

Cloudflare、eBPFでDDoS対策を自作できるProgrammable Flow Protectionを発表
Cloudflareは、Magic Transitの利用者向けに、独自のDDoS緩和ロジックを実装できる「Programmable Flow Protection」を発表した。このシステムは、ユーザーが記述したeBPFプログラムをCloudflareのグローバルネットワーク全体にデプロイし、パケットレベルでの精密な制御を可能にするものだ。
2026年3月31日に公開された情報によると、この新機能は特にUDPをベースとした独自の通信プロトコルを利用するサービスにおいて、これまでにない柔軟な防御手段を提供する。現在はベータ版として、Magic Transit Enterpriseプランのユーザー向けに追加オプションとして提供が開始されている。
従来のDDoS対策システムでは対応が難しかった「未知のプロトコル」に対し、インフラ側が中身を理解するのではなく、ユーザーが「正しいパケット」の定義を教え込むというアプローチが採用された点が、今回のアップデートの核心だ。
UDPプロトコル保護の難しさと従来の限界

ネットワーク通信において、UDP(User Datagram Protocol)は速度とリアルタイム性を重視する場面で多用される。オンラインゲームや音声通話(VoIP)、動画ストリーミングなどがその代表例だ。しかし、このUDPの特性が、DDoS対策においては大きな障壁となってきた。
コネクションレスというUDPの性質
UDPはTCP(Transmission Control Protocol)とは異なり、通信の開始時に「ハンドシェイク」と呼ばれる接続確認の手順を踏まない。パケットが順番通りに届く保証もなく、状態を持たない「コネクションレス」なプロトコルである。このシンプルさが高速な通信を実現する一方で、送信元を偽装した攻撃パケットを見分けることを難しくしている。
DNSやNTPといった標準的なプロトコルであれば、パケットの構造が世界共通であるため、Cloudflareのようなプラットフォーム側で「異常なデータ」を検知しやすい。しかし、独自のゲームエンジンや社内システムで使われるカスタムプロトコルの場合、パケットの中身が暗号化されていたり、独自のヘッダー構造を持っていたりするため、外部の防御システムからは単なる「意味不明なデータの塊」にしか見えないのだ。
従来の「レートリミット」が抱えるジレンマ
これまでのDDoS対策では、こうした未知のUDPプロトコルに対して「レートリミット(帯域制限)」という手段が主に使われてきた。特定のIPアドレスやポート番号からの通信が一定量を超えた場合に、一律で遮断や制限をかける方法だ。しかし、これには大きな欠点がある。
レートリミットは「良い通信」と「悪い通信」を区別しない。攻撃が激しくなると、正規のユーザーの通信も制限に巻き込まれ、ラグや切断が発生してしまう。これは、攻撃者の目的である「サービスの停止」を、防御システム自らが手助けしてしまうような結果を招く。また、ユーザーごとに期待される通信量は異なるため、一律の基準値を設定すること自体が非常に困難であった。
Programmable Flow Protectionの仕組みとeBPFの活用

Programmable Flow Protectionは、前述した「中身がわからない」という課題を、ユーザーにロジックを記述させることで解決する。ここで重要な役割を果たすのが「eBPF(extended Berkeley Packet Filter)」という技術だ。
eBPFによるパケットレベルの制御
eBPFとは、OSのカーネル(中枢部)の機能を、カーネル自体を書き換えることなく安全に拡張できる仕組みだ。最近のシステム開発では、ネットワークの監視やセキュリティ対策で急速に普及している。Programmable Flow Protectionでは、ユーザーがC言語などで記述したeBPFプログラムをCloudflareにアップロードする。
アップロードされたプログラムは、Cloudflareのネットワークに届くすべてのパケットに対して実行される。プログラム内で「パケットの32バイト目にある特定のトークンが正しいか」といった独自の条件をチェックし、合致しなければその場でパケットを破棄(ドロップ)する。これにより、アプリケーションサーバーに届く前に、エッジ(利用者に近い拠点)で攻撃を食い止めることが可能になる。
ユーザー空間での安全な実行環境
通常、eBPFはOSのカーネル内で動作するが、Cloudflareのこのシステムでは「ユーザー空間(アプリケーションが動く領域)」で実行される。これにより、特定のユーザーのプログラムが原因でシステム全体が不安定になるリスクを排除しつつ、高度な柔軟性を確保している。
また、プログラムは実行前に「ベリファイア(検証器)」によってチェックされる。メモリ操作に問題がないか、無限ループに陥らないかなどが厳密に確認されるため、安全性が担保されている。Cloudflareの既存のDDoS緩和システムが動作した後にこのカスタムロジックが適用されるため、標準的な攻撃は従来通り自動で防がれ、その網をすり抜けるような特殊な攻撃だけを自作ロジックで仕留めるという二段構えの構成が可能だ。
具体的なユースケース:オンラインゲームの独自プロトコル

この技術が最も威力を発揮する場面の一つが、オンラインゲームの運営だ。独自のゲームエンジンを使用している場合、攻撃者は正規のパケットに似せたデータを大量に送りつけることで、ゲームサーバーをダウンさせようとする。
カスタムヘッダーによるパケット検証
例えば、あるゲームがUDPの207番ポートを使用しており、パケット内の特定の場所に「認証トークン」を含めているとする。Cloudflare側はこのトークンの構造を知らないが、ゲームの開発者はそれを熟知している。Programmable Flow Protectionを使えば、以下のようなロジックをデプロイできる。
// C言語によるeBPFプログラムのイメージ(一部抜粋)
uint64_t cf_ebpf_main(void *state) {
// パケットヘッダーの解析
struct cf_ebpf_parsed_headers headers;
if (parse_packet_data(ctx, &p, &headers) != 0) return CF_EBPF_DROP;
// ポート207以外はドロップ
if (ntohs(udp_hdr->dest) != 207) return CF_EBPF_DROP;
// 独自ヘッダー内のトークンの末尾が「0xCF」かチェック
uint8_t *last_byte = app->token + token_len - 1;
if (*last_byte != 0xCF) {
return CF_EBPF_DROP; // 不正なパケットを破棄
}
return CF_EBPF_PASS; // 正当なパケットのみ通過
}このように、プロトコルの仕様に基づいた「門番」をCloudflareのエッジに配置することで、ランダムなデータを送りつける攻撃(UDPフラッド)を効率的に排除できる。
リプレイ攻撃を防ぐステートフルな追跡
さらに高度な攻撃として「リプレイ攻撃」がある。これは、過去に送信された正当なパケットを攻撃者が記録し、それをそのまま大量に送り直す手法だ。パケットの構造自体は正しいため、単純なヘッダーチェックだけでは防げない。
Programmable Flow Protectionは、単なるフィルターに留まらず、通信の「状態(ステート)」を保持する機能を持っている。これを利用して、未知の送信元IPアドレスに対して「チャレンジ(暗号的な問いかけ)」を送り、正しく応答できたIPアドレスだけを一定期間「許可リスト」に登録するといった運用が可能だ。スクリプトで動いている攻撃者のツールはこうしたチャレンジに応答できないため、リプレイ攻撃を無効化できる。これは、Webサイトでいうところの「CAPTCHA」や「Cookie確認」を、UDPパケットのレベルで実現しているようなものだ。
開発者視点でのメリットと実装の柔軟性

このシステムの真価は、Cloudflareが提供する強力なインフラを、自社のエンジニアが自由にプログラミングできる点にある。従来のハードウェアベースのファイアウォールや、固定的な設定しかできないクラウドサービスとは一線を画す柔軟性だ。
高度なヘルパー関数の提供
eBPFプログラムをゼロから書くのは骨が折れる作業だが、Cloudflareは開発を支援するための「ヘルパー関数」を多数用意している。例えば、パケットデータの解析、送信元IPアドレスごとの状態保存、暗号学的な検証、チャレンジパケットの生成といった複雑な処理を、APIを通じて簡単に呼び出すことができる。
これにより、開発者は「パケットをどう処理するか」というビジネスロジックに集中でき、ネットワークスタックの深い知識がなくても高度な防御機能を構築できる。また、プログラムはCloudflareの全世界のデータセンターに数秒で反映されるため、新しい攻撃パターンが出現した際も即座に防御コードをアップデートできるというスピード感も大きなメリットだ。
エッジでの実行によるレイテンシ削減
通常、高度なパケット検証を自前のサーバーで行おうとすると、攻撃トラフィックがサーバーにまで到達してしまい、帯域を圧迫したりCPU負荷を増大させたりする。Programmable Flow Protectionは、世界中に分散されたCloudflareのエッジ拠点で処理を行うため、攻撃トラフィックはユーザーのインフラに届く前に消滅する。
結果として、サーバー側のリソースを節約できるだけでなく、正規ユーザーの通信に対する遅延(レイテンシ)を最小限に抑えることができる。特にオンラインゲームのようにミリ秒単位の遅延が致命的となるサービスにおいて、この「エッジでの精密なフィルタリング」は非常に強力な武器となるだろう。
独自の分析:エッジコンピューティングとセキュリティの融合

今回のProgrammable Flow Protectionの登場は、セキュリティのあり方が「プラットフォーム任せ」から「プラットフォームとの共同作業」へとシフトしていることを象徴している。これまでは、DDoS対策ベンダーがいかに多くの攻撃パターン(シグネチャ)を知っているかが重要だった。しかし、インターネット上の通信が多様化し、独自のプロトコルが増え続ける中で、ベンダー側ですべてを把握することには限界がある。
Cloudflareは、防御のための「計算資源」と「ネットワーク帯域」を提供し、その上で動かす「知能(ロジック)」をユーザーに開放した。これは、WAF(Web Application Firewall)におけるカスタムルールの作成を、より低レイヤーなL3/L4(ネットワーク・トランスポート層)で実現したものと言える。開発者がインフラの挙動をコードで制御する「Infrastructure as Code」の概念が、DDoS対策の領域でも完全に定着しつつある。
今後、この仕組みはDDoS対策だけでなく、ネットワークトラフィックのルーティングや、エッジでのデータ変換など、より幅広い用途に応用されていく可能性がある。セキュリティエンジニアには、単なる設定作業だけでなく、eBPFのような低レイヤー技術を駆使して「防御をプログラミングする」スキルがますます求められるようになるだろう。
この記事のポイント
- CloudflareがMagic Transit向けに、eBPFでDDoS対策をカスタマイズできる新機能を発表。
- UDPベースの独自プロトコルなど、従来の自動防御では対応が難しかった通信を精密に守れる。
- eBPFを活用することで、パケットの中身を検証したり、ステートフルに接続を追跡したりできる。
- 攻撃パケットをエッジで破棄するため、オリジンサーバーの負荷軽減と正規ユーザーのラグ防止に直結する。
- 現在はEnterprise顧客向けのベータ版として提供されており、開発者による自由なロジック実装が可能。

Cloudflareが新CMS「EmDash」発表。プラグインのセキュリティ問題を隔離技術で解決
Cloudflare(クラウドフレア)は、WordPressの精神的な後継を謳う新しいオープンソースCMS「EmDash(エムダッシュ)」を発表した。これは現在のWeb環境に合わせてゼロから設計されたもので、TypeScriptをベースに構築されている。
EmDashは、WordPressが長年抱えてきたプラグインに起因するセキュリティ脆弱性を、独自の隔離技術によって根本から解決することを目指している。さらに、最新のフロントエンドフレームワークであるAstro(アストロ)をエンジンに採用し、圧倒的なパフォーマンスを実現した。
現在はプレビュー版であるv0.1.0が公開されており、GitHubからコードを入手できる。Cloudflareのインフラだけでなく、Node.jsが動作する環境であればどこでもデプロイ可能だ。なぜ今、新しいCMSが必要なのか、その詳細を解説する。
プラグインのセキュリティ問題を隔離技術で解決する

WordPressのサイトで発生するセキュリティ問題の約96%は、プラグインが原因だと言われている。従来の仕組みでは、プラグインはPHPスクリプトとして動作し、サイトのデータベースやファイルシステムに直接アクセスできてしまう。これが、一つの脆弱性がサイト全体の崩壊を招く要因だった。
EmDashはこの問題を「Dynamic Workers(ダイナミック・ワーカーズ)」と呼ばれる隔離環境(サンドボックス)で解決した。各プラグインは「Isolate(アイソレート)」という独立した実行単位で動作するため、他のプログラムやシステムの中核に勝手に干渉することができない。
プラグインが何らかの操作を行うには、マニフェストファイルで必要な権限(ケイパビリティ)を明示的に宣言する必要がある。例えば、コンテンツを読み取る権限やメールを送信する権限など、許可された範囲内でのみ動作が保証される仕組みだ。これはスマートフォンのアプリがカメラや位置情報へのアクセス許可を求める挙動に近い。
import { definePlugin } from "emdash";
export default () =>
definePlugin({
id: "notify-on-publish",
version: "1.0.0",
capabilities: ["read:content", "email:send"],
hooks: {
"content:afterSave": async (event, ctx) => {
if (event.collection !== "posts" || event.content.status !== "published") return;
await ctx.email!.send({
to: "editor@example.com",
subject: `新着記事:${event.content.title}`,
text: `「${event.content.title}」が公開されました。`,
});
ctx.log.info(`エディターに通知を送信しました:${event.content.id}`);
},
},
});上記のコード例では、コンテンツの読み取りとメール送信の権限のみを要求している。このプラグインが許可なく外部のネットワークと通信したり、データベースを直接書き換えたりすることは物理的に不可能だ。管理者はインストール時に、そのプラグインが何をしようとしているのかを正確に把握できる。
このデモは、従来のCMSとEmDashにおけるセキュリティ構造の違いを視覚化したものだ。
Astroとサーバーレスがもたらす圧倒的なパフォーマンス

