

Googleが5月コアアップデートの完了を発表。11日間の不安定な変動を振り返る
Googleは2026年6月2日、5月のコアアップデートが完了したと公式に発表した。検索ステータスダッシュボード上で、ロールアウト開始から11日と21時間を経て終了したとの報告が上がっている。
今回のアップデートは、5月21日午前8時40分(太平洋夏時間)に始まり、6月2日午前5時40分(同)に終了した。約12日間の展開期間は、3月のコアアップデートとほぼ同じ長さだ。
実務者が観測したアップデートの激しさ

アップデートの開始と同時に、多くのSEO実務者が大きな変動を報告し始めた。特に注目されたのは、Google I/Oと同日に発表された点だ。
このデモが示すのは、今回の変動が単なる順位付けルールの変更ではなく、検索結果の生成プロセス自体の変化を伴う可能性があったという点だ。
SEOコンサルタントのGlenn Gabe氏は「今回の5月のコアアップデートは、従来の典型的なコアアップデートに近い強力さを見せている。3月のアップデートは地味だったが、5月は大きな動きだ」とXに投稿している。彼の観測では、この影響は特定の業種や国を超え、多岐にわたって見られたという。
また、AmsiveのLily Ray氏もXで週末の動きについて「一握りのサイトで週末に急上昇が見られた」と報告している。これらの投稿から、変動のピークが一過性のものではなく、ロールアウト期間中に何度か訪れたことがわかる。
データ分析を難しくする「多点変動」の正体
今回のアップデートで最も厄介なのは、完了したからといって、ロールアウト期間中のすべての変動が同じ原因で起きたとは言い切れない点だ。
このデモは、単日のランキング比較がいかに危険かを示している。Googleの公式ドキュメントも、アップデート完了から最低1週間はデータを寝かせ、その1週間分のデータとロールアウト開始前の1週間分を比較検証するよう強く推奨している。これに従うと、最も早く正確な比較が可能になるのは6月9日ごろという計算になる。
2026年のアップデートタイムライン

今回の5月コアアップデートは、2026年にGoogleが検索ステータスダッシュボードで確認した4回目のアップデートであり、2回目の検索コアアップデートだ。3月のコアアップデート完了(4月8日)から、5月の開始(5月21日)までは約6週間の間隔があった。
ここ最近のアップデート期間を振り返ると、コアアップデートの展開期間は平均2週間弱で推移していることがわかる。
このタイムラインから読み取れるのは、Googleがコアアップデートを年4〜5回のペースで定期的に配信している現状だ。特に2026年は、スパムアップデートを短時間で差し込むなど、検索品質の維持に対する姿勢がより機動的になっている。
分析を始める前に押さえるべき3つの視点

6月9日のクリーンな比較ウィンドウを待つ間、そしてデータ分析を始めるにあたり、以下の3つの視点を持つことが重要だ。
これらの視点をもとに、6月9日以降、Search Consoleのデータを丁寧に分析することが、今回の大規模アップデートから次なる施策を導き出すための最善の道となる。
この記事のポイント
- Googleの5月コアアップデートは6月2日に完了した。変動は全期間を通じて激しく、複数回のピークが観測された
- 完了直後の単日比較は危険であり、少なくとも1週間後の6月9日以降に週次データで比較分析を行うべきだ
- 今回の変動は、Google I/Oで発表されたAI基盤の更新とタイミングが重なり、AI検索機能との連動が示唆される
- 結局のところ、最も有効な対策は、ユーザーにとって真に価値あるコンテンツの提供であるという原則に変わりはない

Google Cloud、AlloyDB向けリモートMCPサーバーがGA。AIエージェントとDBの安全な統合を実現
Google CloudがAlloyDB向けのリモートMCP(Model Context Protocol)サーバーの一般提供を発表した。これまでローカル開発が中心だったMCPだが、本番環境での運用に耐えるフルマネージドな仕組みとして登場した。AIエージェントが企業のオペレーショナルデータベースに直接アクセスし、安全にクエリを実行できるようになる。
この記事では、リモートMCPサーバーが解決する技術的課題と、AlloyDBを基盤にしたエージェントアプリケーションの構築方法を解説する。データの鮮度、セキュリティ、運用負荷のバランスを取るアーキテクチャを具体的に示す。
リモートMCPとは何か(ローカルMCPとの違い)

MCP(Model Context Protocol)とは、大規模言語モデル(LLM)が外部のデータソースやツールと安全に通信するためのオープン標準プロトコルだ。Anthropicが提唱し、現在では多くのAIエージェントフレームワークで採用されている。従来は開発者のローカルマシン上で動作する「ローカルMCPサーバー」が主流だった。
ローカルMCPサーバーは標準入出力(stdio)を使ってプロセス間通信を行う。これは開発段階では手軽だが、本番環境に持ち込むと途端に問題が顕在化する。複数のエージェントインスタンスが同時にデータベースへアクセスする場合、プロセス管理が複雑化し、ネットワーク越しのセキュリティ確保も難しくなる。
リモートMCPサーバーは、これらの課題をHTTPエンドポイント経由で解決する。Google Cloudのマネージドインフラ上で動作し、OAuth 2.0ベアラートークンによる認証とIAM(Identity and Access Management)によるきめ細かな権限制御を提供する。エージェント開発者はインフラ管理から解放され、クエリ実行に集中できる。
なぜAlloyDBと組み合わせるのか
AlloyDBはGoogle CloudのフルマネージドPostgreSQL互換データベースだ。標準PostgreSQLと比較して、ベクトル検索では最大6倍高速、フィルタ付きクエリでは最大10倍高速というパフォーマンスを備える。ScaNNインデックスを使えば100億ベクトル規模まで拡張でき、AIエージェントのRAG(検索拡張生成)ワークロードに最適化されている。
さらにAlloyDBには、データベース内で直接埋め込みベクトルを生成するAI Functionsや、Gemini Enterprise Platformモデルを使った検索結果のリランキング機能が組み込まれている。エージェントがデータベースにクエリを投げるだけで、最新のオペレーショナルデータに基づいた回答を得られる。データの鮮度を保つためのETLパイプラインが不要になるケースも多い。
リモートMCPサーバーが解決する5つの本番課題

Google Cloudブログの発表によると、リモートMCPサーバーは単なる通信方式の変更にとどまらない。本番環境でAIエージェントを運用するチームが直面する、以下の5つの課題を包括的に解決する設計になっている。
特に注目すべきはIAMによる権限制御だ。従来のデータベース接続では、共有パスワードやAPIキーを使うことが多かった。しかしリモートMCPでは、エージェントごとに特定のテーブルやビューへのアクセス権をIAMで付与できる。読み取り専用のSQL実行ツールを選択すれば、エージェントが誤ってデータを削除するリスクを根本から排除できる。
Model Armorによるプロンプトセキュリティ
リモートMCPサーバーは、Google CloudのModel Armorと統合されている。Model Armorはプロンプトとレスポンスの両方をスクリーニングし、プロンプトインジェクション攻撃や機密データの意図しない流出を防ぐ。エージェントのサービスアカウントが広範なデータベース権限を持っていても、Model Armorがデータの出し方をフィルタリングする仕組みだ。
たとえば、エージェントが顧客のクレジットカード番号を含むカラムにアクセスできる権限を持っていたとしても、Model Armorがレスポンスからその情報を除去できる。これは「権限はあるが出力は制限する」という新しいセキュリティモデルであり、ゼロトラストの考え方をAIエージェントに適用した形だ。
エージェントから見たAlloyDBの強み

