

CSSだけで多階層の状態を管理するラジオボタン・ステートマシンの実装手法
Web制作における状態管理は、多くの場合JavaScriptの役割だと考えられている。しかし、純粋に視覚的なUIの変化であれば、CSSだけで完結させるアプローチが非常に有効な場合がある。
パネルの開閉やアイコンの形態変化、カードの反転といった「表示上の状態」をCSSで管理することで、JavaScriptのオーバーヘッドを削減し、プレゼンテーション層に近い場所でロジックを保持できる。この記事では、従来のチェックボックスハックを進化させた「ラジオボタン・ステートマシン」という手法について詳しく解説する。
この手法をマスターすると、複雑な多段階のUI遷移もHTMLとCSSのみで堅牢に実装できるようになる。技術に詳しい同僚が教えるような感覚で、具体的なコード例を交えながらその仕組みを紐解いていこう。
CSSによる状態管理の新しいアプローチ

Webサイトのインタラクションにおいて、すべての状態変化にJavaScriptが必要なわけではない。ビジネスロジックやデータの永続化が絡まない、純粋な表示の切り替えであれば、CSSの機能を活用したほうがスマートな解決策になることが多い。
JavaScriptを使わない選択肢
JavaScriptは強力だが、依存しすぎるとコードの複雑さが増し、パフォーマンスにも影響を与える。例えば、ダークモードの切り替えやタブメニューの制御をCSSで行うと、ページの読み込み直後から即座に反応し、スクリプトの実行待ちによる遅延が発生しない。これは、ユーザー体験の向上に直結する重要なポイントだ。
従来のチェックボックスハックとその限界
CSSで状態を管理する古典的な手法として「チェックボックスハック」がある。これは、非表示にしたチェックボックスの :checked 擬似クラスを利用し、隣接する要素のスタイルを変更するテクニックだ。しかし、この方法には「オンかオフか」という2つの状態しか持てないという明確な限界がある。3つ以上の状態を切り替えたい場合には、別の工夫が必要になる。
ラジオボタン・ステートマシンの基本構造

2つの状態しか持てないチェックボックスに対し、複数の選択肢から1つだけを選べるラジオボタンを利用するのが「ラジオボタン・ステートマシン」の核心だ。ラジオボタンは同じ name 属性を持つグループ内で排他的に動作するため、これを「現在の状態」として利用する。
相互排他的な状態を作る仕組み
まず、複数のラジオボタンを用意し、それぞれに異なる状態を割り当てる。例えば「状態A」「状態B」「状態C」の3つがある場合、HTML構造は以下のようになる。ここで重要なのは、ラジオボタンを display: none で消すのではなく、アクセシビリティを考慮した方法で隠すことだ。
<div class="state-container">
<input type="radio" name="ui-state" id="state-1" checked>
<input type="radio" name="ui-state" id="state-2">
<input type="radio" name="ui-state" id="state-3">
<div class="content">
<!-- ここに状態に応じて変化する要素を配置 -->
</div>
</div>ボタンの見た目をカスタマイズする
ラジオボタンそのものをUIのボタンとして機能させるには、appearance: none を使用してデフォルトのスタイルを解除する。これにより、ラジオボタンをあたかも普通のボタンやタブのようにスタイリングできるようになる。疑似要素の ::after などを使ってラベルテキストを表示すれば、HTMLタグを最小限に抑えたまま、インタラクティブな要素が完成する。
状態切り替えデモ(簡易版)
このデモはラジオボタンの排他的な性質を利用した状態遷移を視覚化したものだ。実際の実装では、クリックするたびに :checked が移動し、それに応じて下のコンテンツが切り替わる仕組みになる。
循環型と非循環型のフロー制御

ステートマシンを構築する際、ユーザーがどのように状態間を移動するかを設計する必要がある。すべての状態をループさせる「循環型」と、最初から最後まで順番に進む「非循環型(リニア型)」の2パターンが主に使われる。
次の状態へ進むシーケンシャルな遷移
例えば、クリックするたびに「進む」だけのUIを作る場合、現在の状態の「次」にあるラジオボタンだけを表示させるテクニックが使える。CSSの隣接兄弟結合子 + を活用し、input:checked + input というセレクタを使えば、現在選択されている要素の直後にある要素だけにスタイルを適用できる。
input[name="state"] {
position: fixed;
opacity: 0;
pointer-events: none;
}
/* 現在チェックされているものの次にあるボタンだけを表示する */
input[name="state"]:checked + input[name="state"] {
position: relative;
opacity: 1;
pointer-events: all;
appearance: none;
/* ボタンとしてのスタイル */
}前に戻る双方向フローの実装
「戻る」ボタンも実装したい場合は、最新のCSS擬似クラスである :has() が威力を発揮する。input:has(+ input:checked) というセレクタを使えば、「次にチェックされている要素がある場合の、自分自身」をターゲットにできる。これにより、進むボタンと戻るボタンの両方をCSSだけで制御可能になる。
カスタムプロパティと計算式の活用

ラジオボタン・ステートマシンの真価は、CSSカスタムプロパティ(変数)と組み合わせたときに発揮される。各状態に対して直接スタイルを記述するのではなく、変数の値だけを書き換える手法だ。
状態を変数として一括管理する
例えば、状態ごとに要素の位置や色を変えたい場合、各状態の :checked 時に --state-index のような変数の値を変更する。これにより、各コンポーネント側ではその変数を参照するだけで済み、コードの重複を劇的に減らすことができる。
.container:has(#state-1:checked) { --index: 0; --color: #e91e63; }
.container:has(#state-2:checked) { --index: 1; --color: #2196f3; }
.container:has(#state-3:checked) { --index: 2; --color: #4caf50; }
.indicator {
background-color: var(--color);
transform: translateX(calc(var(--index) * 100%));
}calc関数による動的なスタイル適用
変数を数値として扱うことで、calc() 関数を用いた高度なレイアウト計算が可能になる。例えば、スライダーの移動距離や、要素の不透明度、あるいは hsl() 関数を使った色の変化などを、状態のインデックス番号から動的に算出できる。これは、まるでJavaScriptで計算しているかのような柔軟性をCSSにもたらす。
※状態変数 –index の値によってゲージの幅や色を計算
このデモは、内部的な変数値の変化がどのように視覚的なゲージやインジケーターに反映されるかを示している。CSSの計算機能を使うことで、滑らかなアニメーションを伴う状態遷移が実現する。
実用性とアクセシビリティの考慮点

CSSステートマシンは非常に強力だが、実務で導入する際にはアクセシビリティへの配慮が欠かせない。単に「動く」だけでなく、すべてのユーザーが利用できる形でなければならない。
フォームコントロールとしての特性を活かす
ラジオボタンは本来、フォームの入力要素だ。そのため、キーボード操作(Tabキーでの移動や矢印キーでの選択)に標準で対応している。この特性を壊さないようにスタイリングすることが重要だ。display: none を使ってしまうとフォーカスが当たらなくなるため、視覚的に隠しつつもスクリーンリーダーやキーボードからは認識できる状態を維持する必要がある。
視覚的な変化とセマンティクスのバランス
CSSステートマシンが適しているのは、あくまで「視覚的なバリエーション」や「ローカルなUI操作」だ。データの保存が必要なフォーム送信や、複雑なバリデーションが絡む場合は、おとなしくJavaScriptを使用すべきだ。Kinstaの著者Carlo Daniele氏も指摘するように、CSSはプレゼンテーション層に責任を持ち、アプリケーションのロジックはスクリプト層が持つという役割分担を忘れてはならない。
この記事のポイント
- ラジオボタンの「1つだけ選択できる」特性を利用して、3つ以上のUI状態をCSSで管理できる
:has()や隣接兄弟結合子を駆使することで、進む・戻る・循環といった複雑なフローを制御可能だ- カスタムプロパティと
calc()を組み合わせれば、状態に応じた動的なレイアウト計算がCSSのみで行える - アクセシビリティを損なわないよう、
appearance: noneを活用し、キーボード操作性を維持することが重要だ - 純粋な表示上の状態管理にはCSSを使い、ビジネスロジックにはJavaScriptを使うという適切な使い分けが求められる

2026年3月のBaselineアップデート!最新Web技術の互換性と実務への活用法
Webプラットフォームの進化が加速している。2026年3月、主要なブラウザエンジンすべてで相互運用が可能になった機能を示す指標「Baseline」において、多くの強力な機能が新たに「利用可能(Newly available)」な状態となった。
同時に、登場から30ヶ月が経過し、もはやポリフィルなしで安心して本番環境に投入できる「広く普及(Widely available)」の段階に達した技術も大量に増えている。レイアウト制御の高度化から、低遅延なネットワーク通信、洗練されたストリーミング機能まで、Webの可能性はさらに広がった。
この記事では、2026年3月のアップデート内容を整理し、それぞれの技術が実務にどのようなメリットをもたらすのかを詳しく掘り下げていく。Web制作の現場で「今、どの技術を使うべきか」を判断する材料として役立ててほしい。
最新機能とタイポグラフィの進化

今回のアップデートでは、CSSのタイポグラフィ制御に関する機能がいくつかBaselineの「Newly available」となった。これにより、これまで実現が難しかった高度なテキストレイアウトが、標準的なCSSのみで完結するようになる。
数式表示とテキストインデントの自由度
まず注目したいのが、font-family プロパティに新しく追加された math という値だ。これは数式コンテンツ(MathMLなど)をレンダリングするために特別に設計されたフォントセットを指定するものだ。技術文書や教育サイトにおいて、複雑な数式を美しく、かつ正確な間隔で表示するために不可欠な機能となる。
また、text-indent プロパティも大幅に強化された。新しく追加された each-line キーワードを使えば、ブロックの最初の行だけでなく、<br /> による強制改行の後のすべての行にインデントを適用できる。さらに hanging キーワードを使えば、1行目はそのままに、2行目以降をインデントさせる「ぶら下げインデント」が簡単に実現可能だ。
/* ぶら下げインデントの指定例 */
.bibliography {
text-indent: 2em hanging;
}これは通常のテキスト配置だ。1行目の先頭だけが空くのが一般的だが、参考文献リストなどでは2行目以降を下げたい場合がある。
参考文献:Web技術の進化に関する考察。この行は1行目だが、2行目以降は左側に余白が作られ、項目名が際立つようになる。
text-indent: hanging の動作は対応ブラウザで確認してほしい。このコードを適用すると、参考文献リストや箇条書きのような、特定のデザインルールが求められるレイアウトを非常にシンプルに記述できるようになる。従来のようにネガティブマージンとパディングを組み合わせるハックは不要だ。
JavaScriptの反復処理を簡略化する新メソッド
スクリプト面では、Iterator.concat() が全ての主要ブラウザでサポートされた。これは、複数の反復可能なオブジェクト(配列やセットなど)を一つのイテレータに結合する静的メソッドだ。途中で中間的な配列を作成することなく、複数のデータソースを連続して処理できるため、メモリ効率の向上とコードの簡略化に寄与する。
データ通信とパフォーマンスの最適化

Webアプリケーションの「体感速度」を左右する通信技術やストリーミング機能も、Baselineの新たなステージへと進んだ。特にリアルタイム性が求められるサービスにおいて、これらの技術は大きな武器になる。
WebTransportによる低遅延通信
WebTransport は、HTTP/3をベースにした現代的な通信APIだ。クライアントとサーバー間での双方向通信を可能にし、従来のWebSocketよりも効率的で低遅延なデータのやり取りを実現する。信頼性の高いデータ転送と、信頼性は低いが高速な「データグラム」の両方をサポートしている点が特徴だ。
例えば、オンラインゲームやライブストリーミングなど、一分一秒の遅延が許されないアプリケーションにおいて、WebTransport は理想的な選択肢となる。HTTP/3のメリットである「ヘッドオブラインブロッキング(一つのパケット損失が全体の通信を止める現象)」の解消を享受できるため、不安定なネットワーク環境下でもパフォーマンスが安定しやすい。
バイナリデータの効率的なストリーミング
Streams APIにおける「読み取り可能なバイトストリーム(Readable byte streams)」のフルサポートも重要な進展だ。これはバイナリデータの処理に最適化されており、開発者が用意したバッファに直接データを読み込むことができる。これにより、巨大なファイルのアップロードやダウンロード、動画の動的処理などにおけるメモリ管理が劇的に効率化される。
さらに、ブラウザレベルでのエラーやポリシー違反を通知する「Reporting API」も共通の基盤となった。コンテンツセキュリティポリシー(CSP)の違反や、非推奨機能の使用、ブラウザのクラッシュレポートなどを特定の終端(エンドポイント)へ送信し、集中的に監視することが可能になる。これは大規模なWebサービスの運用保守において、問題の早期発見に大きく貢献するはずだ。
「広く普及」した技術:CSS subgridと安定したレイアウト

