

PostgreSQLで大規模削除をスケールさせるならDROP TABLE一択
PostgreSQLでテーブルから大量の行を削除する必要に迫られたとき、DELETE文をそのまま使うのは最悪の選択肢のひとつだ。一見直感的ではないが、大規模なDELETEはデータベースに余計な仕事を追加するだけに終わる。
一方で、DROP TABLEやTRUNCATEはテーブルごと削除することで、デッドタプルやバキュームといった負債を生まず、即座にディスク領域を開放する。この記事では、なぜDELETEがスケールしないのか、そしてDROP TABLEがなぜ高速なのかをMVCCや物理ストレージの観点から解説する。
さらに、大量の不要データが混入したテーブルを安全にクリーンアップする実践的な手法や、日常的な削除処理をパーティショニングでDROPに変える設計術も紹介する。
なぜDELETEはスケールしないのか

このデモはDELETEとDROP TABLEのデータ処理フローの違いを示している。DELETEはデッドタプルとバキュームという負債を生み、領域をOSに返さない。DROP TABLEはファイル削除だけで完了する。
MVCCとデッドタプルの正体
PostgreSQLは行が更新されるたびに、元の行を「古いバージョン」として内部に保持する。これはMVCC(Multi-Version Concurrency Control / マルチバージョン同時実行制御)と呼ばれ、異なるトランザクションがそれぞれの時点のデータを正しく読み取れるようにする仕組みだ。
この設計では、DELETE文を実行しても行が物理的に即座に消えるわけではない。削除された行は「デッドタプル」としてテーブルやインデックスに残り続ける。後にバキューム処理がそれらを回収して領域を再利用可能にするが、その間も読み取りクエリはデッドタプルをスキップするためのオーバーヘッドを負う。
さらに、通常のバキュームや自動バキューム(autovacuum)は、デッドタプルが占めていたページを「書き込み可能」とマークするだけで、OSにディスク領域を返還しない。PostgreSQLはINSERTとDELETEが混在するワークロードで領域を再利用しやすいようにこの挙動を選んでいる。OSへの領域返還にはVACUUM FULLが必要だが、長時間の強力なロックを伴う。
レプリケーションとバキュームの重み
DELETEは書き込み操作としてWAL(Write Ahead Log)に記録され、レプリカにも転送される。同期レプリケーション環境では、大量のDELETEがコミットされるまで他の書き込みトランザクションが待たされる可能性がある。つまり、DELETEは「それ自体が負荷を増やす」のであり、後片付けもバキュームに丸投げする形になる。
インデックスに関しても、DELETE実行時にインデックスのエントリは即座に消されない。読み取り時に「このタプルは無効か」を逐一判定する必要があり、インデックススキャンがデッドタプルを見つけた場合、ベストエフォートでそのエントリを無効化する最適化はあるものの、根本的なオーバーヘッドは残る。
DROP TABLE/TRUNCATEが高速な理由

DROP TABLEとTRUNCATEはテーブルに対してAccessExclusiveLock(アクセス排他ロック)を取得するため、他のトランザクションがそのテーブルを読み書きできなくなる。しかし、処理そのものはデータ量にほぼ依存しない。内部的にはテーブルに関連する物理ファイルをOSから直接削除し、共有バッファキャッシュからも該当ページのメタデータを一掃する。
PostgreSQLの共有バッファは8KBのページ単位で管理され、各ページに64バイトの固定サイズのヘッダが付与される。テーブル削除時にスキャンするのはページ本体ではなく、このヘッダ情報のみだ。例えば128GBの共有バッファがあっても、スキャンするメタデータは全体の1/128の約1GBに過ぎず、シーケンシャルアクセスで高速に処理できる。これがデータサイズに依存しない真の理由である。
一時的な大量削除への実践アプローチ