リモートMCPサーバーは接続の仕組みを提供するが、その先にあるデータベース自体の性能も重要だ。AlloyDBはエージェントアプリケーションに特化したいくつかの特徴を持つ。
まず、ベクトル検索性能だ。ScaNNインデックスを使うと、標準PostgreSQLの最大6倍の速度でベクトルクエリを実行できる。100億ベクトルまでスケールするため、大規模なRAGアプリケーションでもパフォーマンスが劣化しない。フィルタ条件付きのベクトル検索では最大10倍高速化される。これは「直近30日以内のドキュメントから類似検索」のような実用的なクエリで差が出る。
次に、ハイブリッド検索とリランキングだ。RUM(RUMインデックス / Row Usage Matrix)を使った全文検索とベクトル検索の組み合わせや、Reciprocal Rank Fusionによる結果の融合が可能だ。さらにGemini Enterprise Platformモデルを使ったインテリジェントなリランキングにより、エージェントは最も関連性の高い情報を優先的に取得できる。
また、AlloyDBのAI Functionsはデータベース内部で埋め込みを生成する。外部の埋め込みAPIを呼び出す必要がなく、数百万件の埋め込みを効率的に生成できる。Lakehouse Federationを使えば、BigQueryの分析データやIcebergテーブルのアーカイブデータにも、同じPostgreSQLインターフェースから透過的にアクセスできる。
AIエージェントにとって重要なのは「データの鮮度」と「アクセスの容易さ」だ。AlloyDBのリアルタイム埋め込み生成とLakehouse Federationの組み合わせにより、エージェントは最新のオペレーショナルデータと過去の分析データを区別なく扱える。配送車両の位置情報のような刻々と変化するデータでも、クエリを発行した瞬間の状態を取得できる。
実際の導入手順とデモの流れ
Google Cloudは今回のGA発表にあわせて、Codelab(ハンズオン形式のチュートリアル)を公開した。導入手順は以下の4ステップに整理されている。
接続が確立すると、エージェントは自動的にデータベースのスキーマを把握する。テーブル名やカラム名をイントロスペクションクエリで取得し、ユーザーの質問に応じて適切なJOINや集計クエリを組み立てられる。たとえば「過去24時間で最も遅延が発生している配送ルートは?」という質問に対して、エージェントが配送テーブルと車両テーブルをJOINし、リアルタイムの位置情報と組み合わせて回答する。
AIエージェントが実行できる操作の範囲
リモートMCPサーバー経由でエージェントが実行できる操作は、単なるSELECTクエリにとどまらない。AlloyDBのツールセットを使うと、以下のような運用操作も可能になる。
- データのエクスポートとインポート
- バックアップの作成とリストア
- クラスタの設定更新
- AI Functionsを使ったテキストのランキング(AI.RANK())
もちろん、これらの操作はIAM権限の範囲内でのみ実行される。読み取り専用のSQLツールを選択していれば、データ定義や変更を伴う操作はブロックされる。本番環境での安全な運用を第一に設計されている点が重要だ。
導入時に検討すべきポイント
リモートMCPサーバーのGAは、AIエージェントとデータベースの統合を大きく前進させる。しかし導入にあたっては、いくつかの点を事前に検討する必要がある。
まず、コスト構造の把握だ。AlloyDB自体がエンタープライズ向けのプレミアムデータベースであり、さらにMCPサーバーの利用にもGoogle Cloudの料金が発生する。30日間の無料トライアルが提供されているので、まずは小規模なクラスタで検証し、ワークロードに応じたコストを見積もることを推奨する。
次に、IAMポリシーの設計だ。エージェントに必要最小限の権限を付与する「最小権限の原則」を徹底する必要がある。テーブル単位、カラム単位でのアクセス制御が可能だが、データベースの規模が大きくなるとポリシー管理が複雑化する。事前にアクセス制御のルールを整理しておくことが重要だ。
最後に、プロンプト設計の重要性も変わらない。MCPサーバーがデータへのアクセスを提供しても、エージェントが適切なクエリを生成できるかどうかはプロンプトの質に依存する。スキーマの説明やクエリの方針をプロンプトに含めることで、より正確な結果を得られる。
この記事のポイント
- AlloyDB向けリモートMCPサーバーがGAとなり、HTTPエンドポイント経由でAIエージェントが安全にデータベースへアクセス可能になった
- IAMによるテーブル単位の権限制御と、Model Armorによるプロンプトセキュリティで本番運用に耐える設計
- AlloyDBのベクトル検索性能とAI Functionsの組み合わせにより、RAGアプリケーションの構築が効率化される
- 30日間の無料トライアルとCodelabが提供されており、小規模な検証から始められる
2026年5月ウェブ標準 CSS疑似クラスや遅延読み込み新機能まとめ
2026年5月、Chrome 148、Firefox 151、Safari 26.5が安定版としてリリースされた。CSSの疑似クラスやコンテナクエリ、メディア要素の遅延読み込みといった使い勝手を大きく左右する機能群がBaselineへと加わっている。
具体的な変化点は4つだ。開閉状態にスタイルを当てる :open 疑似クラス、名前だけで親を参照できるコンテナクエリ、カスタムプロパティを条件とするスタイルクエリ、そして <video> および <audio> のネイティブ遅延読み込み。これらはすべて、主要ブラウザの最新版で動作するBaseline Newly availableとなった。
この記事では、それぞれの機能が何を解決し、実際のコードでどう使うのか、概観を交えながら見ていく。リリースノートを追いきれていないフロントエンドエンジニアやWeb制作担当者は、この機会にキャッチアップしてほしい。
:open 疑似クラスが Baseline 入り
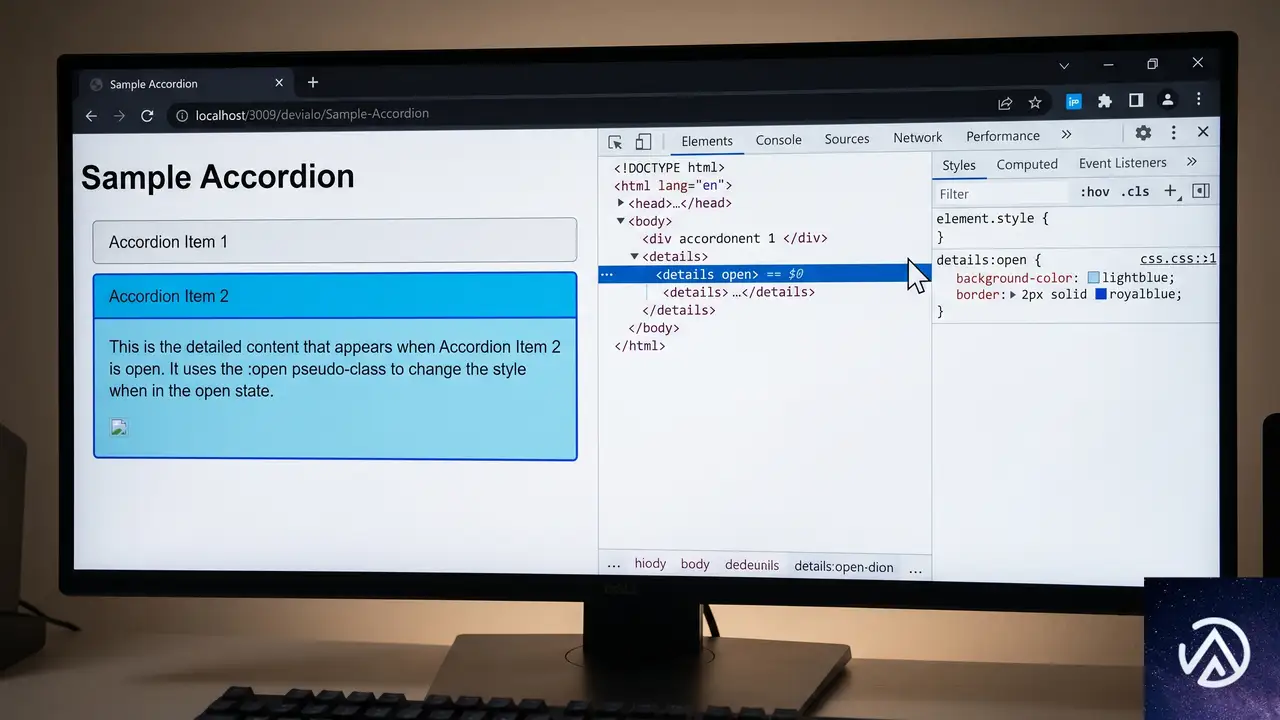
長らくFirefoxとChromeが対応していた :open 疑似クラスが、Safari 26.5のサポートによりBaseline Newly availableとなった。開閉状態を持つHTML要素を、開いているときだけまとめてスタイリングできる疑似クラスだ。
具体的には <details>、<dialog>、<select> といった要素に加え、カラーピッカーや日付ピッカーなどの <input> も対象になる。これまでは details[open] のように属性セレクタで個別に書く必要があったが、より読みやすく一貫性のあるコードにまとめられる。
:open 疑似クラスが解決するもの
従来の手法では、開閉のインタラクションを表現するために要素ごとに異なるセレクタを書く必要があった。たとえば <details> には details[open]、<dialog> には dialog[open] を使う。しかし :open 疑似クラスなら、これらをひとつのセレクタで扱える。
この変化は、コードのメンテナンス性を大きく改善する。とくにデザインシステムを構築するチームでは、コンポーネントの状態管理がシンプルになる利点が大きい。
background: #f0f0f0;
}
dialog[open] {
background: #f0f0f0;
}
background: #f0f0f0;
}
このデモで示したように、:open 疑似クラスを使うと開状態の記述が一箇所に集約される。複数箇所に散らばっていたスタイルを一元管理でき、意図しないスタイル崩れも防ぎやすくなる。
活用シーンと注意点
実務では、FAQのアコーディオンやモーダルダイアログのスタイル定義で即座に役立つ。フォーム部品のピッカーUIにも適用されるため、一貫したブランド表現が可能だ。
ただし、すべての開閉要素が対象になるわけではない。<summary> をクリックして開く <details> のように、ブラウザが開閉状態をネイティブに管理する要素に限定される。JavaScriptで独自に開閉を管理するUI部品には反応しない点に注意が必要だ。
名前のみのコンテナクエリ
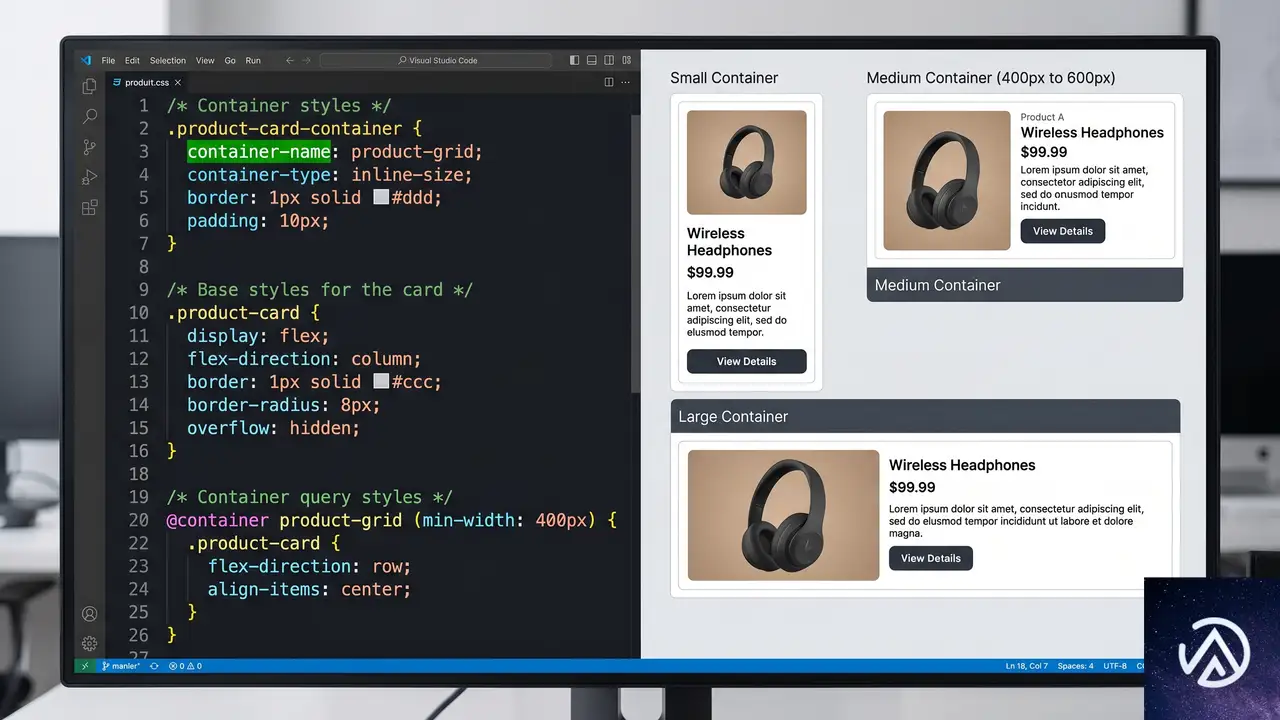
Chrome 148のリリースにより、名前のみのコンテナクエリ(name-only container queries)がBaseline Newly availableになった。コンテナクエリを書く際に、サイズやスタイルの条件を省略してコンテナの「存在」だけを条件にできる。
これまでは container-type プロパティでコンテナの種別を宣言し、かつ @container ルール内でサイズ条件を指定する必要があった。今回の変更で、単に名前でコンテナを参照するだけのクエリが書けるようになり、コードの冗長さが大きく減る。
名前だけでコンテナを参照する仕組み
具体的なコードを見てほしい。従来は「サイドバーという名前のコンテナが、ある幅を超えたら」というクエリが中心だった。新しい構文では「サイドバーという名前のコンテナがあるなら」という条件だけでスタイルを切り替えられる。
/* コンテナの名前を付与 */
#container {
container-name: --sidebar;
}
/* サイズ条件なしで名前だけで参照 */
@container --sidebar {
.content {
padding: 2rem;
}
}container-name: –sidebar;
@container –sidebar (min-width: 300px) { … }
@container –sidebar { … }
この構文によって、container-type の宣言が不要になるケースが増える。名前の指定だけでコンテナを参照したい場面では、CSSの記述量が減り、可読性も上がる。
実務での活用ポイント
大規模なサイトでは、レイアウトのコンポーネント化が進んでいる。コンテナクエリは「親コンポーネントの状態で子のスタイルを決める」設計と相性が良く、名前のみの参照はこの流れを加速する。
たとえば「サイドバーがDOM上に存在するならカードのパディングを変える」といった、レイアウトの有無に応じた条件分岐が簡潔に書ける。メディアクエリでは制御しきれなかったコンポーネント単位のレスポンシブが、より直感的に扱えるようになる。
コンテナスタイルクエリとカスタムプロパティ
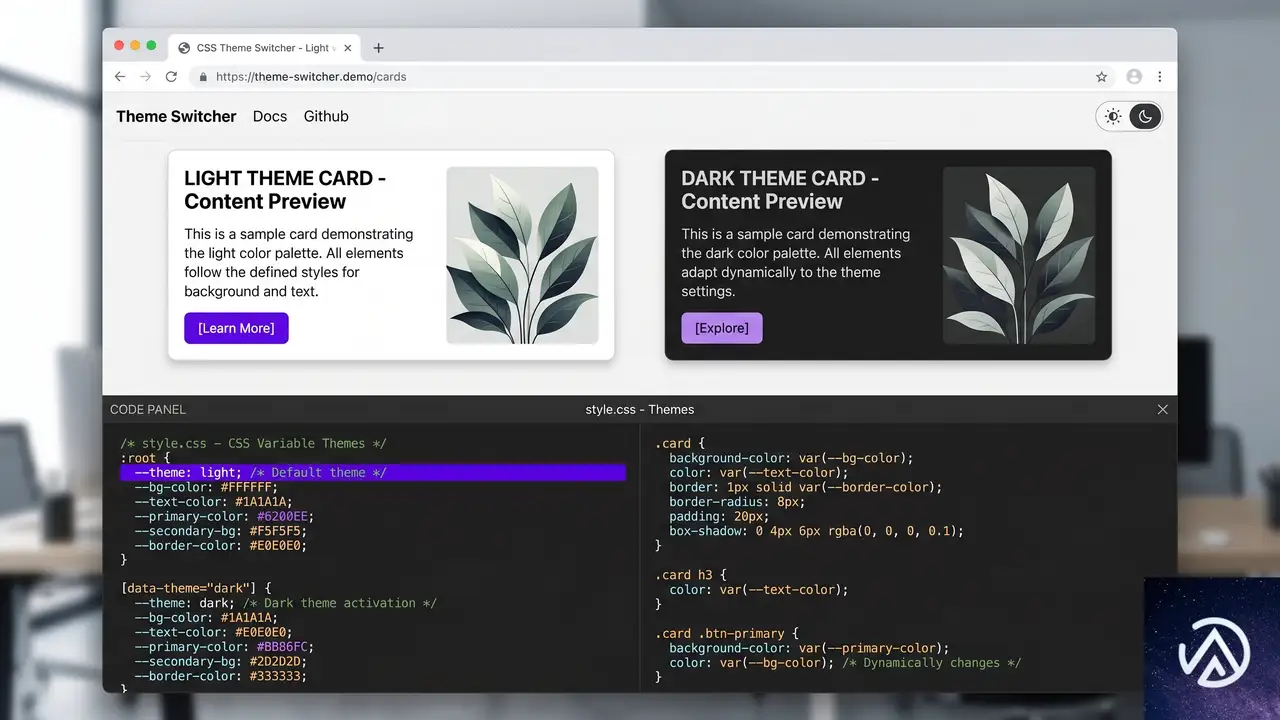
Firefox 151で style() クエリのサポートが加わり、カスタムプロパティを条件とするコンテナスタイルクエリがBaseline Newly availableとなった。これにより、サイズ以外の親コンテナのCSSプロパティを条件にスタイルを切り替えられる。
とりわけ大きな意味を持つのは、カスタムプロパティ(CSS変数)を条件に含められる点だ。たとえば --theme という変数が dark のときに子要素の背景色を変える、といったテーマ切り替えをCSSだけで完結できる。
カスタムプロパティを条件にしたクエリの実例
以下は、親コンテナで定義された --theme: dark というカスタムプロパティを検知し、子の .card にダークモード用のスタイルを適用するコードだ。
@container style(--theme: dark) {
.card {
background-color: #1a1a1a;
color: #fff;
}
}この仕組みを使えば、JavaScriptに依存せずにテーマの切り替えが可能だ。CSS変数を用いた設計基盤が整っているプロジェクトであれば、追加のスクリプトなしでダークモード対応の精度を上げられる。
サイズクエリとの使い分け
サイズクエリは「コンテナの幅が300pxを超えたら」といったレイアウト制御に強い。一方でスタイルクエリは「テーマ」「状態」「モード」といった意味的な条件に向いている。
両者は競合するものではなく、補完関係にある。たとえば「サイドバーが存在し、かつダークテーマのとき」にスタイルを変える、といった複合的な条件設計も可能になる。コンテナクエリ全体がBaselineへと進んだことで、CSSの表現力は確実に一段階上がったと言える。
video と audio のネイティブ遅延読み込み
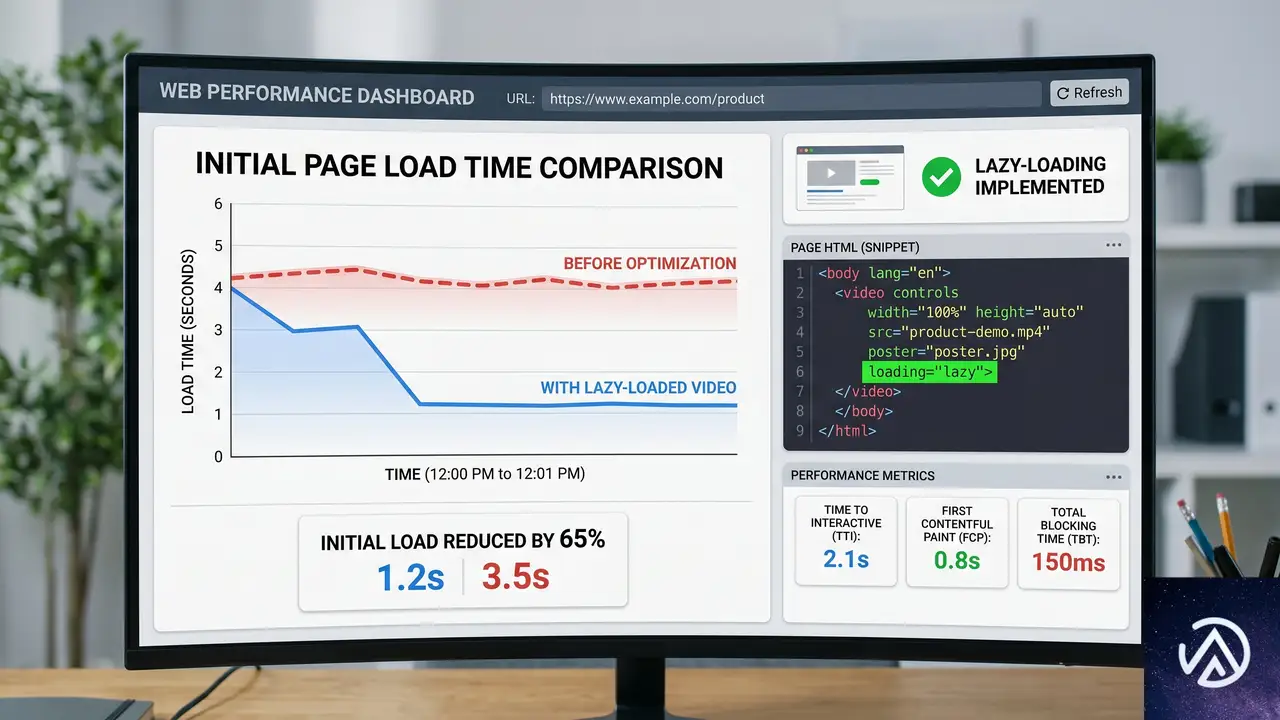
Chrome 148で <video> と <audio> 要素に loading="lazy" 属性が導入された。これにより、画像やiframeと同じく、メディア要素をビューポート付近まで読み込まない動作をブラウザネイティブで制御できる。
サイトのファーストビューに動画を置くケースは増えているが、初期ロードでユーザーの帯域を圧迫する問題は長年の課題だった。この機能はJavaScriptのIntersection Observerを使った手動実装を、宣言的な属性ひとつで置き換える。
実装と効果
実装はきわめてシンプルで、<video> タグに loading="lazy" を追加するだけだ。特別なポリフィルやライブラリは不要で、対応ブラウザであればそのまま動作する。
<video src="hero.mp4" loading="lazy" controls></video>効果は数値にも表れる。Squarespaceのエンジニアリングチームが公開した記事によれば、ネイティブ遅延読み込みによって動画の初期リクエスト数が大幅に減り、LCP(Largest Contentful Paint)の改善に貢献したという。詳細は同チームの技術記事「How To Use Standard HTML Video and Audio Lazy-Loading on the Web Today」を参照してほしい。
対応範囲と今後の展望
Chrome 148でサポートが始まったこの機能は、今後のブラウザ展開によってBaseline化が期待される。FirefoxやSafariの動向はまだこれからだが、loading="lazy" の属性自体は画像やiframeですでに確立された仕組みであり、メディア要素への拡張も自然な流れと言える。
未対応ブラウザでは属性が無視されるだけで壊れないため、今すぐ実装してもリスクは少ない。動画を多用するポートフォリオサイトやLPでは、とくに導入効果が大きい。
Document Picture-in-Picture API とその他のアップデート
CSS以外でも重要な進展があった。Firefox 151でDocument Picture-in-Picture APIがデスクトップ向けに導入され、Web Serial APIもFirefoxデスクトップとChrome Androidでサポートが拡大されている。
Document Picture-in-Picture API の概要
従来のPicture-in-Picture APIは <video> 要素を常に前面の小窓で表示する機能だった。一方、Document Picture-in-Picture APIは任意のHTMLコンテンツを含むウィンドウを常に最前面に表示できる。
これにより、ビデオ会議の参加者グリッドや株価ティッカー、タイマーといったインタラクティブなオーバーレイを、ページ遷移後も維持できるようになる。デスクトップ向けのプログレッシブウェブアプリ(PWA)でとくに威力を発揮するAPIだ。
Web Serial API のプラットフォーム拡大
Web Serial APIは、マイクロコントローラーや3Dプリンター、開発ボードといったシリアルデバイスとウェブサイトが直接通信するための仕組みだ。Firefoxでは専用のサイト権限アドオンを導入することで安全に管理できる設計になっている。
Chrome 148ではAndroid向けにもサポートが拡大され、モバイルデバイスからシリアル機器を制御するユースケースが現実的になった。IoT分野や教育用途での活用が今後広がると見られている。
この記事のポイント
- 2026年5月のブラウザ安定版で、複数のCSS機能とHTML属性がBaseline Newly availableに到達した
:open疑似クラスで開閉状態のスタイリングが一元的に書けるようになった- 名前のみのコンテナクエリにより、サイズ条件なしで親コンテナの存在を参照できる
style()クエリでカスタムプロパティを条件としたテーマ切り替えがCSSだけで実装可能<video>と<audio>のloading="lazy"でメディアの遅延読み込みがネイティブ化され、初期ロードの負荷が軽減される

