

Astro 7が正式リリース、Vite 8とRustコンパイラを導入。Starlight 0.41も登場
2026年6月30日、Astroチームは月次アップデート「What’s new in Astro – June 2026」を公開した。今回の目玉はAstro 7の正式リリースだ。ビルドツールVite 8への移行、Rustで再設計されたコンパイラ、そして柔軟なルーティングを実現するAdvanced Routingが組み込まれている。
同時に、ドキュメントフレームワークStarlightもバージョン0.41へ更新され、Astro 7とSätteriを標準サポートする。エコシステム全体では、新ツールやテンプレートが多数登場し、コミュニティ主導のイベントも予定されている。
Astro 7がもたらす破壊的変更と新機能
Astro 7は、従来のバージョンからいくつかの重要な点で互換性を破る変更を含むメジャーアップデートだ。中核となるビルド基盤が刷新され、開発体験とパフォーマンスが一段階引き上げられた。
上図はビルドプロセスの変化を概念的に示したものだ。Rustコンパイラの導入により、従来のJavaScriptベースの処理に比べて並列性とメモリ効率が向上し、静的サイト生成のスピードが顕著に改善される。
Vite 8への移行とRustコンパイラ
Astro 7は内部のバンドルツールをVite 8に切り替えた。Vite 8自体がパフォーマンス最適化とプラグインエコシステムの成熟を進めており、コールドスタートの高速化やHMR(Hot Module Replacement)の安定性向上が期待できる。
さらに、AstroのコアコンパイラがRustで書き直された。これにより、数百ページ規模のサイトでもビルドが数十秒単位で短縮されるケースが報告されている。Rustの採用は、今後の機能拡張の土台としても重要だ。
Advanced Routingの導入
Astro 7ではAdvanced Routingと呼ぶ新しいルーティング機構が追加された。これはファイルベースルーティングのシンプルさを保ちつつ、動的パラメータやミドルウェア的な処理をより細かく制御できるようにするものだ。複雑なパス構造や多言語対応のサイト構築が容易になる。
たとえば、従来は手動でリダイレクトを記述していたようなケースでも、設定ファイルと規約に沿ったディレクトリ構成で対応できる。大規模なコンテンツサイトやECサイトでの採用が進むと見られている。
Starlight 0.41とSätteriサポート
ドキュメントサイト構築フレームワークStarlightの最新版は、Astro 7との互換性を確保するとともに、新たにSätteriを標準サポートした。Sätteriは、MDX周りの処理を拡張するプラグインで、Mermaidダイアグラムの自動検出やPhotoSwipeによる画像ライトボックスなどを容易に導入できる。
Astro 7との完全互換
Starlight 0.41はAstro 7専用といってよい。Astro 6以下では動作しないため、既存プロジェクトはまずAstro本体のアップグレードが必要になる。移行ガイドに従えば、破壊的変更の影響を抑えつつ最新のパフォーマンスを享受できる。
Sätteriが開く拡張性
SätteriはMDAST/HASTプラグインのエコシステムとして、文書変換パイプラインを柔軟にカスタマイズできる。コミュニティからはすでにMermaid対応やPhotoSwipe連携のプラグインが公開されており、技術文書の表現力が格段に向上する。
コミュニティとエコシステムの活況

Astroの採用は大企業にも広がっている。Astroチームが公表した「Astro Adopters」には、玩具メーカーのMattelやGPS機器のGarminといった有名企業が名を連ねる。企業向けのエージェンシーパートナープログラムも拡充され、大規模運用のノウハウ提供が進む。
ドイツ初のAstro公式イベント
2026年9月5日、ドイツ・ヴィースバーデンで「Astro Together FRA x Seibert」が開催される。ロンドンでの成功を受け、欧州大陸での初の公式コミュニティイベントとなる。メンテナーによるトークやデモ、限定ノベルティの配布が予定されており、定員制のため早期登録が呼びかけられている。
注目のツール・統合
6月のアップデートでは、多数のコミュニティ製ツールが発表された。以下に主要なものを抜粋する。
- @astroanimate/core:Astroネイティブのアニメーションコンポーネントライブラリ。View Transitions APIと連携し、宣言的なアニメーションを実装できる。
- @tinloof/astro-prefetch:Next.jsスタイルの先読み機能。カーソルの軌跡から遷移先を予測し、メモリ内キャッシュで瞬時にページを切り替える。
- @freshjuice/astro-webmcp:サイトコンテンツをWebMCP経由でAIエージェントに公開する統合。AIとの親和性を高める仕組みだ。
- @arraypress/seo-astro:SEOメタタグや構造化データを統一管理するコンポーネント。タイトル、カノニカル、Open Graph、JSON-LDなどをカバーする。
- astro-aeo-image:画像のaltテキストと説明文をXMPメタデータとして埋め込み、Google画像検索やAI回答エンジンに最適化するサービス。
これらのツールは、Astroのシンプルさを保ったまま、実運用に必要な機能を素早く追加できる点が共通している。特にSEO・AEO(Answer Engine Optimization)関連の統合が充実してきたことは、AI時代のWeb制作を意識した動きと言える。
テーマ・テンプレートとサイト事例

Astroテーマカタログには6月中に80以上のテーマが追加または更新された。Shadcn UIを採用したランディングページや、クリエイター向けポートフォリオ、SaaS向けテンプレートなど、バリエーションは豊富だ。
サイトショーケースには、教育機関向けAPI教材サイトやニュージーランドの環境保護団体のサイト、F1歴史アーカイブなど、多様なジャンルの実例が登録された。いずれもAstroの静的生成とアイランドアーキテクチャを活かし、高いパフォーマンスを実現している。
Starlightで構築されたドキュメント
ドキュメントフレームワークStarlightを用いたサイトも増加している。Bablrの開発者向けリファレンスや、BentleyのStrataKitドキュメント、LatticePHPのガイドなどが新たに確認された。Starlightのシンプルな設計と高速な検索機能が、技術文書の制作者に支持されている。
この記事のポイント
- Astro 7がリリースされ、Vite 8とRustコンパイラによりビルド性能が大幅に向上した
- Advanced Routingで複雑なパス制御が容易になり、大規模サイト構築の幅が広がる
- Starlight 0.41がAstro 7とSätteriをサポートし、ドキュメント表現力が強化された
- コミュニティ製ツールの充実が続き、SEO・AEO対策の統合も登場している
- 多数のテーマと実サイト事例がエコシステムの成熟を示している

・ 複数業界における17年間のデジタルビジネス開発経験
・ ウェブサイト開発のためのHTML、PHP、CSS、JavaScript等の実用的知識
・ 15ヶ国語対応の多言語SaaSの開発経験
・ 17年間にも及ぶ、Eコマース長期運営経験
・ 幅広い業界でのSEO最適化の豊富な経験

アクセシビリティは機能ではなく運用能力、その理由と実践法
今、多くの開発現場ではAIアシスタントがUIを高速生成している。しかし、その裏で「Pay Now」ボタンが単なる<div>タグにクリックハンドラを付けただけの状態でリリースされ、スクリーンリーダーを使うユーザーが購入を完了できないという問題が頻発している。これは単なるバグではない。コードの速度と製品の使いやすさの間に横たわる構造的なギャップであり、AI時代のエンジニアリングが直面する決定的な課題だ。
Smashing Magazineの記事では、アクセシビリティをコンプライアンスのチェックリストやプロジェクト終盤の監査で扱うのではなく、セキュリティや信頼性と同じ「運用能力(Operational Capability)」として位置付けるべきだと主張している。本稿ではその考え方と具体的な実践パターンを紹介する。
監査依存の罠とその限界

長い間、アクセシビリティ対策の主流は「外部企業に依頼し、200件の指摘リストを受け取り、その一部を修正して報告書を提出する」という一過性の監査モデルだった。監査そのものは営業資料や調達要件として必要であり、VPAT(Voluntary Product Accessibility Template)やACR(Accessibility Conformance Report)の提出が求められる場面は確かに存在する。だが、このアプローチには根本的な弱点がある。
監査はスプリント計画中の設計判断を助けてくれない。プルリクエスト前に問題を検知できない。デプロイ頻度が上がるほど監査結果はすぐに陳腐化する。ある時点のスナップショットでしかないからだ。半年後に数十回のリリースを重ね、ナビゲーションが刷新された製品に対して、過去の監査報告書はもはや実態を反映しない。コンプライアンスは「到達する状態」ではなく「維持し続ける状態」であり、製品が複雑になるほどその維持は困難になる。
上図のように、アクセシビリティをプロジェクトの最終段階でスポット的に対処するのではなく、開発フロー全体に組み込む継続的な運用モデルが求められる。
WebAIMが毎年100万ページをスキャンする「WebAIM Million」レポートの2026年版では、検出可能なWCAG違反のあるページが95.9%、平均エラー数は56.1件に上った。ページ要素数は前年比で20%以上増加しており、AI支援開発や「Vibe Coding」の普及が拍車をかけていると見られる。要素が増えれば増えるほどアクセシビリティ違反の発生箇所も増える。アクセシビリティの負債は技術的負債と同じ振る舞いをし、放置すれば将来の修正コストを複利的に膨らませていく。
AIがもたらすアクセシビリティの新たな課題

