

OpenAI、Windows版Codexに独自サンドボックス実装 昇格不要プロトタイプから完全制御へ
2026年5月13日、OpenAIはWindows版Codexにおけるサンドボックス実装の技術的詳細を公式ブログで公開した。これまでWindowsユーザーは、コーディングエージェントの操作を逐一承認するか、全アクセスを許可するリスクの高い選択肢しかなかった。今回の独自サンドボックスによって、安全性と生産性を両立する仕組みが実現した。
Codexは開発者のローカルマシン上で動作し、CLIやIDE拡張機能、デスクトップアプリを通じて利用できる。デフォルトではワークスペース内でのファイル書き込みやネットワークアクセスに制限がかかるが、これをOSレベルで強制するサンドボックスが不可欠だった。macOSやLinuxにはSeatbeltやseccompといった確立された分離機能がある一方、Windowsには同様の機能が標準で提供されていなかった。
Codex for Windowsが抱えていた課題

Windows版Codexの初期リリースでは、サンドボックス機能が実装されていなかった。ユーザーは次の2つの不十分な選択肢を強いられていた。
- ほぼすべてのコマンドを手動で承認するモード: ファイル読み取りのような安全な操作も含めて逐一の許可が必要で、煩雑さから本来の自律的作業の利点が損なわれる。
- フルアクセスモード: 承認なしにすべてのコマンドを無制限に実行させる。操作はスムーズだが、意図しないファイル変更やデータ流出のリスクがある。
Codexは本来、ユーザーの代理としてテスト実行やファイル編集、ブランチ作成などを自律的に処理することで生産性を高めるツールだ。したがって、安全性を確保しつつ、許可の承認を最小限に抑える仕組みが求められた。その鍵となるのが、OSが持つ隔離機能を活用したサンドボックスである。
サンドボックスが果たす役割
サンドボックスとは、プロセスに制約を課す隔離実行環境である。Codexがコマンドを実行する際、OSがそのプロセスツリー全体に制限を伝播させることで、許可なくワークスペース外のファイルへ書き込んだり、インターネットへアクセスしたりできないようにする。macOSやLinuxでは標準機能でこれが実現できるが、Windowsでは一から設計する必要があった。
Windowsが提供する3つの分離機能を検証

OpenAIのエンジニアリングチームは、Windowsに用意されている隔離プリミティブとしてAppContainer、Windows Sandbox、Mandatory Integrity Control(MIC)を検討したが、いずれもCodexの用途には合致しなかった。
AppContainer: 強力だがワークフローに柔軟性欠く
AppContainerはWindowsネイティブのサンドボックスで、必要なアクセス権限を事前に定義するケイパビリティベースのモデルである。OS境界による本格的な制限を提供するが、Codexはシェル、Git、Python、パッケージマネージャなど多様なツールを動的に制御する必要がある。事前に厳密に権限を絞るAppContainerでは、エージェントのワークフローに対応できなかった。
Windows Sandbox: 強い隔離だが実環境と分断
Windows Sandboxは、使い捨ての軽量仮想マシンである。セッション終了時に内部の変更はすべて破棄される。セキュリティ面では強力だが、Codexはユーザーの実際のチェックアウト環境やツール群を直接操作する必要があり、外部の仮想デスクトップでは実用的ではなかった。さらにWindows SandboxはHomeエディションでは利用できず、製品上の問題も抱えていた。
MIC: 静的制御だがホストファイルシステムへの影響が大きい
Mandatory Integrity Control(MIC)は、低/中/高の整合性レベルを使ってプロセスやオブジェクトの信頼度を制御する。原則として、低整合性プロセスは高整合性オブジェクトに書き込めない。Codexを低整合性で実行し、書き込み可能ディレクトリを低整合性に再ラベルすることで、書き込み範囲を制限できる可能性があった。
しかし、ワークスペース全体を低整合性にすると、「Codexが書き込める」以上の意味が生じる。低整合性プロセス全般がその領域にアクセスできるようになり、開発マシンの信頼モデルを大きく損なうリスクがあった。またACLと同様に実ファイルシステムに変更を加えるため、サンドボックスの制約を動的に変更することも難しかった。
OpenAIの独自アプローチ: SIDと制限トークンによる非昇格サンドボックス

既存機能では要件を満たせないと判断したOpenAIチームは、WindowsのSID(セキュリティ識別子)と書き込み制限トークンを組み合わせた独自のサンドボックスを設計した。最初のプロトタイプは管理者権限なし(非昇格)で動作することを目標とし、ファイル書き込みとネットワークアクセスを制限する仕組みを目指した。
SIDと書き込み制限トークンの仕組み
SIDはWindowsがユーザーやグループ、ログインセッションを識別するために用いるIDである。たとえば、S-1-5-5-X-Yが現在のセッションに割り当てられる。SIDはACL(アクセス制御リスト)と組み合わせて、ファイルやディレクトリへの読み書き実行権限を制御する。OpenAIのチームは、Codex専用の合成SID sandbox-writeを作成し、このSIDを使って書き込み可能範囲を厳密に定めた。
書き込み制限トークン(write-restricted token)は、プロセストークンに追加の書き込みチェックを課す。通常のユーザー権限に加え、トークン内の制限SIDリストに含まれるSIDのいずれかが書き込み先ACLで許可されていなければ書き込みができない。これにより、Codexプロセスの書き込み権限を、ワークスペースと明示的に許可したディレクトリだけに絞り込んだ。
非昇格プロトタイプの流れ
セットアップ時に、sandbox-write SIDを作成し、カレントディレクトリや設定ファイル config.toml に指定した書き込み可能ルートに書き込み・実行・削除のACLを付与する。一方で .git、.codex、.agents といったディレクトリには明示的に書き込みを拒否した。そのうえでCodexは、制限SIDリストに Everyone、ログインセッションSID、sandbox-write を含む書き込み制限トークンで子プロセスを起動した。
これにより、明示的に許可した場所以外への書き込みはOSレベルでブロックされ、読み取りはユーザー権限で広く許可されるバランスのとれた環境が実現した。しかしネットワーク制御には別の課題が残った。
環境変数によるネットワーク抑制と限界
非昇格環境ではWindows Firewallを管理者権限なしで利用できなかったため、環境変数を用いた間接的なネットワーク抑制が採られた。具体的には HTTPS_PROXY=http://127.0.0.1:9 などのプロキシ変数に無効なアドレスを指定し、GitやSSHなどのツールが外部に接続できないようにした。またPATHにダミーの denybin ディレクトリを追加するなど、一般的なツールの通信を妨げた。
しかしこの方法はあくまで「助言的」な制約であり、プロキシ設定を無視するプログラムや独自のソケット通信を行うバイナリに対しては効果がなかった。悪意あるコードに対しても脆弱だった。
ネットワーク制御を突破した昇格版サンドボックスの実装
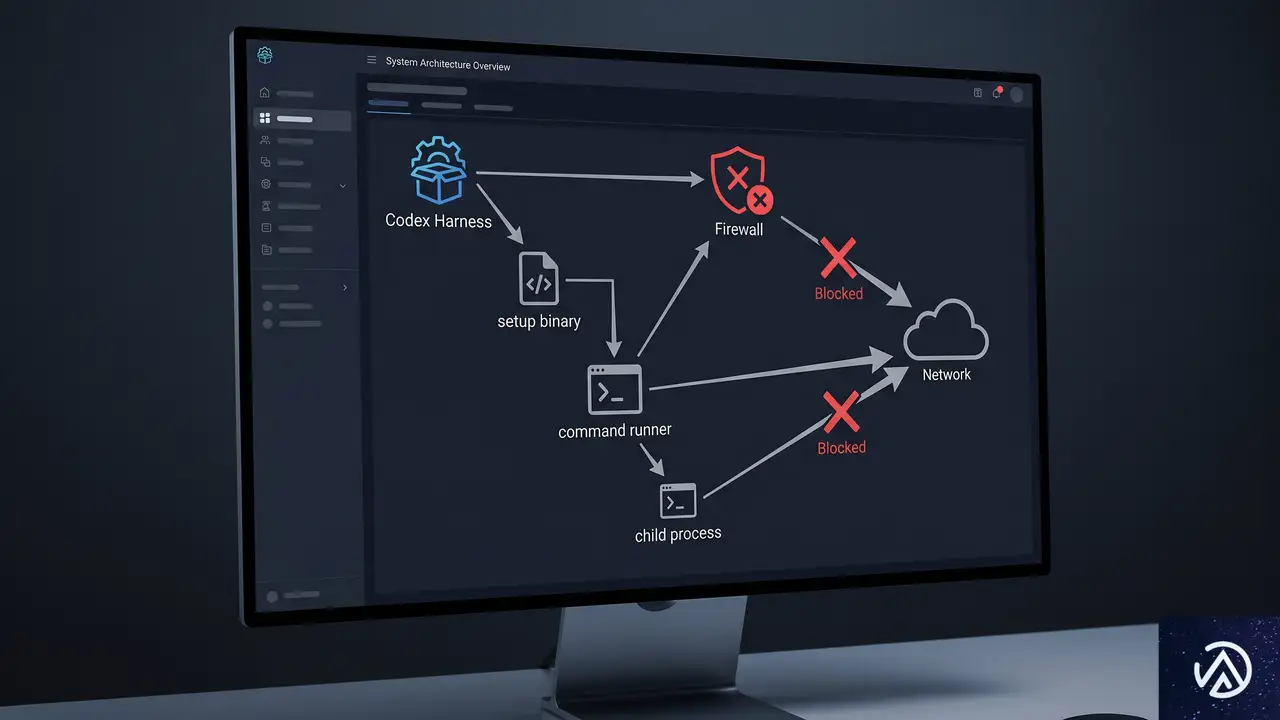
実用的なネットワーク制御を実現するため、OpenAIチームはWindows Firewallの導入を決断した。ファイアウォールルールをプロセスツリー単位で適用するには、サンドボックス専用のユーザー権限が必要となり、結果として管理者権限でのセットアップを許容する「昇格版サンドボックス」へと設計が進化した。
専用ユーザーとファイアウォール
昇格版では、CodexSandboxOffline と CodexSandboxOnline という2つのローカルユーザーを作成する。Offline のユーザーにはすべての外部ネットワーク通信を遮断するファイアウォールルールが適用される。Codexがネットワークを必要としないコマンドを実行する際にはOfflineユーザーで起動し、ネットワーク許可が必要な場合はOnlineユーザーを選択する。これにより、ファイル書き込み制限と同様にOSレベルでの確実なネットワーク遮断が可能になった。
コマンドランナーと4層アーキテクチャ
ユーザー権限を切り替えて子プロセスを起動するには、Windowsのセキュリティ境界を越える必要があった。OpenAIは専用のバイナリ codex-command-runner.exe を導入し、次のような多層構造を採用した。
- codex.exe: 通常のユーザー権限で動作し、コードエージェントのハーネスとして機能する。
- codex-windows-sandbox-setup.exe: 管理者権限でセットアップ処理を担当。サンドボックスユーザーの作成、ファイアウォールルールの追加、必要なACLの付与を実行する。
- codex-command-runner.exe: サンドボックスユーザーとして起動され、自身のトークンから書き込み制限トークンを作成し、最終的な子プロセスを起動する。
- 子プロセス: 制限付きトークンで実行されるGitやPythonなどの実コマンド。
具体的な起動フローは次の通りである。codex.exe が CreateProcessWithLogonW を用いて codex-command-runner.exe をサンドボックスユーザーとして起動。ランナーは自身のプロセストークンからログオンSIDを抽出し、書き込み制限トークンを構築したうえで CreateProcessAsUserW により制限付きの子プロセスを立ち上げる。
このデモで示したように、昇格版ではOSのファイアウォール機能を組み込むことで、非昇格版のネットワーク上の弱点を克服した。また、システム全体へのACL変更は最小限にとどめ、非同期処理を用いてセットアップのブロック時間を短縮している。
この記事のポイント
- Windows版Codexは当初、サンドボックスが存在せず、手動承認かフルアクセスの選択肢しかなかった。
- OpenAIはAppContainer、Windows Sandbox、MICを検討したが、いずれも動的な開発ワークフローに適さず、独自サンドボックスを開発した。
- 最初の非昇格プロトタイプは、SIDと書き込み制限トークンでファイル書き込み範囲を制限したが、ネットワーク抑制は弱かった。
- 最終的な昇格版サンドボックスでは、専用のWindowsユーザーとファイアウォールルールを導入し、ネットワーク遮断をOSレベルで実現。
- codex-command-runner.exeによる多層アーキテクチャで、安全性を保ったままコードエージェントの自律実行を可能にした。

