

Cloudflareが企業のAIコスト爆発を制御、AI Gatewayに利用上限を搭載
企業におけるAI導入の最大の壁はもはや技術力ではない。管理不能なコストの爆発だ。2026年6月5日、Cloudflareは自社のAI Gatewayに新たな「利用上限」機能を搭載し、この課題への直接的な解決策を提示した。
多くの企業では全エンジニアに最先端モデルのAPIキーを共有している。月末に届く高額な請求書を見て、経理とCTOが頭を抱える。誰が何に使ったのか全く分からないのだ。Cloudflareの今回の発表は、まさにこの無法地帯に統制をもたらすものだ。
併せて発表されたアイデンティティベースの予算管理は、Cloudflare Accessと既存のIdP(Identity Provider / アイデンティティプロバイダー)を組み合わせ、個人やチーム単位での正確なコスト帰属を実現する。
なぜAIコストは制御不能に陥るのか
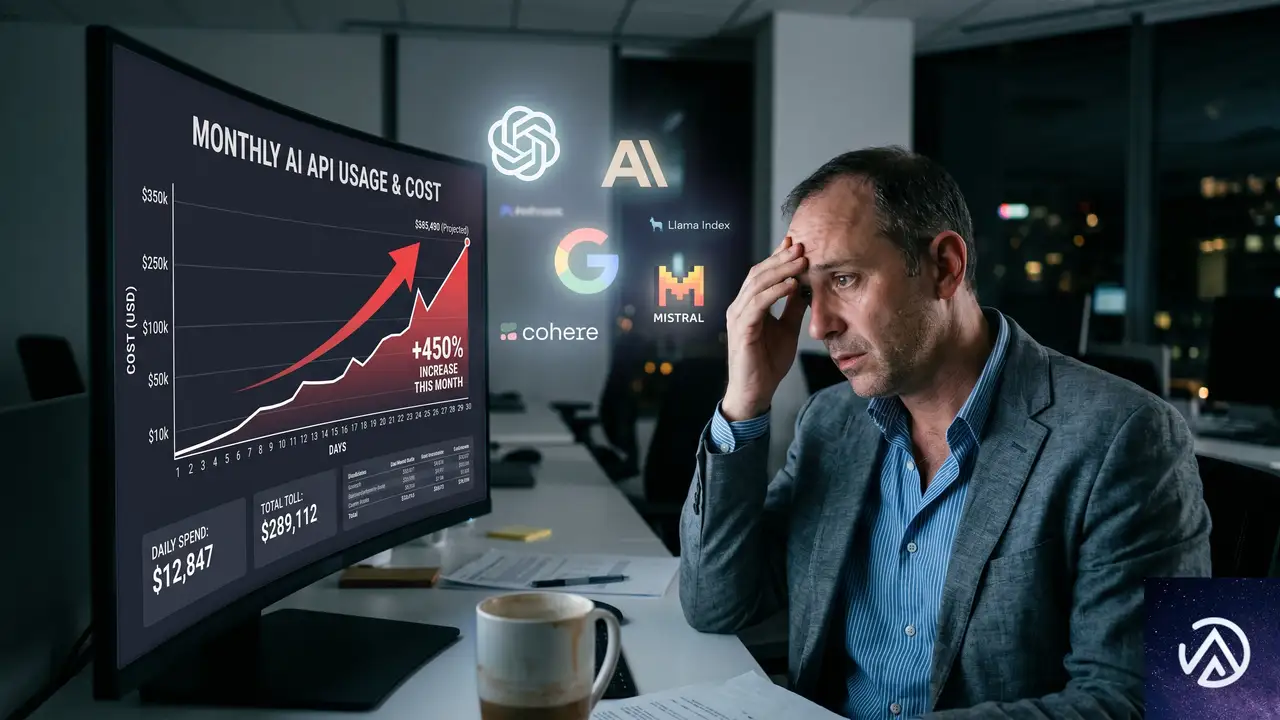
AI導入を進める企業で、まったく同じストーリーが繰り返されている。現場には「まずは最速でAIを使え。勘定は後でなんとかする」という号令が飛ぶ。これは大抵の場合うまくいく。実際、AIを積極的に取り入れたチームの生産性は飛躍的に向上している。しかし、その代償は安くない。月末に経理がAPI利用料の請求書を開くと、にわかには信じがたい桁の数字が目に飛び込んでくるのだ。
Cloudflareのブログ記事でも、この構図は明確に描写されている。社内で共有されているAPIキーでは、コストの発生源を追跡できない。機械学習チームの新規パイプライン構築が原因なのか、インターンがメールの仕分けに高額なClaude Opusを使い倒したのか、あるいはCI/CDジョブが週末のうちに何千万トークンも消費したのか、誰にも分からない。
問題の本質は、指標と制御の欠如により、合理的な判断が歪められてしまうことにある。予算も可視化もなければ、常に最も強力で高価なモデルを選ぶのが個々のエンジニアにとっては合理的な行動となる。コードレビューの要約に、大規模なアーキテクチャ再設計と同じモデルは必要ない。ログパーサーに、顧客向けコンテンツ生成と同じモデルは不要だ。しかし、現場には適切な道具を選ぶ動機も手段も存在しなかったのである。
利用上限機能を深掘りする
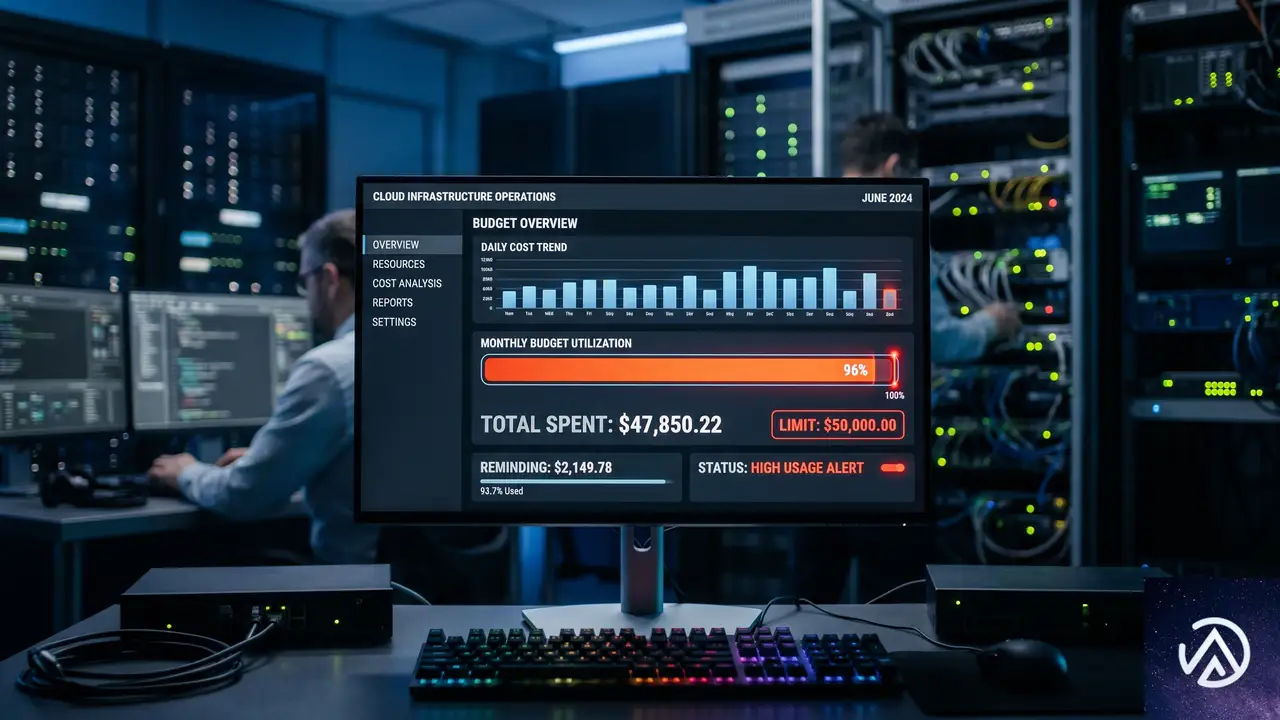
中核となる仕組み
AI GatewayはアプリケーションとAIプロバイダーの中継点として機能する。OpenAIやAnthropicへの直接APIコールを、まずこのゲートウェイを経由させる仕組みだ。これにより、リクエストの永続化ログ、キャッシュ、レート制限、リトライ、分析といった恩恵が得られていた。しかし、従来は「誰がいくら使ったか」の正確なトラッキングに限界があった。
ここに新たに導入された利用上限機能は、真のコスト統制を実現する。トークンベースではなく、ドルベースの予算で累積支出を追跡する点が実務的だ。制限のスコープは、モデル、プロバイダー、ユーザーやチームといった管理者定義のカスタム属性の任意の組み合わせで設定できる。期間も固定(月初リセットや月曜リセット)かローリング(直近N日間)かを選べ、日次、週次、月次での運用が可能だ。
予算超過時の現実的な選択肢
最も重要なポイントは、上限到達時の処理だろう。デフォルトではリクエストをブロックする。だが、ワークフローを完全に止めないための工夫として、ダイナミックルートと連携したフォールバックモデルへの切り替えが可能だ。これなら、最大予算額に達してもエンジニアの作業が完全に停止することはない。
この機能群は本日から全プランの全ユーザーにオープンベータとして提供されており、ダッシュボードかAPI経由で即座に設定できる。
アイデンティティ駆動の予算管理がもたらす透明性

利用上限機能と同時に、Cloudflareはアイデンティティベースの予算とポリシーを限定ベータとして発表した。利用上限がモデルやカスタム属性による制御であるのに対し、こちらは実在の個人とチームに紐づく。アプリケーション側でメタデータを渡す必要はなく、信頼性の低いヘッダー情報に頼る必要もない。
Cloudflare Accessとの統合が生む確実な帰属
AI GatewayをCloudflare Accessと連携させると、リクエストの送信者が誰かを確実に特定できる。単なるアカウント単位ではなく、個々の従業員、IdPグループ、サービス単位だ。Cloudflare社内では既にこの仕組みを実践しており、全従業員がAIツールを利用する中で月間数十億トークンが流れるトラフィックを可視化している。
仕組みはシンプルだ。従業員がCloudflare Access経由で認証されると、そのアイデンティティがJWT(JSON Web Token)から抽出され、AI Gatewayのリクエストにメタデータとして添付される。これにより、ユーザー単位のトークン消費、チーム単位の使用量内訳、組織全体のコスト帰属が一元管理できるようになる。
CI/CDパイプラインへの適用とボット予算
この機能は人間だけのものではない。Accessサービスアカウントを利用すれば、自律的なエージェントやCI/CDパイプラインにも名前付きのIDを付与できる。コードレビューボットが今週500万トークンを消費し、ドキュメント生成器が50万トークンだった、といった詳細が手に取るように分かる。あるエージェントが制御不能に陥ったとしても、他のエージェントに影響を与えることなく個別に予算ポリシーを適用できるのだ。
Cloudflare自身、全社でこのスタックを運用した経験に基づいて本機能を公開した。自社で構築したものを他社もゼロから作る必要はない、という明快なスタンスである。
次の段階はコスト最適化の自動化
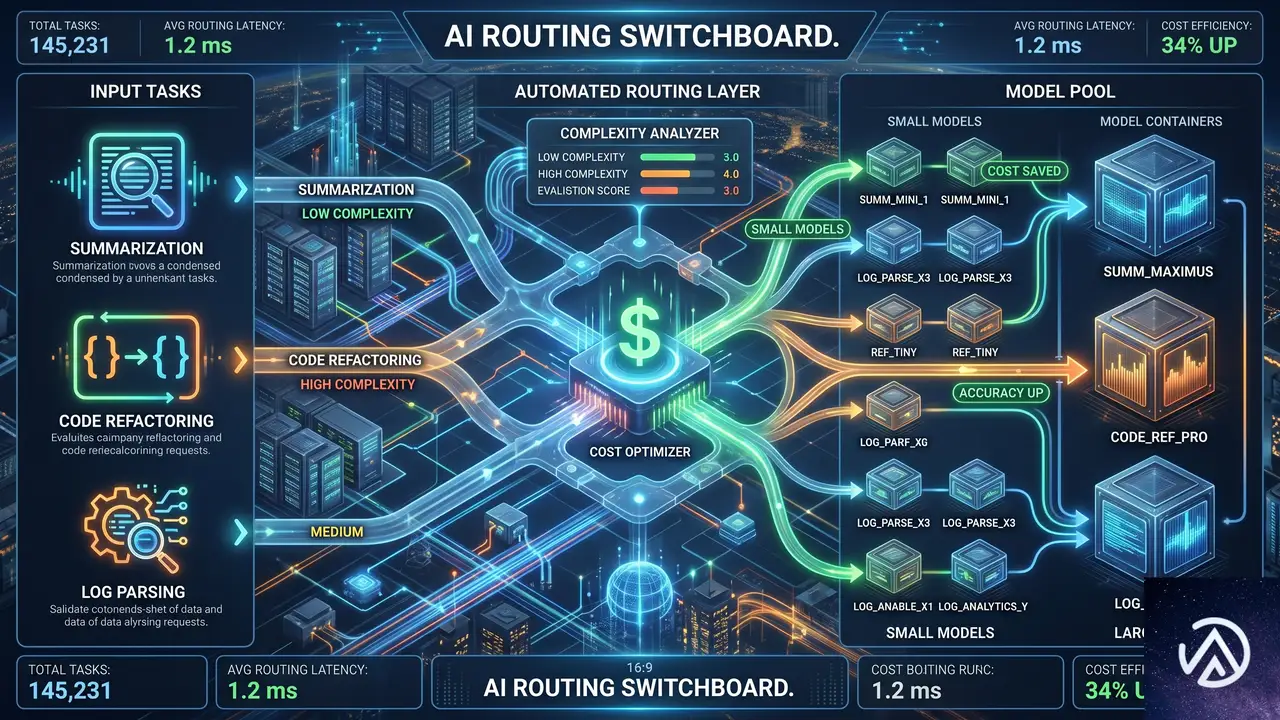
予算を設定し可視化することは、第一段階に過ぎない。次の課題は、限られた予算で最大の成果をどう引き出すかだ。現実には、すべてのリクエストに最先端モデルは不要である。要約タスクはより小さな安価なモデルでも品質を損なわずに実行できる。一方、大規模なコードリファクタリングには最新鋭のモデルが必要だ。しかし、制御がなければ人は常に最も高機能なモデルへ流れてしまう。
この問題に対し、Cloudflareはタスクベースのインテリジェントルーティングを鋭意開発中であると明かした。リクエストを分析し、最もコスト効率の良い結果を導くモデルへ自動的にルーティングする機能だ。詳細はデベロッパードキュメントとチェンジログで追って発表される。
この記事のポイント
- Cloudflare AI Gatewayにドル建ての利用上限機能が全プラン向けに登場した
- 上限到達時はリクエストをブロックするか、より安価なフォールバックモデルに自動で切り替えられる
- 限定ベータのアイデンティティベース予算は、個人やチーム単位で正確なコスト管理を実現する
- これらの機能はCloudflareが自社の大規模AI運用で実証した手法を外部化したものである
- 今後はタスクの複雑さに応じて最適なモデルへ自動ルーティングする機能の開発が予定されている

