

OpenAIがGPT-5.5-Cyberを発表、サイバー防御の最前線に信頼済みアクセス基盤を導入
OpenAIは2026年5月7日、サイバーセキュリティの防御側を支援するための新たな取り組み「Trusted Access for Cyber(TAC / サイバー向け信頼済みアクセス)」を発表した。この枠組みに基づき、研究者やセキュリティチーム向けに最適化されたモデル「GPT-5.5-Cyber」の限定プレビューを公開している。
発表の中核にあるのは、AIの強力なサイバー攻撃支援能力を防御者にだけ安全に開放するという思想だ。すべてのユーザーに同じ性能を提供するのではなく、本人確認と用途の認証を経た防御者のみが、より深い支援を受けられる仕組みを設けている。
この記事では、GPT-5.5-CyberとTACの技術的な仕組み、セキュリティ業界全体への波及効果、そして防御者が実際にどのようなワークフローを加速できるのかを解説する。
信頼済みアクセスでAIの性能を防御側だけに開放する

TACは、AIモデルの振る舞いそのものを利用者の属性に応じて段階的に緩和していく枠組みだ。すべてのユーザーに対して一律に機能制限をかけるのではない。防御タスクを担う検証済みの主体に対してのみ、より踏み込んだ支援をモデルが行うように設計されている。
重要なのは、この仕組みが単なるアカウント管理ではないという点だ。モデル内部の分類器による拒否判断をチューニングし、認可された防御ワークフローでは拒否が起こりにくくなる。OpenAIの記事によれば、この変更によって脆弱性のトリアージ、マルウェア解析、バイナリリバースエンジニアリング、検出エンジニアリング、パッチ検証といった領域で、防御者の作業が大きく加速される見込みだ。
一方で、資格情報の窃取やマルウェア配備といった実害を伴う悪用行為に対する防御壁は、そのまま維持される。このバランス設計こそがTACの根幹をなす。
3段階のアクセスレベル
OpenAIは現在、モデルのアクセス権を3つの層に分けて提供している。一般利用向けの標準的なGPT-5.5、防御ワークフロー向けに拒否判断を最適化した「GPT-5.5 with TAC」、そして最も許容度が高く専門用途向けの「GPT-5.5-Cyber」だ。この3層構造により、用途のリスクに応じた比例的な安全策が実現されている。
GPT-5.5 with TACは、全防御ワークフローの大部分をカバーする設計だ。OpenAIの見解では、ほとんどのセキュリティチームはこの層から始めるのが適切であり、許可済みの作業でなおも拒否に遭遇する場合にのみ、より専門的なアクセスレベルを検討すべきだとされている。
認証とアカウントセキュリティの要件
TACの枠組みでは、防御側に対する本人確認と認証の厳格化が同時に進められている。OpenAIの発表によれば、最もサイバー性能が高く許容度の大きいモデルにアクセスする個人ユーザーは、2026年6月1日以降、フィッシング耐性のある高度なアカウントセキュリティの有効化が必須となる。
組織単位での信頼済みアクセスを利用する場合は、シングルサインオンワークフローの一環としてフィッシング耐性認証を導入していることを表明する代替手段も用意されている。この設計により、利便性を損なわずに信頼性を担保するバランスを取っている。
GPT-5.5-Cyberがもたらす防御ワークフローの加速

GPT-5.5-Cyberの公開にあたり、OpenAIは具体的なユースケースを挙げている。公開済みの脆弱性から概念実証コードを生成し、認可された環境下で修正の有効性を検証するといった作業が、モデルによって大幅に効率化されるという。
OpenAIの公式ブログに掲載された比較例では、標準的なGPT-5.5がセキュリティ関連のコード生成を拒否するのに対し、GPT-5.5 with TACは同じプロンプトに対して詳細な概念実証と分析を提供している。この違いは、分類器のチューニングによってもたらされるものだ。
標準モデルとの違いは「ケイパビリティ」より「許容度」
GPT-5.5-Cyberは、一般的な知識作業やセキュリティタスクにおいて最も賢く直感的なモデルであるGPT-5.5を基盤としている。OpenAIは、この初期プレビューがGPT-5.5を超えるサイバー能力を発揮することを主眼とはしていないと明言している。
性能評価の結果でも、すべてのサイバーセキュリティ評価項目でGPT-5.5を上回るわけではない。このモデルの主な価値は、多段階推論やツール利用を含む現実的な防御ワークフローにおいて、より「許可的」に振る舞う点にある。防御者が分析から検証までを止まらずに進められる環境を提供することが目的だ。
このアプローチは、単純にモデルの性能を引き上げるよりも現実的な安全策といえる。より強力な検証と監視の枠組みと組み合わせることで、専門的な作業が必要な場面にだけ踏み込んだ支援を提供できるからだ。
セキュリティエコシステム全体を回す「フライホイール」

OpenAIの戦略で特に注目すべきなのは、モデルの提供先を多層的なエコシステムとして捉えている点だ。セキュリティベンダー各社との連携を通じて、発見から開発、検出、対応、ネットワーク制御に至る防御の全レイヤーを同時に強化しようとしている。
このサイクルは「セキュリティフライホイール」と呼ばれ、各レイヤーの改善が他のレイヤーの改善を加速させる相乗効果を生み出す。研究者が概念実証とパッチガイダンス付きで脆弱性を開示し、サプライチェーンツールが本番環境への侵入を防ぎ、EDRやSIEMが攻撃の兆候を検出し、ネットワークプロバイダーがWAFレベルの緩和策を展開する。この連鎖をAIが加速する構図だ。
このエコシステム戦略が意味するのは、GPT-5.5シリーズが単独のツールとしてではなく、業界全体の防御基盤として設計されているという点だ。OpenAIは既にCisco、Intel、SentinelOne、Snykといった主要ベンダーと協業を進めており、各社の声明も公式ブログに掲載されている。
各レイヤーでの具体的な活用シナリオ
ネットワークプロバイダーは、修正パッチが完全に展開される前の段階で被害を抑え込む役割を担う。GPT-5.5はWAFルールのレビューや構成分析、インシデント調査、安全な変更管理を支援し、インターネット規模での防御展開を可能にする。
脆弱性研究の領域では、未知のコードベースの理解、影響を受ける範囲の特定、根本原因の追跡、パッチの検証、そして深刻度の優先順位付けまでを一貫して支援する。より踏み込んだ概念実証が必要な場合に、GPT-5.5-Cyberが限定的に提供される設計だ。
検出と監視の分野では、EDRやSIEMのテレメトリデータから重要なシグナルを抽出し、分析官が開示情報から調査までを迅速に進められるようにする。とくにクラウド環境では、露出の把握から修正、検出までが密接に結びついており、AIによる接続が効果を発揮する。
ソフトウェアサプライチェーンセキュリティでは、GPT-5.5 with TACが依存関係の変更点の調査や、所有コード内での悪用可能性の推論、不審なパッケージ動作の早期発見を支援する。OpenAIは、axiosの侵害事例のように、脆弱な依存関係がビルドに入り込む前に阻止することが最速の対処法だと位置づけている。
オープンソースとCodex Securityによる上流支援

OpenAIはエコシステムの上流にあたるオープンソースメンテナーへの投資も進めている。Codex Securityを活用し、コードベース固有の脅威モデルを構築した上で、現実的な攻撃経路の探索やパッチの提案を行う仕組みを研究プレビューとして提供中だ。
さらに「Codex for Open Source」プログラムを通じて、重要なプロジェクトのメンテナーにCodex Securityへの条件付きアクセスとAPIクレジットを提供している。これにより、メンテナンスやレビューの負荷を軽減しながら、上流での脆弱性対処を加速させる狙いがある。
Codex Securityのプラグインも公開されており、既存のワークフローの中で脅威モデリングから発見、検証、攻撃経路分析、修正までをシームレスに進められるよう設計されている。
TACへのアクセス方法と今後の展望

Trusted Access for Cyberへの参加は、個人ユーザーであれば専用ページから本人確認を行うだけで申請できる。企業の場合はOpenAIの担当者を通じて、チーム単位での信頼済みアクセスをリクエストする仕組みだ。承認されたユーザーは、二重用途のサイバー活動に対する分類器の拒否が緩和されたモデルを利用できるようになる。
OpenAIの発表によれば、GPT-5.5-Cyberはアルファテストの段階で既に重要システムの自動レッドチーミングや深刻度の高い脆弱性の検証に活用されている。これらの成果については、責任ある開示の一環として、今後技術的な詳細が公開される予定だ。
モデルのサイバー能力が向上するにつれて、その能力を防御側の手に届けるための信頼基盤の重要度も増していく。より強固な本人確認や組織検証、認可された用途のスコープ定義、悪用監視の仕組みが成熟するにつれて、アクセス権は徐々に拡大されていくと見られる。
この記事のポイント
- TACは利用者の属性に応じてAIの防御支援能力を段階的に開放する枠組みである
- GPT-5.5 with TACは大半の防御ワークフローを安全にカバーし、多くのチームにとって最適な出発点となる
- GPT-5.5-Cyberはレッドチーミングなど専門的な二重用途ワークフロー向けの限定プレビューである
- セキュリティベンダーとの連携により、発見から緩和までの全レイヤーを加速するフライホイール効果を狙う
- オープンソースメンテナーへのCodex Security提供など、エコシステム上流への投資も同時に進められている

Next.js 2026年5月セキュリティリリースの全容、13件の脆弱性を修正
Next.jsの開発元であるVercelは2026年5月7日、調整済みセキュリティリリースを公開した。React Server Componentsの上流脆弱性(CVE-2026-23870)への対応を含む、合計13件の脆弱性が修正されている。フレームワークを利用するすべての開発者にとって、即時のアップデートが強く推奨される内容だ。
今回のリリースで対処された問題は、サービス拒否(DoS)攻撃、ミドルウェアやプロキシのバイパス、サーバーサイドリクエストフォージェリ(SSRF)、キャッシュポイズニング、クロスサイトスクリプティング(XSS)と多岐にわたる。ただちにパッチを適用しなければ、本番環境が深刻な攻撃に晒されるリスクがある。
アップデートの概要と影響範囲
今回のセキュリティリリースはNext.js本体に加え、その根幹をなすReactの特定パッケージにも修正が及ぶ。Vercelの発表によれば、13件の脆弱性アドバイザリが一挙に解決された形だ。アドバイザリの内訳を見ると、攻撃の種類によって影響を受ける機能や設定が明確に分かれている。自社のプロジェクトがどのカテゴリに該当するかを把握することが、迅速な対応への第一歩となる。
● React Server Components の DoS
● キャッシュポイズニング
● SSRF の潜在的リスク
● DoS 攻撃から保護
● キャッシュへの不正注入を防止
● SSRF の脆弱性を遮断
13件の脆弱性が存在する「Before」の状態と、アップデートによってそれらがすべて解決された「After」の状態を比較したイメージだ。リリースによってセキュリティ上のリスクが一掃されることがわかる。
修正対象となったReactとNext.jsのバージョン
影響を受けるバージョンを把握し、修正済みの安全なバージョンへ移行する必要がある。今回のリリースで修正が提供されたバージョンは以下の通りだ。
まず、React本体については、19.0.6、19.1.7、19.2.6の3つのパッチがリリースされた。これらのバージョンでは、サーバーコンポーネントの通信用パッケージである react-server-dom-parcel、react-server-dom-webpack、react-server-dom-turbopack の各パッケージに修正が含まれている。
Next.jsをフレームワークとして利用している場合、これらのReactパッケージはNext.jsのバージョンにバンドルされている。そのため、開発者はNext.js本体を最新のパッチバージョンに更新することで、React側の修正も同時に適用できる。個別にReactパッケージを管理しているプロジェクトは、それらも忘れずにアップデートする必要がある。
各脆弱性の詳細とリスク評価

ここからは、発表されたアドバイザリを深刻度別に整理し、その技術的な背景をひも解いていく。影響を受けるコンポーネントと、攻撃が成立するシナリオを正しく理解することが、開発者としての適切なリスク評価に繋がる。
ミドルウェアとプロキシのバイパス
認証や認可のロジックを middleware.js や proxy.js に依存しているアプリケーションが、致命的な影響を受ける可能性がある。2件の「高」深刻度アドバイザリがこれに該当する。
1件目はApp Routerにおける segment-prefetch のバイパスで、過去の修正が不完全だったための再発フォローアップだ。2件目はPages Routerのi18n機能において、デフォルトロケールのパスがプロキシ認証を迂回してしまう問題である。多言語サイトをPages Routerで運用しており、middlewareでアクセス制御を行っている環境は特に注意が必要だ。
サービス拒否(DoS)攻撃
サーバーのリソースを枯渇させ、正規のユーザーがサイトにアクセスできなくなるDoS攻撃に関する脆弱性が3件報告されている。これらはすべて、Server Functions、Partial Prerendering(PPR)のCache Components、もしくは画像最適化APIの利用が条件となる。
最もクリティカルなものは、React Server Componentsの上流脆弱性(CVE-2026-23870)を突いた攻撃だ。Vercelの発表によると、この脆弱性によりリモートからのDoS攻撃が成立する。また、Cache Componentsを使用するアプリケーションにおける「接続数の枯渇」を引き起こす脆弱性も「高」深刻度と評価されている。画像最適化APIを経由したDoSは「中」深刻度だが、無視できるものではない。
この図は、悪意あるリクエストによってサーバーのリソースが消費され、本来のサービス提供が妨害されるDoS攻撃の基本的な流れを示している。Cache Componentsの脆弱性は、この「リソース枯渇」の段階を特に加速させる危険性がある。
サーバーサイドリクエストフォージェリ(SSRF)
SSRFは、攻撃者がサーバーを踏み台にして内部ネットワークへのリクエストを強制させる攻撃手法だ。今回の脆弱性は、WebSocketへのアップグレードリクエストを処理するアプリケーションが影響を受ける。
この種の攻撃が成功すると、攻撃者は本来アクセスできない内部のメタデータサービスやデータベースと通信できるようになる。クラウド環境(AWSやGCPなど)で稼働しているNext.jsアプリケーションは、特に深刻な被害に繋がる可能性があるため、迅速な対応が求められる。
キャッシュポイズニングとクロスサイトスクリプティング(XSS)
React Server Componentのレスポンスの前にキャッシュ層を配置しているアプリケーションは、キャッシュポイズニングのリスクに晒される。これは、攻撃者が悪意あるレスポンスをキャッシュサーバーに記憶させ、他のユーザーにその不正なコンテンツを配信させる攻撃だ。
XSSに関しては、App RouterでCSP(コンテンツセキュリティポリシー)のnonceを利用しているケース、そして外部からの信頼できない入力を消費する beforeInteractive スクリプトが影響を受ける。これらの設定は比較的高度なカスタマイズで使われるが、該当する場合はすぐに対処しなければ攻撃者によるスクリプト実行を許してしまう。
即時アップデートの必要性と対応手順