OpenAI CodexがDellと提携、オンプレミス環境でエージェントAIを実行可能に
OpenAIとDell Technologiesが、エンタープライズ向けAIコーディングツール「Codex」の導入範囲を大幅に拡大する提携を発表した。週間アクティブ開発者数が400万人を突破したCodexは、クラウド利用が難しい重要データを抱える企業のために、Dellのオンプレミスインフラ上で直接稼働する道を手に入れた。
この提携で、CodexはDell AI Data PlatformおよびDell AI Factoryと接続される。ソースコードや社内ドキュメントといった機密性の高い企業データを外部に出さずに、AIエージェントを構築・運用できるようになる点が最大の意義だ。
AIの業務活用を進めたいがデータ主権やセキュリティの壁に阻まれていた企業にとって、この提携は「自社データセンター内で完結する高度なAIエージェント」という現実的な選択肢を提供する。
Codexの現在地 コーディングツールからビジネスエージェント基盤へ

CodexはOpenAIが提供する開発者向けAIツールだ。IDE(統合開発環境)やCLI(コマンドラインインターフェース)上で動作し、コード補完、バグの自動修正、テスト生成などを行う。2026年5月時点で週間アクティブ開発者数は400万人を超え、OpenAIのエンタープライズ製品群の中で最も急成長しているサービスの一つになっている。
Codexの活用範囲は開発現場を超えて広がっている。ツール間のコンテキスト収集、レポート作成、プロダクトフィードバックの整理とルーティング、リードのスコアリングとフォローアップ文面の作成、さらには複数のビジネスシステムを横断した業務調整まで、エージェントとしての機能を実務に組み込む企業が増えている。
Codexが「開発者のためのツール」から「ビジネスプロセスを動かすエージェント基盤」へと進化している点が、今回のDell提携の文脈で重要になる。エージェントが実用的な価値を発揮するには、その企業固有のデータやシステムと深く接続している必要があるからだ。
Dell AI Data Platformとの統合で実現すること

今回の提携の中核は、CodexがDell AI Data Platformと直接接続される点だ。Dell AI Data Platformは、多くの企業がオンプレミス環境でデータの保存・整理・ガバナンス(管理統制)に利用している基盤である。
エージェントが「使える」内部コンテキストへのアクセス
AIエージェントがビジネスで役立つかどうかは、どれだけ深い「コンテキスト(文脈情報)」を取得できるかにかかっている。単に公開情報を検索するだけのエージェントでは、企業内部のコードベースや非公開の運用ドキュメント、過去のインシデント対応履歴といった重要情報にアクセスできない。
CodexがDell AI Data Platform経由でアクセスできるようになる情報には、以下のようなものが含まれるとOpenAIの記事では説明されている。
- 企業の非公開コードベース
- 内部ドキュメントやナレッジベース
- ビジネスシステムの実データ
- 運用知識やチームのワークフロー情報
この仕組みにより、データを社外に送信することなく、AIエージェントが企業内部の文脈を理解して動作する。金融機関や医療機関、製造業など、データ主権が厳格に問われる業界にとっては特に重要な意味を持つ。
ガバナンスを維持したままのAI導入
ガバナンスとは、データの管理体制や利用ルールを整備し、遵守することだ。企業は法規制や社内ポリシーにより、特定のデータを社外のクラウドサービスに保存できないケースが多い。Dellのオンプレミス基盤上でCodexを動作させることで、既存のデータガバナンスの枠組みを壊さずにAIを導入できる。
Dell AI Factoryとの連携がもたらす応用可能性

OpenAIの発表によると、両社はDell AI Factoryとの接続も検討している。Dell AI Factoryは企業がAIワークロードを実行するための基盤で、データ準備やシステム管理、テスト実行、AIアプリケーションのデプロイ(展開)までをカバーする。
この接続が実現すると、Codexに加えてChatGPT Enterpriseやその他のAPIベースのソリューションも、Dellのハイブリッドまたはオンプレミスインフラ上で統合的に動作する可能性がある。
この構想が示すのは、OpenAIがエンタープライズ市場において単なる「API提供者」から「インフラと一体化したAIプラットフォーム」への転換を図っていることだ。Dellの発表文では「Dell AI Factory with OpenAI Codex」という表現が使われており、両社のブランドを冠した統合ソリューションとして展開される可能性が高い。
エンタープライズAI市場における提携の戦略的意味

今回の提携は、企業向けAI市場での競争軸を読み解く上でも示唆に富む。
「データの所在地」がAI導入の決定打になる
2026年現在、多くの企業がAI導入を進めているが、最大の障壁は技術力ではなく「データをどこに置くか」というポリシー問題だ。GDPR(EU一般データ保護規則)や各国のデータローカライゼーション規制により、クラウド上のAIサービスをそのまま使えない企業は少なくない。
Dellとの提携によりCodexは、企業のデータセンター内で動作する選択肢を手に入れた。これは競合のAIコーディングツールにはない差別化要素であり、特に規制産業からの需要を取り込む上で強力な武器になる。
「エージェントの実用化」に必要なのはコンテキスト
AIエージェントが「良いコードを提案する」だけの段階から「ビジネスプロセスを自律的に実行する」段階へ進むためには、企業固有のコンテキストにアクセスできることが不可欠だ。OpenAIの記事でも、エージェントが役立つために必要な内部情報として、コードベースやドキュメント、業務システム、チームのワークフローが挙げられている。
CodexがDell AI Data Platform経由でこれらの情報に安全にアクセスできるようになることで、エージェントが「汎用的なアドバイザー」から「その企業の業務を深く理解した実行者」へと進化する基盤が整う。
OpenAIのエンタープライズ戦略における位置づけ
OpenAIは2025年以降、ChatGPT EnterpriseやCodex CLIといった企業向け製品を相次いで投入してきた。今回のDell提携は、それらの製品群を「インフラレベルで企業の既存環境に溶け込ませる」動きとして位置づけられる。
Microsoft Azureを通じたクラウド提供に加え、オンプレミスという選択肢を加えたことで、OpenAIのエンタープライズ展開は「パブリッククラウド」「ハイブリッド」「オンプレミス」の三層をカバーする体制に近づいている。
企業が今から準備すべきこと

Dellのインフラを既に利用している企業にとって、Codexのオンプレミス展開は比較的スムーズに導入できる見込みだ。OpenAIの発表では、具体的な提供開始時期や料金体系の詳細は明かされていないが、両社の協業が進むにつれて順次情報が公開されるだろう。
企業の開発部門やIT統括部門は、以下の点を事前に整理しておくと、展開開始時のスピードが上がる。
- Codexエージェントにアクセスさせたい内部データの棚卸し(コードベース、ドキュメント、APIなど)
- 既存のDellインフラ(AI Data Platform / AI Factory)の利用状況確認
- データガバナンスポリシーの見直しとAI利用ルールの整備
- セキュリティチームとの事前協議(エージェントがアクセスするデータ範囲の定義)
AIエージェントの導入で先行する企業は、すでにコードレビューやテスト自動化といった開発領域から始め、段階的にビジネスプロセスへ適用範囲を広げている。Codexのオンプレミス対応は、その拡大をより安全に進めるためのインフラ選択肢として機能するだろう。
この記事のポイント
- OpenAI CodexがDell AI Data Platformとの統合により、オンプレミス環境での稼働が可能に
- 企業のコードベースや内部ドキュメントに安全にアクセスし、AIエージェントの実用性が大幅に向上
- Dell AI Factoryとの連携により、ChatGPT Enterpriseなど他のOpenAIサービスもオンプレミス展開を検討
- 金融や医療など厳格なデータガバナンスが求められる業界でのAI導入障壁が下がる
- 企業は今のうちに内部データの棚卸しとガバナンスポリシーの整備を進めておくことが有効