2026年3月には、多くの技術が「Widely available(広く普及)」へと移行した。これは登場から30ヶ月が経過し、もはや「最新技術」というリスクを負うことなく、あらゆるプロジェクトで標準的に採用できることを意味している。
CSS subgridによるグリッドレイアウトの完成
中でも最大の影響力を持つのが CSS subgrid だ。これは、子要素が親要素のグリッド定義(列や行のサイズ)をそのまま継承できる機能だ。これまでは、異なる階層にある要素同士を正確に整列させるために複雑な計算やHTML構造の妥協が必要だったが、subgridを使えばDOM構造を美しく保ったまま、完璧な整列が実現できる。
このデモが示すように、カード型レイアウト内のタイトルや本文の高さが、隣のカードと完全に一致するように制御できるのが subgrid の強みだ。もはや、JavaScriptで高さを揃える処理(いわゆるmatchHeightのようなもの)を書く必要はない。
表示の最適化とデバイス対応
また、image-set() 関数も普及段階に入った。これは <img> タグの srcset 属性に近い機能をCSSの background-image などで実現するものだ。ユーザーのデバイス解像度(DPI)に応じて、ブラウザが最適な画像ファイルを自動的に選択してダウンロードする。無駄な帯域を消費せず、Retinaディスプレイなどでは鮮明な画像を表示できる。
さらに、update メディアクエリも広く利用可能になった。これはデバイスの画面がどの程度の頻度で更新されるかを判定するものだ。スマートフォンのような高速リフレッシュレートを持つ画面と、電子書籍リーダー(e-ink)のような低速な画面を区別し、それぞれに最適なアニメーションや装飾を出し分けることができる。
実務での技術選定:Baselineをどう活用するか

Web技術がこれほど速く進化する中で、エンジニアやディレクターは「いつ、どの技術を実務に導入するか」という難しい判断を迫られる。GoogleのRachel Andrew氏は、自身の講演の中で、この課題に対する現実的なアプローチを提示している。
「安全」と「最新」のバランスを取る戦略
Andrew氏によると、Baselineのステータスを単なる「安全な機能のリスト」として見るのではなく、プロジェクトのリリース日に合わせてターゲットを設定することが重要だという。例えば、開発開始時点では「Newly available(最新)」であっても、プロジェクトの公開日が数ヶ月先であれば、その頃にはユーザーのブラウザ更新が進み、安全に使えるようになっている可能性がある。
一方で、特定のブラウザバージョンをサポートしなければならない制約がある場合、Baselineの「Widely available(広く普及)」に達している機能を選ぶのが最も堅実だ。この区分に入っている技術は、主要なブラウザすべてで安定して動作することが30ヶ月にわたって証明されている。ポリフィルによるパフォーマンス低下や、予期せぬバグのリスクを最小限に抑えつつ、モダンな開発体験を享受できる基準と言える。
コミュニティでの実装例と可視化
開発者コミュニティでも、このBaselineの考え方を積極的に取り入れる動きが出ている。Stu Robson氏は、自身のサイトに「Baseline status」を表示するWebコンポーネントを導入した事例を紹介している。特定の技術について解説する記事の冒頭に、その技術が現在のブラウザでどの程度サポートされているかをリアルタイムで表示する仕組みだ。
このような取り組みは、読者(またはクライアント)に対して、その技術が「今すぐ使えるものなのか」を即座に伝えるための優れた方法だ。Webコンポーネント自体はオープンソースで公開されており、Eleventyなどの静的サイトジェネレーターに限らず、WordPressなどあらゆるフレームワークで利用可能となっている。
この記事のポイント
- 2026年3月のアップデートで、
WebTransportやtext-indent: hangingなどが主要ブラウザで利用可能になった。 CSS subgridやimage-set()などの強力な機能が「広く普及」の段階に達し、本番環境で安心して使えるようになった。mathフォントファミリーやIterator.concat()により、数式表示やデータ処理のコードがよりシンプルになる。- Baselineのステータスを基準にすることで、プロジェクトのリリース時期に合わせた最適な技術選定が可能になる。

View Transitions APIでサイト体験を劇的に変える!CSSだけで実現する7つのページ遷移レシピ
Webサイトのページを切り替える際、画面が瞬時にパッと切り替わるのではなく、モバイルアプリのような滑らかなアニメーションを伴う手法が注目されている。これを実現するのが「View Transitions API」だ。複雑なJavaScriptライブラリを使わずに、ブラウザの標準機能とCSSだけで高度な遷移エフェクトを実装できる。
View Transitions APIは主要なブラウザでのサポートが進み、実用的な段階に入った。特にマルチページアプリケーション(MPA)でも、ページ間の連続性を保った演出が可能になった点は大きい。ユーザー体験を向上させるための強力な武器になるだろう。
本記事では、CSS-Tricksの記事を基に、すぐに試せる7つのアニメーションレシピを紹介する。基本的なセットアップから、ぼかしや3D回転を組み合わせた応用例まで、その仕組みを詳しく解説していく。技術的なハードルは低いため、最新のWeb制作トレンドを取り入れたいエンジニアやデザイナーにとって有益な情報となるはずだ。
View Transitions APIの基本設定と導入のポイント
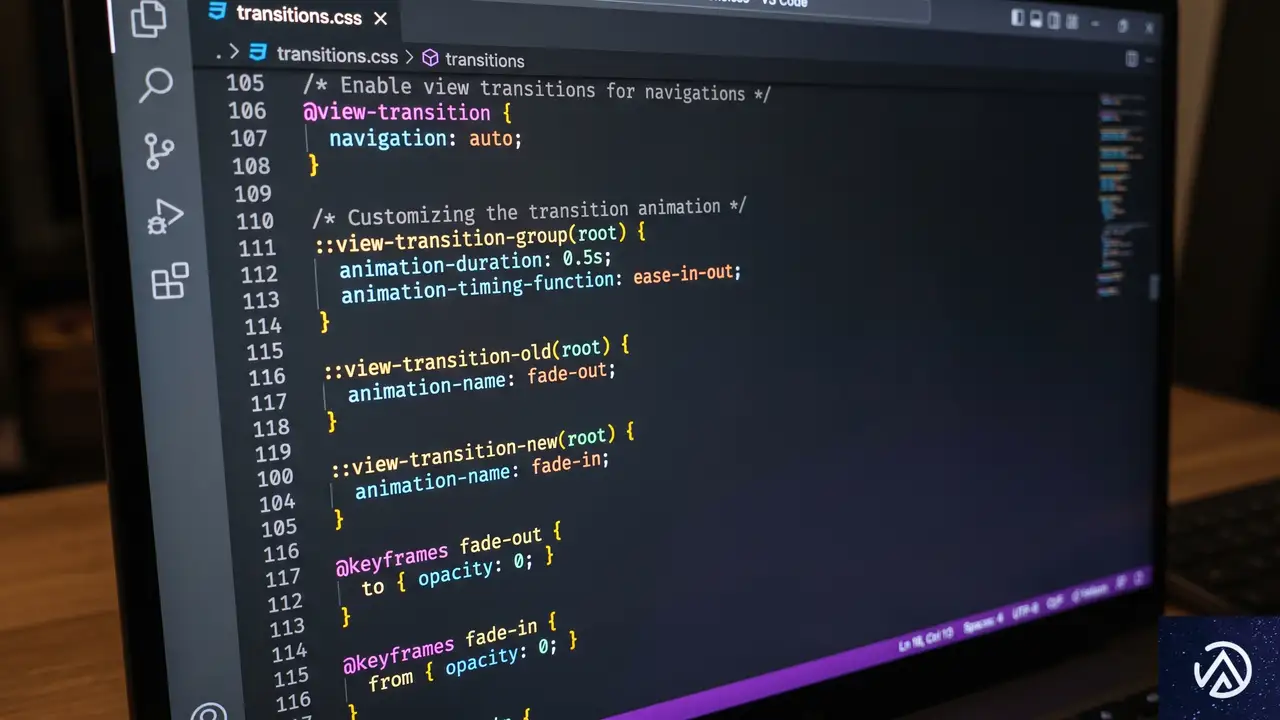
View Transitions APIを利用するには、まずブラウザに対して「このサイトでページ遷移のアニメーションを有効にする」という宣言が必要だ。これを「オプトイン(利用選択)」と呼ぶ。CSSの @view-transition アットルールを使い、遷移元と遷移先の両方のページで設定を行う必要がある。
@view-transitionルールでのオプトイン
最も基本的な設定は、CSSに数行のコードを追加するだけで完了する。共通のCSSファイルに記述しておくことで、サイト全体に適用できる。 navigation: auto を指定すると、通常のリンク移動時にブラウザが自動的にトランジションを実行するようになる。
@view-transition {
navigation: auto;
}この設定だけで、ブラウザのデフォルトである「クロスフェード(前の画面が消えながら次の画面が浮き上がる)」が適用される。さらに特定の名前(タイプ)を付けることで、ページの種類ごとに異なるアニメーションを使い分けることも可能だ。
ユーザーの好みに配慮したアクセシビリティ対応
アニメーションを実装する上で忘れてはならないのが、アクセシビリティへの配慮だ。OSの設定で「視覚効果を減らす」を選択しているユーザーに対しては、激しい動きを控えるべきだ。これを判定するのが prefers-reduced-motion メディアクエリである。
「動きを減らす」設定が無効(no-preference)の場合のみアニメーションを有効にする記述が推奨される。これにより、すべてのユーザーが快適にサイトを閲覧できる環境を整えられる。技術的な新しさを追求するだけでなく、こうした配慮をセットで行うのがプロの仕事だ。
@media (prefers-reduced-motion: no-preference) {
@view-transition {
navigation: auto;
types: my-transition;
}
}視覚効果で魅せるフェードとワイプのレシピ

