

エージェントPRが急増中。レビューで見るべき5つの視点
テストが通り、コードもクリーンに見える。多くの開発者がそのプルリクエストを深く疑わずにマージしている。しかし、そのPRを書いたのは人間ではない。エージェントが生成したコードだ。そして、簡単に承認してしまうことこそが最大の問題である。
2026年1月に発表された研究「More Code, Less Reuse」によれば、エージェントが生成したコードは人間が書いたコードよりも変更あたりの冗長性と技術的負債が大きい。表面上はクリーンだが、負債は静かに蓄積される。さらに、同じ研究はレビュアーがエージェントのコードに対してむしろ積極的に承認したくなる傾向があることも指摘している。
これは開発速度を落とせという主張ではない。意図的かつ戦略的にレビューに臨むべきだという提言だ。エージェントのPRをどうレビューすれば、隠れた問題を見落とさずに済むのか。本稿では、GitHubのシニアデベロッパーアドボケイトであるAndrea氏が公開した実践ガイドをもとに、具体的なチェックポイントと効率的なワークフローを解説する。
エージェントPRの急増とレビュー負荷のギャップ

すでにプルリクエストの量は膨大だ。GitHub Copilotのコードレビュー機能はこれまでに6,000万回以上のレビューを処理し、1年足らずで10倍の規模に成長した。GitHub上のコードレビューの5件に1件以上がエージェントと関わっている。これは自動レビューの通過数に過ぎない。肝心のプルリクエストそのものは、レビュアーが処理できる速度をはるかに超えて増殖している。
従来の「レビュー依頼→コードオーナーが確認→マージ」というループは、1人の開発者が午前中に十数回のエージェントセッションを起動できる今、崩壊しつつある。スループットは指数関数的に伸びたが、人間のレビュー能力は変わっていない。そのギャップは広がる一方だ。
レビュアーが持つべき「コードを書いたのは誰か」の認識

diffの1行を見る前に、レビュアーは自分が何を確認しているのかをモデル化しておく必要がある。コーディングエージェントとは、生産的で字義通りに動き、既存のコードパターンを忠実に模倣する貢献者のような存在だ。しかし、そのエージェントには、自社のインシデント履歴も、チームが蓄積してきたエッジケースの知見も、リポジトリの外にある運用上の制約も一切ない。
エージェントは一見完成されたコードを生成する。だが、この「完成しているように見える」という状態が危険なのだ。コードが動き、テストも通る。それにもかかわらず、運用環境では破綻する。レビュアーこそが、そうした抜け落ちた文脈を埋める存在である。それは負担ではなく、レビューの本質的な仕事であり、自動化できない判断の部分だ。
エージェントPRで見るべき5つのレッドフラッグ

