

クロスドキュメントビュー遷移の三大落とし穴と回避策
クロスドキュメントビュー遷移(Cross-Document View Transitions)は、MPA(マルチページアプリケーション)でありながらSPAのようなスムーズなページ遷移アニメーションを実現するブラウザAPIだ。ReactやAstroといったフレームワークは不要で、HTMLページ間のリンク遷移にブラウザが自動的にアニメーションを付与する。
しかし、この機能の導入にはいくつかの厄介な落とし穴が潜んでいる。CSS-Tricksの記事によれば、著者は実装に丸一日を費やし、何も動作しない状態からデバッグを繰り返したという。ネット上には古い情報や誤解を招くチュートリアルが溢れており、仕様自体も短期間で変更されている。
本記事では、実際の開発現場で遭遇する3つの主要な問題(非推奨metaタグ、4秒タイムアウト、画像の歪み)とその解決策を解説する。加えて、遷移ライフサイクルを制御する2つのイベントについても触れる。
非推奨となったmetaタグの罠
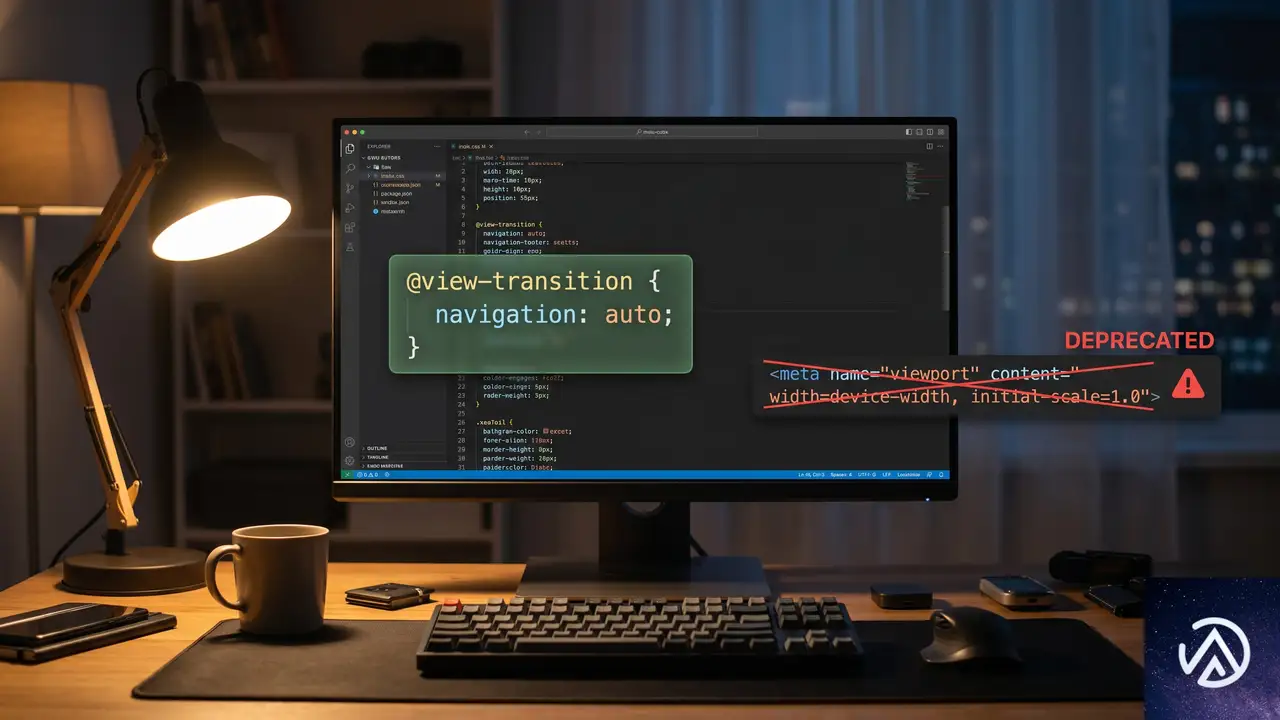
多くの開発者が最初にハマるのが、古いチュートリアルに記載された<meta>タグによるオプトイン方式だ。この方式は既に非推奨であり、現在のブラウザでは完全に無視される。
この比較が示すように、現在の正しい実装方法はCSSの@規則を使用することだ。Chrome 111でmetaタグが導入された後、Chrome 126前後でCSSベースの方式に置き換えられた。非推奨の警告はDevToolsに表示されず、古いコードは静かに動作しなくなる。
なぜCSS方式に移行したのか
metaタグ方式の最大の欠点は、ページ全体でオンかオフかの二択しかできなかったことだ。CSS方式ではメディアクエリや@supportsと組み合わせて、条件付きのオプトインが可能になる。
@media (prefers-reduced-motion: no-preference) {
@view-transition {
navigation: auto;
}
}
@media (min-width: 768px) {
@view-transition {
navigation: auto;
}
}このアプローチにより、アニメーションに敏感なユーザーへの配慮や、モバイルデバイスでのパフォーマンス最適化が容易になった。CSSにオプトインが統合されたことで、既存のスタイル管理フローと一貫性を持って扱える点も大きい。
両方のページでオプトインが必須
もう一つの重要なポイントは、遷移を機能させるには遷移元と遷移先の両方のページで@view-transitionが宣言されている必要があることだ。片方だけでは何も起きない。これは意図的な設計で、404ページやログインリダイレクトなど遷移をスキップしたいページを柔軟に制御できる。
なお、navigation: autoはユーザーがリンクをクリックするかブラウザの戻るボタンを押した場合のみ発動する。window.location.hrefによるプログラム的な遷移や、クロスオリジンのリンク、POSTリクエストでは動作しない。この保守的な設計は、決済処理などの重要な操作に意図しないアニメーションが混入するのを防ぐためだ。
4秒タイムアウトが遷移を静かに殺す
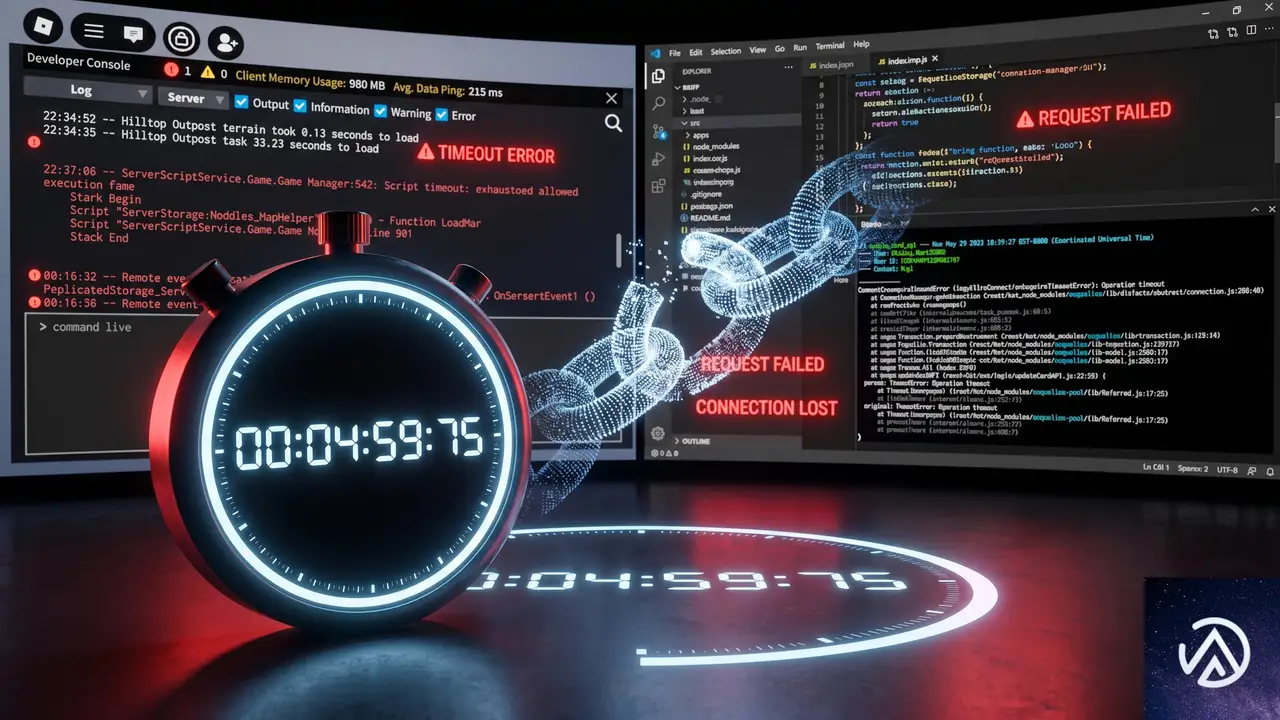
ビュー遷移の実装で最もデバッグが難しい問題が、ハードコードされた4秒のタイムアウトだ。新しいページが4秒以内にレンダリング可能な状態に達しないと、遷移アニメーションは何の通知もなくキャンセルされ、通常のページ読み込みのように切り替わる。
この問題が厄介なのは、ローカル開発環境ではまず発生しないことだ。devサーバーは80msで応答するため遷移は完璧に動作するが、本番環境でサーバーレス関数のコールドスタートやCDNキャッシュミスが発生すると、最初のクリックで遷移が無効化される。
pagerevealイベントでタイムアウトを捕捉する
タイムアウトの発生を検知するには、pagerevealイベントとviewTransition.finishedプロミスを使用する。以下のコードをページに組み込めば、遷移が失敗した際にコンソールで確認できる。
window.addEventListener("pagereveal", (event) => {
if (!event.viewTransition) {
console.log("ビュー遷移なし");
return;
}
event.viewTransition.finished
.then(() => console.log("遷移完了 ✅"))
.catch((err) => {
console.error("遷移中断", err.name, err.message);
});
});このリスナーを早期にセットアップしておけば、本番環境でのデバッグが格段に容易になる。pageswapイベントでも同様に遷移元ページ側でタイムアウトを捕捉可能だ。
実用的な対策
タイムアウト対策の基本はページの読み込み速度改善だが、より実践的なアプローチとしてrel="expect"属性の活用がある。
<link rel="expect" href="#hero" blocking="render">これはブラウザに「#hero要素がDOMに存在するまでページをレンダリング可能と見なさない」と指示するものだ。一見するとパフォーマンスを悪化させるように思えるが、ビュー遷移においては重要なコンテンツが揃ってからスナップショットを取得するため、中途半端な状態での遷移を防げる。
タイムアウトのクロックはナビゲーション開始時からカウントされるため、サーバー応答時間(TTFB)も含まれる点に注意が必要だ。サーバーが2秒かけて応答し、さらに2.5秒かけてレンダリングする場合、個別には遅く感じなくても合計で4.5秒となりタイムアウトに引っかかる。
画像が歪む根本原因と解決策
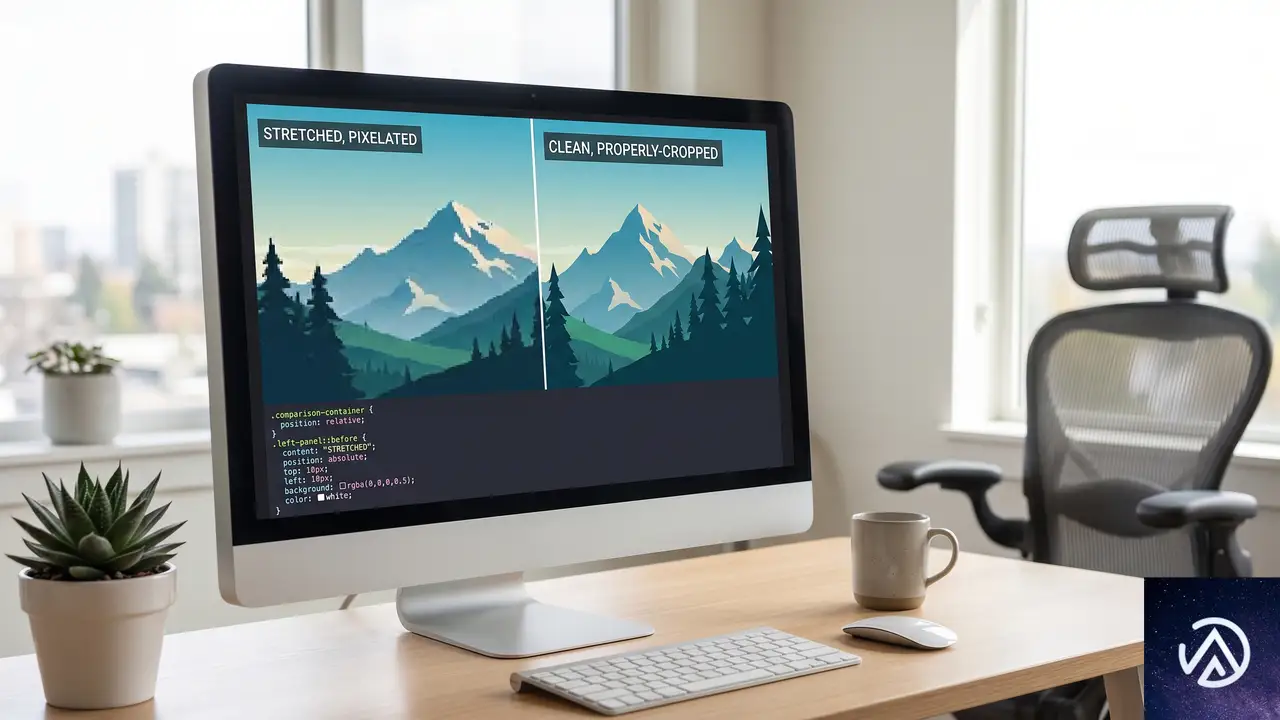
ビュー遷移の実装で視覚的に最も目立つ問題が、アスペクト比の異なる画像間の遷移で発生する歪みだ。サムネイルからヒーロー画像への遷移で、画像が引き伸ばされて見苦しくなる現象は多くの開発者が経験する。
CSS-Tricksの著者は、この問題の原因を特定するのにかなりの時間を費やしたという。根本的な原因は、ブラウザが遷移中に<img>要素そのものをアニメーションさせるのではなく、古い状態と新しい状態のスクリーンショット(ビットマップ)を取得し、それらを変形させることにある。
上記の図が示すように、解決策は疑似要素::view-transition-oldと::view-transition-newに対してobject-fit: coverを適用することだ。これにより、スナップショット画像がアスペクト比を維持したまま切り抜かれるようになる。
疑似要素ツリーの構造を理解する
ビュー遷移が発生すると、ブラウザは内部的に次のような疑似要素ツリーを生成する。
::view-transition
└── ::view-transition-group(hero-img)
├── ::view-transition-old(hero-img)
└── ::view-transition-new(hero-img)::view-transition-groupが古い寸法から新しい寸法へアニメーションするコンテナとして機能し、その中のoldとnewが実際のスナップショットを保持する。デフォルトではこれらの疑似要素にobject-fit: fillが適用されており、これが歪みの原因となる。
アスペクト比が大きく異なるケースでは、object-positionで切り抜き位置を調整することも有効だ。
::view-transition-old(hero-img) {
object-fit: cover;
object-position: center center;
}
::view-transition-new(hero-img) {
object-fit: cover;
object-position: center top;
}このコードでは、新しいヒーロー画像の上部を優先的に表示しつつ、遷移中の歪みを防ぐことができる。CSS-Tricksの著者も指摘するように、object-fit: coverはほぼ全ての画像遷移で必要になる設定であり、デフォルトがfillであることは実用上の大きな障壁となっている。
pageswapとpagerevealによるライフサイクル制御

クロスドキュメントビュー遷移では、遷移元と遷移先のページがJavaScriptで直接通信できないという制約がある。この問題を解決するのがpageswapとpagerevealの2つのイベントだ。
このイベントペアにより、開発者は遷移の両端で状態を制御できる。pageswapは遷移元ページがスナップショットされる直前に発火し、event.activation.entry.urlでユーザーがどこへ向かっているかを知ることができる。
イベントハンドラの実装パターン
これらのイベントを使用する際の重要なポイントは、必ずevent.viewTransitionの存在確認を行うことだ。pagerevealはビュー遷移がない場合も含め、全てのナビゲーションで発火する。
window.addEventListener("pagereveal", (event) => {
if (!event.viewTransition) return;
event.viewTransition.finished.then(() => {
// 遷移完了後のクリーンアップ
}).catch((err) => {
// タイムアウト等のエラー処理
});
});CSS-Tricksの記事では、商品一覧ページから商品詳細ページへの遷移において、pageswapでクリックされた商品カードだけにview-transition-nameを動的に付与するパターンが紹介されている。この動的な名前付けは、数十から数百の要素があるページでのスケーラビリティ問題を解決する重要な手法だ。
この記事のポイント
- metaタグ方式は非推奨。CSSの
@view-transition { navigation: auto; }を使用する - 4秒のタイムアウトはTTFBを含む総時間で判定され、
pagerevealイベントで捕捉可能 - 画像歪みは疑似要素
::view-transition-old/newへのobject-fit: cover適用で解決 pageswapとpagerevealの2つのイベントが遷移全体のライフサイクルを制御する

