

Vibe CodingでSaaS代替は本当に得か?セキュリティや保守の隠れたコスト
Vibe Coding(AIに指示を出すだけでコードを生成する開発手法)を使えば、高額なSaaS契約を打ち切って自社ツールを構築できる。実際、AI活用で初期開発費を50%から70%削減できたスタートアップの報告もある。
だが、そのコスト削減の裏には「品質税」とも呼ばれる代償が潜んでいる。AIが生成したコードは人間が書いたコードより1.7倍多くの重大な問題を引き起こし、サンプルの45%は基本的なセキュリティ基準を満たさない。
TrustInsights.aiの共同創業者Chris Penn氏は、この差は開発の進め方に起因すると指摘する。ソフトウェア開発者であればVibe Codingをうまく使いこなせる。AIがタイピングを肩代わりするだけで、設計やアーキテクチャの重要性は変わらないからだ。本記事では、マーケターがSaaS代替を検討する際に見落としがちな4つのリスクを掘り下げる。
コスト削減の裏にある品質税の実態

Vibe Codingの最大の魅力はコスト削減だ。従来のソフトウェア開発では数千万円かかったプロジェクトが、AIを活用すれば数百万円で済むケースも出てきた。スタートアップのベンチマークでは、SaaS購入と比較して初期コストを半減以下に抑えられるというデータがある。
しかし、この数字には落とし穴がある。AIが生成したコードは「一見動くが、中身がスパゲッティ状態」になりやすい。当面のタスクを解決することを優先するため、システム全体の整合性やスケーラビリティが後回しにされるからだ。結果として、後になってから膨大な手直しコストが発生する。
Penn氏の分析では、Vibe Codingの成否は使い手のスキルに大きく依存する。ソフトウェア開発経験者であれば、AIが吐き出したコードの問題点を直感的に見抜ける。一方、プログラミング未経験のマーケターが一人でツールを構築しようとすると、表面的には動いても内部に深刻な欠陥を抱えたシステムになりがちだ。
統合の問題は設計段階で顕在化する

SaaSが持つ「当たり前」の不在
マーケターが直面する最初の壁は、他のツールとの統合だ。SaaS製品は通常、主要なマーケティングプラットフォームやCRMとのAPI連携を標準機能として提供している。しかし自社開発ツールの場合、こうした連携機能はすべて手動で実装しなければならない。
Penn氏は「マーテック担当者が新製品について最初に聞かれるのは『何と統合できますか』だ」と指摘する。統合を後付けで追加しようとすると、当初の設計と噛み合わず、場当たり的な修正の繰り返しになる。これは建築で言えば、基礎が固まった後に増築を繰り返すようなものだ。
重要なのは、Vibe Codingで代替する際に「そのツールが何とどう連携していたか」を完全に把握することだ。単に機能を再現するだけでは不十分で、既存のマーテックスタック全体との接続性を設計図に最初から組み込む必要がある。
セキュリティと信頼性は無料で付いてこない

AIが学習した「安全でないコード」の遺産
AIが生成するコードのセキュリティ品質は、現時点では深刻な懸念材料だ。大規模言語モデルは公開リポジトリのコードで訓練されており、その中には古いライブラリや脆弱性を含むサンプルが多数含まれている。AIは「動くこと」を優先する傾向があり、安全な実装は二の次になりがちだ。
調査では、AIが生成したコードサンプルの45%が基本的なセキュリティチェックに不合格だった。マーテック環境では顧客データや決済情報を扱うケースも多く、わずかな脆弱性が情報漏洩やコンプライアンス違反に直結する。
技術的負債の蓄積とシステムの脆弱化
もう一つの問題は長期的な信頼性だ。AIが生成したコードは短期的なタスク解決に特化するため、時間とともに技術的負債が雪だるま式に増える。小さな変更が無関係な機能を壊すようになり、メンテナンスコストが指数関数的に上昇する。
この現象は「コードの賞味期限」とも呼ばれる。3ヶ月前には完璧に動いていたツールが、APIの更新や依存ライブラリの変更で突然動作しなくなる。SaaSであればベンダーが責任を持って対応するが、自社開発の場合はすべて自分たちで調査して修正しなければならない。
マーケティング担当者は「コードを書けること」と「ソフトウェアを運用できること」が全く別のスキルセットであることを認識すべきだ。Vibe Codingで開発の敷居は下がったが、運用の敷居は下がっていない。
保守はあなたの仕事になる

SaaS解約が意味する「所有権の移転」
Vibe CodingでSaaSを代替する最大の見落としは「所有権」の概念だ。SaaSの月額料金には、ソフトウェアの更新、セキュリティパッチ、APIの互換性維持、サーバー監視といった運用コストがすべて含まれている。自社開発に切り替えるということは、これらの責任をすべて引き受けることを意味する。
Penn氏の分析によれば、多くのチームがこの切り替えコストを過小評価している。ツールが今日動いていても、数ヶ月後には動作しなくなる可能性がある。依存する外部APIが変更され、コードの修正が必要になる。フレームワークの脆弱性が発表され、緊急パッチの適用を迫られる。これらすべてに時間と専門知識が必要だ。
「ソフトウェアプロジェクトマネージャー」への変容
Penn氏は「Vibe Codingによって、誰もがソフトウェアプロジェクトマネージャーになった」と表現する。マーケターはもはや単なるツールの利用者ではなく、開発プロジェクトの責任者として振る舞わなければならない。
これは単なる技術的な変化ではなく、マインドセットの転換だ。要件定義、優先順位付け、品質管理、リリース判断といった、これまでSaaSベンダーが担っていた意思決定を自社で行う必要がある。そのためのスキルとリソースが社内にない場合、コスト削減効果はすぐに逆転する。
すべてのツールを代替すべきではない

代替候補となる低リスクツールの条件
Vibe CodingによるSaaS代替は、すべてのケースに適しているわけではない。適性を見極める基準として、以下の3つの観点が有効だ。単純な社内ユーティリティや、既存SaaSのごく一部の機能しか使っていないツールは、代替の候補になりやすい。
- リスクレベルが低い(顧客データや決済情報を扱わない)
- 機能セットが限定的で、複雑な統合を必要としない
- 利用頻度が低く、多少のダウンタイムが許容される
例えば、社内用のレポート自動生成ツールや、定型的なデータ変換スクリプトなどは、Vibe Codingで効率的に構築できる。これらのツールは仮に失敗してもビジネスへの影響が限定的で、学習コストとして許容できる範囲だ。
絶対に避けるべき高リスク領域
一方で、以下の領域はVibe Codingによる代替に適さない。決済処理、個人情報管理、コンプライアンス関連のシステムは、エラーが直接的な金銭的損失や法的制裁につながる。
CRMのような基幹システムも注意が必要だ。チームが拡大するにつれて、統制や権限管理の必要性が高まる。エンタープライズ向けSaaSが標準で備えるガバナンス機能を、AIにゼロから実装させるのは現実的ではない。
判断の分かれ目は「そのシステムが停止したときのビジネスインパクト」だ。軽微な業務効率の低下で済むのか、それとも売上に直接響くのか。後者であれば、SaaSを維持する方が結果的に安上がりになる。
コントロールと責任のトレードオフ

Vibe Codingがもたらす本質的な変化は、ベンダーロックインからの解放と引き換えに、運用責任を自社に取り込むことだ。柔軟性とコスト削減というメリットは、リスクと保守負担というデメリットと表裏一体である。
Penn氏の「誰もがソフトウェアプロジェクトマネージャーになった」という言葉は、この現実を端的に表している。マーケターは利用者の視点を捨て、オーナーとしての視点を持つ必要がある。設計、品質管理、セキュリティ監査、継続的なメンテナンス。これらはかつてSaaSベンダーが吸収していたコストだ。
結局のところ、Vibe Codingは魔法の杖ではない。AIはコードを書く速度を飛躍的に上げるが、「何を作るべきか」「どのように運用するか」「リスクにどう備えるか」という本質的な問いに答えるのは依然として人間の役割だ。この現実を直視せずにコスト削減だけを追いかけると、初期の節約額をはるかに上回る代償を後払いすることになる。
この記事のポイント
- AIコード生成で初期開発費を50〜70%削減できるが、品質税として1.7倍の重大バグと45%のセキュリティ未達が発生する
- 統合設計を最初から組み込まないと、後付けで破綻する。SaaS代替時は接続性の完全な再現が必須
- 保守とセキュリティ対応はすべて自社責任に移行し、長期的な運用コストが初期削減額を上回る可能性がある
- 低リスクの社内ツールは代替候補だが、決済や顧客データを扱うシステムはVibe Codingに適さない
- Vibe Codingは開発速度を上げるが、プロジェクト管理やリスク判断は依然として人間の専門知識に依存する

