

Google特許が示す検索の新たな層——AI生成ランディングページの衝撃
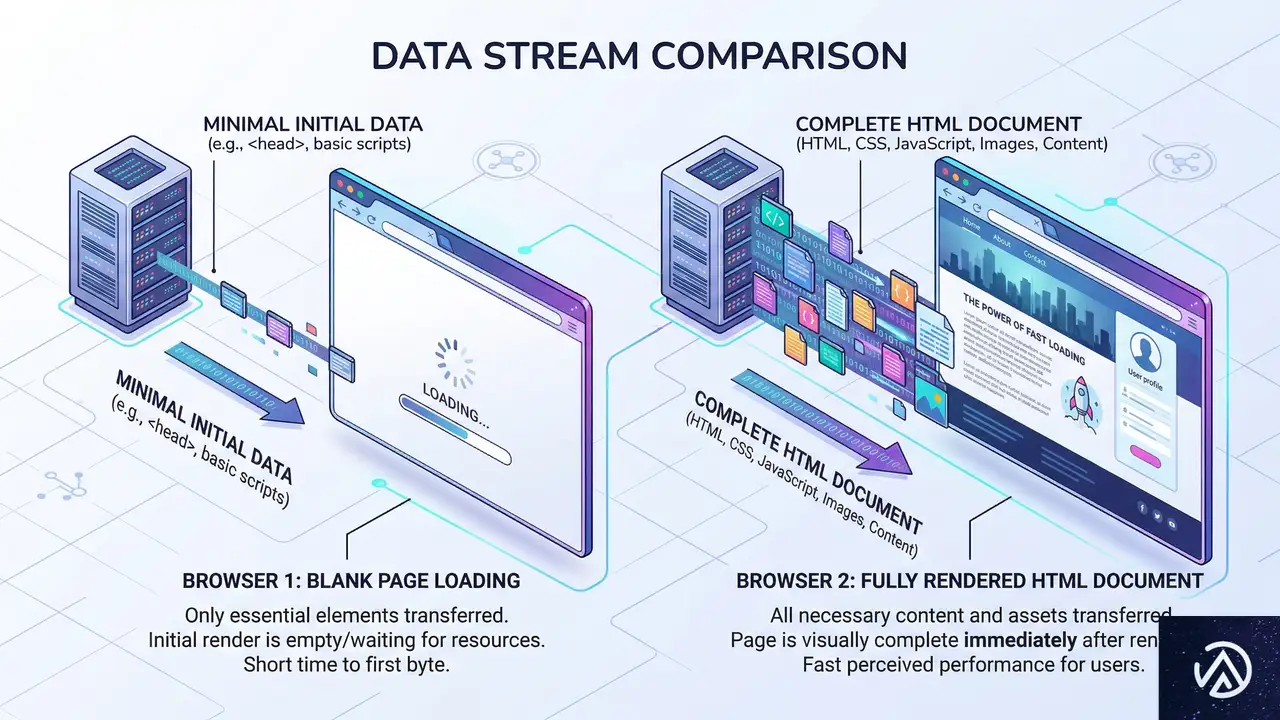
Googleが取得した特許が、検索エンジンの未来像に大きな一石を投じた。特許の内容は、ユーザーの検索クエリとコンテキストに応じて、AIがその場でランディングページを生成するシステムだ。
この技術が実用化されれば、検索結果と従来のウェブサイトの間に、新たな「層」が出現することになる。EC事業者やコンテンツ発信者は、自社サイトのデザインやメッセージングをユーザーに直接届ける機会を、さらに奪われる可能性がある。
本記事では、特許の内容を詳細に読み解き、検索の進化の歴史に照らし合わせてその意味を考察する。さらに、この変化に対応するためにEC事業者が今から取り組むべき具体的な対策を提示する。
特許が描く「AI生成ランディングページ」の仕組み

ユーザーごとに最適化されたページを動的生成
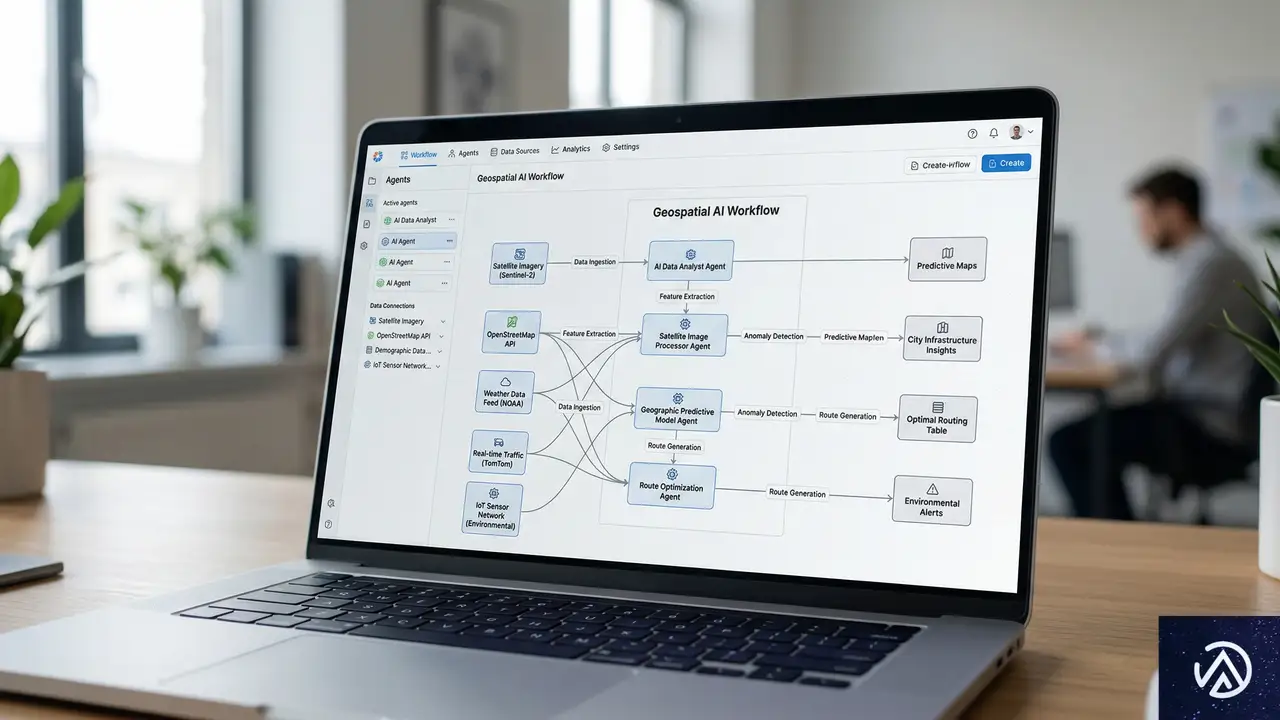
2026年1月27日に米国特許商標庁から発行された特許「US12536233B1」は、AI生成コンテンツページに関するものだ。特許が示すシステムの核は、検索クエリとユーザー情報を基に、そのユーザー専用のランディングページを動的に生成する点にある。
システムはまず、検索クエリとユーザーのコンテキスト、そして従来のランキングアルゴリズムが選び出した候補となるランディングページ群を評価する。評価基準は多岐にわたり、商品情報の不足、コンテンツの薄さ、ナビゲーションの弱さ、ユーザーエンゲージメントの低さなどが低評価の要因となる。
評価の結果、既存ページが不十分と判断されると、システムはそれらのページを「素材」として使い、個々のユーザー向けに最適化された新たなバージョンのページを生成する。例えば、全く同じ「ランニングシューズ」というクエリを検索した二人のユーザーが、異なるランディングページに誘導される可能性がある。一人には商品比較表を中心にしたページが、もう一人には直接購入に導くページが表示されるかもしれない。
フィードバックループによる継続的改善
特許が示すもう一つの重要な要素は、フィードバックループだ。生成されたページは静的なものではない。ユーザーのクリック、ページ滞在時間、コンバージョンなどの行動データがシステムにフィードバックされ、将来生成されるページの精度を高めるために利用される。
この仕組みにより、Googleは膨大な数のユニークなページを生成し、それぞれの検索者をカスタマイズされたバージョンに誘導する動的な体験を提供できる。特に商品検索に関連するクエリでは、購入オプションを前面に押し出したページが生成される可能性が高い。
Practical Ecommerceの記事によれば、この動的ページ実現への現実的な経路は、既に導入されている「AIオーバービュー」を通じたものだと考えられる。AIオーバービューは情報を要約して提示するが、次のステップとして、その要約をインタラクティブな体験に拡張し、最終的には独立したウェブページとして展開する流れが想定される。
検索進化の歴史から見る「新たな層」の位置付け

検索とコンテンツの関係性の変遷
ECコンサルタントのGreg Zakowicz氏は、この特許の概念を「検索の経済学における新たな層」と表現した。この「層」という考え方は、検索エンジンとウェブサイト所有者の間の力関係の変化を理解する上で有効だ。
かつては、検索プラットフォームとコンテンツ所有者は相互依存の関係にあった。プラットフォームは質の高いコンテンツを必要とし、コンテンツ所有者はプラットフォームからのトラフィックを必要とした。しかし、検索産業の進化は、顧客と事業者を次第に引き離す方向に進んでいる。
この図が示すように、モノetization(広告)、Answers(ナレッジグラフ)、Evaluation(リッチリザルト)、Extraction(特集スニペット)、Interaction(垂直検索)、Synthesis(AIオーバービュー)と、各層が追加されるごとに、ユーザーが元のウェブサイトに直接アクセスする必要性は薄れてきた。AI生成ランディングページは、この流れの延長線上にある「最終的な層」と言えるかもしれない。
「検索の経済学」の変化が事業者に与える影響
Zakowicz氏が指摘する「検索の経済学」の変化とは、トラフィックと収益の流れの再分配を意味する。新しい層が出現するたびに、ウェブサイト所有者がレイアウト、メッセージング、商品提示をコントロールする影響力は弱まる。ユーザー体験は、ますますアルゴリズムによって組み立てられるものになる。
Practical Ecommerceの記事は、この状況を「サイトはGoogleの検索結果ページにおいてほとんどコントロールを失っている」と表現する。検索結果ページ自体が、外部サイトへの単なる入り口ではなく、完結した体験の場へと変貌しつつある。
EC事業者が取るべき具体的な対策

オウンドメディアと直接的な顧客関係の構築
アルゴリズムが仲介する体験の影響力が強まる中で、事業者が取るべき第一の対策は、自分自身でコントロールできるチャネルを強化することだ。具体的には、メールマーケティングやSMSなどのオウンドメディアが該当する。
ニュースレターやマーケティングメッセージを通じてサイトに訪れるユーザーは、アルゴリズムが組み立てたページではなく、ブランドそのものを選択して訪問している。検索プラットフォーム内で行われる発見が増えるほど、このような直接的な接点は「絶縁材」としての価値を高める。顧客との関係性を自ら所有することは、検索エンジンの変化に対する最も強力な防御策となる。
構造化データと高品質な入力情報の提供
第二の対策は、アルゴリズムが「読みやすい」データを提供することに注力する姿勢への転換だ。仮に特許のようなシステムが実装されれば、その生成体験は構造化された入力情報に大きく依存するだろう。
この場合、事業者の役割は、美しいランディングページをデザインすることから、正確で豊富な商品属性データ、Schema.orgマークアップ、整った商品フィードといった「高品質な入力情報」を提供することへとシフトする。ボットやプログラム、アルゴリズムが容易に理解し、利用できる形式で情報を提供することが、生成された体験の中に商品が表示され、クリックを獲得するための前提条件となる。
説得力のあるコピー、視覚的な階層、直感的なCTAボタンの配置など、人間のユーザーを説得するためのページ作りが中心だった。
正確な商品仕様、構造化されたレビュー、機械が解釈しやすい属性データなど、AIが「素材」として活用できる高品質な情報の提供が重要になる。
この変化は、SEOの本質的な作業が「検索エンジン向け」から「AI生成システム向け」に移行することを意味する。クリックを獲得する機会は残るが、その入り口の形と、そこに至るための最適化方法が根本から変わる可能性がある。
この記事のポイント
- Googleの特許は、検索クエリとユーザーごとにAIがランディングページを動的に生成するシステムを明らかにした。これは検索結果とウェブサイトの間に現れる「新たな層」となり得る。
- 検索は「発見」から「回答抽出」「統合」へと進化し、ユーザーが元サイトに到達する前の段階で体験が完結する方向にある。AI生成ページはこの流れの延長線上にある。
- この変化により、EC事業者はサイトのデザインやメッセージングを直接ユーザーに届けるコントロールをさらに失う可能性がある。
- 対策の二本柱は「オウンドメディアによる直接的な顧客関係の構築」と「構造化データなどアルゴリズム向けの高品質な入力情報の提供」である。人間向けのデザインから、機械が利用しやすいデータ提供への重心移動が求められる。
- 特許は必ずしも実用化を保証するものではないが、検索プラットフォームの長期的な方向性を示す重要なシグナルとして捉えるべきだ。