Vercelは今回のリリースに際し、新たなWAF(Web Application Firewall)ルールを展開していないと明言している。つまり、これらの脆弱性はWAFレベルで確実にブロックすることができず、パッチ適用が唯一の完全な緩和策となる。
アップデート手順の基本
まず、プロジェクトのNext.jsとReactのバージョンを確認する。package.jsonに記載されているバージョンが、今回の修正対象より古い場合は即座にアップデートを実行する。一般的な手順は以下の通りだ。
# Next.jsのアップデート
npm install next@latest
# 関連するReactパッケージも最新に
npm install react@latest react-dom@latestyarnやpnpmなど、他のパッケージマネージャーを利用している場合も、同等のコマンドで問題ない。パッケージを更新した後は、必ずビルドとテストを実行し、アプリケーションが正常に動作することを確認してほしい。
本番環境でのリスク管理
今回のセキュリティリリースには、破壊的な変更は含まれていない。そのため、動作検証は必要だが、適用を躊躇する技術的理由はほぼない。重要なのは「スピード」だ。
とりわけ、middlewareで認証を実装しているサイト、WebSocketを処理するリアルタイムアプリケーション、そしてPPRやCache Componentsを採用しているパフォーマンス重視のサイトは、緊急度が極めて高い。Vercelの発表でも「all affected users should upgrade immediately(影響を受けるすべてのユーザーは直ちにアップグレードすべき)」と強い表現で呼びかけている。
今回のリリースが示すNext.jsセキュリティの潮流

一見すると大規模な脆弱性の一括修正はネガティブな出来事に思える。しかし、セキュリティの観点からは、むしろフレームワークの成熟度を示すポジティブなシグナルと捉えるべきだ。
まず、対策が「調整済みセキュリティリリース」として計画的に実施されている点が重要だ。これは、VercelとMeta(React)のチームが発見された問題を共有し、エコシステム全体で同時に対処する体制が整っていることを意味する。大規模なOSSプロジェクトでは、このような「調整済み開示」のプロセスがセキュリティ品質の生命線となる。
次に、脆弱性の範囲が「Server Components」「ミドルウェア」「エッジキャッシュ」「画像最適化API」といった、Next.jsの比較的新しい機能や高度な機能に集中している事実に注目したい。これは、攻撃者の標的が、従来のシンプルなWebアプリケーションから、エッジとサーバーを高度に組み合わせたモダンなアーキテクチャへとシフトしている証左だ。
SSRやエッジファンクションの利用が一般化するにつれ、開発者は「新しい機能がもたらす利便性」と「新たな攻撃表面が生まれるリスク」のバランスを常に意識する必要がある。便利なAPIほど、その裏側で何が起きているのかを深く理解することが、これからのフロントエンド開発者には不可欠だ。
この記事のポイント
- Next.js 2026年5月セキュリティリリースは、ReactのCVE-2026-23870を含む13件の脆弱性を修正する
- 影響範囲はDoS、ミドルウェアバイパス、SSRF、キャッシュポイズニング、XSSと多岐にわたる
- WAFでは防げない脆弱性群のため、Next.jsとReact関連パッケージの即時アップデートが唯一の対策
- とくに認証機能やServer Components系の新機能を使うプロジェクトは緊急度が高い
- 調整済みリリースの実施は、Next.jsエコシステムのセキュリティ成熟度を示すポジティブな側面でもある
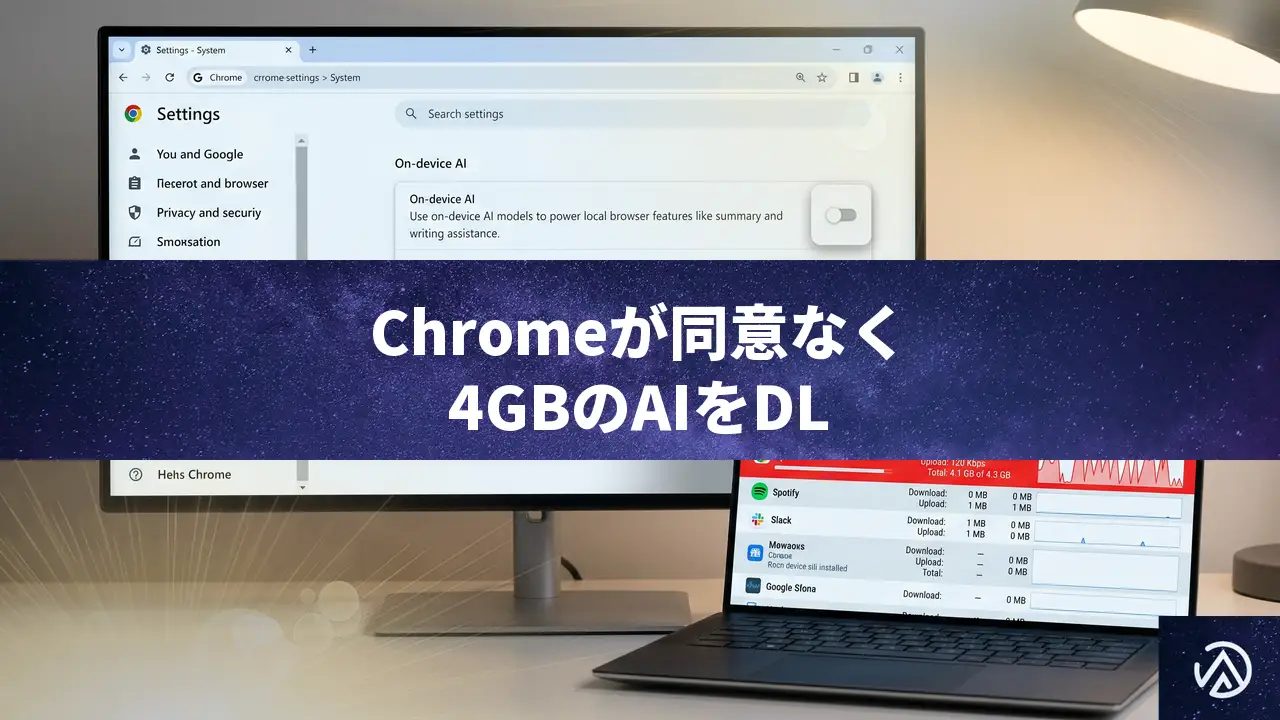
Chromeが同意なく4GBのAIモデルをダウンロードする問題
Google Chromeがユーザーの明示的な許可なく、約4GBに及ぶGemini Nanoのモデルデータをダウンロードしている事実が明らかになった。このデータは「Prompt API」と呼ばれる新機能のためのものだが、その配信方法と利用規約をめぐって、Web標準の専門家から強い懸念が示されている。
CSS-Tricksの記事によれば、このダウンロードはChromeの標準アップデートの一部として扱われ、ユーザーが削除してもブラウザが自動的に再ダウンロードする仕様だという。2025年5月現在、すでに多くのユーザーのデバイスに配信済みの状態だ。
Chromeが密かにダウンロードするGemini Nanoとは
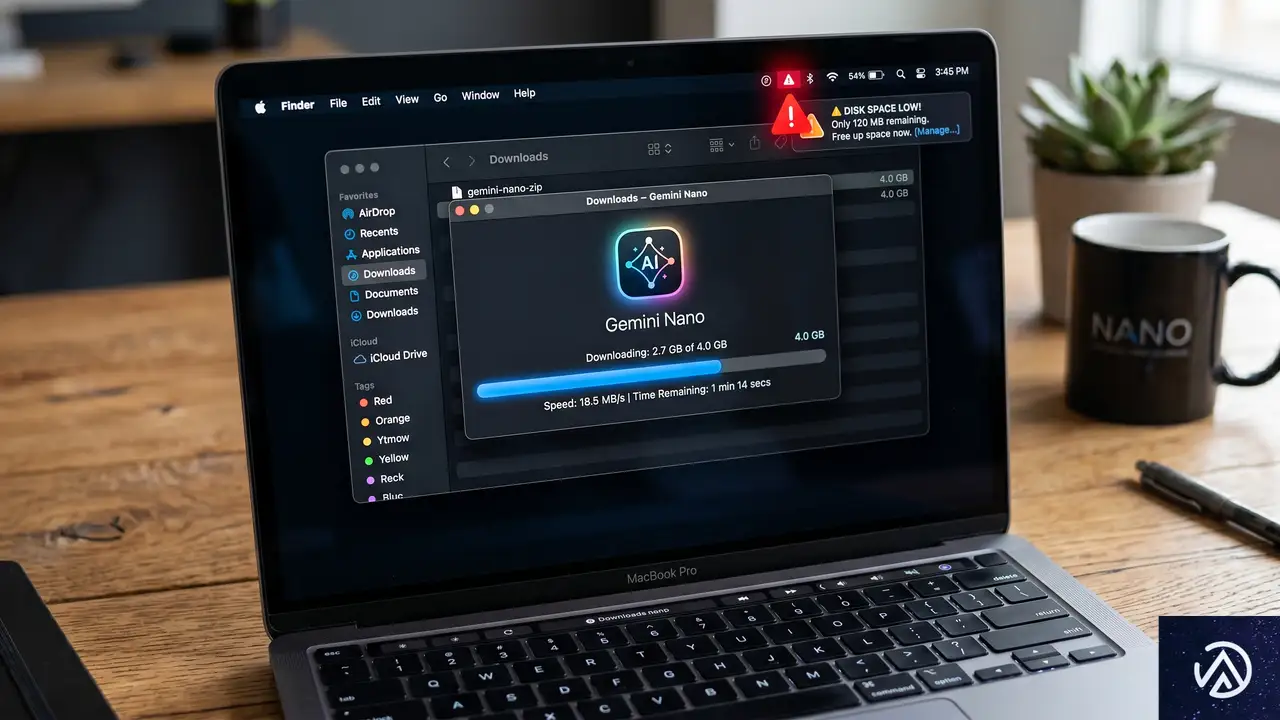
Gemini NanoはGoogleが開発した軽量AIモデルで、デバイス上で直接テキスト生成や要約などのタスクを実行する。クラウドにデータを送信せず、端末のCPUやGPUのみで推論を行うため、プライバシー保護の観点では優れた設計といえる。
問題はその配信方法だ。CSS-Tricksの著者であるMat Marquis氏が指摘したところによれば、この約4GBのデータはChromeの通常アップデートの一部として、ユーザーに何の通知もなく転送される。U2のアルバムがiTunesライブラリに強制的に追加された過去の事例になぞらえ、同意なき配信の奇妙さを強調している。
Gemini Nano(同意なし・通知なし)
削除してもChromeが再ダウンロードを実行するため、ユーザーに実質的な拒否権はない。Chromeの内部機能として扱われているが、実際にはブラウザに統合されたわけではなく、独立した製品が同梱されている状態に近い。Mat Marquis氏は、かつてスパイウェアとして批判されたBonzi Buddyがブラウザに同梱されていた事例を引き合いに出し、その類似性を指摘している。
Prompt APIの仕組みとGoogleの利用制限
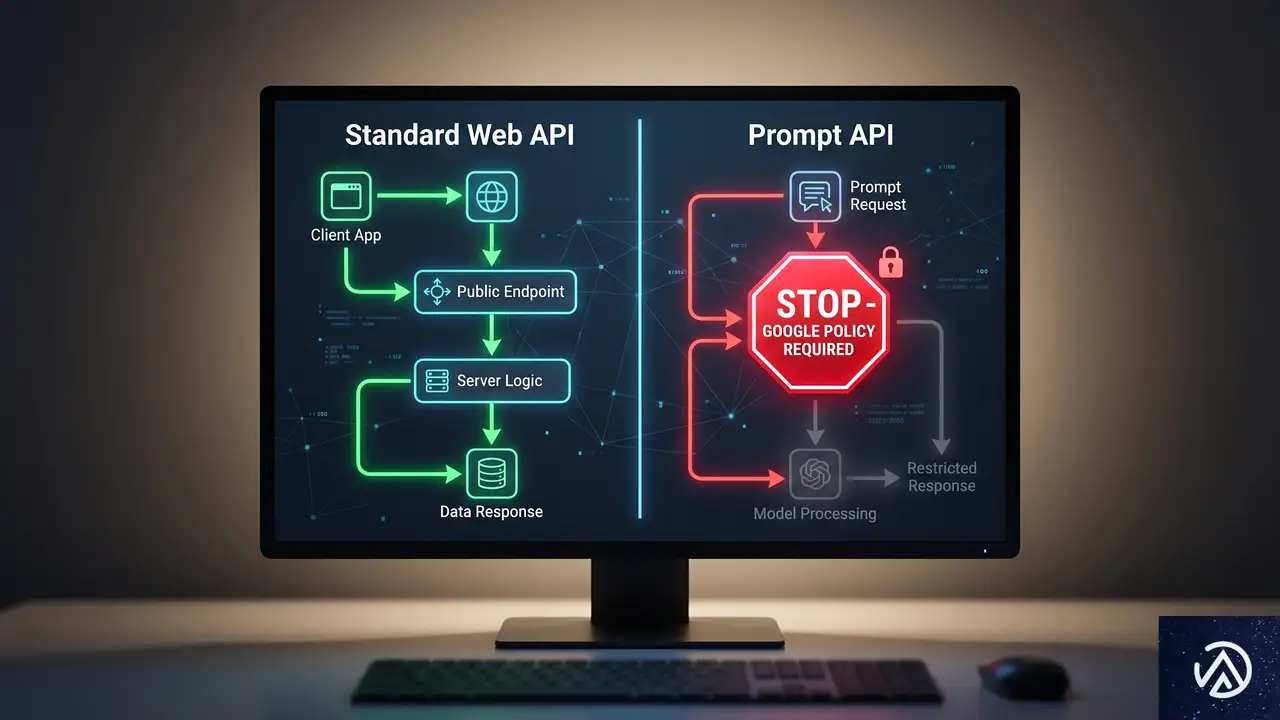
Prompt APIは、Web開発者がChromeの組み込みAIモデルに直接アクセスできるJavaScript APIだ。ユーザーのデバイス上でテキストの要約、文章の言い換え、質問応答といった処理を実行できる。Chromeの開発者向けドキュメントでは、すでに1年以上前から公開されている。
このAPIを利用するには、Googleが定める「Generative AI Prohibited Uses Policy」への同意が必須となる。Mozillaが公式に懸念を表明したのは、この利用ポリシーの内容がWeb標準の原則と相容れないからだ。
Web APIに付随する利用ポリシーの問題点
MozillaのGitHub上のコメントによれば、Googleの禁止事項ポリシーは法律の範囲を超えた制限を含んでいる。具体的には、性的に露骨なコンテンツの生成や配布の禁止、誤情報や政府・民主的プロセスに関する誤解を招く主張の促進禁止などが盛り込まれている。
これらの制限はWebプラットフォームのAPIとしては異例だ。通常、ブラウザAPIは技術的な仕様のみを定義し、その使途を特定企業のポリシーで制限することはない。Mozillaは「これはWebプラットフォームにとって悪しき方向性であり、UA(ユーザーエージェント)固有の使用ルールを持つAPIが増える前例となる」と警告している。
この構造は、Webのオープン性を損なう可能性がある。特定のブラウザベンダーがAPIの利用条件を自由に設定できるなら、Webの相互運用性は徐々に崩れていく。Mozillaの反対表明は、単なる競合他社の立場表明ではなく、Web標準の基本原則を守るための警鐘と受け止めるべきだ。
Web標準プロセスにおけるGoogleの影響力

