

GPT-5.6ファミリー登場、Sol・Terra・Lunaの全容と実務メリット
OpenAIは2026年7月9日、次世代フラッグシップモデル「GPT-5.6」ファミリーを一般提供開始した。プレビュー期間を経て投入された本リリースには、フラッグシップのSol、バランスモデルのTerra、コスト効率重視のLunaの3モデルが揃う。
GPT-5.6 Solはコーディング、知識労働、サイバーセキュリティ、科学研究の各領域で従来のフロンティアモデルを上回る性能を達成しつつ、消費トークン数と推定コストの大幅削減を両立した。これにより同一予算でもより多くの成果を出せる、いわば「コストパフォーマンスの再定義」を実現している。
この記事では、GPT-5.6の各モデルの特徴と性能、実務者にとってのメリット、そしてOpenAIが打ち出した新たな安全性対策を掘り下げる。
GPT-5.6ファミリーの全体像~3モデルの違いと狙い

GPT-5.6ファミリーは3つのモデルで構成される。Sol・Terra・Lunaはいずれも第5.6世代の基盤技術を共有するが、ターゲットとする用途とコスト構造が異なる。OpenAIによれば、これらのモデル名(Sol・Terra・Luna)は永続的な能力階層を示しており、今後それぞれのペースでアップデートが進む見込みだ。
Solが実現する「1トークンあたりの仕事量」の進化
Solの最大の特徴は、消費トークンあたりの実用成果の高さにある。Agents’ Last Exam(55分野の長時間ワークフロー評価)ではスコア53.6を記録し、競合のClaude Fable 5を13.1ポイント上回った。中程度の推論設定でも、Fable 5に対して11.4ポイント優位に立ちつつ、推定コストは約4分の1に抑えている。
この効率性は下位モデルにも波及している。GPT-5.6 TerraとLunaは、Fable 5の性能を上回りながら推定コストは約16分の1だ。単に「強いAI」を作るだけでなく、同じ予算でより多くの知的作業をこなせる点が、今回のリリースの中核的価値といえる。
ultra設定がもたらす並列エージェント駆動
GPT-5.6 Solには「ultra」と呼ばれる最高能力設定が搭載された。ultraはデフォルトで4つのエージェントを並列動作させ、複雑なタスクを複数のワークストリームに分割して処理する。これにより単一エージェント構成と比べて、スコアとレイテンシの両方で改善が確認されている。
BrowseComp、SEC-Bench Pro、Terminal-Bench 2.1の3評価すべてで、並列エージェントの追加により「より高スコアをより短時間で」達成する結果が得られた。開発者はAPIのマルチエージェントベータ機能を通じて、同様の並列処理を独自に構築することも可能だ。
実務者にとってのGPT-5.6~コストと速度の再定義

GPT-5.6の真価はベンチマークスコアだけではない。実務者が日々使うツールやワークフローの中で、どれだけ「手戻り」を減らし「完成度」を高められるかが鍵だ。
Programmatic Tool Callingでツール連携が変わる
GPT-5.6に導入された Programmatic Tool Calling(プログラマティックツール呼び出し)は、モデル自身が軽量なプログラムをメモリ内で作成・実行し、ツール連携や中間結果の処理を自律的に進める仕組みだ。開発者が全ステップをスクリプト化する必要はなく、大量の中間データから必要な情報だけを抽出して次のアクションを判断する。
この仕組みにより、ツールを多用するワークフローでのトークン消費と往復回数が大幅に削減される。Responses APIで利用可能で、Zero Data Retention(ZDR)にも対応している。
max・ultra設定で複雑タスクを加速
GPT-5.6は効率重視のデフォルト動作に加えて、難易度の高いタスクに対して計算リソースを集中的に投下する設定を備える。max設定はxhighより長時間の推論と検証を許容し、ultraは並列エージェントで処理を高速化する。APIの価格帯は Sol が入力100万トークンあたり5ドル、出力同30ドルと公表されている。
コーディング性能の飛躍~開発者にとってのGPT-5.6

GPT-5.6 Solは現時点で最強のコーディングモデルと位置づけられている。Artificial Analysis Coding Agent Indexでは、max推論設定でスコア80を達成し、Claude Fable 5を2.8ポイント上回った。出力トークン数は半分未満、所要時間も半分以下、推定コストは約3分の1減という結果だ。
実コードベースでの強さ~DeepSWEとTerminal-Bench
GPT-5.6の優位性は、実コードベースでの長期エンジニアリングタスクを評価するDeepSWE v1.1やTerminal-Bench 2.1でも確認されている。Terminal-Bench 2.1ではSolが88.8%、ultra設定では91.9%に達し、GPT-5.5(85.6%)やClaude Fable 5(83.1%)を明確に引き離した。
複雑なコマンドラインワークフローを自律的に処理できるようになったことで、開発者がスクリプトの細部を逐一指示する必要は減り、「何を実現したいか」の指示だけで作業が進む体験に近づいている。
知識労働とデザイン判断力の進化

GPT-5.6は知識労働の質でも段違いの進化を見せる。Slack、Notion、Microsoft 365、Google Driveといった日常ツールから雑多な文脈を取り込み、専門家レベルの成果物に変換する能力が強化された。
プレゼンテーション・文書作成の実力
特に顕著なのがプレゼンテーション作成能力だ。GPT-5.6はプロンプトとソース資料から完全に編集可能なスライドを一から生成できる。レイアウト、階層構造、デザインの一貫性を備えた視覚的ナラティブを構築し、テンプレートやリファレンスデッキがある場合は、スライドマスターに埋め込まれたデザインルールさえ推論して適用する。
OpenAIの比較事例では、GPT-5.5が参照ファイルのマスタースライドコンポーネントを欠落させたのに対し、GPT-5.6はレイアウト・タイポグラフィ・配色・コンテンツパターンを忠実に再現した。文書やスプレッドシートでも、複雑な参照フォーマットの遵守、数式や財務モデルの精度、ページレイアウトの洗練度が向上している。
コンピュータ操作とUIデザインの判断力
GPT-5.6のコンピュータ操作能力は、コード生成にとどまらず、レンダリング結果の視覚的検証と改善までカバーする。高水準の指示だけで機能的かつ洗練されたUIを作成し、仕上がりを目視確認してから納品するフローが可能になった。BrowseCompではスコア92.2%と競合を上回り、OSWorld 2.0では62.6%を達成しながら出力トークン数を85%削減している。
セキュリティと安全性~進化した防護策

GPT-5.6はサイバーセキュリティ領域で飛躍的な性能向上を示した。ExploitBenchではGPT-5.5の47.9%から73.5%へ、ExploitGymでは15.1%から24.9%(2時間制限、6時間では33.7%)へと大幅に改善している。
デュアルユースを前提とした安全性設計
サイバーセキュリティは本質的にデュアルユース(両義的利用)の領域だ。脆弱性をつく能力が高まれば、同時にそれを見つけて修正する防御能力も高まる。OpenAIは「過剰なブロックは防御側の活動を阻害し、攻撃者は他のモデルやオープンソースツールを使い続ける」との立場をとっている。
そのためGPT-5.6の安全策は、一律ブロックではなく、リクエストの文脈と想定される結果を評価する多層構造を採用した。モデル内部に訓練された保護機能に加え、リアルタイムチェック、継続的モニタリング、アカウントレベルの制御が重層的に機能する。最も機微な能力はOpenAI DaybreakのTrusted Access for Cyberプログラムを通じて、認証済みの利用者のみに提供される。
約70万GPU時間のレッドチーミング
一般提供に先立ち、OpenAIは過去最大規模の安全性評価を実施した。外部専門家によるレッドチーミングに加え、約70万A100e GPU時間を投じたブラックボックス型の自動レッドチーミングで弱点を体系的に探索した。GPT-5.6 Solのサイバーセーフガードは、GPT-5.5比で約10倍の有害活動をブロックしている。
提供形態と価格~ChatGPT・Codex・APIのロールアウト

GPT-5.6は7月9日から全世界で段階的に提供が開始され、24時間以内に全ユーザーへの展開が完了する予定だ。
Free/Go Terraを利用可能
Terra $2.50 input / $15 output
Luna $1 input / $6 output
ChatGPTでは、Plus・Pro・Business・EnterpriseユーザーがGPT-5.6 Solに中〜高エフォート設定でアクセスできる。ProとEnterpriseは最高品質のSol Proも選択可能だ。Codexでは、Plus以上でSol・Terra・Lunaを選択でき、ultraはProとEnterpriseが利用できる。
APIの価格体系は前世代と比べて明確な選択肢を提供する。TerraとLunaの登場により、予算やタスクの重要度に応じて同じGPT-5.6アーキテクチャの恩恵を受けながら、コストを最適化できるようになった。
AI研究の自己加速~内部導入で見えた効果
OpenAIの社内では、GPT-5.6のテスト期間中に研究者1人あたりの1日平均出力トークン数がGPT-5.5のピーク時の2倍以上に達した。過去6カ月間で社内の研究向けコーディング推論の計算リソース消費は100倍に、エージェント型トークン利用は約22倍に増加している。
OpenAIはこの再帰的自己改善能力を「RSI Index」という内部評価指標でスコア化しており、GPT-5.6 SolはGPT-5.5から16.2ポイントの改善を示した。研究デバッグ、カーネル最適化、機械学習実験の自動化など、AIがAIの開発を加速する好循環が始まっている。
この記事のポイント
- GPT-5.6はSol・Terra・Lunaの3モデル構成で、フラッグシップから低コストまで用途に応じた選択が可能
- コーディング・知識労働・サイバーセキュリティ・科学研究の全領域でGPT-5.5を大幅に上回る性能を達成
- 消費トークン数とコストの大幅削減により、同一予算での成果最大化を実現
- 並列エージェントのultra設定やProgrammatic Tool Callingで複雑タスクの自律処理が加速
- 約70万GPU時間のレッドチーミングを含む多層的安全策で、防御的利用を阻害せずに悪用を抑制

・ 複数業界における17年間のデジタルビジネス開発経験
・ ウェブサイト開発のためのHTML、PHP、CSS、JavaScript等の実用的知識
・ 15ヶ国語対応の多言語SaaSの開発経験
・ 17年間にも及ぶ、Eコマース長期運営経験
・ 幅広い業界でのSEO最適化の豊富な経験

GPT-5.6がMicrosoft 365 Copilotの優先モデルに。WordやExcelでのAI活用が大きく変わる
OpenAIは2026年7月9日、最新のフラッグシップモデル「GPT-5.6」を発表した。このモデルはMicrosoft 365 Copilotの新しい優先モデルとして、Word、Excel、PowerPoint、Copilot Chat、そして新コラボレーションツールのCoworkに導入される。
GPT-5.6の最大の特徴は、トークンあたりの有用な作業量を大幅に向上させたことだ。複雑なタスクをオンデマンドで処理する能力を持ちながら、コストパフォーマンスにも優れている。日常的に使うオフィスツールで、より高度なAI支援が受けられるようになる。
このアップデートは、すでにMicrosoft 365を契約しているユーザーにとっては追加費用なしで利用できる見込みだ。AIアシスタントがビジネス文書の作成からデータ分析まで、より深く関与する時代が本格的に到来する。
GPT-5.6の位置づけと技術的特徴