Googleのタスク型エージェント検索がSEOを今すぐ変える理由と対策
Googleの検索が「タスクを完了する」エージェントへと急速に変化している。従来の「キーワードを入力してウェブサイトのリンクを得る」モデルは、AIが直接レストランの予約を取ったり、情報を収集したりする「タスク実行型」の検索に置き換わりつつある。この変化は未来の話ではなく、すでに現在進行形で起きている。
Search Engine Journalの記事によると、GoogleのCEOサンダー・ピチャイは近い将来、検索の多くが「エージェント型」になると述べている。ユーザーは情報を探すだけでなく、AIエージェントにタスクを管理させ、複数の作業を並行して実行させるようになる。このパラダイムシフトは、SEOとコンテンツ戦略の根本的な見直しを迫るものだ。
検索が「タスク完了」へと変わる瞬間
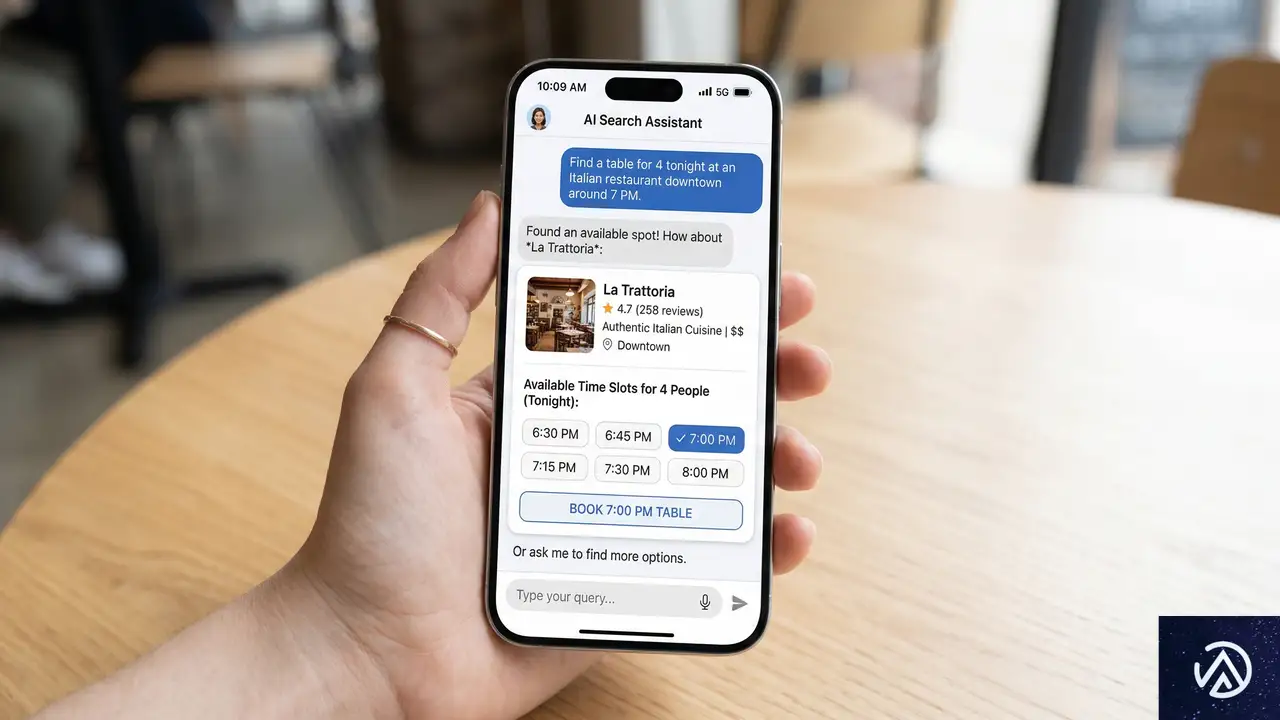
従来のインターネットと検索は、同じキーワードを入力した何百万人ものユーザーに、同じようにインデックスされたウェブページのリストを提供するモデルだった。しかしAIの登場により、ユーザーは単なる情報検索から「トピックの調査」や「タスクの実行」へと行動を移しつつある。リンクをクリックしてサイトを読むだけでは、ユーザーが求める明確な答えが得られないケースが増えている。
レストラン予約にみるエージェント検索の実例
この変化を象徴する具体例が、Googleが全世界で展開を開始した「エージェント型レストラン予約」機能だ。ユーザーは検索ボックスに「6人で土曜の夜、雰囲気の良いイタリアン」といった要望を自然言語で入力する。するとAIエージェントが複数の予約プラットフォームを同時にスキャンし、空き状況やメニューを確認した上で、実際に予約可能な店舗を提示する。
Googleの検索プロダクト責任者であるRose Yao氏は、この機能について「アプリを切り替える必要も、手間もない。ただ美味しい食事を」と説明している。これはもはや従来の「検索」ではなく、「タスクの完了」そのものだ。重要な点は、この機能が「近い将来実現するもの」ではなく、すでに利用可能であることだ。
サイト側に求められる対応
この新しい検索モデルでは、レストランなどの事業者側も対応が迫られる。AIエージェントが情報を取得できるように、空き予約枠やその日のメニュー選択肢などのデータを提供する必要がある。将来的には、AIエージェントと直接予約を完了できる仕組みがウェブサイトに求められるだろう。
これは単なる技術的なアップデートではなく、ビジネスプロセスの変革を意味する。検索マーケティングの専門家は、この変化がもたらす影響を真剣に考える時期に来ている。
「個人専用インターネット」時代の到来

タスク型エージェント検索がもたらすもっと深い変化は、インターネットそのものが「ハイパーパーソナライズ化」する点だ。クラウドフレアは最近の記事で、インターネットの進化を3つの段階に分けて説明している。
インターネット進化の3段階
クラウドフレアの比喩が分かりやすい。従来のアプリケーションは「レストラン」のようなものだ。決まったメニュー(機能)があり、それを大量に提供するために最適化された厨房(インフラ)がある。一方、AIエージェントは「個人専属シェフ」に例えられる。毎回「何が食べたい?」と聞き、その答えに応じて必要な食材や調理法が変わる。レストランの厨房では対応できない。
SEOへの具体的な影響
この変化がSEOに与える影響は計り知れない。ローカルSEO、ショッピング、情報検索のすべてが、ハイパーパーソナライズされたウェブ体験に再構築される。検索が「エージェントマネージャー」に変わるというピチャイの発言は、単なる未来予想ではなく、現在進行形の現実を指している。
デジタルマーケティング担当者が考えるべきは、数十億の人間を代表する数十億のエージェントを支えるインフラではなく、その中で自社のビジネスがどう位置づけられるかだ。エージェントがタスクを完了する過程で、どの情報源を信頼し、どのように意思決定するのか。この「意思決定レイヤー」に自社がどう登場するかが、新しいSEOの核心となる。
コンテンツ管理システムの対応:WordPress 7.0の役割
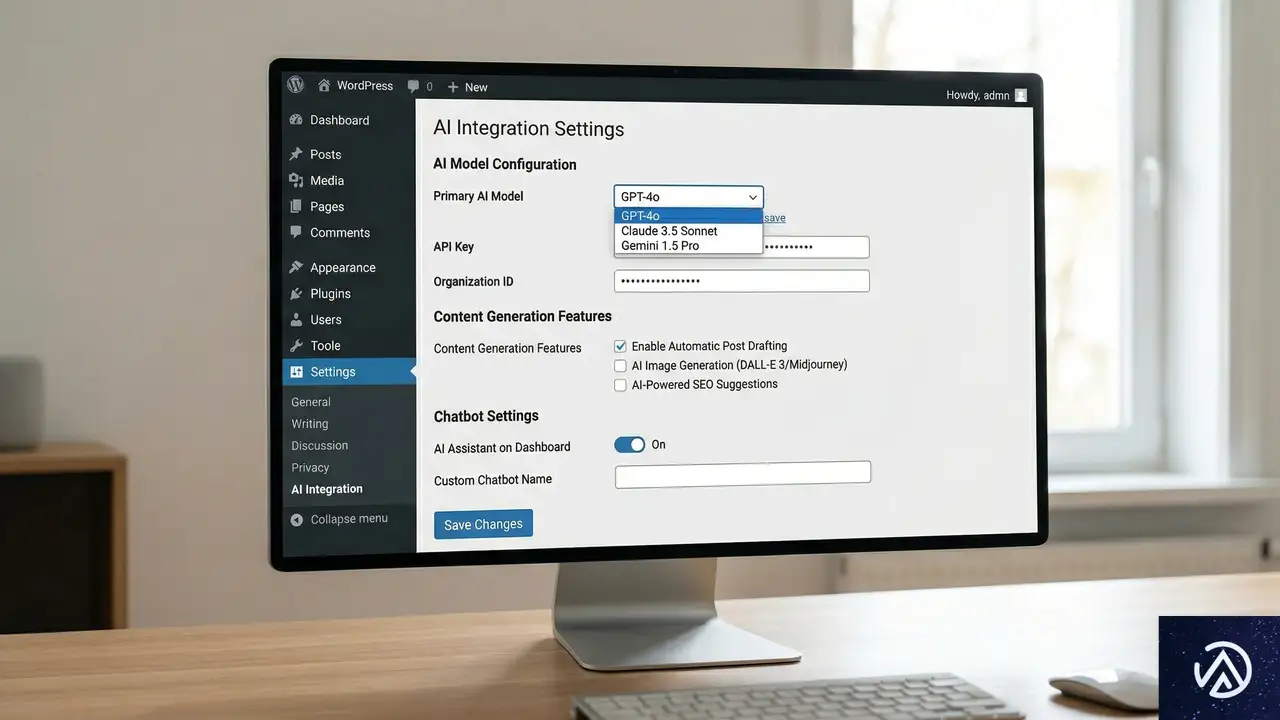
人間中心のウェブからエージェント中心のウェブへの移行に際し、コンテンツ管理システム(CMS)の対応は極めて重要だ。特に間もなくリリース予定のWordPress 7.0は、この変化に対応するための機能が多数盛り込まれている。
AIシステムとの接続機能
現在のインターネットは人間の相互作用のために構築されている。AIエージェントはその構造の中で動作しているが、これは急速に変化する見込みだ。WordPress 7.0が重視しているのは、AIシステムとシームレスに接続する機能だ。これにより、ウェブサイトが人間だけでなく、AIエージェントにも適切に情報を提供できる基盤が整う。
具体的には、構造化データの強化、APIファーストなアーキテクチャ、エージェントが理解しやすいコンテンツ形式などが挙げられる。これらの機能は、従来の人間ユーザー向け最適化に加えて、AIエージェント向けの最適化を可能にする。
エージェントが「信頼する」情報源になるために
検索マーケティングの専門家Mike Stewart氏は、この変化について重要な指摘をしている。彼はFacebookへの投稿で、「これはもはやAIが支援する段階ではなく、AIがあなたに代わって操作する段階だ」と述べた上で、以下の問いを提示している。
Stewart氏はさらに、「エージェント型検索は、それを支えるエコシステム(ウェブサイト、コンテンツ、ビジネス)なしには成立しない。その部分はなくならないが、抽象化される」と付け加えている。つまり、ウェブサイトやコンテンツの重要性は変わらないが、人間が直接アクセスする形ではなく、AIエージェントを通じて間接的に利用される形に変化するということだ。
タスク型エージェント検索への具体的な対策

理論的な理解だけでなく、実際にSEO担当者が今から取り組める対策がある。タスク型エージェント検索の時代に向けて、以下のポイントに注目すべきだ。
構造化データの徹底強化
AIエージェントが情報を正確に理解し、タスクを完了するためには、構造化データがこれまで以上に重要になる。特にSchema.orgの語彙を活用し、以下のような情報を明確にマークアップする必要がある。
APIファーストな情報提供
人間がブラウザで閲覧するHTML形式だけでなく、AIエージェントがプログラム的に情報を取得できるAPIの提供が重要になる。WordPressではREST APIが標準で搭載されているが、エージェント向けに最適化されたエンドポイントを用意する必要があるかもしれない。
情報の更新頻度も鍵となる。エージェントがレストランの空き状況を確認する場合、その情報が数時間前のものでは意味がない。可能な限りリアルタイムに近い情報提供が求められる。
コンテンツの「信頼性」シグナルの強化
Mike Stewart氏が指摘した「エージェントはどの情報源を信頼するのか」という問いは核心を突いている。エージェントが意思決定する際、信頼性の高い情報源を優先するだろう。以下の要素が信頼性シグナルとして機能すると考えられる。
具体的な信頼性シグナルとしては、正確で最新の構造化データ、他の信頼できるサイトからの言及やリンク、ユーザーレビューの質と量、企業の実在証明などが挙げられる。これらは従来のSEOでも重要だったが、エージェント検索ではさらに重要性が増す。
この記事のポイント

Google検索で勝つサイトの共通点とは?400サイトの分析から見えた5つの成功法則
Googleの検索アルゴリズムが複雑化する中で、どのようなサイトが実際にトラフィックを伸ばしているのかを把握することは容易ではない。Zyppyの創設者であるCyrus Shepard氏が実施した400以上のウェブサイトに対する分析により、オーガニックトラフィックを増加させたサイトに共通する5つの特徴が明らかになった。
この調査では、過去12ヶ月間のトラフィック推移を第三者ツールで測定し、サイトのビジネスモデルやコンテンツの性質との相関関係を調べている。その結果、単なる情報の羅列ではなく、ユーザーに対して実利的な価値を提供しているサイトが優位に立っている実態が浮き彫りとなった。
SEOの成功は一つの要因で決まるものではないが、特定の要素を積み重ねることで検索順位の「勝率」を劇的に高められる可能性がある。本記事では、データに基づいた5つの成功要因と、それらを実務にどう活かすべきかを詳しく解説していく。
400サイトのデータが示す勝てるサイトの共通点

Cyrus Shepard氏の調査は、SEO専門家のLily Ray氏が以前に行ったコアアップデートの分析対象サイトを再訪する形で実施された。サイトをビジネスモデルやコンテンツタイプごとに分類し、トラフィックの変化との相関(スピアマンの順位相関係数)を算出している。
調査の概要と相関関係の測定方法
分析の対象となったのは、アフィリエイトサイト、ECサイト、サービス提供サイトなど多岐にわたる。ここで重要なのは、Google Search Consoleの生データではなく、外部ツールによる推定トラフィックに基づいている点だ。しかし、400件というサンプルサイズは、現在の検索環境における大きな傾向を掴むには十分な規模といえる。
調査では、サイトが持つ特定の機能や性質がトラフィックの増減とどれほど強く結びついているかを数値化している。相関係数は0.206から0.391という中程度の値を示しており、これは「その要素があれば必ず勝てる」という魔法の杖ではないものの、無視できない明確な傾向が存在することを示唆している。
・アフィリエイトリンクへの誘導が主目的
・サイト独自のツールや機能がない
■ ユーザーがその場で問題を解決できる機能
■ 他者が模倣できない独自のデータ資産
上記の図が示すように、従来の「情報を整理して伝えるだけ」のスタイルから、より実用的で独自性の高い「価値提供型」のスタイルへの転換が求められていることがわかる。では、具体的にどのような指標が重要視されているのかを深掘りしていこう。
トラフィック増に直結する5つの重要指標

分析の結果、トラフィックを伸ばしたサイト(勝者)と減らしたサイト(敗者)の間で、顕著な差が見られた要素は5つに集約される。これらはGoogleが「どのようなサイトをユーザーにとって有益だと判断しているか」を考える上での強力なヒントになる。
自社製品の有無とタスクの完遂
第一の特徴は「自社製品またはサービスの提供」だ。勝者の70%が自社で何らかの製品やサービスを販売していたのに対し、敗者ではその割合は34%にとどまった。これには物理的な商品だけでなく、サブスクリプション型のサービスやデジタルコンテンツも含まれる。自社製品を持つことは、サイトの信頼性やビジネスとしての実体を示す強力なシグナルになっていると考えられる。
第二に「タスクの完遂が可能であること」が挙げられる。勝者の83%が、ユーザーが検索した目的をそのサイト内で完結できる仕組みを持っていた。例えば、計算ツール、予約フォーム、詳細な比較シミュレーターなどがこれに該当する。単に「やり方を教える」だけでなく「その場で実行できる」環境を提供しているサイトが、Googleからの評価を勝ち取っている。
模倣困難な独自資産とトピックの専門性
第三の要素は「独自の資産(Proprietary Assets)」だ。勝者の92%が、他者が容易に真似できない独自のデータセット、ユーザー生成コンテンツ(UGC)、あるいは専門的なソフトウェアを保有していた。インターネット上に溢れる情報の焼き直しではなく、そのサイトでしか得られない「一次情報」や「ツール」の価値がかつてないほど高まっている。
第四に「絞り込まれたトピックへの特化」がある。単に「特定のジャンルを扱っている」というレベルではなく、一つの狭いテーマを極めて深く掘り下げているサイトが勝者となる傾向が見られた。広範なトピックを浅くカバーする総合サイトよりも、特定のニッチ領域で「このテーマならこのサイト」と言わしめるほどの専門性が、現在のアルゴリズムには好まれている。
最後に「強いブランド力」だ。全体トラフィックに対する指名検索(ブランド名での検索)の割合が高いサイトほど、トラフィックを維持・拡大させている。勝者のブランド検索比率は敗者の2倍に達しており、検索エンジン経由だけでなく、ユーザーから直接指名される存在になることがSEOの安定にも寄与していることがわかる。
意外にも相関が見られなかった要素とその背景

