

Google SREが語る、エージェントAIで変わる運用の新常識
GoogleがSRE(Site Reliability Engineering)にエージェントAIを本格導入し、運用の自動化レベルを引き上げている。異常検知やインシデント管理、信頼性設計といった領域で、AIエージェントが「力の倍増器」として機能し始めたのだ。
この取り組みは、2026年5月に公開されたホワイトペーパー「AI in SRE Practice」で詳細に語られている。本記事ではその核心にある5つの重点領域と、Googleが定めた7つの設計原則を整理しながら、エージェントAIがSREにもたらす変化を読み解く。
なぜ今、SREにエージェントAIなのか

GoogleがSREの概念を提唱してから20年以上が経つ。その間、信頼性を担保すべきシステムは幾重にも複雑化した。マイクロサービス化による分散配置の拡大、クラウド製品群の機能爆発、そしてAIコード生成によるソースコード量の急増。それぞれが単独でも運用負荷を押し上げる要因だが、これらが同時に進行している点が問題を大きくしている。
SREチームは従来、サービスレベル指標(SLI)やサービスレベル目標(SLO)に基づく静的な閾値監視で信頼性を守ってきた。しかし、多様な顧客ワークロードを扱うGoogle Cloudのような製品では、一律の閾値で異常を捉えきれないケースが増えている。そこで注目されるのが、AIによる異常検知とエージェント型の自律対応だ。
エラーレート > 1% でアラート
このデモが示すように、AIエージェントは単に閾値を超えたかどうかではなく、平常時の振る舞いパターンからの逸脱を捉える。これにより、多様なワークロードが混在する環境でも、真に対処すべき異常だけを抽出できる確度が高まる。
SRE AIがカバーする5つの重点領域

Google SREチームは、ソフトウェア開発ライフサイクル(SDLC)全体を見渡し、AIエージェントが価値を発揮できる領域を5つに整理した。いずれも従来のSREプラクティスを補完し、人間の意思決定を加速させることを狙いとしている。
信頼性設計への組み込み
従来、SREは設計段階から信頼性を織り込むため、ポリシー策定やランブック(運用手順書)の整備に多くの時間を割いてきた。AIエージェントはこのプロセスを効率化する。具体的には、過去のインシデントから得た知見を基にランブックを自動生成し、本番環境に近い構成に対して信頼性リスクを事前検出する。人間のレビューは高リスクな変更に絞られ、トイル(労苦)の大幅な削減が見込めるという。
異常検知とアラート処理
この領域はエージェントAIの導入効果が最も顕著に表れる部分だ。Google SREは、TimesFMのような時系列予測モデルを使い、過去の正常パターンから逸脱する動きをAIが検知する仕組みを採用している。異常が検知されると、専用のアラート処理エージェントが起動し、関連情報の集約やコンテキスト付与を自動実行する。その後、自律型のアラートハンドラが可能な範囲で一次対応まで完遂する。
このパイプラインにより、人間のSREが対応すべきアラート件数そのものを減らせる。大事なのは、エージェントがどのデータをどう評価したのか、一貫して透明性を保つ設計になっている点だ。本番状態に意図しない変更を加えないための制御機構も当然組み込まれている。
インシデント管理の高度化
GoogleにはIMAG(Incident Management at Google)という確立されたインシデント管理プロセスがある。SRE AIはその上にエージェント型のオーケストレーション層を追加する形で実装されている。
- チャットや動画、追跡ドキュメントなどインシデント中に発生するコミュニケーションを集約・要約
- 担当者交代時のハンドオフドキュメントを自動生成
- ポストモーテム(障害分析書)のドラフトを自動作成し、品質向上と工数削減に貢献
- 社内外向けのインシデント報告の管理
これらは一見地味だが、大規模インシデントでは情報の混乱が復旧遅延の最大要因になる。エージェントが情報整理を肩代わりすることで、SREは本質的な判断と対応に集中できる。
インシデント調査の自律化
AIエージェントは監視データ(ログ、メトリクス、トレース)に加え、システムトポロジや依存関係情報を使い、ドメイン知識を獲得した上で調査を開始する。ランブックのナビゲーション、アラート参照、異常検知、インサイト抽出といった個別の機能エージェントと連携しながら、仮説形成から緩和策の提案までを行う。状況によっては自律的な緩和実行も視野に入れている。
インサイトとリスク管理
AIエージェントが継続的に学習し続けるための仕組みとして、Google SREは「AI Insights」というシステムを開発した。これは過去の全インシデントを分析し、構造化された知見を抽出する。Geminiの埋め込みモデルとベクターデータベースを活用し、各インシデントにリスクカテゴリを自動付与する。これにより、エージェントは将来の調査時により精度の高い緩和策を提案でき、人間のSREも優先的に対処すべき領域を俯瞰できる。
このように複数のエージェントが役割分担しながら、一つのインシデントに対して協調的に動作する。単一の巨大なAIではなく、目的別に分割されたエージェント群が連携する設計思想がGoogle SREの特徴だ。
エージェント導入に先立つ7つの設計原則