Googleアナリティクス、AIアシスタントをデフォルトチャネルグループに追加
Googleアナリティクス(GA4)がAIアシスタントをデフォルトチャネルグループとして正式に追加した。ChatGPTやGemini、Claudeといった生成AIプラットフォームからWebサイトへの流入を、自動的に専用チャネルへ分類する仕組みだ。
この変更により、これまで「リファラル」トラフィックの中に埋もれていたAI経由の訪問を、特別な設定なしで分離して分析できるようになる。プロパティ管理者は、生成AIが自社のビジネスに与える影響を、よりクリアに把握できるようになった。
従来は正規表現を用いたカスタムチャネルグループの構築が必要だったが、今回のアップデートでその手間が不要になる。まさに、AIがもたらすトラフィックを「見える化」するための、Googleによる重要な一歩だ。
新たに追加されたAIアシスタントチャネルの詳細
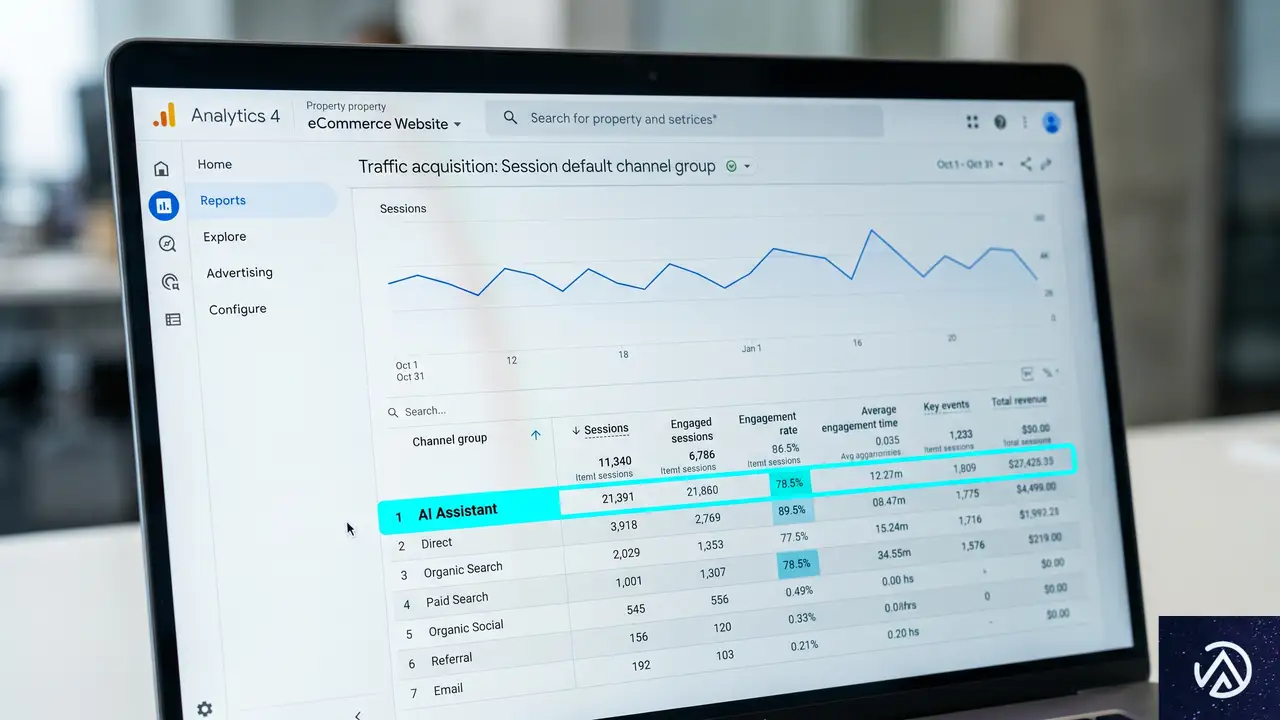
今回のアップデートの中核は、トラフィックの分類方法に関するものだ。これまでAIプラットフォームからの訪問は、単なる「参照(リファラル)」トラフィックとして一括りにされていた。この新機能により、AIアシスタントからの流入は自動的に専用のチャネルグループ「AI Assistant」に振り分けられる。
具体的には、Googleアナリティクスが特定のAIアシスタントのリファラーを検出すると、そのセッションのメディア値に「ai-assistant」が自動的に割り当てられる。その結果、デフォルトチャネルグループレポート上で「AI Assistant」チャネルとして集計される仕組みだ。
chatgpt.com、claude.ai etc.
ChatGPT、Gemini、Claude
その他の参照元
■ 通常の参照トラフィック
このデモが示すように、AIプラットフォームからの流入は「参照」トラフィックの一部として見えづらかった。今回の変更で、専用チャネルとして独立し、そのボリュームが一日で把握できるようになる。
3つのトラフィックソースディメンションが同時に変更
このアップデートは、単にチャネルグループが増えただけではない。トラフィックソースに関連する3つのディメンションが一度に更新されている。
- メディア:AIアシスタントと判定された場合、「ai-assistant」という値が自動付与される
- デフォルトチャネルグループ:該当セッションは新設の「AI Assistant」チャネルにグループ化される
- キャンペーン:ディメンションには予約語「(ai-assistant)」がラベル付けされる
これらの変更はすべてプロパティに自動的に適用される。ユーザー側での手動設定は一切不要だ。
なぜ今、この機能が追加されたのか

GoogleがAIアシスタントを独立したトラフィックチャネルとして扱う動きは、およそ1年前から段階的に進められてきた。Search Engine JournalのMatt G. Southern氏によると、2025年8月に公開されたカスタムチャネルグループ構築ガイドでは、ChatGPTやGemini、Microsoft Copilot、Claude、Perplexityを追跡対象として挙げていた。これは、AIアシスタント経由のトラフィックを「個別に測定すべきカテゴリ」としてGoogleが明示的に認めた瞬間だった。
カスタムチャネルグループが抱えていた課題
これまで、AIアシスタントのトラフィックを分離するには、正規表現によるカスタムチャネルグループの構築が唯一の方法だった。しかし、この手法には運用上のいくつかの壁があった。
- 手動メンテナンスの負荷:AIプラットフォームのドメイン変更に合わせ、正規表現パターンを手動で更新し続ける必要がある
- 権限レベルの制約:GA4プロパティの「編集者」権限が必要で、アクセスできるユーザーが限られる
- リソースの制約:GA4ではカスタムチャネルグループは2つまでという上限がある。AI追跡のために貴重なスロットを1つ消費する必要があった
こうした制約は、特に人員やリソースが限られる中小企業のWeb担当者にとって、大きなハードルとなっていた。
過去の類似アップデートとの共通点
Googleが特定のトラフィックをデフォルトチャネルとして独立させるパターンは、今回が初めてではない。2022年には、Performance MaxキャンペーンやSmart Shoppingキャンペーンのトラフィックを捕捉するため、「クロスネットワーク」チャネルグループが追加された。この時も、手動設定なしにトラフィックを汎用バケットから専用チャネルへ移動させるという、今回と同様のアプローチが取られた。
また、AIトラフィックの計測を巡っては、これまでも課題があった。2025年にはAIモード検索のトラフィックが「参照」ではなく「ダイレクト」として誤って報告されるバグが修正された。さらに、Search ConsoleのパフォーマンスレポートにもAIモードのデータが追加されている。今回のデフォルトチャネル追加は、こうした一連の測定精度向上の流れに位置づけられる。
サイト運営者にとっての実務的メリット

最大の利点は、データ収集と分析の効率化だ。これまでカスタムチャネルグループで対応してきたプロパティは、ネイティブチャネルの適用により、その設定を簡略化できる可能性がある。複雑な正規表現のメンテナンスから解放されることで、分析業務の本質に集中できるようになる。
AI追跡用のチャネルグループを設定していなかったプロパティでは、これまで「参照」として一括りにされていたAIアシスタントからのセッションが、自動的に独立したチャネルとして表示され始める。たとえば、chatgpt.comやclaude.aiからの訪問が「参照」という見出しの下に隠れていた状況が解消され、専用のグラフや数値で確認できるようになる。
注意すべきリファラー制限
ただし、この新機能には依然として限界がある。AIアシスタントからのトラフィックのうち、リファラーヘッダーなしで到達したものは、引き続き「ダイレクト」トラフィックとして分類されてしまう。これは、アプリ内ブラウザやモバイルアプリからのアクセス、ユーザーがAIの回答からURLをコピー&ペーストして訪れた場合などに発生する。新チャネルが捕捉できるのは、あくまでGA4がリファラー情報によって識別できる範囲に限られるのだ。
この図が示すとおり、AIアシスタントからの流入すべてが新チャネルに振り分けられるわけではない。特にモバイルアプリ経由の流入には注意が必要だ。
現時点で判明している制限と今後の展望

Googleは、どのAIアシスタントが「認識済みリファラー」リストに含まれているのか、完全な一覧を公開していない。ヘルプセンターにはChatGPT、Gemini、Claudeの3つが例示されているが、2025年8月のカスタムチャネルガイドでは5つのプラットフォームを挙げていたことを考えると、現行の自動カバー範囲はまだ流動的な部分があると言える。
また、新しいプラットフォームが登場した際に、このリストがどのように更新されるのかについても、具体的なプロセスは示されていない。Search Engine Journalの記事でも指摘されているように、デフォルトチャネルグループの定義ページには、まだ「AI Assistant」がチャネル一覧表に追加されていない。そのため、完全な技術的定義を確認することは現時点ではできない状況だ。
こうしたギャップを埋めるため、昨年公開されたカスタムチャネルグループ向けの正規表現パターンは、依然として有効な補完ツールとなる。認識済みリストに含まれていないAIプラットフォームを個別に追跡したい場合は、従来どおりのカスタム設定が選択肢となる。
この記事のポイント
- GA4がAIアシスタントをデフォルトチャネルグループに追加し、ChatGPT等からのトラフィックを自動分類
- メディア、チャネルグループ、キャンペーンの3ディメンションが同時に更新され、手動設定は不要
- 従来必須だった正規表現によるカスタムチャネル構築が不要に、分析業務の効率が大幅に改善
- リファラーヘッダーがないアプリ経由等の流入は引き続き「ダイレクト」扱いとなる点に注意
- 認識済みAIアシスタントの完全リストは未公開、新興プラットフォームにはカスタム設定が有効