今回の調査では、SEOの世界で重要だと信じられてきたいくつかの要素が、意外にもトラフィックの増減と直接相関しなかったという結果も出ている。この事実は、SEO戦略の優先順位を見直す上で非常に興味深い示唆を含んでいる。
体験談やUGCが決定打にならなかった理由
Cyrus Shepard氏の分析によれば、一次体験(First-hand experience)の記述、個人的な視点、ユーザー生成コンテンツ(UGC)、コミュニティ機能の有無などは、今回のデータセットにおいては勝者と敗者を分ける決定的な要因にはならなかった。また、情報の独自性そのものも、単体では強い相関を示さなかったという。
ただし、Shepard氏はこの結果を「これらの要素が不要である」と解釈すべきではないと注意を促している。これらの要素はすでにGoogleのアルゴリズムに深く組み込まれており、ベースライン(最低限必要な条件)となっている可能性があるからだ。つまり、体験談があるのは「当たり前」であり、それだけで他サイトに差をつけることは難しくなっているという見方ができる。
重要なのは、これらの要素を「持っているかどうか」ではなく、前述した5つの重要指標とどのように組み合わせて、ユーザーの課題解決(タスク完遂)に結びつけるかという点にある。単なる日記のような体験談ではなく、それが自社製品の信頼性を裏付けたり、独自のデータ資産の一部として機能したりすることで、初めて強力な武器になるのだ。
複数の特徴を組み合わせる加点方式の重要性

この調査で最も注目すべき発見は、5つの特徴が「累積的」に作用するという点だ。一つひとつの要素の相関は中程度でも、複数を組み合わせることでサイトの勝率は飛躍的に高まることがデータで示されている。
具体的には、5つの特徴のうち一つも持たないサイトの勝率はわずか13.5%だった。特徴を一つだけ持っている場合も15%程度と、大きな変化は見られない。しかし、3つ以上の特徴を備えるあたりから勝率は急上昇し、5つすべての特徴を持つサイトの勝率は69.7%にまで達した。この「3つの壁」を越えられるかどうかが、SEOの成否を分ける境界線といえそうだ。
このデータから得られる教訓は、部分的な改善に終始するのではなく、サイトの構造やビジネスモデルそのものを「勝者のパターン」に近づけていく努力が必要だということだ。例えば、アフィリエイト記事を書くだけでなく、簡易的な診断ツールを導入したり、独自のアンケート調査結果を公開したりすることで、複数の特徴を同時に満たすことができる。
【独自分析】今後のSEO戦略にどう活かすべきか

今回の分析結果を踏まえると、今後のSEOは「コンテンツ制作」の枠を超え、「サービス設計」に近い領域へとシフトしていくと考えられる。Googleは情報の正確性だけでなく、その情報が「実際に役立ったか」というユーザー体験の完結を重視しているからだ。
情報提供から価値提供への転換
サイト運営者がまず取り組むべきは、自分のサイトが単なる「情報の通過点」になっていないかを確認することだ。ユーザーが検索した後に、別のサイトへ移動して作業を続ける必要があるなら、それは「タスクの完遂」を妨げていることになる。自社でツールを開発するのが難しい場合でも、詳細なステップバイステップのガイドや、独自のチェックリストを提供することで、ユーザーの利便性を高めることは可能だ。
また、ブランド力の強化も欠かせない。指名検索を増やすためには、検索エンジン以外の流入経路(SNS、メールマガジン、外部メディアへの露出など)を確保し、「〇〇のことならこのサイト」という認知を広げる必要がある。これは一朝一夕には達成できないが、長期的なSEOの安定には最も効果的な投資となるだろう。
最後に、独自資産の構築だ。これは必ずしも高度な技術を必要としない。自社で蓄積した顧客の声、独自の実験結果、あるいは膨大な公開データを独自の切り口で分析したレポートなどは、AIには生成できない強力な武器になる。これらをトピックの深掘りと組み合わせることで、競合が容易に追随できない「勝てるサイト」へと進化させることができるはずだ。
この記事のポイント
- トラフィックを伸ばしているサイトの70%は自社製品やサービスを提供している
- ユーザーがサイト内で目的を完遂できる「タスク完了」の仕組みが評価を分ける
- 他者が模倣できない独自データやツールを持つサイトは92%という高い勝率を誇る
- 広範なテーマよりも、一つのニッチなトピックを深く掘り下げることが重要だ
- 5つの成功要因を3つ以上組み合わせることで、検索での勝率が飛躍的に高まる

AI検索可視性データを地域戦略に活かす方法——引用ギャップを埋めるSEO実践
AI検索がSEO戦略の中心的な話題となる中、多くのSEO担当者は経営層から「我が社のAI検索対策はどうなっているのか」というプレッシャーを受けている。従来の検索エンジン最適化とは異なるロジックで動くAI検索において、ブランドが引用されるためにはどのようなシグナルが重要になるのか。そしてそのデータをどう地域別の実行戦略(GEO戦略)に落とし込むのか。この問いに答えるための具体的なフレームワークと実行モデルが、最新のデータ分析から明らかになりつつある。
Search Engine Journal主催のウェビナーでは、Writesonicの創業者兼CEOであるSam Garg氏が、5億件以上のAI検索会話データを分析した結果を基に、AI検索で実際に引用されるコンテンツの特徴と、地域別の引用ギャップを埋めるための優先順位付け手法を解説する。本記事では、そのエッセンスを先取りして紹介する。
AI検索における引用のメカニズム
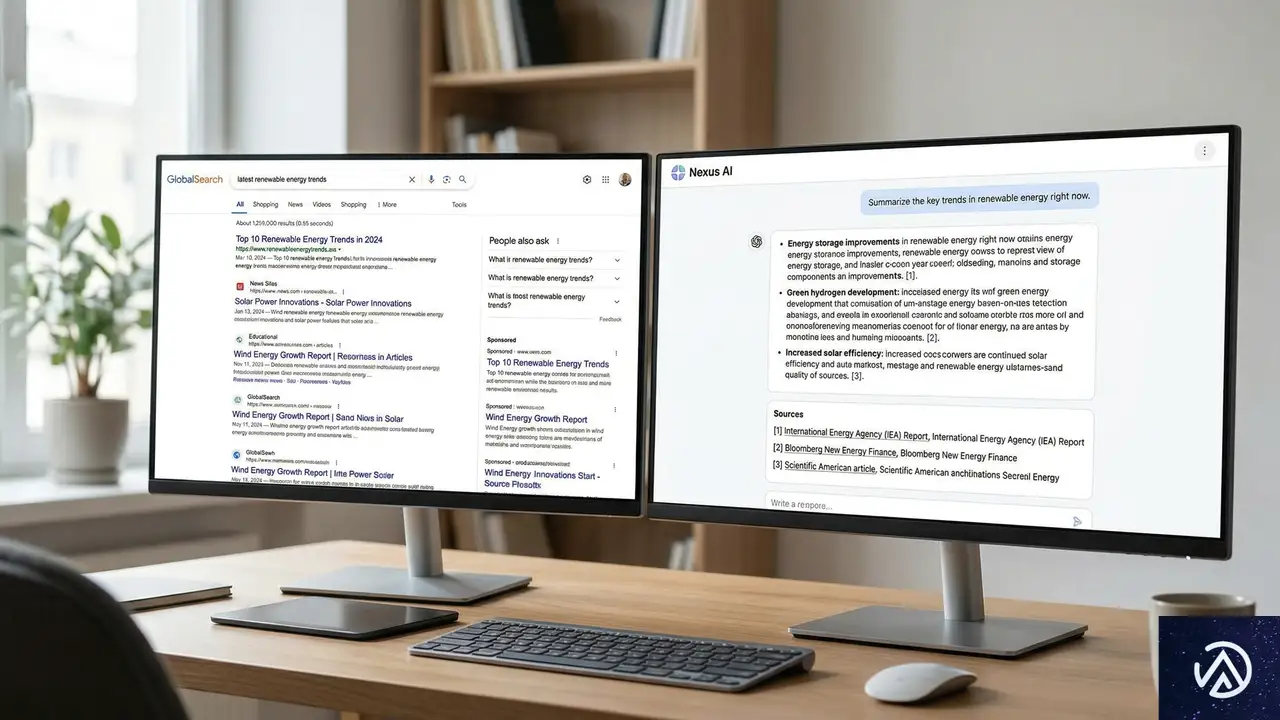
ChatGPT、Perplexity、GeminiといったAI検索ツールは、従来のGoogle検索とは異なる基準で情報源を選択し、回答に引用する。多くのSEOチームは、自社がAI検索で「見えていない」領域をダッシュボードで把握しているが、それを修正する具体的なプロセスを持たない場合が多い。まず理解すべきは、AIがどのようなコンテンツを引用する傾向にあるのか、その根本的なシグナルだ。
従来のSEOとAI検索最適化の根本的な違い
従来の検索エンジン最適化は、キーワードの出現頻度、被リンク、ページの技術的な健全性など、比較的測定可能な数百のシグナルに基づいてランキングが決定される。一方、AI検索ツールは、ユーザーの質問に対する「最も信頼できる回答」を生成するために、情報の新鮮さ、権威性、そして特定の文脈における適切さを総合的に判断する。この判断プロセスにおいて、どの情報源を引用するかは、従来のページランキングとは必ずしも一致しない。
例えば、地域に密着した詳細なデータを持つ中小規模のサイトが、汎用的な大規模メディアよりも特定の質問で優先して引用されるケースがある。AIは、質問の文脈に最も合致し、かつ信頼できると判断したソースを選ぶ。この「信頼性」の判断には、ドメインの権威だけでなく、コンテンツの専門性、構造化データの有無、更新頻度などが複合的に影響する。
引用を獲得するコンテンツの3つの特徴
Writesonicによる大規模データ分析から、AI検索で引用されやすいコンテンツには共通する特徴が浮かび上がっている。
第一に、明確な構造と階層を持つコンテンツだ。見出しタグ(H1〜H3)を適切に使い、箇条書きや表で情報が整理されているページは、AIが内容を理解し、特定の部分を抽出して引用しやすい。逆に、長大な散文調の記事は、関連する部分を見つけるのが難しくなる。
第二に、具体的な数字やデータ、最新の情報を含むこと。AIは「2026年現在」「調査によると約70%」といった定量的で時間的コンテキストが明確な情報を好んで引用する。曖昧な表現や古いデータは信頼性を損なう。
第三に、専門性と権威性を裏付ける外部ソースへのリンクだ。自説を主張するだけでなく、関連する学術論文、公的統計、権威ある業界レポートへのリンクを適切に含めることで、コンテンツ全体の信頼性が高まり、引用される可能性が上がる。
このデモは、AIが引用しやすいコンテンツの特徴を示している。左側の曖昧な表現から、右側のように具体的な数字、調査元、対象地域を明確にした構造に変えることで、情報の信頼性と抽出可能性が高まる。
引用ギャップを特定するデータ分析手法
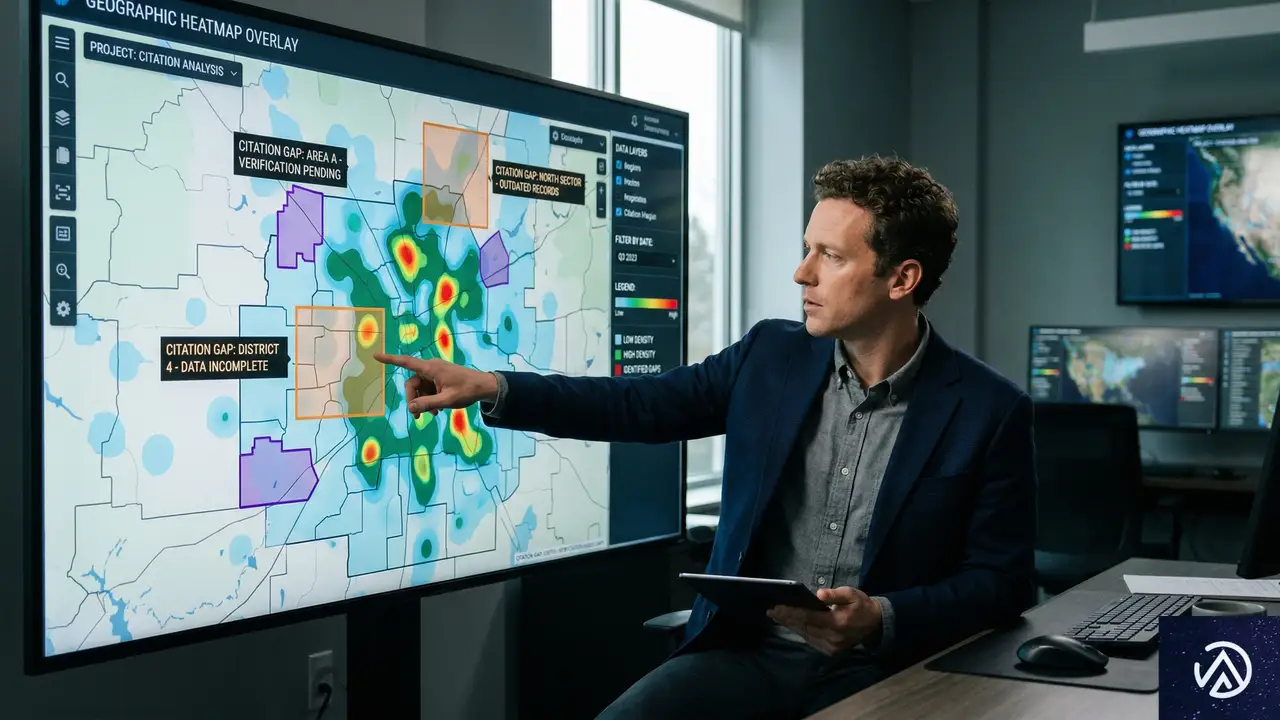
自社ブランドや製品がAI検索でどのように言及されているか、あるいは言及されていないかを把握するには、体系的なデータ分析が必要だ。ここで重要なのは、単に「見えていない」キーワードや地域をリストアップするだけでなく、なぜ見えていないのか、その根本原因を特定することにある。
可視性データの収集と解釈
まず、自社に関連する検索クエリに対して、主要なAI検索ツール(ChatGPT、Perplexity、Gemini等)がどのような回答を生成し、どの情報源を引用しているかをモニタリングする。この際、自社サイトが引用されているか否かだけでなく、競合他社が引用されているクエリ、あるいはどの情報源も引用されていない(AIが独自に生成した回答のみの)クエリも記録する。
得られたデータを「クエリの意図」「地域性」「コンテンツタイプ」の3つの軸で分類する。例えば、「東京 コワーキングスペース おすすめ」というクエリは「商業施設の推薦(意図)」「東京(地域)」「リスト記事(タイプ)」に分類される。この分類ごとに、自社の引用有無と、引用されている他サイトの特徴を分析することで、ギャップのパターンが見えてくる。
ギャップの根本原因を探る優先順位付けフレームワーク
すべての引用ギャップを同時に埋めようとするのは非現実的だ。限られたリソースで最大の効果を上げるためには、優先順位を決める必要がある。Sam Garg氏が提唱するフレームワークでは、以下の2つの指標でギャップを評価する。
第一の指標は「機会の大きさ」だ。そのクエリや地域における検索ボリューム、および自社にとってのビジネス上の重要性(成約率や単価)を数値化する。第二の指標は「埋めやすさ」だ。既存のコンテンツを更新するだけで対応できるのか、ゼロから新しいコンテンツや外部提携が必要なのか。必要な工数と難易度を評価する。
この優先順位付けにより、リソースを「既存資産の最適化」という効果の高い活動に集中させることができる。すべてのギャップを均等に埋めようとする従来のアプローチから脱却する第一歩だ。
AIエージェントを活用した地域戦略の実行自動化
優先すべきギャップが特定できたら、次は実行フェーズだ。特に地域別(GEO)戦略では、対象地域ごとに微妙に異なるコンテンツや情報の更新が必要となり、人的リソースが逼迫しがちである。ここで威力を発揮するのが、AIエージェントを活用したタスクの自動化だ。
無料のオープンソースツールで構築する自動化パイプライン
大規模な予算をかけなくても、現在公開されている無料のオープンソースツールを組み合わせることで、多くのGEO関連タスクを自動化できる。Sam Garg氏のウェビナーでは、具体的なツールの例とその連携方法が紹介される予定だ。
一つの例として、地域別の引用状況を監視するパイプラインを考えてみる。まず、Pythonのスクレイピングライブラリ(BeautifulSoupなど)や、AI検索APIを模倣するツールを使って、定期的に特定の地域クエリに対するAIの回答を収集する。次に、収集したテキストデータから自社ブランドや競合の言及を抽出し、スプレッドシートやデータベースに記録する。このデータ更新をトリガーに、引用ギャップが検出された地域に対して、あらかじめ準備したコンテンツ更新テンプレートや、地域メディアへのコンタクトリストを提示する内部通知システムを構築する。
人的判断とAI自動化の適切な分担
重要なのは、すべてをAIに任せるのではなく、クリエイティブな判断や複雑な交渉が必要な部分は人間が担当し、データ収集、モニタリング、ルーティンワーク、初期ドラフトの作成などをAIエージェントに担当させることだ。この分担を明確にすることで、SEOチームはより戦略的な活動に時間を割くことができる。
例えば、新しい地域での権威構築のために地元メディアへの寄稿を目指す場合、AIエージェントはその地域に関連するメディアリストの作成、編集者の連絡先収集、過去の記事傾向の分析を担当する。人間の担当者は、分析結果を基にパーソナライズされたアプローチ文面を考え、実際のコンタクトと関係構築を行う。
この分担モデルを導入することで、地域別の細やかな対応が人的リソースの限界を超えて可能になる。特に、複数の地域を同時にカバーする必要がある事業者にとって、持続可能な戦略実行の基盤となる。
この記事のポイント
- AI検索での引用は、従来のSEOとは異なるロジックに基づく。具体的なデータ、明確な構造、権威ある外部リンクを含むコンテンツが引用されやすい。
- 引用ギャップを埋めるには、単なる可視性データの収集だけでなく、「機会の大きさ」と「埋めやすさ」で優先順位を付けるフレームワークが有効だ。
- 地域別(GEO)戦略の実行負荷を下げるには、AIエージェントを活用したデータ収集・分析・ルーティンワークの自動化が鍵となる。クリエイティブな判断は人間が担う分担モデルを構築する。
- 無料のオープンソースツールを組み合わせることで、予算をかけずに自動化パイプラインの構築を始めることができる。