EmDashの内部エンジンには、コンテンツ主導のWebサイト向けフレームワークとして評価の高い「Astro」が採用されている。Astroは必要な部分だけをJavaScriptで動かす「アイランドアーキテクチャ」を得意としており、ブラウザでの読み込み速度を極限まで高めることができる。
また、EmDashはサーバーレス環境での動作を前提に設計されている。具体的にはCloudflare Workers(クラウドフレア・ワーカーズ)のランタイムである「workerd」上で動作し、リクエストがあった瞬間にプログラムが起動する仕組みだ。これにより、アクセスがないときはリソースを消費せず、急激なトラフィック増にも即座に対応できる。
従来のWordPressのように、常にサーバーを起動させておく必要がないため、運用コストの大幅な削減が期待できる。Cloudflareによれば、CPUの計算時間に対してのみ課金されるモデルのため、小規模なサイトから大規模なプラットフォームまで効率的にスケールさせることが可能だという。
テーマ制作も現代的だ。開発者はAstroのコンポーネントやスタイル(Tailwind CSSなど)を使って、使い慣れたモダンな手法でサイトのデザインを構築できる。従来のWordPressテーマのように複雑なPHPの作法を覚える必要はなく、フロントエンドエンジニアにとって親和性の高い環境が整っている。
AI時代を見据えた新しい収益化モデルと開発体験

EmDashが他のCMSと一線を画すのが、AIエージェントによる管理を標準でサポートしている点だ。MCP(Model Context Protocol)サーバーを内蔵しており、AIがサイトのコンテンツ構造を理解したり、プラグインを生成したりするためのコンテキストを直接提供できる。
例えば、CLI(コマンドラインインターフェース)を通じてAIエージェントに指示を出し、メディアのアップロードやスキーマの変更、さらにはWordPressテーマの移植ガイドを生成させることも可能だ。これは「人間が管理画面をポチポチ操作する」という従来のCMSのあり方を、根本から変える可能性を秘めている。
さらに、コンテンツの収益化についても新しい提案がなされている。「x402」というインターネットネイティブな決済プロトコルを内蔵しているのだ。これはHTTP 402エラー(支払いが必要)を活用した仕組みで、AIエージェントなどがコンテンツにアクセスする際、都度少額の支払いを行う「ペイ・パー・ユース」のモデルを簡単に導入できる。
広告収益に頼る従来のWebビジネスモデルが、AIによるスクレイピングなどで脅かされている現状に対し、EmDashは技術的な解決策を提示している。管理画面でコンテンツごとの価格を設定し、ウォレットアドレスを登録するだけで、サブスクリプションに頼らない新しい収益源を構築できるのだ。
WordPressからのスムーズな移行とモダンな認証機能

既存のWordPressユーザーを置き去りにしないための工夫も凝らされている。専用のインポータープラグインを使用することで、記事データやメディアライブラリを数分でEmDashへ移行できる仕組みが用意された。
カスタム投稿タイプについても、EmDashでは管理画面から直接スキーマ(データの構造)を定義できる。WordPressでACF(Advanced Custom Fields)などの外部プラグインを駆使して実現していたような複雑なデータ構造も、標準機能としてよりクリーンに管理することが可能だ。
セキュリティ面では、パスワードを廃止し「パスキー(Passkeys)」による認証をデフォルトとしている。これにより、パスワードの漏洩や総当たり攻撃のリスクを事実上ゼロにできる。もちろん、既存のSSO(シングルサインオン)プロバイダーとの連携も可能だ。
CloudflareはEmDashを単なるWordPressの代替品ではなく、これからの20年を見据えた「Webの新しいOS」のような存在として位置づけている。MITライセンスで公開されているため、特定のプラットフォームに縛られることなく、誰もが自由に拡張や開発に参加できる点も大きな魅力だ。
独自の分析:EmDashがWeb制作の現場に与える影響

EmDashの登場は、Web制作のワークフローを劇的に変える可能性がある。特に注目すべきは、プラグインのライセンス問題からの解放だ。WordPressのプラグインは、その構造上GPLライセンスを継承せざるを得ないケースが多かったが、EmDashではプラグインが完全に独立して動作するため、作者が自由にライセンスを選択できる。
これは、高品質な商用プラグインのエコシステムがより健全に発展することを意味する。また、セキュリティが「信頼」ではなく「技術的な制約」によって担保されるため、マーケットプレイスによる中央集権的な審査を待たずとも、安全に新しい機能を導入できるようになるだろう。
一方で、これまでのPHPベースのスキルセットを持つ開発者にとっては、TypeScriptやAstroへの移行という学習コストが発生する。しかし、サーバー管理の苦労から解放され、AIを活用した高速な開発が可能になるメリットは、そのコストを補って余りあるものになるはずだ。まずはプレビュー版を自身の環境で試し、そのスピードと安全性を体感してみることをお勧めする。
この記事のポイント
- EmDashはCloudflareが開発した、TypeScriptベースの新しいオープンソースCMSだ。
- プラグインを独自のサンドボックスで実行することで、WordPressの脆弱性問題を根本的に解決する。
- Astroとサーバーレス技術を採用し、高い表示速度とスケーラビリティを両立している。
- AIエージェントによる管理や、x402プロトコルによる新しい収益化モデルを標準搭載している。
- パスキーによる認証や、WordPressからの簡単なデータ移行機能も備えている。

WordPress開発が劇的に速くなる?次世代ビルドツール「@wordpress/build」の全貌
WordPressのプラグイン開発において、ビルドツールのあり方が大きく変わろうとしている。現在広く使われている @wordpress/scripts の内部エンジンが、より高速でシンプルな @wordpress/build へと移行する計画が進んでいる。この変更は、単なる速度向上にとどまらず、開発者がコードを書く際の手順そのものを効率化するものだ。
2025年10月にプロジェクトが始動し、すでにGutenberg(ブロックエディタ)本体の100以上のパッケージビルドに採用されている。 esbuild(エスビルド)という非常に高速なエンジンを基盤に据えることで、これまでのwebpack(ウェブパック)ベースの環境では数分かかっていた処理が、わずか数秒で完了するようになる。開発の待ち時間がなくなることは、制作現場の生産性に直結する重要な変化だ。
なぜ今、使い慣れたツールを刷新する必要があるのか。それは、WordPress開発における「設定の複雑さ」を解消し、より直感的にコードを書ける環境を整えるためだ。新しいツールが目指すビジョンと、具体的な仕組み、そして今後の開発者がどのように対応すべきかを詳しく解説していく。
WordPressプラグイン開発の新たなスタンダード「@wordpress/build」とは

@wordpress/build は、WordPressコアチームが開発を進めている次世代のビルドツールだ。ビルドツールとは、JavaScriptやCSSなどのソースコードを、ブラウザが読み込める形式にまとめたり、最新の書き方を古いブラウザでも動くように変換したりする道具を指す。
webpack時代の複雑さからの脱却
これまで、WordPressの標準ツールである @wordpress/scripts は、内部でwebpackとBabel(バベル)を使用してきた。これらは非常に多機能で柔軟だが、長年の運用を経て設定が複雑化しすぎている側面があった。特に、依存関係の抽出やPHPファイルの生成など、WordPress特有の処理を組み合わせるために、多くのカスタム設定が必要だった。
結果として、Gutenbergプロジェクト自体が @wordpress/scripts を使わず、独自のカスタムツールでビルドを行うというねじれ現象が起きていた。 @wordpress/build は、この複雑さをツール内部に吸収し、開発者が「設定ファイル」をいじる必要をなくすことを目的としている。
esbuild採用による圧倒的なビルド速度
新しいエンジンの核となるのは esbuild だ。これはGo言語で書かれた非常に高速なバンドラー(ファイルをまとめるツール)で、従来のJavaScript製のツールとは比較にならないほどのパフォーマンスを発揮する。例えるなら、手作業で荷物を仕分けていた倉庫に、最新の高速自動仕分けロボットが導入されるようなものだ。
大規模なプロジェクトでも、フルビルドが数秒で終わる。また、ファイルの変更を監視して自動で再ビルドする「ウォッチモード」では、変更した箇所だけを瞬時に処理するため、修正が即座にブラウザへ反映される。この「待ち時間の消失」こそが、 @wordpress/build を導入する最大のメリットといえるだろう。
「設定」から「規約」へ:新しい開発ワークフロー

@wordpress/build の大きな特徴は、「設定より規約(Convention over Configuration)」という考え方を採用している点にある。これは、あらかじめ決められたルールに従ってフォルダやファイルを配置すれば、ツールが自動的に中身を判断して適切に処理してくれる仕組みだ。
フォルダ構成がそのまま設定になる仕組み
従来のように「どのファイルが入り口(エントリポイント)か」をコードで指定する必要はない。プロジェクト内に特定の名前のフォルダを作るだけで、ツールがビルド対象を自動検知する。
packages/:JavaScriptのパッケージを配置する場所。各サブフォルダが1つのパッケージとして扱われる。routes/:管理画面のルーティング(ページ構成)を定義する場所。blocks/:ブロックのソースコードを置く場所(現在提案中の機能)。
このルールに従うだけで、ツールは各フォルダ内の package.json を読み取り、必要なJavaScriptやスタイルシートを生成する。開発者は「どこに何を書くか」というルールさえ覚えれば、ビルド設定の迷宮に迷い込むことはなくなる。
package.jsonによるシンプルな管理
個別の設定が必要な場合も、webpack.config.jsのような専用ファイルは使わず、 package.json 内に記述する。例えば、あるパッケージをブラウザで読み込むスクリプトとして登録したい場合は、以下のように記述するだけで済む。
{
"name": "@my-plugin/utility",
"wpScript": true
}これだけで、ツールはこのパッケージを「IIFE(即時実行関数式)」形式でビルドし、WordPressの管理画面で適切に読み込めるように準備してくれる。IIFEとは、他のプログラムと名前がぶつからないようにコードをカプセル化する手法のことだ。専門的な知識が必要だった設定が、1行のフラグ指定に集約されている。
PHP登録作業を自動化する革新的な機能

WordPress開発者を悩ませる作業の1つに、JavaScriptファイルを読み込むための wp_enqueue_script() などのPHP記述がある。 @wordpress/build は、このPHP側の登録作業も自動化する道筋を示している。
手動のPHP記述が不要になるメリット
これまでは、ビルドされたファイルのパスを確認し、依存するスクリプト(wp-elementやwp-i18nなど)を手動で配列に書き出す必要があった。新しいツールでは、ビルドプロセスの一環として build/build.php というファイルが生成される。プラグインのメインファイルでこれを1行読み込むだけで、すべての登録が完了する。
require_once plugin_dir_path( __FILE__ ) . 'build/build.php';このファイルには、スクリプト、モジュール、スタイルシートの登録処理がすべて含まれている。開発者がPHP側で「どのファイルを読み込むか」を管理する必要がなくなるため、ファイル名の変更や依存関係の追加に伴うケアレスミスを劇的に減らすことができる。
アセット管理と依存関係の自動解決
JavaScript側で import { __ } from '@wordpress/i18n'; と書けば、ツールは自動的に「このスクリプトはwp-i18nに依存している」と判断し、 .asset.php ファイルを作成する。これは従来も @wordpress/scripts で提供されていた機能だが、 @wordpress/build ではさらに強化されている。
例えば、最新の「スクリプトモジュール(ESM)」と従来のスクリプトの使い分けも、設定一つで切り替え可能だ。さらに、WordPress 6.8で導入された効率的なブロック登録機能(WP_Block_Metadata_Registry)への対応も進められており、最新のコア機能の恩恵を最小限の手間で受けられるようになる。
名前空間と外部依存関係の高度な制御

大規模なプラグインや、複数のプラグインが連携する環境では、「名前空間(Namespace)」の管理が重要になる。 @wordpress/build では、自分のプラグインが提供する機能を他のプラグインからどう参照させるかを、明快に定義できる仕組みが備わっている。
プラグイン間でのスクリプト共有が容易に
例えば、WooCommerceのような他のプラグインが提供するJavaScript機能を利用したい場合、 package.json に外部名前空間として定義する。これにより、コード内で import { Cart } from '@woo/cart'; と書くだけで、実行時には window.woo.cart を参照し、依存関係のリストに自動で追加される。
これは、複数のスクリプトが同じライブラリを二重に読み込んでしまう問題を回避し、サイト全体のパフォーマンス向上に寄与する。開発者は複雑なフックの順序を気にすることなく、モダンなJavaScriptの書き方でプラグイン間の連携を実装できるのだ。
今後のロードマップと開発者が今すべきこと