AI購買エージェントに選ばれるECコンテンツの作り方
AIが人間に代わって購買候補を絞り込む動きが加速している。特にB2B向けのECサイトでは、購買担当者が「SOC2準拠でPython SDKを提供する上位3社」といった条件をAIに投げかけ、そのレポートを参考に最終判断する流れが現実のものになりつつある。
AIエージェントは人間のようにヒーローイメージやキャッチコピーに惹かれるわけではない。構造化された事実データだけを機械的に読み取り、仕様や準拠基準、統合性といったシグナルからベンダー候補をリストアップする。サイトがPDFやフォームの壁に閉ざされた情報ばかりだと、そもそも検討対象にも上がらない。
ここでは、WooCommerceを中心としたECサイト運営者が、AI購買エージェントに自社の商品や技術情報を正しく伝えるための実践的な手法を解説する。
PDF隠しの製品カタログはもう通用しない
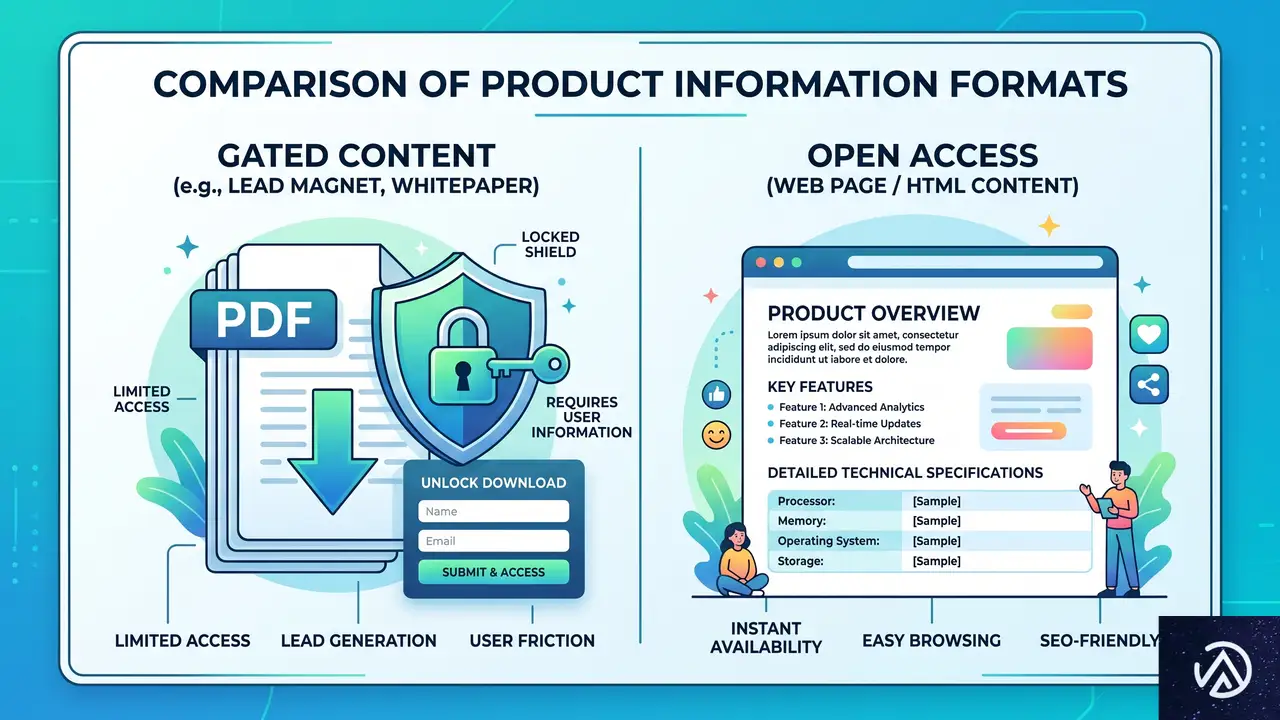
なぜPDFがAIに嫌われるのか
多くのEC事業者はホワイトペーパーや仕様書をPDFで配布し、ダウンロードフォームで囲い込む手法を取ってきた。しかしAIクローラーにとってPDFは重く、内部構造が不統一な場合が多い。テキスト抽出はできても、見出しの階層やリストの関係性を正確に解釈できないケースが少なくない。
結果として、製品スペックや準拠規格といった重要な情報が、AIの「目」にはただの平坦な文字列に映り、意図した評価を得られない。
構造化HTMLへ移行する具体的なステップ
対策はシンプルで、商品の詳細情報を高品質なWebページとして公開することだ。WooCommerceでは標準の商品ページを拡張し、技術仕様を整理したHTMLの表や箇条書きで提供できる。見出しタグの階層を意識し、<h3>に「対応OS」<h4>に「Windows Server 2022」というように、機械が理解しやすい構造を心がける。
次に示すのは、従来のゲート付きPDFとAI向けに最適化したWebページの比較イメージだ。
Model X-210 技術仕様
- 準拠規格: SOC 2 Type II, ISO 27001
- 提供API: Python SDK, RESTful API
- レイテンシ: 99.9%ile 10ms以下
このように、HTML上で仕様が明確に整理されていると、AIクローラーは即座に必要なデータを抽出できる。フォームの壁は不要な離脱を生み、AIには見えない障壁となるだけだ。
スキーママークアップで機械に読ませる
SEO担当者がGoogle向けに構造化データを埋め込むのと同じ理屈で、AIエージェントにページが「製品仕様」や「技術ドキュメント」であることを教え込める。Schema.orgの語彙を使い、製品の互換性や価格体系、認証情報をコード上で明示的に定義するのだ。
高性能プロセッサ搭載、信頼性の高い設計
価格はお問い合わせください
WooCommerceの場合、テーマのfunctions.phpにJSON-LDを追加するか、専用プラグインでProductスキーマを拡張できる。AIはこの情報を読み取り、価格帯や在庫状況、技術的要件を瞬時に理解する。推測の余地が減るほど、自社に有利な評価が返ってくる仕組みだ。
キーワード密度より意味的関連性を重視する
大規模言語モデルを搭載したAIエージェントは、キーワードの出現回数ではなく文脈の深さを評価する。つまり「スケーラブルなクラウドセキュリティパートナー」を探しているエージェントは、単に「スケーラブル」という単語を数えるのではなく、エッジケースへの対応手順や実装上のハードル、セキュリティプロトコルといった周辺知識のまとまりを重視する。
そこで有効なのがトピッククラスターの構築だ。商品ページだけでなく、技術ブログや導入事例、トラブルシューティングガイドなど関連性の高いページ群を内部リンクで結びつける。AIがサイト全体を巡回する際に、自社の専門性と信頼性を一貫したドキュメント群として認識させる狙いがある。
WooCommerceの商品ページでも、関連するドキュメントやFAQをブログカードやカスタムタブで表示する仕組みを導入すると効果的だ。AIはサイト全体の情報密度を評価するため、一貫した情報設計が結果的に購買候補としての優先度を上げる。
長尺資料にはAI向け要約を添える
どうしても詳細な技術資料をPDFなどのゲート付きフォーマットで提供しなければならない場合もある。その場合は、ランディングページにAI専用の「機械可読要約(Machine-Readable Abstract)」を配置する戦略が有効だ。
この要約ブロックは、フォームに入力しなくても読めるオープンなHTMLテキストとして設置する。具体的には、製品の主要な主張、データポイント、技術要件を簡潔にまとめる。いわばAIのための「TL;DR(長すぎて読めない人向けの要約)」であり、約100〜200文字で十分だ。
【X-210 エッジコンピューティングノード】
- SOC2 Type II準拠、ISO 27001認証取得済み
- Python SDK と RESTful API を提供
- 99.9%ile レイテンシ 10ms 以下(自社ベンチマーク)
- 年間サブスクリプション:50万円〜(ボリュームディスカウントあり)
WooCommerceの商品説明欄の冒頭にこうした要約を記述するだけで、PDFをダウンロードする前にAIが内容を評価できる。製品の技術的な強みを素早く伝え、検討リスト入りの確率を高める一手になる。
AI購買エージェントに備えたEC設計の考え方

AIが購買活動の初期調査を担う流れは、B2B領域から着実に広がっている。大規模な広告予算より、アクセスしやすく構造化された正確なデータを持つブランドが優位に立つ時代だ。
ECサイト運営者は、自社の商品カタログや技術ドキュメントを「機械が読むことを前提としたアセット」に引き上げる必要がある。具体的な施策は、PDFの非構造化データからの脱却、スキーママークアップによる意味定義、トピッククラスターを用いた文脈強化、そしてAI向け要約の設置だ。
この記事のポイント
- AI購買エージェントは人間向けの装飾を無視し、構造化された仕様・準拠基準だけを評価する
- 商品情報をHTMLで公開し、スキーママークアップで意味を明確化することが不可欠
- キーワード密度より、トピッククラスターで専門性の高さを示す方がAIに信頼される
- ゲート付き資料には、AIが即座に理解できる要約ブロックを必ず付け加える

GPT-5.5が企業向けエージェントにもたらす変革、Databricks導入事例
大規模言語モデルの進化が、企業の実務ワークフローに直接的な成果をもたらし始めている。データ分析基盤を提供するDatabricksが、OpenAIの最新モデルGPT-5.5を社内向けAIエージェントに組み込んだ結果、複雑な文書処理タスクを評価するベンチマーク「OfficeQA Pro」でエラーが46%も減少した。GPT-5.5はこのベンチマークで初めて正解率50%を超えたモデルとなった。
この結果は「モデルの性能向上が、実際のビジネス指標にどう結びつくか」を示す重要な事例だ。単なる会話能力の評価ではなく、スキャンされたPDFや古い社内フォーマットの文書を解析し、複数ステップのタスクを自律的に遂行する能力が問われている。本記事ではGPT-5.5がどのような技術的進歩を遂げ、企業のAI活用にどんな可能性を開くのかを解説する。
企業向けAIエージェントの現在地、なぜ文書処理が壁になるのか

企業がAIエージェントを導入する際、最初にぶつかる壁が「社内文書の解析」だ。契約書や見積書、古いシステムから出力されたレポートなど、形式がバラバラな文書をAIに理解させるのは想像以上に難しい。特にスキャンされたPDF(画像として取り込まれた文書)や、数十年前のレガシーフォーマットで保存されたファイルは、最新のAIでも正確なテキスト抽出に失敗することが多い。
この問題の深刻さは、小さな認識ミスが後続の処理全体を狂わせる点にある。たとえば請求書の金額を一桁間違えて抽出すれば、その後の経理処理やレポート作成がすべて誤った情報で進んでしまう。人間なら「明らかにおかしい」と気づくようなエラーでも、AIエージェントは抽出した数値をそのまま信じて処理を続ける。これが企業現場でのAI導入を妨げる最大の障壁となっていた。
OfficeQA Proベンチマークの評価観点とは
Databricksが開発したOfficeQA Proは、こうした実務課題を忠実に再現する評価指標だ。このベンチマークでは、モデルに対して以下の3つの能力が求められる。
- 文書解析(Parsing):スキャンPDFやレガシーファイルから正確に情報を抽出する能力
- 情報検索(Retrieval):長大な文書群の中から必要な情報を見つけ出す能力
- 根拠に基づく推論(Grounded Reasoning):抽出した情報をもとに、論理的な判断や回答を生成する能力
単なる知識クイズではない。バラバラなフォーマットの文書を理解し、複数のステップを経て最終的なアウトプットを出す「エージェントとしての実務能力」が試される設計になっている。
上図のように、GPT-5.5への切り替えによって文書解析のエラーが大幅に減り、後続のワークフロー全体の信頼性が向上した。この改善の背景には、モデルの視覚認識能力と言語理解の統合が進んだことがあると見られている。
GPT-5.5が達成した二つの飛躍的改善

Databricksが報告したGPT-5.5の改善点は、大きく二つの領域に分かれる。一つは文書解析精度の劇的な向上、もう一つは複数ステップのタスクを効率的に管理するオーケストレーション能力の進化だ。
スキャン文書解析の「ステップ関数的」な進歩
Databricksの記事で同社のSinghvi氏が指摘するように、GPT-5.4まではスキャンされた古い文書から数字を正確に読み取れないケースが頻発していた。これに対しGPT-5.5は、古い文書やスキャンPDFの解析において「ステップ関数的な性能向上」を見せたという。「ステップ関数的」とは、なだらかな改善ではなく、階段を一段上がるように非連続的な飛躍があったことを意味する。
この進歩が特に重要なのは、企業が保有する文書の多くが過去の資産だからだ。10年前の契約書、5年前の監査レポート、紙をスキャンしてPDF化した資料。こうした「過去の遺産」を正確に解析できるかどうかが、AIエージェントの実用性を左右する。GPT-5.5はこの壁を一つ越えたと言える。
ムダな遠回りをしないタスク実行能力
もう一つの重要な改善が、複数ステップのタスクを実行する際の軌道(Trajectory)の最適化だ。GPT-5.4では、目的に対して不必要な検索を繰り返す「遠回り」が発生し、非効率な処理経路をたどることがあった。これはエージェントが過剰に「慎重」になりすぎる、あるいは文脈を適切に把握できずに余計な確認作業を挟んでしまう問題だ。
GPT-5.5では、必要な情報を必要なタイミングで的確に取得し、最短のステップでタスクを完了する能力が高まった。追加の監視や人間による修正なしに、複雑なワークフローを完遂できる信頼性が向上している。
この改善は、企業がAIエージェントに求める「人間の監視なしで動く自律性」に直結する。タスクが長引けばそれだけコストも増え、途中で人間が介入する必要性も高まる。GPT-5.5はこの課題に対して明確な前進を示した。
企業ワークフローへの実装、AgentBricksとAI Unity Gateway

