

Google-Agent登場、AIがユーザー代理でWebを閲覧する時代へ
Webサイトを訪れるのは人間だけではなくなった。2026年3月20日、Googleは公式のフェッチャーリストに「Google-Agent」という新たな項目を追加した。これはクローラーでもなければ、学習用のボットでもない。ユーザーの指示で動くAIエージェントだ。
AIアシスタントに「この商品をリサーチして」「最安値のサイトを比較して」と頼む場面を想像してほしい。そのとき実際にサイトを訪問し、情報を読み取り、フォームを操作するのがGoogle-Agentである。Googleの実験的ブラウジングツール「Project Mariner」が最初の採用例となる。
これまでのSEOは「クローラーにどう読まれるか」が主眼だった。しかし今回の発表で、Web運営者は「ユーザーの代わりに行動するAI」という第三の訪問者像を明確に意識せざるを得なくなった。
Google-Agentが従来のクローラーと根本的に異なる点

GooglebotはWeb全体を巡回し、検索インデックスを構築する自動プログラムだ。一方、Google-Agentが発動する条件はただ一つ、人間がAIに「調べて」と依頼したときである。この「ユーザートリガー」という性質が、あらゆるルールを塗り替える。
robots.txtは通用しない
GoogleはGoogle-Agentを「ユーザートリガーフェッチャー」に分類している。Google Read Aloud(テキスト読み上げ)やNotebookLM(文書分析)、Feedfetcher(RSS)と同じカテゴリだ。いずれも「人間がリクエストを起こした」という共通点がある。Googleの公式見解は明快で、ユーザートリガーフェッチャーは「原則としてrobots.txtを無視する」としている。
考え方はシンプルだ。ChromeのアドレスバーにURLを入力して開くとき、ブラウザはrobots.txtの内容に関係なくページを取得する。Google-Agentはユーザーの代理であり、自律型クローラーではない。したがって同じ理屈が適用される。
この判断はOpenAIやAnthropicのアプローチと明確に異なる。ChatGPT-UserやClaude-Userはいずれもユーザートリガーフェッチャーでありながら、robots.txtの指示に従う仕様だ。robots.txtでブロックすれば、ユーザーに頼まれてもページを取得しない。Googleはそこに別の線を引いた形になる。
robots.txtを万能のアクセス制御手段と考えていたサイト運営者にとって、これは大きな認識転換になる。Google-Agentを拒否したい場合は、サーバーサイドの認証やIP制限など、人間の訪問者をブロックするのと同じ手段を採る必要がある。
暗号認証「Web Bot Auth」がもたらす信頼性

Google-Agentの発表でより重要なのは、付随する技術的布石だ。公式ドキュメントの一行に、Google-Agentが「web-bot-auth」プロトコルの実験に参加していることが記されている。識別子は「https://agent.bot.goog」である。
デジタルパスポートの仕組み