テンポラリテーブルを使った外科手術
バグによってテーブルに大量の不要データが混入したケースを考えよう。保持すべきデータは数十万行程度で、残りはすべて削除対象だ。ダウンタイムが数分許容できるなら、以下の手順で一気にクリーンアップできる。
-- 1. 対象テーブルを排他ロック
LOCK TABLE big_table IN ACCESS EXCLUSIVE MODE;
-- 2. テンポラリテーブルに保持したいデータだけコピー
CREATE TEMP TABLE temp_keep_big_table AS
SELECT * FROM big_table
WHERE updated_at >= '2026-04-01';
-- 3. 元テーブルをTRUNCATE
TRUNCATE big_table;
-- 4. テンポラリテーブルからデータを再挿入
INSERT INTO big_table SELECT * FROM temp_keep_big_table;この手順ではテーブルを完全にロックするため、オンラインサービスではダウンタイムが発生する。しかし、ロック時間が分単位で許容できるメンテナンスウィンドウがあるなら、数十万行のテーブルでも数分で処理できる。実際にPlanetScale社内のオブザーバビリティツールで同様のケースが発生し、この手法で問題を解決している。WALに書き込まれるのは、4の再挿入で戻された行だけであり、DELETEによる膨大なログは一切発生しない。
トリガーを使ったゼロダウンタイムの切り替え
より高度な手法として、テーブルへの書き込みを新しいテーブルにミラーリングし、タイミングを見計らってアトミックなリネームで切り替える方法がある。具体的には、元のテーブルにトリガーを設定して、INSERTやUPDATE、DELETEを新テーブルにも反映させる。十分にデータが同期された段階で、短時間の排他ロックを取得し、テーブルをリネームして差し替える。
このアプローチはPostgreSQLの拡張であるpg_squeeze(pg_repackの後継)が行っていることと本質的に同じだ。ただし、pg_squeezeは既に肥大化したテーブルを最適化するためのツールであり、この記事で伝えたいのは「設計段階で大規模DELETEを避けておく」ことである。初めからスキーマをコントロールできれば、こうした事後対応は不要になる。
パーティショニングで日常的な削除をDROPに置き換える
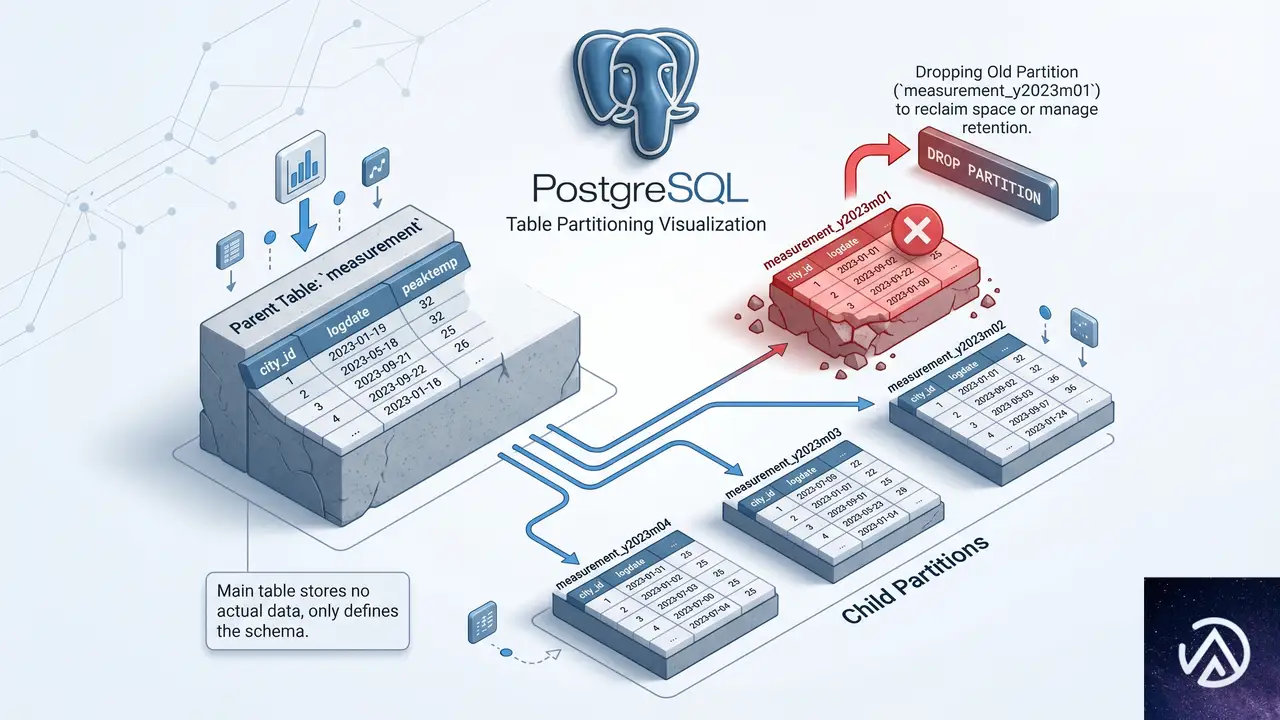
このデモは日付パーティションを使ったエージングアウトと、DROP TABLEによる高速な領域解放の流れを示している。
