

OpenAI、生命科学特化型AI「GPT Rosalind」を大幅刷新。複雑な研究ワークフローを自律支援
OpenAIは2026年6月3日、生命科学研究に特化したAIモデル「GPT-Rosalind」の最新アップデートを発表した。この新版は、GPT-5.5の自律的なコーディングや外部ツール活用の能力を基盤に、医薬品化学やゲノム科学といった創薬の中核領域での知能を大幅に強化している。単なる性能向上に留まらず、実際の研究ワークフローに密着した新機能と評価指標が加わった点が最大の特徴だ。
具体的には、実験計画の批判的レビュー、化学構造の解析、長期的なデータ分析タスクなど、研究者が日々直面する複雑な作業において、処理効率と精度を両立させている。さらに、対話的な研究環境を実現するプラグイン群も公開され、AIが論文や実験データを横断的に解釈し、具体的な次の一手を提示できるようになった。
この記事では、GPT-Rosalindの具体的な改良点、研究現場での活用方法、そしてこの技術が生命科学産業にもたらす実務的なインパクトについて、詳しく解説していく。
複雑な創薬プロセスを支える「審査官」としての知能

今回のアップデートで最も注目すべき点は、AIが研究データの単なる分析者から、研究戦略そのものを批判的に評価する「査読者」の役割を担い始めたことだ。OpenAIの記事では、ある遺伝子治療薬の治験データパッケージをGPT-Rosalindに評価させた事例が紹介されている。
AIに与えられたのは、デュシェンヌ型筋ジストロフィーを対象とした架空の遺伝子治療薬「AAV9-microDys-X」の第1/2相試験データだ。GPT-Rosalindは、このデータを承認申請の根拠として使うにはどのような穴があるか、FDAのような厳しい視点で項目ごとに圧力テストを行った。
AIが見抜いた実験デザインの落とし穴
GPT-Rosalindの回答は、研究開発の現場を知る者にとって非常に実践的な内容だった。例えば、タンパク質の定量法についてだ。この試験では、導入したマイクロジストロフィンというタンパク質の量を、ウェスタンブロット法で測定していた。しかしAIは、使用されたMANEX1A抗体が、治療用のマイクロジストロフィンだけでなく、患者の体内に元からあるごくわずかな正常ジストロフィン(復帰線維由来)にも結合してしまう可能性を指摘した。
これは、測定値が見かけ上、実際より高く出てしまう「アッセイの特異性」に関する根本的な問題だ。AIは、より正確に治療効果を測るには、標的質量分析や導入遺伝子に特異的な抗体を使った直交的な検証が必要だと、具体的な改善策まで提案している。
このほかにも、以下のような多角的な問題点が指摘された。
- 筋肉生検を行った部位が左右で異なることによる、空間的なばらつきの影響
- 比較対照として用いられた外部の自然歴データ群と、治験参加者との背景因子の違い
- 被験者の年齢層が4〜7歳であり、自然な運動機能の発達と治療効果が交絡する可能性
- 治療用ベクターとして使われたAAV9ウイルスに対する免疫反応と、心筋炎リスクの評価不足
重要なのは、これらの指摘が公開済みの一般論ではなく、目の前のデータパッケージに対する徹底した「アイテムごとの圧力テスト」として行われた点だ。OpenAIの記事によれば、GPT-Rosalindはこの複雑な査読タスクを高精度でこなす。これは、創薬企業が社内の専門家レビューを経る前に、AIによる網羅的な事前評価で議論の質を高め、開発の手戻りリスクを減らせる可能性を示している。
専門知識を要するタスクでの圧倒的な性能向上
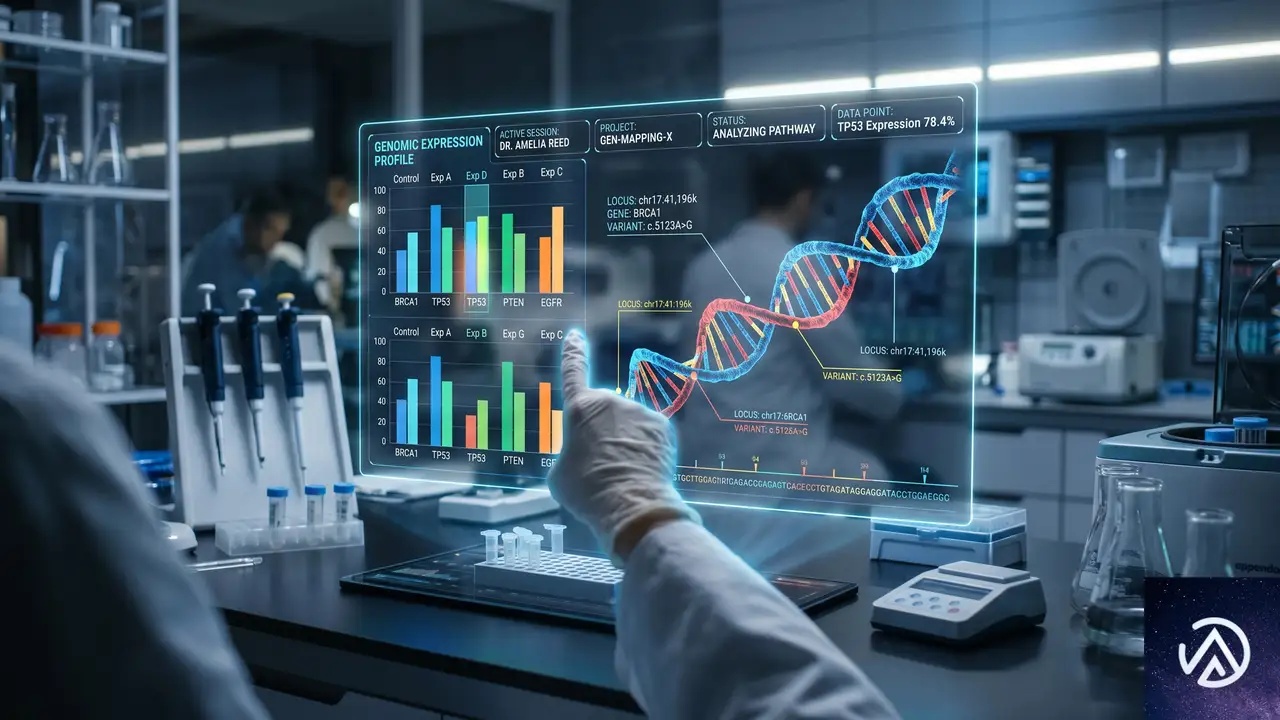
GPT-Rosalindの真価は、生命科学の様々な専門領域を網羅する、新たに設計された評価ベンチマークのスコアによっても裏付けられている。OpenAIは、実際の研究ワークフローを模倣した複数のベンチマークを開発し、モデルの性能を測定した。
創薬化学ベンチマーク「MedChemBench」
創薬化学は、化合物を薬に変えるための学問だ。OpenAIが設計した「MedChemBench」は、化合物の構造理解から、構造活性相関(SAR)、薬効や毒性の予測、複数のパラメータを考慮したリード化合物の最適化、そして合成経路の設計(逆合成解析)まで、実際の創薬化学者の頭の中をそのままトレースするようなベンチマークである。
GPT-RosalindはこのMedChemBenchで27.5%のスコアを達成し、ベースとなったGPT-5.5の25.1%を上回った。特筆すべきは、この性能向上を達成するために消費したトークン数が、GPT-5.5と比較して7.2%も少なかったことだ。これは、より少ない計算リソースでより正確な答えを導き出せる、モデルの推論効率が向上したことを意味する。
ゲノミクス・定量生物学ベンチマーク「GeneBench」
ゲノムデータの解析は、単にツールを順番に動かせば良いというものではない。データの品質管理から始まり、モデリング手法の選択、そして結果の解釈に至るまで、長いステップの中で研究者が適切な判断を下し続ける必要がある。このような「長期的で自律的な分析能力」を測るのが「GeneBench」だ。
機能ゲノミクスや空間トランスクリプトミクス、プロテオミクスなど、多様なドメインの問題を含むこのベンチマークで、GPT-Rosalindは21.6%の正答率を達成。GPT-5.5の20.4%を上回りつつ、消費トークン数は実に31%も削減した。これは、複雑なデータ分析タスクをより効率的に、かつ破綻なく最後まで遂行できる能力が格段に向上した証拠だ。
実験現場の強い味方「LabWorkBench」
AIが論文やデータ分析に強いことは知られているが、実際に白衣を着て実験室(ウェットラボ)に立つ研究者の手助けができるかは別問題だ。OpenAIは、実際の実験プロトコルに基づき、トラブルシューティングや最適化を支援する能力を測る「LabWorkBench」を新たに導入した。
このベンチマークでGPT-Rosalindは63.2%のスコアを叩き出し、GPT-5.5の55.8%から大幅に向上した。ここでも消費トークンは5.3%削減されている。例えば、細胞培養でコンタミネーションが疑われる場合の原因究明や、PCR反応の条件検討など、熟練した研究者の経験に頼っていた領域で、AIが強力な支援を提供できる段階に入ったことを示している。
研究現場とAIをつなぐ実用的な分析プラグイン
いくらAIの性能が高くても、研究者の日常的なツールと切り離されていては宝の持ち腐れだ。OpenAIはこの課題に対し、生命科学研究専用の2つのCodexプラグインを公開した。
NGS分析プラグインでゲノムデータを対話的に探索
「Life Sciences NGS Analysis」プラグインは、次世代シーケンシングデータの解析を対話型で行えるようにするものだ。OpenAIのデモでは、液状腫瘍生検のctDNAデータを分析し、KRAS G12C変異に注目するプロセスが示されている。
このプラグインの強みは、単に解析パイプラインを自動実行するだけではない。処理されたデータから、再発性の変異やサンプルの軌跡をインタラクティブなノートブックとして可視化し、研究者がデータと直接対話しながら調査を進められる点だ。例えば、シングルセルRNAシーケンシングの解析では、品質管理の指標やUMAPによる細胞集団の可視化、細胞タイプのアノテーションまでを一貫して実行し、その過程で生じた判断の根拠やフィルタリングの履歴をすべて保存する。
これにより、解析結果の再現性と信頼性が飛躍的に高まる。従来のように、研究者が手作業でスクリプトを修正し、結果を目視で確認するのに費やしていた膨大な時間を、より創造的な仮説立案に充てられるようになる。
研究エビデンスを収集・解釈するリサーチプラグイン
もう一つの「Life Sciences Research」プラグインは、外部の論文や公開データベースから必要な情報を収集し、生物学的な解釈を加える役割を担う。先ほどのKRAS G12C変異の例でいえば、このプラグインが関連する阻害剤の情報や耐性メカニズムに関する文献を自動で収集し、研究者に提示する。
さらに、タンパク質の立体構造ビューアや塩基配列ビューアといったネイティブなファイル形式に対応したビューアも追加された。これにより、AIが提案した阻害剤がタンパク質のどの部分に結合するのかを、3次元構造を見ながらその場で検討できる。AIが提示するテキスト情報と、研究者自身の視覚的な専門判断をシームレスに統合できる環境が整ったのだ。
信頼できる形での産業展開と社会実装

強力な生物学的知能を有するAIを、どう社会実装するか。OpenAIはこの点について、明確な信頼構築の枠組みを示している。
GPT-Rosalindの利用は、明確な公共の利益をもたらす正当な科学研究を行う組織に限定され、強固なガバナンスと安全管理体制を持つことを条件とした「トラステッドアクセス」構造を通じて提供される。これは、技術の民主化と悪用防止のバランスを取るための、現時点での現実的な解と言える。
この世界的な展開の中で、OpenAIはデンマークの大手製薬企業Novo Nordiskとの協業を発表した。Novo NordiskのAI・デジタルイノベーション担当グループバイスプレジデント、Mishal Patel氏はOpenAIの記事の中で、「生命科学研究は複雑でデータが豊富、かつ学際的だ。研究者に意味のある価値を提供するには、AIモデルが信頼できる科学データに基づき、検証されたツールに接続され、研究者が日常的に使うワークフローに統合されていなければならない」と述べ、両社の協力関係への期待を示している。
この動きは重要だ。単に高性能なAIを作って終わりではなく、実際の創薬現場でどのようにデータを分析し、仮説を検証し、開発スピードを加速させるかという、極めて実務的な価値検証の段階に入ったことを意味する。GPT-Rosalindの強みは、文献情報、ゲノムデータ、トランスクリプトームデータ、タンパク質の立体構造といった異なる階層の情報を結びつけ、一貫した生物学的なストーリーとして研究者に提示できることにある。これは、複雑化する創薬プロセスにおいて、人間の認知負荷を大きく下げる可能性を秘めている。
この記事のポイント
- GPT-Rosalindは、実験計画の批判的レビューや創薬化学、ゲノム解析など、専門性の高いタスクで性能が向上し、従来モデルより少ない計算リソースで高精度な回答を実現する
- NGS解析や文献調査の専用プラグインによって、データ分析から仮説立案までの研究ワークフローがシームレスに統合された
- Novo Nordiskとの協業に象徴されるように、実際の創薬現場での実用性と価値検証の段階に入った
- AIの社会実装にあたり、公共の利益と強固なガバナンスを条件とした信頼構築モデルが採用されている