Amazon Cognitoがマルチリージョンレプリケーションに対応、耐障害性向上とCMKサポートの詳細
AWSがAmazon Cognitoにマルチリージョンレプリケーション機能を追加した。ユーザーデータとM2M(Machine-to-Machine)シークレットを別のAWSリージョンに自動同期し、認証基盤の耐障害性を高める。あわせてカスタマーマネージドキー(CMK)による暗号化制御もサポートされた。
これまでマルチリージョンでの整合性維持には、エンジニアリングチームが手動で複製ソリューションを構築・運用する必要があった。今回のアップデートで、Cognitoが自動的にセカンダリリージョンへデータを複製し、リージョン障害時でも認証を継続できるようになる。
レプリケーションは一方向(プライマリ→セカンダリ)で動作し、プライマリリージョンの障害発生時にはセカンダリで認証処理を受け持つ。セッション継続性も担保され、既存ユーザーは資格情報の再設定なしでサインインを続けられる。
従来は手動レプリケーションに依存し、データ不整合やセキュリティリスクがつきまとっていた。新機能により、複製にかかる運用負荷を大幅に削減しつつ、認証の継続性を確保できる。
Cognitoマルチリージョンレプリケーションとは何か
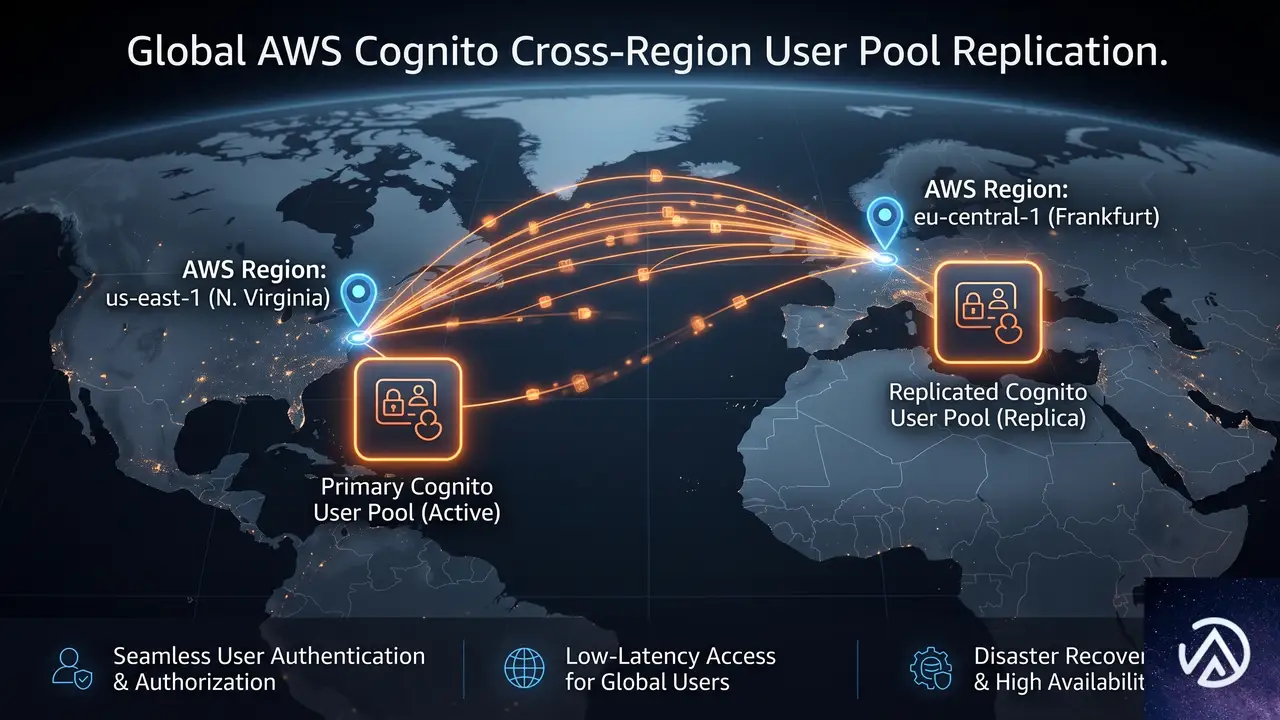
マルチリージョンレプリケーションは、Amazon CognitoがユーザーデータとM2Mシークレットの複製を自動管理する機能だ。プライマリリージョンからユーザーが選択したセカンダリリージョンへ、一方向でデータを同期する。
カバーされるデータの範囲と動作モード
複製の対象はユーザープロファイル、資格情報、ユーザープールの設定全体に及ぶ。セカンダリリージョンは読み取り専用モードで動作し、認証機能の維持に特化する。つまり、新規ユーザー登録やプロファイル更新といった書き込み操作はフェイルオーバー中には行えない。
この設計により、すべての認証方式(ソーシャルプロバイダ経由のフェデレーテッドサインイン、SAML、OIDC連携、API認可フロー)がサポートされる。対人認証だけでなく、バックエンドサービス間のM2M通信もレプリケーションの恩恵を受けられる点がポイントだ。
セッション継続性とトークンの相互認識
レプリケーション済みのユーザープールでは、プライマリ・セカンダリの双方が、どちらのリージョンで発行されたアクセストークンも有効とみなす。そのため、アクティブなセッションはリージョン切り替え前後を通じて中断されない。
この仕組みは、エンドユーザーにとって「裏側でリージョンが切り替わった」ことをまったく意識させずに済むという、実運用上の大きな利点になる。パスワードリセットの強制や再認証といった、ユーザー体験を損なう事態を回避できるわけだ。
CMKサポートで変わる暗号化の主導権

マルチリージョンレプリケーションの利用には、AWS KMS(Key Management Service)上のマルチリージョンカスタマーマネージドキー(CMK)が必須となる。CMKはユーザーデータの保存時暗号化に一貫性をもたらし、利用者側に暗号化戦略の主導権を与える。
CMKの利用は、レプリケーション機能とは独立して提供される。つまり、単一リージョンのユーザープールでもCMKによる暗号化制御は利用可能だ。医療や金融サービスなど、規制の厳しい業界ではとくに重要な選択肢となる。
3ステップで始めるレプリケーション設定
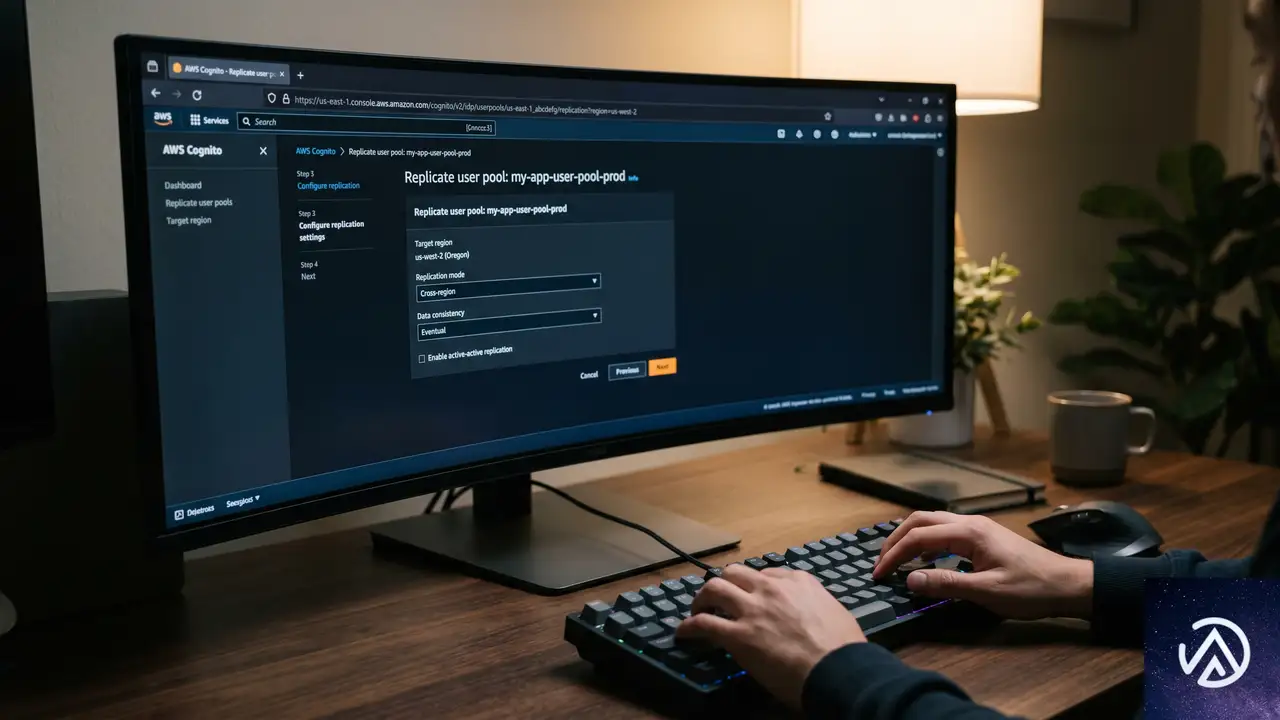
AWS News Blogの記事では、us-west-2(オレゴン)の既存ユーザープールをus-east-1(バージニア北部)に複製するデモが紹介されている。設定は管理コンソールから3つのステップで完了する。
STEP 2のOIDCエンドポイント更新は、クライアントアプリケーション側の必須対応となる。サーバーサイドアプリは再デプロイ、モバイルアプリはストアへの更新申請が必要だ。この変更を怠ると、旧エンドポイントへのリクエストが正しくルーティングされず、認証障害を引き起こす。
追加で必要な設定と注意点
レプリケーション設定の完了後も、いくつかの付随リソースは手動でセカンダリリージョンに展開する必要がある。具体的には、カスタム認証フローに使うLambda関数、SMSやメール通知の設定、ログストリーミング、AWS WAFの構成が該当する。
AWS News Blogの記事では、これらの追加設定を計画的に実施するようコンソール上でトラッキングできる点も紹介されている。フェイルオーバー前に抜け漏れを防ぐ仕掛けとして有効だ。
フェイルオーバー運用とヘルスチェックの設計
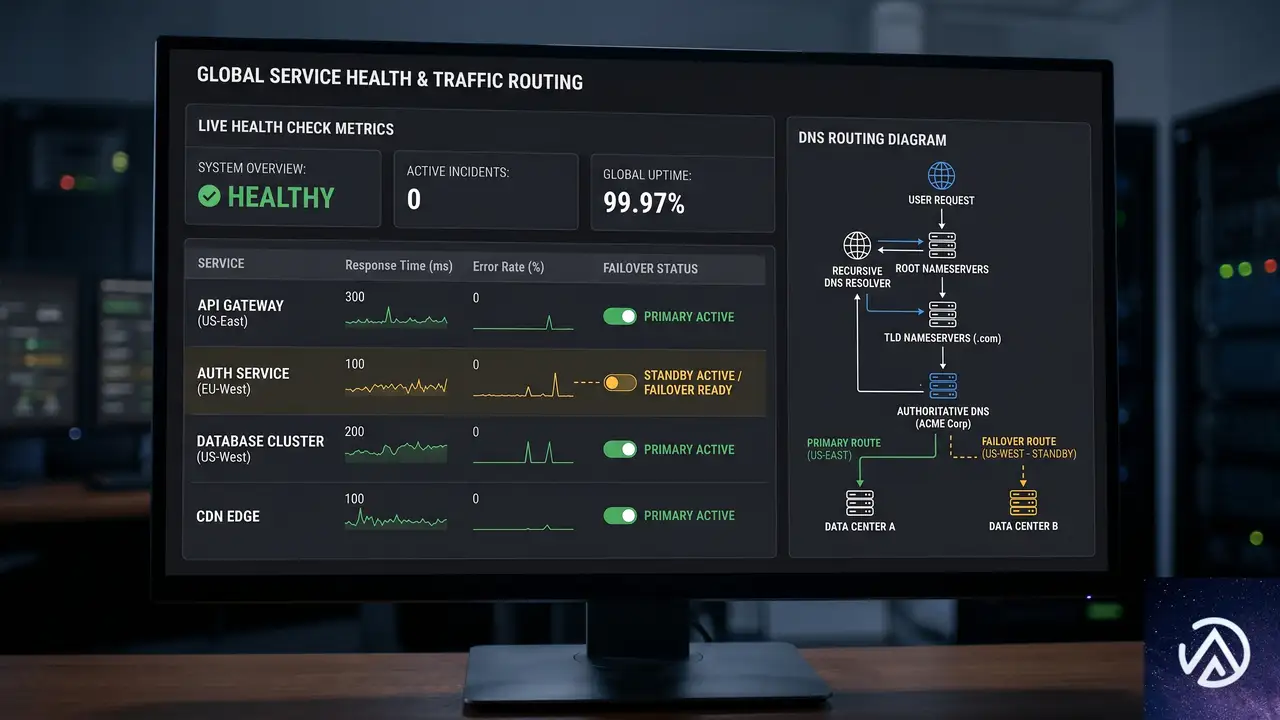
プライマリとセカンダリの両エンドポイントは常時アクティブで、いつでもトラフィックを受け入れ可能な状態にある。フェイルオーバーの判断と実行は、アプリケーションの要件に合わせて利用者側が設計する形だ。
ヘルスチェックでは、エラーレートやレイテンシのパターン、サービスアラートを監視し、事前定義した基準を満たした場合にDNSの切り替えでセカンダリへトラフィックを誘導する。オフピーク時間帯に少量のトラフィックをセカンダリに流し、認証が期待通り動作するか検証しておくことが推奨されている。
カスタムドメインでのマネージドログインやフェデレーションを利用している場合、Amazon Route 53のヘルスチェックIDをCognitoに提供することで、トラフィックルーティング機能を組み込むこともできる。これによりDNSレベルでの自動切り替えが容易になる。
料金体系と利用可能リージョン