・ 複数業界における17年間のデジタルビジネス開発経験
・ ウェブサイト開発のためのHTML、PHP、CSS、Java等の実用的知識
・ 15ヶ国語対応の多言語SaaSの開発経験
・ 17年間にも及ぶ、Eコマース長期運営経験
・ 幅広い業界でのSEO最適化の豊富な経験

ローカルファーストWeb開発のアーキテクチャ クライアント主導のデータ管理と同期の仕組み
ローカルファーストアーキテクチャが注目を集めている。従来のサーバー中心のWebアプリ開発とは異なり、クライアント端末にデータの一次コピーを保持し、読み書きをローカルで即座に処理する設計手法だ。オフラインでも動作し、ネットワーク遅延の影響を受けないため、ユーザー体験が大幅に向上する。
Smashing Magazineの記事「The Architecture Of Local-First Web Development」(2026年5月6日公開)では、実際のプロジェクト経験に基づいた実践的な知見が紹介されている。本記事ではその要点を再構成し、Web制作やシステム開発に携わるエンジニア向けにわかりやすく解説する。
ローカルファーストとは何か 〜オフライン対応との違い
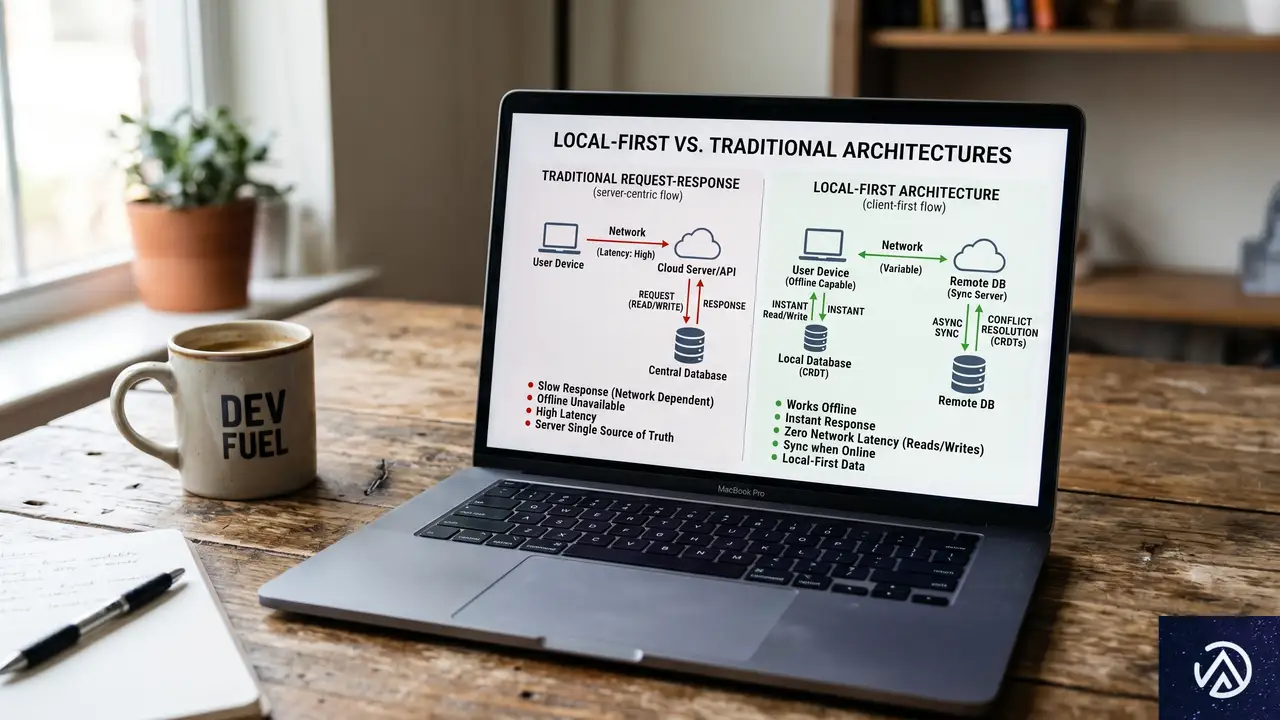
ローカルファーストはよく「オフラインファースト」やPWA(プログレッシブWebアプリ)と混同される。しかしこれらは根本的に異なる。オフラインファーストはネットワーク切断時でもアプリが壊れず動くことを目的とするが、データの主たる権威(正)は依然としてサーバーにある。一方、ローカルファーストは「データアーキテクチャ」の概念であり、ユーザーの端末がデータの一次コピーを持つ。アプリはローカルデータベースに直接読み書きし、画面を即座にレンダリングする。サーバーとの同期はバックグラウンドで行われ、サーバーは認証やバックアップなど特定の役割を担うが、データの門番ではない。
Ink and Switchが2019年に提唱した「ローカルファーストソフトウェア」の7つの理想(高速、マルチデバイス、オフライン、コラボレーション、長寿命、プライバシー、ユーザー所有権)は今でも有効だが、実務において最も重要なのは「クライアントが分散システムのノードであり、独自のデータベースを持つ」という点だ。この考え方が開発全体を変える。
このデモのとおり、ローカルファーストではユーザーの操作がサーバーの応答を待つことなく完結する。この違いがアプリの「遅さ」に対する根本的な解決策になる。
オフラインファーストやPWAとの混同を解く
Service Workerを使ったキャッシュやPWAは、あくまで配信や耐障害性の仕組みだ。データの所有権や正規性は変わらない。ローカルファーストは「端末が真実のコピーを持つ」点で本質的に異なる。これを理解しないまま実装を進めると、後からデータの不整合や同期設計の誤りに悩まされることになる。
ローカルファーストが向いているユースケースと不向きな場面

このアーキテクチャは万能ではない。導入を検討する前に、自社のアプリがどのデータ特性を持つかを見極める必要がある。
適している領域
- ユーザー生成データを扱うアプリ。メモ帳、ドキュメントエディタ、プロジェクト管理、フィールド業務用ツールなど
- リアルタイムコラボレーションが必要なツール。デザインツールや同時編集が前提のアプリ
- プライバシーが売りになるサービス。データをユーザーの手元に置くことで差別化できる
- 通信が不安定な環境向けのアプリ。工事現場、僻地、移動中の利用を想定する場合
不向きな領域
- サーバー生成データが主体のアプリ。分析ダッシュボード、SNSフィード、検索結果など
- 強いトランザクション整合性が求められるシステム。銀行、決済、在庫管理(複数ユーザーが同時に在庫を操作すると問題)
- 単純なCRUDでオフラインやコラボレーションの必要がない社内管理画面。同期エンジンは過剰設計になる
- クライアント端末に収まらない巨大なデータセット
また、アプリ全体を一度にローカルファーストに書き換える必要はない。例えばブログエディタの下書き機能だけをローカルファーストにする、といった段階的な導入が現実的だ。
クライアント側のデータ保存 ストレージ技術の選択

ユーザーの端末にデータを保持するには、適切なストレージ技術を選ぶ必要がある。従来のlocalStorageは同期APIでメインスレッドをブロックし、容量も5〜10MBと限られるため、本格的なデータベース用途には使えない。現在の主流は以下の3つだ。
実案件ではwa-sqliteなどのライブラリを使い、OPFSを介してSQLiteを永続化するのが有力な選択肢だ。初期化のコード例を示す。
import { SQLiteAPI } from 'wa-sqlite';
import { OPFSCoopSyncVFS } from 'wa-sqlite/src/examples/OPFSCoopSyncVFS.js';
async function initDatabase() {
const module = await SQLiteAPI.initialize();
const vfs = new OPFSCoopSyncVFS('app-db');
await vfs.initialize(module);
const db = await module.open_v2('local.db');
await module.exec(db, `PRAGMA journal_mode=WAL`);
await module.exec(db, `
CREATE TABLE IF NOT EXISTS tasks (
id TEXT PRIMARY KEY,
title TEXT NOT NULL,
status TEXT DEFAULT 'backlog',
created_at TEXT DEFAULT (datetime('now'))
)
`);
return db;
}なおSafariのOPFS実装は一部のコンテキストでcreateSyncAccessHandle()が無反応で失敗する既知の不具合があり、IndexedDBへのフォールバックを用意しておくことが推奨される。
データ同期の手法 CRDTとデータベースレプリケーション

クライアントにデータを置くだけなら解決済みだが、複数端末や複数ユーザー間でどう同期するかが本当の難所だ。主なアプローチは次のとおり。
YjsやAutomergeが代表的で、リアルタイム共同編集に強み。テキストの文字レベルでのマージに優れるが、構造化データのマージは意図しない結果を生むこともある。多くのプロジェクトでは、真のリアルタイム共同編集が必要な箇所にのみYjsを採用し、それ以外はデータベースレプリケーションで済ませるハイブリッド構成が無難だ。
同期の流れをコードで見る
ローカルファーストのアプリでは、従来のようにfetch()でデータを取得する必要がない。代わりにuseLiveQueryのようなフックがローカルSQLiteの変更を検知し、UIが自動で再描画される。
import { useLiveQuery } from '@powersync/react';
import { db } from '../lib/database';
function TaskBoard({ projectId }) {
const tasks = useLiveQuery(
`SELECT * FROM tasks WHERE project_id = ? ORDER BY position`,
[projectId]
);
async function addTask(title) {
await db.execute(
`INSERT INTO tasks (id, title, project_id, position)
VALUES (?, ?, ?, ?)`,
[crypto.randomUUID(), title, projectId, tasks.length]
);
// API呼び出しも楽観的更新のロールバックも不要
}
return (
{tasks.map(task => )}
);
}このコードにはローディング状態もエラーハンドリングも書かれていない。データが常にローカルにあるという前提が、これほどまでにUIコードを単純化する。
衝突解決と整合性の課題

複数のレプリカが独立して書き込みを行うと、当然データの衝突が発生する。最もシンプルな解決策は「ラストライトウィン(LWW)」、つまりタイムスタンプが新しい方を採用する方式だ。ただしレコード全体まるごと上書きするのではなく、フィールド単位で適用するのが現実的だ。下記のようなマージ関数を実装すれば、別々のフィールドを編集した場合に両方の変更が生き残る。
function pickWinner(a, b) {
const timeA = new Date(a.updatedAt).getTime();
const timeB = new Date(b.updatedAt).getTime();
if (timeA !== timeB) return timeA > timeB ? a : b;
return a.clientId > b.clientId ? a : b;
}
function mergeTask(local, remote) {
const merged = {};
const allKeys = new Set([...Object.keys(local), ...Object.keys(remote)]);
for (const key of allKeys) {
if (!local[key]) { merged[key] = remote[key]; continue; }
if (!remote[key]) { merged[key] = local[key]; continue; }
merged[key] = pickWinner(local[key], remote[key]);
}
return merged;
}このLWWは約95%の衝突を自動解決するが、同じテキストフィールドを2人が編集した場合は一方が静かに上書きされる。文書編集では問題だが、タスクのタイトル程度なら許容できる場合が多い。
セマンティック衝突への対処
構造的には綺麗にマージできても、意味的に矛盾するケースがある。たとえば2人のユーザーがオフラインで同じ会議室の同じ時間帯に別の予定を入れた場合、フィールド単位では衝突しないがダブルブッキングが発生する。このような「セマンティック衝突」は、サーバー側のバリデーションで検出し、クライアントに通知してユーザーに解決を促す。
重要なのは、違反が起きても書き込み自体は受け入れ、警告フラグとともにクライアントに返す設計だ。もしサーバーが書き込みを拒否すると、クライアントのローカルDBには存在するがサーバーには存在しない「幽霊レコード」が生まれ、回復が困難になる。
実装上の注意点 認証・マイグレーション・テスト

認証と認可
認証は従来どおりJWTやOAuthで行うが、トークンは毎リクエストではなく同期接続の確立時に使われる。認可は同期レイヤーで厳密に適用する必要がある。全データをクライアントに渡して見せたいものだけ表示するのは危険で、DevToolsからすべて覗ける。PowerSyncの「同期ルール」やElectricSQLの「シェイプ」を使い、サーバー側でユーザーに許可された行だけを送信する設計が必須だ。
スキーママイグレーション
サーバーなら1つのデータベースを管理すればよいが、クライアントはアプリを開いていない期間が長ければ古いスキーマのまま放置されている可能性がある。マイグレーションは起動時にバージョン番号を確認して逐次適用する方式が堅実だ。基本的に「カラムの追加」のみとし、削除やリネームは極力避ける。古いクライアントが存在する限り、欠落カラムへの書き込みが同期失敗を引き起こすからだ。
テスト戦略
マージロジックはユニットテストが容易だが、実際のネットワーク断絶や衝突タイミングを再現するのが難しい。2つのクライアントインスタンスをメモリ上で立ち上げ、同時編集後に収束するかを検証する統合テストや、Playwrightのcontext.setOffline(true)を使ったE2Eテストが有効だ。ランダムな操作列を与えて収束性をチェックするプロパティベーステストもCRDTロジックの品質を高める。
この記事のポイント
- ローカルファーストは、クライアント側にデータの一次コピーを置き、読み書きをローカルで即座に行うデータアーキテクチャである
- オフラインファーストやPWAとは異なり、データ所有権と即時性が根本的に変わる
- 向いているのはユーザー生成データを扱う協調ツールやフィールドアプリ。銀行や分析ダッシュボードには不向き
- クライアント側のストレージにはOPFS上のSQLite(WASM)が主力。IndexedDBの直接利用は避ける
- 同期はCRDT(Yjs等)とデータベースレプリケーション(PowerSync等)から選択し、多くの場合は後者で十分
- 衝突解決はフィールド単位のLWWで大半を自動化し、セマンティック衝突はサーバー検出+ユーザー通知で対応する
- 認可・マイグレーション・テストには固有の注意点があり、段階的に導入するのが現実的
・ 複数業界における17年間のデジタルビジネス開発経験
・ ウェブサイト開発のためのHTML、PHP、CSS、Java等の実用的知識
・ 15ヶ国語対応の多言語SaaSの開発経験
・ 17年間にも及ぶ、Eコマース長期運営経験
・ 幅広い業界でのSEO最適化の豊富な経験