ChatGPTメモリがDreamingで進化、長期記憶と時間経過を自動反映
OpenAIが2026年6月4日、ChatGPTのメモリ機能を抜本的に改良したと発表した。新たに「Dreaming V3」というシステムを導入し、大規模なユーザー数と長期間の利用を想定したメモリ管理を実現する。
従来の「保存メモリ」は、明示的な指示がなければ情報を覚えられず、時間とともに内容が陳腐化する課題を抱えていた。今回のアップデートで、ChatGPTはバックグラウンドで会話履歴を分析し、自動的にメモリを最新化する。Plus・Proユーザーは同日より利用可能で、FreeユーザーとGoユーザーへの展開も数週間以内に開始される。
メモリ機能「Dreaming」の仕組み

Dreamingは、ChatGPTがあなたとのあらゆる会話から学習し、メモリを合成するバックグラウンド処理だ。従来の「ノートを取ってくれるが、書かなかったことは忘れる同僚」のような挙動から、「会話の文脈全体を理解し、常に最新情報を反映するパートナー」への変化と言える。
なぜDreamingが必要になったのか
ChatGPTのメモリ機能は2024年4月に初登場した。これは「保存メモリ」と呼ばれ、ユーザーが「覚えておいて」と指示した情報だけを保存する仕組みだった。しかし実際の会話では、明示的に指示されない暗黙の好みや状況が大量に存在する。保存メモリだけでは、数カ月前の旅行計画が終了しても「まだ旅行中」と誤認識するなど、情報の鮮度が落ちる問題が避けられなかった。
2025年4月にDreamingの初期バージョンが導入され、保存メモリを補完する形で改善が図られた。しかし当時はまだ、単独のメモリシステムとして十分に機能する段階にはなかった。今回のDreaming V3は、この補助的な役割を超え、完全なメモリ管理システムとして再設計されている。
Dreaming V3が実現する3つの目標

OpenAIは「優れたメモリ」を定義する3つの柱を提示している。過去の会話から有用な文脈を引き継ぐこと、ユーザーの好みや制約に従うこと、そして時間経過を考慮して情報を最新に保つことだ。Dreaming V3の評価結果は、この3軸すべてで大幅な改善を示している。
文脈の引き継ぎ:過去の自分を忘れない
新しいチャットを始めるたびに自己紹介からやり直す必要がなくなる。たとえば、過去にカメラ機材について相談していれば、ChatGPTは「私の撮影構成に合うもの」という曖昧な質問にも、過去の会話を踏まえた的確な製品を提案できる。これは、長期間にわたる複雑なプロジェクトで特に威力を発揮する。
好みと制約の反映:暗黙のルールを理解する
ユーザーの好みには、明示的な指示(「スタンの話はもう出さないで」)から、個人の制約(「私はベジタリアンです」)、そして地理情報のような暗黙の好み(「サンフランシスコ近郊に住んでいる」から現地情報を優先する)まで様々な形がある。Dreaming V3は、これらの情報を会話の流れから自然に拾い上げ、矛盾のない応答を継続的に生成する。
OpenAIの評価では、「ベジタリアン」と伝えたユーザーが後日食事の提案を求めた際、Dreamingが自動的に菜食対応の選択肢を提示するかがテストされた。結果は、従来の保存メモリ単体に比べて大幅な正答率の向上を示したという。
時間経過への対応:記憶を自動で更新する
従来の最大の弱点は、時間の経過によるメモリの陳腐化だった。Dreamingはここで真価を発揮する。たとえば「7月にシンガポール旅行」という記憶は、旅行が終われば自動的に「2026年7月にシンガポールに行った」という過去の出来事に書き換えられる。ChatGPTはその後、自宅近辺の情報を優先して提供するようになる。
OpenAIの評価では、時間経過が正しい回答に影響を与えるシナリオで、Dreamingが顕著な改善を達成したと報告されている。これは、単なる事実記憶ではなく、時間的文脈を理解した応答が可能になったことを意味する。
計算効率の改善と無料ユーザーへの展開

Dreaming V3のもう一つの重要な進化は、計算効率だ。OpenAIによれば、今回の改良によりDreamingを無料ユーザーに提供するために必要な計算リソースが約5分の1に削減された。これは、大規模なユーザーベースに対して実用的なメモリシステムを展開する上で決定的なブレイクスルーである。
以前は、Dreamingの処理負荷が高く、Freeユーザーに品質基準を満たしたメモリ機能を提供することが難しかった。今回の効率化により、数週間以内にFreeユーザーとGoユーザーへの段階的なロールアウトが開始される。同時に、Plus・Proユーザーのメモリ容量も拡張される予定だ。
この効率化は、単にユーザー数を増やすためだけではない。OpenAIの長期的なビジョンである「全ユーザーに共有メモリ基盤を提供する」という目標に向けた、アーキテクチャ上の重要なマイルストーンでもある。
メモリの透明性とユーザーコントロール

Dreamingが自動で合成したメモリは、すべてメモリサマリーページで確認できる。このページでは、ChatGPTがあなたについて把握しているハイライトを一目で把握し、必要に応じて情報の追加や更新、特定の話題に関する指示を与えることが可能だ。さらに詳細を知りたい場合は、チャットを通じて深掘りすることもできる。
これは、AIのパーソナライズ機能において重要なバランスだ。高い利便性を提供しつつ、ユーザーが自分のデータの全体像を把握し、コントロールできる状態を維持している。自動化と透明性の両立が、Dreamingの設計思想に組み込まれている。
Dreamingがもたらす実務への影響と今後の展望

Dreaming V3の登場は、ChatGPTを単発の質問応答ツールから、長期的なパートナーへと進化させる転換点だ。特に、プロジェクト管理や継続的な学習相談、ビジネス上の意思決定支援など、時間をかけて関係性を構築するユースケースで真価を発揮する。
OpenAIはこのアップデートを「これまでで最も高性能なメモリシステム」と位置づけており、今後も改良を続けるとしている。Dreamingは、将来的により高度なエージェント機能や、複数のChatGPTセッションを横断したタスク実行の基盤となる可能性が高い。
一方で、バックグラウンドで常に会話履歴を分析することへのプライバシー感度は、ユーザーによって異なるだろう。OpenAIはメモリの確認・削除を容易にするインターフェースを提供しているが、AIの記憶が深まるにつれて、データ管理の重要性も比例して高まる。このバランスが、今後の普及速度を左右する要素の一つになる。
このデモは、DreamingがChatGPTの役割を根本から変えることを示している。もはや「賢い検索エンジン」ではなく、あなたの文脈を理解し続ける存在になる。
この記事のポイント
- Dreaming V3は、バックグラウンドで全チャット履歴から自動的にメモリを合成する
- 「文脈引き継ぎ」「好みの反映」「時間経過対応」の3軸で大幅な改善を達成
- 計算効率が約5倍向上し、Free・Goユーザーへの展開が開始される
- メモリサマリーページで、ChatGPTの把握内容を常に確認・編集可能
- 長期的なプロジェクト支援やパーソナライズの質が飛躍的に向上する

WooCommerce 10.9でデュアルAPI登場、PHPコードからGraphQLを自動生成
WooCommerce 10.9で、PHPコードからGraphQL APIを自動生成する「デュアルAPI」が実験的に導入された。AutomatticのRadical Speed Monthイニシアチブの一環として開発されたこの機能は、開発者がPHPクラスに属性(アトリビュート)を付与するだけで、REST APIとGraphQL APIの両方を提供できるようにするものだ。
本記事では、デュアルAPIの技術的な仕組みと、プラグイン開発者にとっての具体的なメリット、現時点での制限と注意点を詳しく解説する。PHP 8.1以上が必須となるため、サーバー環境のバージョンアップを検討している運営者にも役立つ情報をまとめた。
WooCommerceデュアルAPIの概要と狙い

デュアルAPIの3つの構成要素
WooCommerce Developer Blogの記事によれば、デュアルAPIは大きく3つのパーツで成り立っている。1つ目は、PHP属性で装飾されたプレーンなPHPクラスで表現される「コードAPI」だ。これはコマンドパターンで実行可能なクラスか、データ転送オブジェクト(DTO)として定義される。2つ目は、そのコードAPIから自動生成される「GraphQL API」。そして3つ目が、開発時にコードからGraphQLパートを生成する「ビルドスクリプト」である。
なぜGraphQL APIを自動生成するのか
従来のWooCommerce REST APIは、決められたエンドポイントから必要なデータを取得する方式だった。一方、GraphQLはクライアントが必要なフィールドだけをリクエストできるため、オーバーフェッチやアンダーフェッチを防げる。モバイルアプリやヘッドレスコマース構成との相性も良い。しかし、APIを二重にメンテナンスする手間は大きい。そこで、PHPコードを信頼できる唯一の情報源(ソースオブトゥルース)とし、GraphQL側を自動生成することで、開発効率と一貫性を両立させる狙いがある。
コードからGraphQLを自動生成する仕組み
PHPクラスに定義した属性や型情報が、GraphQLスキーマのクエリ名、引数、返却型へと自動的にマッピングされる。開発者はPHPコードだけを書けば、対応するGraphQLエンドポイントが手に入る仕組みだ。
PHP属性によるメタデータの付与
この仕組みの中核が、PHP 8.0で導入された「属性(アトリビュート)」だ。クラスやメソッド、プロパティに #[Name('coupon')] や #[Description('...')] といった形でメタデータを埋め込める。このメタデータをビルドスクリプトが読み取り、GraphQLの型定義やドキュメントを自動構築する。PHPのコードベースがそのままAPIの仕様書になるわけだ。
コマンドクラスとDTOの変換ルール
実行可能なコマンドクラスはGraphQLのクエリやミューテーションに変換される。引数には #[Description] 属性付きで説明がつき、デフォルト値やnull許容もスキーマに反映される。DTOはGraphQLのインプットタイプやアウトプットタイプになる。PHPの列挙型(enum)や #[ArrayOf('int')] のようなカスタム属性を使えば、スカラー型の配列や独自型も正確に表現できる。
ビルドスクリプトの役割
ビルドスクリプトは開発時に一度だけ実行する。WooCommerceコアに同梱されており、プラグイン開発者も自分のコードに対して実行可能だ。スクリプトがコードAPIを解析し、GraphQLスキーマをファイルとして出力する。実行時にはそのスキーマに従ってリクエストが処理されるため、本番環境で毎回コードを解析する必要はない。
プラグイン開発におけるデュアルAPIの活用方法
独自のデュアルAPIを作成する手順
WooCommerce Developer Blogの記事では、プラグイン開発者がこのインフラを再利用して独自のデュアルAPIを構築できる点が強調されている。手順はシンプルだ。まず、プラグイン内にコマンドクラスとDTOを定義し、必要な属性を付与する。次に、WooCommerceのビルドスクリプトを開発時に走らせると、GraphQLパートが自動生成される。最後に rest_api_init フックを使い、ユーティリティメソッドで任意のエンドポイントURLにGraphQL APIを登録すれば完了する。
認証・認可のカスタマイズと拡張ポイント
コアのインフラは、クラスリゾルバ(デフォルトではWooCommerceのDIコンテナ)や、認証用のプリンシパルクラス、認可用の #[RequiredCapability] 属性を提供している。これらはそのまま使うことも、独自の認証・認可ロジックに置き換えることも可能だ。例えば、外部サービスと連携するプラグインであれば、カスタムのプリンシパルクラスを差し込んでAPIキー認証を実装できる。柔軟な拡張性が意識された設計である。
現時点での制限と実験的機能の注意点