GPT-5.6はOpenAIの最新フラッグシップシリーズに位置する。従来のGPT-5シリーズと比較して、モデルアーキテクチャと学習手法の両面で改良が加えられている。特に「トークンあたりの有用な作業量」という指標が大幅に改善された点が重要だ。
トークン効率の改善がもたらすもの
GPT-5.6は、同じプロンプトに対してより少ないトークン数で高品質な結果を返す。これはAPIの利用料金削減に直結するだけでなく、長文のドキュメント作成や大規模なデータ分析において、途中で文脈が途切れるリスクを低減する。
具体的には、GPT-5.5と比較してPDFなどの複雑なドキュメントの読込精度が約20パーセント向上し、プログラミングにおいては20パーセント多くのコード変更を正確に提案できるようになった。日常的なオフィスワークの場面では、素早く意図を理解し、より少ない修正で作業を完了できることを意味する。
オンデマンドの複雑タスク処理能力
GPT-5.6は、単純な質問応答から高度な分析まで、タスクの複雑さに応じて処理能力を段階的に引き上げる設計がなされている。軽いタスクではトークンを節約しつつ、必要なときだけ深い推論を実行する仕組みだ。
このオンデマンド機能は、Microsoft 365 Copilotの利用体験を大きく変える。Wordで文章の校正を依頼するような日常的な操作では軽快に動作し、Excelで売上データの多変量解析を依頼するような複雑なタスクでは、モデルが自律的に深い思考を展開する。
OpenAIのAPIプロダクト責任者であるNikunj Handa氏は、ブログ記事の中で「GPT-5.6をOpenAI API経由でMicrosoft 365 Copilotに提供することで、組織がすべてのトークンからより有用な作業を得られるように支援する」と述べている。
各アプリケーションでの具体的な変化

GPT-5.6の導入により、Microsoft 365の各アプリケーションでどのような改善が期待できるのか。公式発表の内容を基に整理する。
Wordでの文書作成と編集
Wordでは、ドキュメントの下書き作成、編集、推敲にかかるプロンプト操作の往復回数が減る。GPT-5.6が文脈をより深く理解し、ユーザーが求める文体や構成に近い結果を初回から提示できるためだ。
従来のAI支援では「もう少しフォーマルに」「3段落目をもう少し詳しく」といった追加指示が頻繁に必要だった。GPT-5.6では、最初の指示だけで目的に合った文書の完成度が大幅に高まる。ビジネス提案書や報告書の作成時間が短縮されることは間違いない。
Excelでのデータ分析
Excelでは、より深いデータ分析をより効率的なトークン使用量で実行できるようになる。GPT-5.6はスプレッドシートの構造を正確に把握し、複数のシートにまたがる複雑な関係性も理解する。
ユーザーは「売上データから地域別のトレンドを抽出してグラフ化して」といった自然言語での指示から、数クリックでインサイトを得られるようになる。トークン効率が向上したことで、大規模なデータセットを扱う場合でもレスポンスが速く、分析の途中で途切れることが少なくなる。
PowerPointでのプレゼンテーション作成
PowerPointでは、初期アイデアをより洗練されたプレゼンテーションに仕上げるプロセスが加速する。GPT-5.6はスライド構成の提案からビジュアルデザインの方向性まで、従来よりも少ない手動調整で高い完成度を実現する。
特に複数人でのレビューを経る企業プレゼンの作成では、初稿のクオリティが上がることでレビューサイクルが短縮される効果が期待できる。MicrosoftのCopilot & Agents Core担当プレジデントであるNitin Agrawal氏も「より洗練されたアウトプットを生み出せる」と強調している。
Coworkでのチームコラボレーション
CoworkはMicrosoft 365に新たに追加されたコラボレーションツールで、GPT-5.6の優先モデル化対象に含まれている。チーム間の複雑で機能横断的な作業をAIが支援し、手動での調整作業を減らして高品質な成果物を生み出せるようになる。
プロジェクト管理やタスクの割り振り、進捗の可視化といった領域でAIが積極的に関与することで、チーム全体の生産性向上が見込まれる。複数部署が関わる大規模プロジェクトほど、その恩恵は大きいだろう。
実務へのインパクトと今後の展望

GPT-5.6を搭載したMicrosoft 365 Copilotは、単なる文章作成支援ツールの枠を超えつつある。ビジネスの現場でAIが担う役割は、補助から中核へと移行していく転換点にあると言える。
特に重要なのは、Microsoftがモデルをネイティブ提供するだけでなく、OpenAI APIを直接経由してGPT-5.6にアクセスする方式も併用している点だ。これにより、モデルのアップデートサイクルがより柔軟になり、最新のAI機能がより早くユーザーに届くようになる。
従来のCopilotでは、最初の回答に対して追加の指示を出して修正する場面が多かった。GPT-5.6では、最初のプロンプトだけで高品質な結果が得られる可能性が大幅に高まっている。日常的なAI利用の心理的ハードルが下がることを意味する。
中小企業や個人事業主にとっての意味
大企業向けの話に聞こえるかもしれないが、このアップデートは中小企業や個人事業主にとっても大きな意味を持つ。Microsoft 365の契約があれば追加費用なしで利用できるため、高度なAI支援を手軽に業務に取り入れられる。
特に、一人で複数の役割をこなす必要がある個人事業主にとって、文書作成、データ分析、プレゼン資料作成のすべてをAIが支援してくれるのは強力だ。GPT-5.6によるトークン効率の向上は、限られた時間でより多くの成果を出すことにつながる。
今後のAIアシスタントの方向性
GPT-5.6のMicrosoft 365 Copilotへの統合は、AIアシスタントが「質問に答えるツール」から「自律的に作業を進めるパートナー」へと進化する道筋を示している。トークン効率とオンデマンド推論の組み合わせは、今後のAIモデル開発における標準的なアプローチになるだろう。
OpenAIとMicrosoftのパートナーシップは、AIの恩恵をより多くの個人や組織に届けるという共通の目標に基づいている。両社はこの協力関係をさらに深めていく意向を表明しており、今後のアップデートにも注目が集まる。
この記事のポイント
- GPT-5.6はトークン効率を大幅に改善し、Word、Excel、PowerPoint、CoworkでのAI支援がより高精度になった
- 複雑なタスクではオンデマンドで深い推論を実行し、軽いタスクでは素早く応答する設計
- Microsoft 365ユーザーは追加費用なしで最新のAI機能を利用できる見込み
- 中小企業や個人事業主も、日常業務の効率化にこのアップデートを活用できる
- OpenAIとMicrosoftの協力関係は継続し、今後もAIアシスタントの進化が期待される
・ 複数業界における17年間のデジタルビジネス開発経験
・ ウェブサイト開発のためのHTML、PHP、CSS、JavaScript等の実用的知識
・ 15ヶ国語対応の多言語SaaSの開発経験
・ 17年間にも及ぶ、Eコマース長期運営経験
・ 幅広い業界でのSEO最適化の豊富な経験

Hostingerが写真から即決済リンクを生成するAIツール発表、EC販売チャネルの分散化が加速
リトアニア発のホスティング企業Hostingerが、商品写真をアップロードするだけで決済リンクを生成するEC向けAIツール「Quick Links」を発表した。従来のECの常識を覆し、自社サイトを持たない販売手法を一段と推し進めるものだ。
この機能により、販売者はSNS投稿やメッセージ、メールで直接決済リンクを共有できる。見逃せないのは、単なるチェックアウト機能の追加ではなく、ECプラットフォームが「ストアの先」へと進出する方向性を明確に打ち出した点にある。
ここではQuick Linksの仕組みにとどまらず、ウェブサイトを介さないEC販売の潮流、Shopifyなど他のプラットフォームの動き、そして小規模事業者がこれから取るべき販売チャネル戦略について分析していく。
HostingerのQuick Links機能の詳細

AIが商品写真から販売ページを自動生成
Quick Linksの使い方は極めてシンプルだ。販売者が商品の写真を1枚アップロードすると、HostingerのAIが商品説明、詳細スペック、推奨価格を含む商品ページを自動で作成する。そのページには決済機能が組み込まれており、生成されたリンクをSNSやチャットで共有すれば、購入者がそのまま支払いを完了できる。
従来のECでは、まずプラットフォームを選び、ストアを構築し、商品を登録し、決済手段を設定し、集客するという手順が必要だった。Quick Linksは、この流れを「写真1枚で販売開始」まで圧縮する。ECの専門知識がない個人や小規模事業者にとって、参入障壁が極めて低くなる仕組みだ。
ウェブサイト不要のEC販売は目新しいか
しかし、この「サイト不要」というコンセプト自体は完全な新機軸ではない。決済リンク(Payment Links)やリンクインバイオツール、ダイレクトメッセージを使った販売は以前から存在している。StripeやSquare、PayPal、Shopify Starter、TikTok Shop、Instagram、Facebook Marketplace、WhatsAppなど、すでに多くの企業が従来型ストアの外側で取引を完結させる手段を提供してきた。
決定的な違いは、AIによる「写真から商品ページを自動生成する」工程が加わったことだ。これにより、販売者は商品情報を手入力する手間さえも省ける。Hostingerは単なる決済手段の提供ではなく、「AIが販売を組み立てる」という次元へ踏み込んだ。
社会的文脈とHostingerのポジショニング
HostingerのウェブサイトビルダーおよびEC責任者であるAuksė Žirgulė氏は、次のように述べている。「コマースは単純なストアからエコシステムへと移行している。人々は多様なチャネルで商品を発見し、AIエージェントが選択や比較、購入を支援することが増えている。小規模販売者にとって、この変化は大きな機会だが、顧客と同じスピードで事業を動かせる場合に限られる」
この発言の核心は「次にどのチャネルが重要になるかを予測しなくてよい」というホスティング事業者の新たな役割提示にある。販売者はチャネル開拓に頭を悩ませる必要はなく、まず商品を素早く世に出すことが優先される。チャネル戦略の複雑さをプラットフォーム側が吸収する、という宣言ともとれる。
ECプラットフォームが直面する販売チャネルの分散化

上図のように、従来はストア構築から集客、決済まで一気通貫で自前管理するのが常識だった。Quick Linksはこの流れを「商品情報をAIが生成して即座に販売リンク化」するモデルへと変える。販売者は来店を待つ必要がなく、自ら顧客のいる場所へリンクを届けにいける。
ECソフトウェアの従来モデルが揺らぐ理由
ECソフトウェアは長年、「ストアを作り、商品を並べ、トラフィックを集め、訪問者を購入に転換する」という単純明快なモデルに依存してきた。このモデルは今でも通用するが、その確実性は低下している。
- 検索エンジンは質問に直接回答するようになり、ユーザーが商品ページに到達するまでにAIが情報を要約してしまう。
- SNSプラットフォームはユーザーをフィードやアプリ内に留め、外部リンクへの遷移を抑制する傾向を強めている。
- マーケットプレイスは需要を一手に集め、販売ルールをコントロールする。
- 生成AIが商品の比較や選定を、販売者のサイトを訪れる前に行う可能性が高まっている。
Googleが構想する「ユニバーサルカート」は、検索結果やYouTube、Gmail、AI体験上でカートを形成し、販売者のサイト外で購入が完結する世界を示唆している。販売者は在庫やフルフィルメント、カスタマーサービスを引き続き担うが、購買ジャーニーの起点やカートの支配権は手放すことになるかもしれない。
Hostingerの方向性が示すプラットフォーム間競争
この不確実性の高まりこそ、Hostingerのポジショニングの背景だ。同社は単にもっと速く決済リンクを作る機能を提供しているのではない。ECプラットフォームは販売者に対して「今日はSNS投稿で、明日はマーケットプレイスで、来月はAIエージェント経由で」販売できるように支援しなければならない、というメッセージを発している。
Shopifyも同様の方向にかじを切っている。ソーシャルコマース向けツールやPOS(販売時点情報管理)の強化、Shop Payの拡張、マーケットプレイス統合、AIによる商品発見支援などを通じて、販売者がより多くの販売機会を掴めるようにしている。Hostingerの発表は、その小規模販売者版だ。ECプラットフォームの役割が「ストアのホスティング」から「販売成功のための機会創出」へと変わりつつある。
販売者にとっての実務的な意味