クロスドキュメントビュー遷移の三大落とし穴と回避策
クロスドキュメントビュー遷移(Cross-Document View Transitions)は、MPA(マルチページアプリケーション)でありながらSPAのようなスムーズなページ遷移アニメーションを実現するブラウザAPIだ。ReactやAstroといったフレームワークは不要で、HTMLページ間のリンク遷移にブラウザが自動的にアニメーションを付与する。
しかし、この機能の導入にはいくつかの厄介な落とし穴が潜んでいる。CSS-Tricksの記事によれば、著者は実装に丸一日を費やし、何も動作しない状態からデバッグを繰り返したという。ネット上には古い情報や誤解を招くチュートリアルが溢れており、仕様自体も短期間で変更されている。
本記事では、実際の開発現場で遭遇する3つの主要な問題(非推奨metaタグ、4秒タイムアウト、画像の歪み)とその解決策を解説する。加えて、遷移ライフサイクルを制御する2つのイベントについても触れる。
非推奨となったmetaタグの罠
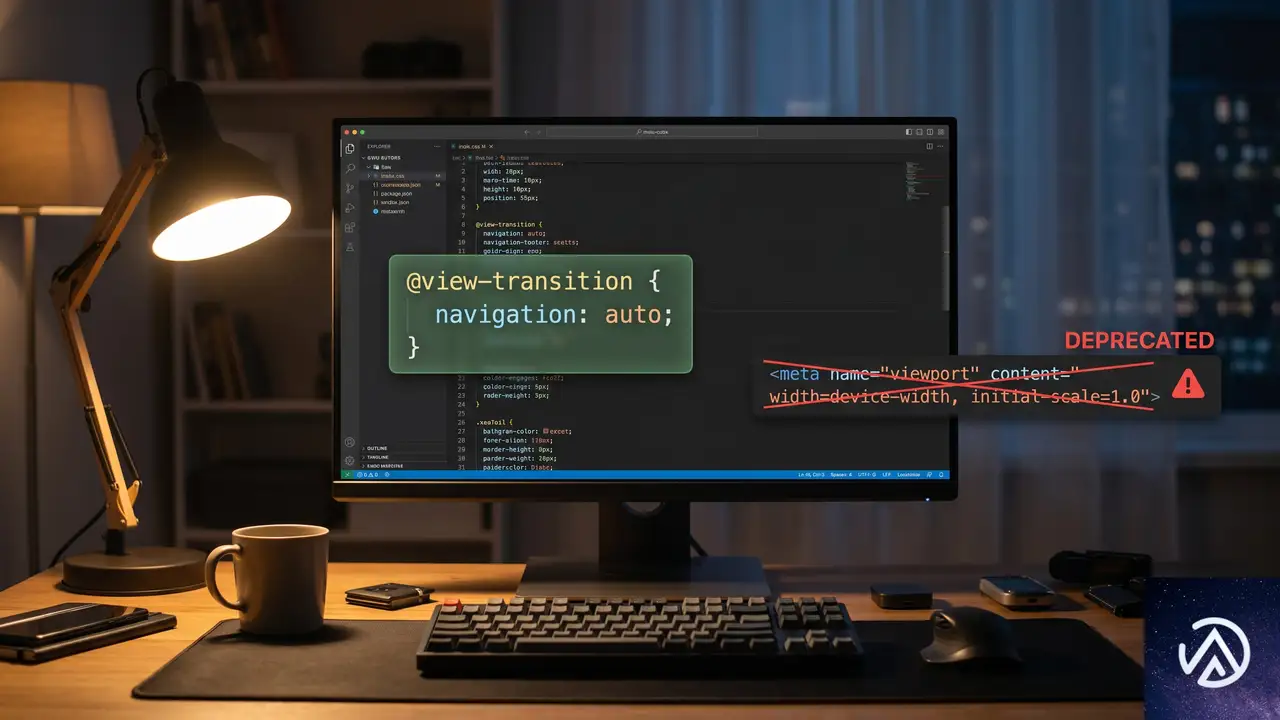
多くの開発者が最初にハマるのが、古いチュートリアルに記載された<meta>タグによるオプトイン方式だ。この方式は既に非推奨であり、現在のブラウザでは完全に無視される。
この比較が示すように、現在の正しい実装方法はCSSの@規則を使用することだ。Chrome 111でmetaタグが導入された後、Chrome 126前後でCSSベースの方式に置き換えられた。非推奨の警告はDevToolsに表示されず、古いコードは静かに動作しなくなる。
なぜCSS方式に移行したのか
metaタグ方式の最大の欠点は、ページ全体でオンかオフかの二択しかできなかったことだ。CSS方式ではメディアクエリや@supportsと組み合わせて、条件付きのオプトインが可能になる。
@media (prefers-reduced-motion: no-preference) {
@view-transition {
navigation: auto;
}
}
@media (min-width: 768px) {
@view-transition {
navigation: auto;
}
}このアプローチにより、アニメーションに敏感なユーザーへの配慮や、モバイルデバイスでのパフォーマンス最適化が容易になった。CSSにオプトインが統合されたことで、既存のスタイル管理フローと一貫性を持って扱える点も大きい。
両方のページでオプトインが必須
もう一つの重要なポイントは、遷移を機能させるには遷移元と遷移先の両方のページで@view-transitionが宣言されている必要があることだ。片方だけでは何も起きない。これは意図的な設計で、404ページやログインリダイレクトなど遷移をスキップしたいページを柔軟に制御できる。
なお、navigation: autoはユーザーがリンクをクリックするかブラウザの戻るボタンを押した場合のみ発動する。window.location.hrefによるプログラム的な遷移や、クロスオリジンのリンク、POSTリクエストでは動作しない。この保守的な設計は、決済処理などの重要な操作に意図しないアニメーションが混入するのを防ぐためだ。
4秒タイムアウトが遷移を静かに殺す
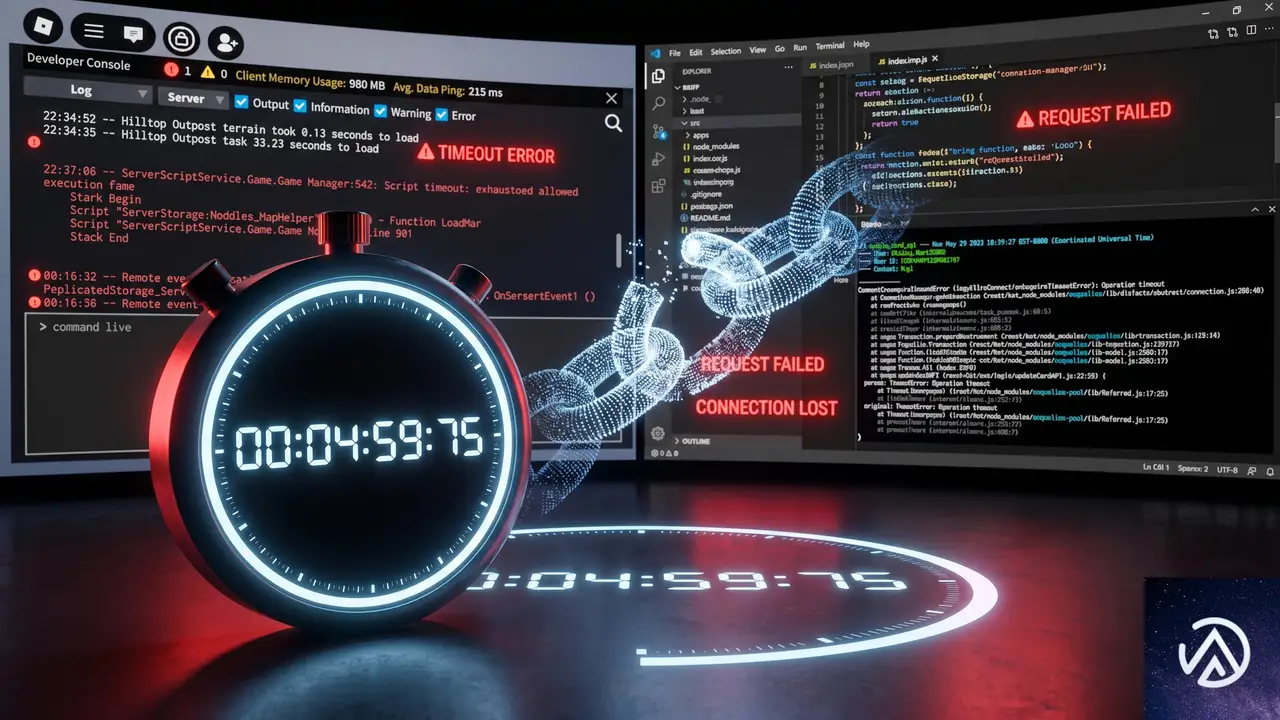
ビュー遷移の実装で最もデバッグが難しい問題が、ハードコードされた4秒のタイムアウトだ。新しいページが4秒以内にレンダリング可能な状態に達しないと、遷移アニメーションは何の通知もなくキャンセルされ、通常のページ読み込みのように切り替わる。
この問題が厄介なのは、ローカル開発環境ではまず発生しないことだ。devサーバーは80msで応答するため遷移は完璧に動作するが、本番環境でサーバーレス関数のコールドスタートやCDNキャッシュミスが発生すると、最初のクリックで遷移が無効化される。
pagerevealイベントでタイムアウトを捕捉する
タイムアウトの発生を検知するには、pagerevealイベントとviewTransition.finishedプロミスを使用する。以下のコードをページに組み込めば、遷移が失敗した際にコンソールで確認できる。
window.addEventListener("pagereveal", (event) => {
if (!event.viewTransition) {
console.log("ビュー遷移なし");
return;
}
event.viewTransition.finished
.then(() => console.log("遷移完了 ✅"))
.catch((err) => {
console.error("遷移中断", err.name, err.message);
});
});このリスナーを早期にセットアップしておけば、本番環境でのデバッグが格段に容易になる。pageswapイベントでも同様に遷移元ページ側でタイムアウトを捕捉可能だ。
実用的な対策
タイムアウト対策の基本はページの読み込み速度改善だが、より実践的なアプローチとしてrel="expect"属性の活用がある。
<link rel="expect" href="#hero" blocking="render">これはブラウザに「#hero要素がDOMに存在するまでページをレンダリング可能と見なさない」と指示するものだ。一見するとパフォーマンスを悪化させるように思えるが、ビュー遷移においては重要なコンテンツが揃ってからスナップショットを取得するため、中途半端な状態での遷移を防げる。
タイムアウトのクロックはナビゲーション開始時からカウントされるため、サーバー応答時間(TTFB)も含まれる点に注意が必要だ。サーバーが2秒かけて応答し、さらに2.5秒かけてレンダリングする場合、個別には遅く感じなくても合計で4.5秒となりタイムアウトに引っかかる。
画像が歪む根本原因と解決策
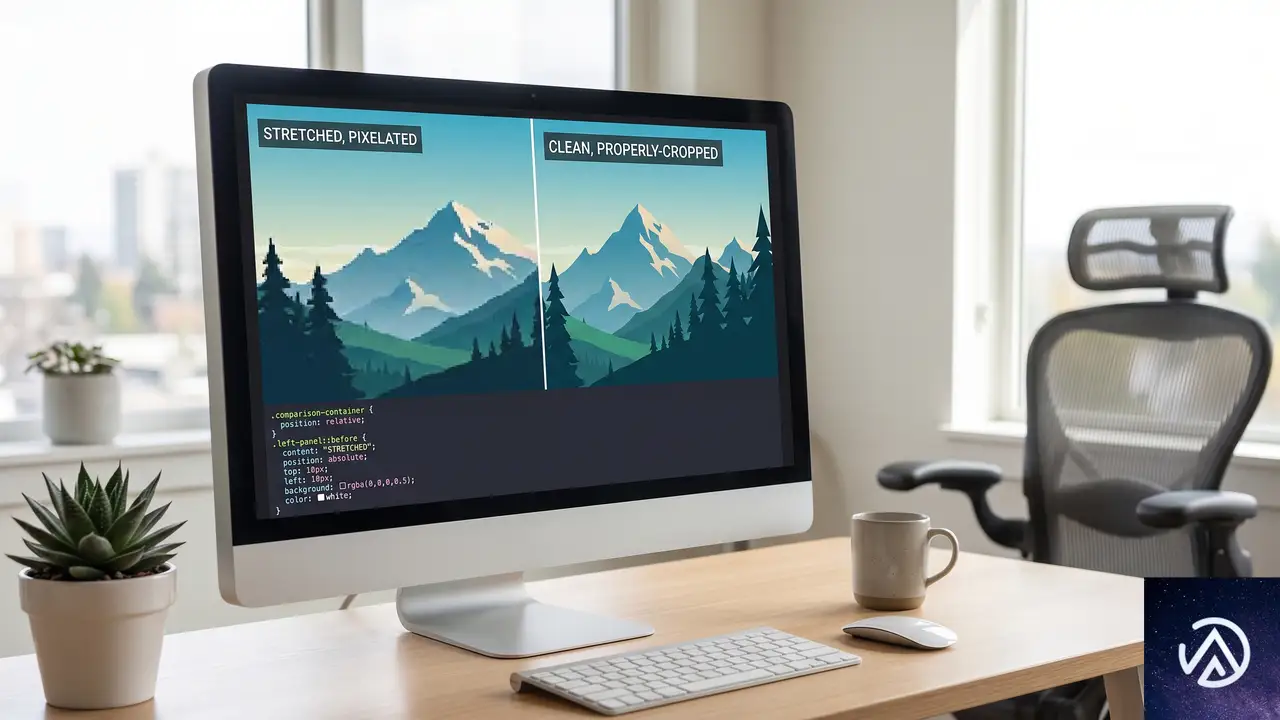
ビュー遷移の実装で視覚的に最も目立つ問題が、アスペクト比の異なる画像間の遷移で発生する歪みだ。サムネイルからヒーロー画像への遷移で、画像が引き伸ばされて見苦しくなる現象は多くの開発者が経験する。
CSS-Tricksの著者は、この問題の原因を特定するのにかなりの時間を費やしたという。根本的な原因は、ブラウザが遷移中に<img>要素そのものをアニメーションさせるのではなく、古い状態と新しい状態のスクリーンショット(ビットマップ)を取得し、それらを変形させることにある。
上記の図が示すように、解決策は疑似要素::view-transition-oldと::view-transition-newに対してobject-fit: coverを適用することだ。これにより、スナップショット画像がアスペクト比を維持したまま切り抜かれるようになる。
疑似要素ツリーの構造を理解する
ビュー遷移が発生すると、ブラウザは内部的に次のような疑似要素ツリーを生成する。
::view-transition
└── ::view-transition-group(hero-img)
├── ::view-transition-old(hero-img)
└── ::view-transition-new(hero-img)::view-transition-groupが古い寸法から新しい寸法へアニメーションするコンテナとして機能し、その中のoldとnewが実際のスナップショットを保持する。デフォルトではこれらの疑似要素にobject-fit: fillが適用されており、これが歪みの原因となる。
アスペクト比が大きく異なるケースでは、object-positionで切り抜き位置を調整することも有効だ。
::view-transition-old(hero-img) {
object-fit: cover;
object-position: center center;
}
::view-transition-new(hero-img) {
object-fit: cover;
object-position: center top;
}このコードでは、新しいヒーロー画像の上部を優先的に表示しつつ、遷移中の歪みを防ぐことができる。CSS-Tricksの著者も指摘するように、object-fit: coverはほぼ全ての画像遷移で必要になる設定であり、デフォルトがfillであることは実用上の大きな障壁となっている。
pageswapとpagerevealによるライフサイクル制御