ここからは具体的なアニメーションレシピを見ていこう。まずは定番のフェード効果をアレンジしたものや、画面を拭き取るようなワイプ効果だ。これらは汎用性が高く、どんなジャンルのサイトにも馴染みやすい。
ぼかしを活用したPixelate dissolve
単なるフェードではなく、画面全体をぼかしながら切り替えるのが「Pixelate dissolve(ピクセレート・ディゾルブ)」だ。CSSの filter: blur() プロパティを使用する。古いページがぼやけて消えていき、新しいページがぼやけた状態から鮮明に現れる演出だ。
このアニメーションは実際には約1.4秒かけて連続的に行われる。中間状態の filter:blur(6px) と opacity:0.6 がスムーズに変化することで、画面全体が一度ぼやけてから鮮明な新画面が立ち上がる演出になる。短く設定すればキビキビとしたモダンな操作感、長くすればゆったりとした高級感のある印象を与えられる。
clip-pathで実現する上下左右のWipe効果
「Wipe(ワイプ)」は、画面をスライドさせて覆い隠すような効果だ。これには clip-path プロパティの inset() 関数を利用する。 inset() は要素の表示領域を上下左右からの距離で指定する仕組みで、この数値を 0% から 100% へ動かすことで、コンテンツを削り取るような動きを作れる。
例えば「Wipe up(上方向へのワイプ)」なら、古いページの表示領域を下から上へ 100% 削り、新しいページを上から下へ 0% に戻していく。 clip-path を使うメリットは、実際のレイアウトを崩さずに表示領域だけを制御できる点にある。非常にパフォーマンスが良く、滑らかな動きを実現できる。
ダイナミックな動きを作る回転とプッシュの演出
次に、より動きの大きいダイナミックな演出を紹介する。これらはユーザーの目を引きやすいため、ポートフォリオサイトやキャンペーンページなど、個性を出したい場面で有効だ。 transform プロパティを駆使して、空間的な広がりを演出する。
遊び心のあるRotate in-out
「Rotate in-out(回転イン・アウト)」は、ページが回転しながら縮小して消え、新しいページが逆回転しながら拡大して現れるエフェクトだ。 scale(0) と rotate(180deg) を組み合わせる。実用性は限られるかもしれないが、View Transitionsの表現力の高さを示す良い例だ。
このアニメーションは実際には約1秒かけて連続的に行われる。中間状態では transform:scale(0.3) rotate(90deg) と opacity:0.4 によって元ページが縮小しながら回転して消え、その直後に新ページが逆方向から拡大して現れる。transform-origin: center を指定して画面中央を軸に回転させるのがポイントだ。また、回転角度を大きくしすぎるとユーザーが酔ってしまう可能性があるため、180度程度に抑えておくのが無難だ。
画面の隅から現れるDiagonal push
「Diagonal push(斜めプッシュ)」は、古いページを斜め方向に押し出し、新しいページを逆の斜め方向から滑り込ませる演出だ。 translate(-100%, -100%) のように X軸 と Y軸 の両方を同時に動かすことで斜めの移動を実現する。
この演出は、スライド資料を切り替えるような感覚をユーザーに与える。移動の軌跡に合わせて opacity (不透明度)を変化させると、より自然で洗練された印象になる。 ease (緩急)の指定を工夫することで、重厚感のある動きから軽快な動きまで調整可能だ。
形状と奥行きを活かした高度なトランジション

最後に、より高度な視覚効果を紹介する。これらは clip-path の応用や 3D変形 を使用しており、実装には少しコツが必要だが、その分インパクトは非常に大きい。ブラウザが自動的に生成するスナップショットをどのように加工するかが鍵となる。
円形に広がるCircle wipe-out
「Circle wipe-out(サークル・ワイプ)」は、画面中央から円形に新しいページが広がっていく演出だ。映画のシーン切り替えなどで見かける手法である。 clip-path: circle() を使い、半径を 0% から 150% まで拡大させることで、画面全体を覆い尽くす動きを作る。
このレシピの面白い点は、背景色が同じページ間での遷移だ。背景が変わらずにコンテンツだけが円形に浮き上がってくるように見えるため、非常にシームレスな体験を提供できる。中心点は at 50% 50% だけでなく、クリックした位置に合わせて動的に変更するような応用も考えられる。
幕が開くようなCurtain reveal
「Curtain reveal(カーテン・リビール)」は、舞台の幕が左右に開くような動きだ。これも clip-path: inset() を使用するが、左右の値を 50% から 0% へと変化させる点が特徴だ。画面中央から左右に向かって新しいページが露出していく様子は、新しい体験の始まりを予感させる。
このアニメーションは実際には約0.8秒かけて連続的に行われる。clip-path: inset(0 50% 0 50%) から inset(0 0 0 0) へと値が変化することで、左右から幕が引かれて中央のコンテンツが露出していく。実際のView Transitionsでは、::view-transition-new(root) に対してこのクリッピングアニメーションを適用することで、滑らかなカーテン効果が実現する。
3D空間でカードがめくれる3D flip
最もインパクトがあるのが「3D flip(3Dフリップ)」だ。ページ全体を一枚のカードに見立て、 Y軸 を中心に回転させて裏返すような演出を行う。 rotateY(90deg) でページを真横に向け、その瞬間に新しいページと入れ替えて 0deg に戻していく。
この演出を成功させるには、 perspective (遠近感)の設定が重要だ。奥行きを感じさせる数値を指定することで、平面的な画面の中に立体的な空間が生まれる。ただし、非常に目立つエフェクトなので、使いどころを慎重に選ぶ必要があるだろう。
実務でView Transitionsを導入する際の注意点
View Transitions APIは非常に強力だが、実務に導入する際にはいくつか考慮すべき点がある。単にコードをコピーするだけでなく、プロジェクトの要件に合わせた最適化が必要だ。ここでは、技術的な側面とユーザー体験の両面から、筆者の見解を交えて解説する。
ブラウザサポートとフォールバックの考え方
View Transitions APIは現在、ChromeやEdgeなどのChromium系ブラウザで先行して実装され、SafariやFirefoxでも順次対応が進んでいる。しかし、すべてのユーザーが最新ブラウザを使っているわけではない。そのため、「アニメーションが動かなくてもコンテンツは正しく表示される」というプログレッシブ・エンハンスメントの考え方が不可欠だ。
幸いなことに、View Transitions APIは「対応していないブラウザでは単にアニメーションが無視されるだけ」という特性を持っている。特別なJavaScriptによる条件分岐を書かなくても、基本的には安全に導入できる。ただし、アニメーションがあることを前提とした複雑なUI設計は避けるべきだ。
パフォーマンスへの影響と最適化
トランジション実行中、ブラウザは画面のスナップショット(画像のようなもの)を作成し、それをアニメーションさせている。そのため、非常に高解像度な画像が大量にあるページや、複雑なDOM構造を持つページでは、一瞬の動作の重さを感じることがあるかもしれない。
対策としては、 will-change プロパティを適切に使ってブラウザに最適化を促すことや、アニメーションさせる要素を view-transition-name で限定することが有効だ。画面全体(root)を動かすのではなく、ヘッダーやロゴなどの共通要素を固定し、中身のコンテンツだけを動かすようにすると、より軽快で自然な遷移になる。
この記事のポイント
- View Transitions APIはCSSだけでモバイルアプリのような滑らかなページ遷移を実現する
@view-transitionルールのnavigation: auto設定でMPAでも簡単に導入できるclip-pathやfilterを組み合わせることで、ぼかしやワイプなど多様な演出が可能になるprefers-reduced-motionを使い、動きを好まないユーザーへの配慮を忘れない- 対応ブラウザ以外では通常の遷移になるため、プログレッシブ・エンハンスメントとして導入しやすい

AIアプリに専用DBを即時提供!CloudflareのDurable Objects Facetsを解説
Cloudflareは、AIが生成したアプリケーションごとに専用のデータベースを割り当てることができる新機能「Durable Objects Facets(デュラブル・オブジェクト・ファセット)」をベータ公開した。この機能は、同社が提供する「Dynamic Workers」の仕組みを拡張したもので、動的に生成されたコードに対して、永続的なストレージを安全かつ高速に提供することを目的としている。
従来のサーバーレス環境では、実行時にコードをロードして実行する「動的なサンドボックス」において、データの永続化を管理することが技術的な障壁となっていた。しかし、Durable Objects Facetsの登場により、AIエージェントが作成した小さなツールや個人用アプリが、それぞれ独自のSQLiteデータベースを持ち、状態を保持し続けることが可能になる。
なぜこのアップデートがAI開発の現場において重要なのか、その背景にある「アイソレート」の技術や、新しいストレージの概念について詳しく紐解いていこう。AIが単にコードを書くだけでなく、自律的にデータを管理する「記憶を持つエージェント」へと進化する大きな一歩だと言える。
Dynamic Workersとアイソレートが支える高速な実行環境

Durable Objects Facetsを理解するためには、まずその基盤となる「Dynamic Workers(ダイナミック・ワーカーズ)」について知る必要がある。Dynamic Workersとは、実行時にWorkerのコードをオンデマンドでロードし、安全なサンドボックス内で実行できる機能だ。
コンテナではなくアイソレートが実現する100倍の起動速度
Cloudflare Workersの最大の特徴は、一般的なクラウドサービスが採用している「コンテナ」技術ではなく、「アイソレート(Isolate)」という仕組みを利用している点にある。アイソレートとは、Google Chromeなどのブラウザを支えるV8エンジンが提供する、非常に軽量な実行環境の単位だ。
アイソレートはコンテナと比較して、起動速度が最大100倍速く、メモリ使用量は10分の1程度で済むという。この圧倒的な軽さにより、コードを実行するたびに環境を立ち上げ、終わったら即座に破棄するという「使い捨てのコンピューティング」が可能になった。Dynamic Workersは、このアイソレートの特性を最大限に活かし、AIが生成した数行のコードを即座に実行するセキュアな「eval()」のような役割を果たす。
このデモは、コンテナとアイソレートの構造的な違いを視覚化したものだ。アイソレートの軽量さが、AIによる動的なコード実行を支えている。
AIエージェントによるコード実行の課題
AIエージェントがユーザーの依頼に応じてコードを書き、それを実行する場合、これまでは「一度きりのタスク」として処理されることが多かった。例えば、データの集計や特定のAPI呼び出しなどは、実行後に結果を返せばコード自体を保持し続ける必要はない。
しかし、ユーザーが「自分専用の家計簿アプリを作って」と依頼した場合、AIはUI(ユーザーインターフェース)だけでなく、入力されたデータを保存し続ける「ストレージ」も提供しなければならない。動的に生成されたコードが、どのようにして安全に、かつ自分専用のデータベースにアクセスするかが大きな課題となっていた。
Durable Objectsがもたらす超低遅延ストレージの仕組み

この課題を解決するための強力な武器が「Durable Objects(デュラブル・オブジェクト)」だ。これはCloudflare Workersの中でも特殊な種類で、世界中で一意の名前を持つインスタンスを作成し、その状態を永続化できる仕組みを指す。
SQLiteをローカルディスクに持つ特殊なWorker
Durable Objectsの最大の特徴は、各インスタンスが自分専用のSQLiteデータベースを持っていることだ。しかも、このデータベースはDurable Objectsが動作している物理マシンの「ローカルディスク」上に配置される。通常のデータベースのようにネットワークを介してリクエストを送る必要がないため、データアクセスにおける遅延は実質的にゼロとなる。
CWV(Core Web Vitals / コアウェブバイタル)などの指標を気にするWeb制作の現場においても、この「ネットワーク遅延がないストレージ」は非常に魅力的だ。ユーザーに近い場所(エッジ)で計算と保存が完結するため、極めてレスポンスの速いアプリケーションを構築できる。
動的なコードとストレージの「相性の悪さ」
しかし、Durable ObjectsをDynamic Workersと組み合わせるには問題があった。通常、Durable Objectsを使用するには、開発者が事前にクラスを定義し、設定ファイル(wrangler.jsonc)で名前空間を宣言し、CloudflareのAPIを通じてプロビジョニング(利用準備)を行う必要がある。AIがその場で生成した未知のコードに対して、この一連の手順を動的に行うことは困難だった。
また、セキュリティ上の懸念もある。AIが生成したコードに、無制限にデータベースを作成する権限を与えてしまうと、リソースの乱用や管理不能なデータの増殖を招く恐れがある。開発者は「AIが書いたコードを実行しつつ、その裏側でストレージやログを適切に管理する」という、監督者のような役割を必要としていた。
新機能「Durable Objects Facets」による解決策