AIによるコード生成が一般化したことで、アクセシビリティの問題は単に「残り続ける」だけでなく「倍増する」フェーズに入った。その背景には、短期的な生産性を優先する開発スタイルがある。
Andrej Karpathyが2025年2月に提唱した「Vibe Coding」は、意図を伝えるだけでモデルがコードを生成し、差分を精読せずに受け入れる働き方だ。もともとは週末の趣味プロジェクト向けだったが、Y Combinatorの2025年冬バッチではスタートアップの25%がコードベースの95%以上をAI生成と報告している。この速度重視の流れは、アクセシビリティの質を根本から脅かす。
AIモデルが非セマンティックなコードを生成しやすいのには理由がある。GitHub上の多くのReactコードは「divのスープ」と呼ばれる構造で書かれており、モデルはそれを学習する。人間のレビューも視覚的な見た目を評価しがちで、セマンティクスよりも見た目を重視するフィードバックループが回る。さらに、<div onClick>の方が<button aria-expanded="true">よりトークン数が少なく、制約がない限りモデルは安価な経路を選ぶ。つまり、AI生成UIはデフォルトでアクセシブルではない。
Frontend Mastersのブログ記事によれば、ある開発者が複数のAIツールでReactコンポーネントを生成した実験では、29行のサイドバーに10のアクセシビリティ違反が見つかった。ランドマークなし、見出しなし、リスト構造なし、クリックハンドラのみでボタン未使用、aria-expandedなし、キーボード操作不可、ラベルのないアイコン。スクリーンリーダーが読むアクセシビリティツリーは平坦で構造化されていないテキストの羅列だった。開発者は「同じピクセルだが、片方はドア、もう片方はドアの絵」と表現している。
この問題はセキュリティとも根が同じだ。Veracodeの2025年GenAIコードセキュリティレポートでは、AI生成コードの多くがOWASP Top 10に該当する脆弱性を含み、特にクロスサイトスクリプティングの失敗が多発していた。モデルの知能が問題なのではなく、開発者がセキュリティ制約を指定せず、検証を体系的に行わないプロセスに原因がある。セキュリティレビューをスキップするショートカットは、アクセシビリティレビューもスキップする。AIはアクセシビリティ格差を縮めるどころか、その原因を産業化しているといえる。
開発速度とアクセシビリティは両立可能

「制約を課すと開発速度が落ちる」という意見は根強いが、実際には逆の傾向がある。DevOpsの基本原則であるシフトレフト(問題を早期に検出する)をアクセシビリティに適用すると、修正コストが劇的に下がる。
設計レビューでアクセシビリティの問題を指摘するのはコメント1つで済む。同じ問題が本番環境で発覚すれば、調査、マークアップの再構築、修正、テスト作成に数時間を要する。さらに監査で数百件の指摘が後から出てくれば、週単位の計画外作業が発生する。早期段階の自動チェックがこれらの高コストな後始末を防ぐ。アクセシビリティの組み込みが速度を損なうのではなく、予期せぬ手戻りこそが速度を損なうのだ。
このフローを日常的に回すチームは、緊急監査やリメディエーションスプリントといった高コストなサプライズを回避できる。アクセシビリティは速度の敵ではなく、予測可能な開発速度を守るための保険として機能する。
エンタープライズ対応のための実装パターン

アクセシビリティを大規模にスケールさせる組織は、個人のヒーロー的な努力に頼らず「システム」を構築している。その中核にあるのがデザインシステムであり、ここが最もレバレッジの効く出発点だ。
GOV.UK Design Systemは好事例だ。コンポーネントはJAWS、NVDA、VoiceOver、TalkBackなどの支援技術を用いた自動テストと手動テストの両方を経ており、自動化の限界を補うために障害を持つユーザーを交えたユーザーテストも実施している。しかしチームは、デザインシステムを使うだけでサービスが魔法のようにアクセシブルになるわけではないと明言しており、「高い出発点を与えるだけ」という現実的なスタンスをとっている。つまり、アクセシビリティはインフラになるという教訓だ。
次に、この基盤はエンジニアリングワークフロー全体に組み込まれる。具体的には、完了の定義にアクセシビリティ要件を含め、プルリクエストレビューで明示的なチェックを行い、インタラクティブなコントロールにはデフォルトで<button>や<a>といったセマンティック要素を使用する。キーボードナビゲーションとフォーカス管理はオプションの装飾ではなく、標準的なエンジニアリング上の関心事として扱われる。
最終的に、アクセシビリティは自動化によって強制力を持つ。eslint-plugin-jsx-a11yはコミット前に一般的な問題を捕捉し、LevelCIやPa11yといったツールがCI/CDパイプラインで自動テストを実行する。@storybook/addon-a11yはコンポーネント開発中に問題を表面化させる。この段階に至ると、アクセシビリティは個人の記憶や善意に依存せず、プロセスによって担保される。プラットフォームの一部になるのだ。
これらのレイヤーを重ねることで、組織はアクセシビリティを持続可能なプラクティスに変えることができる。
システムでスケールするための実践

このアプローチを実現しているチームには、いくつかの共通する実装パターンがある。
第一に、AIにコードを生成させる前に制約を課すことだ。生成後に修正するのではなく、CursorルールやCopilotインストラクション、リポジトリレベルの標準設定にアクセシビリティ要件を直接埋め込む。セマンティックHTMLを使うよう指示し、ボタンとリンクの使い分け、状態とラベルの適切な公開方法を明示する。モデルは一度きりのプロンプトよりも、永続的な制約に対してはるかに信頼性高く従う。
第二に、複雑なウィジェットを手作りしないことだ。コンボボックス、メニュー、タブ、モーダルといったUI要素は、アクセシビリティ上の問題が集中するホットスポットになる。Radix UI、React Aria、Headless UIのようなライブラリは、これらの問題の多くをすでに解決している。スケーラブルなアプローチとは、アクセシビリティを毎回一から実装することではなく、十分にテストされたプリミティブからアクセシブルな振る舞いを継承することだ。
第三に、設計から実装へのハンドオフ時にアクセシビリティ要件を明文化することだ。フォーカス順序、ラベル、見出し階層、インタラクションの状態は実装開始前に規定されているべきである。設計成果物にアクセシビリティ要件が欠けていれば、最終製品にも欠ける可能性が高い。「タブ順序はどうするか」「ラベルは何か」「エラー時に何が起きるか」といった簡単なメモが、後の推測作業を大幅に減らす。
これらのパターンはどれも特別なものではない。DevOpsとプラットフォーム思考をアクセシビリティに適用しただけの話だ。
ビジネスインパクトと運用能力としての価値

エンジニアリングリーダーがアクセシビリティを優先する理由は規制だけではない。しかし、規制、調達要件、ユーザー維持、製品品質はすべて同じ方向を指している。
法的圧力は増加の一途にある。米国ではデジタルアクセシビリティ訴訟が年間数千件に上り、大企業に限った話ではない。欧州では欧州アクセシビリティ法が施行され、Eコマース、銀行、発券、通信など幅広い分野に適用される。企業の所在地を問わないため、日本企業でもEU圏向けのサービスには影響が及ぶ。規制当局の目は「あればよいもの」から「必須」へと変わった。
しかし、規制は話の一部に過ぎない。より大きな話は市場機会の喪失だ。世界経済フォーラム(2023年12月)の推計では、世界の13億人の障害者とその友人・家族が持つ購買力は13兆ドルに達し、障害者消費者の年間可処分所得だけでも約8兆ドルに上る。英国のClick-Away Poundレポート2019では、アクセシビリティの低いサイトを離脱し他社で購入するユーザーの損失額が171億ポンドに達し、2016年の117.5億ポンドから約45%増加した。ユーザーはバグ報告をしない。ただ去って競合から買う。
B2Bや政府向けビジネスでは、アクセシビリティがコストではなく堀(Moat)になる。多くの企業がデジタル製品の購入時にVPATやACRなどのアクセシビリティ証明を求めており、Level Accessの第7回年次レポートによると、取引の75%で「ほとんどの場合」証明が必要とされ、常に要求する割合は27%から31%に上昇している。強固なACRは営業サイクルを加速させ、弱いものや不在は商談を停滞または停止させるレッドラインになる。
一歩引いて見れば、より深いパターンが浮かび上がる。アクセシビリティはエンジニアリング成熟度の代理指標だ。セマンティックHTMLを出力し、フォーカスを管理し、状態を正しく公開し、それをCIでテストするチームは、規律の整ったチームである。アクセシブルなコンポーネントを生み出す同じ規律が、保守性が高く、テスト可能で、バグの少ないコンポーネントを生み出す。開発リーダーやプロダクトリーダーにとって、これこそが本当のビジネスケースだ。アクセシビリティへの投資はプラットフォームへの投資であり、機能出荷をより速く、スムーズに、手戻り少なくするための基盤となる。
この記事のポイント
- アクセシビリティは一過性の監査やチェックリストではなく、セキュリティと同様の継続的な運用能力として組み込むべき
- AIによるコード生成が加速するほど、非セマンティックなUIが量産されアクセシビリティ負債が倍増する
- 設計段階からCI/CDまでシフトレフトすることで、手戻りコストを大幅に削減できる
- デザインシステム、完了の定義、自動化ゲートの3層でアクセシビリティはスケールする
- ビジネス面でも、法規制対応や巨大な市場機会の獲得、調達優位性に直結する
・ 複数業界における17年間のデジタルビジネス開発経験
・ ウェブサイト開発のためのHTML、PHP、CSS、JavaScript等の実用的知識
・ 15ヶ国語対応の多言語SaaSの開発経験
・ 17年間にも及ぶ、Eコマース長期運営経験
・ 幅広い業界でのSEO最適化の豊富な経験