Mat Marquis氏は、GoogleのWeb標準への関与姿勢を痛烈に批判している。同氏の比喩によれば「GoogleのWeb標準プロセスへの参加は、クマがキャンプに参加するようなものだ」という。つまり、表面上は協調しているように見えても、実質的には自社の都合でプロセスを支配しているという指摘だ。
Googleは「開発者のポジティブな感情」を根拠にPrompt APIの推進を正当化しようとしたが、実際に引用された場所にはポジティブな感情など存在しなかった。この矛盾した説明は、同社がWeb標準を「不可避なもの」として語る際の常套句と重なる。
ブラウザAPIとWeb APIの混同が生むリスク
ここで重要なのは、すべてのブラウザAPIがWeb APIではないという事実だ。Chromeだけが実装するAPIは、事実上の標準として扱われるリスクをはらむ。MicrosoftのIEが独自拡張で市場を支配した過去の過ちを、形を変えて繰り返す可能性がある。
Alex Russell氏が繰り返し指摘しているように、ブラウザの選択肢が限られている現状はすでに問題含みだ。その状況下でGoogleがChrome限定のAI APIを推進することは、Webの多様性をさらに損なう。ブラウザの多様性が生態系に与える影響について、CSS-Tricksでも過去に取り上げられているテーマだ。
ユーザーが取るべき対応と無効化手順

この問題に対して、現時点でユーザーが取れる対応は限られている。Chromeの設定画面で「オンデバイスAI」の項目をオフにすることは可能だが、すでにダウンロードされた4GBのモデルデータを完全に削除し、再ダウンロードを防ぐ方法は提供されていない。
この問題に関する報道は複数のメディアで取り上げられている。Engadgetは「Chromeがユーザーの同意なく4GBのAIファイルをダウンロード」と報じ、Cybernewsは「Chromeが我々のデバイスに静かに4GBのAIモデルをインストールしている」と警告した。Android Authorityでは、このダウンロードがスパイウェアに該当するかどうかの議論まで展開されている。
この記事のポイント
- Google Chromeがユーザーの同意なく約4GBのGemini Nanoモデルをダウンロードしている
- 削除しても自動的に再ダウンロードされ、実質的な拒否手段が提供されていない
- Prompt APIの利用にはGoogle独自のコンテンツポリシーへの同意が必須で、MozillaがWeb標準の観点から反対を表明
- ブラウザベンダー固有のAPI利用制限は、オープンなWebの原則を損なう前例となる危険性がある
- Chrome設定の「オンデバイスAI」から機能自体はオフにできるが、データ削除の確実な方法は提供されていない

GPT-5.5 Instant 登場。回答精度とパーソナライズ性能が大幅に向上
OpenAIがChatGPTのデフォルトモデルを「GPT-5.5 Instant」に更新した。これまで標準搭載されていたGPT-5.3 Instantを置き換える形で、全ユーザーに順次提供が開始されている。
今回のアップデートの核心は3つだ。事実誤認の大幅な減少、回答の簡潔さの向上、そして過去のチャット履歴や接続アプリを活用した高度なパーソナライズ機能の追加である。内部評価では、医療や法律、金融といった高精度が求められる分野でのハルシネーション(もっともらしい嘘)が52.5%も削減された。
何億人ものユーザーが日常的に利用するデフォルトモデルだからこそ、小さな改善の積み重ねが実用面では大きな差を生む。本記事ではGPT-5.5 Instantの具体的な進化点と、それが実際の利用体験にどう影響するのかを掘り下げていく。
事実誤認を半減させた精度向上の仕組み

GPT-5.5 Instantにおける最大の改善点は、事実誤認(ハルシネーション)の劇的な減少だ。特に医療、法律、金融といった「間違いが許されない領域」で顕著な成果が出ている。
なぜここまでの改善が実現できたのか
OpenAIの公式ブログによると、GPT-5.5 Instantは高精度が求められるプロンプトにおいて、GPT-5.3 Instantと比較してハルシネーション(幻覚)を52.5%削減した。さらに、ユーザーが事実誤認を指摘したチャレンジングな会話においても、不正確な回答を37.3%減らしている。
この改善は単なる「よくわからないときは正直にわからないと言う」といった表面的な振る舞いの調整ではない。モデル自身が回答の妥当性を検証する能力が底上げされており、途中で誤りに気づいた際には自律的に修正できるようになった点が本質的な進化だ。
具体的な改善例から見えるもの
OpenAIが公開した比較例では、GPT-5.5 Instantは数学の問題に対して最初に不正確な解法を提示してしまった場合でも、代入チェックによって誤りを検出し、二次方程式の正しい解へと自力で修正している。一方でGPT-5.3 Instantは誤りに気づいてはいるものの、「解がない」と早々に結論づけてしまい、問題の本質に迫れなかった。
日常生活で使うAIアシスタントにとって、この「自己修正能力」は極めて重要だ。最初の回答が100%正しい必要はないが、誤りに気づいて軌道修正できるかどうかが実用性を大きく左右する。GPT-5.5 Instantのこの特性は、ビジネス文書の作成やデータ分析など、正確性が求められるシーンで特に頼りになるだろう。
冗長な表現を30.2%削減、それでも情報量は落とさない
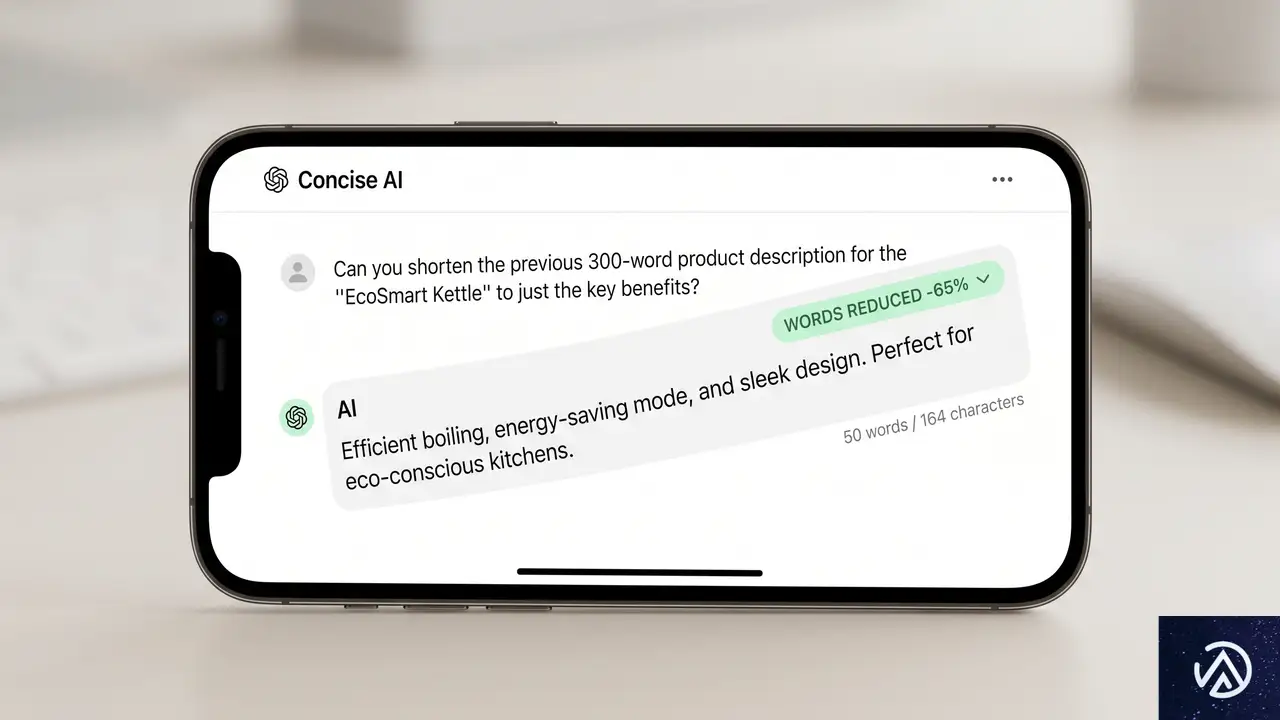
行数:基準値
過剰な絵文字:あり
行数:29.2%削減
不要な装飾:ほぼなし
GPT-5.5 Instantの回答は、前世代モデルと比較して単語数が30.2%、行数が29.2%も削減されている。この数字だけ見ると「情報量が減ったのでは」と心配になるが、実際は逆だ。余計な説明や過剰なフォーマットを省くことで、本当に必要な情報が見つけやすくなっている。
減ったのは「無駄」であって「中身」ではない
OpenAIの説明によると、新モデルは同じ情報をより少ない言葉で届けつつ、むしろ実用性は向上しているという。たとえば職場の人間関係に関するアドバイスを求めるプロンプトでは、GPT-5.3 Instantが「してはいけないこと」を含めた完全なフォーマットで回答するのに対し、GPT-5.5 Instantは状況に応じた実践的な言い回し例を提示し、問題を相手の人格ではなく「境界線」の問題として捉え直す視点を提供している。
ビジネスシーンで重要なのは、この「トーンの適切さ」だ。カジュアルな質問に過剰にフォーマルな回答が返ってくると、むしろ使う側のストレスになる。GPT-5.5 Instantは、状況に応じてフォーマル度を調整できるようになった点で、より人間らしい対話が可能になっている。
チャット履歴や接続アプリを活用した高度なパーソナライズ
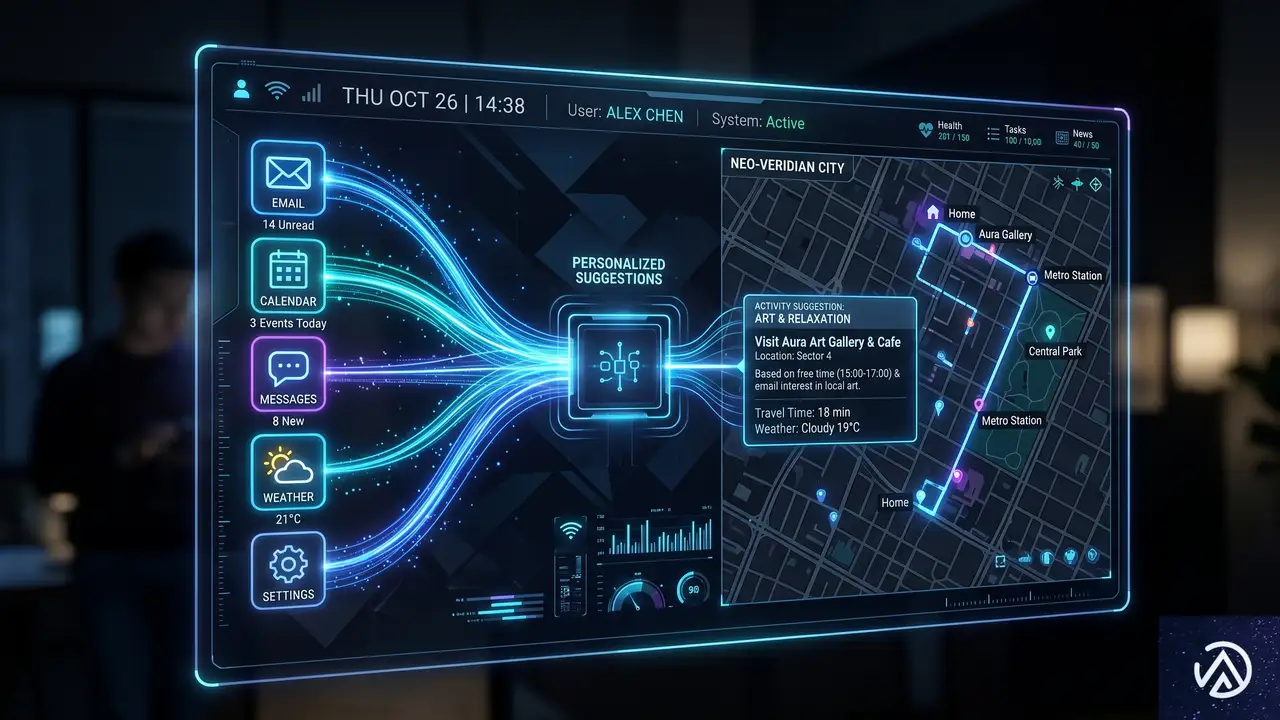
会話の開始 → 過去履歴を検索 → 関連コンテキストを取得 → カスタマイズされた回答を生成
GPT-5.5 Instantのもう一つの大きな進化が、パーソナライズ機能だ。過去のチャット履歴やアップロードしたファイル、さらに接続を許可したGmailの情報などを横断的に参照し、より個人に最適化された回答を提供できるようになった。
「メモリーソース」で見える化されたパーソナライズ
今回のアップデートで特筆すべきは「メモリーソース(Memory Sources)」という新機能の導入だ。これは、AIがどの情報を根拠にパーソナライズされた回答を生成したのかを明示する仕組みである。保存されたメモリーや過去のチャットのうち、回答に使用されたものをユーザーが直接確認でき、不要になった情報は削除や修正ができる。
OpenAIのブログ記事では、サンフランシスコ在住のユーザーに対するレストラン提案の比較例が紹介されている。GPT-5.3 Instantが居住地を考慮した一般的な提案にとどまるのに対し、GPT-5.5 Instantは過去の好みや予定をふまえた、より洗練された個別提案を行っている。この差は日常的な使い勝手に直結するだろう。
プライバシーはユーザーが制御できる設計
パーソナライズが強化されると、当然「どこまで自分の情報が使われるのか」という懸念が出てくる。この点についてOpenAIは、メモリーソースはチャットを共有しても他の人には表示されないこと、不要なチャットは削除できること、一時的なチャット(Temporary Chat)を使えばメモリーが使用も更新もされないことを明記している。
また個人情報の扱いについては、企業や教育機関向けプラン(Business、Enterprise、Edu)では、ユーザーデータがモデル学習に使用されない設定がデフォルトで適用される。個人利用でも、設定からデータ提供の可否を切り替えられる。
APIとロールアウトのスケジュール
GPT-5.5 InstantはChatGPTの全ユーザー向けに5月5日から順次提供が開始されている。APIではchat-latestとして利用可能だ。有料ユーザー向けには、旧モデルのGPT-5.3 Instantも3ヶ月間はモデル設定から選択できる形で残される。
パーソナライズ機能の強化は、まずPlusおよびProユーザー向けにWeb版で展開され、モバイル版にもまもなく対応する予定だ。その後、数週間以内にFree、Go、Business、Enterpriseプランにも拡大される。メモリーソース機能はすべてのコンシューマープランでWeb版から提供開始され、モバイル版も順次対応する。
この記事のポイント
- GPT-5.5 Instantは医療や法律など高精度が求められる分野でハルシネーションを52.5%削減した
- 回答の単語数が30.2%削減され、より簡潔で実践的なアドバイスが得られるようになった
- 過去のチャット履歴やGmailなどの接続アプリを活用したパーソナライズ機能が大幅に強化された
- メモリーソースにより、AIが参照した情報をユーザー自身が確認・管理できるようになった
- 全ユーザー向けに順次提供開始、旧モデルは有料プランで3ヶ月間利用可能