「最初の販売」はサイト外で起こる
オンライン販売者にとって、HostingerのQuick Linksが投げかける最大の含意はこれだ。「最初の販売は、自社サイトの外で起こる時代になった」のである。潜在顧客が最初に商品を目にする場所は、SNSのタイムラインかもしれないし、友人のメッセージかもしれないし、AIアシスタントのレコメンドかもしれない。
しかし、だからといって自社サイトの重要性が消えるわけではない。信頼構築、検索プレゼンスの維持、コンテンツマーケティング、利用規約の提示、メールアドレス収集、カスタマーサービス、リピート購入促進といった要素は、依然として自社サイトが最も適した場所だ。ブランドや商品を丁寧に説明し、顧客との長期的な関係を築く場としての役割は揺るがない。
小規模事業者がまず着手すべきこと
小規模事業者がQuick Linksのようなツールを活用する際、最初に取り組むべきは「販売チャネルの即時展開」だ。商品写真さえあれば、今日からSNS上で直接販売を始められる。特設ページのデザインや決済設定に数日を費やす必要はない。
そのうえで、徐々に自社ECサイトを構築し、ブランド体験の深化やリピーター獲得の仕組みを整えていくという二段構えの戦略が現実的になる。これまでは「まずストアを作り、その後で集客」という順序だったが、これからは「まず販売を始め、その後でストアを育てる」という順序も合理的な選択肢になる。
ECの未来像:ストアとトランザクションの分離

これまでのECは、ストアとトランザクション(取引)が一体化していることが前提だった。商品を買うには、販売者のストアにアクセスし、そのストアのカートを使い、そのストアの決済フローを経由する。この一体型モデルが、技術の進化とともに解体されつつある。
決済リンク、SNSショップ、マーケットプレイス、AIエージェントは、いずれも「販売者のサイトを経由しないトランザクション」を可能にする。ストアはブランドの本拠地として残り続けるが、販売そのものは多様な「セリングサーフェス(販売面)」に分散していく。
このトレンドは国内のEC事業者にも無関係ではない。BASEやSTORESのような国内プラットフォームも、SNS連携やリンク販売機能を強化している。WooCommerceで構築されたECサイトであっても、決済リンクを積極的に外部チャネルで活用する発想が求められるようになるだろう。
プラットフォーム選定の新しい基準
販売者やWeb制作者がECプラットフォームを選ぶ際、これまでは「ストア構築のしやすさ」「デザインの自由度」「決済手段の豊富さ」が主な評価ポイントだった。しかし今後は、「外部チャネルとの連携性」や「AIによる販売支援機能」が選定基準の上位に食い込んでくる可能性が高い。
特にWooCommerceユーザーは、WordPress上でのコンテンツマーケティングとの親和性を強みとしつつも、SNSやメッセージアプリでのダイレクト販売をどう取り込むかが課題になる。プラグインや拡張機能で決済リンクを発行し、AIによる商品情報の自動最適化を組み合わせるといった対策が現実的だ。
この記事のポイント
- HostingerのQuick Linksは、商品写真1枚からAIが商品ページと決済リンクを自動生成する。ストア構築の手間を完全に省くアプローチだ。
- ウェブサイト不要のEC販売自体は新しい概念ではないが、AIによる自動生成が加わったことで、販売開始のスピードが飛躍的に向上する。
- ECプラットフォームは、販売者のストア外での販売を支援する方向へシフトしている。Shopifyも同様の多チャネル戦略を推進中だ。
- 小規模事業者は「最初の販売をサイト外で行い、その後で自社サイトを育てる」という二段構えの戦略を検討する価値がある。
- WooCommerceなど既存のEC環境でも、決済リンクやAIによる販売支援を積極的に取り入れることが、今後の競争力を左右する。
・ 複数業界における17年間のデジタルビジネス開発経験
・ ウェブサイト開発のためのHTML、PHP、CSS、JavaScript等の実用的知識
・ 15ヶ国語対応の多言語SaaSの開発経験
・ 17年間にも及ぶ、Eコマース長期運営経験
・ 幅広い業界でのSEO最適化の豊富な経験

Cloud Run Sandboxesがパブリックプレビュー、AI生成コードを安全に隔離実行
Cloud Run Sandboxesがパブリックプレビューに。AI生成コードを隔離実行

Google Cloudは2026年7月9日、Cloud Run上で信頼できないコードを安全に実行するサンドボックス機能をパブリックプレビューとして公開した。AIが生成したプログラムや、エンドユーザーがアップロードしたスクリプトを、ホスト環境やクラウドの認証情報から完全に分離した状態で動かせる。
起動はミリ秒単位で、既存のCloud RunインスタンスのCPUやメモリを共有する。追加のVMや専用のサンドボックスホスティングプラットフォームを使う必要はなく、追加料金も発生しない。この発表はベルリンで開催中のWeAreDevelopers World Congressで行われた。
これまで開発者は、AIが動的に生成したコードを安全に実行するために、コンテナクラスタを組んだり、サードパーティのmicroVMランタイムを契約したりする必要があった。Cloud Run Sandboxesは、その複雑さを取り除くサーバーレスネイティブの仕組みだ。
サンドボックスとは何か、なぜ必要なのか

サンドボックスとは、プログラムを隔離された領域で実行する仕組みのことだ。子供が砂場(サンドボックス)の中で自由に遊んでも、砂が外に散らばらないのと同じで、中で何が起きても外側のシステムには影響を与えない。
AIエージェントやLLM(大規模言語モデル)がコードを生成する時代では、この隔離が極めて重要になる。モデルが書いたPythonスクリプトに意図しないファイル削除やネットワーク経由のデータ流出が含まれていたとしても、サンドボックス内で止められるからだ。
Cloud Run Sandboxesは、既存のCloud Runサービスインスタンス内でほぼ瞬時に生成できる軽量な隔離実行境界だ。専用のVMを立ち上げる必要がなく、サーバーレス環境を離れずにすべてが完結する。
サンドボックスの仕組みとセキュリティ設計

シンプルな有効化とネイティブな呼び出し
利用開始は驚くほど簡単だ。Cloud Runサービスをデプロイする際に、gcloudコマンドまたはYAML設定でサンドボックスランチャーを有効にするフラグを1つ追加するだけでよい。有効化すると、軽量なサンドボックスCLIバイナリが実行環境に自動でマウントされ、標準的なサブプロセス呼び出しでプログラムからサンドボックスを生成できる。
実際の動作例として、LLMが動的に生成したPythonコードを安全に実行するデモが公開されている。1000個のサンドボックスを起動し、それぞれの処理を実行して停止するまでの平均レイテンシは500ミリ秒だ。
ゼロトラストを前提とした3層のセキュリティ境界
Cloud Run Sandboxesは、悪意あるコードや誤ったコードからホストアプリケーションとクラウドリソースを守るために、3つの重要なセキュリティ境界を強制する。
この3層構造によって、AIが生成したコードがどれほど予測不能な動作をしても、ホスト側への影響は生じない。セキュリティを理由にAIコード実行を諦めていた開発者にとって、大きな転換点になる。
3つの主要ユースケース
Cloud Run Sandboxesは特に以下の3つの用途で力を発揮する。いずれも「信頼できないコードを隔離実行する」という共通の要件を持つシナリオだ。
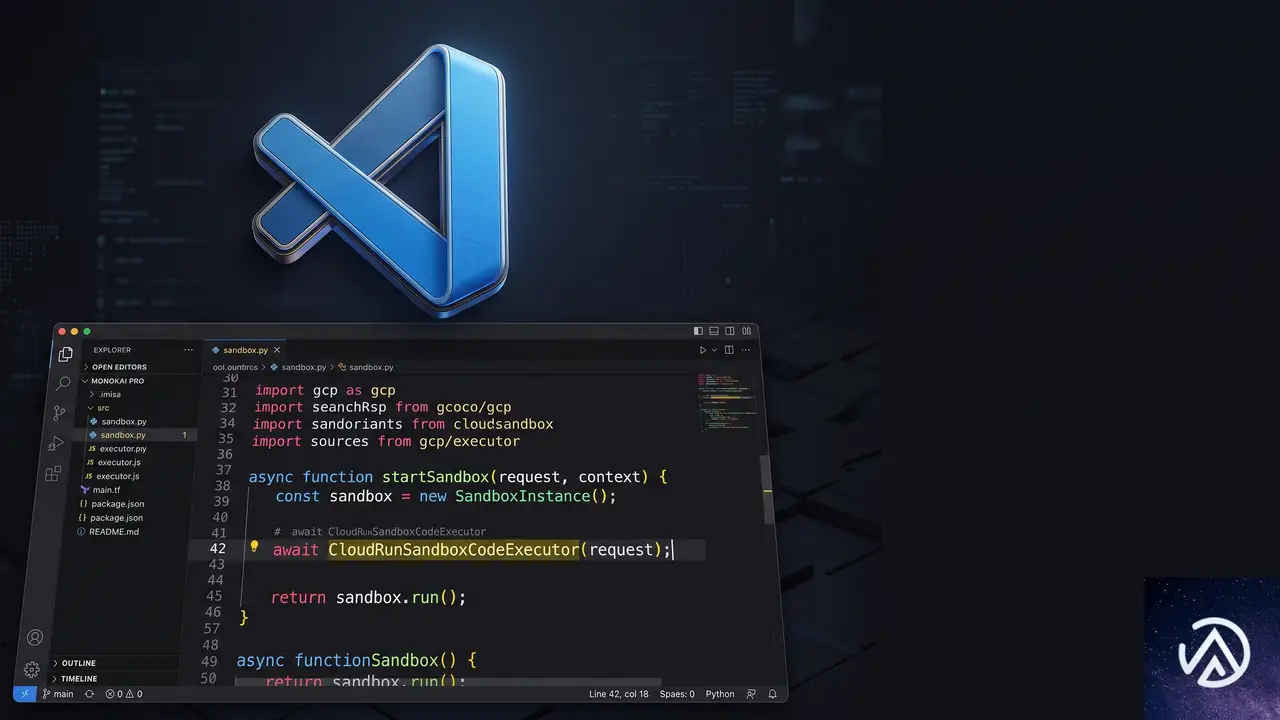
ADKとComputeSDKとの統合
Cloud Run Sandboxesは、Googleのエージェント開発キットであるADK(Agent Development Kit)の次期バージョンでネイティブサポートされる。新しいCloudRunSandboxCodeExecutorを使うと、ADKエージェントがわずか1行のコードでサンドボックス内のコード実行を指示できる。
また、ベンダーに依存しないサンドボックス実行用SDKであるComputeSDKにも対応が追加された。このSDKを使えば、Cloud Runサービスの外部からリモートでサンドボックスを呼び出すことも、サービス上のローカルツールとして直接使うこともできる。既存のツールチェーンにスムーズに組み込める設計だ。
コスト面の利点と実運用への影響
Cloud Run Sandboxesの大きな特長は、追加コストが一切かからないことだ。オンデマンドのVMに対して高いプレミアムを課金する専用サンドボックスホスティングプラットフォームとは異なり、既存のCloud Runインスタンスに割り当てられたCPUとメモリを直接共有する。
起動時間がミリ秒単位であることも実運用上の利点だ。従来のVMベースの隔離環境では、新しいVMを立ち上げるたびに数秒から数十秒の待ち時間が発生していた。Cloud Run Sandboxesなら、ユーザーからのリクエストに対してほぼ待ち時間なく応答できる。
Google Cloud Blogの記事で紹介されたデモでは、1000個のサンドボックスを起動してコードを実行し、終了するまでの平均レイテンシが500ミリ秒だった。これは「AIが生成したコードをリアルタイムで安全に実行する」という要件に対して十分実用的な数値だ。
この記事のポイント
- Cloud Run SandboxesはAI生成コードや信頼できないバイナリを安全に実行する隔離環境で、パブリックプレビューとして公開された
- 起動はミリ秒単位で、既存のCloud Runインスタンスのリソースを共有するため追加コストは発生しない
- 環境変数の隔離、ネットワーク通信のデフォルト遮断、安全なファイルシステムオーバーレイの3層でセキュリティを確保
- LLMコードインタプリタ、ヘッドレスブラウザ、ユーザー提出コードの実行が主要ユースケース
- ADKとComputeSDKに組み込み対応し、開発者は1行のコードでサンドボックス実行を指示できる
・ 複数業界における17年間のデジタルビジネス開発経験
・ ウェブサイト開発のためのHTML、PHP、CSS、JavaScript等の実用的知識
・ 15ヶ国語対応の多言語SaaSの開発経験
・ 17年間にも及ぶ、Eコマース長期運営経験
・ 幅広い業界でのSEO最適化の豊富な経験