@wordpress/build は現在も活発に開発が進んでいる段階だ。すぐにすべてのプロジェクトを移行すべきかというと、そうではない。公式のロードマップでは、段階的な統合が予定されている。
@wordpress/scriptsとの統合プロセス
将来的には、 @wordpress/scripts の中身が @wordpress/build に置き換わる予定だ。つまり、開発者は今まで通り npm run build を実行するだけで、内部的に新しい高速エンジンが動くようになる。この際、標準的な設定を使っている開発者は、コードを一切変更することなく、ビルド速度の向上という恩恵を受けられる見込みだ。
一方で、webpackの設定を細かくカスタマイズしている場合は、将来的に移行ガイドを参照しながら調整が必要になる可能性がある。コアチームは、この移行を可能な限りスムーズに進めるためのAPI設計に注力している。
早期導入のメリットと注意点
現在、複数のパッケージを持つ大規模なプラグインを開発しているエンジニアにとって、 @wordpress/build を試す価値は十分にある。モノレポ(複数のパッケージを1つのリポジトリで管理する手法)構成での開発効率が格段に上がるからだ。
ただし、ブロック登録周りなど、まだ手動での作業が必要な箇所も残っている。現時点では実験的な導入にとどめ、GitHubのGutenbergリポジトリで進行中のディスカッションに参加し、フィードバックを送るのが最も賢明な関わり方といえるだろう。特に「blocks/フォルダをルートに置く規約」についての議論は、今後のプラグイン構造の標準を決める重要なポイントだ。
独自の分析:WordPress開発体験(DX)はどう変わるか

今回の @wordpress/build への移行は、WordPressが「独自の進化」から「モダンなWeb標準との融合」へと、さらに一歩踏み出したことを象徴している。 esbuildのような最先端のツールを標準に取り入れることで、WordPress開発特有の「古臭さ」や「設定の煩わしさ」が解消されようとしている。
特に注目すべきは、PHPとJavaScriptの境界線がより曖昧になり、自動化が進む点だ。これまでWordPressエンジニアには、フロントエンドの知識と、それをWordPressに登録するためのPHPの知識の両方が高いレベルで求められてきた。この「登録」という非創造的な作業が自動化されることで、開発者は「ユーザーにどんな機能を提供するか」という本来の目的に集中できるようになる。
また、ビルドが高速化されることは、単に時間の節約になるだけではない。試行錯誤の回数が増え、結果としてコードの品質が向上する。保存した瞬間に画面が変わる「ライブな開発体験」は、開発者のモチベーションを維持する上でも極めて重要だ。 @wordpress/build は、WordPressを「古いブログシステム」から「洗練されたアプリケーションプラットフォーム」へと進化させるための、強力なインフラになるだろう。
この記事のポイント
@wordpress/buildは@wordpress/scriptsの次世代エンジンとして開発されている。- esbuildの採用により、ビルド速度が分単位から秒単位へと劇的に高速化される。
- 「設定より規約」を重視し、フォルダ構成に従うだけで自動ビルドが可能になる。
- PHP側のスクリプト登録処理が自動生成され、手動での記述が不要になる。
- 将来的には既存のツールに統合されるため、標準的な構成なら変更なしで恩恵を受けられる。

WordPress 7.0 RC2が公開。4月9日の正式リリースに向けた最終テストが開始
WordPress 7.0のリリース候補第2版である「RC2」が、2026年3月26日に公開された。このバージョンは、4月に控えた大規模アップデートに向けた最終調整の段階にあり、開発コミュニティによる徹底的な検証が進められている。本番環境への導入はまだ控えるべきだが、新機能の動作確認や互換性のテストを行うには最適なタイミングだ。
今回のリリースでは、前バージョンのRC1以降に報告されたバグの修正や、細かなUIのブラッシュアップが中心となっている。正式版のリリース日は2026年4月9日に設定されており、WordCamp Asiaの開催時期に合わせたスケジュールとなっている。世界中のサイト運営者や開発者にとって、システムの安定性を左右する重要なマイルストーンといえる。
RC(Release Candidate)とは「リリース候補版」を指し、重大な不具合が見つからない限り、このままの状態で正式版として配布される可能性があるソフトウェアの状態を意味する。つまり、RC2が公開されたということは、新機能の追加はすべて完了しており、現在は「磨き上げ」のフェーズにあるということだ。この記事では、RC2の内容とテスト方法、そしてWordPress 7.0がもたらす変化について詳しく解説していく。
WordPress 7.0 RC2のリリースと今後のスケジュール

WordPress 7.0の開発サイクルは、いよいよ最終盤に差し掛かっている。2026年3月26日にリリースされたRC2は、正式版の公開まで残り2週間というタイミングで登場した。この段階では、機能の追加は行われず、報告された不具合の修正とパフォーマンスの最適化に全力が注がれている。開発チームは、このRC版を実際の運用に近い環境でテストすることを強く推奨している。
正式リリースは4月9日を予定
現在のロードマップによれば、WordPress 7.0の正式リリース日は2026年4月9日だ。この日付は、アジア最大級のWordPressイベントである「WordCamp Asia 2026」の開催期間中にあたる。イベントに合わせてリリースされることで、新機能の普及やコミュニティでの議論が一気に加速することが予想される。ただし、RC2のテストで深刻な問題が見つかった場合は、スケジュールが調整される可能性もゼロではない。
リリース候補(RC)版が持つ意味
RC版は、開発の初期段階である「アルファ版」や、機能がほぼ固まった「ベータ版」を経て提供される。RC2(Release Candidate 2)は、RC1で見つかった細かな修正を反映させたものだ。一般的に、この段階のソフトウェアは機能的に完成しており、安定性も高い。しかし、未知のバグが潜んでいるリスクは依然として残っている。そのため、WordPress.orgは、RC2を本番サイトやミッションクリティカルな環境(停止が許されない重要なシステム)にインストールしないよう警告している。
新機能を安全に試すための4つのテスト方法
WordPress 7.0の新機能を正式リリース前に体験するには、いくつかの方法がある。自分のスキルセットや環境に合わせて、最適なテスト手法を選択することが可能だ。ここでは、初心者からエンジニアまで利用できる4つのアプローチを紹介する。
ブラウザだけで試せるPlayground
最も手軽な方法は「WordPress Playground」を利用することだ。これはWebアセンブリ(Wasm)という技術を使い、ブラウザ上だけでWordPressを動作させる仕組みである。サーバーの契約やローカル環境の構築は一切不要で、リンクをクリックするだけで即座にWordPress 7.0 RC2が起動する。ブラウザを閉じればデータは消去されるため、既存のサイトを壊す心配がなく、気軽に新機能を試すことができる。
プラグインやWP-CLIによる検証
既存のテスト用サイトがある場合は「WordPress Beta Tester」プラグインをインストールするのが便利だ。設定画面で「Bleeding edge」と「Beta/RC Only」を選択すれば、管理画面から簡単にRC2へアップデートできる。また、エンジニア向けには「WP-CLI」を使った方法も用意されている。コマンドラインから wp core update --version=7.0-RC2 を実行することで、迅速に環境を更新できる。より確実に検証したい場合は、公式サイトからzipファイルを直接ダウンロードして手動インストールすることも可能だ。
WordPress 7.0で注目される主な変更点
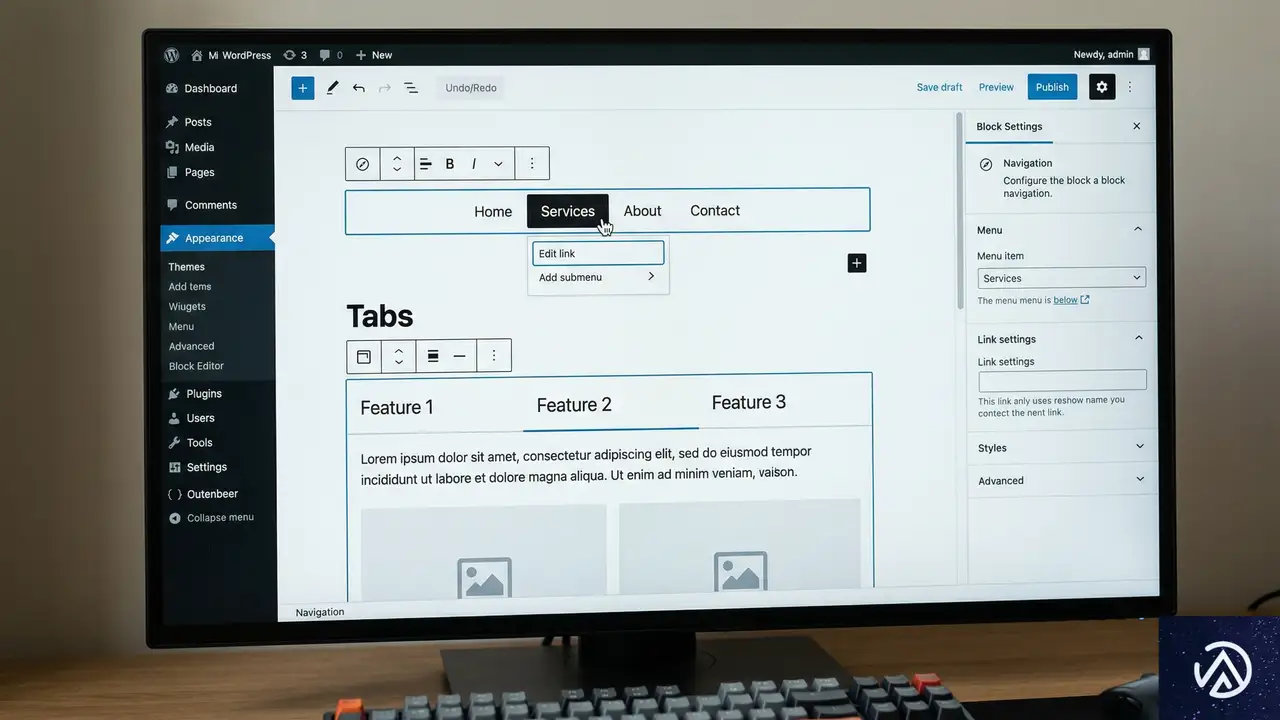
WordPress 7.0は、ユーザー体験(UX)と開発体験の両面で大きな進化を遂げている。特にブロックエディタ(Gutenberg)の機能強化は、Web制作のワークフローを大きく変える可能性を秘めている。これまでのベータ版やRC1での情報を踏まえ、主要な変更点を整理する。
Gutenbergエディタとブロックの進化
今回のアップデートの目玉の一つは、Tabs(タブ)ブロックのリファクタリングだ。タブブロックとは、限られたスペースに複数のコンテンツを切り替えて表示するためのパーツである。コード構造が刷新されたことで、アクセシビリティが向上し、より直感的な編集が可能になった。また、Navigation Overlay(ナビゲーションオーバーレイ)の改善も含まれている。これは、スマートフォンなどでメニューを開いた際の表示や挙動を制御する機能で、モバイルユーザーの利便性が高まっている。
開発者向けの技術的な改善
開発者向けには、内部的なAPIの整理やパフォーマンスの向上が図られている。RC2までの修正では、GitHub上のコミットやTrac(バグ追跡システム)のチケットが多数処理されており、特にブロック間のデータのやり取りや、メタデータの処理速度が改善されている。Breadcrumbs(パンくずリスト)ブロックの微調整なども行われており、SEO(検索エンジン最適化)に配慮した構造がより作りやすくなっている。
プラグイン・テーマ開発者が今すべきこと

WordPressのエコシステムを支えるプラグインやテーマの作者にとって、RC2の期間は最終確認のデッドラインだ。自身のプロダクトが最新のコアと競合しないか、正常に動作するかを確認する責任がある。
互換性テストと「Tested up to」の更新
開発者は、自身のプラグインやテーマをRC2環境で動作テストし、エラーが出ないかを確認する必要がある。問題がなければ、readme.txtファイルの「Tested up to」項目を 7.0 に更新することが推奨されている。これにより、ユーザーは管理画面で「このプラグインは最新バージョンのWordPressで動作確認済みである」という確信を持ってアップデートできるようになる。もし互換性の問題が見つかった場合は、WordPressのサポートフォーラムの「Alpha/Beta」セクションへ詳細を報告することが、コミュニティ全体の利益につながる。
独自の分析:WordPress 7.0がもたらす運用への影響
WordPress 7.0のリリースは、単なる機能追加以上の意味を持っている。特に中小企業のサイト担当者や個人事業主にとって、このアップデートは「運用の内製化」をさらに一歩進めるものになると分析できる。
ノーコード編集の幅が広がるメリット
Tabsブロックの刷新やナビゲーションの改善は、これまでコーディングが必要だった複雑なレイアウトを、マウス操作だけで完結させるための布石だ。これにより、外部の制作会社に依頼することなく、自社でキャンペーンページや製品紹介ページを柔軟に更新できる範囲が広がる。表示速度の向上も期待されており、これはCWV(Core Web Vitals / コアウェブバイタル)というGoogleの検索順位指標にも好影響を与えるだろう。つまり、日常的な運用コストの削減と、SEO効果の向上が同時に期待できるアップデートといえる。
リリースタイミングとリスク管理
4月9日の正式リリース直後にアップデートを行うのは、リスクを伴う場合がある。特に多くのプラグインを導入しているサイトでは、プラグイン側の対応が遅れる可能性があるからだ。筆者の見解としては、正式リリースから1〜2週間ほど様子を見、マイナーアップデート(7.0.1など)が出てから適用するのが、ビジネスサイトにおいては最も安全な戦略である。RC2の段階でテスト環境を構築し、事前に自社サイトの主要機能が動くかを確認しておくことが、スムーズな移行への近道となるだろう。
この記事のポイント
- WordPress 7.0 RC2が公開され、2026年4月9日の正式リリースに向けて最終調整に入った
- RC2はリリース候補版であり、本番環境ではなくテストサーバーやPlaygroundでの検証が推奨される
- Tabsブロックの刷新やNavigation Overlayの改善など、UIとアクセシビリティの強化が主要な変更点である
- プラグイン・テーマ開発者は互換性を確認し、readmeの「Tested up to」を7.0に更新すべき時期である
- 正式リリース後は運用コストの削減が期待できるが、安定性を重視するなら数週間の様子見も有効な戦略となる