ヘッドレスCMSとWordPressの選び方、2026年版アーキテクチャ比較
CMSの選定は2026年、技術的な好みの問題ではなくなった。その選択がマーケティングキャンペーンの展開速度、コンテンツ更新の自由度、ひいては収益に直結する。WordPressが世界のWebサイトの43.5%を支える支配的な存在である一方、ヘッドレスCMS市場は2027年までに16億ドルに達すると予測されている。
両者の違いは単なる「新しいか古いか」ではない。視覚的な構築の自由と、アーキテクチャの厳格な分離という、根本的に異なる哲学のせめぎ合いだ。本記事ではパフォーマンス、運用コスト、セキュリティ、SEO、そしてチームの働き方という実務の観点から、両アプローチを比較する。
根本的なアーキテクチャの違い
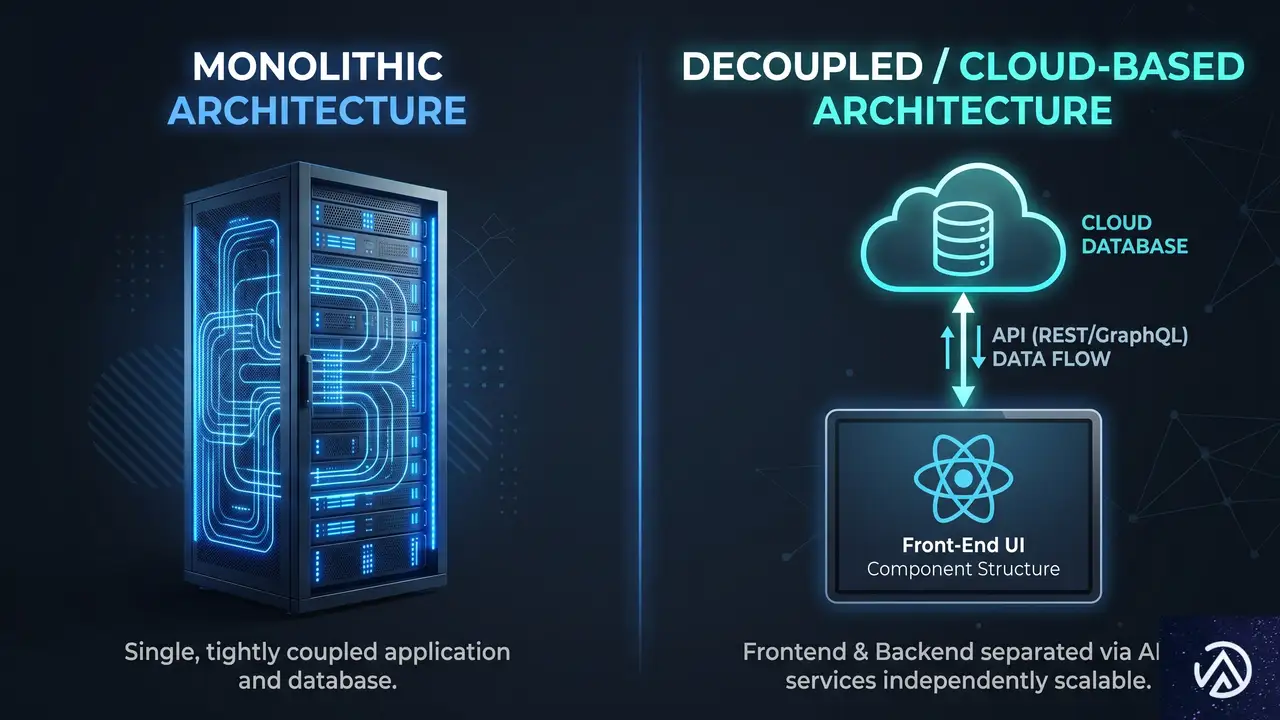
アーキテクチャの議論は開発者だけの専門用語ではない。マーケティングチームが火曜の朝にランディングページを立ち上げられるかどうか、そのスピードを決める。この根本的な違いは採用戦略にも直接影響する。
従来のWordPressはモノリシック(一体型)システムだ。コンテンツデータベース、PHPの処理ロジック、HTML出力がすべて同じアプリケーション環境に同居する。ユーザーがリンクをクリックすると、サーバーはPHPスクリプトを実行しMySQLデータベースに問い合わせ、取得したデータをテーマテンプレートにはめ込み、最終的なHTMLをブラウザに返す。この一連の処理は一つのサーバー内で完結する。
一方、ヘッドレスはデカップルド(分離型)アーキテクチャと呼ばれる。コンテンツはContentfulやStrapiのようなクラウドデータベースに保存され、フロントエンドはReactやVueで構築された完全に別個のアプリケーションになる。フロントエンドアプリはAPIエンドポイントを通じて生のJSONデータを受け取り、コンテンツの見た目には一切関与しない。データの受け渡しと表示が完全に分離されているのだ。
なぜ開発者は分離を好むのか
Elementor Blogの記事によれば、最近のStack Overflow調査でヘッドレス技術への開発者関心が従来のPHPロールと比較して15%増加したという。彼らは「関心の分離」を重視する。バックエンドのコンテンツ管理とフロントエンドのUI実装が完全に切り離されることで、開発効率とコードの保守性が高まるからだ。
ただし、この分離にはトレードオフがある。マーケターがコンテンツの見た目をリアルタイムで確認する「ライブプレビュー」は、ヘッドレス環境では極めて面倒な課題として残っている。草案を確認するだけのために複雑なプレビューサーバーを構築しなければならないケースも多い。
ユーザー体験の決定的な差

ヘッドレスアーキテクチャがマーケティングチームを苦しめる最大の理由がここにある。技術的な純粋さと引き換えに、ワークフローの速度が犠牲になる。
WordPressの視覚的優位性
従来型WordPressは視覚的な構築体験で圧倒的に優位に立つ。Elementor Editor Proを例にとると、118種類以上のウィジェットを使ってCSSを一行も書かずにレイアウトを構築できる。コンテナをドラッグし、ブレークポイントを調整し、すぐに公開する。
ヘッドレスが生む開発者依存
ヘッドレス環境では、ヒーローセクションのレイアウトを変更したいだけでも、マーケターはJiraチケットを発行し、開発者がReactコンポーネントを更新し、GitHubにプッシュし、ビルドパイプラインの完了を待つという手順を踏まなければならない。毎週11本の記事を公開するチームにとって、この依存関係は数百時間の損失になりうる。
Elementor Blogで紹介されているAIアシスタント「Angie」のようなツールは、このギャップを埋めようとしている。チャットで指示するだけで、実用的なレイアウトやフォームを自動生成する。テキスト提案ではなく、実際に動作するアセットを構築する点が従来のAIと異なる。
一方で、スマート冷蔵庫、Apple Watchアプリ、Webサイトに同時にコンテンツを配信する必要があるなら、ヘッドレスのデータエントリーモデルは必須になる。配信先が3つ以上のチャネルに及ぶブランドは、前年比9.5%の収益増加を達成しているとのデータもある。
表示速度、パフォーマンスの現実
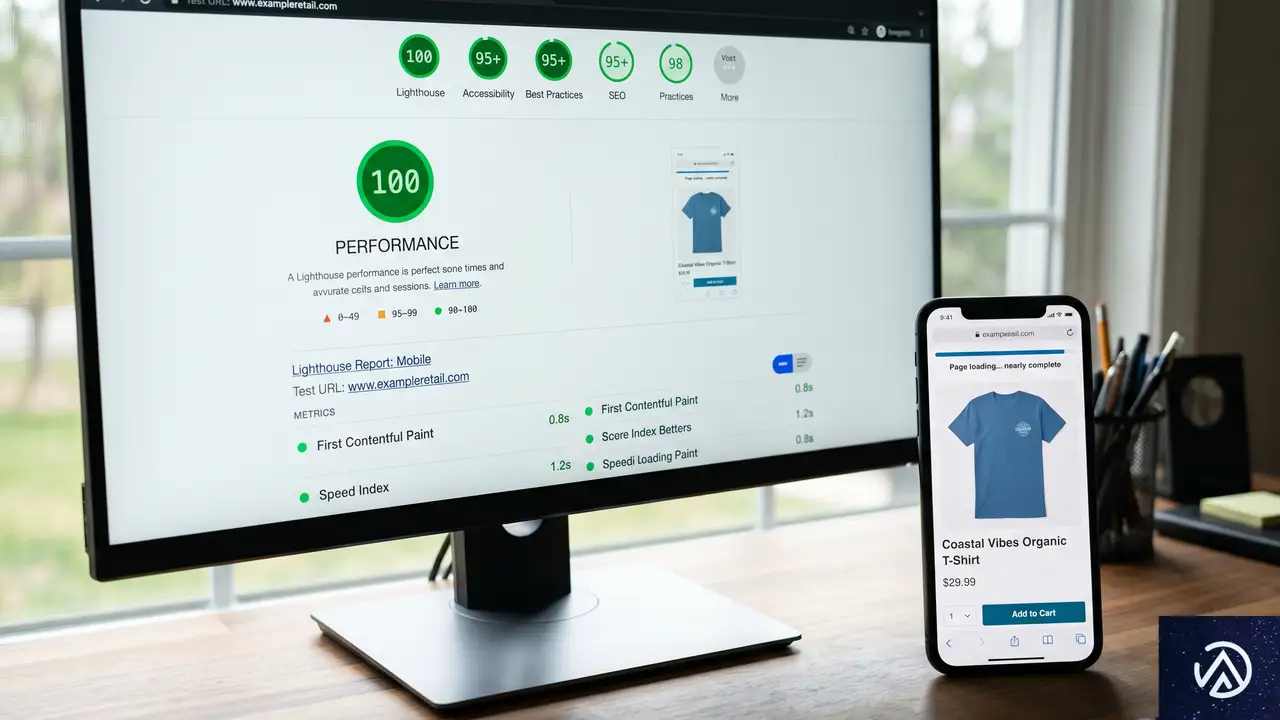
2026年において表示速度は贅沢品ではない。生存のための指標だ。世界のトラフィックの58.67%がモバイルデバイスを経由する中、重いサイトは収益を直接焼き尽くす。
ヘッドレスの圧倒的速度
ヘッドレスシステムは生の速度で容易に優位に立つ。静的サイト生成(SSG)という仕組みを使うからだ。SSGとは、コンテンツのHTMLファイルをあらかじめ生成しておき、CDN(コンテンツ配信ネットワーク。世界中に分散したサーバー拠点から最寄りの場所にデータを届ける仕組み)に保存する手法である。ユーザーがアクセスした瞬間にデータベースへ問い合わせる必要がないため、Next.jsで構築されたサイトは頻繁にLighthouseの満点を叩き出す。
WordPressが抱えるボトルネック
現在、WordPressサイトでGoogleのCore Web Vitals(コアウェブバイタル。ページ体験を測る3つの指標)の全項目を通過しているのは、わずか40.5%だ。PHP処理への依存度の高さと最適化されていないプラグインが深刻なボトルネックを生み出している。参考までに、Next.jsサイトの合格率は約55%に達する。
ただし、WordPressで速度を諦める必要はない。構築方法を変えれば良い。エッジキャッシュの導入、条件付きアセットローディング(必要なときにだけスクリプトを読み込む手法)、画像の自動圧縮、Redisを使ったデータベースクエリのオフロードを徹底する。速度向上は直接売上に跳ね返る。モバイルでわずか0.1秒の改善が小売のコンバージョン率を8.4%押し上げるというデータもある。
セキュリティと保守の実態

セキュリティは従来型CMSエコシステムに突き刺さる最大の棘だ。Elementor Blogの記事が引用する統計は痛烈である。CMS系Webサイトへの攻撃成功事例のうち、実に94%がWordPressを標的にしている。
WordPressの広大な攻撃対象
この数字の理由は明確だ。データベース、ログイン画面(wp-admin)、公開Webサイトがすべて同じサーバーIPアドレスを共有している。攻撃者が古いスライダープラグインの脆弱性を一つ見つければ、データベース全体へのアクセスを奪取できる。攻撃対象領域が極めて広いのだ。
ヘッドレスの構造的安全性
ヘッドレスアーキテクチャはこの攻撃対象領域を劇的に縮小する。フロントエンドはバックエンドから完全に切り離されているため、公開Webサイトにデータベースが接続されていない。ハッカーは静的HTMLファイルにSQLインジェクションを仕掛けることはできない。
もちろん、モノリシックシステムの防御は不可能ではない。共有ホスティングを避け、Cloudflare経由でWAF(Webアプリケーションファイアウォール)を導入し、使っていないプラグインは無効化ではなく即座に削除する。管理ロールには二要素認証を強制し、デフォルトのログインURLを変更する。こうした基本的な対策を徹底するだけでもリスクは大幅に下げられる。
コストの真実、初期費用と総所有コスト

初期構築費用は総所有コスト(TCO)の一部に過ぎない。多くの制作会社がパフォーマンスだけを謳い文句にヘッドレスを販売するが、クライアントに毎月のSaaS料金が重くのしかかる。
ヘッドレスの高い参入障壁
具体的な数字を見てみよう。SANITYのGrowthプランは月額949ドル、ContentfulのTeamティアは月額300ドルからスタートし、エンタープライズプランは通常月額2,000ドルを超える。Strapiのような月額29ドルの選択肢もあるが、Nodeアプリとデータベースを自前でホストする手間が加わる。
WordPressの現実的なコスト
従来型プラットフォームの参入障壁ははるかに低い。中小企業向けの高品質なマネージドWordPressホスティングは、おおむね月額20ドルから115ドルの範囲に収まる。大規模なコンテンツ運用をヘッドレスの数分の一の予算で回せる計算だ。
ただし、WordPressのスケーラビリティは無料ではない。月間100万訪問者を超えると、安価なホスティングは崩壊する。エンタープライズグレードのクラウドインフラ、積極的なキャッシュ階層、高度なセキュリティ設定が必要になる。結局のところ、開発コストもどちらの道でも発生する。ヘッドレスは高給のReact/Vueエンジニアを必要とし、従来型ビルドはPHP/WordPressエキスパートによるテーマロジックの維持や定期的なデータベース最適化を必要とする。
ハイブリッド手法、橋を架ける

極端な二択を迫られる必要はない。2026年、最も賢いチームはハイブリッドアプローチを採用している。ページビルダーの視覚的自由を維持しつつ、特定の機能に最新のAPI技術を利用する。
WordPressを純粋なヘッドレスコンテンツリポジトリとして使うことも可能だ。WordPress REST APIとWPGraphQLを使えば、投稿や固定ページをJSONデータとしてクエリし、Next.jsフロントエンドに供給できる。執筆者には使い慣れたGutenbergインターフェースを提供しながら、開発者はモダンなスタックを手に入れられる。
より効率的なのは、モノリシックを維持しながらスピードを上げるアプローチだ。多数のプラグインをつぎはぎする代わりに、ホスティング、ビジュアルビルド、パフォーマンスツールを一つの環境に統合する。AIにワイヤーフレーム生成を任せ、人間は微調整に集中する。主要なマーケティングサイトはモノリシックのまま実行速度を確保し、求人情報や商品カタログといった特定の投稿タイプだけをREST API経由でモバイルアプリにプッシュする。これでデータを閉鎖的なシステムに閉じ込めず、マーケティングチームも視覚編集から締め出されない。
この記事のポイント
- 従来型WordPressはマーケティングチームの即応性と視覚的編集で圧倒的に優位。
- ヘッドレスは生の表示速度とセキュリティで勝るが、高いSaaSコストと開発者依存が課題。
- WordPressの速度課題はエッジキャッシュと条件付きローディングで大幅に改善可能。
- 3つ以上のチャネルにコンテンツを配信する場合、ヘッドレスのデータエントリーモデルが必須。
- ハイブリッド手法を用いれば、両者の長所を活かした現実的な落とし所が見えてくる。
・ 複数業界における17年間のデジタルビジネス開発経験
・ ウェブサイト開発のためのHTML、PHP、CSS、Java等の実用的知識
・ 15ヶ国語対応の多言語SaaSの開発経験
・ 17年間にも及ぶ、Eコマース長期運営経験
・ 幅広い業界でのSEO最適化の豊富な経験

ストリーミングUIの安定性を高める実装テクニック
WordPressサイトのフロントエンドにチャットボットやリアルタイムのログビューアーを組み込むケースが増えている。こうしたストリーミングUIは、新しいデータが届くたびにDOMを更新するため、適切な制御がないとスクロール位置が勝手に動いたり、ボタンがクリック直前に移動するといった不安定さが目立つ。
特にスクロールの強制移動、レイアウトのシフト、そして過剰な再描画の3つは、ユーザーの操作感を大きく損ねる。本記事では、これらの問題を解決し、WordPressのカスタムエンドポイントや管理画面のダッシュボードにも応用できる安定したUIの実装パターンを紹介する。
ストリーミングUIが不安定になる根本原因
チャット形式のAI応答、ログの逐次表示、ダッシュボードの数値更新。一見異なるこれらのUIは、いずれも同じ3つの根本問題に突き当たる。
スクロールの制御不能
ストリーミング中、多くのUIはビューポートを常に最下部に固定しようとする。これ自体は合理的だが、ユーザーが少し上にスクロールして過去のメッセージを読もうとした瞬間、UIが再び最下部へ引き戻してしまう。ユーザーの意図を無視した自動制御が、インタラクションの邪魔になる。
レイアウトシフト
ストリーミングコンテンツは行数や高さが動的に増えるため、その下にある要素が常に押し下げられる。クリックしようとしたボタンが移動したり、読んでいた行が画面外に消えたりする。DOMを毎回全再構築していると、このシフトはさらに顕著になる。
過剰なレンダリング更新
ブラウザは1秒間に約60回画面を描画するが、ストリームのデータ到着はそれよりも速いことがある。毎回DOMを書き換えていると、実際にはユーザーが目にしないフレームのためにもレイアウト再計算が走り、パフォーマンスがじわじわと低下する。
安定したスクロール動作の実装