Neon、有料プランのデータ転送量を5倍に増量。500GBで実質エグレスフリー
サーバーレスPostgreSQLサービスのNeonは2026年6月1日、全有料プランに含まれる月間データ転送量を従来の100GBから500GBへと5倍に引き上げた。この変更は自動的に適用され、利用者側での設定変更は不要だ。
500GBという上限は、ほとんどの一般的なワークロードにおける全データ転送(エグレス)コストを実質的にゼロにする水準だ。Neonのブログによれば、チャットボットのバックフィル処理や設定ミスによる超過リスクも、この増量によって大幅に緩和される。
本記事では、増量の具体的な内容と背景、利用者が知っておくべきポイントを整理する。
月間500GBへの増量。その具体的な内容

今回の変更の核心はシンプルだ。Neonの全有料プラン(Launch、Scale、Enterprise)において、月間のパブリックデータ転送(エグレス)の無料枠が100GBから500GBに拡大された。
500GBを超過した場合の追加課金体系に変更はない。超過分はこれまでと同一の従量課金レートで計算される。Neonの記事では「データ転送の計測方法や料金体系に変更は一切ない」と明言されている。
変更は自動適用。請求書にも即時反映
この増量は2026年6月1日からユーザー側の操作なしで自動適用される。Neonのコンソール(管理画面)で利用状況を確認可能で、6月分の請求書には新たな500GBの枠が反映される。
なぜNeonは5倍への増量を決断したのか

Neonのブログ記事は、意思決定の背景を率直に説明している。最大の動機は「予期せぬエグレス課金の排除」だ。
エグレス課金のストレスを根本から減らす
クラウドデータベースにおけるデータ転送料金は、しばしば利用者にとっての「見えないコスト」となる。チャットボットが想定以上にデータを取得したケース、分析ジョブが大量の履歴データを読み込んだケース、設定ミスでループ接続が発生したケースなど、原因は多岐にわたる。
これらの超過は後になってから請求書で気づくことが多く、事後対応が難しい。Neonの著者Carlo Daniele氏は「請求書に届いてからでは遅すぎる」と指摘している。500GBへの増量は、この「事後ショック」をほとんどのユーザーから無くす狙いがある。
競合との差別化とサーバーレスの信頼性向上
サーバーレスデータベース市場では、Vercel PostgresやSupabaseなどもデータ転送枠を設けている。500GBという閾値は、これらのサービスと比較しても実質的な「エグレスフリー」を実現する水準だ。
Neonにとって、この変更はプラットフォームの信頼性向上と、サーバーレスアーキテクチャへの移行障壁を下げる施策といえる。特にスタートアップや個人開発者にとって、突発的なコスト増はサービス継続のリスクになりうる。その不安を軽減する効果は大きい。
利用者に求められる対応と確認方法

必要な対応は一切なし
繰り返しになるが、利用者が実施すべき設定変更や申し込みは存在しない。Neonの全有料プラン契約者に対し、2026年6月1日以降の月間データ転送量が自動的に500GBへと引き上げられている。
利用状況の確認方法
自身のデータ転送量を把握したい場合は、Neon Consoleにログインし、請求および利用状況のダッシュボードでエグレス使用量を追跡できる。不明点はNeon公式Discordコミュニティで質問することも可能だ。
今後のデータ転送戦略とユーザーへの影響

今回の増量は、Neonが「データ転送をコスト障壁にしない」という姿勢を明確に打ち出したものと捉えられる。サーバーレスデータベースの利点である「従量課金の柔軟性」は、往々にして「予測不能なコスト」と紙一重だ。
500GBの無料枠は、その両面を切り離す試みだ。実際の利用データにもとづきNeonが「ほとんどのワークロードでエグレス課金が発生しなくなる」と明言している点は、単なるマーケティングではなくユーザー利用統計に裏付けられた判断といえる。
将来的にNeonがさらなるデータ転送枠の拡大や、完全なエグレスフリー化に踏み切る可能性もあるが、現時点ではこの変更が最大のハードルを解消したと評価できる。
この記事のポイント
- Neonは2026年6月1日より、全有料プランの月間データ転送量を100GBから500GBに増量
- 変更は完全自動適用。利用者による操作や設定変更は不要
- 500GB超過分の従量課金体系に変更はなく、データ転送の計測方法も据え置き
- 大半の一般的なワークロードがエグレス課金の対象外に。実質的なコスト障壁が大幅に低下
- 予期せぬエグレス課金への不安を解消し、サーバーレスデータベースの信頼性を強化

Google SREが語る、エージェントAIで変わる運用の新常識
GoogleがSRE(Site Reliability Engineering)にエージェントAIを本格導入し、運用の自動化レベルを引き上げている。異常検知やインシデント管理、信頼性設計といった領域で、AIエージェントが「力の倍増器」として機能し始めたのだ。
この取り組みは、2026年5月に公開されたホワイトペーパー「AI in SRE Practice」で詳細に語られている。本記事ではその核心にある5つの重点領域と、Googleが定めた7つの設計原則を整理しながら、エージェントAIがSREにもたらす変化を読み解く。
なぜ今、SREにエージェントAIなのか

GoogleがSREの概念を提唱してから20年以上が経つ。その間、信頼性を担保すべきシステムは幾重にも複雑化した。マイクロサービス化による分散配置の拡大、クラウド製品群の機能爆発、そしてAIコード生成によるソースコード量の急増。それぞれが単独でも運用負荷を押し上げる要因だが、これらが同時に進行している点が問題を大きくしている。
SREチームは従来、サービスレベル指標(SLI)やサービスレベル目標(SLO)に基づく静的な閾値監視で信頼性を守ってきた。しかし、多様な顧客ワークロードを扱うGoogle Cloudのような製品では、一律の閾値で異常を捉えきれないケースが増えている。そこで注目されるのが、AIによる異常検知とエージェント型の自律対応だ。
エラーレート > 1% でアラート
このデモが示すように、AIエージェントは単に閾値を超えたかどうかではなく、平常時の振る舞いパターンからの逸脱を捉える。これにより、多様なワークロードが混在する環境でも、真に対処すべき異常だけを抽出できる確度が高まる。
SRE AIがカバーする5つの重点領域