AI時代のキャッシュ設計を再考する——AIクローラーがCDNに与える影響と対策
CDN(コンテンツデリバリネットワーク)のキャッシュ設計が、AIクローラーの台頭によって根本的な見直しを迫られている。Cloudflareのデータによると、同社ネットワーク上のトラフィックの32%は自動化されたトラフィックが占める。検索エンジンクローラーや監視ツールに加え、近年はAIアシスタントが回答生成のためにWebから情報を取得するケースが増加している。
AIエージェントは人間とは異なるアクセスパターンを示す。高頻度の並列リクエスト、人気ページではなく長尾コンテンツへの集中的なアクセス、サイト全体の網羅的なスキャンなどが特徴だ。このような振る舞いは、従来の人間向けに最適化されたキャッシュアルゴリズムを無効化し、キャッシュミス率の上昇とオリジンサーバー負荷の増大を引き起こす。
サイト運営者はAIクローラーへの対応に迫られる。ブロックするか、サービスを提供するかの選択を迫られるが、両者のトラフィックパターンは大きく異なるため、既存のキャッシュアーキテクチャでは一方に最適化するしかない。本記事では、AIトラフィックがCDNキャッシュに与える影響を分析し、新しいキャッシュ設計の方向性を探る。
AIクローラーと人間のトラフィックの根本的な違い

AIクローラーのトラフィックは、人間のブラウジング行動と比較して3つの主要な特徴を持つ。高ユニークURL比率、コンテンツの多様性、クロールの非効率性だ。
高ユニークURL比率と長尾コンテンツへのアクセス
Common Crawlの公開データによると、大規模Webクロールでは90%以上のページがコンテンツ的にユニークだ。AIクローラーは特定のコンテンツタイプに特化する傾向があり、技術文書、ソースコード、メディアファイル、ブログ記事など、目的に応じて異なるコンテンツを対象とする。
人間のユーザーがトップページや人気記事に集中するのに対し、AIクローラーはサイトの奥深くまで探索する。Wikipediaの利用データは、かつて「長尾」とされていたほとんどアクセスされないページが、現在では頻繁にリクエストされるようになったことを示している。これはCDNキャッシュ内のコンテンツ人気度分布そのものを変化させている。
クロールの非効率性と反復ループ
AIクローラーは必ずしも最適なクロールパスをたどらない。人気のあるAIクローラーからのフェッチのかなりの割合が404エラーやリダイレクトで終わる。これはURL処理の不備によることが多い。また、ブラウザ側のキャッシュやセッション管理を人間のユーザーと同じように利用しない。
AIエージェントは検索結果を改良するために反復ループを行うことがある。これはRAG(Retrieval-Augmented Generation)における一般的なパターンだ。この反復ループは、エージェントの精度を高める一方で、一貫して高いユニークアクセス比率(70%から100%)を維持する。つまり、各ループで以前に見たページを再訪するのではなく、常に新しいユニークなコンテンツを取得し続ける。
キャッシュへの直接的な影響
長尾アセットへのこのような反復アクセスは、人間のトラフィックが依存するキャッシュをかき回す。既存のプリフェッチや従来のキャッシュ無効化戦略は、クローラートラフィックの量が増加するにつれて効果が低下する。Cloudflareの単一ノードにおけるキャッシュヒット率は、AIクローラーを含む場合と含まない場合で明確な差が見られる。ヒット率の低下は、LRU(Least Recently Used)アルゴリズムがAIクローラーの反復スキャン行動に対処できていないことを示唆している。
実例から見るAIクローラーのインパクト

AIボットトラフィックの急増は、実際のWebサービスに深刻な影響を与えている。大規模サイトにおける影響と対応策は以下の通りだ。
Wikipedia:マルチメディア帯域幅の50%急増
モデル訓練のための画像一括スクレイピングにより、マルチメディア帯域幅使用量が50%急増した。Wikimediaは最終的にクローラートラフィックをブロックする対応を取った。
SourceHutとRead the Docs:サービス不安定化
ソースコードリポジトリをスクレイピングするLLMクローラーにより、サービス不安定化と速度低下が発生。Read the Docsでは、AIクローラーが大きなファイルを1日に数百回ダウンロードし、帯域幅の大幅な増加を引き起こした。両サービスとも一時的にクローラートラフィックをブロックし、IPベースのレート制限を実施した。
FedoraとDiaspora:人間ユーザーへの影響
Fedoraはパッケージミラーを再帰的にクロールするAIスクレイパーにより、人間ユーザーに対する応答速度が低下。Diasporaソーシャルネットワークは、robots.txtを尊重しない積極的なスクレイピングにより、応答速度の低下とダウンタイムを経験した。両者とも既知のボットソースからのトラフィックを地理的にブロックするなどの対応を取った。
これらの事例が示すのは、AIクローラーを単純にブロックするだけでは根本的な解決にならないということだ。よりスマートなキャッシュアーキテクチャがあれば、サイト運営者はAIクローラーにサービスを提供しつつ、人間ユーザーの応答時間を維持できる。
AI時代に向けたキャッシュ設計の新たな方向性

AIトラフィックの特性を考慮した新しいキャッシュ設計が必要とされている。主なアプローチは2つある。AIを意識したキャッシュアルゴリズムによるトラフィックフィルタリングと、AIクローラートラフィック専用の新しいキャッシュ層の追加だ。
ワークロード対応型キャッシュアルゴリズム
現在広く使用されているLRU(Least Recently Used)アルゴリズムは、汎用状況においてシンプルさ、低オーバーヘッド、有効性のバランスが取れている。しかし、人間とAIボットの混合トラフィックに対しては、別のキャッシュ置換アルゴリズムの選択が有効かもしれない。
初期実験では、SEIVEやS3FIFOといったアルゴリズムを使用することで、AIの干渉の有無にかかわらず、人間トラフィックが同じヒット率を達成できる可能性が示されている。さらに、ワークロードを直接意識した機械学習ベースのキャッシュアルゴリズムを開発し、リアルタイムでキャッシュ応答をカスタマイズする実験も進められている。これにより、より高速でコスト効率の高いキャッシュが実現できる。
トラフィック種別に応じた階層化キャッシュアーキテクチャ
長期的には、AIトラフィック専用の別個のキャッシュ層が最善の道となる。人間とAIのトラフィックをネットワークの異なる層に配置された別個の階層にルーティングするキャッシュアーキテクチャが考えられる。
人間トラフィックは、応答性とキャッシュヒット率を優先するCDN PoP(Point of Presence)のエッジキャッシュから引き続きサービスされる。一方、AIトラフィックのキャッシュ処理はタスクタイプによって変えることができる。
RAGやリアルタイム要約のようなライブアプリケーションを支えるAIクローラーでは、レイテンシが重要だ。これらのリクエストは、より大きな容量と適度な応答時間のバランスが取れたキャッシュにルーティングされるべきである。これらのキャッシュは鮮度を保ちつつも、人間向けキャッシュよりもわずかに高いアクセスレイテンシを許容できる。
訓練セットの構築や大規模コンテンツ収集ジョブに使用されるAIクローラーは、かなり高いレイテンシを許容し、時間的制約がない。これらのワークロードは、到達までに時間がかかる深いキャッシュ階層(オリジン側のSSDキャッシュなど)からサービスできる。あるいは、キューベースのアドミッションやレートリミッターを使用して遅延させ、バックエンドの過負荷を防ぐことも可能だ。これにより、インフラに負荷がかかっている場合にバルクスクレイピングを延期する機会も生まれる。
この記事のポイント
- AIクローラーは全ネットワークトラフィックの約3分の1を占め、そのアクセスパターンは人間のブラウジング行動と根本的に異なる。
- 高ユニークURL比率、長尾コンテンツへの集中アクセス、反復ループによるキャッシュチャーンが、従来のLRUキャッシュアルゴリズムの効果を低下させている。
- WikipediaやFedoraなどの大規模サイトでは、AIクローラーによる帯域幅急増やサービス不安定化が実際に発生し、多くのサイトがクローラーブロックに頼らざるを得なくなっている。
- 根本的な解決策として、SEIVEやS3FIFOなどの新しいキャッシュアルゴリズムの採用と、AIトラフィック専用の階層化キャッシュアーキテクチャの構築が検討されている。
- 今後のCDN設計では、人間トラフィックとAIトラフィックを分離し、それぞれの特性に最適化したキャッシュ戦略を適用することが重要になる。

AIに引用されるコンテンツの共通点:120万件のデータから判明したSEOの新常識
AIチャットボットが検索の代替手段となりつつある今、自社のコンテンツがAIに「引用」されるかどうかは、Webサイトのトラフィックを左右する死活問題だ。Search Engine Journalが公開した調査結果によると、AIに選ばれるコンテンツには、従来のSEO(検索エンジン最適化)とは異なる独自の評価基準が存在することが明らかになった。
この調査では、120万件を超えるChatGPTの回答と、約9万8,000件の引用データを詳細に分析している。その結果、業界を問わず引用率を14%向上させる「魔法の導入文」や、逆に引用を妨げてしまう「見出し構成のデッドゾーン」の存在が浮き彫りになった。
本記事では、この膨大なデータに基づいた「AIに好まれるコンテンツ制作」の具体策を解説する。単なる執筆テクニックにとどまらない、AI時代のコンテンツ・アーキテクチャのあり方を探っていこう。
導入文の「断定表現」が引用率を14%向上させる

AIがコンテンツを読み取る際、最も重視しているのは「情報の確実性」だ。Search Engine JournalのKevin Indig氏が分析したデータによると、記事の冒頭で「断定的な表現(Declarative Language)」を使用しているページは、そうでないページに比べて引用率が平均14%高いことが分かった。
「〜かもしれない」という曖昧さを排除する
AIは、ユーザーの質問に対して自信を持って回答を提供しようとする。そのため、「このツールは効率化に役立つ可能性がある」といった慎重な言い回し(ヘッジ表現)よりも、「このツールは業務時間を30%削減する」といった明確な主張を好む傾向がある。
特に冒頭の1,000文字以内において、修飾語や前置きを極力減らし、事実をストレートに述べる構成が有効だ。「[X] は [Y] である」あるいは「[X] を使うと [Z] ができる」という直接的な構文を意識するだけで、AIからの評価は大きく変わる。
結論から書き始める「結論先行型」の徹底
多くのWebライティングでは、読者の共感を得るために「背景の説明」や「問いかけ」から始めることが多い。しかし、AI最適化(AEO:Answer Engine Optimization)の観点では、これは逆効果になる場合がある。
AIは情報の「密度」と「即時性」を評価する。記事の最初の段落で、そのページが提供する核心的な情報を提示することが、引用対象として選ばれるための必須条件となっているのだ。
業界ごとに異なる「最適な見出し数」の正体

見出し(Hタグ)の構成は、AIが情報を構造化して理解するための地図となる。興味深いことに、見出しの数は「多ければ良い」というわけではなく、業界ごとに明確な「スイートスポット(最適値)」が存在する。
見出し3〜4個は「デッドゾーン」になるリスク
調査対象となったすべての業界において共通していたのは、「見出しが3〜4個の記事は、見出しがゼロの記事よりも引用率が低い」という衝撃的な事実だ。これは、中途半端な構造化がAIのナビゲーションを混乱させている可能性を示唆している。
構造化を徹底して情報の階層を明確にするか、あるいは一切の装飾を省いて散文として読ませるか、どちらかの極端なアプローチの方がAIには好まれる。中途半端な見出し構成は、情報の網羅性と構造の明快さの両方を損なう「デッドゾーン」となっているのだ。
業界別:SaaSは20個以上、医療は0個が有利?
最適な見出しの数は、扱うトピックによって大きく異なる。例えば、CRMやSaaS関連の分野では、20個から49個もの見出しを持つ詳細な比較ガイドが高い引用率を記録している。これは、AIが多機能なソフトウェアを比較する際、細かくセクション分けされた情報を求めているためだ。
一方で、医療(Healthcare)分野では、見出しがゼロ、あるいは極めて少ないページの方が好まれる傾向がある。医療情報においては、断片的な見出しの羅列よりも、文脈が維持された一貫性のある記述が「権威ある解説」として評価されやすいと考えられる。
AIが好むエンティティ:日付と数値、そして「価格」の罠

AIは単なる単語の羅列ではなく、意味のある情報の塊(エンティティ)を識別している。Google Natural Language APIを用いた分析によると、特定のエンティティの有無が引用の成否を分けることが判明した。
「日付」と「具体的な数値」は信頼の証
ほぼすべての業界で共通してプラスの信号となったのが、「DATE(日付)」と「NUMBER(数値)」だ。情報の鮮度を示す日付と、客観的な裏付けとなる統計数値は、AIにとって「引用する価値がある」と判断するための強力なトリガーとなる。
特に公開日や更新日を明記し、本文中で具体的なデータ(例:15%の改善、3,000人のユーザーなど)を提示することは、AIからの信頼を勝ち取るための最もシンプルな近道といえる。
価格情報の掲載が引用を妨げる理由
意外なことに、「PRICE(価格)」に関するエンティティは、金融以外のほとんどの業界でマイナスの信号として働いている。冒頭で価格について強調しすぎると、AIはそのコンテンツを「客観的な情報源」ではなく「商業的な広告ページ」と見なす傾向がある。
ただし、金融業界だけは例外で、金利や手数料などの価格情報が引用率を高める要因となっている。これは、金融系のクエリにおいては価格そのものがユーザーの求める「回答」に直結するためだ。業界の特性を理解したエンティティ配置が求められる。
UGC(ユーザー生成コンテンツ)はAIに選ばれない?