マルチリージョンレプリケーションは、EssentialsティアおよびPlusティアのアドオン機能として提供される。料金は認証の種類によって異なる。
利用可能リージョンは、米国東部(オハイオ、バージニア北部)、米国西部(北カリフォルニア、オレゴン)、アジアパシフィック(ムンバイ、ソウル、シンガポール、シドニー、東京)、カナダ(中部)、欧州(フランクフルト、アイルランド、ロンドン、パリ、ストックホルム)、南米(サンパウロ)となっている。これらのリージョンはソース・デスティネーションのどちらとしても使用可能だ。
CMKサポートの提供リージョンはさらに広く、アフリカ(ケープタウン)、アジアパシフィック(香港、ハイデラバード、ジャカルタ、マレーシア、メルボルン、ニュージーランド、大阪など)や、イスラエル(テルアビブ)、メキシコ(中部)、AWS GovCloudもカバーされている。
この記事のポイント
- Amazon Cognitoにマルチリージョンレプリケーション機能が追加され、ユーザーデータとM2Mシークレットの自動同期が可能になった
- レプリケーションにはAWS KMSのマルチリージョンCMKが必須で、暗号化制御の主導権を利用者側に与える
- 設定は3ステップで完了するが、OIDCエンドポイント変更に伴うアプリ側の対応が必須となる
- フェイルオーバー時のセッション継続性が担保され、エンドユーザーはパスワード再設定なしで認証を継続できる
- 料金はアドオン形式で、ユーザー認証はMAUあたりの課金、M2M認証はトークンボリュームに対する30%追加となる

CSSの@functionルール入門。カスタム関数でスタイルを動的に管理
CSSに@functionというルールが導入されつつある。これはCSSで独自の関数を定義し、引数を受け取り、複雑な計算や条件分岐を経て値を返す仕組みだ。Sassの@mixinや@functionに似ているが、プリプロセッサを介さずにブラウザが直接解釈する点が新しい。
CSS-Tricksの記事によると、この機能は「CSS Custom Functions and Mixins Module Level 1」仕様の一部であり、カスタムプロパティ(変数)をさらに動的にした存在として位置づけられる。2026年6月現在は実験的機能だが、Chromeなど一部ブラウザでプレビューが始まっている。
本記事では@functionの基本構文、引数の扱い方、型チェック、カスケーディング、そして使用時の注意点までを整理する。
@functionとは何か、なぜ必要なのか

これまでCSSで動的な値を扱うにはカスタムプロパティ(--name)とcalc()の組み合わせが主だった。しかしcalc()だけでは条件分岐や複数ステップの演算が難しく、複雑な処理はSassに頼っていた。
@functionはこのギャップを埋める。CSSネイティブで「関数」を定義できるようになり、引数のバリデーション、デフォルト値、型チェック、メディアクエリに基づく分岐までを同一のスタイルシート内で完結させられる。
具体的には、色の透明度を動的に変えたり、画面幅に応じてフォントサイズを切り替えたり、複数の値をリストで受け取って最大値や最小値を計算したりといった処理が、プリプロセッサなしで可能になる。
このデモが示すように、@functionは単なる短縮記法ではなく、ブラウザのレンダリングエンジンが直接解釈するため、将来はパフォーマンス面でも恩恵が出ると期待されている。
基本構文を分解する
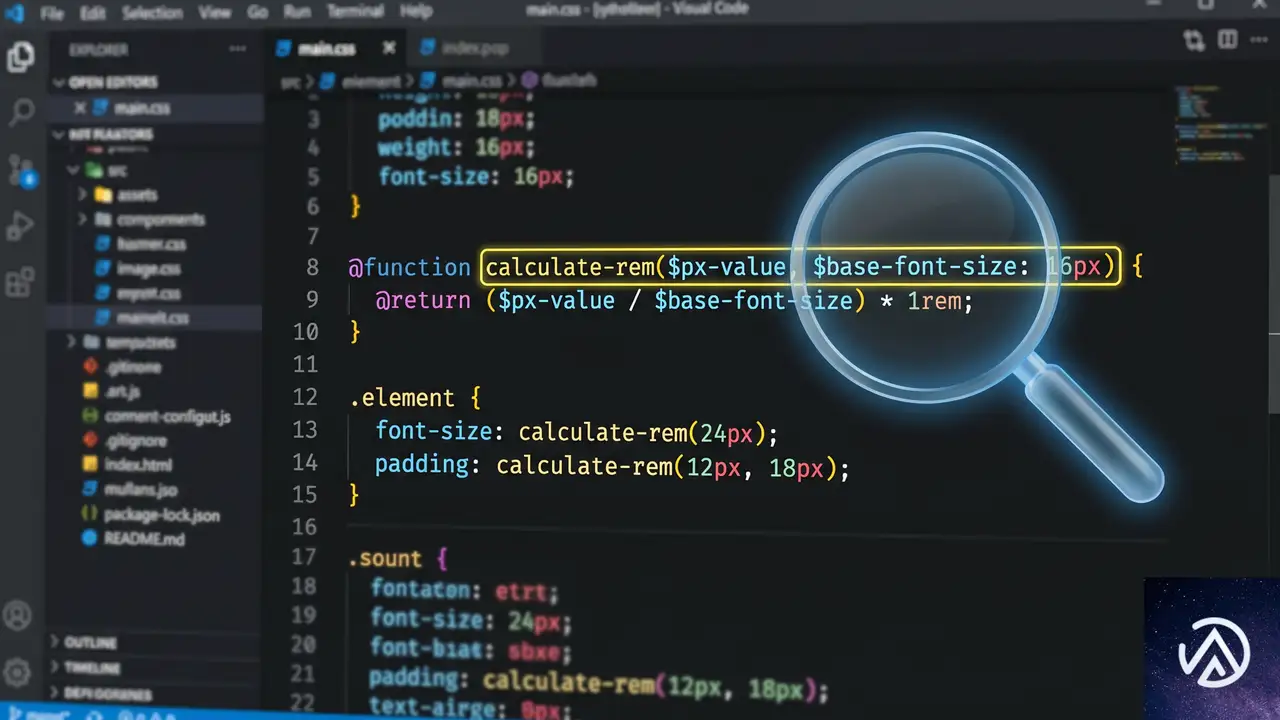
関数の定義とresult記述子
@functionの基本形は以下のようになる。関数名はカスタムプロパティ同様、ダッシュ2つで始める必要がある。
@function --half(--size <length>) {
result: calc(var(--size) / 2);
}この例では--sizeという引数に<length>型を指定し、受け取った値を2で割った結果を返している。使用時は--half(20px)のように呼び出し、10pxが解決値となる。
result記述子は関数の戻り値を定義する必須要素だ。もしresultを書かないと、関数は常に「保証無効値(guaranteed invalid value)」を返し、実質的に機能しない。
returnsによる出力型の指定
returnsキーワードを使うと、関数が返す値の型を明示できる。これはバリデーションに役立つ。
@function --progression(--current <number>, --total <number>) returns <percentage> {
result: calc(var(--current) / var(--total) * 100%);
}上記では引数2つを数値型で受け取り、パーセンテージ型を返すことを宣言している。returnsを省略するとtype(*)相当となり、任意の型を受け入れる。
こうした型チェックは大規模なコードベースでバグの早期発見に寄与する。JavaScriptのTypeScriptのように、CSSでも型安全性を確保できるわけだ。
複数型の許容とリスト引数
引数に複数の型を許容したい場合はtype()と|を使う。
@function --transparent(--color <color>, --alpha type(<number> | <percentage>));さらに、カンマ区切りで複数の値を1つの引数として受け取りたい場合、型の後ろに#を付与する。呼び出し側は波括弧{}で値を囲む。
@function --get-range(--list <length>#, --n <length>) {
result: calc(max(var(--list)) - min(var(--list)) + var(--n));
}
div {
padding-block: --get-range({10px, 100px, 50px, 25px}, 200px); /* 290px */
}これはグラフのレンジ計算や、複数のスペーシング値から最適なマージンを導く際に便利だろう。
カスケードと条件分岐を活用する
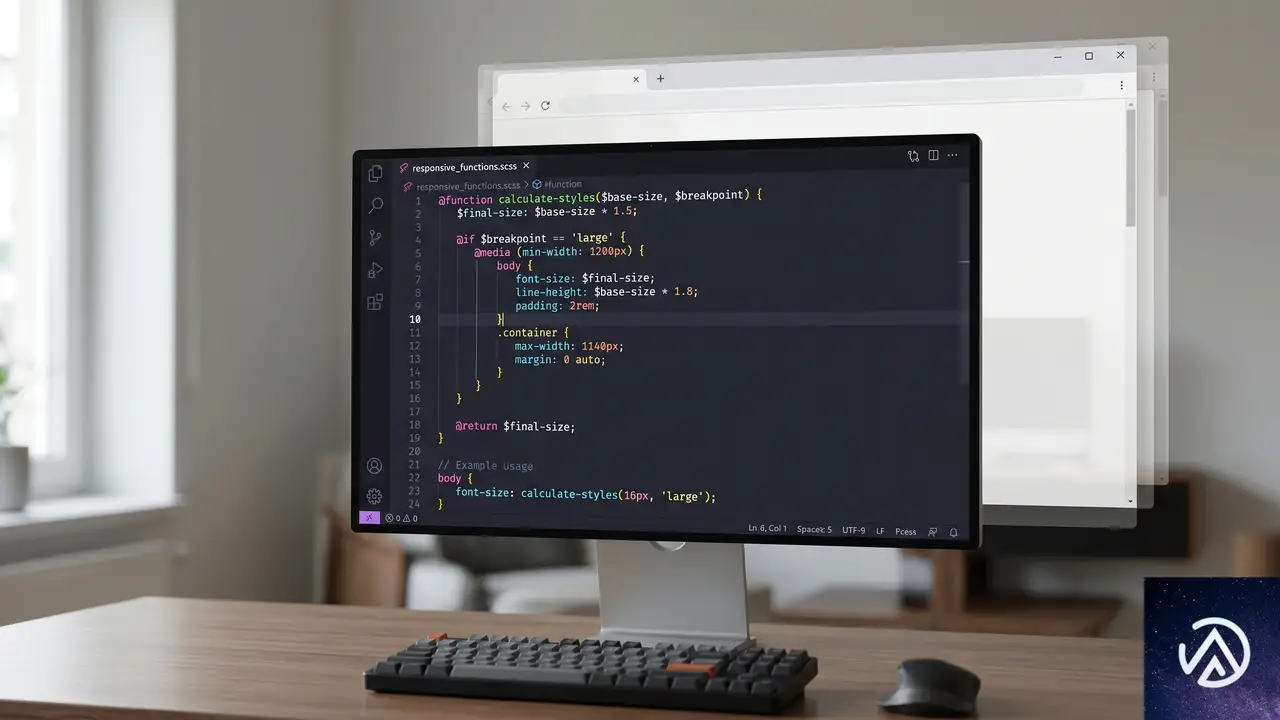
@functionのresultはCSSカスケードのルールに従う。つまり、複数のresultを記述した場合、最後にマッチした有効な値が採用される。
この性質を利用すれば、@mediaや@container、@supportsといった条件付きグループルールと組み合わせて、レスポンシブな値を関数内で完結できる。
@function --suitable-font-size() returns <length> {
result: 16px;
@media (width > 1000px) {
result: 20px;
}
}
body {
font-size: --suitable-font-size();
}この例では画面幅1000px以下なら16px、超えれば20pxを返す。従来はメディアクエリをスタイル宣言側で何度も書く必要があったが、関数に集約できるため保守性が向上する。
ただし、カスケードの「後勝ち」ルールには注意が必要だ。result: 16px;を@mediaブロックより後に書くと、メディアクエリの結果に関わらず常に16pxが返る。記述順序を誤ると意図しない挙動になる。
ローカルスコープのカスタムプロパティ
@function内で定義したカスタムプロパティは、その関数内でのみ有効なローカルスコープとなる。グローバルに漏れ出さないため、命名の衝突を気にせず使える。
@function --spacing-scale(--multiplier) {
--base-unit: 8px;
result: calc(var(--base-unit) * var(--multiplier));
}ここで定義された--base-unitは--spacing-scaleの外部からは参照できない。大規模なCSS設計で名前空間の汚染を防ぐ手段として有効だ。
関数のネスト
ある@functionの中で別の@functionを呼び出すことも可能だ。これにより、単一責務の小さな関数を組み合わせて複雑な計算を構築できる。
@function --square(--n) {
result: calc(var(--n) * var(--n));
}
@function --circle-area(--radius) {
--pi: 3.14159;
result: calc(var(--pi) * --square(var(--radius)));
}
.blob {
width: calc(--circle-area(10) * 1px); /* 314.159px */
}このネスト構造のおかげで、関数をレゴブロックのように組み立てられる。Sassで培われたモジュール設計の考え方を、そのままネイティブCSSに持ち込める未来が見える。
使用上の制約と注意点