Martech2026年調査から読み解く、ECの勝ち筋を変えるAIとSaaSの新しい関係
マーケティング技術の世界で、静かだが決定的な地殻変動が起きている。2026年のMartech市場はツール数が0.7%増とほぼ横ばいだが、その裏では1,500近いツールが新規参入し1,300以上が退出する「創造的破壊」のただ中にある。ツールを積み上げる時代は終わり、AIを中核に据えた価値創出へと競争のルールが変わったのだ。
この構造変化はEC(電子商取引)事業者にとっても対岸の火事ではない。パーソナライゼーションの手法、顧客理解の深さ、そしてマーケティングスタックの組み方が、ルールベースからAIネイティブへと根本から変わりつつある。本記事では「State of Martech 2026」のデータをEC視点で読み解き、これからの競争優位の源泉を考察する。
「ツールの数」が意味を失う日、Martechのダーウィン段階が始まった

長年、Martech市場の代名詞だった「ツール総数」という指標が、もはや実態を映さなくなっている。2026年の総数は15,505で、前年比わずか0.7%増。一見すると成熟しきった停滞市場に見えるが、水面下ではまったく異なる動きが進行していた。参入と退出が激しくぶつかり合う、まさに「ダーウィン段階」への突入である。
この現象をわかりやすくたとえるなら、古い商店街の風景に近い。シャッターが閉まった店がある一方で、新たな業態の店が次々と開店し、人通りそのものは変わらずとも街の質がまったく変わっていく、そんなイメージだ。ツールの総数は増えていないのに、市場が提供する価値の総量は確実に増えている。
成長の質が変わった、4つの状態モデル
「State of Martech 2026」では、市場を「成長」「更新」「安定」「縮小」の4象限に分類している。EC関連に絞って読み解くと、次のような構図が浮かび上がる。
- 成長: CMS、ワークフロー、ECプラットフォーム、iPaaS。これらは確立されたカテゴリだが、AIが「やるべき仕事」を再定義したことで再び拡大している。
- 更新: コンテンツ、コラボレーション、パーソナライゼーション。新規参入と退出が同時に多く、市場が「本当に必要な機能」を探りながら刷新されている。
- 安定: CRM、カスタマーサービス、顧客インテリジェンス。動きは少ないが、AI時代の「土台」として重要性が増している。
- 縮小: チャット、動画、メール。単独カテゴリとしては縮小し、より広範なプラットフォームやAIワークフローに機能が吸収されている。
ここで重要なのは、「安定」や「縮小」が即座に「不要」を意味するわけではないという点だ。メール配信基盤やCRM(顧客関係管理)はAIが価値を生み出すためのデータ基盤として、むしろ存在感を増している。役割が「主役」から「黒子」へと変わったのである。
EC事業者がいま注目すべきは「更新」領域のパーソナライゼーション
ECにとって最も注目すべきは「更新」象限に位置するパーソナライゼーションだ。ここでは、従来の「セグメント分けしてキャンペーンを打つ」という静的アプローチから、AIがリアルタイムで個人のコンテキストを解釈し、動的に体験を生成する手法への移行が加速している。
この変化をWooCommerce運営者の目線で言い換えれば「リピート購入を促すためにどのタイミングでどのクーポンを配るか」といった属人的な運用から、「AIが購入確率の高い瞬間をとらえて自動的に最適なオファーを出す」状態への進化だ。
SaaSは「土台」へ、AIが「価値層」になる構造転換

今回の調査で最も本質的な指摘は「SaaSは差別化の源泉ではなくなり、AIがその上に乗る価値層になった」という点だ。これを映画の発展にたとえるなら、無声映画に音声が加わったようなものだ。映像という基盤は同じでも、体験の質と提供できる価値が根本的に変わるのである。
SaaS(サービスとしてのソフトウェア)はルールと定義済みロジックで動く。一方、AIは言語、文脈、確率で動く。ワークフローを実行するだけでなく、解釈し、判断し、適応する。この二層構造が、これからのマーケティングスタックの基本形になる。
パーソナライゼーションのパラダイムシフト
この構造転換が最も鮮明に表れているのがパーソナライゼーションの進化だ。従来の手法は、年齢や購買履歴といった構造化データを元に「30代女性向け」「新規顧客向け」といったセグメントを作り、決められたシナリオを流すものだった。
しかし、チャネルが多様化し、顧客の動きが予測不能になったいま、事前に設定したルールだけでは対応しきれない。そこで必要になるのが、AIがその瞬間のコンテキスト(閲覧履歴、時間帯、デバイス、過去の反応パターンなど)を総合的に判断し「いま、この顧客に届けるべき最適な一言は何か」をリアルタイムに決める仕組みだ。
- 旧来: ルールベース → 決定論的 → セグメント → 事前設定ワークフロー → キャンペーン主導 → 担当者が設定
- 新時代: コンテキストベース → 確率論的 → 個人単位でリアルタイム → 適応的意思決定 → 継続的対話 → AIが支援・実行
ここで誤解してはならないのは「SaaSが不要になる」わけではないという点だ。顧客の住所や購入履歴のような確定したデータを、確率論的に扱う必要はない。そうした構造化データの管理はSaaSの得意領域であり、むしろAIが正しく機能するための「正確な土台」として欠かせない。SaaSが記録と統合を担い、AIが解釈と適応を担う。この役割分担こそが新しいMartechの基本構造である。
この変化の本質は「体験をあらかじめ設計する」から「体験を動的に生成する」へのパラダイムシフトだ。EC事業者にとっては、キャンペーンカレンダーを埋める仕事から、AIが適切に判断できるだけのデータと指標を整備する仕事へと、マーケターの役割そのものが変わっていくことを意味する。
ECプラットフォームの役割変化
CMSとECプラットフォームが「成長」象限に位置している背景には、AIエージェントが読み取れるマシンリーダブルな基盤への進化がある。WooCommerceを例にとれば、商品データ、顧客情報、注文履歴といった構造化データを、AIが解釈しやすい形で整備することが、これまで以上に重要になる。
単なるオンラインストアの枠を超え、AIが自律的に商品推薦、価格最適化、在庫予測を行うための「データハブ」としてECプラットフォームを位置づけ直す視点が、これからの運営者には求められる。
ECの現場でいま起こっている「更新」と「創造的破壊」