AIエージェントに最適化するWeb制作の新常識!アクセシビリティツリーが鍵を握る理由
主要なAIプラットフォームのすべてが、今やウェブサイトを自律的に閲覧できる能力を備えている。Google Chromeの自動ブラウジング機能はページをスクロールしてクリックを行い、ChatGPTのAtlas(アトラス)はフォームへの入力や購入手続きまで代行する。しかし、これらのAIエージェントは、私たち人間と同じようにウェブサイトを見ているわけではない。
サイバーセキュリティ企業であるImperva(インパーバ)の調査によれば、2024年には自動化されたトラフィックが人間によるトラフィックを初めて追い越し、全ウェブインタラクションの51%に達した。この数字のすべてがAIエージェントではないが、ウェブの主役が非人間に移りつつある事実は明らかだ。私たちは今、人間だけでなくマシンに対しても最適化されたサイトを構築する必要がある。
AIエージェントとの互換性を高めるために最も効果的な方法は、実はウェブアクセシビリティの向上である。かつてはスクリーンリーダーのために用意されていた「アクセシビリティツリー」が、今やAIエージェントがサイトを理解するための主要なインターフェースへと進化している。この記事では、AIがサイトをどのように認識し、制作者がどう対応すべきかを詳しく紐解いていく。
AIエージェントはウェブサイトをどう認識しているのか
人間がサイトを訪れるとき、色やレイアウト、画像、タイポグラフィといった視覚的な情報を処理する。これに対し、AIエージェントがサイトを訪問した際に受け取る情報は、そのプラットフォームの設計思想によって大きく3つのアプローチに分かれる。それぞれの違いを理解することが、対応の第一歩となる。
スクリーンショットによる視覚的解析(Vision)
Anthropic(アンソロピック)の「Computer Use(コンピューター・ユース)」は、最も直感的なアプローチを採用している。AIモデルのClaude(クロード)がブラウザのスクリーンショットを撮影し、その画像を解析して「どこをクリックすべきか」「何をタイプすべきか」を判断する。これは、人間が画面を見て操作するプロセスをデジタルで再現したものだ。
Googleの「Project Mariner(プロジェクト・マリナー)」も同様のループを採用しており、視覚的な要素と背後のコード構造を組み合わせて動作する。この「視覚ベース」のアプローチは汎用性が高い一方で、計算コストが非常に高く、レイアウトのわずかな変更に影響を受けやすいという弱点がある。また、画面に描画されていない情報を読み取ることはできない。
アクセシビリティツリーによる構造把握(Structure)
OpenAIのChatGPT Atlasは、異なる道を選んだ。彼らの公式ドキュメントによれば、AtlasはARIA(エリア)タグを活用してページの構造や対話型要素を解釈している。ARIAとは、視覚障害者が使うスクリーンリーダーなどにウェブサイトの構造を伝えるための技術規格だ。
Atlasはレンダリングされたピクセルを解析するのではなく、ブラウザが生成する「アクセシビリティツリー」に問い合わせを行う。ここから「ボタン」「リンク」といった役割(ロール)や、その要素の名前を取得する。MicrosoftのPlaywright(プレイライト)MCPも同様で、視覚的なレンダリングよりも構造化されたアクセシビリティデータを優先してブラウザの自動操作を行っている。
視覚と構造を組み合わせたハイブリッド方式
実務で最も強力なエージェントは、これら両方の手法を組み合わせている。OpenAIの「Computer-Using Agent(CUA)」は、スクリーンショットの解析に加えて、DOM(ドキュメント・オブジェクト・モデル)の処理とアクセシビリティツリーのパースをレイヤー化して実行する。DOMとは、HTML文書をプログラムから扱うためのデータ構造のことだ。
Perplexity(パープレキシティ)の調査でも、アクセシビリティツリーのスナップショットと選択的な視覚解析を組み合わせた「ハイブリッド・コンテキスト管理」が有効であるとされている。視覚だけで判断するよりも、構造化されたデータを利用する方が、情報の信頼性と処理効率が格段に向上するためだ。
アクセシビリティツリーがAIとの接点になる理由
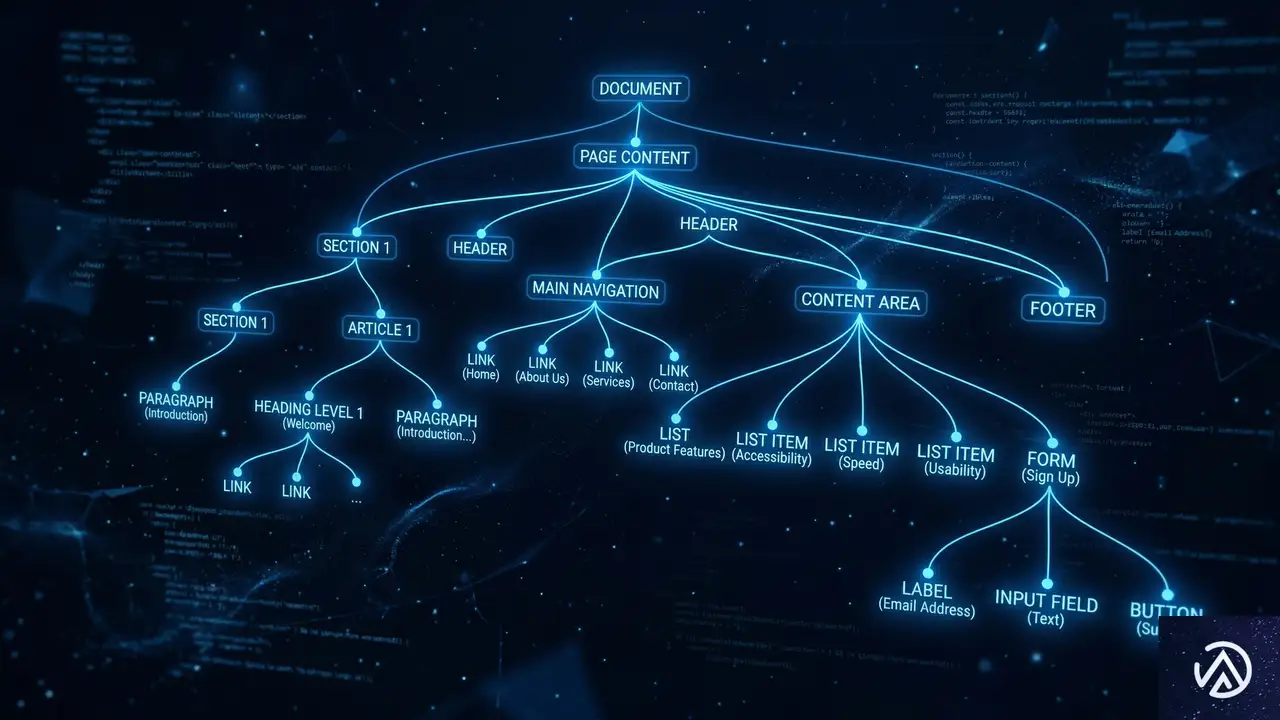
アクセシビリティツリーとは、ブラウザが支援技術のために生成する、DOMの簡略化された表現だ。通常のDOMには、デザインのための <div> や <span> 、スタイル指定、スクリプトなど、膨大な「ノイズ」が含まれている。これに対し、アクセシビリティツリーはそれらを削ぎ落とし、操作に関わる重要な要素だけを抽出する。
AIモデルにとって、処理できる情報の量(コンテキストウィンドウ)には限りがある。数千ものノードがあるDOMをすべて読み込ませるよりも、ボタンやリンク、見出し、フォームといった「意味のある要素」だけに絞り込まれたアクセシビリティツリーを渡す方が、AIははるかに正確にサイトを理解できる。OpenAIが「アクセシブルなサイトにすることは、Atlasがサイトを理解する助けになる」と明言しているのは、このためだ。
研究データが示すアクセシビリティの効果
カリフォルニア大学バークレー校とミシガン大学が2026年に発表した共同研究では、アクセシビリティの状態がAIエージェントの成功率にどう影響するかが検証された。Claude Sonnet 4.5を用いたテストの結果、標準的なアクセシビリティを備えた状態でのタスク成功率は78.33%であった。しかし、アクセシビリティを制限した条件では、その成功率は劇的に低下した。
例えば、キーボード操作のみ(スクリーンリーダー利用時を想定)に制限すると、成功率は41.67%にまで落ち込み、完了時間は2倍に増えた。さらに表示領域を制限した条件では、成功率は28.33%にまで低下している。この結果は、視覚的なヒントや複雑なJavaScript操作に頼り、アクセシブルな代替手段を提供していないサイトでは、AIエージェントが失敗する確率が高まることを示している。
構造化されたデータの優先順位
Perplexityの検索APIに関する論文(2025年9月)によると、彼らのインデックスシステムは、元の構造やレイアウトが保持された高品質なコンテンツを優先している。特にリストやテーブル形式で整理された「構造化データ」が豊富なサイトは、パース(解析)や情報の抽出が容易であるため、AIの回答に引用されやすくなるメリットがある。
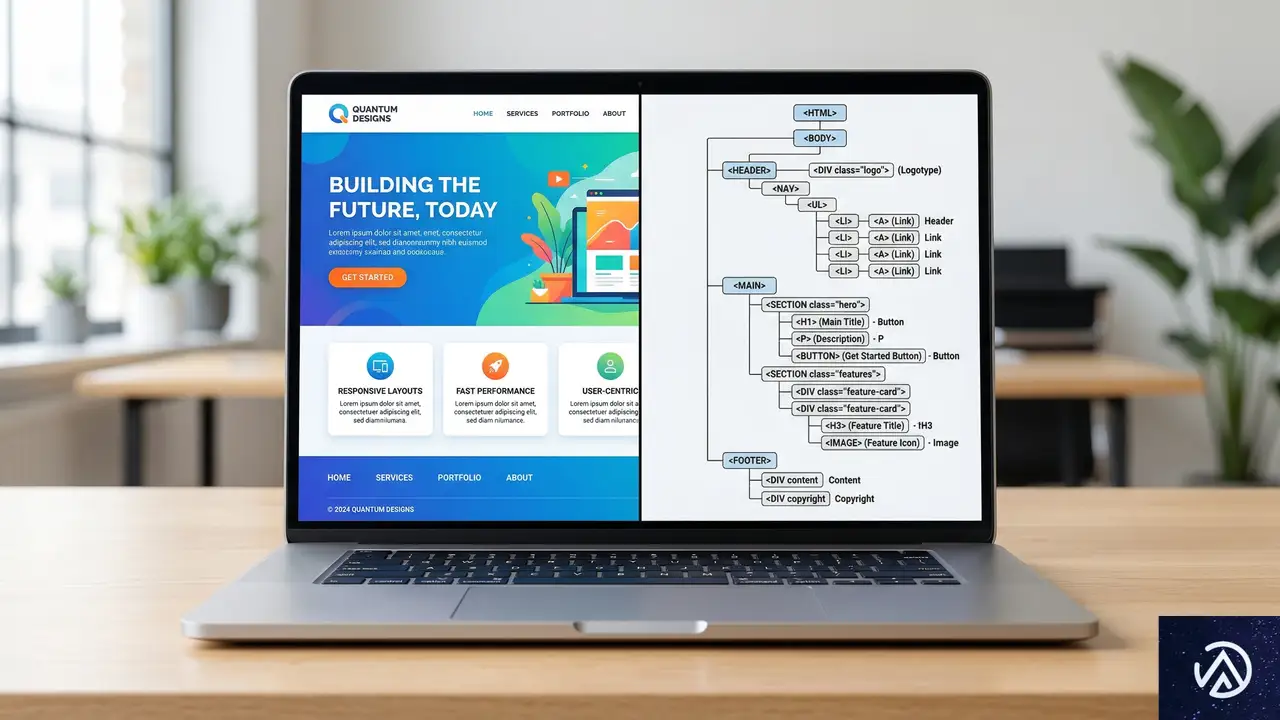
セマンティックHTMLで構築するAIフレンドリーな基盤
アクセシビリティツリーはHTMLから構築される。つまり、正しい「セマンティックHTML」を使うことが、AI対応の最も基本的かつ強力な手段となる。セマンティックHTMLとは、タグそのものが意味を持つHTMLの書き方のことだ。例えば、単なる <div> ではなく <button> を使うことで、ブラウザは自動的にその要素を「ボタン」としてアクセシビリティツリーに登録する。
ネイティブ要素の活用とフォームのラベル付け
開発者が <div onclick="..."> のようなコードを書くと、AIはその要素がクリック可能であることを認識できない場合がある。一方で、ネイティブの <button> 要素を使えば、その役割とテキスト内容が正確に伝わる。同様に、フォームの入力フィールドには必ず <label> を紐付けるべきだ。ラベルがない入力欄を、AIは「何を入れればよいか不明な箱」として扱ってしまう。
また、 autocomplete 属性の活用も重要だ。これを使うことで、「名前」「メールアドレス」「住所」といったデータの種類をAIに明示できる。AIエージェントがユーザーに代わってフォームを入力する際、この属性があれば推測に頼らず自信を持ってフィールドを埋めることが可能になる。
見出しの階層とランドマークの明示
見出しタグ( h1 から h6 )を論理的な順序で使用することも欠かせない。AIエージェントは、見出しを頼りにページの構造を把握し、特定のセクションを探し出す。階層を飛ばして( h1 の次に h4 を使うなど)しまうと、コンテンツの親子関係に混乱が生じる。さらに、 <nav> 、 <main> 、 <footer> といったランドマーク要素を使うことで、ページ内のどこに何があるのかをAIに一義的に伝えることができる。
このデモは、HTMLタグの選び方によってAIエージェントへの情報の伝わり方がどう変わるかを視覚化したものだ。
ARIAとレンダリング戦略の注意点
OpenAIは、動的なウェブコンテンツをアクセシブルにするための標準規格であるARIAの使用を推奨している。しかし、ARIAはあくまで「補足」であり、不完全なHTML構造を隠すための魔法ではない。W3C(ワールド・ワイド・ウェブ・コンソーシアム)が定めた「ARIAの第一ルール」は、ネイティブなHTML要素で実現できるならARIAを使うな、というものだ。
ARIAの誤用が招くリスク
アクセシビリティの専門家であるAdrian Roselli(エイドリアン・ロセリ)氏は、OpenAIの推奨が不適切なARIAの多用を招く可能性を懸念している。実際、WebAIMの調査によれば、ARIAを使用しているサイトは、そうでないサイトよりもアクセシビリティエラーが多い傾向にある。これは、ARIAが「とりあえずの修正」として誤って使われることが多いためだ。
正しいアプローチは、まずセマンティックなHTMLで土台を作り、タブパネルやツリービューのようにHTML標準にないカスタムコンポーネントを作る場合に限って、ARIAで役割や状態( aria-expanded など)を補完することだ。キーワードを aria-label に詰め込むような行為は、初期のSEOにおけるメタキーワードの乱用と同じく、逆効果になる可能性がある。
サーバーサイドレンダリング(SSR)の必須性
ブラウザベースのAIエージェントはJavaScriptを実行できるが、すべてのAIクローラーがそうであるとは限らない。PerplexityBotやOAI-SearchBotなどは、コンテンツを収集する際にクライアント側のJavaScriptを実行しないことが多い。もしサイトがReactなどで構築され、ブラウザで実行されるまで中身が空の <div id="root"></div> であれば、AIは何も見つけることができない。
AIエコシステムにおいて「存在しない」と見なされないためには、サーバーサイドレンダリング(SSR)やプリレンダリングが不可欠だ。また、重要な情報をタブや展開メニューの中に隠さないことも推奨される。Microsoftのガイドラインによれば、AIシステムは隠されたコンテンツをレンダリングしない場合があるため、重要な詳細は初期表示のHTMLに含めるべきだとしている。
AI対応状況を確認するためのテスト手法