OpenAI GPT-Live登場、ChatGPT Voiceに検索機能を統合
OpenAIが音声会話と検索を融合させた新モデル「GPT-Live」の展開を開始した。2026年7月8日に発表されたこのアップデートにより、ChatGPT Voiceは会話の途中で最新の推論モデルやウェブ検索に質問を引き継げるようになる。
有料ユーザー(Go・Plus・Pro)には「GPT-Live-1」、無料ユーザーには「GPT-Live-1 mini」がデフォルトで提供される。Search Engine JournalのMatt G. Southern氏が報じたところによれば、週に1億5千万人以上がChatGPTと音声や音声入力で会話しており、今回の変更はその巨大なユーザー基盤に直接影響を及ぼす。
SEOの観点から特に注目すべきは、音声経由の検索結果が「どのように引用元を扱うか」の詳細がまだ明らかにされていない点だ。テキストベースのChatGPTでは回答の横にソースリンクが表示されるが、音声会話の中でどの程度サイトへの導線が確保されるかは、今後のトラフィック戦略を左右する。
GPT-Liveの仕組みと変更点

GPT-Liveの最大の特徴は、会話の自然さを追求した「全二重(Full-Duplex)」通信への移行だ。これは音声入力と応答生成を同時に行う技術で、ユーザーが話し終える前に割り込まれにくくなり、より人間らしい対話のテンポが実現される。
具体的に以下の要素で構成されている。
- 音声入力の処理と応答の生成を同時に実行し、待ち時間を短縮
- ユーザーが発話をためらった際に適切な間を取り、自然なターンテイキングを実現
- 有料ユーザー向けのGPT-Live-1と、無料ユーザー向けのGPT-Live-1 miniの2種類を用意
- 深い推論が必要な質問は自動的に最先端モデル(現在はGPT-5.5)に引き継ぐ
OpenAIの社内評価では、5分から10分の会話においてGPT-Live-1とGPT-Live-1 miniは従来のAdvanced Voice Modeよりも高く評価された。評価基準は全体的な好ましさ、ターンテイキング、割り込みの少なさ、会話の流れ、自然さだ。
音声検索の裏で動く推論と視覚カード

GPT-Liveの登場により、ChatGPT Voiceは単なる音声応答の枠を超え、天気や株価、スポーツといったトピックに対して視覚的なカードを画面に表示するようになった。これにより、ユーザーは音声で答えを聞きながら同時に画面で詳細を確認できる。
ユーザーは推論レベルを3段階から選択できる仕組みだ。即時応答を求める「Instant」モードはGPT-5.5 Instantで動作し、より深い回答が必要な「Medium」や「High」モードはGPT-5.5 Thinkingを使用する。音声会話の自然さを保ちながら、必要に応じて高度な推論エンジンに処理を委ねる設計になっている。
この仕組みは、音声経由の検索体験を大きく変える可能性がある。画面に情報カードが表示されることで、ユーザーは検索結果ページを経由せずに目的の情報を得られるからだ。
この変化はSEO担当者にとって無視できないシグナルだ。音声検索の結果が可視化されない形で提供されることで、従来の検索エンジン経由のトラフィックが一部置き換わる可能性がある。
GPT-Liveがまだ実装していない機能
GPT-Liveは現時点で、ChatGPTにおけるビデオや画面共有を伴う音声には対応していない。OpenAIはこれらの機能の追加に取り組んでいることを明言しており、ビデオや画面共有が必要な場面では従来のStandard Voice ModeおよびAdvanced Voice Modeが引き続き利用できる。
実務的に重要なのは、この制約が一時的なものである可能性が高いという点だ。ビデオ・画面共有対応が追加されれば、ユーザーは画面を見せながら質問し、GPT-5.5の推論と検索を組み合わせた回答をその場で得られるようになる。視覚的な情報提供の幅がさらに広がることで、従来型の検索エンジンへの依存はより一層低くなるだろう。
引用とソース表示の不透明さがもたらすSEOリスク
OpenAIの発表で最も詳細が不足しているのが、音声検索結果の引用(Citation)の扱いだ。テキスト版のChatGPTでは、回答の横にソースリンクが明示される。しかしGPT-LiveがGPT-5.5のウェブ検索を通じて得た情報を音声で回答する際、どのように引用元を示すのかはまだ明らかにされていない。
可能性としては以下の3つのシナリオが考えられる。
- 音声でソース名を読み上げて紹介する
- 画面上にテキストと同様のソースリンクを表示する
- ソースを一切提示せずに回答のみを提供する
3番目のシナリオが現実になれば、情報を提供しているウェブサイトにとっては深刻な問題となる。ユーザーが音声で質問し、画面を見ずに回答だけを得て終了すれば、検索トラフィックは完全に消失するからだ。
Search Engine JournalのMatt G. Southern氏は、音声検索結果がソースを「口頭で読み上げるのか、画面に表示するのか、あるいは完全に省略するのか」が、検索からサイトへの送客が維持されるかどうかを決める鍵だと指摘している。ChatGPTの音声会話がウェブサイトのトラフィックに与える影響を測る上で、最も注視すべきポイントだ。
音声検索時代に備えるための実務アプローチ

GPT-Liveのような音声と検索の融合が進む中で、SEO対策は従来のランキング上位表示だけでなく、「AIに情報源として選ばれること」を視野に入れる必要がある。以下の3つの観点が重要になる。
構造化データの強化と情報の整理
AIモデルがウェブ上の情報を正確に取得し、適切に引用するためには、ページの情報構造を機械が読み取りやすい形で提供することが欠かせない。Schema.orgに準拠した構造化データのマークアップは、検索エンジンだけでなくAIによる情報抽出の精度にも影響する。
特にFAQページやHowToコンテンツは、音声での質問応答に直接活用される可能性が高い。質問と回答のペアを明確にマークアップし、簡潔で正確な情報を提供することが有効だ。
ブランド認知と信頼性の蓄積
音声検索の結果としてソースが表示される場合、ユーザーがクリックするのは「知っている名前」や「信頼できると感じるサイト」である可能性が高い。AI時代のSEOでは、単なる検索順位だけでなく、ブランドとしての認知度や専門性の確立がクリック率に直結する。
具体的には、業界内での継続的な情報発信、オリジナルデータや独自調査の公開、著名なメディアからの被リンク獲得など、E-E-A-T(経験・専門性・権威性・信頼性)を高める施策がこれまで以上に重要になる。
音声向けコンテンツの設計
音声で読み上げられることを想定したコンテンツ設計も視野に入れるべき段階に入った。長文の説明よりも、要点を簡潔にまとめた「音声向けサマリー」をページの冒頭に配置することで、AIが情報を抽出しやすくなる。
また、天気や株価、スポーツのスコアといったリアルタイム性の高い情報は、構造化データと組み合わせることでAIに直接取得されやすい。これらの情報を提供しているサイトは、API連携やデータフィードの整備を通じて、機械可読な形式での情報提供を強化することが望ましい。
この記事のポイント
- GPT-Liveは音声会話中にGPT-5.5への推論依頼とウェブ検索を自動的に組み合わせる
- 天気・株価・スポーツなどの視覚カードにより、検索結果ページを経由しない情報取得が拡大
- 音声検索結果の引用表示方法が未公表であり、サイトへのトラフィック維持に直結する課題
- 構造化データの強化とブランド認知の蓄積が、AI時代のSEOにおける重要な差別化要素になる
・ 複数業界における17年間のデジタルビジネス開発経験
・ ウェブサイト開発のためのHTML、PHP、CSS、JavaScript等の実用的知識
・ 15ヶ国語対応の多言語SaaSの開発経験
・ 17年間にも及ぶ、Eコマース長期運営経験
・ 幅広い業界でのSEO最適化の豊富な経験

Nano Banana 2 LiteとGemini Omni Flash登場、高速画像生成と動画編集がAPIで利用可能に
Google DeepMindは2026年6月30日、高速画像生成モデル「Nano Banana 2 Lite」と、動画生成・編集モデル「Gemini Omni Flash」を開発者向けに公開した。どちらもGoogle AI StudioとGemini APIから即日利用できる。
Nano Banana 2 Liteはテキストから画像をわずか4秒で生成し、1,000枚あたり0.034ドルという低コストが売りだ。Gemini Omni Flashは自然言語による動画編集と高品質な動画生成を両立し、1秒あたり0.10ドルで提供される。
この2つのモデルを組み合わせることで、画像を生成して即座に動画化するといったマルチメディア制作のワークフローが一気に加速する。本記事では各モデルの性能、活用シナリオ、連携方法を詳しく見ていく。
Nano Banana 2 Liteの概要と位置づけ