Google SREチームは、ソフトウェア開発ライフサイクル(SDLC)全体を見渡し、AIエージェントが価値を発揮できる領域を5つに整理した。いずれも従来のSREプラクティスを補完し、人間の意思決定を加速させることを狙いとしている。
信頼性設計への組み込み
従来、SREは設計段階から信頼性を織り込むため、ポリシー策定やランブック(運用手順書)の整備に多くの時間を割いてきた。AIエージェントはこのプロセスを効率化する。具体的には、過去のインシデントから得た知見を基にランブックを自動生成し、本番環境に近い構成に対して信頼性リスクを事前検出する。人間のレビューは高リスクな変更に絞られ、トイル(労苦)の大幅な削減が見込めるという。
異常検知とアラート処理
この領域はエージェントAIの導入効果が最も顕著に表れる部分だ。Google SREは、TimesFMのような時系列予測モデルを使い、過去の正常パターンから逸脱する動きをAIが検知する仕組みを採用している。異常が検知されると、専用のアラート処理エージェントが起動し、関連情報の集約やコンテキスト付与を自動実行する。その後、自律型のアラートハンドラが可能な範囲で一次対応まで完遂する。
このパイプラインにより、人間のSREが対応すべきアラート件数そのものを減らせる。大事なのは、エージェントがどのデータをどう評価したのか、一貫して透明性を保つ設計になっている点だ。本番状態に意図しない変更を加えないための制御機構も当然組み込まれている。
インシデント管理の高度化
GoogleにはIMAG(Incident Management at Google)という確立されたインシデント管理プロセスがある。SRE AIはその上にエージェント型のオーケストレーション層を追加する形で実装されている。
- チャットや動画、追跡ドキュメントなどインシデント中に発生するコミュニケーションを集約・要約
- 担当者交代時のハンドオフドキュメントを自動生成
- ポストモーテム(障害分析書)のドラフトを自動作成し、品質向上と工数削減に貢献
- 社内外向けのインシデント報告の管理
これらは一見地味だが、大規模インシデントでは情報の混乱が復旧遅延の最大要因になる。エージェントが情報整理を肩代わりすることで、SREは本質的な判断と対応に集中できる。
インシデント調査の自律化
AIエージェントは監視データ(ログ、メトリクス、トレース)に加え、システムトポロジや依存関係情報を使い、ドメイン知識を獲得した上で調査を開始する。ランブックのナビゲーション、アラート参照、異常検知、インサイト抽出といった個別の機能エージェントと連携しながら、仮説形成から緩和策の提案までを行う。状況によっては自律的な緩和実行も視野に入れている。
インサイトとリスク管理
AIエージェントが継続的に学習し続けるための仕組みとして、Google SREは「AI Insights」というシステムを開発した。これは過去の全インシデントを分析し、構造化された知見を抽出する。Geminiの埋め込みモデルとベクターデータベースを活用し、各インシデントにリスクカテゴリを自動付与する。これにより、エージェントは将来の調査時により精度の高い緩和策を提案でき、人間のSREも優先的に対処すべき領域を俯瞰できる。
このように複数のエージェントが役割分担しながら、一つのインシデントに対して協調的に動作する。単一の巨大なAIではなく、目的別に分割されたエージェント群が連携する設計思想がGoogle SREの特徴だ。
エージェント導入に先立つ7つの設計原則

Google SREはエージェントAIを闇雲に導入したわけではない。顧客への約束を守りながら信頼性を向上させるため、以下の7つの高レベル原則を定めている。
- 既存の自動化が機能している領域は、ビジネス要件を満たしている限り無理に置き換えない。
- 新しいAIシステムは、既存および将来のポリシーと手順に準拠すること。
- SRE AIエージェントは、人間と同等のセキュリティ・安全性・プライバシー要件を満たすこと。
- エージェントは強力なアイデンティティを持ち、ロールベースで権限が割り当てられること。
- エージェント自体に高い信頼性SLOを設定し、自動または手動のバックアップ手段を明確に用意すること。
- エージェントは実行したアクションの理由と、検討し却下した選択肢を説明できなければならない。ブラックボックス自動化より透明性を重視する。
- 事業継続計画にAI障害時のコンティンジェンシーを含めること。
とりわけ6番目の「説明可能性」は、SREという領域において極めて重要だ。なぜそのインシデントが発生し、なぜその緩和策を選んだのか。説明できない自動化は、ポストモーテム文化と相性が悪い。GoogleがエージェントAIに対して透明性を強く要求しているのは、SREの根本思想である「非難しない文化」と「学習する組織」をAI時代にも維持するためといえる。
この対比は、単なる技術選定の話ではない。SREの運用文化そのものをどう進化させるかという問いに直結している。
SRE AIを支えるGoogleの基盤技術

これらのエージェント群は、個別の新規プロジェクトとして開発されたものではない。Googleが長年培ってきたインフラストラクチャの上に構築されている。主要な構成要素は次のとおりだ。
- Gemini — 基盤モデル。SREチームは社内データでファインチューニングしたカスタムGeminiモデルも併用。
- Gemini Enterprise Agent Platform(旧Vertex AI) — エージェント開発のためのフルAIスタック。
- Agent Development Kit(ADK) — エージェント構築の開発プラットフォーム。
- MCPサーバー — 標準のGoogle APIインフラ上で動作し、外部顧客向けMCPサポートにも使われるものと同一基盤。
- BigQuery / ベクターデータベース — AI Insightsシステムのデータ基盤。Gemini埋め込みモデルと連携。
- 標準Observabilityインフラ — 監視、ログ、トレーシング。
特筆すべきは、これらの技術がすでにGoogle Cloudの顧客向けにも提供されている点だ。ホワイトペーパーで語られているSRE AIのアーキテクチャは、決してGoogle内部だけの秘伝のたれではなく、クラウド利用者にとっても参照可能な設計パターンとして公開されている。
SRE AIが目指す先

Google SREチームは、SRE AIが達成すべき目標として、次の5つを掲げている。
- 退屈で反復的な運用からエンジニアを解放する
- 意思決定と実行の質と速度を向上させる
- これまで対処できなかった問題の予防・検知・緩和を可能にする
- 信頼性向上に向けた自律的なフィードバックループを形成する
- 全体的な運用コストを削減する
これらは一見するとAI導入の一般的な利点に見える。しかしGoogle SREが強調するのは、単なる効率化ではない。AIが複雑さを増幅させた側面があるからこそ、同じAIを使って複雑さを制御するという考え方だ。SRE AIの本質は「AIがもたらした運用課題を、AI自身の力で解決する」逆説的なアプローチにある。
Googleは以前から自律システムを本番運用してきた実績を持つ。しかし現在のAIベースの自律システムは、非決定的な振る舞いをする点で従来と大きく異なる。この性質を正しく理解し制御するために、自律レベルのトラッキング手法も開発されている。詳細はホワイトペーパー「AI in SRE Practice: Moving Beyond Automation at Google」に譲るが、決定論的自動化からエージェントAIへの移行は、SREという分野にとって20年来の転換点になる可能性を秘めている。
この記事のポイント
- Google SREはAIエージェントを「力の倍増器」と位置づけ、運用の自動化レベルを次の段階へ引き上げている
- 静的な閾値監視からAIによる異常検知への移行は、多様なワークロードに対応するための不可避な進化である
- 7つの設計原則のなかでも「説明可能性」の重視は、SRE文化との整合性を保つ上でとりわけ重要だ
- SRE AIの構成要素はGoogle Cloudの顧客向け技術スタックと地続きであり、外部組織も同様のアーキテクチャを参照できる
- 決定論的自動化からエージェントAIへの移行は、SREの根本的な運用思想を再定義する可能性がある

Amazon対Perplexity訴訟、AIエージェントのアクセス権限を問う
AIブラウザがユーザーの代わりにECサイトで買い物をする時代になった。AmazonはPerplexityのAIブラウザ「Comet」を相手取り、米国で異例の訴訟を起こしている。争点は「ユーザーが明示的に許可したAIエージェントのアクセスは、サイト運営者に対する不正アクセスになるのか」という一点だ。2026年6月11日に第9巡回区控訴裁判所で口頭弁論が開かれるこの裁判は、ECサイト、予約プラットフォーム、SaaS事業者すべてのログイン領域設計を変える分岐点になる。
本裁判はCFAA(Computer Fraud and Abuse Act、コンピュータ不正アクセス法)という1986年に制定された法律が、AIエージェント時代にどう適用されるのかを初めて本格的に問うものだ。差止命令、控訴審での一時停止、そして口頭弁論と、わずか8週間で局面が3度動いた。本記事では、事件の流れを整理しつつ、AIエージェントの訪問権限をめぐる法的構図を平易に解説する。そして、ウェブサイト運営者が今週中に着手できる3つの実務対応を具体的に示す。
事件の経緯と現在地

Search Engine Journalの記事によると、2026年初頭にAmazonがPerplexityをカリフォルニア州北部地区連邦地方裁判所に提訴した。PerplexityのAIブラウザ「Comet」は、ユーザーから預かった認証情報でAmazonアカウントにログインし、商品を閲覧して購入まで完了できる。AmazonはこれがCFAA違反にあたると主張した。商標権侵害や不正競争の訴えも追加されている。
地裁判決で下った差止命令
2026年3月10日、Maxine Chesney連邦地裁判事はAmazonの申し立てを認め、予備的差止命令を出した。CometはAmazon.comのパスワード保護領域(アカウントページ、注文履歴、決済画面)にアクセスできなくなった。公開ページへのアクセスは引き続き許可された。地裁は、Amazonの利用規約がログイン領域へのアクセス権限者を定めており、ユーザーがエージェントに指示したとしても、その権限はエージェント自身には及ばないと判断した。
控訴審での一時停止とPerplexityの反論
差止命令から約1週間後、第9巡回区控訴裁判所はPerplexityの控訴を待つ間、差止命令の効力を一時停止した。Cometは再びAmazonのログイン領域にアクセスできる状態で控訴審を迎えた。控訴審で予備的差止命令が停止されるのは珍しく、地裁判決への懐疑を示すシグナルと受け止められた。
2026年5月8日、Perplexityは控訴趣意書を提出した。Search Engine Journalの記事によれば、Perplexityの主張は次の3点に集約される。第1に、CFAAは本来ハッキング対策の法律であり、ユーザーが明示的に許可したエージェントのアクセスには適用されない。第2に、権限を持つのは常にユーザー本人であり、Cometはユーザーの委任のもとで行動しているにすぎない。第3に、Amazonの利用規約違反を連邦刑事法違反に格上げする解釈は、法律の趣旨を大きく逸脱する。MozillaやEFF(電子フロンティア財団)をはじめとするデジタル権利団体も、Perplexityを支持する法廷助言書を提出した。
CFAA(コンピュータ不正アクセス法)をめぐる両陣営の主張

CFAAは1986年に制定された連邦法だ。映画『ウォー・ゲームズ』の時代にハッキング行為を取り締まる目的で作られた。しかしその後20年で、スクレイピング、自動アクセス、アカウント共有など本来の射程を超える民事訴訟に援用されるようになった。2021年、連邦最高裁はVan Buren対アメリカ合衆国事件でCFAAの適用範囲を狭め、「システムへのアクセス権限を持つ者が、不適切な目的でアクセスしてもCFAA違反にはならない」と判示した。このVan Buren判決の射程が、AIエージェントによるユーザー委任アクセスに及ぶかどうかが、本件の中核的論点だ。
Amazonの3段階ロジック
AmazonのCFAA理論は3つの段階で構成される。第1に、Amazonの利用規約は自動アクセスを明示的に禁止している。アクセス権は自然人によるブラウジングに限定されており、ユーザーの代理として動作するソフトウェアエージェントは対象外だ。第2に、CometがユーザーのAmazonアカウントにログインするとき、リクエストを発行しているのはComet自身である。Amazonから見れば、訪問者はユーザーではなくエージェントだ。第3に、AmazonはCometにアクセスを許可したことが一度もない。したがってCometのアクセスはCFAA上の「権限なし」に該当する。ユーザーがCometに指示した事実は、AmazonがCometに権限を付与したかどうかとは無関係だ。
Perplexityが依拠する委任の法理
Perplexityの反論は正反対の方向から来る。ユーザーが本人(プリンシパル)であり、Cometは法律上の代理人(エージェント)だ。ユーザーがCometに自分のアカウントでログインし、自分が権限を持つ取引を完了するよう指示したとき、Cometのアクセスはユーザー自身のアクセスをソフトウェア経由で実現したものにすぎない。取引のどこにも権限のない当事者は存在しない。CFAAは明示的なユーザー委任のもとで動くソフトウェアを想定しておらず、適用範囲外だ。
この「委任の法理(agency doctrine)」は、代理人が委任者の代わりに行動するとき、代理人の行為の法的効果は委任者に帰属するという、何世紀も前から確立している原則だ。ソフトウェアが明示的なユーザー指示で動くことは、この原則を現代に自動化して拡張したものにほかならない。CFAAがこの原則を無視すれば、オンライン上のタスクをソフトウェアに委任するあらゆるユーザーが、連邦刑事法の罠にかかることになる。
第9巡回区控訴裁が差止命令を一時停止した理由