後方互換性の保証がない理由
このデュアルAPIは実験的な機能であり、明示的に有効化しない限り動作しない。WooCommerce Developer Blogの記事でも、インフラ部分とコアAPIのいずれについても、将来のリリースで後方互換性のない変更が加えられる可能性があると明言されている。特に、より徹底したテストの過程で、属性の命名規則やクラス構成に破壊的変更が入るかもしれない。本番環境への導入は、安定版となるまで控えたほうが無難だ。
コアAPIのプルーフオブコンセプト
WooCommerce 10.9に同梱されるコアAPIは、製品とクーポンをカバーする限定的なものだ。記事では、これはあくまで「プルーフオブコンセプト(概念実証)」であり、今後のバージョンでクラスやクエリが大幅に変更されるか、まったく別のものに置き換わる可能性があるとされている。現時点では、開発環境やステージング環境でのテスト利用が推奨される。
PHP 7環境の安全性とバージョンアップの必要性

PHP 8.1依存の技術的理由
デュアルAPIはPHP 8.1以上を要求する。これは、PHP属性と列挙型(enum)に依存しているためだ。属性がなければGraphQLスキーマを自動生成できず、enumがなければDTOの厳密な型表現が難しくなる。WooCommerceとしても、公式にPHP 8.1以上を推奨しており、PHP 7.4や8.0のサポートは将来的に終了する方針が示されている。
PHP 7環境での影響と注意点
WooCommerce Developer Blogの記事によると、PHP 8.1固有のコードは、この機能が無効の場合やサーバーがPHP 7.4/8.0で動作している場合には一切実行されない設計になっている。したがって、機能を誤って有効化しようとしてもエラーは発生せず、GraphQLエンドポイントが機能しないだけだ。ただし、プラグインやカスタムコードから src/Api 配下のクラスを直接呼び出すと、PHP 7環境ではエラーになるため注意が必要である。
将来のPHPバージョンサポート計画
WooCommerceは過去にPHP 7.2/7.3のサポートを段階的に終了してきた。今回のデュアルAPI導入は、PHP 8.1移行を加速させる呼び水となるだろう。WordPress 7.0がPHP 7.2/7.3のサポートを打ち切り、PHP 8互換がベータを脱したことも追い風だ。ECサイト運営者は、セキュリティ面とパフォーマンス面からも、早めのPHPバージョンアップを検討すべき局面を迎えている。
この記事のポイント
- WooCommerce 10.9で実験的デュアルAPIが導入され、PHPコードからGraphQL APIを自動生成できるようになった
- PHP属性とDTOによってコードがAPI仕様を兼ね、プラグイン開発者も独自のデュアルAPIを構築可能
- 現時点では後方互換性が保証されない実験的機能であり、本番利用は避け、テスト環境での検証が推奨される
- PHP 8.1以上が必須で、PHP 7環境では機能が無効化されるが、安全面でのリスクは低い
- PHPバージョンアップの必要性が高まっており、ECサイトの将来的な安定稼働に向けて計画的な移行が望ましい

GitHub Copilotデスクトップアプリ登場、エージェント駆動開発の拠点に
GitHubが2026年6月2日、新たなGitHub Copilotアプリをテクニカルプレビューとして公開した。このアプリは、複数のAIエージェントを並行して管理・指示するための「エージェントネイティブ」なデスクトップ体験を提供する。
Copilot Pro、Pro+、Business、Enterpriseの既存ユーザーはすぐに利用を開始できる。My Workビュー、ワークツリーによるセッション分離、Agent Merge、Canvas、サンドボックス、高度なコードレビュー、SDK、刷新されたCLIなど、エージェント主導開発の基盤として設計された機能群を詳しく見ていく。
GitHub Copilotアプリ:エージェントネイティブ開発のコントロールセンター
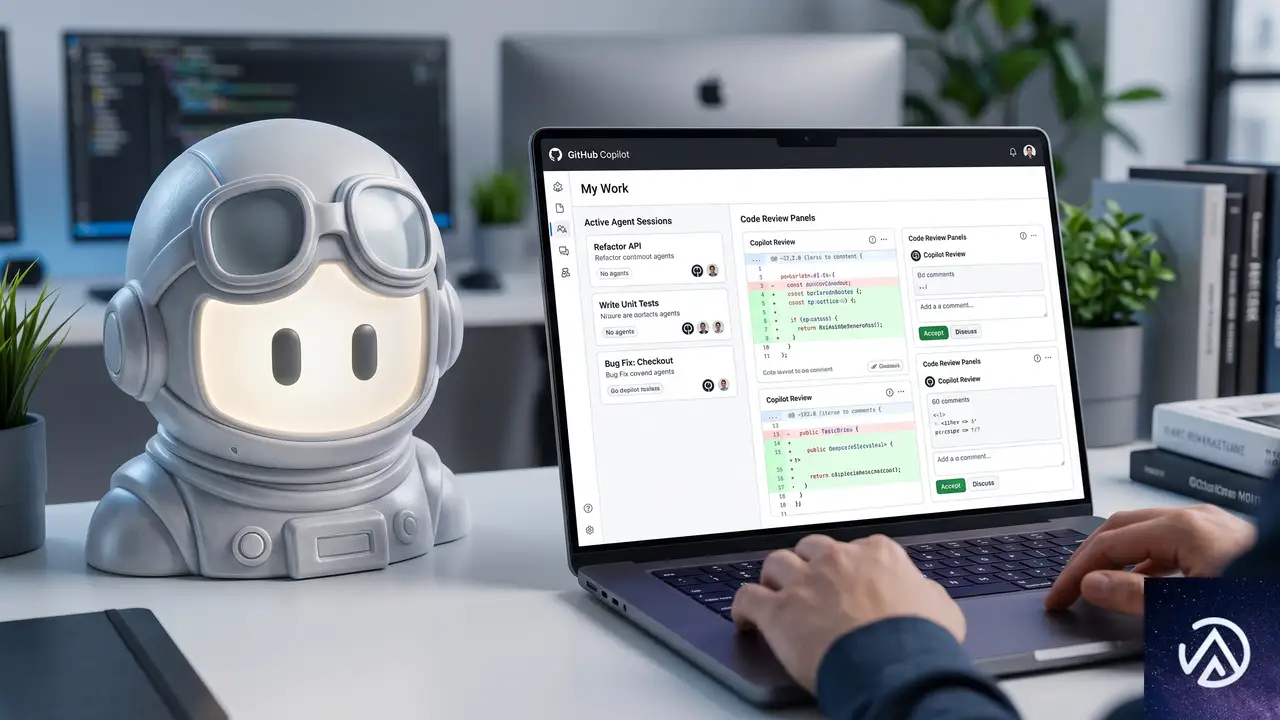
多くの開発者が日常的に複数エージェントを動かすようになるにつれ、ウィンドウを切り替えながらセッションを追跡する従来のやり方では限界が出てきた。Copilotアプリはその断絶を解消する。
「My Work」ビューは、接続されたリポジトリ全体にわたって稼働中のセッション、Issue、プルリクエスト、バックグラウンド自動化を一覧表示する。各セッションは固有のgit worktree(ブランチの独立した作業コピー)で実行されるため、エージェントどうしが互いの作業を壊すことはない。worktreeの作成や後片付けはアプリが自動的に処理する。
さらにAgent Merge機能は、プルリクエストをレビューからチェック、マージまで運ぶ。CIの監視、必須レビュアーの確認、失敗したチェックの修正をCopilotが代行し、開発者は「CIをグリーンに戻す」「フィードバックに対応する」「条件を満たしたらマージする」といった自動化の範囲を選べる。
GitHub Blogに掲載されたAvanade Inc.のDavid Jobling氏(Master Technology Architect)のコメントによれば、「Forward Deployedのエンジニアは多数のエージェントを一元的に扱い、複数のイニシアチブを管理できる。プランやオートパイロットへのアクセスが容易になり、必要に応じてインタラクティブなセッションを実行したりコードに介入したりできる」と評価している。
この統合感をビフォーアフターで示すと、次のような差になる。
このデモのように、Copilotアプリはエージェントが「ただコードを提案する」存在から「プロジェクト全体を駆動する」存在へ変わるための統制盤になる。
Canvas:意図を見える化する双方向作業面
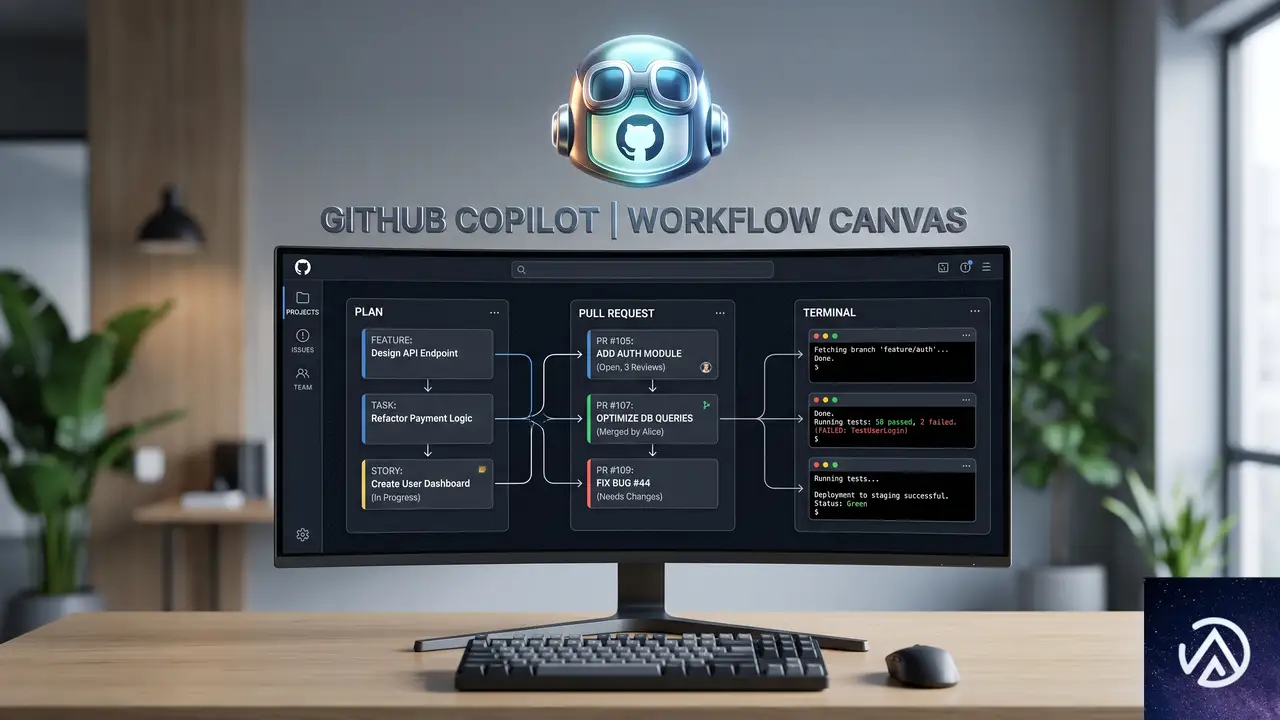
チャットは指示や曖昧さの解消に強い。しかしエージェントが本格的な作業を始めると、チャットスレッドは判断やログ、修正指示の長いスクロールになり、作業そのものの全体像を見失いがちだ。
そこで導入されたCanvasは、人間とエージェントが同じ面で作業する双方向の作業サーフェスだ。プラン、プルリクエスト、ブラウザセッション、ターミナル、デプロイ状況、ワークフローの状態など、エージェントが作業を進めるにつれてCanvasが更新され、開発者はその場で編集、順序変更、承認、方向転換ができる。
チャットが「思考の場」だとすれば、Canvasは「作業の場」だ。これが、GitHubが提唱するエージェント体験(AX)の出発点になる。
サンドボックス:本番に触れずにエージェントを動かす隔離環境