Google SREはエージェントAIを闇雲に導入したわけではない。顧客への約束を守りながら信頼性を向上させるため、以下の7つの高レベル原則を定めている。
- 既存の自動化が機能している領域は、ビジネス要件を満たしている限り無理に置き換えない。
- 新しいAIシステムは、既存および将来のポリシーと手順に準拠すること。
- SRE AIエージェントは、人間と同等のセキュリティ・安全性・プライバシー要件を満たすこと。
- エージェントは強力なアイデンティティを持ち、ロールベースで権限が割り当てられること。
- エージェント自体に高い信頼性SLOを設定し、自動または手動のバックアップ手段を明確に用意すること。
- エージェントは実行したアクションの理由と、検討し却下した選択肢を説明できなければならない。ブラックボックス自動化より透明性を重視する。
- 事業継続計画にAI障害時のコンティンジェンシーを含めること。
とりわけ6番目の「説明可能性」は、SREという領域において極めて重要だ。なぜそのインシデントが発生し、なぜその緩和策を選んだのか。説明できない自動化は、ポストモーテム文化と相性が悪い。GoogleがエージェントAIに対して透明性を強く要求しているのは、SREの根本思想である「非難しない文化」と「学習する組織」をAI時代にも維持するためといえる。
この対比は、単なる技術選定の話ではない。SREの運用文化そのものをどう進化させるかという問いに直結している。
SRE AIを支えるGoogleの基盤技術

これらのエージェント群は、個別の新規プロジェクトとして開発されたものではない。Googleが長年培ってきたインフラストラクチャの上に構築されている。主要な構成要素は次のとおりだ。
- Gemini — 基盤モデル。SREチームは社内データでファインチューニングしたカスタムGeminiモデルも併用。
- Gemini Enterprise Agent Platform(旧Vertex AI) — エージェント開発のためのフルAIスタック。
- Agent Development Kit(ADK) — エージェント構築の開発プラットフォーム。
- MCPサーバー — 標準のGoogle APIインフラ上で動作し、外部顧客向けMCPサポートにも使われるものと同一基盤。
- BigQuery / ベクターデータベース — AI Insightsシステムのデータ基盤。Gemini埋め込みモデルと連携。
- 標準Observabilityインフラ — 監視、ログ、トレーシング。
特筆すべきは、これらの技術がすでにGoogle Cloudの顧客向けにも提供されている点だ。ホワイトペーパーで語られているSRE AIのアーキテクチャは、決してGoogle内部だけの秘伝のたれではなく、クラウド利用者にとっても参照可能な設計パターンとして公開されている。
SRE AIが目指す先

Google SREチームは、SRE AIが達成すべき目標として、次の5つを掲げている。
- 退屈で反復的な運用からエンジニアを解放する
- 意思決定と実行の質と速度を向上させる
- これまで対処できなかった問題の予防・検知・緩和を可能にする
- 信頼性向上に向けた自律的なフィードバックループを形成する
- 全体的な運用コストを削減する
これらは一見するとAI導入の一般的な利点に見える。しかしGoogle SREが強調するのは、単なる効率化ではない。AIが複雑さを増幅させた側面があるからこそ、同じAIを使って複雑さを制御するという考え方だ。SRE AIの本質は「AIがもたらした運用課題を、AI自身の力で解決する」逆説的なアプローチにある。
Googleは以前から自律システムを本番運用してきた実績を持つ。しかし現在のAIベースの自律システムは、非決定的な振る舞いをする点で従来と大きく異なる。この性質を正しく理解し制御するために、自律レベルのトラッキング手法も開発されている。詳細はホワイトペーパー「AI in SRE Practice: Moving Beyond Automation at Google」に譲るが、決定論的自動化からエージェントAIへの移行は、SREという分野にとって20年来の転換点になる可能性を秘めている。
この記事のポイント
- Google SREはAIエージェントを「力の倍増器」と位置づけ、運用の自動化レベルを次の段階へ引き上げている
- 静的な閾値監視からAIによる異常検知への移行は、多様なワークロードに対応するための不可避な進化である
- 7つの設計原則のなかでも「説明可能性」の重視は、SRE文化との整合性を保つ上でとりわけ重要だ
- SRE AIの構成要素はGoogle Cloudの顧客向け技術スタックと地続きであり、外部組織も同様のアーキテクチャを参照できる
- 決定論的自動化からエージェントAIへの移行は、SREの根本的な運用思想を再定義する可能性がある

