

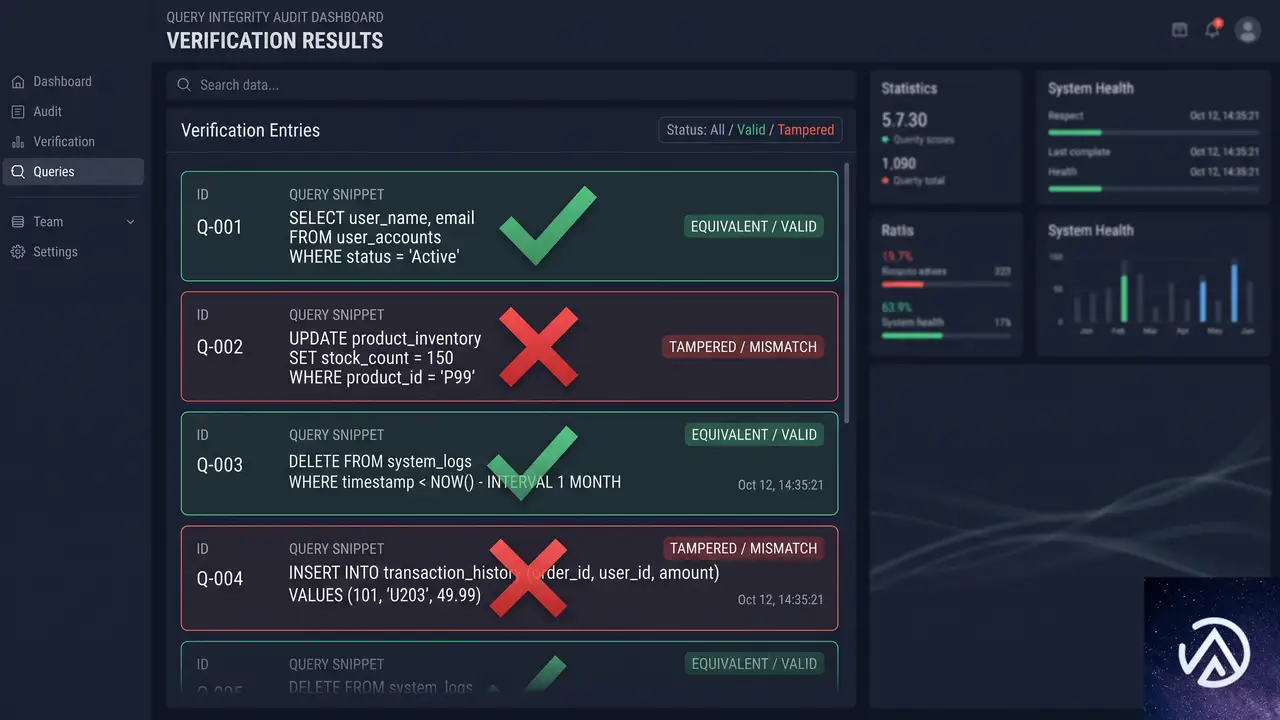
ChatGPT for Small Businessプログラム開始、GPT-5.6搭載のChatGPT Workを提供
ChatGPT WorkとGPT-5.6が中小企業向けプログラムで提供開始

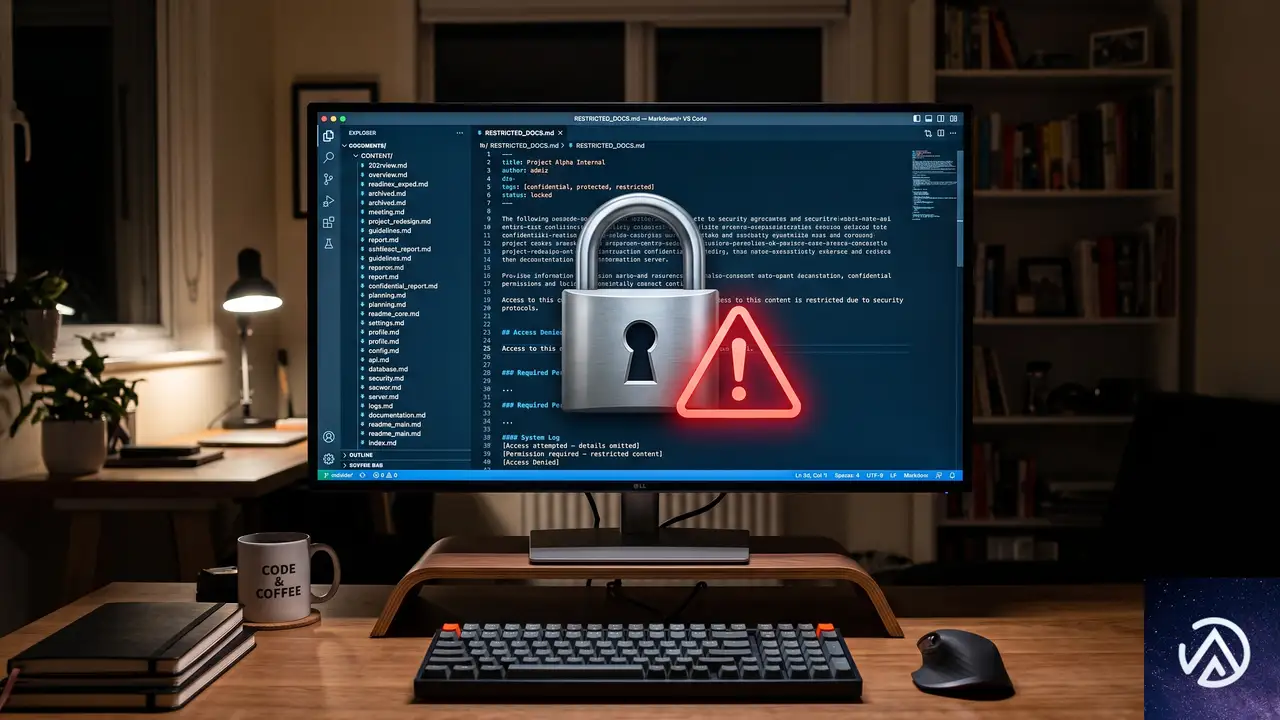
OpenAIは2026年7月21日、中小企業の生産性向上を支援する「ChatGPT for small businesses program」の開始を発表した。このプログラムの中核となるのが、複数の工程にわたる複雑なタスクを最後まで実行できるエージェント「ChatGPT Work」であり、最新モデル「GPT-5.6」を搭載する。
小規模なチーム、限られた時間、そして少数のリソース。中小企業の経営者はマーケティング、経理、営業、オペレーション、戦略立案まで、あらゆる役割をひとりでこなすことが求められる。OpenAIのこのプログラムは、AIを「一人ひとりの専門性を拡張し、処理能力を底上げする力の増幅装置」として位置づけ、誰もが大企業並みのツールを手にできる世界を目指している。
本記事では、プログラムの具体的な内容、ChatGPT Workが中小企業の現場で何を変えるのか、そして実際に得られた導入効果の数字をもとに、この動きが持つ意味を読み解いていく。
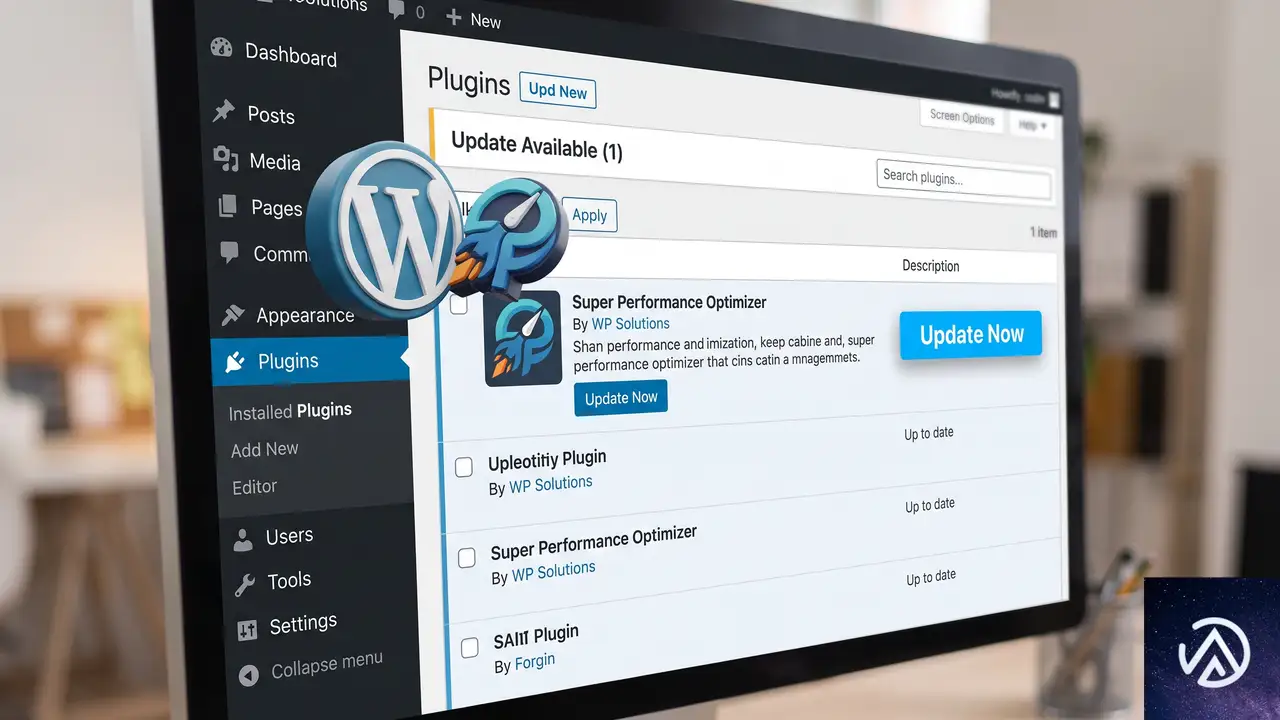
上図のとおり、ChatGPT Workは単なるチャットボットではない。ファイルやアプリケーションと接続し、利用者の思考パターンや執筆スタイルを記憶したうえで、複数の手順を必要とする業務をエンドツーエンドで完遂する自律型エージェントである。
プログラムの4つの柱 オンライン学習から対面イベントまで

今回発表されたプログラムは、以下の4つの要素で構成されている。単なるツール提供にとどまらず、具体的な業務に即した「使いこなし」までをパッケージにした点が特徴だ。
4つの柱はいずれも「すぐに使える」「具体的な業務に直結する」点で共通している。注目すべきなのはSTEP 2の対面型AIアカデミーの実績データで、参加者の78%がわずか1日で実用的なAIワークフローを構築し、42%がAIの活用によって週5時間以上の時間を節約できたという。この数字は、適切なガイドがあればAI導入のハードルは大きく下がることを示している。
業務別にみるChatGPT Work活用の具体例
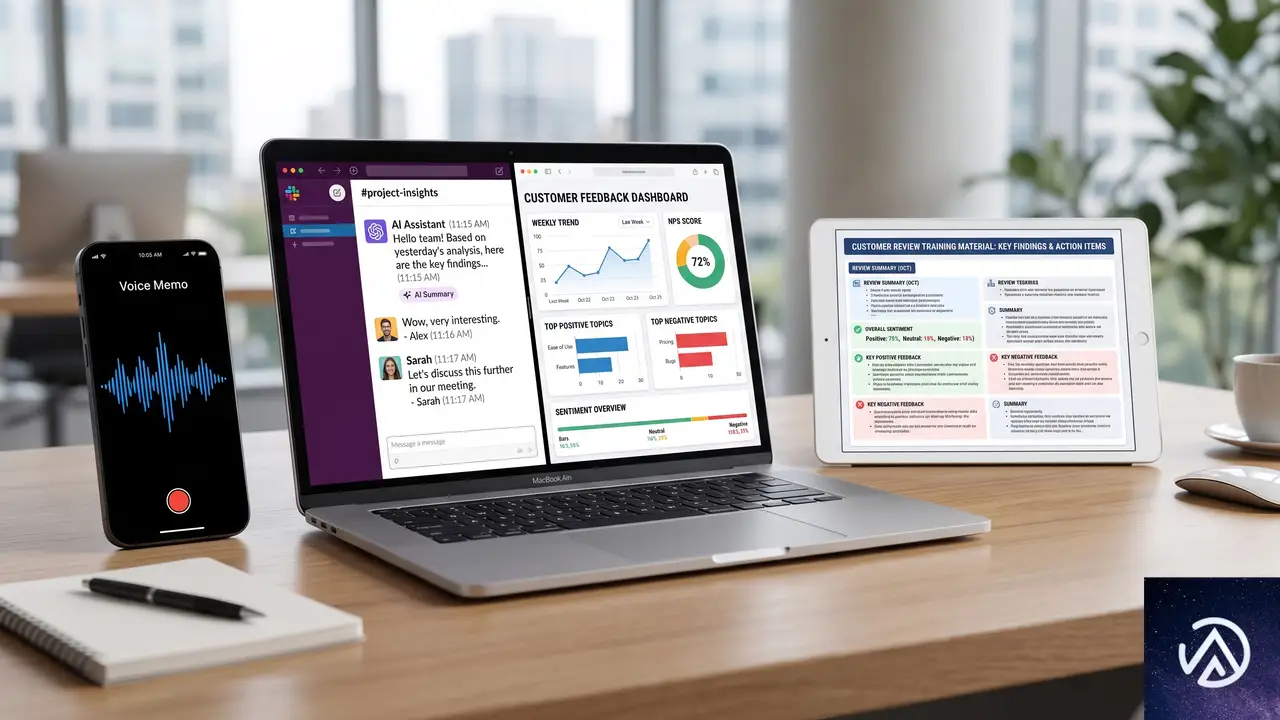
ChatGPT Workは、設計事務所からテック系スタートアップ、非営利団体まで、業種を問わずに利用できる汎用性を持つ。OpenAIの発表では、特に以下の3つのユースケースが紹介されている。
これらのユースケースに共通するのは、「これまで外注するか、手付かずで放置されるか、あるいは経営者が無理をして片づけていたタスク」をAIが肩代わりするという点である。とくに音声メモを起点としたワークフロー自動化は、デスクに座る時間すら惜しい現場経営者にとって現実的な省力化手段といえる。
なぜいま中小企業にAIが必要なのか 数字が示す現実

