定地域の法律へのジオターゲティング、グローバルサイトスタイルに合わせたコード不要のデザインカスタマイズ、高速読み込みのための動的キャッシュ互換性だ。
価格は1サイトあたり年間49ドル。上位のElementor Oneプランにも含まれている。外部スクリプトによるサイト速度低下がなく、グローバルサイトスタイルを自動継承し、ElementorとWooCommerceスタックに特化して構築されている点が利点だ。一方、Elementorが必須であり、独自の法的プライバシーポリシーを生成しない点が欠点となる。
Elementorユーザーが高性能で統合された法的ツールを求める場合、Cookiezは最適な選択肢だ。
2. CookieYes: スケーラブルなクラウド型同意管理
CookieYesは、複数プラットフォームで動作するクラウド管理型ソリューションだ。現在、世界で140万以上のウェブサイトにサービスを提供している。ストアを接続すれば、重い処理はリモートで処理される。ダッシュボードはWordPressから完全に分離しているため、数十のストアを管理する代理店はこのリモート設定を好む傾向がある。
ログイン画面の裏側での自動クッキースキャン、30以上の言語の自動サポート、法的証拠のための詳細な同意ログ、クラウドダッシュボードによるカスタムブランディングが主な機能だ。
小規模サイト向けの無料枠がある。Proプランは月間10万ページビューまで月額10ドルから始まる。セットアップが非常に容易で、マルチサイト管理のための優れたダッシュボードを備える。一方、月額費用はトラフィックに応じて増加し、スタイル設定にはWordPress外での作業が必要となる。
ネイティブプラグインよりも分離されたクラウドベースのダッシュボードを好むストアオーナーにとって、信頼性の高い選択肢だ。
3. Complianz: WooCommerce向け法的設定ウィザード
Complianzはストアのデジタル弁護士のような役割を果たす。自動化された法的文書と厳格な地域設定に重点を置いている。事業内容に関する詳細な質問に答えると、必要な正確なトラッキングルールを生成する。
地域固有の法的文書生成、WooCommerceチェックアウト時のプライバシー通知との統合、同意の証拠ログ、バナーデザインのA/Bテストが主要機能だ。
1サイト向けのComplianz Premiumは年間55ドル。非常に詳細な法的設定ウィザード、ニッチな地域法の優れたサポート、プライバシーポリシーの自動更新が強みである。一方、インターフェースは初心者には圧倒される可能性があり、セットアップウィザードには約45分を要する。
自動生成された法的ページを必要とする、複数の厳格に規制された国際市場で事業を展開するストアに最適だ。
4. Borlabs Cookie 3.0: パフォーマンス最優先の対応
Borlabs Cookie 3.0は技術的精度で知られる有料WordPressプラグインだ。DACH地域(ドイツ、オーストリア、スイス)では絶対的なリーダーである。速度削減のために特別に構築されており、サーバーリクエストの削減にこだわる場合、スクリプトがいつ、どのように発火するかを細かく制御できる。
YouTube、Vimeo、Google Maps用のコンテンツブロッカー、スクリプトマージャーと最適化ツール、欧州市場向けのローカライズ、ドメイン間トラッキング防止が特徴だ。
1ウェブサイトライセンスで年間49ユーロ。PageSpeedスコアへの影響が最小限で、技術的なトリガーのカスタマイズ性が高く、埋め込みコンテンツのブロックが完璧である。一方、学習曲線は他よりも急であり、スタイル設定オプションはビジュアルビルダーのように直感的ではない。
生のサイトパフォーマンスと技術的制御を何よりも優先する開発者向けの選択肢だ。
5. Cookiebot by Usercentrics: 自動化された企業向け監査
Cookiebotは、大規模なWooCommerceカタログ向けのハイエンド企業向けツールとして機能する。月次自動クッキー監査で有名だ。IAB TCF 2.2標準をサポートしており、ターゲット広告ネットワークを運用するパブリッシャーには必須の認証となる。複雑なアドテクに大きく依存する場合、このレベルの認証が必要だ。
月次自動クッキー監査、IAB TCF 2.2認定CMP、複数ストアフロントのためのドメイン間同意共有、Google Tag Managerとの深い統合が主な機能となる。
階層化された価格設定はサブページ数に基づく。「Premium Small」プランは最大500サブページで月額約13ドルだ。完全自動化されたスキャンと分類、主要広告主からの高い信頼、新しく追加されたトラッキングスクリプトを見逃さない点が利点である。一方、大規模なWooCommerceストアでは非常に高額になりやすく、5000の商品ページを追加すると月額請求額が急騰する。
自動監査を必要とする大規模な広告予算を実行する大規模Eコマース企業に最適だ。
6. Termly: オールインワンコンプライアンスプラットフォーム
Termlyは単純なクッキーをはるかに超える。小規模事業向けの完全なコンプライアンスプラットフォームとして機能する。利用規約、返品ポリシー、プライバシーポリシーを一箇所で生成できる。高額な弁護士を雇わなくても済むよう、法的な文言を処理する。
ポリシージェネレーター(利用規約、プライバシー、返品、配送)、サードパーティスクリプトの自動ブロック、国際ストア向けの多言語サポート、訪問者向けユーザー設定センターが特徴だ。
年額払いで月額10ドル。クッキーだけでなくすべての法的基盤をカバーし、非技術ユーザー向けの優れたインターフェース、特定のストアタイプにカスタマイズされたポリシーを生成する点が強みである。一方、他のオプションほどWordPressネイティブな感覚はなく、ポリシーのためにリモートiframeの埋め込みが必要となる。
限られた予算でゼロからすべての法的文書を生成する必要がある新規ストアに理想的だ。
7. Iubenda: グローバルコンプライアンスのモジュラーシステム
Iubendaは、グローバルなプライバシーに対し、高度にプロフェッショナルで弁護士監修のアプローチを提供する。国際的な弁護士チームを雇用し、条項を常に更新している。モジュラーシステムを採用しており、ストアが必要とする特定の法的部分に対してのみ支払う。
リモートホスト型の法的文書、データマッピングのための内部プライバシー管理ツール、電話注文向けのオフライン同意トラッキング、カスタマイズされたAPI統合が主な機能だ。
基本機能は年間約29ドルから始まるが、複雑な設定でははるかに高額になる。非常に高い法的水準、実際の弁護士による絶え間ない更新、多国籍企業に完璧にスケールする点が利点である。一方、複雑な価格体系はほとんどのストアオーナーを悩ませ、多言語サポートの追加は急速に高額になる。
複雑な国境を越えたデータ処理ニーズを持つ高収益ストアに最適だ。
8. GDPR Cookie Compliance by Moove: 開発者向け制御
MooveによるGDPR Cookie Complianceは、非常に人気のある軽量オプションだ。驚異的な速度とシンプルさを誇る。開発者は、あらゆることを実行しようとしないこのプラグインを好む。UIを提供し、ロジックはユーザーが提供する。適切に設定するにはある程度の技術スキルが必要だ。
CSS変数による完全カスタマイズ可能なUI、静的アセットのためのCDNサポート、同意有効期限設定、WPMLおよびQTranslate互換性が特徴となる。
強力な無料版がある。Premiumライセンスは59ポンドだ。非常に高速でWordPressデータベースを膨張させず、開発者向けの優れたフックとフィルター、洗練されたモダンなデフォルトデザインが利点である。一方、CookiebotやCookieYesと比べて自動化機能は少なく、トラッキングスクリプトを手動で分類する必要がある。
自らのコードを手動で制御したい開発者向けの優れた軽量な代替手段だ。
9. WP Cookie Notice: 無料の基本トラッキング
WP Cookie Noticeは、利用可能な最も古く、最も人気のある無料オプションの一つだ。100万以上のアクティブインストールを抱える。非常に基本的で、シンプルなバナーを表示し、はい/いいえの応答を記録する。有料ツールのような深いWooCommerce統合はないが、単純な仕事はこなす。
数分でのシンプルなバナー展開、カスタマイズ可能なメッセージテキスト、プライバシーポリシーページへのリンク、SEOフレンドリーなデザインが特徴だ。
完全に無料である。設定に2分しかかからず、サーバーリソースへの影響はゼロで、何百万人ものウェブユーザーに親しまれている点が利点だ。一方、同意前にスクリプトを自動的にブロックせず、高度な手動コーディングなしでは現代のGCM v2要件を満たせない。
シンプルな個人ブログには問題ないが、現代のWooCommerceトラッキングには非常にリスクが高い。
10. Cookie Notice & Compliance for WordPress by Hu-manity.co
Cookie Notice & Complianceは、シンプルなバナーと複雑なウェブアプリの間のギャップを埋める。トラッキング定義を更新するために独自のAI駆動アプローチを使用する。人権とデータ所有権に焦点を当てており、100か国以上で同時にコンプライアンスを自動化しようとする。
ウェブアプリ経由での自動コンプライアンス更新、同意記録の保存、目的別同意カテゴリ、意図的なデータ共有制御が主な機能だ。
基本版は無料。Premiumは月額14.95ドルから始まる。データプライバシーに関する強い倫理的スタンス、優れたインターフェースデザイン、複雑な国際ルールの処理が強みである。一方、サポートの応答時間が遅れる可能性があり、個人事業主にとってPremium価格はやや高めだ。
自動化された多国間コンプライアンスを求めるストアオーナー向けの堅実なミッドティアオプションだ。
機能比較: 主要クッキー同意プラグイン

適切なツールを選ぶには、ハードなデータの比較が必要だ。法的トラッキングに関しては推測は許されない。
| プラグイン名 | 自動スキャン | GCM v2対応 | ジオターゲティング | 開始価格 |
|---|---|---|---|---|
| Cookiez by Elementor | なし(手動) | あり(アドバンスド) | あり | 49ドル/年 |
| CookieYes | あり | あり | あり | 10ドル/月 |
| Complianz | あり | あり | あり | 55ドル/年 |
| Borlabs Cookie 3.0 | なし(手動) | あり | なし | 49ユーロ/年 |
| Cookiebot | あり | あり | あり | 13ドル/月 |
クラウドツールは月額課金、ネイティブプラグインは通常年額課金である点に注意が必要だ。
レガシープラグインからCookiezへの移行方法

同意管理の切り替えでトラッキングが途切れる必要はない。注意深い手順を踏むだけだ。以下の手順に従えば、WooCommerceストアをCookiezに移行し、1日もAnalyticsデータを失うことなく完了できる。所要時間は約20分だ。
ステップ1は、現在のスクリプトの監査だ。まず、旧プラグインが現在ブロックしているものを特定する。ヘッダーとフッターをチェックし、ハードコードされたGoogle Tag ManagerスニペットやFacebook Pixelを探す。それらすべてを文書化する。
ステップ2は、旧プラグインの無効化だ。レガシーツールをオフにする。旧ショートコードと残りのCSSファイルを消去するために、ホスティングサービスのキャッシュを素早くクリアする。
ステップ3は、ElementorでのCookiez設定だ。Cookiezをインストールする。トラッキング設定に移動し、GCM v2統合を有効にする。トラッキングIDを指定されたネイティブフィールドに貼り付ける。
ステップ4は、スタイル設定とテストだ。Elementor Editorを使用してバナーをブランドアイデンティティに合わせる。最後に、シークレットウィンドウを開き、「すべて同意」を明示的にクリックするまでクッキーが読み込まれないことを確認する。
よくある質問

2026年において無料プラグインは十分か?
いいえ、十分ではない。無料プラグインは通常、Google Consent Mode v2を適切にサポートできない。Googleの高度なAPIにpingを送信しない無料ツールを使用すると、広告トラッキングは単に動作しなくなる。
Cookiezは非Elementorページで動作するか?
いいえ。Cookiezは機能するためにElementorエコシステムを必要とする。高速に読み込み、正確にスタイル設定するために、ビルダーの基盤アーキテクチャを使用する。Elementorを使用しない場合は、BorlabsまたはComplianzを選択する。
Google Consent Mode v2を無視するとどうなるか?
Google Adsキャンペーンは資金を浪費する。Googleは、正しい同意シグナルを受信しない場合、EEA/UKユーザー向けのリマーケティングとコンバージョントラッキングを積極的にブロックする。完全に手探り状態になる。
クッキーバナーはCore Web Vitalsにどのように影響するか?
重いバナーはメインスレッドをブロックする。これによりLargest Contentful Paint(LCP)が遅れ、バナーがポップアップしたときにCumulative Layout Shift(CLS)が発生する。ネイティブツールはこのペナルティを防ぐ。
GDPRとCCPA用に別々のプラグインが必要か?
いいえ、必要ない。有料プラグインは両方のルールセットを同時に処理する。ジオターゲティングを使用して、欧州では厳格なオプトインバナーを、カリフォルニア州ではオプトアウトの「私の情報を販売しないで」リンクを表示する。
バナーの閉じるボタンを隠してもよいか?
絶対にダメだ。法律は、クッキーを拒否することが同意するのと同じくらい簡単でなければならないと要求している。閉じるボタンを隠したり、「拒否」オプションを埋もれさせたりすることは、GDPRの原則に違反し、厳しい罰金を招く。
WooCommerceストアのクッキースキャンはどのくらいの頻度で行うべきか?
新しいプラグインやトラッキングツールをインストールするたびにスキャンを実行すべきだ。Cookiebotのような自動化ツールを使用する場合、予告なしの変更を検出するために、ドメイン全体を毎月スキャンする。
非準拠に対する正確な罰則は?
GDPRの罰金は、2000万ユーロまたは全世界年間売上の4%のいずれか高い方に達する可能性がある。小規模ストアでさえ、不注意なデータ取り扱いに対して壊滅的な罰則に直面する。
この記事のポイント
- WooCommerceストアのクッキー同意管理は法的リスクとサイト速度の両面で重要だ。GDPR罰金は累計450億ユーロを超え、Google Consent Mode v2対応は広告計測に必須である。
- 不適切な同意バナーはLCPを最大500ms遅延させ、モバイルでのバウンス率を25%増加させる。プラグイン選定はSEOとUXに直結する。
- Elementorユーザーには統合性の高い「Cookiez」、多国間法対応には「Complianz」、パフォーマンス最優先には「Borlabs Cookie 3.0」、大規模企業向け自動監査には「Cookiebot」が適している。
- 無料プラグインはGCM v2対応が不十分な場合が多く、2026年の要件を満たすには有料プラグインの導入が現実的だ。
- プラグイン移行時は、現行スクリプトの監査、旧プラグイン無効化、新プラグイン設定、スタイル調整とテストの4ステップでトラッキングデータの損失を防げる。