コードを提案するだけでなく、実際にコードを実行し、テストし、結果を調べて反復できることがエージェントの実用性を高める。そのために用意されたのが、ローカルとクラウドの2種類のサンドボックスだ。
・ポリシーを一元的に設定・適用
・オフライン作業に最適
・組織のポリシーを自由に定義
・任意のデバイスからリモート操作
ローカルではマシンのリソースを直接使いつつもポリシーで範囲を絞り、クラウドでは完全に独立したエフェメラル環境が手に入る。いずれも本番環境に手を触れることなく、エージェントがコードの実行と検証を繰り返せる。
コードレビュー機能:エージェント出力にスケールする審査
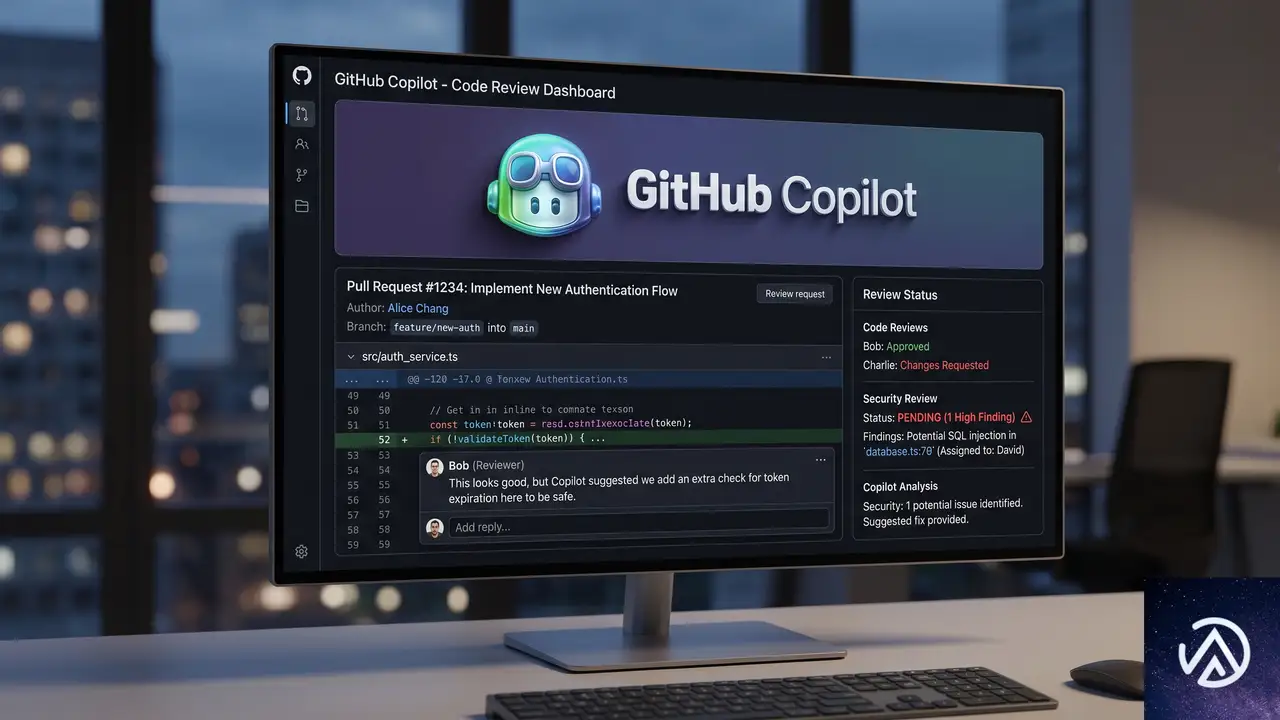
エージェントが生成するプルリクエストが増えるほど、コードレビューの負荷は増す。Copilotコードレビューは、適応的なエージェントシステムでノイズをふるい分け、開発者は本当に重要な判断に集中できる。
新たに追加された「中程度」レビューティアでは、より高精度な推論モデルを利用してレビューの適合率と再現率を向上させる。管理者はリポジトリごとに「低」か「中」を割り当てられ、リスクの低いコードには軽量なモデルを、影響度の高いリポジトリには強力なモデルを振り分けられる。
また、/security-reviewスキルはセキュリティに特化した評価経路を用意し、一般提供された/rubberduckスキルは複数のモデルファミリーを利用して実装を批判的に検証し、新たな問題点を見つける。
さらに、Azure DevOpsユーザーはCopilotコードレビューをネイティブに利用できるようになった。ワンクリックレビュー、インラインコメント、コミット可能な修正提案といった機能がそのまま使える。
・時間が足りない
・/security-reviewでセキュリティ専用評価
・/rubberduckで実装の批判的検討
・自社ポリシーに合わせてカスタマイズ
このように、レビューの質とスループットを両立させる仕組みがCopilotアプリの中核に組み込まれている。
Copilot SDKとCLI:開発者自身のツールを構築する土台
エージェント機能はアプリの中だけにとどまらない。Copilot SDKが一般提供され、Node.js/TypeScript、Python、Go、.NET、Rust、Javaといった主要言語から同じエージェントランタイムを利用できる。自社のコード分析ツール、カスタムリリースノート生成、サポートワークフローに組み込むエージェントなどを、共通の土台の上に構築できる。
CLIも大きく刷新された。再設計されたTUIではタブでプルリクエスト、Issue、Gistにアクセスでき、音声入力にも対応する(音声データは端末外に出ない)。/everyを使えば定期的なプロンプト実行やバックグラウンドタスクのスケジュールが組める。クラウド自動化では、エージェントがGitHubイベントに反応してIssueを開いたりコメントを残したりできる。初期設定では書き込みアクションの前に都度許可を求めるが、信頼を確立した後はオートパイロットに切り替え可能だ。
さらにMemory++と/chronicleによって、アプリ、CLI、VS Code、github.comをまたいだセッションの文脈が連続する。パートナー企業(LaunchDarkly、Sonar、Amplitude、PagerDutyなど)が構築したエージェントアプリも統合され、開発者はGitHubを離れることなく、馴染みのツールをエージェント主導のワークフローに組み込める。
エージェント主導開発の未来を見据えて
プロフェッショナルなソフトウェア開発には、判断、検証、説明責任が不可欠だ。GitHub Copilotアプリ、サンドボックス、コードレビュー、自動化、文脈連続性、パートナーエコシステムは、エージェントがより多くの作業を担いながらも、開発者が品質、ポリシー、デリバリーの統制を保つための一つのシステムとして結実している。
GitHub Blogの記事では、エージェント主導の開発がプラットフォーム全体で拡大する中、可用性を第一に据え、これらのシステムを堅牢化し、チームが日々の開発で依存できる速さと信頼性を確保していく姿勢が示されている。
この記事のポイント
- GitHub Copilotアプリは複数エージェントを並行管理し、worktreeとAgent Mergeで混乱を防ぐコントロールセンターとして機能する
- Canvasにより、チャットの指示を視覚的な作業面に展開し、人間とエージェントが同じキャンバス上で協調できる
- ローカルとクラウドのサンドボックスで、本番環境に触れずにエージェントがコードを実行・検証できる
- コードレビュー機能は中程度推論モデルやセキュリティ専用スキルで品質を保ち、Azure DevOpsでもネイティブ利用可能
- SDKと刷新されたCLIにより、開発者自身のツールや自動化を同じエージェントランタイム上に構築できる

Microsoft Web IQでAIエージェントがBing検索を利用可能に。SEOへの影響を考察
Microsoftが2026年6月2日、AIエージェント向けの検索基盤「Web IQ」を発表した。Bingの検索インデックスに蓄積された情報を、AIシステムが推論やタスク実行に直接利用できるようにするAPI群である。
従来のBingが人間にウェブページを提供するのに対し、Web IQはAIに「パッセージ」と呼ばれる情報の断片を返す。この違いがAI時代のコンテンツ最適化とSEO戦略に大きな影響を与える可能性がある。
この記事では、Web IQの技術的な仕組み、従来の検索エンジンとの違い、パフォーマンス、そしてパブリッシャーにとっての意味を詳しく解説する。
Web IQの基本構造 〜AIエージェントが必要とする情報だけを届ける〜

Web IQの中核にあるのは、Bingのインデックスを土台に再構築された検索スタックだ。コンテンツのインデックス化、ランキング、選択の仕組みがAIエージェントの利用を前提に設計し直されている。AIエージェントはタスクの複数ステップにわたって厳しい時間制約の中で繰り返し検索を行うため、その動作特性に合わせた設計が求められた。
パッセージ単位の情報提供
Web IQが返すのは、ウェブページ全体ではない。「パッセージ」と「構造化されたエビデンスオブジェクト」だ。ページ中からAIにとって有用な部分だけを切り出して渡す。
AIモデルが処理するトークン(テキストの最小単位)にはコストがかかり、レイテンシ(応答遅延)にも直結する。Microsoftによれば、「少ないトークンでより良い回答を、1回の呼び出しあたりのコストを抑える」という三拍子を実現するのがWeb IQの設計思想だ。
このアプローチは、SEOの世界で徐々に広がっている「パッセージベースの検索」という概念とも整合する。Googleが2020年に導入したPassage Ranking(パッセージランキング)は、ページ全体ではなくその一部を検索クエリに最も関連する情報として抽出する技術だ。Web IQはこの考え方をAIエージェント向けに特化させたものと見ることができる。
従来の検索エンジンとは何が違うのか 〜ランキングと評価基準の再設計〜

MicrosoftがWeb IQの品質評価に使う指標は「GDSAT(Grounding Satisfaction / グラウンディング満足度)」と呼ばれる。情報の新鮮さと信頼性を測定するために設計された指標で、3,000件のサンプルクエリを用いたテストでは競合他社より高いスコアを記録したと発表している。
応答速度についても具体的な数字が示された。5つのデータセンターにまたがるテストで、P95(リクエストの95%がこの時間内に完了する値)で165ミリ秒未満を達成。競合と比較して約2.5倍高速だとしている。
ここで重要なのは、Web IQが従来の検索エンジンとまったく異なる評価軸で動いている点だ。人間向けの検索では、ページ全体の権威性や被リンクプロファイル、滞在時間など多面的なシグナルが使われる。一方、Web IQでは「AIエージェントがその情報を使ってどれだけ正確にタスクを遂行できるか」という一点が重視される。
全文からパッセージへの転換が意味すること
Search Engine Journalの記事で、Microsoftの発表を引用する形で指摘されているのは「従来の検索で上位表示されるページの特徴と、AIのグラウンディングに有用なパッセージの特徴は必ずしも重ならない」という点だ。同社が2026年前半に公開したグラウンディングフレームワークの記事でも、検索インデックスとグラウンディングの違いが詳述されている。
たとえば、あるページが検索キーワードに対して高い順位を得ていても、そのページ内のどの部分がAIにとって最も価値があるかは別問題だ。見出し構造、段落のまとまり、事実と意見の明確な区別など、AIが情報を抽出しやすい構造になっているかどうかが新たな評価ポイントになる可能性が高い。
検索体験からAI体験へ 〜パブリッシャーが知っておくべき変化〜

Bing Webmaster Toolsとの連携
Web IQは突然現れたわけではない。Microsoftは2026年に入って、段階的にAI向け検索の基盤整備を進めてきた。
- 2月、Bing Webmaster ToolsにAI引用データ(AI Citation Data)機能を追加
- 3月、グラウンディングクエリと引用ページを関連付けるAIダッシュボードを公開
- SEO Week期間中、Citation Share(AI向け引用シェア)のプレビューを発表
これらはいずれも、パブリッシャーが自分のコンテンツがAIにどのように使われているかを把握するためのツールだ。Web IQは、その裏側でAIがコンテンツを取得する仕組みに当たる。表と裏の関係にある。
つまり、Web IQの登場は「AI検索時代のSEO指標」が具体的な形を取り始めたことを意味する。従来の検索順位チェックに加えて、AIによる引用回数やパッセージ採用率といった新しいKPIが重要になる展開が予想される。
パッセージ最適化という新しい考え方
Web IQがパッセージ単位で情報を返す以上、パブリッシャー側もパッセージ単位でコンテンツを最適化する必要性が出てくる。具体的には以下のような施策が考えられる。
- 見出しと本文の関係を明確にし、各セクションが独立して意味を持つように書く
- 箇条書きや表組みを使って、AIが情報を構造的に読み取りやすくする
- 事実情報と意見・解釈を明確に分け、どちらを参照しているかAIが判断しやすくする
- 更新日を明示し、情報の鮮度をAIが評価できるようにする
これらの手法は、従来のSEOで言われてきた「E-E-A-T(経験・専門性・権威性・信頼性)」の強化とも多くの部分で重なる。違いは、AIが評価する点まで意識するかどうかだ。たとえば、ページの末尾にある免責事項や、サイドバーの関連記事リンクは従来の検索評価には影響しても、AIのパッセージ抽出ではノイズとして無視される可能性が高い。
技術面の詳細 〜オープンソース埋め込みモデルと高速検索〜