ローカルファーストWeb開発のアーキテクチャ クライアント主導のデータ管理と同期の仕組み
ローカルファーストアーキテクチャが注目を集めている。従来のサーバー中心のWebアプリ開発とは異なり、クライアント端末にデータの一次コピーを保持し、読み書きをローカルで即座に処理する設計手法だ。オフラインでも動作し、ネットワーク遅延の影響を受けないため、ユーザー体験が大幅に向上する。
Smashing Magazineの記事「The Architecture Of Local-First Web Development」(2026年5月6日公開)では、実際のプロジェクト経験に基づいた実践的な知見が紹介されている。本記事ではその要点を再構成し、Web制作やシステム開発に携わるエンジニア向けにわかりやすく解説する。
ローカルファーストとは何か 〜オフライン対応との違い
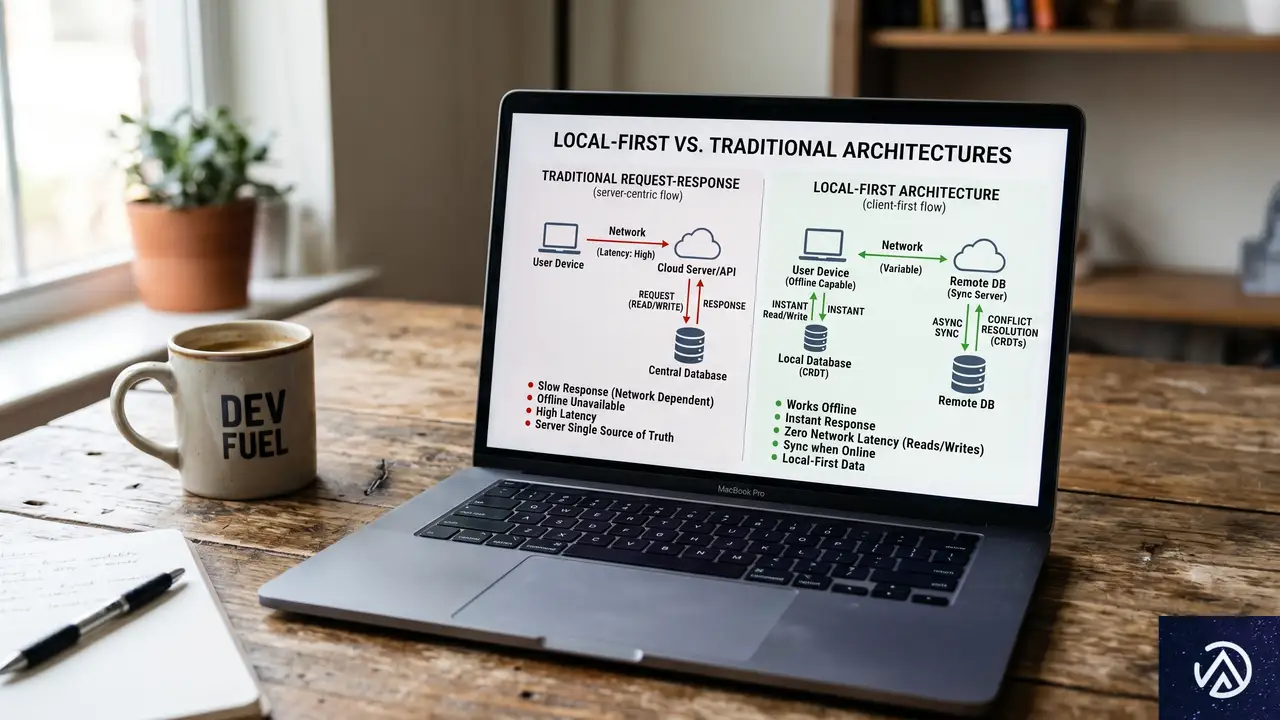
ローカルファーストはよく「オフラインファースト」やPWA(プログレッシブWebアプリ)と混同される。しかしこれらは根本的に異なる。オフラインファーストはネットワーク切断時でもアプリが壊れず動くことを目的とするが、データの主たる権威(正)は依然としてサーバーにある。一方、ローカルファーストは「データアーキテクチャ」の概念であり、ユーザーの端末がデータの一次コピーを持つ。アプリはローカルデータベースに直接読み書きし、画面を即座にレンダリングする。サーバーとの同期はバックグラウンドで行われ、サーバーは認証やバックアップなど特定の役割を担うが、データの門番ではない。
Ink and Switchが2019年に提唱した「ローカルファーストソフトウェア」の7つの理想(高速、マルチデバイス、オフライン、コラボレーション、長寿命、プライバシー、ユーザー所有権)は今でも有効だが、実務において最も重要なのは「クライアントが分散システムのノードであり、独自のデータベースを持つ」という点だ。この考え方が開発全体を変える。
このデモのとおり、ローカルファーストではユーザーの操作がサーバーの応答を待つことなく完結する。この違いがアプリの「遅さ」に対する根本的な解決策になる。
オフラインファーストやPWAとの混同を解く
Service Workerを使ったキャッシュやPWAは、あくまで配信や耐障害性の仕組みだ。データの所有権や正規性は変わらない。ローカルファーストは「端末が真実のコピーを持つ」点で本質的に異なる。これを理解しないまま実装を進めると、後からデータの不整合や同期設計の誤りに悩まされることになる。
ローカルファーストが向いているユースケースと不向きな場面

このアーキテクチャは万能ではない。導入を検討する前に、自社のアプリがどのデータ特性を持つかを見極める必要がある。
適している領域
- ユーザー生成データを扱うアプリ。メモ帳、ドキュメントエディタ、プロジェクト管理、フィールド業務用ツールなど
- リアルタイムコラボレーションが必要なツール。デザインツールや同時編集が前提のアプリ
- プライバシーが売りになるサービス。データをユーザーの手元に置くことで差別化できる
- 通信が不安定な環境向けのアプリ。工事現場、僻地、移動中の利用を想定する場合
不向きな領域
- サーバー生成データが主体のアプリ。分析ダッシュボード、SNSフィード、検索結果など
- 強いトランザクション整合性が求められるシステム。銀行、決済、在庫管理(複数ユーザーが同時に在庫を操作すると問題)
- 単純なCRUDでオフラインやコラボレーションの必要がない社内管理画面。同期エンジンは過剰設計になる
- クライアント端末に収まらない巨大なデータセット
また、アプリ全体を一度にローカルファーストに書き換える必要はない。例えばブログエディタの下書き機能だけをローカルファーストにする、といった段階的な導入が現実的だ。
クライアント側のデータ保存 ストレージ技術の選択

ユーザーの端末にデータを保持するには、適切なストレージ技術を選ぶ必要がある。従来のlocalStorageは同期APIでメインスレッドをブロックし、容量も5〜10MBと限られるため、本格的なデータベース用途には使えない。現在の主流は以下の3つだ。
実案件ではwa-sqliteなどのライブラリを使い、OPFSを介してSQLiteを永続化するのが有力な選択肢だ。初期化のコード例を示す。
import { SQLiteAPI } from 'wa-sqlite';
import { OPFSCoopSyncVFS } from 'wa-sqlite/src/examples/OPFSCoopSyncVFS.js';
async function initDatabase() {
const module = await SQLiteAPI.initialize();
const vfs = new OPFSCoopSyncVFS('app-db');
await vfs.initialize(module);
const db = await module.open_v2('local.db');
await module.exec(db, `PRAGMA journal_mode=WAL`);
await module.exec(db, `
CREATE TABLE IF NOT EXISTS tasks (
id TEXT PRIMARY KEY,
title TEXT NOT NULL,
status TEXT DEFAULT 'backlog',
created_at TEXT DEFAULT (datetime('now'))
)
`);
return db;
}なおSafariのOPFS実装は一部のコンテキストでcreateSyncAccessHandle()が無反応で失敗する既知の不具合があり、IndexedDBへのフォールバックを用意しておくことが推奨される。
データ同期の手法 CRDTとデータベースレプリケーション

クライアントにデータを置くだけなら解決済みだが、複数端末や複数ユーザー間でどう同期するかが本当の難所だ。主なアプローチは次のとおり。
YjsやAutomergeが代表的で、リアルタイム共同編集に強み。テキストの文字レベルでのマージに優れるが、構造化データのマージは意図しない結果を生むこともある。多くのプロジェクトでは、真のリアルタイム共同編集が必要な箇所にのみYjsを採用し、それ以外はデータベースレプリケーションで済ませるハイブリッド構成が無難だ。
同期の流れをコードで見る
ローカルファーストのアプリでは、従来のようにfetch()でデータを取得する必要がない。代わりにuseLiveQueryのようなフックがローカルSQLiteの変更を検知し、UIが自動で再描画される。
import { useLiveQuery } from '@powersync/react';
import { db } from '../lib/database';
function TaskBoard({ projectId }) {
const tasks = useLiveQuery(
`SELECT * FROM tasks WHERE project_id = ? ORDER BY position`,
[projectId]
);
async function addTask(title) {
await db.execute(
`INSERT INTO tasks (id, title, project_id, position)
VALUES (?, ?, ?, ?)`,
[crypto.randomUUID(), title, projectId, tasks.length]
);
// API呼び出しも楽観的更新のロールバックも不要
}
return (
{tasks.map(task => )}
);
}このコードにはローディング状態もエラーハンドリングも書かれていない。データが常にローカルにあるという前提が、これほどまでにUIコードを単純化する。
衝突解決と整合性の課題

複数のレプリカが独立して書き込みを行うと、当然データの衝突が発生する。最もシンプルな解決策は「ラストライトウィン(LWW)」、つまりタイムスタンプが新しい方を採用する方式だ。ただしレコード全体まるごと上書きするのではなく、フィールド単位で適用するのが現実的だ。下記のようなマージ関数を実装すれば、別々のフィールドを編集した場合に両方の変更が生き残る。
function pickWinner(a, b) {
const timeA = new Date(a.updatedAt).getTime();
const timeB = new Date(b.updatedAt).getTime();
if (timeA !== timeB) return timeA > timeB ? a : b;
return a.clientId > b.clientId ? a : b;
}
function mergeTask(local, remote) {
const merged = {};
const allKeys = new Set([...Object.keys(local), ...Object.keys(remote)]);
for (const key of allKeys) {
if (!local[key]) { merged[key] = remote[key]; continue; }
if (!remote[key]) { merged[key] = local[key]; continue; }
merged[key] = pickWinner(local[key], remote[key]);
}
return merged;
}このLWWは約95%の衝突を自動解決するが、同じテキストフィールドを2人が編集した場合は一方が静かに上書きされる。文書編集では問題だが、タスクのタイトル程度なら許容できる場合が多い。
セマンティック衝突への対処
構造的には綺麗にマージできても、意味的に矛盾するケースがある。たとえば2人のユーザーがオフラインで同じ会議室の同じ時間帯に別の予定を入れた場合、フィールド単位では衝突しないがダブルブッキングが発生する。このような「セマンティック衝突」は、サーバー側のバリデーションで検出し、クライアントに通知してユーザーに解決を促す。
重要なのは、違反が起きても書き込み自体は受け入れ、警告フラグとともにクライアントに返す設計だ。もしサーバーが書き込みを拒否すると、クライアントのローカルDBには存在するがサーバーには存在しない「幽霊レコード」が生まれ、回復が困難になる。
実装上の注意点 認証・マイグレーション・テスト