・ 複数業界における17年間のデジタルビジネス開発経験
・ ウェブサイト開発のためのHTML、PHP、CSS、JavaScript等の実用的知識
・ 15ヶ国語対応の多言語SaaSの開発経験
・ 17年間にも及ぶ、Eコマース長期運営経験
・ 幅広い業界でのSEO最適化の豊富な経験
ChatGPT広告が4月に一般開放へ:新たな獲得チャネルか、それともブランド税か
OpenAIがChatGPT内に広告を自社で運用できる「セルフサーブ型プラットフォーム」を2026年4月に公開する。これまでの限定的なテスト運用から、中小企業を含む幅広い広告主が直接出稿できる段階へと移行する。この動きは、GoogleやMetaが支配してきたデジタル広告市場に新たな選択肢を提示するものだ。
先行して実施された米国でのパイロット運用では、開始からわずか6週間で年換算収益が1億ドル(約150億円)を突破した。現在、600社以上の広告主が参加しており、その約80%が中小企業であるという。PPC(Pay Per Click / クリック課金型広告)の担当者にとって、この新しいチャネルをどう評価すべきかが急務となっている。
ChatGPT広告は単なる「検索結果への表示」にとどまらず、ユーザーの対話プロセスに介入する新しい体験を提供する。しかし、初期のデータではクリック率がGoogle検索広告を大きく下回るなど、課題も浮き彫りになっている。本記事では、OpenAIの最新発表に基づき、この新チャネルの可能性とリスクを専門的な視点から分析する。
OpenAIがChatGPT広告をセルフサーブ化へ:4月の一般開放で何が変わるか
OpenAIは2026年4月に、広告主が自ら予算やターゲットを設定して広告を配信できる「セルフサーブ(自社運用型)」のプラットフォームを立ち上げる予定だ。これまでは特定の企業に限定された招待制のテストだったが、今後は誰でもアカウントを作成して広告を出稿できるようになる。
パイロット版から一般開放への転換点
2026年1月から開始された初期のテスト運用では、米国の無料プランおよび「Go」プランの成人ユーザーを対象に広告が表示されていた。この段階では、最低出稿金額が5万ドルから10万ドル(約750万〜1,500万円)と非常に高額に設定されており、実質的には大手ブランド向けのプレミアムな媒体という位置づけだった。
セルフサーブ機能の導入により、この参入障壁が取り払われる。中小企業の担当者が、Google広告やMeta広告と同じように、少額の予算からテストを開始できる環境が整うのだ。これは、ChatGPTが「特別な実験場」から「日常的な広告運用チャネル」へと進化することを意味している。
米国以外への対象地域拡大
Search Engine Journalの記事によれば、OpenAIは4月のセルフサーブ公開に合わせて、広告の配信対象地域をカナダ、オーストラリア、ニュージーランドにも拡大する計画だ。日本市場への展開時期については明示されていないが、英語圏での成功を足がかりに、多言語展開が加速するのは確実と見られている。
広告は引き続き、有料プラン(Plus、Pro、Business、Enterprise、Education)のユーザーには表示されない。あくまで無料ユーザーを対象としたマネタイズ手段として維持される方針だ。OpenAIは、広告が回答の内容を歪めることはなく、回答とは明確に区別された形式で表示されることを強調している。
パイロット運用の実績から見える「期待」と「現実」のギャップ
先行テストの結果として報じられた「年換算収益1億ドル」という数字は、一見すると驚異的な成功に見える。しかし、その内実を詳しく見ると、広告主が手放しで喜べる状況ばかりではないことが分かる。
年換算収益1億ドルの数字をどう読み解くか
「年換算収益(Annualized Revenue)」とは、ある特定の期間の収益を1年間に引き延ばして計算した予測値だ。6週間という短期間での数値をベースにしているため、初期の話題性による「お試し出稿」が含まれている可能性が高い。また、限定された在庫に対して高単価なCPM(Cost Per Mille / 1,000回表示あたりの単価)が設定されていたことも、数字を押し上げる要因となった。
Reutersの報告によると、対象ユーザーの約85%が広告を表示できる設定になっているものの、実際に毎日広告を目にしているユーザーは20%未満に抑えられている。OpenAIはユーザー体験を損なわないよう、慎重に配信量をコントロールしている。裏を返せば、まだ「収益化の余地」を残しているとも言えるが、配信密度を高めた際にユーザーがどう反応するかは未知数だ。
クリック率(CTR)に現れた検索広告との違い
マーケターにとって最も注視すべき数字は、広告の反応率だ。eMarketerの調査によれば、ChatGPT広告のCTR(Click Through Rate / クリック率)は平均で0.91%程度に留まっている。これに対し、Google検索広告の平均CTRは約6.4%とされており、大きな開きがある。
この差は、ユーザーの「インテント(検索意図)」の違いに起因すると考えられる。Google検索のユーザーは特定のウェブサイトや解決策を探しているが、ChatGPTのユーザーは「対話」や「情報の整理」を目的としている。対話の途中に差し込まれる広告は、従来の検索広告よりも「ノイズ」として捉えられやすい可能性があるのだ。
ChatGPT広告は「新しい獲得チャネル」か、それとも「ブランド税」か
ChatGPT広告の登場により、広告業界では「ブランド税(Brand Tax)」という言葉が囁かれ始めている。これは、効果が不透明であっても、競合他社に場所を取られないために出稿し続けなければならない「防衛的なコスト」を指す。
ユーザーの検索行動の変化と対話型AIの親和性
ChatGPT広告が単なるブランド税に終わらず、有効な獲得チャネルになる可能性も十分にある。ユーザーは単にキーワードを検索するのではなく、状況を説明し、選択肢を比較し、意思決定のサポートをAIに求めているからだ。この「相談プロセス」の中に、文脈に沿った解決策(広告)を提示できれば、従来の検索広告よりも深いエンゲージメントを生む可能性がある。
例えば「家族5人で北海道旅行に行く計画を立てて」という対話に対し、レンタカー会社やホテルの広告が表示されるのは、ユーザーにとって有益な情報になり得る。このように、検索(Search)とソーシャル(Social)の中間に位置する「対話型コマース」という新しいカテゴリーが確立されるかどうかが鍵となる。
広告表示のイメージ比較(静的デモ)
従来の検索広告とChatGPT広告の表示イメージの違いを、以下のデモで視覚化する。ChatGPT広告は、回答テキストの下部や横に、より文脈に馴染む形で配置される傾向がある。
/* 検索広告と対話型広告の配置イメージ */
.ad-demo-container {
display: flex;
gap: 24px;
align-items: flex-start;
flex-wrap: nowrap;
}
.ad-box {
min-width: 120px;
flex: 1;
border: 1px solid #ddd;
border-radius: 8px;
padding: 12px;
background: #fff;
box-sizing: border-box;
}※このデモは、従来の検索広告とChatGPTにおける広告の馴染み方の違いを視覚化したイメージだ。実際の広告フォーマットはOpenAIの仕様により変更される可能性がある。
どのような企業がChatGPT広告を試すべきか:適正な商材とタイミング

すべての企業が4月の一般開放と同時に飛びつく必要はない。ChatGPTの特性を考えると、初期段階で成果を出しやすい商材と、そうでない商材がはっきりと分かれるからだ。
意思決定が複雑な「高関与商材」との相性
対話型AIの最大の強みは、ユーザーが抱える複雑な課題に対して段階的に情報を整理できる点にある。そのため、以下のような「検討期間が長く、情報収集が重要な商材」は、ChatGPT広告との相性が良いと考えられる。
- B2Bソフトウェア・サービス:導入にあたって比較検討や要件の確認が必要なもの。
- 教育・スクール:自分に合ったカリキュラムを相談しながら探すユーザー。
- 住宅・リフォーム・不動産:予算や条件をAIに伝えながら選択肢を絞り込む段階。
- 高単価な耐久消費財:家具、家電、車など、スペックや口コミを精査する商品。
これらの商材では、ユーザーがAIに対して「自分の状況」を詳しく説明しているため、広告のターゲティング精度が飛躍的に高まる。単純なキーワードマッチング以上の、コンテクスト(文脈)に基づいたアプローチが可能になるのだ。
中小規模の広告主が静観すべき理由
一方で、衝動買いに近い低単価商品や、緊急性の高いサービス(鍵の紛失修理など)は、現時点ではGoogle検索広告の方が効率的だろう。また、既存の検索広告やSNS広告の運用が最適化されていない段階で、新しい未成熟なプラットフォームに予算を割くのはリスクが高い。
初期のセルフサーブプラットフォームでは、計測ツール(コンバージョン計測など)や最適化アルゴリズムがGoogle広告ほど成熟していないことが予想される。そのため、まずは余剰予算がある企業や、先行者利益を狙いたい特定のカテゴリーに絞ったテストが推奨される。
PPC担当者が今すぐ準備しておくべき3つの評価基準

4月の一般開放に向けて、広告運用担当者は「ただ試す」のではなく、効果を正しく測定するためのフレームワークを構築しておく必要がある。OpenAIが提供するデータだけでは、真の投資対効果(ROI)は見えてこないからだ。
成功を定義するKPI(重要業績評価指標)の策定
前述の通り、ChatGPT広告のCTRは低くなる傾向がある。そのため、クリック数や獲得単価(CPA)だけを指標にすると、チャネルの価値を見誤る可能性がある。以下の多角的な視点でのKPI設定を検討したい。
- アシストコンバージョン:ChatGPTでの接触が、その後の直接検索やSNS経由の成約にどれだけ貢献したか。
- ブランドリフト調査:広告表示によって、ブランド名での検索数や認知度が向上したか。
- リードの質:対話を通じて納得した上で流入したユーザーは、既存チャネルよりも成約率(CVR)が高いか。
既存チャネルとの予算配分の最適化
ChatGPT広告は、ユーザーのジャーニーにおいて「検索(需要の回収)」と「SNS(需要の創出)」の中間に位置する。そのため、予算は検索広告から削るのではなく、まずはディスプレイ広告やコンテンツマーケティングの予算の一部を試験的に充当するのが合理的だ。WP Mayorの記事でも指摘されているように、AIプラットフォームへの出稿は「コンテンツの発見」を助ける側面が強いからだ。
この記事のポイント
- OpenAIは2026年4月にChatGPT広告のセルフサーブプラットフォームを公開し、広告運用を一般開放する。
- 先行テストでは6週間で年換算1億ドルの収益を記録したが、CTRは0.91%とGoogle検索広告(6.4%)に比べ大幅に低い。
- B2Bや高単価商材など、ユーザーが「相談」を必要とする高関与商材において、文脈に沿った高い広告効果が期待される。
- 中小規模の広告主は、既存チャネルの最適化を優先しつつ、アシスト効果を測定できる体制を整えてから参入するのが賢明だ。
- 広告が「ブランド税」になるリスクを避け、対話型AI特有のユーザー体験に合わせたクリエイティブとKPI設計が求められる。
・ 複数業界における17年間のデジタルビジネス開発経験
・ ウェブサイト開発のためのHTML、PHP、CSS、JavaScript等の実用的知識
・ 15ヶ国語対応の多言語SaaSの開発経験
・ 17年間にも及ぶ、Eコマース長期運営経験
・ 幅広い業界でのSEO最適化の豊富な経験

AIに引用されるコンテンツの共通点:120万件のデータから判明したSEOの新常識
AIチャットボットが検索の代替手段となりつつある今、自社のコンテンツがAIに「引用」されるかどうかは、Webサイトのトラフィックを左右する死活問題だ。Search Engine Journalが公開した調査結果によると、AIに選ばれるコンテンツには、従来のSEO(検索エンジン最適化)とは異なる独自の評価基準が存在することが明らかになった。
この調査では、120万件を超えるChatGPTの回答と、約9万8,000件の引用データを詳細に分析している。その結果、業界を問わず引用率を14%向上させる「魔法の導入文」や、逆に引用を妨げてしまう「見出し構成のデッドゾーン」の存在が浮き彫りになった。
本記事では、この膨大なデータに基づいた「AIに好まれるコンテンツ制作」の具体策を解説する。単なる執筆テクニックにとどまらない、AI時代のコンテンツ・アーキテクチャのあり方を探っていこう。
導入文の「断定表現」が引用率を14%向上させる

AIがコンテンツを読み取る際、最も重視しているのは「情報の確実性」だ。Search Engine JournalのKevin Indig氏が分析したデータによると、記事の冒頭で「断定的な表現(Declarative Language)」を使用しているページは、そうでないページに比べて引用率が平均14%高いことが分かった。
「〜かもしれない」という曖昧さを排除する
AIは、ユーザーの質問に対して自信を持って回答を提供しようとする。そのため、「このツールは効率化に役立つ可能性がある」といった慎重な言い回し(ヘッジ表現)よりも、「このツールは業務時間を30%削減する」といった明確な主張を好む傾向がある。
特に冒頭の1,000文字以内において、修飾語や前置きを極力減らし、事実をストレートに述べる構成が有効だ。「[X] は [Y] である」あるいは「[X] を使うと [Z] ができる」という直接的な構文を意識するだけで、AIからの評価は大きく変わる。
結論から書き始める「結論先行型」の徹底
多くのWebライティングでは、読者の共感を得るために「背景の説明」や「問いかけ」から始めることが多い。しかし、AI最適化(AEO:Answer Engine Optimization)の観点では、これは逆効果になる場合がある。
AIは情報の「密度」と「即時性」を評価する。記事の最初の段落で、そのページが提供する核心的な情報を提示することが、引用対象として選ばれるための必須条件となっているのだ。
業界ごとに異なる「最適な見出し数」の正体

見出し(Hタグ)の構成は、AIが情報を構造化して理解するための地図となる。興味深いことに、見出しの数は「多ければ良い」というわけではなく、業界ごとに明確な「スイートスポット(最適値)」が存在する。
見出し3〜4個は「デッドゾーン」になるリスク
調査対象となったすべての業界において共通していたのは、「見出しが3〜4個の記事は、見出しがゼロの記事よりも引用率が低い」という衝撃的な事実だ。これは、中途半端な構造化がAIのナビゲーションを混乱させている可能性を示唆している。
構造化を徹底して情報の階層を明確にするか、あるいは一切の装飾を省いて散文として読ませるか、どちらかの極端なアプローチの方がAIには好まれる。中途半端な見出し構成は、情報の網羅性と構造の明快さの両方を損なう「デッドゾーン」となっているのだ。
業界別:SaaSは20個以上、医療は0個が有利?
最適な見出しの数は、扱うトピックによって大きく異なる。例えば、CRMやSaaS関連の分野では、20個から49個もの見出しを持つ詳細な比較ガイドが高い引用率を記録している。これは、AIが多機能なソフトウェアを比較する際、細かくセクション分けされた情報を求めているためだ。
一方で、医療(Healthcare)分野では、見出しがゼロ、あるいは極めて少ないページの方が好まれる傾向がある。医療情報においては、断片的な見出しの羅列よりも、文脈が維持された一貫性のある記述が「権威ある解説」として評価されやすいと考えられる。
AIが好むエンティティ:日付と数値、そして「価格」の罠

AIは単なる単語の羅列ではなく、意味のある情報の塊(エンティティ)を識別している。Google Natural Language APIを用いた分析によると、特定のエンティティの有無が引用の成否を分けることが判明した。
「日付」と「具体的な数値」は信頼の証
ほぼすべての業界で共通してプラスの信号となったのが、「DATE(日付)」と「NUMBER(数値)」だ。情報の鮮度を示す日付と、客観的な裏付けとなる統計数値は、AIにとって「引用する価値がある」と判断するための強力なトリガーとなる。
特に公開日や更新日を明記し、本文中で具体的なデータ(例:15%の改善、3,000人のユーザーなど)を提示することは、AIからの信頼を勝ち取るための最もシンプルな近道といえる。
価格情報の掲載が引用を妨げる理由
意外なことに、「PRICE(価格)」に関するエンティティは、金融以外のほとんどの業界でマイナスの信号として働いている。冒頭で価格について強調しすぎると、AIはそのコンテンツを「客観的な情報源」ではなく「商業的な広告ページ」と見なす傾向がある。
ただし、金融業界だけは例外で、金利や手数料などの価格情報が引用率を高める要因となっている。これは、金融系のクエリにおいては価格そのものがユーザーの求める「回答」に直結するためだ。業界の特性を理解したエンティティ配置が求められる。
UGC(ユーザー生成コンテンツ)はAIに選ばれない?