クロスドキュメントビュー遷移では、遷移元と遷移先のページがJavaScriptで直接通信できないという制約がある。この問題を解決するのがpageswapとpagerevealの2つのイベントだ。
このイベントペアにより、開発者は遷移の両端で状態を制御できる。pageswapは遷移元ページがスナップショットされる直前に発火し、event.activation.entry.urlでユーザーがどこへ向かっているかを知ることができる。
イベントハンドラの実装パターン
これらのイベントを使用する際の重要なポイントは、必ずevent.viewTransitionの存在確認を行うことだ。pagerevealはビュー遷移がない場合も含め、全てのナビゲーションで発火する。
window.addEventListener("pagereveal", (event) => {
if (!event.viewTransition) return;
event.viewTransition.finished.then(() => {
// 遷移完了後のクリーンアップ
}).catch((err) => {
// タイムアウト等のエラー処理
});
});CSS-Tricksの記事では、商品一覧ページから商品詳細ページへの遷移において、pageswapでクリックされた商品カードだけにview-transition-nameを動的に付与するパターンが紹介されている。この動的な名前付けは、数十から数百の要素があるページでのスケーラビリティ問題を解決する重要な手法だ。
この記事のポイント
- metaタグ方式は非推奨。CSSの
@view-transition { navigation: auto; }を使用する - 4秒のタイムアウトはTTFBを含む総時間で判定され、
pagerevealイベントで捕捉可能 - 画像歪みは疑似要素
::view-transition-old/newへのobject-fit: cover適用で解決 pageswapとpagerevealの2つのイベントが遷移全体のライフサイクルを制御する

Gemini Omni登場、マルチモーダル動画生成の新時代
Google DeepMindは2026年5月17日、新たなマルチモーダル生成AIモデル「Gemini Omni」を発表した。テキスト、画像、音声、動画といったあらゆる形式の入力を組み合わせ、高品質な動画を生成・編集できる点が最大の特徴だ。
ファーストモデルとなる「Gemini Omni Flash」は、発表と同時にGeminiアプリ、Google Flow、YouTube Shortsで提供が開始された。自然言語による会話形式での動画編集や、現実世界の物理法則を反映したリアルな映像生成が可能になっている。
この記事では、Gemini Omniが従来の動画生成AIと何が異なるのか、具体的な機能とその仕組み、そしてコンテンツ制作の現場にもたらす変化について解説する。
上の概念図にあるように、Gemini Omniの最大の進化はインプットの柔軟性にある。テキストプロンプトだけでなく、画像や音声、既存の動画そのものを「参照素材」として組み合わせ、そこからまったく新しい映像を生み出せるのだ。DeepMindの記事によれば、将来的には画像や音声の出力にも対応する予定だという。
自然言語で動画を編集する新体験

Gemini Omniが提供する最も画期的な機能のひとつが、会話形式による動画編集だ。従来の動画編集は、タイムライン上でクリップを切り貼りし、エフェクトを重ねる作業の連続だった。Omniでは、編集内容を自然言語で指示するだけで、AIが映像を理解して変更を加える。
DeepMindの発表によれば、Omniは過去の指示内容を記憶し、編集のたびに映像全体の一貫性を維持する。登場人物の見た目や物理法則、シーンの流れが破綻しない。これは単なる「映像の切り貼り」ではなく、AIが映像の文脈を理解しているからこそ実現するものだ。
映像の一部を変更、または一変させる「トランスフォーム」
Omniは、映像内の特定のオブジェクトだけを変更する、あるいはシーン全体をガラリと変えることができる。DeepMindのデモでは、「彫刻をバブル材質に変える」というプロンプトで、彫刻だけが泡状に変化する映像が紹介されている。
この機能は、例えば商品紹介動画の背景だけを差し替えたい、プロモーション映像の季節感を変更したいといった実務ニーズに直結する。撮影済みの映像を素材として、新たなクリエイティブの出発点にできるのだ。
アクションを再構築し、予想外の映像を生成
撮影済みの動画に対して「このシーンで起こっていることを変えてほしい」と指示するだけで、Omniは映像内のアクションそのものを再構築する。新しいキャラクターの追加も、光が音楽に同期して灯るような複雑な演出も可能だ。
発表資料には「手が鏡に触れた瞬間、鏡が美しい液体のように波打つ」というプロンプト例が掲載されている。こうした物理法則に基づく映像表現は、従来の動画生成AIでは難しかった領域だ。
複数ターンにわたる動画の洗練
Omniの編集は、1回の指示で終わらない。環境の変更、アングルの切り替え、スタイルの変更、特定のディテール調整といった指示を段階的に重ねることで、映像を徐々に洗練させていける。DeepMindは「バイオリニストの演奏動画」を例に、環境変更→バイオリンを透明化→肩越しのアングル変更という一連の編集を示している。
この「対話的な編集の積み重ね」は、ディレクターが編集者に指示を出す感覚に近い。クリエイティブの方向性を言葉で伝え、結果を見ながら微調整するワークフローが、AIによって実現しつつある。
世界知識が映像にリアルな文脈を与える
Gemini Omniのもうひとつの核は、Google DeepMindが「世界知識(world knowledge)」と呼ぶ能力だ。Omniは単に見た目がリアルなシーンを構築するだけでなく、「次に何が起こるべきか」を推論する。物理法則、歴史的事実、科学的知識、文化的文脈を踏まえた映像生成が、単なるフォトリアルを超えた説得力のあるストーリーテリングを可能にする。
より正確な物理演算の再現
Omniは重力、運動エネルギー、流体力学といった物理法則の直感的な理解が従来よりも改善されているという。DeepMindが示した「ビー玉が高速でカラクリ装置の上を転がる連続ショット」のプロンプト例では、ビー玉の動きが物理的に破綻しない映像が生成された。
動画制作の現場では、物理演算が破綻した映像は視聴者に違和感を与え、説得力を損なう。特に製品の動作デモや、教育用の科学解説動画では、物理的正確さが信頼性に直結する。Omniのこの改善は、商用・教育コンテンツの品質を引き上げる要素だ。
知識と創造性の融合
Omniはパターンマッチングを超えたレベルで、言語と映像、意味を結びつける。DeepMindの例として挙げられた「AからZまでの珍しいアイテムを各文字ごとに表示する動画」では、カピバラ(C)、ディスコグローブ(D)、ラバランプ(L)といった具合に、各文字に対応するアイテムをAIが自律的に選定し、映像化している。
これは「指示された映像を生成する」というより、「概念を理解した上で映像化する」という質的に異なる能力だ。クリエイターがアイデアを言葉で伝えれば、AIがそれを映像的な表現に落とし込んでくれる。企画段階でのモックアップ作成や、プレゼンテーション用のビジュアル資料作成が大幅に効率化する可能性がある。
複雑な概念を視覚化する説明動画の生成
Omniは短いプロンプトから、複雑な概念をわかりやすく解説する説明動画を生成できる。DeepMindの例では、タンパク質の折り畳み(プロテインフォールディング)を、すべて粘土で作られたクレイメーション(粘土アニメ)風の映像で解説したデモが紹介された。
「複雑なトピックを短時間で視覚化できる」という点は、教育コンテンツや企業の研修資料、製品のオンボーディング動画など、幅広い用途に応用できる。特にスタートアップや中小企業にとって、高品質な説明動画を低コストで制作できる可能性は大きい。
あらゆる組み合わせから動画を生成する力

Gemini Omniのインプットの柔軟性を示す機能として、DeepMindは「複数形式の参照入力」を強調している。画像、テキスト、動画、音声のいずれかを「参照素材」として与えることで、それらをブレンドしたひとつの映像を生成できる。
現時点で音声入力は「声」による参照のみサポートされているが、DeepMindは他の形式の音声入力にも順次対応していく方針だ。画像からキャラクターの外見を、動画から動きのパターンを、音声からリズムやトーンを取り込むといった複合的な制作が可能になる。
画像・音声・動画を「参照」して統一された映像を出力
DeepMindの発表では、3つの異なる素材(画像、動画、音声)を組み合わせて「SF映画風の映像」を生成する例が示された。画像でシーンのスタイルを、動画でカメラワークやエフェクトを、音声で映像のリズムをコントロールできる。
別の例では、人物のイラストとウォークサイクルの動画を組み合わせて、歩きながらリアルな実写映像に変化していく映像を生成している。これらは、クリエイターが持つ複数の素材アセットをAIが「調和」させてひとつの作品に仕上げるという、新しい制作フローを示唆する。
スタイル、動き、エフェクトを自在に適用
参照素材を使うことで、映像のスタイル、動き、エフェクトを細かくコントロールできる。プロンプトだけで指示する場合と比べて、参照素材があることで「こういう感じ」というニュアンスをAIに正確に伝えやすくなる。
「スケートボードにアニメーションのモーションエフェクトを追加する」という例では、撮影済みの映像とAIによるエフェクト生成がシームレスに融合した。実写とCGの境界線が曖昧になっている現在、Omniは実写素材を出発点に、AIによる拡張を重ねるというハイブリッドな制作スタイルを加速させるだろう。
自分のアバターで動画を制作、そして責任ある開発
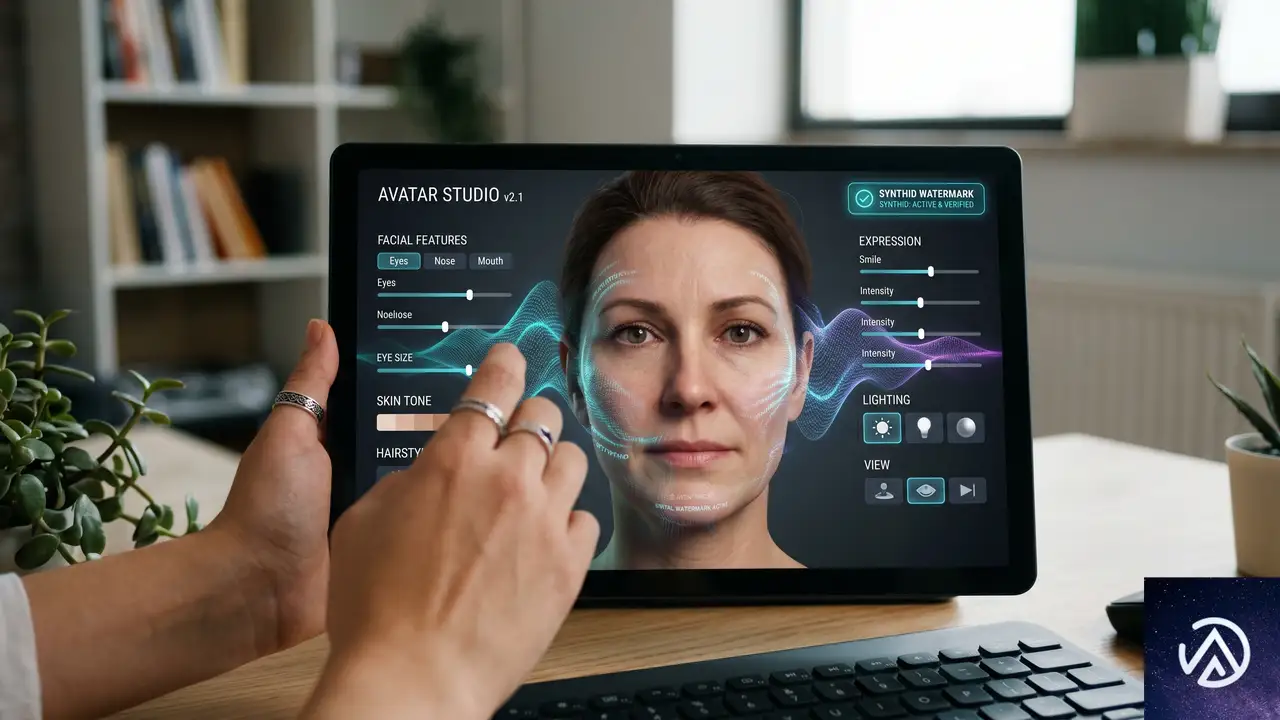
Google DeepMindは、AIの責任ある開発と利用のためのポリシーを明確にしている。その一環として提供されるのが「Avatars」機能だ。これは自分の声と姿をデジタル化したアバターを作成し、そのアバターを使って動画を生成できるというもの。
デジタルアバター機能
アバター機能を使うと、生成された動画はユーザー自身の声と姿を反映したものになる。これはパーソナライズされたコンテンツ制作を可能にする一方、なりすましや悪用のリスクもはらむ。DeepMindは、音声や発話を伴う動画編集機能については、テストを重ねた上で責任ある形での提供方法を模索している段階だとしている。
SynthIDによる電子透かしとコンテンツの透明性
Omniで生成されたすべての動画には、人間の目では認識できないSynthIDのデジタル透かしが埋め込まれる。これにより、GeminiアプリやChrome、Google検索を通じて、その動画がAIによって生成されたものであることを簡単に検証できる。
AIによるコンテンツ生成が一般化するにつれ、その真正性を担保する仕組みの重要性は高まっている。動画メディアの信頼性に関わるこの取り組みは、プラットフォームとしてのGoogleの姿勢を示すものだ。Web制作者やマーケターにとっては、配信する映像コンテンツの透明性を確保する手段として注目に値する。
Gemini Omniの利用を開始するには