Googleの検索結果では、RedditやQuoraといったユーザー投稿型のコミュニティサイトが優遇される傾向(通称:Reddit効果)が見られる。しかし、AIの引用データはこの傾向とは全く異なる結果を示した。
Reddit効果は検索エンジン限定の現象か
調査データによると、ChatGPTが引用するソースの94.7%は企業や専門メディアによる「コーポレート/エディトリアルコンテンツ」であり、UGC(ユーザー生成コンテンツ)の割合は極めて低い。金融や医療といった専門性が求められる分野では、UGCの引用率は1%未満にとどまっている。
これは、AIが回答を生成する際、個人の主観的な意見よりも、組織が責任を持って公開している「構造化された公式情報」を優先していることを意味する。AI時代においても、公式サイトとしての権威性を磨くことの重要性は変わっていない。
暗号資産分野で見られる唯一の例外
唯一の例外は、暗号資産(Crypto)分野だ。この分野ではUGCの引用率が9.2%と比較的高い。技術の進化が速く、公式ドキュメントよりもRedditや開発者コミュニティの方が最新かつ詳細な情報を持っていることが多いため、AIも例外的にこれらのソースを頼りにしている。
この結果から、情報の「速報性」や「技術的な深さ」が公式サイトを上回る場合に限り、コミュニティサイトにもAI引用のチャンスがあることがわかる。
AI時代を生き抜くための新SEO戦略

今回の分析結果を踏まえると、これからのSEO(あるいはAEO)は「文章の質」だけでなく「情報のアーキテクチャ」の戦いになると断言できる。AIに選ばれるためには、人間にとっての読みやすさと、マシンにとっての解析しやすさを高次元で両立させる必要がある。
コンテンツ・アーキテクチャの重要性
AIは、ページ内の特定の場所を重点的にスキャンし、情報の階層を理解しようとする。単にキーワードを詰め込むのではなく、業界ごとの最適な見出し構成(SaaSなら詳細に、医療なら簡潔に)を採用し、AIが情報を抽出しやすい「器」を作ることが重要だ。
また、有名なブランド名や一般的な用語(Knowledge Graphに登録されているような既知の情報)を並べるよりも、特定のニッチな数値や独自の手法といった「具体的で詳細なエンティティ」を含める方が、AIにとっては引用する価値が高いと判断される。
業界特化型の最適化へのシフト
すべての業界に共通する「魔法の公式」は存在しない。導入文を断定的に書くという基本ルールを除けば、最適な文字数、見出しの深さ、含めるべきエンティティの種類は、すべて業界の規範(ノルマ)に依存する。
自社が属する業界において、AIがどのようなコンテンツを好んで引用しているかを分析し、そのパターンに構造を合わせていく「業界特化型の最適化」こそが、これからのWebサイト運営者に求められるスキルとなるだろう。
この記事のポイント
- 導入文は「〜かもしれない」を避け、断定的な表現で結論から書き始める
- 見出しの数は業界ごとに最適化し、中途半端な3〜4個の構成は避ける
- 日付と具体的な数値を積極的に盛り込み、情報の客観性と鮮度をアピールする
- AI引用ではReddit等のUGCよりも、企業・専門サイトの公式情報が圧倒的に有利
- 汎用的なSEOテクニックではなく、業界の特性に合わせた構造設計が必要である

CSS Olfactive APIでウェブに「匂い」を実装する?次世代の嗅覚体験と実装方法の全容
ウェブデザインの歴史は、視覚と聴覚をいかに豊かにするかの歴史だった。しかし、次世代のウェブ標準として「嗅覚」を制御する「CSS Olfactive API(CSS嗅覚API)」の策定が進められている。この技術により、ブラウザを通じてユーザーに特定の香りを届けることが可能になる。
現在、W3C(World Wide Web Consortium)のCSSワーキンググループでは、香りの定義方法やハードウェアとの連携について活発な議論が行われている。香りをデジタルデータとして扱うための新しいファイル形式や、CSSで香りの強度を指定する新しい単位「whf」も導入される見込みだ。
このAPIは、単なるエンターテインメントの枠を超え、ECサイトでの購買体験や、教育コンテンツの没入感を劇的に変える可能性を秘めている。本記事では、CSS Olfactive APIの仕組みから具体的な実装コード、そしてアクセシビリティへの配慮まで、現時点で判明している仕様を詳しく解説する。
ウェブ体験は「嗅覚」の領域へ:Olfactive APIとは何か

ウェブサイトの没入感を高める試みは、静止画から動画へ、そして空間オーディオへと進化してきた。CSS Olfactive APIは、その次のステップとして「香り」をブラウザの制御下に置くことを目的としている。Olfactive(オルファクティブ)とは「嗅覚の」という意味を持つ言葉だ。
ハードウェアとAPIの連携
このAPIが機能するためには、PCやスマートフォンに接続された「香りの放出デバイス」が必要になる。かつてテーマパークの4Dアトラクションで使われていたような技術が、一般消費者向けの小型デバイスとして開発されている。あるスタートアップ企業によれば、1年以内には手頃な価格の家庭用ディフューザーが市場に投入される予定だという。
APIはこれらのデバイスを抽象化し、ブラウザが直接ハードウェアの仕様を意識することなく、標準化された命令で香りを制御できるようにする。これにより、開発者は特定のメーカーのデバイスに依存することなく、共通のCSSプロパティで嗅覚体験をデザインできる。OSレベルでのドライバ対応が進めば、USB接続やBluetooth経由でシームレスに香りが届けられるようになるだろう。
なぜ今、嗅覚なのか
嗅覚は、人間の脳において感情や記憶を司る「大脳辺縁系」に直接結びついている唯一の感覚だと言われている。視覚や聴覚よりも強く、ユーザーの感情を揺さぶり、特定の記憶を呼び起こす力がある。例えば、コーヒーショップのサイトを開いた瞬間に挽きたての豆の香りが漂えば、ユーザーの購買意欲は視覚情報のみの場合よりも格段に高まるだろう。このように、UX(ユーザーエクスペリエンス)の観点から嗅覚の活用は非常に強力な武器になる。
香りを構成する4つのファミリーと15のサブカテゴリ

デジタルで香りを表現するために、香水業界で長年使われてきた「フレグランスホイール(香りの輪)」という概念が採用された。CSS Olfactive APIでは、このホイールをベースに香りを分類し、コードで指定できる識別子を割り当てている。
4つのメインファミリー
香りは大きく分けて以下の4つのメインファミリーに分類される。これらは、デザインにおける「プライマリカラー」のような役割を果たす基本的なカテゴリだ。
- Floral(フローラル):花の香り。最も一般的で親しみやすい。
- Amber(アンバー):以前はオリエンタルと呼ばれていた、官能的で温かみのある香り。
- Woody(ウッディ):樹木や森林を思わせる、落ち着いた香り。
- Fresh(フレッシュ):シトラスや水、草木のような爽やかな香り。
15のサブカテゴリと識別子
メインファミリーはさらに細分化され、合計15のサブカテゴリが定義されている。CSSではこれらを2文字の識別子で指定する。例えば、フローラルの中には「Soft Floral(sf)」や「Floral Amber(fa)」といった細かな違いが存在する。これらを組み合わせることで、複雑な調香を再現する仕組みだ。
「Fresh」ファミリーは特に種類が多く、柑橘系の「Citrus(ct)」、水の香りの「Water(ho)」、果物の「Fruity(fu)」など、ウェブコンテンツと親和性の高い香りが揃っている。これらの識別子は、後述する scent() 関数の引数として使用されることになる。
HTMLとCSSによる実装:<scent>要素とscent-profile

実装方法は、既存の <video> や <audio> 要素と非常によく似ている。HTMLで香りのソースを定義し、CSSで要素に香りのプロファイルを割り当てるという流れだ。
<scent>要素による外部ファイルの読み込み
香りのデータは、専用のファイル形式で提供される。現在、Google、Mozilla、そして香料メーカーの連合がそれぞれ .smll、.arma、.smly という形式を提案中だ。HTMLでは <scent> 要素を使い、複数のソースを指定できる。
<scent controls autosmell="none">
<source src="forest.smll" type="scent/smll">
<source src="forest.arma" type="scent/arma">
<a href="forest.smll">森林の香りをダウンロード</a>
</scent>ここで重要なのが autosmell 属性だ。動画の autoplay と同様、ユーザーの意図しないタイミングで香りが放出されるのを防ぐため、デフォルトは none に設定することが推奨されている。アクセシビリティの観点からも、勝手に匂いが出る設定は避けるべきだ。
scent-profileプロパティ
CSSでは、新しく追加される scent-profile プロパティを使用して、特定の要素に香りを紐付ける。背景画像を指定する background-image と似た感覚で利用できる。以下のデモは、CSS Olfactive APIの指定方法を視覚化したものだ。
このデモは、要素に scent-profile: url(forest.smll); を適用した際の概念を示している。右側の要素にマウスを乗せたり、フォーカスを合わせたりした際に、デバイスから香りが放出される仕組みだ。
調香のコントロール:whf単位とscent()関数の使い方

外部ファイルを読み込むだけでなく、CSS内で直接香りを合成することも可能だ。ここで使われるのが scent() 関数と、新しい単位 whf である。 whf は「Waftage High Frequency(香気拡散強度)」の略で、香りの強さを表す。
香りのブレンドと強度指定
scent() 関数には、最大5つまでのサブカテゴリ識別子を指定できる。それぞれの識別子に whf 単位の数値を添えることで、配合比率を細かく調整できる。最大値は 100whf であり、指定した合計値が100を超えた場合、ブラウザは先頭から順に処理し、100に達した時点で残りの指定を無視する仕様だ。
/* ウッディ20%、水13%、フルーティ67%のブレンド */
.orchard-in-rain {
scent-profile: scent(wo 20whf, ho 13whf, fu 67whf);
}
/* 全体的にほのかな香りにする場合 */
.subtle-scent {
scent-profile: scent(wo 5whf, ho 2whf, fu 14whf);
}この whf 単位の面白い点は、単なる「比率」ではなく、放出デバイスの「出力強度」に直結していることだ。 100whf で指定すれば部屋中に広がるような強い香りに、 10whf 程度であればユーザーが顔を近づけた時にだけ感じる微かな香りになる。デザインの目的に応じて、香りの「距離感」をコントロールできるのが特徴だ。
ネストと兄弟要素の制限
香りが混ざりすぎて不快な体験になるのを防ぐため、APIには強力な制限が設けられている。1つの親要素のツリー内では、1つの scent-profile しか有効にならない。つまり、ある div に香りを設定した場合、その子要素や兄弟要素に別の香りを重ねることはできない。これにより、開発者が誤って「香りのカオス」を作り出してしまうのを防いでいる。複数の香りを切り替えたい場合は、要素同士を十分に離すか、JavaScriptで動的にプロパティを書き換える必要がある。
ユーザーへの配慮とアクセシビリティ:過剰な演出を防ぐ仕組み

嗅覚は非常にデリケートな感覚であり、特定の人にとっては不快感やアレルギー反応を引き起こす原因にもなり得る。そのため、CSS Olfactive APIではアクセシビリティへの配慮が最優先事項として組み込まれている。
prefers-reduced-pungency メディアクエリ
視覚的な動きを抑える prefers-reduced-motion と同様に、香りの刺激を抑えるための prefers-reduced-pungency メディアクエリが導入される。ユーザーはブラウザやOSの設定で「香りを無効にする」あるいは「弱める」を選択できる。
.product-card {
scent-profile: scent(fl 50whf, fu 50whf);
}
/* ユーザーが「刺激を抑える」設定にしている場合 */
@media (prefers-reduced-pungency: reduce) {
.product-card {
scent-profile: scent(fl 10whf, fu 10whf);
}
}
/* ユーザーが「香りをオフ」にしている場合 */
@media (prefers-reduced-pungency: remove) {
.product-card {
scent-profile: none;
}
}開発者はこのメディアクエリを活用し、ユーザーの好みに合わせた最適な強度を提供しなければならない。特に公共の場やオフィスでの利用を想定すると、デフォルトで香りをオフにする設定の普及は必須といえるだろう。
嗅覚インターフェースの倫理
香りは記憶と結びついているため、悪意のあるサイトが不快な匂いを放出してユーザーにトラウマを植え付けるといった攻撃も理論上は可能だ。これを防ぐため、ブラウザベンダーは「信頼できるドメイン」のみに嗅覚APIの権限を与える、あるいはマイクやカメラのように「このサイトが香りの放出を求めています」という許可ダイアログを表示する機能を検討している。技術の進化とともに、嗅覚のプライバシーと安全性を守るガイドラインの策定が急がれている。
今後の展望と課題:ハードウェア普及と実用性の壁