DatabricksはGPT-5.5を単独のチャットボットとして使っているわけではない。同社の「AI Unity Gateway」を通じて、AgentBricksやAgent Supervisor APIといったエージェント構築基盤と統合し、実際のビジネスワークフローに組み込んでいる。
AgentBricksとは、Databricksが提供するエージェント構築フレームワークだ。専門特化した複数のエージェントを組み合わせ、複雑な業務プロセスを自動化できる。ここでGPT-5.5は「監督者(Supervisor)」として機能する。各専門エージェントが文書解析やデータ検索、レポート生成といった個別タスクを担当し、GPT-5.5が全体の流れを管理して適切なタイミングで適切なエージェントに指示を出す。このアーキテクチャによって、単一モデルでは扱いきれない複雑な業務フローが実現できる。
この「監督者モデル」のアプローチは、今後の企業向けAI活用の主流になると考えられる。一つの巨大モデルがすべてを処理するのではなく、専門エージェントを束ねる統括役としてLLMを配置する設計だ。GPT-5.5のオーケストレーション能力の向上は、この設計思想と見事にマッチしている。
ナレッジワークにおけるGPT-5.5のインパクト

DatabricksのSinghvi氏は「GPT-5.5は知識作業においてステップ関数的な変化をもたらした」と評している。単に質問に答えるだけでなく、複数の文書を横断して情報を統合し、文脈を理解した上で判断を下す「知識労働の代替」としての性能が大きく向上したという評価だ。
この評価が特に重要なのは、AIが「単なる道具」から「業務のパートナー」へと役割を変えつつあることを示唆しているからだ。従来のAIアシスタントは、人間が明確に指示したタスクを実行するのが限界だった。GPT-5.5を中核に据えたエージェントは、曖昧な指示や複雑な文脈でも自律的に判断し、複数ステップの業務を完遂できる水準に近づきつつある。
日本企業への示唆、データ資産の再活用という視点
この事例から日本企業が学ぶべきポイントは明確だ。多くの企業が「過去の文書資産」を抱えている。紙で保管された契約書、古い基幹システムから出力された帳票、スキャンされたPDFの山。これらをAIで解析し、活用可能なデータに変換する技術が現実のものになりつつある。
ただし注意点もある。GPT-5.5の性能向上が顕著だったのは「スキャン文書の解析」と「複数ステップのオーケストレーション」であり、これはモデル自体の進化に加えて、Databricksのエージェント基盤との統合設計が効いている。単に高性能なLLMを導入するだけでは同様の成果は得られない。データ基盤とエージェント設計の両面からアプローチする必要がある。
この記事のポイント
- GPT-5.5は企業の実務ベンチマークOfficeQA Proでエラーを46%削減し、初めて正解率50%を突破した
- 特にスキャンPDFやレガシー文書の解析精度が飛躍的に向上し、古い文書資産の活用が現実的に
- 複数ステップのタスクを効率的に管理するオーケストレーション能力も改善し、自律的な業務遂行が可能に
- DatabricksではGPT-5.5を監督エージェントとして配置し、専門エージェント群を統括する設計を採用
- 日本企業にとっては、過去の文書資産をAIで再活用できる可能性が開けた事例として注目すべき

GitHubがアクセシビリティエージェントを試験運用。3,535件のPRをレビューし解決率68%
GitHubは2026年5月、実験的な汎用アクセシビリティエージェントの試験運用を開始した。このエージェントはプルリクエスト内のフロントエンドコードを自動的にレビューし、アクセシビリティ上の問題を指摘する。さらに多くのケースで修正案まで提示する。
運用開始後に3,535件のプルリクエストをチェックし、68%という高い解決率を達成。構造の明確化やインタラクティブ要素の名前付け、テキスト代替など、日常的に発生するバリアを自動で取り除く仕組みだ。
GitHubのブログで公開された知見には、アクセシビリティチームが取り組んだ設計方針や、LLMエージェントならではの制限への対処法が詰まっている。本記事ではその要点を技術者向けに掘り下げる。
エージェントの目的と初期成果
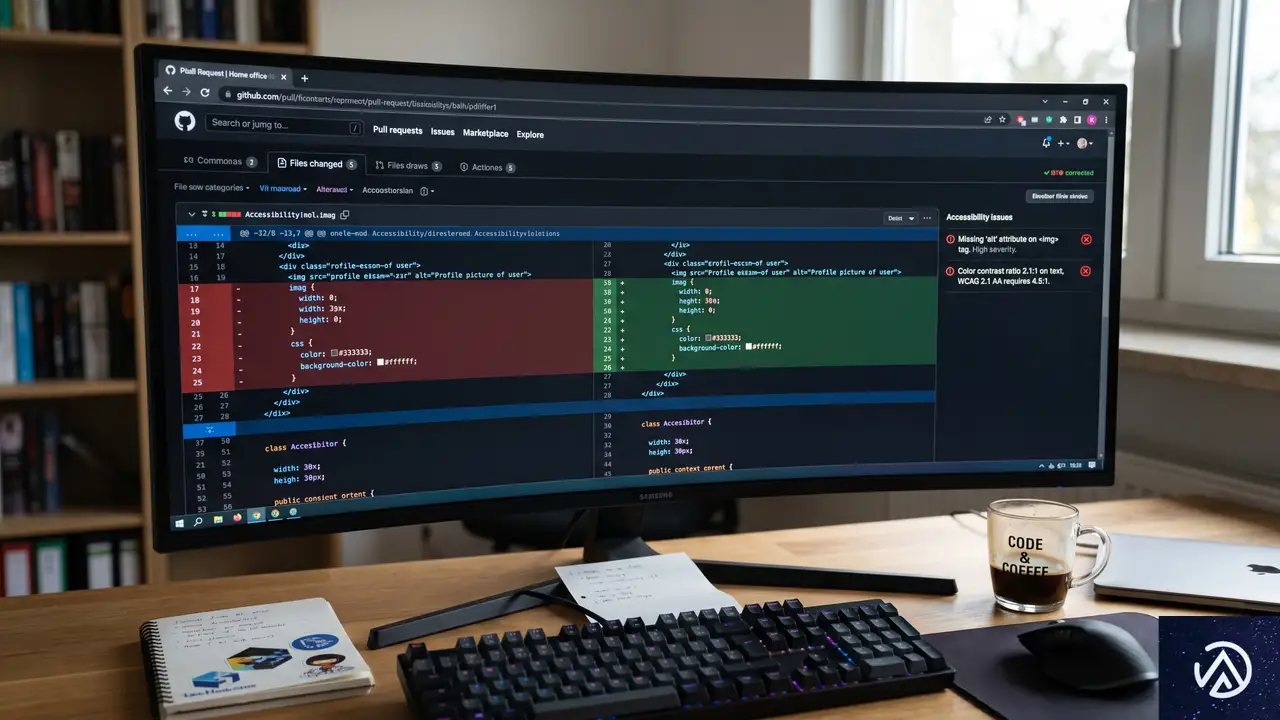
📋 エージェントが検出した問題の上位5種
- 支援技術への構造と関係性の明示不足
- インタラクティブ要素の名前の不明瞭さ
- 重要なアナウンスがユーザーに届かない
- 非テキストコンテンツの代替テキスト欠如
- フォーカス順序が視覚レイアウトと一致しない
※エージェントは自動修正を適用するか、開発者に具体的な提案を提示する
GitHubの発表によれば、このエージェントはアクセシビリティを「完全に解決する」ことを狙っていない。現場のエンジニアがアクセシビリティ上のバリアを見つけて取り除く作業を「増強する」存在として設計された。そのため、あらゆるケースに対応する「銀の弾丸」ではないと明言されている。
この姿勢が実験の立ち上げを加速させ、社内の賛同を得るうえで有効だった。スコープを限定し、明確な責任範囲を共有することで、過度な期待を防ぎつつ素早く実装できたという。
エージェント設計を支える考え方
GitHubのチームは「障害の社会モデル」に基づき、環境の作り方によってアクセス障壁が生まれると捉えている。ユーザーインターフェースの構築方法そのものが障壁を生み出すため、エージェントは仲間の作業を補い、そうした障壁の除去を支援する役割を担う。
つまり「人間の判断を置き換えるAI」ではなく、「アクセシビリティ専門家の補助輪」として機能させる考え方だ。この方針が、後述するサブエージェント構造や複雑性評価の仕組みに一貫して織り込まれている。
過去のアクセシビリティ改善がエージェントを支えた

GitHubにはLLMが普及する以前から、アクセシビリティの問題を体系的に記録し修正する仕組みが存在していた。テンプレート化された報告フォーム、再現手順、WCAG達成基準との紐付け、修正プルリクエストへのクロスリンクといった豊富なメタデータを備えた単一のリポジトリに、すべての問題が集約されている。
この構造化されたデータの蓄積こそが、エージェントにとって理想的な「学習素材」になった。GitHubのブログ記事は「過去の手作業による監査と修正こそが最大の資産」と強調している。問題とその修正コードを参照することで、エージェントは組織固有のコーディング規約やUIパターンに沿った適切な提案を引き出せるようになった。
さらに、LLMの非決定的な「あいまい一致」がここでは強みに転じた。定型のスキルファイルだけで「アクセシビリティのベストプラクティスに従え」と指示しても、膨大な非アクセシブルコードで訓練されたモデルはむしろアンチパターンを生成しがちだ。過去の修正履歴から具体的な文脈を参照できることで、質の高い出力が安定した。
効率的なトークン消費のためのサブエージェント戦略
アクセシビリティはコード、デザイン、ライティングなど多領域にまたがる全体的な関心事だ。そのため、一般的なエージェントを作ろうとすると、1回の処理で大量のトークンを消費し、応答速度の低下や運用コスト増、信頼性の低下を招く。
⏺ 親エージェント(Orchestrator)
- リクエストの振り分けとコードスキャン
- 複雑性スコアの算出
- エスカレーション判断と再監査ループ
コード監査とWCAG調査を実施し、構造化された監査レポートを出力する。コード変更は一切行わない。
親エージェントから渡された構造化レポートを基に、コード修正またはガイダンス文書を生成する。
親エージェントが出力を検証し、必要なら人間の専門家へエスカレーションする
2つのサブエージェントはサンドボックス化され、直接通信はしない。構造化テンプレートを介して情報を受け渡す。
GitHubは当初、1つのモノリシックなエージェントで始めたが、すぐに限界を感じたという。そこで採用したのが、2つの専用サブエージェントによるアーキテクチャだ。
1つ目は「パッシブなレビューア」。コードの監査とWCAG達成基準との照合を行い、構造化されたレポートを出力する。2つ目は「アクティブな実装者」。親エージェントがレポートを精査した後、修正が必要な箇所だけにコード変更を加える。両者は直接情報をやり取りせず、テンプレート化されたスキーマファイルで内容を渡す。
この構成には明確な意図がある。レビューサブエージェントは「意見を持たず」すべての問題を列挙し、親エージェントが重要度を評価する。複数の重大なWCAG違反がある場合や、高リスクと判定されたパターンでは自動修正を試みず、アクセシビリティチームへのエスカレーションを促す。コードの複雑性が閾値を超えれば、修正ではなくガイダンス提供のみの「ガイダンス専用モード」に切り替わる。
さらに、メソッド的な手順で指示を実行させることが精度向上の鍵だった。親エージェントに「フェーズ1 調査」「フェーズ2 コード監査」「フェーズ3 構造化出力」という順序を徹底させ、各フェーズ内のステップも固定順で実行する。この線形な流れは、人間が手動で監査と修正を行うときの思考手順をそのままなぞったものだ。
エージェントの限界を理解し対策する