現在提供されているのは「Gemini Omni Flash」モデルで、Google AI Plus、Pro、Ultraの各プラン加入者がGeminiアプリとGoogle Flowで利用できる。また今週より、YouTube ShortsとYouTube Create Appでは無償で提供が開始される予定だ。
今後数週間以内には、API経由で開発者やエンタープライズ顧客にも提供が拡大される。これにより、既存の制作ワークフローやサービスにOmniの動画生成機能を組み込んだアプリケーションの登場が期待される。
この記事のポイント
- Gemini Omniはテキスト・画像・音声・動画の組み合わせ入力に対応した動画生成AIで、最初のモデル「Flash」が提供開始された
- 自然言語による会話形式で動画を編集でき、複数ターンの指示で映像を段階的に洗練できる
- 物理法則や世界知識に基づいたリアルで一貫性のある映像生成が可能になった
- 生成動画にはSynthIDの電子透かしが埋め込まれ、コンテンツの透明性が確保される
- API提供により、今後のサービス連携や制作フローへの組み込みが加速する見込みだ

GoogleがAI最適化ガイドを発表、核心は「従来のSEOこそがAI対策」
Googleが2026年5月15日、生成AI検索向けのサイト最適化ガイダンスを公式に公開した。多くのマーケターが待ち望んでいたこのガイドだが、その中身は全く目新しいものではなかった。Googleは「AIのための最適化は、これまでの検索体験のための最適化であり、すなわちSEOだ」と断言している。
AI OverviewsやAI Modeで自社のECサイトが参照されるようにするための特別な技術は存在しない。新しい構造化データも不要、専用のマークダウンページも不要、AI向けの特別な文章術すら求められていない。求められているのは、人間にとって価値あるコンテンツを作り、クロール可能な状態に保つという基本中の基本だ。
今回のGoogleの公式見解は、AI時代のSEO対策に踊らされていたEC事業者にとって、立ち止まり基本を見直す契機となる。小手先のハックではなく、本質的なサイト改善がそのままAIにも通用するという事実を解説する。
この図が示す通り、SNSや一部メディアで話題になった「GEO(Generative Engine Optimization)」の独自手法の多くは、Googleによって完全に否定された形だ。
Googleが定義するAI時代のSEOの正体

Googleが公開したガイドライン「Optimizing your website for generative AI features on Google Search」の最大のポイントは、AI最適化を特別視していない点にある。実務者は腰を据えてこの前提を理解する必要がある。
AI OverviewsやAI Modeは、独自のクローラーでWebを巡回しているわけではない。これらは通常のGoogle検索エンジンが収集したインデックスを参照し、そこから回答を生成する。つまり、そもそもオーガニック検索で認知されていないページは、AIの回答にも決して登場しない仕組みだ。
「AIに読まれるための特殊なマークアップ」や「AI専用のテキスト要約」を用意する動きも一部で見られたが、Googleはそれらを不要と切り捨てている。むしろ、機械向けの不自然な最適化はスパム判定のリスクすらある。
AIが読むからこそ、人間を第一に考えたサイト設計を
Googleのガイドラインは「人間を第一に考えたコンテンツを作成せよ」という従来のポリシーを改めて強調している。独自の視点や専門知識、経験に基づく情報こそが、AIによる情報抽出の対象になる。
ECサイトでいえば、商品のコピーをメーカー提供のまま掲載するのではなく、実際の使用感やスタッフのレビュー、独自の比較情報を加えることが有効だ。AIはWeb上の膨大なテキストを学習しているため、どこにでもある汎用的な文言よりも、固有の情報を優先して抽出する傾向がある。
ECサイトが今すぐ見直すべき7つの基本対策

Googleが提示したAI時代のSEO対策は、すべて従来のGoogleサーチエッセンシャルズに準拠している。ここでは特にEC事業者に影響が大きい7つのポイントを深掘りする。
商品フィードはAI時代の生命線
この中で特にEC事業者が注力すべきは、STEP 6の商品フィード最適化だ。Googleはガイドライン内で、ECサイトの商品データを詳細かつ正確にMerchant Centerへ送信することを強く推奨している。
AI Overviewsが商品に関する質問に答える際、構造化された商品フィードデータは非常に処理しやすい。価格、在庫状況、送料、商品画像、レビュー評価といった情報が正確に提供されていれば、ユーザーの「比較検討」フェーズでAIに参照されやすくなる。
軽量化とクロール最適化の実務
STEP 4の「JavaScript無効環境でのコンテンツ可視性」も見逃せない。GooglebotはJavaScriptを実行する能力を持つが、クロールバジェットの観点から、サーバーサイドレンダリングや静的HTMLでのコンテンツ配信が依然として有利だ。特にWooCommerceサイトでは、商品バリエーションの切り替えなどでJavaScriptに依存しすぎていないか、今一度確認が必要になる。
Googleが一蹴した「GEO神話」とその真実

AI時代のSEOに関して、ここ半年で様々な「GEOテクニック」が提唱されてきた。Googleの今回のガイドラインは、それらの大半を無価値と断じている。
EC事業者にとっての教訓は明快だ。AIに理解してもらうために「裏口」を探すのではなく、正面から人間の顧客に価値を提供し、それを検索エンジンが問題なく読み取れるようにすること。それ以上でも以下でもない。
EC事業者が備えるべき「エージェント時代」の新常識

Googleのガイドラインは、近い将来の「AIエージェント」の到来にも言及している。AI Overviewsのように単に情報を要約するだけでなく、ユーザーに代わってホテルの予約や商品の購入といった「行動」を実行するエージェント機能の開発が進んでいる。
この文脈でGoogleがEC事業者に推奨しているのが、Universal Commerce Protocol(ユニバーサルコマースプロトコル / UCP)への理解だ。UCPは、AIエージェントがECサイト上で商品の検索や購入をプログラム的に実行するための共通仕様である。まだ広く普及しているとは言えないが、今後の標準になる可能性がある。
もちろんこれは未来の話だ。現在はUCPに対応していなければ売上が立たないというわけではない。しかしECサイトのデータ構造を整理し、構造化データを充実させておくことは、このようなエージェント経済への自然な準備となる。
この記事のポイント
- GoogleのAI最適化ガイドラインは、従来のSEO対策と完全に一致している
- AI OverviewsやAI Modeはオーガニック検索結果を参照しており、特別な経路は存在しない
- LLMs.txt や専用マークダウンなど、巷の「GEOテクニック」は大部分が不要
- ECサイトは独自の商品説明の作成、商品フィードの充実、技術的SEOの徹底が最優先
- UCPのようなエージェント時代のプロトコルにも、構造化データで間接的に備えられる

Google Universal Cart発表。AIが越境する新買い物体験と検索広告への波及
Googleは2026年5月のI/Oにおいて、新たなAI買い物かご「Universal Cart(ユニバーサルカート)」を発表した。検索、Gemini、YouTube、Gmail、そして提携小売店を横断し、ユーザーの購買行動をAIが継続的に支援する仕組みだ。単なる商品推薦を超え、価格監視や在庫確認、適合性チェック、決済補助までを自律的にこなす「代理型商取引(エージェンティックコマース)」への本格的な布石といえる。
この発表は、検索広告やEC事業に携わる企業にとって看過できない転換点を含んでいる。Googleが単なる情報の入り口から、商取引自体を内包するプラットフォームへと進化する過程で、広告の役割や商品データの重要性が根本的に変わるからだ。ここでは、Universal Cartの仕組み、基盤となるUniversal Commerce Protocol(UCP)、そして広告主やリテーラーへの影響を掘り下げる。
Universal Cartがもたらす「永続する買い物体験」とは

Universal Cartの核心は、買い物かごを「その場限りの仮置き場」から「AIが能動的に管理する永続的な購買アシスタント」へと変える点にある。Search Engine Journalの記事によれば、Googleはこの機能を「ユーザーを追いかけるインテリジェントなショッピングカート」と表現しているという。
具体的には、ユーザーがGoogle検索で商品を調べ、Geminiとの対話で比較検討し、YouTubeのレビュー動画を見て、Gmailのクーポンを確認するといった一連の行動が、すべて単一のカートに集約される。裏側ではGeminiモデルが稼働し、価格変動や在庫状況、製品同士の互換性までを自動判定する仕組みだ。
AIが「待つ買い物」から「代行する買い物」へ変える
従来のオンラインショッピングでは、ユーザーが自ら価格を監視し、クーポンを探し、セールを待つ必要があった。Universal Cartはこれを反転させる。AIがユーザーに代わってバックグラウンドで価格下落を追跡し、ロイヤルティ特典の適用機会を探し、より適合性の高い代替商品を提案する。
Google Walletとの統合も発表されており、支払い方法やポイントプログラムの情報をAIが参照しながら、購入手続きの手間を減らす方向だ。Search Engine Journalの記事では、Nike、Sephora、Target、Walmart、Wayfair、そしてShopify加盟店などの大手小売業者が、この夏から決済機能の展開に参加すると報じられている。
カスタムPCのような複雑な買い物でも互換性を自動検証
Googleは、複数の小売店にまたがる部品で構成されるカスタムPCの購入においても、Universal Cartが部品間の互換性問題を決済前に検証できると説明している。これは単なるレコメンド機能の延長ではなく、購買判断そのものにAIが深く関与する設計であることを示している。
この能動性こそが、今回の発表の最大の特徴だ。Search Engine Journalの記事も「Googleがいかに積極的にUniversal Cartをリアクティブではなくプロアクティブなものとして位置づけているかが注目に値する」と指摘している。ユーザーが質問するのを待つのではなく、AIが先回りして提案する姿勢への転換である。
Universal Commerce Protocol(UCP)が切り拓く商取引インフラ

Universal Cartの裏側で動くのが、Googleが2026年初頭に発表したUniversal Commerce Protocol(UCP)だ。これは、異なる商取引システムやAIエージェントが共通言語でやり取りするためのインフラ層と位置づけられている。GoogleはI/Oで、すでに複数の小売業者やテクノロジーパートナーがUCPの採用を進めていることを明らかにした。
UCPの役割を簡単にたとえるなら、商取引の世界における「共通通貨」のようなものだ。これまでECサイトごとにバラバラだった商品情報や在庫データ、決済手段の記述方式を統一し、AIがサイトを越えてシームレスに買い物を支援できるようにする。
UCPの地理的・業種的拡大
I/OではUCPに関する以下の拡大計画も発表された。
- UCP経由の決済機能がカナダとオーストラリアに拡大。英国も後日対応予定
- 米国内でYouTubeにUCPが導入される
- ホテル予約や地域のフードデリバリーなど、新たな商取引カテゴリへの展開を計画
特にYouTubeへのUCP導入は、動画コンテンツと商取引の結びつきを一段と強める動きとして重要だ。Search Engine Journalの記事も「YouTubeの拡大は際立っている」と評しており、ブランドにとってYouTubeを単なる認知チャネルではなく、ECチャネルとして捉え直す必要性が高まることを示唆している。
広告主にとってUCPが意味するもの
Search Engine Journalの記事は、UCPの拡大が広告主やリテーラーにとって「カートそのものよりも最終的に重要かもしれない」と指摘している。これは本質を突いた見方だ。Googleは商品の発見から購買行動、決済、AIエージェントまでを包含する商取引インフラを構築しつつある。
このインフラ上では、Merchant Centerの商品データ品質が従来以上に重要になる。AIが商品を理解し、推薦し、互換性を判断するための基盤データとなるからだ。構造化された商品情報の正確さが、AIによる露出機会を左右する時代に入りつつある。
広告主とEC事業者に迫る3つの変化