認証と認可
認証は従来どおりJWTやOAuthで行うが、トークンは毎リクエストではなく同期接続の確立時に使われる。認可は同期レイヤーで厳密に適用する必要がある。全データをクライアントに渡して見せたいものだけ表示するのは危険で、DevToolsからすべて覗ける。PowerSyncの「同期ルール」やElectricSQLの「シェイプ」を使い、サーバー側でユーザーに許可された行だけを送信する設計が必須だ。
スキーママイグレーション
サーバーなら1つのデータベースを管理すればよいが、クライアントはアプリを開いていない期間が長ければ古いスキーマのまま放置されている可能性がある。マイグレーションは起動時にバージョン番号を確認して逐次適用する方式が堅実だ。基本的に「カラムの追加」のみとし、削除やリネームは極力避ける。古いクライアントが存在する限り、欠落カラムへの書き込みが同期失敗を引き起こすからだ。
テスト戦略
マージロジックはユニットテストが容易だが、実際のネットワーク断絶や衝突タイミングを再現するのが難しい。2つのクライアントインスタンスをメモリ上で立ち上げ、同時編集後に収束するかを検証する統合テストや、Playwrightのcontext.setOffline(true)を使ったE2Eテストが有効だ。ランダムな操作列を与えて収束性をチェックするプロパティベーステストもCRDTロジックの品質を高める。
この記事のポイント
- ローカルファーストは、クライアント側にデータの一次コピーを置き、読み書きをローカルで即座に行うデータアーキテクチャである
- オフラインファーストやPWAとは異なり、データ所有権と即時性が根本的に変わる
- 向いているのはユーザー生成データを扱う協調ツールやフィールドアプリ。銀行や分析ダッシュボードには不向き
- クライアント側のストレージにはOPFS上のSQLite(WASM)が主力。IndexedDBの直接利用は避ける
- 同期はCRDT(Yjs等)とデータベースレプリケーション(PowerSync等)から選択し、多くの場合は後者で十分
- 衝突解決はフィールド単位のLWWで大半を自動化し、セマンティック衝突はサーバー検出+ユーザー通知で対応する
- 認可・マイグレーション・テストには固有の注意点があり、段階的に導入するのが現実的
・ 複数業界における17年間のデジタルビジネス開発経験
・ ウェブサイト開発のためのHTML、PHP、CSS、JavaScript等の実用的知識
・ 15ヶ国語対応の多言語SaaSの開発経験
・ 17年間にも及ぶ、Eコマース長期運営経験
・ 幅広い業界でのSEO最適化の豊富な経験

ヘッドレスCMSとWordPressの選び方、2026年版アーキテクチャ比較
CMSの選定は2026年、技術的な好みの問題ではなくなった。その選択がマーケティングキャンペーンの展開速度、コンテンツ更新の自由度、ひいては収益に直結する。WordPressが世界のWebサイトの43.5%を支える支配的な存在である一方、ヘッドレスCMS市場は2027年までに16億ドルに達すると予測されている。
両者の違いは単なる「新しいか古いか」ではない。視覚的な構築の自由と、アーキテクチャの厳格な分離という、根本的に異なる哲学のせめぎ合いだ。本記事ではパフォーマンス、運用コスト、セキュリティ、SEO、そしてチームの働き方という実務の観点から、両アプローチを比較する。
根本的なアーキテクチャの違い
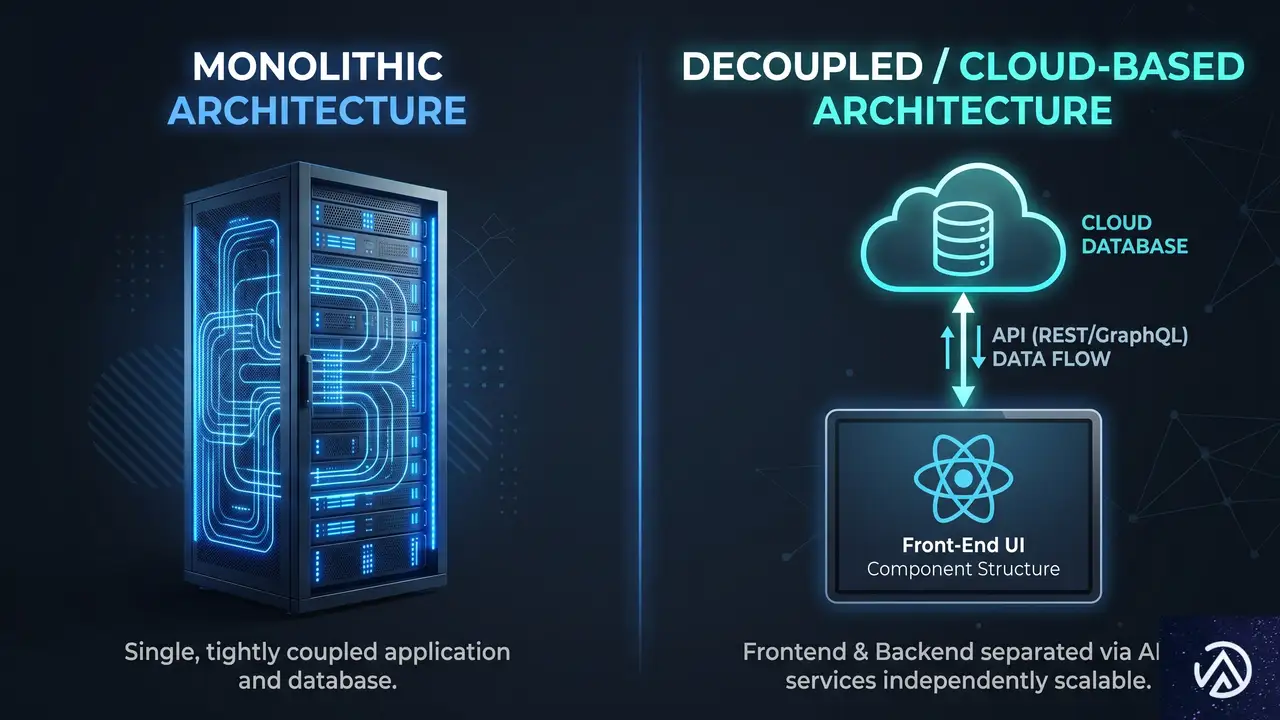
アーキテクチャの議論は開発者だけの専門用語ではない。マーケティングチームが火曜の朝にランディングページを立ち上げられるかどうか、そのスピードを決める。この根本的な違いは採用戦略にも直接影響する。
従来のWordPressはモノリシック(一体型)システムだ。コンテンツデータベース、PHPの処理ロジック、HTML出力がすべて同じアプリケーション環境に同居する。ユーザーがリンクをクリックすると、サーバーはPHPスクリプトを実行しMySQLデータベースに問い合わせ、取得したデータをテーマテンプレートにはめ込み、最終的なHTMLをブラウザに返す。この一連の処理は一つのサーバー内で完結する。
一方、ヘッドレスはデカップルド(分離型)アーキテクチャと呼ばれる。コンテンツはContentfulやStrapiのようなクラウドデータベースに保存され、フロントエンドはReactやVueで構築された完全に別個のアプリケーションになる。フロントエンドアプリはAPIエンドポイントを通じて生のJSONデータを受け取り、コンテンツの見た目には一切関与しない。データの受け渡しと表示が完全に分離されているのだ。
なぜ開発者は分離を好むのか
Elementor Blogの記事によれば、最近のStack Overflow調査でヘッドレス技術への開発者関心が従来のPHPロールと比較して15%増加したという。彼らは「関心の分離」を重視する。バックエンドのコンテンツ管理とフロントエンドのUI実装が完全に切り離されることで、開発効率とコードの保守性が高まるからだ。
ただし、この分離にはトレードオフがある。マーケターがコンテンツの見た目をリアルタイムで確認する「ライブプレビュー」は、ヘッドレス環境では極めて面倒な課題として残っている。草案を確認するだけのために複雑なプレビューサーバーを構築しなければならないケースも多い。
ユーザー体験の決定的な差