サイトを公開する前にブラウザで表示を確認するように、AIエージェントがどう認識しているかをテストすることも重要だ。最も手軽で効果的な方法は、スクリーンリーダー(macOSのVoiceOverやWindowsのNVDA)を使ってサイトを操作してみることだ。視覚を使わずに主要なタスクを完了できるなら、AIエージェントも同様に操作できる可能性が高い。
ツールによるアクセシビリティスナップショット
より直接的にAIの「目」を確認したい場合は、MicrosoftのPlaywright MCPが提供するアクセシビリティスナップショット機能が役立つ。これは視覚的なプレゼンスを取り除き、AIが処理する「役割」「名前」「状態」だけを構造化されたテキストとして出力してくれる。もし重要なボタンがこのスナップショットに現れない、あるいは適切な名前が付いていない場合は、改善が必要だ。
テキストブラウザでの見え方を確認する
Lynx(リンクス)のようなテキスト専用ブラウザでサイトを表示してみるのも有効な手段だ。画像やレイアウトをすべて剥ぎ取った状態で、コンテンツの順序や階層が論理的に整理されているかを確認できる。AIエージェントは、私たちがデザインした美しいレイアウトを見ているのではなく、その背後にある情報の流れを読み取っているからだ。
この記事のポイント
- AIエージェントはアクセシビリティツリーを主要なインターフェースとして利用している
- セマンティックHTML(正しいタグ選び)がAI最適化の最も重要な基盤となる
- ARIAは魔法ではなく、ネイティブHTMLで足りない部分を補うために使うべきだ
- JavaScriptに依存しすぎず、SSRを活用して初期HTMLにコンテンツを含めることが重要だ
- スクリーンリーダーでのテストは、AIエージェントとの互換性を測る最良の指標になる

CSS段組みレイアウトの革命!column-wrapで横スクロール問題を解消する
CSSのMulti-column Layout(マルチカラムレイアウト)は、長い文章を新聞のように複数の列に分割して表示する仕組みだ。これまでWeb制作の現場では、コンテンツが溢れた際に強制的に横スクロールが発生してしまうという致命的な課題があり、利用シーンが限られていた。しかし、Chrome 145から導入された新しいプロパティによって、この状況が劇的に変わろうとしている。
最新のアップデートでは、column-wrap(カラム・ラップ)とcolumn-height(カラム・ハイト)という2つのプロパティが追加された。これにより、指定した高さを超えたコンテンツを次の「行」へと折り返して表示する、いわゆる「2Dフロー」が可能になった。これはWebにおけるテキスト表現の幅を大きく広げる重要な進化といえる。
本記事では、CSS-Tricksが報じた最新情報を基に、新しい段組みレイアウトの仕組みや具体的な活用方法、そして既存のCSS GridやFlexboxとの使い分けについて詳しく解説する。新しいプロパティがどのようにWebのユーザー体験を改善するのか、その全容を紐解いていこう。
従来のCSS段組みレイアウトが抱えていた大きな課題

CSSの段組みレイアウトは、古くから存在する仕様でありながら、現代のWebデザインでは主役になりきれなかった。その最大の理由は、コンテンツの量が増えたときの挙動がWebの閲覧スタイルに合っていなかったからだ。ここでは、なぜ従来の段組みが使いにくかったのかを振り返る。
横スクロールというUX上の壁
従来の段組みレイアウトでは、column-count(列の数)やcolumn-width(列の幅)を指定して文章を流し込む。しかし、親要素に高さを設定している場合、テキストがその高さを超えると、ブラウザは右側に新しい列を勝手に追加していく。その結果、ユーザーはページを横にスクロールしなければ最後まで読めないという状態に陥る。
Webサイトの基本は垂直(縦)スクロールだ。スマートフォンの普及により、縦に指を動かす操作が標準となった現代において、突如として現れる横スクロールはユーザーに混乱を与える。これが「UX(ユーザーエクスペリエンス)上の禁じ手」とみなされ、多くのデザイナーが段組みの使用を避ける原因となっていた。
レスポンシブ対応の難しさ
また、従来の段組みは「1次元的」な流れしか持っていなかった。コンテンツは常に左から右へと流れるだけで、画面の下に回り込むことはない。画面幅が狭いモバイル端末では、列を1つにするなどの調整が必要だが、高さの制限がある中でコンテンツを適切に収めるには、複雑な計算やJavaScriptによる制御が不可欠だった。CSSだけで完結できない点が、開発のハードルを上げていたのだ。
Chrome 145で登場した「column-wrap」と「column-height」

2026年4月にリリースされたChrome 145では、これらの問題を一挙に解決する新機能が実装された。それがcolumn-wrapプロパティだ。このプロパティの登場により、段組みレイアウトは「横に伸び続ける」仕組みから「縦に折り返す」仕組みへと進化した。
2Dフローを実現する新しい仕組み
新しく導入されたcolumn-wrap: wrapを指定すると、コンテンツが指定された高さを超えた際、右に新しい列を作るのではなく、下に新しい「段組みの行」を作成する。これにより、コンテンツ全体を縦スクロールの中で完結させることができるようになる。これは、Flexboxがflex-wrap: wrapで要素を次の行に送る挙動に近いが、段組みレイアウト独自の「テキストの分割」機能を保持している点が異なる。
具体的なコードの書き方と挙動の変化
新しいプロパティを使用する場合、基本的には対象の要素にcolumn-countとcolumn-wrap、そして基準となる高さを指定する。以下のコード例を見てほしい。column-wrap: wrapを加えるだけで、横への溢れが解消される。
.article {
column-count: 3;
column-gap: 20px;
column-wrap: wrap; /* 新プロパティ */
height: 400px;
}上記のデモが示すように、column-wrap: wrapを適用することで、コンテンツは親要素の幅の中で適切に折り返される。これは単なる見た目の変化ではなく、Webサイト全体のアクセシビリティとユーザビリティを向上させる大きな一歩だ。
新しい段組みプロパティが活躍する3つの具体的な場面

この新機能は、どのようなWebサイトで威力を発揮するのだろうか。CSS-Tricksの記事では、いくつかの実用的なユースケースが紹介されている。特に「固定の高さ」を扱うデザインにおいて、そのメリットは顕著だ。
高さが決まっているカード型レイアウト
もっとも身近な例は、ブログの記一覧や製品紹介などのカード型レイアウトだ。各カードの最大高さが決まっている場合、段組みレイアウトを使うことで、要素を美しく並べることができる。column-wrap: wrapを使えば、カードの数が増えてもレイアウトが崩れず、シームレスに次の行へと流れていく。Flexboxでも同様のことは可能だが、段組みレイアウトは「要素の途中で改行させない」といった制御(break-inside: avoidなど)が容易であるため、より洗練されたカード配置が可能になる。
雑誌や新聞のような本格的なマガジン形式
オンラインマガジンやニュースサイトにおいて、新聞のような多段組みデザインを採用したいケースは多い。これまでは、画面サイズに合わせて手動でコンテンツを分割するか、横スクロールを許容するしかなかった。新しいプロパティを使えば、デバイスの高さに合わせて自動的に段を折り返すことができるため、どの端末で見ても「読みやすい新聞スタイル」を維持できる。これは、コンテンツの連続性を保ちつつ、視覚的なリズムを生み出すのに最適だ。
垂直スクロールを活用したフルスクリーン・カルーセル
個人的に興味深い活用法として挙げられているのが、垂直方向のページめくり体験だ。column-heightをビューポート(画面の表示領域)いっぱいの高さ(100dvhなど)に設定し、CSSのscroll-snap-typeと組み合わせる。すると、コンテンツが画面の高さに合わせて自動的に「ページ」として分割され、ユーザーは縦にフリックするだけで雑誌をめくるように記事を読み進めることができる。JavaScriptを使わずに、CSSだけでこのような高度なインタラクションが実現できるのは驚きだ。
既存のCSSレイアウト手法と新機能の使い分け

新しい段組みレイアウトが登場したからといって、CSS GridやFlexboxが不要になるわけではない。むしろ、それぞれの特性を理解し、適切に使い分けることが重要だ。ここでは、それぞれの設計思想の違いを整理する。
CSS GridやFlexboxとの決定的な違い
CSS GridやFlexboxは、基本的に「個別の要素(子要素)」をどのように配置するかを管理するシステムだ。対して、段組みレイアウト(Multi-column)は「単一の連続したコンテンツ」をどのように分割するかを管理する。この違いは大きい。
例えば、1つの長い長文を途中で切り離すことなく複数の列に流し込みたい場合、GridやFlexboxでは文章を物理的に分割して複数のHTML要素に分ける必要がある。しかし、段組みレイアウトなら1つの<p>タグの中身をそのまま分割できる。構造を壊さずにレイアウトを変更できるのは、段組みレイアウトだけの特権だ。
注目が集まるCSS Masonryとの比較
現在、CSSの仕様策定が進んでいる「Masonry(メーソンリー)レイアウト」とも比較されることが多い。Masonryは高さの異なる要素を隙間なく敷き詰める手法だが、段組みレイアウトもcolumn-countを使えば似たような見た目を作ることができる。ただし、Masonryが「要素の順序」を重視するのに対し、段組みレイアウトはあくまで「コンテンツの流れ」を重視する。情報の優先順位が重要なニュース記事などでは段組みが適しており、ビジュアル重視のギャラリーサイトなどではMasonryが適しているといえるだろう。
導入時に注意すべき制限事項とブラウザ対応状況

非常に便利な新機能だが、実務で採用する際にはいくつか注意点がある。まず、2026年4月時点でのブラウザ対応状況だ。このプロパティは現在、Chrome 145以降でのみサポートされている。FirefoxやSafari、Edgeではまだ利用できないため、現時点では「プログレッシブ・エンハンスメント」の考え方で導入するのが現実的だ。
プログレッシブ・エンハンスメントとは、基本の機能はすべてのブラウザで提供しつつ、最新ブラウザではより良い体験を提供する設計手法を指す。未対応ブラウザでは従来の1カラム表示やシンプルな段組みにし、Chromeユーザーには進化した2Dフローを提供するという構成が望ましい。
また、動的なコンテンツへの対応も課題だ。ユーザーが投稿するコメントやCMSから配信される記事など、高さが予測できないコンテンツの場合、column-heightを固定してしまうと、不自然な余白ができたり、意図しない場所で折り返されたりする可能性がある。完全にレスポンシブな設計にするには、依然としてメディアクエリを駆使して、画面サイズごとに最適な列数や高さを微調整する作業が必要になるだろう。
この記事のポイント
- Chrome 145で導入された
column-wrap: wrapにより、段組みの横スクロール問題が解消された。 - コンテンツが高さを超えた際に「下の行」へ折り返す2Dフローが実現可能になった。
- 固定高のカードレイアウトや、新聞スタイルのデザイン、垂直カルーセルなどで特に威力を発揮する。
- GridやFlexboxが「要素の配置」を得意とするのに対し、段組みは「単一コンテンツの分割」に特化している。
- 現時点ではブラウザ対応が限定的なため、未対応環境へのフォールバックを考慮した設計が不可欠だ。