調査データが示すもう一つの重要な事実は、現在のMartech市場の大部分が「更新」状態にあるということだ。これは単なる不安定さではなく、第一世代のツールがAIネイティブなソリューションに置き換わる創造的破壊のプロセスである。
コンテンツ領域で起きたことが、その典型だ。生成AIの登場でコンテンツ生成ツールが爆発的に増えた後、コア機能がコモディティ化することで急速に淘汰が進んだ。同じパターンがいま、パーソナライゼーションとコラボレーションの領域で再現されている。ECの文脈では、商品レコメンデーションエンジンやチャットボット、メールマーケティング自動化の分野で、まさにこの入れ替わりが進行中だ。
淘汰されるツール、生き残るツール
「縮小」象限に位置するチャット、動画、メールといったカテゴリは、機能そのものが消えるわけではない。むしろAIによって機能は高度化している。変わったのは、それらが独立した「専用ツール」としての意味を失い、より大きなプラットフォームやAIワークフローの一部として吸収されつつある点だ。
たとえば、メール配信専用ツールを単体で導入・最適化するのではなく、AIが「いまこの顧客に届ける最適なチャネル」としてメール、SMS、プッシュ通知の中から自律的に選択する。チャネルそのものは手段に過ぎず、目的は「適切なタイミングで適切な人に届けること」だからだ。EC事業者が評価すべきは「多機能さ」ではなく「AIが価値を発揮しやすい環境を提供できるか」という視点に変わりつつある。
「更新」領域がEC事業者に突きつける問い
創造的破壊の波は、EC事業者にシンプルだが重い問いを投げかけている。「いま使っているツールは、第一世代のルールベース型か、それともAIネイティブな第二世代か」。この問いに答えられなければ、気づかぬうちに競争力を削がれている可能性がある。
具体的には、商品レコメンデーションが「購入履歴ベースの静的レコメンド」なのか「リアルタイムの行動コンテキストから動的に生成されるレコメンド」なのか、カスタマーサービスが「シナリオ型チャットボット」なのか「生成AIによる自律応答」なのか、といった視点での棚卸しが必要だ。
EC事業者がいま着手すべき2つの視点
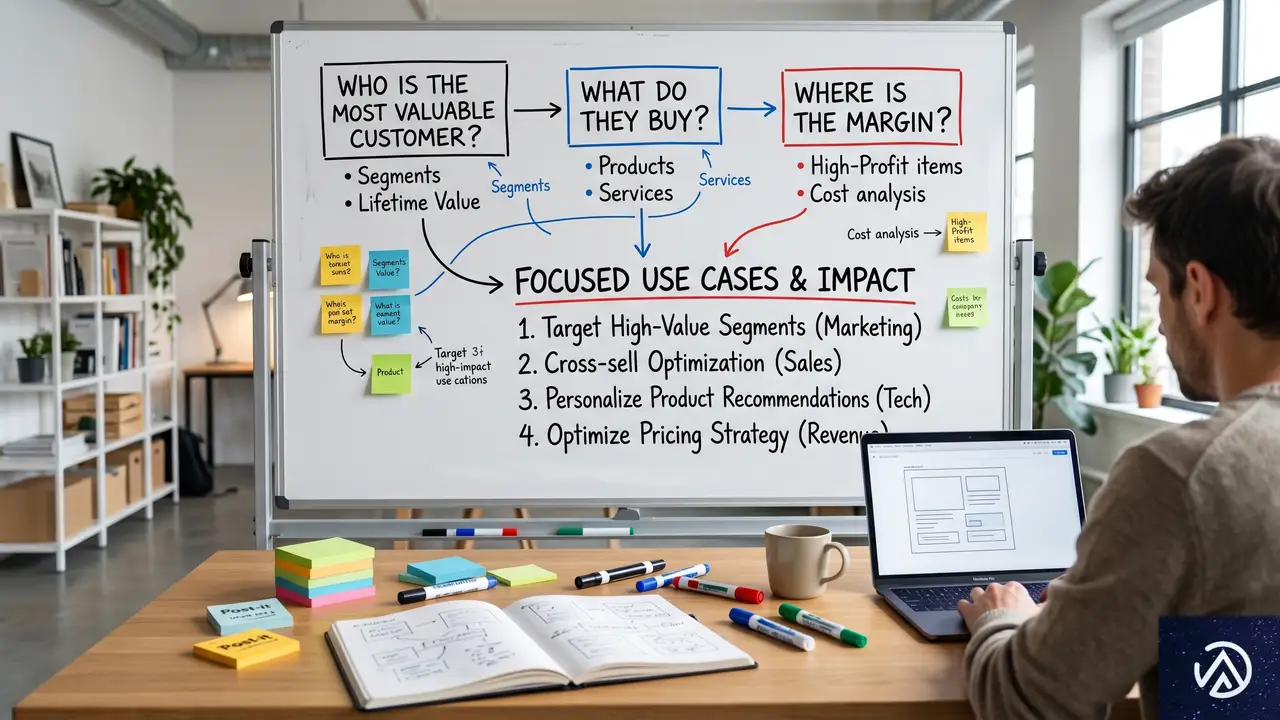
では、この構造変化の中でEC事業者は具体的に何をすべきか。調査レポートが提示する方向性は明快だ。「ツールの数」ではなく「AIが価値を最大化できる環境」を構築すること。そのために必要なのは以下の2つの視点である。
視点1 価値起点でスタックを設計する
SaaSの役割が「差別化の源泉」から「価値を引き出す土台」へと変わった以上、目的は「すべてのユースケースをツールでカバーすること」ではなくなった。限られたリソースを、最もビジネス価値の高い3〜5のユースケースに集中させる発想が求められる。
そのために、技術選定の前に次の3つの問いに答える必要があるという。誰が最も価値の高い顧客なのか、その顧客が最も購入する商品は何か、そして利益率が最も高いのはどこか。ECの文脈で言えば、LTV(顧客生涯価値)が高い顧客層の特定、リピート率の高い商品カテゴリの把握、粗利率の高い商材の見極め、というシンプルな分析から始めるべきだ。
- 最も価値の高い顧客は誰か(LTV分析)
- その顧客が最も購入する商品は何か(リピート分析)
- 最も利益率が高いのはどこか(粗利分析)
この3つの問いに答えて初めて、AIに何を任せるべきかの優先順位が明確になる。逆に言えば、この土台がないまま「AIツール」を導入しても、価値は最大化できない。
視点2 コンテキストを設計する
もう一つの重要な視点は「コンテキストエンジニアリング」と呼ぶべき考え方だ。調査によれば、マーケティング組織の90.3%が何らかの形でAIエージェントを利用しているにもかかわらず、本格的な本番運用にこぎつけているのはわずか23.3%だ。このギャップの最大の原因は「分断されたデータとワークフロー」にある。
AIが正しく機能するには、データ、ワークフロー、意思決定基準が一貫して整備されていなければならない。SaaSが提供するのは「構造」(データの整合性、ワークフローの一貫性)であり、AIが提供するのは「適応」(コンテキストの解釈、リアルタイムの判断)だ。この二層がかみ合って初めて、価値が生まれる。
WooCommerce運営者にとっての実践はこうだ。商品マスタのデータ品質を上げる、顧客情報と購買履歴を統合する、AIが判断に使えるタグやカテゴリを整備する。これらは派手な作業ではないが、AIの効果を左右する決定的な土台になる。最も価値の高いスタックとは、機能が最も多いスタックではなく、データとワークフローが最も整然と整備されたスタックなのである。
この図式で言えば、EC事業者の仕事は「AIツールを導入すること」そのものではなく、「SaaS層のデータ品質を高め、AIが判断に使えるコンテキスト情報を整備し、特定の高インパクトなユースケースに集中させる」という環境づくりだと言える。
2026年後半、ECマーケターが取り組むべき道筋

Martech市場の構造転換を踏まえ、EC事業者が2026年後半に取るべきアクションは次の3段階に整理できる。
第一段階 スタックの現状を棚卸しする
いま使っているツール群を「記録と統合を担うSaaS」と「解釈と適応を担うAI」に分類してみる。後者が「ルールベースの第一世代」なのか「AIネイティブの第二世代」なのかを評価し、入れ替えが必要な領域を特定する。
第二段階 価値の高いユースケースを3つに絞る
「誰が最も価値の高い顧客か」「その顧客が最も買う商品は何か」「利益率が高いのはどこか」の3つの問いに答え、AIに任せるべきユースケースを3つに絞る。たとえば「LTV上位顧客へのリピート促進」「カゴ落ち対策の高度化」「休眠顧客の再活性化」など、具体的かつ測定可能なユースケースを定義する。
第三段階 コンテキストの土台を整備する
商品マスタ、顧客データ、購買履歴の品質を検証し、AIが判断に使える状態に整える。タグやカテゴリの整理、データの正規化、ワークフローの文書化といった地道な作業が、AIの効果を左右する決定的な要素になる。
重要なのは、これらの作業が「技術的な統合」というより「戦略的な資産構築」だという認識だ。最も優れたECスタックとは、最も多機能なスタックではない。最もデータとワークフローが整然とし、AIが価値を最大化できるスタックである。
この記事のポイント
- 2026年のMartech市場はツール総数0.7%増とほぼ横ばいだが、1,500近いツールの参入と1,300以上の退出が同時に起きる「創造的破壊」の段階に入った
- 差別化の源泉はSaaSからAIへとシフトし、ECのパーソナライゼーションは「ルールベースのセグメント配信」から「AIによるリアルタイムなコンテキスト駆動型」へと移行している
- EC事業者は「ツールの数」ではなく「AIが価値を最大化できる環境」を構築すべきで、LTV分析など3つの問いに答えた上で、注力するユースケースを3〜5に絞ることが有効
- 最も価値の高いスタックとは、データとワークフローが整然と整備され、SaaSの土台の上でAIが適応的に判断できるスタックである

Azure Integrated HSM がオープンソース化、FIPS 140-3 Level 3 準拠のハードウェアセキュリティを全サーバーに統合
Microsoft は2026年4月30日、全 Azure サーバーに統合されるハードウェアセキュリティモジュール「Azure Integrated HSM」をオープンソース化する計画を発表した。このモジュールは改ざん耐性を備え、FIPS 140-3 Level 3 に準拠する。クラウド上の暗号鍵を、ソフトウェアやネットワーク層ではなくハードウェアチップ内で保護する設計だ。
Azure Integrated HSM は、従来の集中型 HSM サービスとは異なり、各サーバーに直接組み込まれる。鍵の生成から利用までをサーバー内の専用チップに閉じ込め、メモリ上やネットワーク越しの鍵窃取を原理的に不可能にする。本記事では、この仕組みとオープンソース化の意義、そして鍵管理の新しいアプローチを解説する。
Azure Integrated HSM がもたらすサーバーローカルの保護

HSM(Hardware Security Module)は、暗号鍵を安全に生成・保管するための専用ハードウェアだ。耐タンパー性を持ち、物理的な分解や不正アクセスを検知すると鍵を自動消去する仕組みを備える。Azure Integrated HSM はこの HSM を Azure サーバーのマザーボード上に統合し、すべての新規サーバーに標準搭載する。
本モジュールが準拠する FIPS 140-3 Level 3 は、政府や金融など規制産業で要求される最高水準のセキュリティ認証だ。Level 3 では、強固な改ざん抵抗性、ハードウェアによる隔離、物理的・論理的な鍵抽出の防止が求められる。この基準をクラウドインフラのデフォルトとして実装する点が、今回の取り組みの大きな特徴といえる。
従来の集中型 HSM とローカル保護モデルの違い
集中型モデルでは、鍵管理サービスがネットワークの向こう側にあり、すべてのサーバーがそこへ依存する。一方、Integrated HSM は鍵をサーバー内のハードウェア境界に留め、ワークロードが直接利用できる。これにより、ネットワークを介した盗聴や、ホストメモリを狙った攻撃が根本から排除される。
オープンソース化で透明性と信頼を強化

Azure Blog の記事によれば、Microsoft は OCP(Open Compute Project)EMEA Summit で、Azure Integrated HSM のファームウェア、ドライバ、ソフトウェアスタックをオープンソースとして公開する計画を明らかにした。あわせて OCP ワークグループを立ち上げ、アーキテクチャ設計やプロトコル仕様の策定までコミュニティ主導で進める。
すでに GitHub 上に Azure Integrated HSM のファームウェアリポジトリが公開され、OCP SAFE 監査レポートなどの検証成果物も参照可能だ。これにより、クラウド事業者の自己申告だけに頼らず、第三者が実装を直接検証できる土台が整う。特に、独立した監査が必須となる規制産業やソブリンクラウドにとって、この透明性は大きな意味を持つ。
セキュリティ機能を「信じて使う」から「検証して使う」へ移行できることは、AI 推論や国家規模のデジタルインフラを支える暗号基盤として極めて重要だ。プロプライエタリなプロトコルへの依存を減らし、相互運用性と監査可能性を高める実践的な一歩といえる。
階層化された鍵管理のアプローチ

Azure Integrated HSM は、既存の Azure Key Vault や Azure Managed HSM を置き換えるものではない。これらはこれまで通り、一元的な鍵ライフサイクル管理やポリシー制御を提供する。Integrated HSM は新たなレイヤーとして、鍵が「保存中」だけでなく「使用中」もサーバーローカルで保護する仕組みを追加する。
また、TDISP(TEE Device Interface Security Protocol)などの業界標準をサポートし、機密コンピューティング環境との安全なバインドを実現する。今後数週間で、Azure V7 仮想マシンを通じて全世界の顧客が利用可能になる予定だ。
クラウドセキュリティの新標準としての可能性

Azure Integrated HSM では、暗号鍵がハードウェアの外部に一切出ない。鍵はホストメモリ、ゲストメモリ、ソフトウェアプロセスに現れることなく、暗号処理が実行される。これにより、メモリやソフトウェア層を標的とした鍵・認証情報の窃取攻撃のクラスが根本から無効化される。
セキュリティはポリシーや運用規律に頼らず、シリコンによって強制される。信頼は「契約上の約束」ではなく、ハードウェアによる証明へと変わる。さらに、ハードウェアのルートオブトラスト、計測ブート、アテステーションにより、承認済みのハードウェアやファームウェアが稼働していることを暗号学的に検証可能だ。
サーバー単位で保護がスケールするため、共有ボトルネックやネットワークホップが不要になり、パフォーマンスを犠牲にすることなくセキュリティを確保できる。機密コンピューティングや Azure Boost、データセンター制御モジュールと組み合わせることで、シリコンからソフトウェアまでの垂直統合された信頼チェーンが構築される。Microsoft は、この基盤をオープンにすることで、より安全で透明性の高いクラウドインフラの標準化を目指している。
この記事のポイント
- Azure Integrated HSM は全 Azure サーバーに統合され、改ざん耐性と FIPS 140-3 Level 3 準拠の鍵保護をハードウェアで実現する
- ファームウェアやドライバがオープンソース化され、OCP を通じたコミュニティ主導の開発が進む
- 集中型 HSM に依存せず、ローカルで鍵を守ることでネットワーク越しの攻撃やメモリ窃取を排除する
- Azure Key Vault など既存の鍵管理サービスと組み合わせ、鍵のライフサイクル全体を階層的に保護する
- アテステーションによりハードウェアレベルの信頼を検証可能とし、クラウドセキュリティの新たな標準を築く