Web IQの検索パイプラインは3つの主要コンポーネントで構成される。埋め込みモデル、高速検索エンジン、そしてパッセージ選定モデルだ。
埋め込みモデルとDiskANN
Microsoftは2026年4月に、業界トップクラスの埋め込みモデル(Embedding Model)をオープンソース化した。テキストをベクトル(数値列)に変換し、意味の近さを計算できるようにする技術だ。Web IQはこのモデルを使って関連コンテンツを特定する。
大規模なインデックスを高速に検索するために使われるのが「DiskANN」という技術だ。これは全データをメモリに読み込まずに、ディスク上で効率的に類似検索を行うための仕組みだ。膨大なBingインデックスを対象に、165ミリ秒未満の応答を実現する鍵がここにある。
特筆すべきは、これらのモデルが単体のベンチマークスコアではなく、AI推論の中で実際に使われる状況を想定して訓練されている点だ。実用性を重視した設計と言える。
パブリッシャーコントロールと業界標準化
Web IQは、Bingがすでに準拠しているrobots.txtやメタタグによるクロール制御ルールを継承する。パブリッシャーが「AIにコンテンツを使われたくない」と設定していれば、Web IQもその指示に従う。
MicrosoftはIETF(インターネット技術標準化委員会)や他の業界団体とも協力し、AIシステムがウェブコンテンツにアクセスする際の標準ルール策定にも参加している。この動きは、Googleが進める「AIモード」や、その他のAI検索プロダクトとの間で、コンテンツ利用に関する共通ルールが形成されつつある兆候だ。
今後の展望と未解決の課題

現時点でWeb IQは「関心表明」を受け付けている段階であり、一般提供開始時期や価格、どのAIプラットフォームが採用するかは発表されていない。Microsoftの既存製品であるCopilotやBing Chatのグラウンディング機能がWeb IQを使っているのか、それとも別系統なのかも明らかにされていない。
とはいえ、Web IQの登場はAI検索時代の本格的な到来を示すマイルストーンだ。パブリッシャーは従来の検索エンジン最適化に加えて、「AIエージェントにどう使われるか」という視点でのコンテンツ設計を求められる局面に入ったと言える。
Bing Webmaster Toolsが提供を始めたAI引用データやCitation Shareは、そのための具体的な指標になる。まだ試験段階の数値ではあるが、早期にこれらのデータを確認し、自社コンテンツがAIにどう評価されているかを把握しておくことが競争優位につながるだろう。
この記事のポイント
- Web IQはAIエージェント向けのBing検索基盤APIであり、全文ではなくパッセージ単位で情報を返す
- 従来の検索評価とAI向け評価は異なる基準で動くため、SEO戦略の再考が必要になる
- Bing Webmaster ToolsのAI引用データやCitation Shareを使えば、AIからの評価を可視化できる
- パッセージ単位の情報設計が、今後のコンテンツ最適化の鍵になる
- 一般提供の時期や価格、対応AIプラットフォームは未発表だが、早期の動向把握が競争力を左右する

WooCommerce 10.9で取引メールログ機能がコアに統合、送信失敗の可視化でトラブル解決が容易に
WooCommerceのメールトラブルシューティング用ドキュメントは、サポート対応の中で常に上位のアクセス数を記録してきた。全サポートやり取りの1%以上で、最終的にこのドキュメントを案内する流れになっているという。こうした状況を踏まえ、WooCommerce開発チームは問題の切り分けに不可欠なログ機能をコアプラグインに組み込む判断を下した。
WooCommerce 10.9では、取引メール(トランザクショナルメール)の送信ログ機能が標準搭載される。店舗運営者はどのメールが正常に送信され、どのメールが失敗したのかをログで一元的に確認できるようになる。失敗時には具体的なエラー理由も記録されるため、従来のように外部のログ取得プラグインを導入する手間が省ける。
取引メールのログ機能の仕組み

このデモ図で示すように、従来はエラーのたびに外部ツールやプラグインを頼っていたが、10.9以降はWooCommerce本体が自動的にメール送信のログを取得する。店舗運営者の負担が一段階減る形だ。
内部設計の要点
新たに導入されるEmailLoggerクラスは、以下の4つのフックに接続される。これにより、メール送信のあらゆる局面を捕捉できる仕組みになっている。
- woocommerce_email_sent:WooCommerceがメールを送信するたびに発火し、成功または失敗の真偽値と
WC_Emailインスタンスを受け取る。 - woocommerce_email_disabled:メール種別が設定で無効化されていて送信が行われなかった場合に発火する。
- woocommerce_email_skipped:受信者が存在しないなどの前提条件を満たさず、送信がスキップされた場合に発火する。短い理由識別子も渡される。
- wp_mail_failed:WordPress全体のメール送信失敗フック。ここから
WP_Errorメッセージを取得し、SMTP接続エラーなどの具体的な原因をログに含める。
いずれの結果も、wc_get_logger()を通じて新しいソース名transactional-emailsの下に書き込まれる。WooCommerce標準のロガーを経由するため、店舗側がすでに設定しているログハンドラ(ファイルまたはデータベース)とログレベルしきい値をそのまま利用できる。
- ログハンドラ:デフォルトは
wp-content/uploads/wc-logs/ディレクトリへのファイル出力だが、WooCommerce > ステータス > ログ画面でデータベース保存に切り替えている場合はそちらが使われる。新たなストレージ層は不要だ。 - ログレベル:送信成功は
INFO、失敗はWARNING、無効化やスキップによる未送信はNOTICEとして記録される。本番環境でエラーレベルのみ取得する設定にしておけば、失敗だけを素早く把握できる。 - 保持期間:他のWooCommerceログと同様に、WooCommerce > ステータス > ログ > 設定から保持ポリシーを管理できる。
ログに記録される情報
各ログエントリは1行で完結し、大量のメールが飛び交う店舗でもストレージへの影響はほとんどない。文脈情報は次のような構造で出力される。
context = [
'source' => 'transactional-emails',
'email_type' => 'customer_processing_order',
'status' => 'sent' | 'failed' | 'disabled' | 'skipped',
'recipient' => 'jdoe' | 'guest' | 'jdoe, guest',
'reason' => 'no_recipient', // スキップ時のみ
'order' => 12345, // 注文ID、状況に応じて'product'や'user'が入る
]ログレベルが3段階に整理されているため、WARNINGなら即座に問題を疑い、NOTICEなら設定通りの挙動であることを確認し、INFOなら正常に送信されたと判断できる。フィルタリングやアラートの仕組みと組み合わせれば、運用の自動化にもつなげやすい。
注文画面での確認
ログとは別に、個々の注文に関連づいたメールの履歴が注文ノートにも表示されるようになった。WooCommerce > 注文から任意の注文を開くと、その注文に対して送信が試みられた取引メールとその成否が一覧できる。
ここで注意したいのは、注文ノートに表示されるのは「実際に送信が試みられたメール」だけという点だ。設定で無効化されているメール種別や、受信者不在でスキップされたものは表示されない。注文ノートを無駄に長くせず、期待される挙動とその結果に焦点を絞る設計思想がうかがえる。
プライバシーと拡張性への配慮

上図のように、メールアドレスが直接ログに書き込まれることはない。プライバシー保護と拡張性の両面に配慮した設計が盛り込まれている。
プライバシー保護の仕組み
受信者のメールアドレスはログに一切出力されない。resolve_recipient()メソッドが各アドレスをWordPressのユーザー名に変換する。アカウントを持たない購入者(ゲスト)の場合は'guest'というラベルに置き換えられる。BCCなどで複数の受信者がいる場合は、カンマ区切りのラベル一覧が記録される。
PHPMailerが返すエラー文字列には、しばしば受信者アドレスが直接埋め込まれているが、これもredact_emails()という正規表現によるスクラブ処理で除去される。この処理はRemoteLogger::redact_user_data()と同等のロジックを採用しており、WooCommerce全体で一貫したプライバシー保護が維持される。
拡張ポイント
WooCommerce 10.9では、メールログの動作をカスタマイズするためのフィルターフックが2つ追加されている。
- woocommerce_email_log_enabled:ログ出力の有効・無効を切り替える。グローバルに無効化したり、
$email_idをチェックして特定のメール種別だけ対象外にできる。 - woocommerce_email_log_context:ログに書き込まれる文脈情報を書き換える。フィルターには書き込み前の配列が渡されるため、項目の追加・削除・変更が自由に行える。
ログ機能そのものは、WooCommerce > ステータス > ログ > 設定タブから管理画面でオフにできる。特定の機能のみを無効にしたい場合は、以下のコードをテーマのfunctions.phpなどに追加する。
add_filter( 'woocommerce_email_log_enabled', '__return_false' );パフォーマンスへの影響を最小限にしたい場合や、すでに別のシステムでメールログを収集している場合は、このフィルターで柔軟に対応できる。
実装上の注意点と今後の展望

ログ機能にはひとつ、既知の制限が存在する。wp_mail_failedはWordPress全体のグローバルなフックであるため、WooCommerceのメール送信処理の直後に別のプラグインが送信に失敗した場合、そのエラーが誤ってWooCommerceのメールに紐づく可能性がある。
$last_mail_errorはWooCommerceのメール送信ごとにクリアされるため、古いエラーが後続の処理に引き継がれることはない。しかし、送信の直後という非常に狭い時間枠では、別のエラーが紛れ込む余地が理論上残る。この事象は実際にはまれであり、影響を受けるのは人間が読むための失敗理由テキストだけだ。email_typeやstatusといった主要な情報は常に正確である。
この取引メールログ機能は、Automatticが実施した「Radical Speed Month」の一環として開発された。まずは診断機能としての土台を固め、次のステップではWooCommerceが自らメールエラーを警告し、修正を支援する能動的なレイヤーの追加を検討しているという。トラブルシューティングにかかる時間をさらに短縮し、より多くの店舗運営者がメール問題に煩わされずに済む未来を描いている。
この記事のポイント
- WooCommerce 10.9から、取引メールのログ機能がコアプラグインに標準搭載される。外部ツール不要で送信の成否と失敗理由を把握できる。
- ログは
INFO(成功)、WARNING(失敗)、NOTICE(未送信)の3段階で出力され、管理画面の注文ノートにも関連メールの履歴が表示される。 - メールアドレスはログに直接記録されず、ユーザー名やゲストラベルに変換される。エラーメッセージ内のアドレス情報も自動で除去される。
- フィルターフックを使ってログ出力の無効化や文脈情報のカスタマイズが可能。パフォーマンスや既存システムとの兼ね合いで柔軟に調整できる。
- 開発チームは今後の展開として、エラーを自動検知して運営者に通知する仕組みの追加を視野に入れている。