Nano Banana 2 Lite(モデル名 gemini-3.1-flash-lite-image)は、Nano Bananaファミリーの中で最も高速かつ低コストな画像生成モデルだ。主に短時間でのプロトタイピングや大量の画像生成が必要な開発パイプラインを想定している。
旧モデルであるNano Banana(gemini-2.5-flash-image)からの置き換えが推奨されており、差し替えるだけで速度・品質・コストのすべてで改善が見込める。
速度とコストの具体的な数値
- レイテンシ(処理時間) テキストから画像を出力するまでの時間は約4秒。対話的なプロトタイピングや下書き用途に向く。
- 料金 1,000枚あたり0.034ドル。大量生成や予算管理が求められるプロジェクトでコストを抑えやすい。
- 品質のバランス 速度優先ながら、プロンプトへの忠実度・キャラクターの一貫性・画像内テキストの可読性は確保されている。
Nano Bananaファミリー全体の比較
Nano Bananaシリーズには4つのモデルが存在し、用途に応じて使い分ける設計だ。以下が各モデルの位置づけである。
開発者は自分たちのプロジェクトが「速度」を求めるのか「品質」を求めるのかによって、Lite・標準・Proを切り替えられる。たとえば広告バナーの大量生成ならNano Banana 2 Lite、製品写真の精密な加工ならNano Banana Proといった使い分けが現実的だ。
Gemini Omni Flashがもたらす動画編集の変化
Gemini Omni Flash(gemini-omni-flash-preview)は、テキスト・画像・動画を組み合わせたマルチモーダル入力をネイティブに扱い、高品質な動画生成と会話型編集を実現するモデルだ。2026年5月のGoogle I/Oで発表され、今回初めてGemini APIとGoogle AI Studioに公開された。
料金は出力動画1秒あたり0.10ドル。Veo 3.1 Fastと同水準であり、動画生成AIとしては競争力のある価格設定だ。
4つの得意領域
従来の動画生成AIでは「1回のプロンプトで動画を出力して終わり」という単発的な使い方が多かった。Omni Flashは会話を重ねながら微調整できる点が大きく異なる。動画の一部だけを修正したり、複数回の編集を積み重ねたりするワークフローが自然に回せるようになる。
現在の制限事項
- 生成できる動画の長さは現時点で10秒まで。長時間の動画生成は今後対応予定。
- 音声参照のアップロードとシーン延長機能は、今回のAPIでは未サポート。
- APIの仕様上は3秒までの動画参照を受け付けるが、現時点では正しく処理されない。
- シーン切り替えやパン(カメラの横移動)時のキャラクター一貫性に制限あり。改善中。
「10秒制限」は短く感じるかもしれないが、SNS向けショート動画やeコマースの商品紹介動画であれば十分な長さだ。3秒の動画参照制限についても、短いクリップを下敷きにした編集という使い方であれば実用範囲内といえる。
2つのモデルを連携させた実践ワークフロー

Nano Banana 2 LiteとGemini Omni Flashの真価は、両者を組み合わせることで発揮される。具体的には次のような流れだ。
Interactions APIを使うことでセッション履歴とコンテキストが保持されるため、ユーザーは最大3回まで連続した編集を積み重ねられる。1回の生成で終わらない、試行錯誤を前提としたクリエイティブ制作に適した設計だ。
公式デモアプリに見る実用例
Google DeepMindは両モデルを組み合わせた3つのデモアプリを公開している。いずれもGoogle AI Studio上で動作し、ソースコードをリミックスして自社サービスに組み込める。
これらのデモは、画像生成と動画編集を別々のAIに任せるのではなく、一つのワークフローとして統合することで生まれる価値を示している。eコマース事業者であれば、商品写真のバリエーションを大量生成し、その中から選んだ数枚だけを動画化するといった効率的な運用が可能になる。
開発者が知っておくべき安全性とモデル情報

両モデルともGoogleのセキュアなインフラ上で動作し、SynthIDによる電子透かし(ウォーターマーク)が埋め込まれる。SynthIDはAI生成コンテンツであることを検証可能にする技術で、GeminiアプリやChrome、Google検索を通じてコンテンツの来歴を確認できる。
すでにNano Banana 2 Liteは検索のAI Mode、Geminiアプリ、NotebookLM、Google Photos、Stitch、Google Flow、Google Adsなど、Googleの一般向けサービスにも順次展開されている。
API経由での利用にあたっては、各モデルの詳細な機能やリージョン別の制限が公式ドキュメントにまとめられている。開発を始める前に、Google AI Studioのプレイグラウンドで実際の挙動を試すのが確実だ。
この記事のポイント
- Nano Banana 2 Liteは4秒で画像を生成し、1,000枚あたり0.034ドルの低コストで利用できる
- Gemini Omni Flashは自然言語による動画編集と高品質な動画生成を両立し、1秒あたり0.10ドルで提供される
- 両モデルを連携させると、画像生成から動画化・編集までを一貫したワークフローで回せる
- Google AI StudioとGemini APIから即日利用可能で、具体的なデモアプリも公開済み
- SynthIDによるAI生成コンテンツの検証機能が組み込まれており、商用利用にも配慮されている
・ 複数業界における17年間のデジタルビジネス開発経験
・ ウェブサイト開発のためのHTML、PHP、CSS、JavaScript等の実用的知識
・ 15ヶ国語対応の多言語SaaSの開発経験
・ 17年間にも及ぶ、Eコマース長期運営経験
・ 幅広い業界でのSEO最適化の豊富な経験

Safari MCP ServerでAIデバッグ、SEOとCWV改善の新時代
Safari MCP Serverとは何か、その本質
WebKitチームが2026年7月、Safariブラウザ向けのMCPサーバーを発表した。これはAIエージェントがSafariブラウザの内部データに直接アクセスし、デバッグやパフォーマンス分析を自律的に行うための仕組みである。開発者やSEO担当者が手作業で行っていたSafari固有の問題検出が、AIとの対話によって自動化される可能性を示している。
Safariは世界で2番目に利用者の多いブラウザであり、特に米国市場では25%から30%超のシェアを維持する。日本国内でもiPhoneユーザーを中心に無視できない存在だ。つまり、Safariでサイトが正常に動作しないことは、ビジネス機会の直接的な損失を意味する。今回のMCP対応は、この課題を根底から変える契機となる。
デモが示すように、手動で行っていた一連の作業をAIが肩代わりする。この変化は単なる効率化ではなく、Safari対応の質そのものを底上げする力を持つ。
発表の背景とSafariの市場地位
Statcounterの2026年データによれば、Safariの米国市場シェアは四半期によって25%から33%の間で推移している。モバイルに限定すればさらに高く、iOSデバイスが支配的な日本市場でも同様の傾向だ。Web制作者にとってSafari対応は「できれば対応したい」ではなく「対応しなければ事業機会を逃す」段階に入っている。
しかしSafariは、Chromium系ブラウザとは異なるレンダリングエンジン(WebKit)を採用しており、CSSの解釈やJavaScriptの挙動に差異が生じる。これまではMac実機やSafariの開発者ツールを使い、人間が一つひとつ問題を探る必要があった。この非効率をAIで解決するのが、今回のMCPサーバー投入の狙いだ。
MCPが変えるブラウザとAIの関係
MCP(Model Context Protocol)は、AIモデルが外部のツールやデータソースと安全に通信するためのオープンプロトコルである。Anthropicが2024年に提唱し、いまではWordPressやShopify、Google Search Console、Screaming Frogなど主要なCMSやSEOツールが対応している。ブラウザがMCPに対応するのは自然な流れであり、Safariはその先陣を切った形だ。
従来、AIにデバッグを依頼する際は、開発者が問題状況を文章で詳細に説明する必要があった。状況説明が曖昧だとAIの回答精度も落ちる。Safari MCPサーバーはこの壁を取り払う。AIエージェントが自らブラウザのDOM構造やネットワークリクエストを取得し、問題を直接把握できるようになるからだ。
なぜ今Safariのデバッグが重要なのか

Webサイトの表示崩れや機能不全は、直帰率の上昇とコンバージョン率の低下に直結する。とくにSafariはiOSユーザーという購買意欲の高い層を抱えており、ここでの不具合はECサイトや予約サイトにとって致命的だ。にもかかわらず、Safari固有のバグ検出にはこれまで大きな労力がかかっていた。
さらに、Core Web Vitals(CWV)の評価は検索順位にも影響を与える。Googleのランキングシグナルとして機能するCWVにおいて、Safari上での読み込み遅延やレイアウトシフトが起きていれば、それは検索パフォーマンス全体を引き下げる要因になる。AIデバッグによってこの問題を素早く特定し修正できる意義は大きい。
Safari固有の問題がSEOに与える損害
Safariでは、特定のCSSプロパティ(例えばbackdrop-filterの挙動やscroll-behaviorの解釈)が他ブラウザと異なる。JavaScriptにおいてもResizeObserverのループ制限やIntersection Observerのしきい値処理に差異が見られる。これらの不一致がCWVのスコア悪化を引き起こし、結果として検索順位の低下を招く。
従来は、Mac環境がないチームはSafari検証を後回しにする傾向があった。しかしAIが代わりに検証してくれるなら、開発プロセスの初期段階からSafari互換性を組み込める。SEOの観点では、これはリリース後の急な順位下落リスクを減らす直接的な効果を持つ。
デバッグの民主化がもたらす競争環境の変化
AIエージェントによる自動デバッグは、個人事業主や小規模チームにこそ恩恵が大きい。専任のSafari検証担当者を置けない組織でも、AIがその役割を果たすからだ。大企業と中小企業のあいだにあった「ブラウザ互換性の検証格差」が縮まり、Safari上でのユーザー体験を基準にした真の実力勝負に近づく。
これはSEOの世界においても、小手先のテクニックよりも基本品質がモノを言う時代の到来を意味する。Safari MCPサーバーはその流れを加速させるツールであり、いち早く導入したサイト運営者が優位に立つ構図が予想される。
上記のリストは、Safari MCPサーバーがSEO施策に与えるインパクトを整理したものだ。これらの効果はすべて、従来の手動デバッグでは「時間がかかりすぎるから後回し」とされてきた領域である。AIがこの障壁を取り除く。
MCP(Model Context Protocol)の基礎知識

MCPはAIモデルが外部リソースと対話するための標準プロトコルだ。簡単に言えば「AIのためのUSB規格」のような存在である。USBがあらゆる周辺機器を共通の接続方式で扱えるように、MCPはあらゆるデータソースやツールをAIが共通の手順で扱えるようにする。
従来、AIに特定のタスクを実行させるには、そのツール専用のAPI連携を個別に開発する必要があった。MCPはこの非効率を解消する。SafariがMCPサーバーを提供することで、あらゆるMCP対応AIクライアントがSafariのブラウザ情報にアクセスできるようになった。
MCPのエコシステムと業界全体の動き
MCPはAstroやWordPress、WooCommerce、Shopifyといった主要CMSがすでにサポートを表明している。SEOツールのScreaming FrogもMCPを採用し、Google Search Consoleも対応を進めている。Safariの参入は、このプロトコルがブラウザというWeb技術の最前線にまで到達したことを示すマイルストーンだ。
Search Engine Journalの記事では、この流れを「ブラウザとAIの統合が新たな段階に入った」と評している。AIが単にコードを提案するだけの存在から、実行環境の状態をリアルタイムで把握しながら問題解決する存在へと進化しているのだ。
MCP対応の広がりは、AIエージェントが一つのプロトコルで多様なツールを横断的に操作できる未来を示している。SEO担当者はScreaming FrogとSafariとGoogle Search Consoleのデータを、一つのAI対話の中で統合的に扱えるようになるだろう。
Safari MCP Serverが切り拓くAIデバッグの実態