まずはスクロールの自動制御をユーザーの意図に合わせる。基本的な考え方は以下の通りだ。
- ユーザーが最下部にいるときは自動スクロールを有効にする
- ユーザーが上方向にスクロールしたら自動スクロールを止める
- 再び最下部に戻ったら自動スクロールを再開する
これを実現するには、ユーザーが意図的にスクロール位置を変えたかどうかを追跡するフラグを設ける。
let userScrolled = false;
chatEl.addEventListener('scroll', () => {
const gap = chatEl.scrollHeight - chatEl.scrollTop - chatEl.clientHeight;
userScrolled = gap > 60; // 60px以上離れたらユーザー操作とみなす
});ここで60pxのしきい値が重要になる。新しい行が追加されて生じる微小な高さ変化でフラグが切り替わらないようにし、本当にユーザーがスクロールした時だけ自動スクロールを停止させる。
自動スクロール関数はフラグを参照するだけでよい。
function autoScroll() {
if (!userScrolled) {
chatEl.scrollTop = chatEl.scrollHeight;
}
}なお、新たなストリームが開始されたら必ず userScrolled をリセットする。これを見落とすと、前回のメッセージでのスクロールが原因で次の自動スクロールが無効になり、読みづらさが続く。
レイアウトシフトを防ぐDOMの差分更新

従来の実装では、新しい文字が届くたびに要素を innerHTML で全再構築することが多い。以下はその典型例だ。
bubble.innerHTML = '';
fullText.split('\n').forEach(line => {
const p = document.createElement('p');
p.textContent = line || '\u00A0';
bubble.appendChild(p);
});
bubble.appendChild(cursorEl);これで動作はするが、更新のたびにDOMツリー全体を破壊して再生成するため、レイアウト再計算が必ず発生する。さらに、カーソルも毎回削除と追加が繰り返され、高速ストリーミング時にはちらつきの原因にもなる。
解決策はシンプルだ。あらかじめ空のテキストノードを持った段落を作り、そこへ直接文字を追記していく。改行が来た時にだけ新しい段落を追加する。
let currentP = null;
function initBubble(bubble, cursor) {
currentP = document.createElement('p');
currentP.appendChild(document.createTextNode(''));
bubble.insertBefore(currentP, cursor);
}
function appendChar(char, bubble, cursor) {
if (char === '\n') {
currentP = document.createElement('p');
currentP.appendChild(document.createTextNode(''));
bubble.insertBefore(currentP, cursor);
} else {
currentP.firstChild.textContent += char;
}
}この方法では、通常の文字追加はテキストノードの拡張だけで済み、レイアウトシフトはほとんど発生しない。改行の時だけ新しい段落が挿入されるが、それ以外の無駄な再構築が一切なくなる。カーソルのちらつきも自然に消える。
レンダリング頻度を抑えるバッファリング戦略
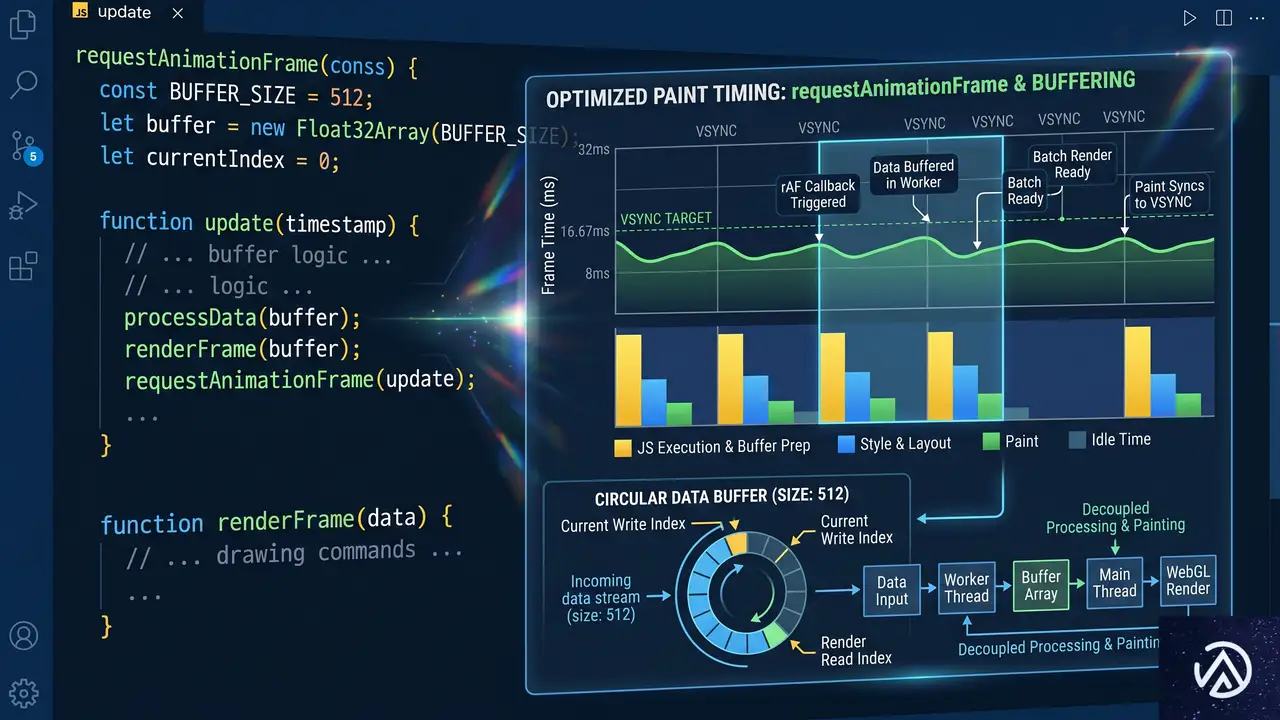
DOMの差分更新だけでもUIは安定するが、まだ文字が届くたびにペイントのトリガーを引いている。特にストリーム速度が速い場合、短時間に大量の小更新が発生し、ブラウザの負荷が積み重なる。
ここで有効なのが受信データのバッファリングと requestAnimationFrame によるフレーム単位のフラッシュだ。到着した文字をいったんバッファに溜め、次の描画直前にまとめてDOMへ書き出す。
let pending = '';
let rafQueued = false;
function onChar(char) {
pending += char;
if (!rafQueued) {
rafQueued = true;
requestAnimationFrame(flush);
}
}
function flush() {
for (const char of pending) {
appendChar(char);
}
pending = '';
rafQueued = false;
autoScroll();
}rafQueued フラグが二重スケジューリングを防ぐ。こうすることで、データ到着頻度とUI更新タイミングが完全に分離され、ブラウザが行う実際の描画回数に最適化されたペースでDOM変更が行われる。変更後の見た目は変わらなくても、特に高速ストリーミング設定時に操作感が格段に滑らかになる。
ストリーム中断への対応とユーザーフィードバック

ユーザーがストリームを途中で停止したり、ネットワークエラーで途切れたりした場合、UIを中途半端な状態のまま放置してはいけない。停止ボタンを押しただけでカーソルが点滅し続けたり、ボタン表示が変わらなかったりすると不信感につながる。
中断時のクリーンアップ
function stopStream() {
clearTimeout(streamTimer);
isStreaming = false;
pending = ''; // 未処理バッファを破棄
rafQueued = false;
if (cursorEl && cursorEl.parentNode) cursorEl.remove();
markStopped(aiBubble); // 「応答が停止しました」ラベルを付与
stopBtn.style.display = 'none';
retryBtn.style.display = '';
retryBtn.focus(); // キーボード操作のため即フォーカス
}バッファをクリアするのは、停止後に残っていた文字が次のフレームで書き込まれるのを防ぐためだ。カーソルの親ノードチェックも、すでに削除済みの場合のエラー回避に必要になる。
再試行機能の提供
中断後は同じ質問を再送信する「リトライ」ボタンを表示する。ユーザーに再度質問を入力させるのではなく、直前の入力を保持しておき、ワンクリックでストリームを最初からやり直せる。
let lastQuestion = '';
function retryStream() {
if (currentMsgEl && currentMsgEl.parentNode) {
currentMsgEl.remove();
}
charIndex = 0;
userScrolled = false;
pending = '';
rafQueued = false;
isStreaming = true;
// ボタン表示切替など
setTimeout(() => {
initAIMsg();
tick(lastAnswer);
}, 200);
}状態の完全リセットが肝だ。前回の文字インデックス、スクロールフラグ、バッファをすべて初期化しなければ、新しいストリームに前の残骸が混ざる。
新規メッセージ送信時の既存ストリーム停止
もう一つ見落としやすいのが、古いストリームが動いている最中に新しいメッセージが送信されたケースだ。そのままにすると2つのストリームが同時にDOMを更新し、文字が混ざり合ってしまう。新しいメッセージの処理を始める前に、必ず進行中のストリームを停止する。
function startStream(question, answer) {
if (isStreaming) {
clearTimeout(streamTimer);
isStreaming = false;
pending = '';
rafQueued = false;
if (cursorEl && cursorEl.parentNode) cursorEl.remove();
}
// ここで新規ストリームのセットアップ
}断りなく上書きするのではなく、明示的に前のストリームをクリーンアップすることで、イレギュラーな重複動作を防ぐ。
アクセシビリティを考慮したストリーミングUI
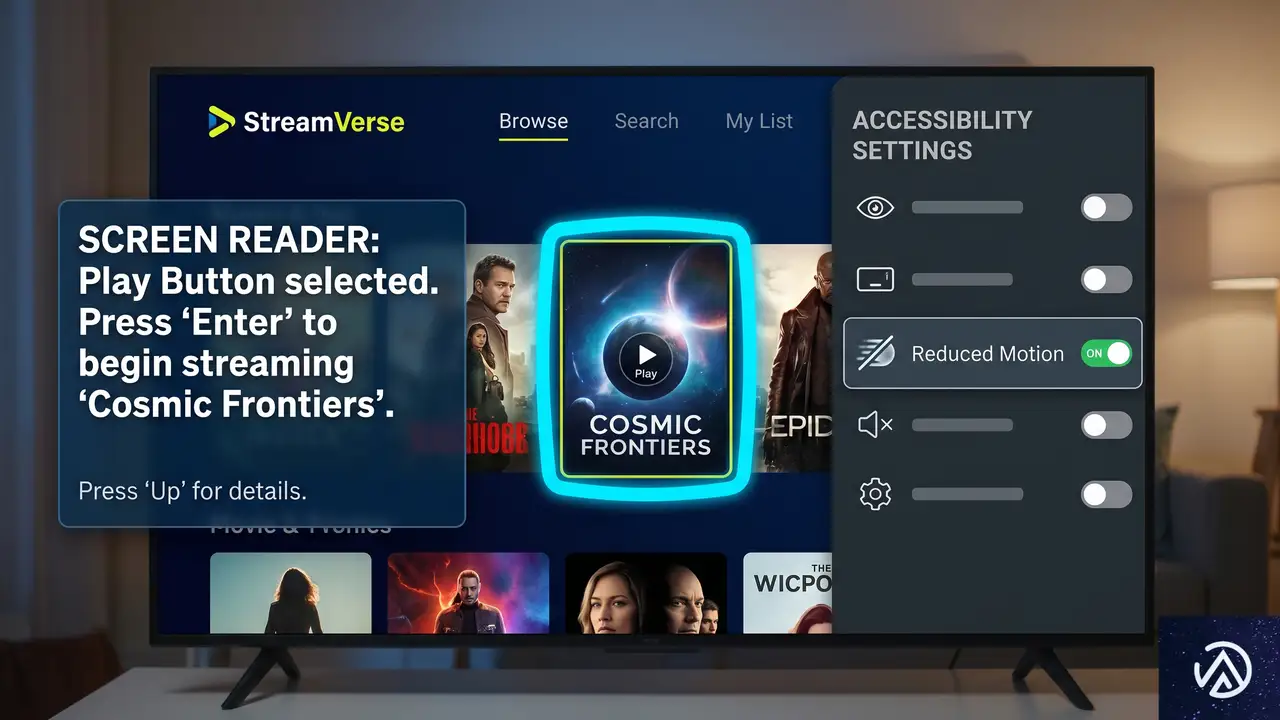
ストリーミングUIはマウス操作を前提に開発されがちで、支援技術やキーボード操作、動きへの敏感さへの配慮が後回しにされる。しかし、これらは上乗せの追加対応で十分改善できる。
スクリーンリーダーへの対応
スクリーンリーダーは自動で現れたコンテンツを読み上げない。そこで aria-live 属性を使ってライブリージョンを設定する。
<div id="chat" role="log" aria-live="polite"
aria-atomic="false" aria-label="チャットメッセージ"></div>role="log" はこれが逐次更新されるトランスクリプトであることを支援技術に伝える。aria-atomic="false" によって、新しく追加された部分だけが読み上げられ、全文の再読み上げが発生しない。aria-live="polite" なら現在の読み上げを邪魔せず、適切なタイミングで通知される。
中断時に挿入される「応答が停止しました」ラベルも、このライブリージョン内にあれば自動的にアナウンスされる。リトライボタンには、何をリトライするのか分かるように aria-label を設定する。
retryBtn.setAttribute('aria-label',
`リトライ: ${lastQuestion.slice(0, 60)}`);キーボードナビゲーションの確保
停止ボタンやリトライボタンは、ストリーミング中でもTabキーで到達できなければならない。非表示にする際は display: none を使うことでフォーカス順からも除外される。opacity: 0 や visibility: hidden だと不可視要素にフォーカスが当たり混乱を招く。
カーソル点滅エフェクトには aria-hidden="true" を付け、スクリーンリーダーが読み上げないようにする。フォーカスリングは :focus-visible を用い、マウスクリック時には表示せず、キーボード操作時のみ明示する。
動きの抑制
タイピングアニメーションのような連続的な動きは、前庭障害などを持つユーザーにとって負荷になる。OSレベルで設定された動きの設定を、prefers-reduced-motion メディアクエリで検出し、それに従う。
const reducedMotion = window.matchMedia(
'(prefers-reduced-motion: reduce)'
).matches;
if (reducedMotion) {
initAIMsg();
for (const char of text) appendChar(char);
if (cursorEl && cursorEl.parentNode) cursorEl.remove();
done();
return;
}縮小モードが有効なら、ストリーミングアニメーションを完全にスキップし、完成したテキストを一度に表示する。CSS側でもカーソルの点滅を止める。
@media (prefers-reduced-motion: reduce) {
.cursor { animation: none; opacity: 1; }
}この記事のポイント
- ストリーミングUIの不安定さは、スクロール制御・レイアウトシフト・過剰描画の3点に集約される
- ユーザーのスクロール位置を追跡し、最下部にいる時だけ自動スクロールを有効にする
innerHTMLの全再構築をやめ、テキストノードへの差分追記でレイアウト計算を最小限に抑えるrequestAnimationFrameでデータ到着と描画を分離し、ブラウザの負荷を軽減する- ストリーム中断時はバッファクリア、カーソル除去、リトライ機能などで中途半端な状態を残さない
aria-liveやprefers-reduced-motionを用いて、支援技術や動きに敏感なユーザーにも配慮する
・ 複数業界における17年間のデジタルビジネス開発経験
・ ウェブサイト開発のためのHTML、PHP、CSS、Java等の実用的知識
・ 15ヶ国語対応の多言語SaaSの開発経験
・ 17年間にも及ぶ、Eコマース長期運営経験
・ 幅広い業界でのSEO最適化の豊富な経験

WooCommerce 10.7リリース。HPOS高速化と注文フルフィルメントAPIの進化を解説
WooCommerce 10.7が2026年4月14日に正式リリースされた。今回のアップデートでは、大規模サイトの運用に直結するパフォーマンスの劇的な改善と、開発者向けの新しいAPIが導入されている。
特にHPOS(High-Performance Order Storage)におけるデータベースクエリの51%削減は、バックエンドの負荷軽減に大きく寄与する。注文処理の効率化を目指す運営者にとって、見逃せない内容となっている。
本記事では、パフォーマンス向上、新設されたフルフィルメントAPI、そして管理画面のアクセシビリティ改善など、主要な変更点を技術的な視点で解説する。
HPOSのクエリ削減とパフォーマンスの劇的向上