Web Bot AuthはIETF(インターネット技術標準化委員会)で策定が進む標準規格である。簡単に言えば、ボットのためのデジタルパスポートだ。各エージェントは秘密鍵を持ち、公開鍵をディレクトリに登録する。そして全てのHTTPリクエストに暗号署名を付与する。
Webサイト側はその署名を検証することで、訪問者が名乗る通りの存在であることを暗号学的に確認できる。ユーザーエージェント文字列は誰でも偽装できるが、Web Bot Authの署名は偽装できない。この差は決定的だ。
すでにAkamai、Cloudflare、AmazonのAgentCore Browserがこのプロトコルをサポートしている。Googleの参入は、標準化に向けたクリティカルマス(臨界量)の獲得を意味する。
なぜこの仕組みが今必要なのか
Webは深刻なアイデンティティ問題に直面しつつある。AIエージェントのトラフィックが増えるほど、正規のエージェントと、エージェントを装うスクレイパーを区別する必要が高まる。IPアドレスによる検証は有効だが、暗号署名のほうが大規模にスケールしやすく、なりすましも極めて難しい。
Google-AgentへのWeb Bot Auth導入は実験段階だが、エージェント認証の方向性を強く示す一手とみられている。Search Engine Journalの記事でも、この暗号認証こそがGoogle-Agent発表の最も重要な要素だと指摘されている。
Webサイト運営者が今すべき具体的対応

Google-Agentの登場で、Webの訪問者モデルは3層構造として明確化された。人間が直接ブラウジングする層、GooglebotやGPTBotのようにコンテンツをインデックスするクローラー層、そして特定の人間の指示でリアルタイムにタスクを実行するエージェント層である。それぞれに異なるアクセスルールと目的がある。
この3層構造を前提に、運営者が取るべき現実的な対策は以下の通りだ。
サーバーログの監視を始める
Google-Agentはユーザーエージェント文字列に「compatible; Google-Agent」を含む。Googleは検証用のIPレンジも公開している。まずは自社サイトにどの程度の頻度でエージェントが訪れているか、どのページを標的にしているか、何を試みているかを把握することが出発点になる。
CDNとファイアウォールの設定を確認する
非ブラウザトラフィックを積極的にブロックするセキュリティ設定を導入している場合、Google-Agentがサーバーに到達する前に拒否されている可能性がある。公開されているIPレンジが許可リストに含まれているか、確認しておくべきだ。
フォームや予約フローの検証
Google-Agentはフォームの送信や複数ステップのフロー操作も行う。チェックアウト、予約、問い合わせといった機能がJavaScriptに過度に依存していると、エージェントが正常に処理できず、裏側で静かに失敗しているケースが生じる。セマンティックなHTMLと明確なラベル設計が、これまで以上に重要になる。
robots.txtは完全なアクセス制御手段ではないと認識する
robots.txtはクローラー向けに設計された仕組みであり、エージェントの時代には通用しない場面が増える。どうしてもアクセスを制限すべきコンテンツには、認証を導入する必要がある。境界線の引き直しが求められている。