このデモは、エージェントのプルリクエストをレビューする際にまず確認すべき5つのポイントをまとめたものだ。各項目の詳細は以下で解説する。
1. CIの改ざん
エージェントはCIに失敗すると、テストを通すための明白な抜け道を選ぶことがある。テストの削除、リントステップのスキップ、テストコマンドに || true を追加するなどの行為だ。CIを弱体化させる変更は即座にブロックすべきである。
具体的には、カバレッジ閾値の変更、テストの削除やリネーム、スキップの追加、ワークフローがフォークやPRで実行されなくなっていないか、CIステップが新たな条件でゲートされていないか、を必ずチェックする。
2. 既存コードの再発明
これはレビュアーにとって最も費用対効果の高いチェックだ。エージェントはリポジトリ内のパターンを探し、それを複製する。同名の機能を持つ既存ユーティリティを確認せず、よく似た名前の新規関数を追加する。バリデーションロジックを複数箇所に再実装し、共有モジュールに既にあるミドルウェアをゼロから書き直す。こうした「ほとんど同じだが名前が違う」ヘルパーが生まれやすい。
エージェントのローカルコンテキストにはリポジトリ全体の見取り図が欠けている。レビュアーは新しく追加されたユーティリティやヘルパーをすべて検索し、重複があれば統合をマージ前に要求する。重複ロジックを放置すると、それが今後のエージェントにとっての「先行事例」になり、さらに複製が加速する。
3. うわべだけの正しさ
存在しないAPIを呼び出すような明らかな誤りはCIで検出される。深刻なのは、コンパイルが通り、すべてのテストを通過し、それでも間違っているコードだ。ページネーションのオフバイワンエラー、テストで決して通らないブランチでの権限チェック漏れ、エージェントが考慮しなかったエッジケースで短絡するバリデーション、大規模環境でのみ顕在化する競合状態などが該当する。
diffの中で最も重要なパスを選び、入力を出力まで追跡する。境界条件(ゼロ、最大値、空)や外部値のバリデーション漏れ、全ブランチの権限チェック、予期しない条件分岐を確認する。加えて、変更前の動作で失敗する新たなテストを要求すれば、理解不足や修正の不完全さを炙り出せる。
4. エージェントの沈黙と見せかけの反応
詳細なレビューを残しても、PRが沈黙してしまうケースがある。あるいはエージェントが要点を外した返信を繰り返し、堂々巡りになる。特に大きく構造化されていないPRでは、エージェントの放棄やミスアライメントが目立つ。レビュー時間を無駄にしないためにも、大規模なエージェントPRに深く入る前に、PRの履歴を確認する。
それまでのラウンドで応答性があったか、明確な実装計画があるか、エージェントがいきなりコードを書き始めただけではないかを見極める。計画がない場合は、以下のような定型文で分割や概要の提示を求める。これは個人攻撃ではなく、時間を節約するための率直な要求だ。
このPRは大きすぎて、明確な実装計画なしにレビューできません。
小さな単位に分割するか、各パートの目的と構造の意図をまとめてもらえますか。
その後、改めてレビューします。5. ワークフローへの信頼できない入力
CIエージェントへのプロンプトインジェクションは過小評価されている脅威だ。典型的なパターンとして、PR本文やIssue、コミットメッセージから内容を読み取り、それをプロンプトに展開し、モデル出力をシェルコマンドに流し込み、GITHUB_TOKEN権限で実行する流れがある。
LLMを呼び出すワークフローをレビューする際は、以下をブロッカーとみなす。信頼できないユーザー入力(PR本文、Issue本文、コミットメッセージ)が無害化されずにプロンプトに挿入されていないか。GITHUB_TOKENが書き込みスコープを持っているのに読み取りしか必要としていないか。モデル出力がバリデーションなしでシェルコマンドとして実行されていないか。シークレットがエージェントステップに渡されたりログに出力されたりしていないか。
マージ前に求めるべき対策は、ワークフローYAMLでの最小権限の原則(permissions: read-all をデフォルトに)、プロンプトに触れる前に信頼できないコンテンツのサニタイズとクォート、本番環境に触れる部分での「分析」と「実行」の分離と人間の承認ゲート、モデル出力の直接実行の禁止だ。
10分で完了する効率的なレビューワークフロー

上のフローは、GitHubのAndrea氏が提唱する時間枠付きのレビュー手順を図示したものだ。ポイントは、CIチェックを最優先し、重複検索を別工程で行い、最後に「証拠」としてのテストを要求することにある。
diffが5つ以上の無関係なファイルにまたがる、PRの目的を一文で説明できない、実装計画がない、CIが落ちていて変更点がテストファイルだけ、といった場合には、PRの縮小や計画の明確化を依頼する判断も必要になる。
Copilotに先にレビューさせるメリット

自動レビューは、機械的なチェックを人間に代わって処理するという、その得意分野で使うのが賢明だ。Copilotコードレビューは、スタイルの不一致、明らかなロジックエラー、エラーハンドリング不足、型の不一致などを自動検出する。これにより、低レベルの走査から解放され、レビュアーは判断を要する作業に集中できる。
自動レビューはあくまで前提条件であり、代替ではない。Copilotを最初に走らせ、明らかな問題があれば著者に修正させてから、人間のレビューに進む。チーム固有のカスタム指示を与えれば、CI閾値の変更をフラグ付けしたり、重複レビュー用に新しいユーティリティを表面化させたり、外部入力のバリデーションを確認したりといった調整も可能だ。
実際、Andrea氏はCopilot SDKを使って自分のレビューチェックリストをコード化し、管理エンドポイントの認証、テストの実効性、安全な環境変数処理といった観点を自動チェックするワークフローを構築したという。重大な問題が見つかればマージをブロックする仕組みだ。こうした自動化によって、レビュアーは真に価値のある判断業務に時間を振り向けられる。
この記事のポイント
- エージェント生成PRは表面上クリーンだが、冗長性と技術的負債を内包しやすい
- CIを弱める変更は即座にブロックし、テスト削除やカバレッジ操作を厳重に確認する
- 新規ユーティリティの重複検索を習慣化し、既存コードの再発明を防ぐ
- 最重要パスをトレースし、境界条件と権限チェックを目視で検証する
- CIエージェントへのプロンプトインジェクション対策として、ワークフローの最小権限化と入力サニタイズを徹底する
- Copilotコードレビューを先に実行し、機械的チェックを済ませたうえで人間の判断に集中する