どれほど精心に設計しても、LLMベースのエージェントには避けられない落とし穴がある。GitHubは実験を通じて、以下の領域に特に注意を払った。
コードの複雑性を数値化して介入を制御する。シェルスクリプトでコードの相対的な複雑度をスコア化し、閾値を超えた場合は自動修正を禁止する。エージェントは「アクセシビリティチームに相談してください」と開発者に伝えるだけにとどめる。
高リスクパターンをブラックリスト化する。ドラッグアンドドロップ、トースト通知、リッチテキストエディタ、ツリービュー、データグリッドなど、現在のLLMでは支援技術と完全に調和する実装が困難なUIパターンが対象だ。これらのパターンを含むコードに対しては、エージェントは修正を生成せず、必ず人間の介入を求める。
「行動バイアス」を抑える。LLMはとにかく何かを生成したがる性質があるため、コードを書かないよう指示されたルールをかいくぐろうとする行動が見られた。これに対抗するため、指示違反を防ぐ「アンチゲーミング」ルールを導入した。
自動化で検出できない36%の壁を認識する。WCAG 2.1のレベルAとAAの達成基準は55項目あるが、そのうち決定論的な自動チェックで検出できるのは35項目にとどまる。残り約36%は手動評価が不可避だ。エージェントの成功率だけを見て安心してはならず、設計段階から手動でアクセシビリティを検討する重要性をGitHubは強調している。
WCAG A/AA達成基準55項目の内訳
自動検出可能
手動評価が必要
LLMエージェントはこの36%の領域に挑戦しているが、まだ完全ではない。設計とプロトタイピングの段階で人間がバリアを特定するプロセスが不可欠。
加えて、エージェントの出力を定期的に手動レビューし、プルリクエストレビュアーのフィードバックを収集する仕組みも整えている。これにより、指示やリソースを改善すべき領域を継続的に特定している。
この記事のポイント
- GitHubのアクセシビリティエージェントは、3,535件のPRをレビューし68%の解決率を記録した
- エージェントは「人間の代替」ではなく「増強」を目的とし、スコープを限定して運用
- 過去の手動監査で蓄積した構造化データが、エージェントの精度を飛躍的に高めた
- サブエージェント構造と線形な指示実行でトークン消費を抑え、精度を向上
- 自動検出できないWCAG基準の約36%を手動で補い、高リスクパターンは生成を禁止する対策が鍵

Google-Agent登場、AIがユーザー代理でWebを閲覧する時代へ
Webサイトを訪れるのは人間だけではなくなった。2026年3月20日、Googleは公式のフェッチャーリストに「Google-Agent」という新たな項目を追加した。これはクローラーでもなければ、学習用のボットでもない。ユーザーの指示で動くAIエージェントだ。
AIアシスタントに「この商品をリサーチして」「最安値のサイトを比較して」と頼む場面を想像してほしい。そのとき実際にサイトを訪問し、情報を読み取り、フォームを操作するのがGoogle-Agentである。Googleの実験的ブラウジングツール「Project Mariner」が最初の採用例となる。
これまでのSEOは「クローラーにどう読まれるか」が主眼だった。しかし今回の発表で、Web運営者は「ユーザーの代わりに行動するAI」という第三の訪問者像を明確に意識せざるを得なくなった。
Google-Agentが従来のクローラーと根本的に異なる点

GooglebotはWeb全体を巡回し、検索インデックスを構築する自動プログラムだ。一方、Google-Agentが発動する条件はただ一つ、人間がAIに「調べて」と依頼したときである。この「ユーザートリガー」という性質が、あらゆるルールを塗り替える。
robots.txtは通用しない
GoogleはGoogle-Agentを「ユーザートリガーフェッチャー」に分類している。Google Read Aloud(テキスト読み上げ)やNotebookLM(文書分析)、Feedfetcher(RSS)と同じカテゴリだ。いずれも「人間がリクエストを起こした」という共通点がある。Googleの公式見解は明快で、ユーザートリガーフェッチャーは「原則としてrobots.txtを無視する」としている。
考え方はシンプルだ。ChromeのアドレスバーにURLを入力して開くとき、ブラウザはrobots.txtの内容に関係なくページを取得する。Google-Agentはユーザーの代理であり、自律型クローラーではない。したがって同じ理屈が適用される。
この判断はOpenAIやAnthropicのアプローチと明確に異なる。ChatGPT-UserやClaude-Userはいずれもユーザートリガーフェッチャーでありながら、robots.txtの指示に従う仕様だ。robots.txtでブロックすれば、ユーザーに頼まれてもページを取得しない。Googleはそこに別の線を引いた形になる。
robots.txtを万能のアクセス制御手段と考えていたサイト運営者にとって、これは大きな認識転換になる。Google-Agentを拒否したい場合は、サーバーサイドの認証やIP制限など、人間の訪問者をブロックするのと同じ手段を採る必要がある。
暗号認証「Web Bot Auth」がもたらす信頼性

Google-Agentの発表でより重要なのは、付随する技術的布石だ。公式ドキュメントの一行に、Google-Agentが「web-bot-auth」プロトコルの実験に参加していることが記されている。識別子は「https://agent.bot.goog」である。
デジタルパスポートの仕組み
Web Bot AuthはIETF(インターネット技術標準化委員会)で策定が進む標準規格である。簡単に言えば、ボットのためのデジタルパスポートだ。各エージェントは秘密鍵を持ち、公開鍵をディレクトリに登録する。そして全てのHTTPリクエストに暗号署名を付与する。
Webサイト側はその署名を検証することで、訪問者が名乗る通りの存在であることを暗号学的に確認できる。ユーザーエージェント文字列は誰でも偽装できるが、Web Bot Authの署名は偽装できない。この差は決定的だ。
すでにAkamai、Cloudflare、AmazonのAgentCore Browserがこのプロトコルをサポートしている。Googleの参入は、標準化に向けたクリティカルマス(臨界量)の獲得を意味する。
なぜこの仕組みが今必要なのか
Webは深刻なアイデンティティ問題に直面しつつある。AIエージェントのトラフィックが増えるほど、正規のエージェントと、エージェントを装うスクレイパーを区別する必要が高まる。IPアドレスによる検証は有効だが、暗号署名のほうが大規模にスケールしやすく、なりすましも極めて難しい。
Google-AgentへのWeb Bot Auth導入は実験段階だが、エージェント認証の方向性を強く示す一手とみられている。Search Engine Journalの記事でも、この暗号認証こそがGoogle-Agent発表の最も重要な要素だと指摘されている。
Webサイト運営者が今すべき具体的対応

Google-Agentの登場で、Webの訪問者モデルは3層構造として明確化された。人間が直接ブラウジングする層、GooglebotやGPTBotのようにコンテンツをインデックスするクローラー層、そして特定の人間の指示でリアルタイムにタスクを実行するエージェント層である。それぞれに異なるアクセスルールと目的がある。
この3層構造を前提に、運営者が取るべき現実的な対策は以下の通りだ。
サーバーログの監視を始める
Google-Agentはユーザーエージェント文字列に「compatible; Google-Agent」を含む。Googleは検証用のIPレンジも公開している。まずは自社サイトにどの程度の頻度でエージェントが訪れているか、どのページを標的にしているか、何を試みているかを把握することが出発点になる。
CDNとファイアウォールの設定を確認する
非ブラウザトラフィックを積極的にブロックするセキュリティ設定を導入している場合、Google-Agentがサーバーに到達する前に拒否されている可能性がある。公開されているIPレンジが許可リストに含まれているか、確認しておくべきだ。
フォームや予約フローの検証
Google-Agentはフォームの送信や複数ステップのフロー操作も行う。チェックアウト、予約、問い合わせといった機能がJavaScriptに過度に依存していると、エージェントが正常に処理できず、裏側で静かに失敗しているケースが生じる。セマンティックなHTMLと明確なラベル設計が、これまで以上に重要になる。
robots.txtは完全なアクセス制御手段ではないと認識する
robots.txtはクローラー向けに設計された仕組みであり、エージェントの時代には通用しない場面が増える。どうしてもアクセスを制限すべきコンテンツには、認証を導入する必要がある。境界線の引き直しが求められている。
ハイブリッドWebはすでに始まっている

1年前まで、AIエージェントが人間と並んでWebサイトを閲覧する未来はカンファレンスの予測トークに過ぎなかった。しかし今、その存在にはユーザーエージェント文字列があり、公開されたIPレンジがあり、暗号認証プロトコルがあり、Googleの公式ドキュメントへの記載がある。
Webは人間用と機械用に分岐しなかった。融合したのだ。公開する全てのページは、人間とエージェントの両方に同時にサービスを提供している。Googleが可視化したのは、その非人間のオーディエンスがいつ現れたかを正確に把握できる手段である。
Search Engine Journalの記事は、この動きを「SEO史上最大の意識改革」と位置づけている。誇張ではない。検索エンジンにどう読まれるかだけでなく、「ユーザーの代理としてやってくるAI」にどう対応するかが、これからのWeb運営の新たな基軸になる。
この記事のポイント
- Googleがユーザー代理でWebを閲覧する新フェッチャー「Google-Agent」を公開、Project Marinerが最初の採用例
- ユーザートリガーフェッチャーに分類されるためrobots.txtは原則無効、アクセス制御にはサーバー認証が必要
- 「Web Bot Auth」暗号認証プロトコルを実験導入中、エージェントのなりすまし防止を狙う
- Web訪問者は「人間」「クローラー」「エージェント」の3層構造へ移行、各層で対応が異なる
- サーバーログ監視、CDN設定確認、フォームのセマンティックHTML対応が即時の実務対策となる