副作用の禁止
@functionは値を返すことだけが許されており、プロパティの変更や複数宣言の生成といった副作用は起こせない。これは関数型プログラミングの「純粋関数」に近い制約だ。
もし複数行のCSSプロパティをまとめて出力したい場合は、仕様策定中の@mixinルールを待つ必要がある。@functionと@mixinが揃えば、Sassの主要機能がCSSネイティブで再現されることになる。
循環依存の厳格な防止
CSSは循環参照に極めて厳しい。関数Aが関数Bを呼び、関数Bが関数Aを呼ぶような構造はブラウザが即座に検出し、両方の関数を無効化する。
これはカスタムプロパティの循環参照と同様の挙動だ。意図せず再帰を作り込まないよう、関数同士の呼び出し関係は明確に設計する必要がある。
–func-b が –func-a を呼び出す
ブラウザサポートとプログレッシブエンハンスメント
2026年6月時点で@functionは実験的機能であり、未対応ブラウザでは単に無視される。そのため、フォールバックの記述が重要になる。
理想的には@supports (at-rule(@function))でサポートを判定したいが、この@supportsのat-rule評価機能自体がChrome 148以降でしか動作しないという皮肉な状況がある。
現実的な対策としては、従来のカスタムプロパティとcalc()で書いたスタイルをフォールバックとして先に宣言し、その下に@functionを使ったスタイルを記述する方法が考えられる。ブラウザが@functionを解釈できれば上書きされ、できなければ従来の記述が適用される。
/* フォールバック */
.container {
margin-inline: 10px;
}
/* @function対応ブラウザでは上書き */
.container {
margin-inline: --half(20px);
}Sassの@functionとの違い
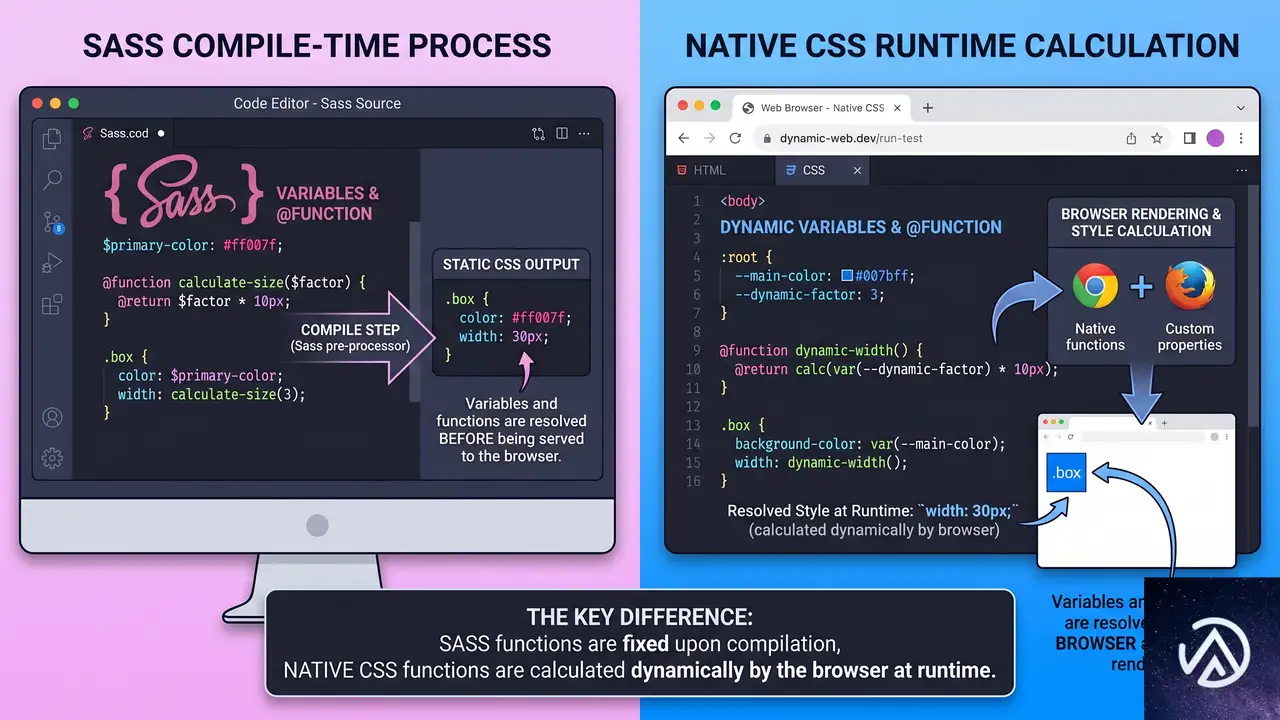
Sassにも同名の@functionがあるが、両者は動作の仕組みが根本的に異なる。Sassの@functionはコンパイル時にサーバーサイドで処理され、出力されるCSSには関数の痕跡が残らない。
一方、CSSネイティブの@functionはブラウザが実行時に解釈する。スタイルシート内に関数定義がそのまま存在し、ユーザーの画面幅やコンテナサイズに応じて動的に値が解決される。
この違いはパフォーマンス特性やデバッグのしやすさにも影響する。Sassの場合、コンパイル後のCSSしか確認できないが、ネイティブ@functionならブラウザのDevToolsで関数の解決過程を追えるようになる可能性がある。
なお、SassプロジェクトにCSSネイティブの@functionを混在させることは技術的には可能だが、同名の関数が競合する可能性があるため命名規則の整理が推奨される。
この記事のポイント
- @functionはCSSネイティブでカスタム関数を定義するルールである
- 引数、型チェック、デフォルト値、メディアクエリ分岐を1つの関数に集約できる
- result記述子はカスケードに従い、複数記述時は後勝ちのルールが適用される
- 副作用は禁止で、複数宣言の生成には@mixinの正式化を待つ必要がある
- 循環依存は厳格に防止され、未対応ブラウザ向けのフォールバックが必須だ

Codexで開発速度20倍、WasmerがNode.jsエッジランタイムを2週間で構築
OpenAIのCodexとGPT-5.5を活用し、開発速度を10倍から20倍に引き上げたチームが現れた。エッジコンピューティングプラットフォームを手がけるWasmerは、これを用いてNode.jsのエッジ向けランタイム「Edge.js」をわずか2週間で構築したのだ。従来なら1年を要する規模のプロジェクトである。
Wasmerは少人数のチームながら、WebAssemblyサンドボックス内でNode.jsワークロードを実行するという技術的挑戦を達成した。これにより、開発者はDockerを使わずにJavaScriptアプリケーションやMCP(Model Context Protocol)エージェントを動作させられるようになる。この成果の背後にあるCodex活用の実態と、小規模チームが大企業並みの開発速度を実現したプロセスを掘り下げる。
プロジェクトの全容と達成された技術的ブレークスルー

Wasmerが今回リリースしたEdge.jsは、Node.jsのワークロードをWebAssembly(Wasm)サンドボックス内で安全に実行するJavaScriptランタイムだ。WebAssemblyはブラウザやサーバーで高速に動作するバイナリ命令形式で、いわば「アプリケーションを隔離された環境で動かすための軽量な箱」のような役割を果たす。サンドボックス化により、ホストシステムへの不正アクセスやリソースの浪費を防ぎつつ、高いパフォーマンスを維持できる。
この技術の最大の意義は、Dockerコンテナを使わずにNode.jsアプリをデプロイできる点にある。コンテナ技術は強力だが、イメージのビルドやレジストリ管理、起動時間などのオーバーヘッドを伴う。Wasmerのアプローチなら、より軽量かつ瞬時にエッジ環境へ展開可能だ。同社の創業者兼CEOであるSyrus Akbary Nieto氏はOpenAIのブログ記事で「AIやエッジコンピューティング向けのNode.jsワークロードを動かせる初のクラウドホストになった」と述べている。
Wasmサンドボックスは「アプリを小さな防護壁で囲む」ような仕組みで、Node.jsの全機能を安全にエッジ層で提供できるようにする。これにより、レイテンシに敏感なAI推論やリアルタイムAPI、MCPエージェントといった用途で威力を発揮する。
Codexによる開発速度の飛躍的向上
WasmerがEdge.jsを構築するのにかかった期間は、わずか2週間だ。Nieto氏によれば、AIを使わなければ「容易に1年はかかっていた」プロジェクトである。CodexとGPT-5.5の導入により、開発速度は10倍から20倍に跳ね上がったという。この数字は単なる体感ではなく、実際のプロジェクト完了までの期間短縮に基づく。
Wasmerのエンジニアはプロジェクトの最初から最後までCodexを活用した。初期のアーキテクチャ設計から、最終製品の仕上げに至るまで、あらゆる段階でAIが開発を支援した形だ。特に効果を発揮したのは、バグの発見と原因特定のプロセスである。
上記のフローは、従来の開発サイクルに比べて圧倒的に短い時間で完了する。特にステップ3のデバッグ工程で、Codexは人間のエンジニアが気づきにくい低レイヤーの問題を素早く見つけ出した。
Codexがもたらしたデバッグの質的変化
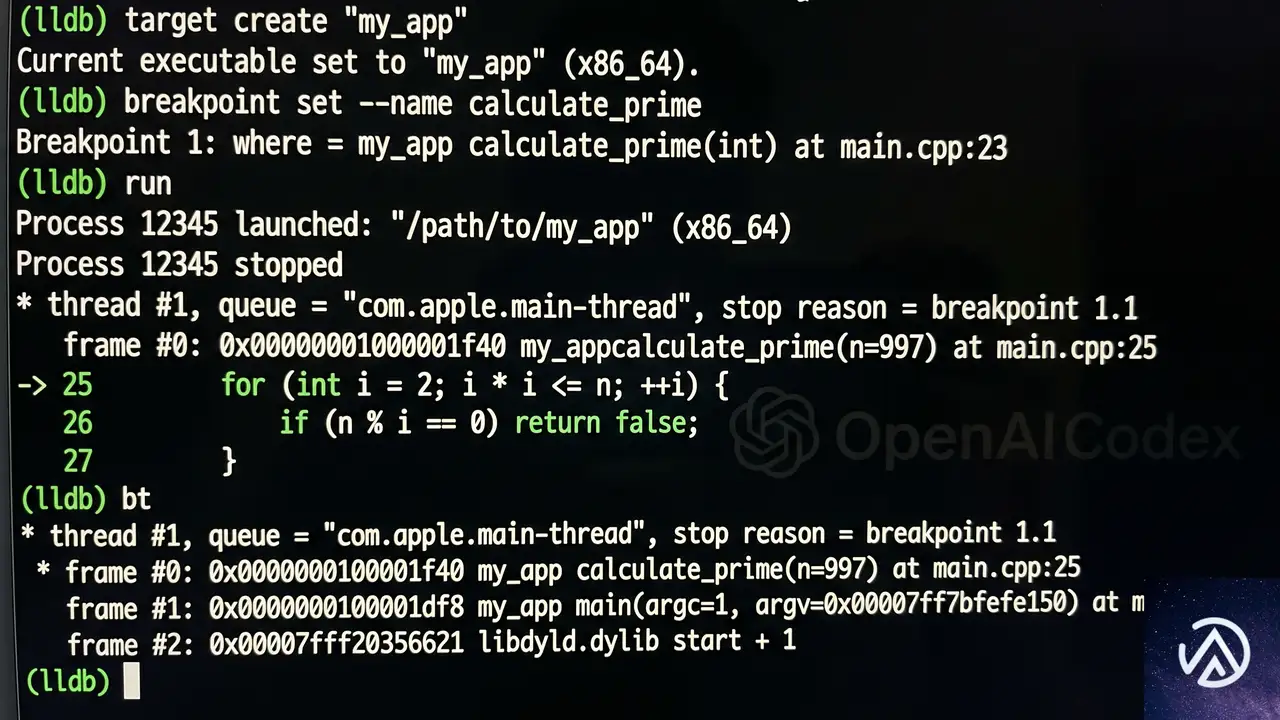
Edge.jsの開発で特に印象的だったのは、Codexのデバッグ能力だとNieto氏は語る。通常、WebAssemblyやNode.js内部のような低レイヤーのバグを特定するには、C++やアセンブリレベルの深い知識が必要になる。しかし、少人数のチームではそうした専門家を常に確保できるわけではない。
CodexはLLD(LLVM Debugger)のような低レベルデバッガを使いこなし、アセンブリレベルでコードの挙動を追跡した。さらに、コンソールログを活用して関数呼び出しのトレースを行い、問題の根本原因を特定するまでの時間を大幅に短縮したという。Nieto氏はOpenAIの記事で「我々はC++の専門家ではないため気づけない微妙な問題を、Codexはかなり早い段階で見つけ出した」と述べている。
ここでいうLLDとは、コンパイル済みプログラムの動作を命令単位で追跡できるツールだ。通常のデバッガがソースコード行単位で止めるのに対し、LLDはCPUが実際に実行する機械語レベルで問題を観察できる。Codexはこのツールを自律的に操作し、バグの兆候から原因、解決策までを一気通貫で提示したことになる。
IDEから離れる開発スタイルへの移行
Wasmerのエンジニアたちは、Codexの推論能力が向上するにつれて、次第にIDE(統合開発環境)から手を離し始めたという。Nieto氏は「我々は実際にIDE自体から離れつつある。コードに直接触れるのではなく、どこに向かいたいかを指示するだけになっている」と述べている。
これは開発者の役割が「コードを書く人」から「AIに方向性を与える人」へと変化していることを示す。もちろん、最終的な判断や設計の意図は人間が持つ。しかし、実装の大部分をAIが担うことで、小規模チームでも大規模プロジェクトに挑戦できるようになった。
この変化は、開発生産性の概念そのものを再定義する可能性を秘めている。コードを書く速度ではなく、AIに適切な指示を与え、出力を評価し、設計判断を下す能力が重要になるからだ。
AI活用に懐疑的だったチームの変遷
Wasmerのエンジニアたちも、当初はAIの出力に懐疑的だった。Nieto氏は「最初はAIのアウトプットをあまり信用していなかった」と振り返る。これは多くの開発者が経験する感覚だろう。AIが生成するコードが本当に正しいのか、セキュリティ上の問題はないのかといった懸念は自然なものだ。
しかし、実験を重ねるうちに結果が期待を上回り始めた。特にここ数カ月でCodexの推論能力が飛躍的に向上し、信頼性が格段に高まったという。Nieto氏は「ここ1年、特にここ数カ月間Codexと仕事をしてきたが、結果は本当に非常に良かった」と述べている。
信頼構築のプロセスは段階的だった。最初は小さなタスクから任せ、出力を丹念にレビューする。やがて、より複雑な問題を任せられるようになり、最終的には前述のようにIDEから手を離す段階に至った。この流れは、AI開発支援ツールを導入する多くのチームにとって参考になるパターンだ。
Codexが解き放つ小規模チームの可能性
Wasmerの事例が示す最大の教訓は、AI開発支援が「チーム規模の制約」を打ち破る力を持つことだ。Nieto氏は「Codexによって、小さな会社が大企業でしか不可能だったことを達成できるようになった。このプロジェクトは文字通り、Codexなしでは不可能だった」と断言している。
Node.jsのエッジランタイムをゼロから構築するという挑戦は、通常なら専門のインフラエンジニアやC++のエキスパートを複数抱える大企業のプロジェクトだ。Wasmerのような小規模チームがこれに挑むこと自体が、AIの存在を前提とした新たな開発パラダイムの到来を感じさせる。
Nieto氏は今後について「以前は不可能だったことが手の届く範囲にある。我々はさらに困難な問題に目を向ける必要がある」と語っている。Wasmerのチームは既に、次の野心的なプロジェクトを見据えている段階だ。
エッジコンピューティングとNode.jsの新しい関係
Edge.jsの登場は、エッジコンピューティングにおけるNode.jsの位置づけを大きく変える可能性がある。エッジコンピューティングとは、データの発生源に近い場所で処理を行うアーキテクチャだ。ユーザーの近くにサーバーを置くことで、応答速度を高め、中央サーバーへの負荷を減らせる。CDN(コンテンツ配信ネットワーク)がその代表例だが、近年はより複雑なアプリケーションロジックをエッジで動かす需要が高まっている。
従来、エッジ環境でJavaScriptを本格的に動かすには、Cloudflare Workersのような専用ランタイムを使う必要があった。これらはNode.jsと完全な互換性があるわけではなく、多くのnpmパッケージやNode.js組み込みモジュールが使えなかった。Edge.jsはこの制約をWebAssemblyサンドボックスで解決する。Node.jsアプリをほぼそのままエッジで動かせる道を開いたことになる。
MCP(Model Context Protocol)エージェントへの対応も見逃せない。MCPはAIモデルが外部ツールやデータソースと連携するための標準プロトコルで、AIエージェントの基盤として注目されている。エッジで動作するNode.jsランタイムがMCPをサポートすることで、低レイテンシのAIエージェントを構築しやすくなる。
実運用で期待される効果
Edge.jsを利用すると、具体的に以下のような恩恵が見込まれる。まず、コールドスタート(初回起動時の遅延)が大幅に短縮される。Dockerコンテナの起動には数百ミリ秒から数秒かかることがあるが、Wasmサンドボックスならマイクロ秒単位で実行を開始できる。
次に、リソースの隔離が強固になる。WebAssemblyは設計段階からサンドボックス化を前提としており、メモリアクセスやシステムコールを厳格に制限する。これにより、マルチテナント環境でも安全にNode.jsアプリをホストできる。また、デプロイの簡素化も大きな利点だ。コンテナイメージのビルドやレジストリへのプッシュが不要になり、コードを書いてすぐにエッジへ展開できるワークフローが実現する。
この記事のポイント
- WasmerはOpenAI CodexとGPT-5.5を使い、Node.jsエッジランタイム「Edge.js」を2週間で開発した
- AIを活用しない場合の開発期間は約1年と見積もられており、速度は10〜20倍に向上した
- Codexは低レベルデバッガLLDを使いこなし、人間のエンジニアが気づきにくいバグの根本原因を迅速に特定した
- 小規模チームでも大企業レベルのプロジェクトに挑戦できるようになり、開発のパラダイムシフトが起きつつある
- WebAssemblyサンドボックスにより、Docker不要で安全かつ高速にNode.jsをエッジで実行できる