WooCommerce 10.7における最大の焦点は、データベース処理の最適化だ。特にHPOS(High-Performance Order Storage / 高性能注文ストレージ)を利用している環境での改善が目覚ましい。HPOSとは、注文データを従来の「投稿(posts)」テーブルではなく、専用のカスタムテーブルに保存することで検索や更新を高速化する仕組みだ。
REST APIにおけるN+1問題の解消
Developer WooCommerce Blogの報告によると、注文データを取得するエンドポイント(/wc/v4/orders)において、キャッシュプライミング(事前読み込み)が導入された。これにより、いわゆる「N+1問題」が解消されている。
N+1問題とは、1回のデータ取得(1ページ分の注文リストなど)に対して、関連するデータを取得するために何度も追加のクエリを発行してしまう非効率な状態を指す。今回の改善により、リクエストあたりのSQLクエリ数が271個から132個へと、約51%も削減された。これは、サーバーのCPU負荷を抑え、APIのレスポンス速度を向上させることに直結する。
チェックアウトと配送設定の高速化
チェックアウト(決済)プロセスにおいても、下書き注文を保持するためのSQLクエリ数が削減された。オブジェクトキャッシュが有効な環境では、クエリ数が127個から115個程度まで減少する。わずかな差に思えるかもしれないが、同時アクセス数が多い大規模セール時などには、この積み重ねがサイトの安定性に寄与する。
また、配送ゾーンのメソッド管理テーブル(woocommerce_shipping_zone_methods)に新しいインデックスが追加された。インデックスとは、本でいう「索引」のようなもので、データベースが特定のデータを素早く見つけるための目印だ。これにより、配送オプションの読み込み速度が向上している。
注文フルフィルメントAPIのベータ版導入

開発者にとって大きな前進となるのが、注文の「フルフィルメント(注文から配送までの業務)」を管理するための専用APIが整備されたことだ。これまで、配送追跡番号などの管理はプラグインごとに独自の実装がなされることが多かったが、WooCommerceコアレベルで標準的な手法が提供されるようになる。
型定義されたPHPメソッドの提供
新しいAPIでは、PHPの型が明示されたメソッドを使用して、配送追跡データにアクセスできるようになった。これにより、コードの補完が効きやすくなり、開発時のミスを減らすことができる。以下のようなメソッドが利用可能だ。
$fulfillment->get_tracking_number();
$fulfillment->set_tracking_number( '1Z999AA10123456784' );
$fulfillment->get_shipping_provider();
$fulfillment->set_shipping_provider( 'ups' );カスタム配送業者の管理
設定画面(設定 > 配送 > 配送業者)から、独自の配送業者を定義できるようになった。これは新しいタクソノミー(分類機能)によって管理されており、各業者ごとに追跡URLのテンプレートを設定できる。注文一覧画面には新しい配送業者で絞り込むためのドロップダウンも追加され、運用効率が向上している。
アナリティクスとUIの改善

ストア運営者が日々利用する分析ツールやチェックアウト画面にも、細かな修正が加えられている。特に、データの正確性と使いやすさに重点が置かれている。
分析レポートのエクスポート機能強化
これまでのアナリティクス機能では、レポートをエクスポートする際に通貨設定やフィルタ条件が正しく反映されないケースがあった。WooCommerce 10.7では、バックグラウンド処理にこれらのパラメータが正しく引き継がれるよう改善された。また、フィルターフックを利用して、エクスポートするCSVに独自の列を追加することも可能になった。
チェックアウト画面のUX修正
カートおよびチェックアウトブロックにおいて、支払い方法の選択肢が1つしかない場合でも、ラジオボタンが常に表示されるように変更された。従来は1つしかない場合にボタンが非表示になっていたが、これでは支払い方法の名称と説明が視覚的に混ざってしまい、ユーザーが混乱する原因になっていた。この修正により、現在どの支払い方法が選ばれているのかが明確になる。
カード情報を入力してください。
カード情報を入力してください。
この変更により、ユーザーは「自分がどの手段で支払おうとしているのか」を直感的に理解できるようになり、コンバージョン率の低下を防ぐ効果が期待できる。
アクセシビリティとセキュリティの強化

WooCommerce 10.7では、多様なユーザーがストレスなく利用できるようにアクセシビリティ(利用しやすさ)の改善も進められている。また、バックエンドの堅牢性を高めるためのセキュリティ強化も含まれている。
WCAG 2.2 AA準拠への対応
システムステータス画面などの緑色のステータスインジケーターが、WCAG 2.2 AAのコントラスト比要件を満たすように調整された。コントラスト比とは、文字の色と背景の色の明暗差のことで、これが不十分だと視覚に制限のあるユーザーが情報を読み取ることが困難になる。今回の修正により、より多くのユーザーがシステムの健全性を正確に把握できるようになった。
REST APIとAJAXハンドラの保護
セキュリティ面では、v4 REST APIの注文ノートエンドポイントに wp_kses_post() によるサニタイズ(有害なコードの除去)が追加された。これにより、XSS(クロスサイトスクリプティング)攻撃のリスクを低減している。
また、商品の並べ替えなどを行うAJAXハンドラにCSRF(クロスサイトリクエストフォージェリ)対策の check_ajax_referer() が追加された。これにより、意図しない不正なリクエストによって設定が書き換えられるのを防いでいる。さらに、決済ゲートウェイのパスワードフィールドにおいて、特定の記号(%)が誤って削除される問題も修正され、パスワードの整合性が保たれるようになった。
独自の分析:WooCommerceは「エンタープライズ」への道を歩んでいる

今回のWooCommerce 10.7のアップデートを俯瞰すると、単なる機能追加ではなく「基盤の成熟」に重きを置いていることがわかる。特にHPOSにおける51%ものクエリ削減は、数千、数万の注文を抱える大規模ストアにとって決定的な意味を持つ。データベースの負荷が半分になるということは、同じサーバー構成でもより多くのトラフィックを捌けるようになるということだ。
また、フルフィルメントAPIの整備は、WooCommerceが単なる「カートプラグイン」から、外部の物流システムやERP(企業資源計画)とシームレスに連携する「プラットフォーム」へと進化しようとしている証左だ。開発者が型定義されたメソッドを使えるようになったことで、サードパーティ製プラグインの品質も底上げされるだろう。
WooCommerceは、小規模な個人商店から大規模なEC企業までをカバーする柔軟性を持っている。今回の10.7アップデートは、特に「成長し続けるストア」にとって、将来の拡張性と安定性を担保するための重要なステップだと言える。今後、フルフィルメント機能がベータ版を脱し、さらに洗練されることで、物流管理の自動化がより身近なものになるだろう。
この記事のポイント
- HPOS環境でのAPIクエリ数が51%削減され、大規模ストアのレスポンスが高速化された
- 注文フルフィルメント専用のAPI(ベータ版)が導入され、配送追跡番号の管理が標準化された
- アナリティクスのエクスポート機能が改善され、通貨設定やカスタムフィルタが正しく反映されるようになった
- アクセシビリティが改善され、WCAG 2.2 AA基準のコントラスト比に対応した
- REST APIやAJAXハンドラにセキュリティ強化が施され、XSSやCSRFへの耐性が向上した
・ 複数業界における17年間のデジタルビジネス開発経験
・ ウェブサイト開発のためのHTML、PHP、CSS、Java等の実用的知識
・ 15ヶ国語対応の多言語SaaSの開発経験
・ 17年間にも及ぶ、Eコマース長期運営経験
・ 幅広い業界でのSEO最適化の豊富な経験

2026年EUクッキー法完全対応ガイド——WordPressサイトの必須対策と実装手順
EU域内のユーザーを対象とするWebサイト運営者にとって、クッキー法への対応はもはや選択肢ではない。2026年現在、規制当局の監視は厳しさを増し、業界全体で21億ユーロに上る制裁金が科せられている。単純なテキストバナーではビジネスを守れない時代だ。
法的に準拠し、高速で、コンバージョンにも寄与する同意管理システムをWordPress上に構築するには、明確なルールに従う必要がある。この記事では、2026年の最新規制を理解し、サイトとユーザーを保護するための具体的な実装ステップを解説する。
2026年のEU法規制を理解する:GDPRとePrivacyの違い

多くの開発者が混同しがちなのが、GDPR(一般データ保護規則)とePrivacy Directive(電子プライバシー指令)の違いだ。GDPRは個人データの収集全般を規定する法律である。一方、ePrivacy Directiveは特にクッキーやローカルストレージといったトラッキング技術そのものを規制する。
基本的な通知を表示するだけでは不十分であり、規制当局は無知を言い訳として認めない。2026年に適用される具体的な法的要件は以下の通りだ。
- 事前同意:ユーザーが「同意する」を能動的にクリックするまで、非必須のトラッカーを一切読み込んではならない。事前にチェックが入ったボックスは法的に無効だ。
- 同等の視認性:「すべて拒否」ボタンは「すべて同意」ボタンと視覚的に同一でなければならない。拒否オプションを二次メニューに隠すことはできない。
- 詳細な制御:ユーザーは、統計トラッカーを拒否しながらマーケティングトラッカーに同意するといった、カテゴリーごとの選択が可能でなければならない。
- 同意の撤回の容易さ:同意を与えるのと同程度に簡単に同意を撤回できる必要がある。ユーザーが考えを変えられるよう、永続的なフローティングアイコンを設置する。
- 証拠の記録:ユーザーがいつ、どのように同意したかをサーバーサイドで記録し、証明を残さなければならない。
世界の同意管理プラットフォーム(CMP)市場は21.3%成長し、24億ドル規模に達すると予測されている。これは、手動での対応がほぼ不可能になったことを示している。専用ツールを活用するにせよ、その背後にある法的ロジックを理解することが第一歩だ。
WordPressサイトのクッキー監査:コンプライアンスギャップの特定
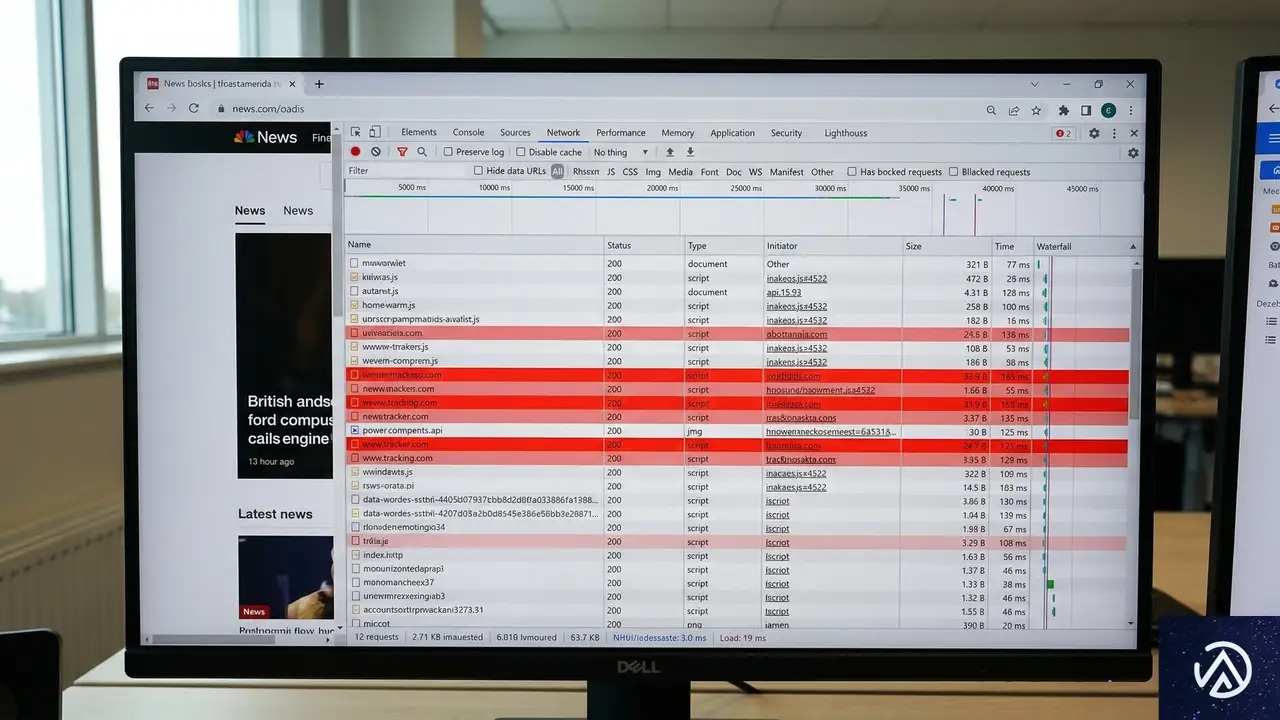
新しいプラグインを導入する前に、自らのWordPressサイトが裏で何をしているかを正確に把握する必要がある。問題を診断できなければ修正もできない。2026年現在、WordPressはインターネットの43.3%を支えており、自動化されたプライバシースキャナーの主要な標的となっている。
平均的なWebサイトは、ユーザーの初回訪問時に22個のサードパーティークッキーを読み込む。これはEU規制当局の目から見れば即座の違反だ。以下の手順で、実際のサイトを監査する。
- シークレットウィンドウを開く:自身の管理者セッションが結果を歪めないよう、ホームページを新規に読み込む。
- 開発者ツールを開く:ページを右クリックして「検証」し、ChromeまたはEdgeの「Application」タブに移動する。
- ローカルストレージとクッキーを確認:左サイドバーの「Cookies」セクションを展開し、バナーに触れる前にここにリストされているすべての項目を記録する。
- Networkタブを確認:ページをリロードしながらNetworkタブを監視し、Google AnalyticsやMeta Pixel、外部広告ネットワークへのリクエストを探す。
- トラッカーを分類:発見したトラッカーを「必須」「分析」「マーケティング」「機能」のカテゴリーにグループ分けする。
多くのプレミアムテーマやページビルダーは、レイアウトの記憶やA/Bテストのために機能的なトラッカーを注入している。サイトの機能に厳密に必要でないものは、デフォルトでブロックされる必要がある。
WordPressへの同意管理プラットフォーム(CMP)導入
同意ロジックシステムをスクラッチでコーディングすべきではない。ルールは頻繁に変更される。代わりに、専用の同意管理プラットフォーム(CMP)が必要だ。これらのシステムはスクリプトをインターセプトし、適切なボタンがクリックされるまで保留する。
適切なCMPの選択は、コンプライアンスプロセスの滑らかさを決定する。Complianz Privacy Suiteのようなソリューションは30万以上のアクティブインストールを誇り、Cookiebotは小規模サイト向けに月額12ユーロから提供している。WordPress環境にCMPを適切に展開する手順は以下の通りだ。
- コアプラグインをインストール:WordPressリポジトリで選択したCMPを検索し、有効化する。
- 初期スキャンを実行:プラグインにサイトのスキャンを許可する。グローバルデータベースと照合し、アクティブなトラッカーを自動的に分類する。
- スクリプトブロッキングを設定:Google Tag ManagerやMeta Pixelのような重いスクリプトをプラグインが正しく識別し、インターセプトしていることを確認する。これが重要だ。
- 法的文書を生成:多くの高品質CMPは、スキャン結果に基づいてCookieポリシーページを自動生成する。このページを即座に公開する。
- バナー制約をテスト:新規のシークレットウィンドウからサイトにアクセスする。「同意する」を明示的にクリックするまで、Networkタブに一切のトラッキングスクリプトが実行されないことを確認する。
5番目のステップを省略すれば、コンプライアンスは達成されない。バナーが見た目上問題なくても、背後でトラッキングスクリプトが即座に実行されているサイトは多い。視覚的な準拠は技術的な準拠と同義ではない。
Elementor Editor Proによるカスタム準拠バナーの構築
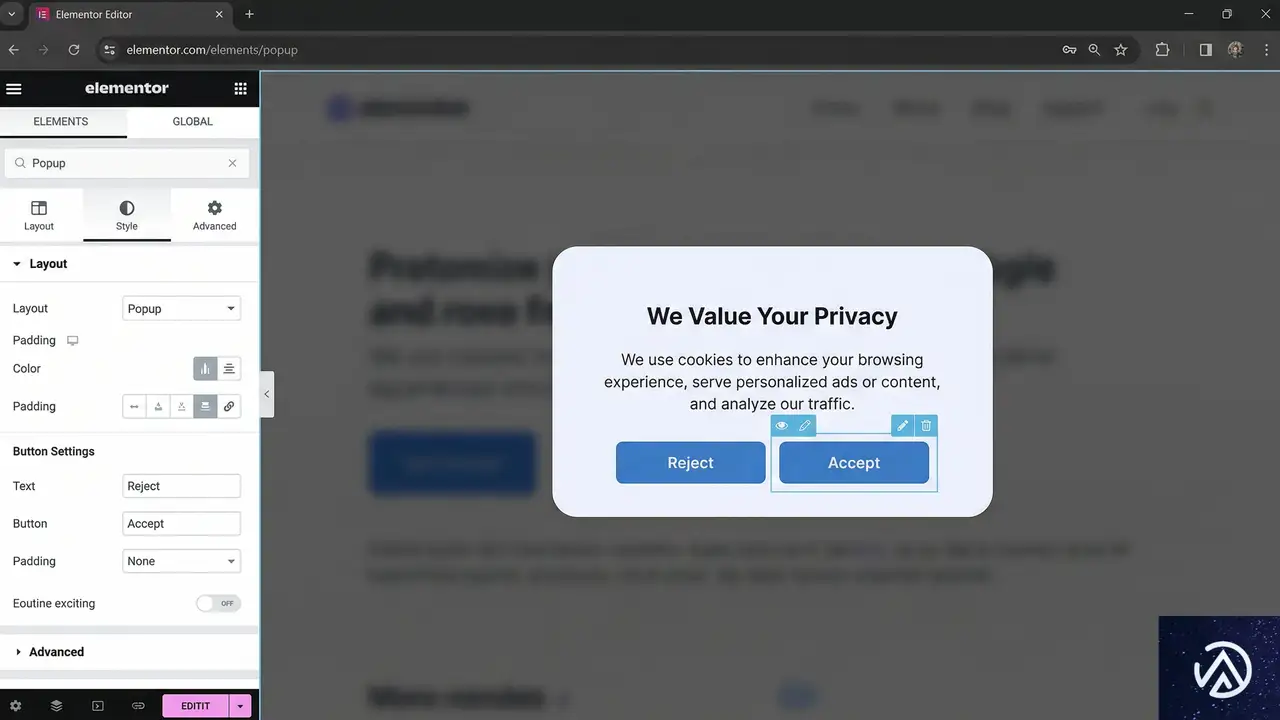
デフォルトのCMPバナーは概して見た目が悪く、ブランドのスタイルに合わないことが多い。しかし、醜い汎用ポップアップに妥協する必要はない。Elementor Editor Proを使えば、サイトの美学にシームレスに統合されながら、厳格な法的基準を満たすカスタム同意バナーをデザインできる。
ユーザーはモバイルデバイスで「すべて同意」をクリックする可能性が25%高い。小さな画面では侵襲的なバナーが煩わしいためだ。より良いユーザー体験を設計することは、マーケティングデータの保持率に直接影響する。
同意ポップアップをデザインする際、法的トラブルを避けるために以下の必須要素を含めなければならない。
- 明確な見出し:ポップアップの目的を正確に述べる。「あなたのプライバシーを尊重します」のような曖昧な表現は避ける。
- 対称的なボタン:「同意」と「拒否」ボタンは、まったく同じサイズ、色のコントラスト、タイポグラフィでなければならない。
- 詳細設定リンク:ユーザーがカテゴリーごとに設定をカスタマイズできる明確なテキストリンクを含める。
- ポリシーリンク:バナーテキスト内に、完全なプライバシーポリシーとクッキーポリシーへの直接リンクを提供する。
- ダークパターンの禁止:ボタンのラベルに紛らわしい言語や二重否定を使用してはならない。
Elementorの高度な表示条件を使って、欧州経済領域(EEA)内に位置する訪問者にのみカスタムクッキーポップアップを表示させる方法もある。これらの要件がない地域からの訪問者に厳格なePrivacyバナーを強制する法的理由はない。
また、バナーにはポップアップの詳細設定で非常に高いZ-index値を設定し、選択が行われるまでスティッキーヘッダーやモバイルメニューの上に確実に表示されるようにする。ウェブアクセシビリティも忘れてはならない。ElementorのHTMLタグコントロールを使って、ポップアップのラッパーに正しいARIAロールを持たせ、スクリーンリーダーが同意オプションを明確に解析できるようにする。
パフォーマンス最適化:速度を損なわないコンプライアンス実装
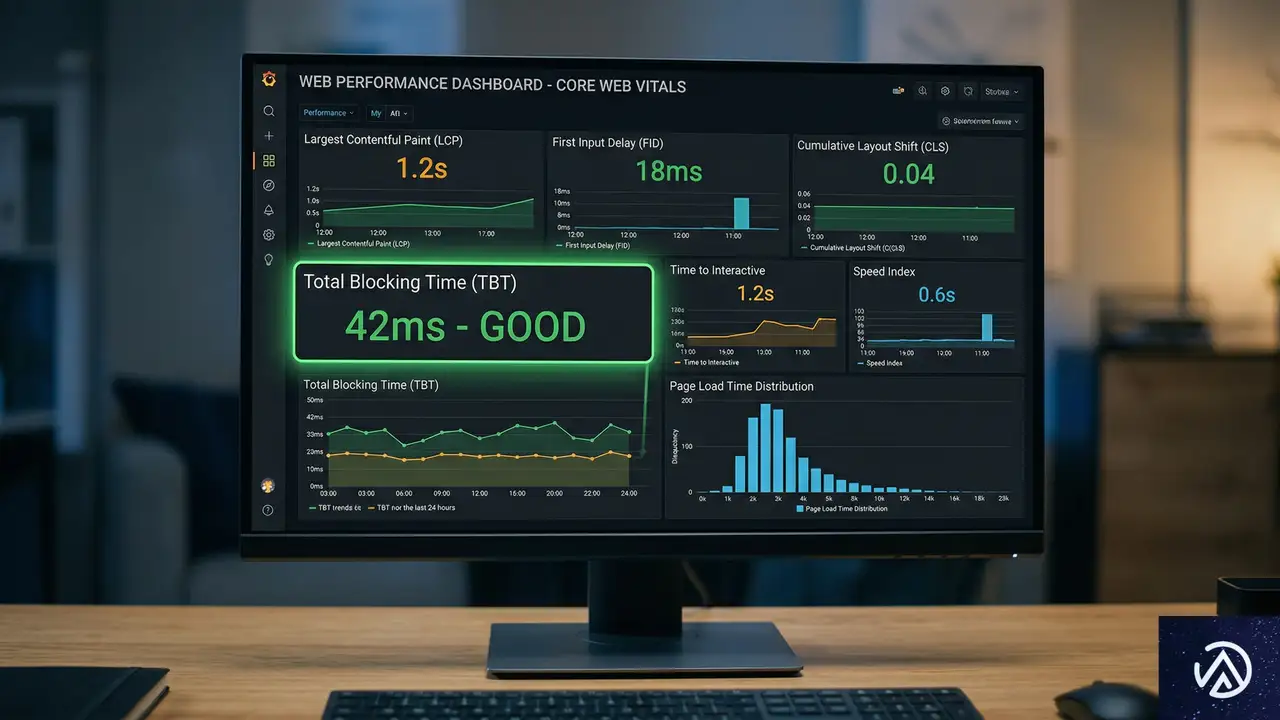
コンプライアンス層の追加は、ほぼ常にWebサイトの速度を低下させる。最適化されていないサードパーティの同意スクリプトは、平均してTotal Blocking Time(TBT)を200msから500ms増加させる可能性がある。法的に準拠しようとするあまり、Core Web Vitalsを失敗させるわけにはいかない。
WP Rocketのようなトップティアのキャッシュソリューションは、必須のクッキースクリプト用の特定の統合機能を含んでいる。これにより、キャッシュルールが「同意済み」状態をキャッシュして、新しい訪問者に提供してしまうことを防ぐ。CMPによって設定される特定のクッキーをキャッシュのバイパスルールから除外する設定が必須だ。
実装方法がサイト速度に与える影響を比較してみよう。
Cumulative Layout Shift(CLS)にも注意が必要だ。巨大なバナーがページ上部に注入されると、すべてのコンテンツが押し下げられ、パフォーマンススコアを損なう。ビューポート下部にバナーのための固定スペースをCSSで確保するか、ドキュメントフローを乱さないオーバーレイを提供する機能を活用する。
コンプライアンスの維持:月次監査と文書化