Googleの検索結果では、RedditやQuoraといったユーザー投稿型のコミュニティサイトが優遇される傾向(通称:Reddit効果)が見られる。しかし、AIの引用データはこの傾向とは全く異なる結果を示した。
Reddit効果は検索エンジン限定の現象か
調査データによると、ChatGPTが引用するソースの94.7%は企業や専門メディアによる「コーポレート/エディトリアルコンテンツ」であり、UGC(ユーザー生成コンテンツ)の割合は極めて低い。金融や医療といった専門性が求められる分野では、UGCの引用率は1%未満にとどまっている。
これは、AIが回答を生成する際、個人の主観的な意見よりも、組織が責任を持って公開している「構造化された公式情報」を優先していることを意味する。AI時代においても、公式サイトとしての権威性を磨くことの重要性は変わっていない。
暗号資産分野で見られる唯一の例外
唯一の例外は、暗号資産(Crypto)分野だ。この分野ではUGCの引用率が9.2%と比較的高い。技術の進化が速く、公式ドキュメントよりもRedditや開発者コミュニティの方が最新かつ詳細な情報を持っていることが多いため、AIも例外的にこれらのソースを頼りにしている。
この結果から、情報の「速報性」や「技術的な深さ」が公式サイトを上回る場合に限り、コミュニティサイトにもAI引用のチャンスがあることがわかる。
AI時代を生き抜くための新SEO戦略

今回の分析結果を踏まえると、これからのSEO(あるいはAEO)は「文章の質」だけでなく「情報のアーキテクチャ」の戦いになると断言できる。AIに選ばれるためには、人間にとっての読みやすさと、マシンにとっての解析しやすさを高次元で両立させる必要がある。
コンテンツ・アーキテクチャの重要性
AIは、ページ内の特定の場所を重点的にスキャンし、情報の階層を理解しようとする。単にキーワードを詰め込むのではなく、業界ごとの最適な見出し構成(SaaSなら詳細に、医療なら簡潔に)を採用し、AIが情報を抽出しやすい「器」を作ることが重要だ。
また、有名なブランド名や一般的な用語(Knowledge Graphに登録されているような既知の情報)を並べるよりも、特定のニッチな数値や独自の手法といった「具体的で詳細なエンティティ」を含める方が、AIにとっては引用する価値が高いと判断される。
業界特化型の最適化へのシフト
すべての業界に共通する「魔法の公式」は存在しない。導入文を断定的に書くという基本ルールを除けば、最適な文字数、見出しの深さ、含めるべきエンティティの種類は、すべて業界の規範(ノルマ)に依存する。
自社が属する業界において、AIがどのようなコンテンツを好んで引用しているかを分析し、そのパターンに構造を合わせていく「業界特化型の最適化」こそが、これからのWebサイト運営者に求められるスキルとなるだろう。
この記事のポイント
- 導入文は「〜かもしれない」を避け、断定的な表現で結論から書き始める
- 見出しの数は業界ごとに最適化し、中途半端な3〜4個の構成は避ける
- 日付と具体的な数値を積極的に盛り込み、情報の客観性と鮮度をアピールする
- AI引用ではReddit等のUGCよりも、企業・専門サイトの公式情報が圧倒的に有利
- 汎用的なSEOテクニックではなく、業界の特性に合わせた構造設計が必要である
・ 複数業界における17年間のデジタルビジネス開発経験
・ ウェブサイト開発のためのHTML、PHP、CSS、JavaScript等の実用的知識
・ 15ヶ国語対応の多言語SaaSの開発経験
・ 17年間にも及ぶ、Eコマース長期運営経験
・ 幅広い業界でのSEO最適化の豊富な経験

Google Zeroの先にある真実:AIエージェントに最適化する「エージェントSEO」の重要性
Googleからの検索流入がゼロになるという「Google Zero」の言説が、Webマーケティングの世界で波紋を広げている。しかし、真に直面している課題はトラフィックの消失ではなく、Webサイトを訪れる主役が人間から「AIエージェント」へと交代し始めている事実だ。
最新の調査データによれば、Webトラフィックの51%はすでに人間によるものではなく、ボットによる自動化されたアクセスが占めている。この劇的な変化は、従来のSEO戦略を根本から書き換える必要性を物語っている。
本記事では、AIクローラーの急増やAIエージェントによる意思決定の代行がWebサイト運営にどのような影響を与えるのかを分析する。その上で、これからの時代に求められる「エージェントSEO」の具体的な実践方法について解説していく。
「Google Zero」説の裏側とボットトラフィックの急増

SEO業界では、Googleの検索結果にAIによる回答(AI Overview)が表示されることで、Webサイトへのクリックが激減するという懸念が根強い。しかし、SEOコンサルタントのBarry Adams氏が指摘するように、主要なWebサイトへのGoogleトラフィックは世界全体で2.5%程度の減少にとどまっているとのデータもある。
一方で、サーバーログの向こう側では別の巨大な変化が起きている。人間のクリックが完全に消滅したわけではないが、訪問者の構成比率が劇的に変わっているのだ。
AIクローラーが検索エンジンを追い抜く日
Impervaの「2025 Bad Bot Report」によると、自動化されたトラフィックが10年ぶりに人間による活動を上回った。現在、全Webトラフィックの51%がボットによるものだという。これには悪意のある攻撃ボットも含まれるが、最も急速に成長しているのはAIクローラーのセグメントだ。
Cloudflareの分析によれば、AIクローラーは全クローラー・トラフィックの51.69%を占めるまでに成長し、従来の検索エンジンクローラー(34.46%)を追い越した。AIボットによるクロール活動は、前年比で15倍以上に増加している。特にOpenAIの活動は凄まじく、AIボットリクエスト全体の42.4%を占めているとされる。
クローラーとは、Webサイトの情報を収集するために自動でページを巡回するプログラムのことだ。かつてはGooglebotがその主役だったが、現在はChatGPTやClaudeなどのAIをトレーニングするためのボットが、それ以上の頻度でサイトを訪れている状況だ。
「訪問者の半分は人間ではない」という前提
この数字が意味するのは、Webサイト運営者が最適化すべき対象が「人間の読者」だけではなくなっているということだ。AIは情報を収集し、自らの知識ベースに取り込むためにサイトを訪れる。その際、人間のようにバナー広告を見たり、感情に訴えるコピーに反応したりすることはない。AIが必要としているのは、純粋なデータと論理的な構造だ。
崩壊する「コンテンツ提供と引き換えの集客」という互恵関係
これまでの検索エンジンとWebサイト運営者の間には、シンプルな取引が成立していた。サイト側が良質なコンテンツを提供し、Googleがそれをインデックス(登録)する代わりに、情報を探しているユーザーをサイトへ送り返すというモデルだ。しかし、AIの台頭はこの互恵関係を揺るがしている。
AIボットの圧倒的な「持ち去り」比率
Cloudflareが公開した「クロール数に対するリファラル(流入)の比率」は衝撃的だ。Anthropic社のClaudeBotは、1件の流入をサイトに送るために、23,951ページものクロールを行っている。OpenAIのGPTBotも、1,276ページを読み込んでようやく1人をサイトへ送る計算だ。
対照的に、従来のGooglebotはサイトの情報を読み取った後、AIシステムよりも831倍多くの訪問者をサイトに送り返している。AIボットの主な目的は「トレーニング」であり、ユーザーをサイトへ誘導することではない。情報を「取る」だけで「返さない」という、非対称な関係が鮮明になっている。
Google自身のAI化によるゼロクリックの加速
Google自体もこの流れに追随している。AIによる概要表示(AI Overview)が行われる検索クエリでは、オーガニック検索のクリック率が58〜61%低下するという調査結果がある。さらに、Googleの新しい「AIモード」では、ゼロクリック率(検索結果からどこにも遷移しない割合)が93%に達することもあるという。
また、GoogleのAIが回答の引用元として自社サービス(Google.comやYouTubeなど)を優先的に表示する傾向も強まっている。SE Rankingの調査では、AIモードの引用元の約20%がGoogle関連のプロパティで占められていた。外部サイトへのトラフィックを促すという検索エンジンの役割が、自社AIの回答精度を高めるための「データソース利用」へと変質しつつあるのだ。
次の波は「AIエージェント」による意思決定の代行

ボットトラフィックの増加は序章にすぎない。次にやってくるのは、人間に代わって調査、比較、そして購入の意思決定までを行う「AIエージェント」の普及だ。これは単なる検索の自動化ではなく、購買プロセスの構造そのものを変える可能性を秘めている。
購買プロセスの自動化とB2B市場への影響
Gartnerの予測によれば、2028年までにB2B(企業間取引)における購買活動の90%が、AIエージェントを介したものになるという。これは15兆ドルを超える支出が、AI同士のやり取りによって決定されることを意味する。AIエージェントは、調達チームのためにベンダーを調査し、スペックを比較し、最終的な候補リストを作成する。
このプロセスにおいて、AIエージェントはWebサイトの派手なヒーロー画像や、信頼感を演出するバッジには見向きもしない。彼らが読み取るのは、構造化されたデータ、技術仕様、そしてクリーンなHTMLで記述された価格表だ。人間がサイトを訪れて「なんとなく良さそうだ」と感じる前に、マシンが冷徹に候補から外してしまう可能性がある。
人間の目に触れない「訪問」の正体
AIエージェントによる「訪問」は、従来のアクセス解析ツールでは正しく計測できないことが多い。解析画面上では「滞在時間0秒のボットアクセス」として片付けられてしまうか、あるいはフィルタリングされて表示すらされない。しかし、その0秒のアクセスの裏側で、AIが数千万円規模の契約判断を行っているかもしれないのだ。
Salesforceの報告によると、2025年のサイバーウィーク(大規模セール期間)では、AIエージェントが全世界の注文の20%に影響を与え、670億ドルの売上を牽引したという。AIエージェントを活用している小売業者は、活用していない業者に比べて6倍以上の売上成長率を記録している。AIに「見つけてもらい、選んでもらう」ことの経済的価値は、すでに無視できない規模に達している。
マシンに選ばれるための「エージェントSEO」の実践

訪問者が人間からマシン(AIエージェント)へとシフトする中で、私たちは何を最適化すべきなのだろうか。それは従来の「検索順位を上げるためのSEO」とは異なるアプローチ、いわば「エージェントSEO」と呼ぶべき手法だ。
構造化データが「店舗の顔」になる
これまでの構造化データ(Schema markup)は、検索結果に星印や価格を表示させるための「おまけ」のような扱いだった。しかしAIエージェントにとっては、これが情報の主要な入り口となる。構造化データが正しく実装されていれば、AIは推測に頼ることなく、製品のスペックや価格、FAQを正確に読み取ることができる。
以下に、AIエージェントが情報を読み取りやすい構造化データ(JSON-LD)の概念を視覚化してみよう。AIは人間が見るデザインではなく、このような「整理されたデータ」をスキャンしている。
“name”: “CRM Pro”,
“price”: 5000,
“currency”: “JPY”,
“category”: “SaaS”
このデモのように、AIは視覚的なデザインを無視して、背後にあるデータの整合性をチェックする。構造化データは単なるSEOのテクニックではなく、Webサイトという店舗における「AI向けの商品棚」としての役割を担うようになる。
複雑な複合質問(コンパウンド・クエスチョン)への対応
AIエージェントは「中小企業向け CRM」といった単純なキーワードで検索しない。彼らは「月額5,000円以下で、会計ソフトと連携でき、オフライン対応のモバイルアプリがあるCRMはどれか?」といった、複数の条件が重なった複雑な質問(複合質問)を投げかける。
これに対応するには、コンテンツの作り方を変える必要がある。単にキーワードを散りばめるのではなく、具体的な仕様、互換性、価格体系、制限事項などを、明確かつ論理的に記述しなければならない。曖昧な表現を排除し、AIが「この製品は条件を満たしている」と断定できる材料を提供することが重要だ。
計測不能な領域にどう立ち向かうか