OpenAIの最先端モデルとCodexがAWSで一般提供開始。Bedrock経由で本番導入が加速
2026年6月1日、OpenAIの最先端モデルとCodexがAmazon Bedrock上で一般提供を開始した。すでにAWSをインフラ基盤として使う数百万の組織が、同じ管理画面とセキュリティポリシーのままOpenAIのAI機能を本番環境へ組み込めるようになる。
Codexは毎週500万人以上の開発者が使うソフトウェアエンジニアリングエージェントだ。コードの記述、レビュー、デバッグ、レガシーコードのモダナイズまで、開発の全工程をAWS環境の中で完結できる。商用リージョンとGovCloudの両方に対応する。
企業にとって最大の意味は「AI導入の運用障壁が一段下がる」ことにある。調達、セキュリティ審査、ガバナンス、請求管理といった本番運用に必須のプロセスを、すでに信頼済みのAWSガードレールの中で処理できるからだ。
企業がAI導入でぶつかっていた3つの壁

OpenAIのAPIはここ数年で急速に高性能化した。GPT-4oをはじめとするフロンティアモデルは、自然言語の理解と生成だけでなく、構造化データの処理やマルチモーダル推論までこなす。それでも大企業の本番導入は想定より緩やかだった。理由は技術そのものではなく、運用プロセスにある。
セキュリティ審査とガバナンスの再構築
新しい外部サービスを本番環境につなぐには、情報セキュリティ部門による審査が避けられない。データの送信先、暗号化の有無、ログの保管場所、アクセス制御ポリシーとの整合性。これらを一から確認する作業は数週間から数ヶ月に及ぶ。OpenAI単体のAPIを使う場合、この審査プロセスが最初のハードルだった。
請求管理と調達フローの分断
クラウド費用をAWSで一元管理している企業にとって、別のSaaS契約を追加することは経理と調達の両面で負荷が増す。予算承認のフロー、請求書の処理、利用量の監視。それぞれが独立したサイロになり、小さなPoC(概念実証)の段階で手続きに埋もれてしまうケースも少なくなかった。
開発パイプラインとの統合コスト
AIの推論結果をアプリケーションに組み込むには、API呼び出しの認証、レート制限の管理、エラーハンドリング、モニタリングの仕組みを別途構築する必要があった。AWSのIAMやCloudWatchと統合されていないサービスを追加するたびに、運用スクリプトと監視設定を一から書く工数が発生していたのだ。
このデモ図が示すように、AWS Bedrockを経由することで調達・審査・監視のステップが一本化される。これが今回の発表でOpenAIが強調している「摩擦の低減」の正体だ。
2つの提供ルートが開いた意味
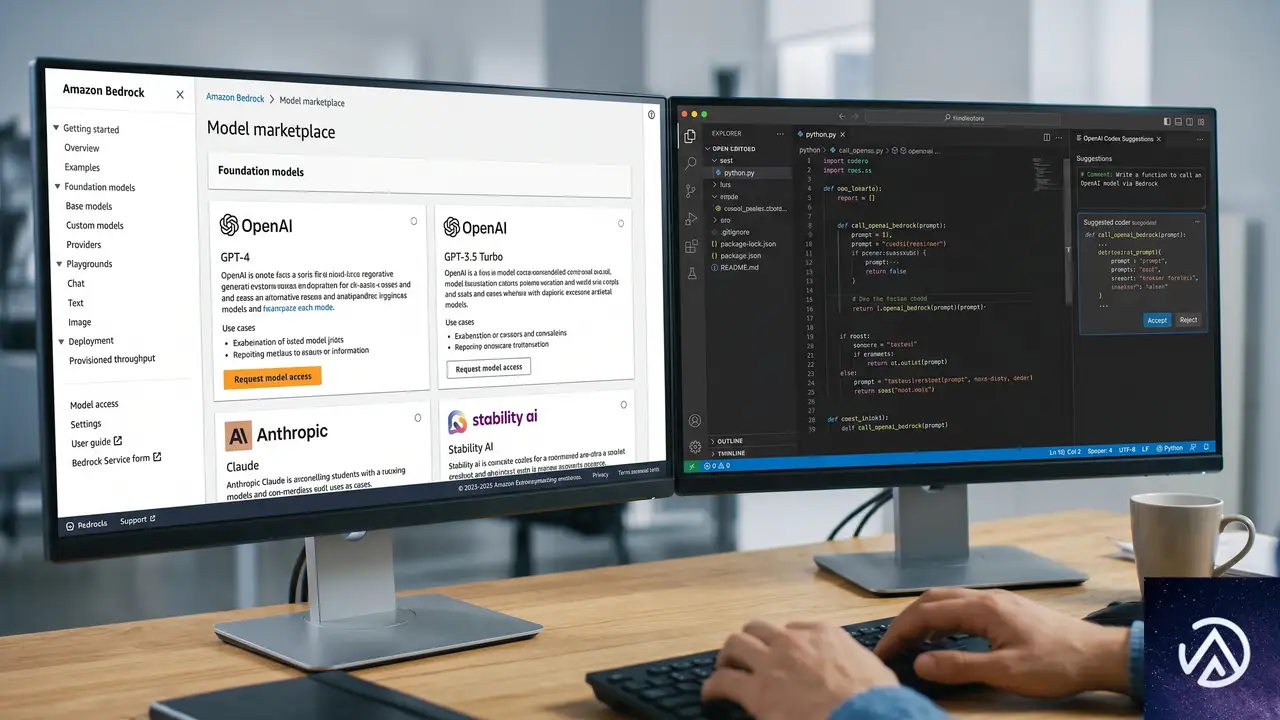
OpenAIの機能はAWS上で2つの形態で提供される。どちらもAmazon Bedrockを基盤とするが、用途と対象者が異なる。
OpenAI models on Amazon Bedrock
GPT-4oをはじめとするOpenAIのフロンティアモデルを、BedrockのAPI経由で呼び出せる。BedrockはAWSが提供するフルマネージド型の基盤モデルサービスだ。すでにBedrock上で他のモデルを使っているチームであれば、同じIAMロール、同じVPCエンドポイント、同じCloudTrailの監査ログでOpenAIのモデルを追加できる。
これにより、チャットボット、文書要約、マルチモーダル分析といったユースケースを、セキュリティチームが事前承認したネットワーク境界の中で実装可能になる。データがAWSリージョン外に送信される心配もなく、社内ポリシーとの整合性を取りやすい。
Codex on Amazon Bedrock
CodexはOpenAIが提供するソフトウェアエンジニアリングエージェントだ。コードの自動生成だけでなく、プルリクエストのレビュー、バグの特定、依存関係の分析、レガシーコードのリファクタリング提案までを対話型で実行する。GitHubやIDEと統合して使うのが一般的だったが、今回の発表でAWS環境から直接Codexを呼び出せるようになった。
週に500万人以上の開発者がすでにCodexを利用している。この数字はGitHub Copilotのユーザー数に匹敵し、AIコーディング支援が一部のアーリーアダプターの手を離れ、メインストリームの開発プラクティスになったことを示している。AWS上でCodexを使えるようになることで、CI/CDパイプラインへの組み込みや、組織全体のコードレビューポリシーとの統合が現実的になる。
Codexが開発パイプラインの中に組み込まれることで、コードレビューや依存関係チェックがプルリクエストのたびに自動で走るようになる。レビュアーの負荷が下がり、バグの早期発見にもつながる設計だ。
商用とGovCloudの両対応が示す信頼性

今回の発表で見逃せないのは、OpenAIの機能がAWSの商用リージョンとGovCloud(米国政府向けクラウド)の両方で提供される点だ。GovCloudはFedRAMPやITARなどの厳格なコンプライアンス基準を満たすために設計された隔離環境である。
政府機関や防衛産業、高い規制要件を持つ金融機関にとって、AIモデルをGovCloud内で実行できることの意味は大きい。データが閉域網から出ず、監査証跡もAWSの既存フレームワークで一貫管理される。OpenAIのモデルをパブリッククラウド越しに使うことに抵抗があった組織も、このオプションで導入検討の敷居が下がる。
OpenAIのCarlo Daniele氏は公式ブログで「企業が直面する最大の障壁は、最先端AIを既存のセキュリティとコンプライアンスの枠組みの中で本番運用することだ」と指摘している。GovCloud対応はまさにその障壁をターゲットにした一手といえる。
Daybreak構想とセキュリティ開発の未来

今回の発表と同時に、OpenAIは「Daybreak」という構想の将来提供も示唆した。Daybreakはソフトウェアの「作り方」と「守り方」の両方を変えることを狙ったビジョンだ。
Codex Securityが開発ループに入る日
Daybreakの中核には、サイバーセキュリティに特化したモデル群と「Codex Security」がある。これらは以下の機能を日常的な開発ループに組み込むことを目指している。
- セキュアコードレビューの自動化
- 脅威モデリングの支援
- パッチ検証の効率化
- 依存関係のリスク分析
- 脆弱性の検出と修復ガイダンスの提示
現状、これらの作業の多くはセキュリティ専任チームが限られた時間の中で手動で行っている。コード量が増えるほどチェックが追いつかなくなり、既知の脆弱性が修正されないまま本番環境に残るリスクが高まる。Codex Securityはこのギャップを、開発者がコードを書くタイミングで自動的に埋めようという発想だ。
AWSがセキュリティ導入の加速路になる
Daybreakのような専用機能が本格提供されたとき、AWSはその導入経路として重要な役割を果たすとOpenAIは見ている。すでにAWS上でセキュリティ運用(GuardDuty、Security Hub、Inspectorなど)を回している組織であれば、Codex Securityの出力を既存のSOC(セキュリティオペレーションセンター)ワークフローに直接流し込めるからだ。
OpenAIの記事では「セキュリティチームがすでに使っているセキュリティ、ガバナンス、調達、運用のフレームワークの中でDaybreakを導入できる」と説明されている。セキュリティ強化のための新ツール導入が、逆に運用負荷を増やすという矛盾を避ける設計思想だ。
このフローが実現すれば、セキュリティは「後付けの検査工程」から「開発と同時並行で走る自動プロセス」に変わる。Daybreakの提供時期はまだ明言されていないが、AWS基盤の上でこの構想が動き始めたこと自体が重要なシグナルだ。
開発チームが今から準備すべきこと

OpenAI on AWSはすでに一般提供が始まっている。商用リージョンとGovCloudの両方で利用可能だ。開発チームがこの変化を活かすために、今から着手できることがいくつかある。
Bedrockのアクセス権を確認する
まず、自組織のAWSアカウントでBedrockが有効化されているか確認する。IAMポリシーでBedrockのモデルアクセス権限が適切に設定されているかも見直す必要がある。特にOpenAIのモデルを呼び出すには、Bedrock内でモデルアクセスを明示的にリクエストするステップが必要だ。
CodexをCI/CDパイプラインに組み込む設計を始める
Codex on BedrockはAPIとして提供されるため、GitHub ActionsやAWS CodePipelineと組み合わせて、プルリクエストの自動レビューやコード品質チェックに活用できる。すでにCodexをIDEで使っているチームは、パイプライン全体への展開を検討する段階に入ったといえる。
セキュリティチームとDaybreakのロードマップを共有する
Daybreakの具体的な提供日は未定だが、Codex Securityの方向性を事前にセキュリティチームと共有しておくことで、導入時の社内調整をスムーズにできる。脅威モデリングや依存関係分析の自動化がどのように既存のセキュリティ運用と統合されるのか、概念レベルで議論を始めておくのが有効だ。
この記事のポイント
- OpenAIのフロンティアモデルとCodexがAmazon Bedrockで一般提供を開始
- 既存のAWSセキュリティ・ガバナンス・請求管理の枠組みでAIを本番導入可能に
- Codexは週500万人以上が使うエンジニアリングエージェントで、開発パイプラインへの統合が加速
- 商用リージョンとGovCloudの両対応により、規制業界や政府機関の導入障壁が低下
- Daybreak構想(Codex Security)が将来提供されれば、セキュリティレビューが開発と同時進行する形に変わる