・ 複数業界における17年間のデジタルビジネス開発経験
・ ウェブサイト開発のためのHTML、PHP、CSS、Java等の実用的知識
・ 15ヶ国語対応の多言語SaaSの開発経験
・ 17年間にも及ぶ、Eコマース長期運営経験
・ 幅広い業界でのSEO最適化の豊富な経験

Googleのタスク型エージェント検索がSEOを今すぐ変える理由と対策
Googleの検索が「タスクを完了する」エージェントへと急速に変化している。従来の「キーワードを入力してウェブサイトのリンクを得る」モデルは、AIが直接レストランの予約を取ったり、情報を収集したりする「タスク実行型」の検索に置き換わりつつある。この変化は未来の話ではなく、すでに現在進行形で起きている。
Search Engine Journalの記事によると、GoogleのCEOサンダー・ピチャイは近い将来、検索の多くが「エージェント型」になると述べている。ユーザーは情報を探すだけでなく、AIエージェントにタスクを管理させ、複数の作業を並行して実行させるようになる。このパラダイムシフトは、SEOとコンテンツ戦略の根本的な見直しを迫るものだ。
検索が「タスク完了」へと変わる瞬間
従来のインターネットと検索は、同じキーワードを入力した何百万人ものユーザーに、同じようにインデックスされたウェブページのリストを提供するモデルだった。しかしAIの登場により、ユーザーは単なる情報検索から「トピックの調査」や「タスクの実行」へと行動を移しつつある。リンクをクリックしてサイトを読むだけでは、ユーザーが求める明確な答えが得られないケースが増えている。
レストラン予約にみるエージェント検索の実例
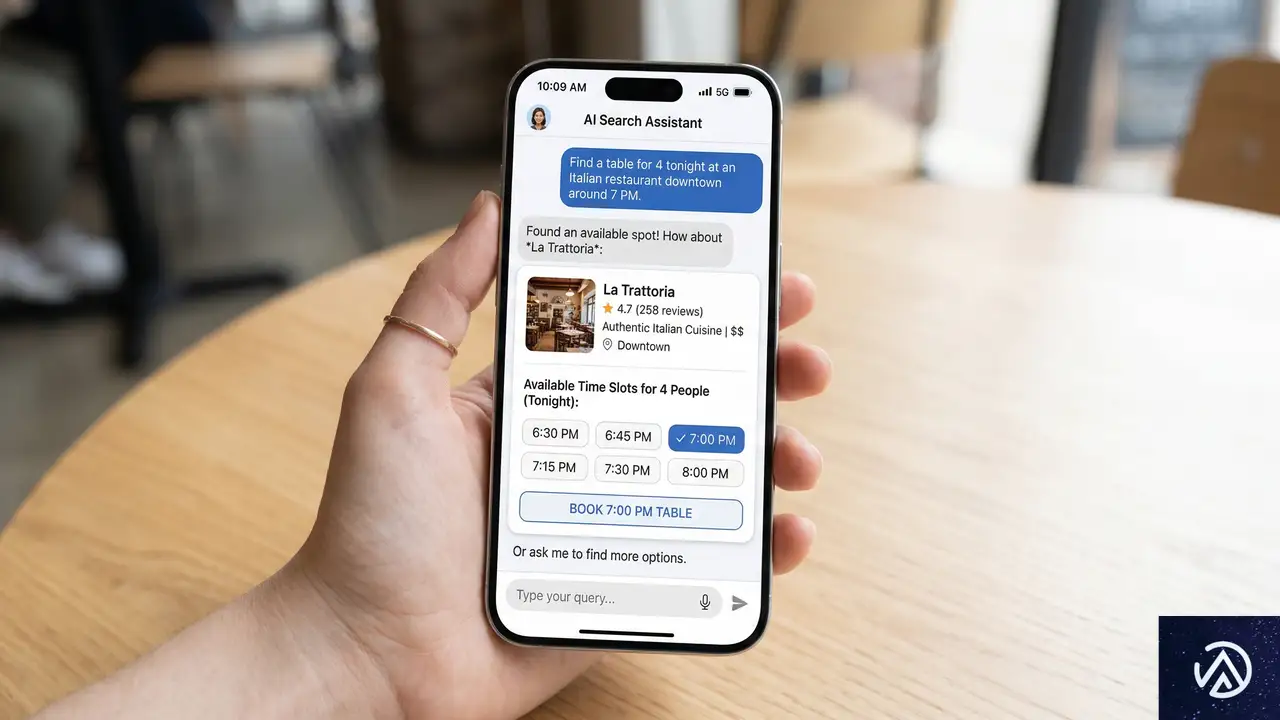
この変化を象徴する具体例が、Googleが全世界で展開を開始した「エージェント型レストラン予約」機能だ。ユーザーは検索ボックスに「6人で土曜の夜、雰囲気の良いイタリアン」といった要望を自然言語で入力する。するとAIエージェントが複数の予約プラットフォームを同時にスキャンし、空き状況やメニューを確認した上で、実際に予約可能な店舗を提示する。
Googleの検索プロダクト責任者であるRose Yao氏は、この機能について「アプリを切り替える必要も、手間もない。ただ美味しい食事を」と説明している。これはもはや従来の「検索」ではなく、「タスクの完了」そのものだ。重要な点は、この機能が「近い将来実現するもの」ではなく、すでに利用可能であることだ。
サイト側に求められる対応
この新しい検索モデルでは、レストランなどの事業者側も対応が迫られる。AIエージェントが情報を取得できるように、空き予約枠やその日のメニュー選択肢などのデータを提供する必要がある。将来的には、AIエージェントと直接予約を完了できる仕組みがウェブサイトに求められるだろう。
これは単なる技術的なアップデートではなく、ビジネスプロセスの変革を意味する。検索マーケティングの専門家は、この変化がもたらす影響を真剣に考える時期に来ている。
「個人専用インターネット」時代の到来