「Google Zero」論争が有害なのは、Googleからの流入数という目に見える指標だけに固執させ、その裏で起きている「計測できない価値」を無視させてしまう点にある。GA4などの一般的なアクセス解析ツールでは、AIエージェントがもたらした貢献を追跡することはほぼ不可能だ。
既存のアクセス解析の限界
これまでのWebマーケティングは、クリックからコンバージョンまでを線で結ぶことができた。しかし、AIエージェントの世界では、AIがWebサイトを数回クロールし、その情報を元にユーザーに推薦を出し、ユーザーが直接公式サイトの「購入ページ」を訪れる、あるいはAIが決済まで代行するといった経路を辿る。この場合、最初のきっかけとなったWebサイトへの貢献度は、アクセス解析上では「ノーリファラー(直接流入)」や「ボット」として埋もれてしまう。
この「測定のギャップ」を放置すると、経営層は「SEOの効果が落ちている」と判断し、予算を削ってしまうかもしれない。しかし、実際にはAIエージェントを介して大きな売上が発生している可能性がある。私たちは、クリック数以外の新しい指標――例えば「AIプラットフォームでの言及数」や「ブランド名の指名検索数」などを組み合わせた、多角的な評価軸を持つ必要がある。
今すぐ取り組むべき5つのステップ
AIエージェント時代に備えるために、Webサイト運営者が今すぐ着手すべきアクションをまとめた。これらはGoogle SEOを捨てることではなく、その上に新しいレイヤーを追加する作業だ。
- 構造化データの完全監査:製品、サービス、FAQ、組織情報などのスキーマが正確で最新かを確認する。これはAIにとっての「履歴書」である。
- 複合質問への回答コンテンツ作成:ユーザー(またはAI)が抱く具体的な条件付きの疑問に対し、表やリストを用いて明確に回答するページを用意する。
- サーバーログのモニタリング:GPTBotやClaudeBot、PerplexityBotなどのAIクローラーがどの程度の頻度で訪れているかを把握する。
- robots.txtの戦略的判断:AIへの情報提供を拒否するか、あるいはAIに選ばれるために開放するかを、技術的な設定ではなく「経営判断」として決定する。
- AI引用のトラッキング:SemrushやPerplexityなどのツールを使い、自社ブランドがAIの回答内でどのように引用されているかを定期的にチェックする。
この記事のポイント
- Webトラフィックの51%はすでにボットであり、AIクローラーの活動は前年比15倍に急増している。
- AIボットは情報を収集するだけでサイトへユーザーを返さない傾向があり、従来の互恵関係が崩壊しつつある。
- 2028年までにB2B購買の90%にAIエージェントが介在すると予測され、マシン向けの最適化が不可欠になる。
- 「エージェントSEO」の核は、正確な構造化データの実装と、複雑な条件付き質問への論理的な回答である。
- 従来のアクセス解析ではAIの貢献を測定しきれないため、クリック数以外の新しい評価指標を持つことが求められる。
・ 複数業界における17年間のデジタルビジネス開発経験
・ ウェブサイト開発のためのHTML、PHP、CSS、JavaScript等の実用的知識
・ 15ヶ国語対応の多言語SaaSの開発経験
・ 17年間にも及ぶ、Eコマース長期運営経験
・ 幅広い業界でのSEO最適化の豊富な経験

Googleの新技術TurboQuantが検索とAIの未来を変える
Googleがベクトル検索技術の新たな突破口となるTurboQuantを発表した。この技術はAI処理に必要なサイズとメモリ要件を劇的に削減し、検索エンジンの仕組みを根本から変える可能性がある。
TurboQuantは高度なアルゴリズムの集合体で、ベクトルデータベースの構築時間を「ほぼゼロ」に短縮する。従来の検索システムではコストが高く限定的だった大規模な意味検索が、低コストで瞬時に行えるようになる。これは検索結果の質、AI概要の増加、パーソナライズされた検索体験に直接影響を与える技術革新だ。
TurboQuantが解決するベクトル検索の課題

TurboQuantの重要性を理解するには、まずベクトル検索の基本とその課題を知る必要がある。従来のキーワードマッチングとは異なるアプローチで、検索エンジンはより深い意味理解を実現しようとしている。
ベクトル埋め込み:言葉を数値に変換する技術
ベクトル埋め込みは、テキストや画像、動画を一連の数値に変換する技術だ。これらの数値は単語や概念の意味的関係をエンコードする。例えば「王様」から「男性」を引き、「女性」を足すと「女王」に近いベクトルが得られる。言葉の数学的操作が可能になるのは、各単語が文脈に基づいてベクトル空間にマッピングされるためだ。
この技術はGoogleが2013年に発表したWord2Vecの研究から発展した。当時から、単語の意味を学習するベクトル表現の可能性は認識されていた。現在の検索エンジンは、この技術をさらに発展させてユーザーの検索意図を深く理解しようとしている。
ベクトル検索とメモリのボトルネック
ベクトル検索は、ベクトル空間内で互いに近い点を見つけるプロセスだ。ユーザーの検索クエリをベクトル空間に埋め込み、意味的に類似したコンテンツを近傍から探し出す。従来のキーワード完全一致ではなく、概念的な関連性に基づく検索が可能になる。
しかし課題があった。多次元空間でのベクトル検索は膨大なメモリを消費する。メモリは近傍探索のボトルネックとなり、大規模なデータセットでの実用的な応用を制限していた。GoogleのエンジニアPandu Nayak氏がDOJ対Google裁判で証言したように、RankBrainのようなシステムでもコストの高い処理であるため、上位20〜30件の結果に限定して適用されていた。
ベクトル量子化の限界とTurboQuantの解決策
メモリ問題に対処するため、ベクトル量子化という技術が開発された。これは巨大なデータポイントのサイズを縮小する数学的手法で、超効率的なzipファイルのようなものだ。しかしデータを圧縮すると結果の品質が低下し、さらに圧縮データに追加されるビットがメモリ負荷を増やすという逆説的な問題があった。
TurboQuantはこの問題を根本から解決する。大きなデータベクトルを回転させて幾何学的に単純化し、JPEG圧縮のように各部分を個別に小さな離散集合にマッピングする。これにより元のベクトルの主要概念を保持しながら、メモリ使用量を大幅に削減できる。隠れたエラーはQJLと呼ばれる数学的手法で1ビットのメモリを使用して検証・修正され、精度を維持したまま高速処理を実現する。
検索エンジンへの具体的な影響

TurboQuantの実用化は、検索エンジンの動作とユーザー体験に具体的な変化をもたらす。従来の技術的制約によって実現できなかった機能が、現実的なコストで提供可能になる。
大規模な意味検索の実現とAI概要の増加
TurboQuantにより、Googleは大規模な意味検索を実行できるようになる。従来はコストが高すぎて上位20〜30件の結果に限定されていたベクトル検索が、数百件の候補に対して瞬時に行える。これによりAI概要(AI Overviews)の質と量が向上し、複雑な質問にも即座にAI生成の回答を提供できるようになる。
Search Engine Journalの記事では、TurboQuantが検索結果の多様性と関連性を高める可能性が指摘されている。ユーザーの特定のニーズと意図に合致した、真に役立つコンテンツがより容易に表面化する仕組みだ。
高度にパーソナライズされた検索体験
Googleが導入したパーソナルインテリジェンスは、TurboQuantによってさらに強化される見込みだ。個人の検索履歴、ドキュメント、メール、好みを瞬時に検索可能なベクトル空間に格納し、リアルタイムのAIアシスタントとして機能する。DeepMind CEOのDemis Hassabis氏が描くユニバーサルAIアシスタントの構想に近づく一歩となる。
視覚データをベクトル空間に変換する技術も進化する。AIグラスやGemini Liveを通じて取得した大量の視覚情報が検索可能になり、「鍵をどこに置いたか」といった日常的な質問にも視覚的記憶に基づいて回答できるようになる。
エージェントシステムとロボティクスの進化
エージェントシステムの能力向上
AIエージェントは従来、コンテキストウィンドウの制限と情報取得の遅さに制約されていた。TurboQuantにより、AIエージェントは無限の完全に想起可能な長期記憶を持つことができる。あらゆるインタラクション、ドキュメント、メール、好みをミリ秒単位で瞬時に検索し、他のエージェントと大量の情報を通信できるようになる。
ロボティクスの実用化加速
ロボットが現実世界で動作する際、周囲の物体の意味的文脈を理解するのは複雑な課題だ。TurboQuantはロボットが環境内の物体を意味的に分類し、適切な行動を判断する能力を大幅に向上させる。Google DeepMindとBoston Dynamicsのパートナーシップも、この技術進化の文脈で捉えることができる。ロボットの知能化と実用化が加速する見込みだ。
SEO担当者への実践的影響

TurboQuantのような技術進化は、SEOの実践方法に具体的な変化を要求する。単なる技術的最適化から、ユーザー意図の本質的理解へと重心が移行する。
コンテンツ戦略の再考が必要な理由
TurboQuantがもたらす最大の変化は、AI概要がより多くの検索クエリでユーザーを満足させるようになる点だ。世界の情報を整理するだけのコンテンツは、AI回答によって代替される可能性が高まる。一方で、人々がAI回答よりも関わりたいと思うようなコンテンツは、より高い価値を持つようになる。
Search Engine Journalの著者Marie Haynes氏は、自身のコミュニティ「The Search Bar」での議論を紹介している。そこで指摘されているのは、ユーザー意図を徹底的に理解し満たすことに焦点を当てたSEO担当者にとって、基本的なアプローチは変わらないという点だ。しかしビジネスモデルによって影響は異なる。
従来のSEO要素の相対的重要性変化
TurboQuantがGoogleのランキングシステムに導入されれば、意味検索の精度と範囲が拡大する。その結果、従来のSEO要素である被リンクやSEOに特化したコピーの重要性が相対的に低下する可能性がある。Googleは数百件の可能な結果に対して意味検索を行い、ユーザーに瞬時に正確で役立つ情報を提供できるようになる。
技術的な観点から見ると、TurboQuantの研究論文は2025年4月に公開されており、Googleは約1年間かけて改善を重ねてきた。このタイムラインは、2025年6月のコアアップデートで観測された変化の背景にMUVERAというベクトル検索の突破があったとする同氏の以前の推測と一致する。技術の研究公開から実装までには時間的余裕があり、突然の変化ではなく計画的に進化が進んでいる。
AIと検索の未来像

TurboQuantは単なる技術的改善ではなく、AIと検索の関係性を再定義する転換点となる。Demis Hassabis氏が予測する5〜10年以内のAGI(人工汎用知能)実現に向けた、重要なブレークスルーの一つと位置付けられる。
エージェント型AIの普及とウェブサイトの最適化
エージェント型AIの普及に伴い、ウェブサイトは人間だけでなく機械に対しても情報を伝達できるように最適化する必要が生じる。これは従来のSEOやCRO(コンバージョン最適化)から、AAIO(エージェント型AI最適化)への移行を意味する。コンテンツは構造化され、意味的に明確に記述され、AIエージェントが容易に理解・処理できる形式であることが重要になる。
回答エンジン最適化(Answer Engine Optimization)という概念も注目を集めている。AI応答にコンテンツが採用されるための最適化手法で、従来の検索エンジン最適化とは異なるアプローチが求められる。
技術進化に対応するビジネスモデルの変革
TurboQuantのような技術進化は、一部のビジネスモデルに根本的な変革を迫る。情報のキュレーションを主要な価値提案とするサービスは、AI概要によって需要が減少する可能性がある。一方で、深い専門性、独自の洞察、人間ならではの創造性を提供するコンテンツは、より高い差別化要因となる。
重要なのは、現在のビジネスモデルがAIの進化によってどのような影響を受けるかを客観的に評価し、必要に応じて適応することだ。Marie Haynes氏が提供するGemini Gemは、この評価プロセスを支援するツールとして機能する。複数のドキュメントを知識ベースに入力し、AIの世界でのビジネスの将来についてブレインストーミングを行うことができる。
この記事のポイント
- GoogleのTurboQuantはベクトル検索のインデックス作成時間を「ほぼゼロ」に短縮し、AI処理のメモリ要件を大幅に削減する技術だ。
- 従来はコストが高く限定的だった大規模な意味検索が可能になり、AI概要の質と量が向上する見込みである。
- パーソナライズされた検索体験が強化され、ユニバーサルAIアシスタントの実現に近づく。
- SEOにおいては、ユーザー意図の本質的理解と真に役立つコンテンツの提供が従来以上に重要になる。
- エージェント型AIの普及に伴い、ウェブサイトは機械に対しても情報を伝達できる最適化(AAIO)が必要となる。
・ 複数業界における17年間のデジタルビジネス開発経験
・ ウェブサイト開発のためのHTML、PHP、CSS、JavaScript等の実用的知識
・ 15ヶ国語対応の多言語SaaSの開発経験
・ 17年間にも及ぶ、Eコマース長期運営経験
・ 幅広い業界でのSEO最適化の豊富な経験

生成AI時代のSEO戦略——ChatGPT・Geminiに選ばれるECサイトの作り方
生成AIが検索エンジンの代わりに使われる時代が来つつある。ChatGPTやGemini、Perplexityといった大規模言語モデル(LLM)は、ユーザーの質問に答えるためにGoogleを検索し、情報を収集している。検索結果で上位に表示されない、あるいは全くランキングされていないページは、これらのAIプラットフォームからもほぼ見えない状態だ。
つまり、従来の検索エンジン最適化(SEO)は、生成AIプラットフォーム上での可視性を確保するための基盤技術として、その重要性を増している。ECサイト運営者は、人間の顧客だけでなく、AIエージェントにも発見され、引用されるための新しいSEO戦略を考える必要がある。
生成AIが検索エンジンをどう使うか
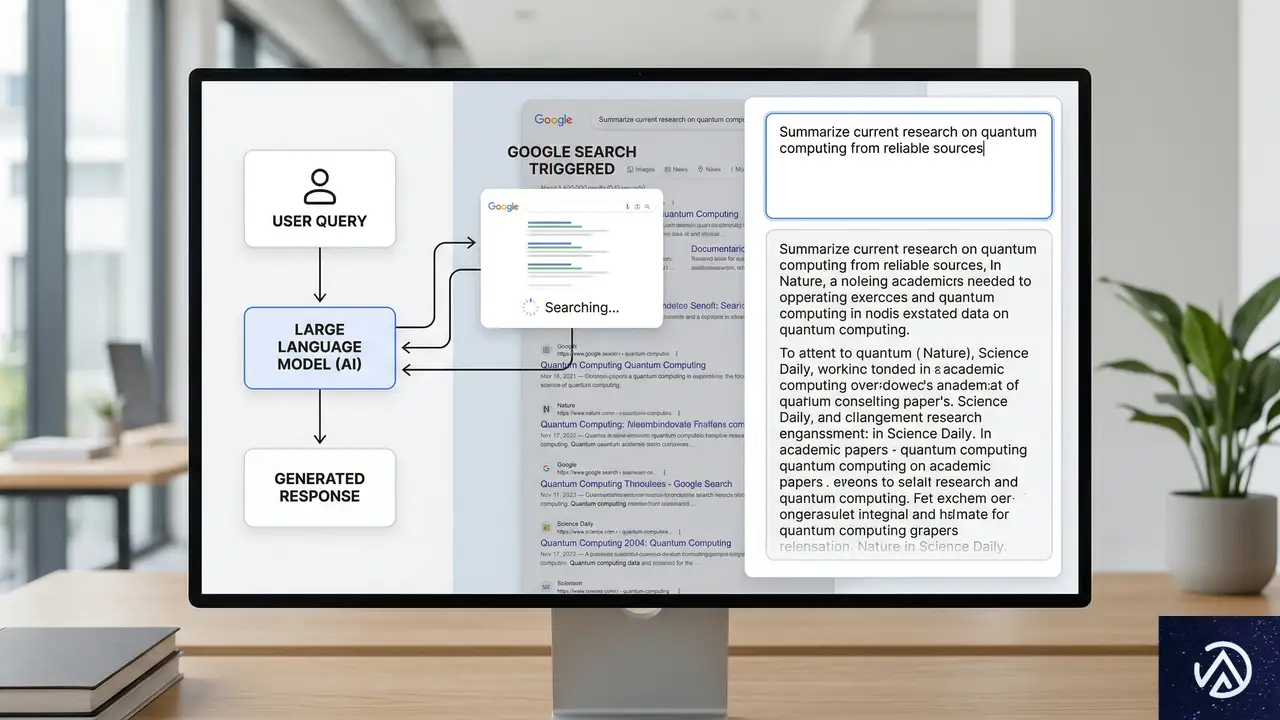
Practical Ecommerceの記事によると、ChatGPTなどの大規模言語モデルは、ユーザーの質問に答える際、内部でGoogle検索を実行して情報を収集している。この事実は、AI時代のSEOを考える上で決定的に重要だ。
AIが参照するのは、あくまでGoogleの検索インデックスだ。したがって、Googleで上位にランキングされていないページは、AIの回答にも引用されにくい。逆に言えば、従来のSEO対策でGoogleからの評価を高めることが、AIからの可視性を高める最も確実な近道となる。
AIの回答生成と引用のメカニズム
AIがユーザーに回答を提供する際、必ずしも情報源のサイト名を明示するとは限らない。内容を要約し、独自の言葉で回答を構成する場合が多い。しかし、その回答の根拠となる情報があなたのサイトから引用されていれば、それは間接的なブランド認知と信頼の構築に繋がる。
さらに、AIが特定の分野で繰り返しあなたのサイトの情報を参照するようになれば、将来的には「信頼できる情報源」として、より積極的な推薦を行う可能性も生まれる。この段階に至るためには、まずAIに「発見される」ことが不可欠だ。
AI時代のキーワードリサーチ