そこで登場したのが、Durable Objects Facets(ファセット)だ。「Facet」とは「切り口」や「側面」を意味する言葉で、一つのDurable Objectの中に、複数の独立した実行環境とデータベースを持たせる概念を指す。
監視役(Supervisor)と実行役(Facet)の分離
この機能の核となるのは、開発者が書いた「監視役(Supervisor)」のコードの中で、AIが書いた「実行役(Facet)」のコードを動的にロードする仕組みだ。監視役は通常のDurable Objectとして動作し、リクエストを受け取ると、必要に応じてAIのコードをFacetとして呼び出す。
FacetとしてロードされたAIのコードは、自分専用のSQLiteデータベースを与えられる。このデータベースは監視役のデータベースとは論理的に分離されており、AIのコードが監視役の重要なデータ(課金情報や管理ログなど)を読み書きすることはできない。一方で、物理的には同じDurable Objectの一部として管理されるため、パフォーマンスの高さは維持される。
・ログ記録、レート制限
・管理用データベースを保持
・アプリ専用のSQLite DB
・親のDBにはアクセス不可
この図のように、一つのDurable Objectの中に「管理領域」と「AIの自由領域」を共存させるのがFacetの狙いだ。これにより、安全性を確保しながら動的なデータ永続化が可能になる。
親子関係で実現するセキュリティと制御
開発者は、AIが作成できるFacetの数を制限したり、各Facetが使用するストレージ容量を監視したりすることができる。これにより、AIが勝手に大量のデータを保存してコストを増大させるリスクを防げる。また、監視役のコードを通じてネットワークアクセスを制限(globalOutbound: null)することで、AIが生成したコードが外部にデータを送信するのを遮断することも可能だ。
これは、大規模なAIプラットフォームを構築するエンジニアにとって非常に重要な制御機能となる。ユーザーごとに異なるAIアプリを動かしても、インフラ側での統制が容易になるからだ。
実装例から見るAIアプリのプラットフォーム構築

実際に、どのようにしてこの仕組みを構築するのか、Cloudflareが公開したコード例を基に解説しよう。ここでは、AIが生成した「アクセス回数をカウントするアプリ」を動的にロードする例を考える。
コードの動的ロードとクラスのインスタンス化
まず、監視役となる AppRunner クラスを作成する。このクラスは this.ctx.facets.get() という新しいメソッドを使い、AIのコードをFacetとして取得する。もしFacetがまだ存在しない場合は、コールバック関数内でDynamic Workerをロードし、その中からAIが定義したクラスを取り出す。
// 監視役のコード例
export class AppRunner extends DurableObject {
async fetch(request) {
// "app" という名前のFacetを取得。なければ作成する。
let facet = this.ctx.facets.get("app", async () => {
// AIのコードをロード
let worker = this.#loadDynamicWorker();
// コード内から "App" という名前のクラスを取得
let appClass = worker.getDurableObjectClass("App");
return { class: appClass };
});
// リクエストをFacet(AIアプリ)に転送
return await facet.fetch(request);
}
}注目すべきは、AIが書いたコード側でも extends DurableObject を使っている点だ。AIは通常のDurable Objectを書くのと同じ感覚でコードを生成でき、特別なFacet用の記法を覚える必要はない。
データベースの分離と永続化の管理
AIアプリ(Facet)が this.ctx.storage.kv.put() などのメソッドを使ってデータを保存すると、それはそのFacet専用のSQLiteデータベースに書き込まれる。監視役の AppRunner も自身のストレージを持っているが、これらは完全に別のファイルとして管理される。
この構造により、例えばあるユーザーのAIアプリがバグでデータを壊したとしても、監視役が持っている管理データや、他のユーザーのアプリには一切影響が及ばない。マルチテナント(複数のユーザーが一つのシステムを共有すること)な環境を構築する上で、この分離は極めて強力な防御壁となる。
今後のAIエージェント開発への影響と展望

Durable Objects Facetsの登場は、AIエージェントのあり方を大きく変える可能性を秘めている。これまでは「指示を聞いて答えるだけ」だったエージェントが、ユーザー固有のデータを蓄積し、それを基にパーソナライズされた体験を提供する「自律的なアプリケーション」へと進化するからだ。
「使い捨て」から「自律的な成長」へ
これまでのAI生成コードは、実行が終われば消えてしまう「刹那的」なものだった。しかし、専用のデータベースを持つことで、AIアプリは前回の実行時の状態を覚えていることができる。例えば、ユーザーの好みを学習し続けるレコメンドエンジンや、過去の対話履歴を構造化して保存する秘書アプリなどが、AI自身の手によって構築・運用されるようになるだろう。
Cloudflareの著者であるCarlo Daniele氏によれば、これは「Vibe-coded(雰囲気で書かれた)」個人用アプリを、セキュアな環境で永続化するための最適な解決策だという。プログラミングの知識がなくても、AIとの対話を通じて自分専用のツールを作り、それをクラウド上で安全に動かし続けることができる時代の到来だ。
開発者が考慮すべきコストとガバナンス
一方で、この技術を活用する開発者には、新たな責任も生じる。動的にデータベースが増えていくため、リソースのライフサイクル管理が不可欠だ。使われなくなったFacetをいつ削除するのか、バックアップはどうするのかといった、データガバナンスの設計が重要になる。
幸い、Durable ObjectsはCloudflareのインフラによって高度に抽象化されており、運用負荷は低い。しかし、AIが生成するコードの品質やデータの正当性をどう保証するかという点は、依然として人間(プラットフォーム開発者)が設計すべき領域として残っている。Durable Objects Facetsは、そのための「管理ツール」を開発者に提供したと言えるだろう。
この記事のポイント
- Durable Objects Facetsは、AI生成コードごとに専用のSQLiteデータベースを割り当てる新機能である。
- アイソレート技術により、コンテナよりも圧倒的に高速かつ軽量に動的なサンドボックスを起動できる。
- 監視役(Supervisor)がAIのコードを制御することで、セキュリティと管理性を両立させている。
- AIエージェントが「記憶」を持つことが可能になり、パーソナライズされたアプリ開発が加速する。
- 現在はWorkers Paidプランのユーザー向けにオープンベータとして提供されている。

MetaがGoogleの広告収益を逆転へ!2026年に起きる歴史的転換の背景とSEO・広告戦略への影響
デジタル広告の世界で、長らくトップに君臨してきたGoogleの牙城がついに崩れようとしている。2026年、Metaの広告収益がGoogleを追い抜き、世界シェア1位に躍り出る見通しが明らかになった。これは単なる収益の逆転ではなく、広告の仕組みそのものが「検索」から「AIによる自動最適化」へとシフトしている現実を物語っている。
米調査会社のEmarketerが発表した予測によれば、2026年のMetaの広告収益は2,434億6,000万ドル(約37兆円)に達する見込みだ。対するGoogleは2,395億4,000万ドルにとどまり、僅差ながらも首位が入れ替わることになる。Googleがデジタル広告のトップから陥落するのは、同社が市場を支配して以来、初めての出来事だ。
この変化は、Webサイトを運営する企業や個人にとって無視できない兆候といえる。ユーザーの行動がGoogle検索から、InstagramやFacebook、WhatsAppといったSNS上の「発見」へと移り変わっているからだ。本記事では、この歴史的な逆転劇の背景と、今後のWebマーケティングに与える影響を深掘りしていく。
数字で見る広告市場の勢力図塗り替え

広告収益のシェアで見ると、その変化はより鮮明になる。2026年、Metaは世界のデジタル広告支出の26.8%を占めると予測されている。一方で、Googleのシェアは26.4%まで低下する見込みだ。かつてはGoogleが圧倒的な差をつけていたが、この数年でMetaが猛烈な勢いで差を詰めてきた結果である。
Googleの成長鈍化とMetaの加速
Googleの広告ビジネスが停滞しているわけではない。検索広告やYouTube広告は依然として巨大な収益源だが、その成長スピードが以前に比べて緩やかになっている。背景には、検索市場の成熟と、後述するAI検索の台頭による不確実性がある。既存の検索広告モデルが、かつてのような爆発的な伸びを維持できなくなっているのだ。
対照的に、MetaはAIを活用した広告運用の自動化に成功し、収益を飛躍的に伸ばしている。特に「Advantage+」などのAIツールが、広告主にとっての投資対効果(ROI)を劇的に改善させた。人間が細かくターゲットを設定しなくても、AIが最適なユーザーに広告を届ける仕組みが、企業の予算を引き寄せている。
マクロ経済が後押しするパフォーマンス広告
世界的な経済の先行き不透明感も、この逆転を後押ししている。景気が厳しくなると、企業は「認知」を目的としたブランディング広告よりも、直接的な「売上」につながるパフォーマンス広告を優先する傾向がある。Metaの広告プラットフォームは、ユーザーの興味関心に基づいた高精度なターゲティングが可能であり、より短いスパンで成果を証明しやすい。この「測れる成果」こそが、現在の市場で最も求められている価値だといえる。
なぜMetaがGoogleに競り勝つのか

Metaが勝利を収めつつある最大の要因は、広告運用の「手軽さ」と「精度の高さ」の両立にある。Google検索広告は、適切なキーワードを選定し、競合の入札状況を監視するなど、運用に一定のスキルと工数が必要とされる。しかし、Metaの最新の広告システムは、クリエイティブ(画像や動画)を用意するだけで、あとはAIがすべてを最適化してくれるレベルに達している。
AIによる「運用の民主化」
Metaは広告主に対し、AIを使ってターゲット設定やクリエイティブの生成を自動化する機能を次々と提供している。これにより、専門の広告運用担当者がいない中小企業でも、大企業に引けを取らない成果を出せるようになった。この「運用の民主化」が、Metaの広告主の裾野を大きく広げている。
● ターゲット層の細かな手動設定
● 入札単価の頻繁な調整
★ 画像・動画の自動バリエーション生成
★ リアルタイムでの予算最適化
この図は、広告運用の手間がAIによっていかに削減され、成果へと直結するようになったかを示している。
「検索」を必要としない発見のプロセス
Googleの強みは「ユーザーが何かを探している瞬間」を捉えることにある。しかし、Metaは「ユーザーが気づいていなかった欲しいもの」を提示することに長けている。SNSのタイムラインを流れるパーソナライズされた広告は、ユーザーにとって受動的な発見をもたらす。検索という能動的なアクションを必要としないこのプロセスは、スマホ時代の消費行動に極めて適合している。
Googleが直面する三重苦

王座を明け渡す形となるGoogleだが、同社は現在、非常に困難な舵取りを迫られている。主な要因は、AIによる検索体験の変化、法的な規制、そして主力事業の成熟という3つの課題だ。
AI検索(SGEなど)による広告モデルの破壊
PerplexityやChatGPTのようなAI回答エンジン、そしてGoogle自身が導入を進める「AI Overviews(旧SGE)」は、従来の検索広告のあり方を根底から変えようとしている。AIが直接回答を提示することで、ユーザーは検索結果のリンクをクリックする必要がなくなる。これは、クリック課金で収益を上げてきたGoogleにとって、自らのビジネスモデルを破壊しかねないリスクを孕んでいる。
独占禁止法を巡る法廷闘争
Googleは米国や欧州で、広告技術における市場独占を巡る厳しい監視下に置かれている。複数の訴訟が進行中であり、最悪の場合、広告事業の分割を命じられる可能性もゼロではない。こうした法的なリスクは、同社の積極的な事業拡大の足かせとなっており、投資家や広告主の心理に影を落としている。
YouTubeの競争激化
Googleのもう一つの柱であるYouTubeも、TikTokという強力なライバルの出現により、若年層の視聴時間と広告予算を奪われている。ショート動画市場での競争は激しさを増しており、かつてのような独走状態ではない。MetaもInstagramのリール(Reels)を通じてこの分野で強く対抗しており、動画広告の予算もMetaへと流れる要因となっている。
Web担当者が取るべき今後の戦略

広告収益のシェアが逆転するということは、ユーザーの関心がどこに集まっているかを示す指標でもある。これからのWebマーケティングでは、Google検索だけに頼るのではなく、プラットフォームの変化に合わせた柔軟な予算配分と戦略の構築が求められる。
マルチチャネルでの予算配分の再考
もし現在の集客をGoogle検索広告に依存しているなら、Meta広告への予算分散を検討する時期だ。特に、AIによる自動運用ツール(Advantage+など)を積極的に活用し、自社のデータとAIを組み合わせた最適化を試すべきである。Googleが弱体化するわけではないが、Metaの方が「安く、広く、正確に」リーチできるケースが増えている事実は無視できない。
「検索される」から「見つけられる」コンテンツ作り
SEO(検索エンジン最適化)の重要性は変わらないが、その定義は広がりつつある。これからはGoogleの検索窓に入力される言葉を狙うだけでなく、SNSのアルゴリズムに「おすすめ」として選ばれるためのコンテンツ作りが必要だ。視覚的に訴求力のある画像や、数秒で価値が伝わる縦型動画の制作は、もはやSNS担当者だけの仕事ではなく、Webマーケター全体の必須スキルとなっている。
独自の分析:広告は「意図」から「予測」へ