タスク型エージェント検索がもたらすもっと深い変化は、インターネットそのものが「ハイパーパーソナライズ化」する点だ。クラウドフレアは最近の記事で、インターネットの進化を3つの段階に分けて説明している。
インターネット進化の3段階
クラウドフレアの比喩が分かりやすい。従来のアプリケーションは「レストラン」のようなものだ。決まったメニュー(機能)があり、それを大量に提供するために最適化された厨房(インフラ)がある。一方、AIエージェントは「個人専属シェフ」に例えられる。毎回「何が食べたい?」と聞き、その答えに応じて必要な食材や調理法が変わる。レストランの厨房では対応できない。
SEOへの具体的な影響
この変化がSEOに与える影響は計り知れない。ローカルSEO、ショッピング、情報検索のすべてが、ハイパーパーソナライズされたウェブ体験に再構築される。検索が「エージェントマネージャー」に変わるというピチャイの発言は、単なる未来予想ではなく、現在進行形の現実を指している。
デジタルマーケティング担当者が考えるべきは、数十億の人間を代表する数十億のエージェントを支えるインフラではなく、その中で自社のビジネスがどう位置づけられるかだ。エージェントがタスクを完了する過程で、どの情報源を信頼し、どのように意思決定するのか。この「意思決定レイヤー」に自社がどう登場するかが、新しいSEOの核心となる。
コンテンツ管理システムの対応:WordPress 7.0の役割
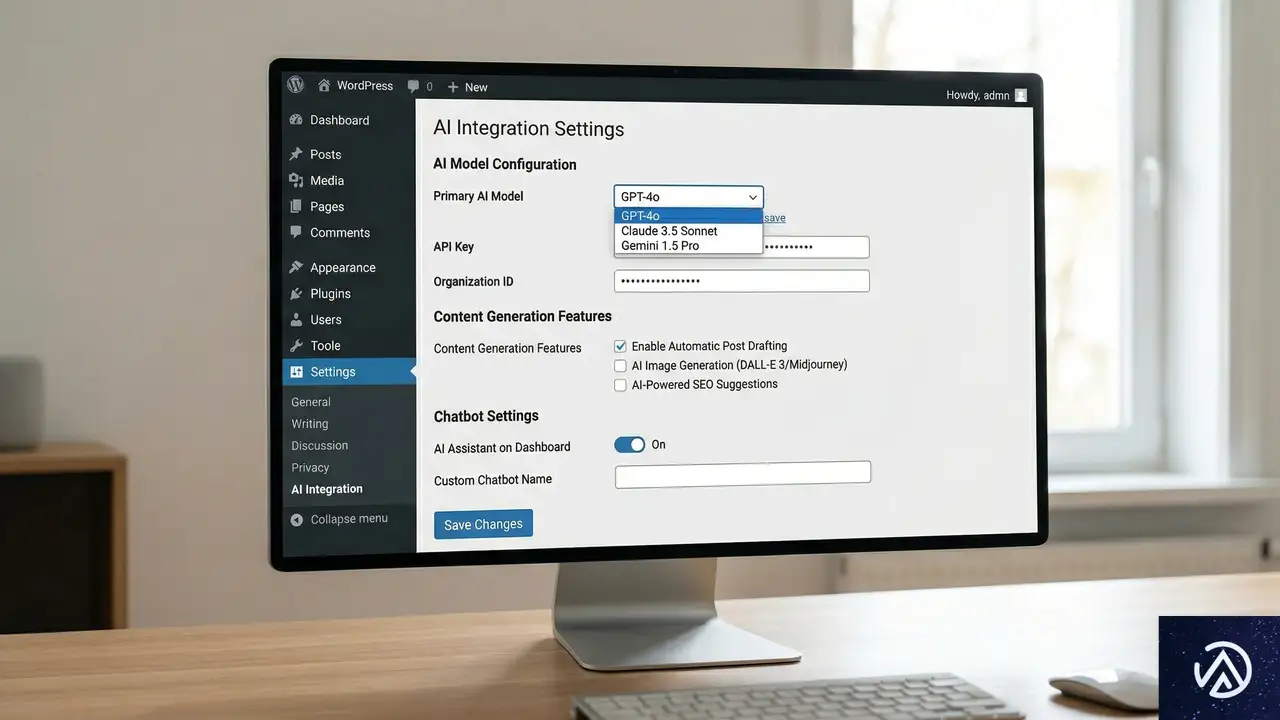
人間中心のウェブからエージェント中心のウェブへの移行に際し、コンテンツ管理システム(CMS)の対応は極めて重要だ。特に間もなくリリース予定のWordPress 7.0は、この変化に対応するための機能が多数盛り込まれている。
AIシステムとの接続機能
現在のインターネットは人間の相互作用のために構築されている。AIエージェントはその構造の中で動作しているが、これは急速に変化する見込みだ。WordPress 7.0が重視しているのは、AIシステムとシームレスに接続する機能だ。これにより、ウェブサイトが人間だけでなく、AIエージェントにも適切に情報を提供できる基盤が整う。
具体的には、構造化データの強化、APIファーストなアーキテクチャ、エージェントが理解しやすいコンテンツ形式などが挙げられる。これらの機能は、従来の人間ユーザー向け最適化に加えて、AIエージェント向けの最適化を可能にする。
エージェントが「信頼する」情報源になるために
検索マーケティングの専門家Mike Stewart氏は、この変化について重要な指摘をしている。彼はFacebookへの投稿で、「これはもはやAIが支援する段階ではなく、AIがあなたに代わって操作する段階だ」と述べた上で、以下の問いを提示している。
Stewart氏はさらに、「エージェント型検索は、それを支えるエコシステム(ウェブサイト、コンテンツ、ビジネス)なしには成立しない。その部分はなくならないが、抽象化される」と付け加えている。つまり、ウェブサイトやコンテンツの重要性は変わらないが、人間が直接アクセスする形ではなく、AIエージェントを通じて間接的に利用される形に変化するということだ。
タスク型エージェント検索への具体的な対策