Universal CartとUCPの登場は、広告主やEC事業者にとって以下の3つの変化をもたらす。
変化1、購買ジャーニーのGoogle内包化
これまでのGoogle検索は、商品情報を提供した後、ユーザーを小売店のサイトへ送り出す役割だった。Universal Cartはこの流れを逆転させ、比較検討や価格監視、再訪問、決済までをGoogleのエコシステム内に引き戻す。
Search Engine Journalの記事でも「歴史的にGoogle検索は主にユーザーを小売店サイトへ送り出していたが、Universal Cartはその活動の多くをGoogle内部に引き戻し始めている」と指摘されている。これは機会であると同時に課題でもある。Google内での露出を最大化できる事業者と、そうでない事業者の差が拡大する可能性が高い。
変化2、商品データがAI時代の新たな広告資産に
AIが能動的に商品を推薦し、価格下落を通知し、互換性を検証する世界では、商品データの質がそのまま販売機会に直結する。正確な在庫情報、詳細な製品スペック、競争力のある価格設定、ロイヤルティプログラムとの統合が、AIによる露出の前提条件となる。
これは従来のShoppingキャンペーンの最適化を超えた、より根源的なデータ戦略を求めている。Merchant Centerのフィード最適化は、もはや運用施策ではなく、AI時代の事業基盤そのものだ。
変化3、YouTubeがECチャネルとして本格化
YouTubeへのUCP導入は、動画プラットフォームが商取引の場へと進化する決定的な一歩だ。商品レビュー動画を見ながらワンクリックでカートに追加し、そのまま購入まで至る体験が現実になる。
この変化は、ブランドのYouTube戦略にも影響を与える。認知獲得のための動画広告から、直接的な売上に結びつく商取引動画へのシフトが加速するだろう。Search Engine Journalの記事も「ブランドはYouTubeを単なる動画認知プラットフォームとしてではなく、ECチャネルとして考える必要性が高まる」と述べている。
計測とアトリビューションの再考が迫られる

Universal Cartが普及すれば、購買行動のより多くの部分がGoogleインターフェース内で完結する。これは広告の効果測定にも大きな影響を与える。従来のクリックベースのアトリビューションモデルでは、Google内で進む比較検討やAIによる価格監視の影響を捉えきれない。
Search Engine Journalの記事は「より多くのショッピング活動がGoogleインターフェース内で発生するようになれば、広告主はアトリビューションやアシストコンバージョン、クロスチャネルのカスタマージャーニーレポートの評価方法を再考する必要があるかもしれない」と指摘している。これは単なる技術的な課題ではなく、広告予算の配分やROI評価の根幹に関わる問題だ。
具体的には、以下のような再考が求められる。
- ラストクリック至上主義からの脱却。AIが長期にわたって関与する購買ジャーニーでは、初期の商品発見や中期の価格監視が持つ価値を適切に評価する必要がある
- Googleエコシステム内の複数タッチポイント(検索、YouTube、Gmail、Gemini)を横断した統合的な計測手法の確立
- AIによるプロアクティブな提案(価格下落通知や互換性アラート)がコンバージョンに与える影響の定量化
代理型商取引の成熟と今後の展望

Universal Cartはまだ初期段階にある。Search Engine Journalの記事も「より高度な代理型商取引機能の多くは成熟に時間がかかるだろう」と現実的な見方を示している。それでも、今回の発表はGoogleがショッピング領域でどこへ向かおうとしているのか、かなり明確な絵を示したといえる。
GoogleはAIによる商品発見の強化を超え、購買ジャーニーのより深い部分へと進出している。商品推薦やカート管理から、価格洞察、決済インフラに至るまで、購買プロセスの占有率を着実に高めているのだ。
広告主やリテーラーにとって、これは単に「広告の表示場所が変わる」という話ではない。ブランドが影響力を測定する方法、コンバージョンを帰属させる枠組み、購買ジャーニーの中で可視性を競う土俵そのものが変わる可能性を秘めている。
こうした変化に備えるには、以下の3点が当面の具体的なアクションとなるだろう。
- Merchant Centerの商品データ品質を最優先で引き上げること。AIが商品を理解し推薦するための「原材料」はデータであり、その質が露出機会を決める
- YouTubeをECチャネルとして位置づけ直し、商取引に直結する動画コンテンツ戦略を構築すること
- アトリビューションモデルを再評価し、AIが介在する長期の購買ジャーニーを捉えられる計測基盤を整えること
この記事のポイント
- Universal Cartは検索・YouTube・Gmailを横断するAI駆動の永続的買い物かごであり、価格監視や互換性チェックまで自律的に実行する
- 基盤となるUCPは商取引の共通言語として機能し、Googleエコシステム内外の決済や商品情報連携を支えるインフラである
- 広告主には購買ジャーニーのGoogle内包化、商品データの戦略的重要性の高まり、YouTubeのECチャネル化という3つの変化が訪れる
- AIが購買判断に深く関与する時代には、アトリビューションや効果測定の抜本的な再考が避けられない

Gemini 3.5 Flash がVercel AI Gatewayで利用可能に。並列処理能力と推論機能が大幅向上
Googleの最新モデル「Gemini 3.5 Flash」が2026年5月19日からVercel AI Gatewayで利用可能になった。このモデルはコーディング能力と並列エージェント実行ループの性能が大きく向上し、複雑なタスクでも高い推論精度を発揮する。
AI Gatewayの統合APIを通じて呼び出せ、使用量の追跡やコスト管理、リトライやフェイルオーバーの設定も標準で備わっている。開発者は面倒な基盤管理なしに、最新のAIモデルを本番環境へ素早く組み込める。
この記事では、Gemini 3.5 Flash の進化点、AI Gateway での具体的な使い方、実装時の注意点までを整理する。
Gemini 3.5 Flash の概要と新モデルの位置づけ

Flash シリーズの進化
Gemini Flash シリーズは、Google が提供する軽量で応答速度に優れたAIモデル群だ。前世代のFlash 2.0と比べて、3.5 Flash では単なる速度向上にとどまらず、複数ステップのタスクを自律的に並列実行できるようになった点が大きな違いだ。
これにより、コーディングの効率化や、複数のAPIを同時に呼び出すようなエージェント型アプリケーションで強力なパフォーマンスを発揮する。
今回のアップデートで強化された点
- コーディング補完の精度向上
- 並列エージェント実行ループの大幅な最適化
- コア推論能力と命令追従性の改善
- マルチターン会話の一貫性向上
- 思考モード(thinking mode)での高品質な推論トレースの生成
並列エージェント実行ループの進化

並列化によるパフォーマンス向上
従来のFlashモデルは、一連のタスクを逐次的に処理する傾向があった。たとえばコードリファクタリングの際に「API呼び出しAの完了を待ってからAPI呼び出しBを実行する」といった流れになる。これに対し、3.5 Flash は複数の独立した処理を同時に並列実行する能力が格段に上がっている。
並列実行のメリットは、応答待ち時間の大幅な短縮と、システム全体のスループット向上だ。特にマイクロサービス間の連携や、複数の外部データソースを一括で処理する場面で効果を発揮する。
この比較はあくまで概念図だが、実際のアプリケーションでは複数の独立した処理を同時に走らせることで、体感速度やスループットが大きく改善される。
thinking モードと推論トレースの強化

thinking level の選択
Gemini 3.5 Flash はデフォルトで「medium」のthinking levelが設定されている。これは、応答の品質と生成速度、そしてコスト効率のバランスを取るための設計だ。より複雑な推論が必要な場合は high レベルに変更することも可能で、その場合は推論プロセスがより深く行われる。
たとえば、コードのリファクタリングや多段階の意思決定が必要なタスクでは、thinking level を high に設定することで、AIが問題をより細かく分解し、質の高い答えを導き出す。
マルチターンコヒーレンスと複雑タスク
3.5 Flash では、マルチターンの会話における一貫性も改善されている。以前のFlashモデルに比べて、前のやり取りを適切に保持しながら、矛盾のない回答を返す精度が向上している。これにより、長時間のコード生成や、会話型のエージェントアプリケーションでも安定した挙動が期待できる。
複雑なタスクでは「thinking traces(思考の痕跡)」がより詳細に出力されるため、モデルがどのような過程で結論に至ったかを検証しやすい。デバッグや品質管理の面で大きなメリットだ。
Vercel AI Gateway の機能とメリット

統合APIとプロバイダールーティング
Vercel AI Gatewayは、複数のAIプロバイダーを統一的なインターフェースで利用できるプラットフォームだ。開発者はプロバイダーごとに異なるAPIキー管理やエンドポイントを意識することなく、model の指定だけでモデルを切り替えられる。
さらに、AI Gatewayはインテリジェントなルーティング機能を備えており、特定のプロバイダーに障害が発生した場合に自動で別のモデルへフェイルオーバーしたり、リクエストをリトライしたりできる。これにより、単一プロバイダーを直接使うよりも可用性が向上する。
観測性とカスタムレポート
AI Gatewayには、使用量の追跡やコスト分析のためのカスタムレポート機能が組み込まれている。プロジェクトごと、環境ごとにAPI呼び出し回数やトークン消費量を可視化できるため、予算管理やボトルネックの発見に役立つ。
また、AI SDK Observability との連携により、モデルの応答時間やエラーレートを詳細に監視できる。Bring Your Own Key にも対応しており、自社で契約したAPIキーをAI Gateway経由で安全に利用できる点も企業ユースに適している。
AI SDK での実装方法と注意点

コード例
AI SDK を用いて Gemini 3.5 Flash を呼び出すには、以下のように streamText 関数を使う。モデル名に google/gemini-3.5-flash を指定し、必要に応じて thinking level を設定する。
import { streamText } from 'ai';
const result = streamText({
model: 'google/gemini-3.5-flash',
prompt: 'Refactor this service to run API calls in parallel.',
providerOptions: {
google: {
thinkingConfig: {
thinkingLevel: 'high',
includeThoughts: true,
},
},
},
});thinking level は 'medium'(デフォルト)と 'high' から選択でき、複雑なタスクでは 'high' を指定すると良い。なお、includeThoughts: true にすると推論過程のトレースもレスポンスに含められる。
サポート外のパラメータと制約
Gemini 3.5 Flash では temperature、topP、topK、thinking_budget といったパラメータはサポートされていない。以前のモデルでこれらの値を調整していた場合は、デフォルトの挙動に任せるか、他のモデルを検討する必要がある。
特に thinking_budget が使えない点は、推論にかかるコストを細かく制御したい場合に注意が必要だ。そのぶん thinking level の切り替えで大まかな品質とコストのバランスを取る設計になっている。
この記事のポイント
- Gemini 3.5 Flash は並列エージェント実行ループの性能が大幅に向上し、コーディングや複数API呼び出しに強い
- デフォルトで medium の thinking level を採用し、品質・速度・コストのバランスを最適化
- Vercel AI Gateway によって統合API、リトライ、フェイルオーバー、観測機能をフル活用できる
- temperature や topP などの一部パラメータは非対応のため、移行時には注意が必要
- AI SDK 経由で数行のコードで導入可能、並列化のメリットをすぐに享受できる

WooCommerceがClaude連携の実験プラグインを公開、AI店舗分析の新形
WooCommerceの開発チームが、AIアシスタント「Claude」とECサイトを直接連携させる実験的プラグインを公開した。このプラグインは、単にAIがサイトのデータを読み取るだけでなく、店舗運営者が実際に求める「売上の傾向分析」や「クーポンの効果測定」といった問いに、具体的で意味のある答えを返すことを目指している。
発表元のWooCommerce Developer Blogの記事によれば、これは「Radical Speed Month」と名付けられた社内実験プロジェクトの一環だ。新機能の発表でも、将来のロードマップへのコミットメントでもない。あくまでアイデアを形にし、コミュニティからのフィードバックを得るための試金石である点が強調されている。
実験「WooCommerce for Claude」が解決しようとする課題