今回の逆転劇を分析すると、広告の本質的な価値が「ユーザーの意図に応えること」から「ユーザーの行動を予測すること」へと移行したことがわかる。Googleは、ユーザーが入力したキーワードという「明確な意図」を収益化してきた。しかしMetaは、膨大な行動データから「次に何に興味を持つか」をAIで予測し、意図が生まれる前に先回りして広告を提示する。
この「予測型広告」の勝利は、現代人が「探す」という手間を極限まで嫌っていることを示唆している。Webサイトの運営においても、ユーザーに検索させて情報を探させる構造よりも、パーソナライズされたおすすめを提示するような体験の提供が、今後のコンバージョン率を左右する鍵になるだろう。
この記事のポイント
- 2026年にMetaの広告収益がGoogleを上回り、世界シェア1位になる見通しだ
- Metaの勝因はAIによる広告運用の自動化であり、高いROIが広告主を惹きつけている
- GoogleはAI検索の台頭や独占禁止法の訴訟など、構造的な課題に直面している
- Web担当者は「検索」だけでなく、SNSでの「発見」を重視した戦略への転換が必要だ
- 今後のマーケティングは、ユーザーの意図を待つのではなく、行動を予測するアプローチが主流になる

WooCommerceで注文制限を設定する方法!最小・最大数量で在庫と利益を守る
WooCommerceでネットショップを運営していると、注文の「量」に関する悩みに直面することがある。安価な商品を1点だけ注文されて送料や決済手数料で赤字になったり、逆に人気商品を1人で買い占められて在庫が底をついたりするケースだ。
これらの問題は、注文の最小数量や最大数量を適切に設定することで解決できる。適切な制限を設けることは、在庫管理を容易にするだけでなく、配送の効率化やビジネスの収益性向上に直結する重要な戦略だ。
本記事では、WooCommerceで注文制限をかけるための3つの手法を詳しく解説する。無料のプラグインで手軽に始める方法から、B2B(企業間取引)向けの高度な設定まで、サイトの状況に合わせた最適な方法が見つかるはずだ。
なぜWooCommerceで注文制限が必要なのか

注文制限を導入する最大の理由は、店舗の予測可能性を高めて運営を安定させることにある。制限がない状態では、予期せぬ少額注文や極端な大量注文によって、梱包作業の負担や配送コストの増大を招くリスクがある。
少額注文による「送料負け」を防ぐ
数百円の小物を1点だけ購入された場合、梱包資材費や発送の手間、決済手数料を差し引くと利益がほとんど残らない場合がある。WP Beginnerの記事でも指摘されているが、例えば2ドルのキーホルダー1点の注文に対し、配送コストがそれを上回ってしまうような事態は避けなければならない。
最小注文金額や数量を設定することで、顧客に対して「ついで買い」を促す効果も期待できる。これは客単価の向上につながり、ショップ全体の収益構造を改善するきっかけとなる。
在庫の枯渇と買い占めを防止する
一方で、最大数量の制限は在庫保護に役立つ。特定の顧客が在庫をすべて買い占めてしまうと、他の多くの顧客に商品が行き渡らなくなり、ショップの評判を下げる要因になりかねない。
特に限定品やセール品において「1人5点まで」といった制限を設けることは、公平な販売機会を提供するために不可欠だ。また、配送業者の重量制限や梱包サイズの上限に合わせることで、配送トラブルを未然に防ぐ役割も果たす。
● 特定ユーザーが100個まとめ買い → 即完売で機会損失
● 「1人最大5個まで」に設定 → 多くの顧客に商品を供給
このデモは注文制限を導入した際のメリットを視覚化したイメージだ。
無料プラグインで手軽に数量制限をかける方法

予算をかけずに基本的な制限を導入したい場合、無料のプラグインを利用するのが最も効率的だ。初心者でも扱いやすく、コードを書く必要がない選択肢として「Minimum and Maximum Quantity for WooCommerce」が挙げられる。
プラグインの導入と基本設定
まずはWordPressの管理画面から「Plugins」の「Add New」へ進み、プラグイン名で検索してインストールと有効化を行う。Dotstoreという開発者によるものが対象だ。有効化すると、管理画面のメニューに専用の設定項目が追加される。
設定画面では「Add New」ボタンから新しいルールを作成する。ルールには任意の名前を付け、どの商品やカテゴリに適用するかを選択する仕組みだ。特定の1商品だけに制限をかけることも、特定のカテゴリ全体にルールを適用することもできる。
具体的な制限値の入力
ルールの詳細設定では「Action」セクションで最小数量(Min Quantity)と最大数量(Max Quantity)を入力する。例えば、最小を2、最大を5に設定した場合、顧客はカートに最低2個入れる必要があり、6個以上は追加できなくなる。
設定を保存して公開すると、商品詳細ページの「カートに入れる」ボタンの横に、設定した最小数量が初期値として表示されるようになる。顧客がこの範囲外の数量を指定しようとすると、自動的に制限がかかる仕組みだ。これにより、管理者の意図しない注文をシステム的にブロックできる。
商品・カテゴリごとに高度な制御を行う方法

無料プラグインよりも柔軟な設定が必要な場合、有料の「YITH WooCommerce Minimum Maximum Quantity」が有力な候補となる。このツールは、カート全体の合計金額に基づいて制限をかけたり、特定のタグが付いた商品群を一括で制御したりする機能に優れている。
カート全体の制限(グローバル設定)
YITHのプラグインでは、個別の商品だけでなくカート全体に対して「合計10点以上、50点以内」といった制限をかけることができる。また、合計金額(サブトータル)による制限も可能だ。例えば「合計5,000円以上の注文のみ受け付ける」といった運用が容易になる。
さらに「グループ購入」の強制機能も興味深い。これは「6の倍数でのみ購入可能」といった設定だ。ワインのダース販売や、特定の梱包箱にぴったり収まる数量で販売したい場合に非常に重宝する機能だ。
バリエーション商品の柔軟な集計
サイズや色が異なるバリエーション商品(Variable Product)の扱いも高度だ。例えば「Tシャツを合計5枚以上」というルールを作った際、赤を3枚、青を2枚選んだ場合に「合計5枚」としてカウントするか、あるいは「各色5枚ずつ」必要とするかを設定で選べる。
WP Beginnerの調査によれば、多くのストアではバリエーションの合計で判定する「sum」オプションが好まれている。顧客にとって柔軟性が高く、買い物のハードルを上げすぎずに制限を適用できるからだ。こうした細かな配慮が、カゴ落ちを防ぐ鍵となる。
B2B・卸売サイト向けの高度な設定方法

企業間取引(B2B)や卸売をメインとするサイトでは、一般顧客と卸先顧客で異なる制限を設ける必要がある。このようなケースでは「Wholesale Prices」プラグインが適している。これは「Wholesale Suite」の一部として提供されており、ユーザー権限(ロール)に基づいた制御が可能だ。
ユーザー権限ごとの注文条件
この手法の最大の特徴は、ログインしているユーザーの役割に応じて条件を動的に変えられる点にある。一般の小売客には制限をかけず、卸売客(Wholesale Customer)に対してのみ「1回100個以上」や「合計3万円以上」といった厳しい条件を課すことができる。
卸売客が条件を満たしていない場合、カート内では通常価格が表示され、条件を満たすまで卸売価格が適用されないという通知が表示される。これにより、小口注文で卸売価格を乱用されるリスクを確実に防ぐことができる。
商品ごとの個別オーバーライド
サイト全体の基本ルールとは別に、特定の商品だけ特別な条件を設定することも可能だ。例えば、通常は「合計10点以上」が条件であっても、非常に高価な商品や大型の商品については「1点から卸売価格を適用する」といった例外設定ができる。
このような柔軟な設定は、手動での注文管理コストを大幅に削減する。システムが自動で条件を判定するため、管理者は不適切な注文のキャンセル作業に追われることなく、本来の業務に集中できるようになる。
顧客満足度を下げずに注文制限を運用するコツ

注文制限は店舗側には都合が良いが、顧客にとっては不便に感じられることもある。制限を導入する際は、顧客が納得して買い物を続けられるような工夫が欠かせない。心理的なハードルを下げるための施策をいくつか紹介する。
制限の理由を明確に伝える
単に「注文できません」と表示するのではなく、なぜその制限があるのかを短く添えるのが効果的だ。例えば「配送品質を維持するため、2点以上からのご注文をお願いしております」や「卸売専用価格のため、最低数量を設定しております」といった説明があるだけで、顧客の受ける印象は大きく変わる。
また、商品詳細ページの「カートに入れる」ボタンの近くに、あらかじめ制限の内容を明記しておくことも重要だ。決済画面に進んでから初めてエラーが出ると、顧客のフラストレーションが最大化し、離脱の原因となるからだ。
インセンティブとの組み合わせ
制限を「強制」ではなく「特典への条件」として見せる手法もある。例えば、最小注文金額を送料無料のラインと一致させる方法だ。「5,000円以上の注文で送料無料(かつ、5,000円未満は注文不可)」とすることで、顧客は「制限されている」という感覚よりも「送料無料の恩恵を受けている」という感覚を強く持つようになる。
こうしたUX(ユーザー体験)の設計は、店舗の信頼性を高める。技術的な制限をかけるだけでなく、それが顧客にとってどのようなメリット、あるいは納得感につながるかを常に考える必要がある。
このチェックリストは、注文制限を導入する際のUX設計の指針となる。
この記事のポイント
- 注文制限は、少額注文による赤字防止や在庫の買い占め対策に非常に有効だ。
- 初心者は無料の「Minimum and Maximum Quantity for WooCommerce」で十分対応できる。
- 高度な制御や金額ベースの制限が必要なら「YITH」のプラグインが適している。
- B2Bや卸売サイトでは「Wholesale Prices」を使い、ユーザー権限ごとに条件を変えるのが正解だ。
- 制限を導入する際は、顧客を突き放さないメッセージングとUXの工夫が成功の鍵を握る。

Googleが「戻るボタンの乗っ取り」をスパムと定義。6月15日からペナルティ対象に
Googleは検索セントラルのスパムポリシーを更新し、ブラウザの「戻る」操作を妨害する行為を「悪意のある行為」として明確に禁止した。この新ルールは2026年6月15日から適用が開始される予定だ。
ポリシーの追加により、ユーザーの意図に反して履歴を操作するサイトは検索順位の低下や手動ペナルティの対象となる。サイト運営者には2ヶ月の猶予期間が与えられており、その間に自社サイトの挙動を確認する必要がある。
今回の変更は、長年ユーザーから報告されていた「ページを戻ろうとしても同じサイト内に留め置かれる」という不快な体験を根絶するための強力な措置といえる。
戻るボタンの乗っ取り(Back Button Hijacking)とは何か
戻るボタンの乗っ取りとは、ウェブサイトのスクリプトを使用してブラウザのナビゲーション機能を操作し、ユーザーが前のページに戻るのを阻止する手法を指す。本来、ブラウザの「戻る」ボタンを押せば直前に閲覧していたページに戻るはずだが、この手法が使われていると正常に機能しない。
Googleの公式ブログによれば、この乗っ取りにはいくつかのパターンが存在する。代表的なものは、ユーザーが一度も訪問していないページをブラウザ履歴に強制的に挿入する手法だ。これにより、戻るボタンを押しても同じサイト内の別の広告ページや推奨記事ページが表示される仕組みになっている。
また、戻るボタンを完全に無効化したり、クリックした瞬間に別のURLへ強制リダイレクトをかけたりする悪質なケースも確認されている。これらはすべて、ユーザーの「前の画面に戻りたい」という基本的な期待を裏切る行為であり、Googleはこれをスパムと定義した。
上記の図のように、ユーザーの意図しない遷移を強制することがポリシー違反の核心だ。
技術的な仕組みと履歴の操作
この乗っ取りの多くは、JavaScriptの history.pushState() という関数を悪用して実現されている。この関数は、ページをリロードせずにブラウザの履歴スタックに新しいエントリを追加できる便利な機能だが、これを悪用すると「戻る」ボタンの行き先を勝手に書き換えることが可能になる。
例えば、ページが読み込まれた瞬間に、現在のページの履歴を2回分挿入するスクリプトが動くとする。ユーザーが「戻る」を1回押しても、履歴スタックにはまだ同じサイトのエントリが残っているため、画面が切り替わらない。このような挙動は、ユーザーに「ブラウザが故障した」あるいは「このサイトから逃げられない」という恐怖感や不快感を与える。
Googleがポリシー改訂に踏み切った背景