ハイブリッドWebはすでに始まっている

1年前まで、AIエージェントが人間と並んでWebサイトを閲覧する未来はカンファレンスの予測トークに過ぎなかった。しかし今、その存在にはユーザーエージェント文字列があり、公開されたIPレンジがあり、暗号認証プロトコルがあり、Googleの公式ドキュメントへの記載がある。
Webは人間用と機械用に分岐しなかった。融合したのだ。公開する全てのページは、人間とエージェントの両方に同時にサービスを提供している。Googleが可視化したのは、その非人間のオーディエンスがいつ現れたかを正確に把握できる手段である。
Search Engine Journalの記事は、この動きを「SEO史上最大の意識改革」と位置づけている。誇張ではない。検索エンジンにどう読まれるかだけでなく、「ユーザーの代理としてやってくるAI」にどう対応するかが、これからのWeb運営の新たな基軸になる。
この記事のポイント
- Googleがユーザー代理でWebを閲覧する新フェッチャー「Google-Agent」を公開、Project Marinerが最初の採用例
- ユーザートリガーフェッチャーに分類されるためrobots.txtは原則無効、アクセス制御にはサーバー認証が必要
- 「Web Bot Auth」暗号認証プロトコルを実験導入中、エージェントのなりすまし防止を狙う
- Web訪問者は「人間」「クローラー」「エージェント」の3層構造へ移行、各層で対応が異なる
- サーバーログ監視、CDN設定確認、フォームのセマンティックHTML対応が即時の実務対策となる

・ 複数業界における17年間のデジタルビジネス開発経験
・ ウェブサイト開発のためのHTML、PHP、CSS、Java等の実用的知識
・ 15ヶ国語対応の多言語SaaSの開発経験
・ 17年間にも及ぶ、Eコマース長期運営経験
・ 幅広い業界でのSEO最適化の豊富な経験

Googlebotの正体は「数百のクローラー」の集合体。未公開システムの仕組みとSEOへの影響
Googlebotは単一のプログラムではなく、実際には数百もの異なるクローラーやフェッチャーが組み合わさった巨大なシステムの総称だ。GoogleのGary Illyes(ゲイリー・イリェーシュ)氏とMartin Splitt(マーティン・スプリット)氏が公開したポッドキャストにより、その複雑な内部構造が明らかになった。
2026年3月に公開されたこの情報によると、Googleが運用するクローラーの大部分は公開ドキュメントに記載されていない。これは、特定のチームが小規模な目的で使用するクローラーが膨大に存在するためだという。
Webサイト運営者やSEO担当者にとって、この事実はログ解析やクローラー制御の考え方を根本から見直すきっかけとなる。Googlebotという名称の裏側に隠された、巨大なクロール・インフラの実態を詳しく紐解いていく。
Googlebotは単一の存在ではない?クローラーの正体
一般的に「Googlebot」といえば、Webサイトを巡回してインデックスを作成する一つのロボットをイメージしがちだ。しかし、著者のGary Illyes氏によれば、現在のGooglebotは独立した一つのシステムではない。
「Googlebot」という名称の歴史的背景