・ 複数業界における17年間のデジタルビジネス開発経験
・ ウェブサイト開発のためのHTML、PHP、CSS、Java等の実用的知識
・ 15ヶ国語対応の多言語SaaSの開発経験
・ 17年間にも及ぶ、Eコマース長期運営経験
・ 幅広い業界でのSEO最適化の豊富な経験

AWS Resilience Hubが大幅刷新、生成AIで障害モードを分析しSREの信頼性管理を効率化
AWSが「Resilience Hub」の次世代版を一般公開した。最大の変更点は生成AIを活用した障害モード評価の搭載だ。組織全体の信頼性を構造化されたポリシーで管理し、数百に及ぶアプリケーションの可用性リスクを一元的に可視化する。
今回の刷新では新たなアプリケーションモデルが導入され、依存関係の自動検出機能やモジュール式の信頼性ポリシーも追加された。SREチームと開発チームが同じ指標で対話し、エンタープライズ全体のレジリエンスを継続的に改善する基盤が整った形だ。
従来のResilience Hubが個々のアプリケーション評価に留まっていたのに対し、今回の刷新は「信頼性の管理」を組織のガバナンス領域に引き上げる。本記事ではその具体的な機能と実務への影響を詳しく解説する。
AWS Resilience Hubの全体像と考え方の変化
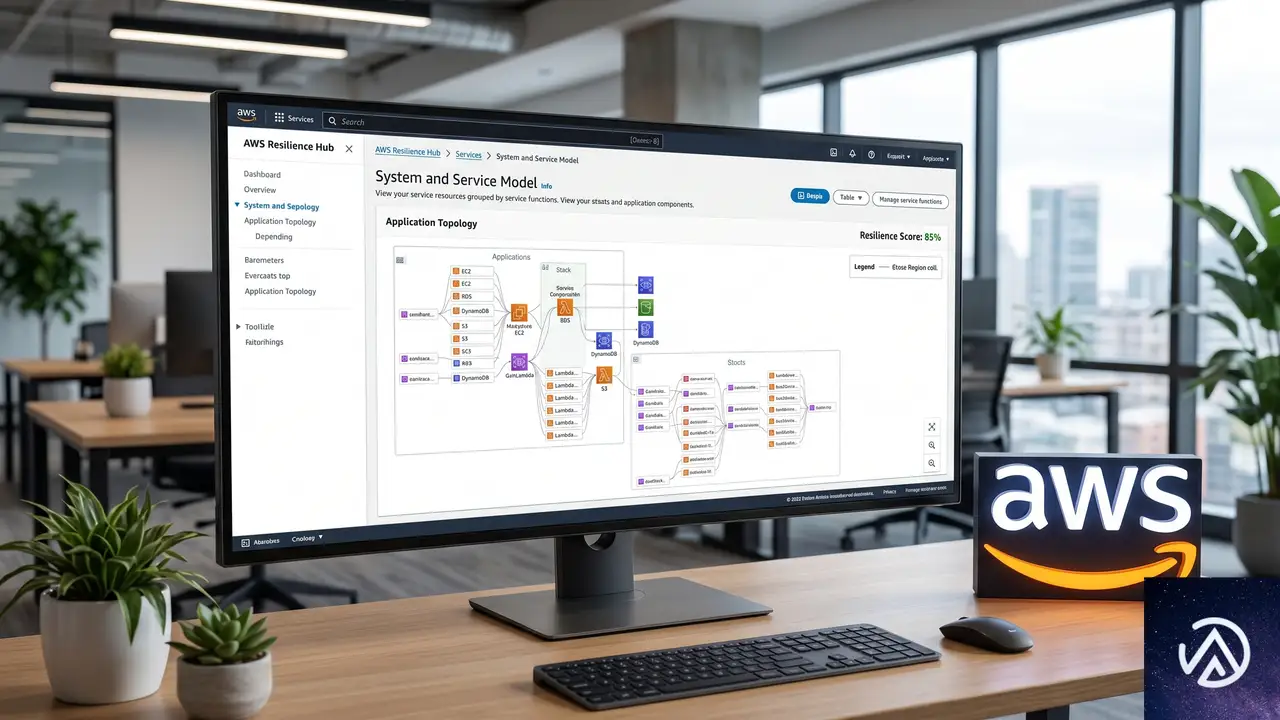
この比較が示すように、次世代版の本質は「個別最適から全体最適への転換」だ。AWS Organizationsとの統合により、委任管理者アカウントから複数アカウントを横断したレジリエンス評価が可能になった。
「ビジネス視点」で捉え直されたアプリケーションモデル
新しいモデルは3層構造になっている。最上位にビジネスアプリケーション全体を表す「システム」、その下にクリティカルな業務経路を示す「ユーザージャーニー」、さらに実際のデプロイ単位である「サービス」が配置される。サービスはAWSリソースやコード、オブザーバビリティの構成要素を束ねる役割だ。
この構造により「ログインできないと売上が止まる」という業務インパクトと、IAMロールの設定ミスという技術的リスクが地続きで評価できるようになる。AWS News Blogの記事でChanny氏は「ビジネス成果に直接結びつくクリティカルなエンドユーザー経路」という表現でこの概念を説明している。
モジュール式ポリシーでチーム間の共通言語を確立
信頼性ポリシーも大きく変わった。旧来は固定されたポリシータイプを選ぶ方式だったが、次世代版では必要な要件を組み合わせて構築できる。たとえば「可用性SLO 99.95%」「マルチリージョン災害復旧」「RTO 15分、RPO 5分」といった要素を選択し、金融系アプリケーション用のポリシーとして再利用する運用が可能だ。
SREと開発チームの間で「どの水準を目指すか」の共通理解が生まれ、属人的な判断を減らせる効果が期待できる。特に複数の開発チームを持つ組織では、この統一ポリシーがガバナンスの要になる。
生成AIが障害モードを評価する仕組み