ヘッドレスアーキテクチャがマーケティングチームを苦しめる最大の理由がここにある。技術的な純粋さと引き換えに、ワークフローの速度が犠牲になる。
WordPressの視覚的優位性
従来型WordPressは視覚的な構築体験で圧倒的に優位に立つ。Elementor Editor Proを例にとると、118種類以上のウィジェットを使ってCSSを一行も書かずにレイアウトを構築できる。コンテナをドラッグし、ブレークポイントを調整し、すぐに公開する。
ヘッドレスが生む開発者依存
ヘッドレス環境では、ヒーローセクションのレイアウトを変更したいだけでも、マーケターはJiraチケットを発行し、開発者がReactコンポーネントを更新し、GitHubにプッシュし、ビルドパイプラインの完了を待つという手順を踏まなければならない。毎週11本の記事を公開するチームにとって、この依存関係は数百時間の損失になりうる。
Elementor Blogで紹介されているAIアシスタント「Angie」のようなツールは、このギャップを埋めようとしている。チャットで指示するだけで、実用的なレイアウトやフォームを自動生成する。テキスト提案ではなく、実際に動作するアセットを構築する点が従来のAIと異なる。
一方で、スマート冷蔵庫、Apple Watchアプリ、Webサイトに同時にコンテンツを配信する必要があるなら、ヘッドレスのデータエントリーモデルは必須になる。配信先が3つ以上のチャネルに及ぶブランドは、前年比9.5%の収益増加を達成しているとのデータもある。
表示速度、パフォーマンスの現実
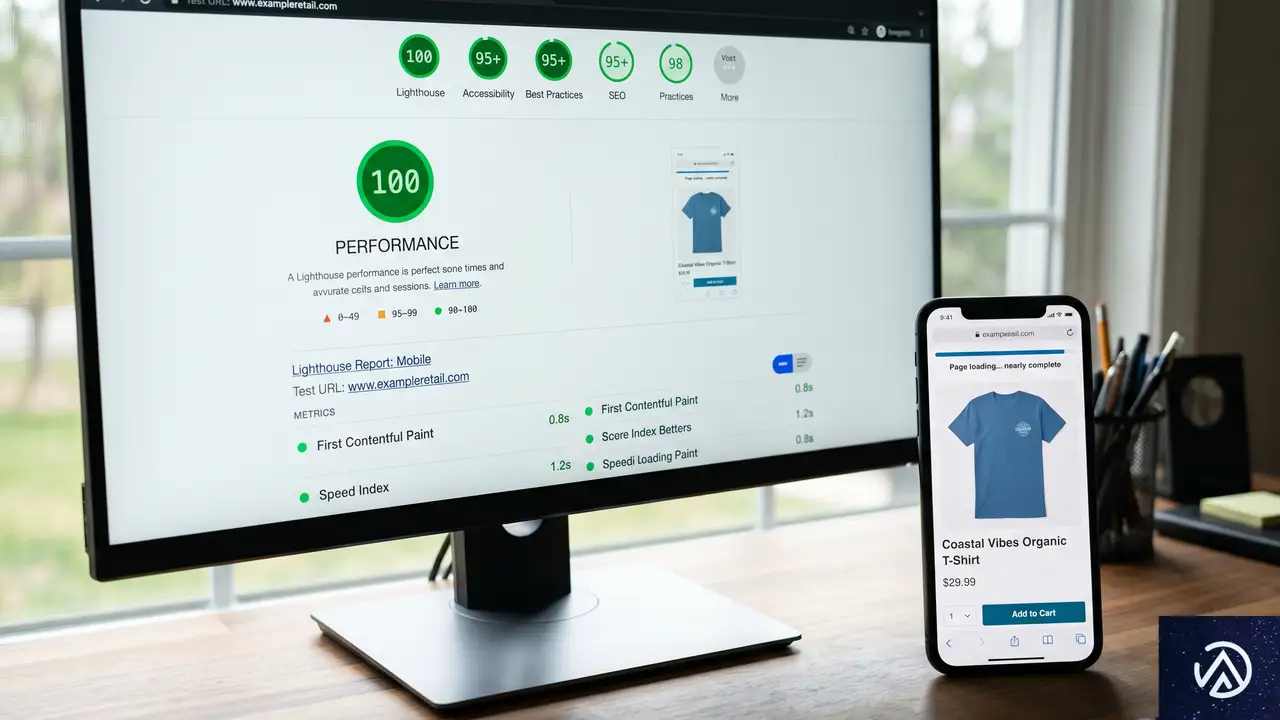
2026年において表示速度は贅沢品ではない。生存のための指標だ。世界のトラフィックの58.67%がモバイルデバイスを経由する中、重いサイトは収益を直接焼き尽くす。
ヘッドレスの圧倒的速度
ヘッドレスシステムは生の速度で容易に優位に立つ。静的サイト生成(SSG)という仕組みを使うからだ。SSGとは、コンテンツのHTMLファイルをあらかじめ生成しておき、CDN(コンテンツ配信ネットワーク。世界中に分散したサーバー拠点から最寄りの場所にデータを届ける仕組み)に保存する手法である。ユーザーがアクセスした瞬間にデータベースへ問い合わせる必要がないため、Next.jsで構築されたサイトは頻繁にLighthouseの満点を叩き出す。
WordPressが抱えるボトルネック
現在、WordPressサイトでGoogleのCore Web Vitals(コアウェブバイタル。ページ体験を測る3つの指標)の全項目を通過しているのは、わずか40.5%だ。PHP処理への依存度の高さと最適化されていないプラグインが深刻なボトルネックを生み出している。参考までに、Next.jsサイトの合格率は約55%に達する。
ただし、WordPressで速度を諦める必要はない。構築方法を変えれば良い。エッジキャッシュの導入、条件付きアセットローディング(必要なときにだけスクリプトを読み込む手法)、画像の自動圧縮、Redisを使ったデータベースクエリのオフロードを徹底する。速度向上は直接売上に跳ね返る。モバイルでわずか0.1秒の改善が小売のコンバージョン率を8.4%押し上げるというデータもある。
セキュリティと保守の実態

セキュリティは従来型CMSエコシステムに突き刺さる最大の棘だ。Elementor Blogの記事が引用する統計は痛烈である。CMS系Webサイトへの攻撃成功事例のうち、実に94%がWordPressを標的にしている。
WordPressの広大な攻撃対象
この数字の理由は明確だ。データベース、ログイン画面(wp-admin)、公開Webサイトがすべて同じサーバーIPアドレスを共有している。攻撃者が古いスライダープラグインの脆弱性を一つ見つければ、データベース全体へのアクセスを奪取できる。攻撃対象領域が極めて広いのだ。
ヘッドレスの構造的安全性
ヘッドレスアーキテクチャはこの攻撃対象領域を劇的に縮小する。フロントエンドはバックエンドから完全に切り離されているため、公開Webサイトにデータベースが接続されていない。ハッカーは静的HTMLファイルにSQLインジェクションを仕掛けることはできない。
もちろん、モノリシックシステムの防御は不可能ではない。共有ホスティングを避け、Cloudflare経由でWAF(Webアプリケーションファイアウォール)を導入し、使っていないプラグインは無効化ではなく即座に削除する。管理ロールには二要素認証を強制し、デフォルトのログインURLを変更する。こうした基本的な対策を徹底するだけでもリスクは大幅に下げられる。
コストの真実、初期費用と総所有コスト

初期構築費用は総所有コスト(TCO)の一部に過ぎない。多くの制作会社がパフォーマンスだけを謳い文句にヘッドレスを販売するが、クライアントに毎月のSaaS料金が重くのしかかる。
ヘッドレスの高い参入障壁
具体的な数字を見てみよう。SANITYのGrowthプランは月額949ドル、ContentfulのTeamティアは月額300ドルからスタートし、エンタープライズプランは通常月額2,000ドルを超える。Strapiのような月額29ドルの選択肢もあるが、Nodeアプリとデータベースを自前でホストする手間が加わる。
WordPressの現実的なコスト
従来型プラットフォームの参入障壁ははるかに低い。中小企業向けの高品質なマネージドWordPressホスティングは、おおむね月額20ドルから115ドルの範囲に収まる。大規模なコンテンツ運用をヘッドレスの数分の一の予算で回せる計算だ。
ただし、WordPressのスケーラビリティは無料ではない。月間100万訪問者を超えると、安価なホスティングは崩壊する。エンタープライズグレードのクラウドインフラ、積極的なキャッシュ階層、高度なセキュリティ設定が必要になる。結局のところ、開発コストもどちらの道でも発生する。ヘッドレスは高給のReact/Vueエンジニアを必要とし、従来型ビルドはPHP/WordPressエキスパートによるテーマロジックの維持や定期的なデータベース最適化を必要とする。
ハイブリッド手法、橋を架ける

極端な二択を迫られる必要はない。2026年、最も賢いチームはハイブリッドアプローチを採用している。ページビルダーの視覚的自由を維持しつつ、特定の機能に最新のAPI技術を利用する。
WordPressを純粋なヘッドレスコンテンツリポジトリとして使うことも可能だ。WordPress REST APIとWPGraphQLを使えば、投稿や固定ページをJSONデータとしてクエリし、Next.jsフロントエンドに供給できる。執筆者には使い慣れたGutenbergインターフェースを提供しながら、開発者はモダンなスタックを手に入れられる。
より効率的なのは、モノリシックを維持しながらスピードを上げるアプローチだ。多数のプラグインをつぎはぎする代わりに、ホスティング、ビジュアルビルド、パフォーマンスツールを一つの環境に統合する。AIにワイヤーフレーム生成を任せ、人間は微調整に集中する。主要なマーケティングサイトはモノリシックのまま実行速度を確保し、求人情報や商品カタログといった特定の投稿タイプだけをREST API経由でモバイルアプリにプッシュする。これでデータを閉鎖的なシステムに閉じ込めず、マーケティングチームも視覚編集から締め出されない。
この記事のポイント
- 従来型WordPressはマーケティングチームの即応性と視覚的編集で圧倒的に優位。
- ヘッドレスは生の表示速度とセキュリティで勝るが、高いSaaSコストと開発者依存が課題。
- WordPressの速度課題はエッジキャッシュと条件付きローディングで大幅に改善可能。
- 3つ以上のチャネルにコンテンツを配信する場合、ヘッドレスのデータエントリーモデルが必須。
- ハイブリッド手法を用いれば、両者の長所を活かした現実的な落とし所が見えてくる。
・ 複数業界における17年間のデジタルビジネス開発経験
・ ウェブサイト開発のためのHTML、PHP、CSS、JavaScript等の実用的知識
・ 15ヶ国語対応の多言語SaaSの開発経験
・ 17年間にも及ぶ、Eコマース長期運営経験
・ 幅広い業界でのSEO最適化の豊富な経験