Googlebotという名前が使われ始めた2000年代初頭、Googleには実際に一つのクローラーしか存在しなかった。当時は提供しているサービスも検索エンジンのみであり、単一のシステムで事足りていたからだ。しかし、AdWords(現在のGoogle 広告)などの新サービスが登場するたびに、専用のクローラーが追加されていった経緯がある。
現在では、ニュース、画像、動画、広告など、用途別に最適化された無数のクローラーが動いている。それでも「Googlebot」という名称が使われ続けているのは、歴史的な慣習によるものだ。実態としては、一つの巨大な「クロール・インフラ」を多くのクライアントが利用している状態に近い。
内部インフラとクライアントの関係性
Googlebotの本質は、クロール・インフラそのものではなく、そのインフラを利用する「クライアント」の一つである。これは、図書館(インフラ)に対して、本を借りに行く利用者(Googlebot)が複数いる状態に例えられる。利用者はGooglebotだけでなく、他にも何百人と存在するのだ。
この仕組みにより、Google内部の各開発チームは、共通の強力なクロール基盤を利用しながら、自分たちの目的に合わせた独自のクローラーを走らせることができる。私たちが普段目にしているGooglebotは、氷山の一角に過ぎないのである。
クロール・インフラの仕組みと「SaaS」的側面
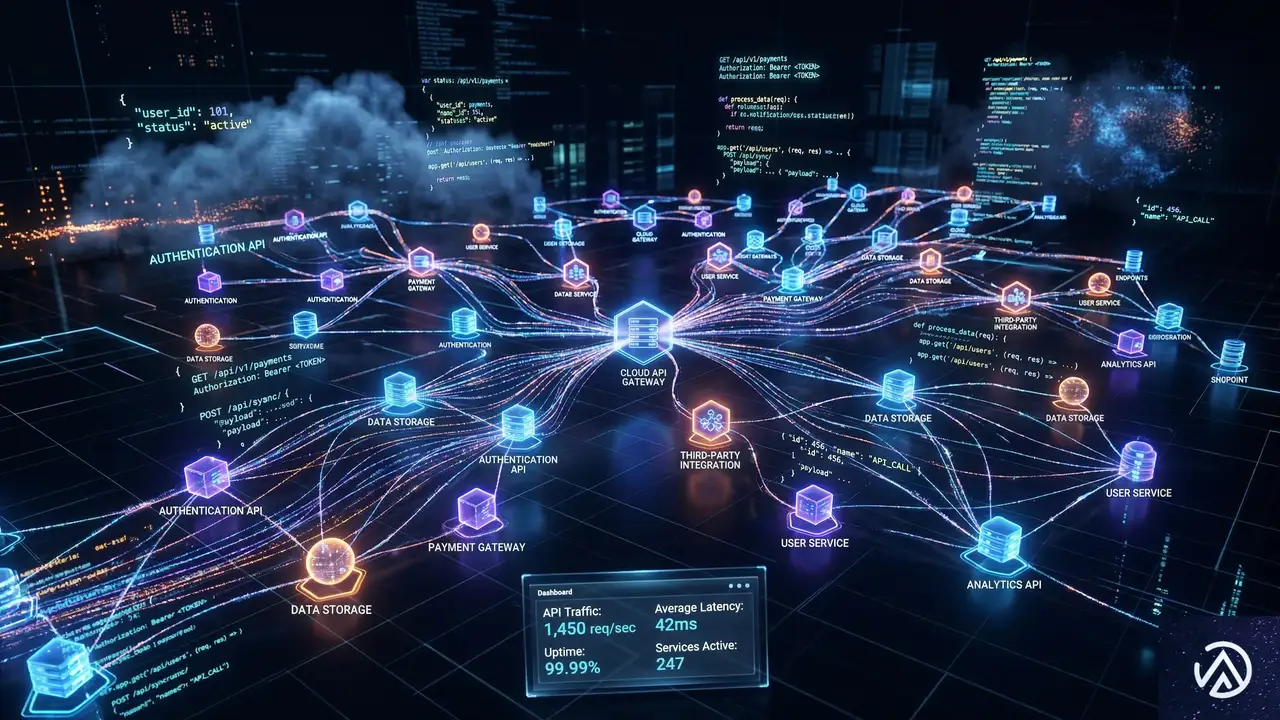
Google内部で運用されているクロール・インフラには特定の名称があるが、Gary Illyes氏はその公開を控えた。彼はこのインフラを、ソフトウェアをサービスとして提供する「SaaS(Software as a Service)」のようなものだと説明している。
内部APIを通じたデータの取得プロセス
Googleのエンジニアがインターネット上のデータを取得したい場合、このインフラが提供するAPIエンドポイントを呼び出す。API(Application Programming Interface)とは、ソフトウェア同士が機能を共有するための窓口のことだ。エンジニアはこの窓口を通じて、「このURLのデータを取ってきてほしい」というリクエストを送る。
リクエストを受けたインフラ側は、クラウドやデータセンターのリソースを使い、対象のWebサイトに負荷をかけすぎないよう配慮しながらフェッチ(取得)を実行する。つまり、クローラーをゼロから開発する必要はなく、共通のAPIを叩くだけで高度なクロール機能を利用できる仕組みが整っているのだ。
パラメータ設定による柔軟な制御
APIを呼び出す際には、さまざまなパラメータを指定できる。例えば、データの返信を待つ時間(タイムアウト設定)、名乗る名前(ユーザーエージェント)、遵守すべきrobots.txtのルールなどだ。多くの場合はデフォルト設定が適用されるため、開発者は複雑な設定なしに利用できる。
ユーザーエージェントとは、クローラーがWebサーバーにアクセスする際に提示する「自己紹介文」のようなものだ。この設定を変更することで、特定のチーム専用のクローラーとして振る舞うことが可能になる。この柔軟性が、数百種類ものクローラーを生み出す要因となっている。