次世代版の目玉機能が、生成AIを用いた障害モード評価である。サービスにポリシーを紐付けて評価を実行すると、AIが自動的に設定ミスや単一障害点を洗い出し、具体的な改善策を提案する。
この4ステップのフローにより、人手では発見が難しいクロスアカウントの依存関係や、リージョンをまたぐ意図しない呼び出しまで検出できる。AIは単にデータを収集するだけでなく、障害が発生した場合の影響範囲を推定し、優先度付きの修正ガイダンスを出力する。
AWS Well-Architectedと分析フレームワークの統合
AIの評価ロジックはAWS Well-Architectedフレームワークのベストプラクティスと、AWS Resilience Analysis Frameworkを参照している。これにより「なんとなく不安」ではなく、定義された基準に照らした再現性のある評価が実現する。
評価結果では「どのポリシー要件に違反しているか」が明示される。たとえば「RTO 15分を満たすには、このAuto Scalingグループのインスタンスが起動するまでの時間が長すぎる」といった具体的な指摘が得られる。対策の優先順位をビジネスインパクトに基づいて判断できる点が実務的に価値が高い。
また、ユーザーがAssertion(表明)を追加してAIの分析精度を高める仕組みも用意されている。たとえば「このサービスは特定のリージョンでのみ稼働する」といった前提条件をAIに伝えることで、無関係なマルチリージョン構成の提案を除外できる。
依存関係の自動検出がもたらす可視性の向上

多くの障害は「認識されていない依存関係」から発生する。次世代Resilience HubはDNSクエリログを解析し、VPC内のエンドポイントから呼び出されているAWSサービスや内部API、サードパーティの外部エンドポイントを自動で特定する。
この機能の価値は運用の暗黙知を形式知に変換する点にある。「ベテランSREだけが知っている」依存関係を、システムが自動でドキュメント化してくれる。異動や退職によるナレッジロスを防ぎ、障害対応の属人性を低減する効果が期待できる。
依存関係検出はサービス作成時に有効化する。VPCフローログではなくDNSクエリログを解析する仕組みのため、ネットワークトラフィックの暗号化状況に影響されず、比較的軽量に動作する設計だ。不要な場合は管理画面の設定から無効化できる。
実際の利用フローと移行パス

新規導入の基本的な流れ
導入の流れはシンプルだ。まず信頼性ポリシーを作成し、次にビジネスアプリケーションを表す「システム」を登録する。システム配下に、マイクロサービスなどのデプロイ単位である「サービス」を作成し、AWSリソースのタグやCloudFormationスタック、Terraformのステートファイル、EKSクラスタなどを指定してリソースを関連付ける。
準備が整ったら「障害モード評価の実行」をクリックする。Resilience HubがInvokerロールを引き受け、指定されたリソースの親子関係を解析し、トポロジを構築。その上でAIがポリシーに対するギャップを評価する。
評価完了後は「サービス詳細」画面の「Assessment」タブで発見事項を確認できる。各項目には障害モードの説明、アーキテクチャへの影響、修正方法、関連するポリシー要件が明記される。対応が完了した項目は「Mark as resolved」でクローズし、未対応の課題だけをトラッキングできる。
既存ユーザー向けの移行API
すでに従来版のResilience Hubを利用している組織向けには、移行用APIが提供されている。従来の評価ポリシーを新ポリシー形式に変換し、複数の関連アプリケーションを新モデルの「1システム配下の複数サービス」構造に再マッピングする機能だ。
手動での再設定が不要なため、既存の評価データを活かしつつスムーズな移行が可能になっている。大規模組織ほどこの移行APIの価値は大きい。
運用に組み込む際のポイントと今後の展望