Amazon WorkSpacesがAIエージェント専用デスクトップを提供開始
企業がAIエージェントを本格導入しようとすると、大きな壁に突き当たる。基幹業務を支える既存のデスクトップアプリケーションやレガシーシステムは、最新のAPIを備えていないことがほとんどだ。2024年のGartnerレポートによれば、75%の組織がモダンなAPIを持たないレガシーアプリを運用しており、Fortune 500社の71%は十分なプログラムアクセス手段のないメインフレーム上で重要プロセスを動かしている。
AWSはこの課題に対して、新しいアプローチを発表した。2026年5月5日、Amazon WorkSpacesがAIエージェントに対して安全なデスクトップ環境を提供する機能をプレビュー公開した。これにより、アプリケーションの改修やAPIの新規開発なしで、AIエージェントが既存のデスクトップアプリケーションを人間と同じように操作できるようになる。
レガシーアプリケーションの課題とAI導入の壁

従来は、AIエージェントが業務システムと連携するには、アプリケーション側にAPIを実装するか、RPAによる擬似的な操作を行うしかなかった。いずれも大がかりな作業とメンテナンスを伴い、特に規制産業では監査やセキュリティ面でハードルが高かった。WorkSpacesの新機能は、仮想デスクトップという“もう一つの画面”をAIエージェントに渡すことで、この問題を一気に解消する。
WorkSpacesがAIエージェントに提供するもの

この新機能の核は、人間用に管理されてきたWorkSpaces環境を、AIエージェントにも安全に割り当てられるようにした点にある。エージェントはAWS Identity and Access Management(IAM)で認証され、WorkSpacesへ接続する。操作はすべてAWS CloudTrailとAmazon CloudWatchで監査ログが残り、既存のセキュリティ制御やコンプライアンスポリシーがそのまま適用される。
また、業界標準のModel Context Protocol(MCP)に対応しているため、LangChainやCrewAI、Strands Agentsなど、さまざまなAIエージェントフレームワークから利用できる。特定のSDKに縛られない設計は、企業の既存AI基盤に組み込みやすい。
AWSのブログ記事では、Nuvens ConsultingのディレクターChris Noon氏が次のようにコメントしている。「WorkSpacesは、クライアントが従業員に提供しているのと同じ安全でガバナンスの効いたデスクトップ環境を、AIエージェントにも提供できる。カスタムAPI統合は不要で、完全な監査証跡とエンタープライズグレードの隔離が最初から組み込まれている。規制の厳しい業界では、これは単なる追加機能ではなく、前提条件だ」
AIエージェント用WorkSpacesの設定手順

AWS Management Consoleから設定を開始する。WorkSpacesコンソールで「スタックの作成」を選択し、スタック名やフリートの関連付け、VPCエンドポイントなどの基本情報を入力する。作成ウィザードのステップ3では、AIエージェント用の新しいセクションが追加されている点がポイントだ。
ここでは「AIエージェントの追加」オプションを選択する。これにより、人間用のスタックとは別に、エージェント専用のIDと権限でデスクトップにアクセスできるようになる。続いてエージェント機能を有効化する設定へ進む。「コンピューター入力」はマウスクリックやキーボード入力、スクロール操作を許可し、「コンピュータービジョン」はエージェントがデスクトップのスクリーンショットを取得できるようにする。これはエージェントが画面を「見る」仕組みだ。さらにスクリーンショットの保存先を指定し、監査やデバッグに備える。
画面レイアウトの設定では、解像度や画像フォーマットを選ぶ。UI要素が密集した複雑なアプリケーションでは高解像度が有効だが、ターミナル風のシステムであれば720pで十分だ。これらの設定を済ませると、WorkSpacesがマネージドMCPエンドポイントを生成する。あとはAIエージェントのフレームワーク側で、このエンドポイントとIAM認証情報を指定するだけで接続が完了する。
実際の動作とユースケース

実際のデモでは、AWSがStrands Agent SDKとAmazon Bedrockを組み合わせて構築したエージェントが、架空の薬局システム上で処方箋の再発行処理を一通り実行している。患者レコードの検索から薬剤の選択、注文、再発行確認まで、すべてAPIなしで完結する。アプリケーション側はエージェントが操作していることを一切意識しておらず、ソフトウェアの改修も再構築も行われていない。
このようなアプローチは、金融機関の勘定系システムや医療機関の電子カルテ、物流システムの倉庫管理アプリなど、何十年も使い続けられている業務アプリケーションにすぐに適用できる。モダナイズに踏み切れずAI導入を断念していた企業にとって、有力な選択肢になるだろう。
今後の展望と利用可能リージョン
今回の機能はパブリックプレビューとして、米国東部(バージニア北部、オハイオ)、米国西部(オレゴン)、カナダ(中部)、欧州(フランクフルト、アイルランド、パリ、ロンドン)、アジアパシフィック(東京、ムンバイ、シドニー、ソウル、シンガポール)の各リージョンで追加料金なしで利用できる。
エージェントが人間と同じデスクトップを共有するという発想は、レガシーシステムとAIの架け橋として大きな可能性を秘めている。AWSのブログでは、GitHubリポジトリにサンプルコードが公開されており、すぐに試せる環境が整っている。今後は、より細かな権限制御やマルチエージェント対応など、エンタープライズ利用を加速させる機能拡張が期待される。
この記事のポイント
- Amazon WorkSpacesがAIエージェントに仮想デスクトップを提供する機能をパブリックプレビュー開始
- レガシーアプリのAPI改修不要で、AIエージェントがクリックや入力、スクリーンショット取得で操作可能
- IAMによる認証とCloudTrailの監査証跡で、既存のセキュリティ・コンプライアンスを維持
- MCP対応でLangChainやCrewAIなど主要フレームワークと接続可能
- 東京リージョンを含む多数のリージョンで追加費用なしで試用可能

OpenAIが高度なアカウント保護機能を発表、パスワードレス認証を標準化
OpenAIは2026年4月30日、ChatGPTアカウントのための新たな保護オプション「Advanced Account Security(高度なアカウントセキュリティ)」の提供を開始した。ChatGPTとCodexの両方に適用される、フィッシング耐性を備えた認証手段を標準化する設定だ。特にジャーナリストや研究者、政治家など、高度な標的型攻撃のリスクに晒されるユーザーを主な対象としている。
この設定を有効にすると、パスワードによるログインが無効化され、パスキーまたは物理セキュリティキーが必須になる。同時に、メールやSMSによるアカウント復旧も停止される。OpenAIのサポートチームでさえ、この設定を有効にしたアカウントの復旧支援はできない仕様だ。セキュリティと引き換えに自己責任の範囲が拡大する点が特徴といえる。
Advanced Account Securityとは何か、そしてなぜ今必要なのか

ChatGPTは個人の相談事から業務の自動化まで利用範囲が急拡大している。アカウントには長期間にわたる会話履歴、個人情報、接続された外部ツールの認証情報などが蓄積される。OpenAIのブログ記事では「時間の経過とともに、ChatGPTアカウントは機密性の高い個人情報や業務コンテキストを保持し、接続されたツールやワークフローの中心に位置するようになる」と指摘されている。
フィッシング攻撃やセッション乗っ取りによってAIアカウントが侵害された場合、単なるパスワード漏洩以上の被害が想定される。過去の会話から企業秘密が推測されたり、APIキーや連携ツール経由で二次被害が広がるリスクがある。この新機能は、そうしたアカウント乗っ取り(Account Takeover)の脅威に対抗するための総合的な防御策だ。
上記の比較で示したように、認証手段と復旧フローの両面で防御が強化される。重要なのは、この設定がOpenAIの「Cybersecurity Action Plan(サイバーセキュリティ行動計画)」の一環であることだ。同社は国家安全保障や重要システムの保護に貢献する技術へのアクセス拡大を掲げており、本機能の提供はその具体的な施策にあたる。
標的になりやすいユーザー層とは
OpenAIのブログ記事では、ジャーナリスト、選挙で選ばれた公職者、政治的反体制活動家、研究者、そして「特にセキュリティ意識の高い人々」が具体的な対象として挙げられている。こうした層は国家支援のハッキンググループや高度なソーシャルエンジニアリング攻撃の標的になりやすく、標準的なパスワード認証やSMS認証では防御が不十分だ。
フィッシング攻撃では、精巧な偽ログインページでパスワードやワンタイムコードを入力させ、その情報を攻撃者がリアルタイムで転送する手法(中間者攻撃)が多用される。こうした攻撃に対し、FIDO(Fast IDentity Online)規格に準拠したパスキーや物理セキュリティキーは、ドメイン名と秘密鍵が数学的に結びつく仕組みで偽サイトへの認証情報入力を根本的に阻止する。
4つの柱で構成される保護メカニズム

Advanced Account Securityは単一の機能ではなく、認証から復旧、セッション管理、プライバシー設定に至るまで、4つの独立したセキュリティ強化策を一括で適用するパッケージだ。ここでは各要素を詳しく解説する。
1. パスワードレス認証の強制
この設定を有効にすると、パスワードによるログインが完全に無効化される。以降はパスキー(生体認証やデバイスPINを利用したFIDO認証情報)か、YubiKeyのような物理セキュリティキーのいずれかでしかログインできなくなる。これにより、フィッシングに強い認証がデフォルトになるわけだ。
パスキーとは、公開鍵暗号方式を応用した新しい認証技術である。簡単に説明すると、ユーザーのデバイス内に秘密鍵が安全に保管され、サービス側に公開鍵が登録される仕組みだ。ログイン時には生体認証やデバイスロック解除で本人確認が行われ、偽サイトでは秘密鍵が応答しないためフィッシングが成立しない。パスワード管理の手間もなくなる点が実務上の利点として大きい。
2. アカウント復旧手段の厳格化
通常のChatGPTアカウントでは、メールアドレスや電話番号を使ってパスワードをリセットし、アカウントへのアクセスを復旧できる。しかし攻撃者がメールアカウントを侵害したり、SIMスワップ(携帯電話番号の乗っ取り)を行った場合、この復旧経路自体が弱点になりうる。
Advanced Account Securityを有効にすると、メールとSMSによる復旧が無効化される。代わりにバックアップ用のパスキー、セキュリティキー、またはリカバリーキー(事前に発行される使い切りの文字列)のいずれかでしか復旧できなくなる。OpenAIのブログ記事では「復旧がこれらのより安全な手段に制限されるため、OpenAIサポートは本機能を有効化したユーザーのアカウント復旧を支援できない」と明記されている。利便性と引き換えに、復旧は完全に自己責任になる点を理解しておく必要がある。
3. セッション管理と通知
サインイン後のセッション有効期間が短縮される。これはデバイスの紛失や盗難、あるいは社内システム上でセッションが残ったままになるリスクを低減する狙いがある。仮にアクティブなセッションが侵害されたとしても、攻撃者が悪用できる時間枠が狭まる。
加えて、アカウントに新しいログインが発生するたびに警告通知が届くようになる。ユーザーは自身のアカウントにサインインしている全デバイスのアクティブセッションを一覧表示し、不要なセッションを手動で終了させることも可能だ。これにより、異常なログインを早期に検知し対処できる。
4. モデル学習データからの自動除外
機密性の高い情報を扱うユーザーの中には、自身の会話がAIモデルの学習に使われることを望まないケースがある。Advanced Account Securityを有効にすると、この設定が自動的に適用され、該当アカウントの会話データはOpenAIのモデル訓練に使用されなくなる。通常は手動でオプトアウト設定を行う必要があるが、セキュリティ強化機能を有効にすることで同時にプライバシー保護も担保される設計だ。
Yubicoとの提携と物理セキュリティキーの提供

OpenAIはハードウェア認証のリーディングカンパニーであるYubicoと提携し、Advanced Account Securityの利用者向けに割引価格のセキュリティキーバンドルを提供する。具体的には、ノートPCに挿しっぱなしで日常的な認証に使う「YubiKey C Nano」と、バックアップおよびスマートフォン認証用の「YubiKey C NFC」の2本セットだ。
物理セキュリティキーは、フィッシング攻撃に対する最も強力な防御手段のひとつとされる。偽のログインページでは正しい認証応答を生成できず、仮にユーザーが騙されて違うサイトでキーをタッチしても、認証情報が盗まれることはない。OpenAIのブログ記事では、この割引バンドルを「Advanced Account Securityの利用者向け」としながらも、すべての対象ユーザーがウェブ版ChatGPTのセキュリティ設定から購入できるとも述べている。FIDO準拠の他社製セキュリティキーや、ソフトウェアベースのパスキーも併用可能だ。
Codexおよびエンタープライズ利用への影響

今回の機能はChatGPTだけでなく、Codexアカウントにも保護を適用する。Codexは自然言語からコードを生成する開発者向けツールで、APIキーや本番環境の設定情報など、侵害された場合の影響が極めて大きい情報を扱う。OpenAIはCodexについて「開発者がアイデアを動作するソフトウェアに変える方法を変革している」と位置づけており、そのアカウント保護は開発者コミュニティ全体のセキュリティに直結する。
さらにOpenAIは、サイバーセキュリティ分野の検証済み防御者に対して最も高度なモデルへのアクセスを提供する「Trusted Access for Cyber」プログラムを展開している。2026年6月1日以降、このプログラムに参加する個人メンバーはAdvanced Account Securityの有効化が必須になる。組織向けには、シングルサインオンのワークフローにフィッシング耐性のある認証が組み込まれていることを証明する代替手段も用意される。
OpenAIのブログ記事では「ChatGPTの広範な消費者リーチは、職場への強力な流通チャネルを生み出している。需要は基本的なモデルアクセスから、ビジネス運営を再構築するインテリジェントシステムへと急速に移行している」と述べられており、個人利用から業務利用への広がりを背景に、エンタープライズ環境へのセキュリティ対策拡大も示唆されている。
任意でのオプトイン。セキュリティ設定画面から有効化。
同一ログインで保護が適用される。APIキーやコード資産も防御対象。
2026年6月1日から有効化が必須。個人は強制、組織は代替証明も可。
この記事のポイント
- OpenAIがChatGPTとCodex向けに「Advanced Account Security」を提供開始。アカウント乗っ取り対策を強化するオプトイン設定だ
- パスワードログインを無効化し、パスキーまたは物理セキュリティキーを必須にする。フィッシング耐性が飛躍的に向上する
- SMSやメールによるアカウント復旧を停止。復旧はバックアップキーでのみ可能で、サポートによる復旧支援も受けられなくなる
- Yubicoと提携し、2本組のセキュリティキーバンドルを割引価格で提供。FIDO準拠の他社製品も利用可能だ
- Trusted Access for Cyber参加者は2026年6月1日以降、本機能の有効化が必須となる