AIとWebサービスの連携は、APIを通じて生のデータを取得させるだけでは不十分だ。データの文脈や、事業者にとっての意味まで理解しなければ、役に立つ回答は得られない。
この実験の核心は、「どうすればAIを単なるデータ呼び出しツールではなく、店舗運営の実用的な相談相手にできるか」という問いにある。WooCommerceの開発チームは、この課題に対して3つの仕組みを基盤となるMCP(Model Context Protocol)の上に構築した。
MCPとは、AIモデルが外部のツールやデータソースと安全にやり取りするための共通規格だ。すでにWooCommerceのコアには開発者向けプレビューとしてMCPサポートが組み込まれている。この実験プラグインは、その仕組みを拡張し、AIに対してより深い店舗理解を与えることを狙っている。
このデモで示したように、AIに「考えるための材料」を構造化して与えることが、この実験の設計思想だ。単に問い合わせの窓口を作るのではなく、AIが店舗の状態を理解した上で回答できるようにする。
分析スキル
店舗運営者が本当に知りたい質問に対して、事前に集計された回答を返す仕組みだ。「今週の売上はどうだったか」「どの商品が売上を牽引しているか」「クーポンは効果を発揮しているか」といった質問が想定されている。
重要な点は、これらの分析が商品投稿(wp_posts)の生データを直接参照するのではなく、WooCommerceの分析用参照テーブルに対して実行されることだ。これにより、データベースへの負荷を抑えつつ、高速に意味のある集計結果を返せる。
知識レイヤー
AIがツールを呼び出す前に、店舗のプロフィール、カタログのスキーマ、ポリシー、拡張された商品データをMCPリソースとして露出させる層だ。これにより、AIは「どのような店舗なのか」という文脈を最初から理解した状態で対話を始められる。
たとえば、投資家に店舗を説明するような抽象度の高い質問や、返金が多い注文を洗い出すような具体的な調査にも、前提知識を持って対応できるようになる。
AI準備スコアリングエンジン
商品の完全性、スキーマの網羅率、コンテンツの品質、ポリシーの完全性という4つの要素を重み付けし、0から100のスコアを算出する。その上で、改善すべき項目を優先順位付きのリストとして提示する機能だ。
このスコアは、AIが店舗データをどれだけ正確に解釈できるかの指標となる。データが整備されていない店舗では、AIの回答精度も下がるという前提に立った、実用的な診断ツールといえる。
実際の使用感とセットアップ

プラグインを導入すると、1つのエンドポイント(/wp-json/woocommerce-claude/mcp)がWordPressの「Abilities」として登録される。別プロセスやcronによる同期処理は一切不要で、MCPリクエストが来たときにだけ動作する省リソース設計だ。
Claude Desktopとの接続は、ワンクリックの.mcpbバンドルファイルで完結する。手動セットアップの場合も、読み取り専用のWooCommerce REST APIキーがあらかじめ埋め込まれたJSONスニペットが店舗ごとに生成されるため、煩雑な設定は不要だ。
接続後は、自然言語で以下のような質問を投げかけられる。
- 過去7日間の売上が振るわないが、何が変わったのか?商品別、カテゴリ別、時間帯別に分解してほしい
- 前回のプロモーションは収益を押し上げたのか、それとも定価販売からの付け替えにすぎないのか
- 新しい投資家になったつもりで、この店舗の全体像を説明してほしい。強み、リスク、成長機会は何か
- 現在の収益漏れはどこにある?最大の値引き、最大の返金、支払い保留や失敗で滞留している最古の注文を洗い出して
- 売上のうちリピート購入者の割合は?どの商品が顧客を呼び戻しているのか
- カタログのAI準備スコアを監査し、最も減点の大きい項目と、最初に改善すべき点を教えてほしい
これらの質問は、単なるデータの抽出ではなく、分析と洞察を求めるものだ。AIが「構造化された店舗知識」を持っているからこそ、意味のある回答が可能になる。
拡張開発者向けの設計思想

このプラグインが実験として公開された目的の一つは、エクステンション開発者からのフィードバック獲得だ。プラグインはプロバイダーパターンを採用しており、あらゆる拡張機能がAIの見る知識レイヤーに自らのデータを流し込める。
add_action( 'woocommerce_claude_register_providers', function( $registry ) {
$registry->register( new My_Extension_Provider() );
});このコードが示すように、開発者は独自のプロバイダーを登録するだけで、AIが参照できる情報を拡張できる。さらに、AI準備スコアに独自の評価基準を追加したり、出力される商品データをフィルタリングしたりすることも可能だ。
開発チームは、この「プロバイダー + アビリティ + 単一MCPエンドポイント」という設計図が、実際にエクステンション作者が採用したいと思える形かどうかを検証したいと考えている。
デモで示したとおり、プロバイダーパターンの追加により、AIが店舗について持つ知識の幅が大きく変わる。このアーキテクチャがコミュニティに受け入れられれば、サードパーティ製プラグインとの連携も大きく加速するだろう。
この実験が探る実用性とリスク

開発チームは、この実験が公式機能でも完成品でもないことを明確にしている。Radical Speed Monthの成果物の一部は将来の正式プロダクトになるが、多くはならない。このプラグインがどちらの道をたどるかも、まだ決まっていない。
だからこそ、実店舗や制作会社の環境でのテストが求められている。特に知りたいのは、以下の3つの失敗モードだ。
- AIが店舗運営者には実行不可能な提案をしてしまわないか
- 集計データから個人情報や秘匿すべきビジネス情報が漏洩しないか
- 大規模カタログ(シードされたデモ店舗よりはるかに大きい規模)でのパフォーマンスは許容範囲か
机上の設計では見えない問題を、実際の多様な店舗環境で洗い出すことが、この公開テストの最大の目的だ。
テスト環境と始め方

リポジトリはGitHubで公開されており、クローン後にcomposer installを実行して有効化するだけで試せる。ローカル開発環境は、npx @wordpress/env start コマンドでWordPress、WooCommerce、そして本プラグインが立ち上がる。
テスト用に、24ヶ月分・5000件の注文データを生成する決定論的シードスクリプトが付属している。これにより、分析機能が十分なデータを基に動作する様子を確認できる。
開発チームは、AIが自信満々に間違った回答をしたケースや、拡張機能の開発者体験に違和感があった場合など、あらゆるフィードバックをGitHubのIssueで求めている。この実験が将来の製品に繋がるかどうかを判断する材料として、コミュニティのテスト結果が重視されているのだ。
この記事のポイント
- WooCommerce for Claudeは、AIと店舗の新しい連携形を模索するRadical Speed Monthの実験プロダクトである
- 分析スキル、知識レイヤー、AI準備スコアの3層構造で、AIが「文脈を理解した回答」を返せるように設計されている
- プロバイダーパターンにより、サードパーティ拡張がAIの知識ベースに自ら統合できる拡張性を持つ
- 公式機能やリリース予定のものではなく、実店舗環境でのテストフィードバックを目的としている
- データプライバシーと大規模カタログでのパフォーマンスが、現時点で確認すべき主要な論点である

EU一般製品安全規則(GPSR)の全貌とEC事業者の対応策
EU(欧州連合)向けに商品を販売する越境EC事業者にとって、2024年12月から本格適用された「一般製品安全規則(GPSR)」への対応は、もはや避けて通れない関門となっている。
従来のVAT(付加価値税)登録や通関手続きに加え、域内に拠点を持たない事業者に新たな義務が課せられることになった。この規則への違反は、AmazonやeBayといった販売プラットフォームから強制的に除外されるリスクに直結する。
本記事ではGPSRの全体像を紐解きながら、WooCommerceなど自社ECサイトを運営する事業者が今日から着手すべき実務対応を具体的に解説する。
GPSRの全体像と影響範囲

GPSR(General Product Safety Regulation)は、EU市場における消費者製品の安全性を確保するための包括的な法的枠組みだ。2001年に初版が発行されたのち、2024年12月に全面改訂版が施行された。
玩具や電子機器だけでなく生活用品全般が対象
ポイントとなるのは、この規則が玩具や電子機器といった特定分野向けではなく、既存の安全規制でカバーしきれていない広範な消費者製品に横断的に適用される点だ。具体的には、家庭用品、スポーツ用具、キッチン用品、ファッションアクセサリー、ライフスタイル雑貨など、EU域内で販売されるほぼすべての非食品系消費者製品が対象となる。
つまり、これまで製品安全規制の対象外だった商材を扱っていた事業者こそ、新たにGPSRの網にかかる可能性が高い。自社の商品が対象かどうかを判断するには、まず「消費者向けの非食品製品かどうか」を基準にするのが確実だ。
例:玩具安全指令、電子機器安全指令など
家庭用品、スポーツ用品、日用品なども対象
この比較で明らかなように、対象品目の拡大は越境EC事業者のリスク範囲を劇的に広げた。従来は安全規制を気にせず出品できていた商品が、今や適切な情報表示と責任者の指名なしには販売できなくなっている。
域外事業者を直撃する「責任者」指名義務

GPSR対応で最も大きなハードルとなるのが、EU域内に拠点を持つ「責任者(Responsible Person)」の選任義務だ。責任者は「責任経済事業者(Responsible Economic Operator)」と呼ばれることもある。
責任者に求められる役割と具体的な候補
EU域外の製造業者や販売事業者は、域内の誰かに製品安全の遵守について正式な責任を負わせなければならない。具体的な候補としては、輸入業者、正規代理店、フルフィルメント事業者、物流倉庫事業者、あるいはコンプライアンス専門の代行会社などが挙げられる。
この責任者の氏名または企業名、そして連絡先は、製品本体、パッケージ、または付属書類に必ず記載する必要がある。AmazonやeBayの商品ページ上でも、購入前にこの情報が表示されていなければならない。
従来、自国からの直送モデルに慣れ親しんできた越境事業者にとって、海外の法人や個人と責任委任契約を結ぶことは運営上の大きな負担となる。だが、GPSRにおいてこの手続きを回避する方法は存在しない。
ECサイト運営者が押さえるべき表示要件