WebKitの公式発表によれば、Safari MCPサーバーは以下の5つの主要ユースケースを想定している。(1)アクセシビリティテスト、(2)Safari互換性テスト、(3)任意のユーザー状態の検証、(4)Safari上でのWeb開発、(5)Webパフォーマンス分析、である。これらはいずれもSEOに密接に関係する領域だ。
特筆すべきは、AIエージェントが「ブラウザの中で何が起きているかを自分で調べる」能力を得た点だ。公式アナウンスにある「完璧なプロンプトを書く必要がなくなる」という言葉が、この変化の本質を突いている。開発者はAIに「このページのCWVを改善して」と大まかに指示するだけで、AIが必要なデータを収集し分析し提案まで行う。
アクセシビリティとSEOの融合
アクセシビリティテストの自動化は、SEOの観点からも見逃せない。画像のalt属性不足やセマンティックHTMLの欠如は、スクリーンリーダー利用者の体験を損なうだけでなく、検索エンジンのコンテンツ理解も阻害する。AIがSafari上でこれらの問題を自動検出することで、SEOとアクセシビリティの両面改善が同時に進む。
Webパフォーマンス分析の深化
Webパフォーマンス分析では、ネットワークリクエストのタイムラインやDOMの構築過程をAIが精査する。従来のLighthouse監査では検出できなかったSafari固有のボトルネック、例えば特定のフォント読み込みがWebKitでだけ遅延する問題なども、AIが実ブラウザ上で直接観測できる。
この「実機ブラウザベースのパフォーマンス分析」は、合成監視では得られないリアルなデータをもたらす。CWVのフィールドデータとラボデータの乖離に悩まされてきたSEO担当者にとって、Safari MCPサーバーは問題の根本原因を特定する強力な武器になる。
5つのユースケースはそれぞれ独立しているが、実際の開発フローではこれらが複合的に作用する。たとえばアクセシビリティの問題を修正した結果、DOM構造が変わりCWVにも影響が出る、といった連鎖的な改善をAIが一括管理できる点が新しい。
SEOとCore Web Vitalsへの実戦的インパクト

Safari MCPサーバーがSEOにもたらす最大の恩恵は、CWV(Core Web Vitals)のスコア改善スピードが飛躍的に上がることだ。これまでLCP(Largest Contentful Paint)の改善には、どのリソースがクリティカルレンダリングパスを塞いでいるかを人間が特定する必要があった。AIがSafariのネットワークタイムラインを直接解析すれば、この作業は数秒で完了する。
CLS(Cumulative Layout Shift)についても同様だ。Safariはフォントのレンダリング方式や画像の遅延読み込みの挙動がChromium系と微妙に異なり、意図しないレイアウトシフトが発生することがある。AIが実際のSafariブラウザ上で測定することで、ラボツールでは再現できない問題まで捕捉できる。
フィールドデータとラボデータの統合分析
Google Search ConsoleのCWVレポートはフィールドデータに基づくが、問題の原因特定にはラボデータが必要になる。Safari MCPサーバーは、実ブラウザのラボデータをAIが直接取得するため、この二つのデータの橋渡し役を担う。フィールドデータでCWV低下を検知したら、すぐにSafari上でAIデバッグを実行し、具体的な修正案を得られる流れが現実的になる。
AI時代のSEOワークフロー
従来のSEOワークフローは「監視→検出→人間が仮説立案→人間が検証→修正→再測定」というサイクルだった。Safari MCPサーバーの登場により、「監視→AIが検出→AIが原因特定→AIが修正案提示→人間が承認→修正→AIが再検証」という形に変わる。人間の役割は「仮説立案」から「AI提案の判断と承認」へとシフトする。
この変化は、SEO担当者のスキルセットにも影響を与えるだろう。Safari DevToolsを細かく操作する技術よりも、AIに適切な指示を出し、出力結果の品質を見極める能力が重視されるようになる。Search Engine Journalの記事が伝える内容からも、このパラダイムシフトは2026年後半から本格化すると見られる。
このワークフロー比較が示すように、Safari MCPサーバーはSEOオペレーションの速度と精度を根本から変える。人間は戦略判断に集中し、反復的な検証作業はAIに任せるという分業が可能になる。
導入から活用までの具体的ステップ

Safari MCPサーバーは発表されたばかりであり、本格的な実装と提供方法についてはAppleからの続報が待たれる段階だ。しかし、すでにMCPを導入している他ツールの事例から、準備すべき環境と心構えは明確になっている。以下に、現時点で想定される導入ステップを示す。
環境準備とAIクライアントの選定
まず必要なのはMac環境と、MCP対応のAIクライアントだ。Claude Desktopや、Cursor、WindsurfなどMCPをサポートするエディタが候補になる。Safari Technology Previewの最新版にMCPサーバー機能が組み込まれる可能性が高く、WebKit公式ブログのアップデートを追うことが最初の一歩になる。
既存のデバッグフローへの組み込み方
AIデバッグは強力だが、いきなり全工程を任せるのではなく、まずは既存のCWV監視フローの補助として導入するのが現実的だ。たとえば、Search ConsoleでCLS悪化を検知したら、AIにSafari上でのCLS発生箇所の特定を依頼する。AIの提案を人間が評価し、問題なければ本番環境に適用するという段階的なアプローチが失敗を防ぐ。
また、AIの出力にはハルシネーション(もっともらしい誤情報)が含まれる可能性がある。特にCSSの修正提案は、Safariで意図通りに動作するかを必ず実機で確認するプロセスを残すべきだ。AIは検出と提案を高速化するが、最終的な品質保証は人間の役割である。
上記の3ステップは、あくまで現時点での想定に基づく。Safari MCPサーバーの正式リリース時に詳細なドキュメントが公開されるはずだ。WebKit公式ブログやApple Developerサイトの情報を定期的に確認し、最新の導入手順に従うことを推奨する。
この記事のポイント
- Safari MCPサーバーはAIエージェントがブラウザ内部データに直接アクセスしデバッグを自動化する仕組みである
- 米国で25%超のシェアを持つSafariの互換性問題をAIが解決することでSEOとCWVが大幅に改善する
- MCPは業界標準プロトコルとしてWordPressやGoogle Search Consoleも対応しておりエコシステムが拡大している
- 導入はMac環境とMCP対応AIクライアントから始め段階的に既存フローへ組み込むのが現実的な戦略だ
- AIの提案を鵜呑みにせず最終的な品質確認は人間が行うプロセスを維持することが失敗を防ぐ鍵になる
・ 複数業界における17年間のデジタルビジネス開発経験
・ ウェブサイト開発のためのHTML、PHP、CSS、JavaScript等の実用的知識
・ 15ヶ国語対応の多言語SaaSの開発経験
・ 17年間にも及ぶ、Eコマース長期運営経験
・ 幅広い業界でのSEO最適化の豊富な経験

EC向けAIフライホイール構築、4つの価値レバーと実践法
EC事業におけるAI活用は、単純なタスクの自動化から、複数の施策が連鎖的に成果を生み出す仕組み作りへと移行しつつある。マッキンゼー・アンド・カンパニーが2026年6月に公開したレポート「Europe’s new ecommerce agenda How AI is resetting growth and competition」では、AIがもたらす価値は断片的な実験ではなく統合にあると指摘されている。
成功するEC事業者は、商品のパーソナライズ、需要予測、在庫管理、価格設定といった複数の意思決定をAIでつなぎ合わせ、全体として加速度的に回転する「フライホイール」を構築している。このフライホイールは、各施策が互いに強化し合い、一度回り始めると追加のリソースを大きく投じなくても成果が積み上がっていく。
この記事では、マッキンゼーが示した「4つの価値レバー」を軸に、大企業だけでなくデータや人的リソースが限られる中小規模EC事業者でも実践できる小さなAIフライホイールの始め方を、具体例とともに解説する。
AIフライホイールの基本概念
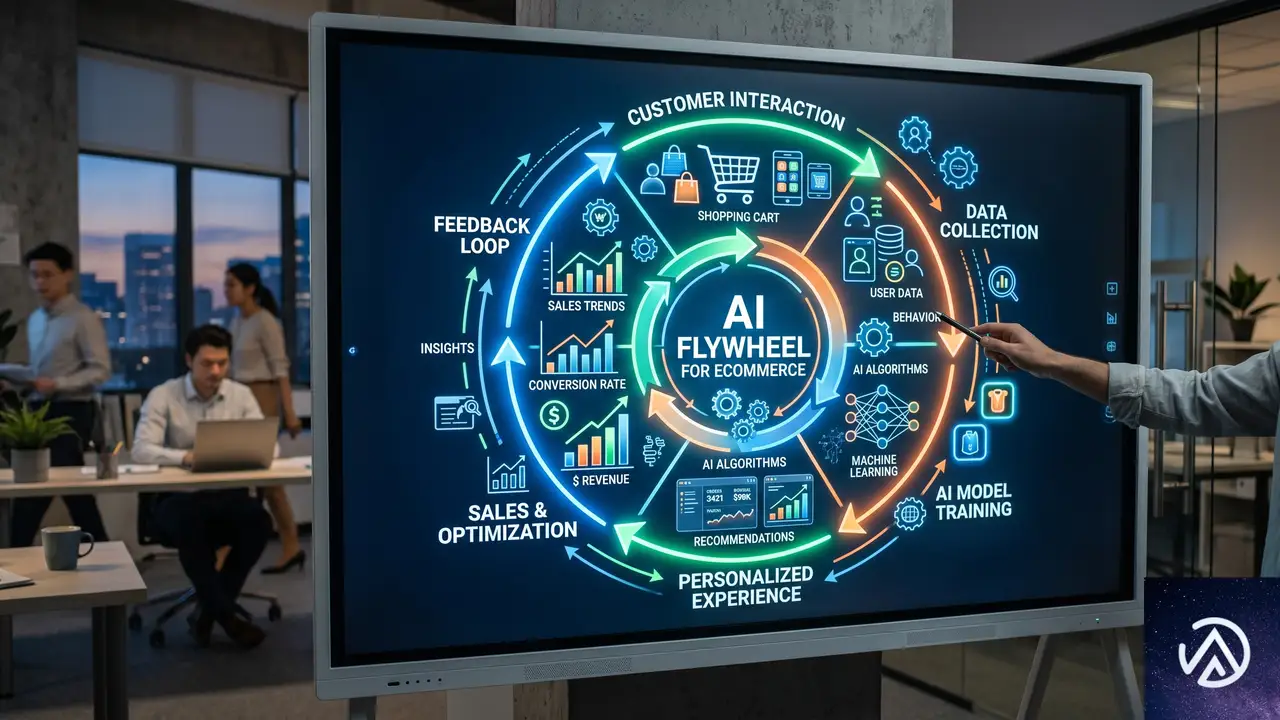
フライホイールが回る仕組み
AIフライホイールとは、あるプロセスが次のプロセスを改善し、その改善が再び最初のプロセスを後押しする、自己強化型の循環システムのことだ。たとえば、AIによるパーソナライズで顧客エンゲージメントが高まると、より正確な需要シグナルが得られる。そのシグナルを使って価格や在庫の判断を最適化すれば、再びエンゲージメントが向上し、さらに多くのデータが蓄積される。
このループを1回転させるごとに、データの質と意思決定の精度が上がり、フライホイールはより少ないエネルギーで回り続ける。一度きりのプロジェクトではなく、持続的な成長エンジンとして機能する点が最大の特徴だ。
単体タスクの自動化との違い
AIフライホイールは、単一の作業をAIに任せる「自動化」とは根本的に異なる。商品説明文をAIで生成すれば時間は短縮できるが、それだけではビジネス全体の流れは変わらない。一方、フライホイール思考では、顧客からの問い合わせ内容をAIで分析し、商品ページの改善に活かし、コンバージョン率の変化を追跡し、その結果を次の仕入れや価格戦略に反映させる。こうした相互連鎖によって、初めて収益構造が強化される。
この概念図では、断片化されたAI活用と、連鎖的に回るフライホイールの違いを視覚化している。単体の導入では部分最適にとどまるが、相互に強化し合うループを作ることで、事業全体の底上げが可能になる。
成長を加速する4つの価値レバー