AI導入の具体的なリターン
AI導入の効果は抽象的な話ではない。OpenAIが2025年に開催した「Small Business AI Jams」では、具体的な数字が報告されている。
- 参加者の78%が、わずか1日で実用的なAIワークフローを構築
- 42%が、AIの活用で週5時間以上の時間を節約
週5時間の節約は、年間に換算すると約260時間に相当する。これは約6.5週間分の労働時間に匹敵し、中小企業の経営者にとっては事業戦略や新規顧客開拓といった、より付加価値の高い業務へ時間を振り向けられることを意味する。
GPT-5.6がもたらす民主化
ChatGPT Workに搭載されるGPT-5.6は、あらゆる規模のビジネスとすべてのサブスクリプションプランで利用できる最先端モデルである。これは重要な意味を持つ。従来、最高性能のAIモデルは大企業の専有物になりがちだったが、OpenAIはこの垣根を取り払った。
中小企業は、必要なときに必要なだけ高度なAIの知能を呼び出し、品質とスピード、コストのバランスを柔軟に調整できる。デスクでの集中作業中でも、外出先の移動中でも、同じモデルにアクセスできる環境が整ったことになる。
この「AIの民主化」は、中小企業の競争環境を大きく変える可能性を持つ。限られた人材と予算のなかで、AIが文字どおり「チームの一員」として機能し始めるからである。
フィードバックが製品ロードマップを動かす 参加型プログラムの狙い

本プログラムのもうひとつの特徴は、OpenAIが参加者からのフィードバックを製品開発に直接反映させる仕組みを組み込んでいる点である。ウェビナー後のQ&Aセッション、地域イベントでの対話、アンケート調査を通じて、「何が機能し、何が欠けているか、次に何を見たいか」という声を集めるという。
これは、単なるプロモーション施策ではない。実際の業務でAIを使うユーザーの生の声が、ChatGPT Workの機能改善や今後のリソース開発、ひいては中小企業向けの製品体験全体を方向づける。参加者は単なる受益者ではなく、製品の共創者として位置づけられているのである。
OpenAIは専用の登録フォームを用意しており、最新情報やイベントへの参加機会をメールで受け取ることができる。
この記事のポイント
- OpenAIが中小企業向けプログラムを発表し、ChatGPT WorkとGPT-5.6を全プランで提供開始
- プログラムはウェビナー、対面トレーニング、導入ガイド、パートナー連携の4本柱で構成
- 2025年の対面イベントでは参加者の78%が1日でAIワークフローを構築、42%が週5時間以上を節約
- 音声メモの自動Slack変換、市場分析の自動更新、カスタマーレビュー分析など具体的な活用例を提示
- 参加者からのフィードバックが製品ロードマップに直接反映される双方向型の設計

WordPressサイト全体にアクセスできなくなった時の原因と復旧手順
サイトにも管理画面にもまったくアクセスできなくなった場合、最初に確認すべきはサーバーのファイル構造とWordPressのインストールパスだ。外部からの不正アクセスを受けた後にページが表示されなくなる症状では、改ざんされたプラグインの残骸や、不完全に変更された設定ファイルが読み込みを妨げている可能性が高い。
なぜサイト全体にアクセスできなくなったのか
管理画面も含めてあらゆるページが表示されない状態は、WordPressの根幹となるファイルが破損しているか、サーバーがPHPを正しく処理できなくなっていることを意味する。特に不正アクセスを受けた後であれば、攻撃者が設置した不正なコードがセキュリティプラグインや手動の復旧作業によって一部だけ削除され、不完全な状態で残っている可能性が高い。
最も厄介なのは、WordPress本体のコアファイルや設定ファイルそのものが破損しているケースだ。テーマやプラグインの不具合であれば、それらを無効化することで少なくとも管理画面にはアクセスできるようになるが、コア破損ではそれすらも不可能になる。
不正アクセスからの復旧作業で起こりやすい副次的な破損
外部から侵入を受けた後、多くのユーザーはパスワード変更やソルトキーの更新、不審なプラグインの削除といった応急処置を行う。しかしこれらの作業中に誤って重要なファイルを削除してしまったり、修正が中途半端な状態で終わってしまったりすることがある。特にソルトキーを手動で更新した場合、wp-config.php内で閉じ引用符が欠落していたり、PHPの定数定義が壊れていたりすると、WordPress全体が読み込めなくなる。
最初に試すべき緊急アクセス手順
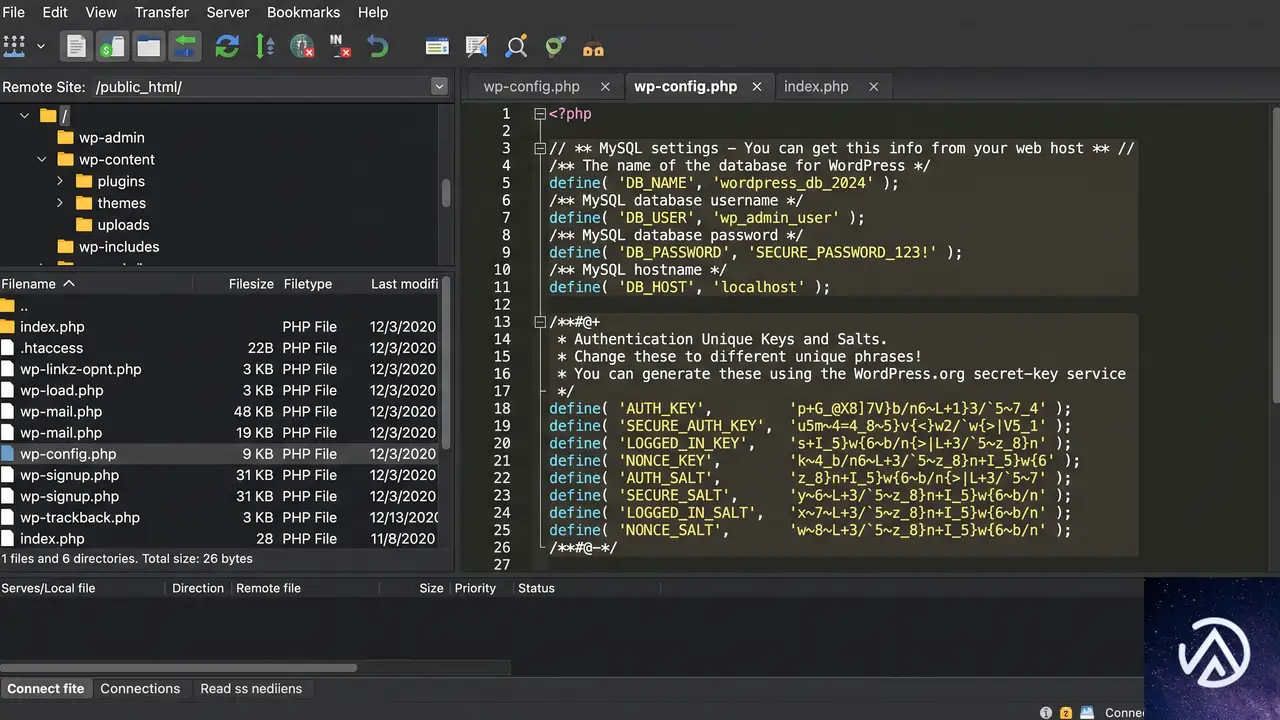
サイトが完全に応答しなくなった場合、まずはブラウザの問題ではなくサーバー側の問題であることを確認する。シークレットウィンドウで自分のサイトURLを開く、別の端末やネットワークからアクセスしてみる、example.com/readme.htmlのような静的なHTMLファイルが表示されるか試すといった切り分けが有効だ。静的なHTMLすら表示されないなら、DNS設定やサーバー自体の停止を疑う必要がある。
wp-config.phpを開き、文法ミスがないか確認する上記の手順で管理画面に到達できるようになれば、あとは管理画面からプラグインを1つずつ有効化して原因を特定し、テーマを正式に切り替えればよい。
wp-config.php の破損を確認する
ソルトキーを変更した直後にアクセス不能になったなら、wp-config.phpが最も疑わしい。このファイルはWordPressのルートディレクトリにあり、データベース接続情報や認証用のユニークキーを定義している。編集時にシングルクォートが1つ抜けている、余分な文字が混入している、PHPの開始タグ<?phpが欠落しているといった単純なミスで、サイト全体が真っ白になる。
サーバーのファイルマネージャーやFTPクライアントでwp-config.phpをダウンロードし、バックアップを取った上で内容を確認する。特にソルトキーを定義しているセクション(AUTH_KEYやLOGGED_IN_KEYなどが並ぶ部分)に注目し、各行がdefine('キー名', '値');の形式を正しく守っているか、閉じ括弧とセミコロンが揃っているかを1行ずつ検証する。不安があれば、WordPressの公式ソルトキー生成ページから新しいキーセットをコピーし、該当セクションを丸ごと置き換えるのが安全だ。
プラグインを強制的に全無効化する
管理画面にさえアクセスできない状態では、データベースを直接操作するか、FTPでプラグインフォルダの名前を変更することでプラグインを無効化する。手順はシンプルで、/wp-content/plugins/ディレクトリに移動し、その中にある全プラグインのフォルダ名の先頭に「_」や「disabled_」を付け加えるだけだ。例えばwordfenceを_wordfenceにリネームすれば、WordPressはそのプラグインを認識しなくなる。
この方法の利点は、プラグイン本体のファイルを削除せずに済むため、原因特定後にすぐ元の名前に戻して復元できることだ。大量のプラグインを1つずつリネームするのが面倒な場合は、pluginsフォルダ自体をplugins_backupにリネームし、空のpluginsフォルダを新規作成すると一括で無効化できる。
WordPress コアファイルを手動で上書きする
wp-config.phpに問題がなく、プラグインをすべて無効化しても症状が改善しない場合、WordPress本体のプログラムファイルが改ざんまたは破損している。攻撃者がwp-adminやwp-includesディレクトリに仕込んだバックドアが、不完全に削除されたまま残っているケースも多い。
対処法は、WordPress公式サイトから最新版の ZIP ファイルをダウンロードし、展開した中身をFTP経由でサーバーにアップロードすることだ。このとき絶対に上書きしてはいけないファイルが2つある。wp-config.php(サイト固有の設定)と/wp-content/ディレクトリ(テーマ・プラグイン・アップロードメディア)だ。これらを除くすべてのファイルとフォルダを上書きアップロードすることで、コアファイルだけがクリーンな状態にリセットされる。
サーバー側のエラーログを確認する方法

ここまでの手順で復旧しない場合は、具体的なエラー内容を把握する必要がある。ブラウザには「重大なエラーが発生しました」としか表示されないが、サーバーには詳細なエラーログが記録されている。レンタルサーバーの管理パネル(cPanelやカスタムコントロールパネル)で「エラーログ」や「error_log」という項目を探し、直近のエントリを確認する。
error_logファイル/wp-content/debug.log(WP_DEBUG有効時)エラーログには「PHP Fatal error」や「Allowed memory size exhausted」といった具体的な原因が記録されている。特に不正アクセス後によく見られるのが、改ざんされたファイルから呼び出された存在しない関数によるエラーや、不完全に削除されたコードの残骸による構文エラーだ。ログの内容を手がかりに、問題のファイルを特定して修正するか、該当プラグインを完全に削除する。
WP_DEBUG を一時的に有効化して詳細を表示する
サーバーのエラーログが見つからない場合は、WordPressのデバッグモードを有効にしてエラーを画面に直接表示させる。これはwp-config.phpに以下の定数を追加または変更することで実現できる。
define('WP_DEBUG', true);
define('WP_DEBUG_LOG', true);
define('WP_DEBUG_DISPLAY', true);WP_DEBUGをtrueにするとWordPressがエラーを表示するようになり、WP_DEBUG_LOGで/wp-content/debug.logにエラーが記録される。WP_DEBUG_DISPLAYをtrueにすると、ブラウザ上にもエラーメッセージが直接表示される。なお、作業が終わったらこれらの定数をfalseに戻すか削除すること。本番サイトでデバッグ表示を有効にしたままにすると、訪問者にもエラー内容が見えてしまいセキュリティリスクになる。
.htaccess ファイルの破損を疑う
不正アクセスの痕跡として、.htaccessファイルが改ざんされているケースも多い。このファイルはWebサーバー(Apache)の挙動を制御しており、ここに不正なリダイレクトルールやアクセス制限が書き込まれていると、サイト全体にアクセスできなくなる。
WordPressルートディレクトリの.htaccessをダウンロードしてバックアップを取り、一度ファイル名を.htaccess_backupに変更して無効化する。その後、WordPress管理画面の「設定」→「パーマリンク設定」で「変更を保存」をクリックすれば、クリーンな.htaccessが自動生成される。ただし管理画面にアクセスできない現状では、以下の内容で新規に.htaccessを作成してもよい。
# BEGIN WordPress
<IfModule mod_rewrite.c>
RewriteEngine On
RewriteRule .* - [E=HTTP_AUTHORIZATION:%{HTTP:Authorization}]
RewriteBase /
RewriteRule ^index\.php$ - [L]
RewriteCond %{REQUEST_FILENAME} !-f
RewriteCond %{REQUEST_FILENAME} !-d
RewriteRule . /index.php [L]
</IfModule>
# END WordPressこれでサイトが表示されるようになれば、原因は.htaccessの改ざんだったと特定できる。旧ファイルは内容を精査し、不審な行(知らないドメインへのリダイレクトや、怪しいIPアドレスからのアクセス許可ルールなど)がないか確認してから削除する。
バックアップからの復元がうまくいかない場合の対処