Resilience Hubの次世代版を実運用に組み込む場合、いくつか意識すべき点がある。第1にポリシー設計の重要性だ。SLOやRTO、RPOの値はビジネス要件から逆算する必要がある。「とりあえず99.99%」といった一律設定では、過剰なコストを生むか、逆に重要なサービスを見落とすリスクがある。
第2に、依存関係検出のスコープ調整だ。DNSクエリログ解析は強力だが、ノイズとなる外部通信も拾う可能性がある。検出結果を精査し、クリティカルでない依存関係をフィルタリングする運用プロセスを組み込むことが望ましい。
第3に、AIの分析結果を鵜呑みにしないことだ。Assertion機能を活用し、自社のアーキテクチャ特性をAIに正しく伝える努力が求められる。あくまで「AIの提案をSREが判断する」という協調モデルが効果的である。
料金体系は新たなサービスベースモデルに移行した。各サービスにつき月2回の障害モード評価が含まれ、依存関係の自動評価はオプションとなる。大規模環境では評価回数がボトルネックになる可能性があるため、クリティカルなサービスに絞って評価頻度を設定するなどの工夫が必要だ。
今後はAWS Organizationsとの統合がさらに強化され、組織全体のレジリエンススコアをスコアカード化する機能や、CI/CDパイプラインへの組み込みによるシフトレフトな信頼性評価への展開が期待される。
この記事のポイント
- 生成AIによる障害モード評価で、人手では困難な依存関係や設定ミスを自動的に発見できる
- ビジネス視点のアプリケーションモデルにより、技術リスクと業務インパクトを地続きで評価可能になった
- モジュール式ポリシーがチーム間の共通言語として機能し、ガバナンスの実効性が高まる
- DNSクエリログ解析による依存関係の自動可視化で、運用の暗黙知を形式知に変換できる
- 既存ユーザー向けの移行APIが用意されており、大規模組織でもスムーズに移行可能である
・ 複数業界における17年間のデジタルビジネス開発経験
・ ウェブサイト開発のためのHTML、PHP、CSS、Java等の実用的知識
・ 15ヶ国語対応の多言語SaaSの開発経験
・ 17年間にも及ぶ、Eコマース長期運営経験
・ 幅広い業界でのSEO最適化の豊富な経験

Kubernetesの1行修正で年600時間を削減——Cloudflareが直面したPVマウントの罠
Kubernetesの設定ファイルをたった1行書き換えるだけで、年間600時間ものエンジニア工数を削減した事例がある。Cloudflare(クラウドフレア)のインフラチームが直面したこの問題は、システムの規模が拡大するにつれて静かに忍び寄る「デフォルト設定の罠」を浮き彫りにした。
原因は、ストレージの権限管理を行うKubernetesの標準的な振る舞いにあった。数百万ものファイルを抱えるボリュームにおいて、再起動のたびに30分ものダウンタイムが発生していた事態を、彼らはどのように特定し、解決したのだろうか。
本記事では、CloudflareのエンジニアであるBraxton Schafer氏が公開したデバッグの過程と、大規模なKubernetes運用において見落としがちなパフォーマンスのボトルネックについて詳しく解説する。
Atlantisの再起動がなぜか「30分」もかかる謎