控訴審で予備的差止命令が停止されるのは異例であり、それ自体が重要なシグナルだ。第9巡回区控訴裁判所は差止命令の停止判断に4要素テストを用いるが、その第一要素は「本案で勝訴する見込み」である。停止を認めたということは、パネル(裁判官団)がPerplexity側に合理的な勝訴可能性を見ていることを示唆する。
Search Engine Journalの記事では、パネルが地裁のCFAA解釈に懐疑的である可能性を示す2つの法的圧力が指摘されている。1つ目は前述のVan Buren判決だ。連邦最高裁は2021年に、アクセス権限を持つ者が不適切な目的でシステムにアクセスしてもCFAA違反にはならないと判断した。地裁の判断はVan Buren以前の拡大解釈に近く、Van Burenが狭めたはずの範囲を再び広げているように見える。
2つ目は委任の法理だ。人間が別の人間に代理を頼むとき、代理人の行為は本人に帰属する。ソフトウェアエージェントがユーザーの明示的指示で動くことは、この原則を現代化したものにすぎない。CFAAがこの原則を無視すれば、オンラインタスクをソフトウェアに委任するすべてのユーザーが刑事罰のリスクに晒される。両方の圧力がそろったことで、パネルは地裁判決の維持に慎重な姿勢を示したと考えられる。
判決がWebサイト運営者にもたらす影響
この裁判の帰結は、AmazonとPerplexityの一訴訟にとどまらない。AIエージェントの訪問権限に関する米国初の本格的な司法判断として、あらゆるECサイト、予約プラットフォーム、金融機関、SaaS事業者のログイン領域設計に波及する。
地裁理論が維持された場合
Search Engine Journalの記事によれば、地裁のCFAA理論が控訴審で維持された場合の帰結は明快だ。主要なウェブサイトはすべて、ユーザーが完全に所有するアカウントに対しても、AIエージェントのアクセスをブロックする法的武器を手にする。利用規約に自動アクセス禁止条項を書けば、ユーザーが明示的に許可したエージェントでもCFAA違反で訴えられる。AmazonがCometに対して使った設計図が、あらゆるプラットフォームの標準プレイブックになる。
影響は業種ごとに連鎖する。小売サイトはAIショッピングエージェントによる価格比較をブロックできる。予約サイトはAI旅行エージェントによる予約完了を拒否できる。銀行や証券会社はAI資産管理エージェントをダッシュボードから締め出せる。マーケットプレイスはAIエージェントが出品するのを防げる。SaaS事業者はAIエージェントがサブスクリプションを管理したりワークフローを実行したりするのをブロックできる。いずれのケースでも、利用規約の文言が支配的文書となり、ユーザーの明示的指示は法的に無意味になる。
控訴裁が地裁判決を覆した場合
第9巡回区控訴裁が地裁判決を覆せば、CFAAは本来の狭い射程に押し戻される。ウェブサイトはユーザー委任エージェントをブロックする連邦刑事法の手段を失い、エージェントアクセスの問題は契約と技術のレイヤーに移る。Search Engine Journalの記事が指摘する通り、ウェブサイトは引き続き技術的手段、民事救済を伴う規約、あるいはパートナーシップAPIを通じてエージェントをブロックできる。しかし連邦刑事法をテコとして使うことはできなくなる。
中間的判断の可能性
全面勝訴か全面敗訴かだけではない。Search Engine Journalの記事は中間的結果の可能性も指摘している。控訴裁はより狭い理由で差止命令を維持したり、エージェントアクセスの種類を区別したり、事実審理の差し戻しを命じたりするかもしれない。たとえば、取引を完了するエージェントとデータ取得のみのエージェント、保存された認証情報を使うエージェントと毎回ユーザーにログインを求めるエージェント、検証済みプロトコルを使うエージェントと未識別のブラウザ自動化ツールを区別する可能性だ。線引きを伴う判決は、全面肯定・全面否定の判決以上に、ウェブサイトがアクセスポリシーを設計する際の実務を細かく規定することになる。
口頭弁論で注目すべき3つのシグナル

6月11日の口頭弁論では、3つのシグナルに注目する価値がある。Search Engine Journalの記事が挙げる観測点を紹介する。
第1に委任の法理への言及だ。裁判官がAmazon側の弁護士に対し「ユーザーの明示的指示が、なぜユーザーが選んだ代理人に権限を拡張しないのか」と強く追及するようなら、パネルが地裁の解釈に違和感を持っているサインだ。逆にPerplexity側に対し「自動化エージェントを人間のユーザーと同一に扱うべき理由は何か」と追及するようなら、地裁の枠組みに親和的な可能性がある。
第2にエージェントアクセスの種類の区別だ。これまでの審理では「エージェントアクセス」はひとまとめに扱われてきた。パネルは、取引を完了するエージェントとデータ取得のみのエージェント、保存された認証情報を使うエージェントと毎回ログインを求めるエージェントなど、線引きを試みるかもしれない。線引きのある判決は、全面勝敗の判決以上に実務を規定する。
第3にCFAAの将来的解釈だ。裁判官には、AIエージェント全般に対するCFAAの適用枠組みを書く機会がある。AmazonとPerplexity固有の事実に絞った狭い判決なら、より大きな問題は別の巡回区の別の事件に委ねられる。広い判決なら、カテゴリー全体の法的枠組みが決まる。
第9巡回区控訴裁の口頭弁論は公開されており、音声は通常数時間以内に公開される。パネルの構成が判明すれば、どのような聴取になるかの手がかりにもなる。この3つのシグナルを追うことが、ウェブサイト運営者にとって最も低コストで方向性を読む方法だ。
今週から着手すべき3つの実務対応

6月11日の口頭弁論を前に、Search Engine Journalの記事はウェブサイト運営者が今週中に実行できる3つの具体的アクションを挙げている。判決がどう転んでも、デフォルトのまま放置することが最大のリスクになる。
1. 利用規約の自動アクセス条項を読み直す
多くのウェブサイトの利用規約にある自動アクセス禁止文言は、「自動アクセス=スクレイピングボットや不正スクリプト」を想定したエージェント以前の時代に書かれたものだ。ユーザー自身のAIエージェントが明示的指示で動いているときに、その文言が自社の意図を正確に表現しているかを確認する必要がある。ユーザー委任エージェントを歓迎するなら、その旨を明記すべきだ。ブロックするなら、それも明記し、robots.txtやアクセス制御の設定と整合させるべきだ。
2. AIエージェントのユーザーエージェントを監査する
現在、主要なAIエージェントのユーザーエージェント(UA)には、GPTBot、OAI-SearchBot、ChatGPT-User、PerplexityBot、ClaudeBot、Google-Extended(検索・引用クローラー)に加え、Perplexity Comet、ChatGPT Atlas、各種Geminiサーフェス(ユーザー委任ブラウザ)が含まれる。Search Engine Journalの記事によれば、robots.txtやWAF(Webアプリケーションファイアウォール)がこれらをデフォルトでブロックしている場合、ユーザーはすでに自分のアカウントで壁にぶつかっている可能性がある。ブロックするか許可するかは運営者の判断だが、デフォルト設定に任せるのではなく、意図的な判断であるべきだ。
3. エージェントアクセスへの自社姿勢を決める
3つの一貫した姿勢がある。第1は「歓迎」だ。ユーザー委任エージェントのアカウントアクセスを受け入れ、エージェント駆動の取引に異なる料金体系を設定し、エージェントが読み取りやすい専用インターフェースを公開する。第2は「ブロック」だ。ユーザー委任エージェントを不正アクセスと見なし、規約と技術的制御で裏打ちし、一部のユーザーが歓迎姿勢のサイトに移行することを受け入れる。第3は「パートナー」だ。エージェントがログインページをスクレイピングせずに使えるAPIを構築し、正面玄関ではなく専用ドアを通す。
現在ほとんどのウェブサイトが取っているデフォルト姿勢は、エージェントが訪問者として実在する以前に作られたものだ。6月11日に第9巡回区控訴裁がどのような判断を下すにせよ、そのデフォルトはすでに多くのサイトにとって誤った姿勢になっている。意図的に選び直すべきタイミングだ。
この記事のポイント
- Amazon対Perplexity裁判は、AIエージェントの訪問権限を問う米国初の本格的司法判断となる
- 争点は「ユーザーが明示許可したAIエージェントのアクセスがCFAA上の不正アクセスに該当するか」だ
- 第9巡回区控訴裁が差止命令を一時停止した事実自体が、地裁判決への懐疑を示している
- 判決結果によってEC、予約、金融、SaaSの全ログイン領域設計が変わる
- 今週中に利用規約の見直し、UA監査、自社のエージェントアクセス方針決定を進めるべきだ

AWS BedrockでOpenAI GPT-5.5とCodexが利用可能に。開発効率が飛躍
AWSが2026年6月、Amazon Bedrock上でOpenAI GPT-5.5モデル、GPT-5.4モデル、そしてコーディングエージェントCodexの一般提供を開始した。これにより、Bedrockのセキュアなインフラ上で最先端の大規模言語モデルを利用できる。
GPT-5.5は最も難しいタスク向け、GPT-5.4はコストパフォーマンス重視のシナリオに適する。いずれも、新しい推論エンジン上で高速かつ信頼性の高い応答が得られる。Codexは週あたり400万人以上の開発者が使用するAIコーディングツールで、複数のIDEと連携しつつ、推論エンジン経由でBedrockからモデルを呼び出す。
データ主権要件に対応するため、すべての処理は選択したBedrockリージョン内に留まる。トークン単位の課金で、シートライセンスや開発者あたりの固定費は発生しない。本記事では利用開始手順と技術的な注意点を解説する。
AWS BedrockでOpenAI GPT-5.5とCodexが一般提供
AWSの年次カンファレンスでプレビューされていたOpenAIモデルの対応が、正式に利用可能になった。GPT-5.5とGPT-5.4は、コーディング、推論、エージェントワークフロー、複雑な専門業務に優れる。AWS News BlogのChanny Yun氏は、GPT-5.5を「最も難しい顧客のワークロード」向け、GPT-5.4を「最良の価格性能比」と位置づける。
モデルへのアクセスは、新しいBedrock推論エンジンが提供するResponses APIを介して行う。このAPIは、マルチターン状態管理、ホストツール、ファンクションツール、バックグラウンド実行をサポートする。
この構成により、機密データを外部に送信することなく、AWSの管理下で最先端AIを活用できる。リージョンごとのデータ主権も担保される。
GPT-5.5モデルの利用方法

モデルへは、OpenAIのResponses APIを用いてアクセスする。Bedrock専用のエンドポイントbedrock-mantleを経由し、OpenAI SDKやcurlから呼び出す形だ。以下にセットアップ手順を示す。
Python SDKを使った呼び出し
まずOpenAI SDKを最新版にアップデートする。
pip install -U openai認証用の環境変数を設定する。BedrockのAPIキーはAWSマネジメントコンソールから取得できる。
export OPENAI_BASE_URL="https://bedrock-mantle.us-east-2.api.aws/openai/v1"
export OPENAI_API_KEY="<BEDROCK_API_KEY>"
export BEDROCK_OPENAI_MODEL_ID="openai.gpt-5.5"以下のサンプルコードで、GPT-5.5に分散アーキテクチャの設計を依頼できる。
import os
from openai import OpenAI
client = OpenAI(
base_url=os.environ["OPENAI_BASE_URL"],
api_key=os.environ["OPENAI_API_KEY"],
)
response = client.responses.create(
model=os.environ["BEDROCK_OPENAI_MODEL_ID"],
input=[
{
"role": "developer",
"content": "You are a software engineer with excellent AWS cloud knowledge. Be concise and practical.",
},
{
"role": "user",
"content": "Design a distributed architecture on AWS in Python that should support 100k requests per second across multiple geographic regions.",
},
],
reasoning={"effort": "medium"},
text={"verbosity": "low"},
)
print(response.output_text)curlによる直接アクセス
curlを使う場合も同様に環境変数を設定した上で、エンドポイントへPOSTリクエストを送る。
curl "$OPENAI_BASE_URL/responses" \
-H "Content-Type: application/json" \
-H "Authorization: Bearer $OPENAI_API_KEY" \
-d '{
"model": "openai.gpt-5.5",
"input": [
{
"role": "developer",
"content": "You are a software engineer with excellent AWS cloud knowledge."
},
{
"role": "user",
"content": "Design a distributed architecture on AWS in Python that should support 100k requests per second across multiple geographic regions."
}
],
"reasoning": {"effort": "medium"},
"text": {"verbosity": "low"}
}'コード内のreasoning.effortは推論の深さを制御する。GPT-5.5ではmediumから始め、必要に応じてhighに変更すると良い。GPT-5.4の場合は明示的にeffortを指定すべきだ(デフォルトがnoneのため)。
CodexでAI駆動開発を体験する
Codexは、GPT-5.5を推論エンジンとしてバックグラウンドで利用するコーディングエージェントだ。CLI、デスクトップアプリ、VS CodeやJetBrains、Xcodeの拡張機能が提供され、大規模コードベースの作成、リファクタリング、デバッグ、テスト、検証をAIが支援する。
Codex CLIの設定手順
Codex CLIをインストール後、Bedrock認証を有効にする。APIキー認証とAWS SDKの認証情報チェーンの2方式があり、APIキーが優先される。
export AWS_BEARER_TOKEN_BEDROCK=<your-bedrock-api-key>次に、~/.codex/config.tomlにモデル情報とリージョンを記述する。
model = "openai.gpt-5.5"
model_provider = "amazon-bedrock"
[model_providers.amazon-bedrock.aws]
region = "us-east-2"デスクトップアプリやVS Code拡張では、必要な環境変数を~/.codex/.envに記述しておく。設定変更後はアプリケーションを再起動すれば反映される。
CLIで/statusタブを表示すると、モデルがBedrock経由で接続されていることを確認できる。Channy Yun氏の記事では、実際のステータス画面が示されており、モデルとしてopenai.gpt-5.5と表示される。
レイテンシやスケーリングの注意点