Cloudflare Organizationsベータ版登場!複数アカウントの一元管理とセキュリティ強化の全容
Cloudflare(クラウドフレア)は、大規模なエンタープライズ企業が自社のインフラをより効率的に管理するための新機能「Cloudflare Organizations(クラウドフレア・オーガニゼーションズ)」をベータ版として公開した。この機能は、これまで独立していた複数のCloudflareアカウントを一つの「組織」としてまとめ、一元的な管理を可能にするものだ。
大規模な組織では、数千人規模のユーザーが開発やセキュリティ、ネットワークなどの多岐にわたる業務でCloudflareを利用している。今回のアップデートにより、管理者は個別のログインや設定の繰り返しから解放され、組織全体のアナリティクスやポリシーを一括で制御できるようになる。
なぜこの機能が重要なのか。それは、セキュリティの鉄則である「最小権限の原則」を維持しながら、管理の複雑さを劇的に解消できるからだ。本記事では、Cloudflare Organizationsがもたらす変化とその技術的な背景を詳しく解説していく。
Cloudflare Organizationsが解決する大規模運用の課題

多くのエンタープライズ企業は、セキュリティを担保するために複数のCloudflareアカウントを使い分けている。これは、特定のチームに必要以上の権限を与えないための「最小権限の原則(Principle of Least Privilege)」に基づいた運用だ。
複数アカウントによる管理の断片化
最小権限の原則とは、ユーザーに業務遂行に必要な最小限のアクセス権だけを与える考え方だ。例えば、マーケティングチームが管理する特設サイトの設定と、基幹システムのネットワーク設定は、異なるアカウントで管理するのが望ましい。これにより、万が一ひとつのアカウントが侵害されても、被害を限定的に抑えられるからだ。
しかし、この運用には大きなデメリットがあった。管理者はすべてのアカウントに個別にアクセスし、権限を設定しなければならない。アカウントが増えるほど管理は「断片化」し、誰がどのアカウントに対してどのような権限を持っているのかを把握することが困難になっていたのだ。
運用の煩雑さとヒューマンエラーのリスク
従来、全社的なセキュリティレポートを作成する場合、管理者は各アカウントにログインして個別にデータを収集する必要があった。また、共通のセキュリティポリシーを適用する際も、アカウントごとに同じ設定を手動で繰り返す必要があり、これが設定ミスや漏れといったヒューマンエラーの原因となっていた。
Cloudflare Organizationsは、こうした「セキュリティのためのアカウント分割」が生み出した管理コストを削減するために設計されている。アカウントの独立性を保ったまま、管理レイヤーだけを統合する仕組みだ。
■ アカウントB(本番用)→ 個別にログイン
■ アカウントC(外部用)→ 個別にログイン
※管理者がバラバラに管理する必要がある
├ ■ アカウントB
└ ■ アカウントC
このデモは、Organizationsがアカウントの階層構造をどのように整理するかを視覚化したものだ。
Organizationsの主要機能と新しい管理ロール

Cloudflare Organizationsの導入により、新しい管理権限の仕組みが導入された。その中心となるのが「Org Super Administrator(組織スーパー管理者)」というロールだ。
「Org Super Administrator」の役割
これまで、管理者は各アカウントの「Super Administrator」として登録される必要があった。しかし、Organizationsでは組織レベルで管理者を任命できる。この組織スーパー管理者は、組織に紐づけられたすべてのアカウントに対して、自動的に最高権限を持つことになる。
特筆すべきは、この管理者が個別のアカウントのユーザーリストに表示されない点だ。これにより、アカウント内の一般ユーザーが誤って管理者を削除してしまうといった事故を防ぐことができる。また、新しくアカウントが組織に追加された際も、管理者は即座にそのアカウントを制御できるため、オンボーディングのスピードが向上する。
複数アカウントを横断するダッシュボード
Organizationsのもう一つの大きな特徴は、アカウントを跨いだ情報の集約だ。ベータ版ではまず、HTTPトラフィックのアナリティクスが提供される。これにより、組織全体のトラフィック傾向や、特定のドメインでの異常なアクセス増加を一つの画面で監視できるようになった。
今後は、監査ログ(Audit Logs)や請求レポート(Billing Reports)も組織レベルで統合される予定だ。これにより、誰がいつ、どのアカウントで設定を変更したのかを組織全体で追跡できるようになり、コンプライアンスの強化にもつながる。
セキュリティと効率を両立する共有ポリシー

エンタープライズ企業にとって、セキュリティ基準を社内全体で統一することは至上命題だ。Cloudflare Organizationsは、この課題に対して「共有ポリシー」という強力な解決策を提示している。
WAFやGatewayポリシーの一括適用
これまでは、WAF(Web Application Firewall / ウェブアプリケーションファイアウォール)のルールを更新する場合、各アカウントにログインして同じ作業を繰り返す必要があった。しかし、Organizationsでは、特定のアカウントで作成したポリシーセットを、組織内の他のアカウントへ共有できる。
例えば、セキュリティ専門チームが管理する「マスターアカウント」で最新の脆弱性対策ルールを作成し、それを全社のアカウントに一括で適用するといった運用が可能になる。これにより、セキュリティレベルのばらつきをなくし、全社的な防御力を底上げできる。
この仕組みにより、各チームの担当者は自前で複雑なセキュリティ設定を行う必要がなくなり、本来の開発業務に集中できるようになる。
開発の舞台裏とパフォーマンスの改善

このOrganizations機能の実現は、Cloudflareの内部システムにおける大規模な刷新の結果でもある。Cloudflareのチームは、これを単なる新機能の追加ではなく、システム基盤の再構築として取り組んだ。
13万行のコード刷新とインナーソース開発
開発にあたっては「インナーソース(Innersource)」という手法が採用された。これは、オープンソースの開発手法を社内のプロジェクトに適用するものだ。このプロジェクトでは、約133,000行の新しいコードが追加され、32,000行の古いコードが削除された。Cloudflareの権限システム史上、最大級の変更となったという。
この刷新の目的は、古いコードパスを排除し、すべての認可チェックを「ドメインスコープのロールシステム」に集約することだ。これにより、将来的に新しいロールや機能をより迅速にリリースできる強固な土台が完成した。
権限チェック速度が27%向上
この基盤刷新は、ユーザー体験にも直接的なメリットをもたらしている。特に、数千ものアカウントやゾーン(ドメイン)にアクセス権を持つパワーユーザーにおいて、アカウント一覧やゾーン一覧の表示速度が課題となっていた。今回の最適化により、権限チェックのパフォーマンスが27%向上し、大規模環境での管理画面のレスポンスが大幅に改善された。
Organizationsの導入方法と今後の展望

Cloudflare Organizationsは、まずエンタープライズプランの顧客を対象にパブリックベータとして公開されている。今後数ヶ月以内に、Pay-as-you-go(従量課金)プランを含むすべての顧客に拡大される予定だ。
安全な移行プロセス
導入はセルフサービス形式で行われる。エンタープライズアカウントのスーパー管理者であれば、ダッシュボードに招待が表示される仕組みだ。Cloudflare側が勝手に組織を作成することはない。これは、意図しない権限昇格を防ぐための配慮だ。
もし社内の別のユーザーがすでに組織を作成している場合は、そのユーザーから招待を受けるか、自分を組織の管理者として追加してもらう必要がある。このプロセスにより、どのアカウントを組織に含めるかを、各アカウントの管理者が明示的に承認する形が維持されている。
ロードマップに並ぶ強力な機能
Organizationsは、今後一年をかけてさらに進化する予定だ。現在公開されているロードマップには以下の項目が含まれている。
- 組織レベルの監査ログ(Audit Logs)
- 組織レベルの請求レポート
- より詳細なアナリティクスレポートの拡充
- 組織レイヤーでの追加ユーザーロール
- セルフサービスによる新規アカウント作成
独自の分析:なぜ今、Cloudflareは「組織」単位の管理に注力するのか

今回のアップデートは、Cloudflareが単なる「CDNベンダー」から、企業の「統合ネットワークインフラ」へと完全に脱皮したことを象徴している。かつてCloudflareは、個々のドメインを高速化・保護するためのツールだった。しかし現在、企業はアイデンティティ管理(Zero Trust)やサーバーレス開発(Workers)など、ビジネスの根幹をCloudflare上で動かしている。
利用範囲が広がれば、当然ながら管理する単位はドメインから「組織」へとシフトする。Organizationsの導入は、AWS(Amazon Web Services)が「AWS Organizations」を導入した際と同様の進化のプロセスと言えるだろう。
特に、WAFポリシーの共有機能は、セキュリティの民主化を加速させる可能性がある。高度なスキルを持つ中央のセキュリティチームが作成した「盾」を、全社の開発チームが意識することなく利用できる。この「ガードレール」としての役割こそが、現代のプラットフォームエンジニアリングが目指す姿だ。Cloudflareは今回の基盤刷新により、その理想を実現するための強力な武器を手に入れたと言える。
この記事のポイント
- Cloudflare Organizationsにより、複数のアカウントを一元管理できるようになった
- 「組織スーパー管理者」ロールにより、個別のアカウント管理が不要になる
- WAFやGatewayのポリシーを組織全体で共有・一括適用が可能に
- 内部システムの刷新により、権限チェックの速度が27%向上した
- 現在はエンタープライズ向けベータ版で、順次全ユーザーに開放予定

2026年EUクッキー法完全対応ガイド——WordPressサイトの必須対策と実装手順
EU域内のユーザーを対象とするWebサイト運営者にとって、クッキー法への対応はもはや選択肢ではない。2026年現在、規制当局の監視は厳しさを増し、業界全体で21億ユーロに上る制裁金が科せられている。単純なテキストバナーではビジネスを守れない時代だ。
法的に準拠し、高速で、コンバージョンにも寄与する同意管理システムをWordPress上に構築するには、明確なルールに従う必要がある。この記事では、2026年の最新規制を理解し、サイトとユーザーを保護するための具体的な実装ステップを解説する。
2026年のEU法規制を理解する:GDPRとePrivacyの違い