理論的な理解だけでなく、実際にSEO担当者が今から取り組める対策がある。タスク型エージェント検索の時代に向けて、以下のポイントに注目すべきだ。
構造化データの徹底強化
AIエージェントが情報を正確に理解し、タスクを完了するためには、構造化データがこれまで以上に重要になる。特にSchema.orgの語彙を活用し、以下のような情報を明確にマークアップする必要がある。
APIファーストな情報提供
人間がブラウザで閲覧するHTML形式だけでなく、AIエージェントがプログラム的に情報を取得できるAPIの提供が重要になる。WordPressではREST APIが標準で搭載されているが、エージェント向けに最適化されたエンドポイントを用意する必要があるかもしれない。
情報の更新頻度も鍵となる。エージェントがレストランの空き状況を確認する場合、その情報が数時間前のものでは意味がない。可能な限りリアルタイムに近い情報提供が求められる。
コンテンツの「信頼性」シグナルの強化
Mike Stewart氏が指摘した「エージェントはどの情報源を信頼するのか」という問いは核心を突いている。エージェントが意思決定する際、信頼性の高い情報源を優先するだろう。以下の要素が信頼性シグナルとして機能すると考えられる。
具体的な信頼性シグナルとしては、正確で最新の構造化データ、他の信頼できるサイトからの言及やリンク、ユーザーレビューの質と量、企業の実在証明などが挙げられる。これらは従来のSEOでも重要だったが、エージェント検索ではさらに重要性が増す。
この記事のポイント
・ 複数業界における17年間のデジタルビジネス開発経験
・ ウェブサイト開発のためのHTML、PHP、CSS、Java等の実用的知識
・ 15ヶ国語対応の多言語SaaSの開発経験
・ 17年間にも及ぶ、Eコマース長期運営経験
・ 幅広い業界でのSEO最適化の豊富な経験