サーバー会社のサポートからバックアップ復元を提案されたが失敗したという状況は、バックアップデータ自体が破損しているか、復元先の環境に不整合があることを示している。特に多いのが、バックアップを上書き復元した後にデータベースの接続情報が古いままになっているケースだ。
バックアップ復元後にサイトが表示されない場合、まずwp-config.php内のデータベース名・ユーザー名・パスワード・ホスト名が、現在のサーバー環境と一致しているか確認する。バックアップが別のサーバーや別のデータベースインスタンスの情報を持ったまま復元されると、WordPressはデータベースに接続できず「データベース接続確立エラー」を返す。
もうひとつの可能性は、バックアップに不正アクセス後の改ざんファイルが含まれていたケースだ。攻撃を受けた後の状態をバックアップしてしまい、それを復元しても問題が再発するだけという悪循環に陥っている。この場合、バックアップからwp-content/uploads/(メディアファイル)とデータベースのダンプファイルだけを取り出し、WordPressのコアファイルとプラグインは公式のクリーンなファイルで置き換える方法が有効だ。
よくある質問
FTPの接続情報がわからない場合はどうすればよいか
多くのレンタルサーバーでは、契約時に送られてくる「サーバーアカウント情報」メールにFTPのホスト名・ユーザー名・パスワードが記載されている。見つからない場合はサーバーの管理パネルにログインし、「FTPアカウント」や「ファイルマネージャー」の項目から確認できる。管理パネル自体にログインできない場合は、サーバー会社のサポートに連絡してFTP情報を再発行してもらう必要がある。
「このサイトで重大なエラーが発生しました」のメールが届いたが確認できない
WordPress 5.2以降では、サイトに致命的なエラーが発生すると管理者メールアドレスに自動通知が届く。このメールには「リカバリーモード」へのリンクが含まれており、クリックするとプラグインを無効化した状態で管理画面にログインできる。メールが届いていない場合は、サーバーのPHPバージョンが古くてメール送信機能が動作していない、または管理者メールアドレスが間違って設定されている可能性がある。
不正アクセスを受けた後、どのプラグインを疑うべきか
攻撃者は多くの場合、更新が長期間止まっている脆弱なプラグインや、公式リポジトリ以外から入手したnulledプラグイン(正規ライセンスを回避した改変版)を経由して侵入する。/wp-content/plugins/内で更新日時が不自然に新しいファイル、プラグイン名とは無関係なファイル名(config.bakやabout.phpなど)が紛れ込んでいないか確認する。また、長期間更新されていないプラグインは、たとえ攻撃の経路でなかったとしても今後のリスクになるため、代替プラグインへの移行を検討すべきだ。
すべて試しても復旧しない場合の最終手段は
サーバー上の全ファイルをローカルにバックアップし、データベースをエクスポートした上で、WordPressを新規インストールする。その後、エクスポートしたデータベースのうちwp_posts(投稿・固定ページ)とwp_postmeta(カスタムフィールド)、wp_options(サイト設定)のテーブルだけをインポートし直す。この方法ではテーマやプラグインの設定の一部が失われる可能性があるが、コンテンツを救出できる可能性が最も高い。作業前には必ず現状の完全バックアップを取っておくことが大前提だ。
この記事のポイント
- 管理画面もサイトも表示されない場合、まずは静的なHTMLファイルが表示されるか確認し、問題の切り分けを行う
wt-config.phpの文法ミスやプラグインの強制無効化、.htaccessのリセットで多くのケースが解決する- 不正アクセス後はコアファイルが改ざんされている可能性があるため、
wp-content以外をクリーンなファイルで上書きする - バックアップ復元に失敗したら、データベース接続情報の不一致やバックアップ自体の破損を疑う
- エラーログやWP_DEBUGで具体的なエラー内容を特定し、根本原因に対処するのが最も確実な復旧手順である

Google広告の目標ベース入札が8月17日に変更、EC事業者が取るべき対策
8月17日からGoogle広告の入札ロジックが変わる。予算制限キャンペーンの「隠れ効率」を守るには

Google広告の目標ベース入札戦略(目標CPA・目標ROAS)を使っているEC事業者は、2026年8月17日の変更を無視できない。予算が不足しているキャンペーンで、実際のパフォーマンスが目標を大幅に上回っていた場合、その「おまけの効率」が失われる可能性があるからだ。
具体的には、予算不足のステータスにある目標CPA・目標ROASキャンペーンが、設定された目標値に積極的に近づくように最適化される。これまでは予算が上限だったために自動的に抑えられていたCPAが、目標値まで上昇するリスクがある。変更は自動適用で、オプトアウトは不可能だ。
この記事では、変更の技術的な中身、影響を受けるアカウントの見分け方、そして8月17日までに打つべき具体的な対策を解説する。
目標ベース入札の「おまけ」はなぜ生まれていたのか

まず、なぜ「目標よりも良い数字」が出ていたのか、その仕組みを整理しておこう。
予算上限が事実上のストッパーになっていた
予算不足のキャンペーンでは、アルゴリズムは与えられた予算内で最も安いコンバージョンをかき集める動きをする。目標CPAが100ドルでも、予算が尽きれば50ドルのコンバージョンしか取れず、結果として目標値を大きく下回る実績が続く。これはアルゴリズムの優秀さではなく、単に「目標まで使い切れなかった」状態だ。
つまり、50ドルと100ドルの差額は「アルゴリズムが本当に達成できる上限」ではなく、「予算という壁によって未使用のまま残されていた余地」だった。この余地が8月17日以降、システムに「使える領域」として認識される。
変更後は目標が「天井」から「到着点」に変わる
アップデート後、予算不足の状態でもアルゴリズムは「設定された目標CPAまで単価を上げてでも、コンバージョンを追求する」方向にシフトする。これまで自動的に節約されていた差分がなくなり、実際のCPAが目標値に近づいていく。
重要なのは、Googleが予算そのものを自動的に引き上げるわけではない点だ。あくまで、すでに広告主が設定した目標値を「本気で達成しようとする」挙動に変わる。Search Engine Journalの記事でも、Google広告担当Ginny Marvin氏が「これは広告主に支出を増やすよう促す変更ではない」と明確に述べている。目標が実態と合っていなければ、それは広告主側の設定ミスとして表面化する。
最もリスクが高いのは「放置された目標値」だ

今回の変更で真っ先にダメージを受けるのは、目標CPAや目標ROASを「とりあえずの数字」で設定したまま、実績だけが良かったアカウントである。
「なんとなく目標」が突然、現実のコストになる
たとえば、目標CPAを100ドルと設定したが、実際の損益分岐点は80ドルだったとする。これまで実績が50ドルで推移していたため誰も気にしなかったが、8月17日以降はシステムが100ドルを目指し始める。結果として、CPAは80ドルの損益ラインを超え、静かに赤字が発生する。数字が表面化するのは翌月のレポートだ。
ROASでも構図は同じだ。目標ROASを400%としていたが、実際には600%で回っていたキャンペーンは、変更後に400%へと低下する。これが許容できる数字かどうかは、粗利益率に基づいて決めるべきであり、変更後に「気づいた」では遅い。
「予算不足」のラベルがついたキャンペーンをすべて洗い出せ
まずやるべきは、現状の棚卸しだ。Google広告の管理画面で「予算不足」と表示されているキャンペーンのうち、目標CPAまたは目標ROASを使用しているものをすべて抽出する。過去90日間の実際のCPA・ROASと、設定された目標値を比較し、実績が目標を大幅に下回っている(CPAの場合)、または上回っている(ROASの場合)キャンペーンを特定する。
これらが、8月17日以降に数字が動く「要注意リスト」である。
8月17日までに選ぶべき3つの選択肢
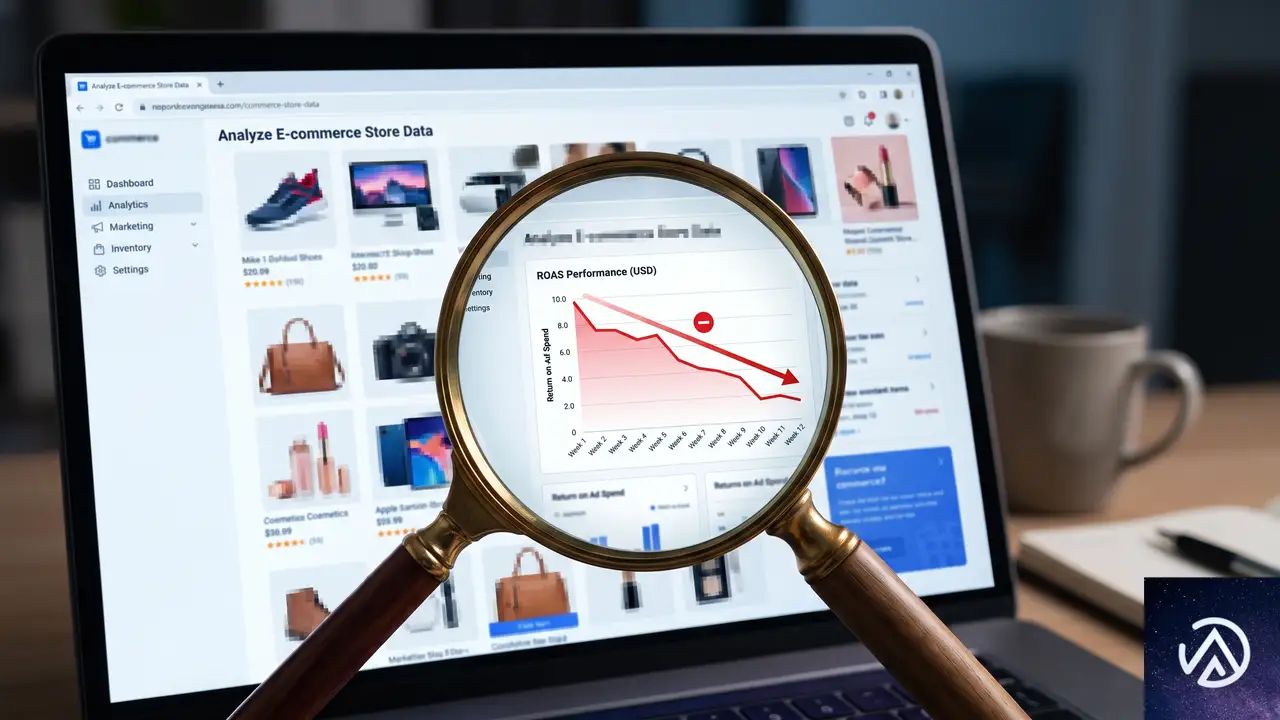
要注意リストに載ったキャンペーンごとに、以下の3つの方針から1つを選ぶことになる。放置は最もコストのかかる選択だ。
いずれを選ぶにせよ、重要なのは8月17日より前に手を打つことだ。変更後に数字が動いてから「なぜCPAが上がったのか」を説明するのは、社内でもクライアントに対しても難しい。事前に「このキャンペーンは目標を調整した」「予算を増やして拡大フェーズに入る」と一言共有しておくだけで、後のトラブルを防げる。
ECのP-MAX・ショッピングキャンペーンで特に注意すべき点