なぜ「未公開」のクローラーが数百も存在するのか

Googleの公式サイトには主要なクローラーの一覧が掲載されているが、そこに含まれないクローラーが圧倒的に多い。これには、ドキュメント管理の現実的な限界と、情報の重要度による線引きが関係している。
公開ドキュメントに記載される基準
Gary Illyes氏によれば、すべてのクローラーをドキュメント化することは事実上不可能だという。Googleは巨大な組織であり、数多くのチームがそれぞれの目的でクローラーを運用しているからだ。もし数百のクローラーをすべて詳細に記載すれば、開発者向けのドキュメントページは膨大な量になり、かえって利便性を損なうことになる。
そのため、Googleは「トラフィック量」という基準で線を引いている。インターネット全体に対して目に見えるほどの影響力を持つ、あるいは頻繁にサイトを訪れる主要なクローラーのみを公開対象としている。小規模なテスト用や特定の機能限定のクローラーは、あえて非公開のままにされているのだ。
内部チームによる多様な用途
未公開のクローラーは、検索以外の多種多様な目的で使用されている。例えば、新機能のプロトタイプ作成、内部的なデータ分析、あるいは特定のセキュリティチェックなどが考えられる。これらのクローラーは取得するURLの数が非常に少ないため、一般的なWebサイト運営者がその存在に気づくことはほとんどない。
ただし、特定のクローラーが一定の閾値を超えて大量のアクセスを行うようになった場合、Gary Illyes氏らはそのチームに連絡を取り、動作の正当性を確認した上でドキュメント化を検討するという。これにより、Webエコシステムへの悪影響を防ぐ監視体制が敷かれている。
「クローラー」と「フェッチャー」の決定的な違い
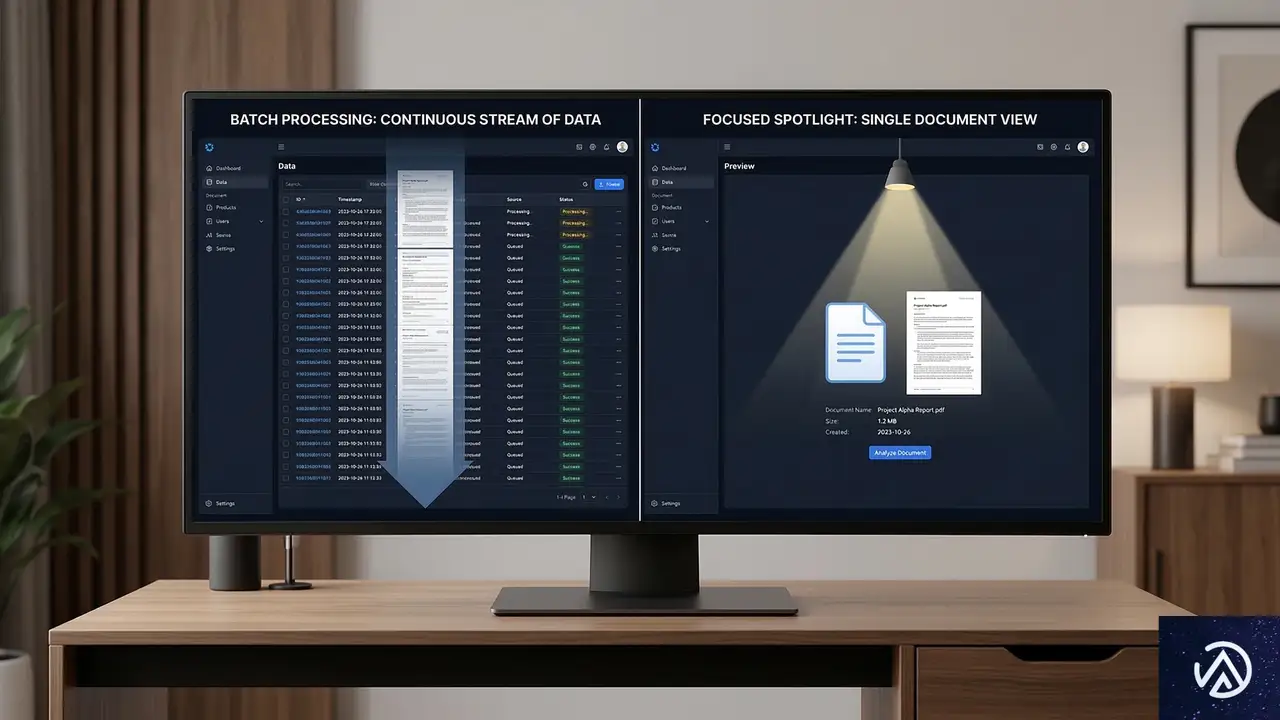
Google内部では、データを取得する仕組みを「クローラー(Crawler)」と「フェッチャー(Fetcher)」の2種類に明確に使い分けている。これらは動作の仕組みも、実行されるタイミングも大きく異なる。
バッチ処理と個別リクエストの使い分け
クローラーは「バッチ処理」で動作する。バッチ処理とは、大量のデータをまとめて一括で処理する方式のことだ。クローラーには常に巡回すべきURLのリストが供給され、24時間365日、システムが空いている時間に継続的にデータを取得し続ける。これが一般的な検索インデックス作成の仕組みだ。
一方、フェッチャーは「個別URL」単位で動作する。特定のURLを指定して、その1件だけを即座に取得するのが役割だ。クローラーが「広範囲を網羅する網」だとすれば、フェッチャーは「ピンポイントで狙う釣り竿」のようなものだと言える。
ユーザー操作がトリガーとなるフェッチ
フェッチャーが動く際の特徴は、多くの場合「ユーザーの操作」が起点となっている点だ。例えば、Search Consoleで「URL検査」を実行し、現在の状態をライブテストする場合などがこれに当たる。画面の向こう側に、結果を待っている人間がいる状態だ。
Googleの内部ポリシーでは、フェッチャーはユーザーの制御下にあるべきだと定められている。これに対してクローラーは、システムの都合に合わせて自律的に動く。この違いを理解しておくことは、サーバーログを見て「なぜ今このアクセスが来たのか」を推測する際の大きなヒントになる。