生成AIプラットフォームは、ユーザーがどのようなプロンプト(質問)を入力しているかのデータを公開していない。このため、従来の検索エンジン向けのキーワードリサーチ手法が、AI時代においても主要な情報源となる。
検索意図の深掘りがカギ
ユーザーが商品を購入するに至るまでの道筋(カスタマージャーニー)を理解することが重要だ。第三者のキーワードツールを活用し、キーワードを「情報収集」「比較検討」「購入」といった検索意図別に分類する。これにより、研究段階のユーザーから購入直前のユーザーまで、あらゆる段階でターゲットを捕捉するコンテンツ戦略が立てられる。
キーワードギャップ分析も有効だ。これは、競合サイトが獲得しているが自社サイトが獲得できていないキーワードを特定する手法である。これらのキーワードをターゲットにしたコンテンツを作成することで、見込み客を取り込む機会を増やせる。
長く、予測不能なプロンプトへの備え
AIへのプロンプトは、従来の検索クエリよりも長く、会話調である傾向がある。また、その内容は多様で予測が難しい。しかし、高レベルのキーワード最適化を行い、ユーザーの根本的なニーズ(問題解決、欲求充足)に応えるコンテンツを用意しておくことが、あらゆる形式の問い合わせに対する最良の備えとなる。
AIと人間の両方に最適化されたコンテンツ
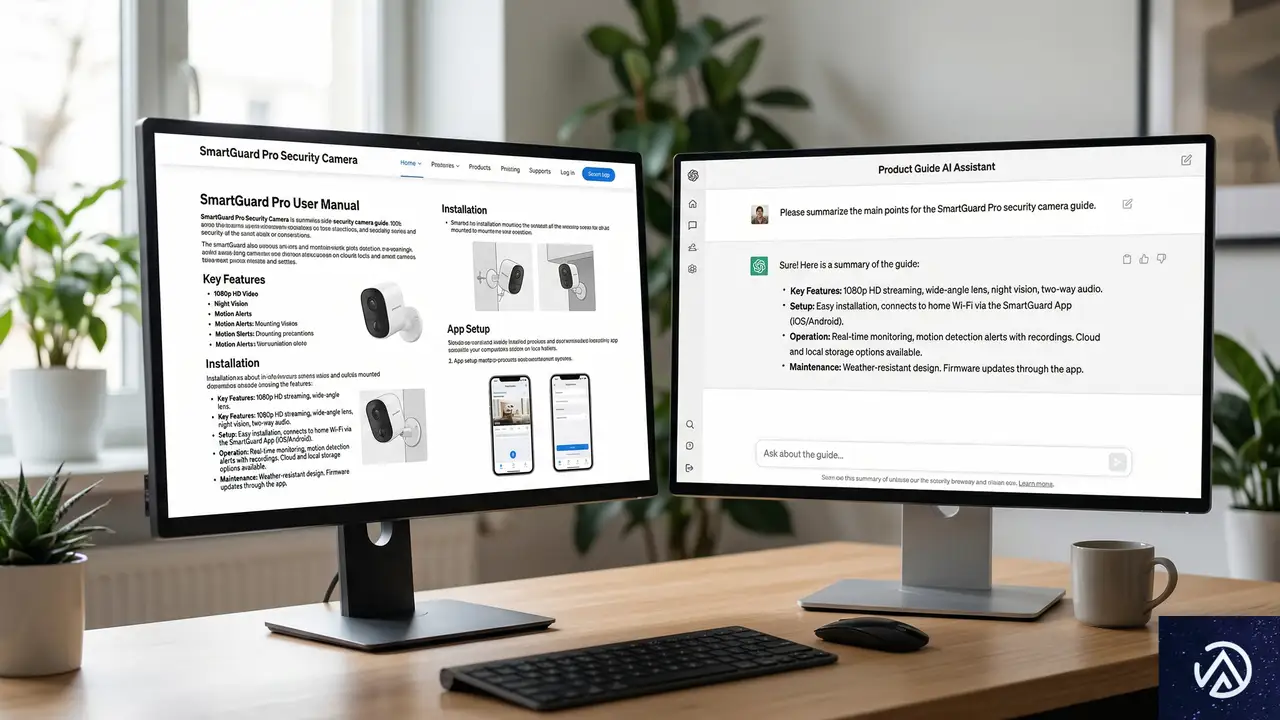
最高のECコンテンツとは、自社の商品が消費者のニーズに対応し、問題を解決する方法を説明するものだ。トラフィックの絶対量は数年前より減少しているかもしれないが、商品発見のための基盤としての重要性は変わらない。
ファネル全体をカバーするコンテンツ戦略
「購入直前」(ボトムオブザファネル)のクエリのみに焦点を当てるのは短絡的だ。確かにコンバージョンに直結しやすいが、新規顧客の発見という観点では機会を狭めてしまう。認知段階や検討段階のユーザーを惹きつけるトップ・ミドルファネルのコンテンツも充実させることで、AIが幅広い質問に対してあなたのサイトを情報源として参照する可能性が高まる。
要約されても価値がある
AIがあなたのコンテンツを要約し、会社名を明示せずに回答に組み込むこともある。一見するとブランド露出の機会を失っているように思える。しかし、あなたの情報が「信頼できるLLMソリューションの一部」として回答に含まれることは、将来的な直接的な推薦への布石となり得る。まずは質の高い情報を提供し、AIの学習データの一部になることが第一歩だ。
AIエージェントが理解しやすいサイト構造
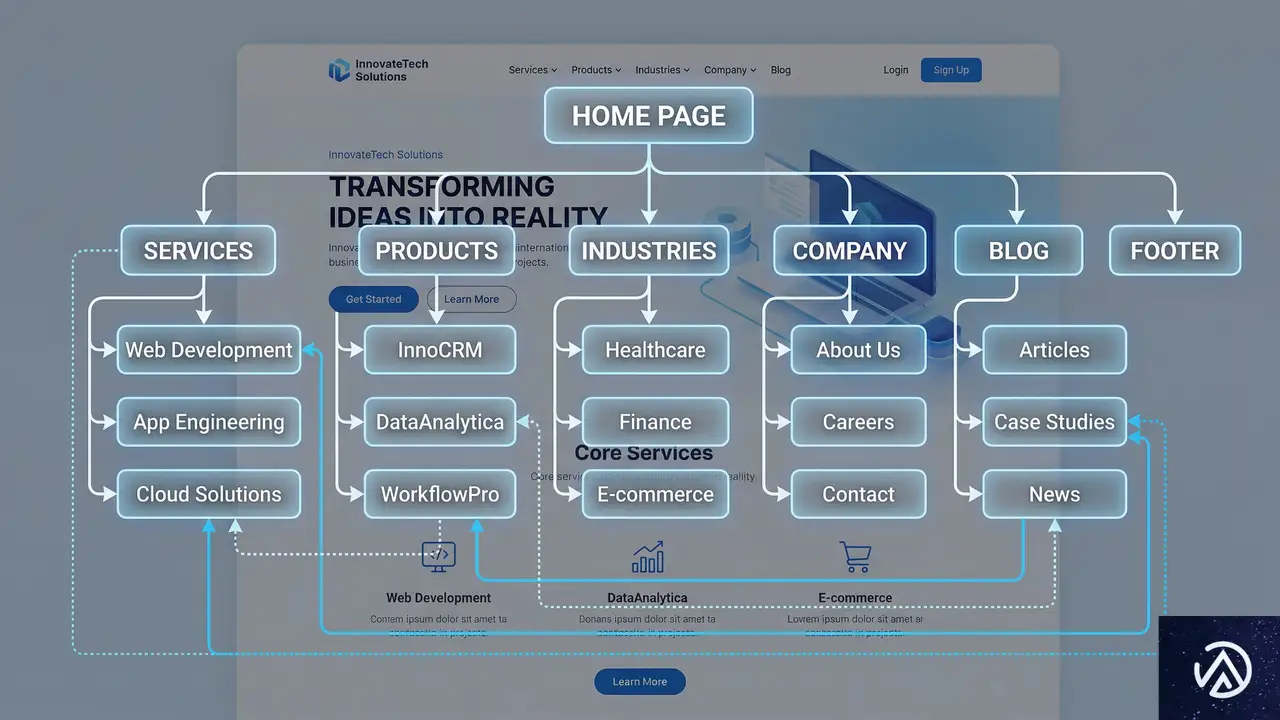
サイトのアーキテクチャ(構造)は、人間のユーザーだけでなく、AIボットがサイトを理解する上でも極めて重要だ。水平型のサイトアーキテクチャ(ページが深く埋もれていない構造)と適切な内部リンクは、ボットの巡回性を高め、ロングテールキーワードでのランキング機会を増やす。
明確な構造がAIの理解を助ける
整理されたサイト構造は、AIがあなたのビジネスを理解し、その商品やサービスをトレーニングデータ内で正しく位置づける手助けをする。これは、関連する質問に対してあなたのサイトが候補として挙がりやすくなることを意味する。
最適化されたナビゲーションの条件
AIエージェントにも対応した最適化されたサイトナビゲーションは、以下の条件を満たしている。
- 人間とAIエージェントの両方が、素早く必要なものを見つけられる構造である。
- JavaScriptが無効でも利用可能で、あらゆるウェブブラウザでアクセスできる。
- サイトの最も重要なセクションと、提供する主なベネフィットに焦点が当てられている。
このような堅牢な構造は、あらゆるクローラー(Googleボット、AIボット)に対して、サイトの価値を明確に伝える基盤となる。
リンク構築と権威性の信号
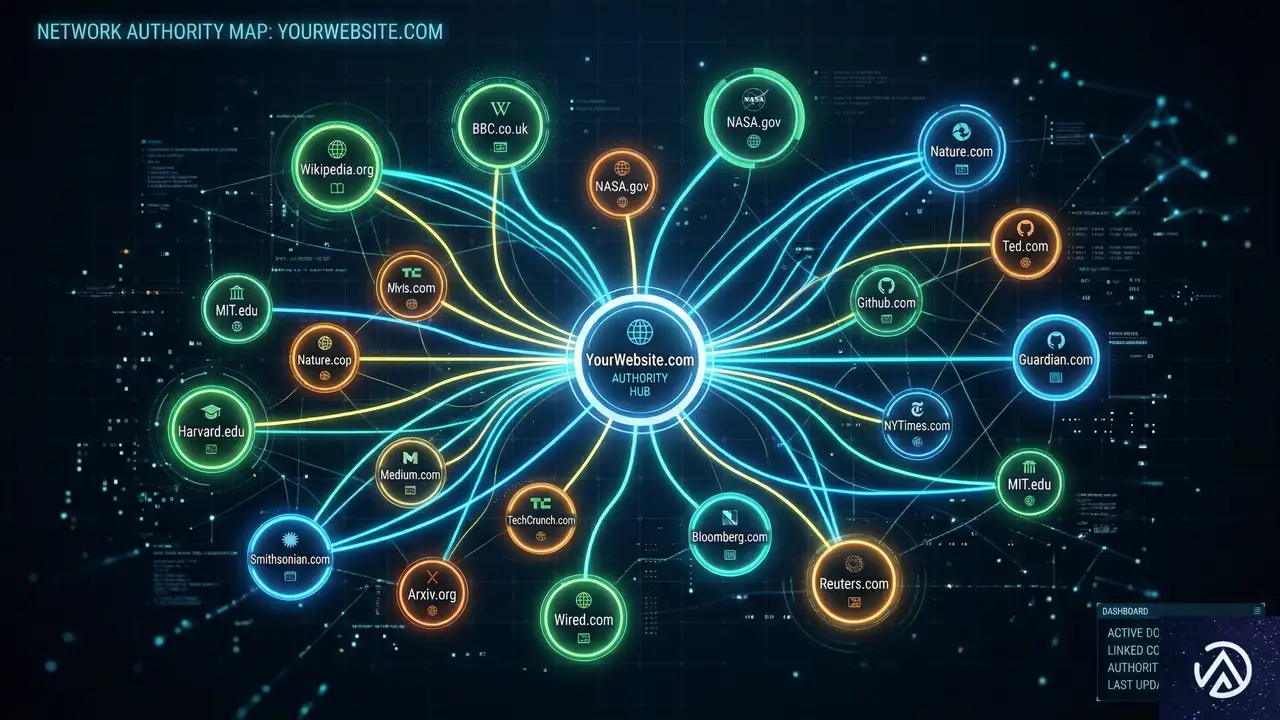
バックリンクなどの権威性の信号が、生成AIの可視性にどの程度影響するかは、現時点では完全には解明されていない。しかし、間接的な証拠や専門家の推察から、従来のSEOと同様に重要な役割を果たしていると考えられる。
間接的だが無視できないシグナル
高い有機検索順位は、そのままAIによる発見を促進する。さらに、権威ある競合他社と共に言及・リンクされる「エンティティ関連性」は、検索順位を押し上げる。自社サイトから権威ある出版物への一貫した言及やリンクは、AIがあなたのビジネスを信頼する材料を提供する。
これらの間接的なAIシグナルは、従来のリンク構築手法を通じて獲得できる。ジャーナリストへのアウトリーチ、専門家としてメディアに引用されること、ソーシャルメディア上での関係構築などがその具体策だ。
可視性が第一歩
生成AI検索最適化(GEO)における成功の第一定義は、実際の売上ではなく「可視性」である。AIの回答に引用され、ユーザーの目に触れる機会を増やすことが初期目標だ。そして、従来のSEO対策を怠ったサイトがAIに見いだされる可能性は、限りなくゼロに近い。
この記事のポイント
- ChatGPTなどの生成AIは、回答生成のためにGoogleを検索している。したがって、Google SEOはAI可視性の基礎となる。
- AI向けのキーワードリサーチでは、検索意図を深掘りし、カスタマージャーニーの全段階をカバーすることが重要だ。
- コンテンツは、商品が問題を解決する方法を説明するものに注力する。AIに要約されても、信頼できる情報源としての地位を築く第一歩となる。
- 水平型のサイト構造と明確なナビゲーションは、AIボットがサイトを理解し、情報を正しく処理するために不可欠だ。
- バックリンクやブランド言及は、AIがサイトの権威性を判断する間接的なシグナルとして機能する可能性が高い。
・ 複数業界における17年間のデジタルビジネス開発経験
・ ウェブサイト開発のためのHTML、PHP、CSS、JavaScript等の実用的知識
・ 15ヶ国語対応の多言語SaaSの開発経験
・ 17年間にも及ぶ、Eコマース長期運営経験
・ 幅広い業界でのSEO最適化の豊富な経験