予算不足で運用しているアカウントの多くは中小規模のEC事業者である。特にショッピングキャンペーンやP-MAX(パフォーマンスマックス)キャンペーンでは、2つの点に警戒が必要だ。
実績ROASの下方シフトは「静かな利益消失」を招く
予算上限があるショッピングキャンペーンやP-MAXで目標ROASを設定し、実績がそれを上回っていた場合、8月17日以降はROASが目標値付近まで下がる。これはつまり、同じ予算で得られる売上高が減るか、売上を維持するために広告費が増えることを意味する。
対策はシンプルで、目標ROASを「切りの良い数字」ではなく、粗利益率(貢献利益)から逆算した損益分岐点に設定し直すことだ。400%というラウンドナンバーに根拠はない。実務に基づいた数値に置き換えるべきである。
チャネル間のトラフィックシフトを見逃すな
P-MAXキャンペーンは検索、ショッピング、YouTube、ディスプレイなど複数のチャネルにまたがって配信される。Googleは今回の変更に伴い、「システムが目標値にリバランスする過程で、チャネル間のトラフィック比率が変わる可能性がある」と明言している。
具体的には、CPAやROASを目標に近づけるために、単価の安いが購買意欲の低い在庫(たとえば、ディスプレイネットワークの特定のプレースメント)へトラフィックが流れるリスクがある。8月17日以降は、キャンペーンのチャネル別レポートを週次で確認し、「コンバージョンは増えたが、すべてディスプレイ経由だった」といった質の変化を早期に捉える必要がある。
「スマート自動入札の探索」はコントロールされた拡大の手段になる
もし「現在の効率を維持しつつ、新しいコンバージョン機会も探りたい」と考えるなら、8月17日の変更にただ流されるよりも、積極的な手段を取れる。
Googleが6月15日に拡大した「スマート自動入札の探索」機能は、設定したROASの許容範囲内で、普段はスキップされるようなクエリにも入札できるようにするものだ。P-MAXキャンペーン(商品フィードなし)では全アカウントで利用でき、フィードありのショッピング・P-MAXではベータ版として提供されている。
Googleの社内テストでは、ユニークなコンバージョンクエリカテゴリが18%増加し、コンバージョン数が19%増加したと報告されている。これはあくまでGoogleの数値であり、独立した検証ではないが、「狙ってリーチを広げる」ためのレバーとして存在していることは押さえておきたい。
8月17日の変更は、広告主が放置していた「目標値と実績のギャップ」を自動的に埋める。探索機能は、そのギャップを「広告主が定義したルールの下で」使うための道具だ。「なんとなくボリュームが増えた」ではなく、「この範囲なら受け入れる」と決めて臨む方が、はるかに健全である。
この記事のポイント
- 8月17日から、予算不足の目標CPA・目標ROASキャンペーンは、実際のパフォーマンスが目標値に近づくように自動調整される。オプトアウトはできない。
- これまで「目標より良い数字」が出ていたのは、予算上限が効率的に働いていただけであり、変更後はその余剰分が失われる。
- 最も危険なのは、実態とかけ離れた目標値を設定したまま放置しているアカウント。8月17日より前に、予算不足キャンペーンの目標値を見直す必要がある。
- 対策は「目標を実績に合わせる」「予算を増やして拡大する」「意図して変更を受け入れる」の3つから選択する。
- P-MAXではチャネル間のトラフィックシフトにも注意し、変更後の数字をチャネル別に監視すること。

WordPress 7.1 Beta 3リリース、グローバルスタイル適用の改善点を解説
Beta 3がもたらす現場へのインパクト
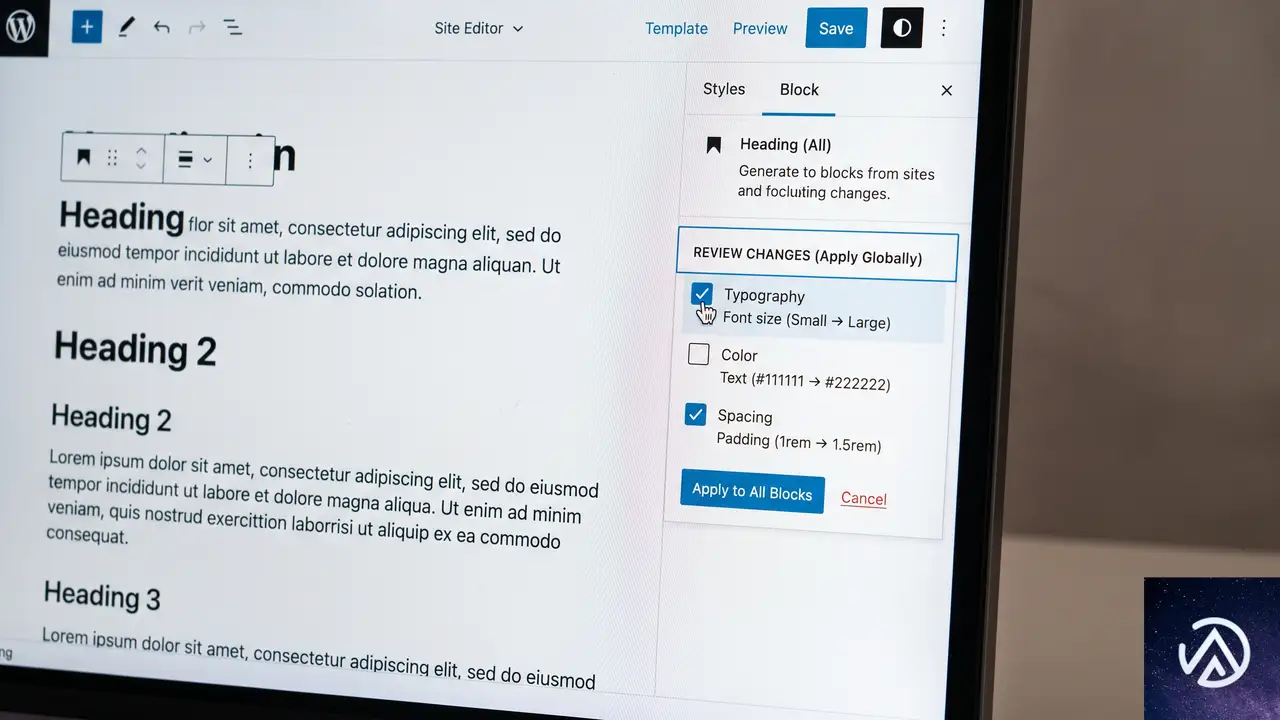
WordPress 7.1の正式リリースは2026年8月19日に迫っている。今回公開されたBeta 3は、単なるバグ修正の積み上げではない。ブロックエディタのスタイル管理に根本的な考え方の変更をもたらす機能が含まれている点が最大の注目点だ。
具体的には、「Apply globally(グローバルに適用)」機能の改善だ。これまで、あるブロックに加えたスタイル変更をサイト全体に反映させる操作は、すべての変更を一括で上書きするか、まったく適用しないかの二者択一だった。この「全か無か」の動作は、実際のデザインワークフローにおいて多くの小さなストレスを生んでいた。
Beta 3で導入された改良では、適用前にレビューステップが挿入される。これにより、変更したスタイルのうち、どれをグローバルに適用し、どれをそのブロックだけのローカルな変更として残すかを選択できるようになる。部分的なグローバル適用が可能になることで、サイト全体のデザイン整合性を保ちながら、特定のブロックだけ微調整するという、現実的な運用が格段にやりやすくなった。
このレビューステップの導入により、デザイナーやサイト運営者は「うっかり全ブロックのスタイルを壊してしまった」というヒヤリハットから解放される。部分的な適用が可能になったことで、より積極的にグローバルスタイルを活用できるようになるだろう。
メディアアップロードの地味だが確実な改善
Beta 3には、日々の運用で遭遇しがちなメディア関連のバグ修正も含まれている。長尺のGIFアニメーションをアップロードした際に処理が停止してしまう問題が解消された。また、EXIFメタデータで回転情報が埋め込まれた画像が、正しい向きで処理されるようになった。
Safariブラウザで単一のHEIC画像をアップロードすると、誤ってエントリーが二重に作成される問題も修正されている。これらの修正は派手さこそないが、クライアントワークで大量の画像を扱う制作会社や、更新頻度の高いメディアサイトの運用者にとっては、地味に嬉しい改善と言える。
テストに参加する4つの方法
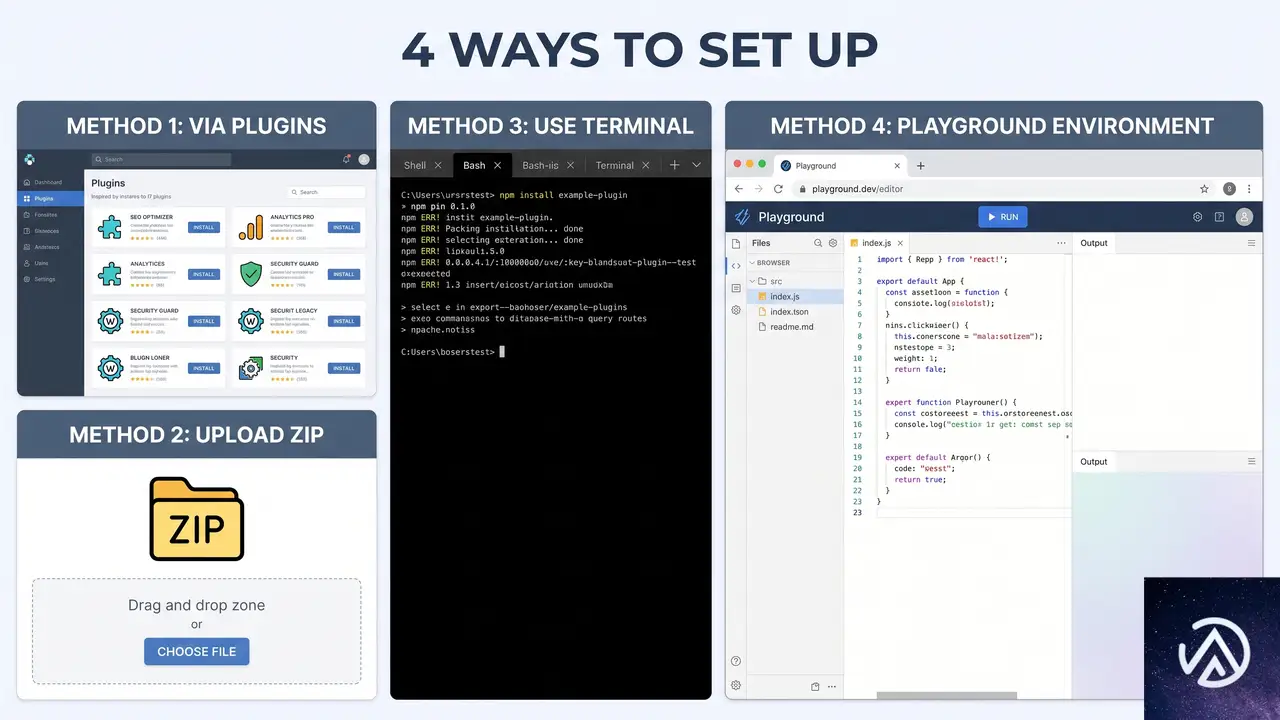
WordPress 7.1 Beta 3は、本番サイトでの使用を想定していない。あくまでテストと開発を目的としたリリースだ。テスト環境は、ローカルPC上のLocal by FlywheelやDevKinsta、あるいはXAMPPやDockerを使った手動セットアップなど、普段使い慣れたもので問題ない。
テスト環境を用意したら、以下のいずれかの方法でBeta 3を入手できる。
特にWordPress Playgroundは、データベースすら必要としないブラウザ完結型のテスト環境だ。とりあえず新機能を触ってみたいという場合には、最もハードルが低い選択肢だろう。
なぜベータテストへの参加が重要なのか

WordPressのメジャーバージョンアップは、世界中のサイトに影響を及ぼす。7.1では、Beta 1以降だけでも71件以上の課題が修正されている。これらの修正の質を高めるには、多様な環境でのテストが不可欠だ。
ベータテストは、開発経験の有無を問わない。普段使っているプラグインやテーマとの組み合わせで問題が起きないかを確認するだけでも、リリースの品質向上に大きく貢献できる。公式のテストガイドには、特に重点的に確認すべき項目がまとめられている。
不具合の報告はフォーラムへの投稿で十分だ。再現手順を明確に説明できる場合は、Tracでのチケット発行が推奨される。報告の前に既知のバグ一覧を確認すれば、重複を避けられ、開発チームの負荷も減らせる。
7.1正式版に向けた最終段階

WordPress 7.1のリリーススケジュールは、2026年8月19日が最終目標だ。8月16日から19日まで開催されるWordCamp US 2026の会期と重なるタイミングでのリリースは、コミュニティにとっても大きな節目となるだろう。
今回のBeta 3では、スタイル管理の柔軟性向上に加え、メディア処理の安定化、Notes機能やレスポンシブスタイリング、カスタムCSSに関するエディタの修正も含まれている。開発者向けには、WordPress Coding Standardsがバージョン3.4.0に更新された。
一方で、Unicodeメールアドレス対応は7.1への搭載が見送られることが決まった。この機能はコミュニティプラグインとして開発が継続され、互換性やセキュリティ面の検証がより広範囲に行われる予定だ。
なお、7月17日にはBeta 2がWordPress 7.0.2のリリースの一環として公開されており、重要なセキュリティ修正が含まれている。テスト環境を最新の状態に保つ際は、この点にも注意が必要だ。
この記事のポイント
- Apply globally機能にレビューステップが追加され、スタイル変更を部分的にグローバル適用できるようになった
- 長尺GIFの処理停止やSafariでのHEIC二重登録など、メディアアップロードの実用的な不具合が修正された
- テスト参加はプラグイン、直接ダウンロード、WP-CLI、Playgroundの4経路から選択可能
- Unicodeメールアドレス対応は7.1への搭載が見送られ、コミュニティプラグインとして開発が継続される
- 正式リリースは2026年8月19日、WordCamp US 2026の開催期間と重なるタイミングで公開予定