本番利用を始めるにあたり、いくつかの技術的なポイントを把握しておく必要がある。
モデルレイテンシの特性
GPT-5.5は高速、GPT-5.4は中速と位置づけられるが、実際の遅延は推論の深さ、出力長、ツール呼び出しの有無、バックグラウンドモード、リージョン、クォータ、スロットリング、プロンプトサイズ、キャッシュヒットに依存する。GPT-5.5ではreasoning.effortをmediumで開始し、GPT-5.4では明示的にeffortを設定することを推奨する(デフォルトがnoneで十分な推論が得られない可能性があるため)。
スケーリングとキャパシティ管理
Bedrockの新しい推論エンジンは、多数のモデルにわたって迅速にキャパシティをプロビジョニングし、需要変動に応じてスケールする設計だ。定常的なワークロードの実行を優先し、需要急増時にはリクエストをキューイングする(拒否はしない)。そのため、予期せぬトラフィック増加時にも安定した動作が期待できる。ただし、クォータ上限を事前に確認し、必要に応じて引き上げ申請を行うことが望ましい。
この記事のポイント
- Amazon Bedrock上でOpenAI GPT-5.5・GPT-5.4モデルとCodexが一般提供開始
- Responses APIを通じてモデルを呼び出し、複雑なワークロードに対応
- CodexはGPT-5.5をバックエンドに、CLI・デスクトップアプリ・IDE拡張で利用可能
- データは選択したBedrockリージョン内で処理され、データ主権を確保
- レイテンシは複数要因に依存し、effort設定やキャッシュが影響するため、初期はmediumから
- スケーリングは自動だが、クォータ管理を怠らないこと
Googleで1位でも半数は画面外。検索順位より「ピクセル」で測る新常識
Google検索で1位を獲得しても、ユーザーの半数近くはその存在にすら気づかない。これは仮説ではなく、最新のSERP(検索結果ページ)ピクセル分析で明らかになった事実だ。
デスクトップでオーガニック1位が画面内に収まる確率は57%。スマートフォンではわずか40%ほどに低下する。1位でも画面の可視領域(ファーストビュー)からはみ出しているケースが日常化している。
この記事では、従来の「順位」という指標が陳腐化しつつある理由と、代わりに何を追うべきかを数字で整理する。検索マーケティングの成果指標をピクセル単位で捉え直す時代が来ている。
順位だけでは測れない。SERPの物理的変化
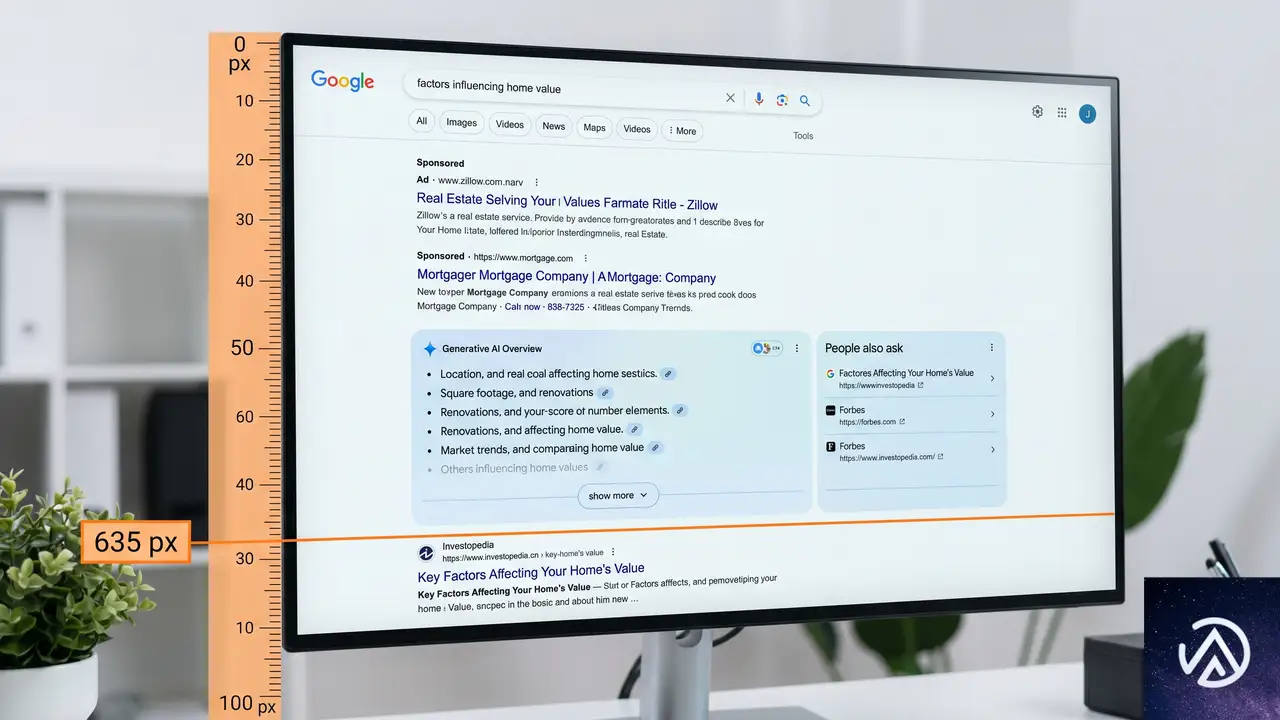
1位の中央値は635ピクセル下
Search Engine Journalの記事によると、デスクトップにおけるオーガニック検索1位の表示位置は、ページ最上部から平均635ピクセルも下がっている。標準的なノートPCのビューポート(画面の表示領域)が約800ピクセルであることを考えると、1位の半分以上はスクロールしなければ見えない計算だ。
2位になると、状況はさらに厳しい。もはや過半数のケースでファーストビューから完全に外れている。10位に至っては、スクロールを約5画面分も重ねなければ到達できない。
順位という数字が「視認される確率」と直結しなくなった要因は明確だ。AI Overviews(旧SGE)やナレッジグラフ、広告枠の拡大が、オーガニック検索結果を物理的に押し下げている。
情報系クエリと商業系クエリ、それぞれの侵食度
オーガニック検索結果を押しのけている要素は、検索意図によって顔ぶれが異なる。
情報検索型のSERPでは、AI Overviewsだけでファーストビュー領域の約3分の1を占有する。これにナレッジグラフが加わると、その割合は約41%に達する。ユーザーがスクロールする前に目にする領域のうち、実に5分の2がオーガニック以外の要素で埋まっている計算だ。
商業検索型のSERPはさらに偏りが激しい。リスティング広告とショッピングユニットの合計で、ファーストビューの60%超を占める。カテゴリによっては「人気商品」枠がそれに拍車をかけ、オーガニックの占有率は約16%にまで縮小する。
業種やクエリの種類によって侵食パターンは異なるため、自社の主要キーワードがどのカテゴリに属するかを把握しておく必要がある。情報系と商業系では、画面内での戦い方がまったく変わるからだ。
順位ではなく「結果サイズ」で戦う発想
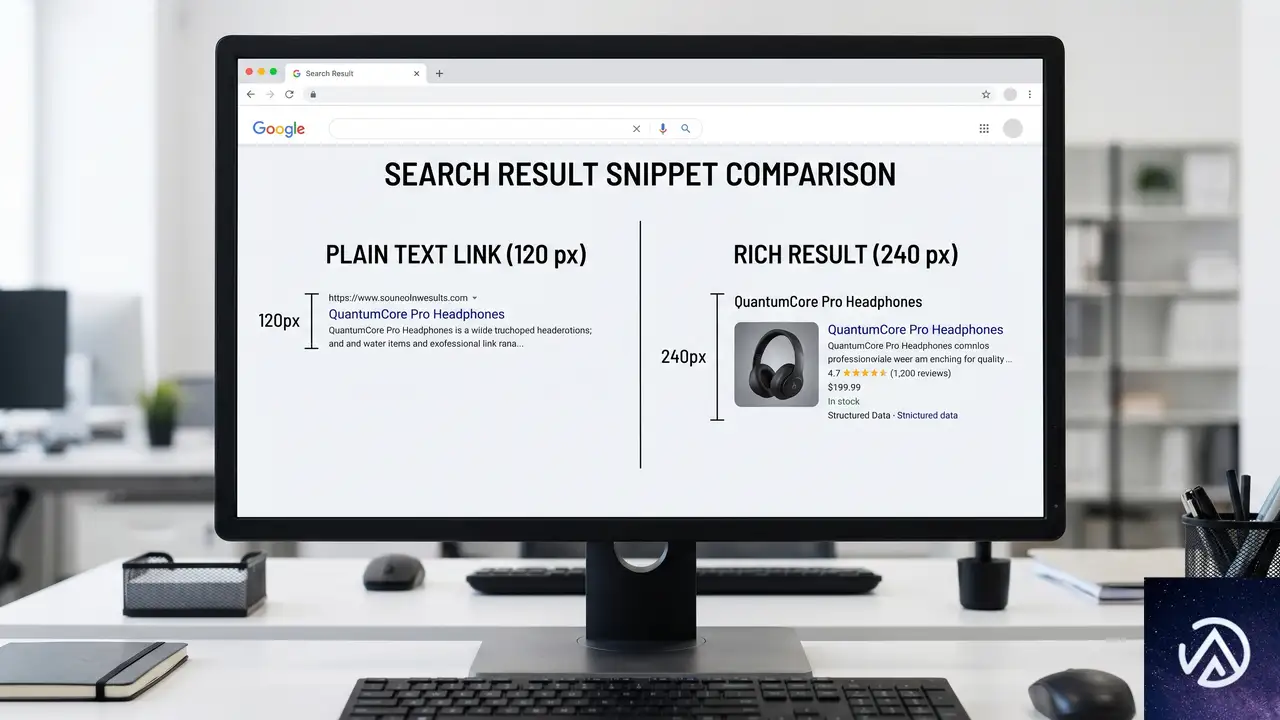
Search Engine Journalの記事において、順位トラッキング企業のTom Capper氏が提示した最も実践的な視点転換がこれだ。キーワードの優先順位を検索ボリュームや順位だけで決めるのではなく、SERP上でその結果が占める「ピクセルサイズ」で判断する。
通常スニペットは120ピクセル、リッチリザルトは240ピクセル
標準的なオーガニック検索結果1件の高さは約120ピクセル。これに対し、画像・価格・評価スター(IPR / Images Prices Ratings)を伴うリッチリザルトは約240ピクセルを占める。視覚的な存在感は単純計算で2倍だ。
Capper氏はこの差を『ロード・オブ・ザ・リング』の戦闘シーンに例えている。巨大な戦象を倒しても「1体としてしか数えない」と言うギムリに対し、それは明らかにおかしい、という指摘だ。SERP上でも、画像や価格が並ぶリッチな表示と、プレーンなテキストリンク1行を「同じ1位」と括ってはならない、というわけだ。
実務に落とし込むなら、主要な商業キーワードをIPR対応可能かどうかで棚卸しし、獲得できるピクセルサイズの大きい施策から優先的に構造化データの実装を進めるのが合理的だ。検索ボリュームの大小より、表示されたときの視覚的インパクトを基準にする発想である。
ブランド検索ボリュームが順位予測因子としてドメインオーソリティを上回る
Search Engine Journalの記事ではさらに、順位トラッキング企業のCapper氏が9年前に行った分析が再紹介されている。当時から「ブランド検索ボリューム」はドメインオーソリティよりもオーガニック順位との相関が強かった。そして現在、同じ分析をやり直すと、その相関はさらに強まっている。
「ブランドは順位の予測因子として、ますます強力になっている」とCapper氏は指摘する。そしてブランドを構築する手段こそが、SEOによる可視性の確保だ、と。
ここにフライホイール(弾み車)効果が生まれる。検索結果での可視性がブランド認知を高め、ブランド名での検索が増え、それが順位を押し上げ、さらに可視性が強化される。SEO担当者が長年うまく言語化できなかったこの循環を、「ふわっとした認知施策」ではなく「計測可能なオーガニックパフォーマンスの入力値」として扱う視点が求められている。
オーソリティ指標を無視してよいわけではない。だが、ブランドを「成果」ではなく「投入資源」として捉え直すことが、これからのSEOに求められる姿勢だ。
上位層に可視性指標をどう売り込むか

Search Engine Journalのウェビナーでは、このピクセル基準の考え方を社内上層部にどう説明するかについても具体的な助言があった。
ピクセル指標は従来のシェア・オブ・ボイスより直感的に通る
記事によると、Capper氏は「ピクセルデータのほうが上層部への説明がしやすい」と述べている。理由はシンプルだ。従来のシェア・オブ・ボイス(SOV / 声の占有率)という指標は、本来「どれだけ見えているか」の代替指標だった。しかし順位だけを基準にしたSOVは、実際の視認性を反映していない。SERPのスクリーンショットを並べて「この指標では勝っているが、実際はこう見えている」と示せば、ピクセル計測の必要性は一目で伝わる。
より難易度が高いのは「SEOをブランドチャネルとして再定義する」という提案だ。しかしこれにも近道がある。「他の施策で獲得しているインプレッションデータを用意し、SEOで生成しているインプレッション数と並べて提示する」という方法だ。SEOは極めて効率のよいインプレッション獲得チャネルであり、その事実を他のマーケティング指標と同じテーブルに載せることで、予算獲得の説得力が増す。
AEO・GEOの可視性をどう測るか
AI OverviewsやLLM(大規模言語モデル)経由の検索に対する可視性計測についても、記事では実践的な方針が示されている。現時点でSearch Consoleに相当するLLM向けダッシュボードは存在しないが、以下の3つのアプローチが現実的だ。
- プロンプトレベルのブランド視認性を追跡する。ただし「キーワード1万件を追うのにプロンプトは50件」という運用は避ける。LLMは回答のバリエーションが大きいため、統計的に意味のあるサンプルサイズが必要
- プロンプト数ではなくトピック数で考える。個別のプロンプトは検索ボリュームが1に等しいケースが大半であるため、トピック単位でカバレッジを評価する
- 引用ではなく「言及・推奨」を追う。従来の順位トラッキングとは異なり、「どのツール・製品・ブランドが回答の中で推奨されているか」を見る。また、サーバーログを分析し、LLMのグラウンディングボットが実際にどのページをクロールしているかを把握するのも有効だ
有機検索はこのまま悪化し続けるのか

