

AWS BedrockでOpenAI GPT-5.5とCodexが利用可能に。開発効率が飛躍
AWSが2026年6月、Amazon Bedrock上でOpenAI GPT-5.5モデル、GPT-5.4モデル、そしてコーディングエージェントCodexの一般提供を開始した。これにより、Bedrockのセキュアなインフラ上で最先端の大規模言語モデルを利用できる。
GPT-5.5は最も難しいタスク向け、GPT-5.4はコストパフォーマンス重視のシナリオに適する。いずれも、新しい推論エンジン上で高速かつ信頼性の高い応答が得られる。Codexは週あたり400万人以上の開発者が使用するAIコーディングツールで、複数のIDEと連携しつつ、推論エンジン経由でBedrockからモデルを呼び出す。
データ主権要件に対応するため、すべての処理は選択したBedrockリージョン内に留まる。トークン単位の課金で、シートライセンスや開発者あたりの固定費は発生しない。本記事では利用開始手順と技術的な注意点を解説する。
AWS BedrockでOpenAI GPT-5.5とCodexが一般提供
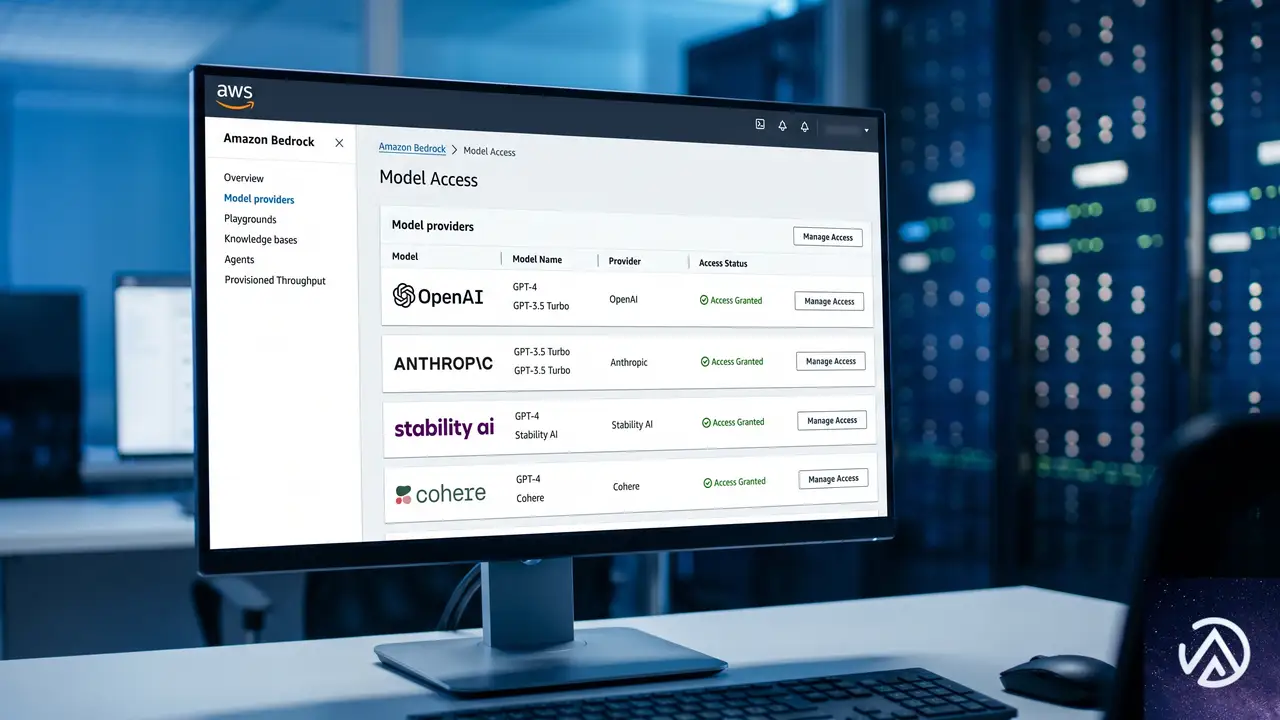
AWSの年次カンファレンスでプレビューされていたOpenAIモデルの対応が、正式に利用可能になった。GPT-5.5とGPT-5.4は、コーディング、推論、エージェントワークフロー、複雑な専門業務に優れる。AWS News BlogのChanny Yun氏は、GPT-5.5を「最も難しい顧客のワークロード」向け、GPT-5.4を「最良の価格性能比」と位置づける。
モデルへのアクセスは、新しいBedrock推論エンジンが提供するResponses APIを介して行う。このAPIは、マルチターン状態管理、ホストツール、ファンクションツール、バックグラウンド実行をサポートする。
この構成により、機密データを外部に送信することなく、AWSの管理下で最先端AIを活用できる。リージョンごとのデータ主権も担保される。
GPT-5.5モデルの利用方法

モデルへは、OpenAIのResponses APIを用いてアクセスする。Bedrock専用のエンドポイントbedrock-mantleを経由し、OpenAI SDKやcurlから呼び出す形だ。以下にセットアップ手順を示す。
Python SDKを使った呼び出し
まずOpenAI SDKを最新版にアップデートする。
pip install -U openai認証用の環境変数を設定する。BedrockのAPIキーはAWSマネジメントコンソールから取得できる。
export OPENAI_BASE_URL="https://bedrock-mantle.us-east-2.api.aws/openai/v1"
export OPENAI_API_KEY="<BEDROCK_API_KEY>"
export BEDROCK_OPENAI_MODEL_ID="openai.gpt-5.5"以下のサンプルコードで、GPT-5.5に分散アーキテクチャの設計を依頼できる。
import os
from openai import OpenAI
client = OpenAI(
base_url=os.environ["OPENAI_BASE_URL"],
api_key=os.environ["OPENAI_API_KEY"],