多くの開発者が混同しがちなのが、GDPR(一般データ保護規則)とePrivacy Directive(電子プライバシー指令)の違いだ。GDPRは個人データの収集全般を規定する法律である。一方、ePrivacy Directiveは特にクッキーやローカルストレージといったトラッキング技術そのものを規制する。
基本的な通知を表示するだけでは不十分であり、規制当局は無知を言い訳として認めない。2026年に適用される具体的な法的要件は以下の通りだ。
- 事前同意:ユーザーが「同意する」を能動的にクリックするまで、非必須のトラッカーを一切読み込んではならない。事前にチェックが入ったボックスは法的に無効だ。
- 同等の視認性:「すべて拒否」ボタンは「すべて同意」ボタンと視覚的に同一でなければならない。拒否オプションを二次メニューに隠すことはできない。
- 詳細な制御:ユーザーは、統計トラッカーを拒否しながらマーケティングトラッカーに同意するといった、カテゴリーごとの選択が可能でなければならない。
- 同意の撤回の容易さ:同意を与えるのと同程度に簡単に同意を撤回できる必要がある。ユーザーが考えを変えられるよう、永続的なフローティングアイコンを設置する。
- 証拠の記録:ユーザーがいつ、どのように同意したかをサーバーサイドで記録し、証明を残さなければならない。
世界の同意管理プラットフォーム(CMP)市場は21.3%成長し、24億ドル規模に達すると予測されている。これは、手動での対応がほぼ不可能になったことを示している。専用ツールを活用するにせよ、その背後にある法的ロジックを理解することが第一歩だ。
WordPressサイトのクッキー監査:コンプライアンスギャップの特定
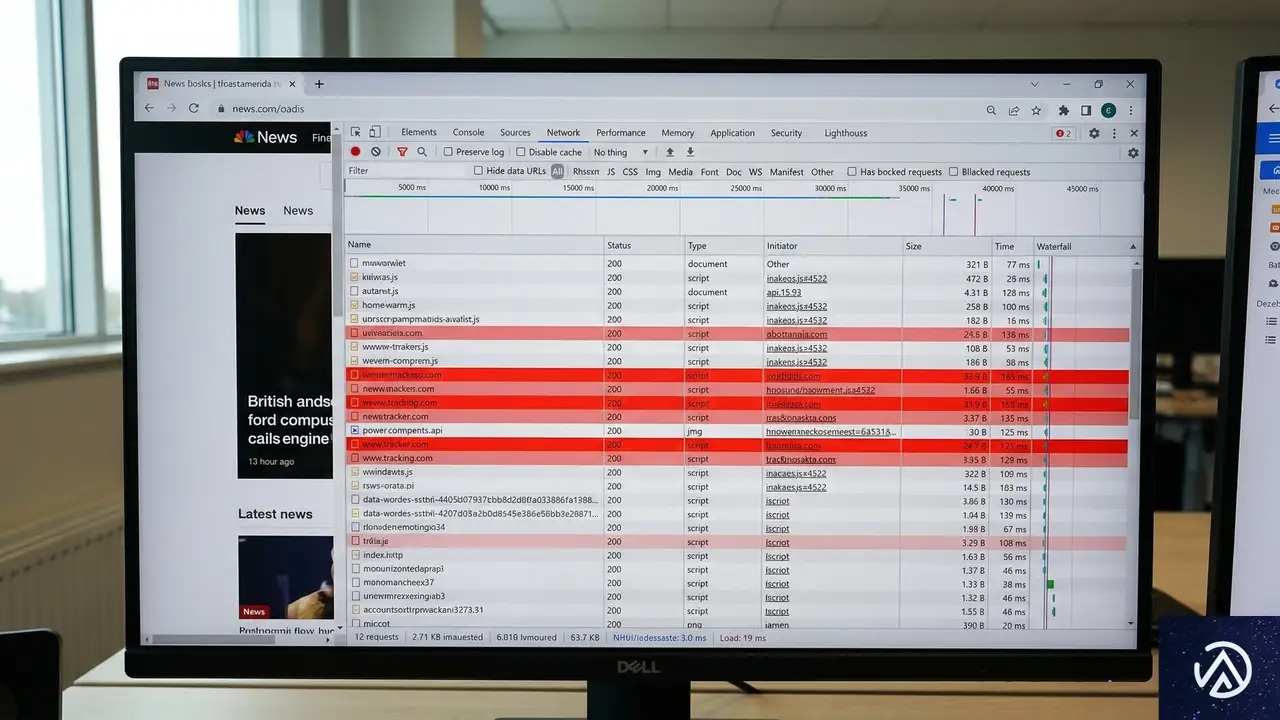
新しいプラグインを導入する前に、自らのWordPressサイトが裏で何をしているかを正確に把握する必要がある。問題を診断できなければ修正もできない。2026年現在、WordPressはインターネットの43.3%を支えており、自動化されたプライバシースキャナーの主要な標的となっている。
平均的なWebサイトは、ユーザーの初回訪問時に22個のサードパーティークッキーを読み込む。これはEU規制当局の目から見れば即座の違反だ。以下の手順で、実際のサイトを監査する。
- シークレットウィンドウを開く:自身の管理者セッションが結果を歪めないよう、ホームページを新規に読み込む。
- 開発者ツールを開く:ページを右クリックして「検証」し、ChromeまたはEdgeの「Application」タブに移動する。
- ローカルストレージとクッキーを確認:左サイドバーの「Cookies」セクションを展開し、バナーに触れる前にここにリストされているすべての項目を記録する。
- Networkタブを確認:ページをリロードしながらNetworkタブを監視し、Google AnalyticsやMeta Pixel、外部広告ネットワークへのリクエストを探す。
- トラッカーを分類:発見したトラッカーを「必須」「分析」「マーケティング」「機能」のカテゴリーにグループ分けする。
多くのプレミアムテーマやページビルダーは、レイアウトの記憶やA/Bテストのために機能的なトラッカーを注入している。サイトの機能に厳密に必要でないものは、デフォルトでブロックされる必要がある。
WordPressへの同意管理プラットフォーム(CMP)導入
同意ロジックシステムをスクラッチでコーディングすべきではない。ルールは頻繁に変更される。代わりに、専用の同意管理プラットフォーム(CMP)が必要だ。これらのシステムはスクリプトをインターセプトし、適切なボタンがクリックされるまで保留する。
適切なCMPの選択は、コンプライアンスプロセスの滑らかさを決定する。Complianz Privacy Suiteのようなソリューションは30万以上のアクティブインストールを誇り、Cookiebotは小規模サイト向けに月額12ユーロから提供している。WordPress環境にCMPを適切に展開する手順は以下の通りだ。
- コアプラグインをインストール:WordPressリポジトリで選択したCMPを検索し、有効化する。
- 初期スキャンを実行:プラグインにサイトのスキャンを許可する。グローバルデータベースと照合し、アクティブなトラッカーを自動的に分類する。
- スクリプトブロッキングを設定:Google Tag ManagerやMeta Pixelのような重いスクリプトをプラグインが正しく識別し、インターセプトしていることを確認する。これが重要だ。
- 法的文書を生成:多くの高品質CMPは、スキャン結果に基づいてCookieポリシーページを自動生成する。このページを即座に公開する。
- バナー制約をテスト:新規のシークレットウィンドウからサイトにアクセスする。「同意する」を明示的にクリックするまで、Networkタブに一切のトラッキングスクリプトが実行されないことを確認する。
5番目のステップを省略すれば、コンプライアンスは達成されない。バナーが見た目上問題なくても、背後でトラッキングスクリプトが即座に実行されているサイトは多い。視覚的な準拠は技術的な準拠と同義ではない。
Elementor Editor Proによるカスタム準拠バナーの構築
デフォルトのCMPバナーは概して見た目が悪く、ブランドのスタイルに合わないことが多い。しかし、醜い汎用ポップアップに妥協する必要はない。Elementor Editor Proを使えば、サイトの美学にシームレスに統合されながら、厳格な法的基準を満たすカスタム同意バナーをデザインできる。
ユーザーはモバイルデバイスで「すべて同意」をクリックする可能性が25%高い。小さな画面では侵襲的なバナーが煩わしいためだ。より良いユーザー体験を設計することは、マーケティングデータの保持率に直接影響する。
同意ポップアップをデザインする際、法的トラブルを避けるために以下の必須要素を含めなければならない。
- 明確な見出し:ポップアップの目的を正確に述べる。「あなたのプライバシーを尊重します」のような曖昧な表現は避ける。
- 対称的なボタン:「同意」と「拒否」ボタンは、まったく同じサイズ、色のコントラスト、タイポグラフィでなければならない。
- 詳細設定リンク:ユーザーがカテゴリーごとに設定をカスタマイズできる明確なテキストリンクを含める。
- ポリシーリンク:バナーテキスト内に、完全なプライバシーポリシーとクッキーポリシーへの直接リンクを提供する。
- ダークパターンの禁止:ボタンのラベルに紛らわしい言語や二重否定を使用してはならない。
Elementorの高度な表示条件を使って、欧州経済領域(EEA)内に位置する訪問者にのみカスタムクッキーポップアップを表示させる方法もある。これらの要件がない地域からの訪問者に厳格なePrivacyバナーを強制する法的理由はない。
また、バナーにはポップアップの詳細設定で非常に高いZ-index値を設定し、選択が行われるまでスティッキーヘッダーやモバイルメニューの上に確実に表示されるようにする。ウェブアクセシビリティも忘れてはならない。ElementorのHTMLタグコントロールを使って、ポップアップのラッパーに正しいARIAロールを持たせ、スクリーンリーダーが同意オプションを明確に解析できるようにする。
パフォーマンス最適化:速度を損なわないコンプライアンス実装
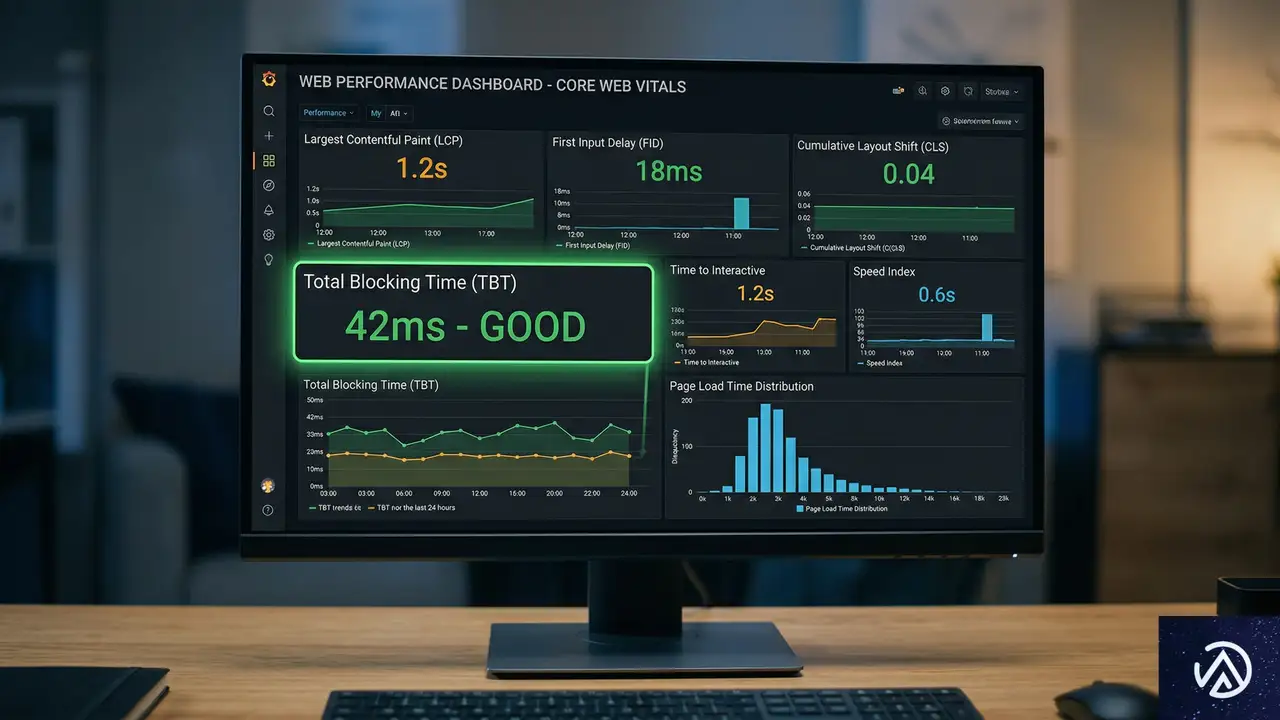
コンプライアンス層の追加は、ほぼ常にWebサイトの速度を低下させる。最適化されていないサードパーティの同意スクリプトは、平均してTotal Blocking Time(TBT)を200msから500ms増加させる可能性がある。法的に準拠しようとするあまり、Core Web Vitalsを失敗させるわけにはいかない。
WP Rocketのようなトップティアのキャッシュソリューションは、必須のクッキースクリプト用の特定の統合機能を含んでいる。これにより、キャッシュルールが「同意済み」状態をキャッシュして、新しい訪問者に提供してしまうことを防ぐ。CMPによって設定される特定のクッキーをキャッシュのバイパスルールから除外する設定が必須だ。
実装方法がサイト速度に与える影響を比較してみよう。
Cumulative Layout Shift(CLS)にも注意が必要だ。巨大なバナーがページ上部に注入されると、すべてのコンテンツが押し下げられ、パフォーマンススコアを損なう。ビューポート下部にバナーのための固定スペースをCSSで確保するか、ドキュメントフローを乱さないオーバーレイを提供する機能を活用する。
コンプライアンスの維持:月次監査と文書化

コンプライアンスは一度きりのプロジェクトではない。継続的な運用上の要件だ。1月にバナーを設定したきりチェックしなければ、3月までに準拠から外れている可能性が高い。テーマの更新、新しいマーケティングキャンペーン、新規プラグインが常に新しいトラッカーを導入する。
中小企業は、カスタム設定がこれらの厳格な基準を満たしていることを確認するために、平均2500ドルから7000ドルの法律相談費を負担している。簡単に予防できるミスに無駄な出費をしないため、月次のメンテナンスルーチンを構築する。
継続的なコンプライアンスチェックリストには、以下の具体的なアクションを含めるべきだ。
- クッキースキャンの自動化:CMPを設定し、ライブサイトの詳細スキャンを30日ごとに実行する。レポートをリード開発者に直接メール送信させる。
- 同意ログの確認:サーバーがユーザーID、タイムスタンプ、同意した具体的なカテゴリーを正確に記録していることを確認する。監査が入った場合、このログが唯一の防御手段となる。
- 撤回プロセスのテスト:自サイトの永続的な「クッキー設定」ウィジェットをクリックし、以前に付与された権限が即座に取り消され、ローカルクッキーが削除されることを確認する。
- ポリシー日付の更新:新しいツール(新しいCRMや分析プラットフォームなど)を追加するたびに、公開されているクッキーポリシーを更新し、「最終更新日」のタイムスタンプを変更する。
- 業界制裁金の監視:欧州データ保護委員会(EDPB)による最新の裁定に目を配り、執行戦術がどのように変化しているかを把握する。
法的枠組みの突然の変化に不意を突かれたくはない。同意アーキテクチャに行ったすべての変更を完璧な記録として保管することが、ビジネスを救う。
この記事のポイント
- 2026年のコンプライアンスには、単なるバナー表示を超えた技術的なスクリプトブロッキングが必須である。
- 同意管理プラットフォーム(CMP)の選定と正しい設定が、法的リスクと運用負荷を大きく左右する。
- 「すべて拒否」ボタンの視認性と、同意の詳細設定・撤回の容易さは、法的要件の核心部分である。
- コンプライアンス対策はサイト速度に影響を与えるため、キャッシュ設定や実装方法の最適化が不可欠だ。
- コンプライアンスは継続的プロセスであり、プラグイン更新や新機能追加のたびに監査と文書化が必要である。

AIボットのトラフィックが300パーセント急増 パブリッシング業界を牽引するOpenAIとMetaの動向
AIボットによるウェブサイトへのトラフィックが、過去1年間で爆発的に増加している。セキュリティ大手のAkamai(アカマイ)が発表した最新のレポートによると、グローバルでのAIボット活動は300パーセントもの急増を記録した。特にパブリッシング(出版・メディア)業界は、AI開発企業にとって貴重なデータ源として激しいターゲティングを受けている実態が浮き彫りになった。
この調査は、Akamaiのボット管理ツールを通じて収集されたアプリケーション層のトラフィックデータを分析したものだ。AIボットのトラフィックが最も集中しているのはEコマース分野で、全体の48パーセントを占める。それに次ぐのがメディア業界で、全体の13パーセントを記録した。メディア業界の内訳を見ると、パブリッシング企業へのアクセスが40パーセントと最も多く、放送やOTT(動画配信サービス)の29パーセントを大きく上回っている。
パブリッシャーにとって、これらのボットは単なるアクセス増を意味するのではない。自社のコンテンツが無断でAIの学習に利用されたり、検索結果に直接回答を表示されることでサイト訪問者が減少したりするリスクを孕んでいる。本記事では、パブリッシング業界を席巻する主要なAIボットの動向と、それらに対する現実的な防衛策について詳しく解説していく。
パブリッシング業界を狙う主要なAIプレイヤー

メディア企業に送られるAIボットのリクエストにおいて、圧倒的なシェアを誇っているのがOpenAIだ。同社はメディア業界へのリクエストで首位に立っており、そのリクエストの40パーセントがパブリッシング企業に向けられている。OpenAIがこれほど高いトラフィックを生成している背景には、複数の役割を持つボットを使い分けている点がある。
OpenAIが運用する3種類のボット
OpenAIは、用途に応じて主に3つのボットを稼働させている。まず「GPTBot」は、大規模言語モデル(LLM)のトレーニングのためにウェブ上のデータを収集する。次に「OAI-SearchBot」は、AIによる検索機能を支えるための情報を収集する役割を担う。そして「ChatGPT-User」は、ユーザーがChatGPTで質問をした際に、リアルタイムで最新の情報を取得するために動くボットだ。このように、学習、検索、リアルタイム応答という異なる目的でサイトを巡回しているため、トラフィックが累積しやすい構造になっている。
追随するMetaとByteDanceの動向
OpenAIに次いで多くのトラフィックを生成しているのが、MetaとByteDanceだ。MetaはLlamaなどの独自モデルの強化を進めており、SNS以外の外部コンテンツ収集にも力を入れている。TikTokを運営するByteDanceも、AI技術の高度化に向けて広範囲なクローリングを行っている。これら上位3社に続き、Anthropic(アンソロピック)やPerplexity(パープレキシティ)も名を連ねているが、上位陣に比べるとそのボリュームは現時点では小さい。
学習用クローラーとフェッチャーボットの決定的な違い

Akamaiのレポートでは、AIボットをその挙動に基づいて4つのタイプに分類している。その中でも、パブリッシャーが特に注目すべきなのが「学習用クローラー(Training Crawlers)」と「フェッチャーボット(Fetcher Bots)」の2種類だ。これらはサイトに与える影響が根本的に異なる。
長期的な影響を与える学習用クローラー
学習用クローラーは、将来のAIモデルを構築するために膨大なコンテンツを収集することを目的としている。2025年後半のメディア業界におけるAIボット活動の63パーセントをこのタイプが占めていた。これらのボットをブロックすれば、将来のAIが自社のコンテンツを学習することを防げる。しかし、これは「今現在のアクセス」には直接的な影響を及ぼさない長期的な対策という意味合いが強い。
収益に直結するフェッチャーボットの脅威
一方で、より差し迫った脅威とされているのがフェッチャーボットだ。これは、ユーザーがAIチャットボットに質問を投げた際、その回答を作成するためにリアルタイムで特定のページを取得しに行くボットを指す。メディア業界におけるAIボット活動の24パーセントを占め、そのうち43パーセントがパブリッシング企業をターゲットにしている。
フェッチャーボットは、パブリッシャーの収益に直接的なダメージを与える可能性がある。AIが記事の内容を読み取り、要約してユーザーに提示してしまうため、ユーザーは元の記事を読みに行く必要がなくなるからだ。これを「ゼロクリック問題」と呼ぶ。サイトへの流入が失われれば、広告収入や購読者獲得の機会も同時に失われることになる。
■ 影響:数ヶ月〜数年後のAIの回答精度に関わる
■ 影響:現在のサイト流入と広告収益が減少する
上記の図が示すように、学習用クローラーとフェッチャーボットでは対策の優先順位が変わってくる。将来のAIのあり方をコントロールしたいのか、それとも現在の収益を守りたいのかによって、ブロックすべき対象を精査する必要がある。
パブリッシャーが取るべき3つの対抗策