Search Engine Journalの記事でCapper氏は、オーガニック検索の表示領域が改善に向かう可能性は低いが、悪化のペースは鈍化するかもしれないとの見方を示している。
根拠の一つが、Google I/OでAI Modeの広範な展開が見送られたことだ。情報検索にはある程度対応できるものの、ナビゲーショナル(特定サイトへの移動目的)検索や天気ウィジェットのような即時情報には弱く、Google社内でもユーザーの受け入れ準備が整っていないという空気がある。また、ChatGPTもAI Modeも、時間の経過とともに表示するリンクの数を増やしている。ユーザーが依然として「サイトに到達したい」という欲求を持っている証拠だ。
ただし、「以前の状態に戻るとは考えていない」と記事の見解は締めくくっている。ユーザーは「自分で探すより、答えを出してもらう」体験を気に入りつつある。有機検索の未来は、機械可読な形でSERPに情報を供給し続けるインフラとしての役割にシフトしていくだろう。
この記事のポイント
- オーガニック1位の可視率はデスクトップ57%、スマホ40%。順位だけでは視認性を保証できない
- SERP上での結果サイズ(ピクセル高さ)を基準にキーワード優先度を再評価する必要がある
- ブランド検索ボリュームはドメインオーソリティ以上に順位との相関が強い
- ピクセル指標は経営層への説明ツールとしても有効。SERPのスクリーンショット比較が決め手になる
- AI OverviewsやLLM経由の可視性計測は、トピック単位・推奨ベース・サーバーログ分析で手がかりを得る

TikTok Shopが欧州全域で販売一元化、6月15日に4カ国追加
動画SNSから立ち上がったTikTok Shopが、欧州EC市場で独自のマーケットプレイスへと進化している。6月15日にオーストリア、ベルギー、オランダ、ポーランドの4カ国でサービスを開始し、欧州展開は計10カ国へ拡大する。さらに注目すべきは、その後まもなく導入される「Sell Across Europe」機能だ。
TikTok Shopは単なる動画内の買い物機能ではない。販売者が一度の登録でEU複数カ国に出品できる汎欧州マーケットプレイスへの進化を遂げつつある。2025年には欧州EC総取扱高の61%がマーケットプレイス経由だった中で、この動きは加盟店にとって大きな商機となる。
同プラットフォームは新規参入市場で急速にシェアを伸ばしてきた実績がある。スペインではサービス開始から18カ月で国内第16位のオンライン小売業者となり、ドイツではさらに短期間で第15位に浮上した。TikTokによれば、フランス、ドイツ、アイルランド、イタリア、スペインの5カ国で既に10万を超える販売者が参加している。
欧州10カ国展開の全容

新規4カ国は6月15日、本日から登録受付開始
6月15日にTikTok Shopが開設されるのは、オーストリア、ベルギー、オランダ、ポーランドの4カ国だ。これにより欧州での展開国は計10カ国となる。販売者向けの事前登録は本日から受け付けが始まっている。
欧州でのTikTok Shopの歩みを振り返ると、まず2021年末にイギリスでサービスを開始した。続いて2024年末にスペインとアイルランドに進出し、2025年春にはドイツ、フランス、イタリアで大規模なローンチを行っている。
この段階的な拡大戦略は、単なる地理的拡張ではない。各国の消費者行動や物流網、規制環境を検証しながら、汎欧州展開の基盤を慎重に構築してきたプロセスといえる。
新規市場での急成長に注目
TikTok Shopの特徴は、新規参入市場での立ち上がりの速さにある。スペインではサービス開始から18カ月で、取扱高(GMV)ベースで同国第16位のオンライン小売業者となった。ドイツではさらに短期間で第15位にまで順位を上げている。
TikTokの発表によると、フランス、ドイツ、アイルランド、イタリア、スペインの5カ国における1日あたりのGMV(総取扱高)は、2025年8月から2026年2月にかけて3桁成長を達成した。つまり短期間で取引規模が倍以上になった計算だ。
イギリスでは既に20万以上の販売者が参加しており、同国ではより成熟したマーケットプレイスとして機能している。5カ国で10万販売者という数字と合わせ、欧州全体での販売者基盤は順調に拡大しているとみてよい。
Sell Across Europe機能の中身
一度の登録でEU複数カ国へ出品
今回の発表で最も注目すべきは「Sell Across Europe」機能の導入だ。この機能により、販売者はTikTok Shopへの一度の登録で、TikTok Shopが利用可能なEU複数カ国に商品を出品できるようになる。
TikTokの公式発表によれば、このEU域内サービスは販売者が商品説明を容易にローカライズできる設計になっている。言語や通貨、消費者保護規制が異なるEU市場に対応するための仕組みが組み込まれていると考えられる。
物流パートナーを活用した直接配送
物流面でも大きな変更がある。販売者はTikTok Shopと提携する物流プロバイダー、または承認済みの運送業者を通じて、他のEU市場へ直接発送できる。従来は国ごとに倉庫や配送契約を個別に手配する必要があったが、この仕組みにより越境ECのハードルが大幅に下がる。
加えて、TikTokのクリエイターネットワークを欧州の複数市場で活用できる点も販売者にとってはメリットとなる。商品プロモーションを依頼できる動画クリエイターの選択肢が格段に広がるからだ。
マーケットプレイス型ECとの類似と差別化
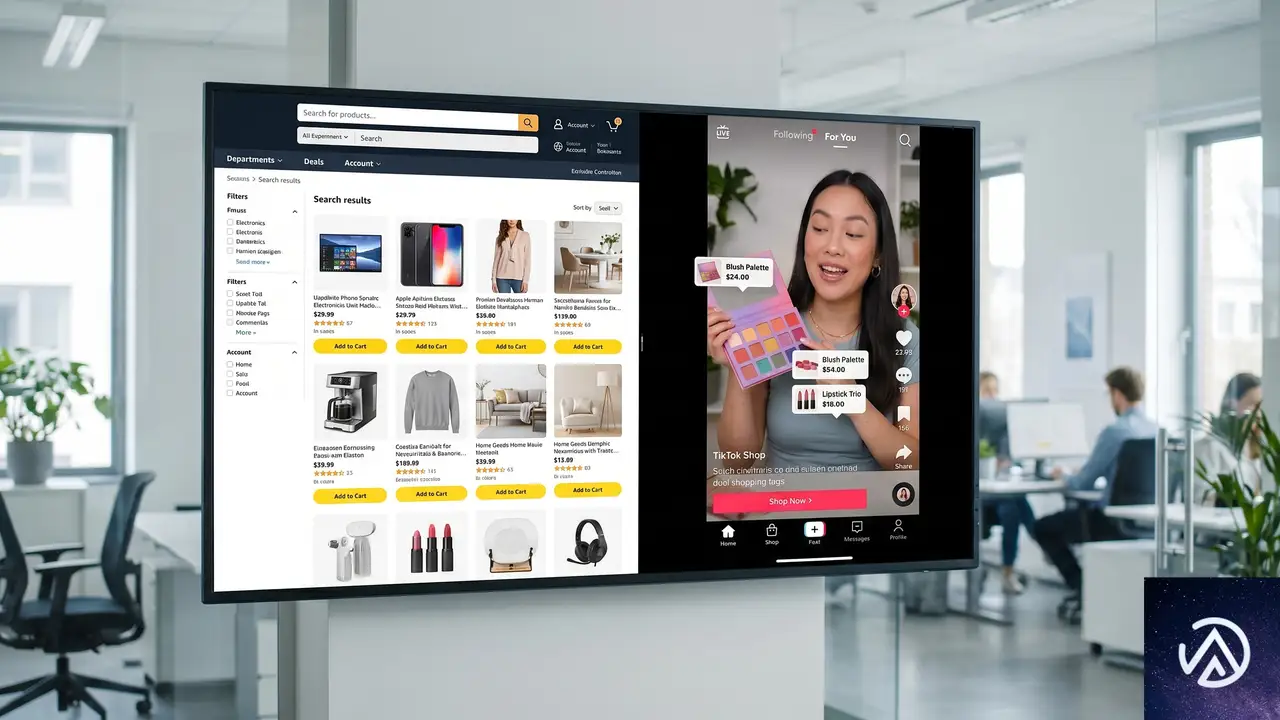
一括設定で欧州全域リーチ
Sell Across Europe機能の導入により、TikTok ShopはAmazonに代表される大規模マーケットプレイスと同様の構造に近づきつつある。一度のセットアップで欧州の広範な購買層にリーチできるという点で、販売者にとっての利便性は格段に向上する。
Ecommerce News EUのデータによれば、2025年には欧州ECの総取扱高の61%がオンラインマーケットプレイス経由だった。つまり欧州の消費者は既にマーケットプレイス型での購入に慣れており、TikTok Shopの狙いもこの流れに乗る形だ。
動画プラットフォームならではの強み
ただしTikTok Shopが従来のマーケットプレイスと決定的に異なるのは、動画コンテンツと購買体験が融合している点だ。商品検索から入るAmazonとは異なり、TikTok Shopは動画視聴中の偶発的な購買や、クリエイターの影響力による販売促進が中心となる。
この特徴は特にファッション、美容、食品など視覚的訴求が強いカテゴリーで効果を発揮する。Sell Across Europe機能によってクリエイターネットワークが複数国で活用できるようになれば、ブランドは国をまたいだインフルエンサーマーケティングを一元的に展開できる。
域内越境ECのハードルを下げる仕組み

通関と税務の対応はプラットフォーム側に
EU域内の越境ECでは、VAT(付加価値税)の申告やインボイス(送り状)の作成、現地の消費者保護法への準拠など、販売者側の負担が大きい。Sell Across Europe機能は、これらの管理業務をプラットフォーム側で取りまとめる方向だ。
TikTok Shopと提携する物流プロバイダーによる配送も、域内越境のハードルを下げる要素となる。販売者は自前で国際配送の仕組みを整える必要がなく、承認済みの運送業者を使えば済む。中小規模のEC事業者にとっては、欧州展開の敷居が大きく下がる変更だ。
言語ローカライズの自動化に期待
商品説明のローカライズ機能も、実務上の大きな課題を解決する。欧州は23の公用語が存在し、国ごとに商品ページを作り直すのは小規模事業者には現実的ではない。TikTokが提供する翻訳や自動最適化の仕組みがどの程度の品質かは未知数だが、少なくともゼロから多言語対応するよりは大幅に省力化できる。
EC事業者が今すぐ確認すべき準備項目

Sell Across Europe導入前の下準備
Sell Across Europe機能が本格稼働する前に、EC事業者が整えておくべきポイントは大きく3つある。
1つ目は商品情報の整理だ。多言語展開を見据え、商品名や説明文、素材情報などをあらかじめ構造化してデータベース化しておくと、ローカライズ機能が提供された際にスムーズに移行できる。2つ目は在庫管理と配送体制の確認。複数国からの注文を想定し、自社の在庫引き当てルールや出荷リードタイムを再確認しておく必要がある。
3つ目はTikTok側の販売者ポリシーの理解だ。国ごとに返品規定や消費者保護法が異なるため、自社が販売したいカテゴリーの商品が対象国でどのような規制を受けるかを把握しておくべきだろう。TikTokの公式セラーポータルで公開される最新情報を定期的にチェックすることが重要だ。
国内ECとの比較で見える可能性
日本のEC事業者にとって、TikTok Shopの欧州展開は販路拡大の選択肢として検討に値する。国内のECモール出店と比較すると、TikTok Shopは動画コンテンツによる商品認知と購買が一体になっている点が最大の違いだ。
ただし、越境ECには国際配送コストや為替リスク、カスタマーサポートの多言語対応といった追加負担が伴う。Sell Across Europe機能がこれらの課題をどの程度軽減してくれるか、実際の提供内容を待って判断するのが現実的だろう。
この記事のポイント
- TikTok Shopは6月15日にオーストリア、ベルギー、オランダ、ポーランドで開始し欧州10カ国体制へ
- Sell Across Europe機能で一度の登録によりEU複数カ国への出品が可能に
- 提携物流パートナーによる直接配送とクリエイターネットワークの複数国活用も実現
- 新規市場での立ち上がりは早く、スペインでは18カ月で国内第16位のオンライン小売業者に
- 欧州EC取扱高の61%がマーケットプレイス経由という市場構造に合致した戦略