AIエージェントに最適化されたWebサイトとは?Cloudflareが提唱するAgent Readinessスコアの全容
Webサイトのあり方が、人間がブラウザで閲覧するものから、AIエージェントが自律的に情報を収集し処理するものへと劇的に変化している。かつてWebサイトが検索エンジンに最適化(SEO)されたように、これからはAIエージェントが理解しやすい形に最適化される必要がある。
Cloudflare(クラウドフレア)は、自社サイトがどの程度AIエージェントに対応できているかを測定するツール「isitagentready.com」を公開した。これは、AIがサイトをクロールし、内容を理解し、さらには決済まで行える状態にあるかを数値化する指標である。
現在、インターネット上の主要な20万ドメインを調査した結果、AIエージェントへの最適化が進んでいるサイトは極めて少ないことが判明した。しかし、これは早期に対応することで、競合他社よりもAIによる情報提供やサービス利用の面で優位に立てる可能性があることを示唆している。
AIエージェント向けのWeb最適化指標であるAgent Readinessとは

Agent Readiness(エージェント・レディネス)は、WebサイトがAIエージェントという新しい「訪問者」をどれだけ歓迎し、効率的に情報を渡せるかを示す新しい概念である。Cloudflareが提供を開始した「isitagentready.com」では、URLを入力するだけで、そのサイトの対応状況をスコア化できる。
このスコアは、単に「AIを拒否していないか」を確認するだけのものではない。AIがサイト内を迷わずに移動できるか、情報を処理する際のコスト(トークン数)を削減できているか、そしてAIが自律的にアクションを起こせるかといった多角的な視点で評価される。
評価を構成する4つの主要な軸
Agent Readinessスコアは、主に以下の4つのカテゴリに基づいて算出される。それぞれの要素は、AIエージェントがサイトを訪れた際の「体験」を向上させるために不可欠なものだ。
- ディスカバリー(発見しやすさ):AIがサイトの構造を即座に把握し、必要なページへたどり着けるか
- コンテンツの最適化:AIが理解しやすい形式(Markdownなど)でデータを提供しているか
- 制御とセキュリティ:AIの行動範囲を適切に制限し、信頼できるAIかどうかを認証できるか
- インタラクション(相互作用):AIがAPIを介してツールを操作したり、決済を行ったりできるか
Cloudflare Radarの調査によれば、現在インターネット上の主要なサイトの約78%が「robots.txt」を設置しているが、そのほとんどは従来の検索エンジン向けに書かれたものである。AIエージェントに特化した設定を行っているサイトは、まだ全体の数パーセントに過ぎない。
AIエージェントに情報を届けるための新規格と実装方法

AIエージェントがWebサイトを巡回する際、最大の障壁となるのが「HTMLの複雑さ」である。人間向けの装飾や広告が含まれるHTMLは、AIにとってノイズが多く、処理に多くのトークンを消費させる。これを解決するための新しい標準規格が登場している。
llms.txtによる「AI専用のお品書き」の提供
「llms.txt」は、Webサイトのルートディレクトリに配置するプレーンテキストファイルである。これは、AI(大規模言語モデル)に対して、サイトの概要や重要なコンテンツへのリンクをリスト化した「読書リスト」のような役割を果たす。サイトマップをAIが読みやすい言葉で書き直したものと考えると分かりやすい。
# サイト名
> サイトの短い説明文
## 主要ドキュメント
- [導入ガイド](https://example.com/docs/intro.md)
- [APIリファレンス](https://example.com/docs/api.md)このファイルを設置することで、AIは数千ページあるサイトの中から、どのページを優先的に読むべきかを瞬時に判断できる。これにより、AIエージェントの回答精度が向上し、ユーザーが求める情報にたどり着くまでの時間が短縮される。
Markdownコンテンツ・ネゴシエーションによる軽量化
コンテンツ・ネゴシエーションとは、クライアント(訪問者)の要望に合わせて、サーバーが最適な形式のデータを返す仕組みである。AIエージェントがHTTPヘッダーに Accept: text/markdown を含めてリクエストを送った際、サーバーがHTMLではなくMarkdown形式を返すように設定することが推奨されている。
HTMLからMarkdownへの切り替えは、AIが消費するトークン数を最大で80%削減できるというデータがある。トークンの削減は、AIの処理速度を上げ、運用コストを下げることに直結する。以下のデモは、HTMLとMarkdownでどれほど情報の密度が異なるかを視覚化したものである。
投稿日:2026年4月17日
# 最新ニュース
WebサイトのAI最適化が始まりました。
[詳細](https://example.com/news/1)
このデモのように、AIにとっては構造化されたテキストのみの方が扱いやすく、誤認のリスクも低い。Cloudflareでは、URLの末尾に /index.md を付与することで、動的にMarkdownを返す仕組みを推奨している。
AIエージェントの制御とセキュリティの新基準

すべてのAIエージェントにサイトを解放するのが正解とは限らない。コンテンツの無断学習を拒否したい、あるいは特定の信頼できるエージェントにのみアクセスを許可したいというニーズがある。これに対応するための規格が「Content-Signal」と「Web Bot Auth」である。
Content-Signalによる詳細な意思表示
従来の robots.txt では、アクセスを許可するか拒否するかという二択しかできなかった。新しい「Content-Signal」ディレクティブを使うと、AIによる学習(ai-train)、推論への利用(ai-input)、検索結果への表示(search)を個別に制御できる。
User-agent: *
Content-Signal: ai-train=no, search=yes, ai-input=yes例えば、上記の記述では「AIの学習には使わせないが、AIがユーザーの質問に答える際の参考資料(RAG)としての利用や、検索結果への掲載は許可する」という柔軟な設定が可能になる。これにより、著作権を守りつつ、AIを介したトラフィックを確保できる。
Web Bot Authによるエージェントの身元確認
悪意のあるボットがAIエージェントを装ってアクセスしてくるリスクに対し、「Web Bot Auth」という認証規格が提案されている。これは、エージェントがリクエストにデジタル署名を付与し、サイト側がその署名を公開鍵で検証する仕組みである。
これにより、サイト運営者は「このアクセスは確かにOpenAIの公式エージェントからのものだ」と確信を持ってアクセスを許可できるようになる。匿名のスクレイパーと、正当なAIサービスを明確に区別するための重要なインフラとなるだろう。
自律的なアクションを可能にするAPIと決済の統合

AIエージェントの真の価値は、情報の閲覧だけでなく、ユーザーの代わりに「行動」することにある。買い物、予約、データの処理といったタスクをAIが自律的にこなすためには、WebサイトがAI向けの「窓口」を備えていなければならない。
MCP(Model Context Protocol)の活用
MCPは、AIモデルが外部のデータソースやツールと接続するためのオープン標準である。サイト側が「MCPサーバー」を用意し、その機能(ツール)を記述した「サーバーカード」を /.well-known/mcp/server-card.json に配置することで、AIはどのような操作が可能かを理解できる。
例えば、ドキュメント検索ツールや在庫確認ツールをMCP経由で公開すれば、AIエージェントは自らそのツールを呼び出し、ユーザーの複雑な要求に応えることができるようになる。これは、AIが「サイトを読む」段階から「サイトを使う」段階への進化を意味する。
HTTP 402によるマシン間決済の復活
AIエージェントが有料の情報を取得したり、商品を購入したりする場合、人間向けのクレジットカード入力画面は機能しない。そこで注目されているのが、長らく使われてこなかったHTTPステータスコード「402 Payment Required」の活用である。
「x402」と呼ばれるこの新しい決済フローでは、AIがリクエストを送ると、サーバーが402エラーとともに「支払い条件」を機械読み取り可能な形式で返す。エージェントはその条件に従って決済を行い、再度リクエストを送ることでコンテンツを取得できる。人間を介さない、マシン間の経済圏を支える技術である。
Cloudflare ドキュメントに見るAI最適化の実践事例
Cloudflareは自社の開発者向けドキュメントにおいて、これらの規格をいち早く導入している。その結果、AIエージェントによる回答速度が66%向上し、消費トークン数が31%削減されたという。具体的にどのような工夫がなされているのかを見てみよう。
URL書き換えによる動的なMarkdown提供
Cloudflareは、既存のHTMLページをわざわざMarkdownで書き直すのではなく、エッジコンピューティング(Cloudflare Rules)を活用して動的に変換している。URLの末尾に /index.md を付けると、オリジナルのHTMLからタグを取り除き、Markdownとして配信する仕組みだ。
これにより、メンテナンスコストを増やすことなく、人間向けとAI向けのコンテンツを両立させている。また、大規模なサイトでは llms.txt が巨大になりすぎるため、ディレクトリごとに分割した llms.txt を用意し、ルートからそれらをリンクする階層構造を採用している。
古い情報をAIに学習させないためのリダイレクト
Webサイトには、歴史的な理由で残されている古いドキュメント(非推奨のツールなど)が存在する。人間は「非推奨」という警告バナーを見て判断できるが、AIクローラーはテキストをそのまま飲み込んでしまい、古い情報をユーザーに教えてしまうことがある。
Cloudflareでは、AI学習用クローラーを識別し、古いページから最新のページへと強制的にリダイレクトさせる処理を行っている。これにより、AIが常に最新かつ正確な情報のみを学習するように制御している。これは、AI時代の新しいコンテンツ管理の形と言えるだろう。
独自の分析:Webサイトは「読むもの」から「使われるもの」へ