CSS Olfactive APIは非常に野心的なプロジェクトだが、普及までにはまだ高い壁がある。最大の課題は、やはりハードウェアの普及率だ。どれほど洗練されたCSSを書いても、ユーザーの元に放出デバイスがなければ意味をなさない。
ブラウザの対応状況
驚くべきことに、現在このAPIを試験的に実装しているのは、新興市場向けの「KaiOS」ブラウザのみだ。ChromeやFirefox、Safariといった主要ブラウザは、仕様の推移を慎重に見守っている段階にある。しかし、AppleがVision Proのような空間コンピューティングに注力していることを考えると、没入感を補完する要素として嗅覚が注目される日は遠くないかもしれない。
実用的なユースケースの模索
単なる「お遊び」に終わらせないためには、実用的なメリットを示す必要がある。例えば、火災報知器と連動した「焦げ臭い匂い」のウェブ通知や、アロマセラピーの遠隔体験、あるいは歴史教育における「当時の街の匂い」の再現など、社会に役立つ応用例が期待されている。香りを「情報」として伝達する手段が確立されれば、ウェブの可能性は文字通りもう一つの次元へと広がるだろう。
この記事のポイント
- CSS Olfactive APIは、ブラウザを通じて香りを制御するための新しいWeb標準である。
- 香りは「Floral」「Amber」「Woody」「Fresh」の4ファミリーと15のサブカテゴリで定義される。
scent-profileプロパティとwhf単位により、香りの種類と強度をCSSで指定できる。prefers-reduced-pungencyメディアクエリにより、ユーザーが香りの強度を制御できるアクセシビリティが確保されている。- 実用化には専用ハードウェアの普及と、安全に利用するためのセキュリティガイドラインが不可欠だ。

Web制作会社がホスティング選定で重視すべきSLAと保証のチェックポイント
Webサイトの公開直後にサーバーがダウンしたり、サポートの返信が来なかったりするトラブルは、多くの制作現場で頭を悩ませる問題だ。こうした事態を防ぐための指標となるのが、SLA(Service Level Agreement / サービス品質保証)である。
SLAとは、サービス提供者が利用者に対して「どの程度の品質を保証するか」を明文化した合意書を指す。多くのホスティング会社が「高い信頼性」を謳うが、具体的な数字や補償内容が伴わなければ、それは単なるスローガンに過ぎない。
特に複数のクライアントサイトを管理するエージェンシーにとって、インフラの安定性は自社の信頼に直結する。この記事では、ホスティングパートナーを選ぶ際に確認すべきSLAの核心と、見落としがちな保証の裏側について詳しく掘り下げていく。
SLAの正体とWeb制作会社が注視すべき理由

SLAは、ホスティングプロバイダーが提供するサービスの品質を定義し、その目標が達成されなかった場合の救済措置を定めた正式な文書だ。これには稼働率の目標値、サポートの応答時間、セキュリティ対応などが含まれる。
SLAは「単なる努力目標」ではない
マーケティング資料で見かける「高速なパフォーマンス」や「専門家によるサポート」といった言葉には、客観的な基準がない。一方でSLAは、これらを測定可能な数値で定義する。例えば「月間稼働率99.9%を維持し、下回った場合は利用料金の一定割合を返金する」といった具体的な約束事だ。
KinstaのCarlo Daniele氏によれば、SLAはプロバイダーが自社のサービスにどれだけの責任を持っているかを示す指標となる。障害が起きた際のフレームワークが事前に決まっていることで、利用者側はリスク管理がしやすくなるという利点がある。
クライアントへの信頼性に直結するインフラの裏付け
Web制作会社にとって、ホスティングのトラブルは自社のトラブルとしてクライアントに認識されることが多い。サーバーが原因のダウンタイムであっても、クライアントが最初に連絡を入れるのは制作担当者だからだ。
明確なSLAを持つパートナーを選んでおけば、万が一の際にも「どのような保証があるか」「いつまでに復旧が期待できるか」をクライアントへ論理的に説明できる。これは、制作会社のプロフェッショナリズムを守るための防波堤となるのだ。
稼働率99.9%の落とし穴と数字の読み解き方
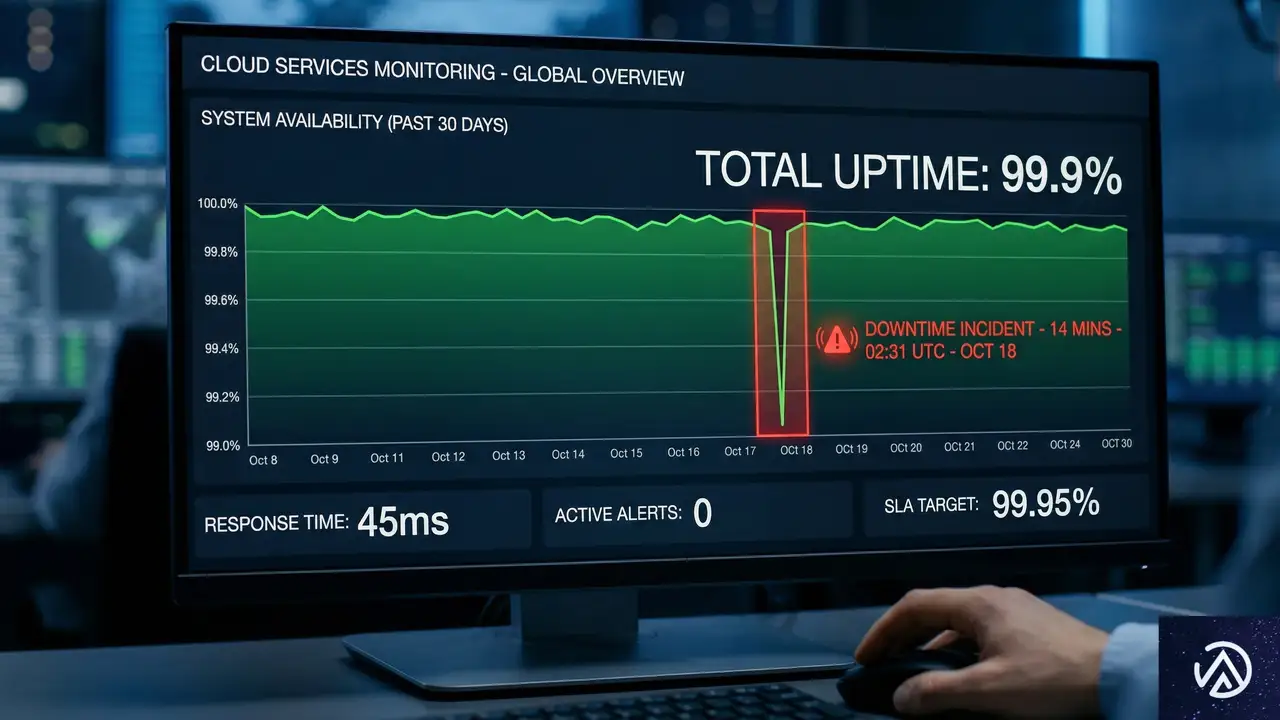
ホスティングの比較で最も頻繁に目にするのが「稼働率(Uptime)」のパーセンテージだ。一見すると99.9%も99.99%も大差ないように思えるが、年間の停止時間に換算するとその差は歴然としている。
わずか0.01%の差が年間ダウンタイムに与える影響
稼働率の数字が意味する「許容される停止時間」を整理してみよう。以下のデモ表は、各稼働率における年間の最大停止時間を示している。
この表からわかる通り、99.9%の保証では年間で1営業日近い停止が発生する可能性がある。ECサイトや広告キャンペーン中のランディングページにとって、数時間の停止は大きな機会損失につながるため、この差は無視できない。
ネットワーク層かアプリケーション層か:測定範囲の重要性
稼働率をどこで測定しているかも重要なチェックポイントだ。一部のプロバイダーは「ネットワークの稼働」のみを保証し、サーバー上のアプリケーション(WordPressなど)が正常に動作しているかどうかを保証対象外としている場合がある。
実務においては、ネットワークが生きていてもデータベース接続エラーでサイトが表示されなければ「ダウン」と同じだ。アプリケーションレベルでの稼働を監視し、保証に含めているプロバイダーの方が、Web制作の実務に即しているといえるだろう。
サポートとパフォーマンスの保証をどう評価するか
サーバーが動いていることと同じくらい重要なのが、問題が発生したときの「人の対応」と、平常時の「表示速度」だ。これらもSLAの対象となることがある。
応答時間と解決時間は別物である
サポートのSLAでよく見られるのが「初回応答時間(First Response Time)」だ。これはチケットを発行してから最初の返信が来るまでの時間を指す。しかし、ここには落とし穴がある。最初の返信が自動送信メールや「確認します」というだけの定型文であっても、応答時間はカウントされてしまうからだ。
本当に評価すべきは、問題を解決するまでのプロセスや、技術レベルの高いエンジニアに直接つながる仕組みがあるかどうかだ。24時間365日の対応はもちろん、緊急時のエスカレーションパス(上位エンジニアへの引き継ぎルート)が明確に定義されているかを確認したい。
インフラ構成がパフォーマンス保証の根拠となる
パフォーマンスに関する保証は、単なる数値目標よりも「それを実現するためのインフラ」に注目すべきだ。例えば、以下のような要素がSLAの信頼性を支える技術的根拠となる。
- 隔離されたコンテナ環境:他のサイトの負荷影響を受けない仕組み
- 自動スケーリング:急激なトラフィック増に対応できるリソース配分
- グローバルなCDN統合:物理的な距離による遅延を最小化する配信網
これらの技術が組み込まれているプロバイダーは、結果として安定したレスポンスタイムを提供できる可能性が高い。パフォーマンスの低下は直帰率の増加やSEO順位の下落を招くため、インフラの堅牢性はビジネス上の成果に直結する。
セキュリティとバックアップに関する合意事項

セキュリティ事故が起きた際、誰がどこまで責任を負うのかを明確にすることもSLAの役割だ。特にWordPressのようなCMSを利用する場合、プラットフォーム側の保護範囲を知っておく必要がある。
マルウェア除去とDDoS対策の責任範囲
多くのプロバイダーがセキュリティ対策を謳っているが、実際にサイトが改ざんされた際の「無償での復旧」までを保証しているケースは限られる。SLAの中にマルウェアの検出だけでなく、除去作業が含まれているかどうかは大きな分かれ目だ。
また、DDoS攻撃(大量のアクセスでサーバーを麻痺させる攻撃)に対するネットワークレベルの防御が標準で含まれているかも確認したい。攻撃を受けてから対策を追加するのではなく、インフラ側で常にトラフィックを監視・遮断する体制が保証されているのが理想的だ。
RTO(目標復旧時間)とRPO(目標復旧時点)の確認
バックアップは「取っていること」よりも「戻せること」が重要だ。ここで重要になるのがRTO(Recovery Time Objective / 目標復旧時間)とRPO(Recovery Point Objective / 目標復旧時点)という概念である。
- RTO:障害発生からどれだけの時間で復旧させるか(例:2時間以内)
- RPO:どの時点のデータまで戻せるか(例:1時間前のバックアップまで)
これらが明文化されているホスティングサービスは、万が一のデータ消失時にも事業継続性を担保しやすい。制作会社としては、クライアントの要件に合わせてこれらの指標をチェックする必要がある。
契約前に確認すべき「隠れた制限事項」と除外規定

SLAには必ずといっていいほど「除外規定(Exclusions)」が存在する。ここを読み飛ばすと、いざという時に保証が受けられない事態になりかねない。
最も一般的な除外項目は「計画メンテナンス」だ。サーバーのアップデートなどのために事前に通知された停止時間は、稼働率の計算から除外されるのが通例だ。ただし、その頻度や時間帯(深夜帯かどうかなど)が適切かどうかは確認しておくべきだろう。
また、アプリケーション層の不具合も除外されることが多い。例えば、特定のプラグインが原因でサイトが真っ白になった場合、それはサーバーの責任ではなく利用者の責任とみなされる。SLAがカバーするのはあくまで「ホスティング側がコントロールできる範囲」であることを理解しておく必要がある。
さらに、補償の申請方法も重要だ。稼働率を下回った場合に自動で返金(クレジット付与)されるのか、あるいは利用者側がログを添えて申請しなければならないのか。WP Mayorなどの専門メディアでも指摘されている通り、申請の手間が壁となり、実質的に補償を受けられないケースも少なくない。
独自の分析:マネージドホスティングがSLAを強化する理由
筆者の見解として、SLAの信頼性を最も高めるのは「マネージド(管理代行型)」の運用体制だ。単にサーバーを貸し出すだけのサービスとは異なり、マネージドホスティングはプラットフォーム全体を最適化し、プロアクティブ(先回り的)な監視を行う。
問題が起きてからSLAに基づいて補償を求めるよりも、問題が起きないように常にリソースを調整し、脆弱性をパッチで塞ぐ運用のほうが、結果としてWeb制作会社のコスト(対応工数)を抑えられる。SLAの数字そのものだけでなく、その数字を維持するための「運用の質」に投資するという視点が重要だ。
エージェンシーにとっては、自社のエンジニアがサーバーの保守に時間を取られるのを防ぎ、本来の業務であるクリエイティブやマーケティングに集中できる環境を作ることこそが、真のSLAの価値といえるのではないだろうか。
この記事のポイント
- SLAは単なる宣伝文句ではなく、品質未達時の救済措置を含む法的合意である
- 稼働率99.9%と99.99%の間には、年間で約8時間の停止時間の差が存在する
- サポートの評価は「返信の速さ」だけでなく「解決までの技術力」を重視すべき
- セキュリティやバックアップの保証範囲を確認し、責任の所在を明確にする
- 計画メンテナンスやユーザー起因のトラブルなど、SLAの除外規定を必ずチェックする