AI時代のブランド監査、ローカルビジネスに必要なSEO戦略とは
AIがビジネスの評判を決める時代に入った。検索窓に質問を打ち込むユーザーは、もはやリンクのリストをクリックしない。AIが瞬時に要約した「答え」だけを見て、店を選び、サービスを予約する。この変化はローカルビジネスの集客構造を根底から揺るがしている。
GatherUpが2025年秋に集計したデータによると、消費者の55%がGoogleやBingのAI要約を参照し、48%がChatGPTに地域ビジネスについて質問した経験を持つ。さらに31%は複数回質問している。問題は、AIが提示する「おすすめ」が、必ずしも最高評価の店舗ではないことだ。
実際の検索で起きた象徴的な事例がある。バージニア州ノーフォークで「SUVが入る非接触洗車機」をGoogleに尋ねたユーザーに対し、AIは評価3.3の店舗を提示した。検索クエリとのマッチ度が、星評価より優先されたのである。この事実は、AI時代のローカルSEO戦略が星集めだけでは成立しないことを示している。
AIは地域ビジネスをどう探すようになったか

従来のローカル検索は「近くのラーメン」という短いキーワードが主流だった。ユーザーはMapPackやオーガニック検索結果から複数店舗を見比べた。AI検索ではこの流れが完全に変わる。ユーザーは「子供連れでも入れて、駐車場があって、あっさり系の醤油ラーメンが人気の店」のように、自然言語で条件をすべて盛り込んだ質問を一度に投げる。
質問型クエリが標準になった
この変化を端的に表すのが洗車場の事例だ。検索クエリは「no-touch car wash for my SUV in Norfolk, VA」。車種、洗車方式、場所、すべてが1文に含まれている。Googleは保有する3億件の施設データと5億人のレビュー投稿者情報を即座に処理し、1件の店舗を返した。
注目すべきは、この店舗の評価が3.3だった点である。GatherUpのアニー・ジャクソン氏(収益オペレーション&成長担当ディレクター)はSearch Engine Journalの記事で「Googleは私の質問に答えましたが、このビジネスは3.3つ星なのです。星評価よりクエリの文脈が優先されたのです」と指摘している。
※AI検索では1回の質問で店舗決定まで完結する
検索の文脈には時間帯やユーザーの属性も含まれる。Search Engine Journalの記事でジェイソン・ワーサム氏(レビューディフェンス運営担当VP)が警告しているように、LLMが「ユーザーはSUVを持っている」「大型犬を飼っている」といった情報を学習すると、以降の検索では毎回その文脈が適用される。ユーザーが再び条件を入力しなくても、AIは過去の対話を覚えている。
AIはレビューをどう読んでいるのか
多くのマーケティング担当者が誤解している点がある。GoogleビジネスプロフィールやYelpに投稿されたレビューは、AIが直接読み取れるわけではない。これらの主要ディレクトリは、LLMクローラーがビジネスプロフィール上のレビューをスクレイピングするのをブロックしている。
レビューがAIに渡る経路
ワーサム氏はこのメカニズムを明確に説明している。「ChatGPTやClaudeなどのLLMツールは、GoogleやYelpといった主要ディレクトリ上のレビューデータをクロールできません。実際、AIが特定のレビューを引用しないのはこのためです」。
しかし同じレビューでも、一度Web上に再掲載されると状況が一変する。レビューを自社サイトのウィジェットで公開したり、SNSに投稿したりした瞬間、その情報はLLMのクロール対象になる。ワーサム氏の言葉を借りれば「その時点でLLMツールの餌食になる」のだ。
※「人気の店」を尋ねるユーザーにはクロール可能なレビューが回答を左右する
この仕組みは、AI検索でどのクエリに勝てるかを決定的に左右する。ユーザーが「人気の」「高評価の」ビジネスを尋ねたとき、LLMはアクセス可能なレビューテキストを検索する。ディレクトリ内に閉じ込められたレビューは、回答に一切貢献しない。
そのため実務上の優先順位は明確だ。レビューを自社サイトやSNSで定期的に再発信し、AIが参照できる形でWeb上に存在させることが、AI時代のローカルSEOでは必須になる。ディレクトリ任せでは不十分だとワーサム氏も強調している。
星評価はAI検索で通用しなくなる
これまでのローカルSEOは星の数を増やすことが目標だった。しかしAI検索において、平均星評価の重要度は急速に低下している。Search Engine Journalが報じた監査事例では、AIが平均星評価を引用したケースはゼロだった。代わりに参照されたのはすべて、具体的なレビュー本文の内容である。
AIが重視するのは「鮮度」と「量」
消費者データも同じ傾向を示す。45%のユーザーが星評価よりレビューの新しさを優先し、60%が評価点だけのレビューより詳細な文章レビューを信頼する。さらに70%が、購入後72時間以内のレビュー依頼を好むというデータもある。
ワーサム氏はこの変化を明確に言語化している。「星5の30件より、星3.9で1,000件の店に行く。古い高評価より、現在も続く安定したレビューの流れの方が価値が高い」。Googleのデフォルト表示が「最も関連性の高い」レビューであっても、ユーザーの多くはわざわざ「新しい順」に並べ替える。それは最新のレビューが、自分がこれから受ける体験を最も正確に予測するからだ。
※ユーザーはGoogleの表示順を「新しい順」に切り替える傾向がある
対策は3つの柱に整理できる。構築(リスティングの一貫性とレビュー量の確保)、管理(72時間以内の返信とモニタリング)、防御(ポリシー違反レビューの削除依頼とレビューの埋没対策)。この3つを同時に回すことで、AIが参照する情報の質と量をコントロールできる。
AIの回答が毎回違う理由

LLMが生成する回答は確率的な出力だ。同じ質問をしても、デバイスやアカウント、時間帯によって結果が変わる。SparkToroの調査では、異なるユーザーが同じ質問をLLMに投げたところ、結果の順序が一度も同じにならなかった。
スロットマシンのような仕組み
ジャクソン氏はこの性質を「AIへの質問はスロットマシンのようなものだ」と表現している。毎回似たデータが返ってくるが、その都度少しずつ異なる。この特性を理解しないまま「AI検索で1位」を目標にするのは無意味だ。
AI検索における正しいKPIは順位ではない。評価すべきは引用総数、つまりAIの回答に自社情報がどれだけ使われているかである。ブランドが特定の端末で回答から完全に除外されることもあれば、次の検索ではトップに立つこともある。重要なのは、どの検索でも「存在する」ことだ。
※異なるデバイスや時間帯で結果が変わる前提の測定が必要
監査の際には必ずシークレットモードやテンポラリーチャットを使用する。保存されたコンテキストが結果を歪めるからだ。さらに定期的な再実行が不可欠で、月次での定点観測によって、AI上のブランド認知が実際に改善しているかを評価する。
緊急ブランド監査 4つのプロンプト

GatherUpのセッションでは、多店舗ブランドが今すぐ実行できる4段階の監査プロンプトが紹介された。目的は、ChatGPTやGoogleのAI Overviews、Ask Mapsが自社について何を答えているかを可視化することだ。
自社把握から店舗別診断まで
監査はブランド名の単純な質問から始まり、徐々に深掘りしていく。最終段階では店舗ごとにAIがどう説明しているかをチェックする。Search Engine Journalの記事に掲載された監査ハンドアウトには、この4段階の具体的なプロンプト例が含まれている。
注目すべきは、Googleが今月更新したAI最適化ガイドの変更点だ。Search Engine Journalの記事でワーサム氏が指摘しているように、GoogleはAI生成の低品質コンテンツを検出し、ペナルティを科し始めている。汎用的なAIブログ投稿やFAQスクレイピングは、もはや無視されるだけでなくマイナス評価の対象になる。
※GoogleはAI生成の低品質コンテンツへのペナルティを開始している
この記事のポイント
- AI検索では星評価よりクエリとのマッチ度とレビューテキストが優先される
- LLMはGoogleやYelp上のレビューを直接クロールできず、自社サイトやSNSへの再掲載がAIの情報源になる
- 星評価よりレビューの鮮度と量がAIの回答を左右する。評価が3.9でも1,000件ある店舗が星5の30件より強い
- AIの回答は確率的で毎回変わるため、順位ではなく引用総数で評価する
- 4段階の監査プロンプトを月次実行し、AIが自社をどう説明しているかを把握することがブランド防衛の第一歩

WordPressサブディレクトリ環境でプラグイン管理画面が404になる原因と対処
WordPress をサブディレクトリに置いている環境で、一部プラグインの管理画面にアクセスすると「ページが見つかりません(404)」になる。これはプラグイン内部で作られた管理画面の URL が、実際のディレクトリ構造と合っていないのが主な原因だ。プラグインの更新で修正されることが多く、一時的に URL へ正しいパスを手動で加えればすぐに操作を再開できる。
なぜ管理画面のプラグインページが404になるのか

WordPress の管理画面は通常 /wp-admin/ で始まるが、Bedrock(roots.io スタック)のようなカスタム構成では、コアファイルを /wp/ の下に配置する。管理画面の URL は /wp/wp-admin/ のようにサブディレクトリが一段深くなる。ここで、プラグインが管理画面へのリンクを作る際に「/wp-admin/ はルート直下にある」という前提でコードを書いていると、リンク先が https://example.com/wp-admin/... のようにサブディレクトリを反映しない形になり、フロントエンドで処理されて結果的に404になる。
これはコアファイルの場所を変更していない標準的なインストールでは表面化しない。Bedrock や独自に /cms/ などへ配置を変えているサイトで、かつプラグインが管理画面のパスをハードコード(直書き)している場合に限って起こる。エラーログには何も残らず、ただ「ページが見つかりません」と表示されるため、原因の特定に手間取ることが多い。
上記デモのとおり、プラグインが出力したパスに /wp/ が1つ欠けているために「そんなページはフロントエンドに存在しない」と判断され、404 が返っている。見た目はありふれた存在しないページへのアクセスと変わらず、管理画面の一部だけが突然消えたように感じる。
サブディレクトリ環境で発生する404の一時的な回避策
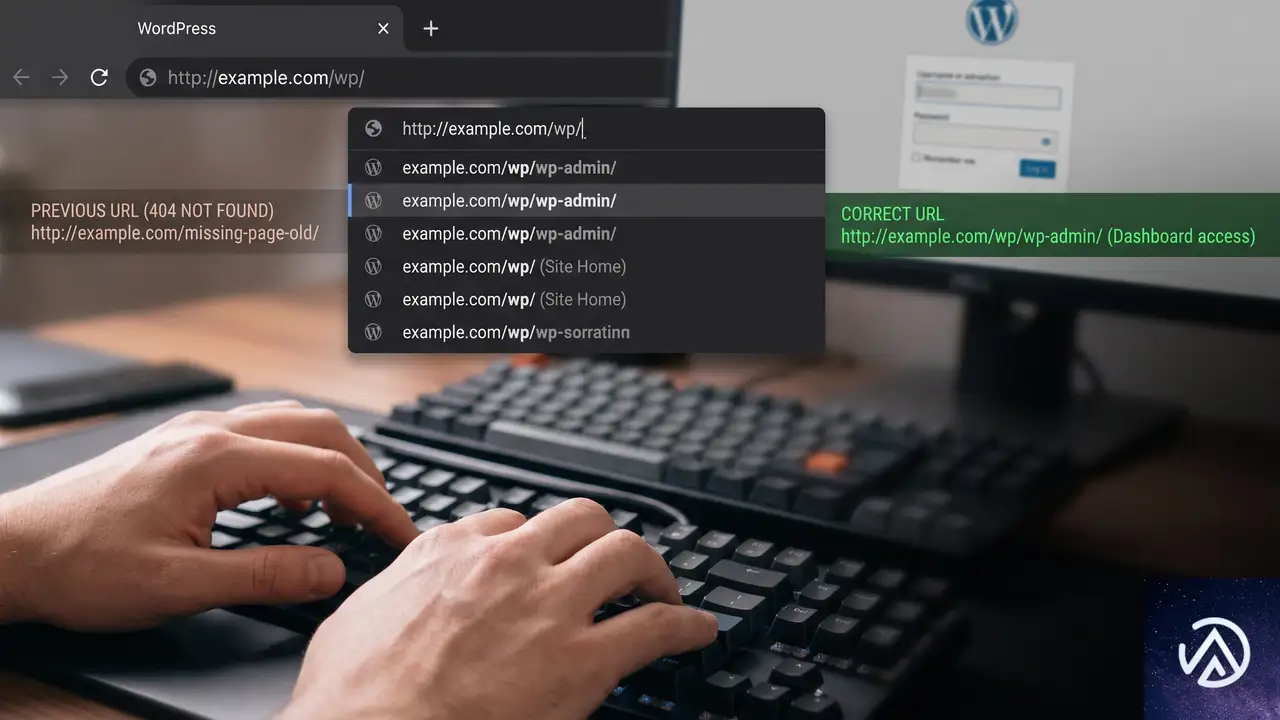
プラグインのアップデートを待たずに、今すぐ該当画面を操作したい場合は、ブラウザのアドレスバーで404になった URL を直接編集する。たとえば /wp-admin/ の直前に、自分の環境で実際に使っているサブディレクトリ名(Bedrock なら /wp/)を挿入して再度アクセスすれば、多くの場合そのまま画面が開く。修正後の正しいパスは /wp/wp-admin/admin.php?page=... の形になる。
この操作はあくまで一時しのぎで、管理画面内の他のリンクも同じ問題を抱えている可能性がある。ページを移動するたびに手動で URL を直すのは現実的ではないため、根本的な解決にはプラグインの修正が必要になる。
プラグインのアップデートで完全に解決する
この種の不具合は、プラグインが WordPress 標準の関数(admin_url() など)を使わずにパスを決め打ちで書いてしまったために起こる。開発者がこの問題に気づけば、次のバージョンで修正されるのが一般的だ。実際、今回の事例の Milo Subscriptions でも、内部の管理画面リンクを WordPress が返す正しい URL から組み立て直す修正がバージョン 1.8.7 で適用された。まずは管理画面の「プラグイン」から当該プラグインの更新がないか確認し、最新版が提供されていれば即座に適用する。
更新がすぐに提供されていない場合でも、問題が発見された後のバージョンでは修正されていることが多い。プラグインの公式ページの「Changelog(変更履歴)」に “Fix admin URLs on subdirectory installs” のような記載があれば、それを当てるだけで解決する。
恒久的な修正のためにプラグイン開発者へ報告する