)
response = client.responses.create(
model=os.environ["BEDROCK_OPENAI_MODEL_ID"],
input=[
{
"role": "developer",
"content": "You are a software engineer with excellent AWS cloud knowledge. Be concise and practical.",
},
{
"role": "user",
"content": "Design a distributed architecture on AWS in Python that should support 100k requests per second across multiple geographic regions.",
},
],
reasoning={"effort": "medium"},
text={"verbosity": "low"},
)
print(response.output_text)curlによる直接アクセス
curlを使う場合も同様に環境変数を設定した上で、エンドポイントへPOSTリクエストを送る。
curl "$OPENAI_BASE_URL/responses" \
-H "Content-Type: application/json" \
-H "Authorization: Bearer $OPENAI_API_KEY" \
-d '{
"model": "openai.gpt-5.5",
"input": [
{
"role": "developer",
"content": "You are a software engineer with excellent AWS cloud knowledge."
},
{
"role": "user",
"content": "Design a distributed architecture on AWS in Python that should support 100k requests per second across multiple geographic regions."
}
],
"reasoning": {"effort": "medium"},
"text": {"verbosity": "low"}
}'コード内のreasoning.effortは推論の深さを制御する。GPT-5.5ではmediumから始め、必要に応じてhighに変更すると良い。GPT-5.4の場合は明示的にeffortを指定すべきだ(デフォルトがnoneのため)。
CodexでAI駆動開発を体験する
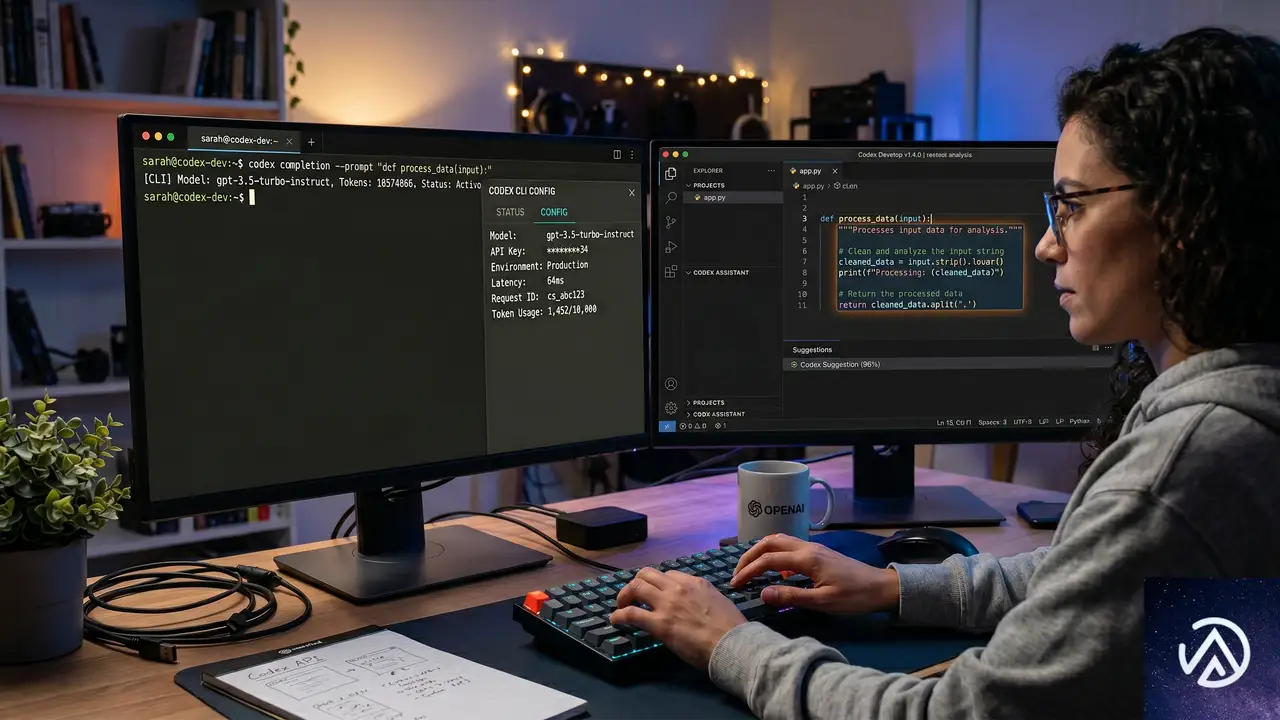
Codexは、GPT-5.5を推論エンジンとしてバックグラウンドで利用するコーディングエージェントだ。CLI、デスクトップアプリ、VS CodeやJetBrains、Xcodeの拡張機能が提供され、大規模コードベースの作成、リファクタリング、デバッグ、テスト、検証をAIが支援する。
Codex CLIの設定手順
Codex CLIをインストール後、Bedrock認証を有効にする。APIキー認証とAWS SDKの認証情報チェーンの2方式があり、APIキーが優先される。