Googleが今回の決定を下した背景には、ウェブ全体でこの「戻るボタンの操作」を伴う悪質なサイトが増加しているという事実がある。Googleの報告によれば、多くのユーザーがこうした操作によって「操作されている」と感じ、見知らぬサイトへの訪問をためらうようになっているという。
実は、Googleは2013年の時点ですでに、ブラウザの履歴に欺瞞的なページを挿入することに対して警告を発していた。しかし、当時は「推奨されない行為」という扱いに近く、明確なスパムポリシーとしての定義はされていなかった。今回の更新により、この行為は「マルウェアの配布」や「不要なソフトウェアのインストール」と同等の「悪意のある行為」として格上げされた形だ。
検索エンジンとしての信頼性を維持するためには、検索結果から訪れたサイトがユーザーを「閉じ込める」ような挙動を許してはならない。Googleは、ユーザー体験(UX)を著しく損なう要素を排除することで、検索エコシステム全体の健全性を高めようとしている。
6月15日からの取り締まりプロセス
今回のポリシー適用には、約2ヶ月の猶予期間が設けられている。2026年6月15日以降、Googleは自動化されたシステム(SpamBrainなど)および手動レビューの両面で違反サイトの特定を開始する。違反が確認されたサイトには、検索順位の極端な低下や、検索結果からの完全な削除といった厳しいペナルティが科される可能性がある。
このスケジュール感は、2024年3月に行われた大規模なスパムアップデート(サイト評判の不正利用など)の際と同様だ。十分な準備期間を与えることで、意図せず違反状態にあるサイト運営者が修正を行う機会を提供している。
サードパーティ製スクリプトによる意図しない違反のリスク
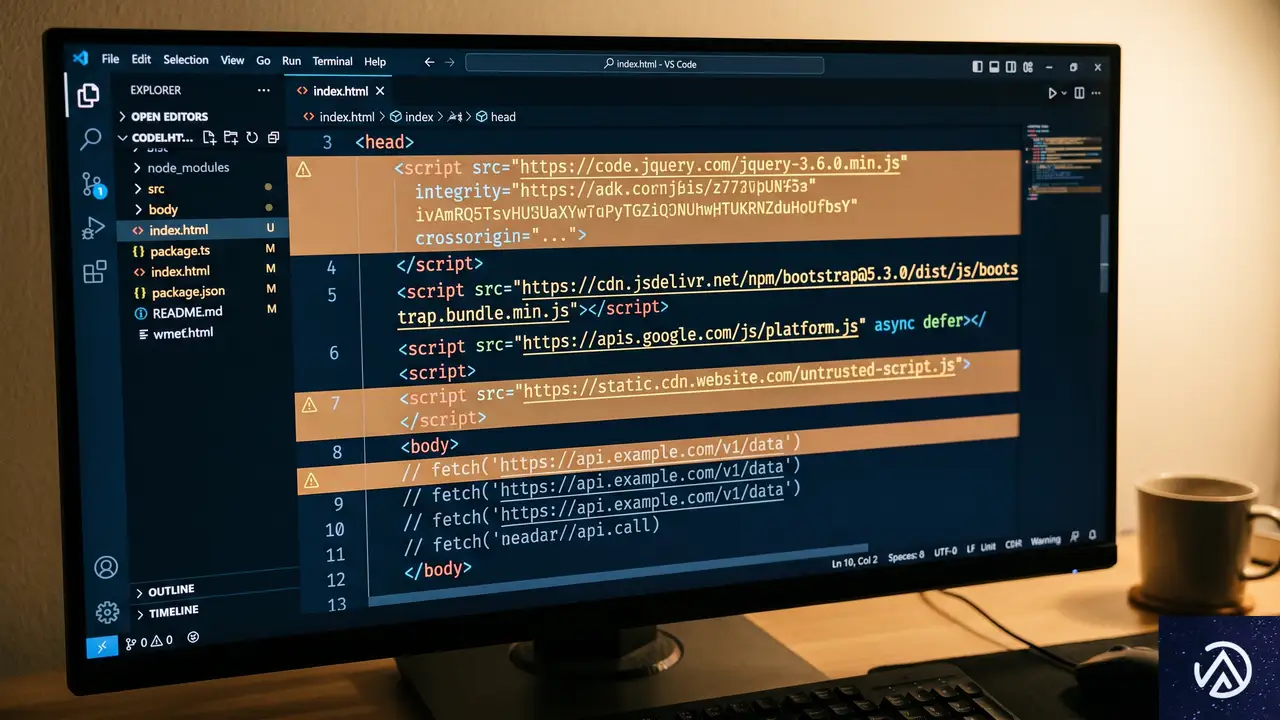
サイト運営者にとって最も注意すべき点は、自らが意図的に乗っ取りを行っていなくても、ポリシー違反と判定される可能性があることだ。Googleのブログでは、一部の「戻るボタンの乗っ取り」は、サイトに組み込まれた外部ライブラリや広告プラットフォームが原因である可能性を指摘している。
例えば、無料で利用できるアクセス解析ツールや、コンテンツ推奨ウィジェット(レコメンドエンジン)、あるいは収益性の高さを謳う特定の広告ネットワークなどが、勝手に履歴を操作しているケースがある。運営者が「便利なツールを導入しただけ」のつもりでも、そのコードがユーザーのナビゲーションを妨害していれば、サイト全体の責任としてペナルティを受けることになる。
このため、自社のエンジニアが書いたコードだけでなく、外部から読み込んでいるすべてのスクリプトがどのような挙動をしているかを把握することが不可欠だ。特に、ページ遷移を伴わないSPA(シングルページアプリケーション)構成のサイトでは、履歴管理のロジックが複雑になりやすいため、意図しないバグが乗っ取りと見なされないよう注意が必要である。
外部ツールを導入する際は、そのツールがブラウザ履歴(History API)に干渉していないか、ドキュメントを確認したり実際にテスト環境で挙動を検証したりすることが求められる。
サイト運営者が今すぐ実施すべき対策と監査方法

猶予期間である6月15日までに、サイト運営者は自社サイトの「戻るボタン」の挙動を徹底的にチェックすべきだ。最も確実な方法は、シークレットモード(プライベートブラウジング)を使用して、一般的なユーザーと同じ条件でサイトを回遊してみることである。
チェックの際は、検索エンジンからサイトへ流入し、数ページ閲覧した後に「戻る」ボタンを連打してみる。もし、前のページに戻るために2回以上のクリックが必要だったり、見たこともない広告ページに飛ばされたりする場合は、即座に原因を特定しなければならない。開発者ツールの「Network」タブや「Console」タブを確認し、履歴を操作している不審なスクリプトが動いていないかを調査する。
もし万が一、6月15日以降に手動ペナルティ(手動による対策)を受けてしまった場合は、Google Search Consoleを通じて通知が届く。その際は問題を修正した上で、再審査リクエストを送信する必要がある。自動アルゴリズムによる順位下落の場合は通知が来ないため、定期的な順位計測とUX指標の監視が重要となる。
チェックリスト:ポリシー違反を避けるために
以下の項目に当てはまる挙動がないか、サイトの全ページを確認することを推奨する。
- 戻るボタンを1回押しただけで、直前のページ(検索結果など)に戻れるか
- 履歴スタックに、ユーザーが訪問していないURLが勝手に追加されていないか
- 戻る操作をした際に、ポップアップ広告や全画面広告が表示されないか
- 特定のサードパーティ製スクリプトを停止した状態で、戻るボタンの挙動が変わらないか
特に、収益化を優先するあまり過度な広告設定を行っているサイトや、古いJavaScriptライブラリを更新せずに使い続けているサイトは、意図せずスパムと判定されるリスクが高い。技術的な負債を解消し、ユーザーが自由にサイトを出入りできる環境を整えることが、長期的なSEOの成功につながる。
独自の分析:UXの健全化がSEOの「最低条件」になる時代

今回のポリシー更新は、Googleが「コンテンツの質」だけでなく「ブラウザ操作の安全性」を極めて重視していることの表れだ。かつては検索順位を上げるためのテクニックが注目されていたが、現在は「ユーザーに不快な思いをさせないこと」がSEOのスタートラインとなっている。
戻るボタンの乗っ取りは、短期的な滞在時間やページビュー(PV)を稼ぐためには有効だったかもしれない。しかし、そうした小細工はブランドの信頼を損なうだけでなく、今や検索エンジンによって明確に排除される対象となった。サイト運営者は、数字上の指標を追う前に、ユーザーがブラウザの標準機能をストレスなく使えるかどうかを最優先すべきだ。
また、この動きは今後、他のブラウザ操作(右クリックの禁止やテキストコピーの妨害など)にも波及する可能性がある。ウェブのオープンな性質を損なう実装は、長期的には検索トラフィックの損失を招くリスクであることを、すべてのマーケターやエンジニアは再認識すべきだろう。
この記事のポイント
- Googleが「戻るボタンの乗っ取り」をスパムポリシーの違反項目に追加した
- ユーザーの意図に反して履歴を操作し、前のページに戻らせない行為が禁止される
- 新ルールは2026年6月15日から適用され、順位下落やペナルティの対象となる
- 自社コードだけでなく、広告や外部ウィジェットなどのサードパーティ製スクリプトも監査が必要だ
- 猶予期間中に「戻る」ボタンの挙動を実機でテストし、不審な挙動を修正すべきだ

AI検索の利用率は年収で決まる?EC担当者が知るべき検索行動の二極化と対策
AI検索の普及は、すべてのユーザーに平等に進んでいるわけではない。最新の調査データによると、生成AIツールの利用率は世帯年収によって明確な差が生じている。高所得層ほどAIを使いこなし、情報の探し方が根本から変化している実態が明らかになった。
英国のマーケティングメディアであるMarTechが報じたデータでは、世帯年収が10万ポンド(約2,000万円)を超える層の約半数がAIを常用している。一方で、年収が3万ポンド以下の層ではその割合が2割を下回る。この所得による「検索の二極化」は、EC事業者にとって見過ごせない課題だ。
顧客がどのツールで情報を探し、どのように意思決定を行うのか。その前提条件が所得層によって分断されつつある。本記事では、AI検索の普及がもたらす新たなデジタル格差と、断片化する顧客行動に対応するための戦略を詳しく解説する。
AI検索の普及に潜む年収格差の実態

AI検索はすでに一般的になったという論調が多いが、現実はそれほど単純ではない。MarTechの記事で紹介されているBecky Simms氏の分析によれば、生成AIの採用ペースは世帯年収に強く依存している。これは、単なる技術への関心の差ではなく、社会的な構造が背景にある。
高所得世帯ほど生成AIを日常的に活用している
具体的な数字を見ると、その差は歴然としている。世帯年収が2万5,000〜3万ポンドの層では、ChatGPTなどのAIツールを定期的に利用している割合は約18%にとどまる。しかし、年収が7万ポンドを超えると、その利用率は一気に49%まで跳ね上がる。
年収10万ポンド以上の層に至っては、48%から58%という高い水準でAIを利用している。つまり、高所得層は低所得層の2倍から3倍近い頻度でAIを検索や業務に活用していることになる。この格差を視覚化すると、以下のようになる。
このデモが示す通り、年収の上昇に伴ってAI利用率が加速度的に高まっている。高単価な商品やサービスを扱うブランドにとって、ターゲットとなる層がすでに「AIファースト」な行動をとっている可能性が高いことを示唆している。
デジタルスキルの差が情報のアクセシビリティを左右する
この格差は、単なるツールの所有状況だけではなく、基礎的なデジタルスキルの差とも連動している。非営利団体のFutureDotNowのデータによれば、英国の労働年齢層の約52%が、仕事に必要な基本的なデジタルタスクを完遂できない状態にあるという。
AIの利用は、既存のデジタルスキル格差の上にさらに積み重なる新たな層となっている。情報の検索、評価、そして行動。これらのプロセスをAIで効率化できる層と、従来通りの方法でしか情報を得られない層の間で、情報の非対称性が広がっているのだ。
作家のウィリアム・ギブソンは「未来はすでにここにある。ただ、均等に分配されていないだけだ」という言葉を残している。まさに現在のAI検索の状況は、この言葉を体現しているといえるだろう。
なぜAI利用に格差が生まれるのか(3つの要因)