AI時代のEC集客戦略:高品質コンテンツを生む12ステップのフレームワーク
AIによってコンテンツ制作のコストが劇的に下がった一方で、インターネット上には似たような質の低い記事が溢れかえっている。2026年の現在、ECサイトが検索エンジンやSNSのフィードで生き残るためには、単にAIで文章を生成するだけでは不十分だ。
検索結果のクリック率低下や、AIチャットによるユーザー行動の変化に対応するためには、AIを活用しながらも「人間が書いた以上の価値」を提供できるプロセスが求められている。Practical Ecommerceの記事では、この課題を打破するための具体的なフレームワークが提示された。
この記事では、AIを強力な武器に変え、オーガニックトラフィックを確実に獲得するための「12ステップのフレームワーク」を詳しく解説する。量産型の「AIスロップ(AI製のゴミコンテンツ)」から脱却し、真に顧客を惹きつけるコンテンツ作りのヒントを探っていこう。
2026年のAIコンテンツ市場が直面する負のスパイラル

現在、コンテンツマーケティングの世界では大きな地殻変動が起きている。かつては記事を書き、検索順位を上げれば自然とトラフィックが流入してきたが、その「当たり前」が通用しなくなっているのだ。
ゼロクリック検索とAIチャットの台頭
ゼロクリック検索とは、ユーザーが検索エンジンで検索を行った際、結果画面に表示される情報だけで満足し、どのサイトもクリックせずに離脱する現象を指す。2026年、この割合はさらに増加している。Googleの検索結果画面にはAIによる回答(AI Overviews)が鎮座し、ユーザーが個別の記事を訪れる必要性は薄れつつある。
さらに、多くの消費者が検索の入り口としてChatGPTやPerplexityのようなAIチャットを使い始めている。検索の「始まりから終わりまで」をAIとの対話で完結させてしまうため、従来のSEO(検索エンジン最適化)だけでは顧客との接点を持つことが難しくなっているのが現状だ。
アルゴリズム更新によるトラフィックの激変
2026年2月に実施されたGoogleのアルゴリズムアップデートは、多くの大手メディアに衝撃を与えた。特に、スマートフォンなどのフィードに表示される「Google Discover」への影響が大きかった。DiscoverSnoopの調査によれば、Yahooのような巨大サイトですら、このアップデートによってコンテンツの露出が約50%減少し、オーディエンスが6割以上も激減したという。
こうした状況下で、多くのマーケターは「トラフィックが減った分を、AIによる大量生産で補おう」という誘惑に駆られる。しかし、これが負のスパイラルの始まりだ。安易なAI生成コンテンツはどれも似たようなトーンになり、結果として競争力を失い、さらにパフォーマンスが悪化するという悪循環に陥ってしまう。
なぜ「量」ではなく「質」が差別化要因になるのか

1年前まで、AIを活用する最大のメリットは「スピード」や「コスト」だった。しかし、誰もがAIを使えるようになった現在、そのアドバンテージは消失した。今、他社と差をつけるために必要なのは、AIをどう使いこなして「質」を担保するかという実行力の差である。
AIスロップからの脱却
AIスロップ(AI Slop)とは、AIによって生成された、価値の低い、あるいは不正確なコンテンツを指す。読者は直感的に「これはAIが書いた中身のない記事だ」と見抜くようになっている。検索エンジンもまた、こうした低品質な情報の氾濫を食い止めるべく、より専門性(Expertise)、体験(Experience)、権威性(Authoritativeness)、信頼性(Trustworthiness)の「E-E-A-T」を重視するようになっている。
単に「プロンプト(AIへの指示文)」を工夫するだけでは、この壁を越えることはできない。必要なのは、AIの出力を厳密に管理し、検証し、洗練させるための「プロセス」そのものの構築だ。
人間を超えるAIライティングの可能性
一方で、適切に管理されたAIコンテンツは、人間が書いたものと同等、あるいはそれ以上の評価を受けることもある。ニューヨーク・タイムズが行ったクイズ形式の調査では、人間が書いた文章と、それをAIがリライトした文章を比較した際、約半数の読者がAI版を好むという結果が出た。
これは「AIの文章は冷たい」「人間味がない」という先入観を捨てるべきであることを示唆している。AIは構造化、論理の整理、多角的な視点の提供において非常に優れている。その強みを引き出しつつ、人間が最終的な品質を保証する体制こそが、2026年の勝ちパターンだ。
高品質なAIコンテンツを生む12ステップ・フレームワーク

Practical Ecommerceが提唱する「12ステップ・フレームワーク」は、コンテンツ制作を細分化し、各工程でAIと人間が協力することで品質を極限まで高める手法だ。このプロセスを自動化のワークフローに組み込むことで、安定して高い成果を出すことが可能になる。
企画から検証までの初期段階
最初のステップは、具体的なトピックと記事の目的を明確にすることだ(ステップ1:アイデア)。次に、信頼できる情報源(ソース)を収集し、記事のトーンやスタイルを定義する(ステップ2:ソースとブリーフ)。ここで重要なのは「どの情報をAIに与えるか」を人間が厳選することである。
続いて、入力した情報の信頼性をチェックする(ステップ3:検証)。AIが誤った情報を元に文章を作らないよう、ソースの信憑性を確認する工程だ。その後、各ソースから重要な事実やデータ、主張を抽出して要約し(ステップ4:要約)、記事の骨組みとなる構成案を作成する(ステップ5:構成)。
執筆・校正・最適化のプロセス
構成案に基づき、AIにフルバージョンの記事を書かせる(ステップ6:草案)。ここからが品質を分ける重要な工程だ。生成された草案をブリーフや構成案と照らし合わせ、AI自身に批判的に添削させる(ステップ7:校正)。さらに、ソースとの類似性をチェックし、意図しない盗用を防ぐ(ステップ8:盗用チェック)。
また、AI特有の言い回しや不自然な表現を排除し(ステップ9:AI臭の排除)、検索エンジンだけでなく、AIチャット(回答エンジン)やGoogle Discoverに最適化させる(ステップ10:最適化)。最後に、これまでの工程をクリアしているかをAIに採点させ、高得点のものだけを人間が最終チェックする(ステップ11:評価)。最後に、情報の鮮度を保つための更新予定日を設定して完了だ(ステップ12:更新トリガー)。
【独自分析】ECサイトにおけるAIコンテンツの活用戦略

このフレームワークを実際のECサイト、例えばWooCommerce(ウーコマース)を運用しているショップにどう適用すべきか。単なる商品説明にとどまらない、戦略的なアプローチが必要だ。
Google Discoverへの最適化とクリック率予測
ECサイトにとって、Google Discoverは爆発的なトラフィックをもたらす宝庫だ。Discoverに掲載されるためには、ユーザーの興味を強く惹きつけるタイトルと画像が欠かせない。12ステップの「最適化」段階では、AIを使って複数のタイトル案を生成し、それぞれのクリック率を予測するツール(Discover click-through predictorなど)を活用するのが有効だ。
また、Discoverは「新しさ」だけでなく「関連性」を重視する。過去に売れた商品の活用事例や、季節ごとの悩み解決記事などを、このフレームワークに沿って高品質に仕上げることで、フィードへの露出機会を最大化できる。
AIスロップと高品質コンテンツの視覚的比較
ここで、単にAIに書かせただけの「AIスロップ」と、フレームワークを経て構造化された「高品質コンテンツ」の違いを視覚的に見てみよう。ECサイトのブログ記事を想定したデモだ。
<!-- 高品質なコンテンツの構造例 -->
<div class="content-comparison">
<div class="slop-example">
<h4>AIスロップ(NG例)</h4>
<p>商品は良いです。多くの人が買っています。特徴は3つあります。1つ目は安さ、2つ目は速さ、3つ目は便利さです。ぜひ買ってください。</p>
</div>
<div class="quality-example">
<h4>高品質コンテンツ(OK例)</h4>
<p>最新の調査データによれば、ユーザーの8割が「時短」を重視しています。本製品は独自の技術により、従来比30%の効率化を実現しました。</p>
</div>
</div>※このデモは、具体性の欠ける一般的な記述(左)と、データとベネフィットを構造化した記事(右)の対比を視覚化したイメージである。
左側の例は、AIに「おすすめの靴について記事を書いて」と丸投げした際によく見られるパターンだ。一方、右側は「具体的なデータ(2026年の歩行解析)」や「具体的なターゲットの悩み(立ち仕事の疲れ)」をソースとして与え、フレームワークに沿って出力させた結果を想定している。どちらがユーザーに刺さり、検索エンジンに評価されるかは明白だ。
この記事のポイント
- 2026年はゼロクリック検索やAIチャットの普及により、単純なSEO記事では流入が稼げない。
- Google Discoverなどのフィードで生き残るには、アルゴリズムの変動に耐えうる「質の高いコンテンツ」が必須となる。
- AIによる量産は「負のスパイラル」を招くため、量ではなくプロセスによる差別化を目指すべきだ。
- 12ステップのフレームワークを活用し、検証・校正・最適化をシステム化することで、AIスロップを回避できる。
- ECサイトでは、具体的なデータや顧客のベネフィットに基づいた「構造化された情報」の提供が勝敗を分ける。
・ 複数業界における17年間のデジタルビジネス開発経験
・ ウェブサイト開発のためのHTML、PHP、CSS、JavaScript等の実用的知識
・ 15ヶ国語対応の多言語SaaSの開発経験
・ 17年間にも及ぶ、Eコマース長期運営経験
・ 幅広い業界でのSEO最適化の豊富な経験

Google-Agent登場でSEO激変?エージェント・ウェブの到来とWebMCPの衝撃
Googleが新しいユーザーエージェント「Google-Agent」を発表した。これは単なる情報の収集だけでなく、AIエージェントが人間に代わってウェブサイト上で「行動」することを前提とした仕組みだ。従来の「人間がブラウザでページを閲覧する」というウェブのあり方が、根本から覆されようとしている。
この変化は、SEO(検索エンジン最適化)の歴史において最も大きなパラダイムシフトになると予測されている。これまではキーワードで検索結果の上位を狙い、ユーザーのクリックを誘発することがゴールだった。しかし、これからは「AIエージェントがいかにスムーズにサイトの機能を利用できるか」が重要になる。
本記事では、Googleが推進する「エージェント・ウェブ」の正体と、それを支える技術プロトコル、そして今後のウェブ運営者が取るべき対策について深掘りしていく。検索の未来は、単なる情報の提示から「タスクの完了」へと急速にシフトしているのだ。
Google-Agentとは何か?新しいクローラーが示唆する未来