AIショッピングの信頼上限、利用拡大でも支払い自動化に壁
AIを使った買い物が急速に広がっている。Exploding Topicsの調査では、過去半年間に77.6%の消費者がAIをショッピングに活用し、40%以上が週に一度は使っている。商品リサーチや価格比較には頼るが、最終的な決済を任せる人はまだ少ない。
この数字が示すのは「AIは意思決定の補助にはなっても、代理購入の域には踏み込めない」という現実だ。EC事業者、とりわけWooCommerceで店舗を運営する事業者は、この信頼の天井を理解し、顧客体験の設計に活かす必要がある。
AIを活用したショッピングの現状

AI利用者の約68.6%が「AIがなければ買わなかった商品を購入した」と回答している。AIは商品発見から比較検討までの流れを大きく変え、購買意欲を引き出す力を持つ。だが、使い方はあくまで「情報収集」に偏っている。
最も使われるのは商品調査と価格比較
AIを使う目的で多いのは、商品スペックの確認、口コミのまとめ読み、類似商品の相場チェックだ。WooCommerceで言えば、カテゴリページや商品詳細ページを訪れる前段階でAIが大きな影響を及ぼしている。チャットボットに「この予算で買えるおすすめのワイヤレスイヤホン」と尋ねれば、複数商品を比較してくれる。
一方、カートに入れた後の行為、つまり支払いや個人情報の入力にはほとんど使われていない。MarTechの記事(2026年5月1日)が伝える調査でも、半数以上の消費者がAIにカード情報を保存させることに強い抵抗感を示した。
信頼の天井とは何か

AIに任せられる金額の中央値は「0ドル」だった。利用頻度の高いヘビーユーザーでも、許容額は50ドル以下が大半だ。つまり、AIに「自分のかわりに買う」という最終決定権を預けることへの心理的ハードルは極めて高い。
ここに「信頼の天井」が存在する。AIが与える提案や比較は便利だと思っていても、お金の動きが絡むと途端に警戒する。これはAI技術そのものへの不信というより、人間がコントロールを手放したくない本能に近い。
上の図のように、AIが力を発揮するのは購買ファネルの初期から中期までで、最終段階の決済にはまだ踏み込めない。この溝を埋めずにAI自動化を急ぐと、かえって顧客離れを招くリスクがある。
EC事業者にとっての意味

AIが決済の最終スイッチを押せないなら、ECサイトやWooCommerceストアは何をすべきか。まず重要なのは、AIによる「影響力」の部分を最大限に活かすことだ。
生成AI検索でのプレゼンス確保
消費者の約半数がAIから買い物を始めたり、購入前の確認にAIチャットを利用する。これは、商品がAIの回答に引用されるかどうかが、そのまま売上に直結する時代に入ったことを意味する。従来のSEOに加え、GEO(Generative Engine Optimization)の観点から、商品データの構造化やFAQコンテンツの充実が欠かせない。
AI決済への不信感を和らげる設計
AIによる自動購入に抵抗があるのは、消費者が「自分の利益よりもプラットフォームや広告主の利益を優先している」と感じるからだ。MarTechの記事でも、AIショッピングツールは消費者側のためというより、プラットフォーム側を利すると考える声が多いと指摘されている。
WooCommerce店舗でAIチャットボットやレコメンドエンジンを導入する場合、「これはあなたのために選んだ」という姿勢をUIや文言で明確に示す必要がある。チェックアウト直前で「AIが選んだけど、最終確認はあなた自身で」という流れを強調するだけでも安心感が変わる。
WooCommerceでAIを活用する方法

信頼の天井を意識しつつ、実際にどんなAI機能を取り入れられるかを整理しよう。
WooCommerceでこれらを実装するなら、AIチャットボットにはオープンソースのRAG構成を組み合わせたり、パーソナライズにはJetpack Searchや専用プラグインを活用する手がある。いずれにせよ、決済周りの自動化は控えめにし、顧客が安心して買える設計を優先することが長期的な関係構築につながる。
今後の展望

AIの利用は増え続けるが、購買ファネルにおける役割は層によって差が広がるだろう。商品の発見や評価はますますAIに依存し、一方で購入の最終決定は人間が握り続ける。この二層構造がしばらくは続くと見られる。
EC事業者としては、AIがもたらす影響力を正面から受け止め、商品情報やコンテンツをAIフレンドリーに整備する一方、決済体験の「信頼のラストワンマイル」を自社の強みとして磨くことが重要になる。WooCommerceなら、オープンなプラグイン構成を活かして、段階的にAIを導入しつつ、顧客からのフィードバックを細かく拾えるのが強みだ。
この記事のポイント
- AIを買い物に使う消費者は77.6%に達するが、自動決済への信頼は極めて低い
- 許容できるAI自動購入額の中央値は0ドルで、利用頻度が高くても50ドル以下が大半
- WooCommerce店舗ではAI検索やレコメンドから取り入れ、決済の完全自動化は避けるのが現実的
- 生成AI検索で自店の商品が引用されるよう、構造化データとFAQの充実がSEOの次なる課題
- AIが意思決定を助け、人間が最終購入を行う二層構造を前提に顧客体験を設計する