Vercelがソースマップ保護機能を発表、本番環境のコード露出を防止
Vercelは2026年5月、本番環境のソースマップを安全に配信する新機能「Protected Source Maps」をリリースした。ブラウザが読み取る .map ファイルを Vercel Authentication の背後に置き、開発チームだけがアクセスできる仕組みだ。これにより、デバッグ情報を必要な人間にだけ提供し、それ以外の第三者には 404 を返す。
フロントエンドのバンドルは本番ビルドで圧縮・ミニファイされるため、可読性を保つにはソースマップが欠かせない。しかし従来は、そのソースマップが認証なしで公開されてしまい、コードの内部ロジックやコメントが誰でも閲覧できる状態だった。Protected Source Maps は、このセキュリティリスクを根本的に解決する。
ソースマップがなぜ重要か

ミニファイとデバッグのジレンマ
本番サイトの JavaScript や CSS は、ファイルサイズ削減のためにミニファイされる。変数名を短縮し、空白やコメントを取り除く処理だ。ところが、エラーが発生したとき、ブラウザのコンソールには圧縮後のコードしか表示されず、スタックトレースが「at a.a (bundle.js:1:2345)」のように読めなくなる。デバッグがほぼ不可能になるのだ。
この問題を解決するのがソースマップである。ミニファイ元のファイル名や行番号、元の変数名を記録した .map ファイルとして生成し、ブラウザがそれを使って元のソースコードを復元する。つまり、ビルド後の難読コードを、開発時の読みやすいコードに戻す「翻訳辞書」のような役割だ。
ソースマップの仕組み
ソースマップは通常、ミニファイされたファイルの末尾に //# sourceMappingURL=app.js.map というコメントを挿入することでブラウザに通知される。ブラウザがこのコメントを見つけると、対応する .map ファイルを別途リクエストし、デベロッパーツール上でオリジナルのソースコードを表示する。ここまでは開発者にとって日常的な光景だ。
しかし、本番環境でこの .map ファイルが認証なしに取得できると、第三者が容易にソースコードを読めてしまう。公開を想定していないコメントや、内部のビジネスロジックがダダ漏れになるリスクがある。
本番ソースマップが晒されてきたリスク

従来の典型的な対策は、ビルド時にソースマップを生成しないか、本番サーバーにアップロードしないというものだった。しかし、それでは本番環境で発生したエラーの調査が困難になる。また、サーバー側で特定の IP アドレスや VPN 経由のみアクセスを許可する方法もあるが、設定が複雑で、動的に変わるチームメンバーの管理には向かない。
実際に、JavaScript フレームワークの設定ミスによってソースマップが公開され、内部の API キーやテスト用のパスワードが漏えいした事例も報告されている。ソースマップは開発者にとって便利な一方、扱いを誤ると大きなセキュリティホールになりうる。
上の図は、認証がない場合と今回の保護機能を適用したあとの応答の違いを示している。従来は誰でも .map を取得できたが、Protected Source Maps を有効にすると、チーム外のリクエストには 404 Not Found が返る。
Protected Source Maps の動作と設定

Vercel Authentication によるアクセス制限
この機能の核は、プロジェクトの .map ファイルが Vercel Authentication で保護される点にある。通常、Vercel Authentication はデプロイプレビューや特定のパスをチームメンバーだけに公開するために使われる認証フレームワークだ。今回これがソースマップにも適用された。
つまり、ブラウザがソースマップをリクエストしても、Vercel のエッジネットワークが認証情報を確認する。チームの開発者であれば、普段から使っているブラウザのセッションでそのまま .map ファイルを取得できる。しかし、チーム外の人物や認証されていないブラウザからのリクエストには 404 が返るため、存在そのものを隠蔽する効果もある。
新規プロジェクトではデフォルトで有効、既存も後から移行可能
Vercel は、新規に作成するプロジェクトでは Protected Source Maps をデフォルトで有効にした。これにより、これからデプロイするプロジェクトは意識せずとも本番ソースマップが保護される。既存のプロジェクトについては、管理画面の「Settings」〜「Deployment Protection」からスイッチをオンにするだけで有効化できる。再デプロイも不要だ。
この設定変更は即座にエッジネットワーク全体に反映される。認証なしの .map リクエストはその瞬間から 404 になるため、段階的な移行作業を必要としない。
開発フローへの影響と注意点

セキュリティとデバッグ効率の両立
Protected Source Maps を導入しても、認証済みの開発者には従来通りソースマップが提供される。つまり、ブラウザのデベロッパーツールでエラーを追う際に元のコードが見えなくなることはない。本番環境で発生した問題を調査するチームにとって、利便性は一切損なわれない。
一方で、認証されていないサードパーティには 404 が返るため、ソースコードの漏えいリスクを大幅に低減できる。特に、エラーログに .map ファイルの URL が含まれていた場合でも、外部からはアクセスできない。
導入時に確認すべき点
この機能を使ううえで、いくつか注意点がある。まず、Vercel Authentication はブラウザのセッションを利用するため、開発者がログイン状態である必要がある。シークレットウィンドウやチームアカウント外のブラウザからはデバッグできない点に注意が必要だ。
また、CI/CD ツールなど自動化された環境でソースマップを処理する場合は、Vercel の API トークンを使って認証を通すか、あるいは別途プライベートなストレージにマップをアップロードする運用を検討してもよい。ただし、多くのケースでは開発者のブラウザからのリクエスト以外にソースマップが必要になるシチュエーションは少ないため、まずは Protected Source Maps をオンにして、必要に応じて調整するのが現実的だ。
この記事のポイント
- Vercel が Protected Source Maps をリリース、本番ソースマップをチーム限定に
- ブラウザからの
.mapリクエストは Vercel Authentication で保護される - 認証なしのアクセスには
404 NotFoundを返却、コードの露出を防止 - 新規プロジェクトはデフォルトで有効、既存プロジェクトも管理画面から即時有効化可能
- 導入後も開発者のデバッグ体験は変わらず、セキュリティと利便性を両立

WordPress 7.0 RC4リリース、正式版は5月20日予定
WordPress 7.0のリリース候補第4版(RC4)が2026年5月14日に公開された。正式版のリリース予定日は5月20日で、今回のRC4はその最終段階にあたるバージョンだ。すでに本番環境への適用は推奨されていないが、テスト環境での検証を通じて、より安定したWordPress 7.0のリリースに貢献できる段階に入っている。
リリース候補版とは、正式版と同等の品質を持つと判断されたバージョンのことだ。しかし、さまざまな環境やプラグインとの組み合わせで予期せぬ問題が発生する可能性は常に残る。そのため、RC4の段階でもコミュニティ全体でのテストが引き続き重要になる。本記事ではRC4のテスト方法と協力の手段を整理し、WordPress 7.0の正式リリースに向けた現状を解説する。
WordPress 7.0 RC4の概要とテスト方法

RC4はリリースサイクルの最終段階
WordPressの開発プロセスでは、アルファ版、ベータ版、リリース候補版(RC)の順に段階を踏んでいく。RCは「リリース可能」と判断された状態を指し、新機能の追加は停止され、バグ修正と安定化に集中するフェーズだ。RC4はこの最終段階の4回目のビルドにあたる。WordPress 7.0の開発において、これまでのRC1〜RC3で発見された問題が修正され、さらに安定性が高められている。
今回のRC4では、2026年5月8日以降に報告された問題に対応する修正が含まれている。具体的な変更点はWordPress Core TracやGutenbergのGitHubリポジトリで確認できる。特にブロックエディタ関連のコミットが多く、エディタの動作安定性が向上している点が特徴だ。
テスト環境を用意する4つの方法
RC4のテストは以下の4つの方法で行える。いずれも本番サイトでの使用は避け、必ずテスト用の環境で実行することが前提だ。
上記の4つの方法のうち、WordPress Playgroundは特に導入のハードルが低く、環境構築の手間なくRC4の動作を確認したい場合に有効だ。テストサーバーを用意できない場合でも、ブラウザひとつでブロックエディタの新機能やテーマとの互換性を試せる。
RC4に含まれる修正と技術的な詳細

WordPress Core Tracのクローズチケット
RC4では、2026年5月8日から5月14日までの間に報告されたWordPress Coreのチケットがクローズされている。これらは主にRC3までのテストで発見されたバグや、エッジケースでの動作不具合に対応するものだ。具体的なチケットの一覧は公式のTracで公開されており、コンポーネントごとに分類された修正内容を確認できる。
また、Gutenbergのコミットログにも同期間の修正が反映されている。ブロックエディタはWordPress 7.0の中核機能であり、RC段階でのエディタ関連の修正は正式版の品質を左右する重要な要素だ。GitHubのコミット履歴を追うことで、どのブロックやAPIに変更が加えられたかを詳細に把握できる。
ハードストリングフリーズと言語翻訳
RC4の公開と同時に、翻訳のハードストリングフリーズ(Hard String Freeze)が実施された。これは、WordPress 7.0のインターフェースに含まれる文字列が確定し、これ以上の変更が行われないことを意味する。翻訳コントリビューターはこのタイミングで、100以上の言語へのローカライズ作業を集中して進められる。
翻訳作業に参加するには、WordPressの翻訳プラットフォーム(translate.wordpress.org)でプロジェクトに参加し、未翻訳の文字列を各言語に翻訳していく。日本語を含む多くの言語で、正式リリースまでに翻訳を完了させることが目標とされている。
WordPress 7.0の正式リリースに向けたスケジュール

5月20日の正式リリース予定
WordPress 7.0の正式リリースは2026年5月20日に予定されている。RC4がテストでの最終関門となり、ここで重大な問題が発見されなければ、予定通り正式版が公開される見込みだ。ただし、リリース候補版の段階で新たな重要課題が見つかった場合には、RC5やさらなる修正が行われる可能性もある。
WordPress 7.0の開発スケジュール全体は、Make WordPress Coreブログで公開されている。7.0関連の投稿にはタグが付与されており、過去のベータ版やRC版の詳細、フィールドガイド(開発者向けの技術解説)などがまとめて参照できるようになっている。
テスト参加が正式版の品質を左右する
RC版のテストに参加することは、WordPressの品質向上に直接貢献する手段だ。テストは開発者だけでなく、普段WordPressを使用しているサイト運営者であれば誰でも参加できる。使用しているテーマやプラグインとの互換性を確認し、問題があれば報告することで、正式リリース時のトラブルを未然に防げる。
バグの報告は、サポートフォーラムのAlpha/Betaエリアか、WordPress Tracで直接行う。再現手順を明確に記載したバグ報告は、開発チームが問題を迅速に特定し修正するための重要な手がかりとなる。また、既知のバグ一覧と照合することで、重複報告を避けられる。
コミュニティによる協力と貢献の方法