AIの採用が所得によって分かれるのは、単に「有料プランを契約できるかどうか」という金銭的な理由だけではない。Simms氏の分析によれば、人間の行動に根ざした3つの要素が大きく関わっている。それは「アクセス」「能力」「信頼」だ。
職場環境によるアクセスの差
第一の要因は、日常生活や業務の中でAIに触れる機会、すなわち「アクセス」の差だ。ITやビジネス、知識集約型の職種に従事している人々は、ワークフローの一部としてAIの使用を推奨される、あるいは期待される場面が多い。
こうした環境に身を置く人々は、自然とAIを使いこなすようになる。一方で、物理的な労働が中心の職種や、デジタル化が遅れている現場では、AIに触れる機会はニュースなどの二次的な情報に限られる。この初期段階での露出の差が、後の大きな習熟度の差へとつながる。
プロンプトを操る能力とAIへの信頼
第二の要因は、AIを使いこなす「能力」だ。AIとの対話には、適切な指示を出す「プロンプト(命令文)」のスキルが求められる。日常的にAIを使う層は、回答を洗練させ、間違いを修正し、出力を組み立てる方法を経験から学んでいく。
第三の要因は、AIに対する「信頼」だ。AIが生成する情報の正確性をどう評価し、どの程度頼ってもよいと判断するか。Perplexityのような信頼性を重視するプラットフォームの台頭はあるものの、AIを使い慣れていない層にとっては、未知のツールに対する心理的な障壁や不信感が拭えない場合も多い。
これらの要素が組み合わさることで、デジタルに自信のある層がさらにAIで優位性を高めるという、新たなデジタルデバイド(情報格差)が形成されている。ECサイトの運営者は、自社の顧客がどの程度のAIリテラシーを持っているかを慎重に見極める必要がある。
断片化するユーザーの検索行動パターン

検索行動はもはや一様ではない。かつては「何かを知りたければGoogleで検索する」という単一の道筋があったが、現在はユーザーの属性や目的によって、複数のルートに断片化している。これを理解せずに戦略を立てることは、ターゲットの一部を完全に見落とすリスクを伴う。
AIファースト層からAI回避層までの3つの分類
現代のユーザーは、AIへの関与度によって大きく3つのタイプに分類できる。それぞれの層で、情報の受け取り方や期待するコンテンツの形式が異なっている。
- AIファースト層:タスクの代行、情報の要約、選択肢の絞り込みをAIに委ねる。サイトを訪問する前にAIの回答で完結することを好む。
- AIアシスト層:AIで概要を把握しつつ、従来の検索エンジンやSNSで情報の正しさを検証する。複数のプラットフォームを跨いで行動する。
- AI回避層:従来通りのGoogle検索、小売サイト内の検索、あるいはコミュニティ(Redditや掲示板など)を信頼し、AIツールの利用を避ける。
重要なのは、同じユーザーであっても、タスクの内容によってこれらの行動を使い分ける点だ。例えば、法律文書の草案作成にはAIを使い、商品の口コミを調べる際にはGoogleやSNSを使う、といった具合だ。
同じユーザーでも目的によってツールを使い分ける
検索の断片化は、カスタマージャーニーをより複雑にしている。以前のように「検索キーワード」だけでユーザーの意図を把握することは難しくなっている。AIが情報の「要約」と「簡略化」を担う一方で、SNS(TikTokやInstagram)は「人間味のある文脈」や「視覚的な納得感」を提供する場となっている。
以下のデモは、従来の検索と、現代の断片化された検索プロセスの違いを視覚化したものだ。
この変化により、ECブランドは「サイトに来てから説得する」のではなく、「AIやSNSの段階で選ばれている」状態を作らなければならなくなっている。クリックされる前の段階で、いかにブランドを認知させ、信頼を獲得するかが勝負の分かれ目だ。
EC・マーケティング戦略への影響と具体的な対策

高所得層がAIを使い、意思決定をAIに委ね始めているという事実は、ECのマーケティング戦略を根本から変える。ターゲットがAIファーストであるならば、従来のSEO(検索エンジン最適化)だけでなく、GEO(生成エンジン最適化)への対応が急務となる。
属性ではなく行動でターゲットを分析する
年齢や年収といったデモグラフィック(属性)データは、誰がターゲットかを教えてくれるが、彼らが「どう決めるか」までは教えてくれない。これからは、ユーザーがどのプラットフォームで、どのタイミングでAIを使うのかという「行動」に基づいたセグメンテーションが必要だ。
AIを使いこなす「高自信ユーザー」は、AIに選択肢を絞り込ませることを好む。一方、AIに不慣れな「低自信ユーザー」は、馴染みのある環境や人間の声を求める。ブランドは、この両方のジャーニー(顧客体験)を設計しなければならない。
AIに推奨されるための情報の構造化と信頼性向上
AIに自社ブランドを正しく理解させ、推薦してもらうためには、情報の「明快さ」が不可欠だ。複雑で曖昧な表現は、AIによる解釈ミスを招き、結果として検索結果から除外される原因となる。具体的で構造化されたデータを提供することが、AI時代のSEOの基本となる。
また、AIは効率化には優れているが、最終的な「安心感」を与えるのは依然として人間による証明だ。レビュー、権威ある第三者の評価、ブランドの歴史といった「信頼のシグナル」を強化することで、AIが提示した候補の中から「最後に選ばれるブランド」になることができる。
効率性が重視されるAI検索の世界であっても、最終的な決断を下すのは人間だ。技術の進化に目を向けつつも、その背後にある人間の心理や行動の変化を深く理解することが、これからのEC運営には求められている。
この記事のポイント
- AI検索の利用率は世帯年収に比例し、高所得層は低所得層の2倍以上活用している
- AI採用の差は、職場でのアクセス、プロンプト能力、ツールへの信頼度の違いから生まれる
- 検索行動はAIファースト層、AIアシスト層、AI回避層へと断片化が進んでいる
- 高価値な顧客はサイト訪問前にAIで意思決定を終えている可能性が高いため、AIへの最適化が重要になる
- 技術への対応と同時に、レビューや権威性などの「人間による信頼の証明」が選ばれる鍵となる

WordPressで性格診断クイズを作成しリード獲得を自動化する方法
Webサイトの訪問者を単なる閲覧者で終わらせず、メールマガジンの購読者や顧客へと転換させることは、多くのサイト運営者にとって共通の課題だ。従来の「ホワイトペーパーのダウンロード」や「ニュースレター登録」といった手法は、今や一般的になりすぎてしまい、ユーザーの反応が鈍くなっている傾向がある。
WPBeginnerの記事によると、こうした状況を打破する強力なツールとして「性格診断クイズ」が注目されている。診断クイズは、ユーザーが能動的に参加するインタラクティブなコンテンツであり、楽しみながら自身の特性を知ることができるため、心理的なハードルが低いのが特徴だ。
この記事では、WordPressプラグインのWPFormsを活用して、専門的なコードを一切書かずに高度な性格診断クイズを構築する方法を詳しく解説する。診断結果を表示する直前にメールアドレスの入力を促すことで、高い転換率を実現するリード獲得マシンへとサイトを進化させることが可能だ。
なぜ性格診断クイズがリード獲得に強力なのか

診断クイズが従来のリードマグネット(メールアドレス登録の対価として提供する無料特典)よりも優れている理由は、その「パーソナライズ性」にある。ユーザーは自分自身に関する情報を求めており、その答えを得るためであれば、メールアドレスを提供する心理的コストを許容しやすい。
コンテンツの双方向性が滞在時間を延ばす
静的な記事を読むだけの体験とは異なり、クイズはユーザーに選択を求める。この双方向のやり取りはユーザーのエンゲージメントを高め、結果としてサイトへの滞在時間を延ばす効果がある。滞在時間の向上は、検索エンジンからの評価にも好影響を与える重要な指標だ。
また、クイズの回答を通じてユーザーは自身の悩みや興味を再認識する。例えば「あなたの旅行スタイル診断」というクイズがあれば、ユーザーは設問に答える過程で「自分はリラックスよりも冒険を求めているのだ」と自覚する。この自覚が、その後に提示される提案への納得感を高めることになる。
ユーザーの興味関心に基づいたセグメンテーション
セグメンテーションとは、顧客を特定の属性や興味に基づいてグループ分けすることだ。診断クイズの最大の利点は、リードを獲得した瞬間にそのユーザーの属性が判明している点にある。従来の登録フォームでは「誰が登録したか」はわかっても「その人が何を求めているか」までは把握しにくい。
WPBeginnerの著者によれば、診断結果に基づいて購読者をリスト分けすることで、その後のメールマーケティングの精度が劇的に向上するという。例えば「冒険家タイプ」と診断されたユーザーにはアウトドア用品の情報を、「リラックス派」にはスパやホテルの情報を送るといった、パーソナライズされたアプローチが可能になる。
「最新情報をお届けします」
専用オファー
専用オファー
専用オファー
このデモは、クイズを導入することでユーザーを自動的に分類し、適切なアプローチへつなげる流れを示している。
WPFormsを使った診断クイズの作成手順

WordPressで診断クイズを作成するためのツールはいくつかあるが、操作性と機能のバランスで優れているのがWPFormsだ。特にPro版以上に搭載されている「Quiz Addon(クイズアドオン)」を使用すると、複雑なスコアリング設定を直感的なUIで行うことができる。
診断モードの有効化とタイプ選択
まず、WPFormsの管理画面から「Addons」を選択し、Quiz Addonをインストールして有効化する。その後、新規フォーム作成画面で「Settings」タブの「Quiz」メニューを開き、「Enable Quiz Mode」にチェックを入れる。これでフォームがクイズ機能を備えた状態になる。
診断クイズを作成する場合、クイズタイプとして「Personality Quiz(性格診断クイズ)」を選択することが重要だ。これは正解・不正解を判定するテスト形式ではなく、ユーザーの回答傾向から最も合致する「タイプ」を導き出す形式だ。
診断結果(パーソナリティタイプ)の定義
質問を作り始める前に、まずは「どのような結果を用意するか」を定義する。これをパーソナリティタイプと呼ぶ。例えば旅行サイトであれば「アドベンチャー派」「リラックス派」「文化探求派」といった具合だ。
WPBeginnerの記事では、このタイプ数を3〜5個に絞ることを推奨している。選択肢が多すぎると回答の紐付けが複雑になり、ユーザーにとっても結果の差異が分かりにくくなるからだ。各タイプには、ユーザーが納得し、かつ次の行動(商品の購入や記事の閲覧)に移りたくなるような魅力的な名前を付ける必要がある。
回答と結果を紐づけるロジックの構築