Shopify障害で店舗停止、広告費消失のリスクと対策
2026年6月3日、Shopifyで大規模なサービス障害が発生した。店舗フロントの表示不具合やチェックアウト機能の停止により、世界中のEC事業者が売上機会を失った。とりわけGoogleやMetaに広告予算を投下していた事業者は、クリックを集めながら購入完了に結びつけられないという致命的な状況に陥っている。
本記事では、この障害がECサイトの広告パフォーマンスとSEOに及ぼす実務的な影響、および同様の事態を想定したリスク分散策を整理する。Shopifyに限らず、SaaS型ECプラットフォームに依存する事業者共通の課題として捉えてほしい。
障害の概要と影響範囲

Shopifyは米国東部時間9時27分に問題を認識し、管理画面やPOSレジ、カスタマーサポートへのアクセス障害を公表した。店舗フロントやチェックアウトにも波及し、購入完了ができない状態が約1時間にわたって続いた。10時37分には根本原因を特定し、回復に向かっていると発表している。
影響を受けたのは以下の4領域だ。いずれもEC事業の中核を担う機能であり、たとえ短時間の停止でも事業者の損失は無視できない。
- 店舗フロントの表示
- チェックアウト処理
- 管理画面へのログイン
- 実店舗向けPOSレジ
Search Engine Landの記事によれば、この障害を最初に報告したのはSenior Paid Media ManagerのAyisha Yousef氏だ。同氏はLinkedIn上でエラーメッセージのスクリーンショットを共有し、広告運用担当者へ注意を呼びかけた。
Shopify障害の時系列
このタイムラインからわかるのは、障害検知から復旧まで約1時間10分というスピード感だ。しかしEC事業者にとって、ピーク時間帯の1時間は致命的な機会損失になりうる。
チェックアウト停止が広告運用に直撃する仕組み
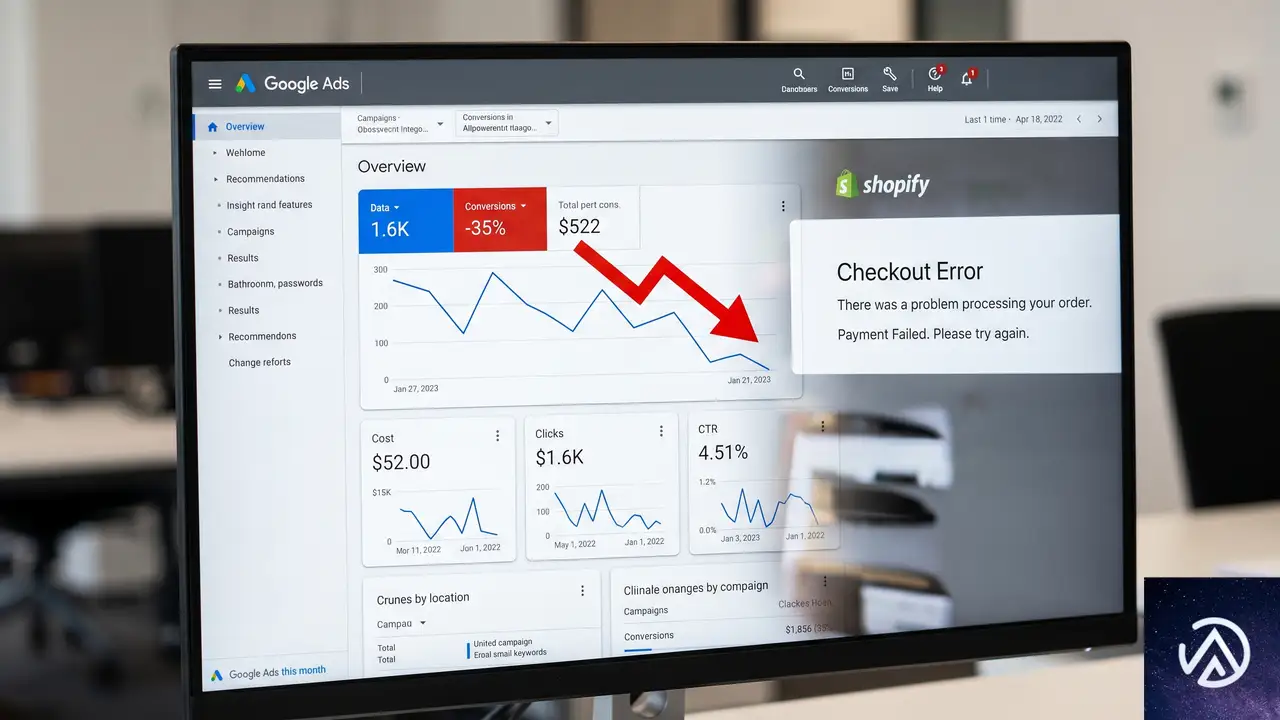
最も深刻なのが、広告経由で流入したトラフィックが一切売上に結びつかない状況だ。Googleショッピング広告やMetaのダイナミック広告で商品を表示し、ユーザーがクリックして店舗に到達しても、チェックアウト画面でエラーが発生すれば購入は成立しない。
広告費はクリック単位で課金される。つまり「クリックは発生するがコンバージョンはゼロ」という状態が続けば、ROAS(広告費用対効果)は急落する。以下の図は、障害発生中に起こる広告費消失のメカニズムを単純化したものだ。
この構造は、広告キャンペーンのパフォーマンスデータにも深刻な歪みをもたらす。障害時間帯のコンバージョン率が異常に低くなるため、キャンペーン全体の平均値を押し下げ、自動入札戦略の学習にも悪影響を与える可能性がある。
Google広告とMeta広告への具体的な影響
Google広告では、コンバージョンデータがスマート自動入札のシグナルとして使われる。障害によるゼロコンバージョンが一定期間続くと、アルゴリズムが「このキャンペーンは効果が低い」と判断し、入札単価の引き下げや表示頻度の低下を招く。
Meta広告(Facebook・Instagram)も同様だ。コンバージョンAPIで送信される購入イベントが途絶えると、アルゴリズムが最適なオーディエンスを見失い、その後の配信精度が低下する。特に障害直後の数日間は、通常よりもCPA(顧客獲得単価)が跳ね上がる傾向があると指摘する広告運用者もいる。
Search Engine Landの記事では、Shopify障害中は広告キャンペーンの成果を通常通り評価できないため、後日パフォーマンスを検証する際には障害時間帯を除外するか、別途注釈を加えることが推奨されている。
EC事業者が直面するプラットフォーム依存リスク

今回の障害は、多くのEC事業者が単一のプラットフォームに売上インフラのすべてを依存している現実を浮き彫りにした。Shopifyは数百万のオンラインストアを支える巨大プラットフォームであり、その停止は個別店舗の努力ではどうにもならないレイヤーで発生する。
とりわけ、以下のような状況にある事業者ほど影響が大きい。
- プロモーションや新商品発売のタイミングと重なったケース
- インフルエンサー施策で集中的にトラフィックを集めていたケース
- Shopifyペイメント以外の決済手段を持たないケース
これは「SaaS型ECの構造的リスク」と言い換えられる。自社サーバーでECサイトを構築するオンプレミス型に比べ、SaaS型は運用負荷が低い半面、障害発生時のコントロール権はゼロに等しい。復旧を待つ以外に打てる手が限られるのだ。
依存度を下げるための分散戦略
完全にShopifyから離れるのは現実的ではない。しかし、致命的な売上機会損失を減らすための「保険」として、以下のような分散策を検討する価値はある。
- バックアップ用のランディングページを外部で用意しておく(NotionやGoogleサイトで簡易的な注文フォームを設置するなど)
- InstagramショップやAmazonストアなど、販売チャネルを複数持つ
- 広告のリンク先をShopifyストア以外にも切り替えられる体制を整える
- Shopifyとは別の決済リンク(Stripe Payment Linksなど)をSNSプロフィールに常設する
これらの対応は、日常的には使わなくても、緊急時に即座に切り替え可能な「避難経路」として機能する。障害発生から復旧までの1時間を耐え抜くための備えだ。
障害発生時に取るべき3つの即時対応

Shopifyに限らず、ECプラットフォームの障害を検知した際に、広告運用とSEOの両面で即座に実行すべき対応を整理した。以下の3ステップは、今回のShopify障害の事例をもとに構成している。
STEP 1の広告停止が最も重要だ。検索広告のクリック単価はリアルタイムで消費され続けるため、障害を検知してから数分以内に対応できるかどうかで、無駄になる広告費の額が大きく変わる。Google広告の自動化ルールで「コンバージョンがゼロになったらキャンペーンを停止する」条件を事前に設定しておくと、人的対応の遅れを防げる。
SEO視点で見る障害時の注意点
チェックアウトや管理画面の障害が直接的にSEOにペナルティを与えることはない。ただし、店舗フロントが完全に表示されない状態が長時間続くと、Googlebotがクロールに失敗し、インデックスの鮮度が落ちる可能性はある。
より実務的に注意すべきは、SNSや口コミで「このストア使えない」というネガティブな評判が広がることだ。ブランド検索の増加に対して、表示される検索結果がネガティブな情報に偏ると、その後のオーガニック流入にも影響が出る。障害発生時には、自社のSNSアカウントで状況を説明し、検索結果のコントロールに努めることが重要になる。
この記事のポイント
- Shopifyの大規模障害はEC事業者に広告費の無駄遣いと機会損失をもたらした
- チェックアウト停止中は広告キャンペーンを即座に停止し、復旧後にデータ補正を行う必要がある
- 単一プラットフォームへの依存度を下げるため、販売チャネルと決済手段の分散が有効
- 障害発生時に備えた広告自動化ルールの設定が、被害を最小化する鍵となる
- 復旧後はキャンペーンパフォーマンスを適切に評価し、アルゴリズムの誤学習を防ぐこと

Azure Cobalt 200 VMが50%性能向上、エージェンティックAIに最適化
Cobalt 200 VMの概要とプレビュー提供開始
Microsoft Build 2026にあわせ、Azure Cobalt 200 Armベース仮想マシンの早期アクセスプレビューが発表された。Azure Blogの記事によれば、第2世代の自社設計Armプロセッサを搭載するこのVMは、前世代Cobalt 100と比べて最大50%のCPU性能向上を達成し、とくにエージェンティックAIやクラウドネイティブなスケールアウト型ワークロードでの利用を見据えている。
Cobalt 200はシリコンからサーバー、サービスまでを一貫してMicrosoftが設計し、セキュリティ、ネットワーク、ストレージ、オフロード処理の最新技術を統合した。これにより、AI推論、データパイプライン、Web API層といった多様な負荷で、パフォーマンスとコスト効率の両立を狙う。Azure Blogの記事では「エージェントは従来のワークロードとは異なり、推論や逐次的意思決定を連続的に大規模実行するため、根本的に異なる計算プロファイルが求められる」と指摘している。Cobalt 200はまさにその要件に応える設計だ。
Cobalt 100からの性能向上と新アーキテクチャ

Cobalt 100はすでに世界32のAzureリージョンで稼働し、DatabricksやSnowflakeといったクラウド分析の大手が導入している。Microsoft自身のサービスでも、以前の基盤と比べて最大45%の性能向上を達成しつつ、使用コア数を35%削減できた実績がある。Azure Blogの記事によると、Microsoft Defender for Endpointのサイバーデータキュレーターでは40%の性能改善が確認され、大規模な脅威対応の高速化に貢献した。
Cobalt 200 VMは、この知見を土台にさらに一段上の性能を提供する。SoC(System-on-Chip)には、Arm Neoverse V3 Compute Subsystems(Armの高性能Vシリーズコア)を採用し、TSMCの3nm(N3P)プロセスで製造される。チップレットアーキテクチャ、カスタムアクセラレータ、そして専用設計のメモリコントローラを備え、L2キャッシュはコアあたり3MB、システムレベルのL3キャッシュは192MBに拡張された。これにより、データベースやインメモリキャッシュ、分析エンジンなど、データ集約型サービスのレイテンシ低減と応答性向上が期待できる。
この図は主要なクラウドワークロードにおけるCobalt 100からCobalt 200への相対性能の向上を示している。CPU性能は50%、Webサービングは40%、そしてデータベース処理では最大135%の改善を達成している(Azure Blogの記事に基づく)。
ネットワーク帯域幅は15%向上し、NVMeリモートストレージのIOPSは20%、スループットは10%改善する。さらに最大128vCPUまでのスケールアップが可能になった。メモリ暗号化がデフォルトで有効化されている点も、セキュリティ要件の厳しいエンタープライズ環境にとっては大きな前進だ。
エージェンティックAIに最適化された設計
Azure Blogの説明では、Cobalt 200の各コアは完全な物理コアであり、3MBの専用L2キャッシュとコアあたりの高いメモリ帯域を備える。この設計により、負荷時のアイソレーション性能が高く、エージェントのサンドボックスをVMあたりにより多く詰め込める。エージェンティックAIでは、複数のAIエージェントが並行して推論やツール呼び出しを行うため、スループットとレイテンシの両面で安定した性能が求められる。Cobalt 200はその期待に応える基盤となる。
データ集約型のキャッシュワークロードでは最大80%の性能向上が報告されており、通信暗号化処理では45%、クラウドデータベースでは135%という数字がAzure Blogの記事に示されている。こうした値は、大規模な本番サービスで確認された実測値であり、単なる理論上のピーク性能にとどまらない。
パートナー企業とMicrosoft内部サービスでの導入