Webサイト運営者が知っておくべき実務上の注意点

Googlebotが数百のクローラーの集合体であるという事実は、実務においてどのような意味を持つのか。特にセキュリティやパフォーマンスの観点から、サイト運営者が意識すべきポイントを整理する。
未知のユーザーエージェントへの対応
サーバーログを分析していると、GoogleのIPアドレス帯域からのアクセスであるにもかかわらず、ドキュメントに載っていないユーザーエージェントを見かけることがあるかもしれない。これまでは「偽装されたボット」と判断して遮断していたケースもあるだろうが、その一部はGoogle内部の正当な未公開クローラーである可能性がある。
重要なのは、ユーザーエージェント名だけで判断せず、IPアドレスの逆引き(DNSルックアップ)を行って、本当にGoogleからのアクセスかどうかを確認することだ。正当なGoogleのインフラからのアクセスであれば、むやみにブロックせず、サイトのクロールバジェット(クローラーが巡回できる許容量)の範囲内で許容するのが賢明だ。
サーバー負荷とログ解析の視点
数百のクローラーが存在するということは、それだけ多様な目的でサイトがスキャンされる可能性があることを意味する。しかし、Gary Illyes氏が述べている通り、未公開のクローラーは通常、極めて低頻度でしか動作しない。もし特定のボットが大量のアクセスを行い、サーバー負荷を高めているのであれば、それは主要なクローラーであるか、あるいは設定ミスによる異常動作である可能性が高い。
また、robots.txtでの制御も、基本的には「Googlebot」というメインのトークン(識別子)で大部分をカバーできる。個別の未公開クローラーをすべて制御しようとするのは現実的ではなく、主要な指示系統を整理しておくことこそが、SEOにおけるクローラビリティ最適化の王道であることに変わりはない。
この記事のポイント
- Googlebotは単一のプログラムではなく、数百種類のクローラーやフェッチャーが共通のインフラを利用する集合体である。
- Google内部ではクロール機能を「SaaS」のように提供しており、APIを通じて誰でもフェッチリクエストを送れる仕組みがある。
- 公開ドキュメントに載っているのは主要なクローラーのみで、トラフィックの少ない小規模なものは非公開とされている。
- 「クローラー」はバッチ処理で継続的に動き、「フェッチャー」はユーザー操作などを起点に個別URLを取得する。
- サイト運営者は、ドキュメント外のクローラーも存在することを前提に、IPアドレスベースでの正当性確認を行うことが推奨される。
出典
- Search Engine Journal「Google Says Hundreds Of Their Crawlers Are Not Documented」(2026年3月13日)
・ 複数業界における17年間のデジタルビジネス開発経験
・ ウェブサイト開発のためのHTML、PHP、CSS、Java等の実用的知識
・ 15ヶ国語対応の多言語SaaSの開発経験
・ 17年間にも及ぶ、Eコマース長期運営経験
・ 幅広い業界でのSEO最適化の豊富な経験