Google Zeroの先にある真実:AIエージェントに最適化する「エージェントSEO」の重要性
Googleからの検索流入がゼロになるという「Google Zero」の言説が、Webマーケティングの世界で波紋を広げている。しかし、真に直面している課題はトラフィックの消失ではなく、Webサイトを訪れる主役が人間から「AIエージェント」へと交代し始めている事実だ。
最新の調査データによれば、Webトラフィックの51%はすでに人間によるものではなく、ボットによる自動化されたアクセスが占めている。この劇的な変化は、従来のSEO戦略を根本から書き換える必要性を物語っている。
本記事では、AIクローラーの急増やAIエージェントによる意思決定の代行がWebサイト運営にどのような影響を与えるのかを分析する。その上で、これからの時代に求められる「エージェントSEO」の具体的な実践方法について解説していく。
「Google Zero」説の裏側とボットトラフィックの急増

SEO業界では、Googleの検索結果にAIによる回答(AI Overview)が表示されることで、Webサイトへのクリックが激減するという懸念が根強い。しかし、SEOコンサルタントのBarry Adams氏が指摘するように、主要なWebサイトへのGoogleトラフィックは世界全体で2.5%程度の減少にとどまっているとのデータもある。
一方で、サーバーログの向こう側では別の巨大な変化が起きている。人間のクリックが完全に消滅したわけではないが、訪問者の構成比率が劇的に変わっているのだ。
AIクローラーが検索エンジンを追い抜く日
Impervaの「2025 Bad Bot Report」によると、自動化されたトラフィックが10年ぶりに人間による活動を上回った。現在、全Webトラフィックの51%がボットによるものだという。これには悪意のある攻撃ボットも含まれるが、最も急速に成長しているのはAIクローラーのセグメントだ。
Cloudflareの分析によれば、AIクローラーは全クローラー・トラフィックの51.69%を占めるまでに成長し、従来の検索エンジンクローラー(34.46%)を追い越した。AIボットによるクロール活動は、前年比で15倍以上に増加している。特にOpenAIの活動は凄まじく、AIボットリクエスト全体の42.4%を占めているとされる。
クローラーとは、Webサイトの情報を収集するために自動でページを巡回するプログラムのことだ。かつてはGooglebotがその主役だったが、現在はChatGPTやClaudeなどのAIをトレーニングするためのボットが、それ以上の頻度でサイトを訪れている状況だ。
「訪問者の半分は人間ではない」という前提
この数字が意味するのは、Webサイト運営者が最適化すべき対象が「人間の読者」だけではなくなっているということだ。AIは情報を収集し、自らの知識ベースに取り込むためにサイトを訪れる。その際、人間のようにバナー広告を見たり、感情に訴えるコピーに反応したりすることはない。AIが必要としているのは、純粋なデータと論理的な構造だ。
崩壊する「コンテンツ提供と引き換えの集客」という互恵関係
これまでの検索エンジンとWebサイト運営者の間には、シンプルな取引が成立していた。サイト側が良質なコンテンツを提供し、Googleがそれをインデックス(登録)する代わりに、情報を探しているユーザーをサイトへ送り返すというモデルだ。しかし、AIの台頭はこの互恵関係を揺るがしている。
AIボットの圧倒的な「持ち去り」比率
Cloudflareが公開した「クロール数に対するリファラル(流入)の比率」は衝撃的だ。Anthropic社のClaudeBotは、1件の流入をサイトに送るために、23,951ページものクロールを行っている。OpenAIのGPTBotも、1,276ページを読み込んでようやく1人をサイトへ送る計算だ。
対照的に、従来のGooglebotはサイトの情報を読み取った後、AIシステムよりも831倍多くの訪問者をサイトに送り返している。AIボットの主な目的は「トレーニング」であり、ユーザーをサイトへ誘導することではない。情報を「取る」だけで「返さない」という、非対称な関係が鮮明になっている。
Google自身のAI化によるゼロクリックの加速
Google自体もこの流れに追随している。AIによる概要表示(AI Overview)が行われる検索クエリでは、オーガニック検索のクリック率が58〜61%低下するという調査結果がある。さらに、Googleの新しい「AIモード」では、ゼロクリック率(検索結果からどこにも遷移しない割合)が93%に達することもあるという。
また、GoogleのAIが回答の引用元として自社サービス(Google.comやYouTubeなど)を優先的に表示する傾向も強まっている。SE Rankingの調査では、AIモードの引用元の約20%がGoogle関連のプロパティで占められていた。外部サイトへのトラフィックを促すという検索エンジンの役割が、自社AIの回答精度を高めるための「データソース利用」へと変質しつつあるのだ。
次の波は「AIエージェント」による意思決定の代行

ボットトラフィックの増加は序章にすぎない。次にやってくるのは、人間に代わって調査、比較、そして購入の意思決定までを行う「AIエージェント」の普及だ。これは単なる検索の自動化ではなく、購買プロセスの構造そのものを変える可能性を秘めている。
購買プロセスの自動化とB2B市場への影響
Gartnerの予測によれば、2028年までにB2B(企業間取引)における購買活動の90%が、AIエージェントを介したものになるという。これは15兆ドルを超える支出が、AI同士のやり取りによって決定されることを意味する。AIエージェントは、調達チームのためにベンダーを調査し、スペックを比較し、最終的な候補リストを作成する。
このプロセスにおいて、AIエージェントはWebサイトの派手なヒーロー画像や、信頼感を演出するバッジには見向きもしない。彼らが読み取るのは、構造化されたデータ、技術仕様、そしてクリーンなHTMLで記述された価格表だ。人間がサイトを訪れて「なんとなく良さそうだ」と感じる前に、マシンが冷徹に候補から外してしまう可能性がある。
人間の目に触れない「訪問」の正体
AIエージェントによる「訪問」は、従来のアクセス解析ツールでは正しく計測できないことが多い。解析画面上では「滞在時間0秒のボットアクセス」として片付けられてしまうか、あるいはフィルタリングされて表示すらされない。しかし、その0秒のアクセスの裏側で、AIが数千万円規模の契約判断を行っているかもしれないのだ。
Salesforceの報告によると、2025年のサイバーウィーク(大規模セール期間)では、AIエージェントが全世界の注文の20%に影響を与え、670億ドルの売上を牽引したという。AIエージェントを活用している小売業者は、活用していない業者に比べて6倍以上の売上成長率を記録している。AIに「見つけてもらい、選んでもらう」ことの経済的価値は、すでに無視できない規模に達している。
マシンに選ばれるための「エージェントSEO」の実践

訪問者が人間からマシン(AIエージェント)へとシフトする中で、私たちは何を最適化すべきなのだろうか。それは従来の「検索順位を上げるためのSEO」とは異なるアプローチ、いわば「エージェントSEO」と呼ぶべき手法だ。
構造化データが「店舗の顔」になる
これまでの構造化データ(Schema markup)は、検索結果に星印や価格を表示させるための「おまけ」のような扱いだった。しかしAIエージェントにとっては、これが情報の主要な入り口となる。構造化データが正しく実装されていれば、AIは推測に頼ることなく、製品のスペックや価格、FAQを正確に読み取ることができる。
以下に、AIエージェントが情報を読み取りやすい構造化データ(JSON-LD)の概念を視覚化してみよう。AIは人間が見るデザインではなく、このような「整理されたデータ」をスキャンしている。
“name”: “CRM Pro”,
“price”: 5000,
“currency”: “JPY”,
“category”: “SaaS”
このデモのように、AIは視覚的なデザインを無視して、背後にあるデータの整合性をチェックする。構造化データは単なるSEOのテクニックではなく、Webサイトという店舗における「AI向けの商品棚」としての役割を担うようになる。
複雑な複合質問(コンパウンド・クエスチョン)への対応
AIエージェントは「中小企業向け CRM」といった単純なキーワードで検索しない。彼らは「月額5,000円以下で、会計ソフトと連携でき、オフライン対応のモバイルアプリがあるCRMはどれか?」といった、複数の条件が重なった複雑な質問(複合質問)を投げかける。
これに対応するには、コンテンツの作り方を変える必要がある。単にキーワードを散りばめるのではなく、具体的な仕様、互換性、価格体系、制限事項などを、明確かつ論理的に記述しなければならない。曖昧な表現を排除し、AIが「この製品は条件を満たしている」と断定できる材料を提供することが重要だ。
計測不能な領域にどう立ち向かうか

「Google Zero」論争が有害なのは、Googleからの流入数という目に見える指標だけに固執させ、その裏で起きている「計測できない価値」を無視させてしまう点にある。GA4などの一般的なアクセス解析ツールでは、AIエージェントがもたらした貢献を追跡することはほぼ不可能だ。
既存のアクセス解析の限界
これまでのWebマーケティングは、クリックからコンバージョンまでを線で結ぶことができた。しかし、AIエージェントの世界では、AIがWebサイトを数回クロールし、その情報を元にユーザーに推薦を出し、ユーザーが直接公式サイトの「購入ページ」を訪れる、あるいはAIが決済まで代行するといった経路を辿る。この場合、最初のきっかけとなったWebサイトへの貢献度は、アクセス解析上では「ノーリファラー(直接流入)」や「ボット」として埋もれてしまう。
この「測定のギャップ」を放置すると、経営層は「SEOの効果が落ちている」と判断し、予算を削ってしまうかもしれない。しかし、実際にはAIエージェントを介して大きな売上が発生している可能性がある。私たちは、クリック数以外の新しい指標――例えば「AIプラットフォームでの言及数」や「ブランド名の指名検索数」などを組み合わせた、多角的な評価軸を持つ必要がある。
今すぐ取り組むべき5つのステップ
AIエージェント時代に備えるために、Webサイト運営者が今すぐ着手すべきアクションをまとめた。これらはGoogle SEOを捨てることではなく、その上に新しいレイヤーを追加する作業だ。
- 構造化データの完全監査:製品、サービス、FAQ、組織情報などのスキーマが正確で最新かを確認する。これはAIにとっての「履歴書」である。
- 複合質問への回答コンテンツ作成:ユーザー(またはAI)が抱く具体的な条件付きの疑問に対し、表やリストを用いて明確に回答するページを用意する。
- サーバーログのモニタリング:GPTBotやClaudeBot、PerplexityBotなどのAIクローラーがどの程度の頻度で訪れているかを把握する。
- robots.txtの戦略的判断:AIへの情報提供を拒否するか、あるいはAIに選ばれるために開放するかを、技術的な設定ではなく「経営判断」として決定する。
- AI引用のトラッキング:SemrushやPerplexityなどのツールを使い、自社ブランドがAIの回答内でどのように引用されているかを定期的にチェックする。
この記事のポイント
- Webトラフィックの51%はすでにボットであり、AIクローラーの活動は前年比15倍に急増している。
- AIボットは情報を収集するだけでサイトへユーザーを返さない傾向があり、従来の互恵関係が崩壊しつつある。
- 2028年までにB2B購買の90%にAIエージェントが介在すると予測され、マシン向けの最適化が不可欠になる。
- 「エージェントSEO」の核は、正確な構造化データの実装と、複雑な条件付き質問への論理的な回答である。
- 従来のアクセス解析ではAIの貢献を測定しきれないため、クリック数以外の新しい評価指標を持つことが求められる。