まだ修正されていないプラグインで同じ症状が出るなら、サポートフォーラムや公式リポジトリの Issues で「サブディレクトリ構成だと管理画面のリンクが404になる」と具体的に伝えるのが最も建設的だ。報告の際は、自分の WordPress が /wp/ や /cms/ などのサブディレクトリにインストールされていること、問題が起こる画面の URL、使っているテーマや主要プラグインのバージョンを添えると、開発者が原因を特定しやすい。サブディレクトリ環境に限ったバグはテストで見落とされやすいため、利用者からの報告がなければ長期間放置される可能性がある。
よくある質問
サブディレクトリへ WordPress をインストールするのは特別なのか
標準的な構成であっても、WordPress 本体を /wp/ や /cms/ といったサブディレクトリに置くことは公式にも認められた設定だ。Bedrock や一部のセキュリティ寄りのスタックは、コアファイルをルートから分離する目的でこの構造を採用している。ただし、プラグインやテーマの開発者が標準構成だけを想定してテストしていると、今回のようなパス解決のミスが残りやすい。
サブディレクトリ環境だと他にどんな不具合が起きるのか
管理画面のリンク切れ以外にも、REST API や Ajax のエンドポイントが見つからずに動作が止まるケースがある。たとえば画像の一括処理やリアルタイム検索が動かなくなることがある。いずれも WordPress が提供する URL 取得関数(rest_url() や admin_url())を使わずにパスを直書きしていることが原因だ。
自分でプラグインのコードを修正してもよいのか
管理画面のリンクをすぐに直す必要があるなら、プラグインの該当ファイルを子テーマやカスタムプラグインで上書きできれば対処できる。ただし、元のプラグインが更新されると上書きが無効になるため、恒久的な対応としては推奨しない。一時しのぎと割り切ったうえで、開発者へのフィードバックとセットで行うのが現実的だ。
Bedrock 以外の構成でも同じ問題は起こるのか
WordPress を /wp/ 以外の任意のディレクトリ(/cms/ /admin/ など)に配置している場合、まったく同じ仕組みで発生する。また、マルチサイトのサブディレクトリ構成でも、特定の管理画面リンクが正しく生成されないことがある。原因の構造は共通しているため、対処の考え方は変わらない。
この記事のポイント
- サブディレクトリ環境ではプラグインの管理画面リンクが404になることがある
- 原因はプラグインがパスをルート相対でハードコードしていること
- 一時的には URL へ正しいサブディレクトリを手動で挿入すればアクセスできる
- プラグインの最新版を確認し、修正があればすぐに更新する
- 修正がまだなら開発者へ具体的な環境情報を添えて報告する

Node.js 2026年7月27日セキュリティリリース、3ラインにHIGH脆弱性修正
Node.jsプロジェクトは2026年7月27日、3つのアクティブなバージョンラインを対象とするセキュリティリリースを公開した。修正される脆弱性の最大深刻度はHIGHだ。対象は26.x系、24.x系、22.x系の3ラインである。
今回のリリースで特筆すべきは、EOL(End of Life / サポート終了)バージョンにも同様の脆弱性が存在するという点だ。公式のリリーススケジュールに従い、サポートが継続しているバージョンへの速やかなアップデートが強く推奨されている。
今回のセキュリティリリースの概要

Node.jsのセキュリティリリースは、発見された脆弱性を修正するために定期的に提供される特別なアップデートだ。通常の機能追加やバグ修正を含むマイナーリリースとは異なり、セキュリティ上の問題に絞って修正が行われる。公開前には事前告知が行われ、ユーザーがアップデートを計画しやすいよう配慮されている。
最大深刻度がHIGHという評価は、CVSS(共通脆弱性評価システム)で7.0〜8.9に相当する。情報漏洩やサービス停止につながる可能性があり、放置するとシステム全体のリスクになる種類の脆弱性だ。実運用環境では速やかな対応が求められる。
影響を受けるバージョンラインと深刻度

今回のセキュリティリリースでは、以下の3つのバージョンラインで修正が提供される。各ラインとも最大深刻度はHIGHだ。現時点で具体的なCVE番号や脆弱性の詳細は公開されていないが、公開後にNode.jsの公式ブログで詳細がアナウンスされる見込みである。
- 26.x系: 最新のメジャーバージョン。最大深刻度HIGH
- 24.x系: LTS(長期サポート)対象バージョン。最大深刻度HIGH
- 22.x系: メンテナンスLTS対象バージョン。最大深刻度HIGH
深刻度HIGHが意味するもの
Node.jsのセキュリティ分類におけるHIGHは、CIA(機密性・完全性・可用性)のいずれかに重大な影響を及ぼす可能性がある脆弱性だ。具体的には、リモートからの攻撃によってサービスが停止したり、メモリ上のデータが漏洩したりするリスクが考えられる。Critical(緊急)ほどの即時性はないが、放置すれば深刻な被害につながるため、計画的なアップデートが必要になる。
過去のNode.jsセキュリティリリースでは、HTTPリクエストのスマグリングやTLS証明書の検証バイパスなどがHIGHとして分類されてきた。いずれもインターネットに公開されているサーバーにとっては重大な脅威だ。
なぜ複数バージョンラインで同時リリースされるのか
Node.jsは複数のバージョンラインを並行してメンテナンスしている。これは、ユーザーが異なるリリースサイクルを選択できるようにするためだ。最新機能を使いたい開発者は偶数系の最新バージョン、安定性を重視するプロジェクトはLTSを選ぶ。
脆弱性が発見された場合、その影響はコードベースを共有する複数のバージョンラインに及ぶことが多い。そのため、Node.jsプロジェクトは全アクティブラインに対して同時に修正パッチを提供する。今回の26.x、24.x、22.xの3ライン同時リリースは、この典型的な対応パターンだ。
EOLバージョンのリスクと対応策

今回のアナウンスで公式が強調しているのが「EOLバージョンも常に影響を受ける」という事実だ。EOL(End of Life)とは、Node.jsプロジェクトが公式サポートを終了したバージョンのこと。20.x系より古いバージョンラインはすでにEOLを迎えており、今回のようなセキュリティリリースの対象外となる。
EOLバージョンを使い続けると、既知の脆弱性が修正されないまま放置されることになる。攻撃者は修正済みの脆弱性を逆解析し、未パッチのシステムを狙うのが一般的な手口だ。とくにインターネットに公開されているサーバーでは、EOLバージョンの使用は極めて危険である。
EOLバージョンからの移行を急ぐべき理由
Node.js 20.x系のEOLはすでに2026年4月30日に迎えている。18.x系はさらに古く、2023年10月にEOLとなった。これらのバージョンにはここ数年で発見された多数の脆弱性が未修正のまま残っている可能性が高い。
移行を躊躇する理由として「動作確認の工数が取れない」「依存パッケージの互換性が心配」といった声がある。しかしセキュリティリスクと天秤にかければ、移行の優先度は明らかに高い。Node.jsのメジャーバージョンアップは、適切なテスト計画を立てれば比較的スムーズに進められるケースが多い。
アップデート手順と注意点
セキュリティリリースの適用方法は、使用しているNode.jsのバージョン管理方法によって異なる。ここでは代表的な3つのケースを紹介する。
nvm install 24
nvm install 22
docker pull node:24
docker pull node:22
sudo apt update && sudo apt upgrade nodejs
# CentOS/RHEL
sudo yum update nodejs
アップデート前の確認ポイント
本番環境に適用する前に、以下の点を確認しておくことが望ましい。とくにNode.jsのバージョンに依存するネイティブモジュール(C++アドオンなど)がある場合は注意が必要だ。
- 依存パッケージの互換性:
package.jsonのenginesフィールドで指定しているNode.jsバージョンと齟齬がないか確認する - CI/CDパイプラインの更新: テスト環境やビルド環境のNode.jsバージョンも合わせて更新する
- ステージング環境での動作確認: 本番適用前にステージング環境でテストを実行し、アプリケーションの動作に問題がないことを検証する
とくにメジャーバージョンをまたぐ移行(20.xから22.x、あるいは20.xから24.x)の場合は、Node.jsの変更履歴を確認し、非推奨APIの削除や動作変更がないか事前にチェックしておくべきだ。
Node.jsセキュリティ情報の継続的な入手方法

今回のようなセキュリティリリースの情報を逃さないために、Node.jsプロジェクトは複数の情報チャネルを提供している。日常的に監視する仕組みを整えておくことで、脆弱性公開から対応までのリードタイムを短縮できる。
組織で取り組むべきセキュリティ監視体制
Node.jsに限らず、利用しているすべてのランタイムやフレームワークのセキュリティ情報を継続的に収集する仕組みが重要だ。具体的には以下の施策が有効である。
- 依存関係の自動監視: DependabotやRenovateなどのツールを使い、セキュリティパッチが公開されたら自動的にプルリクエストが作成されるように設定する
- SBOM(ソフトウェア部品表)の活用: 利用しているコンポーネントを一覧化し、脆弱性情報が公開された際に影響範囲をすぐ特定できるようにする
- セキュリティ情報のRSS購読: Node.js公式ブログのRSSフィードを監視ツールに登録しておく
今回のセキュリティリリースを単発の対応で終わらせず、継続的なセキュリティ監視体制を整えるきっかけにすることを推奨する。
この記事のポイント
- Node.js 26.x/24.x/22.xの3ラインでセキュリティリリースが公開された。最大深刻度はHIGH
- EOLを迎えた20.x以前のバージョンは今回の修正対象外であり、既知の脆弱性が残り続けるリスクがある
- nvm、Docker、パッケージマネージャのいずれかを用いて速やかに最新パッチを適用すべき
- nodejs-secメーリングリストや公式ブログで継続的にセキュリティ情報を入手できる

WooCommerce マイアカウントで顧客情報が保存されない原因と直し方
WooCommerce のマイアカウントページで顧客情報(アカウント詳細)を更新しても、保存や再読み込み後に古い情報に戻ってしまう場合、多くの原因はプラグインの重複フックや非互換性にある。なかでも EU VAT 系プラグインがアカウントページへ勝手に項目を追加し、保存時のデータ上書きや無効化を引き起こす事例が頻発している。
なぜアカウント詳細が保存されないのか

この不具合は大きく分けて3つのパターンに分類できる。優先度が高い順に、VAT フィールドの重複登録、他プラグインとの競合、そしてキャッシュやセッションの不整合だ。
実際のところ、管理画面から何度更新しても「このサイトで重大なエラーが発生しました」という表示が出ず、静かに更新前の値に戻ってしまうケースでは、原因1か原因2の可能性が極めて高い。
VAT フィールドの重複が引き起こす保存不能の仕組み

WooCommerce の最新バージョンでは、ブロックベースのチェックアウトに VAT フィールドを自動で追加する機能が実装された。これが影響し、特定の EU VAT 系プラグイン(WP VAT MOSS など)がマイアカウントページに別途 VAT 項目を出力する場合、同一ページに同じ名前のフィールドが2つ存在する状態になる。
この重複によって、ブラウザが送信する POST データとサーバー側で処理されるフィールド名が食い違い、WooCommerce の `update_user_meta` フックが期待どおりに動作しなくなる。保存ボタンを押しても「処理中」のまま動かない、または一瞬成功したように見えて古い情報が再表示されるという症状が起きる。
WP VAT MOSS など EU VAT 系プラグインの特定と更新

まず管理画面のプラグイン一覧から、以下のキーワードを含むプラグインが有効化されているかを確認する。
- WP VAT MOSS
- EU VAT Assistant
- WooCommerce EU VAT Number
- EU/UK VAT Compliance
これらのプラグインが1つでもインストールされていれば、バージョンが最新かどうかを確かめる。特に WP VAT MOSS の場合、バージョン1.4.6以前で今回の「VAT 重複」バグが報告されており、1.4.7以降にアップデートすることで重複フィールドが解消されるように修正されている。
アップデート後も改善しない場合は、プラグインを一時停止し、標準テーマ(Twenty Twenty-Four など)に切り替えてから再テストする。これで直れば、テーマまたは他のプラグインが VAT フィールドを追加出力している可能性が高い。
プラグインの競合を特定する手順