export AWS_BEARER_TOKEN_BEDROCK=<your-bedrock-api-key>次に、~/.codex/config.tomlにモデル情報とリージョンを記述する。
model = "openai.gpt-5.5"
model_provider = "amazon-bedrock"
[model_providers.amazon-bedrock.aws]
region = "us-east-2"デスクトップアプリやVS Code拡張では、必要な環境変数を~/.codex/.envに記述しておく。設定変更後はアプリケーションを再起動すれば反映される。
CLIで/statusタブを表示すると、モデルがBedrock経由で接続されていることを確認できる。Channy Yun氏の記事では、実際のステータス画面が示されており、モデルとしてopenai.gpt-5.5と表示される。
レイテンシやスケーリングの注意点

本番利用を始めるにあたり、いくつかの技術的なポイントを把握しておく必要がある。
モデルレイテンシの特性
GPT-5.5は高速、GPT-5.4は中速と位置づけられるが、実際の遅延は推論の深さ、出力長、ツール呼び出しの有無、バックグラウンドモード、リージョン、クォータ、スロットリング、プロンプトサイズ、キャッシュヒットに依存する。GPT-5.5ではreasoning.effortをmediumで開始し、GPT-5.4では明示的にeffortを設定することを推奨する(デフォルトがnoneで十分な推論が得られない可能性があるため)。
スケーリングとキャパシティ管理
Bedrockの新しい推論エンジンは、多数のモデルにわたって迅速にキャパシティをプロビジョニングし、需要変動に応じてスケールする設計だ。定常的なワークロードの実行を優先し、需要急増時にはリクエストをキューイングする(拒否はしない)。そのため、予期せぬトラフィック増加時にも安定した動作が期待できる。ただし、クォータ上限を事前に確認し、必要に応じて引き上げ申請を行うことが望ましい。
この記事のポイント
- Amazon Bedrock上でOpenAI GPT-5.5・GPT-5.4モデルとCodexが一般提供開始
- Responses APIを通じてモデルを呼び出し、複雑なワークロードに対応
- CodexはGPT-5.5をバックエンドに、CLI・デスクトップアプリ・IDE拡張で利用可能
- データは選択したBedrockリージョン内で処理され、データ主権を確保
- レイテンシは複数要因に依存し、effort設定やキャッシュが影響するため、初期はmediumから
- スケーリングは自動だが、クォータ管理を怠らないこと

・ 複数業界における17年間のデジタルビジネス開発経験
・ ウェブサイト開発のためのHTML、PHP、CSS、Java等の実用的知識
・ 15ヶ国語対応の多言語SaaSの開発経験
・ 17年間にも及ぶ、Eコマース長期運営経験
・ 幅広い業界でのSEO最適化の豊富な経験
海田 洋祐
・ 複数業界における17年間のデジタルビジネス開発経験 ・ ウェブサイト開発のためのHTML、PHP、CSS、Java等の実用的知識 ・ 15ヶ国語対応の多言語SaaSの開発経験 ・ 17年間にも及ぶ、Eコマース長期運営経験 ・ 幅広い業界でのSEO最適化の豊富な経験