プレビュー期間中から複数のテクノロジーパートナーがCobalt 200 VMを評価し、すでに有望な結果を得ている。Azure Blogに掲載されたTeradataのEngineering FellowであるBrandon Mincey氏のコメントでは、早期テストが有望だったとし、両社の共同顧客のニーズに合わせた設計へのフィードバックを続けているという。Elasticのプロダクト管理ディレクターYuvraj Gupta氏も、検索AIプラットフォームの性能とコスト効率のさらなる改善に期待を示した。
ArmのCloud AIビジネスユニット担当VP Eddie Ramirez氏は、エージェンティックAIがクラウドを再構築していると述べ、Arm Neoverse CSS V3をベースにしたCobalt 200が、次世代のAI駆動型サービスを可能にするとコメントしている。CanonicalのPublic Cloud AllianceディレクターJehudi Castro-Sierra氏は、メモリ暗号化のデフォルト有効化や圧縮・暗号化のアクセラレーションといった進歩が本番Linuxワークロードにとって重要だとし、Ubuntu ProのLivepatchによるArm環境での再起動不要なカーネル更新にも言及した。
Microsoft自身のサービスでも導入が進む。Power Platformの中核を担うDataverseでは、Cobalt 100での良好な実績を踏まえ、Cobalt 200の検証でベースワークロードが最大60%高速化したとAzure Blogの記事は紹介している。Azure SQL Databaseにおいても、圧縮・暗号化アクセラレータを活用することで、重要なクエリ処理リソースを解放できると期待されている。
VMファミリーと仕様
Cobalt 200 VMでは、従来の汎用(Dp, Dpl)やメモリ最適化(Ep)に加え、新たに高メモリ最適化Mpsv4シリーズと高密度ローカルストレージのLpsv5シリーズが追加された。これにより、大規模インメモリデータベースやビッグデータ分析、検索エンジンといった多様なニーズに対応できる。以下が主なシリーズの概要だ。
リモートディスクはStandard SSD、Standard HDD、Premium SSD、Ultra Diskに対応し、Azureポータル、SDK、API、CLIなど既存の手法でデプロイできる。プレビューは米国西部3、東部2、中央、スウェーデン中部などから開始され、今後リージョンが拡大される予定だ。
開発者エコシステムとArm互換性

Cobalt 200 VMは、現行のCobalt 100ワークロードとの完全な互換性を維持する。C++、.NET、Java、Python、Rustといった主要言語のArmネイティブ版がすでに最適化されており、GitHub ActionsもセルフホストランナーやGitHub-hostedランナーを通じてArmをサポートする。Azure Kubernetes Service(AKS)ではArmエージェントノードとx86/Arm混在クラスタの両方に対応し、コンテナ化されたワークロードの移行も容易だ。
クラウドインフラにおけるArm採用の流れはとどまるところを知らない。Cobalt 200の登場は、単なる性能向上にとどまらず、エンタープライズ向けのセキュリティと管理性をArmエコシステム全体に持ち込む転換点になるだろう。Azure Blogの記事は「Cobalt 200はAzureのカスタムシリコン戦略の新章」と位置づけており、今後のさらなる展開が注目される。
この記事のポイント
- Cobalt 200 VMがMicrosoft Build 2026で早期アクセスプレビュー公開。Cobalt 100比で最大50%のCPU性能向上
- 128vCPUまでのスケールアップ、NVMeストレージのIOPS/スループット改善、デフォルトのメモリ暗号化を実装
- エージェンティックAIに求められる高い並列性と低レイテンシに最適化された専用設計
- Teradata、Elastic、Arm、Canonicalなど主要パートナーが早期評価で有望な結果を示し、Microsoftの内部サービスでも性能改善を確認
- 新たなVMファミリーでより多様なワークロードに対応し、Armエコシステムの成熟がさらに加速する見通し

VoidZeroがCloudflareに参画、ビルドツールViteはオープンソースを維持
Vite、Vitest、Rolldown、OxcといったJavaScriptエコシステムの中核ツールを開発するVoidZeroが、Cloudflareに参画した。全チームメンバーがCloudflareに合流する大規模な動きだ。
この発表で最も強調されているのは、これらのプロジェクトがこれからもオープンソースであり続けるという点だ。ViteはMITライセンスを維持し、ベンダーに依存せず、コミュニティ主導で開発が進められる。この原則が揺らぐことはないとCloudflareは明言する。
背景には、AI時代のソフトウェア開発の変化と、フルスタック化するモダンアプリケーションの複雑さがある。Viteがエコシステム全体の共有基盤となった今、この参画はツールチェーンの未来を左右する重要な転換点だ。
VoidZeroのCloudflare参画の内容

オープンソースとベンダー中立の堅持
Cloudflareは、Viteや周辺ツールの独立性を何よりも優先するとしている。具体的な約束は以下の通りだ。
- Vite、Vitest、Rolldown、Oxc、Vite+は今後もMITライセンスのオープンソースであり続ける
- 特定のクラウドベンダーに依存しない設計を維持する。Viteで構築したアプリケーションは、どこでも動作し続ける
- ロードマップはViteチームとコミュニティが引き続き主導し、公開の場で開発される
- Evan You氏をはじめとするVoidZeroチームが、プロジェクトのリーダーシップを継続する
- Cloudflareはこれらのプロジェクトにエンジニアリングリソースを投入するが、方向性を自社向けに曲げることはしない
Cloudflareのブログ記事では、このコミットメントを「言葉ではなく、日々の開発支援とプロジェクト運営で証明していく」と表現している。年初にAstroがCloudflareに参画した際と同様の、独立性を尊重するモデルだ。
100万ドルのViteエコシステム基金
この参画に伴い、CloudflareはViteエコシステム基金として100万ドルを拠出する。この基金はViteのコアチームによって管理され、メンテナーやコントリビューターへの支援に充てられる。
「ViteはVoidZeroやCloudflareよりも大きな存在だ」とCloudflareは述べており、エコシステムを支える無数の開発者を巻き込む意図が明確に示された。オープンソースの持続可能性を金銭面から支える、具体的な施策である。
この比較から分かるように、今回の参画はエコシステムの信頼を損なわないための設計が徹底されている。Viteが多くのフレームワークに採用されている共有基盤だからこそ、中立性の維持は絶対条件となる。
AIが変えたビルドツールの役割
エージェントがツールチェーンを回す時代
Cloudflareのブログ記事は、Viteの驚異的な普及の背景にAIの存在があると分析する。現在Viteの週間ダウンロード数は約1億2900万回、Cloudflare Viteプラグイン(@cloudflare/vite-plugin)は約1400万回に達している。これはVite本体のダウンロード数の10%を超える規模だ。
この急成長を牽引しているのが、AIコーディングエージェントだ。開発者だけが使っていた開発サーバーやリンター、フォーマッターを、今やAIエージェントが常時利用している。彼らはプロジェクトのスキャフォールディングから開発サーバーの起動、エラー解析、テスト実行までを自動で行う。
エージェントにとって重要なのは、高速なフィードバックループだ。ビルドが速く、テストが速く、エラーが明確で、CLIの挙動が一貫していること。VoidZeroのツールチェーン(Vitest、Rolldown、Oxc、Oxlint、Oxfmt)は、まさにこの要件に最適化されている。それぞれのカテゴリで最速クラスの性能を持ち、エージェントが何度も繰り返し実行してもストレスが少ない。
この図は、AIエージェントがコード生成からテスト、リント、修正までのサイクルを高速に回す様子を表している。各ツールの応答速度がエージェントの生産性に直結するため、VoidZeroのツールチェーンが選ばれる理由が明確になる。
フルスタック化するViteとVoidの知見

ビルドツールを超えた役割
モダンなアプリケーションは、単なる静的ファイルのバンドルでは完結しない。サーバーサイドレンダリング、API、バックグラウンドジョブ、キュー、データベース、オブジェクトストレージ、リアルタイム通信、認証、そしてAIエージェントの統合までが必要になる。
Viteはこれに対応するため、ビルドツールからフルスタックアプリケーションの基盤へと進化しつつある。Cloudflareはこの流れを加速させるために、Vite本体にプロバイダ非依存の抽象化レイヤーを追加していく方針だ。バックエンド、API、エージェント、デプロイメントのためのフックをVite側に用意し、各クラウドベンダーがそれを実装する形を目指している。
すでにVoidZeroが実験していた「Void」プラットフォームの知見が、この方向性を後押ししている。VoidはVite向けのデプロイメントプラットフォームとして設計され、モダンアプリのライフサイクル全体を一つのツールチェーンで統一する試みだった。Cloudflareは将来的にこのVoidプラットフォームをオープンソース化し、誰でも独自のプラットフォームをVite上に構築できるようにする計画も示している。
Workerd統合による開発体験の向上
CloudflareとViteの協業は2024年のVite Environment APIから始まっている。このAPIによって、Viteの開発サーバーはNode.js以外のランタイムでもサーバーコードを実行できるようになった。
Cloudflare Viteプラグインを使用すると、vite devの実行時にサーバーコードがWorkerd(Cloudflare Workersのオープンソースランタイム)上で動作する。Durable Objects、D1、KV、R2、Workers AI、エージェントなど、本番環境と同じランタイムモデルがローカルで再現される。開発環境が本番の劣化版だった時代は、このAPIによって終わりを迎えつつある。
この図が示すように、Environment APIの導入前後で開発体験は大きく変わった。ローカル環境と本番環境のランタイムが一致することで、デプロイ後の予期せぬエラーが激減する。
CloudflareがVite基盤に移行する意味

CLI統合とcfコマンドの未来
Cloudflareは自社ツールの方向性を「Viteに合わせる」と明確に宣言している。最近テクニカルプレビューが公開された新しい統合CLI「cf」は、Viteを基盤として設計される。
このCLIの目指す姿は、ViteのエルゴノミクスをそのままCloudflareプラットフォーム全体に拡張することだ。cf devはvite devのスーパーセットとして動作し、同じ速度、同じホットモジュールリプレースメント、同じプラグインモデルを持ちながら、必要に応じてCloudflareのランタイムとバインディングを利用できる。cf buildはViteプロジェクトをネイティブに理解し、cf deployはViteアプリのデプロイをシンプルにする。
すでにCloudflareのダッシュボード自体がVite上に構築されており、OxlintはCloudflareのコードベースで「数日分のエンジニアリング時間を節約している」と報告されている。Astroチームのエージェントハーネスフレームワーク「Flue」もVite基盤に移行中だ。Cloudflare自身がViteをドッグフーディングし、その価値を内部で証明している。
短期的な影響と長期的な展望
短期的には、Viteユーザーにとって何も変わらない。Vite、Vitest、Rolldown、Oxc、Vite+は引き続きリリースされ、VoidZeroチームがこれらを主導する。Cloudflare Viteプラグインも改善が続き、Environment APIもCloudflare以外のランタイムを含めて進化していく。
長期的には、CloudflareのCLIがVite上に完全に統合される。Viteにはフルスタックアプリとエージェントのためのプロバイダ非依存のプリミティブが追加され、あらゆるプラットフォームで利用可能になる。そしてVoidプラットフォームがオープンソース化され、誰でもViteとCloudflareの上に独自のプラットフォームを構築できるようになる。
この計画が実現すれば、ViteはJavaScriptエコシステムの単なるビルドツールから、アプリケーション開発全体を支える普遍的な基盤へと進化する。Cloudflareのインフラは、その基盤の上で最も統合された選択肢の一つとして位置づけられることになる。
この記事のポイント
- VoidZeroの全メンバーがCloudflareに参画。ViteやVitestなどのツールはMITライセンスのままでベンダー中立を維持する
- CloudflareはViteエコシステム基金として100万ドルを拠出し、コミュニティ主導の開発を資金面から支援する
- Viteの週間ダウンロード数1億2900万回の背景には、AIエージェントによる高速フィードバックループ需要がある
- Environment APIにより、ローカル開発環境でも本番と同じWorkerdランタイムが使用可能になった
- Cloudflareの新CLI「cf」はViteを基盤に統合され、全プラットフォームで一貫した開発体験を提供する計画だ

OpenAI、生命科学特化型AI「GPT Rosalind」を大幅刷新。複雑な研究ワークフローを自律支援
OpenAIは2026年6月3日、生命科学研究に特化したAIモデル「GPT-Rosalind」の最新アップデートを発表した。この新版は、GPT-5.5の自律的なコーディングや外部ツール活用の能力を基盤に、医薬品化学やゲノム科学といった創薬の中核領域での知能を大幅に強化している。単なる性能向上に留まらず、実際の研究ワークフローに密着した新機能と評価指標が加わった点が最大の特徴だ。
具体的には、実験計画の批判的レビュー、化学構造の解析、長期的なデータ分析タスクなど、研究者が日々直面する複雑な作業において、処理効率と精度を両立させている。さらに、対話的な研究環境を実現するプラグイン群も公開され、AIが論文や実験データを横断的に解釈し、具体的な次の一手を提示できるようになった。
この記事では、GPT-Rosalindの具体的な改良点、研究現場での活用方法、そしてこの技術が生命科学産業にもたらす実務的なインパクトについて、詳しく解説していく。
複雑な創薬プロセスを支える「審査官」としての知能