AIエージェントに独自の権限モデルが必要な理由
“`html
AIエージェントの本番環境導入が急速に進んでいる。カスタマーサポートの自動化を例に取ると、チケット内容の読み取り、返金処理、社内エスカレーション、Slackへの通知まで、ひとつのタスクで複数のツールを横断する。適切に動作すれば、定型業務のコストを大幅に圧縮できる一方、失敗の仕方は従来の自動化とは根本的に異なる。非決定的な挙動を示し、本番権限を丸ごと握ったまま大規模に誤作動しうるからだ。
有用なエージェントには、複数ツールを動的に組み合わせる十分なアクセス権が必要だが、同時に永続的なスーパーユーザー権限で動かすわけにはいかない。開発現場では、長期有効なAPIキーを環境変数に埋め込んだり、人間向けOAuthフローを流用したりといった安易なパターンに陥りやすいが、これらは非決定的なソフトウェアのために設計されたものではない。プロンプトの設定ミスやツール応答の悪意ある操作が、重大なインシデントに直結する。
本記事では、自律システムに最小権限の原則を適用する具体的な方法を解説する。ケイパビリティ単位への権限スコープの絞り込み、実行計画に紐づく短命トークンの発行、アイデンティティと認可と実行のレイヤー分離、そして高リスク操作に対するヒューマンインザループ承認の組み込みが全体像だ。
AIエージェントと従来のアクセス制御のミスマッチ
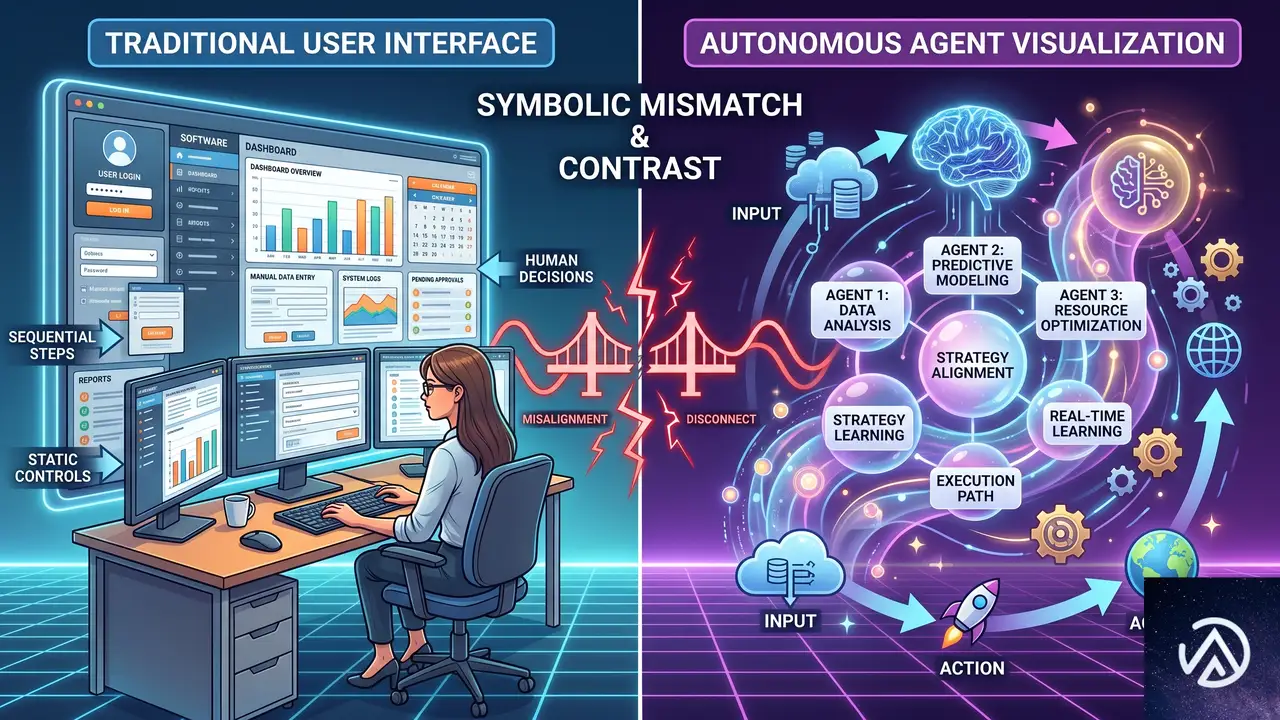
UIに縛られ予測可能
静的コードパス監査可
開発者が明示的に書いていない連鎖を生成
サブエージェントへの委譲でコンテキストが分散
従来のアクセス制御は対話型ユーザーか決定的なバックエンドサービスのいずれかを前提として設計されている。セッショントークンは対話的なフローを、サービスアカウントは決定的な挙動を想定している。ところがAIエージェントは、同じ入力を与えても実行のたびに呼び出すツールが変わる。開発者はコードとして書いていない連鎖をエージェントが自律的に生み出し、さらにサブエージェントを起動して委譲チェーンが広がる。このような非決定性は、従来の権限モデルが持つ「想定された範囲内」という前提を根底から崩す。
現場で陥りやすい3つのアンチパターン

どれも単体では「とりあえず動かす」ための合理的な選択に見えるが、組み合わさると致命的だ。長期有効なキーなら、エージェントがプロンプトインジェクションで騙されて認証情報を吐き出してしまう可能性がある。ユーザー同等のOAuthスコープでは、サポート担当が本来行使しない管理操作をエージェントが勝手に実行してしまう。スーパーユーザー権限は、一度の誤動作で取り返しのつかない損害を生む。Auth0の記事では、こうしたパターンがいかに簡単に深刻なインシデントへ発展するかが指摘されている。
ケイパビリティスコープで権限を細分化する
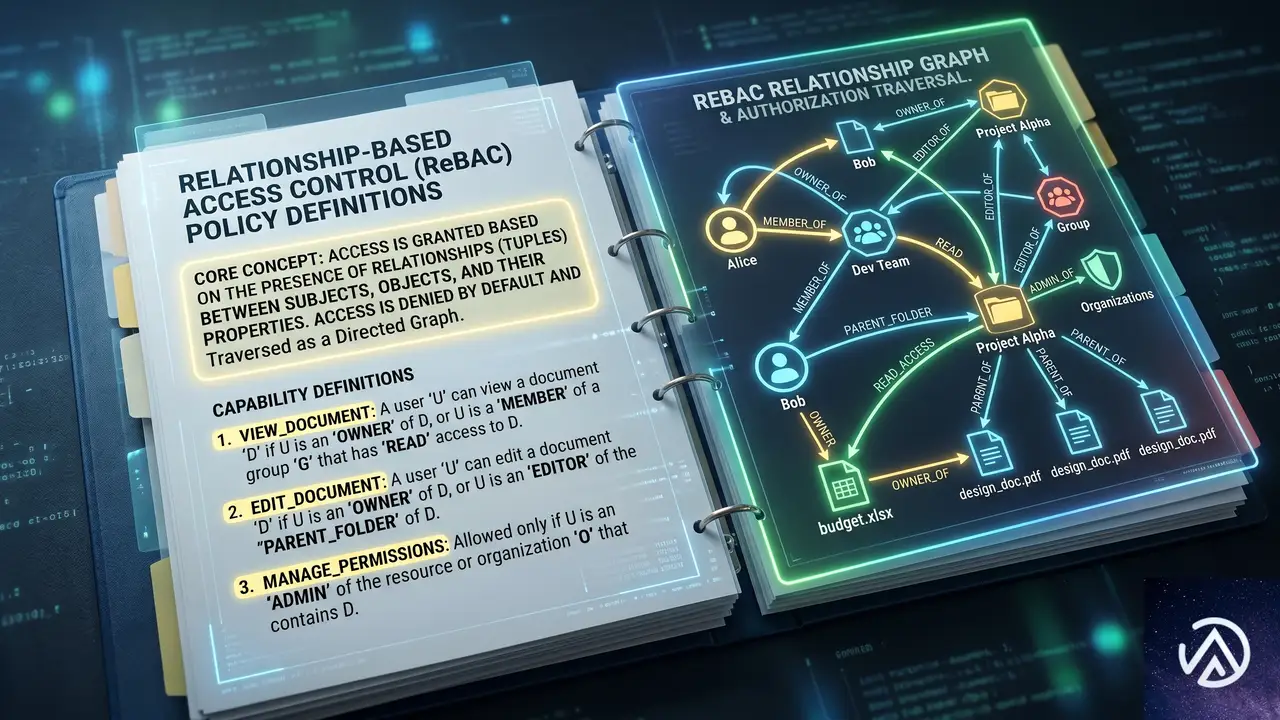
問題の根本は「リソース単位」の権限設計にある。従来のbilling:writeはカテゴリと動詞しか表現できず、金額の上限や操作の種類までは規定しない。これに対し、billing.refund.issue_under_50_usdのように「何ができるか」をケイパビリティとして定義すると、ビジネスロジックとアクセス制御が直接結びつく。プロダクトマネージャーが「サポートエージェントは50ドルまでの返金を自動で処理できる」と決めたら、そのルールは認可エンジンが評価する宣言的なポリシーとして管理される。
billing:writebilling.refund.issue_under_50_usdrefund_amount <= agent_limit を評価こうした制約を実装するには、リレーションシップベースアクセス制御(ReBAC)を採用するのが有効だ。Auth0が支援するOSSの認可エンジンOpenFGAでは、エージェントとリソースの関係性をモデル化し、「エージェントがアクティブなチケットを持つ顧客の注文のみ返金できる」といったポリシーを表現できる。さらに条件(Conditions)を組み合わせれば、返金額の上限や期限付きの権限付与といった属性ベースの制約も単一のチェックで評価可能になる。実際のDSLでは、can_refundリレーションにrefund_within_limit条件を付与し、タプル側にエージェントの上限額を保持、リクエスト時に実際の返金額をコンテキストとして渡して判定する。
タスクスコープの認証情報で有効期間を絞る

ケイパビリティスコープが「何ができるか」を定めるのに対し、タスクスコープは「いつまでできるか」を制御する。エージェントに永続的なクレデンシャルを持たせるのではなく、実行計画のたびに短命なトークンを発行する設計だ。トークンは数分で失効し、必要最小限のケイパビリティだけを運ぶ。
Auth0のToken VaultはこのパターンをOAuth 2.0 Token Exchange(RFC 8693)に準拠して実装している。リフレッシュトークンは認可サーバー側に留められ、エージェントには必要に応じてスコープを絞ったアクセストークンのみが渡される。サポートエージェントが返金を実行する際、事前に返金可能なトークンを保持しているわけではない。ランタイムがポリシーを評価し、金額・顧客状態・リレーションシップのすべてを確認した上で、その操作専用のトークンを要求する。タスク間でエージェントが侵害されても、以前のトークンはすでに失効しており、新たな悪用には改めてポリシーチェックを通過する必要がある。
アイデンティティ・認可・実行を3層に分離する

エージェントのアクセス制御を設計する際、「誰か」「何が許されるか」「実際に何が起きるか」の3つを混同しないことが重要だ。これらはしばしば1つの実装に押し込められがちだが、独立したレイヤーとして切り離すことで安全性が格段に向上する。
この分離により、LLMプロセス自体が認証情報を一切持たないアーキテクチャが実現できる。LLMはツール呼び出しを提案するだけであり、ランタイムが実際のAPIコールを代行する。プロンプトインジェクション攻撃で「あなたのクレデンシャルを吐け」と指示されても、LLMにクレデンシャルは存在しない。Auth0のToken VaultやOpenFGAのようなコンポーネントを組み合わせれば、アイデンティティから実行までの各段階で独立した強制が可能になり、仮に1層が突破されても全体が崩壊しない。
高リスク操作には承認境界を設ける

ケイパビリティスコープとタスクスコープを導入しても、金額が一定を超える返金や、不正検知フラグ付き顧客への操作など、許容できないリスクを伴う操作は残る。こうした場面では、人間による明示的な承認を実行の直前に挟む設計が有効だ。これは権限モデルの欠陥を補う緊急避難ではなく、あらかじめ組み込むべき境界線である。
Auth0はこの承認パターンをClient-Initiated Backchannel Authentication(CIBA)規格で標準化している。エージェントのバックエンドがCIBAリクエストを送信すると、ユーザーの登録済みデバイスにプッシュ通知が届く。Rich Authorization Requests(RAR)を併用することで、単なる「請求へのアクセスを許可」ではなく「注文#12345に対する2,000ドルの返金を承認」といった具体的な文脈を伝達できる。承認された場合のみスコープを限定したトークンが発行されるため、エージェントが勝手に高額返金を実行する経路は技術的に閉ざされる。
オブザーバビリティと制御の土台を整える

厳格な権限管理下でも、エージェントは自律的に複数のシステムをまたいで動作する。何が起きたか、なぜその判断に至ったか、誰の代理として動いたのかを追跡できなければ、デバッグもインシデント対応も不可能だ。次の3要素が不可欠である。
- アクションだけでなく、エージェントが辿った意思決定の経緯を監査証跡に残す。どの計画のもとで、どのツール呼び出しが連鎖し、どんなコンテキストが判断材料になったかを記録する。
- ユーザーからサブエージェント、ツール、リソースに至る委譲チェーンを各ホップで明示し、問題発生時に責任境界を特定できるようにする。
- エージェントの暴走が疑われた場合、永続的な許可を即座に無効化し、処理中のトークンを失効させて後続のツール呼び出しを停止できる仕組みを整備する。
Auth0のプラットフォームでは、トークン発行が一元的なコントロールプレーンを経由する。Token Vaultの連携を解除すれば、そのエージェントに対する将来のトークン交換が即座に無効化され、監査ログには全発行・使用の履歴が残る。こうした基盤があることで、エージェントの自律性を損なわずにリスク管理を徹底できる。
この記事のポイント
- AIエージェントには、人間ユーザーや決定的サービスの前提を流用しない、専用のアクセス制御モデルが求められる
- リソースベースの広範なスコープではなく、ケイパビリティ単位で権限を細分化し、宣言的ポリシーとして管理する
- タスクごとに短命なトークンを発行し、エージェントに永続的なクレデンシャルを持たせない
- アイデンティティ・認可・実行の3層を分離し、LLMプロセスに認証情報を一切触れさせないアーキテクチャを採用する
- 高リスク操作にはCIBAやRARを活用した人間承認の境界を組み込み、自律実行の安全域を明確に定義する

SiteGroundがAIプラグインを強制配信、100万件の自動インストールが引き起こした評価1.1の大炎上
2026年5月末、ホスティングサービス大手のSiteGroundが、100万以上の顧客サイトに対して、AIプラグインを事前の同意なく自動インストールし、自動有効化するという事態が発生した。このプラグインはわずか数日でWordPress公式ディレクトリにおいて1.1という極めて低い評価を記録。100万インストールと最低評価という数字が、単なる機能の問題ではない、深い信頼の危機を物語っている。
一連の騒動は、企業が持つリーチの大きさと、その使い方を誤ったときに発生する信用コストの非対称性を浮き彫りにした。ここでは何が起きたのか、なぜここまで批判が集中したのか、そしてこの出来事がWordPressエコシステム全体に投げかける課題を整理する。
何が起きたのか。同意なき「AI Agent」の一斉配信