コンプライアンスは一度きりのプロジェクトではない。継続的な運用上の要件だ。1月にバナーを設定したきりチェックしなければ、3月までに準拠から外れている可能性が高い。テーマの更新、新しいマーケティングキャンペーン、新規プラグインが常に新しいトラッカーを導入する。
中小企業は、カスタム設定がこれらの厳格な基準を満たしていることを確認するために、平均2500ドルから7000ドルの法律相談費を負担している。簡単に予防できるミスに無駄な出費をしないため、月次のメンテナンスルーチンを構築する。
継続的なコンプライアンスチェックリストには、以下の具体的なアクションを含めるべきだ。
- クッキースキャンの自動化:CMPを設定し、ライブサイトの詳細スキャンを30日ごとに実行する。レポートをリード開発者に直接メール送信させる。
- 同意ログの確認:サーバーがユーザーID、タイムスタンプ、同意した具体的なカテゴリーを正確に記録していることを確認する。監査が入った場合、このログが唯一の防御手段となる。
- 撤回プロセスのテスト:自サイトの永続的な「クッキー設定」ウィジェットをクリックし、以前に付与された権限が即座に取り消され、ローカルクッキーが削除されることを確認する。
- ポリシー日付の更新:新しいツール(新しいCRMや分析プラットフォームなど)を追加するたびに、公開されているクッキーポリシーを更新し、「最終更新日」のタイムスタンプを変更する。
- 業界制裁金の監視:欧州データ保護委員会(EDPB)による最新の裁定に目を配り、執行戦術がどのように変化しているかを把握する。
法的枠組みの突然の変化に不意を突かれたくはない。同意アーキテクチャに行ったすべての変更を完璧な記録として保管することが、ビジネスを救う。
この記事のポイント
- 2026年のコンプライアンスには、単なるバナー表示を超えた技術的なスクリプトブロッキングが必須である。
- 同意管理プラットフォーム(CMP)の選定と正しい設定が、法的リスクと運用負荷を大きく左右する。
- 「すべて拒否」ボタンの視認性と、同意の詳細設定・撤回の容易さは、法的要件の核心部分である。
- コンプライアンス対策はサイト速度に影響を与えるため、キャッシュ設定や実装方法の最適化が不可欠だ。
- コンプライアンスは継続的プロセスであり、プラグイン更新や新機能追加のたびに監査と文書化が必要である。
・ 複数業界における17年間のデジタルビジネス開発経験
・ ウェブサイト開発のためのHTML、PHP、CSS、Java等の実用的知識
・ 15ヶ国語対応の多言語SaaSの開発経験
・ 17年間にも及ぶ、Eコマース長期運営経験
・ 幅広い業界でのSEO最適化の豊富な経験

WooCommerceの決済・配送APIが遅い?サードパーティ障害からサイトを守る技術
WordPressサイト、特にWooCommerceを利用したECサイトの表示が急に重くなったとき、多くの運用者はまずホスティングサーバーの性能を疑う。しかし、実際にはサイトが依存している「外部サービス」が真の原因であるケースが少なくない。
決済ゲートウェイの応答待ち、配送キャリアの送料計算APIの遅延、あるいはアクセス解析スクリプトの読み込み停滞など、サードパーティの不調はサイト全体のパフォーマンスを道連れにする。これらの要素はホスティング側の制御を超えた場所にあり、適切な対策なしにはサイト全体の「連鎖的な崩壊」を招くリスクがある。
本記事では、WordPressにおけるサードパーティ依存の障害がどのようにサイトを停止させるのか、その仕組みを解明する。また、コンテナ隔離技術による保護や、アプリケーションレベルでのタイムアウト設定、フォールバック(代替処理)の実装など、プロが実践すべき具体的な防御策を詳しく解説していく。
サードパーティ依存が引き起こす「連鎖的障害」の正体

現代のWordPressサイトは、単体で完結していることは稀だ。特にWooCommerceを運用している場合、チェックアウトのプロセスだけでも多くの外部APIと通信している。決済処理のためにストライプ(Stripe)やペイパル(PayPal)とやり取りし、リアルタイムの送料を算出するために配送会社のシステムへ問い合わせ、税金の計算サービスと同期するといった具合だ。
これらの依存関係のうち、たった一つでも応答が遅くなると、その影響は特定の機能だけに留まらない。WordPressが外部APIのレスポンスを待っている間、サーバー内の「PHPスレッド」と呼ばれる処理の枠組みが占有されたままになるからだ。これは、レジで客が財布を忘れて取りに戻っている間、後ろに並んでいる全員が待たされる状態に似ている。
PHPスレッドの枯渇と504エラーの相関
PHPスレッドとは、サーバーが一度に実行できる作業の単位だ。例えば、ある決済APIがタイムアウトするまでに30秒かかるとしよう。その間、一つのスレッドはその通信を待つためだけに拘束され、他のリクエストを処理できなくなる。もし複数のユーザーが同時にチェックアウトを試みれば、利用可能なスレッドはあっという間に使い果たされてしまう。
スレッドがすべて埋まると、新しくサイトを訪れたユーザーのリクエストは順番待ちになる。そして一定時間を過ぎても処理が始まらない場合、ブラウザには「504 Gateway Timeout」などのエラーが表示される。このエラーはサーバーのスペック不足で起きるものと見た目が同じであるため、本当の原因が外部APIにあることを見逃しやすいという問題がある。
可視性のギャップ:インフラか外部要因か
504エラーが発生した際、多くの管理者はCPU使用率やメモリ残量といったインフラのメトリクス(指標)を最初に確認する。しかし、外部APIの遅延が原因の場合、インフラ側の負荷はそれほど高くないにもかかわらず、サイトが停止しているという矛盾が生じる。この「可視性のギャップ」が、問題解決を遅らせる大きな要因となるのだ。
↓ API応答待ち(30秒間スレッド占有)
× 後続のユーザー全員がエラーになる
↓ タイムアウト設定(5秒で切り上げ)
○ 予備の送料を表示して処理を続行
外部APIの遅延がサイト全体を停止させる仕組みと、タイムアウト設定による保護のイメージだ。
ホスティング環境による「被害の局所化」:コンテナ隔離の重要性

外部サービスの障害による影響範囲を最小限に抑えるためには、ホスティング側のアーキテクチャが重要になる。一般的な共有サーバーでは、一つのサイトで外部APIの遅延によるスレッド枯渇が起きると、同じサーバーに同居している他の無関係なサイトまで道連れにして停止させてしまうことがある。これは、すべてのサイトが共通のスレッドプールを奪い合っているからだ。
対照的に、Kinstaのようなモダンなホスティング環境では、各WordPressサイトを「隔離されたコンテナ」の中で実行している。この方式の最大のメリットは、障害の「爆発半径」をそのサイト内だけに閉じ込められる点にある。
専用スレッドプールによる防御線
コンテナ技術を採用している環境では、各サイトに専用のPHPスレッドプールが割り当てられている。たとえ自サイトで決済APIの不調によりスレッドがすべて埋まったとしても、同じサーバー上の他のサイトには一切影響が及ばない。また、スレッドが一時的に不足した場合でも、リクエストはNginxやPHP-FPMのキュー(待ち行列)に保持され、スレッドが空き次第順次処理されるため、即座にエラーを返さず踏みとどまることが可能だ。
実行時間制限とタイムアウトの落とし穴
サーバーには通常、max_execution_time という設定があり、PHPスクリプトの実行時間を制限している。しかし、ここに大きな落とし穴がある。Linux環境では、PHPが外部APIとの通信(ストリーム操作)を待っている時間は、この実行時間としてカウントされない仕様なのだ。
つまり、たとえサーバーの制限が30秒に設定されていても、外部APIからの返答を待っている間は、その制限時間を超えてスレッドを占有し続ける可能性がある。このため、サーバー側の設定だけに頼るのではなく、WordPressのアプリケーション側で明示的なタイムアウトを設定することが不可欠となる。
Kinsta APMを活用したボトルネックの特定手順