今回のアップデートで最も注目すべき点は、AIが研究データの単なる分析者から、研究戦略そのものを批判的に評価する「査読者」の役割を担い始めたことだ。OpenAIの記事では、ある遺伝子治療薬の治験データパッケージをGPT-Rosalindに評価させた事例が紹介されている。
AIに与えられたのは、デュシェンヌ型筋ジストロフィーを対象とした架空の遺伝子治療薬「AAV9-microDys-X」の第1/2相試験データだ。GPT-Rosalindは、このデータを承認申請の根拠として使うにはどのような穴があるか、FDAのような厳しい視点で項目ごとに圧力テストを行った。
AIが見抜いた実験デザインの落とし穴
GPT-Rosalindの回答は、研究開発の現場を知る者にとって非常に実践的な内容だった。例えば、タンパク質の定量法についてだ。この試験では、導入したマイクロジストロフィンというタンパク質の量を、ウェスタンブロット法で測定していた。しかしAIは、使用されたMANEX1A抗体が、治療用のマイクロジストロフィンだけでなく、患者の体内に元からあるごくわずかな正常ジストロフィン(復帰線維由来)にも結合してしまう可能性を指摘した。
これは、測定値が見かけ上、実際より高く出てしまう「アッセイの特異性」に関する根本的な問題だ。AIは、より正確に治療効果を測るには、標的質量分析や導入遺伝子に特異的な抗体を使った直交的な検証が必要だと、具体的な改善策まで提案している。
このほかにも、以下のような多角的な問題点が指摘された。
- 筋肉生検を行った部位が左右で異なることによる、空間的なばらつきの影響
- 比較対照として用いられた外部の自然歴データ群と、治験参加者との背景因子の違い
- 被験者の年齢層が4〜7歳であり、自然な運動機能の発達と治療効果が交絡する可能性
- 治療用ベクターとして使われたAAV9ウイルスに対する免疫反応と、心筋炎リスクの評価不足
重要なのは、これらの指摘が公開済みの一般論ではなく、目の前のデータパッケージに対する徹底した「アイテムごとの圧力テスト」として行われた点だ。OpenAIの記事によれば、GPT-Rosalindはこの複雑な査読タスクを高精度でこなす。これは、創薬企業が社内の専門家レビューを経る前に、AIによる網羅的な事前評価で議論の質を高め、開発の手戻りリスクを減らせる可能性を示している。
専門知識を要するタスクでの圧倒的な性能向上
GPT-Rosalindの真価は、生命科学の様々な専門領域を網羅する、新たに設計された評価ベンチマークのスコアによっても裏付けられている。OpenAIは、実際の研究ワークフローを模倣した複数のベンチマークを開発し、モデルの性能を測定した。
創薬化学ベンチマーク「MedChemBench」
創薬化学は、化合物を薬に変えるための学問だ。OpenAIが設計した「MedChemBench」は、化合物の構造理解から、構造活性相関(SAR)、薬効や毒性の予測、複数のパラメータを考慮したリード化合物の最適化、そして合成経路の設計(逆合成解析)まで、実際の創薬化学者の頭の中をそのままトレースするようなベンチマークである。
GPT-RosalindはこのMedChemBenchで27.5%のスコアを達成し、ベースとなったGPT-5.5の25.1%を上回った。特筆すべきは、この性能向上を達成するために消費したトークン数が、GPT-5.5と比較して7.2%も少なかったことだ。これは、より少ない計算リソースでより正確な答えを導き出せる、モデルの推論効率が向上したことを意味する。
ゲノミクス・定量生物学ベンチマーク「GeneBench」
ゲノムデータの解析は、単にツールを順番に動かせば良いというものではない。データの品質管理から始まり、モデリング手法の選択、そして結果の解釈に至るまで、長いステップの中で研究者が適切な判断を下し続ける必要がある。このような「長期的で自律的な分析能力」を測るのが「GeneBench」だ。
機能ゲノミクスや空間トランスクリプトミクス、プロテオミクスなど、多様なドメインの問題を含むこのベンチマークで、GPT-Rosalindは21.6%の正答率を達成。GPT-5.5の20.4%を上回りつつ、消費トークン数は実に31%も削減した。これは、複雑なデータ分析タスクをより効率的に、かつ破綻なく最後まで遂行できる能力が格段に向上した証拠だ。
実験現場の強い味方「LabWorkBench」
AIが論文やデータ分析に強いことは知られているが、実際に白衣を着て実験室(ウェットラボ)に立つ研究者の手助けができるかは別問題だ。OpenAIは、実際の実験プロトコルに基づき、トラブルシューティングや最適化を支援する能力を測る「LabWorkBench」を新たに導入した。
このベンチマークでGPT-Rosalindは63.2%のスコアを叩き出し、GPT-5.5の55.8%から大幅に向上した。ここでも消費トークンは5.3%削減されている。例えば、細胞培養でコンタミネーションが疑われる場合の原因究明や、PCR反応の条件検討など、熟練した研究者の経験に頼っていた領域で、AIが強力な支援を提供できる段階に入ったことを示している。
研究現場とAIをつなぐ実用的な分析プラグイン
いくらAIの性能が高くても、研究者の日常的なツールと切り離されていては宝の持ち腐れだ。OpenAIはこの課題に対し、生命科学研究専用の2つのCodexプラグインを公開した。
NGS分析プラグインでゲノムデータを対話的に探索
「Life Sciences NGS Analysis」プラグインは、次世代シーケンシングデータの解析を対話型で行えるようにするものだ。OpenAIのデモでは、液状腫瘍生検のctDNAデータを分析し、KRAS G12C変異に注目するプロセスが示されている。
このプラグインの強みは、単に解析パイプラインを自動実行するだけではない。処理されたデータから、再発性の変異やサンプルの軌跡をインタラクティブなノートブックとして可視化し、研究者がデータと直接対話しながら調査を進められる点だ。例えば、シングルセルRNAシーケンシングの解析では、品質管理の指標やUMAPによる細胞集団の可視化、細胞タイプのアノテーションまでを一貫して実行し、その過程で生じた判断の根拠やフィルタリングの履歴をすべて保存する。
これにより、解析結果の再現性と信頼性が飛躍的に高まる。従来のように、研究者が手作業でスクリプトを修正し、結果を目視で確認するのに費やしていた膨大な時間を、より創造的な仮説立案に充てられるようになる。
研究エビデンスを収集・解釈するリサーチプラグイン
もう一つの「Life Sciences Research」プラグインは、外部の論文や公開データベースから必要な情報を収集し、生物学的な解釈を加える役割を担う。先ほどのKRAS G12C変異の例でいえば、このプラグインが関連する阻害剤の情報や耐性メカニズムに関する文献を自動で収集し、研究者に提示する。
さらに、タンパク質の立体構造ビューアや塩基配列ビューアといったネイティブなファイル形式に対応したビューアも追加された。これにより、AIが提案した阻害剤がタンパク質のどの部分に結合するのかを、3次元構造を見ながらその場で検討できる。AIが提示するテキスト情報と、研究者自身の視覚的な専門判断をシームレスに統合できる環境が整ったのだ。
信頼できる形での産業展開と社会実装

強力な生物学的知能を有するAIを、どう社会実装するか。OpenAIはこの点について、明確な信頼構築の枠組みを示している。
GPT-Rosalindの利用は、明確な公共の利益をもたらす正当な科学研究を行う組織に限定され、強固なガバナンスと安全管理体制を持つことを条件とした「トラステッドアクセス」構造を通じて提供される。これは、技術の民主化と悪用防止のバランスを取るための、現時点での現実的な解と言える。
この世界的な展開の中で、OpenAIはデンマークの大手製薬企業Novo Nordiskとの協業を発表した。Novo NordiskのAI・デジタルイノベーション担当グループバイスプレジデント、Mishal Patel氏はOpenAIの記事の中で、「生命科学研究は複雑でデータが豊富、かつ学際的だ。研究者に意味のある価値を提供するには、AIモデルが信頼できる科学データに基づき、検証されたツールに接続され、研究者が日常的に使うワークフローに統合されていなければならない」と述べ、両社の協力関係への期待を示している。
この動きは重要だ。単に高性能なAIを作って終わりではなく、実際の創薬現場でどのようにデータを分析し、仮説を検証し、開発スピードを加速させるかという、極めて実務的な価値検証の段階に入ったことを意味する。GPT-Rosalindの強みは、文献情報、ゲノムデータ、トランスクリプトームデータ、タンパク質の立体構造といった異なる階層の情報を結びつけ、一貫した生物学的なストーリーとして研究者に提示できることにある。これは、複雑化する創薬プロセスにおいて、人間の認知負荷を大きく下げる可能性を秘めている。
この記事のポイント
- GPT-Rosalindは、実験計画の批判的レビューや創薬化学、ゲノム解析など、専門性の高いタスクで性能が向上し、従来モデルより少ない計算リソースで高精度な回答を実現する
- NGS解析や文献調査の専用プラグインによって、データ分析から仮説立案までの研究ワークフローがシームレスに統合された
- Novo Nordiskとの協業に象徴されるように、実際の創薬現場での実用性と価値検証の段階に入った
- AIの社会実装にあたり、公共の利益と強固なガバナンスを条件とした信頼構築モデルが採用されている

ChatGPTメモリがDreamingで進化、長期記憶と時間経過を自動反映
OpenAIが2026年6月4日、ChatGPTのメモリ機能を抜本的に改良したと発表した。新たに「Dreaming V3」というシステムを導入し、大規模なユーザー数と長期間の利用を想定したメモリ管理を実現する。
従来の「保存メモリ」は、明示的な指示がなければ情報を覚えられず、時間とともに内容が陳腐化する課題を抱えていた。今回のアップデートで、ChatGPTはバックグラウンドで会話履歴を分析し、自動的にメモリを最新化する。Plus・Proユーザーは同日より利用可能で、FreeユーザーとGoユーザーへの展開も数週間以内に開始される。
メモリ機能「Dreaming」の仕組み

Dreamingは、ChatGPTがあなたとのあらゆる会話から学習し、メモリを合成するバックグラウンド処理だ。従来の「ノートを取ってくれるが、書かなかったことは忘れる同僚」のような挙動から、「会話の文脈全体を理解し、常に最新情報を反映するパートナー」への変化と言える。
なぜDreamingが必要になったのか
ChatGPTのメモリ機能は2024年4月に初登場した。これは「保存メモリ」と呼ばれ、ユーザーが「覚えておいて」と指示した情報だけを保存する仕組みだった。しかし実際の会話では、明示的に指示されない暗黙の好みや状況が大量に存在する。保存メモリだけでは、数カ月前の旅行計画が終了しても「まだ旅行中」と誤認識するなど、情報の鮮度が落ちる問題が避けられなかった。
2025年4月にDreamingの初期バージョンが導入され、保存メモリを補完する形で改善が図られた。しかし当時はまだ、単独のメモリシステムとして十分に機能する段階にはなかった。今回のDreaming V3は、この補助的な役割を超え、完全なメモリ管理システムとして再設計されている。
Dreaming V3が実現する3つの目標

OpenAIは「優れたメモリ」を定義する3つの柱を提示している。過去の会話から有用な文脈を引き継ぐこと、ユーザーの好みや制約に従うこと、そして時間経過を考慮して情報を最新に保つことだ。Dreaming V3の評価結果は、この3軸すべてで大幅な改善を示している。
文脈の引き継ぎ:過去の自分を忘れない
新しいチャットを始めるたびに自己紹介からやり直す必要がなくなる。たとえば、過去にカメラ機材について相談していれば、ChatGPTは「私の撮影構成に合うもの」という曖昧な質問にも、過去の会話を踏まえた的確な製品を提案できる。これは、長期間にわたる複雑なプロジェクトで特に威力を発揮する。
好みと制約の反映:暗黙のルールを理解する
ユーザーの好みには、明示的な指示(「スタンの話はもう出さないで」)から、個人の制約(「私はベジタリアンです」)、そして地理情報のような暗黙の好み(「サンフランシスコ近郊に住んでいる」から現地情報を優先する)まで様々な形がある。Dreaming V3は、これらの情報を会話の流れから自然に拾い上げ、矛盾のない応答を継続的に生成する。
OpenAIの評価では、「ベジタリアン」と伝えたユーザーが後日食事の提案を求めた際、Dreamingが自動的に菜食対応の選択肢を提示するかがテストされた。結果は、従来の保存メモリ単体に比べて大幅な正答率の向上を示したという。
時間経過への対応:記憶を自動で更新する
従来の最大の弱点は、時間の経過によるメモリの陳腐化だった。Dreamingはここで真価を発揮する。たとえば「7月にシンガポール旅行」という記憶は、旅行が終われば自動的に「2026年7月にシンガポールに行った」という過去の出来事に書き換えられる。ChatGPTはその後、自宅近辺の情報を優先して提供するようになる。
OpenAIの評価では、時間経過が正しい回答に影響を与えるシナリオで、Dreamingが顕著な改善を達成したと報告されている。これは、単なる事実記憶ではなく、時間的文脈を理解した応答が可能になったことを意味する。
計算効率の改善と無料ユーザーへの展開

Dreaming V3のもう一つの重要な進化は、計算効率だ。OpenAIによれば、今回の改良によりDreamingを無料ユーザーに提供するために必要な計算リソースが約5分の1に削減された。これは、大規模なユーザーベースに対して実用的なメモリシステムを展開する上で決定的なブレイクスルーである。
以前は、Dreamingの処理負荷が高く、Freeユーザーに品質基準を満たしたメモリ機能を提供することが難しかった。今回の効率化により、数週間以内にFreeユーザーとGoユーザーへの段階的なロールアウトが開始される。同時に、Plus・Proユーザーのメモリ容量も拡張される予定だ。
この効率化は、単にユーザー数を増やすためだけではない。OpenAIの長期的なビジョンである「全ユーザーに共有メモリ基盤を提供する」という目標に向けた、アーキテクチャ上の重要なマイルストーンでもある。
メモリの透明性とユーザーコントロール

Dreamingが自動で合成したメモリは、すべてメモリサマリーページで確認できる。このページでは、ChatGPTがあなたについて把握しているハイライトを一目で把握し、必要に応じて情報の追加や更新、特定の話題に関する指示を与えることが可能だ。さらに詳細を知りたい場合は、チャットを通じて深掘りすることもできる。
これは、AIのパーソナライズ機能において重要なバランスだ。高い利便性を提供しつつ、ユーザーが自分のデータの全体像を把握し、コントロールできる状態を維持している。自動化と透明性の両立が、Dreamingの設計思想に組み込まれている。
Dreamingがもたらす実務への影響と今後の展望

Dreaming V3の登場は、ChatGPTを単発の質問応答ツールから、長期的なパートナーへと進化させる転換点だ。特に、プロジェクト管理や継続的な学習相談、ビジネス上の意思決定支援など、時間をかけて関係性を構築するユースケースで真価を発揮する。
OpenAIはこのアップデートを「これまでで最も高性能なメモリシステム」と位置づけており、今後も改良を続けるとしている。Dreamingは、将来的により高度なエージェント機能や、複数のChatGPTセッションを横断したタスク実行の基盤となる可能性が高い。
一方で、バックグラウンドで常に会話履歴を分析することへのプライバシー感度は、ユーザーによって異なるだろう。OpenAIはメモリの確認・削除を容易にするインターフェースを提供しているが、AIの記憶が深まるにつれて、データ管理の重要性も比例して高まる。このバランスが、今後の普及速度を左右する要素の一つになる。
このデモは、DreamingがChatGPTの役割を根本から変えることを示している。もはや「賢い検索エンジン」ではなく、あなたの文脈を理解し続ける存在になる。
この記事のポイント
- Dreaming V3は、バックグラウンドで全チャット履歴から自動的にメモリを合成する
- 「文脈引き継ぎ」「好みの反映」「時間経過対応」の3軸で大幅な改善を達成
- 計算効率が約5倍向上し、Free・Goユーザーへの展開が開始される
- メモリサマリーページで、ChatGPTの把握内容を常に確認・編集可能
- 長期的なプロジェクト支援やパーソナライズの質が飛躍的に向上する