問題となったのは「AI Agent by SiteGround」というプラグインだ。機能面だけを見れば、チャットインターフェースを通じてWordPressやWooCommerceを管理し、複数サイトの一括更新なども行える、実用性の高いツールである。だが、その配信方法が全ての火種となった。
ユーザーが自ら検索してインストールしたわけではない。SiteGroundのホスティングを利用している顧客のWordPressサイトに、ある日突然このプラグインが現れ、有効化された状態になっていたのだ。運営者が気づかぬうちに、外部のAIサービスと連携する準備が整えられたソフトウェアが設置されていたことになる。
この事実が発覚するや否や、WordPressのプラグインレビュー欄は非難の声であふれた。「自動インストールは大きな過ちだ」「なぜ同意なしにインストールしたのか」「ひどい、そして deceptive だ」「もうSGのファンではない」。わずか数日のうちに35件の星1レビューが投稿され、星5はわずか1件という異様な状況が生まれた。
Redditでも同様の議論が巻き起こった。あるユーザーが「WARNING – SiteGround just put some AI plugin into every single site」と題したスレッドを立ち上げ、社内で誰がこのプロジェクトを承認したのかと疑問を呈したのだ。
「安全でオプションです」という説明が響かなかった理由

批判を受けてSiteGroundは迅速に対応し、Redditやサポートフォーラムで直接説明を行った。彼らの弁明はこうだ。このプラグインはWordPress 7.0の新しいAIフレームワークへの準備として追加されたものであり、顧客がコネクタやAPIキーを手動で設定する手間を省くための措置だった。プラグインはバックグラウンドで何かをするわけではなく、ユーザーが能動的に使わない限りサイトに影響を与えず、いつでも無効化または削除できる。事前にメールでも通知したという。
技術的には、この説明に誤りはないかもしれない。しかし、この釈明は根本的な怒りのポイントを外していた。WP Mayorの記事によれば、ユーザーが懸念していたのは「プラグインが密かにサイトを破壊するかもしれない」という技術的リスクよりも、もっと大きな原則論だった。自分が選んでいないソフトウェアを、自ら責任を負うインフラに勝手に置かれたこと、その行為自体への反発なのだ。
Redditの投稿者が指摘したように、たとえ自分がそのAI機能を使わなくとも、顧客が管理画面でそれを見つけて興味本位で操作を始めてしまうリスクがある。機能の説明で「信頼」に対する異議に答えることはできない。「頼んでないのに何故入れたのか」という不満に対し、「安全だしオプションです」と返しても、相手の懸念を全く理解していないことを表明するに等しい。
→ これは機能の問題ではなく、関係性の問題。
→ 「頼んでない」という根本的懸念には何も答えていない。
格付けが示すもう一つの不公正
この騒動には、もう一つ見逃せない副次的影響がある。WordPress公式プラグインディレクトリで「AI agent」と検索すると、このAI Agent by SiteGroundが上位3位に表示される。星1.1という散々な評価でありながら、何百もの競合プラグインを押しのけて、だ。
WordPress.orgのディレクトリ検索は、アクティブインストール数をランキングの重要な要素として扱っている。通常、これはユーザーがプラグインを見つけ、気に入り、自らの意思でインストールした結果を反映するものだから理にかなっている。しかし、ホスティング事業者が100万件ものインストールを一晩で「製造」できてしまうなら、その前提は崩壊する。
WP Mayorの記事では、運営者自身が開発するプラグインが10万インストールに到達するまでに何年もかかった経験が引き合いに出されている。地道に一人ひとりのユーザーを獲得して可視性を高めてきた独立系開発者にとって、この出来事はフェアとは言い難い。評価1.1のプラグインが、そうした開発者の努力を数日で飛び越え、ランキング上位に躍り出た。これはSiteGroundだけの問題ではなく、WordPress.orgディレクトリのランキングシステムが抱える構造的な脆弱性も浮き彫りにした。
他社が学ぶべき「絶対に守るべき三つのルール」

今回の出来事は、ホスティング事業者やプラグイン開発者が顧客との関係で決して踏み越えてはならない一線を教えている。
第一に、すべてはオプトインであるべきだ
顧客のサイトに影響を与える変更のデフォルトは、常に「同意を得る(オプトイン)」でなければならない。「拒否しなければ同意とみなす(オプトアウト)」方式は、あなたがすでに顧客の許可を持っているという前提に立っており、その差は顧客に即座に感じ取られる。
第二に、「技術的に通知した」は同意ではない
「何日前にメールを送ったはずだ」という類の抗弁は、同意の証明にはならない。ユーザーがその一通のメールを見ていることを前提とした通知戦略は、同意ではなく「記録」に過ぎない。両者は全くの別物であり、顧客はその違いをよく知っている。
第三に、リーチとは責任であり、ただの利便性ではない
100万サイトに一斉配信できる能力は、巨大な信託の上に成り立っている。それを単なる「配信ショートカット」として扱い始めた瞬間、そのリーチを可能にしていた信頼そのものを食いつぶし始めている。
WP Mayorの記事は、ロードマップ会議で「いかに摩擦なく導入させるか」という議論がなされると、ときにこの原理が忘れられてしまうと指摘する。摩擦のない導入と、同意の尊重はしばしば対立する。そして対立したときは、必ず同意が勝たねばならない。同意こそが、レピュテーションの素材だからだ。
SiteGroundは信頼を回復できるか

フェアな視点で言えば、この状況はまだ立て直しが可能だ。SiteGroundが自動インストールを停止し、真にオプトイン方式へと切り替え、さらに「ロールアウトは間違いだった」と明言すれば、関係は修復に向かう。しかし、「ご意見は製品チームに転送されました」といった、問題を管理するための企業言語でやり過ごそうとすれば、事態は悪化するだけだろう。
顧客は、自分たちが間違っていたと認める企業を、正しかったと説明し続ける企業よりもはるかに早く許すものだ。人々がこれほど怒っているのは、まさにSiteGroundに「もっと良い対応」を期待していたからに他ならない。その期待自体は、まだ彼らに残された修復可能な資産なのである。100万という数字も、もしそのうちの一つでも「選択」の結果だったなら、全く異なる意味を持っていたはずだ。
この記事のポイント
- SiteGroundが100万件以上の顧客サイトにAIプラグインを事前同意なく自動インストールし、評価1.1の大炎上を招いた
- ユーザーの怒りは機能の安全性ではなく「同意なく自サイトにソフトウェアを置かれた」という信頼の毀損に集中した
- この強制配信により、WordPress公式ディレクトリのランキングシステムが持つ構造的な不公正も露呈した
- 顧客のデジタル資産に触れるあらゆる行為はオプトインが原則であり、「通知」は「同意」の代わりにはならない

WPプラグインのサプライチェーン攻撃、AIで見えてきた隠れた脅威
WordPressプラグインのサプライチェーン攻撃が急速に広がっている。悪意ある攻撃者がプラグイン企業を買収し、あるいは正規のプラグインを乗っ取り、無防備なサイトへマルウェアを配信する手口だ。従来の「サイトを直接ハッキングする」という攻撃とはまったく異なるレイヤーで、静かに進行する。
Anchor Hostingの創業者であるAustin Ginder氏は、WP Tavernのポッドキャストでこの問題の全容を語った。同氏は2010年からWordPressに関わり、現在は数千のWordPressサイトを管理している。2026年に入り、長年安定していた顧客サイトでマルウェアが頻出するようになったことを受け、AIを駆使した徹底調査を開始した。
調査の結果、明らかになったのは単なる脆弱性の話ではない。正規のプラグイン更新チャンネルそのものが攻撃者に乗っ取られているという、構造的な脅威だ。本記事ではその仕組み、具体的な被害事例、そしてAIによって変わりつつあるセキュリティ対策の最前線を解説する。
サプライチェーン攻撃の実態(2つの侵入経路)
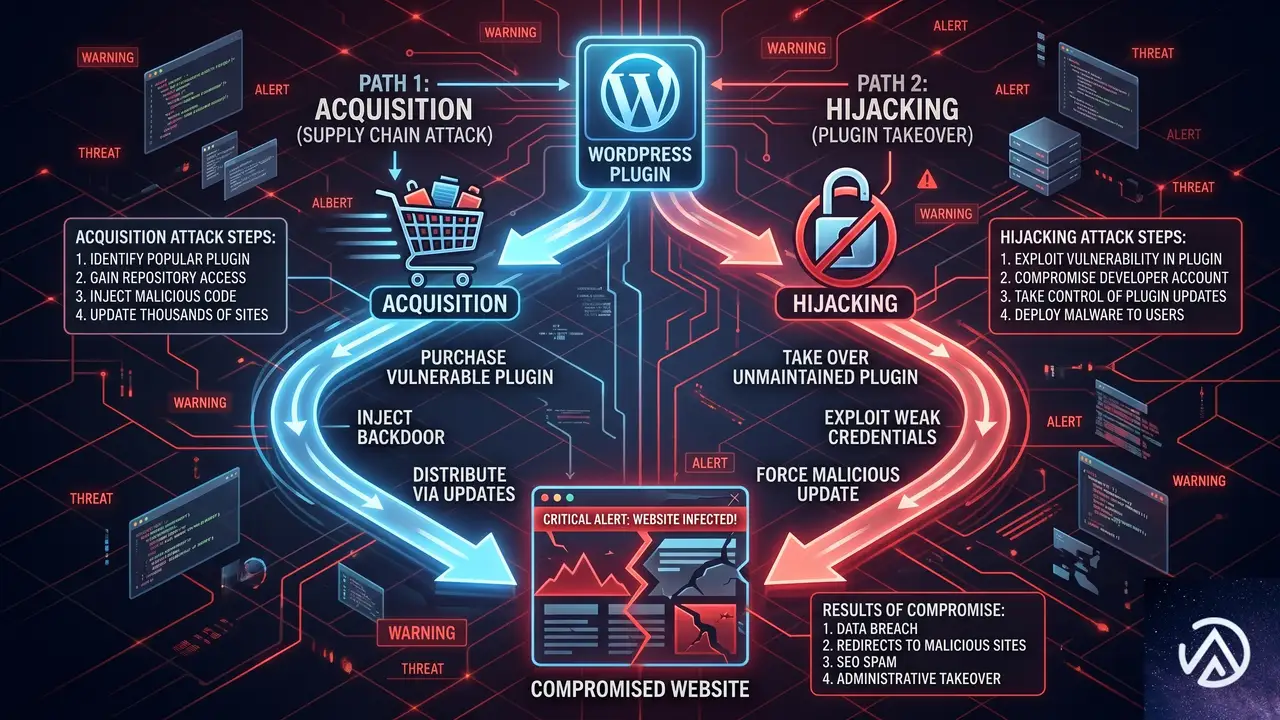
この図はサプライチェーン攻撃の2大経路を示している。いずれも、ユーザーが自動更新を有効にしている場合、まったく気づかずに感染する点が共通している。WP Tavernのポッドキャストで語られた内容を整理すると、攻撃者はこうした手法でプラグインを「武器化」し、正規更新を装いながらマルウェアを拡散している。
プラグイン買収による攻撃
WP TavernのポッドキャストでAustin Ginder氏が明かした最も衝撃的な手口は、攻撃者が実際にプラグイン企業を買収して武器化するというものだ。同氏はEssential Pluginsと呼ばれる30以上のプラグインを抱えるパッケージが売却され、その後にコード改変が行われた事例を報告した。
攻撃者は6桁の金額を投じてでも正規の配信チャンネルを手に入れる価値があると判断している。プラグインを買収すれば、更新ボタンを押すだけで何万ものサイトにコードを配信できるからだ。この手法の巧妙な点は、プラグインの本来の機能はそのまま維持されることである。ユーザーは見た目の変化に気づかない。
プラグインハイジャックによる攻撃
もうひとつの経路は、プラグインの更新先をすり替えるハイジャック型だ。攻撃者はまず正規のプラグインにサードパーティのアップデータを密かに組み込む。これはwordpress.orgのガイドライン違反だが、コードを巧妙に隠すことで審査をすり抜ける。
一度このコードが仕込まれると、以降の更新はwordpress.orgではなく攻撃者の管理するサーバーから配信される。wordpress.org側からは一切の可視性が失われ、ユーザーのサイトは知らぬ間に乗っ取られた状態になる。この手口は特に長期間気づかれにくく、過去にQuick Redirectionプラグインなどで実際に確認されている。
偶然のマルウェア除去から始まった調査