VAT 以外の情報(名前、メールアドレス、住所など)も更新できない場合は、より広範な競合テストが必要だ。以下の順でトラブルシューティングを進める。
STEP 2 で一時的に無効化するカスタムコードの例を挙げる。`woocommerce_save_account_details` や `woocommerce_save_account_details_errors` などアカウント保存に関わるアクションフックをすべて一時的にコメントアウトし、素の WooCommerce で保存が通るかどうかを見極めるのが確実だ。
キャッシュに惑わされず正しくテストするには
テスト中に「直ったかも」と思ったら実はキャッシュのせいだった、というのはよくある落とし穴だ。以下の点を押さえてテストを進める。
- テストは必ずシークレットウィンドウ(プライベートブラウズ)で行う
- W3 Total Cache や WP Rocket などのキャッシュプラグインを使用している場合は、テスト中は全キャッシュをクリアし、できればプラグインを一時停止する
- サーバー側で Varnish や Nginx の FastCGI キャッシュが動いているレンタルサーバーでは、サーバー管理画面からキャッシュを完全にパージする
- Cloudflare などの CDN を経由している場合は、Cloudflare ダッシュボードで「キャッシュを削除」を実行する
また、WooCommerce のセッションハンドラーがユーザー情報を保持しているケースもある。管理画面の「WooCommerce > ステータス > ツール」から「顧客セッションをクリア」を実行し、そのうえでアカウント更新を試してほしい。
デバッグログを有効にして根本原因を可視化する
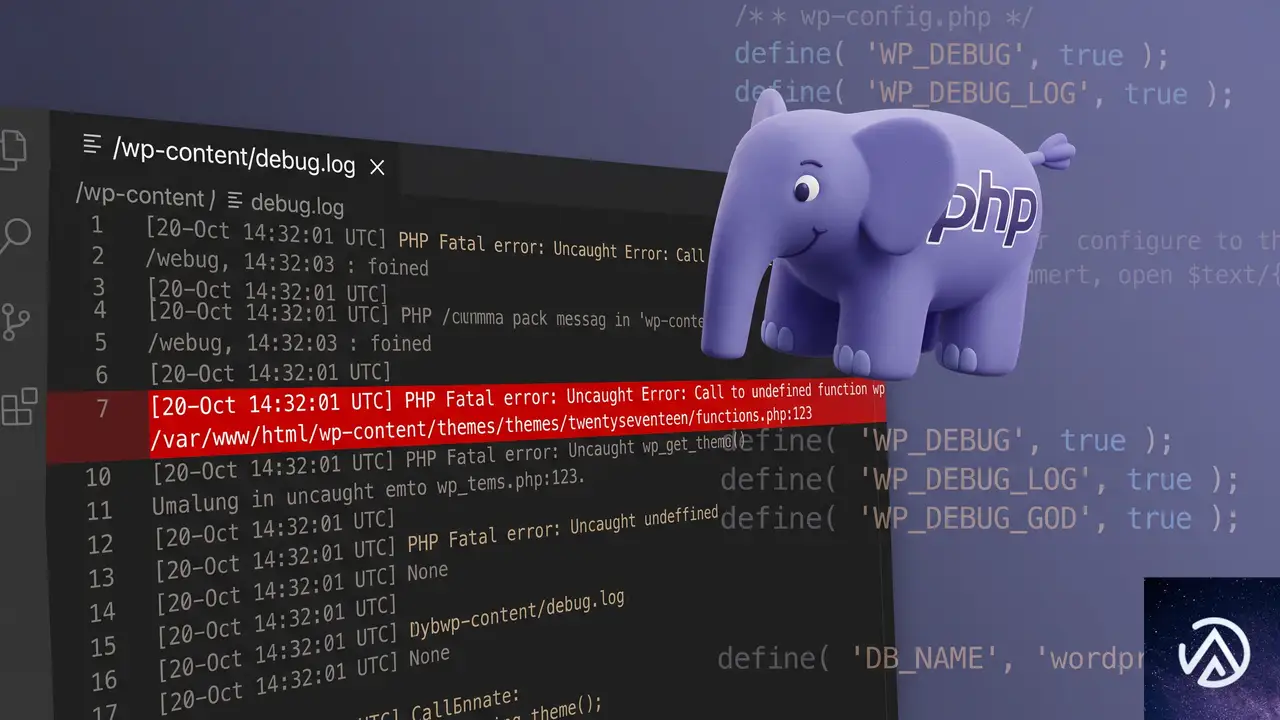
ここまでの方法で解決しない、または原因プラグインを特定できない場合は、WordPress のデバッグモードを有効にしてエラーログを確認する。
FTP またはサーバーのファイルマネージャーから `wp-config.php` を開き、以下の定数を追加または変更する。
define( 'WP_DEBUG', true );
define( 'WP_DEBUG_LOG', true );
define( 'WP_DEBUG_DISPLAY', false );これにより `/wp-content/debug.log` に PHP エラーが出力されるようになる。アカウント詳細の更新を再現したあと、このファイルを開けば、どのプラグインのどのファイルでエラーが発生しているかが具体的に記録される。たとえば「PHP Fatal error: Uncaught Error: Call to undefined function vat_number_save…」のような行が見つかれば、該当するプラグインが犯人だ。
よくある質問
VAT フィールドが増えただけで保存できなくなるのはなぜか
WooCommerce はアカウント保存時に、同名のフィールドが複数あると最後の値だけを処理するか、あるいは処理自体をスキップする。このため表面上は入力できるのにサーバーに反映されず、リロードで元に戻ってしまう。
プラグインのアップデート後も改善しない場合はどうするか
プラグインを完全に削除してから再インストールし、データベースに残った不要なオプション値を手動で削除する。wp_options テーブルにプラグイン固有の設定が残っていると、バージョンアップ後も誤動作することがある。
標準テーマに切り替えられない事情があるときはどうすればよいか
ステージング環境(テスト用の複製サイト)を作成し、そこでのみテーマとプラグインの切り分けテストを行う。本番環境を触らずに原因究明できる方法として最も安全だ。
アカウント詳細の保存だけ失敗し、注文や住所変更は問題なく更新できるのはなぜか
WooCommerce のアカウント保存フックは、注文処理や住所変更のフックとは別に実行される。特定のプラグインがこのフックだけに悪影響を及ぼしている可能性が高い。逆に言えば、影響範囲が限定的なため原因プラグインの絞り込みはしやすい。
PHP のバージョンが古いと起きる問題か
直接的ではないが推奨環境を満たしていないと、プラグインが最新の WooCommerce フックに対応できず、予期せぬ挙動を引き起こすことがある。PHP 8.0 以上を強く推奨する。
この記事のポイント
- アカウント詳細の更新不能は VAT フィールド重複が最も多い原因
- WP VAT MOSS 1.4.7 以降へのアップデートで解決する事例が多数報告されている
- それ以外の競合はプラグインの1つずつ停止とキャッシュクリアで切り分けられる
- デバッグログでエラーを可視化すれば、修正の手がかりが得られる
- テストは必ずシークレットウィンドウとキャッシュ無効状態で行う

Google Cloud、OKF v0.2でエージェント間の信頼問題に挑む
Google Cloudは2026年7月24日、エージェントやAIが生成・共有する知識の信頼を体系的に扱えるフォーマット「Open Knowledge Format(OKF)」のバージョン0.2を発表した。OKF v0.2では、来歴・信頼レベル・鮮度・ライフサイクル・計算結果の証明という5つの問いにファイルのメタデータで直接答えられるようになる。
エージェント同士が大量の知識を自動生成してやり取りする世界では「誰がいつ作り、本当に確認済みで、今も正しいのか」という情報抜きに安心して使えない。OKF v0.2はこの課題に、マークダウンとYAMLフロントマターというシンプルな仕組みで応えるものだ。
すべての新フィールドはオプションであり、v0.1からの後方互換性も保たれている。ただし、これらの信頼信号が「ない」こと自体が「未検証」として識別可能になる点が重要である。
エージェント間知識共有で失われる「暗黙の信頼」を補う
OKFは、テーブルスキーマやメトリクス定義、運用ルールブックといったエージェントが必要とするコンテキストを、特定プロプライエタリなサービスではなく、標準的なフォーマット上に保持することを目指して登場した。2026年6月のv0.1では、マークダウン本体とYAMLのフロントマター、少数の規約という最低限の構成だった。
今回のv0.2は、コミュニティからのフィードバックを踏まえたものである。多くの拡張提案やエコシステムツールのカタログ化が進む一方、最も大きな懸念として浮上していたのが「エージェントが書き込んだ知識を信用できるのか」という問いだった。
人が手書きしたWikiページには、作成者の責任という暗黙の保証がある。しかし、エージェントが一晩で数千もの概念を生成する世界では、その保証は機能しない。消費者(これも別のエージェントであることが多い)は、明示的な信号だけを頼りに概念を評価しなければならず、具体的には次の5つの問いに答える必要がある。
- 何から作られたのか(来歴)
- どれだけ信頼できるのか(信頼)
- まだ正しいのか(鮮度)
- 現在のバージョンはどれか(ライフサイクル)
- その数値は規定の方法で算出されたか(証明)
OKF v0.2では、これらすべての問いにフロントマターのフィールド群で答えられ、しかもフォーマットとしての意見の少なさは維持される。
記述から判断へ、信頼をフィルタリングするメタデータ
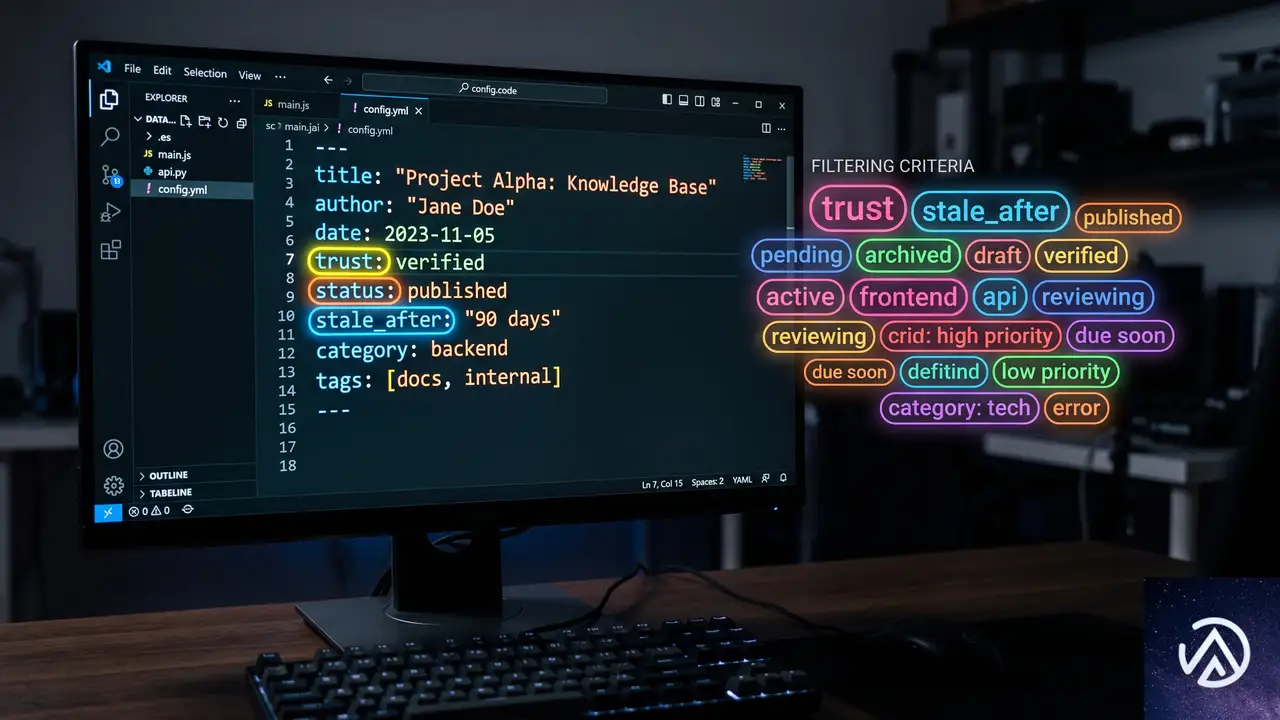
v0.1のフロントマターには、概念のタイプやタイトル、説明、リソース、タグといった「その概念が何か」を示す情報が含まれていた。v0.2ではこれに加え、「読む前にその概念について決断するための情報」、すなわち誰が作り、検証済みか、鮮度はどうか、値がどう計算されるべきかといったフィールドが追加されている。
これらの信号をフロントマターに置く理由は明確だ。エージェントが検索・探索する際、最初に行うのは「この概念がそもそも関連性があるか」の判断であり、多くの場合、ファイル本文にまでアクセスする必要はない。本文に含まれる情報は簡潔であるべきだが、フロントマターは信頼性と関連性の判断だけを支援する信号を凝縮して提供する。トークン消費を抑えつつ、高頻度で安価にチェックできるためだ。
これにより、信頼は「読み始める前にフィルタリングできる」ものになる。
来歴(Provenance)で素材と信頼信号を記録する
新しい sources フィールドは、概念が派生した素材を記録する。外部ドキュメント、バンドル内の相対パス、あるいは「プロジェクトXの全クエリ」といったスコープ記述子まで格段に表現できる。同時に、各エントリは author、usage_count、last_modified といった客観的なクレジビリティ信号を持てる。
ここであえて「信頼スコア」を導入しなかった点がOKFの設計思想を表している。スコアは主観的で、消費者ごとに通用せず、付けられた瞬間から陳腐化しやすい。OKFは信号を記録し、信頼度の推論は消費者側に委ねる。利用頻度が高く、最近更新され、信頼できる作成者がいる素材ほど信頼されるのは人の判断と変わらず、必要に応じて動的にスコアリングも可能だ。
本文中で特定の素材を引用する場合は、通常のマークダウンの脚注記法([^export-schema])を使い、末尾に追いやるのではなく主張単位で出典を結びつける。
信頼の階層を generated と verified で分離する
信頼は2つの独立したフィールドで確立される。何かを作った者とそれを確認した者は必ずしも同一ではないからだ。
generated { by, at }現在のコンテンツが誰によって、いつ最後に意味的な変更を加えられたかを記すverified [ { by, at } ]素材や元リソースに対する独立した確認のリスト。人間の承認、定期的な財務プロセス、あるいは両方を含む
verified の有無と内容から、消費者は「信頼ティア」を導出できる。未入力なら未検証、機械のアクターだけならマシン確認済み、human:<id> が含まれれば人間レビュー済みとなる。これはあくまで助言信号であり、アクセス制御ではない。しかし、エグゼクティブ向けダッシュボードでは「人間レビュー済みのメトリクスだけを表示する」といったフィルタリングがフロントマターだけで可能になる。
title: 売上高
description: 当四半期の純売上
(信頼信号は皆無 / エージェントにとって不透明)
title: 売上高
generated:
by: reference_agent
at: 2026-07-20
verified:
– by: human:vp_finance
at: 2026-07-23
stale_after: 2026-12-31
status: stable
このように、v0.2のフロントマターは「読まずに判断する」ための情報を一箇所にまとめる。概念の本文を開く前に、信頼性でフィルタリングできるため、大量のエージェント生成知識を効率よく扱える。
鮮度とライフサイクルを stale_after と status で宣言する