Cloudflareでは、Terraform(テラフォーム)によるインフラ管理の自動化ツールとして「Atlantis(アトランティス)」を利用している。Terraformはコードでインフラを定義するツールだが、Atlantisを導入することで、GitHubやGitLabのプルリクエスト上で実行計画(Plan)の確認や適用(Apply)が可能になる。
AtlantisはKubernetes上で「StatefulSet(ステートフルセット)」として動作しており、リポジトリの状態を保持するためにPV(Persistent Volume / 永続ボリューム)を使用している。StatefulSetとは、Pod(ポッド)の再起動後もデータの永続性を保証するための仕組みだ。
頻繁な再起動がエンジニアの時間を奪う
問題は、このAtlantisを再起動するたびに発生していた。新しいプロジェクトの設定を読み込ませたり、認証情報を更新したりするために、Cloudflareでは月に約100回ほどの再起動を行っていた。しかし、再起動を開始してからPodが正常に立ち上がるまで、毎回30分もの時間がかかっていたという。
この間、エンジニアはインフラの変更を行うことができず、作業が完全にブロックされてしまう。月100回の再起動で毎回30分待機が発生すれば、月間で50時間、年間では600時間もの時間が「ただの待ち時間」として消えていく計算だ。これは、一人のエンジニアが数ヶ月間フルタイムで働く時間に匹敵する大きな損失である。
「inode不足」がきっかけで表面化した問題
この遅延が決定的な問題として認識されたのは、ストレージの「inode(アイノード)」が枯渇した際だった。inodeとは、ファイルシステム上でファイルやディレクトリの情報を管理するためのデータ構造だ。ファイルが大量に作成されると、ディスク容量が残っていてもinodeが足りなくなり、新しいファイルが作成できなくなる。
Cloudflareの環境では、ファイルシステムを拡張することでしかinodeを増やせない仕様だった。拡張を反映させるにはPodの再起動が必要となり、そのたびに30分のダウンタイムが発生する。チームは当初、アラートの通知設定を調整して「見かけ上の問題」を回避することも検討したが、根本的な原因の調査に乗り出すことを決めた。
Kubernetesのログを深掘りして見えてきたボトルネック
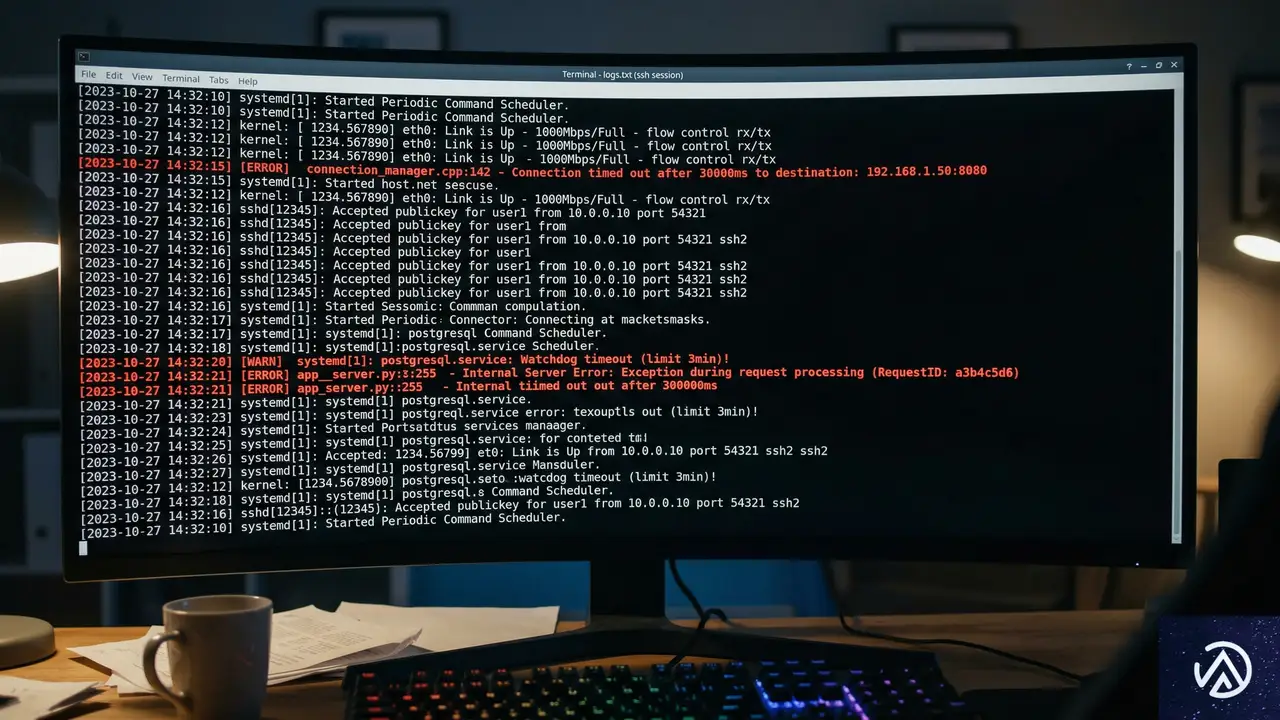
調査を開始したBraxton Schafer氏は、まずkubectl rollout restartコマンドを実行し、新しいPodが立ち上がる様子を観察した。Pod自体はすぐにスケジュールされるものの、ステータスが「Init(初期化中)」のまま30分間も停止していることが判明した。
Podのイベントログを確認しても、イメージのプルが開始されるまでに不可解な空白時間があることしかわからなかった。そこで氏は、より低レイヤーのログを確認するため、各ノードで動作するコンポーネント「kubelet(クブレット)」のログを調査した。
kubeletのログに隠された「空白の時間」
kubeletは、各ノードでPodの実行を管理し、ボリュームのマウントなどを制御する重要なエージェントだ。システム管理ツールであるKibana(キバナ)を使ってログを分析したところ、PVのマウント自体は成功しているものの、その直後にタイムアウトエラーが発生し、リトライを繰り返している様子が記録されていた。