Agent Readinessの普及は、Webサイトの設計思想を根本から変える可能性がある。これまでのWebデザインは、いかに人間の視線を誘導し、クリックさせるかという「UI/UX」が中心だった。しかし、AIエージェントが主役となる世界では、いかに機械が迷わず、低コストで目的を達成できるかという「DX(Developer Experience)ならぬAX(Agent Experience)」が重要になる。
特に注目すべきは、AIエージェントが「ブラウザ」を介さずに直接サーバーと対話するようになる点だ。これは、Webサイトが「情報の展示場」から「プログラム可能なインターフェース」へと進化することを意味している。APIが公開されていない小規模なサイトでも、llms.txt やMarkdown配信を導入することで、AIという強力な力を味方につけることができる。
今後、Googleなどの検索エンジンも、Agent Readinessスコアが高いサイトを「AIフレンドリーな良質なソース」として優遇する可能性がある。SEOの次のステージとして、この「AI最適化」への取り組みは、企業のデジタル戦略において避けて通れない課題となるだろう。
この記事のポイント
- Agent Readinessスコアの登場:WebサイトがAIエージェントにどれだけ最適化されているかを測定する新しい指標が公開された
- llms.txtとMarkdownの重要性:AI専用の案内図(llms.txt)と軽量なデータ形式(Markdown)が、AIの回答精度向上とコスト削減に直結する
- 詳細なアクセス制御:Content-Signalにより、学習は拒否しつつ検索や推論への利用を許可するなど、柔軟な意思表示が可能になる
- マシン間経済の加速:MCPによるツールの公開や、x402による自動決済など、AIが自律的にアクションを起こすためのインフラが整いつつある
- 早期対応のメリット:現状では対応サイトが少ないため、今すぐ対策を始めることでAI経由のトラフィックや利便性において大きなアドバンテージを得られる
・ 複数業界における17年間のデジタルビジネス開発経験
・ ウェブサイト開発のためのHTML、PHP、CSS、JavaScript等の実用的知識
・ 15ヶ国語対応の多言語SaaSの開発経験
・ 17年間にも及ぶ、Eコマース長期運営経験
・ 幅広い業界でのSEO最適化の豊富な経験

2026年3月のBaselineアップデート!最新Web技術の互換性と実務への活用法
Webプラットフォームの進化が加速している。2026年3月、主要なブラウザエンジンすべてで相互運用が可能になった機能を示す指標「Baseline」において、多くの強力な機能が新たに「利用可能(Newly available)」な状態となった。
同時に、登場から30ヶ月が経過し、もはやポリフィルなしで安心して本番環境に投入できる「広く普及(Widely available)」の段階に達した技術も大量に増えている。レイアウト制御の高度化から、低遅延なネットワーク通信、洗練されたストリーミング機能まで、Webの可能性はさらに広がった。
この記事では、2026年3月のアップデート内容を整理し、それぞれの技術が実務にどのようなメリットをもたらすのかを詳しく掘り下げていく。Web制作の現場で「今、どの技術を使うべきか」を判断する材料として役立ててほしい。
最新機能とタイポグラフィの進化

今回のアップデートでは、CSSのタイポグラフィ制御に関する機能がいくつかBaselineの「Newly available」となった。これにより、これまで実現が難しかった高度なテキストレイアウトが、標準的なCSSのみで完結するようになる。
数式表示とテキストインデントの自由度
まず注目したいのが、font-family プロパティに新しく追加された math という値だ。これは数式コンテンツ(MathMLなど)をレンダリングするために特別に設計されたフォントセットを指定するものだ。技術文書や教育サイトにおいて、複雑な数式を美しく、かつ正確な間隔で表示するために不可欠な機能となる。
また、text-indent プロパティも大幅に強化された。新しく追加された each-line キーワードを使えば、ブロックの最初の行だけでなく、<br /> による強制改行の後のすべての行にインデントを適用できる。さらに hanging キーワードを使えば、1行目はそのままに、2行目以降をインデントさせる「ぶら下げインデント」が簡単に実現可能だ。
/* ぶら下げインデントの指定例 */
.bibliography {
text-indent: 2em hanging;
}これは通常のテキスト配置だ。1行目の先頭だけが空くのが一般的だが、参考文献リストなどでは2行目以降を下げたい場合がある。
参考文献:Web技術の進化に関する考察。この行は1行目だが、2行目以降は左側に余白が作られ、項目名が際立つようになる。
text-indent: hanging の動作は対応ブラウザで確認してほしい。このコードを適用すると、参考文献リストや箇条書きのような、特定のデザインルールが求められるレイアウトを非常にシンプルに記述できるようになる。従来のようにネガティブマージンとパディングを組み合わせるハックは不要だ。
JavaScriptの反復処理を簡略化する新メソッド
スクリプト面では、Iterator.concat() が全ての主要ブラウザでサポートされた。これは、複数の反復可能なオブジェクト(配列やセットなど)を一つのイテレータに結合する静的メソッドだ。途中で中間的な配列を作成することなく、複数のデータソースを連続して処理できるため、メモリ効率の向上とコードの簡略化に寄与する。
データ通信とパフォーマンスの最適化

Webアプリケーションの「体感速度」を左右する通信技術やストリーミング機能も、Baselineの新たなステージへと進んだ。特にリアルタイム性が求められるサービスにおいて、これらの技術は大きな武器になる。
WebTransportによる低遅延通信
WebTransport は、HTTP/3をベースにした現代的な通信APIだ。クライアントとサーバー間での双方向通信を可能にし、従来のWebSocketよりも効率的で低遅延なデータのやり取りを実現する。信頼性の高いデータ転送と、信頼性は低いが高速な「データグラム」の両方をサポートしている点が特徴だ。
例えば、オンラインゲームやライブストリーミングなど、一分一秒の遅延が許されないアプリケーションにおいて、WebTransport は理想的な選択肢となる。HTTP/3のメリットである「ヘッドオブラインブロッキング(一つのパケット損失が全体の通信を止める現象)」の解消を享受できるため、不安定なネットワーク環境下でもパフォーマンスが安定しやすい。
バイナリデータの効率的なストリーミング
Streams APIにおける「読み取り可能なバイトストリーム(Readable byte streams)」のフルサポートも重要な進展だ。これはバイナリデータの処理に最適化されており、開発者が用意したバッファに直接データを読み込むことができる。これにより、巨大なファイルのアップロードやダウンロード、動画の動的処理などにおけるメモリ管理が劇的に効率化される。
さらに、ブラウザレベルでのエラーやポリシー違反を通知する「Reporting API」も共通の基盤となった。コンテンツセキュリティポリシー(CSP)の違反や、非推奨機能の使用、ブラウザのクラッシュレポートなどを特定の終端(エンドポイント)へ送信し、集中的に監視することが可能になる。これは大規模なWebサービスの運用保守において、問題の早期発見に大きく貢献するはずだ。
「広く普及」した技術:CSS subgridと安定したレイアウト

2026年3月には、多くの技術が「Widely available(広く普及)」へと移行した。これは登場から30ヶ月が経過し、もはや「最新技術」というリスクを負うことなく、あらゆるプロジェクトで標準的に採用できることを意味している。
CSS subgridによるグリッドレイアウトの完成
中でも最大の影響力を持つのが CSS subgrid だ。これは、子要素が親要素のグリッド定義(列や行のサイズ)をそのまま継承できる機能だ。これまでは、異なる階層にある要素同士を正確に整列させるために複雑な計算やHTML構造の妥協が必要だったが、subgridを使えばDOM構造を美しく保ったまま、完璧な整列が実現できる。
このデモが示すように、カード型レイアウト内のタイトルや本文の高さが、隣のカードと完全に一致するように制御できるのが subgrid の強みだ。もはや、JavaScriptで高さを揃える処理(いわゆるmatchHeightのようなもの)を書く必要はない。
表示の最適化とデバイス対応
また、image-set() 関数も普及段階に入った。これは <img> タグの srcset 属性に近い機能をCSSの background-image などで実現するものだ。ユーザーのデバイス解像度(DPI)に応じて、ブラウザが最適な画像ファイルを自動的に選択してダウンロードする。無駄な帯域を消費せず、Retinaディスプレイなどでは鮮明な画像を表示できる。
さらに、update メディアクエリも広く利用可能になった。これはデバイスの画面がどの程度の頻度で更新されるかを判定するものだ。スマートフォンのような高速リフレッシュレートを持つ画面と、電子書籍リーダー(e-ink)のような低速な画面を区別し、それぞれに最適なアニメーションや装飾を出し分けることができる。
実務での技術選定:Baselineをどう活用するか

Web技術がこれほど速く進化する中で、エンジニアやディレクターは「いつ、どの技術を実務に導入するか」という難しい判断を迫られる。GoogleのRachel Andrew氏は、自身の講演の中で、この課題に対する現実的なアプローチを提示している。
「安全」と「最新」のバランスを取る戦略
Andrew氏によると、Baselineのステータスを単なる「安全な機能のリスト」として見るのではなく、プロジェクトのリリース日に合わせてターゲットを設定することが重要だという。例えば、開発開始時点では「Newly available(最新)」であっても、プロジェクトの公開日が数ヶ月先であれば、その頃にはユーザーのブラウザ更新が進み、安全に使えるようになっている可能性がある。
一方で、特定のブラウザバージョンをサポートしなければならない制約がある場合、Baselineの「Widely available(広く普及)」に達している機能を選ぶのが最も堅実だ。この区分に入っている技術は、主要なブラウザすべてで安定して動作することが30ヶ月にわたって証明されている。ポリフィルによるパフォーマンス低下や、予期せぬバグのリスクを最小限に抑えつつ、モダンな開発体験を享受できる基準と言える。
コミュニティでの実装例と可視化
開発者コミュニティでも、このBaselineの考え方を積極的に取り入れる動きが出ている。Stu Robson氏は、自身のサイトに「Baseline status」を表示するWebコンポーネントを導入した事例を紹介している。特定の技術について解説する記事の冒頭に、その技術が現在のブラウザでどの程度サポートされているかをリアルタイムで表示する仕組みだ。
このような取り組みは、読者(またはクライアント)に対して、その技術が「今すぐ使えるものなのか」を即座に伝えるための優れた方法だ。Webコンポーネント自体はオープンソースで公開されており、Eleventyなどの静的サイトジェネレーターに限らず、WordPressなどあらゆるフレームワークで利用可能となっている。
この記事のポイント
- 2026年3月のアップデートで、
WebTransportやtext-indent: hangingなどが主要ブラウザで利用可能になった。 CSS subgridやimage-set()などの強力な機能が「広く普及」の段階に達し、本番環境で安心して使えるようになった。mathフォントファミリーやIterator.concat()により、数式表示やデータ処理のコードがよりシンプルになる。- Baselineのステータスを基準にすることで、プロジェクトのリリース時期に合わせた最適な技術選定が可能になる。
・ 複数業界における17年間のデジタルビジネス開発経験
・ ウェブサイト開発のためのHTML、PHP、CSS、JavaScript等の実用的知識
・ 15ヶ国語対応の多言語SaaSの開発経験
・ 17年間にも及ぶ、Eコマース長期運営経験
・ 幅広い業界でのSEO最適化の豊富な経験