Google 3月コアアップデートで何が変わったか、集約サイトに逆風で自社サイトに追い風
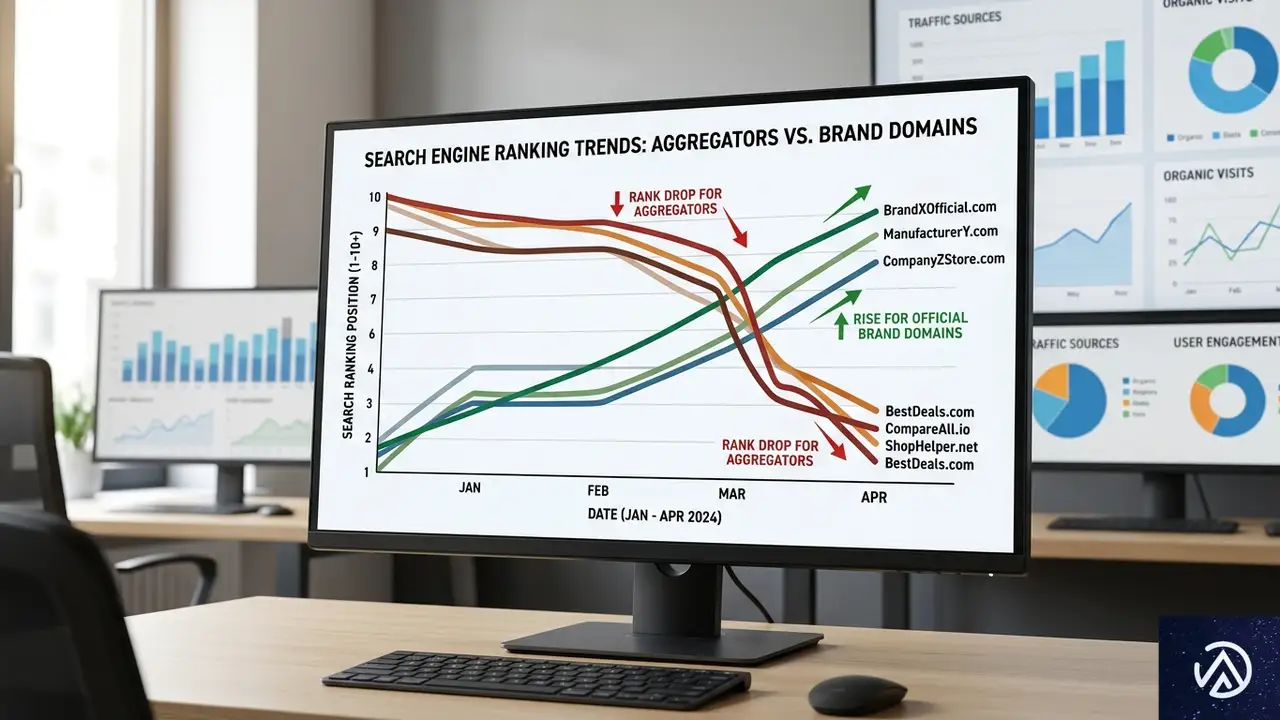
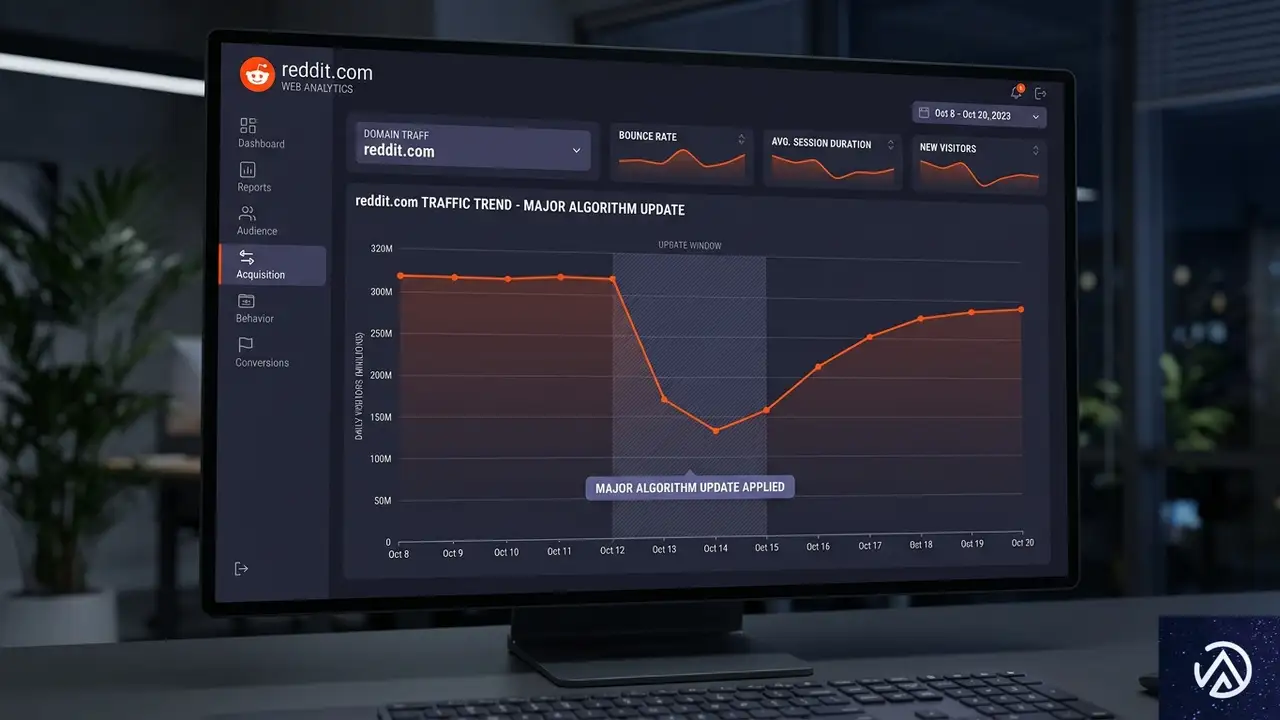
2026年3月に実施されたGoogleのコアアップデートで、検索結果の可視性に大きな地殻変動が起きた。特に影響を受けたのは、YouTubeやRedditに代表される「集約サイト」や「ユーザー投稿型プラットフォーム」だ。これらが軒並み可視性を落とす一方で、ブランドの公式サイトや政府機関ドメインが上昇した。
デジタルマーケティング企業Amsiveの分析によれば、YouTubeは可視性スコアを567ポイントも失い、全ドメイン中最大の下落を記録した。TripAdvisorも45ポイント減、Redditも64ポイント減と、多くの有名サービスが影響を受けている。こうした動きは「情報の一次発信者をより重視する」というGoogleの姿勢を反映したものだと受け止められている。
この記事では、Amsiveの調査データの詳細に加え、業界別の勝ち組・負け組、そして復活パターンまでを解説する。3月のアップデートで自社サイトがどう評価されたかを振り返り、今後のSEO戦略を練るための材料としてほしい。
3月コアアップデートで何が起きたのか
AmsiveはSISTRIX Visibility Indexを用いて、2,000以上のドメインを分析した。分析対象期間は2026年3月27日(ロールアウト開始日)から4月8日(完了日)までである。さらにDataForSEO APIを使い、各ドメインにGoogleの商品分類タグを付与して、業界別の傾向を浮き彫りにした。
ここで言う「可視性スコア」とは、SISTRIXが算出するキーワード単位の表示機会の指標であり、実際のオーガニックトラフィックそのものとは異なる。ただ、大規模なランキング変動を捉えるには十分なデータセットだ。
「情報の一次発信者」を優遇する流れ
Amsiveは今回の変化を「過度にインデックスされていたUGCやアグリゲーターコンテンツに対する是正」と位置づけている。つまり、「ある物事について人々が話し合うプラットフォーム」よりも、「その物事を実際に提供・所有する企業や組織」のサイトを上位に表示しようという補正だ。
この傾向は、旅行、求人、健康など複数の業界で一貫して見られた。たとえば旅行分野では、OTA(オンライン旅行代理店)が集客力を落とし、ホテルチェーンや空港の公式サイトが上昇した。これは、単なるアルゴリズムの一時的な揺らぎではなく、意図的な方向修正である可能性が高い。
このデモで示したように、単なる口コミや他者コンテンツの再掲載ではなく、自社サービスや公式情報そのものを発信するサイトが検索上で優位に立つ構図が鮮明になった。
ドメイン別の勝者と敗者
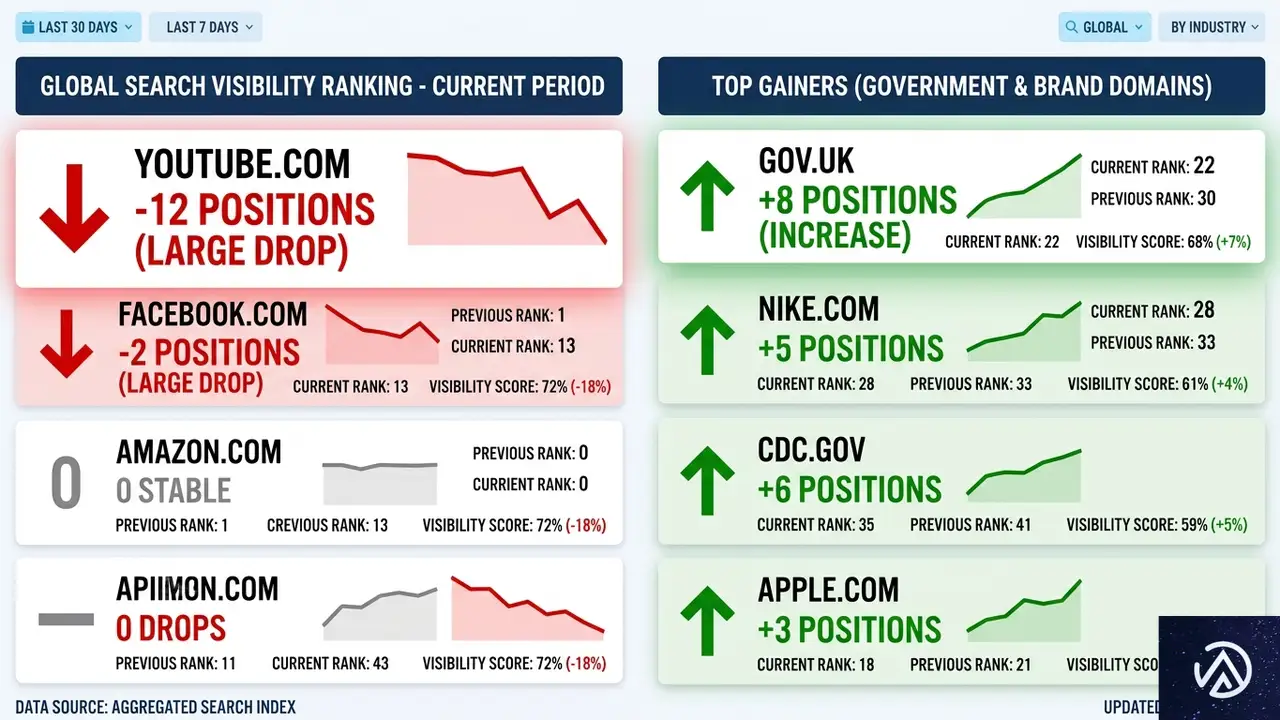
Amsiveのデータセットで最も激しい動きを見せたのはYouTubeだった。可視性スコアを567ポイントも下げており、これは全ドメイン中最大の下落幅である。比較対象として、2025年12月のコアアップデートでWikipediaが経験した435ポイント減よりも約30%大きい。
主要ドメインのスコア変動
以下のリストは、AmsiveがSISTRIXデータから抽出した可視性変動の一部である。
- YouTube 567ポイント減(最大の下げ幅)
- Reddit 64ポイント減
- Instagram 48ポイント減
- X(旧Twitter) 46ポイント減
- TripAdvisor 45ポイント減
- Yelp 33ポイント減
- Expedia 33ポイント減
注目すべきは、YouTubeの下落が「過去の一時的な急騰の反動」である可能性だ。AmsiveのLily Ray氏は、YouTubeの可視性は3月初旬の急上昇前の水準に戻ったに過ぎず、過去最低を更新したわけではないと補足している。つまり、異常値の補正と見ることもできる。
一方で、RedditやXといったテキスト系UGCプラットフォームの低下は構造的だ。これらは2024年から2025年にかけて大幅に検索可視性を伸ばしてきた経緯があり、今回のアップデートはその反動という見方が強い。
この視覚化からもわかるとおり、減少幅ではYouTubeが突出している。それでも、複数のUGC系プラットフォームがまとまってスコアを落とした点が、今回のアップデートの特徴と言える。
業界別の影響 旅行、求人、健康
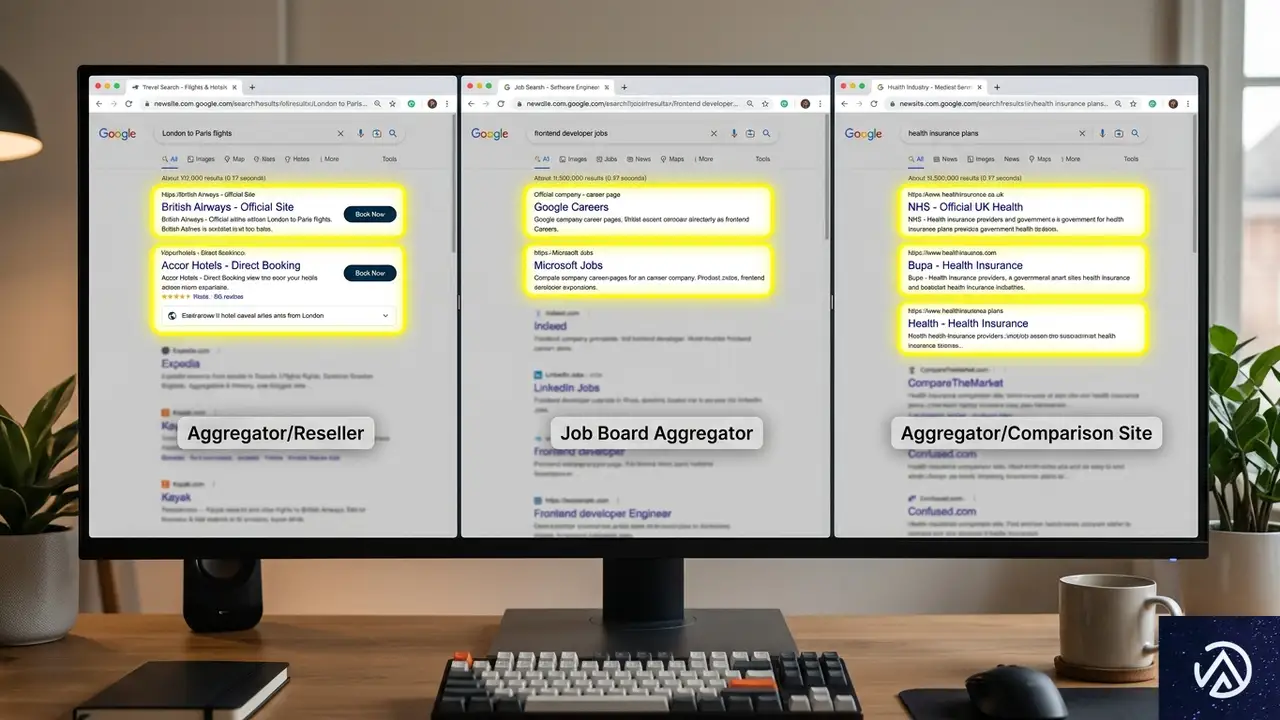
ドメイン単位の分析に加えて、業界カテゴリ別のパターンも明確になった。AmsiveはDataForSEOのAPI経由でGoogle商品分類タグを各ドメインに割り当て、旅行、求人、健康の3分野を重点的に分析している。
旅行分野 OTAが後退しホテル公式が台頭
旅行業界では、TripAdvisor(45ポイント減)、Yelp(33ポイント減)、Expedia(33ポイント減)がそろって下げた。代わりに上昇したのは、ヒルトンの公式サイト(4ポイント増)、Hotels.com(3.6ポイント増)、Trivago(3.2ポイント増)だった。さらに、米国国立公園局のNPS.govが9.9ポイント増、複数の空港公式サイトも大幅に上げている。
これは「旅行先を探す」という行動において、Googleが「個人のレビューを集めたサイト」よりも「宿泊施設や交通機関の公式情報」を優先するようになったことを示唆する。OTAのマーケティング担当者にとっては、SEOの前提を見直す転換点になるかもしれない。
求人分野 雇用主のキャリアページが評価上昇
求人・教育カテゴリでも、Indeed(18ポイント減)、ZipRecruiter(13ポイント減)といった求人アグリゲーターが下げた一方で、米国労働統計局のBLS.gov(5.4ポイント増)、米国政府求人サイトのUSAJobs.gov(16%増)、Disney Careers(59%増)、CVS Health Careers(45%増)といった雇用主直轄のキャリアページや政府系ドメインが目立って上昇した。
求職者が「特定の企業で働きたい」と考えたとき、検索結果の上位に企業の公式採用ページが表示されやすくなった形だ。これにより、求人専門サイト経由での応募導線に依存していた企業は、自社キャリアページのSEO強化が急務となっている。
健康分野 信頼できる公的機関が選ばれる傾向
健康分野では、処方薬割引サービスのGoodRxが55%増(9.5ポイント増)と大幅に伸び、米国国立衛生研究所(NIH.gov)も9.3ポイント増えた。その一方で、クリーブランドクリニックは12ポイント減、WebMDは9ポイント減、メイヨークリニックは6ポイント減と、有名な消費者向け健康情報サイトが軒並み下げた。
ここでの解釈は慎重を要するが、「権威性の高い公的機関の情報」をより重視する動きの一環と見ることができる。医学情報のように正確性が求められるジャンルでは、この傾向が今後も強まる可能性がある。
回復パターンと注意点
今回の分析で興味深いのは、一部の「敗者」ドメインがアップデート直後に可視性を急回復させた点だ。RedditとIndeedは、ロールアウト完了からほどなくしてスコアを取り戻した。このことから、アップデート期間中のスナップショットだけを見て「負けた」と判断するのは早計であることがわかる。
AmsiveのLily Ray氏も、今回の敗者リストはあくまで「アップデート期間中」の変動を捉えたものであり、その後に各ドメインがどこに落ち着いたかまでは示していないと強調している。SEO担当者は、ランキング変動を確認する際に、少なくともロールアウト完了後1〜2週間のデータを見て判断することが重要だ。
Zyppyの先行分析とも整合
今回のAmsiveによる発見は、同月に公開された別の分析結果とも整合している。ZyppyのCyrus Shepard氏が400以上のサイトを調査したレポートでは、「タスクを完了させる製品・サービスを提供するサイト」がオーガニックトラフィックを伸ばす傾向が示されていた。
手法は異なる。Shepard氏はサードパーティのトラフィック推計データとの相関を測定したのに対し、AmsiveはSISTRIXの可視性スコアをアップデート期間で追跡した。それでも、到達した結論はほぼ同じで、「情報の受け売りではなく、本物の価値を提供するサイト」が評価されるという方向性は確からしい。
さらに、ドイツのデータを用いたSISTRIX独自の分析でも同様の結果が得られている。オンラインショップや便利系サイトが可視性を下げ、公式サイトやブランドドメインが相対的に強かった。この世界的な共通傾向は、Googleがグローバルに同様の評価軸を適用している可能性を示す。
自社サイトへの示唆と対策

今回の一連のデータは、あくまでGoogleが内部で何を変更したかを確定するものではない。しかし、旅行、求人、健康、金融、エンターテインメントという異なる業界で同じパターンが繰り返された事実は重い。これは単発の異常値ではなく、検索エンジンの評価基準に構造的なシフトがあったことを示唆している。
つまり、「他人のコンテンツを集めて並べるだけのサイト」や「ユーザーが自発的に投稿したレビューに依存するサイト」よりも、「その分野の専門知識や実サービスを持つサイト」が優遇される方向へとかじが切られたのだ。
上記の診断フローは、今回のアップデートで評価されたサイトの特徴を整理したものだ。たとえば、自社商品の技術仕様を詳述したページを持っているか、実際の導入事例データを公開しているか。そうした「自社ならではの資産」をコンテンツ化できているかどうかが、これまで以上にSEOの成否を分ける。
また、Cyrius Shepard氏の分析が示す「タスク完了型サイトの優位性」も見逃せない。ユーザーが情報を得たあとに、そのまま資料請求、購入、予約へと進める流れをサイト内で完結させることが、オーガニック検索からの流入増加につながっている。
この記事のポイント
- 2026年3月のGoogleコアアップデートでは、YouTubeやRedditなどの集約サイトが可視性を大幅に下げた
- 旅行、求人、健康の各分野でブランド公式サイトや政府ドメインが評価を上げた
- 一部ドメインはアップデート後に急回復しており、短期的なスコアだけで判断するのは危険
- 自社の一次情報を強化し、タスクをその場で完了できる体験を提供することが今後のSEOの軸になる