CSSのletter-spacingでテキスト表示を切り替える実装テクニック
CSSでテキストを一文字ずつ表示したり、特定の単語を切り替えたりする演出は、直感的には難しいものだ。::nth-letter()のような仮想的なセレクタがあれば楽だが、現状のCSS仕様には存在しない。しかし、letter-spacingプロパティの負の値とcolor: transparentを組み合わせることで、限定的ながらも文字単位の表示制御が実現できる。
CSS-Tricksの記事では、このテクニックを使ってチェックボックス操作によるラベル切り替えや、アクロニムの全文表示といった実装例が紹介されている。本記事ではその仕組みと実装手順を掘り下げ、日本国内のWeb制作現場での活用ポイントを考察する。
letter-spacingの基本と隠しテキストの仕組み
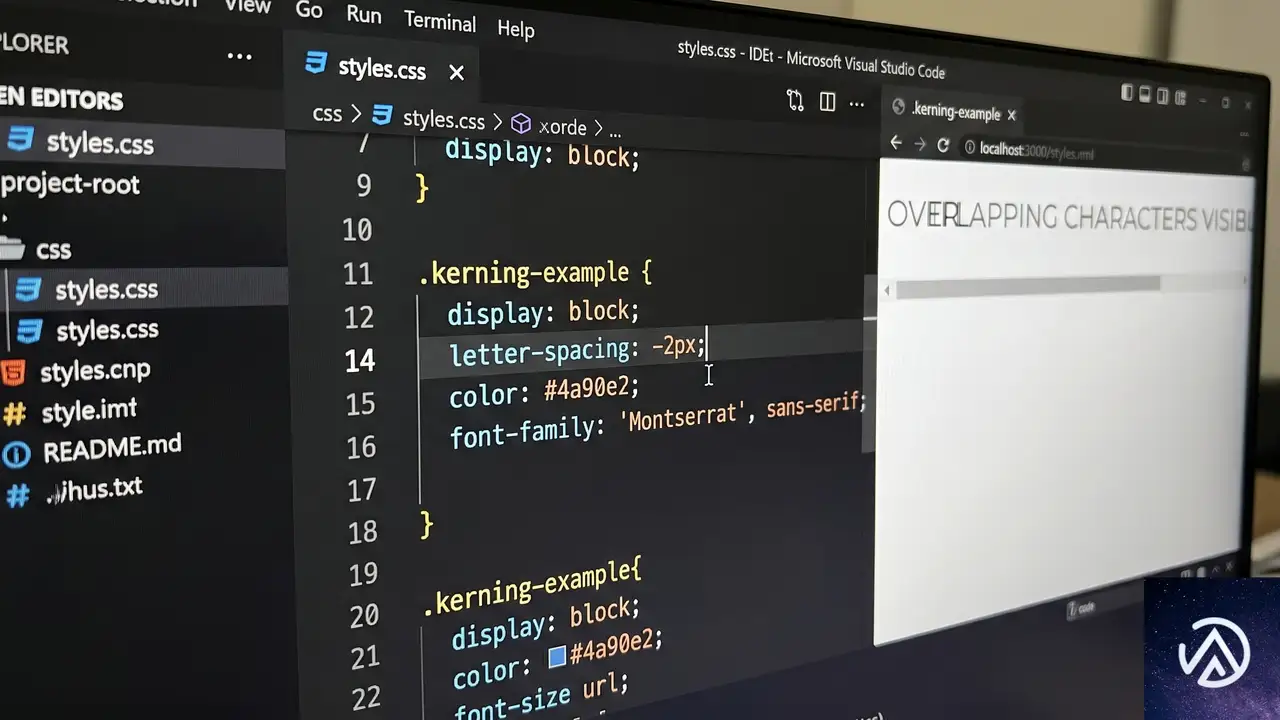
正の値と負の値の効果
letter-spacingプロパティは、各文字の右側に追加されるスペースを調整する。正の値では文字間隔が広がり、負の値ではグリフボックスの幅が縮まる。値を十分に小さく設定すると、隣り合う文字同士が重なり合い、最終的には一箇所に集約された状態になる。
この状態でテキストの色をtransparentに指定すれば、ユーザーからは完全に見えなくなる。逆に正の値に戻すと文字が再び分離して表示される。この性質をアニメーションと組み合わせることで、表示と非表示を切り替える演出が可能になる。
上記のデモでは、負の値によって文字が詰まったビジュアルと、正の値(0)で通常表示に戻る様子を並べている。実際にはtransitionプロパティを加えることで、この変化をなめらかに動かせる。
ch単位を使う理由
文字の重なり具合を指定する負の値には、ch単位が特に相性が良い。1chは数字の「0」のグリフ幅に相当する相対単位であり、フォントファミリーやサイズに応じて自動調整される。これにより、使用する書体が変わっても一貫した重なり効果を維持しやすくなる。
例えばletter-spacing: -1chを指定すると、各文字が1文字分ずつ左に詰められ、理論上は完全に重なる。実際にはフォントのデザインやカーニングによって微妙なズレが生じることもあるが、調整の起点として扱いやすい。
チェックボックスと組み合わせたテキスト切り替え
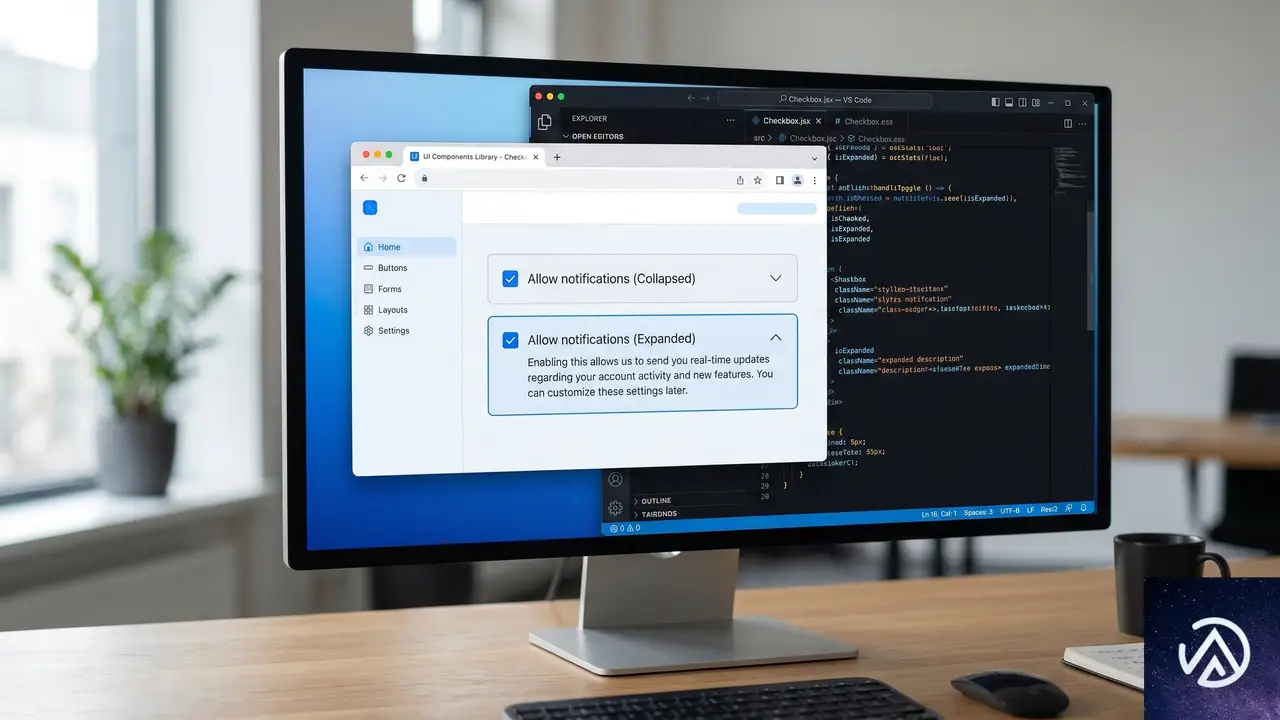
HTMLとCSSのコード例
このテクニックを応用すると、チェックボックスの状態に応じてラベルテキストを動的に切り替えるUIを作成できる。以下は、クリックによって「入会する」のような案内文が「ようこそ」メッセージに変化するパターンだ。
input:checked + label .initial-text {
letter-spacing: -2ch;
text-indent: -1.5ch;
transition: 0.4s letter-spacing cubic-bezier(.8, -.5, .2, 1.4),
0.1s text-indent;
}
input:checked + label .revealed-text {
letter-spacing: 0ch;
color: #1a1a2e;
transition:
0.4s letter-spacing cubic-bezier(.8, -.5, .2, 1.4) 0.3s,
0.8s color 0.4s;
}デモではoverflow: clipが適用されたコンテナ内で、一方のテキストがletter-spacing: -2chとtext-indentで左に押し出され、もう一方が通常の間隔に戻る仕組みだ。実際の環境ではチェックボックス操作によりこれらのプロパティが切り替わる。
アニメーションの調整ポイント
CSS-Tricksの著者Carlo Daniele氏の実装例では、cubic-bezier(.8, -.5, .2, 1.4)というイージングが使われている。この曲線は、変化の途中で値が目標値を超えて戻る「バウンス」効果を生み出し、文字が勢いよく離れるような動きを演出する。
また、2つのテキストのtransition-delayをずらすことで、古いテキストが消え始めてから新しいテキストが現れるまでの間に自然なオーバーラップが作られている。この遅延調整は、ユーザーが違和感なく情報の切り替わりを認識できるようにするための工夫だ。
アクロニムの全文表示テクニック
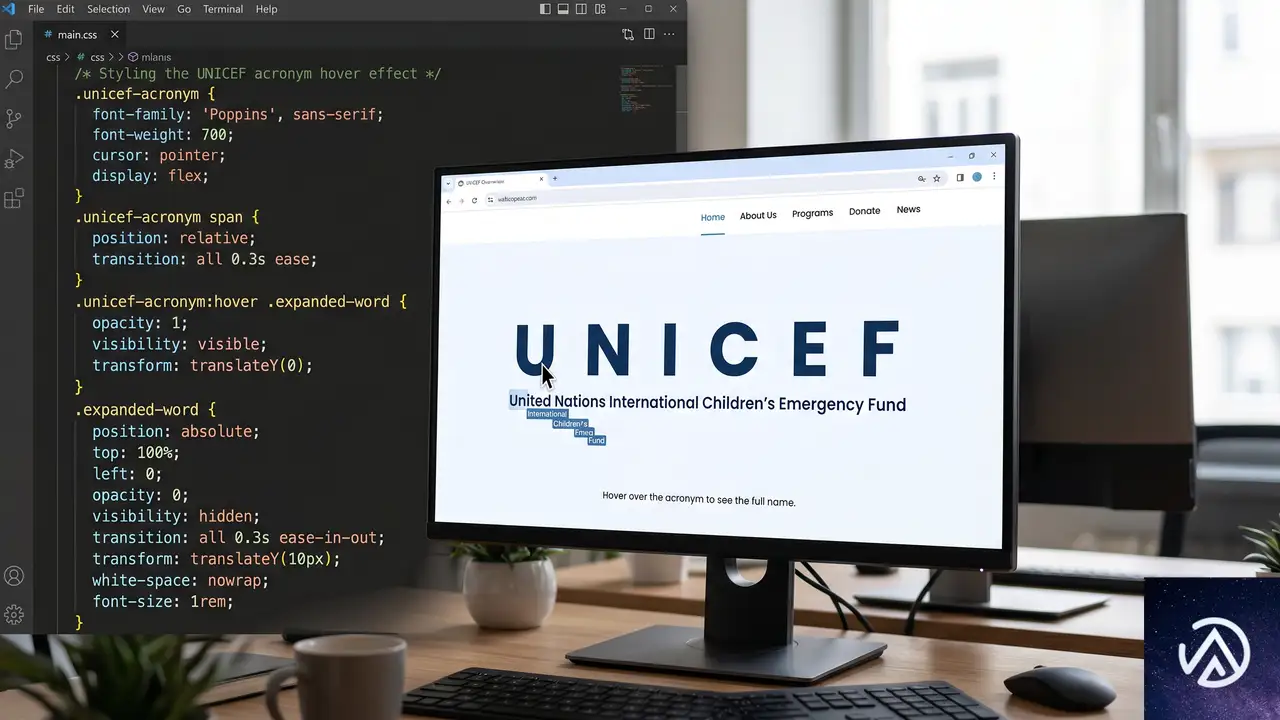
::first-letterの活用
UNICEF(United Nations International Children’s Emergency Fund)のようなアクロニムを題材に、各単語の最初の文字だけを常に表示し、ホバー時に残りの文字を出現させるテクニックが紹介されている。
.acronym-word {
letter-spacing: -1ch;
color: transparent;
}
.acronym-word::first-letter {
color: #1a1a2e;
}
figure:hover + .acronym .acronym-word {
letter-spacing: 0ch;
color: #1a1a2e;
transition: letter-spacing 0.4s cubic-bezier(.8, -.5, .2, 1.4);
}::first-letter疑似要素で頭文字だけを黒く表示し、残りの文字はcolor: transparentで不可視にしておく。ホバーイベントでletter-spacingを0に戻すと、すべての文字が可視状態で展開される仕組みだ。
実装の注意点
このパターンでは、各単語を個別の<span>で囲む必要がある。単一のテキストブロックに対して::first-letterは最初の1文字にしか適用されないからだ。UNICEFの例のように6つの単語があれば、6つの要素でマークアップすることになる。
また、スクリーンリーダーはcolor: transparentのテキストも読み上げるため、アクセシビリティ面では注意が必要だ。このテクニックはあくまでビジュアル面の演出であり、情報の一次的な伝達手段としては適さない。重要なテキストはaria-labelなどで別途提供するか、この効果を装飾的な目的に限定するのが安全だ。
実務での活用アイデア
このテクニックは、以下のようなシーンで効果を発揮する。
いずれも、派手なアニメーションライブラリを使わずにCSSだけで完結するのが利点だ。パフォーマンス面でもJavaScriptによるDOM操作より軽量で、メインスレッドへの負荷が少ない。
制約と対応ブラウザ

letter-spacingのアニメーションは主要なモダンブラウザで広くサポートされている。ただし、cubic-bezierによるバウンス効果は、イージングの値によっては環境間で微妙な見え方の差が出ることがある。
また、ch単位はフォントの「0」の幅に依存するため、和文フォントと欧文フォントが混在する日本語サイトでは、想定よりも文字の重なり方が異なるケースがある。実装時は実際のフォントスタックで表示確認を行うことが重要だ。
この記事のポイント
letter-spacingの負値とcolor: transparentを組み合わせると、文字を一箇所に重ねて不可視にできる- チェックボックスの状態に応じたラベル切り替えは、
transition-delayの調整で自然なUI演出になる - アクロニムの全文表示には
::first-letterと単語ごとの<span>分割が必要 - アクセシビリティに配慮し、重要な情報は視覚効果だけに依存しない設計が求められる