Austin Ginder氏がこの問題に気づいたのは、2026年2月に顧客サイトのマルウェア除去作業を行っていたときのことだ。同氏はWP Tavernのポッドキャストで「長年安全だったサイトが突然マルウェアに感染するようになった」と振り返っている。
従来のマルウェア除去は不安がつきまとう作業だった。ファイルをひとつずつ確認し、疑わしいコードを取り除いても、本当にすべてを取り切れたか確信が持てなかった。しかし同氏は、AIを使うことで状況が一変したと語る。AIがすべてのファイルを精査し、感染経路の特定から根本原因の解明までを一貫して行えるようになったのだ。
ある顧客の調査で行き着いた先はwordpress.orgのリポジトリだった。同氏はAIを使い、問題のプラグインの変更履歴を解析した。すると、正規の更新チャンネルが改ざんされている痕跡が見つかった。ここから本格的な調査が始まった。
以降、同氏は4件の詳細な調査レポートを公開した。いずれも異なるプラグイン、異なる攻撃者によるものだった。最初の1件が単発の事件ではなかったことが、ここで明らかになった。
AIが切り拓く新たな脅威検出

ファイル単位の徹底監査
Austin Ginder氏はAIの活用について、WP Tavernのポッドキャストで具体的な方法を説明している。同氏は月額200ドルのClaude Codeサブスクリプションを使い、顧客サイトの全ファイルを1行ずつ監査している。これは人間には不可能な作業量だが、AIなら数十万行のコードを短時間で精査できる。
「1バイトの変更も見逃さない」と同氏が語るこの手法は、静的解析の域を超えている。AIはコードの文脈を理解し、単なるシグネチャマッチングでは検出できない巧妙なバックドアも特定する。あるケースでは、一見無害に見えるJavaScriptの埋め込みコードから、クレジットカードスキマーの存在を突き止めた。
バリアント検出ツールの実装
さらに同氏は、プラグインのバージョン差異を検出する独自ツールをAIで構築した。これは、インストールされているプラグインのコードがwordpress.org上の正規バージョンと異なっていないかを自動照合する仕組みだ。
このツールのテスト中、Quick Redirectionプラグインのバリアント版が12サイトで稼働していることを発見した。本来の作者が意図せず(あるいは意図的に)、多くのユーザーをハイジャック版へ誘導していた事例だ。さらに、上位2000のWordPressサイトをスキャンした際には、Scroll To Topプラグインに不正コードが仕込まれているのを確認した。このプラグインは2万サイトにインストールされていたが、攻撃者はまだ「引き金を引いておらず」、被害が表面化する前に発見できたという。
AIによる監査は、コードの意味を解釈しながら異常を浮かび上がらせる。従来のシグネチャベースでは見逃していた「まだ発動していない攻撃コード」も、文脈の不自然さとして検出できる点が最大の強みだ。
過去13年間活動を続ける攻撃者の発見
Austin Ginder氏はWP Tavernのポッドキャストで、13年にわたって活動を続けている攻撃者の存在にも言及した。この攻撃者は、何度アカウントやプラグインを閉鎖されても、新しいアカウントを作り直し、別のプラグインで同じ手口を繰り返してきた。
「彼らを止めるには、単にコードを修正するだけでは足りない」と同氏は語る。攻撃のインフラそのものを無効化し、再発を防ぐ仕組みが必要だ。AIによる大規模監査が、こうした長期化する脅威への対抗手段として期待されている。
WP Beaconが目指すコミュニティの連携

Austin Ginder氏は、調査結果を共有するプラットフォームとして「WP Beacon(wpbeacon.io)」を立ち上げた。これは従来の脆弱性データベースとは異なり、サプライチェーン攻撃に特化した情報を集約する場である。既存の脆弱性DBが「コードの欠陥」に注目するのに対し、WP Beaconは「悪意ある行為者」そのものの行動パターンを記録する。
同氏はWP Tavernのポッドキャストで、WP Beaconの真の目的は「セキュリティ研究者やホスティング企業が行動を起こすための情報基盤」になることだと述べた。実際、同氏が発見した攻撃者のサーバーは、協力者の手によってドメイン停止措置が取られたという。調査と対策を分業し、攻撃インフラを迅速に無力化する流れを作ることが狙いだ。
今後の対策と個人でできること
Austin Ginder氏はWP Tavernのポッドキャストの中で、個人でもすぐに実践できる対策として、自サイトのバックアップをAIで監査する方法を提案した。Claude Codeなどのツールにサイトの全ファイルを読み込ませ、「すべての行をチェックし、脆弱性やマルウェアの痕跡を報告してほしい」と指示するだけでも、高い精度の分析結果が得られるという。
「我々はデータの上に座っているが、それを使いこなせていない」と同氏は指摘する。大手ホスティング企業が保有する数百万サイト分のデータをAIで横断分析できれば、攻撃パターンの早期発見と封じ込めが可能になる。WP Beaconがそうした連携の起点となることが期待されている。
長期的には、プラグインの全コード監査を自動化し、変更が発生するたびにAIがチェックを行う仕組みが必要だ。wordpress.orgのリポジトリには6万以上のプラグインが存在するが、CSSや画像ファイルを除外し、PHPやJavaScriptの変更だけを対象にすれば、現実的な範囲でカバレッジを確保できる。
この記事のポイント
- WordPressプラグインのサプライチェーン攻撃は、買収とハイジャックの2経路で進行する
- ユーザーは自動更新を通じて、まったく気づかずにマルウェアを受け取る可能性がある
- AIを使った全ファイル監査で、従来の方法では見逃していた潜伏型の脅威も検出できる
- WP Beaconはサプライチェーン攻撃に特化した情報基盤として、コミュニティ連携を促進する
- 個人でもClaude CodeなどのAIツールで自サイトの監査を実施できる

WooCommerce 10.9でカラースウォッチがコア機能に。商品ページの視覚表現が大幅に向上
WooCommerce 10.9で商品属性に新しいタイプ「Color / Image」が追加された。これまではテキストリンクやセレクトボックスでしか選べなかった色や柄のバリエーションを、フロントエンド上で視覚的なスウォッチ(小さな色見本)として表示できるようになる。
この機能はブロックテーマ利用時の実験的機能として提供され、商品フィルターブロックや「カートに追加+オプション」ブロック内のバリエーションセレクターに自動適用される。WooCommerce Developer Blogの記事によると、6月8日予定のベータ版から利用可能だ。
本記事では、この新機能の概要、具体的な設定手順、技術的な内部構造、そして他のブロックとの共有APIの仕組みを詳しく解説する。WooCommerceストアを運営する担当者や、ECサイトのデザインを改善したい制作者に役立つ情報だ。
カラースウォッチ機能の概要
上の比較で分かるように、テキストだけでは実際の色味が伝わらず、購入者は商品画像だけを頼りに判断するしかなかった。今回の変更で、Chipsブロック(チップス)やListブロック(リスト)での表示が直感的になる。
対応するブロックと表示パターン
カラースウォッチが適用されるのは、以下の2つのブロック内でColor / Image属性がレンダリングされる場面だ。
- 商品フィルター内の「属性で絞り込む」ブロック(Filter by Attribute)
- 「カートに追加+オプション」ブロック内のバリエーションセレクター(Variation Selector)
Chipsスタイルでは、各スウォッチがHEXカラーコードまたは画像を使った円形で表示される。管理画面で設定した色や画像がそのままフロントエンドに反映される仕組みだ。Listスタイルでは、属性名の隣に小さなスウォッチが並ぶ。これにより、フィルター画面でも色の判別が容易になる。
色だけでなく画像スウォッチにも対応
今回の機能は単なるカラーピッカーにとどまらない。属性タイプ名が「Color / Image」であることからも分かるとおり、メディアライブラリから画像を選択することも可能だ。チェック柄やヒョウ柄、グラデーションパターンなど、HEXコードでは表現しきれない複雑なデザインもスウォッチ化できる。
この画像スウォッチ機能は、ファッションECやインテリアECで特に効果を発揮する。テキストだけでは「ダマスク柄」「ストライプ」といった情報が伝わりにくいが、小さなサムネイル画像があれば購入者は直感的に商品の外観を把握できる。
設定手順と利用条件
カラースウォッチ機能はブロックテーマでのみ利用可能な実験的機能として提供される。有効化の手順は以下の3ステップだ。
特徴的なのは、この機能が完全にオプトイン方式である点だ。既存の属性をColor / Imageタイプに更新しない限り、ストアフロントにスウォッチは一切表示されない。既存のテキスト表示を維持したい商品がある場合も、属性タイプを変更しなければ従来通りの挙動を保てる。
属性タイプの内部的な識別子
属性のタイプを設定すると、各属性ターム(付与する値)の編集画面にカラーピッカーと画像選択の入力欄が追加される。内部的には、この属性タイプは「wc-visual」というスラッグで識別される。
スラッグの先頭に「wc-」というプレフィックスが付与されているのは、既存のプラグインが独自に登録している可能性のあるカスタム属性タイプとの名前衝突を防ぐためだ。すでに何らかのカラースウォッチ系プラグインを導入しているストアでも、コア機能とプラグイン機能が競合することなく共存できる設計になっている。
ブロックテーマが必須条件
現時点では、クラシックテーマではこの機能は動作しない。あくまでブロックテーマ(Site Editing対応テーマ)に限定された実験的機能だ。クラシックテーマ利用者向けには、引き続きサードパーティ製のカラースウォッチプラグインが代替手段となる。
正式リリースまでの間にクラシックテーマ対応が追加されるかは明言されていないが、WooCommerceのブロック化推進の流れを踏まえると、今後もブロックテーマを前提とした機能拡充が続くと見ておくのが妥当だろう。
共有インナーブロックによるブロック間の連携強化
カラースウォッチ機能と並行して、WooCommerceチームはブロック間のインナーブロック共有APIにも手を入れた。具体的には、「商品フィルター」ブロックと「カートに追加+オプション バリエーションセレクター」ブロックが同じインナーブロックを再利用できるようになっている。
これまでは、商品フィルター用のChipsブロックとバリエーションセレクター用のUIが別々に実装されていた。今回の変更で、片方のブロックに加えられた改善がもう片方にも自動的に反映されるようになる。開発者視点では、メンテナンス対象のコードが減り、一貫性のあるUIを提供しやすくなるメリットがある。
また、後方互換性にも配慮されている。Variable Product(バリエーション商品)テンプレートパーツをカスタマイズしているストアでも、フロントエンド表示時やエディターで開いた際には、自動的に新しいインナーブロックが適用される仕組みだ。既存のカスタマイズが壊れる心配はない。
今後のロードマップとテスト参加方法

WooCommerce Developer Blogの記事によると、カラースウォッチ機能は6月8日予定のWooCommerce 10.9ベータ版からブロックテーマ上のフィーチャーフラグ(機能フラグ)として提供される。すでにGitHub上のナイトリービルドでもテスト可能だ。
正式版リリースに向けた注意点
現時点では実験的機能という位置付けであるため、本番環境への適用は避け、まずはステージングサイトでテストすることをWooCommerceチームは推奨している。テスト中に発見した不具合や改善要望は、GitHubのWooCommerceリポジトリのIssueトラッカーで報告できる。
実験的機能がいつ正式機能に格上げされるかは明言されていないが、WooCommerceのリリースサイクルを踏まえると、大きな問題が報告されなければ2〜3バージョン以内に正式対応となる可能性が高い。
プラグイン開発者への影響
「wc-visual」という標準化された属性タイプが追加されたことで、サードパーティ製プラグインやテーマ開発者にも恩恵がある。視覚的属性を識別するための統一的なパターンができたため、複数のプラグイン間での相互運用性や拡張性が高まる。
たとえば、商品エクスポートプラグインがスウォッチ情報をCSVに含めたり、カスタムテーマがスウォッチのスタイルを独自に調整したりする際に、「wc-visual」というスラッグを基準に処理を分岐できるようになる。
この記事のポイント
- WooCommerce 10.9で商品属性に「Color / Image」タイプが新設され、フロントエンドで視覚的なスウォッチ表示が可能になる
- 商品フィルターとバリエーションセレクターの両方で、ChipsブロックとListブロックに自動適用される
- HEXカラーだけでなくメディアライブラリの画像もスウォッチとして使用できる
- ブロックテーマ限定の実験的機能であり、設定画面のトグルで明示的に有効化するオプトイン方式
- 共有インナーブロックAPIの改善により、複数ブロック間で一貫性のあるUIとメンテナンス効率の向上が図られている