テスト参加の具体的な手順
WordPress 7.0のテストに参加するための詳細なガイドが公式テストチームから公開されている。このガイドでは、テスト環境のセットアップから、確認すべき機能、バグ報告の方法までが段階的に説明されている。テスト初心者向けの一般的なセットアップガイドも用意されており、初めてテストに参加する場合でも迷わずに始められる。
テスト中に問題を発見した場合は、前述のAlpha/BetaフォーラムかWordPress Tracに報告する。Tracでの報告に慣れている場合は、再現手順を含めた詳細なチケットを作成することで、開発チームが効率的に対応できる。また、Make WordPress Slackの#core-testチャンネルでは、テストに関する最新情報の共有や、他のテスターとのコミュニケーションが行われている。
翻訳以外の貢献手段
WordPressはオープンソースプロジェクトであり、コードのコントリビューション以外にもさまざまな貢献手段が用意されている。ドキュメントの作成、フォーラムでのサポート、イベントの運営、アクセシビリティの検証など、技術スキルに関係なく参加できる分野が多い。
WordPress 7.0のリリースに向けては、テストと翻訳が特に重視されている段階だ。RC4の段階ではコードの変更は最小限に抑えられているため、テストと翻訳がコミュニティによる主な貢献領域となる。Make WordPress Coreブログでは、7.0関連の最新情報が継続的に発信されているため、関心のある分野の投稿をフォローすることで、自分に合った参加方法を見つけられる。
この記事のポイント
- WordPress 7.0 RC4が5月14日に公開され、正式リリースは5月20日を予定している
- テスト方法はプラグイン、直接ダウンロード、WP-CLI、Playgroundの4つから選択できる
- RC4では5月8日以降のバグ修正が含まれ、翻訳のハードストリングフリーズも実施された
- テストと翻訳は正式版の品質を左右する重要なコミュニティ貢献の手段である
- 本番環境でのRC4の使用は避け、テスト環境での検証を行うことが前提となる

VS Code 1.121が公開、AIエージェントのターミナル連携とモデル管理が進化
マイクロソフトは2026年5月20日、コードエディタ「Visual Studio Code」のバージョン1.121を公開した。今回のリリースでは、Copilot Chatが備えるエージェント機能とターミナルとの連携部分に多くの改良が加えられている。
具体的には、ツール呼び出しの表示が見やすくなり、特定のLLMモデルをピン留めして素早く選択できる仕組みが追加された。加えて、長いテストやビルドの出力を自動で圧縮する範囲が大幅に拡大され、エージェントが生成するコマンドの実行効率と可読性が一段と向上している。
開発者のワークフローに与える影響は小さくない。ターミナルに流れるログ情報が整理され、エージェントが勝手にバックグラウンド処理に移行するタイミングが賢くなったおかげで、より思考の流れを途切らせずに済むのだ。本記事ではこれらの改善点を実務的な視点で掘り下げていく。
エージェントホストの操作性向上

まず目を引くのが、エージェントホスト内でのツール表示まわりの改善だ。Copilot Chatのエージェントモードでは、AIが「ファイルを読む」「ターミナルでコマンドを打つ」などのツールを自律的に呼び出す。今回のアップデートで、それらのツール名がより直感的な表示になった。
これまでは内部的で分かりにくかった呼称が、人間にとって理解しやすい「ファイル読み取り」「コマンド実行」といったラベルに置き換わっている。入力と出力のUIも再設計され、どのツールに何を渡し、何が返ってきたかが一目で追えるようになった。エージェントの行動をレビューしたり、デバッグしたりする局面で役立つ変更だ。
自動承認ピッカーとワークスペースの事前選択
もうひとつ、エージェントホスト接続時の「自動承認ピッカー」が追加された。外部のエージェントホストへ接続する際に、あらかじめ信頼できるものを選んでおける仕組みで、毎回承認操作を求められる煩わしさが減る。
また、VS Codeを既に特定のワークスペースで起動している場合、エージェントウィンドウを開くとそのワークスペースのフォルダが自動で事前選択される。手動でプロジェクトフォルダを指定し直す手間が不要になるため、作業開始時のリズムが良くなる。小さな改良だが、1日に何度も繰り返す操作だけに、開発効率への積み重ね効果は意外と大きい。
上の図は、ツール表示とワークスペース選択の流れをビフォーアフターで示したものだ。変更前は開発者がエージェントの内部的な動きを読み解く必要があったが、変更後は視覚的に整理され、作業開始時の手数も減っている。
モデル管理の進化と「お気に入り」機能

続いて、言語モデルピッカーに「ピン留め」機能が追加された。これは、よく使うモデルをお気に入り登録して、ドロップダウンリストの上部に固定する機能だ。
現在、VS CodeのCopilot Chatでは複数のAIモデルを切り替えて使える。コーディング向きのモデル、自然言語のやり取りに向いたモデル、軽量で反応が速いモデルなど、タスクに応じて選び分ける開発者も多い。ピン留め機能により、毎回リストをスクロールして探すストレスから解放される。
環境変数「VSCODE_AGENT」の追加とその効果
Copilot Chatがターミナルでコマンドを実行する際、専用の環境変数「VSCODE_AGENT」がセットされるようになった。この変数は、AIが起動したターミナルセッションであることを明示的に示すためのものだ。
実務では、シェルのプロンプト表示を変えたり、エージェント向けのログフォーマットを自動判別したりする用途に使える。たとえば、AI用のターミナルでは冗長なカラー表示をオフにして、パースしやすいテキスト出力に切り替える、といった使い方が考えられる。自分でシェル初期化ファイルをカスタマイズしている開発者にとっては、自動化の可能性が広がる嬉しい追加だ。
チャットと統合ブラウザの連携強化

統合ブラウザ(Simple Browser)で表示中のWebページを、ワンクリックでCopilot Chatに共有できる「Add to Chat」オプションが右クリックメニューに追加された。
VS Codeの統合ブラウザは、エディタ内でドキュメントやAPIリファレンスを閲覧するのに使われる。今回の機能で、例えばReactの公式ドキュメントを開きながら「このセクションの内容を要約して」とAIに投げる操作が、ドラッグやコピーペーストなしで完結する。Web上の情報をコーディングの文脈にスムーズに取り込めるのは、エディタを離れずに作業を続けたい開発者にとって大きな利点だ。
また、チャットエージェントが内部的に生成したバックグラウンドターミナルは、コマンド完了後に自動で破棄されるようになった。これにより、使われないプロセスが蓄積してシステムリソースを圧迫するのを防げる。エージェントがテストの実行や依存関係のインストールなどを一括操作した後、きれいに後片付けされるイメージだ。
これらの改善は、AIアシスタントを「裏方」として使う際の体験を底上げする。情報収集からコード生成、実行、後始末まで、一連の流れに無駄がなくなっていく方向性だ。
ターミナルツールの出力処理が大幅に改善

今回のリリースで最も実務的なインパクトが大きいかもしれないのが、ターミナルツールの出力圧縮まわりの拡張だ。
エージェントがテストランナーやビルドツールを実行すると、膨大なログが出力され、チャット画面が埋め尽くされることがある。この問題に対応するため、出力圧縮(冗長な行を折りたたみ、重要な結果だけを強調表示する仕組み)の対象が一気に広がった。
圧縮対象が大幅に拡大されたコマンド群
新たに対象となったのは、以下のツール群だ。
- テストランナー:
pytest、jest、cargo test - ビルドツール:
tsc(TypeScriptコンパイラ)、cargo build、make - リンター類
- Docker関連コマンド
- パッケージマネージャ(npm、yarn、pipなど)
これらのツールが出力する長大なログから、本当に必要なエラー行やサマリーだけを抽出し、チャット画面上ではコンパクトに表示してくれる。テストが数千件走っても、失敗したケースだけに集中できるわけだ。
アイドルサイレンスタイマーで同期実行を自動バックグラウンド化
ターミナルツールには、同期コマンドが一定時間まったく出力を返さない場合に、自動的にバックグラウンド実行に切り替える「アイドルサイレンスタイマー」が導入された。設定した時間内に何の進捗も表示されなければ、AIエージェントはそのコマンドをバックグラウンドに回し、別のタスクに取り掛かれる。
従来は、長時間かかる処理が走っている間、エージェントの思考がブロックされがちだった。この機能は、CI/CDパイプラインや重いデータベースマイグレーションの待ち時間中に、エージェントが他の作業を並行して進められるようにするものだ。
(数千行のログが流れる)
エージェントは完了まで他の操作ができない
出力が折りたたまれ、エラー行のみ表示
一定時間出力なし → 自動でバックグラウンド化
アイドルサイレンスタイマーは設定可能なため、プロジェクトの特性に合わせて閾値を調整できる。テストが沈黙するのはバグではなく重い処理の前触れ、というチームなら長めに取ればいい。
マルチラインコマンドの修正とConPTYの最新化
エージェントホストのターミナルツールでは、複数行にまたがるシェルコマンドの実行時に問題が発生することがあったが、今回のアップデートで修正された。bashやPowerShellでループや条件分岐を含むスクリプトを生成させるケースで、従来は行の継続が正しく解釈されないバグに遭遇することがあった。この修正によって、AIが生成した複数行スクリプトの信頼性が高まっている。
さらに、Windows環境向けに、擬似ターミナルAPIの基盤となるConPTY(conpty.dll)の新しいバージョンがVS Code本体に直接バンドルされるようになった。これまではシステム側のバージョンに依存しており、古いWindowsではターミナルの描画に問題が出ることがあった。バンドル化により、VS Code側で一貫したターミナル挙動を保証できるようになった。
SSH接続におけるキーボード対話認証のサポート

最後に、エージェントホストがSSH接続する際に、キーボードインタラクティブ認証(パスワード入力やワンタイムパスコードの要求を含む対話形式の認証)がサポートされた。多要素認証が求められるサーバーや、接続時に追加の質問が表示される環境でも、エージェントホスト経由の自動接続が可能になったわけだ。
セキュリティ要件が厳しい本番環境や、企業ポリシーで対話認証を強制されているサーバーに対して、Copilot Chatのエージェントを遠隔操作するハードルが下がる。VS Code Remote Developmentの既存ユーザーにとっては、よりシームレスにAI支援を組み込めるようになる変更だ。
この機能は、特にDevSecOpsの文脈で歓迎されそうだ。開発環境と本番環境を明確に分離しつつ、AIアシスタントの支援を安全に受けられる選択肢が増えたことを意味する。
この記事のポイント
- VS Code 1.121ではAIエージェントのツール表示が見直され、入力と出力の可読性が向上した
- モデルピッカーにお気に入りのピン留め機能が追加され、切り替え操作が高速化した
- ターミナル出力の圧縮対象が拡大され、テストやビルドのログがコンパクトに表示される
- アイドルサイレンスタイマーにより、長時間コマンドの自動バックグラウンド化が可能になった
- SSHのキーボード対話認証サポートで、よりセキュアな環境へのエージェント接続が容易になった