PostgreSQL 10以降、パーティショニング機能が大幅に強化された。親テーブルの背後に子テーブルを複数持ち、クエリは自動的に該当の子テーブルに振り分けられる。日付ベースのRANGEパーティションを使えば、過去のデータを保持する子テーブルを定期的にDROP TABLEするだけで、古いデータを一瞬で削除できる。これは、数百万行単位のDELETEを定常的に実行していたワークロードを、数秒のDROP TABLEに置き換える強力なテクニックだ。
pg_partman拡張を利用すれば、子テーブルの自動作成や古いパーティションの削除をスケジュール実行できる。また、パーティショニングは再帰的に構成できるため、より高度な設計も可能だ。たとえば、最上位をLISTパーティションで「可視行」と「不可視行」に分け、「不可視行」の子テーブルをさらにRANGEパーティションで日付ごとにエージアウトさせる、といった多次元の構成が組める。
スキーマ設計でDELETEをDROPに置き換える視点
大量データを削除する必要が生じるアプリケーションでは、テーブル設計の段階からDELETEをDROPやTRUNCATEで代替できるか検討することが重要だ。DELETEを多用しない設計にすることで、読み取りクエリのレイテンシ低減、レプリケーションラグの抑制、バキューム負荷の軽減といった効果が期待できる。
パーティショニングしかり、トリガーベースのテーブル差し替えしかり、選択肢は多様だ。PostgreSQLのMVCCが持つ根本的な制約を理解し、大規模な行削除は「テーブルごと破棄して必要なデータだけを再構築する」という発想でスキーマを組み立てる。その結果、データベースの健全性は飛躍的に向上する。
この記事のポイント
- DELETEはデッドタプルを生成し、バキュームやレプリケーションに余計な負荷をかける。大規模削除には向かない
- DROP TABLEやTRUNCATEはデータ量に依存せず、物理ファイルの削除とバッファキャッシュのメタデータスイープで瞬時に領域を解放する
- 一度きりの大量削除はテンポラリテーブルとTRUNCATEの組み合わせが有効。ダウンタイムを許容できるなら強力な手法
- 定常的な古いデータの削除には、パーティショニングでDROP TABLEに置き換える設計が有効。日付パーティションとpg_partman拡張で自動化できる
- アプリケーション設計時に「大量削除が必要なテーブル」をDROPできるようスキーマを工夫することで、データベースの健全性を大幅に向上できる

・ 複数業界における17年間のデジタルビジネス開発経験
・ ウェブサイト開発のためのHTML、PHP、CSS、Java等の実用的知識
・ 15ヶ国語対応の多言語SaaSの開発経験
・ 17年間にも及ぶ、Eコマース長期運営経験
・ 幅広い業界でのSEO最適化の豊富な経験