AIボットの急増に対し、サイト運営者はどのような手を打てるのだろうか。Akamaiのレポートによれば、現在多くの企業が採用している対策は主に3つの手法に集約される。単純にすべてを拒否するのではなく、戦略的にボットをコントロールする動きが出ている。
1. 拒否(Deny)による完全遮断
最も一般的な方法は、特定のボットからのリクエストを完全に拒否することだ。robots.txtで指定したり、WAF(Web Application Firewall)の設定でボットのIPアドレスやユーザーエージェントをブロックしたりする。これにより、サーバー負荷を軽減し、コンテンツの無断取得を防ぐことができる。ただし、AI検索からの流入も完全に断たれるリスクがある。
2. ターピット(Tarpit)によるリソース消費
「ターピット(底なし沼)」とは、ボットからの接続をあえて切断せず、非常に遅い速度で応答を返し続ける手法だ。ボット側の接続枠を長時間占有させることで、ボットを運用する側のコンピューティングリソースを無駄に消費させる効果がある。あるパブリッシャーはこの手法を用いて、AIボットのリクエストの97パーセントを制御することに成功したという。完全に拒否するよりも巧妙な対抗策と言える。
3. 遅延(Delay)による制限
応答を返す前に意図的な一時停止を入れる手法だ。これにより、ボットによる高速なクローリングを物理的に不可能にする。サーバーへの瞬間的な負荷を抑えつつ、コンテンツの取得効率を大幅に下げることができる。人間がブラウザで閲覧する分には影響が出ない程度の遅延を設定することで、UX(ユーザーエクスペリエンス)を維持しながら対策が可能だ。
一律ブロックが最適解ではない理由

AIボットをすべて遮断すれば安心かというと、話はそう単純ではない。Akamaiのレポートでは、すべてのAIボットを無差別にブロックすることに対して警鐘を鳴らしている。そこには、将来的なビジネスチャンスを損失するリスクが含まれているからだ。
コンテンツライセンス契約の可能性
現在、OpenAIなどのAI開発企業は、高品質なデータを確保するためにパブリッシャーと直接ライセンス契約を結ぶ動きを加速させている。一律にすべてのアクセスを遮断してしまうと、こうした交渉のテーブルに載る機会を自ら放棄することになりかねない。実際に、一部のパブリッシャーはあえてボットのアクセスを完全に遮断せず、交渉の余地を残しながら「ターピット」などで制御する戦略をとっている。
AI検索経由のトラフィック確保
Googleの「AI Overviews」やPerplexityのようなAI検索エンジンは、回答の根拠として出典元へのリンクを表示することがある。フェッチャーボットをすべてブロックすると、こうしたAI検索の結果に自社のコンテンツが表示されなくなり、新しい形の検索流入を完全に失うことになる。これからのSEO(検索エンジン最適化)は、従来の検索結果だけでなく、AIの回答の中にいかに適切に引用されるかを考える必要が出てくるだろう。
今後の展望とサイト運営者の課題

AIボットの活動は今後さらに洗練され、増加の一途をたどると予想される。パブリッシャーにとって重要なのは、学習用クローラーとフェッチャーボットを区別して管理することだ。学習用をブロックして自社の知財を守りつつ、フェッチャーを部分的に許可してAI検索からの露出を確保するといった、きめ細やかな制御が求められる。
また、Akamaiのようなボット管理ソリューションを導入することも一つの選択肢だが、まずは自社のログを確認し、どのボットがどれだけの頻度でアクセスしているかを把握することから始めるべきだ。AIボットとの共存か、それとも徹底抗戦か。その判断が、今後のパブリッシングビジネスの成否を分けることになるだろう。
この記事のポイント
- AIボットのトラフィックは前年比300パーセント増と爆発的に伸びている。
- OpenAI、Meta、ByteDanceの3社がトラフィックの大部分を占めている。
- 学習用クローラーは将来のモデルのため、フェッチャーは現在の回答のために動く。
- フェッチャーボットはユーザーのサイト訪問を奪う「ゼロクリック問題」を引き起こす。
- 一律ブロックではなく、ターピットや遅延などの手法を組み合わせた戦略的制御が重要だ。

500 Tbpsに達したCloudflareのネットワーク網!DDoS防御とAI時代のインフラを徹底解説
Cloudflareのグローバルネットワークが、外部接続容量500 Tbps(テラビット毎秒)という大きな節目を超えた。2010年にパロアルトの小さなオフィスから始まった同社のインフラは、16年の歳月を経て世界330以上の都市に広がる巨大なデジタル基盤へと成長している。
この「500 Tbps」という数字は、単なるピーク時のトラフィック量ではない。トランジットプロバイダーやピアリングパートナー、インターネットエクスチェンジ(IX)などと接続された外部ポートの総容量を指している。この膨大な余剰キャパシティこそが、日々発生する大規模なDDoS攻撃を吸収するための「防御予算」として機能しているのだ。
現代のインターネットにおいて、これほどの規模を持つネットワークがどのように構築され、どのように自律的な防御を実現しているのか。最新の技術スタックと、急増するAIトラフィックへの対応策を含めて詳しく紐解いていく。
500 Tbpsの衝撃〜Cloudflareが到達した巨大ネットワークの現在地

Cloudflareのネットワーク容量が500 Tbpsに達したことは、インターネットの歴史における一つの到達点といえる。2010年の設立当初、同社はたった一つのトランジットプロバイダーと契約し、ネームサーバーを2つ書き換えるだけで利用できるリバースプロキシとしてスタートした。それが今や、全ウェブサイトの20%以上を保護する巨大インフラへと変貌を遂げている。
世界330都市以上に広がる物理インフラの重み
「インターネットはクラウドである」と表現されることが多いが、その実体はケーブルとサーバーが詰まった物理的な部屋の集合体だ。Cloudflareはシカゴ、アッシュバーン、サンノゼ、アムステルダム、東京といった主要都市から始まり、カトマンズ、バグダッド、レイキャビクといった地域まで網羅してきた。
データセンターを一つ開設するごとに、コロケーション契約の交渉、光ファイバーの敷設、サーバーのラッキングといった地道な作業が繰り返される。2018年には、わずか24日間で31都市に拠点を展開するという驚異的なスピードで拡張を続けた。この物理的な拠点の多さが、ユーザーに近い場所でコンテンツを配信し、攻撃を水際で食い止めるための鍵となっている。
外部キャパシティ500 Tbpsが意味するもの
500 Tbpsという数字は、すべての外部接続ポートの合計値だ。日常的なトラフィックのピークは、この数字のほんの一部に過ぎない。残りの広大な帯域は、DDoS攻撃が発生した際にその衝撃を和らげるためのバッファとして確保されている。
かつては国家レベルのリソースがなければ対抗できなかったような大規模な攻撃も、この巨大なパイプラインの中では「日常的なイベント」として処理される。ネットワークの規模そのものが、セキュリティにおける最強の武器となっているのだ。
攻撃を呼吸するように受け流す〜31.4 TbpsのDDoSを防ぐ仕組み

2025年、Cloudflareのネットワークは秒間31.4 Tbpsという猛烈なDDoS攻撃を検知し、わずか35秒で完全に無害化した。この攻撃には、感染したAndroid TVなどで構成された「Aisuru-Kimwolf」と呼ばれるボットネットが関与していた。驚くべきは、この規模の攻撃に対してもエンジニアが呼び出されることなく、システムが自律的に対処した点だ。
eBPFとXDPによる超高速パケット処理
この自律的な防御を支えているのが、Linuxカーネル内で動作する「eBPF(extended Berkeley Packet Filter)」と「XDP(eXpress Data Path)」という技術だ。パケットがネットワークカード(NIC)に到着した瞬間、OSの通常のネットワークスタックを通過する前に、XDPプログラムがそのパケットを評価する。
これにより、不正なパケットはCPUサイクルをほとんど消費することなく、入口で即座に破棄される。アプリケーション層に到達する前に処理が終わるため、サーバーの負荷を極限まで抑えることが可能だ。この仕組みを視覚化すると、以下のようになる。
このデモは、パケットがどのように段階を経て処理されるかを示したものだ。XDPレイヤーでのフィルタリングが、後続のシステムをいかに保護しているかがわかる。
自律分散型の防御システム「dosd」
Cloudflareのすべてのサーバーには「dosd」と呼ばれるDDoS対策用のデーモンが常駐している。各サーバーは流入するトラフィックをサンプリングし、異常な通信パターンを検出すると、その情報を同じデータセンター内の全サーバーにブロードキャストする。
データセンター内のすべてのサーバーが同じデータに基づいて判断を下すため、特定のサーバーに負荷が集中することなく、拠点全体で一貫した防御が可能になる。さらに、決定されたルールは同社の分散型キーバリューストア「Quicksilver」を通じて数秒以内に全世界の拠点へ伝播される。これにより、ある拠点で検知された攻撃手法が、瞬時に地球の裏側の拠点でも通用しなくなる仕組みだ。
ネットワーク自体が開発プラットフォームへ〜Edge Computingの進化

ネットワークを保護するためにすべてのサーバーでコードを実行できる環境を整えた結果、そのリソースを顧客に開放するという自然な流れが生まれた。これが「Cloudflare Workers」の始まりだ。現在では、単なるスクリプトの実行にとどまらず、より複雑なワークロードをエッジで動かすことが可能になっている。
WorkersからContainersへ
2025年、CloudflareはWorkersに「Containers」機能を追加した。これにより、V8アイソレートでは難しかった、より重量級のアプリケーションもエッジで動作させることができるようになった。独自のファイルシステムレイヤーにより、コールドスタート(起動時の遅延)を最小限に抑えつつ、ユーザーのすぐそばで計算リソースを提供する。
開発者が書いたコードは、前述のDDoS防御と同じサーバー上で動作する。つまり、攻撃トラフィックがl4dropによって破棄された直後の、クリーンな環境でアプリケーションが実行されるわけだ。インフラのセキュリティとパフォーマンスを同時に享受できるこの構造は、従来の中央集約型クラウドとは一線を画している。
インターネットの信頼性を担保する〜RPKIとASPAの重要性

ネットワークの規模が大きくなるほど、ルーティングの安全性に対する責任も増大する。BGP(Border Gateway Protocol)の脆弱性を突いたルートハイジャックは、インターネットの通信を誤った方向へ誘導し、大規模な障害やセキュリティ侵害を引き起こす原因となる。Cloudflareはこれらのリスクを低減するため、最新のプロトコル採用を強力に推進している。
ルートハイジャックを防ぐRPKI
RPKI(Resource Public Key Infrastructure)は、IPアドレスの所有者が誰であるかを証明するための仕組みだ。Cloudflareは早期からRPKIを導入し、無効なルートからのトラフィックを拒否する設定を徹底している。現在、グローバルなルーティングテーブルのうち、86万7,000件以上のプレフィックスが有効なRPKI証明書を持っており、10年前のほぼゼロに近い状態から劇的に改善された。
パスの正当性を検証するASPA
次に同社が注力しているのが「ASPA(Autonomous System Provider Authorization)」だ。RPKIが「誰が所有しているか」を検証するパスポートチェックだとすれば、ASPAは「どのような経路を通ってきたか」を検証するフライトマニフェスト(搭乗名簿)チェックに相当する。
ASPAが普及すれば、設定ミスによるルート漏洩や、悪意のある経路誘導をより確実に防げるようになる。Cloudflareのような巨大ネットワークが先行して導入することで、インターネット全体のエコシステムを健全な方向へ導く狙いがある。
AIエージェントが変えるトラフィック構造〜4%の衝撃

近年、インターネット上のトラフィックに大きな変化が起きている。人間がブラウザでリンクをクリックして発生する通信に加え、AIクローラーや自律型エージェントによるアクセスが急増しているのだ。現在、Cloudflareのネットワークを流れるHTMLリクエストの4%以上が、AI関連の通信で占められている。
ブラウザとクローラーの挙動の違い
AIクローラーは、人間が操作するブラウザとは根本的に異なる動きを見せる。ブラウザはページを読み込んだ後に一時停止するが、クローラーはリンクされたリソースを最大スループットで、休むことなく次々と取得していく。この挙動は、インフラ側から見るとDDoS攻撃と区別がつきにくい場合がある。
Cloudflareは、正規のAIクローラーと悪意のある攻撃を識別するために、TLSフィンガープリントや行動分析を組み合わせた高度な検知システムを運用している。例えば、ブラウザを装いつつもTLSのライブラリが不自然な構成であれば、それをシグナルとして検出し、サイト所有者が適切な判断を下せるようにデータを提供している。
独自の分析〜500 Tbps時代に企業が備えるべきインフラ戦略

Cloudflareが500 Tbpsという驚異的な容量を確保したことは、一企業のリリースの枠を超えた意味を持っている。これは、インターネットが「物理的な限界」を技術と規模で克服しつつあることを象徴している。しかし、インフラが強力になる一方で、攻撃の質も変化している点には注意が必要だ。
「防御の自動化」が企業の必須条件になる
31.4 Tbpsという攻撃を人間が介在せずに防いだという事実は、もはや「人間がログを見て遮断ルールを書く」という旧来の運用が通用しないフェーズに入ったことを示している。今後の企業インフラには、eBPF/XDPのようなカーネルレベルでの高速処理と、AIを活用した自律的なパターン認識が欠かせなくなるだろう。
エッジシフトとセキュリティの統合
Cloudflareの事例が示すように、これからは「セキュリティ対策」と「アプリケーション実行環境」を切り離して考えるべきではない。攻撃を捨てる場所でコードを動かすという「エッジコンピューティング」の思想は、パフォーマンス向上だけでなく、攻撃の爆風をアプリケーションに届かせない最強の盾となる。企業は、中央集約的なサーバー構成から、分散型のエッジインフラへの移行を真剣に検討すべき時期に来ているといえる。
この記事のポイント
- Cloudflareの外部ネットワーク容量が500 Tbpsの大台を突破した
- eBPFとXDPを活用し、31.4 Tbpsもの巨大DDoS攻撃を自動的に無害化している
- 世界330以上の都市に分散された拠点が、ユーザーに近い場所でセキュリティと計算リソースを提供している
- RPKIやASPAといった次世代プロトコルの導入により、ルーティングの安全性を世界規模で向上させている
- トラフィックの4%を占めるようになったAIクローラーに対し、高度な識別技術で対応している