GPSRでは、商品の安全性に関する情報を「購入前」にユーザーが確認できる状態にすることを求めている。物理的なパッケージへの表示だけでなく、ECサイトの商品ページ(リスティング)への明示が必須となる。
Amazon・eBay・自社ECすべてに適用される共通ルール
このルールは販売チャネルを問わない。Amazon、eBay、Etsyといったマーケットプレイスはもちろん、WooCommerceやShopifyで構築した自社ECサイトであっても、EUの消費者に販売する以上は同じ条件を満たす必要がある。
商品ページに記載すべき情報は、品目によって異なるが、一般的には以下の要素を含めることになる。製造者名とEU責任者の連絡先は最低限必須の項目だ。さらに、商品を一意に特定できるバッチ番号やシリアル番号、意図された使用目的、緊急時の安全警告、お手入れ方法なども、製品の性質に応じて求められる。
マーケットプレイスによる「門番」としての取り締まり
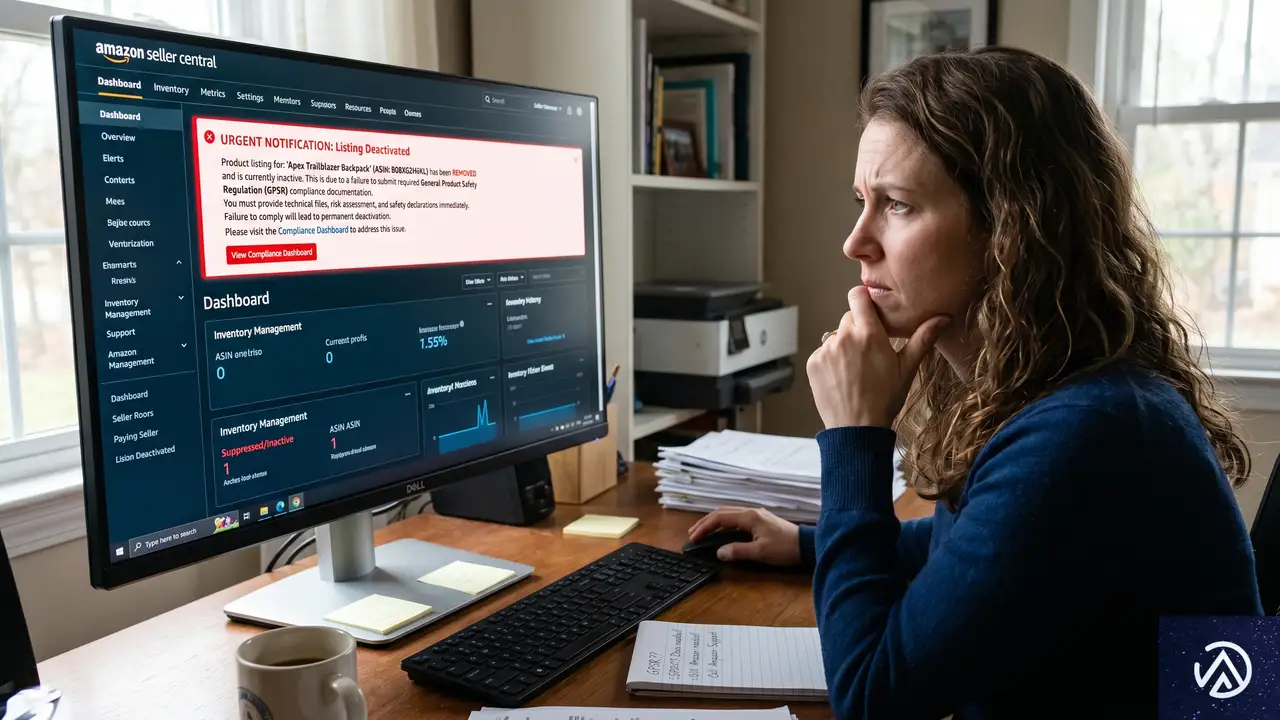
GPSR対応の最前線に立つのがAmazonやeBayといったマーケットプレイスだ。これらのプラットフォームには、法令順守を確認する「ゲートキーパー」としての責任が課せられている。違反を放置すれば、プラットフォーム自体が罰金や営業許可への制裁を受ける可能性がある。
行政指導より先にくる「強制出品停止」の現実
実務上は、規制当局から直接連絡が来るよりも前に、マーケットプレイス側の自動チェックや定期監査によって出品が停止されるケースが急増している。特に、EU責任者の情報が未登録だったり、商品安全情報のセクションが空白だったりすると、システムが即座にリスティングを非表示にする仕組みだ。
これは小規模事業者にとって大きな痛手となる。行政からの警告や改善命令には数週間の猶予が与えられることも多いが、マーケットプレイスのアルゴリズムによる除外は即時かつ無慈悲だ。日々の売上の大部分を特定のモールに依存している事業者ほど、GPSR対応の遅れは事業継続の危機に直結する。
トレーサビリティと10年間の記録保管義務

GPSRのもう一つの柱が、サプライチェーン全体にわたるトレーサビリティ(追跡可能性)の強化だ。製品に問題が発覚した際、当局がその流通経路を遡り、迅速に市場から回収できる体制を構築することを目的としている。
技術文書とリスク評価の保管が必須
具体的には、各製品にロット番号やシリアル番号などの識別情報を付与し、サプライチェーン上で追跡できるようにする義務が生じる。加えて、製造者は最大10年間にわたり、技術文書やリスク評価を含む安全関連の文書を保管しなければならない。
数十から数百のSKU(在庫保管単位)を扱う事業者にとって、これは軽視できない運用作業だ。特にWooCommerceのような自社ECサイトでは、商品登録時のカスタムフィールドを活用し、追跡情報や文書ファイルへのリンクを体系的に管理する仕組みを構築することが望ましい。
商品ごとに識別番号(SKU、バッチ番号等)を付与
製造元からEU責任者までの流通経路を文書化
リスク評価書と安全試験レポートを保管(最大10年間)
この図が示すように、GPSR対策は単に「責任者を決めて終わり」ではなく、データの整備と長期的な文書保管を前提とした継続的なコンプライアンス業務であることを理解しておく必要がある。
事業者が今日から着手すべき3つの対応ステップ

ここまでGPSRの要求事項を整理してきたが、実際にEU向け販売を継続する事業者は、大きく分けて3つのアクションを取る必要がある。
対応ステップと優先順位の整理
- 適用範囲の確定:自社の取り扱い商品がGPSRの対象かを確定させる。ほとんどの非食品系消費者製品は対象となるため、例外を探すより「全商品が対象」という前提で動くのが安全だ。
- EU責任者の選任と表示反映:EU域内に拠点を持つ責任者を指名し、契約を締結する。そのうえで、商品ラベル、パッケージ、そしてECサイトの商品リスティングのすべてに責任者の連絡先を反映させる。WooCommerce利用者であれば、商品編集画面のカスタム属性や専用プラグインで管理する方法が現実的だ。
- 技術文書の整備と保管:各商品のリスク評価書、安全テストの結果、技術仕様書などを収集し、体系的に保管する仕組みを作る。クラウドストレージ上にSKU別のフォルダを設け、いつでも取り出せる状態にしておく必要がある。
これらの対応は、VAT(付加価値税)の登録や通関手続きと同様に、EU市場でビジネスを行うための「必要経費」として捉えるべき段階に入っている。市場参入前にGPSR対策を計画しておくことが、結果的に最もコストのかからない道だ。
この記事のポイント
- GPSRはEU向けの非食品消費者製品ほぼ全てに適用される包括的な安全規制である
- 域外事業者はEU域内に「責任者」を指名し、商品ページに連絡先を表示しなければならない
- マーケットプレイスによる取り締まりは厳格で、違反時は即時に出品停止となるリスクがある
- トレーサビリティ情報と安全文書を最大10年間保管する義務が生じる
- VAT登録と同様に、事業運営の前提コストとして事前準備を進める必要がある

WooCommerce 10.9、バリエーションギャラリーがコアに統合。追加プラグイン不要へ
WooCommerce 10.9で「バリエーションギャラリー」機能がコアに統合される。これまで有料の追加プラグイン「Additional Variation Images」で提供されていた機能が、標準で無料利用できるようになる。
WooCommerceチームの「More in Core」構想の一環だ。既存のブランド機能統合に続き、マーチャントが本当に必要とする機能をデフォルトで提供し、開発者はより価値の高い差別化に集中できる環境を整えている。
Daniele氏の公式ブログ記事によると、この変更は段階的にロールアウトされ、10.9ではオプトインによるテストが可能になる。最終的には全ストアで有効化される予定だ。
バリエーションギャラリーがストアにもたらす変化

バリエーションギャラリーとは、ひとつの可変商品の中にある各バリエーション(色違いやサイズ違い)ごとに、複数の商品画像を紐づけられる仕組みだ。従来のWooCommerceでは、バリエーションに設定できる画像は「おもな画像」として1枚だけだった。これがギャラリーとして複数枚扱えるようになる。
購入者がストアフロントでバリエーション(たとえば「色:青」)を選択すると、ギャラリー全体がそのバリエーションの画像セットに切り替わる。管理画面では、バリエーションの「おもな画像」と「ギャラリー」をひとつの統合フィールドで管理し、1枚目が自動的におもな画像として扱われる設計だ。
有効化の手順と段階的ロールアウト

この機能はWooCommerce 10.9で導入されるが、初期状態では全ユーザーに対して無効化されている。利用を開始するには、明示的な有効化操作が必要だ。
管理画面からの有効化
最も簡単なのは、WooCommerceの設定画面からチェックボックスをオンにする方法だ。
コードスニペットでの有効化
よりプログラム的な制御を好む場合は、テーマのfunctions.phpまたはCode Snippetsプラグインなどを通じて以下のコードを追加する。
add_action( 'init', function() {
update_option( 'wc_feature_woocommerce_additional_variation_images_enabled', 'yes' );
} );WP-CLIでの有効化
WP-CLIが利用できる環境なら、以下のコマンドを実行するだけだ。
wp option update wc_feature_woocommerce_additional_variation_images_enabled 'yes'段階的ロールアウトの計画
この機能は3段階で展開される。まず10.9で手動テスト用に提供され、次に後続リリースで5%のストアに対して自動的に有効化される「カナリアリリース」が実施される。カナリアフェーズで問題がなければ、最終的に100%のストアで有効化される計画だ。
カナリアとは、新しい変更を一部のユーザーに先行適用して問題の有無を確認するソフトウェアリリース手法を指す。本番環境全体に影響が及ぶ前に、不具合を検知できる利点がある。
技術的な実装と移行のポイント

今回のコア統合は、既存ユーザーがスムーズに移行できるように慎重に設計されている。技術的な要点を整理しよう。
データの保存場所と後方互換性
バリエーションギャラリーのデータは_product_image_galleryというメタキーに保存される。これはWooCommerceが従来から親商品のギャラリーに使っているキーと同じだ。既存の仕組みを再利用することで、テーマの互換性を保っている。
REST APIでも初日からサポートされ、バリエーションエンドポイントのgallery_image_idsプロパティを通じてギャラリーにアクセスできる。このペイロードは、従来のストアフロント経路でもブロックベースの商品ギャラリーでも内部的に利用されている。
旧プラグインからのデータ移行
現在「Additional Variation Images」拡張機能を使っているストアでは、コア機能の有効化時に自動移行が走る。WooCommerceはAction Schedulerを用いたバックグラウンドジョブをスケジュールし、1回あたり250バリエーションずつレガシーデータを正規の場所にコピーする。全件が完了するまでジョブは自動的に再キューイングされる。
移行はべき等性を持っている。つまり、既に移行済みのバリエーションに対して再実行されても何も変更されず、安全だ。レガシーメタデータ(_wc_additional_variation_images)は意図的にディスク上に保持されるため、サードパーティコードが従来のキーを直接読み取っていても動作し続ける。
ストアフロントの互換性
バリエーションギャラリーは、従来のシングル商品テンプレートとブロックベースの商品ギャラリーの両方で動作する。新旧のブロックが混在する環境でも問題ない。テーマがsingle-product/add-to-cart/variable.phpを上書きしている場合もサポート対象だ。
テストとフィードバックの方法

この機能は6月8日予定のWooCommerce 10.9ベータ版に含まれる。上記のスニペットまたはWP-CLIコマンドで有効化してテストできる。今すぐ試したい場合は、GitHub上のナイトリービルドでも利用可能だ。
本番環境への適用前に、必ずステージング環境でのテストを推奨する。WooCommerceチームはGitHub Discussionを開設しており、フィードバックや使用感の報告を求めている。
スタンドアロン拡張機能の提供終了について

コア統合が100%ロールアウトされた後、スタンドアロンの「Additional Variation Images」拡張機能はWooCommerceマーケットプレイスから提供終了となる。これは先のBrands拡張機能の終了時と同じ手順だ。
現在のサブスクリプションユーザーは、コア機能がストアで有効化されるまで既存プラグインをそのまま使える。有効化時には競合を防ぐため、スタンドアロンプラグインは自動的に無効化される。マーケットプレイスからの提供終了時にはアクティブなサブスクリプションがキャンセルされ、影響を受けるユーザーはサポートチームに返金またはクレジットを申請できる。該当ユーザーにはロールアウトの重要な節目でメール通知が届く予定だ。
この記事のポイント
- WooCommerce 10.9でバリエーションギャラリーがコア機能として無料利用可能になる
- 初期は無効化されており、管理画面・コード・WP-CLIのいずれかで手動有効化が必要
- 既存の「Additional Variation Images」ユーザーは自動移行でデータが引き継がれる
- 段階的ロールアウトで慎重に展開され、最終的には全ストアで有効化される予定
- REST APIも初日から対応、開発者にとって扱いやすい設計になっている