相互に強化し合う4つの要素
マッキンゼーのレポートでは、ECにおけるAIフライホイールを構成する4つの「価値レバー」として、成長、生産性、バリューチェーン効率、収益性が挙げられている。いずれも独立した施策ではなく、意図的につなぎ合わせることでレバレッジが効く。
成長は、商品発見の最適化やレコメンデーション、メールセグメンテーション、広告クリエイティブの自動生成などを通じて、適切な購入者に適切な商品を届ける活動を指す。AIが顧客行動を深く理解し、一人ひとりに合った購買体験を提供することで、売上の上昇に直結する。
生産性は、カスタマーサポートやコンテンツ制作、販売管理、レポート作成といった反復作業をAIで削減する領域だ。定型業務から人手を解放し、戦略的な思考が求められる高付加価値業務に人材を集中させられる。
バリューチェーン効率は、需要予測と在庫管理、フルフィルメント、返品処理をAIで連携させるものだ。何が売れるか、どこに在庫があるか、いつ届くかをリアルタイムに把握し、コストと在庫リスクを最小化する。
収益性は、価格設定やプロモーション、バンドル販売、値下げ判断をデータ駆動で行う領域である。AIは利益率を損なう過度な値引きや無駄なキャンペーンを可視化し、マージンを最大化する行動を提案する。
商品発見、レコメンド、広告クリエイティブの最適化で適切な顧客にリーチ
反復作業の削減と人員の高付加価値業務へのシフト
需要・在庫・配送・返品を統合しコストを最小化
価格・プロモーション・値下げ判断のデータ駆動化で利益率を向上
これら4つのレバーは、相互にデータを供給し合うことで単体の数倍の効果を発揮する。たとえば、成長施策で得たエンゲージメントデータが在庫効率を改善し、その結果生まれた余剰在庫をデータに基づく値下げ判断で処理しながら収益性を守る、といった連携が可能だ。
中小規模ECが実践できる小さなフライホイール

顧客フィードバック分析から商品ページ改善へ
大企業のように整備されたデータ基盤や高度なシステムがなくても、AIフライホイールは始められる。中小規模EC事業者であっても、問い合わせメールやチャット履歴、レビュー、返品理由といった顧客の声は確実に存在している。これらをAIで分析し、たとえば「サイズ感が合わない」「同梱物がわかりにくい」「配送目安が不明瞭」といった共通の課題を抽出することが、最初の一手になる。
次に、得られたインサイトを商品ページの改善に反映する。サイズガイドの追加や比較表の設置、よくある質問の充実、利用シーンを想起させる商品写真の差し替えなど、具体的な対応を取るのが有効だ。これらの変更は、無料または低コストのAIツールで十分に実施できる。
改善が次のサイクルを生む
商品ページの改修後は、コンバージョン率や返品率、サポートへの問い合わせ件数といった指標を追跡する。ここでもAIを活用すれば、変更の効果を自動で検知し、仮説の精度を高めていくことが可能だ。たとえば「返品理由の上位にあったサイズ感の問題が解消され、返品率が15パーセント低下した」といった成果が得られれば、次の購買データもクリーンになる。
こうした小さなサイクルを繰り返すことで、顧客の声が商品体験を改善し、改善がより良いデータを生み、そのデータがさらに精度の高い意思決定を支えるループが出来上がる。規模は小さくとも、自己強化のメカニズムは大企業のそれと同じだ。
この小さなフライホイールは、初期投資を抑えながら着実に成果を出せる。顧客フィードバックはすでに手元にある資産であり、AIを分析エンジンとして活用するだけで、商品改善と売上向上のエンジンが動き始める。
意思決定の連鎖がもたらすもの

部門を横断したAI活用
AIフライホイールの本質は、カスタマーサービスと商品コンテンツ、サイト内検索とマーチャンダイジング、在庫管理とプロモーションといった、これまで別々に行われてきた意思決定を一本の線でつなぐことにある。AIが仲介役となり、各部門から得られるデータを相互に変換しながら、最適なアクションを導き出す。
たとえば、顧客からの問い合わせに使われる自然言語の傾向をAIが学習すれば、それはサイト内検索のレコメンド精度向上にも活かせる。また、返品理由の分析結果をプロモーション担当に共有すれば、値引きすべき商品や強化すべき訴求ポイントが明確になる。AIがデータの共通言語となることで、組織全体の意思決定が同期し始める。
マネジメント視点の重要性
中小EC事業者が真にAIで競争優位を築けるかどうかは、最新モデルへのアクセスよりも、経営的な視点の差で決まる。AIを単なるツールとして導入するのではなく、業務プロセス全体を俯瞰し、データが流れる経路を設計し、測定と改善を繰り返す管理のしくみを構築することが求められる。
これは技術の話ではなく、経営戦略の話だ。顧客の声を商品に反映し、その成果を在庫や価格に転嫁し、得られた利益を再び顧客体験に投資する。この連鎖を回す主体は、AIではなく事業者自身である。AIはその回転を支えるエンジンに過ぎない。
この記事のポイント
- AIフライホイールは、部分的な自動化ではなく、複数の施策が連鎖して加速する自己強化型のシステムである
- マッキンゼーが示す成長、生産性、バリューチェーン効率、収益性の4つのレバーを組み合わせることで、レバレッジが最大化される
- 中小EC事業者は、すでに保有する顧客フィードバックをAIで分析し、商品ページ改善につなげる小さなサイクルから始められる
- AIの真価は、部門を横断した意思決定の同期と、経営全体をデータ駆動で回すマネジメントの仕組みにある
・ 複数業界における17年間のデジタルビジネス開発経験
・ ウェブサイト開発のためのHTML、PHP、CSS、JavaScript等の実用的知識
・ 15ヶ国語対応の多言語SaaSの開発経験
・ 17年間にも及ぶ、Eコマース長期運営経験
・ 幅広い業界でのSEO最適化の豊富な経験
建築許可の審査期間を半減。英国政府がGemini活用ツール、2027年全国展開
英国政府は2029年までに150万戸の新築住宅を供給する目標を掲げている。しかし自治体の計画許可部門は、大量の紙書類と行政手続きの滞留に直面しており、目標達成の大きな足かせとなっている。
この課題に対し、Google DeepMindは英国政府、Google Cloud、ならびにFacultyとの協力のもと、建築許可申請の審査にかかる時間を抜本的に短縮するAIプロトタイプの開発を進めている。目標は担当官の判断にかかる時間を半減させること。2026年6月時点で一部自治体での試験運用が始まっており、2027年には全国のすべてのカウンシルで利用可能になる見通しだ。
建築許可のボトルネックとAI活用の背景

年間の計画申請のうち、住宅所有者による増築やロフト改修といった比較的単純な申請が約7割を占める。ところが担当官は一件ごとに地域の方針書、過去の許可事例、住民からの意見書など大量のPDFを手作業で照合しなければならず、この単純作業が大きなボトルネックになっている。
こうした背景から、英国政府のAIインキュベーター(i.AI)はすでにExtractというツールを開発し、旧来の文書を構造化データに変換する取り組みを進めてきた。今回のプロトタイプは、その土台の上にGeminiによる高度な解析支援を組み合わせ、審査プロセス全体を加速させる狙いがある。
AIが支援する新たな計画審査プロトタイプ
このプロトタイプは、Barnet、Camden、Dorsetの3つの自治体と共同で開発が進められている。計画担当官にとっては「熟練したアシスタント」のように機能し、データ抽出や事例分析といった重労働を肩代わりする。具体的には以下の4つの作業をAIが自動化する。
- データ統合:滞留している申請情報を前処理し、不足データの可視化やサイト主要情報の抽出を行う。担当官は1つの画面で全体を把握できる。
- 地域方針の照合:国および地域の関連方針を自動でハイライトし、事前にコンプライアンスを評価。正確な引用情報を添えて担当官に提示する。
- 住民意見の要約:個別の意見書を分析し、主要な反対意見や判例を要約する。
- 審査レポートの下書き作成:最終報告書の初稿を生成し、判断の根拠や提案する条件を整理する。
ここで重要なのは、最終的な判断を下すのは常に計画担当官であり、人間の監視が必ず残る点だ。プロトタイプは生成した文章を一歩一歩記録し、明確な思考の連鎖と監査証跡を残す設計になっている。担当官はAIが提案した内容を一行ずつレビューし、根拠を編集したうえで許可・却下を決定する。
手動では数時間かかっていた作業が、AIによる事前のデータ整理と下書き作成によって大幅に短縮される。計画担当官は単純な転記や照合から解放され、より複雑な案件や公共の利益に資する判断に集中できるようになる。
試運用で見える効果と全国展開への展望
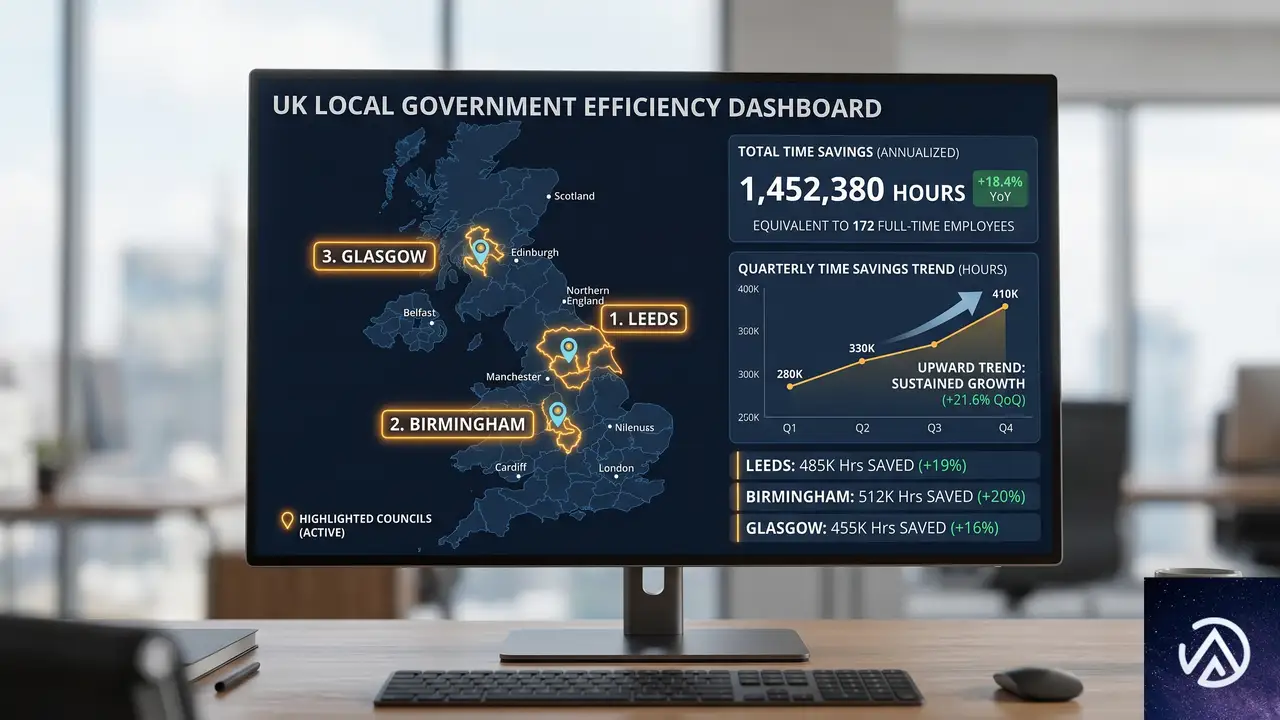
今回のプロトタイプのベースとなったExtractは、すでに20以上の自治体で試験運用され、平均的なカウンシルで年間約255時間の手動作業を削減できる実績を残している。2026年6月には全イングランドのカウンシルで利用可能となり、旧式のPDFをわずか数分で構造化データに変換できるようになった。
新しいAIツールはこのExtractの成果に加え、審査そのものの自動下書きまで踏み込んでいる。Barnet、Camden、Dorsetでの初期試験を経て、英国政府は2027年から全国すべてのカウンシルに展開する計画だ。もし全国で導入されれば、担当官の審査時間が半減し、戸建て住宅の増改築といった日常的な申請が迅速に処理されるようになる。これにより住宅供給の加速だけでなく、地域経済の活性化にもつながると期待されている。
行政におけるAI活用では、透明性と説明責任の確保が常に課題となるが、今回のプロトタイプは全ステップを記録し、人間が最終判断する設計を徹底している点が特徴だ。AIが下書きを生成し、担当官がそれを検証・修正するハイブリッド型のワークフローは、他の公共サービス分野にも応用可能なモデルケースとなるだろう。
この記事のポイント
- 英国政府とGoogle DeepMindがGeminiを活用した建築許可審査AIツールを共同開発中
- 書類統合、方針照合、意見要約、レポート下書きの4機能で担当官の負荷を大幅に軽減
- 計画担当官が最終判断を保持し、全ステップが監査証跡として記録される設計
- 試験運用を経て2027年までにイングランド全カウンシルへの提供を予定
- 単純作業の自動化により住宅供給の加速と行政リソースの最適化が期待される
・ 複数業界における17年間のデジタルビジネス開発経験
・ ウェブサイト開発のためのHTML、PHP、CSS、JavaScript等の実用的知識
・ 15ヶ国語対応の多言語SaaSの開発経験
・ 17年間にも及ぶ、Eコマース長期運営経験
・ 幅広い業界でのSEO最適化の豊富な経験