Googleが新たに導入した「Google-Agent」は、特定のAIエージェントがユーザーの指示を受けてウェブサイトにアクセスする際に使用される識別子だ。Google DeepMindが開発した「Project Mariner」のような、ブラウザを操作するAIモデルがこれを利用する。従来のGooglebotが検索インデックス作成のために巡回するのに対し、Google-Agentは「実務の代行」のためにサイトを訪れる点が異なる。
ユーザーに代わって「行動」するAIエージェント
AIエージェントとは、ユーザーの意図を汲み取り、自律的にタスクを実行するソフトウェアのことだ。例えば「来週の出張のために、予算3万円以内で東京駅近くのホテルを予約してほしい」と頼めば、エージェントが複数のサイトを巡回し、条件に合うプランを見つけ、予約フォームの入力まで済ませてくれる。この一連の動作において、人間は一度もサイトの画面を見る必要がない。
Googleの検索部門責任者であるLiz Reid氏は、将来的に「多くのエージェント同士が会話する世界」が来ると予測している。ユーザーのエージェントがホテルの予約システム(エージェント)と直接交渉し、最適な取引を成立させる。これが、Googleが描く「エージェント・ウェブ」の姿だ。
Google-Agentの識別とサイト側の対応
Google-Agentは、HTTPリクエストのUser-Agentヘッダーに含まれる。これにより、ウェブサイトの運営者は「今アクセスしているのは人間か、それともGoogleのAIエージェントか」を判別できる。Search Engine Journalの記事によれば、モバイル版とデスクトップ版の両方でこの新しいタグが使用されることが確認されている。
現在、多くのSEO担当者が「AIによるクローリングを拒否すべきか」を議論している。しかし、Google-Agentをブロックすることは、AIエージェント経由で訪れる「購買意欲の高いユーザー」を門前払いすることと同義だ。これからのウェブサイトは、AIが読みやすく、かつ操作しやすい構造を持つことが生き残りの条件となる。
「エージェント・ウェブ」を支える5つの主要プロトコル
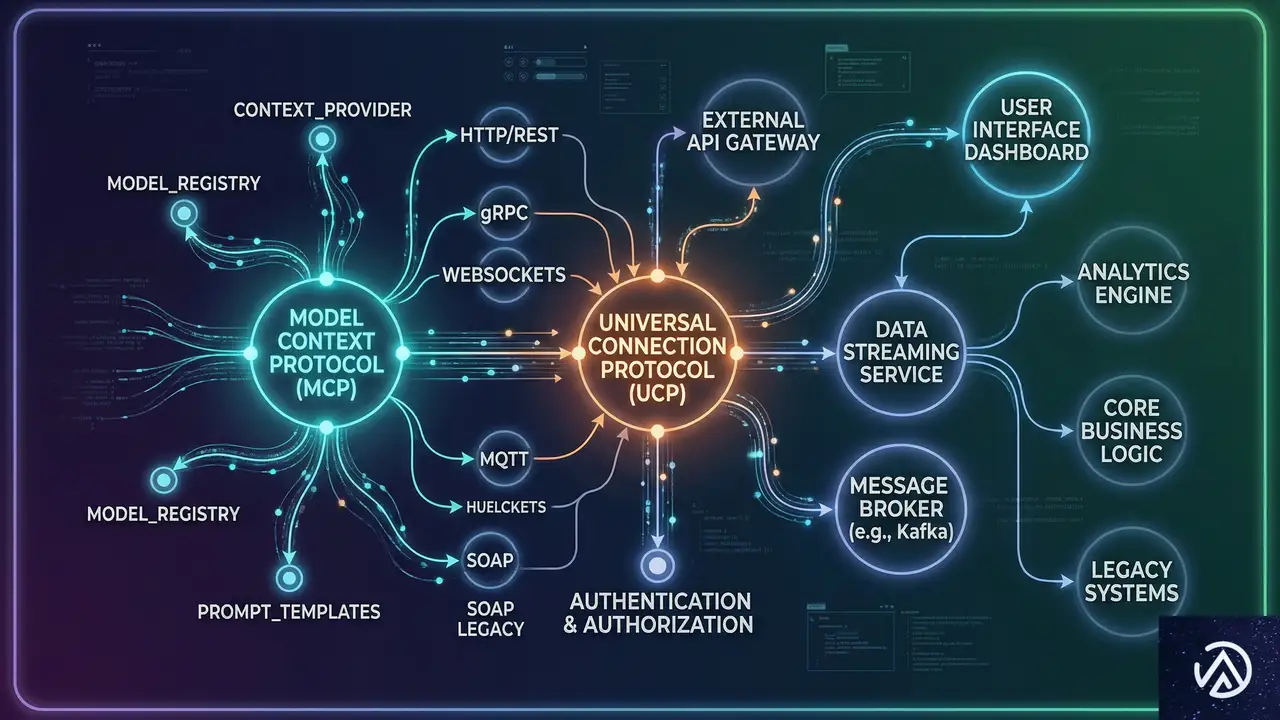
AIエージェントがウェブサイトを効率的に利用するためには、人間向けの視覚的なUI(ユーザーインターフェース)だけでは不十分だ。Googleは、マシン同士がデータをやり取りし、機能を実行するための複数のプロトコルを提唱している。これらは、今後のウェブ開発における共通言語となる可能性が高い。
WebMCP:サイトの機能をネイティブに操作する
WebMCP(Model Context Protocol)は、AIエージェントがウェブサイトのバックエンドデータや機能に安全にアクセスするための仕組みだ。従来のブラウザ操作では、AIは画面上のピクセルを解析してボタンの場所を探す必要があり、処理が遅くエラーも起きやすかった。WebMCPを使えば、エージェントはサイトが提供する「ツール」を直接呼び出せるようになる。
例えば、問い合わせフォームを埋める際、エージェントはHTMLの構造を解析するのではなく、WebMCP経由で必要なデータ項目を直接受け取り、正確な値を流し込む。これにより、人間が操作するよりも遥かに高速かつ正確なタスク実行が可能になる。これは、ウェブサイトが「閲覧される文書」から「呼び出し可能なAPIの集合体」に変わることを意味している。
UCPとA2A:AI同士が商談し決済する世界
ECサイトにとって特に重要なのが、UCP(Universal Commerce Protocol)だ。これは、検索結果画面(SERPs)から直接、AIが商品の購入手続きを行えるようにするプロトコルだ。ユーザーは商品詳細ページに遷移することなく、AIアシスタントに「これを買って」と伝えるだけで注文が完了する。
また、A2A(Agent to Agent)は、異なるサービスのエージェント同士が通信するための規格だ。Marie Haynes氏によれば、将来的には「私のSEOエージェントが、あなたの提供するツールのエージェントと価格交渉を行う」といったシナリオも現実味を帯びている。ビジネスの接点が、人間対人間から、プログラム対プログラムへと移行していくのだ。
このデモは、従来の人間主体のウェブ閲覧と、AIエージェントが直接システムと対話する次世代のウェブ構造の違いを視覚化したイメージだ。
検索の概念が変わる。AI Searchへの完全移行

GoogleのNick Fox氏は「検索はAI Search(AI検索)になりつつあり、Geminiアプリはあなたのパーソナルアシスタントである」と述べている。これは、従来の「10本の青いリンク」が並ぶ検索結果ページが、最終的にはAIとの対話インターフェースに吸収されることを示唆している。Googleは「AIモード」と「AI Overviews(AIによる概要回答)」を一体のものとして捉え始めている。
「検索結果」から「パーソナルアシスタント」へ
これまでの検索エンジンは、ユーザーが入力したクエリに対して「関連する可能性が高いページ」を提示する場所だった。しかし、これからのGoogleは、ユーザーの代わりに問題を解決する「アシスタント」へと進化する。ユーザーが情報を探す手間を省き、答えを直接提示したり、アクションを実行したりすることが主目的となる。
この変化により、ウェブサイトへの流入(クリック数)は減少する可能性がある。AIが検索結果画面でユーザーの疑問を解決してしまえば、サイトを訪れる必要がなくなるからだ。しかし、Marie Haynes氏は、これを「摩擦のない商取引(フリクションレス・コマース)」のチャンスだと捉えている。クリックを稼ぐのではなく、AIを通じて直接コンバージョン(成果)を得るモデルへの転換が求められている。
コンテンツ制作者とプラットフォームの新たな関係
1998年の創業以来、Googleとコンテンツ制作者の間には「コンテンツを提供すれば、代わりにトラフィックと広告収益を還元する」という暗黙の了解があった。しかし、AIがコンテンツを学習し、その要約をユーザーに提供する現在のモデルでは、このパートナーシップは崩壊しつつあるとの見方もある。
これからのクリエイターや企業は、単に情報を発信するだけでなく、AIエージェントが「利用できる価値」を提供する必要がある。それは独自のデータであったり、AIが実行可能な特定のサービス機能であったりする。情報の「量」ではなく、エージェントにとっての「有用性」が、新しい評価軸となるだろう。
実務者が今すぐ取り組むべき3つのアクション

エージェント・ウェブの全貌はまだ不透明だが、今から準備を始めることは可能だ。技術の進化をただ待つのではなく、AIが好むサイト構造へと段階的にシフトしていくことが推奨される。ここでは、具体的な3つのステップを挙げる。
構造化データを超えた「機能の公開」
これまでのSEOでは、Schema.orgなどの構造化データを用いて、情報の意味を検索エンジンに伝えてきた。これからはさらに一歩進んで、サイトの「機能」をAIが利用できるように整備する必要がある。具体的には、WebMCPのようなプロトコルの動向を注視し、将来的にAPIやエージェント専用のインターフェースを提供できる準備をしておくことだ。
特にECサイトを運営している場合は、UCP(Universal Commerce Protocol)について学ぶことが不可欠だ。Googleのショッピング機能と連携し、AIが商品を正しく認識し、決済フローを理解できるようにデータを整えておくことが、将来の売上に直結する。
「バイブ・コーディング」による開発スピードの向上
Marie Haynes氏は、AIツールを活用して直感的に開発を行う「バイブ・コーディング(Vibe Coding)」の重要性を説いている。Claude CodeやGoogle AI Studioなどのツールを使い、自然言語で指示を出しながら、AIエージェントに対応した機能を素早く実装していく手法だ。
技術的な詳細をすべて手書きするのではなく、AIと対話しながら「エージェントが使いやすい構造」をプロトタイピングしていく。このスピード感が、変化の激しいAI時代には武器になる。開発者だけでなく、マーケターもこれらのツールに触れ、AIがどのようにコードやデータを解釈するのかを肌感覚で理解しておくべきだ。
独自分析:SEO担当者は「エージェント最適化」へ舵を切るべきか
筆者の見解として、今後のSEOは「Search Engine Optimization」から「Agentic Ecosystem Optimization(エージェント・エコシステム最適化)」へと変質していくだろう。これまでは「人間にどう見せるか」というUX(ユーザーエクスペリエンス)が重視されてきたが、今後はそれに加えて「AIエージェントにとっての使い勝手」を考慮したAX(エージェントエクスペリエンス)が重要になる。
これは、小規模なサイト運営者にとっては大きなチャンスかもしれない。巨大なドメインパワーを持つサイトが検索結果を独占する時代から、特定のタスクを最も効率的に解決できるエージェントを持つサイトが選ばれる時代になる可能性があるからだ。ユーザーの「悩み」を解決する具体的な「機能」を提供できれば、検索順位に関わらずAIエージェントがあなたのサイトを指名してくれるようになるだろう。
一方で、単なる情報のまとめサイトや、独自の価値がないコンテンツは、AI Overviewsによって完全に代替され、存在意義を失うリスクが高い。これからのウェブサイトは、単なる「情報の置き場所」ではなく、特定の目的を遂行するための「道具」として再定義される必要がある。Google-Agentの登場は、その長い旅の始まりに過ぎない。
この記事のポイント
- Google-Agentは、AIエージェントがユーザーに代わってサイトを操作するための新しい識別子だ。
- WebMCPやUCPといった新プロトコルにより、AIがサイトの機能をネイティブに利用可能になる。
- 検索は「情報の提示」から「タスクの実行(パーソナルアシスタント)」へと進化している。
- 今後のSEOは、クリックを稼ぐことよりも、AIエージェントを通じた直接的なアクションの完了を目指すべきだ。
- 「バイブ・コーディング」などのAI開発ツールを活用し、変化に即応できる体制を整えることが重要だ。
・ 複数業界における17年間のデジタルビジネス開発経験
・ ウェブサイト開発のためのHTML、PHP、CSS、JavaScript等の実用的知識
・ 15ヶ国語対応の多言語SaaSの開発経験
・ 17年間にも及ぶ、Eコマース長期運営経験
・ 幅広い業界でのSEO最適化の豊富な経験

AEO(回答エンジン最適化)の新戦略:AI検索でコンテンツを引用させるための構造化手法
検索エンジンの役割が「リンクの羅列」から「直接的な回答」へと劇的に変化している。GoogleのAI OverviewsやMicrosoft Copilot、PerplexityといったAI検索エンジンの普及により、Webサイトの運営者は従来のSEO(検索エンジン最適化)に加えて、AEO(Answer Engine Optimization:回答エンジン最適化)への対応を迫られている状況だ。
最新の調査データによれば、AI検索からのトラフィックは月間約1%のペースで成長を続けており、特定の業界では無視できない規模に達している。AIにコンテンツを引用させ、自社の認知度を高めるためには、これまでの「ページ単位の評価」という考え方を捨てる必要がある。
この記事では、AIがどのようにコンテンツを解析し、どの断片を回答として採用するのかを、最新の研究結果と技術的な視点から詳しく解説する。AI時代に生き残るためのコンテンツ構造の作り方を、具体的なステップと共に見ていこう。
AIは「ページ」ではなく「断片」でコンテンツを評価する

従来の検索エンジンは、キーワードの関連性やリンクの強さを基に「Webページ全体」をランク付けしてきた。しかし、AI検索エンジンは全く異なるアプローチを取る。AIはページを読み込む際、内容を細かな「断片(フラグメント)」に分解して理解しようとする。このプロセスは「パージング(解析)」と呼ばれ、AIが回答を生成するための基礎となる。
パージング(解析)というプロセスの理解
MicrosoftのBingチームでプリンシパル・プロダクトマネージャーを務めるKrishna Madhavan氏によれば、AIアシスタントはコンテンツを構造化された小さな断片に分解し、それぞれの権威性と関連性を評価する。そして、複数のソースから抽出した最適な断片を組み合わせて、一つの首尾一貫した回答を作り出すのだ。
これは、たとえGoogleで検索順位が1位だったとしても、コンテンツの構造がAIにとって抽出困難であれば、AIの回答には引用されない可能性があることを示している。AIは「最も優れたページ」を探しているのではなく、「質問に対する最も適切な回答の断片」を探しているからだ。
AIトラフィックの現状と成長率
2026年1月のConductor AEO/GEOベンチマークレポートによると、AI経由のトラフィックはWebサイト全体のセッションの約1.08%を占めている。数字だけ見れば小さく感じるかもしれないが、前年比で357%もの急増を見せたケースもあり、その成長速度は驚異的だ。
特に医療分野では、Google検索の約2回に1回がAIによる概要表示(AI Overviews)を伴うというデータもある。ユーザーが検索結果のリンクをクリックする前にAIの回答で満足してしまう「ゼロクリック検索」が増える中で、AIの回答内に自社サイトが「出典」として引用されることは、新たな流入経路を確保するための生命線となる。
研究結果から判明した「引用されやすいコンテンツ」の条件

どのようなコンテンツがAIに好まれるのかについては、すでに複数の大学や研究機関が実証実験を行っている。その中でも、プリンストン大学やジョージア工科大学などが発表した「GEO(Generative Engine Optimization:生成エンジン最適化)」に関する論文は、非常に示唆に富んでいる。
GEO(生成エンジン最適化)の有効な手法
この研究では、9つの最適化戦略をテストした結果、特定のテクニックによってAI回答での視認性が最大40%向上することが確認された。最も効果的だったのは「信頼できる情報源の引用」だ。統計データや専門家の発言を適切に引用しているサイトは、そうでないサイトに比べて視認性が115.1%も増加したという。
一方で、意外な事実も判明している。文章を「説得力のあるトーン」や「権威を感じさせる文体」で書くことは、AIの引用率向上にはほとんど寄与しなかった。AIはレトリック(修辞学)に惑わされることはなく、検証可能な事実と論理的な構造を重視している。マーケティング的な装飾よりも、裏付けのある情報提供が優先される環境だ。
第三者メディア(アーンドメディア)の圧倒的な影響力
トロント大学が2025年9月に行った調査では、ChatGPTやPerplexityなどの主要AIエンジンが、自社サイトよりも「第三者による評価」を圧倒的に信頼していることが明らかになった。例えば家電分野では、AIが引用するソースの92.1%が第三者の専門メディアやレビューサイトであり、メーカー公式サイトの引用率は極めて低かった。
これは、自社サイト内でのSEOだけでは不十分であることを意味している。業界紙への寄稿、プレスリリース、信頼性の高い比較サイトへの掲載といった「アーンドメディア(獲得メディア)」での露出が、間接的にAI検索での視認性を高める鍵となる。AIはインターネット全体を俯瞰し、多くの場所で言及されている情報を「真実」として採用する傾向があるからだ。
AIに選ばれるための具体的な構造化テクニック