WooCommerce 10.6.2リリース——WordPress 7.0対応と変動商品ブロックの不具合修正
WooCommerce 10.6.2が3月30日にリリースされた。今回のアップデートは、WordPress 7.0の正式リリースに備えた管理画面の互換性向上と、Add to Cart with Optionsブロックにおける変動商品の選択不具合修正が主な内容だ。
WooCommerce 10.6.1で部分的に修正された問題を完全に解決し、WordPressの次期メジャーバージョンに向けた安定性を確保する。ECサイト運営者は、WordPress 7.0への移行を円滑に進めるための重要なアップデートとして位置づけられる。
変動商品の属性選択不具合を完全解決
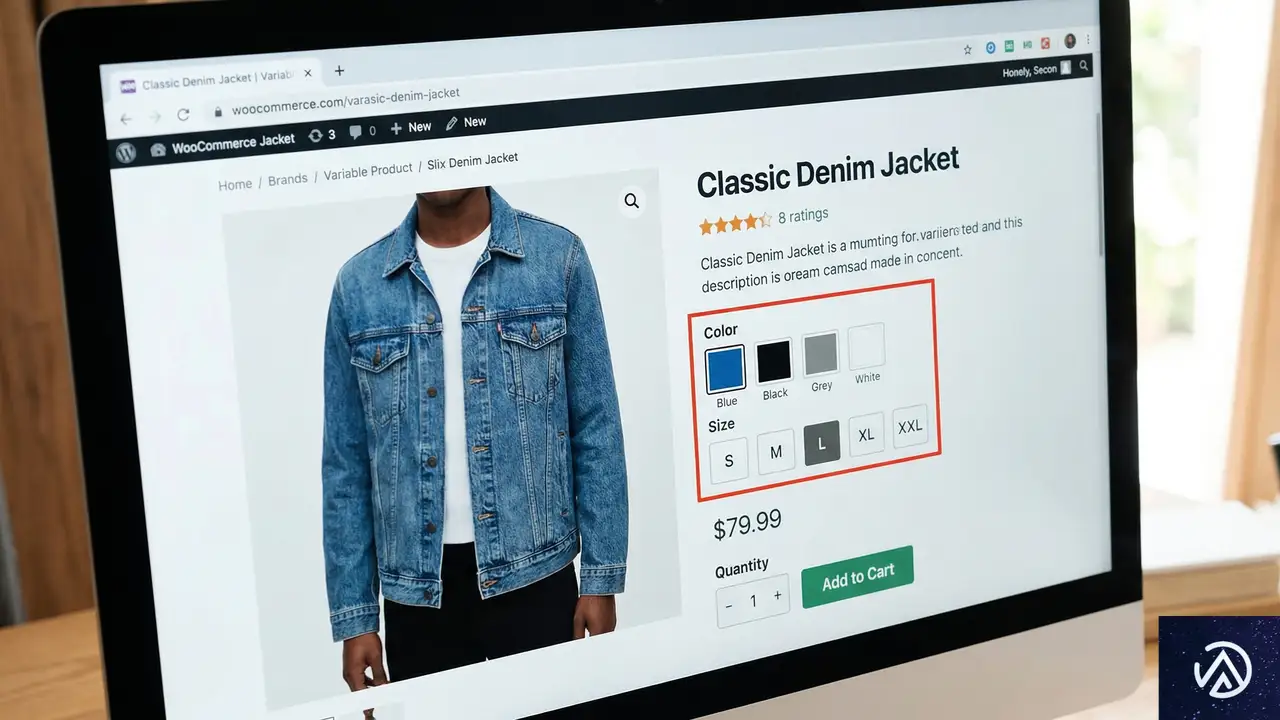
WooCommerce 10.6.2では、Add to Cart with Optionsブロックにおける変動商品の選択問題が修正された。この問題は、商品属性の名前に特殊文字が含まれている場合や、カスタムスラッグが変換後の名前と異なる場合に発生していた。
属性名とスラッグの不一致が原因
変動商品とは、色やサイズなどの属性(バリエーション)を持つ商品だ。顧客は商品ページでこれらの属性を選択し、購入する特定の商品を決定する。
問題は、属性の「表示名」と内部的に使用される「スラッグ」が一致しない場合に生じていた。例えば、表示名が「Blue/Green」でも、スラッグが「blue-green」に変換されるケースがある。Add to Cart with Optionsブロックは、以前は変換後の名前とスラッグを比較していたため、この不一致により正しい属性を選択できない不具合が発生していた。
WooCommerce 10.6.2では、比較ロジックを「表示名と表示名」を直接比較する方式に変更した。これにより、内部的なスラッグ変換の影響を受けず、顧客が画面で見ている属性名通りに選択が可能になる。
10.6.1からの継続的な改善
この修正は、WooCommerce 10.6.1で行われた部分的対応の続きとなる。開発チームはGitHubのプルリクエスト#63771を通じて、問題の根本原因を特定し、より堅牢な解決策を実装した。
変動商品を多く扱うECサイト、特にファッションや食品など多様なバリエーションを持つ業種では、この修正により顧客の商品選択体験が確実に向上する。属性選択が正しく機能しないことは、直帰率の上昇やカート放棄率の増加につながるため、EC運営者にとっては重要な改善点だ。
WordPress 7.0への対応を強化
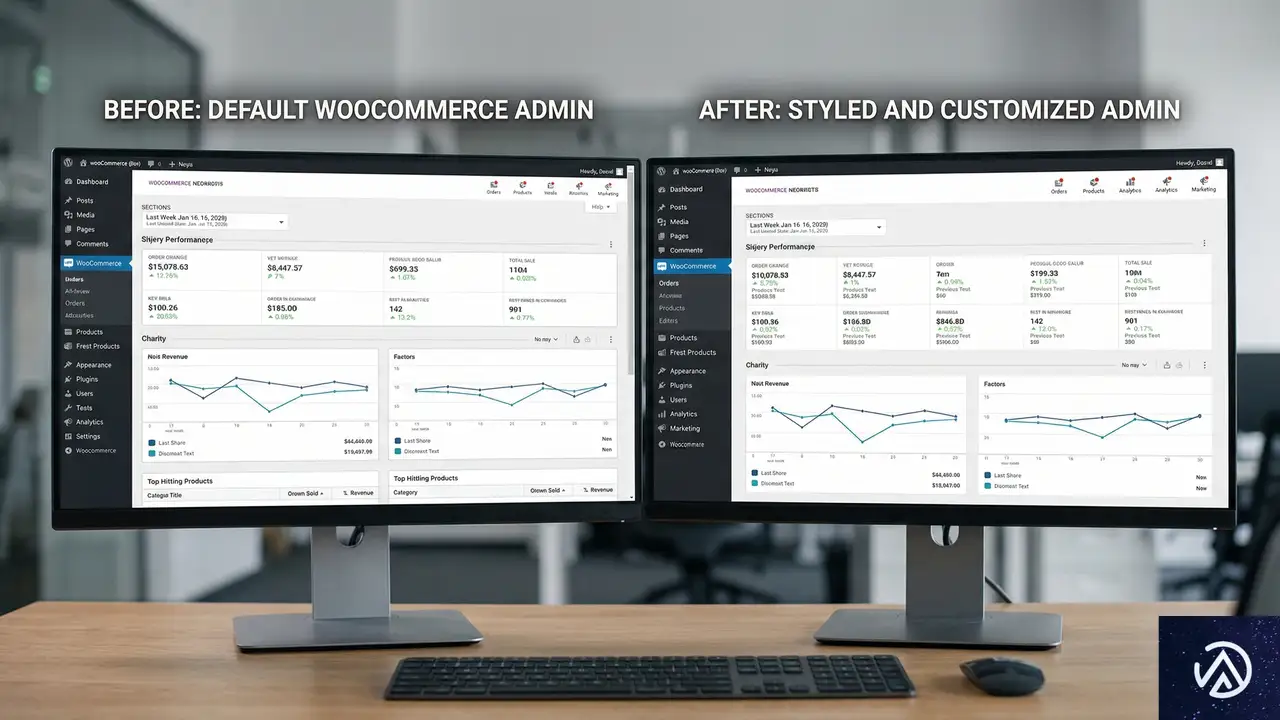
WooCommerce 10.6.2のもう一つの主要なテーマは、WordPress 7.0との互換性確保だ。WordPressのコアが更新されると、管理画面のスタイルやコンポーネントの挙動が変化する。これに伴い、WooCommerceの管理画面でも様々な表示上の問題が発生していた。
管理画面の表示不具合を一括修正
修正された問題は多岐にわたる。分析テーブルやダッシュボードカードに余計なパディング(余白)が表示される問題、小さな画面でアクションボタンが不自然に折り返される問題、注文管理画面全体での配置やサイズの不整合などが含まれる。
特に注目すべきは、アクティビティパネルでの無限再レンダリングループの修正だ。この問題は、特定の条件下で管理画面の一部が応答しなくなる原因となっていた。WordPress 7.0の新しいReactレンダリングエンジンとの相互作用で発生していたと見られる。
メタボックスとコントロール要素の表示改善
メタボックスとは、WordPressの編集画面で投稿や商品の追加情報を入力するボックスのことだ。WooCommerceでは商品データや注文情報の入力に多用される。WordPress 7.0ではこれらのUIコンポーネントのスタイルが更新されたため、WooCommerce側でも調整が必要だった。
複数のプルリクエスト(#63873、#63881、#63836など)を通じて、管理画面全体のスタイル一貫性が確保された。これにより、商品登録や注文処理といった日常業務におけるユーザー体験が、WordPress 7.0環境下でも安定して維持される。
ECサイト運営者が取るべきアクション

WooCommerce 10.6.2はメンテナンスリリースであり、新機能は含まれない。その性質上、ECサイト運営者は速やかな適用を検討すべきだ。
ステージング環境での事前テストが必須
まず、本番環境に直接アップデートする前に、ステージング環境(本番環境のコピー)でテストを実施する。WordPress 7.0がまだ正式リリース前であっても、WooCommerce 10.6.2の互換性修正が既存のWordPress 6.x環境に悪影響を及ぼさないかを確認する必要がある。
テストの重点項目は3つある。1つ目は、変動商品を持つ商品ページで、Add to Cart with Optionsブロックが正しく動作するか。2つ目は、管理画面の分析レポートや注文一覧などの表示が崩れていないか。3つ目は、カスタマイズしたテーマやプラグインとの互換性だ。
WordPress 7.0への移行計画と連動
WooCommerce 10.6.2の適用は、WordPress 7.0への移行計画と連動させるべきだ。WordPressのメジャーバージョンアップデートは、テーマやプラグインの互換性に大きな影響を与える可能性がある。
理想的な順序は、まずWooCommerceを10.6.2に更新し、問題がないことを確認した後でWordPressを7.0にアップデートすることだ。これにより、問題が発生した際の原因切り分けが容易になる。WooCommerce開発チームは、WordPress 7.0の正式リリースに先立ち、主要な互換性問題を解消した形だ。
開発者コミュニティからの貢献
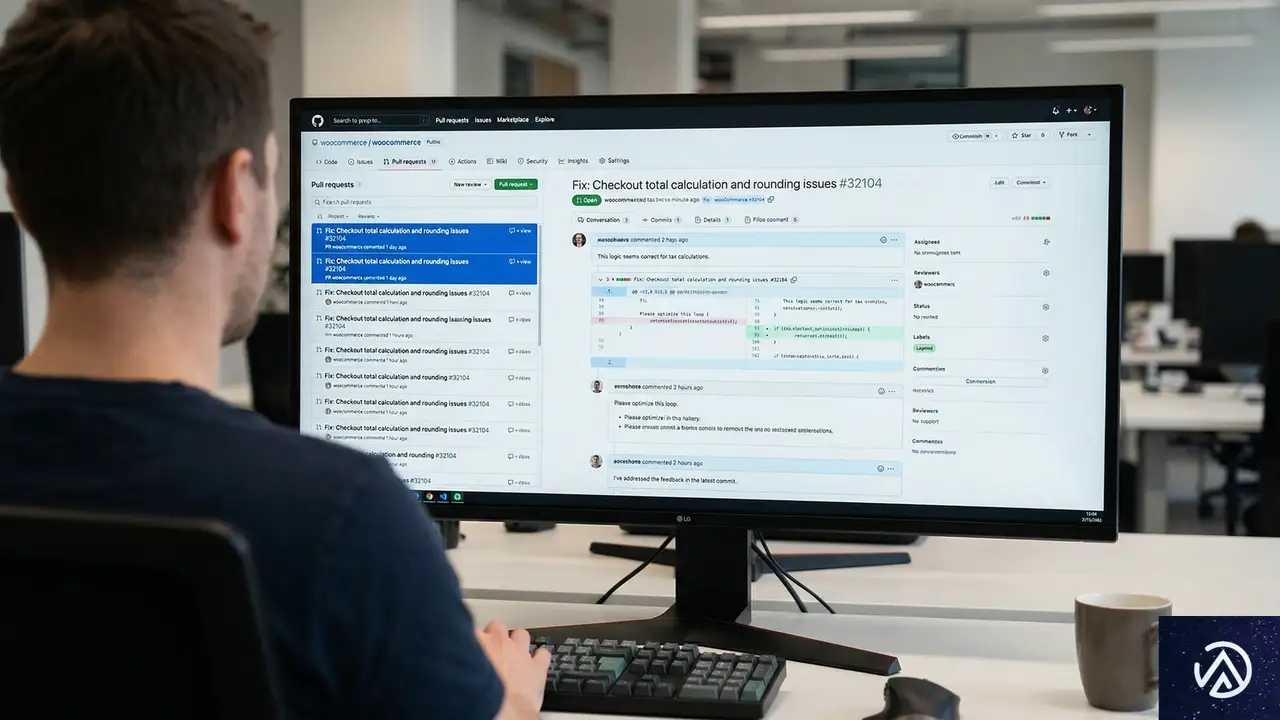
今回のリリースには、GitHub上で報告された多数のイシューとプルリクエストが反映されている。オープンソースプロジェクトとしてのWooCommerceは、世界中の開発者やユーザーからのフィードバックによって改善が続けられている。
GitHubを中心とした協働開発
修正内容はすべてGitHubのプルリクエストで公開され、コードレビューを経て本体にマージされた。例えば変動商品の問題は#63771で、WordPress 7.0対応の様々な修正は#63873や#63881など複数のPRで追跡できる。
この透明性の高い開発プロセスは、ユーザーが問題を理解し、必要に応じて一時的な修正を自身で適用することを可能にする。また、特定の不具合が自分のサイトにどのような影響を与えるかを事前に評価する材料にもなる。
今後のリリースに向けた準備
WooCommerce 10.6.2は、WordPress 7.0という大きな環境変化の前に行われた重要な調整リリースと位置づけられる。開発チームは、コアとなるEC機能の安定性を最優先し、新機能の追加は次の機会に委ねた形だ。
ECサイト運営者は、このリリースを通じて基盤の堅牢性が強化されたと捉えることができる。特に変動商品の取引が多いサイトや、管理画面を頻繁に利用する運営者にとっては、業務効率と顧客体験の両面でメリットが大きい。
この記事のポイント
- WooCommerce 10.6.2は、WordPress 7.0正式リリースに先立つ互換性向上リリースである。
- Add to Cart with Optionsブロックで、特殊文字を含む属性名の変動商品が正しく選択できるよう修正された。
- 管理画面の分析レポート、注文一覧、アクティビティパネルなど、多数のUI表示不具合が解消されている。
- 本番環境適用前には、必ずステージング環境で表示や機能のテストを行うことが推奨される。
- 修正内容はGitHubのプルリクエストで公開されており、開発者や上級ユーザーは詳細を確認できる。