診断クイズの核心部分は、ユーザーの回答をあらかじめ定義したパーソナリティタイプにどう結びつけるかというロジックにある。WPFormsでは、各質問の選択肢ごとに「この回答を選んだらどのタイプにカウントするか」を個別に設定できる。
質問項目の作成とAI活用
質問の作成には「Multiple Choice(多肢選択)」フィールドを主に使用する。ユーザーが直感的に答えられるよう、画像付きの選択肢(Image Choices)を活用するのも有効だ。視覚的な情報はテキストよりも素早く認識されるため、回答の離脱率を下げる効果が期待できる。
質問のアイデアに詰まった場合は、WPFormsに搭載されている「AI Choices」機能を利用するとよい。質問文を入力してプロンプトを送るだけで、AIが関連性の高い選択肢を自動生成してくれる。これにより、クイズ作成にかかる時間を大幅に短縮することが可能だ。
回答ごとのスコアリング設定
各質問のフィールド設定を開くと、各選択肢の横にパーソナリティタイプを選択するドロップダウンが表示される。ここで「海で泳ぐのが好き」という回答には「リラックス派」を、「未開の地を歩きたい」という回答には「アドベンチャー派」を割り当てていく。
最終的な診断結果は、全設問を通じて最も多くカウントされたタイプが表示される仕組みだ。そのため、すべての選択肢に漏れなくタイプを割り当てることが重要となる。一つでも未設定の項目があると、計算が狂い、ユーザーに不適切な結果を表示してしまう恐れがあるため注意が必要だ。
診断結果をメールマガジン登録につなげる設計

クイズを単なる娯楽で終わらせず、リード獲得の手段とするためには、導線の設計が極めて重要だ。最も効果的なのは、診断結果を表示する直前にメールアドレスの入力を求める「ゲート型」の配置だ。
ページ区切りとメールアドレス入力欄の設置
すべての質問が終わった後に「Page Break(ページ区切り)」を挿入し、新しいページにメールアドレス入力フィールドを配置する。ここで「あなたの診断結果をメールで送信します」や「結果を見るためにメールアドレスを入力してください」といったメッセージを添える。
ユーザーはすでに数分を費やしてクイズに回答しており、「答えを知りたい」という欲求が高まっている。このタイミングでの入力要請は、通常の登録フォームよりもはるかに高いコンバージョン率を記録する傾向がある。ただし、プライバシーポリシーへの同意チェックボックスを設置するなど、法的・倫理的な配慮も忘れてはならない。
外部メール配信サービスとの連携
獲得したメールアドレスは、自動的にメール配信サービス(Constant ContactやMailchimpなど)へ転送されるよう設定する。WPFormsの「Marketing」タブから、利用しているサービスとの連携が可能だ。
この際、単にリストに追加するだけでなく、診断されたタイプに応じた「タグ」を付与するように設定する。これにより、登録直後から「アドベンチャー派の人だけに向けたウェルカムメール」を自動配信できるようになり、非常に高い開封率とクリック率を実現できる。
全10問の設問にユーザーが回答
「結果を見るためにメールを入力してください」
診断結果を表示し、配信サービスへデータを送信
このフロー図は、ユーザーが診断結果という報酬を得るためにメールアドレスを提供する心理的なプロセスを視覚化したものだ。
独自の分析:クイズを「売れる仕組み」に変えるためのポイント

WPFormsでクイズを作成するのは技術的に難しくないが、それを実際の収益や成果につなげるには、マーケティング視点での工夫が必要だ。ここでは、診断クイズの効果を最大化するための独自の分析結果を紹介する。
結果画面でのパーソナライズされた提案
診断結果の画面(Outcome)は、ユーザーが最も集中して画面を見ている瞬間だ。ここに単なる「あなたは〜タイプです」という説明だけで終わらせるのは、大きな機会損失と言える。各タイプの結果画面に、その属性に最適化された「次にとるべき行動(CTA)」を配置すべきだ。
例えば「アドベンチャー派」と出たユーザーには、おすすめの登山靴の商品リンクや、秘境ツアーの予約ページへのリンクを表示する。WPFormsのスマートタグ({quiz_personality_type}など)を活用すれば、ユーザーの名前や診断結果を文章の中に自然に組み込むことができ、親近感と信頼感を醸成できる。
診断データを活用したステップメール配信
クイズで獲得したデータは、登録直後のメール配信だけでなく、中長期的なナーチャリング(顧客育成)にも活用できる。診断結果に基づいて、そのユーザーが抱えているであろう課題を推測し、解決策を提示するステップメールを組むのが効果的だ。
この手法は、サードパーティクッキーの規制が進む現代において、ユーザーから直接提供される「ゼロパーティデータ」を活用する極めて健全かつ強力な戦略となる。ユーザーは自分の好みを伝えているため、その後に届くメールを「自分向けの有益な情報」として受け取り、広告としての嫌悪感を抱きにくいからだ。
この記事のポイント
- 性格診断クイズは、従来のリードマグネットよりも高いエンゲージメントと登録率を期待できる。
- WPFormsのQuiz Addonを使えば、ノーコードで高度な診断ロジックとスコアリングを構築可能。
- 診断結果を表示する直前にメール入力を求める「ゲート設計」がリード獲得の鍵となる。
- 獲得した属性データ(タイプ)をメール配信サービスと連携させ、パーソナライズされた追客を行う。
- 結果画面に具体的な商品提案やCTAを配置することで、診断を直接的な収益機会に変えることができる。

Google特許が示す検索の新たな層——AI生成ランディングページの衝撃
Googleが取得した特許が、検索エンジンの未来像に大きな一石を投じた。特許の内容は、ユーザーの検索クエリとコンテキストに応じて、AIがその場でランディングページを生成するシステムだ。
この技術が実用化されれば、検索結果と従来のウェブサイトの間に、新たな「層」が出現することになる。EC事業者やコンテンツ発信者は、自社サイトのデザインやメッセージングをユーザーに直接届ける機会を、さらに奪われる可能性がある。
本記事では、特許の内容を詳細に読み解き、検索の進化の歴史に照らし合わせてその意味を考察する。さらに、この変化に対応するためにEC事業者が今から取り組むべき具体的な対策を提示する。
特許が描く「AI生成ランディングページ」の仕組み

ユーザーごとに最適化されたページを動的生成
2026年1月27日に米国特許商標庁から発行された特許「US12536233B1」は、AI生成コンテンツページに関するものだ。特許が示すシステムの核は、検索クエリとユーザー情報を基に、そのユーザー専用のランディングページを動的に生成する点にある。
システムはまず、検索クエリとユーザーのコンテキスト、そして従来のランキングアルゴリズムが選び出した候補となるランディングページ群を評価する。評価基準は多岐にわたり、商品情報の不足、コンテンツの薄さ、ナビゲーションの弱さ、ユーザーエンゲージメントの低さなどが低評価の要因となる。
評価の結果、既存ページが不十分と判断されると、システムはそれらのページを「素材」として使い、個々のユーザー向けに最適化された新たなバージョンのページを生成する。例えば、全く同じ「ランニングシューズ」というクエリを検索した二人のユーザーが、異なるランディングページに誘導される可能性がある。一人には商品比較表を中心にしたページが、もう一人には直接購入に導くページが表示されるかもしれない。
フィードバックループによる継続的改善
特許が示すもう一つの重要な要素は、フィードバックループだ。生成されたページは静的なものではない。ユーザーのクリック、ページ滞在時間、コンバージョンなどの行動データがシステムにフィードバックされ、将来生成されるページの精度を高めるために利用される。
この仕組みにより、Googleは膨大な数のユニークなページを生成し、それぞれの検索者をカスタマイズされたバージョンに誘導する動的な体験を提供できる。特に商品検索に関連するクエリでは、購入オプションを前面に押し出したページが生成される可能性が高い。
Practical Ecommerceの記事によれば、この動的ページ実現への現実的な経路は、既に導入されている「AIオーバービュー」を通じたものだと考えられる。AIオーバービューは情報を要約して提示するが、次のステップとして、その要約をインタラクティブな体験に拡張し、最終的には独立したウェブページとして展開する流れが想定される。
検索進化の歴史から見る「新たな層」の位置付け

検索とコンテンツの関係性の変遷
ECコンサルタントのGreg Zakowicz氏は、この特許の概念を「検索の経済学における新たな層」と表現した。この「層」という考え方は、検索エンジンとウェブサイト所有者の間の力関係の変化を理解する上で有効だ。
かつては、検索プラットフォームとコンテンツ所有者は相互依存の関係にあった。プラットフォームは質の高いコンテンツを必要とし、コンテンツ所有者はプラットフォームからのトラフィックを必要とした。しかし、検索産業の進化は、顧客と事業者を次第に引き離す方向に進んでいる。
この図が示すように、モノetization(広告)、Answers(ナレッジグラフ)、Evaluation(リッチリザルト)、Extraction(特集スニペット)、Interaction(垂直検索)、Synthesis(AIオーバービュー)と、各層が追加されるごとに、ユーザーが元のウェブサイトに直接アクセスする必要性は薄れてきた。AI生成ランディングページは、この流れの延長線上にある「最終的な層」と言えるかもしれない。
「検索の経済学」の変化が事業者に与える影響
Zakowicz氏が指摘する「検索の経済学」の変化とは、トラフィックと収益の流れの再分配を意味する。新しい層が出現するたびに、ウェブサイト所有者がレイアウト、メッセージング、商品提示をコントロールする影響力は弱まる。ユーザー体験は、ますますアルゴリズムによって組み立てられるものになる。
Practical Ecommerceの記事は、この状況を「サイトはGoogleの検索結果ページにおいてほとんどコントロールを失っている」と表現する。検索結果ページ自体が、外部サイトへの単なる入り口ではなく、完結した体験の場へと変貌しつつある。
EC事業者が取るべき具体的な対策

オウンドメディアと直接的な顧客関係の構築
アルゴリズムが仲介する体験の影響力が強まる中で、事業者が取るべき第一の対策は、自分自身でコントロールできるチャネルを強化することだ。具体的には、メールマーケティングやSMSなどのオウンドメディアが該当する。
ニュースレターやマーケティングメッセージを通じてサイトに訪れるユーザーは、アルゴリズムが組み立てたページではなく、ブランドそのものを選択して訪問している。検索プラットフォーム内で行われる発見が増えるほど、このような直接的な接点は「絶縁材」としての価値を高める。顧客との関係性を自ら所有することは、検索エンジンの変化に対する最も強力な防御策となる。
構造化データと高品質な入力情報の提供
第二の対策は、アルゴリズムが「読みやすい」データを提供することに注力する姿勢への転換だ。仮に特許のようなシステムが実装されれば、その生成体験は構造化された入力情報に大きく依存するだろう。
この場合、事業者の役割は、美しいランディングページをデザインすることから、正確で豊富な商品属性データ、Schema.orgマークアップ、整った商品フィードといった「高品質な入力情報」を提供することへとシフトする。ボットやプログラム、アルゴリズムが容易に理解し、利用できる形式で情報を提供することが、生成された体験の中に商品が表示され、クリックを獲得するための前提条件となる。
説得力のあるコピー、視覚的な階層、直感的なCTAボタンの配置など、人間のユーザーを説得するためのページ作りが中心だった。
正確な商品仕様、構造化されたレビュー、機械が解釈しやすい属性データなど、AIが「素材」として活用できる高品質な情報の提供が重要になる。
この変化は、SEOの本質的な作業が「検索エンジン向け」から「AI生成システム向け」に移行することを意味する。クリックを獲得する機会は残るが、その入り口の形と、そこに至るための最適化方法が根本から変わる可能性がある。
この記事のポイント
- Googleの特許は、検索クエリとユーザーごとにAIがランディングページを動的に生成するシステムを明らかにした。これは検索結果とウェブサイトの間に現れる「新たな層」となり得る。
- 検索は「発見」から「回答抽出」「統合」へと進化し、ユーザーが元サイトに到達する前の段階で体験が完結する方向にある。AI生成ページはこの流れの延長線上にある。
- この変化により、EC事業者はサイトのデザインやメッセージングを直接ユーザーに届けるコントロールをさらに失う可能性がある。
- 対策の二本柱は「オウンドメディアによる直接的な顧客関係の構築」と「構造化データなどアルゴリズム向けの高品質な入力情報の提供」である。人間向けのデザインから、機械が利用しやすいデータ提供への重心移動が求められる。
- 特許は必ずしも実用化を保証するものではないが、検索プラットフォームの長期的な方向性を示す重要なシグナルとして捉えるべきだ。