OpenAI、Windows版Codexに独自サンドボックス実装 昇格不要プロトタイプから完全制御へ
2026年5月13日、OpenAIはWindows版Codexにおけるサンドボックス実装の技術的詳細を公式ブログで公開した。これまでWindowsユーザーは、コーディングエージェントの操作を逐一承認するか、全アクセスを許可するリスクの高い選択肢しかなかった。今回の独自サンドボックスによって、安全性と生産性を両立する仕組みが実現した。
Codexは開発者のローカルマシン上で動作し、CLIやIDE拡張機能、デスクトップアプリを通じて利用できる。デフォルトではワークスペース内でのファイル書き込みやネットワークアクセスに制限がかかるが、これをOSレベルで強制するサンドボックスが不可欠だった。macOSやLinuxにはSeatbeltやseccompといった確立された分離機能がある一方、Windowsには同様の機能が標準で提供されていなかった。
Codex for Windowsが抱えていた課題

Windows版Codexの初期リリースでは、サンドボックス機能が実装されていなかった。ユーザーは次の2つの不十分な選択肢を強いられていた。
- ほぼすべてのコマンドを手動で承認するモード: ファイル読み取りのような安全な操作も含めて逐一の許可が必要で、煩雑さから本来の自律的作業の利点が損なわれる。
- フルアクセスモード: 承認なしにすべてのコマンドを無制限に実行させる。操作はスムーズだが、意図しないファイル変更やデータ流出のリスクがある。
Codexは本来、ユーザーの代理としてテスト実行やファイル編集、ブランチ作成などを自律的に処理することで生産性を高めるツールだ。したがって、安全性を確保しつつ、許可の承認を最小限に抑える仕組みが求められた。その鍵となるのが、OSが持つ隔離機能を活用したサンドボックスである。
サンドボックスが果たす役割
サンドボックスとは、プロセスに制約を課す隔離実行環境である。Codexがコマンドを実行する際、OSがそのプロセスツリー全体に制限を伝播させることで、許可なくワークスペース外のファイルへ書き込んだり、インターネットへアクセスしたりできないようにする。macOSやLinuxでは標準機能でこれが実現できるが、Windowsでは一から設計する必要があった。
Windowsが提供する3つの分離機能を検証

OpenAIのエンジニアリングチームは、Windowsに用意されている隔離プリミティブとしてAppContainer、Windows Sandbox、Mandatory Integrity Control(MIC)を検討したが、いずれもCodexの用途には合致しなかった。
AppContainer: 強力だがワークフローに柔軟性欠く
AppContainerはWindowsネイティブのサンドボックスで、必要なアクセス権限を事前に定義するケイパビリティベースのモデルである。OS境界による本格的な制限を提供するが、Codexはシェル、Git、Python、パッケージマネージャなど多様なツールを動的に制御する必要がある。事前に厳密に権限を絞るAppContainerでは、エージェントのワークフローに対応できなかった。
Windows Sandbox: 強い隔離だが実環境と分断
Windows Sandboxは、使い捨ての軽量仮想マシンである。セッション終了時に内部の変更はすべて破棄される。セキュリティ面では強力だが、Codexはユーザーの実際のチェックアウト環境やツール群を直接操作する必要があり、外部の仮想デスクトップでは実用的ではなかった。さらにWindows SandboxはHomeエディションでは利用できず、製品上の問題も抱えていた。
MIC: 静的制御だがホストファイルシステムへの影響が大きい
Mandatory Integrity Control(MIC)は、低/中/高の整合性レベルを使ってプロセスやオブジェクトの信頼度を制御する。原則として、低整合性プロセスは高整合性オブジェクトに書き込めない。Codexを低整合性で実行し、書き込み可能ディレクトリを低整合性に再ラベルすることで、書き込み範囲を制限できる可能性があった。
しかし、ワークスペース全体を低整合性にすると、「Codexが書き込める」以上の意味が生じる。低整合性プロセス全般がその領域にアクセスできるようになり、開発マシンの信頼モデルを大きく損なうリスクがあった。またACLと同様に実ファイルシステムに変更を加えるため、サンドボックスの制約を動的に変更することも難しかった。
OpenAIの独自アプローチ: SIDと制限トークンによる非昇格サンドボックス

既存機能では要件を満たせないと判断したOpenAIチームは、WindowsのSID(セキュリティ識別子)と書き込み制限トークンを組み合わせた独自のサンドボックスを設計した。最初のプロトタイプは管理者権限なし(非昇格)で動作することを目標とし、ファイル書き込みとネットワークアクセスを制限する仕組みを目指した。
SIDと書き込み制限トークンの仕組み
SIDはWindowsがユーザーやグループ、ログインセッションを識別するために用いるIDである。たとえば、S-1-5-5-X-Yが現在のセッションに割り当てられる。SIDはACL(アクセス制御リスト)と組み合わせて、ファイルやディレクトリへの読み書き実行権限を制御する。OpenAIのチームは、Codex専用の合成SID sandbox-writeを作成し、このSIDを使って書き込み可能範囲を厳密に定めた。
書き込み制限トークン(write-restricted token)は、プロセストークンに追加の書き込みチェックを課す。通常のユーザー権限に加え、トークン内の制限SIDリストに含まれるSIDのいずれかが書き込み先ACLで許可されていなければ書き込みができない。これにより、Codexプロセスの書き込み権限を、ワークスペースと明示的に許可したディレクトリだけに絞り込んだ。
非昇格プロトタイプの流れ
セットアップ時に、sandbox-write SIDを作成し、カレントディレクトリや設定ファイル config.toml に指定した書き込み可能ルートに書き込み・実行・削除のACLを付与する。一方で .git、.codex、.agents といったディレクトリには明示的に書き込みを拒否した。そのうえでCodexは、制限SIDリストに Everyone、ログインセッションSID、sandbox-write を含む書き込み制限トークンで子プロセスを起動した。
これにより、明示的に許可した場所以外への書き込みはOSレベルでブロックされ、読み取りはユーザー権限で広く許可されるバランスのとれた環境が実現した。しかしネットワーク制御には別の課題が残った。
環境変数によるネットワーク抑制と限界
非昇格環境ではWindows Firewallを管理者権限なしで利用できなかったため、環境変数を用いた間接的なネットワーク抑制が採られた。具体的には HTTPS_PROXY=http://127.0.0.1:9 などのプロキシ変数に無効なアドレスを指定し、GitやSSHなどのツールが外部に接続できないようにした。またPATHにダミーの denybin ディレクトリを追加するなど、一般的なツールの通信を妨げた。
しかしこの方法はあくまで「助言的」な制約であり、プロキシ設定を無視するプログラムや独自のソケット通信を行うバイナリに対しては効果がなかった。悪意あるコードに対しても脆弱だった。
ネットワーク制御を突破した昇格版サンドボックスの実装
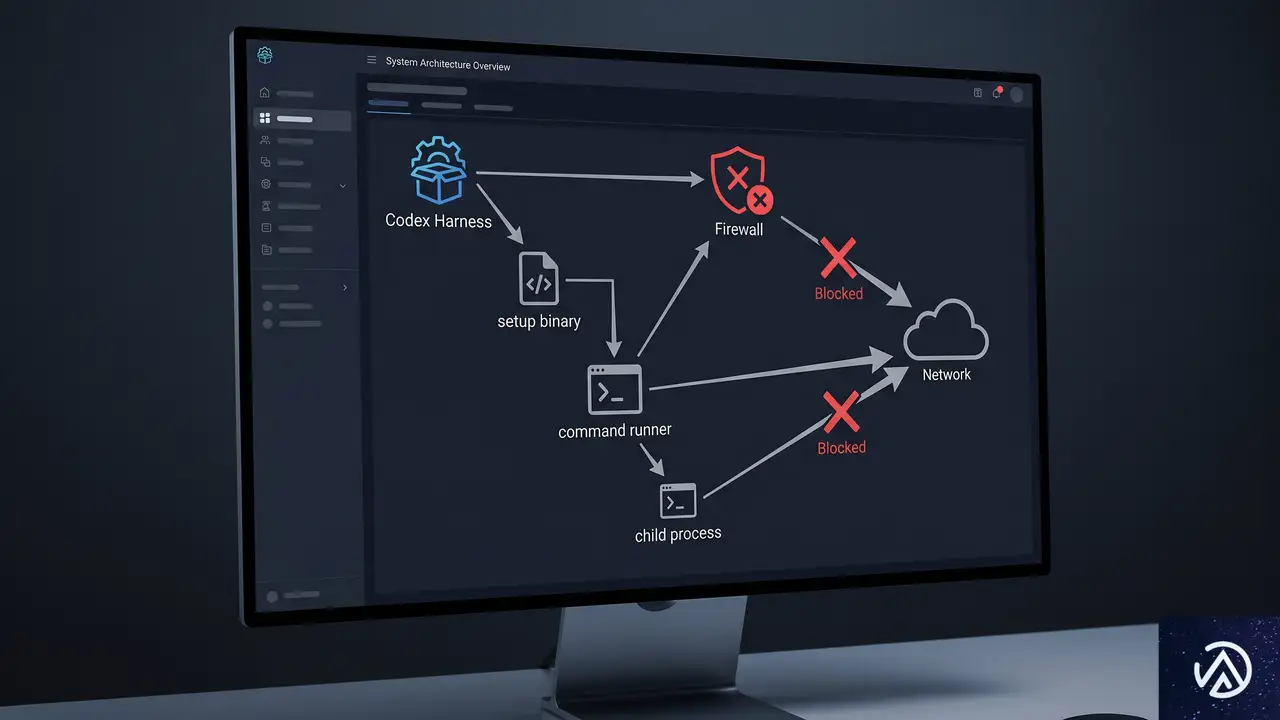
実用的なネットワーク制御を実現するため、OpenAIチームはWindows Firewallの導入を決断した。ファイアウォールルールをプロセスツリー単位で適用するには、サンドボックス専用のユーザー権限が必要となり、結果として管理者権限でのセットアップを許容する「昇格版サンドボックス」へと設計が進化した。
専用ユーザーとファイアウォール
昇格版では、CodexSandboxOffline と CodexSandboxOnline という2つのローカルユーザーを作成する。Offline のユーザーにはすべての外部ネットワーク通信を遮断するファイアウォールルールが適用される。Codexがネットワークを必要としないコマンドを実行する際にはOfflineユーザーで起動し、ネットワーク許可が必要な場合はOnlineユーザーを選択する。これにより、ファイル書き込み制限と同様にOSレベルでの確実なネットワーク遮断が可能になった。
コマンドランナーと4層アーキテクチャ
ユーザー権限を切り替えて子プロセスを起動するには、Windowsのセキュリティ境界を越える必要があった。OpenAIは専用のバイナリ codex-command-runner.exe を導入し、次のような多層構造を採用した。
- codex.exe: 通常のユーザー権限で動作し、コードエージェントのハーネスとして機能する。
- codex-windows-sandbox-setup.exe: 管理者権限でセットアップ処理を担当。サンドボックスユーザーの作成、ファイアウォールルールの追加、必要なACLの付与を実行する。
- codex-command-runner.exe: サンドボックスユーザーとして起動され、自身のトークンから書き込み制限トークンを作成し、最終的な子プロセスを起動する。
- 子プロセス: 制限付きトークンで実行されるGitやPythonなどの実コマンド。
具体的な起動フローは次の通りである。codex.exe が CreateProcessWithLogonW を用いて codex-command-runner.exe をサンドボックスユーザーとして起動。ランナーは自身のプロセストークンからログオンSIDを抽出し、書き込み制限トークンを構築したうえで CreateProcessAsUserW により制限付きの子プロセスを立ち上げる。
このデモで示したように、昇格版ではOSのファイアウォール機能を組み込むことで、非昇格版のネットワーク上の弱点を克服した。また、システム全体へのACL変更は最小限にとどめ、非同期処理を用いてセットアップのブロック時間を短縮している。
この記事のポイント
- Windows版Codexは当初、サンドボックスが存在せず、手動承認かフルアクセスの選択肢しかなかった。
- OpenAIはAppContainer、Windows Sandbox、MICを検討したが、いずれも動的な開発ワークフローに適さず、独自サンドボックスを開発した。
- 最初の非昇格プロトタイプは、SIDと書き込み制限トークンでファイル書き込み範囲を制限したが、ネットワーク抑制は弱かった。
- 最終的な昇格版サンドボックスでは、専用のWindowsユーザーとファイアウォールルールを導入し、ネットワーク遮断をOSレベルで実現。
- codex-command-runner.exeによる多層アーキテクチャで、安全性を保ったままコードエージェントの自律実行を可能にした。