WAFの「ログかブロックか」を卒業。Cloudflareが提唱するAttack Signature Detectionの革新性
WAF(Web Application Firewall / ウェブ・アプリケーション・ファイアウォール)の運用において、セキュリティ担当者を長年悩ませてきた「ログモードかブロックモードか」という二者択一に、終止符が打たれようとしている。
Cloudflareが発表した「Attack Signature Detection(アタック・シグネチャ・デテクション)」は、検知と遮断のアクションを分離することで、防御性能を維持しながらトラフィックの完全な可視化を実現する技術だ。
この新機能は、従来のWAFが抱えていた「遮断を優先すると、他の攻撃シグネチャがどう反応したかのデータが失われる」という構造的な欠陥を解消する。
WAFの課題「検知か遮断か」のジレンマを解消する新アプローチ

従来のWAF運用では、新しいアプリケーションを公開する際、まず「ログ専用モード」で数週間稼働させることが一般的だった。
これは、WAFが正規の通信を誤って攻撃と判断してしまう「誤検知(False Positive)」を防ぐための調整期間だ。
ログモードとブロックモードの壁
ログモードでは攻撃を防げず、ブロックモードでは誤検知によってビジネス機会を損失するリスクがある。
さらに深刻なのは、ブロックモードで特定のルールがリクエストを遮断した場合、その時点で処理が終了してしまう点だ。
これにより、他のシグネチャ(攻撃のパターンを定義した識別子)がそのリクエストをどう評価したかという貴重なインサイトが得られなくなる。
多角的な防御策を講じる上で、この「可視性の欠如」は防御の最適化を妨げる大きな要因となっていた。
検知とアクションを分離する「常時稼働」モデル
Attack Signature Detectionは、このトレードオフを「検知の常時稼働」という概念で解決する。
リクエストが届いた際、まず全ての検知シグネチャを走らせてリッチなメタデータを付与し、その後に実際の遮断アクションを行うかどうかを判定する仕組みだ。
これにより、たとえリクエストをブロックしたとしても、背後でどのシグネチャが反応していたかを全て記録に残すことが可能になる。
Attack Signature Detection:常時稼働する高精度な検知エンジン
Attack Signature Detectionは、Cloudflareのマネージドルールセットと同じ高度なヒューリスティック(経験則に基づいた分析手法)を利用している。
SQLインジェクション(SQLi)やクロスサイトスクリプティング(XSS)といった代表的な攻撃から、最新のCVE(Common Vulnerabilities and Exposures / 共通脆弱性識別子)まで、700以上のルールがリアルタイムで適用される。
信頼度(Confidence)による分類
各シグネチャには「カテゴリー」と「信頼度」というタグが付与されている。
信頼度は、そのシグネチャが正規の通信を誤検知する可能性の低さを示す指標だ。
- High(高信頼度): 誤検知が極めて少なく、即座にブロックモードでの運用が推奨される。
- Medium(中信頼度): トラフィックの特性によっては誤検知の可能性があるため、事前の分析が推奨される。
運用者はこれらの指標を基に、「信頼度が高いシグネチャに一致した時だけブロックする」といった柔軟なポリシーをノーコードで作成できる。
パフォーマンスへの影響を最小限に抑える設計
「全てのシグネチャを常時稼働させると、通信速度が低下するのではないか」という懸念が生じるのは自然なことだ。
しかし、このフレームワークは効率性を極限まで高めている。
特定の検知に基づいた遮断ルールが設定されていない場合、検知処理はリクエストがオリジンサーバー(Webサイトの本体が稼働しているサーバー)へ送信された「後」に実行される。
この非同期処理により、検知そのものがユーザーの体感速度に影響を与えることはない。
Full-Transaction Detection:レスポンスまで見通す次世代の防御
Attack Signature Detectionのさらに先を行く進化として開発されているのが、「Full-Transaction Detection(フル・トランザクション・デテクション)」だ。
従来のWAFは、ユーザーからの「リクエスト(問いかけ)」の内容だけを見て攻撃を判断していた。
しかし、Full-Transaction Detectionは、サーバーからの「レスポンス(回答)」も含めた一連のやり取り(トランザクション)を分析対象とする。
「攻撃の成否」を判断する重要性
例えば、URLの末尾にSQLインジェクションのコードが含まれていたとする。
リクエストだけを見れば攻撃だが、サーバーが「500 Internal Server Error」や「404 Not Found」を返していれば、その攻撃は失敗したと判断できる。
一方で、サーバーが「200 OK」を返し、かつレスポンスボディにユーザーのパスワード一覧のような機密データが含まれていた場合、それは「攻撃が成功した」ことを意味する。
このように、レスポンスを相関分析することで、誤検知を劇的に減らし、真に危険なイベントだけを抽出することが可能になる。
データ漏洩と設定ミスの検知
この技術は、外部からの攻撃だけでなく、内部の設定ミスや意図しないデータ露出の検知にも威力を発揮する。
例えば、管理者が誤って公開設定にしてしまったElasticsearch(検索エンジン)のインターフェースや、Apacheの機密エンドポイントへのアクセスを検知できる。
また、正規のAPIリクエストであっても、レスポンスに数千件のクレジットカード番号が含まれているような異常な事態(データエクスフィルトレーション / データ持ち出し)を即座に特定できる点は、従来のWAFにはない強みだ。
セキュリティ運用を劇的に変える分析とルールのカスタマイズ
Attack Signature Detectionがもたらす最大の価値は、セキュリティ運用の「データ駆動型」への転換だ。
Security Analytics(セキュリティ・アナリティクス)のダッシュボードを活用することで、専門家でなくても自社サイトがどのような攻撃にさらされているかを詳細に把握できる。
Security Analyticsによる可視化
ダッシュボードでは、どのCVEを狙った攻撃が多いか、どのエンドポイント(URL)が標的になっているかがグラフ化される。
例えば、特定のAPIパス(`/api/v1/`など)に対して執拗に攻撃を繰り返しているIPアドレスを特定し、その場で遮断ルールを作成するといったアクションがスムーズに行える。
また、過去のトラフィックデータに対して「もしこのルールを適用していたらどうなっていたか」というシミュレーションを行うことも可能だ。
柔軟なルールエンジンの活用
検知されたメタデータは、Cloudflareの「Edge Rules Engine」で自由に利用できる。
「信頼度がMediumのシグネチャに一致した場合は、即座にブロックせず、Managed Challenge(人間であることを確認する認証画面)を表示する」といった、ユーザー体験を損なわない防御策も容易に実装できる。
こうした「多層防御」の構築が、複雑なスクリプトを書くことなくGUI上で行える点は、リソースの限られた中小企業のWeb担当者にとっても大きなメリットとなるだろう。
独自の分析:Web制作現場におけるWAF運用のパラダイムシフト

これまでのWeb制作や保守運用の現場では、WAFは「導入して終わり」か、あるいは「誤検知が怖いからオフにする」という極端な運用に陥りがちだった。
しかし、Attack Signature Detectionの登場により、WAFは「静的な壁」から「動的なセンサー」へと進化したと捉えるべきだ。
筆者の分析では、この技術が普及することで、以下の3つの変化が起こると予測している。
第一に、WAF導入の心理的ハードルが下がる。
「とりあえず検知だけさせてデータを貯める」というスモールスタートが、パフォーマンスへの影響なしに可能になるからだ。
第二に、インシデント対応の迅速化だ。
リクエストとレスポンスの両面から攻撃の成否が可視化されるため、ログを数時間かけて解析しなくても、どの脆弱性が突かれたのかが瞬時に判明する。
第三に、開発とセキュリティの融合(DevSecOps)が加速する。
開発者はWAFの検知データをフィードバックとして受け取り、コードレベルでの修正が必要なのか、WAFでの対応で十分なのかをデータに基づいて判断できるようになる。
もはやセキュリティは、開発の足を引っ張る存在ではなく、安全なリリースを支える強力なインフラへと変貌を遂げている。
この記事のポイント
- WAFの課題だった「検知(ログ)か遮断(ブロック)か」の選択を、機能を分離することで解消した。
- Attack Signature Detectionは常時稼働し、リクエストに詳細なメタデータを付与して可視性を高める。
- Full-Transaction Detectionにより、レスポンスまで分析して攻撃の成功・失敗を正確に判別できる。
- 非同期処理の導入により、高度な検知を行いながらもユーザーの通信速度に影響を与えない設計を実現した。
- 専門知識がなくても、信頼度に基づいた柔軟なセキュリティポリシーの運用が可能になった。
出典
- Cloudflare Blog「Always-on detections: eliminating the WAF “log versus block” trade-off」(2026年3月4日)
・ 複数業界における17年間のデジタルビジネス開発経験
・ ウェブサイト開発のためのHTML、PHP、CSS、JavaScript等の実用的知識
・ 15ヶ国語対応の多言語SaaSの開発経験
・ 17年間にも及ぶ、Eコマース長期運営経験
・ 幅広い業界でのSEO最適化の豊富な経験