「サイトが重い」と感じたとき、それがサーバーの問題なのか外部サービスのせいなのかを切り分けるには、APM(Application Performance Monitoring)ツールが威力を発揮する。Kinstaが提供しているAPMツールは、PHPのプロセス、MySQLクエリ、そして外部へのHTTPコールを時系列で詳細に記録してくれる。
「External」タブで外部通信を監視する
APMの管理画面にある「External」タブは、サードパーティ依存の問題を特定するための鍵となる。ここには、プラグインやテーマが実行したすべての外部HTTPリクエストがリストアップされる。各リクエストの平均所要時間、最大所要時間、そして1分あたりのリクエスト数が表示されるため、どのAPIが足を引っ張っているかが一目瞭然だ。
例えば、特定の決済APIの最大所要時間が数秒以上に達していれば、そのサービスがボトルネックであることは疑いようがない。ホスティング環境自体は正常に動作していても、外部の特定のピースが欠けているために全体が遅くなっていることがデータで証明できるのだ。
トランザクショントレースによる詳細分析
さらに詳しく調査したい場合は、個別のリクエストをクリックして「トランザクショントレース」を確認する。これは、一つのリクエストが完了するまでに行われた全処理をタイムライン形式で表示するものだ。処理全体の90%以上を外部APIとの通信が占めているような場合、サーバー構成の変更やキャッシュの調整よりも、そのAPIの利用方法を見直す方が遥かに効果的だと言える。
サイトの表示を止めないための非同期読み込みとタイムアウト戦略

インフラ側での隔離ができたら、次はアプリケーション側での防御策を講じる。最も基本的なのは、スクリプトの「非同期読み込み」だ。WordPressはデフォルトでスクリプトを同期的に読み込むが、これは外部サーバーからスクリプトがダウンロードされるまで、ブラウザがページの描画をストップ(ブロック)してしまうことを意味する。
asyncとdeferの使い分け
アクセス解析やマーケティング用のスクリプトなど、ページの表示に直接関係ないものは、async または defer 属性を付けて読み込むべきだ。WordPress 6.3からは、wp_enqueue_script() 関数でこれらの属性を簡単に指定できるようになった。実行順序が重要なものは defer、順不同で即座に実行して良いものは async を選ぶのが鉄則だ。
add_action( 'wp_enqueue_scripts', function() {
// 解析スクリプト:表示をブロックしないようdeferを指定
wp_enqueue_script(
'google-analytics',
'https://www.googletagmanager.com/gtag/js?id=G-XXXXXXXX',
[],
null,
[ 'strategy' => 'defer', 'in_footer' => false ]
);
// マーケティングツール:順不同で良いのでasyncを指定
wp_enqueue_script(
'marketing-tool',
'https://example.com/script.js',
[],
null,
[ 'strategy' => 'async', 'in_footer' => false ]
);
} );APIタイムアウトのフィルタ設定
PHP側で行うAPI通信についても、待ち時間の上限を厳格に定める必要がある。WordPressには http_request_timeout というフィルタが用意されており、これを使って外部リクエストのタイムアウト時間を制御できる。デフォルトの5秒でも長すぎる場合があるため、重要度に応じて短縮を検討すべきだ。
add_filter( 'http_request_timeout', function( $timeout, $url ) {
// 特定のAPIに対しては、最大3秒までしか待たない設定にする
if ( str_contains( $url, 'api.shipping-service.com' ) ) {
return 3;
}
return $timeout;
}, 10, 2 );障害を「なかったこと」にするフォールバックの実装パターン

タイムアウトを設定して通信を遮断するだけでは、ユーザーにはエラーが表示されてしまう。そこで重要になるのが「フォールバック(代替処理)」の仕組みだ。外部APIが死んでいても、サイトとしての最低限の機能を維持するための工夫である。
具体的には、WordPressの「トランジェント(一時的なキャッシュデータ)」を活用する。APIとの通信が成功した際のレスポンスを一定期間保存しておき、APIがエラーを返したりタイムアウトしたりした場合には、その保存されている「古いデータ」を代わりに使うという手法だ。
二段構えのキャッシュ戦略
より堅牢なシステムにするなら、通常のキャッシュ(1時間程度)とは別に、より長期のバックアップ用キャッシュ(24時間程度)を保持する「二段構え」の構成が推奨される。APIがダウンしている間、ユーザーは昨日時点の送料データを基に買い物を続けることができる。全く注文が受けられない状態に比べれば、多少のデータの古さは許容範囲内であることが多い。
優雅な劣化(Graceful Degradation)
もしキャッシュすら存在しない場合は、あらかじめ設定しておいた「一律料金」などのデフォルト値を返すように設計する。これを「優雅な劣化(Graceful Degradation)」と呼ぶ。システムの一部が壊れても、全体を停止させずに、機能を縮小しながら稼働し続けるという考え方だ。この設計思想があるかないかで、障害時の売上損失は劇的に変わってくる。
外部APIの状況に応じた、段階的なフォールバック(代替処理)の優先順位だ。
この記事のポイント
- サードパーティAPIの遅延は、PHPスレッドを占有し、サイト全体の504エラーを引き起こす。
- サーバー側の実行時間制限(max_execution_time)は、API通信の待機時間には効かない場合がある。
- コンテナ隔離技術を採用したホスティングなら、他サイトのAPI障害による巻き添えを防げる。
- 非同期読み込み(async/defer)やHTTPタイムアウト設定により、アプリ側で防御線を張るべきだ。
- キャッシュ(トランジェント)を活用したフォールバック実装が、障害時のビジネス継続性を左右する。
・ 複数業界における17年間のデジタルビジネス開発経験
・ ウェブサイト開発のためのHTML、PHP、CSS、Java等の実用的知識
・ 15ヶ国語対応の多言語SaaSの開発経験
・ 17年間にも及ぶ、Eコマース長期運営経験
・ 幅広い業界でのSEO最適化の豊富な経験

MDNのフロントエンド刷新の裏側:ReactからWeb ComponentsとRspackへの移行
世界中のエンジニアが頼りにする技術ドキュメントサイト「MDN Web Docs」が、フロントエンドのアーキテクチャを根本から作り直した。今回の刷新は単なるデザインの変更ではなく、長年抱えていた技術的な課題を解決するための大規模な再設計となっている。
MDNのチームは、これまで利用していたReactベースのSPA(Single Page Application / シングルページアプリケーション)から脱却し、Web Componentsと独自のサーバーサイドレンダリング(SSR)を組み合わせた新しい仕組みへ移行した。さらに、ビルドツールをWebpackからRust製のRspackに切り替えることで、開発環境の起動時間を2分から2秒へと劇的に短縮している。
なぜMDNのような巨大なサイトがReactを離れ、ネイティブに近い技術を選んだのか。その背景には、ドキュメントサイト特有の課題と、最新のWeb標準技術への信頼があった。この記事では、MDNの新しいフロントエンドがどのような思想で構築されたのか、その詳細を解説する。
なぜMDNはフロントエンドを根本から作り直したのか

MDNのフロントエンド刷新の最大の動機は、旧システム「yari」が抱えていた深刻な技術負債の解消だ。yariはCreate React Appをベースに構築されていたが、MDNのような静的コンテンツが主体のサイトには不向きな部分が多く、場当たり的な修正が積み重なっていた。
React SPAが抱えていた「ラッパー」という限界
旧システムにおいて、Reactアプリは静的なHTMLコンテンツを包む「ラッパー」に過ぎなかった。MDNのドキュメントの大部分はMarkdownから生成された静的なテキストだが、Reactはこのコンテンツの内容を直接把握することができなかった。
そのため、ドキュメント内に「コードのコピーボタン」のようなインタラクティブな要素を追加する場合、Reactの枠組みの外で標準的なDOM API(Document Object Model API / ブラウザがHTMLを操作するための仕組み)を直接操作する必要があった。これにより、サイトの一部はReactで書かれ、別の部分は直接的なDOM操作で書かれるという、管理しにくい二重構造が生まれていた。
複雑化しすぎたビルド設定とCSSの管理
ビルド環境も限界に達していた。Create React Appのデフォルト設定では対応できない要件が増えた結果、設定を「eject(イジェクト / ツールによる自動管理を解除して手動管理に移行すること)」せざるを得なくなり、Webpackの設定が複雑怪奇なものになっていた。
CSSについても、Sass(サス / CSSを効率的に書くための拡張言語)とモダンなCSS変数が混在し、スコープ(影響範囲)の管理が不十分だった。あるコンポーネントのスタイルを変更すると、予期せぬ場所のデザインが崩れるといった問題が頻発していた。また、CSSを適切に分割する仕組みがなかったため、ユーザーは常に巨大なCSSファイルをダウンロードさせられていた。
Web ComponentsとLitがもたらした相互運用の柔軟性

技術負債を解消するための切り札として選ばれたのが、Web Components(ウェブコンポーネント)だ。Web Componentsとは、HTMLの新しいタグを自分で定義できるブラウザ標準の機能だ。MDNチームは、このコンポーネント開発を効率化するために「Lit(リット)」という軽量なライブラリを採用した。
コンテンツ内にインタラクティブ要素を直接埋め込む
Web Componentsの最大の利点は、どんなHTML環境でも「カスタムタグ」として機能することだ。Reactのような特定のフレームワークに依存せず、Markdownから生成されたHTMLの中に <mdn-copy-button> のようなタグを直接配置するだけで動作する。
これにより、ドキュメント本文という「静的な世界」と、UIコンポーネントという「動的な世界」の境界線が消えた。MDNの著者は、複雑なJavaScriptの知識がなくても、特定のタグを記述するだけで高度な機能を記事に追加できるようになった。
Scrimbaの事例で見えた「ネイティブに近い」開発
Web Componentsの有効性を証明したのが、学習プラットフォーム「Scrimba」との連携だ。MDNのカリキュラムページでは、インタラクティブな学習環境を埋め込む必要があった。これをWeb Componentsで実装することで、ユーザーがクリックするまで重い <iframe> を読み込まない、といった制御が非常に簡潔に記述できるようになった。
Litを使用することで、ReactのJSX(JavaScript内にHTML風の構文を書く手法)に近い感覚で開発できつつ、コンパイル不要な標準のJavaScriptとして動作する。これにより、開発のしやすさと実行時のパフォーマンスを両立させた。
SPAを脱却し「アイランド・アーキテクチャ」へ

MDNは今回の刷新で、サイト全体を一つの巨大なアプリとして動かすSPAを完全にやめた。代わりに採用したのが、静的なHTMLをベースにしつつ、必要な部分だけを独立したコンポーネントとして動かす「アイランド・アーキテクチャ」に近い考え方だ。
必要な場所だけで動くWeb Components
新しいMDNでは、ページが読み込まれた後にDOM全体をスキャンし、mdn- で始まるカスタムタグを探す仕組みを導入している。特定のコンポーネントがページ内に存在する場合のみ、そのコンポーネントに必要なJavaScriptを非同期で読み込む。
このアプローチにより、ユーザーは自分が閲覧しているページに関係のないJavaScriptをダウンロードする必要がなくなった。トップページのナビゲーション、検索モーダル、記事内のインタラクティブな例など、それぞれが独立した「島」として機能する。
● 読み込みが遅い
● 全体が1つの塊
● 表示が爆速
● 機能ごとに独立
このデモは、ページ全体のJSを一度に読み込むSPAと、必要な部品だけを読み込む新方式の違いを視覚化したものだ。
Litを活用した独自のサーバーコンポーネント
MDNのチームは、クライアントサイドだけでなくサーバーサイドのレンダリングにもLitの仕組みを応用した。独自の「ServerComponent」クラスを作成し、Node.js上でHTMLを組み立てている。
特筆すべきは、CSSの最適化だ。サーバー側でどのコンポーネントが使われたかを追跡し、そのページに必要なCSSだけを <link> タグとして書き出す。これにより、未使用のスタイルシートが読み込まれることを防ぎ、レンダリングの高速化に成功している。
徹底したパフォーマンス最適化と開発体験の向上

アーキテクチャの変更に加え、MDNは開発ツールやブラウザ互換性の判断基準も刷新した。これにより、エンドユーザーだけでなく、サイトを維持管理するエンジニアの生産性も向上している。
Rspackの採用で起動時間を2分から2秒へ
開発環境の劇的な改善をもたらしたのは、ビルドツール「Rspack」への移行だ。Rspackは、広く使われているWebpackと互換性を持ちながら、コア部分がRust(ラスト / 高速なシステム開発向け言語)で書かれているため、非常に高速に動作する。
以前の環境では、開発サーバーを立ち上げるだけで約2分かかっていた。ちょっとした修正を確認するために数分待つ必要があり、開発者の大きなストレスとなっていた。Rspackの導入により、この待ち時間はわずか2秒にまで短縮された。開発体験の向上は、結果としてサイトの更新頻度や品質の向上に直結する。
Baselineに基づいたモダン機能の積極採用
MDNは「どの技術がどのブラウザで使えるか」を定義する「Baseline(ベースライン)」プロジェクトを推進している。自サイトの開発においても、このBaselineの基準を厳格に適用している。
「Baseline Widely Available(主要ブラウザで広く利用可能)」な技術は積極的に使い、比較的新しい技術についてはポリフィル(古いブラウザで新しい機能をエミュレートするコード)を最小限に抑えつつ、段階的な機能拡張(Progressive Enhancement)として実装している。これにより、最新ブラウザの性能を最大限に引き出しつつ、古い環境でも情報を損なわない設計を実現した。
独自の分析:静的サイトの未来とMDNの選択

今回のMDNの決断は、近年のWeb開発トレンドにおける重要な転換点を示している。一時期、あらゆるサイトをReactなどのSPAで構築するのが正解とされた時期があった。しかし、MDNの事例は「コンテンツ主体のサイトには、HTMLネイティブに近い構成が最適である」という原点回帰の正当性を証明している。
特筆すべきは、Web Componentsという「標準技術」への信頼だ。特定のフレームワークの流行り廃りに左右されず、ブラウザが直接理解できる形式でコンポーネントを構築することは、MDNのような「Webの辞書」としての永続性が求められるサイトにとって、最も合理的な選択と言える。
また、RspackのようなRust製ツールの台頭も無視できない。JavaScriptで書かれたツールチェーンの限界を、低レイヤーの言語で書かれたツールが打破していく流れは、今後さらに加速するだろう。MDNの刷新は、最新のWeb標準と高速なビルドツールが組み合わさることで、いかに強力なプラットフォームが構築できるかを示す、最高の手本となっている。
この記事のポイント
- MDNはReact SPAからWeb Componentsベースの新アーキテクチャへ移行した。
- Litを採用し、静的なMarkdownコンテンツ内に動的な要素を直接埋め込める柔軟性を確保した。
- アイランド・アーキテクチャにより、必要なJavaScriptだけを非同期で読み込む高速な表示を実現した。
- Rspackの導入により、開発環境の起動時間を2分から2秒へと劇的に短縮した。
- Baseline基準を採用し、モダンなWeb標準技術を最大限に活用しつつ互換性を維持している。
・ 複数業界における17年間のデジタルビジネス開発経験
・ ウェブサイト開発のためのHTML、PHP、CSS、Java等の実用的知識
・ 15ヶ国語対応の多言語SaaSの開発経験
・ 17年間にも及ぶ、Eコマース長期運営経験
・ 幅広い業界でのSEO最適化の豊富な経験

WordPressのパフォーマンス低下は「アクセス減少時」に起こる?共有サーバーの落とし穴と対策
WordPressサイトのパフォーマンス対策といえば、多くの場合はアクセス急増(スパイク)への備えを連想する。キャンペーンの開始や新製品の発表時にサーバーがダウンしないよう、リソースの増強やキャッシュの強化を行うのが一般的だ。
しかし、実は「アクセスが減少していく時期」にこそ、サイトの健全性を損なう大きなリスクが潜んでいる。キャンペーンが終わり、トラフィックが平時に戻る過程で、共有サーバー環境では予期せぬパフォーマンスの劣化が発生することがあるのだ。
なぜアクセスが減っているのに、サイトの動作が重くなるのか。その裏側には、多くのホスティングサービスが採用している「リソースの割り当てロジック」と、WordPress特有のバックグラウンド処理の仕組みが深く関わっている。
共有サーバーの不都合な真実:アクセスが減ると「後回し」にされる理由