MDN MCPサーバーでAIに正確なCSSブラウザ互換性情報を提供、開発効率が向上
MDN Web DocsがMCP(Model Context Protocol)サーバーを公開した。このサーバーを使うと、AIコーディングアシスタントにMDNの最新ドキュメントとブラウザ互換性データを直接読み込ませられる。CSSの新機能やブラウザサポートを正確に把握できるため、誤ったコード提案を防ぐことが可能だ。
特に、CSSの最新機能(light-dark()画像対応、:buffering疑似クラスなど)はLLMの学習データに含まれていないことが多い。MDN MCPを導入すれば、AIが正しい情報を参照して回答を生成するため、開発者はわざわざブラウザで互換性を調べる手間が省ける。
MDN MCPサーバーとは

MCPはAIツールが外部データソースに接続するためのオープンスタンダードだ。MDN MCPサーバーはこのプロトコルを使って、MDNの豊富なWebプラットフォーム情報(HTML・CSS・JavaScript・Web APIのリファレンス、ブラウザ互換性データ)をAIエージェントやIDEに提供する。これにより、AIが常に最新のWeb標準に基づいてコードを提案できるようになる。
MCPの基本とMDNの役割
MCP(Model Context Protocol)はAnthropicが中心となって策定したオープンプロトコルで、LLMが外部ツールやデータベースと通信するための共通インタフェースを提供する。MDN MCPサーバーはHTTPトランスポートで動作し、クライアント(VS CodeやClaude Codeなど)がリクエストを送ると、MDNのコンテンツAPIから必要な情報を抽出して返す仕組みだ。
たとえば、AIが「CSSのlight-dark()は画像でも使えるか」と問われた場合、通常のLLMは学習時の知識だけを頼りにする。しかしMDN MCPサーバーが接続されていれば、AIはリアルタイムで正式な仕様とブラウザ実装状況を取得し、誤った回答を防げる。
対応しているツール一覧
MDN MCPサーバーは主要な開発ツールと連携する。エディタではVS Code、Zed、Cursorがサポートされており、AIコーディング支援機能から直接MDNを参照できる。ターミナルベースのエージェントとしてはClaude Code、OpenAI Codex CLI、Google Antigravity CLI(旧Gemini CLI)が対応。チャットアプリではClaude Desktopで利用可能だ。
これらのツールにMCPサーバーを登録する手順は各公式ドキュメントに記載されている。基本はHTTPエンドポイントを指定するだけで、追加のAPIキーなどは不要だ。
なぜ今、MCPが必要なのか

Webプラットフォームの進化は速い。CSSだけを見ても、light-dark()の画像対応、@view-transition、:buffering疑似クラスなど、直近1年以内に実装が始まった機能は多い。AIの学習データは数カ月から1年以上前の情報で固定されているため、こうした新機能に関する質問には正確に答えられない可能性がある。
MDN Blogの記事では、Claude Code Opus 4.7を用いてテストを行った結果、MCPなしではWeb Serial APIについて「Firefoxでは未実装で、Mozillaの標準ポジションでは有害とされている」と誤った回答をしたと報告されている。実際にはFirefox 151でサポートが開始されており、MCPを有効にすることでこの誤りは解消された。
AIの回答が誤っていると、開発者はブラウザの実装状況を手動で調べ直す必要が生じる。MDN MCPはその手間を省き、AIが確かなソースに基づいて回答する仕組みを提供する。
実際のCSS機能で検証、MCP有無の比較
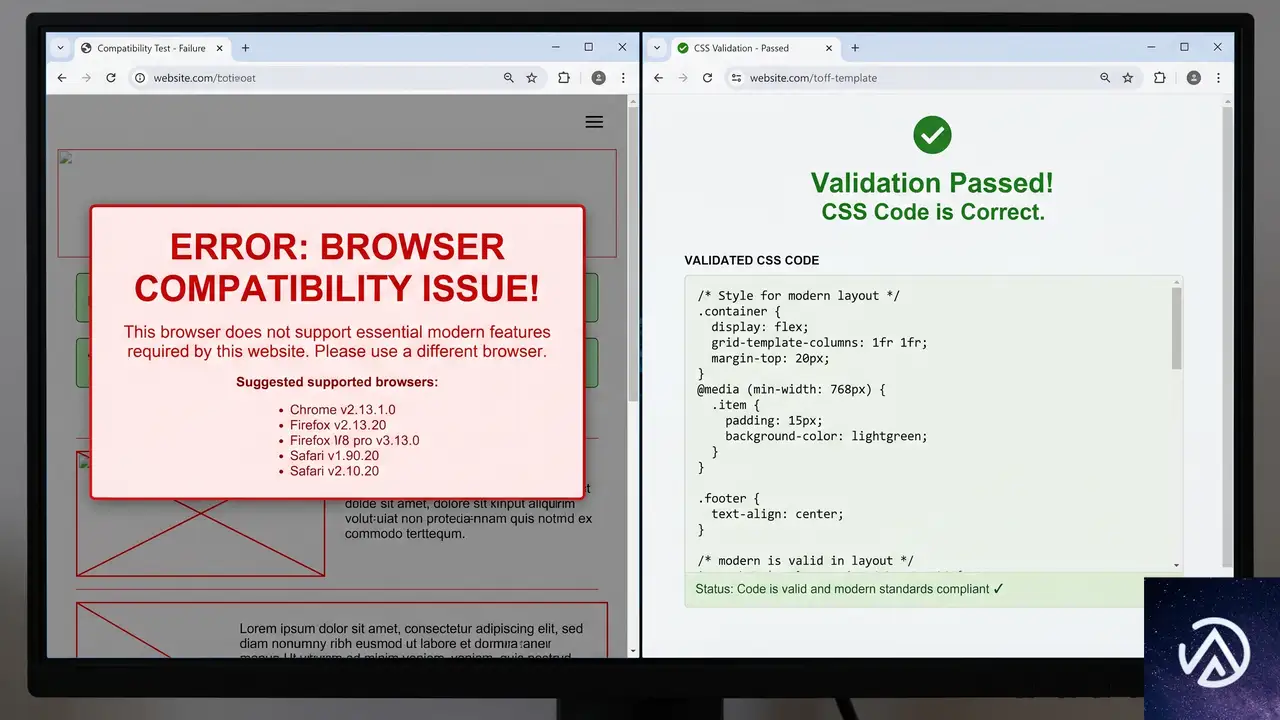
light-dark()画像対応のブラウザサポート
light-dark()はカラースキームに応じて値を切り替えるCSS関数だが、画像も受け付ける。たとえば次のように書ける。
.profile-avatar {
background-image: light-dark(url(avatar-light.png), url(avatar-dark.png));
}light-dark()はOSのカラースキームに応じて自動で画像を切り替える。画像以外にもグラデーションやURLが使用可能だ。
このlight-dark()の画像対応について、Claude CodeにMCPなしで質問した場合、色の値に関する説明しか得られず、画像がサポートされていることは明確に示されなかった。一方、MCPを有効にすると、Firefox 150以降、Chrome(フラグ付き)でサポートされていることが即座に回答された。
:buffering疑似クラスとWeb Serial APIの誤情報
:buffering疑似クラスは、メディア要素がバッファリング中であることを検出するため、MCPなしでも正しいブラウザサポート情報が返された数少ない事例だ。しかしshadowrootslotassignment属性やWeb Serial APIについては、MCPなしでは誤った情報が目立った。
MCPを導入すると、最新のブラウザ互換性データが参照されるため、誤情報を防げる。
特にWeb Serial APIのケースでは、MCPなしのAIは「有害」という強い表現を使ってまで非対応と主張しており、誤った知識で開発を妨げるリスクがあった。MDN MCPはこのような誤解を回避し、確かな情報に基づいたコーディング支援を実現する。
導入方法と活用のポイント

Claude Codeでの設定手順
MDN MCPサーバーはHTTPエンドポイントが公開されており、対応クライアントでMCPサーバーとして追加するだけで利用できる。たとえばClaude Codeの場合、次のコマンドをターミナルで実行する。
claude mcp add --transport http mdn https://mcp.mdn.mozilla.net/この設定後、AIアシスタントがMDNの情報を必要とする質問を受け取ると、自動的にMCPサーバーへリクエストが送られ、最新のドキュメントが参照される。他のエディタやCLIツールでも同様に、MCPサーバーのURLを登録するだけで連携が完了する。
プライバシーと注意点
現在のMDN MCPサーバーは実験的な提供段階であり、使用時にはMDNのプライバシー通知を確認することが推奨されている。サーバーは利用者が送信したクエリを一時的に処理するが、データの取り扱いについては今後アップデートされる可能性がある。
また、MCPが参照するデータはMDNの公式コンテンツとブラウザ互換性テーブルであるため、正確だが、あくまでAIの出力はLLMの生成結果である点に注意が必要だ。複数の情報源と組み合わせながら活用するのが賢い使い方といえる。
この記事のポイント
- MDN MCPサーバーは、AIツールにMDNの最新ドキュメントとブラウザ互換性データを提供する。
- CSSの新機能(light-dark()画像対応、:bufferingなど)の正確な情報を得られる。
- MCPなしではWeb Serial APIのように「未実装」と誤った回答をするケースがあった。
- VS CodeやClaude Codeなど主要な開発ツールで利用可能。導入はURL登録のみ。
- AIの回答が古い知識に依存するリスクを減らし、開発効率を高める。
・ 複数業界における17年間のデジタルビジネス開発経験
・ ウェブサイト開発のためのHTML、PHP、CSS、JavaScript等の実用的知識
・ 15ヶ国語対応の多言語SaaSの開発経験
・ 17年間にも及ぶ、Eコマース長期運営経験
・ 幅広い業界でのSEO最適化の豊富な経験