ログには「context deadline exceeded(処理時間の制限を超過した)」というメッセージが並んでいた。何らかの処理が異常に時間を要しており、Kubernetesの監視機構がそれを「失敗」とみなして処理を中断、再試行するというループに陥っていたのだ。
数百万個のファイルが引き起こす権限変更の罠
さらに詳細なログを追うと、決定的なメッセージが見つかった。そこには「Setting volume ownership(ボリュームの所有権を設定中)」という記述があった。実はこれが、30分もの時間を浪費させていた真犯人だった。
Kubernetesには、Pod内のプロセスがボリュームにアクセスできるように、マウント時に所有権を自動で調整する機能がある。具体的には、PodのsecurityContextで指定されたfsGroupのIDに合わせて、ボリューム内の全ファイルに対して再帰的にchgrp(グループ変更)を実行する。Atlantisのようなツールは運用期間が長くなるほど管理するファイル数が増大し、Cloudflareの環境では数百万個ものファイルが蓄積されていた。高速なストレージであっても、数百万個のファイルに対して一つずつ権限を確認・変更していく処理には膨大な時間がかかるのは必然だ。
わずか1行の修正でパフォーマンスが劇的に改善
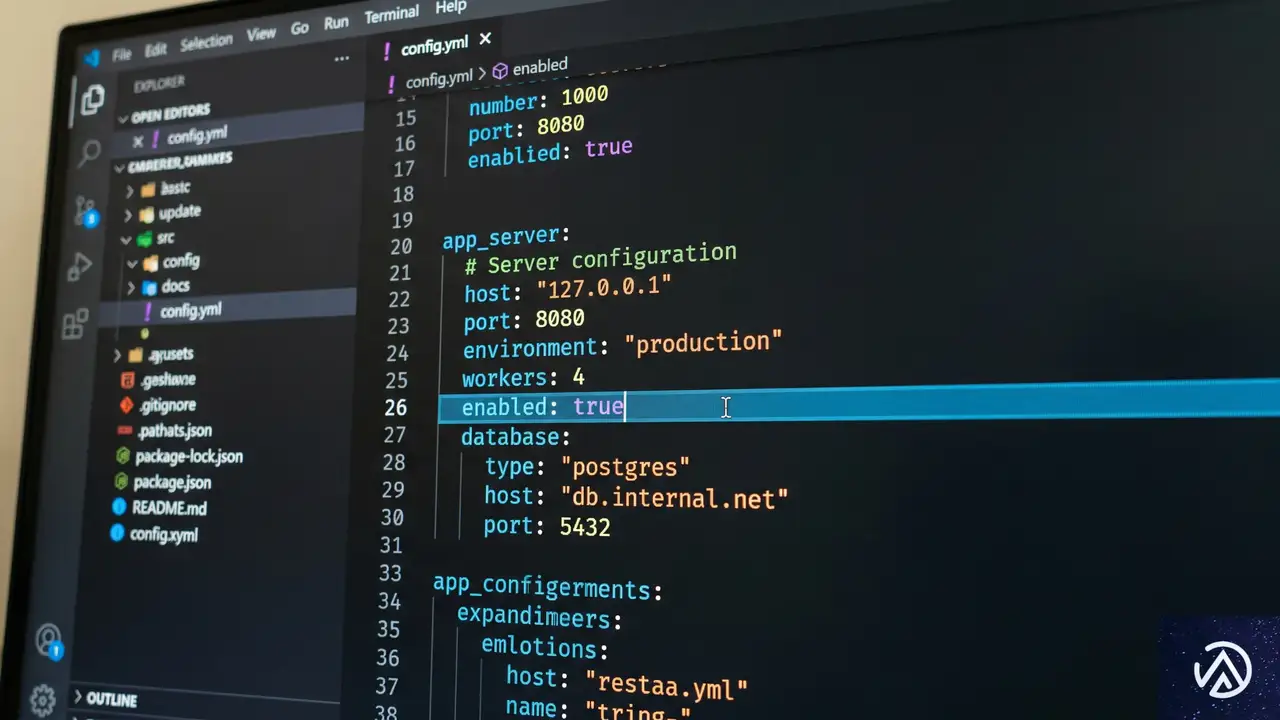
原因が「再帰的な権限変更」であると特定できれば、解決策は非常にシンプルだった。Kubernetes 1.20以降、この振る舞いを制御するための新しい設定項目が追加されている。それがfsGroupChangePolicy(エフエスグループ・チェンジ・ポリシー)だ。
デフォルトでは、このポリシーはAlways(常に実行)に設定されている。つまり、Podが起動するたびに、すでに権限が正しく設定されていようがいまいが、すべてのファイルをスキャンして権限を上書きしようとする。これが大規模なボリュームにおいて致命的な遅延を引き起こす。
fsGroupChangePolicyの設定とは
解決策は、このポリシーをOnRootMismatch(ルートディレクトリが不一致の場合のみ実行)に変更することだ。この設定にすると、Kubernetesはまずボリュームのルートディレクトリの権限を確認する。もしルートの権限がすでに正しく設定されていれば、配下のファイルに対する再帰的なスキャンをスキップする。
spec:
template:
spec:
securityContext:
fsGroupChangePolicy: OnRootMismatchこの1行をマニフェストファイルに追加するだけで、権限変更のプロセスが大幅に簡略化される。Cloudflareのケースでは、これまで30分かかっていた再起動時間が、わずか30秒にまで短縮された。実に60倍の高速化だ。
30分から30秒へ、驚異的な短縮効果
この修正により、エンジニアがデプロイの待ち時間に拘束されることがなくなった。また、再起動が長引くことによって発生していた「Podが正常に起動しない」という偽のアラートに、オンコール担当者が夜中に叩き起こされることもなくなったという。技術的には極めて単純な変更だが、組織全体の生産性に与えたインパクトは計り知れない。
大規模システムにおける「デフォルト設定」の落とし穴