多くの安価なレンタルサーバー(共有サーバー)では、1台の物理的なサーバー内に数百から数千のウェブサイトを収容している。ここで問題となるのが「オーバーセリング(過剰販売)」という手法だ。
オーバーセリングとは、物理的なサーバーの総リソース(CPUやメモリ)よりも多くの容量を、顧客に割り当てて販売することを指す。これは銀行の仕組みに似ている。すべての預金者が一度に現金を全額引き出そうとしない限り、銀行は預かっている以上の資金を運用できる。サーバーも同様に、すべてのサイトが同時にフル稼働しないことを前提に運用されている。
リソースの動的割り当てという名の「選別」
共有サーバー環境では、限られたリソースを効率よく分配するために「動的リソース割り当て」が行われる。これは、アクセスが多い「活発なサイト」に優先的にリソースを振り向け、アクセスが少ない「静かなサイト」への割り当てを削る仕組みだ。
つまり、あなたのサイトのアクセスが減少すると、サーバー側は「このサイトには今はリソースを割く必要がない」と判断する。その結果、余ったリソースは他の高トラフィックなサイトへと奪われてしまう。パフォーマンスがインフラの質ではなく、トラフィック量に依存してしまうという逆転現象が起きるのだ。
スロットリングによる制限の正体
リソースの制限は「スロットリング(Throttling)」と呼ばれる手法で実行される。これには主に3つの形態がある。
- CPU制限:計算処理能力に上限を設ける
- RAM(メモリ)割り当て:一度に扱えるデータ量を制限する
- I/O制限:ディスクへの読み書き速度を抑える
アクセスが多いときはリソースを消費し尽くすことで制限に触れるが、アクセスが少ないときは「最初からパイが小さく設定される」ため、わずかなバックグラウンド処理でも制限に引っかかるようになる。
スロットリングが招く「サイレント障害」:WP-Cronの遅延とデータベースの肥大化

フロントエンドの表示速度が落ちる以上に深刻なのが、WordPressのバックグラウンド処理への影響だ。WordPressには「WP-Cron(ダブルピー・クロン)」という、予約投稿やプラグインの更新チェック、データベースの最適化などを自動で行う仕組みが備わっている。
WP-Cronは、誰かがサイトにアクセスしたタイミングで実行される。アクセスが減少すると、そもそも実行される機会が減る。さらにリソースを制限された環境では、ようやく実行のチャンスが巡ってきても、CPUやメモリの不足によって処理が途中で失敗したり、実行が大幅に遅れたりする事態を招く。
蓄積される技術的負債
バックグラウンド処理の失敗は、目に見えないところでサイトの健康状態を悪化させる。例えば、以下のような問題が蓄積していく。
- データベース最適化の失敗:不要なデータ(リビジョンや一時データ)が削除されず、クエリの実行速度が徐々に低下する
- キャッシュのクリーンアップ遅延:古いキャッシュが残り続け、ディスク容量を圧迫する
- セキュリティスキャンの未完了:脆弱性の発見が遅れ、リスクが高まる
これらの問題は、アクセスが回復したときに自動的に解消されるわけではない。むしろ、肥大化したデータベースが足かせとなり、次のアクセス増の際にサーバーが耐えきれなくなる原因を作る。
共有環境と独立環境の視覚的イメージ
共有サーバーでのリソース奪い合いと、独立した環境の違いを視覚的に理解するためのデモを作成した。左側は他サイトの影響を受ける共有環境、右側は常に一定のリソースが確保された環境をイメージしている。
(アクセス減少時)
(アクセス減少時)
このデモは、共有環境では自分のサイト(青)が他サイト(赤)に圧迫されるのに対し、コンテナ型では常に一定の枠が保証される概念を示している。
独自の分析:トラフィックの「凪」がサイトの健康寿命を削るメカニズム

ここで独自の分析を加えたい。アクセス減少時のパフォーマンス低下は、単なる一時的な速度低下ではなく、サイトの「健康寿命」を削る慢性疾患のようなものだ。筆者はこれを「メンテナンス・デット(保守の負債)」の蓄積と呼んでいる。
自動車に例えるなら、レース(アクセス急増)のときだけオイル交換をし、街乗り(アクセス減少)のときは整備を一切受けられない状態に近い。整備不良のまま放置された車は、次に高速道路に乗った瞬間に故障する。WordPressサイトも同様で、平時のメンテナンスが滞ることで、サイトの構造自体が脆弱になっていくのだ。
SEOへの悪影響という負のループ
さらに深刻なのは、Googleの「CWV(Core Web Vitals / コアウェブバイタル)」への影響だ。アクセスが少ない時期にスロットリングによってページ読み込みが遅くなると、検索エンジンはそのサイトの評価を下げる可能性がある。
「アクセスが減る」→「リソースを削られる」→「表示が遅くなる」→「SEO評価が落ちる」→「さらにアクセスが減る」という負のスパイラルに陥る危険性がある。このループは、一度入り込むと抜け出すのが非常に困難だ。
コンテナ技術が実現する「トラフィックに左右されない」安定性

こうした共有サーバーの構造的な問題を解決するのが、Linuxコンテナ技術を活用したホスティングだ。Kinstaなどのモダンなホスティングサービスが採用しているこの方式では、各ウェブサイトが完全に独立した「コンテナ」内で動作する。
コンテナ型の最大の特徴は、他のサイトとリソースを共有しない点にある。あなたのサイトに割り当てられたCPUやメモリは、たとえアクセスがゼロになっても、他のサイトに転用されることはない。常にあなたのサイト専用の待機リソースとして確保され続ける。
キャッシュ機能もトラフィックに依存しない
また、多層構造のキャッシュシステムも安定性に寄与する。エッジキャッシュやサーバーレベルのキャッシュは、トラフィックの増減に関わらず一貫して動作する。Cloudflareなどのグローバルネットワークを利用したエッジキャッシュなら、オリジンサーバーにリクエストが届く前に応答できるため、アクセス減少時でも高速なレスポンスを維持できる。
静的アセット(画像やCSS)を配信するCDN(Content Delivery Network)も同様だ。これらはサーバーの負荷状況とは無関係に、世界中の拠点から最適な速度で配信される。
運用コストを最適化する:なぜ安定期こそ高品質なホスティングが必要なのか

「アクセスが少ない時期は、安いサーバーにダウングレードしてコストを抑えたい」と考えるのは自然な心理だ。しかし、WordPressサイトの複雑さはトラフィック量に比例して減るわけではない。
プラグインの動作、セキュリティスキャン、管理画面でのコンテンツ編集、ステージング環境でのテスト。これらすべての作業には、安定したインフラが必要だ。特にサイトを管理するエンジニアやディレクターにとって、管理画面のレスポンスがトラフィック減少時に悪化することは、作業効率を著しく低下させる要因となる。
長期的なビジネス成長を支えるインフラ選び
予測可能なインフラは、ビジネスの計画を容易にする。メンテナンス作業がスケジュール通りに完了し、WP-Cronが確実に実行され、管理画面が常にサクサク動く。この「当たり前」の環境を維持することが、長期的なサイト運営における最大のコスト削減につながる。
トラフィックの波に合わせてサーバーを右往左往させる管理コストや、劣化したパフォーマンスの調査に費やす時間を考えれば、最初からリソースが保証された環境を選ぶメリットは大きい。ホスティングは単なる「場所貸し」ではなく、サイトの健康を守る「維持装置」として捉えるべきだ。
この記事のポイント
- 共有サーバーでは「オーバーセリング」により、アクセスが少ないサイトのリソースが他へ転用されるリスクがある
- リソース制限(スロットリング)は、WP-Cronなどのバックグラウンド処理を停止させ、技術的負債を蓄積させる
- データベースの最適化不足やSEO評価の低下は、アクセス減少期に進行する「サイレント障害」である
- コンテナ型ホスティングなら、トラフィックの増減に関わらず専用リソースが確保され、安定した運用が可能になる
- 管理画面のレスポンスやメンテナンスの確実性を維持するためには、安定期こそ高品質なインフラが重要だ
・ 複数業界における17年間のデジタルビジネス開発経験
・ ウェブサイト開発のためのHTML、PHP、CSS、Java等の実用的知識
・ 15ヶ国語対応の多言語SaaSの開発経験
・ 17年間にも及ぶ、Eコマース長期運営経験
・ 幅広い業界でのSEO最適化の豊富な経験

AI時代のキャッシュ設計を再考する——AIクローラーがCDNに与える影響と対策
CDN(コンテンツデリバリネットワーク)のキャッシュ設計が、AIクローラーの台頭によって根本的な見直しを迫られている。Cloudflareのデータによると、同社ネットワーク上のトラフィックの32%は自動化されたトラフィックが占める。検索エンジンクローラーや監視ツールに加え、近年はAIアシスタントが回答生成のためにWebから情報を取得するケースが増加している。
AIエージェントは人間とは異なるアクセスパターンを示す。高頻度の並列リクエスト、人気ページではなく長尾コンテンツへの集中的なアクセス、サイト全体の網羅的なスキャンなどが特徴だ。このような振る舞いは、従来の人間向けに最適化されたキャッシュアルゴリズムを無効化し、キャッシュミス率の上昇とオリジンサーバー負荷の増大を引き起こす。
サイト運営者はAIクローラーへの対応に迫られる。ブロックするか、サービスを提供するかの選択を迫られるが、両者のトラフィックパターンは大きく異なるため、既存のキャッシュアーキテクチャでは一方に最適化するしかない。本記事では、AIトラフィックがCDNキャッシュに与える影響を分析し、新しいキャッシュ設計の方向性を探る。
AIクローラーと人間のトラフィックの根本的な違い

AIクローラーのトラフィックは、人間のブラウジング行動と比較して3つの主要な特徴を持つ。高ユニークURL比率、コンテンツの多様性、クロールの非効率性だ。
高ユニークURL比率と長尾コンテンツへのアクセス
Common Crawlの公開データによると、大規模Webクロールでは90%以上のページがコンテンツ的にユニークだ。AIクローラーは特定のコンテンツタイプに特化する傾向があり、技術文書、ソースコード、メディアファイル、ブログ記事など、目的に応じて異なるコンテンツを対象とする。
人間のユーザーがトップページや人気記事に集中するのに対し、AIクローラーはサイトの奥深くまで探索する。Wikipediaの利用データは、かつて「長尾」とされていたほとんどアクセスされないページが、現在では頻繁にリクエストされるようになったことを示している。これはCDNキャッシュ内のコンテンツ人気度分布そのものを変化させている。
クロールの非効率性と反復ループ
AIクローラーは必ずしも最適なクロールパスをたどらない。人気のあるAIクローラーからのフェッチのかなりの割合が404エラーやリダイレクトで終わる。これはURL処理の不備によることが多い。また、ブラウザ側のキャッシュやセッション管理を人間のユーザーと同じように利用しない。
AIエージェントは検索結果を改良するために反復ループを行うことがある。これはRAG(Retrieval-Augmented Generation)における一般的なパターンだ。この反復ループは、エージェントの精度を高める一方で、一貫して高いユニークアクセス比率(70%から100%)を維持する。つまり、各ループで以前に見たページを再訪するのではなく、常に新しいユニークなコンテンツを取得し続ける。
キャッシュへの直接的な影響
長尾アセットへのこのような反復アクセスは、人間のトラフィックが依存するキャッシュをかき回す。既存のプリフェッチや従来のキャッシュ無効化戦略は、クローラートラフィックの量が増加するにつれて効果が低下する。Cloudflareの単一ノードにおけるキャッシュヒット率は、AIクローラーを含む場合と含まない場合で明確な差が見られる。ヒット率の低下は、LRU(Least Recently Used)アルゴリズムがAIクローラーの反復スキャン行動に対処できていないことを示唆している。
実例から見るAIクローラーのインパクト

AIボットトラフィックの急増は、実際のWebサービスに深刻な影響を与えている。大規模サイトにおける影響と対応策は以下の通りだ。
Wikipedia:マルチメディア帯域幅の50%急増
モデル訓練のための画像一括スクレイピングにより、マルチメディア帯域幅使用量が50%急増した。Wikimediaは最終的にクローラートラフィックをブロックする対応を取った。
SourceHutとRead the Docs:サービス不安定化
ソースコードリポジトリをスクレイピングするLLMクローラーにより、サービス不安定化と速度低下が発生。Read the Docsでは、AIクローラーが大きなファイルを1日に数百回ダウンロードし、帯域幅の大幅な増加を引き起こした。両サービスとも一時的にクローラートラフィックをブロックし、IPベースのレート制限を実施した。
FedoraとDiaspora:人間ユーザーへの影響
Fedoraはパッケージミラーを再帰的にクロールするAIスクレイパーにより、人間ユーザーに対する応答速度が低下。Diasporaソーシャルネットワークは、robots.txtを尊重しない積極的なスクレイピングにより、応答速度の低下とダウンタイムを経験した。両者とも既知のボットソースからのトラフィックを地理的にブロックするなどの対応を取った。
これらの事例が示すのは、AIクローラーを単純にブロックするだけでは根本的な解決にならないということだ。よりスマートなキャッシュアーキテクチャがあれば、サイト運営者はAIクローラーにサービスを提供しつつ、人間ユーザーの応答時間を維持できる。
AI時代に向けたキャッシュ設計の新たな方向性

AIトラフィックの特性を考慮した新しいキャッシュ設計が必要とされている。主なアプローチは2つある。AIを意識したキャッシュアルゴリズムによるトラフィックフィルタリングと、AIクローラートラフィック専用の新しいキャッシュ層の追加だ。
ワークロード対応型キャッシュアルゴリズム
現在広く使用されているLRU(Least Recently Used)アルゴリズムは、汎用状況においてシンプルさ、低オーバーヘッド、有効性のバランスが取れている。しかし、人間とAIボットの混合トラフィックに対しては、別のキャッシュ置換アルゴリズムの選択が有効かもしれない。
初期実験では、SEIVEやS3FIFOといったアルゴリズムを使用することで、AIの干渉の有無にかかわらず、人間トラフィックが同じヒット率を達成できる可能性が示されている。さらに、ワークロードを直接意識した機械学習ベースのキャッシュアルゴリズムを開発し、リアルタイムでキャッシュ応答をカスタマイズする実験も進められている。これにより、より高速でコスト効率の高いキャッシュが実現できる。
トラフィック種別に応じた階層化キャッシュアーキテクチャ
長期的には、AIトラフィック専用の別個のキャッシュ層が最善の道となる。人間とAIのトラフィックをネットワークの異なる層に配置された別個の階層にルーティングするキャッシュアーキテクチャが考えられる。
人間トラフィックは、応答性とキャッシュヒット率を優先するCDN PoP(Point of Presence)のエッジキャッシュから引き続きサービスされる。一方、AIトラフィックのキャッシュ処理はタスクタイプによって変えることができる。
RAGやリアルタイム要約のようなライブアプリケーションを支えるAIクローラーでは、レイテンシが重要だ。これらのリクエストは、より大きな容量と適度な応答時間のバランスが取れたキャッシュにルーティングされるべきである。これらのキャッシュは鮮度を保ちつつも、人間向けキャッシュよりもわずかに高いアクセスレイテンシを許容できる。
訓練セットの構築や大規模コンテンツ収集ジョブに使用されるAIクローラーは、かなり高いレイテンシを許容し、時間的制約がない。これらのワークロードは、到達までに時間がかかる深いキャッシュ階層(オリジン側のSSDキャッシュなど)からサービスできる。あるいは、キューベースのアドミッションやレートリミッターを使用して遅延させ、バックエンドの過負荷を防ぐことも可能だ。これにより、インフラに負荷がかかっている場合にバルクスクレイピングを延期する機会も生まれる。
この記事のポイント
- AIクローラーは全ネットワークトラフィックの約3分の1を占め、そのアクセスパターンは人間のブラウジング行動と根本的に異なる。
- 高ユニークURL比率、長尾コンテンツへの集中アクセス、反復ループによるキャッシュチャーンが、従来のLRUキャッシュアルゴリズムの効果を低下させている。
- WikipediaやFedoraなどの大規模サイトでは、AIクローラーによる帯域幅急増やサービス不安定化が実際に発生し、多くのサイトがクローラーブロックに頼らざるを得なくなっている。
- 根本的な解決策として、SEIVEやS3FIFOなどの新しいキャッシュアルゴリズムの採用と、AIトラフィック専用の階層化キャッシュアーキテクチャの構築が検討されている。
- 今後のCDN設計では、人間トラフィックとAIトラフィックを分離し、それぞれの特性に最適化したキャッシュ戦略を適用することが重要になる。
・ 複数業界における17年間のデジタルビジネス開発経験
・ ウェブサイト開発のためのHTML、PHP、CSS、Java等の実用的知識
・ 15ヶ国語対応の多言語SaaSの開発経験
・ 17年間にも及ぶ、Eコマース長期運営経験
・ 幅広い業界でのSEO最適化の豊富な経験