AIがコンテンツを「断片」として抽出する以上、制作者側も「抽出されやすい形」で情報を提供しなければならない。ここでは、MicrosoftやGoogleのガイドライン、および最新の研究に基づいた具体的な構成案を提示する。
見出しの役割とQ&A形式の採用
見出し(H2やH3タグ)は、AIにとって「ここから新しい概念が始まる」という強力なシグナルになる。「概要」や「詳細はこちら」といった曖昧な見出しは避け、そのセクションの内容を正確に記述した見出しを付けるべきだ。例えば「AIによるコンテンツ解析の仕組み」といった具体的な表現が望ましい。
また、ユーザーの質問をそのまま見出しにし、その直後で端的に回答する「Q&A形式」はAIとの相性が抜群だ。AIアシスタントは、この質問と回答のペアをそのままコピーしてユーザーに提示することが多いため、引用される確率が飛躍的に高まる。結論を先に述べ、その後に詳細な解説を続ける「逆ピラミッド型」の記述を徹底しよう。
「スニッパブル(切り出し可能)」なレイアウト設計
AIは長い段落よりも、箇条書き、番号付きリスト、比較表といった構造化されたデータを好む。これらは「スニッパブル(Snippable)」、つまり簡単に切り出せる形式だからだ。情報を整理して提示することで、AIは人間と同じように「このサイトは情報が整理されていて分かりやすい」と判断する。
以下のデモは、AIが情報を抽出しやすい「構造化された比較」のイメージだ。このように明確な境界線とラベルを持つ構成は、AIによるパージングを助ける効果がある。
<!-- 構造化された情報の例 -->
<div class="comparison-box">
<h4>SEOとAEOの違い</h4>
<ul>
<li>SEO:検索順位を上げ、サイトへの流入を最大化する</li>
<li>AEO:AIの回答に採用され、情報の正確性を担保する</li>
</ul>
</div>対象:ページ全体の評価
指標:クリック率(CTR)
対象:情報の断片(フラグメント)
指標:引用シェア・ブランド認知
このデモのように、情報を対比させて整理することで、AIは「SEOとAEOの違い」という文脈を即座に理解できる。
権威性のシグナルとスキーママークアップの活用
AIに「この情報は正しい」と確信させるためには、技術的な裏付けが必要だ。ここで重要になるのが、Googleも重視しているE-E-A-T(経験・専門性・権威性・信頼性)の概念と、それを機械に伝えるための「構造化データ」である。
E-E-A-Tと情報の鮮度
Microsoftのガイドラインでは、成功するコンテンツの条件として「新鮮で、権威があり、構造化され、意味的に明確であること」を挙げている。特に「意味的な明確さ」についてはシビアだ。「革新的な」「最先端の」といった曖昧な形容詞は、AIにとっては評価の対象にならない。それよりも「従来比で処理速度が30%向上した」といった、測定可能な事実に基づいた記述が求められる。
また、情報の鮮度(フレッシュネス)も重要なシグナルだ。古いデータや更新が止まったコンテンツは、AIに「不正確な可能性がある」と判断され、引用候補から外されやすい。定期的なリライトと、公開日・更新日の明示は必須と言える。
AIの理解を助ける構造化データの種類
スキーママークアップ(構造化データ)は、人間向けのテキストを「機械が理解できるデータ」に変換する翻訳機の役割を果たす。Microsoftは、スキーマを利用することでAIがコンテンツの内容を推測する必要がなくなり、自信を持って回答に採用できるようになると指摘している。
特にAEOにおいて優先順位が高いスキーマは以下の通りだ。
- FAQPage:質問と回答のペアを定義する。AIが最も引用しやすい形式だ。
- HowTo:手順やステップを定義する。ハウツー系の回答に採用されやすくなる。
- Product:価格、在庫、レビューを定義する。ECサイトのAI検索対応には必須だ。
- Article / BlogPosting:著者情報や公開日を定義し、情報の信頼性を高める。
これに加えて、サイトの更新を検索エンジンに即座に通知する「IndexNow」を併用することで、情報の鮮度と正確性を高いレベルで維持することが可能になる。
クローラー制御と計測の進め方

AI検索エンジンに対応するためには、どのクローラーを許可し、どのクローラーを制限するかという戦略も重要になる。また、施策の結果をどのように計測するかも、従来のSEOとは異なる視点が必要だ。
robots.txtによる学習と検索の切り分け
主要なAIプラットフォームは、クローラーを「検索用」と「モデル学習用」で分けていることが多い。例えばOpenAIの場合、OAI-SearchBot はChatGPTの検索機能(回答への引用)に使用されるが、GPTBot は将来のモデル学習に使用される。
自社のコンテンツをAIの回答に引用させたいが、AIモデルの学習に無償で使われるのは避けたいという場合は、robots.txt で個別に制御することが可能だ。検索用ボットを許可し、学習用ボットを拒否することで、著作権を保護しつつ検索流入を確保するバランスが取れる。
AI経由の流入を可視化する方法
AEOの成果を測る最も手軽な方法は、Bing Webmaster Toolsを活用することだ。ここには「AIパフォーマンスレポート」があり、Microsoft Copilotでの引用状況やクリック数を確認できる。Googleについては、Search Consoleの検索パフォーマンスから「検索タイプ:AI Overview(またはそれに類するフィルタ)」で動向を追うことになる。
また、ChatGPTからの流入は、アクセス解析ツールで utm_source=chatgpt.com というパラメータが付与される仕様になっている。これをモニタリングすることで、AI検索がどの程度自社サイトへのトラフィックに貢献しているかを具体的に把握できる。従来の「キーワード順位」だけでなく、「AI回答内でのシェア」を新たな指標として設定すべきだ。
この記事のポイント
- AIはページ全体ではなく、構造化された「断片(フラグメント)」を抽出して回答を生成する。
- 信頼できるソースの引用や統計データは、AI回答での視認性を100%以上向上させる可能性がある。
- 自社サイトの改善だけでなく、第三者メディアでの露出(アーンドメディア)がAIの信頼獲得に直結する。
- Q&A形式、箇条書き、スキーママークアップを活用し、AIが解析しやすい「スニッパブル」な構造を作る。
- Googleは「質の高いコンテンツ」と抽象的に述べるが、Microsoftは具体的な構造化の手法を公開しており、後者のガイドラインがAEOの指針となる。
・ 複数業界における17年間のデジタルビジネス開発経験
・ ウェブサイト開発のためのHTML、PHP、CSS、JavaScript等の実用的知識
・ 15ヶ国語対応の多言語SaaSの開発経験
・ 17年間にも及ぶ、Eコマース長期運営経験
・ 幅広い業界でのSEO最適化の豊富な経験

Google 2026年3月コアアップデート開始——2026年最初の広範な更新とサイト運営者の対策
2026年3月27日、Googleは検索ランキングシステムの広範な変更を伴う「2026年3月コアアップデート」のリリースを公表した。Google検索ステータスダッシュボードによれば、展開の開始は太平洋標準時の午前2時である。今回のアップデートは、2026年に入ってから初めての広範なコアアップデートとなる。
このアップデートは、完了までに最大2週間を要する見込みだ。Googleは公式なブログ記事や具体的な目的の詳細については現時点で発表していない。しかし、コアアップデートの性質上、検索結果の信頼性と有用性を高めるための包括的な調整が行われていると考えられる。
サイト運営者やSEO担当者にとって、この2週間は検索順位の動向を注視すべき期間となる。ランキングの変動は一過性のものである可能性も高いため、展開が完全に終了するまでは冷静な対応が求められる。この記事では、アップデートの概要と、私たちが取るべき具体的なアクションについて解説する。
2026年3月コアアップデートの概要とスケジュール

今回のアップデートは、Googleが定期的に実施するランキングアルゴリズムの抜本的な見直しの一環だ。特定のサイトやページを狙い撃ちにするものではなく、ウェブ全体のコンテンツ評価を再定義することを目的としている。
展開期間と影響の範囲
Googleの発表によれば、ロールアウト(展開)には約2週間かかる見通しだ。つまり、4月上旬までは検索結果が不安定な状態が続く可能性がある。コアアップデートとは、Googleの検索アルゴリズムの核となる部分を更新する作業を指す。これにより、以前は高く評価されていたページが下落したり、逆に低迷していたページが上昇したりする現象が起こる。
記事によれば、この変更は特定のコンテンツ形式や特定の違反を対象としたものではない。Googleは「ヘルプフルコンテンツ(読者にとって役立つコンテンツ)」をより正確に識別し、信頼できる情報を上位に表示させるための調整であると説明している。
2026年のアップデート履歴と今回の位置づけ
2026年に入り、Googleはすでにいくつかのアップデートを実施している。2月には「Google Discover」のみを対象としたアップデートが行われたが、これは通常の検索ランキングには影響を与えなかった。また、今回のコアアップデートのわずか2日前には、記録的な速さ(約20時間)で完了した「2026年3月スパムアップデート」が実施されたばかりだ。
これらの背景から、今回のコアアップデートは直前のスパム対策と連動し、より質の高い検索体験を提供するための「仕上げ」のような役割を担っている可能性がある。広範な検索順位に影響を与えるアップデートとしては、2025年12月以来、約3ヶ月ぶりの実施となる。
コアアップデートの本質と評価基準

コアアップデートによる順位変動に直面した際、多くの運営者は「自社のサイトに不備があったのではないか」と不安を感じる。しかし、Googleは順位の下落が必ずしもガイドライン違反を意味するわけではないと明言している。
相対的な評価の見直し
コアアップデートを理解する上で有効なたとえが「映画のトップ10リスト」の更新だ。2024年に作成されたリストが、2026年に新しく公開された優れた映画を含めて更新されるようなものである。以前ランクインしていた映画がリストから漏れたとしても、その映画の質が悪くなったわけではない。単に、より優れた、あるいはより現代のニーズに合った映画が登場したに過ぎないのだ。
ウェブサイトも同様で、他サイトのコンテンツが相対的に向上したり、Googleが「今のユーザーにはこちらの情報がより適切だ」と判断基準を変えたりすることで、順位が変動する。この「相対的な評価」こそが、コアアップデートの本質である。
E-E-A-Tとヘルプフルコンテンツ
Googleが重視している指標は、一貫して「E-E-A-T(経験、専門性、権威性、信頼性)」だ。特に最近では、筆者の実体験に基づいた情報(Experience)がより高く評価される傾向にある。AIによって生成された画一的な情報が増える中で、人間にしか書けない独自の視点や検証データが含まれているかどうかが、評価の分かれ目となる。
ヘルプフルコンテンツとは、検索エンジンのために書かれた文章ではなく、ユーザーの悩みを解決するために書かれた文章を指す。記事によれば、Googleは継続的に小規模なアップデートも行っているが、今回のコアアップデートのような大規模な更新では、これらの評価軸がより強力に適用されることになる。
変動が起きた際の具体的なチェックリスト

アップデートの展開中に順位が大きく動いたとしても、焦ってサイトを修正するのは避けるべきだ。Googleは、アップデートの完了から少なくとも1週間は経過を見てから分析を開始することを推奨している。
Search Consoleを用いたデータ分析
まず行うべきは、Google Search Console(サーチコンソール)での比較分析だ。アップデート開始前の期間と、完了後の期間を比較し、どのキーワードやページでクリック数や掲載順位が減少したのかを特定する。Search Consoleとは、Google検索での自サイトのパフォーマンスを管理する無料ツールである。
分析の際は、サイト全体が下がっているのか、特定のカテゴリーだけが下がっているのかを見極める必要がある。特定のトピックで順位が落ちている場合、その分野において競合サイトがより「ヘルプフル」なコンテンツを提供している可能性がある。
コンテンツの再評価ポイント
順位が下落したページについては、以下の視点でセルフチェックを行うことが推奨される。まず、その記事は独自の調査や分析、体験談を含んでいるか。次に、タイトルは内容を正確に表しており、過度な「釣り」になっていないか。そして、その分野に詳しくない人が読んでも理解しやすい構成になっているか、という点だ。
特に「独自性」は重要だ。他サイトの情報をまとめただけのページは、コアアップデートのたびに評価を落とすリスクが高まっている。自社にしか出せないデータや、実際に製品を使った感想など、付加価値を加えることが長期的な順位維持の鍵となる。
独自分析:AI時代のコンテンツ品質とGoogleの意図

今回のアップデートで注目すべき点は、3月24日から25日にかけて行われた「スパムアップデート」との近接性だ。わずか20時間という異例の速さで完了したスパムアップデートの直後に、このコアアップデートが開始されたことには大きな意味があると考えられる。
低品質なAI生成コンテンツへの包囲網
現在、生成AIの普及により、ウェブ上には大量の「それらしいが中身のない」記事が溢れている。Googleにとっての最大の課題は、これらのノイズを排除し、ユーザーが求める真実味のある情報を届けることだ。直前のスパムアップデートで明らかな悪質サイトを排除し、今回のコアアップデートで「良質だが独自性に欠けるサイト」と「真に価値のあるサイト」の選別を行っているのではないか、との見方がある。
筆者の分析によれば、Googleは単なる「情報の正確さ」だけでなく、「情報の鮮度」と「発信者の実在性」をより厳格に評価するフェーズに入っている。匿名性の高い、いわゆる「こたつ記事(現場に行かずネットの情報だけで書いた記事)」の評価は、今後さらに厳しくなるだろう。
「検索意図の充足」から「ユーザー体験の向上」へ
これまでのSEOは、特定のキーワードに対して適切な答えを返す「検索意図の充足」がゴールだった。しかし、これからのSEOは、ページを開いた後のユーザー体験(UX)までが評価の対象となる。例えば、ページの読み込み速度や、モバイルでの操作性、そして何より「そのページを読んでユーザーの行動がどう変わったか」という定性的な価値が問われている。
今回のアップデートを通じて、Googleは検索結果を単なるリンク集から、信頼できるアドバイザーのような存在へと進化させようとしている。サイト運営者は、テクニカルなSEO手法に固執するのではなく、読者の期待を上回る価値をどう提供するかに注力すべきだ。
この記事のポイント
- 2026年3月27日から、今年初の広範なコアアップデートが開始された。
- 展開の完了には最大で2週間かかる見込みであり、4月上旬までは順位が不安定になる。
- アップデートは特定の違反を罰するものではなく、ウェブ全体の相対的な評価を見直すものだ。
- 順位が変動しても即座に修正せず、展開完了から1週間後にSearch Consoleで詳細な分析を行うべきである。
- AI生成コンテンツが増加する中で、独自の体験や専門性(E-E-A-T)の重要性がさらに高まっている。
出典
- Search Engine Journal「Google Begins Rolling Out March 2026 Core Update」(2026年3月27日)
- Google Search Status Dashboard(2026年3月27日)
・ 複数業界における17年間のデジタルビジネス開発経験
・ ウェブサイト開発のためのHTML、PHP、CSS、JavaScript等の実用的知識
・ 15ヶ国語対応の多言語SaaSの開発経験
・ 17年間にも及ぶ、Eコマース長期運営経験
・ 幅広い業界でのSEO最適化の豊富な経験