知識が「今も正しいか」を機械的に判断するために、OKF v0.2は stale_after と status を使う。status は概念を draft → stable → deprecated と遷移させ(省略時は stable)、stale_after は絶対日付で鮮度切れを表す。相対TTL(Time to Live)ではなく絶対日付を採用したのは、非LLMの決定論的な消費者が単純な日付比較で陳腐化を判定できるようにするためだ。
たとえば、ある小売企業の財務チームが毎年1月にポリシーを再承認する場合、関連メトリクスには stale_after: 2026-12-31 を付与する。2027年1月1日以降、これらの概念は再検証を経なければ利用させない、といったルールをコード化できる。また、status: deprecated を設定すれば、古い計算式で定義されたメトリクスを履歴再現用に保存しつつ、新しい作業では表示させないことも簡単だ。
計算の正当性を検証するAttested Computation
来歴は「主張がどこから来たか」を答えるが、エージェントが実際にドル換算の数字を報告する瞬間には、より厳しい問いが必要になる。「その数値は規定された方法で算出されたのか、それともエージェントが勝手にSQLをでっち上げたのか」である。
OKF v0.2は Attested Computation という新しい概念タイプを導入した。これは値の意味だけでなく、認可された計算方法と、それが実際に実行されたことを検査する手段を併せ持つ。エージェントは宣言されたパラメータを埋めるだけで、計算式そのものを編集してはならない。消費者は、指定されたエグゼキューターで計算を実行し、レシート(実行されたSQLやジョブID、結果)を取得し、決定論的なアテスター(LLM不要の検証プロセス)でレシートを検査する。
アテスターは、承認済みの計算定義と実行されたクエリが等価であるか、表示された値がレシートの情報源と一致するかを機械的に確認する。SQLを正規化し、コメントや空白を除去して比較するといった方法で、テーブル名の差し替えやフィルタの追加、JOINの欠落を検出する。検証に失敗すれば、消費者はその値を表示しない。
この仕組みによって、定義の検証(verified)と実行時の証明(アテステーション)が分離される。定義が古くても実行時の証明は通る可能性があり、定義が最新でも毎回の実行で証明を取らなければならない。両者が必要だからこそ、OKF v0.2は双方を備えている。
v0.2の互換性とエコシステム
v0.2はマイナーバージョンアップであり、v0.1のバンドルは無変更でそのまま読み込める。意図的な名称変更として、timestamp が generated.at に、本文末尾の引用リストが sources フィールドに置き換わっているが、いずれもv0.2の消費者がv0.1の形式にフォールバックできる。
GitHub上のリファレンス実装もv0.2対応が進められており、サンプルバンドル(GA4 eコマース、Stack Overflow、Bitcoin、本稿で紹介された小売の例)はv0.2のフィールドを備える。また、Google CloudのKnowledge Catalog(旧Dataplex)を用いたデモでは、OKFの信頼信号をカタログ往復後も維持できることが示されている。
この記事のポイント
- OKF v0.2は来歴・信頼・鮮度・ライフサイクル・計算結果の証明をフロントマターで表現し、エージェント間知識の信頼を形式化する
generatedとverifiedの分離により、作成と確認の責任を切り分け、人間レビュー済みなどのティア別フィルタリングが可能stale_afterとstatusで機械的な鮮度管理とライフサイクル制御を実現- Attested Computationでは計算式の改ざんを検出し、結果の証明を決定論的に行う
- 後方互換性を保ちつつ、信号の不在が「未検証」として区別されることで、暗黙の信頼から脱却できる

WordPress REST APIの400エラーを解決する原因と対処法
WordPressの管理画面でウィジェットの更新や新規ページの公開ができず、REST APIの400エラーが発生する場合、まずW3 Total Cacheの設定とプラグイン同士の干渉を疑う。W3 Total CacheがREST APIのリクエストに干渉してエラーを引き起こすケースが多いため、オブジェクトキャッシュとデータベースキャッシュを一時停止して症状が改善するかを確認するのが最も早い切り分けになる。
REST APIの400エラーが起きる原因は何か

WordPress 4.7以降、管理画面の多くの操作はREST APIを通じて行われる。ウィジェットの更新、固定ページの保存、ブロックエディターのオートセーブなどだ。このAPIのエンドポイントにリクエストを送った際、サーバーが「400 Bad Request」を返すということは、送信されたデータの形式やヘッダー情報に不備があるとサーバーが判断したことを意味する。
ただ、実際には送信データそのものに問題がなくても、プラグインがリクエストの内容を改変したり、キャッシュ機構がAPIのレスポンスを破損させたりして400エラーが発生することが多々ある。特に、W3 Total Cacheのような全ページキャッシュ・オブジェクトキャッシュ・データベースキャッシュを一括して扱うプラグインでは、キャッシュの設定ミスや競合が原因で管理画面の動作に支障をきたしやすい。
ウィジェット更新 → 400 Bad Request
固定ページ公開 → 400 Bad Request
投稿保存 → 200 OK
ウィジェット更新 → 200 OK
固定ページ公開 → 200 OK
上記の図は、投稿だけが正常に動作し、固定ページとウィジェットだけが400エラーになる典型的な症状を示している。これは、投稿の保存パスと他の管理画面パスで異なるキャッシュルールが適用されている可能性を示唆する。
また、管理画面そのものへのキャッシュ適用や、サーバーレベル(cPanel)でのキャッシュ層、セキュリティプラグインによるREST APIアクセス制限も、同様の400エラーを引き起こす。原因は複合的なこともあるため、順を追って切り分ける必要がある。
REST APIエラーを解決する手順

W3 Total Cacheのキャッシュを段階的に無効化する
第一に、W3 Total Cacheの管理画面(「パフォーマンス」→「一般設定」)から、各キャッシュモジュールを一つずつ無効化して症状が改善するか確認する。すべて一気にではなく段階的に止めることで、どのキャッシュ機能がエラーの原因になっているかを特定できる。
W3 Total Cacheの「一般設定」で「オブジェクトキャッシュ」のチェックを外して保存
同様に「データベースキャッシュ」のチェックを外す
ページキャッシュ、ミニファイも停止し、症状が改善するかテストする
各ステップで設定を変更したあとは、W3 Total Cacheの「すべてのキャッシュをクリア」を実行してから、問題の操作(固定ページの公開やウィジェットの更新)を試す。もしオブジェクトキャッシュまたはデータベースキャッシュを停止した段階で問題が解消するなら、それらのキャッシュ方式が使用しているバックエンド(MemcachedやRedis)との通信に問題があるか、cPanel環境で利用できるリソースに制限がかかっている可能性が高い。
管理画面ページをキャッシュ対象から除外する
W3 Total Cacheのページキャッシュ設定には、キャッシュ対象から外すURLパターンを指定する項目がある。管理画面のパス(/wp-admin/)がキャッシュされてしまうと、ノンス(セキュリティトークン)の不整合が起こり400エラーを引き起こす。
「パフォーマンス」→「ページキャッシュ」→「高度な設定」→「キャッシュしないページ」に以下のパターンを追加する。
/wp-admin/
/wp-login.php
/wp-json/それでも改善しない場合は、W3 Total Cacheの設定ファイル(通常は/wp-content/w3tc-config/以下)に直接手を入れる方法もあるが、管理画面からの設定で解決することがほとんどだ。cPanelの「ファイルマネージャー」からFTPアカウントを使ってアクセスできる。
テーマとプラグインの干渉を調べる
Catch Boxのような無料テーマでも、プラグインとの特定の組み合わせでREST APIのリクエストに余計なデータを付加してしまうケースがある。W3 Total Cacheの設定変更だけで解決しない場合は、プラグインの一括無効化による切り分けを行う。
すべてのプラグインを無効化し、デフォルトテーマ(Twenty Twenty-Fiveなど)に切り替えた状態で問題が再現するか確認する。これでエラーが消えるなら、一つずつプラグインを有効化していき、どのプラグインがトリガーになっているかを特定する。特定後は、そのプラグインのREST API関連の設定を見直すか、代替プラグインを検討する。
ブラウザの開発者ツールでエラーの詳細を確認する
ChromeやFirefoxの開発者ツール(F12キー)を開き、「ネットワーク」タブでウィジェット保存時や固定ページ公開時のリクエストを観察する。400エラーが返ってきたリクエストをクリックすると、サーバーから返されたレスポンスボディに具体的なエラーメッセージが含まれていることがある。
例えば、「無効なパラメーター」「cookie nonce is invalid」などのメッセージが確認できる。これにより、キャッシュによるノンス不整合なのか、リクエストパラメーターの欠落なのかをより正確に判断できる。また、ブラウザのコンソールタブにJavaScriptエラーが出ている場合も、それらを併せて確認する。
再発を防ぐための恒久的な設定

原因となったキャッシュ機能を一時停止して問題が解決した場合、そのまま無効にし続けるとサイト表示速度に影響が出る。恒久的な対策としては、W3 Total Cacheのオブジェクトキャッシュやデータベースキャッシュを再び有効化した上で、管理画面のURLパターンをキャッシュ対象から明示的に除外する設定を施す。
また、cPanelからPHPのバージョンやメモリ制限も確認しておく。多くのレンタルサーバーでは、PHPのメモリ制限が256MBに設定されているが、W3 Total Cacheの一部機能はそれ以上のメモリを消費することがある。PHPの設定でmemory_limitを512MB程度に引き上げられるなら引き上げておくと、予期せぬキャッシュ破損やプロセス停止を避けやすくなる。
よくある質問
REST APIエラーはサイトのフロントエンドにも影響するか
通常、REST APIの400エラーは管理画面の操作に限られることが多い。ただし、フロントエンドでWordPressのREST APIを利用した動的な機能(リアルタイム検索や読み込みボタンなど)を使っている場合は、来訪者が同様のエラーに遭遇する可能性がある。
キャッシュプラグインをすべて停止しても直らない場合はどうするか
サーバーレベル(cPanel)のキャッシュ(Varnishなど)が動作している可能性がある。cPanelに「キャッシュマネージャー」や「サイトパフォーマンス」がある場合は、そちらも一時的に無効化して検証する。また、mod_securityなどのセキュリティモジュールがREST APIのリクエストをブロックしているケースもあるため、ホスティング会社のサポートに確認する必要がある。
同じ症状でプラグインがW3 Total Cache以外の場合はどう切り分けるか
WP Super CacheやLiteSpeed Cacheなど、他のキャッシュプラグインでも同様の干渉が起きることがある。切り分け手順は共通で、いったん全プラグインを無効化してから、キャッシュプラグインだけを先に有効化して問題が再現するかを見る。再現すればそのプラグインの設定を調整する。
ブラウザのコンソールに「nonce」関連のエラーが出ている
ノンスエラーは、キャッシュによって管理画面の古いHTML(古いセキュリティトークンを含む)が表示されてしまう場合に起きる。ページキャッシュの除外設定で/wp-admin/ディレクトリ全体をキャッシュ対象から外し、W3 Total Cacheの「クエリ文字列をキャッシュする」設定を無効化すると解消しやすい。
この記事のポイント
- REST APIの400エラーはW3 Total Cacheの設定が主な原因になりやすい
- オブジェクトキャッシュとデータベースキャッシュから段階的に停止して切り分ける
- 管理画面のURLをキャッシュ対象から除外してノンス不整合を防ぐ
- テーマや他プラグインとの干渉がないか全無効化で確認する
- cPanelのPHPメモリ制限やサーバーレベルキャッシュも併せて点検する