今回の事例から学べる最も重要な教訓は、Kubernetesの「安全なデフォルト設定」が、規模の拡大とともに牙を向く可能性があるということだ。fsGroupによる自動的な権限変更は、初心者が権限エラーに悩まされないようにするための親切な機能として設計されている。
しかし、エンタープライズレベルの運用において、数テラバイトのデータや数百万のファイルを扱うようになると、その「親切心」がシステムの可用性を損なう要因へと変わる。これは、小規模なプロジェクトでは決して表面化しない問題だ。
小規模なら問題ないが、スケールするとボトルネックになる
多くのインフラエンジニアは、マウントが遅い場合にネットワークやストレージ装置の性能を疑う。しかし、今回のケースのように「OSレベルのファイル操作」がバックグラウンドで走っていることに気づくには、深いオブザーバビリティ(観測性)が必要だ。Braxton Schafer氏が、Kubernetesのイベントログだけでなく、kubeletのシステムログまで掘り下げたことが早期解決の鍵となった。
SRE的視点での教訓
SRE(Site Reliability Engineering / サイト信頼性エンジニアリング)の観点では、「なぜシステムはこのように振る舞うのか?」という問いを持ち続けることの重要性が再確認された。30分の待ち時間を「そういうものだ」と受け入れてしまえば、年間600時間の損失は永遠に解消されなかっただろう。
もし読者の環境でも、特定のPodの起動が異常に遅かったり、ボリュームをマウントする際にInitコンテナで止まっていたりする場合は、securityContextの設定を見直してみる価値がある。特に、大量の静的ファイルを保持するCMSや、データベースのバックアップファイルを扱うPodなどは、同様の問題を抱えている可能性が高い。
この記事のポイント
- 原因の特定: Atlantisの再起動に30分かかっていたのは、Kubernetesがマウント時に全ファイルの所有権を再帰的に変更していたため。
- 1行の修正:
fsGroupChangePolicy: OnRootMismatchを設定することで、不要な権限変更をスキップできる。 - 劇的な改善: Cloudflareはこの修正により、再起動時間を30分から30秒に短縮し、年間600時間の工数を削減した。
- 教訓: 安全のためのデフォルト設定が、大規模環境では深刻なパフォーマンス低下を招くことがある。
- 推奨アクション: 大容量PVを使用するPodでは、
securityContextの設定を監査し、不必要な再帰処理を避ける設定を検討すべきだ。
出典
- Cloudflare Blog「A one-line Kubernetes fix that saved 600 hours a year」(2026年3月26日)
・ 複数業界における17年間のデジタルビジネス開発経験
・ ウェブサイト開発のためのHTML、PHP、CSS、Java等の実用的知識
・ 15ヶ国語対応の多言語SaaSの開発経験
・ 17年間にも及ぶ、Eコマース長期運営経験
・ 幅広い業界でのSEO最適化の豊富な経験